Babel Finance, the Hong Kong-based crypto lender, apparently had other designs when its worldwide user base handed over their crypto to the company than just borrowing and lending. It seems to have been doing what everyone else does with crypto, rapidly speculating and trying to make “line go up.” Of course, all that changed when the line no longer went up.
The Block reported based on restructuring proposal documents that Babel Finance had lost 8,000 bitcoin and 56,000 ether in June, worth close to $280 million, though of course the price is constantly fluctuating. The company had apparently been conducting proprietary trading with customers’ funds. It remains unclear based on reporting if users were/are aware their crypto was/is being used in this way.
Built by Sony AI, a research lab launched by the company in 2020, Gran Turismo Sophy is a computer program trained to control racing cars inside the world of Gran Turismo, a video game known for its super-realistic simulations of real vehicles and tracks. In a series of events held behind closed doors last year, Sony put its program up against the best humans on the professional sim-racing circuit.
What they discovered during those racetrack battles—and the ones that followed—could help shape the future of machines that work alongside humans, or join us on the roads.
[…]
Sony soon learned that speed alone wasn’t enough to make GT Sophy a winner. The program outpaced all human drivers on an empty track, setting superhuman lap times on three different virtual courses. Yet when Sony tested GT Sophy in a race against multiple human drivers, where intelligence as well as speed is needed, GT Sophy lost. The program was at times too aggressive, racking up penalties for reckless driving, and at other times too timid, giving way when it didn’t need to.
Sony regrouped, retrained its AI, and set up a rematch in October. This time GT Sophy won with ease. What made the difference? It’s true that Sony came back with a larger neural network, giving its program more capabilities to draw from on the fly. But ultimately, the difference came down to giving GT Sophy something that Peter Wurman, head of Sony AI America, calls “etiquette”: the ability to balance its aggression and timidity, picking the most appropriate behavior for the situation at hand.
This is also what makes GT Sophy relevant beyond Gran Turismo. Etiquette between drivers on a track is a specific example of the kind of dynamic, context-aware behavior that robots will be expected to have when they interact with people, says Wurman.
An awareness of when to take risks and when to play it safe would be useful for AI that is better at interacting with people, whether it be on the manufacturing floor, in home robots, or in driverless cars.
“I don’t think we’ve learned general principles yet about how to deal with human norms that you have to respect,” says Wurman. “But it’s a start and hopefully gives us some insight into this problem in general.”
Twitter has published its 20th transparency report, and the details still aren’t reassuring to those concerned about abuses of personal info. The social network saw “record highs” in the number of account data requests during the July-December 2021 reporting period, with 47,572 legal demands on 198,931 accounts. The media in particular faced much more pressure. Government demands for data from verified news outlets and journalists surged 103 percent compared to the last report, with 349 accounts under scrutiny.
The largest slice of requests targeting the news industry came from India (114), followed by Turkey (78) and Russia (55). Governments succeeded in withholding 17 tweets.
As in the past, US demands represented a disproportionately large chunk of the overall volume. The country accounted for 20 percent of all worldwide account info requests, and those requests covered 39 percent of all specified accounts. Russia is still the second-largest requester with 18 percent of volume, even if its demands dipped 20 percent during the six-month timeframe.
The company said it was still denying or limiting access to info when possible. It denied 31 percent of US data requests, and either narrowed or shut down 60 percent of global demands. Twitter also opposed 29 civil attempts to identify anonymous US users, citing First Amendment reasons. It sued in two of those cases, and has so far had success with one of those suits. There hasn’t been much success in reporting on national security-related requests in the US, however, and Twitter is still hoping to win an appeal that would let it share more details.
You can find AI that creates new images, but what if you want to fix an old family photo? You might have a no-charge option. Louis Bouchard and PetaPixel have drawn attention to a free tool recently developed by Tencent researchers, GFP-GAN (Generative Facial Prior-Generative Adversarial Network), that can restore damaged and low-resolution portraits. The technology merges info from two AI models to fill in a photo’s missing details with realistic detail in a few seconds, all the while maintaining high accuracy and quality.
Conventional methods fine-tune an existing AI model to restore images by gauging differences between the artificial and real photos. That frequently leads to low-quality results, the scientists said. The new approach uses a pre-trained version of an existing model (NVIDIA’s StyleGAN-2) to inform the team’s own model at multiple stages during the image generation process. The technique aims to preserve the “identity” of people in a photo, with a particular focus on facial features like eyes and mouths.
You can try a demo of GFP-GAN for free. The creators have also posted their code to let anyone implement the restoration tech in their own projects.
This project is still bound by the limitations of current AI. While it’s surprisingly accurate, it’s making educated guesses about missing content. The researchers warned that you might see a “slight change of identity” and a lower resolution than you might like. Don’t rely on this to print a poster-sized photo of your grandparents, folks. All the same, the work here is promising — it hints at a future where you can easily rescue images that would otherwise be lost to the ravages of time.
Energy, mass, velocity. These three variables make up Einstein’s iconic equation E=MC2. But how did Einstein know about these concepts in the first place? A precursor step to understanding physics is identifying relevant variables. Without the concept of energy, mass, and velocity, not even Einstein could discover relativity. But can such variables be discovered automatically? Doing so could greatly accelerate scientific discovery.
This is the question that researchers at Columbia Engineering posed to a new AI program. The program was designed to observe physical phenomena through a video camera, then try to search for the minimal set of fundamental variables that fully describe the observed dynamics. The study was published on July 25 in Nature Computational Science.
The researchers began by feeding the system raw video footage of phenomena for which they already knew the answer. For example, they fed a video of a swinging double pendulum known to have exactly four “state variables”—the angle and angular velocity of each of the two arms. After a few hours of analysis, the AI produced the answer: 4.7.
The image shows a chaotic swing stick dynamical system in motion. The work aims at identifying and extracting the minimum number of state variables needed to describe such system from high dimensional video footage directly. Credit: Yinuo Qin/Columbia Engineering
“We thought this answer was close enough,” said Hod Lipson, director of the Creative Machines Lab in the Department of Mechanical Engineering, where the work was primarily done. “Especially since all the AI had access to was raw video footage, without any knowledge of physics or geometry. But we wanted to know what the variables actually were, not just their number.”
The researchers then proceeded to visualize the actual variables that the program identified. Extracting the variables themselves was not easy, since the program cannot describe them in any intuitive way that would be understandable to humans. After some probing, it appeared that two of the variables the program chose loosely corresponded to the angles of the arms, but the other two remain a mystery.
“We tried correlating the other variables with anything and everything we could think of: angular and linear velocities, kinetic and potential energy, and various combinations of known quantities,” explained Boyuan Chen Ph.D., now an assistant professor at Duke University, who led the work. “But nothing seemed to match perfectly.” The team was confident that the AI had found a valid set of four variables, since it was making good predictions, “but we don’t yet understand the mathematical language it is speaking,” he explained.
After validating a number of other physical systems with known solutions, the researchers fed videos of systems for which they did not know the explicit answer. The first videos featured an “air dancer” undulating in front of a local used car lot. After a few hours of analysis, the program returned eight variables. A video of a lava lamp also produced eight variables. They then fed a video clip of flames from a holiday fireplace loop, and the program returned 24 variables.
A particularly interesting question was whether the set of variable was unique for every system, or whether a different set was produced each time the program was restarted.
“I always wondered, if we ever met an intelligent alien race, would they have discovered the same physics laws as we have, or might they describe the universe in a different way?” said Lipson. “Perhaps some phenomena seem enigmatically complex because we are trying to understand them using the wrong set of variables. In the experiments, the number of variables was the same each time the AI restarted, but the specific variables were different each time. So yes, there are alternative ways to describe the universe and it is quite possible that our choices aren’t perfect.”
The researchers believe that this sort of AI can help scientists uncover complex phenomena for which theoretical understanding is not keeping pace with the deluge of data—areas ranging from biology to cosmology. “While we used video data in this work, any kind of array data source could be used—radar arrays, or DNA arrays, for example,” explained Kuang Huang, Ph.D., who co-authored the paper.
The work is part of Lipson and Fu Foundation Professor of Mathematics Qiang Du’s decades-long interest in creating algorithms that can distill data into scientific laws. Past software systems, such as Lipson and Michael Schmidt’s Eureqa software, could distill freeform physical laws from experimental data, but only if the variables were identified in advance. But what if the variables are yet unknown?
Lipson, who is also the James and Sally Scapa Professor of Innovation, argues that scientists may be misinterpreting or failing to understand many phenomena simply because they don’t have a good set of variables to describe the phenomena.
“For millennia, people knew about objects moving quickly or slowly, but it was only when the notion of velocity and acceleration was formally quantified that Newton could discover his famous law of motion F=MA,” Lipson noted. Variables describing temperature and pressure needed to be identified before laws of thermodynamics could be formalized, and so on for every corner of the scientific world. The variables are a precursor to any theory.
“What other laws are we missing simply because we don’t have the variables?” asked Du, who co-led the work.
The paper was also co-authored by Sunand Raghupathi and Ishaan Chandratreya, who helped collect the data for the experiments.
More information: Boyuan Chen et al, Automated discovery of fundamental variables hidden in experimental data, Nature Computational Science (2022). DOI: 10.1038/s43588-022-00281-6
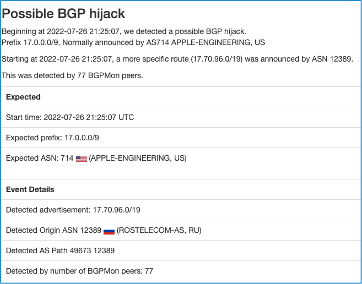
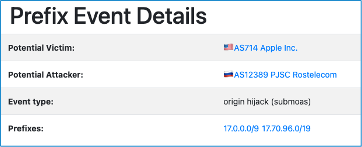
For a little over 12 hours on 26-27 July, a network operated by Russia’s Rostelecom started announcing routes for part of Apple’s network. The effect was that Internet users in parts of the Internet trying to connect to Apple’s services may have been redirected to the Rostelecom network. Apple Engineering appears to have been successful in reducing the impact, and eventually Rostelecom stopped sending the false route announcements. This event demonstrated, though, how Apple could further protect its networks by using Route Origin Authorizations (ROAs).
We are not aware of any information yet from Apple that indicates what, if any, Apple services were affected. We also have not seen any information from Rostelecom about whether this was a configuration mistake or a deliberate action.
Let’s dig into what we know so far about what happened, and how Route Origin Authorization (ROA) can help prevent these kinds of events.
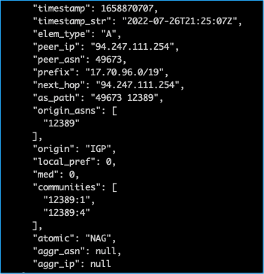
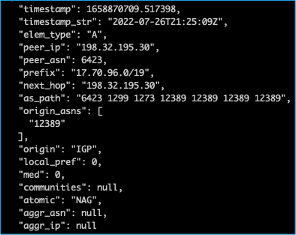
Around 21:25 UTC On 26 July 2022, Rostelecom’s AS12389 network started announcing 17.70.96.0/19. This prefix is part of Apple’s 17.0.0.0/8 block; usually, Apple only announces the larger 17.0.0.0/9 block and not this shorter prefix length.
When the routes a network is announcing are not covered by valid Route Origin Authorization (ROA), the only option during a route hijack is to announce more specific routes. This is exactly what Apple Engineering did today; upon learning about the hijack, it started announcing 17.70.96.0/21 to direct traffic toward AS714.
RIPE RIS data, captured via pybgpkit tool
It is not clear what AS12389 was doing, as it announced the same prefix at the same time with AS prepend as well.
RIPE RIS data, captured via pybgpkit tool
In the absence of any credible data to filter out any possible hijack attempts, the route announced by AS12389 was propagated across the globe. The incident was picked up by BGPstream.com (Cisco Works) and GRIP Internet Intel (GA Tech).
Apple must have received the alert too. Whatever mitigation techniques they tried didn’t stop the Rostelecom announcement and so Apple announced the more specific route. As per the BGP path selection process, the longest-matching route is preferred first. Prefix length supersedes all other route attributes. Apple started announcing 17.70.96.0/21 to direct traffic toward AS714.
Researchers have unpacked a major cybersecurity find—a malicious UEFI-based rootkit used in the wild since 2016 to ensure computers remained infected even if an operating system is reinstalled or a hard drive is completely replaced.
The firmware compromises the UEFI, the low-level and highly opaque chain of firmware required to boot up nearly every modern computer. As the software that bridges a PC’s device firmware with its operating system, the UEFI—short for Unified Extensible Firmware Interface—is an OS in its own right. It’s located in an SPI-connected flash storage chip soldered onto the computer motherboard, making it difficult to inspect or patch the code. Because it’s the first thing to run when a computer is turned on, it influences the OS, security apps, and all other software that follows.
Exotic, yes. Rare, no.
On Monday, researchers from Kaspersky profiled CosmicStrand, the security firm’s name for a sophisticated UEFI rootkit that the company detected and obtained through its antivirus software. The find is among only a handful of such UEFI threats known to have been used in the wild. Until recently, researchers assumed that the technical demands required to develop UEFI malware of this caliber put it out of reach of most threat actors. Now, with Kaspersky attributing CosmicStrand to an unknown Chinese-speaking hacking group with possible ties to cryptominer malware, this type of malware may not be so rare after all.
“The most striking aspect of this report is that this UEFI implant seems to have been used in the wild since the end of 2016—long before UEFI attacks started being publicly described,” Kaspersky researchers wrote. “This discovery begs a final question: If this is what the attackers were using back then, what are they using today?”
While researchers from fellow security firm Qihoo360 reported on an earlier variant of the rootkit in 2017, Kaspersky and most other Western-based security firms didn’t take notice. Kaspersky’s newer research describes in detail how the rootkit—found in firmware images of some Gigabyte or Asus motherboards—is able to hijack the boot process of infected machines. The technical underpinnings attest to the sophistication of the malware.
The United States’ federal court system “faced an incredibly significant and sophisticated cyber security breach, one which has since had lingering impacts on the department and other agencies.”
That quote comes from congressional representative Jerrold Lewis Nadler, who uttered them on Thursday in his introductory remarks to a House Committee on the Judiciary hearing conducting oversight of the Department of Justice National Security Division (NSD).
Nadler segued into the mention of the breach after mentioning the NSD’s efforts to defend America against external actors that seek to attack its system of government. He commenced his remarks on the attack at the 4:40 mark in the video below:
The rep’s remarks appear to refer to the January 2021 disclosure by James C. Duff, who at the time served as secretary of the Judicial Conference of the United States, of “an apparent compromise” of confidentiality in the Judiciary’s Case Management/Electronic Case Files system (CM/ECF).
That incident may have exploited vulnerabilities in CM/ECF and “greatly risk compromising highly sensitive non-public documents stored on CM/ECF, particularly sealed filings.”
Such documents are filed by the US government in cases that touch on national security, and therefore represent valuable intelligence.
The star witness at the hearing, assistant attorney general for National Security Matthew Olsen, said the Department of Justice continues to investigate the matter, adding the attack has not impacted his unit’s work.
But Olsen was unable – or unwilling – to describe the incident in detail.
However, a report in Politico quoted an unnamed aide as saying “the sweeping impact it may have had on the operation of the Department of Justice is staggering.”
For now, the extent of that impact, and its cause, are not known.
The nature of the vulnerability and the methods used to exploit it are also unknown, but Nadler suggested it is not related to the SolarWinds attack that the Judiciary has already acknowledged.
Olsen said he would update the Committee with further information once that’s possible. Representatives in the hearing indicated they await those details with considerable interest.