
In this article I take a look at AI Slop and how it is effecting the current internet. I also look at what exactly the internet of today looks like – it is hugely centralised. This centralisation creates a focused trashcan for the AI generated slop. This is exactly the opportunity that curated content creators need to shine and show relevant, researched, innovative and original content on smaller, decentralised content platforms.
What is AI Slop?
As GPTs swallow more and more data, it is increasingly used to make more “AI slop”. This is “low to mid quality content – “low- to mid-quality content – video, images, audio, text or a mix – created with AI tools, often with little regard for accuracy. It’s fast, easy and inexpensive to make this content. AI slop producers typically place it on social media to exploit the economics of attention on the internet, displacing higher-quality material that could be more helpful.” (Source: What is AI slop? A technologist explains this new and largely unwelcome form of online content).
Recent examples include Facebook content, Careless speech, especially in bought up abandoned news sites, Reddit posts, Fake leaked merchandise, Inaccurate Boring History videos, alongside the more damaging fake political images – well, you get the point I think.
A lot has been written about the damaging effects of AI slop, leading to reduced attention and congnitive fatigue, feelings of emptiness and detachment, commoditised homogeneous experiences, etc.
However, there may be a light point on the horizon. Bear with me for some background, though.
Centralisation of Content
It turns out that Netflix alone is responsible for 14.9% of global internet traffic. Youtube for 11.6%.
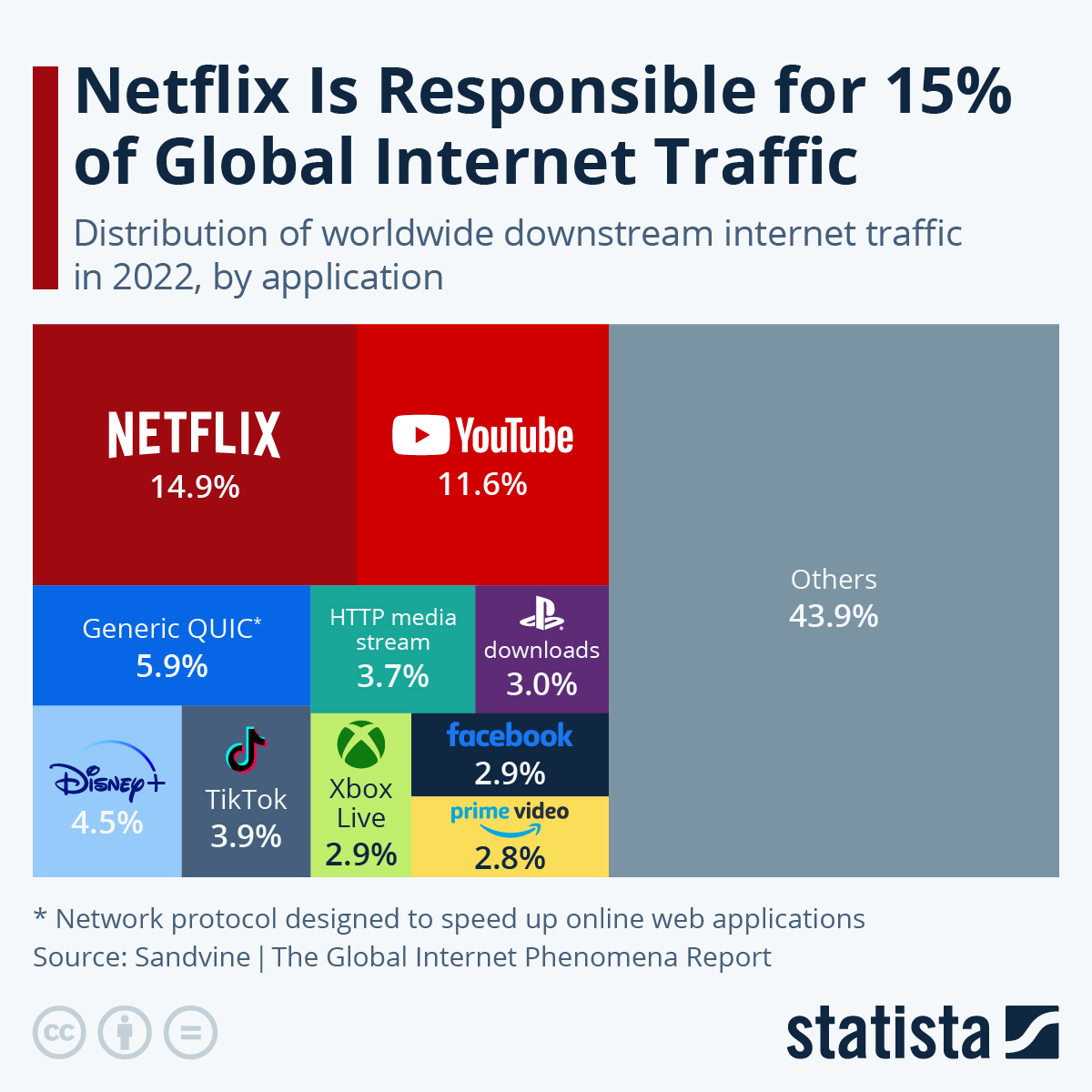
Sandvine’s 2024 Global Internet Phenomena Report shows that 65% of all fixed internet traffic and 68% of all mobile traffic is driven through eight of the internet giants
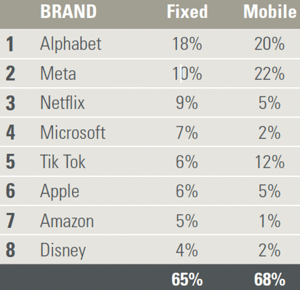
This concentration of the internet is not something new and has been studied for some time:
A decade ago, there was a much greater variety of domains within links posted by users of Reddit, with more than 20 different domains for every 100 random links users posted. Now there are only about five different domains for every 100 links posted.
In fact, between 60-70 percent of all attention on key social media platforms is focused towards just ten popular domains.
Beyond social media platforms, we also studied linkage patterns across the web, looking at almost 20 billion links over three years. These results reinforced the “rich are getting richer” online.
The authority, influence, and visibility of the top 1,000 global websites (as measured by network centrality or PageRank) is growing every month, at the expense of all other sites.
Source: The Same Handful of Websites Are Dominating The Web And That Could Be a Problem / Evolution of diversity and dominance of companies in online activity (2021)
The online economy’s lack of diversity can be seen most clearly in technology itself, where a power disparity has grown in the last decade, leaving the web in the control of fewer and fewer. Google Search makes up 92% of all web searches worldwide. Its browser, Chrome, which defaults to Google Search, is used by nearly two thirds of users worldwide.
Source: StatCounter Global Stats – Search Engine Market Share
Media investment analysis firm Ebiquity found that nearly half of all advertising spend is now digital, with Google, Meta (formerly Facebook) and Amazon single-handedly collecting nearly three quarters of digital advertising money globally in 2021.
Source: Grandstand platforms (2022)
And of course we know that news sites have been closing as advertisers flock to Social media sites, leading to a dearth of trustworthy journalism and ethical, rules bound journalism.
Centralisation of Underlying Technologies
And it’s not just the content we consume that has been centralised: The underlying technologies of the internet have been centralised as well. The Internet Society shows that data centres, DNS, top level domains, SSL Certificates, Content Delivery Networks and Web Hosting have been significantly centralised as well.
In some of these protocols there is more variation within regions:
We highlight regional patterns that paint a richer picture of provider dependence and insularity than we can through centralization alone. For instance, the Commonwealth of Independent States (CIS) countries (formed following the dissolution of Soviet Union) exhibit comparatively low centralization, but depend highly on Russian providers. These patterns suggest possible political, historical, and linguistic undercurrents of provider dependence. In addition, the regional patterns we observe between layers of website infrastructure enable us to hypothesize about forces of influence driving centralization across multiple layers. For example, many countries are more insular in their choice of TLD given the limited technical implications of TLD choice. On the other extreme, certificate authority (CA) centralization is far more extreme than other layers due to popular web browsers trusting only a handful of CAs, nearly all of which are located in the United States.
Source: On the Centralization and Regionalization of the Web (2024)
Why is this? A lot of it has to do with the content providers wanting to gather as much data as possible on their users as well as being able to offer a fast, seamless experience for their users (so that they stay engaged on their platforms):
The more information you have about people, the more information you can feed your machine-learning process to build detailed profiles about your users. Understanding your users means you can predict what they will like, what they will emotionally engage with, and what will make them act. The more you can engage users, the longer they will use your service, enabling you to gather more information about them. Knowing what makes your users act allows you to convert views into purchases, increasing the provider’s economic power.
The virtuous cycle is related to the network effect. The value of a network is exponentially related to the number of people connected to the network. The value of the network increases as more people connect, because the information held within the network increases as more people connect.
Who will extract the value of those data? Those located in the center of the network can gather the most information as the network increases in size. They are able to take the most advantage of the virtuous cycle. In other words, the virtuous cycle and the network effect favor a smaller number of complex services. The virtuous cycle and network effect drive centralization.
[…]
How do content providers, such as social media services, increase user engagement when impatience increases and attention spans decrease? One way is to make their service faster. While there are many ways to make a service faster, two are of particular interest here.
First, move content closer to the user. […] Second, optimize the network path.
[…]
Moving content to the edge and optimizing the network path requires lots of resources and expertise. Like most other things, the devices, physical cabling, buildings, and talent required to build large computer networks are less expensive at scale
[…]
Over time, as the Internet has grown, new regulations and ways of doing business have been added, and new applications have been added “over the top,” the complexity of Internet systems and protocols has increased. As with any other complex ecosystem, specialization has set in. Almost no one knows how “the whole thing works” any longer.
How does this drive centralization?
Each feature—or change at large—increases complexity. The more complex a protocol is, the more “care and feeding” it requires. As a matter of course, larger organizations are more capable of hiring, training, and keeping the specialized engineering talent required to build and maintain these kinds of complex systems.
Source: The Centralization of the Internet (2021)
So what does this have to do with AI Slop?
As more and more AI Slop is generated, debates are raging in many communities. Especially in the gaming and art communities, there is a lot of militant railing against AI art. In 2023 a study showed that people were worried about AI generated content, but unable to detect it:
research employed an online survey with 100 participants to collect quantitative data on their experiences and perceptions of AI-generated content. The findings indicate a range of trust levels in AI-generated content, with a general trend towards cautious acceptance. The results also reveal a gap between the participants’ perceived and actual abilities to distinguish between AI-generated content, underlining the need for improved media literacy and awareness initiatives. The thematic analysis of the respondent’s opinions on the ethical implications of AI-generated content underscored concerns about misinformation, bias, and a perceived lack of human essence.
However, politics has caught up and in the EU and US policy has arisen that force AI content generators to also support the creation of reliable detectors for the content they generate:
In this paper, we begin by highlighting an important new development: providers of AI content generators have new obligations to support the creation of reliable detectors for the content they generate. These new obligations arise mainly from the EU’s newly finalised AI Act, but they are enhanced by the US President’s recent Executive Order on AI, and by several considerations of self-interest. These new steps towards reliable detection mechanisms are by no means a panacea—but we argue they will usher in a new adversarial landscape, in which reliable methods for identifying AI-generated content are commonly available. In this landscape, many new questions arise for policymakers. Firstly, if reliable AI-content detection mechanisms are available, who should be required to use them? And how should they be used? We argue that new duties arise for media and Web search companies arise for media companies, and for Web search companies, in the deployment of AI-content detectors. Secondly, what broader regulation of the tech ecosystem will maximise the likelihood of reliable AI-content detectors? We argue for a range of new duties, relating to provenance-authentication protocols, open-source AI generators, and support for research and enforcement. Along the way, we consider how the production of AI-generated content relates to ‘free expression’, and discuss the important case of content that is generated jointly by humans and AIs.
This means that although people may or may not get better at spotting AI generated slop for what it is, work is being done on showing it up for us.
With the main content providers being inundated with AI trash and it being shown up for what it is, people will get bored of it. This gives other parties, those with the possibility of curating their content, possibilities for growth – offering high quality content that differentiates itself from other high quality content sites and especially from the central repositories of AI filled garbage. Existing parties and smaller new parties have an incentive to create and innovate. Of course that content will be used to fill the GPTs, but that should increases the accuracy of the GPTs that are paying attention (and who should be able to filter out AI slop better than any human could), who will hopefully redirect their answers to their sources – as legally explainability is becoming more and more relevant.
So together with the rise of anti Google sentiment and opportunities to DeGoogle leading to new (and de-shittified, working, and non-US!) search engines such as Qwant and SearXNG I see this as an excellent opportunity for the (relatively) little man to rise up again to diversify and decentralise the internet.