Verizon, which bought Yahoo In 2017, has suspended email addresses of archivists who are trying to preserve 20 years of content that will be deleted permanently in a few weeks.
The mass deletion includes files, polls, links, photos, folders, database, calendar, attachments, conversations, email updates, message digests, and message histories that was uploaded to Yahoo servers since pre-Google 1990s.
Verizon planned to allow users to download their own data from the site’s privacy dashboard, but apparently it has a problem with the work of The Archive Team who wants to save content to upload it to the non-profit Internet Archive, which runs the popular Wayback Machine site.
“Yahoo banned all the email addresses that the Archive Team volunteers had been using to join Yahoo Groups in order to download data,” reported the Yahoo Groups Archive Team.
“Verizon has also made it impossible for the Archive Team to continue using semi-automated scripts to join Yahoo Groups – which means each group must be rejoined one by one, an impossible task (redo the work of the past four weeks over the next 10 days).”
The Yahoo Groups Archive Team argues that it is facing a near total “80% loss of data” because Verizon is blocking the team members’ email accounts.
The Yahoo Groups site isn’t widely used today but it was in the past. The size of the archive that the group is trying to save is substantial and the group had saved about 1.8 billion messages as of late 2018.
According to the Archive Team: “As of 2019-10-16 the directory lists 5,619,351 groups. 2,752,112 of them have been discovered. 1,483,853 (54%) have public message archives with an estimated number of 2.1 billion messages (1,389 messages per group on average so far). 1.8 billion messages (86%) have been archived as of 2018-10-28.”
Verizon has issued a statement to the group supporting the Archive Team, telling concerned archivists that “the resources needed to maintain historical content from Yahoo Groups pages is cost-prohibitive, as they’re largely unused”.
The telecoms giant also said the people booted from the service had violated its terms of service and suggested the number of users affected was small.
“Regarding the 128 people who joined Yahoo Groups with the goal to archive them – are those people from Archiveteam.org? If so, their actions violated our Terms of Service. Because of this violation, we are unable reauthorize them,” Verizon said.
As reporters raced this summer to bring new details of Ring’s law enforcement contracts to light, the home security company, acquired last year by Amazon for a whopping $1 billion, strove to underscore the privacy it had pledged to provide users.
Even as its creeping objective of ensuring an ever-expanding network of home security devices eventually becomes indispensable to daily police work, Ring promised its customers would always have a choice in “what information, if any, they share with law enforcement.” While it quietly toiled to minimize what police officials could reveal about Ring’s police partnerships to the public, it vigorously reinforced its obligation to the privacy of its customers—and to the users of its crime-alert app, Neighbors.
However, a Gizmodo investigation, which began last month and ultimately revealed the potential locations of up to tens of thousands of Ring cameras, has cast new doubt on the effectiveness of the company’s privacy safeguards. It further offers one of the most “striking” and “disturbing” glimpses yet, privacy experts said, of Amazon’s privately run, omni-surveillance shroud that’s enveloping U.S. cities.
[…]
Gizmodo has acquired data over the past month connected to nearly 65,800 individual posts shared by users of the Neighbors app. The posts, which reach back 500 days from the point of collection, offer extraordinary insight into the proliferation of Ring video surveillance across American neighborhoods and raise important questions about the privacy trade-offs of a consumer-driven network of surveillance cameras controlled by one of the world’s most powerful corporations.
And not just for those whose faces have been recorded.
Examining the network traffic of the Neighbors app produced unexpected data, including hidden geographic coordinates that are connected to each post—latitude and longitude with up to six decimal points of precision, accurate enough to pinpoint roughly a square inch of ground.
[…]
Guariglia and other surveillance experts told Gizmodo that the ubiquity of the devices gives rise to fears that pedestrians are being recorded strolling in and out of “sensitive buildings,” including certain medical clinics, law offices, and foreign consulates. “I think this is my big concern,” he said, seeing the maps.
Accordingly, Gizmodo located cameras in unnerving proximity to such sensitive buildings, including a clinic offering abortion services and a legal office that handles immigration and refugee cases.
It is possible to acquire Neighbors posts from anywhere in the country, in near-real-time, and sort them in any number of ways. Nearly 4,000 posts, for example, reference children, teens, or young adults; two purportedly involve people having sex; eight mention Immigration and Customs Enforcement; and more than 3,600 mention dogs, cats, coyotes, turkeys, and turtles.
While the race of individuals recorded is implicitly suggested in a variety of ways, Gizmodo found 519 explicit references to blackness and 319 to whiteness. A Ring spokesperson said the Neighbors content moderators strive to eliminate unessential references to skin color. Moderators are told to remove posts, they said, in which the sole identifier of a subject is that they’re “black” or “white.”
Ring’s guidelines instruct users: “Personal attributes like race, ethnicity, nationality, religion, sexual orientation, immigration status, sex, gender, age, disability, socioeconomic and veteran status, should never be factors when posting about an unknown person. This also means not referring to a person you are describing solely by their race or calling attention to other personal attributes not relevant to the matter being reported.”
“There’s no question, if most people were followed around 24/7 by a police officer or a private investigator it would bother them and they would complain and seek a restraining order,” said Jay Stanley, senior policy analyst at the American Civil Liberties Union. “If the same is being done technologically, silently and invisibly, that’s basically the functional equivalent.”
[…]
Companies like Ring have long argued—as Google did when it published millions of people’s faces on Street View in 2007—that pervasive street surveillance reveals, in essence, no more than what people have already made public; that there’s no difference between blanketing public spaces in internet-connected cameras and the human experience of walking or driving down the street.
But not everyone agrees.
“Persistence matters,” said Stanley, while acknowledging the ACLU’s long history of defending public photography. “I can go out and take a picture of you walking down the sidewalk on Main Street and publish it on the front of tomorrow’s newspaper,” he said. “That said, when you automate things, it makes it faster, cheaper, easier, and more widespread.”
Stanley and others devoted to studying the impacts of public surveillance envision a future in which Americans’ very perception of reality has become tainted by a kind of omnipresent observer effect. Children will grow up, it’s feared, equating the act of being outside with being recorded. The question is whether existing in this observed state will fundamentally alter the way people naturally behave in public spaces—and if so, how?
“It brings a pervasiveness and systematization that has significant potential effects on what it means to be a human being walking around your community,” Stanley said. “Effects we’ve never before experienced as a species, in all of our history.”
The Ring data has given Gizmodo the means to consider scenarios, no longer purely hypothetical, which exemplify what daily life is like under Amazon’s all-seeing eye. In the nation’s capital, for instance, walking the shortest route from one public charter school to a soccer field less than a mile away, 6th-12th graders are recorded by no fewer than 13 Ring cameras.
Gizmodo found that dozens of users in the same Washington, DC, area have used Neighbors to share videos of children. Thirty-six such posts describe mostly run-of-the-mill mischief—kids with “no values” ripping up parking tape, riding on their “dort-bikes” [sic] and taking “selfies.”
Ring’s guidelines state that users are supposed to respect “the privacy of others,” and not upload footage of “individuals or activities where a reasonable person would expect privacy.” Users are left to interpret this directive themselves, though Ring’s content moderators are supposedly actively combing through the posts and users can flag “inappropriate” posts for review.
Ángel Díaz, an attorney at the Brennan Center for Justice focusing on technology and policing, said the “sheer size and scope” of the data Ring amasses is what separates it from other forms of public photography.
[…]
Guariglia, who’s been researching police surveillance for a decade and holds a PhD in the subject, said he believes the hidden coordinates invalidate Ring’s claim that only users decide “what information, if any,” gets shared with police—whether they’ve yet to acquire it or not.
“I’ve never really bought that argument,” he said, adding that if they truly wanted, the police could “very easily figure out where all the Ring cameras are.”
The Guardian reported in August that Ring once shared maps with police depicting the locations of active Ring cameras. CNET reported last week, citing public documents, that police partnered with Ring had once been given access to “heat maps” that reflected the area where cameras were generally concentrated.
The privacy researcher who originally obtained the heat maps, Shreyas Gandlur, discovered that if police zoomed in far enough, circles appeared around individual cameras. However, Ring denied that the maps, which it said displayed “approximate device density,” and instructed police not to share publicly, accurately portrayed the locations of customers.
Nikon is ending its authorized repair program in early 2020, likely leaving more than a dozen repair shops without access to official parts and tools, and cutting the number of places you can get your camera fixed with official parts from more than a dozen independent shops to two facilities at the ends of the U.S.
That means that Nikon’s roughly 15 remaining Authorized Repair Station members are about to become non-authorized repair shops. Since Nikon decided to stop selling genuine parts to non-authorized shops back in 2012, it’s unlikely those stores will continue to have access to the specialty components, tools, software, manuals, and model training Nikon previously provided. But Nikon hasn’t clarified this, so repair shops have been left in the dark.
“This is very big, and we have no idea what’s coming next,” said Cliff Hanks, parts manager for Kurt’s Camera Repair in San Diego, Calif. “We need more information before March 31. We can make contingency plans, start stocking up on stuff, but when will we know for sure?”
In a letter obtained by iFixit, Nikon USA told its roughly 15 remaining Authorized Repair Station members in early November that it would not renew their agreements after March 31, 2020. The letter notes that “The climate in which we do business has evolved, and Nikon Inc. must do the same.” And so, Nikon writes, it must “change the manner in which we make product service available to our end user customers.”
In other words: Nikon’s camera business, slowly bled by smartphones, is going to adopt a repair model that’s even more restrictive than that of Apple or other smartphone makers. If your camera breaks, and you want it fixed with official parts or under warranty, you’ll now have to mail it to one of two ends of the country. This is more than a little inconvenient, especially for professional photographers.
Boring 2D images can be transformed into corresponding 3D models and back into 2D again automatically by machine-learning-based software, boffins have demonstrated.
The code is known as a differentiable interpolation-based renderer (DIB-R), and was built by a group of eggheads led by Nvidia. It uses a trained neural network to take a flat image of an object as inputs, work out how it is shaped, colored and lit in 3D, and outputs a 2D rendering of that model.
This research could be useful in future for teaching robots and other computer systems how to work out how stuff is shaped and lit in real life from 2D still pictures or video frames, and how things appear to change depending on your view and lighting. That means future AI could perform better, particularly in terms of depth perception, in scenarios in which the lighting and positioning of things is wildly different from what’s expected.
Jun Gao, a graduate student at the University of Toronto in Canada and a part-time researcher at Nvidia, said: “This is essentially the first time ever that you can take just about any 2D image and predict relevant 3D properties.”
During inference, the pixels in each studied photograph are separated into two groups: foreground and background. The rough shape of the object is discerned from the foreground pixels to create a mesh of vertices.
Next, a trained convolutional neural network (CNN) predicts the 3D position and lighting of each vertex in the mesh to form a 3D object model. This model is then rendered as a full-color 2D image using a suitable shader. This allows the boffins to compare the original 2D object to the rendered 2D object to see how well the neural network understood the lighting and shape of the thing.
You looking for an AI project? You love Lego? Look no further than this Reg reader’s machine-learning Lego sorter
During the training process, the CNN was shown stuff in 13 categories in the ShapeNet dataset. Each 3D model was rendered as 2D images viewed from 24 different angles to create a set of training images: these images were used to show the network how 2D images relate to 3D models.
Crucially, the CNN was schooled using an adversarial framework, in which the DIB-R outputs were passed through a discriminator network for analysis.
If a rendered object was similar enough to an input object, then DIB-R’s output passed the discriminator. If not, the output was rejected and the CNN had to generate ever more similar versions until it was accepted by the discriminator. Over time, the CNN learned to output realistic renderings. Further training is required to generate shapes outside of the training data, we note.
As we mentioned above, DIB-R could help robots better detect their environments, Nvidia’s Lauren Finkle said: “For an autonomous robot to interact safely and efficiently with its environment, it must be able to sense and understand its surroundings. DIB-R could potentially improve those depth perception capabilities.”
Academics from three universities across Europe have disclosed today a new attack that impacts the integrity of data stored inside Intel SGX, a highly-secured area of Intel CPUs.
The attack, which researchers have named Plundervolt, exploits the interface through which an operating system can control an Intel processor’s voltage and frequency — the same interface that allows gamers to overclock their CPUs.
Academics say they discovered that by tinkering with the amount of voltage and frequency a CPU receives, they can alter bits inside SGX to cause errors that can be exploited at a later point after the data has left the security of the SGX enclave.
They say Plundervolt can be used to recover encryption keys or introduce bugs in previously secure software.
Online shoppers typically string together a few words to search for the product they want, but in a world with millions of products and shoppers, the task of matching those unspecific words to the right product is one of the biggest challenges in information retrieval.
Using a divide-and-conquer approach that leverages the power of compressed sensing, computer scientists from Rice University and Amazon have shown they can slash the amount of time and computational resources it takes to train computers for product search and similar “extreme classification problems” like speech translation and answering general questions.
The research will be presented this week at the 2019 Conference on Neural Information Processing Systems (NeurIPS 2019) in Vancouver. The results include tests performed in 2018 when lead researcher Anshumali Shrivastava and lead author Tharun Medini, both of Rice, were visiting Amazon Search in Palo Alto, California.
In tests on an Amazon search dataset that included some 70 million queries and more than 49 million products, Shrivastava, Medini and colleagues showed their approach of using “merged-average classifiers via hashing,” (MACH) required a fraction of the training resources of some state-of-the-art commercial systems.
“Our training times are about 7-10 times faster, and our memory footprints are 2-4 times smaller than the best baseline performances of previously reported large-scale, distributed deep-learning systems,” said Shrivastava, an assistant professor of computer science at Rice.
[…]
“Extreme classification problems” are ones with many possible outcomes, and thus, many parameters. Deep learning models for extreme classification are so large that they typically must be trained on what is effectively a supercomputer, a linked set of graphics processing units (GPU) where parameters are distributed and run in parallel, often for several days.
“A neural network that takes search input and predicts from 100 million outputs, or products, will typically end up with about 2,000 parameters per product,” Medini said. “So you multiply those, and the final layer of the neural network is now 200 billion parameters. And I have not done anything sophisticated. I’m talking about a very, very dead simple neural network model.”
“It would take about 500 gigabytes of memory to store those 200 billion parameters,” Medini said. “But if you look at current training algorithms, there’s a famous one called Adam that takes two more parameters for every parameter in the model, because it needs statistics from those parameters to monitor the training process. So, now we are at 200 billion times three, and I will need 1.5 terabytes of working memory just to store the model. I haven’t even gotten to the training data. The best GPUs out there have only 32 gigabytes of memory, so training such a model is prohibitive due to massive inter-GPU communication.”
MACH takes a very different approach. Shrivastava describes it with a thought experiment randomly dividing the 100 million products into three classes, which take the form of buckets. “I’m mixing, let’s say, iPhones with chargers and T-shirts all in the same bucket,” he said. “It’s a drastic reduction from 100 million to three.”
In the thought experiment, the 100 million products are randomly sorted into three buckets in two different worlds, which means that products can wind up in different buckets in each world. A classifier is trained to assign searches to the buckets rather than the products inside them, meaning the classifier only needs to map a search to one of three classes of product.
“Now I feed a search to the classifier in world one, and it says bucket three, and I feed it to the classifier in world two, and it says bucket one,” he said. “What is this person thinking about? The most probable class is something that is common between these two buckets. If you look at the possible intersection of the buckets there are three in world one times three in world two, or nine possibilities,” he said. “So I have reduced my search space to one over nine, and I have only paid the cost of creating six classes.”
Adding a third world, and three more buckets, increases the number of possible intersections by a factor of three. “There are now 27 possibilities for what this person is thinking,” he said. “So I have reduced my search space by one over 27, but I’ve only paid the cost for nine classes. I am paying a cost linearly, and I am getting an exponential improvement.”
In their experiments with Amazon’s training database, Shrivastava, Medini and colleagues randomly divided the 49 million products into 10,000 classes, or buckets, and repeated the process 32 times. That reduced the number of parameters in the model from around 100 billion to 6.4 billion. And training the model took less time and less memory than some of the best reported training times on models with comparable parameters, including Google’s Sparsely-Gated Mixture-of-Experts (MoE) model, Medini said.
He said MACH’s most significant feature is that it requires no communication between parallel processors. In the thought experiment, that is what’s represented by the separate, independent worlds.
“They don’t even have to talk to each other,” Medini said. “In principle, you could train each of the 32 on one GPU, which is something you could never do with a nonindependent approach.”
Three weeks after the Internet Society announced the controversial sale of the .org internet registry to an unknown private equity firm, the organization that has to sign off on the deal has finally spoken publicly.
In a letter [PDF] titled “Transparency” from the general counsel of domain name system overseer ICANN to the CEOs of the Internet Society (ISOC) and .org registry operator PIR, the organization takes issue with how the proposed sale has been handled and notes that it is “uncomfortable” at the lack of transparency.
The letter, dated Monday and posted today with an accompanying blog post, notes that ICANN will be sending a “detailed request for additional information” and encourages the organizations “to answer these questions fully and as transparently as possible.”
As ICANN’s chairman previously toldThe Register, the organization received an official request to change ownership of PIR from ISOC to Ethos Capital in mid-November but denied ICANN’s request to make it public.
The letter presses ISOC/PIR to make that request public. “While PIR has previously declined our request to publish the Request, we urge you to reconsider,” the letter states. “We also think there would be great value for us to publish the questions that you are asked and your answers to those questions.”
Somewhat unusually it repeats the same point a second time: “In light of the level of interest in the recently announced acquisition of PIR, both within the ICANN community and more generally, we continue to believe that it is critical that your Request, and the questions and answers in follow up to the Request, and any other related materials, be made Public.”
Third time lucky
And then, stressing the same point a third time, the letter notes that on a recent webinar about the sale organized by concerned non-profits that use .org domains, ISOC CEO Andrew Sullivan said he wasn’t happy about the level of secrecy surrounding the deal.
From the ICANN letter: “As you, Andrew, ISOC’s CEO stated publicly during a webcast meeting… you are uncomfortable with the lack of transparency. Many of us watching the communications on this transaction are also uncomfortable.
“In sum, we again reiterate our belief that it is imperative that you commit to completing this process in an open and transparent manner, starting with publishing the Request and related material, and allowing us to publish our questions to you, and your full Responses.”
Here is what Sullivan said on the call [PDF]: “I do appreciate, however, that this creates a level of uncertainty, because people are uncomfortable with things that are done in secret like that. I get it. I can have the same reaction what I’m not included in a decision, but that is the reason we have trustees. That’s the reason that we have our trustees selected by our community. And I believe that we made the right decision.”
As ICANN noted, there remain numerous questions over the proposed sale despite both ISOC and Ethos Capital holding meetings with concerned stakeholders, and ISOC’s CEO agreeing to an interview with El Reg.
One concerned .org owner is open-source organization Mozilla, which sent ICANN a letter noting that it “remains concerned that the nature of the modified contractual agreement between ICANN and the registry does not contain sufficient safeguards to ensure that the promises we hear today will be kept.”
It put forward a series of unanswered questions that it asked ICANN to request of PIR. They include [PDF] questions over the proposed “stewardship council” that Ethos Capital has said it will introduce to make sure the rights of .org domain holders are protected, including its degree of independence; what assurances there are that Ethos Capital will actually stick to its implied promise that it won’t increase .org prices by more than 10 per cent per year; and details around its claim that PIR will become a so-called B Corp – a designation that for-profit companies can apply for if they wish to indicate a wider public interest remit.
Connections
While those questions dig into the future running of the .org registry, they do not dig into the unusual connections between the CEOs of ISOC, PIR and Ethos Capital, as well as their advisors.
The CEO of ISOC, Andrew Sullivan worked for a company called Afilias between 2002 and 2008. It was Afilias that persuaded ISOC to apply to run the .org registry in the first place and Sullivan is credited with writing significant parts of its final application. Afilias has run the .org back-end since 2003. Sullivan became ISOC CEO in June 2018.
The CEO of PIR, Jonathon Nevett, took over the job in December 2018. Immediately prior to that, he was Executive VP for a registry company called Donuts, which he also co-founded. Donuts was sold in September 2018 to a private equity company called Abry Partners.
At Abry Partners at the time was Eric Brooks, who left the company after 20 years at some point in 2019 to become the CEO of Ethos Capital – the company purchasing PIR. Also at Abry Partners at the time was Fadi Chehade, a former CEO of ICANN. Chehade is credited as being a “consultant” over the sale of PIR to Ethos Capital but records demonstrate that Chehade registered its domain name – ethoscapital.com – personally.
Chehade is also thought to have personally registered Ethos Capital as a Delaware corporation on May 14 this year: an important date because it was the day after his former organization, ICANN, indicated it was going to approve the lifting of price caps on .org domains, against the strong opposition of the internet community.
Now comes the ICA
As well as Mozilla’s questions, there is another series of questions [PDF] over the sale from the Internet Commerce Association (ICA) that are pointed at ICANN itself.
Those questions focus on the timeline of information: what ICANN knew about the proposed sale and when; and whether it was aware of the intention to sell PIR when it approved lifting price caps on the .org registry.
It also asked various governance questions about ICANN including why the renewed .org contract was not approved by the ICANN board, the involvement of former ICANN executives, including Chehade and former senior vice president Nora Abusitta-Ouri who is “chief purpose officer” of Ethos Capital, and what policies ICANN has in place over “cooling off periods” for former execs.
While going out of its way to criticize ISOC and PIR for their lack of transparency and while claiming in the letter to ISOC that “transparency is a cornerstone of ICANN and how ICANN acts to protect the public interest while performing its role,” ICANN has yet to answer questions over its own role.
The ability to perceive the shape and motion of hands can be a vital component in improving the user experience across a variety of technological domains and platforms. For example, it can form the basis for sign language understanding and hand gesture control, and can also enable the overlay of digital content and information on top of the physical world in augmented reality. While coming naturally to people, robust real-time hand perception is a decidedly challenging computer vision task, as hands often occlude themselves or each other (e.g. finger/palm occlusions and hand shakes) and lack high contrast patterns. Today we are announcing the release of a new approach to hand perception, which we previewed CVPR 2019 in June, implemented in MediaPipe—an open source cross platform framework for building pipelines to process perceptual data of different modalities, such as video and audio. This approach provides high-fidelity hand and finger tracking by employing machine learning (ML) to infer 21 3D keypoints of a hand from just a single frame. Whereas current state-of-the-art approaches rely primarily on powerful desktop environments for inference, our method achieves real-time performance on a mobile phone, and even scales to multiple hands. We hope that providing this hand perception functionality to the wider research and development community will result in an emergence of creative use cases, stimulating new applications and new research avenues.
3D hand perception in real-time on a mobile phone via MediaPipe. Our solution uses machine learning to compute 21 3D keypoints of a hand from a video frame. Depth is indicated in grayscale.
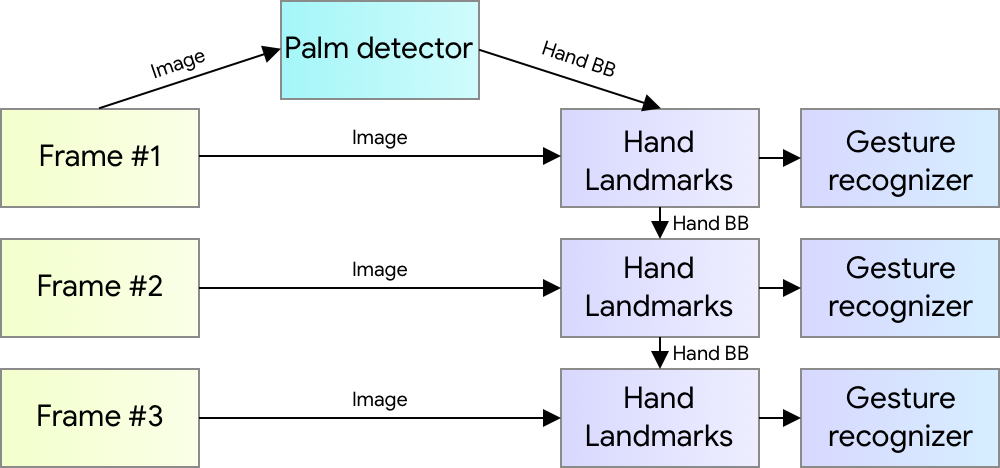
An ML Pipeline for Hand Tracking and Gesture Recognition Our hand tracking solution utilizes an ML pipeline consisting of several models working together:
A palm detector model (called BlazePalm) that operates on the full image and returns an oriented hand bounding box.
A hand landmark model that operates on the cropped image region defined by the palm detector and returns high fidelity 3D hand keypoints.
A gesture recognizer that classifies the previously computed keypoint configuration into a discrete set of gestures.
This architecture is similar to that employed by our recently published face meshML pipeline and that others have used for pose estimation. Providing the accurately cropped palm image to the hand landmark model drastically reduces the need for data augmentation (e.g. rotations, translation and scale) and instead allows the network to dedicate most of its capacity towards coordinate prediction accuracy.
Hand perception pipeline overview.
BlazePalm: Realtime Hand/Palm Detection To detect initial hand locations, we employ a single-shot detector model called BlazePalm, optimized for mobile real-time uses in a manner similar to BlazeFace, which is also available in MediaPipe. Detecting hands is a decidedly complex task: our model has to work across a variety of hand sizes with a large scale span (~20x) relative to the image frame and be able to detect occluded and self-occluded hands. Whereas faces have high contrast patterns, e.g., in the eye and mouth region, the lack of such features in hands makes it comparatively difficult to detect them reliably from their visual features alone. Instead, providing additional context, like arm, body, or person features, aids accurate hand localization. Our solution addresses the above challenges using different strategies. First, we train a palm detector instead of a hand detector, since estimating bounding boxes of rigid objects like palms and fists is significantly simpler than detecting hands with articulated fingers. In addition, as palms are smaller objects, the non-maximum suppression algorithm works well even for two-hand self-occlusion cases, like handshakes. Moreover, palms can be modelled using square bounding boxes (anchors in ML terminology) ignoring other aspect ratios, and therefore reducing the number of anchors by a factor of 3-5. Second, an encoder-decoder feature extractor is used for bigger scene context awareness even for small objects (similar to the RetinaNet approach). Lastly, we minimize the focal loss during training to support a large amount of anchors resulting from the high scale variance. With the above techniques, we achieve an average precision of 95.7% in palm detection. Using a regular cross entropy loss and no decoder gives a baseline of just 86.22%.