Not having learned the lessons of age verification problems, Indonesia now thinks it can spy on it’s population by making them register for services.
Following in the footsteps of Australia, Indonesia will be the latest country to limit social media usage for children under 16. Meutya Hafid, Indonesia’s communication and digital affairs minister, announced that a new government regulation will require “high-risk” platforms to delete any accounts from Indonesia that are under 16, starting on March 28. Hafid said in the announcement that the implementation would be done in stages, starting with major platforms like YouTube, TikTok, Facebook, Instagram, Threads, X, Roblox and Bigo Live, a live-streaming platform based in Singapore. The minister added that all platforms will have to fulfill compliance obligations from the Indonesian government, but didn’t specify what they were. In response to the ban, a Meta spokesperson told The New York Times that the company hasn’t received an official regulation from the country yet and was awaiting details. While Australia was the first country to implement such a sweeping ban on social media, many other countries are currently in the process of doing the same. Spain’s Prime Minister Pedro Sanchez announced last month that the country is also ready to ban social media for users under 16, while Malaysia’s cabinet approved a similar ban that will reportedly go into effect sometime this year.
Microsoft spent last week rejecting emails to Outlook recipients after what appears to be either a fault or overzealous blocking rules.
The problem affects certain IP addresses, whose emails are rejected due to falling foul of reputation rules or appearing on a block list.
A Register reader told us, “At the back end of January we noticed a sudden spike in customers static IP’s being rejected by only Microsoft Outlook free / personal accounts.”
The message returned was a 550, telling customers to contact their Internet Service Provider (ISP) “since part of their network is on our block list.”
A block list is a good thing. It helps stem the flow of spam from networks or addresses associated with junk email. However, the confusing thing for our reader is that his company was not on Microsoft’s naughty step for email. A glance at Microsoft’s Smart Network Data Service (SNDS) showed no issues with the IP.
“We’re also a member of their JMRP (Junk Mail Reporting Program),” our reader went on, “which is intended to inform us when people are reporting spam sent from our IP’s – except, we never get any reports.”
The problem worsened in February. On Microsoft’s support forums, users began to complain about similar issues as the IP net presumably widened. One wrote “We are currently experiencing a critical and recurring email delivery issue affecting recipients at outlook.com, live.com, hotmail.com, and msn.com,” and provided a copy of an error that suggested that the mail server has been “temporarily rate limited due to IP reputation.”
The user drily noted, “Although the error indicates rate limiting, in practice no emails are being delivered.”
A large number of users, ranging from the administrator of a server sending automated notifications on behalf of Estonian Public Libraries to an email provider for healthcare professionals, chimed in to confirm that they, too, were having delivery problems and that Microsoft support was not helpful.
Our reader told us, “We’ve seen customers struggling to send invoices, order delivery notifications, authentication codes – all sorts, which have been perfectly acceptable to Microsoft / Outlook for many years – now rejected, or blocked.
“Customers rarely read, or understand DSN’s – they jump to blaming the ISP or sender, and then head off to find someone else.”
Unsurprisingly, our reader spoke on condition of anonymity. After all, nobody wants to be the ISP that has to say, “Yeah, we can deliver your email anywhere but Outlook.com” to customers.
We asked Microsoft if it had any comment to make, but other than acknowledging our questions, the company did not respond.
Blocking email from spammers is a good thing, and anything that reduces the amount of junk that clutters up inboxes is to be applauded. However, when there is an error, customers need a rapid and transparent process for resolution. Every failed delivery of an invoice or receipt due to overzealous or misapplied rules can chip away at a business’s reputation, through no fault of the owner. ®
Updated at 13.33 UTC on March 6, 2025, to add:
Microsoft has finally responded, days after this article was published. A spokesperson told The Register:
“We are working to address a temporary rate‑limit issue that may be causing some messages to be incorrectly throttled when sent from a specific IP address. Customers who continue to experience issues sending emails should contact our Support team or raise a ticket in their Admin portal to apply the appropriate mitigation.”
Not much you can do though. Once some idiot friend of you has uploaded your number it’s there and it’s not going away. Just a bit like if family members take a DNA test and don’t realise they have also uploaded your DNA.
ChatGPT is getting more social, with a new feature that allows you to sync your contacts to see if any of your friends are using the chatbot or any other OpenAI product.
Details are light; the company has not shared images of what this experience will look like or what it will unlock for users. However, it has changed its privacy policy to say that contact syncing will help users “find friends.” It’s “completely optional,” it says. However, even if you don’t opt in, anyone with your number who syncs their contacts are giving OpenAI your digits.
“OpenAI may process your phone number if someone you know has your phone number saved in their device’s address book and chooses to upload their contacts,” the company says.
If you are the person who syncs your contacts, and OpenAI finds an account with matching numbers, it will suggest you connect to that person. If you choose to follow them, that person may receive a notification with an option to follow back.
But why would you follow someone on ChatGPT? It lines up with reports, dating back to April, that OpenAI is building a social network. We haven’t seen much since then, save for the Sora generative video app, which exists outside of ChatGPT and is more of a novelty. Contact sharing might be the first step toward a much bigger evolution for the world’s most popular chatbot.
ChatGPT also supports group chats that let up to 20 people discuss and research something using the chatbot. Contact syncing could make it easier to invite people to these chats.
OpenAI will routinely check if someone in your contacts has made a new account, so it can try to connect you. The company claims it will not store the full data that might appear in your contact list, such as names or email addresses—just phone numbers. However, the company does store the phone numbers in its servers in a coded (or hashed) format. You can also revoke access in your device’s settings.
Also this week, OpenAI began rolling out advertisements inside ChatGPT. Free users can opt out of ads, though that restricts their messaging rate limits. This comes after rival AI firm Anthropic aired a Super Bowl spot criticizing OpenAI for its ad plan. CEO Sam Altman fired back, calling Anthropic dishonest.
Reddit, Meta, and Google voluntarily “complied with some of the requests” for identifying details of users critical of Immigration and Customs Enforcement (ICE) sent as part of a recent wave of administrative subpoenas the Department of Homeland Security has been distributing to Big Tech the past few months, according to an anonymously sourced New York Times report.
Those three companies, plus Discord, have received “hundreds” of such requests that have come from DHS recently. Meta, it should be noted, is the parent company of Instagram, Facebook, and WhatsApp.
Administrative subpoenas used for this purpose represent an escalation. This tool, which comes not from a judge but from DHS itself, was formerly reserved for situations like child abductions, according to the Times.
The users were targeted because their posts “criticized ICE or pointed to the locations of ICE agents,” the Times says.
A Google spokesperson replied to the Times with a statement, saying “When we receive a subpoena, our review process is designed to protect user privacy while meeting our legal obligations,” and “We inform users when their accounts have been subpoenaed, unless under legal order not to or in an exceptional circumstance. We review every legal demand and push back against those that are overbroad.”
Gizmodo requested comment from Meta, Discord, and Reddit. We will update if we hear back.
According to the Times, one or multiple of the relevant companies have stated that they notify users of these requests from DHS, and give them a 14-day window to “fight the subpoena in court” before complying.
Amazon has also been accused of at least some degree of participation with ICE’s ongoing mass deportation efforts. In October, Amazon-owned Ring announced a partnership with Flock that would loop the AI-powered network into the content coming from users’ doorbell cameras. According to a 404 Media investigation, that network feeds information to law enforcement agencies at the local and federal levels, allowing for reasonable concern that ICE has access to all that footage.
Protesters have launched an effort called “Resist and Unsubscribe” targeting ten tech companies they perceive as exceptionally supportive of ICE. That list includes Meta, Google, and Amazon, but not Reddit.
Why on earth modify Notepad to do anything else than open a file and allow you to edit it? The bloatware now means it’s not only slower but insecure and a threat to your PC.
Microsoft has fixed a “remote code execution” vulnerability in Windows 11 Notepad that allowed attackers to execute local or remote programs by tricking users into clicking specially crafted Markdown links, without displaying any Windows security warnings.
With the release of Windows 1.0, Microsoft introduced Notepad, a simple, easy-to-use text editor that, over the years, became popular for quickly jotting notes, reading text files, creating to-do lists, or acting as a code editor.
For those who needed a rich text format (RTF) editor that supported different fonts, sizes, and formatting tools like bold, italics, and lists, you could use Windows Write and later WordPad.
However, with the release of Windows 11, Microsoft decided to discontinue WordPad and remove it from Windows.
Instead, Microsoft rewrote Notepad to modernize it so it could act as both a simple text editor and an RTF editor, adding Markdown support that lets you format text and insert clickable links.
Markdown support means Notepad can open, edit, and save Markdown files (.md), which are plain text files that use simple symbols to format text and represent lists or links.
[…]
Microsoft fixes Windows Notepad RCE flaw
As part of the February 2026 Patch Tuesday updates, Microsoft disclosed that it fixed a high-severity Notepad remote code execution flaw tracked as CVE-2026-20841.
“Improper neutralization of special elements used in a command (‘command injection’) in Windows Notepad App allows an unauthorized attacker to execute code over a network,” explains Microsoft’s security bulletin.
[…]
“An attacker could trick a user into clicking a malicious link inside a Markdown file opened in Notepad, causing the application to launch unverified protocols that load and execute remote files,” explains Microsoft.
“The malicious code would execute in the security context of the user who opened the Markdown file, giving the attacker the same permissions as that user,” continued the Advisory.
The novelty of the flaw quickly drew attention on social media, with cybersecurity researchers quickly figuring out how it worked and how easy it was to exploit.
All someone had to do was create a Markdown file, like test.md, and create file:// links that pointed to executable files or used special URIs like ms-appinstaller://.
Markdown for creating links to executables or to install an app Source: BTtea
If a user opened this Markdown file in Windows 11 Notepad versions 11.2510 and earlier and viewed it in Markdown mode, the above text would appear as a clickable link. If the link is clicked with Ctrl+click, it would automatically execute the file without Windows displaying a warning to the user.
This article is incredibly apologetic to TikTok and tries to frame the way in which TikTok is grabbing your location data without your consent as a good thing somehow. It does however give a good indication of how the TikTok system grabs your location continually at all times without your consent – and if you don’t want TikTok following you (even if it is with “coarse location data” – which is actually quite accurate!) your only option is to uninstall the app entirely.
It hasn’t even been a month since the U.S. arm of TikTok came under new ownership, and already American users are getting an exclusive feature. In a surprise move, the app today introduced a new “Local Feed” specific to U.S. users, ostensibly aimed at helping Americans see content from their immediate area. Technically, it’s similar to the “Nearby Feed” that was introduced in the U.K. and Europe in December, although this specific iteration might differ in the minor details, like the name. Perhaps more importantly, the company wants access to your GPS data to power the Local Feed
[…]
It’s worth noting that I was already occasionally getting these recommendations on my For You feed, and when I go on vacation, these posts usually change to match wherever I’m staying. So the app’s algorithm did already take location into account, at least to a degree
[…]
he Local Feed showed up for me automatically when I opened my app today, and TikTok confirmed to me on a phone call that you do not have to opt in to seeing it.
[…]
TikTok’s Local Feed has two ways of knowing your location
[…]
Essentially, there are two ways for TikTok’s Local Feed to know where you are, “coarse location data collection” and “precise GPS data collection.”
Coarse data collection is how the app worked previously, and it uses information like your IP address, which network you’re connecting from, and some of your posting activity (such as how you’ve been tagged) to generally figure out where you are. This does not use your GPS […] This functionality cannot be disabled
[…]
What’s new is the ability to share your precise GPS data with TikTok […]
According to the TikTok representative I spoke with, there was initially some confusion among users, as the Local Feed appeared to be showing them content specific to their area even while the app did not appear to be tracking their GPS location in their phones’ settings
[…]
In other words, the Local Feed does not track your GPS data by default, but that doesn’t mean you won’t see anything if you don’t opt in to sharing your GPS data—it’ll instead use the same course location data the app has had access to for years to fill that feed.
You Should absolutely in every case need to opt in to sharing any kind of location data – even coarse location data!
If you do enable Location Services for TikTok, the company says it will only track your location while you’re using the app, and that when it does, you will see an on-screen indicator while your location is being accessed.
[…]
Meanwhile, if you want to turn off approximate location tracking, your only choice is to delete the app altogether—although that was also true before the Local Feed was introduced.
“The Diary of a Young Girl” is a Dutch language diary written by the young Jewish writer Anne Frank while she was in hiding for two years with her family during the Nazi occupation of the Netherlands. Although the diary and Anne Frank’s death in the Bergen-Belsen concentration camp are well known, few are aware that the text has a complicated copyright history – one that could have important implications for the legal status and use of Virtual Private Networks (VPNs) in the EU. TorrentFreak explains the copyright background:
These copyrights are controlled by the Swiss-based Anne Frank Fonds, which was the sole heir of Anne’s father, Otto Frank. The Fonds states that many print versions of the diary remain protected for decades, and even the manuscripts are not freely available everywhere.
In the Netherlands, for example, certain sections of the manuscripts remain protected by copyright until 2037, even though they have entered the public domain in neighboring countries like Belgium.
A separate foundation, the Netherlands-based Anne Frank Stichting, wanted to publish a scholarly edition of Anne Frank’s writing, at least in those parts of the world where her diary was in the public domain:
To navigate these conflicting laws, the Dutch Anne Frank Stichting published a scholarly edition online using “state-of-the-art” geo-blocking to prevent Dutch residents from accessing the site. Visitors from the Netherlands and other countries where the work is protected are met with a clear message, informing them about these access restrictions.
However, the Anne Frank Fonds was unhappy with this approach, and took legal action. Its argument was that such geo-blocking could be circumvented with VPNs, and so its copyrights in the Netherlands could be infringed upon by those using VPNs. The lower courts in the Netherlands dismissed this argument, and the case is now before the Dutch Supreme Court. Beyond the specifics of the Anne Frank scholarly edition, there are important issues regarding the use of VPNs to get around geo-blocking. Because of the potential knock-on effect the ruling in this case will have on EU law, the Dutch Supreme Court has asked for guidance from the EU’s top court, the Court of Justice of the European Union (CJEU).
The CJEU has yet to rule on the issues raised. But one of the court’s advisors, Advocate General Rantos, has published a preliminary opinion, as is normal in such cases. Although that advice is not binding on the CJEU, it often provides some indication as to how the court may eventually decide. On the main issue of whether the ability of people to circumvent geo-blocking is a problem, Rantos writes:
the fact that users manage to circumvent a geo-blocking measure put in place to restrict access to a protected work does not, in itself, mean that the entity that put the geo-blocking in place communicates that work to the public in a territory where access to it is supposed to be blocked. Such an interpretation would make it impossible to manage copyright on the internet on a territorial basis and would mean that any communication to the public on the internet would be global.
Moreover:
As the [European] Commission pointed out in its written observations, the holder of an exclusive right in a work does not have the right to authorise or prohibit, on the basis of the right granted to it in one Member State, communication to the public in another Member State in which that right has ceased to have effect.
Or, more succinctly: “service providers in the public domain country cannot be subject to unreasonable requirements”. That’s a good, common-sense view. But perhaps just as important is the following comment by Rantos regarding the use of VPNs to circumvent geo-blocking:
as the Commission points out in its observations, VPN services are legally accessible technical services which users may, however, use for unlawful purposes. The mere fact that those or similar services may be used for such purposes is not sufficient to establish that the service providers themselves communicate the protected work to the public. It would be different if those service providers actively encouraged the unlawful use of their services.
The hope has to be that the CJEU will agree with its Advocate General’s sensible and fair analysis, and will rule accordingly. But there is another important aspect to this story. The basic issue is that the Anne Frank Stichting wants to make its scholarly edition of Anne Frank’s diary available as widely as possible. That seems a laudable aim, since it will increase understanding and appreciation of the young woman’s remarkable diary by publishing an academically rigorous version. And yet the Anne Frank Fonds has taken legal action to stop that move, on the grounds that it would represent an infringement of its intellectual monopoly in some parts of Frank’s work, in some parts of the world. The current dispute is another clear example of how copyright has become for some an end in itself, more important than the things that it is supposed to promote.
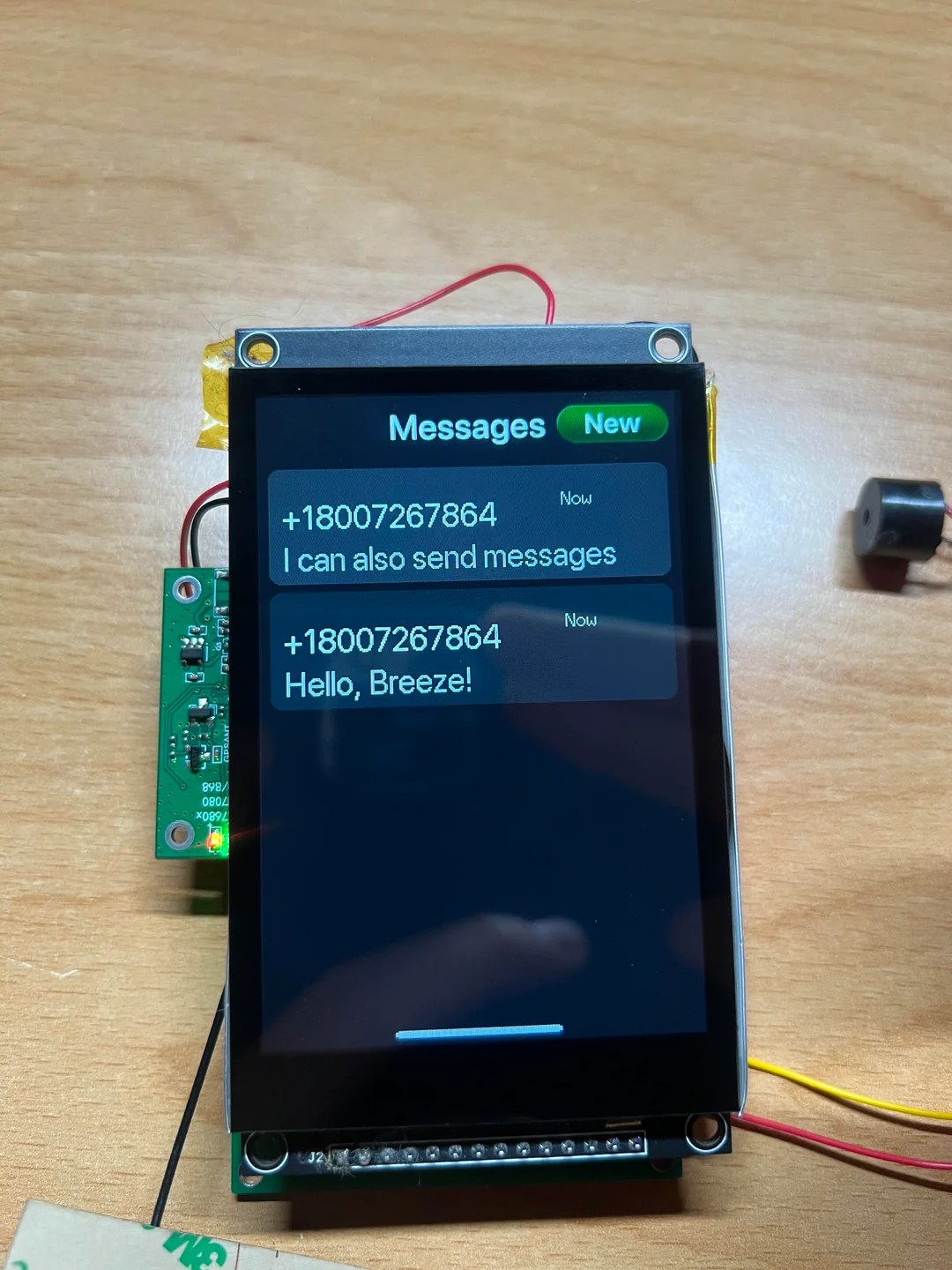
You may or may not be reading this on a smartphone, but odds are that even if you aren’t, you own one. Well, possess one, anyway — it’s debatable if the locked-down, one-way relationships we have with our addiction slabs counts as ownership. [LuckyBor], aka [Breezy], on the other hand — fully owns his 4G smartphone, because he made it himself.
OK, sure, it’s only rocking a 4G modem, not 5G. But with an ESP32-S3 for a brain, that’s probably going to provide plenty of bandwidth. It does what you expect from a phone: thanks to its A7682E simcom modem, it can call and text. The OV2640 Arducam module allows it to take pictures, and yes, it surfs the web. It even has features certain flagship phones lack, like a 3.5 mm audio jack, and with its 3.5″ touchscreen, the ability to fit in your pocket. Well, once it gets a case, anyway.
It talks, it texts, it… does not julienne fry, but that’s arguably a good thing.
This is just an alpha version, a brick of layered modules. [LuckyBor] plans on fitting everything into a slimmer form factor with a four-layer PCB that will also include an SD-card adapter, and will open-source the design at that time, both hardware and software. Since [LuckyBor] has also promised the world documentation, we don’t mind waiting a few months.
It’s always good to see another open-source option, and this one has us especially chuffed. Sure, we’ve written about Postmarket OS and other Linux options like Nix, and someone even put the rust-based Redox OS on a phone, but those are still on the same potentially-backdoored commercial hardware. That’s why this project is so great, even if its performance is decidedly weak compared to flagship phones that have as more horsepower as some of our laptops.
We very much hope [LuckyBor] carries through with the aforementioned promise to open source the design.
Australia’s government may take a strict stance on ensuring younger users cannot access AI chatbots. Reuters reports that Australian regulators may require app storefronts to block AI services that do not implement age verification for restricting mature content by March 9.
“eSafety will use the full range of our powers where there is non-compliance,” a representative for the commissioner said in a statement to the publication. Those paths could include “action in respect of gatekeeper services such as search engines and app stores that provide key points of access to particular services.”
A review by Reuters found that of 50 leading text-based AI chat services in the region, only nine had introduced or shared plans for age assurance. Eleven services reportedly “had blanket content filters or planned to block all Australians from using their service,” according to the report, leaving a large number that had not taken public action a week ahead of the country’s deadline. Failure to comply could see AI companies face fines of up to A$49.5 million ($35 million).
The question of which parties are responsible for keeping children from accessing potentially harmful content is being debated around the world. In the US, for instance, Apple and Google have been lobbying to have the task delegated to platforms rather than app store operators. The language from the Australian regulators about all stores is hardly definitive at this stage, but given the breadth of its sweeping ban on the use of social media and some highly social digital platforms for citizens under age 16 enacted last year, an aggressive stance seems to align with leaders’ priorities.
Today’s implants are commonly made from the patient’s own bone, called autografts, or from metal and ceramic materials. Autografts require an additional operation to collect the bone tissue, which increases recovery time and surgical risk. Metal implants can also create problems because they are much stiffer than natural bone and may loosen over time, reducing long term stability.
Designing Bone Implants That Work With Biology
Bone is far more intricate than it appears. It contains countless microscopic tunnels and hollow spaces that are essential for strength and function. “For proper healing, it is vital that biology is incorporated into the repair process,” says Xiao-Hua Qin, Professor of Biomaterials Engineering at ETH Zurich. Successful bone repair depends on multiple types of cells moving into the implant first, then working together to build new tissue.
To better match this biological complexity, Qin and his team, together with ETH Professor Ralph Müller, developed a new type of hydrogel designed for future bone implants. The soft material, similar in texture to jelly, gradually dissolves inside the body and may eventually allow for customized implants tailored to individual patients. Their findings were recently published in Advanced Materials.
Inspired by the Body’s Natural Healing Process
When a bone first breaks, the body does not immediately create hard tissue. Instead, it forms a soft, permeable structure. In the early days after injury, a hematoma or bruise develops at the fracture site. This temporary scaffold allows immune and repair cells to move in while delivering nutrients. A network of fibrin holds these cells together. Over time, this flexible framework slowly transforms into solid bone.
The newly developed hydrogel is designed to imitate this early healing phase. It consists of 97 percent water and 3 percent biocompatible polymer. To control when and where it hardens, the researchers added two specialized molecules. One connects the polymer chains, while the other reacts when exposed to light, triggering the solidification process.
[…]
“Hydrogels resemble jelly, making them difficult to shape,” says ETH Professor Qin. “With our newly developed connecting molecule, we can now not only structure the hydrogel in a stable and extremely fine manner but also produce it at high writing speeds of up to 400 millimeters per second. That’s a new world record.”
Around 15.8 million administrative files were stolen after attackers breached a software supplier to France’s health ministry.
The supplier, Cegedim Santé, confirmed the data was compromised in late 2025. Approximately 165,000 of these files contained notes penned by doctors, which in “very limited cases” contained sensitive information about an individual’s medical history.
According to broadcaster France 24, which first reported the news, these medical histories included, in some cases, details of conditions such as HIV/AIDS and individuals’ sexual orientations. Top politicians were reportedly among the individuals whose info was extracted.
The attack targeted Cegedim’s MonLogicielMedical (MLM) software, which it claims is used by 3,800 doctors across France, 1,500 of whom were affected.
MLM allows patients to check their health records electronically, communicate with their physician, and offers doctors a range of administrative features.
Cegedim confirmed that all the stolen information was contained in patients’ administrative files. In addition to doctors’ notes accessed “in free text,” the files also included information such as full names, genders, dates of birth, telephone numbers, home addresses, and email addresses.
An anonymous reader shares a CTech article with the caption: “A brilliantly executed operation.” From the report: Years before the air strike that killed Ayatollah Ali Khamenei, Israeli intelligence had been quietly mapping the daily rhythms of Tehran. According to reporting by the Financial Times(paywalled), nearly all of the Iranian capital’s traffic cameras had been hacked years earlier, their footage encrypted and transmitted to Israeli servers. One camera angle near Pasteur Street, close to Khamenei’s compound, allowed analysts to observe the routines of bodyguards and drivers: where they parked, when they arrived and whom they escorted. That data was fed into complex algorithms that built what intelligence officials call a “pattern of life,” detailed profiles including addresses, work schedules and, crucially, which senior officials were being protected and transported. The surveillance stream was one of hundreds feeding Israel’s intelligence system, which combines signals interception from Unit 8200, human assets recruited by the Mossad and large-scale data analysis by military intelligence.
When US and Israeli intelligence determined that Khamenei would attend a Saturday morning meeting at his compound, the opportunity was judged unusually favorable. Two people familiar with the operation told the FT that US intelligence provided confirmation from a human source that the meeting was proceeding as planned, a level of certainty required for a target of such magnitude. Israeli aircraft, reportedly airborne for hours, fired as many as 30 precision munitions. The strike was carried out in daylight, which the Israeli military said created tactical surprise despite heightened Iranian alertness. The Financial Times reports that the assassination was a political decision as much as a technological feat. Even during last year’s 12-day war, when Israeli strikes killed more than a dozen Iranian nuclear scientists and senior military officials and disabled air defences through cyber operations and drones, Israel did not attempt to kill Khamenei.
The capability to do so, however, had been built over decades. Former Mossad official Sima Shine told the FT that Israel’s strategic focus on Iran dates back to a 2001 directive from then-prime minister Ariel Sharon instructing intelligence chief Meir Dagan to make the Islamic Republic the priority target. What distinguishes the latest operation, according to the FT, is the scale of automation. Target tracking that once required painstaking visual confirmation has increasingly been handled by algorithm-driven systems parsing billions of data points. One person familiar with the process described it as an “assembly line with a single product: targets.”Further reading:America Used Anthropic’s AI for Its Attack On Iran, One Day After Banning It
Your latest chat transcript could be bought and sold. Data brokers are selling access to sensitive personal data captured during chatbot conversations, despite claims that the data is anonymized and obtained with consent.
Lee S Dryburgh, an expert in AI visibility for consumer health and longevity brands, explained how this works in a report provided to The Register.
People install browser extensions that purport to offer free VPN service or ad blocking or some other capability, likely without reading or understanding the extension’s privacy policy.
These extensions may silently intercept users’ communications with AI services like ChatGPT, Gemini, Claude, and DeepSeek. They can do so by overriding the browser’s native fetch() and XMLHttpRequest() functions in order to capture every prompt and every response.
“This data is captured from real people’s private AI conversations via browser extensions, stored in a vector database, and exposed via API to authenticated customers,” said Dryburgh in his report. “The panelists have pseudonymized IDs (SHA-256 hashes) but the content of their conversations is stored verbatim and searchable — and many prompts contain real names, dates of birth, medical record numbers, and diagnosis codes.”
It’s a technique that Dryburgh discussed with The Register in September 2025 and that Koi Security documented in December 2025 in its report titled “8 Million Users’ AI Conversations Sold for Profit by ‘Privacy’ Extensions.”
The companies that aggregate this web clickstream data insist that their data handling is lawful and the data is anonymized. That isn’t much of a consolation given that it has long been known that anonymized profiles can sometimes be re-identified by connecting a few data points, a process that AI assistance has made much easier. And, in any event, Dryburgh claims to have found many conversations that reveal names and other sensitive details.
Dryburgh said he had access to a major VC-backed generative engine optimization platform and, through that platform, was able to examine the aggregated clickstream data made available to customers.
He said he made 205 queries to the platform using the platform’s own semantic search and received ~490 unique prompts from ~435+ unique panelists across 20 sensitive categories.
One set of queries returned conversations about depression, suicide, self-harm, medication, abuse, and eating disorders. A second provided access to chat about substance abuse, medical diagnoses, financial vulnerability, children, sexuality, and immigration. A third covered HIV/STDs, cancer, fertility/pregnancy, children, sexual violence, financial crisis, and medical diagnoses. And a fourth provided chats about clinical HIPAA notes, legal PII, relationships, gender identity, criminal records, workplace harassment, and religious identity.
The most damning finding, he said in his report, is that “healthcare workers are pasting real patient data into AI chatbots, and that data is now a commercial database.”
Users of Meta’s AI smart glasses in Europe may be unknowingly sharing intimate video and sensitive financial information with moderators outside of the bloc, according to a report from Sweden’s Svenska Dagbladetreleased last week. Employees in Kenya doing AI “annotation” told the journalists that they’ve seen people nude, using the toilet and engaging in sexual activity, along with credit card numbers and other sensitive information.
With Meta’s Ray-Ban Display and other glasses with AI capabilities, users can record what they’re looking at or get answers to questions via a Meta AI assistant. If a wearer wants to make use of that AI, though, they must agree to Meta’s terms of service that allow any data captured to be reviewed by humans. That’s because Meta’s large language models (LLMs) often require people to annotate visual data so that the AI can understand it and build its training models.
This data can end up in places like Nairobi, Kenya, often moderated by underpaid workers. Such actions are subject to Europe’s GDPR rules that require transparency about how personal data is processed, according to a data protection lawyer cited in the report.
However, Svenska Dagbladet’s reporters said they needed to jump through some hoops to see Meta’s privacy policy for its wearable products. That policy states that either humans or automated systems may review sensitive data, and puts the onus on the user to not share sensitive information.
Meta declined to comment directly on the story, and simply said that “when live AI is being used, we process that media according to the Meta AI Terms of Service and Privacy Policy.” To find out more, check out Svenska Dagbladet‘s detailed reporting on the subject.
Security researchers say a highly sophisticated iPhone exploitation toolkit dubbed “Coruna,” which possibly originated from a U.S. government contractor, has spread from suspected Russian espionage operations to crypto-stealing criminal campaigns. Apple has patched the exploited vulnerabilities in newer iOS versions, but tens of thousands of devices may have already been compromised. An anonymous reader quotes an excerpt from Wired’s report: Security researchers at Google on Tuesday released a report describing what they’re calling “Coruna,” a highly sophisticated iPhone hacking toolkit that includes five complete hacking techniques capable of bypassing all the defenses of an iPhone to silently install malware on a device when it visits a website containing the exploitation code. In total, Coruna takes advantage of 23 distinct vulnerabilities in iOS, a rare collection of hacking components that suggests it was created by a well-resourced, likely state-sponsored group of hackers.
In fact, Google traces components of Coruna to hacking techniques it spotted in use in February of last year and attributed to what it describes only as a “customer of a surveillance company.” Then, five months later, Google says a more complete version of Coruna reappeared in what appears to have been an espionage campaign carried out by a suspected Russian spy group, which hid the hacking code in a common visitor-counting component of Ukrainian websites. Finally, Google spotted Coruna in use yet again in what seems to have been a purely profit-focused hacking campaign, infecting Chinese-language crypto and gambling sites to deliver malware that steals victims cryptocurrency.
Conspicuously absent from Google’s report is any mention of who the original surveillance company “customer” that deployed Coruna may have been. But the mobile security company iVerify, which also analyzed a version of Coruna it obtained from one of the infected Chinese sites, suggests the code may well have started life as a hacking kit built for or purchased by the US government. Google and iVerify both note that Coruna contains multiple components previously used in a hacking operation known as “Triangulation” that was discovered targeting Russian cybersecurity firm Kaspersky in 2023, which the Russian government claimed was the work of the NSA. (The US government didn’t respond to Russia’s claim.)
Coruna’s code also appears to have been originally written by English-speaking coders, notes iVerify’s cofounder Rocky Cole. “It’s highly sophisticated, took millions of dollars to develop, and it bears the hallmarks of other modules that have been publicly attributed to the US government,” Cole tells WIRED. “This is the first example we’ve seen of very likely US government tools — based on what the code is telling us — spinning out of control and being used by both our adversaries and cybercriminal groups.” Regardless of Coruna’s origin, Google warns that a highly valuable and rare hacking toolkit appears to have traveled through a series of unlikely hands, and now exists in the wild where it could still be adopted — or adapted — by any hacker group seeking to target iPhone users. “How this proliferation occurred is unclear, but suggests an active market for ‘second hand’ zero-day exploits,” Google’s report reads. “Beyond these identified exploits, multiple threat actors have now acquired advanced exploitation techniques that can be re-used and modified with newly identified vulnerabilities.”
GitHub alternative Tangled has raised a $4.5 million funding round. The code platform offers a primary European alternative to GitHub for developers, providing an open and extensible network built for the next generation of software creation.
The funding round was led by byFounders, the community-powered VC firm, with participation from Bain Capital Crypto and existing investor Antler.
Notable angel investors also joined the round, including:
Thomas Dohmke, the former CEO of GitHub,
Avery Pennarun, CEO of Tailscale,
Mårten Mickos, former CEO of MySQL and HackerOne and
Sami Honkonen, a prominent Finnish angel investor and the founder of DIAS.
Tangled was founded by brothers Akshay and Anirudh Oppiliappan, who bring extensive experience building large-scale distributed systems and code intelligence platforms at Y Combinator startups. Akshay is based in London, while Anirudh is based in Helsinki, reflecting the company’s cross-border European roots.
Here we see the creeping sliding scale that is the terror of Age Verification. First of all, an OS does not need an age – it’s like saying any technology needs age verification: all gadgets use an OS, whether it is your washing machine, your smart light switch, your PSP or your PC. Second of all, an OS has no business being forced online – they are supposed to be non-cloud, personal, non-connected unless you want them to connect. Age verification requires external suppliers and so you would need to connect to perform the age verification – and send who knows what kind of other personal data. Eg Windows sends hardware data (along with a whole load of other data) that works much like a fingerprint. This makes it easy to track a users movements online. This is one reason why people want to bypass the online account creation on Windows and use local accounts.
As more US states consider online age-verification requirements, two Colorado lawmakers want to implement the age checks at the operating system-level, after California enacted a similar law.
Colorado’s SB26-051, introduced last month, would require operating systems to register the owner’s age, which third-party apps can then leverage to determine if the user is an adult. The bill calls for the device owner to register their birthdate or age, but for the purposes of creating an “age bracket,” which can then be shared to an app developer through an API to learn their age range, according to BiometricUpdate.com.
The bill comes from state Sen. Matt Ball and Rep. Amy Paschal, both Democrats. “The intent is to create thoughtful safeguards for kids online through a privacy-forward framework for age assurance,” Ball told PCMag. “Unlike some laws in other states, SB 51 doesn’t require users to share personally identifiable information or use facial recognition technology.”
Ball also said the legislation was based on California’s bill AB 1043, which was passed last year. It too requires OS makers to create a way for the device owner to register their age bracket, which can then be shared to app developers over an API. The California law starts to take effect January 1, 2027.
Ball added: “SB 26-51 is very closely modeled on it. One of the reasons for bringing SB 51 was that the tech and software industry is already complying with AB 1043, so there’s minimal added burden.”
Note here: they are not. Several Linux distributions have in fact already changed their ToU making it illegal for the software to be used in California.
The legislation also promises to centralize the age check through the OS, rather than mandating that each app enforce their own age-verification mechanism, which can involve scanning the user’s official ID, thus raising privacy and security concerns. The bill also forbids the sharing of the age-bracket data for any other purpose.
But it looks like it’s easy to bypass the age check proposed by SB26-051. The legislation itself doesn’t mention any state ID check to verify the owner’s age. In addition, the bill doesn’t seem to cover websites, only apps and app stores.
New research shows that behaviors that occur at the very lowest levels of the network stack make encryption—in any form, not just those that have been broken in the past—incapable of providing client isolation, an encryption-enabled protection promised by all router makers, that is intended to block direct communication between two or more connected clients.
The isolation can effectively be nullified through AirSnitch, the name the researchers gave to a series of attacks that capitalize on the newly discovered weaknesses. Various forms of AirSnitch work across a broad range of routers, including those from Netgear, D-Link, Ubiquiti, Cisco, and those running DD-WRT and OpenWrt.
AirSnitch “breaks worldwide Wi-Fi encryption, and it might have the potential to enable advanced cyberattacks,” Xin’an Zhou, the lead author of the research paper, said in an interview. “Advanced attacks can build on our primitives to [perform] cookie stealing, DNS and cache poisoning. Our research physically wiretaps the wire altogether so these sophisticated attacks will work. It’s really a threat to worldwide network security.” Zhou presented his research on Wednesday at the 2026 Network and Distributed System Security Symposium.
Paper co-author Mathy Vanhoef, said a few hours after this post went live that the attack may be better described as a Wi-Fi encryption “bypass,” “in the sense that we can bypass client isolation. We don’t break Wi-Fi authentication or encryption. Crypto is often bypassed instead of broken. And we bypass it ;)” People who don’t rely on client or network isolation, he added, are safe.
[…]
The lowest level, Layer-1, encompasses physical devices such as cabling, connected nodes, and all the things that allow them to communicate. The highest level, Layer-7, is where applications such as browsers, email clients, and other Internet software run. Levels 2 through 6 are known as the Data Link, Network, Transport, Session, and Presentation layers, respectively.
Identity crisis
Unlike previous Wi-Fi attacks, AirSnitch exploits core features in Layers 1 and 2 and the failure to bind and synchronize a client across these and higher layers, other nodes, and other network names such as SSIDs (Service Set Identifiers). This cross-layer identity desynchronization is the key driver of AirSnitch attacks.
The most powerful such attack is a full, bidirectional machine-in-the-middle (MitM) attack, meaning the attacker can view and modify data before it makes its way to the intended recipient. The attacker can be on the same SSID, a separate one, or even a separate network segment tied to the same AP. It works against small Wi-Fi networks in both homes and offices and large networks in enterprises.
[…]
Even when HTTPS is in place, an attacker can still intercept domain look-up traffic and use DNS cache poisoning to corrupt tables stored by the target’s operating system. The AirSnitch MitM also puts the attacker in the position to wage attacks against vulnerabilities that may not be patched. Attackers can also see the external IP addresses hosting webpages being visited and often correlate them with the precise URL.
Given the range of possibilities it affords, AirSnitch gives attackers capabilities that haven’t been possible with other Wi-Fi attacks, including KRACK from 2017 and 2019 and more recent Wi-Fi attacks that, like AirSnitch, inject data (known as frames) into remote GRE tunnels and bypass network access control lists.
“This work is impressive because unlike other frame injection methods, the attacker controls a bidirectional flow,” said HD Moore, a security expert and the founder and CEO of runZero.
[…]
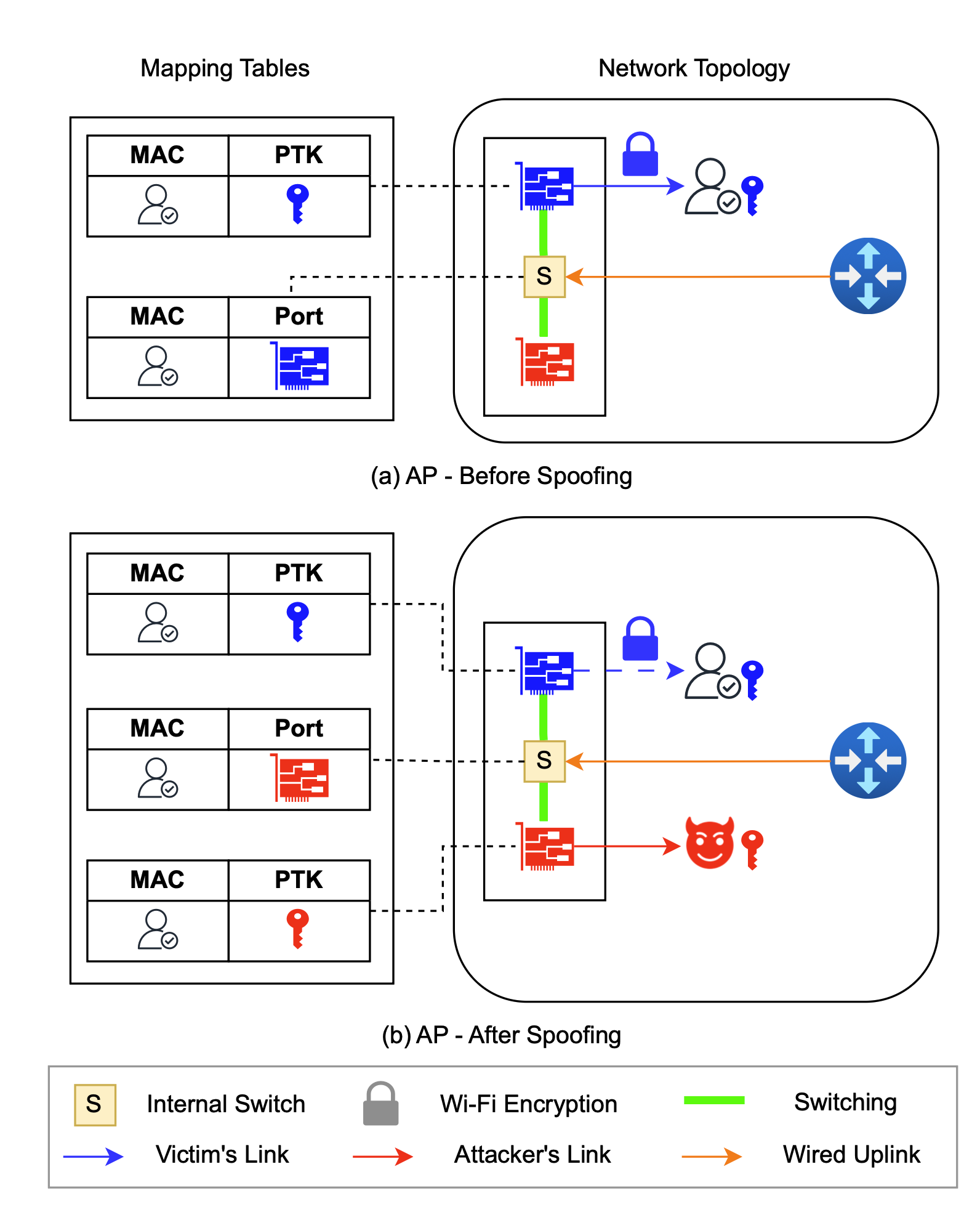
The MitM targets Layers 1 and 2 and the interaction between them. It starts with port stealing, one of the earliest attack classes of Ethernet that’s adapted to work against Wi-Fi. An attacker carries it out by modifying the Layer-1 mapping that associates a network port with a victim’s MAC—a unique address that identifies each connected device. By connecting to the BSSID that bridges the AP to a radio frequency the target isn’t using (usually a 2.4GHz or 5GHz) and completing a Wi-Fi four-way handshake, the attacker replaces the target’s MAC with one of their own.
The attacker spoofs the victim’s MAC address on a different NIC, causing the internal switch to mistakenly associate the victim’s address with the attacker’s port/BSSID. As a result, frames intended for the victim are forwarded to the attacker and encrypted using the attacker’s PTK. Credit: Zhou et al.
In other words, the attacker connects to the Wi-Fi network using the target’s MAC and then receives the target’s traffic. With this, an attacker obtains all downlink traffic (data sent from the router) intended for the target. Once the switch at Layer-2 sees the response, it updates its MAC address table to preserve the new mapping for as long as the attacker needs.
This completes the first half of the MitM, allowing all data to flow to the attacker. That alone would result in little more than a denial of service for the target. To prevent the target from noticing—and more importantly, to gain the bidirectional MitM capability needed to perform more advanced attacks—the attacker needs a way to restore the original mapping (the one assigning the victim’s MAC to the Layer-1 port). An attacker performs this restoration by sending an ICMP ping from a random MAC. The ping, which must be wrapped in a Group Temporal key shared among all clients, triggers replies that cause the Layer-1 mapping (i.e., port states) to revert back to the original one.
“In a normal Layer-2 switch, the switch learns the MAC of the client by seeing it respond with its source address,” Moore explained. “This attack confuses the AP into thinking that the client reconnected elsewhere, allowing an attacker to redirect Layer-2 traffic. Unlike Ethernet switches, wireless APs can’t tie a physical port on the device to a single client; clients are mobile by design.”
The back-and-forth flipping of the MAC from the attacker to the target, and vice versa, can continue for as long as the attacker wants. With that, the bidirectional MitM has been achieved. Attackers can then perform a host of other attacks, both related to AirSnitch or ones such as the cache poisoning discussed earlier. Depending on the router the target is using, the attack can be performed even when the attacker and target are connected to separate SSIDs connected by the same AP. In some cases, Zhou said, the attacker can even be connected from the Internet.
“Even when the guest SSID has a different name and password, it may still share parts of the same internal network infrastructure as your main Wi-Fi,” the researcher explained. “In some setups, that shared infrastructure can allow unexpected connectivity between guest devices and trusted devices.”
Although port stealing was originally devised for hosts on the same switch, we show that attackers can hijack MAC-to-port mappings at a higher layer, i.e., at the level of the distribution switch—to intercept traffic to victims associated with different APs. This escalates the attack beyond its traditional limits, breaking the assumption that separate APs provide effective isolation.
This discovery exposes a blind spot in client isolation: even physically separated APs, broadcasting different SSIDs, offer ineffective isolation if connected to a common distribution system. By redirecting traffic at the distribution switch, attackers can intercept and manipulate victim traffic across AP boundaries, expanding the threat model for modern Wi-Fi networks.
[…]
AirSnitch, by contrast, requires that the attacker already have some sort of access to the Wi-Fi network. For many people, that may mean steering clear of public Wi-Fi networks altogether.
If the network is properly secured—meaning it’s protected by a strong password that’s known only to authorized users—AirSnitch may not be of much value to an attacker. The nuance here is that even if an attacker doesn’t have access to a specific SSID, they may still use AirSnitch if they have access to other SSIDs or BSSIDs that use the same AP or other connecting infrastructure.
[…]
“We expand the threat model showing an attacker can be on another channel or port, or can be from the Internet,” Zhou said. “Firewalls are also networking devices. We often say a firewall is a Layer-3 device because it works at the IP layer. But fundamentally, it’s connected by wire to different network elements. That wire is not secure.”
Some of the threat can be mitigated by using VPNs, but this remedy has all the usual drawbacks that come with them. For one, VPNs are notorious for leaking metadata, DNS queries, and other traffic that can be useful to attackers, making the protection limited.
[…]
Another potential mitigation is using wireless VLANs to isolate one SSID from another. Zhou said such options aren’t universally available and are also “super easy to be configured wrong.” Specifically, he said VLANs can often be implemented in ways that allow “hopping vulnerabilities.” Further, Moore has argued why “VLANs are not a practical barrier” against all AirSnitch attacks
The most effective remedy may be to adopt a security stance known as zero trust, which treats each node inside a network as a potential adversary until it provides proof it can be trusted. This model is challenging for even well-funded enterprise organizations to adopt, although it’s becoming easier. It’s not clear if it will ever be feasible for more casual Wi-Fi users in homes and smaller businesses.
Probably the most reasonable response is to exercise measured caution for all Wi-Fi networks managed by people you don’t know. When feasible, use a trustworthy VPN on public APs or, better yet, tether a connection from a cell phone.
[…]
“It will be interesting to see if the wireless vendors care enough to resolve these issues completely and if attackers care enough to put all of this together when there might be easier things to do (like run a fake AP instead),” Moore said. “At the least it should make pentesters’ lives more interesting since it re-opens a lot of exposure that many folks may not have any experience with.
Posted inHacks|Comments Off on Airsnitch WiFi attack: Stay away from public WiFi (unless you have a VPN you trust) and don’t let anyone onto your guest WiFi unless it’s isolated via VLAN!
This data breach should not have been so large. Yes, it’s good that Odido stood up to ransomware actors and did not pay the ransom. No, they should have deleted most of that data years and years ago as per their own TOS and EU regulation.
Odido is a Dutch telecommunications company and one of the largest mobile network operators in the Netherlands. It was formed when T-Mobile Netherlands and Tele2 were rebranded as Odido in 2023 after private equity firms Apax Partners and Warburg Pincus acquired the business.
Odido serves around 8 million mobile subscribers and about 1 million fixed broadband customers nationwide. The company provides mobile telephony, wireless broadband, and related services under multiple brands including Odido, Ben, and Simpel.
In mid-February, the cybercrime group ShinyHunters broke into the Dutch telecom firm Odido and accessed data from 6.2 million accounts. At the time, the company confirmed the breach and said attackers took names, addresses, phone numbers, email addresses, bank account details, dates of birth, and passport or ID numbers.
“Odido has been hit by a cyberattack, which compromised customer data. This involved personal data from a customer contact system used by Odido. No passwords, call logs, or billing information were affected.” reads a notice published by the company on its website. “The unauthorized access to the system was terminated as quickly as possible. Odido also engaged external cybersecurity experts to assist with implementing additional security measures as part of the incident response.”
The telco said the breach did not expose My Odido account passwords, call records, location data, invoice details, or scans of ID documents.
Odido’s subsidiary Ben also warned its customers that hackers may have stolen their information.
Now, an alleged final dump has exposed 4.6 million more unique email addresses from Dutch telecom provider Odido, bringing the total to 6.1 million across four separate releases.
“Due to recent developments regarding this telco, daily leaks will not happen anymore. Instead, you can download the Odido dataset concerning its full former and current customers below.” ShinyHunters wrote on its Tor data leak site. “Over 15m Salesforce records containing Full Names, Physical addresses, email addresses, phone numbers, and plaintext passwords, IBAN, passport numbers, driver license numbers and other internal corporate data have been compromised. This is your fault, Odido. You are the reason why an entire country is about to suffer for an unestimated amount of years. Unprecedented.”
The data breach notification service Have I Been Pwned (HIBP) added the compromised dataset to its archive. The final release includes a total of 6.1M unique addresses.
The Norwegian Consumer Council, a government funded organization advocating for consumer’s rights, released a report on the trend of “enshittification” in digital consumer goods and services, suggesting ways consumers for consumers to resist. But they’ve also dramatized the problem with a funny four-minute video about the man whose calls for him to make things shitty for people.
“It’s not just your imagination. Digital services are getting worse,” the video concludes — before adding that “Luckily, it doesn’t have to be this way.” The Consumer Council’s announcement recommends:
Stronger rights for consumers to control, adapt, repair, and alter their products and services,
Interoperability, data portability, and decentralisation as the norm, so the threshold for moving to different services becomes as low as possible,
Deterrent and vigorous enforcement of competition law, so that Big Tech companies are not allowed to indiscriminately acquire start-ups, competitors or otherwise steer the market to their advantage,
Better financing of initiatives to build, maintain or improve alternative digital services and infrastructure based on open source code and open protocols,
Reduce public sector dependence on big tech, to regain control and to contribute to a functioning market for service providers that respect fundamental rights,
Deterrent and consistent enforcement of other laws, including consumer and data protection law.
The Norwegian Consumer Council is also joining 58 organisations and experts in a letter asking the Norwegian government to rebalance power with enforcement resources and by prioritizing the procurement of services based on open source code. And “Our sister organisations are sending similar letters to their own governments in 12 countries.”
They’re also sending a second letter to the European Commission with 29 civil society organisations (including the EFF and Amnesty International) warning about the risks of deregulation and calling for reducing dependency on big tech.
Posted inHardware, Software|Comments Off on Norway’s Consumer Council Calls for Right to Repair and Antitrust Enforcement – and Mocks ‘Enshittification’
So this is basically an agentic coordinator (which the correct technical term is an orchestrator). The agents are like microservices, or little programs designed to do a specific job – usually by interacting with a tool (eg a weather API). This is part of the puzzle that was missing in Agentic AI, but which an upstart coming from nowhere (OpenClaw) threw out there. Now we are seeing more of these coming out. It looks like people are copying OpenClaw pretty quickly.
The idea is that the user describes a specific outcome — something like “plan and execute a local digital marketing campaign for my restaurant” or “build me an Android app that helps me do a specific kind of research for my job.” Computer then ideates subtasks and assigns them to multiple agents as needed, running the models Perplexity deems best for those tasks. The core reasoning engine currently runs Anthropic’s Claude Opus 4.6, while Gemini is used for deep research, Nano Banana for image generation, Veo 3.1 for video production, Grok for lightweight tasks where speed is a consideration, and ChatGPT 5.2 for “long-context recall and wide search.”
This kind of best-model-for-the-task approach differs from some competing products like Claude Cowork, which only uses Anthropic’s models. All this happens in the cloud, with prebuilt integrations. “Every task runs in an isolated compute environment with access to a real filesystem, a real browser, and real tool integrations,” Perplexity says. The idea is partly that this workflow was what some power users were already doing, and this aims to make that possible for a wider range of people who don’t want to deal with all that setup.
People were already using multiple models and tailoring them to specific tasks based on perceived capabilities, while, for example, using MCP (Model Context Protocol) to give those models access to data and applications on their local machines. Perplexity Computer takes a different approach, but the goal is the same: have AI agents running tailor-picked models to perform tasks involving your own files, services, and applications. Then there is OpenClaw, which you could perceive as the immediate predecessor to this concept.
“The Diary of a Young Girl” is a Dutch language diary written by the young Jewish writer Anne Frank while she was in hiding for two years with her family during the Nazi occupation of the Netherlands. Although the diary and Anne Frank’s death in the Bergen-Belsen concentration camp are well known, few are aware that the text has a complicated copyright history – one that could have important implications for the legal status and use of Virtual Private Networks (VPNs) in the EU. TorrentFreak explains the copyright background:
These copyrights are controlled by the Swiss-based Anne Frank Fonds, which was the sole heir of Anne’s father, Otto Frank. The Fonds states that many print versions of the diary remain protected for decades, and even the manuscripts are not freely available everywhere.
In the Netherlands, for example, certain sections of the manuscripts remain protected by copyright until 2037, even though they have entered the public domain in neighboring countries like Belgium.
A separate foundation, the Netherlands-based Anne Frank Stichting, wanted to publish a scholarly edition of Anne Frank’s writing, at least in those parts of the world where her diary was in the public domain:
To navigate these conflicting laws, the Dutch Anne Frank Stichting published a scholarly edition online using “state-of-the-art” geo-blocking to prevent Dutch residents from accessing the site. Visitors from the Netherlands and other countries where the work is protected are met with a clear message, informing them about these access restrictions.
However, the Anne Frank Fonds was unhappy with this approach, and took legal action. Its argument was that such geo-blocking could be circumvented with VPNs, and so its copyrights in the Netherlands could be infringed upon by those using VPNs. The lower courts in the Netherlands dismissed this argument, and the case is now before the Dutch Supreme Court. Beyond the specifics of the Anne Frank scholarly edition, there are important issues regarding the use of VPNs to get around geo-blocking. Because of the potential knock-on effect the ruling in this case will have on EU law, the Dutch Supreme Court has asked for guidance from the EU’s top court, the Court of Justice of the European Union (CJEU).
The CJEU has yet to rule on the issues raised. But one of the court’s advisors, Advocate General Rantos, has published a preliminary opinion, as is normal in such cases. Although that advice is not binding on the CJEU, it often provides some indication as to how the court may eventually decide. On the main issue of whether the ability of people to circumvent geo-blocking is a problem, Rantos writes:
the fact that users manage to circumvent a geo-blocking measure put in place to restrict access to a protected work does not, in itself, mean that the entity that put the geo-blocking in place communicates that work to the public in a territory where access to it is supposed to be blocked. Such an interpretation would make it impossible to manage copyright on the internet on a territorial basis and would mean that any communication to the public on the internet would be global.
Moreover:
As the [European] Commission pointed out in its written observations, the holder of an exclusive right in a work does not have the right to authorise or prohibit, on the basis of the right granted to it in one Member State, communication to the public in another Member State in which that right has ceased to have effect.
Or, more succinctly: “service providers in the public domain country cannot be subject to unreasonable requirements”. That’s a good, common-sense view. But perhaps just as important is the following comment by Rantos regarding the use of VPNs to circumvent geo-blocking:
as the Commission points out in its observations, VPN services are legally accessible technical services which users may, however, use for unlawful purposes. The mere fact that those or similar services may be used for such purposes is not sufficient to establish that the service providers themselves communicate the protected work to the public. It would be different if those service providers actively encouraged the unlawful use of their services.
The hope has to be that the CJEU will agree with its Advocate General’s sensible and fair analysis, and will rule accordingly. But there is another important aspect to this story. The basic issue is that the Anne Frank Stichting wants to make its scholarly edition of Anne Frank’s diary available as widely as possible. That seems a laudable aim, since it will increase understanding and appreciation of the young woman’s remarkable diary by publishing an academically rigorous version. And yet the Anne Frank Fonds has taken legal action to stop that move, on the grounds that it would represent an infringement of its intellectual monopoly in some parts of Frank’s work, in some parts of the world. The current dispute is another clear example of how copyright has become for some an end in itself, more important than the things that it is supposed to promote.
The west is in the midst of the most serious assault on free speech and academic freedom since the heyday of McCarthyism seven decades ago. For years, we were told the danger came from the left: oversensitive students, censorious activists, no-platforming zealots. Yet the most aggressive and successful campaign to police speech in our public institutions is being waged by cheerleaders of a state currently committing genocide.
Consider a recent case. Last December, a pro-Israel lobby group, UK Lawyers for Israel (UKLFI), celebrated another apparent victory. It describes its mission as contributing “generally as lawyers to creating a supportive climate of opinion in the United Kingdom towards Israel”. In practice, this has meant lawfare, directed not only at pro-Palestinian activism, but at the public existence of Palestinian identity itself.
The offence this time? The Open University’s use of the term “ancient Palestine” to describe the birthplace of the Virgin Mary, which UKLFI argued was “historically inaccurate”. More than that, they argued it risked erasing “Jewish historical identity”, potentially breaching the Equality Act 2010 by creating “a hostile or offensive learning environment for Jewish and Israeli students”.
The OU’s Palestine Solidarity Group responded with a freedom of information request to see how their institution had handled the complaint. The reply from the OUwas clear. “Ancient Palestine” was “academically appropriate”. The fifth-century BC Greek historian Herodotus used the term Palestine to describe a region broader than that acknowledged by UKLFI. While the lobby group insisted Mary was born in the “predominantly Jewish region” of Galilee, the university noted that there is no academic consensus that Mary existed at all, still less where she was born.
That should have been the end of the matter. But instead, the OU conceded that “associations of this term with Roman colonial rule and with the contemporary political context require us to think about the meaning of the term to current and future students”. Academics did not “want the use of the term to imply or be read as a comment on the conflict between Israel and Palestine”, it added. In response to the UKLFI complaint, staff accepted that “the term is now problematic in a way that, perhaps, it was not when the materials were written in 2018”.
And so, despite affirming the term’s historical accuracy, the OU agreed to “not use the term ‘ancient Palestine’ in any future course materials”, and to “explain and contextualise its use in existing materials for current learners”. Last month, staff received an internal bulletin confirming the university had “agreed to change references to ‘Ancient Palestine’”, complete with a link to the UKLFI’s triumphant press release: “Open University agrees to change use of ‘ancient Palestine’ following UKLFI intervention.”
Strip away the bureaucratic phrasing and the picture is stark. A university accepted that a historically accurate term would be removed from future teaching because a partisan lobbying organisation objected to its claimed contemporary political resonance. “This is a despicable attempt by political hacks to dictate academic terminology,” says the esteemed historian Rashid Khalidi, author of The Hundred Years’ War on Palestine. “Every reputable history covering periods from ancient history to the present uses the term ‘Palestine,’ including scores of works by distinguished Israeli scholars.”
Enter the Higher Education (Freedom of Speech) Act 2023, introduced by the last Conservative government amid warnings that leftwing activists were strangling academic debate. The act imposes a duty on universities to secure lawful freedom of speech, even where that speech “may be offensive or hurtful to some”.
The OU had landed themselves in a mess. When the Palestine Solidarity Group argued that censoring an academically defensible term on the grounds that it was politically “problematic” violated the 2023 legislation, the vice-chancellor circulated a clarifying note: the university stood by academic freedom. The school would continue using the term, albeit with “an additional contextual note to support students’ understanding of differing perspectives”. His statement failed to say whether this change was a response to the intervention by a partisan lobby group.
[…]
This is just one example of UKLFI’s assault on Palestinian identity, past and present. Months before Israel’s genocide began, Chelsea and Westminster hospital removed a display of artwork by Palestinian children after a complaint by UKLFI claimed it made Jewish patients feel “vulnerable, harassed and victimised”. A pro-Palestinian concert planned at Morley College in London was cancelled after a UKLFI complaint in 2024. The group also sought to cancel the Falastin film festival in Scotland.skip past newsletter promotion
The Solicitors Regulation Authority is now investigating a complaint alleging that eight of UKLFI’s letters “demonstrate a seeming pattern of vexatious and legally baseless correspondence aimed at silencing and intimidating Palestine solidarity efforts”. Whatever the outcome of that investigation, the wider context is impossible to ignore.
[…]
This is the real crisis of free speech in the west. The target is not just protest, but a people. Israel seeks to erase Palestinians as a society. First they are destroyed in the present. Then they are deleted from the past.
Posted inPolitics|Comments Off on Freedom of speech? Open University deletes “ancient Palestine” references under Israeli lobby pressure despite historical accuracy
The U.S. has used LUCAS kamikaze drones for the first time in combat, U.S. Central Command acknowledged on Saturday. The drones, based on the Iranian Shahed-136, were launched from the ground by Task Force Scorpion Strike (TFSS). The task force was set up in December “to flip the script on Iran,” a U.S. official told us at the time. The launch of LUCAS drones marks a rare instance when the U.S. adopted Iran’s drone playbook and used it against them.
Today’s strikes were part of Operation Epic Fury, an attack the U.S. launched along with Israel on targets across Iran. You can read more about that in our initial story here.
The LUCAS drones are designed to be a far less expensive strike weapon than missiles, which not only cost more, but are far more difficult and time-consuming to produce.
“Costing approximately $35,000 per platform, LUCAS is a low-cost, scalable system that provides cutting-edge capabilities at a fraction of the cost of traditional long-range U.S. systems that can deliver similar effects,” Navy Capt. Tim Hawkins, a CENTCOM spokesperson, told TWZ back in December. “The drone system has an extensive range and the ability to operate beyond line of sight, providing significant capability across CENTCOM’s vast operating area.”
In addition, the LUCAS design includes features that allow for “autonomous coordination, making them suitable for swarm tactics and network-centric strikes,” a U.S. official told us. As we have explained in detail in the past, the swarming capabilities combined with some of the drones being equipped with Starlink terminals, means extremely advanced cooperative tactics and dynamic targeting are possible, all while keeping humans in the loop.
The LUCAS drones have “an extensive range and are designed to operate autonomously,” CENTCOM said in a press release announcing the creation of Task Force Scorpion Strike. “They can be launched with different mechanisms to include catapults, rocket-assisted takeoff, and mobile ground and vehicle systems.”
Low-cost Unmanned Combat Attack System (LUCAS) drones are positioned on the tarmac at a base in the U.S. Central Command operating area, Nov. 23. Costing approximately $35,000 per platform, LUCAS drones are providing U.S. forces in the Middle East low-cost, scalable capabilities to strengthen regional security and deterrence. (Courtesy Photo)
Though the LUCAS drones fired against Iran were ground-launched, U.S. Navy personnel in the Middle East test-fired one from the Independence class Littoral Combat Ship (LCS) USS Santa Barbara. This came two weeks after the U.S. military announced the formation of Task Force Scorpion Strike.
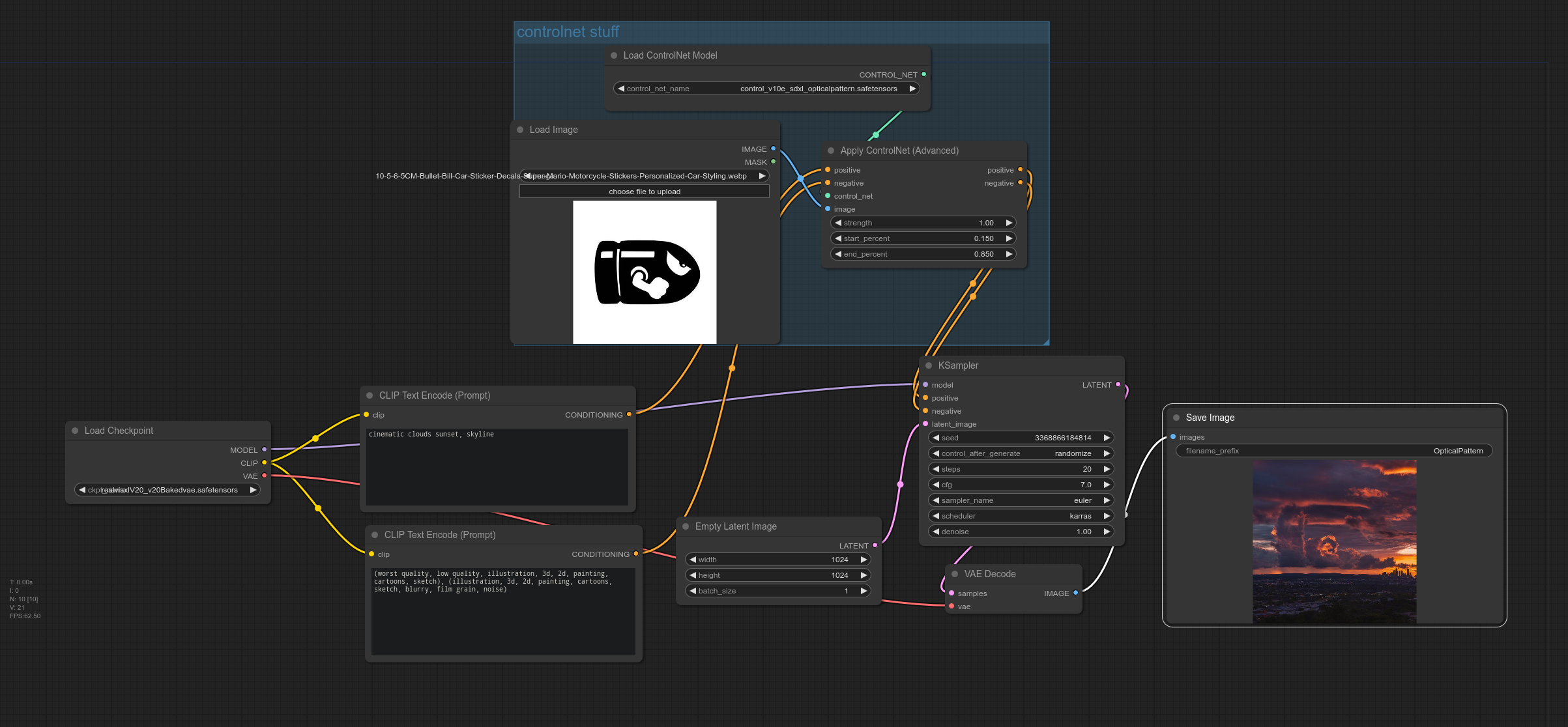
Images that are generated with Stable Diffusion with QR Codes as ControlNet’s input, making the QR Code data points blend into the artwork while still being scannable by QR Code readers.
There are a few online services you can try, but this guide will focus on doing it locally on our own. You will need the basic knowledge of Stable Diffusion and ControlNet, a computer with a GPU (or a cloud GPU instance) to start.





{kind=link}