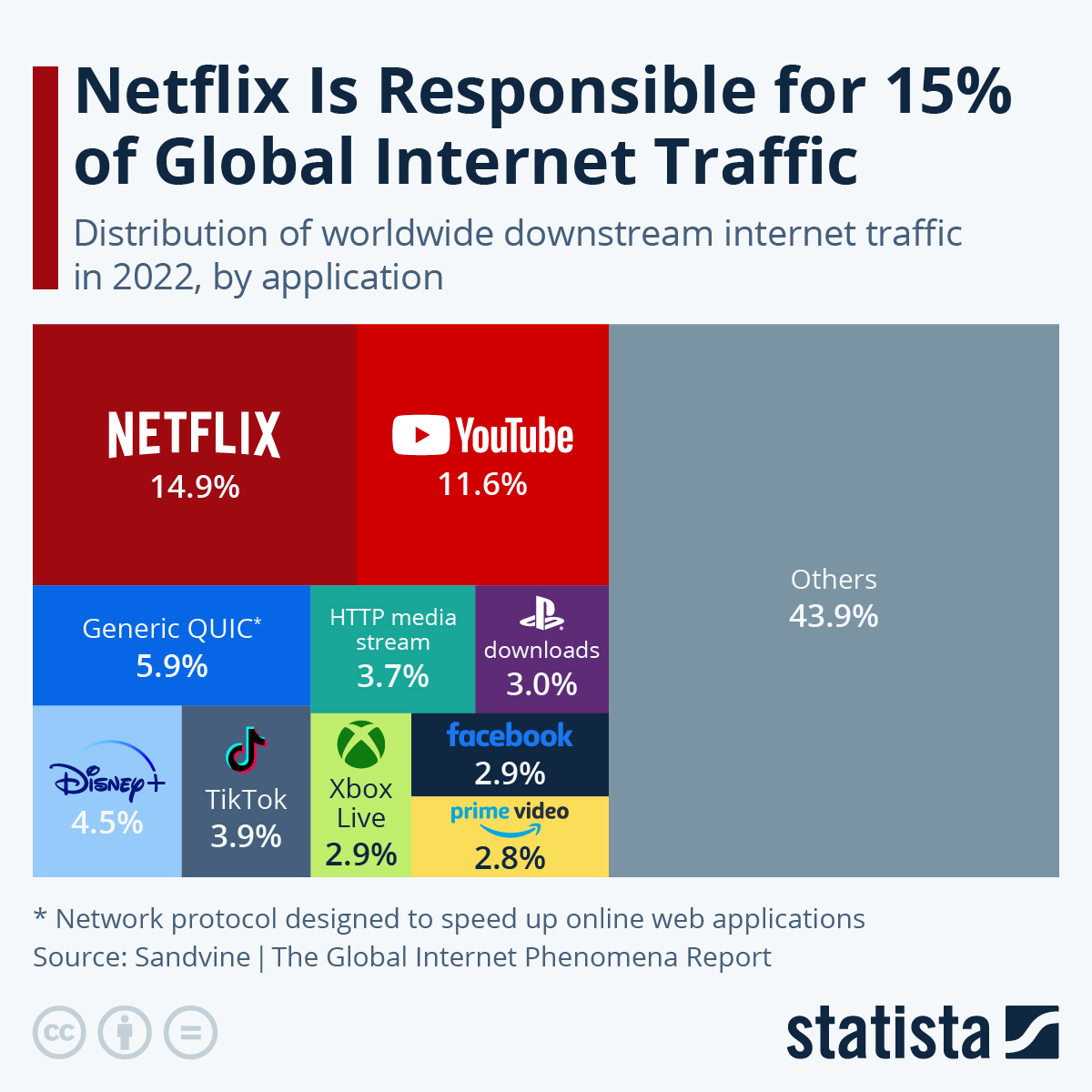
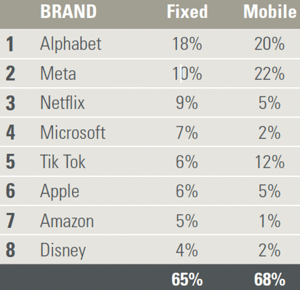
The epigram for my forthcoming book, Enshittification: Why Everything Suddenly Got Worse and What To Do About It is a quote from Ed Zitron: “I hate them for what they’ve done to the computer” (Ed even recorded a little cameo of this for the audiobook):
https://www.kickstarter.com/projects/doctorow/enshittification-the-drm-free-audiobook/
Ed’s a smart and passionate guy, and this was definitely the quote to sum up the rage I felt as I wrote the book. Ed’s got a whole theory of who “they” are and “what they did to the computer,” which he calls “the Rot Economy”:
https://www.wheresyoured.at/the-rot-economy/
The Rot Economy describes the ideology of bosses, starting with monsters like GE’s Jack Welch, who financialized companies, optimizing them for making short term cash gains for investors, at the expense of their workers, their customers, their products and services, and, ultimately, their long-term health.
For Ed, these bosses (especially tech bosses) are the sociopaths who destroyed “the computer” (a stand-in for tech more generally). I don’t disagree at all. The there is a direct, undeniable line from the ideas and conduct of tech bosses and the tech hellscape we live in today. A good read on this subject is Anil Dash’s scorching post from yesterday, “How Tim Cook sold out Steve Jobs”:
https://www.anildash.com/2025/09/09/how-tim-cook-sold-out-steve-jobs/
I find the Rot Economy hypothesis entirely compelling, but also, incomplete. Ed’s explaining why we should hate the players and why we should hate the game, but the enshittification thesis goes even further and explains why we need to hate the umpires – the policymakers, enforcers, economists and legal theorists who created the enshittogenic environment in which the Rot Economy took hold.
Some early reviews of Enshittification have expressed dissatisfaction with book’s “solutions” section, complaining that all the solutions are policy oriented, and there’s nothing suggested for us to do in our capacity as individual consumers:
https://pluralistic.net/2025/07/31/unsatisfying-answers/#systemic-problems
Those criticisms are correct: there is nothing we can do as individual consumers. Agonizing about your consumption choices will not fight enshittification any more than conscientiously sorting your recycling will end the climate emergency. Enshittification isn’t caused by “lazy consumers” who choose “convenience” or are “too cheap to pay for online services”:
https://pluralistic.net/2024/04/12/give-me-convenience/#or-give-me-death
The wellspring of enshittification isn’t poor consumption choices, it’s poor policy choices. The reason monsters are able to destroy our online lives isn’t their personal moral failings, it’s the system that rewards predatory, deceptive and unfair commercial practices and elevates their foremost practitioners to positions of power within firms:
https://pluralistic.net/2023/07/28/microincentives-and-enshittification/
And here’s the kicker: we know where those policy choices came from! The people who made these policy choices did so in living memory. They were warned at the time about the foreseeable consequences of their choices. They made those choices anyway. They faced zero consequences for doing so, even after every one of the prophesied horrors came to pass. Not only were they spared consequences for their actions, but they prospered as a result – they are revered as statesmen, lawyers, scholars and titans of economics.
As Trashfuture showrunner Riley Quinn often says, the curse of being a leftist is that you have object permanence – you actually remember the stuff that happened and how it happened. You don’t live in an eternal now that has no causal relationship to the past.
It’s not enough to hate the player, nor the game – we’ve got to remember the crooked umps who rigged the match. We have to say their names, because that’s how we root out their terrible ideas and ensure that our policy interventions make real change. If Elon Musk OD’ed on ketamine tomorrow, there’d be ten Big Balls who’d tear each others’ throats out in the ensuing succession fight, and the next guy would be just as stupid, racist, and authoritarian. Musk, Cook, Zuck, Pichai, Nadella, Larry Ellison – they’re just filling the monster-shaped holes that policy-makers installed in our society.
Start with Robert Bork, the jurist who championed the “consumer welfare” theory of antitrust, which promotes monopolies as efficient and counsels policymakers not to punish companies that take over markets, because the only way to really dominate a market is to be so good that everyone chooses your products and services. Wouldn’t it just be perverse to use public funds to shut down the public’s favorite companies? Bork was a virulent racist, a Nixonite criminal, and he was dead wrong about the law and the economics of monopoly:
https://pluralistic.net/2022/02/20/we-should-not-endure-a-king/
Bork’s legacy of pro-monopoly advocacy is, unsurprisingly, monopolies. Monopolies that make everything more expensive and worse: from athletic shoes to microchips, glass bottles to pharmaceuticals, pro wrestling to eyeglasses:
https://www.openmarketsinstitute.org/learn/monopoly-by-the-numbers
These monopolies did not arise because of the iron laws of economics. They are not the product of the great forces of history. They are the direct and undeniable consequence of Robert Bork convincing the world’s governments to embrace his bullshit, pro-monopoly policies.
Satan took Bork to hell in 2012, but you know who’s still with us? Bruce Lehman. Bruce Lehman was Bill Clinton’s copyright czar, the man who, in his own words, “did an end-run around Congress” by getting an UN treaty passed that obliged its signatories to ban reverse engineering:
https://www.cbc.ca/listen/cbc-podcasts/1353-the-naked-emperor/episode/16145640-ctrl-ctrl-ctrl
Lehman’s used the treaty to get Congress to pass the Digital Millennium Copyright Act (DMCA) and section 1201 of the DMCA made it a felony to break DRM. Bruce Lehman is why farmers can’t fix their own tractors, hospitals can’t fix their own ventilators, and your mechanic can’t fix your car. He’s why, when the manufacturer of your artificial eyes bricks a computer that is permanently wired to your nervous system, no one else can revive it:
https://pluralistic.net/2022/12/12/unsafe-at-any-speed/
Bruce Lehman is why you can’t use the apps of your choosing on your phone or games console. He’s why we can’t preserve beloved old video games. He’s why Apple and Google get to steal 30 cents out of every dollar you send to a performer, software author, or creator through an app:
https://pluralistic.net/2025/05/01/its-not-the-crime/#its-the-coverup
Yeah, Tim Cook is a venal billionaire who owes his wealth to the Chinese sweatshops of iPhone City, where they had to install suicide nets to catch the workers who’d rather end it all than work another day for Tim Apple, but Tim Cook’s power over those workers is owed to Bruce Lehman and Robert Bork.
Then there’s the ISP sector, whose Net Neutrality violations and underinvestment mean that people who live in the country where the internet was invented have some of the slowest, most expensive internet in the world. Big ISP bosses are some of the worst people on Earth. Take Thomas Rutledge, who CEO of Charter/Spectrum when covid broke out. At the time, Rutledge was America’s highest-paid CEO. He dictated that his back-office staff could not work from home (imagine a telco boss who doesn’t believe in telework!), and those back-offices all turned into super-spreader sites. Rutledge’s field workers – the people who came to our homes and upgraded our internet so we could work from home – did not get PPE or danger pay. Instead, they got vouchers exclusively redeemable at restaurants that had shut down during the pandemic:
https://pluralistic.net/2020/04/22/filternet/#thomas-rutledge-murderer
Fuck Thomas Rutledge and may his name be a curse forever. But the reason Thomas Rutledge – and all the other terrible telco bosses – were able to reap millions by supplying us with dogshit internet while literally murdering their employees was that Trump’s FCC chairman, an ex-Verizon lawyer named Ajit Pai, let them get away with it:
https://pluralistic.net/2021/02/12/ajit-pai/#pai
Ajit Pai engaged in some of the most flagrant cheating ever seen in American regulation (prior to Jan 20, 2025, at least). When he decided to kill Net Neutrality, he accepted obviously fraudulent comments into the official record, including one million identical comments from @pornhub.com email addresses, as well as millions of comments whose return addresses were taken from darknet data-dumps, including the email addresses of dead people and of sitting US senators who supported Net Neutrality:
https://pluralistic.net/2023/11/10/digital-redlining/#stop-confusing-the-issue-with-relevant-facts
Pai – and his co-conspirators – are the umps who rigged the game. Hate Thomas Rutledge to be sure, but to prevent people like Rutledge from gaining power over your digital life in future, you must remember Ajit Pai with the special form of white-hot rage that keeps people like him from ever making policy decisions again.
Then there’s Canada’s hall of shame, which is full of monsters. Two of my least favorite are James Moore and Tony Clement, who, as ministers under Stephen Harper, rammed through a Canadian version of the DMCA, 2012’s Bill C-11, despite their own consultation, which found that Canadians overwhelmingly rejected the idea:
https://pluralistic.net/2024/11/15/radical-extremists/#sex-pest
Clement (now a disgraced sex-pest) and Moore (still accepted into polite society as a corporate lawyer) are the reason that Canada’s Right to Repair and interop laws are dead on arrival. They’re also why Canada can’t retaliate against Trump’s tariffs by jailbreaking US products, making everything cheaper for Canadians and birthing new, global Canadian tech businesses:
https://pluralistic.net/2025/01/15/beauty-eh/#its-the-only-war-the-yankees-lost-except-for-vietnam-and-also-the-alamo-and-the-bay-of-ham
In Europe, there’s Axel Voss, the man behind 2019’s “filternet” proposal, which requires tech platforms to spend hundreds of millions of euros for copyright filters that use AI to process everything posted to the public internet in Europe and block anything the AI thinks is “copyrighted”:
https://memex.craphound.com/2019/03/26/article-13-will-wreck-the-internet-because-swedish-meps-accidentally-pushed-the-wrong-voting-button/
For years, Voss maintained that none of this was true, that there would be no filters, and dismissed his critics as hysterical fools:
https://memex.craphound.com/2019/04/03/after-months-of-insisting-that-article13-doesnt-require-filters-top-eu-commissioner-says-article-13-requires-filters/
But then, after his law passed, he admitted he “didn’t know what he was voting for”:
https://memex.craphound.com/2018/09/14/father-of-the-catastrophic-copyright-directive-reveals-he-didnt-know-what-he-was-voting-for/
Fuck the media lobbyists who spent hundreds of millions of euros to push this catastrophic law through:
https://memex.craphound.com/2018/12/13/clash-of-the-corporate-titans-whos-spending-what-in-europes-copyright-directive-battle/
But especially and forever, fuck Axel Voss, the policymaker who helped turn those corporate bribes into policy.
Ed Zitron is right to hate the people who implement the Rot Economy for what they did to the computer. But those people are only doing what policymakers let them do. Corporate monsters thrive in an enshittogenic environment.
But political monsters are the ones create that enshittogenic environment. They’re the ones who are terraforming our planet to sideline human life and replace it with the immortal colony organisms we call “limited liability corporations.”