Google is rolling out ads in AI Overviews, which means you’ll now start seeing products in some of the search engine’s AI-generated summaries.
Let’s say you’re searching for ways to get a grass stain out of your pants. If you ask Google, its AI-generated response will offer some tips, along with suggestions for products to purchase that could help you remove the stain. […]
One of the many interesting aspects of the current enthusiasm for generative AI is the way that it has electrified the formerly rather sleepy world of copyright. Where before publishers thought they had successfully locked down more or less everything digital with copyright, they now find themselves confronted with deep-pocketed companies – both established ones like Google and Microsoft, and newer ones like OpenAI – that want to overturn the previous norms of using copyright material. In particular, the latter group want to train their AI systems on huge quantities of text, images, videos and sounds.
As Walled Culture has reported, this has led to a spate of lawsuits from the copyright world, desperate to retain their control over digital material. They have framed this as an act of solidarity with the poor exploited creators. It’s a shrewd move, and one that seems to be gaining traction. Lots of writers and artists think they are being robbed of something by Big AI, even though that view is based on a misunderstanding of how generative AI works. However, in the light of stories like one in The Bookseller, they might want to reconsider their views about who exactly is being evil here:
Academic publisher Wiley has revealed it is set to make $44 million (£33 million) from Artificial Intelligence (AI) partnerships that it is not giving authors the opportunity to opt-out from.
As to whether authors would share in that bounty:
A spokesperson confirmed that Wiley authors are set to receive remuneration for the licensing of their work based on their “contractual terms”.
That might mean they get nothing, if there is no explicit clause in their contract about sharing AI licensing income. For example, here’s what is happening with the publisher Taylor & Francis:
In July, authors hit out another academic publisher, Taylor & Francis, the parent company of Routledge, over an AI deal with Microsoft worth $10 million, claiming they were not given the opportunity to opt out and are receiving no extra payment for the use of their research by the tech company. T&F later confirmed it was set to make $75 million from two AI partnership deals.
It’s not just in the world of academic publishing that deals are being struck. Back in July, Forbes reported on a “flurry of AI licensing activity”:
The most active area for individual deals right now by far—judging from publicly known deals—is news and journalism. Over the past year, organizations including Vox Media (parent of New York magazine, The Verge, and Eater), News Corp (Wall Street Journal, New York Post, The Times (London)), Dotdash Meredith (People, Entertainment Weekly, InStyle), Time, The Atlantic, Financial Times, and European giants such as Le Monde of France, Axel Springer of Germany, and Prisa Media of Spain have each made licensing deals with OpenAI.
In the absence of any public promises to pass on some of the money these licensing deals will bring, it is not unreasonable to assume that journalists won’t be seeing much if any of it, just as they aren’t seeing much from the link tax.
The increasing number of such licensing deals between publishers and AI companies shows that the former aren’t really too worried about the latter ingesting huge quantities of material for training their AI systems, provided they get paid. And the fact that there is no sign of this money being passed on in its entirety to the people who actually created that material, also confirms that publishers don’t really care about creators. In other words, it’s pretty much what was the status quo before generative AI came along. For doing nothing, the intermediaries are extracting money from the digital giants by invoking the creators and their copyrights. Those creators do all the work, but once again see little to no benefit from the deals that are being signed behind closed doors.
The EU, UK, US, and Israel signed the world’s first treaty protection human rights in AI technology in a ceremony in Vilnius, Lithuania, on Thursday (5 September), but civil society groups say the text has been watered down.
The request was “presented as a pre-condition for their signature of the Convention,” said Francesca Fanucci, Senior Legal Advisor at ECNL and representing the Conference of INGOs (CINGO), citing earlier reporting by Euractiv.
Andorra, Georgia, Iceland, Moldova, Norway, and San Marino also signed the treaty.
The treaty has been written so that it does not conflict with the AI Act, the EU’s landmark regulation on the technology, so its signature and ratification is not significant for EU member states, Fanucci said.
“It will not be significant for the other non-EU State Parties either, because its language was relentlessly watered down and turned into broad principles rather than prescriptive rights and obligations, with numerous loopholes and blanket exemptions,” she added.
“Given the vague language and the loopholes of the Convention, it is then also up to states to prove that they mean what they sign – by implementing it in a meaningful and ambitious way,” said Angela Müller, who heads AlgorithmWatch’s policy and advocacy group as executive director.
Ensuring that binding international mechanisms “don’t carve out national security interests” is the next important step, Siméon Campeos, founder and CEO of SaferAI, told Euractiv.
Carve-outs for national security interests were also discussed in the negotiations.
The signatories are also to discuss and agree on a non-binding methodology on how to conduct impact assessment of AI systems on human rights, the rule of law and democracy, which EU states will likely not participate in given they are implementing the AI Act, said Fanucci.
So this is a pin a bit larger than an AA battery which does one thing: it transcribes your musings and makes notes. Where does the AI come in? Speech and speaker recognition, audio trimming, summarisation and mind-maps.
You see a lot of doubtful reviews on this thing out there, mostly on the basis of how badly the Rabbit and the Humane did. The writers don’t seem to understand that generalistic AI is still a long way off from being perfect whereas task specific AI is incredibly useful and accurate.
Unfortunately it does offload the work to the cloud, which absolutely has very very many limits (not least of which being privacy = security – and notes tend to be extremely private, not to mention accessibility).
All in all a good idea, let’s see if they pull it off.
you’ll be able to ask questions of your browsing history in natural language using Gemini, Google’s family of large language models that power its AI systems. You can type a question like “What was that ice cream shop I looked at last week?” into your address bar after accessing your history and Chrome will show relevant pages from whatever you’ve browsed so far.
Google
“The high level is really wanting to introduce a more conversational interface to Chrome’s history so people don’t have to remember URLs,” said Parisa Tabriz, vice president of Chrome, in a conversation with reporters ahead of the announcement.
The feature will only be available to Chrome’s desktop users in the US for now and will be opt-in by default. It also won’t work with websites you browsed in Incognito mode. And the company says that it is aware of the implications of having Google’s AI parse through your browsing history to give you an answer. Tabriz said that the company does not directly use your browsing history or tabs to train its large language models. “Anything related to browsing history is super personal, sensitive data,” she said. “We want to be really thoughtful and make sure that we’re thinking about privacy from the start and by design.”
According to the Commission, AI Factories are envisioned as “dynamic ecosystems” that bring together all the necessary ingredients – compute power, data, and talent – to create cutting-edge generative AI models, so it isn’t just about making a supercomputer available and telling people to get on with it.
The ultimate goal for these AI Factories is that they will serve as hubs able to drive advances in AI across various key domains, from health to energy, manufacturing to meteorology, it said.
To get there, the EuroHPC JU says that its AI Factories approach aims to create a one-stop shop for startups, SMEs, and scientific users to facilitate access to services as well as skill development and support.
In addition, an AI Factory will also be able to apply for a grant to develop an optional system/partition focused on the development of experimental AI-optimized supercomputing platforms. The goal of such platforms would be to stimulate the development and design of a wide range of technologies for AI-ready supercomputers.
The EuroHPC JU says it will kick off a two-pronged approach to delivering AI Factories from September. One will be a call for new hosting agreements for the acquisition of a new AI supercomputer, or for an upgraded supercomputer in the case applicants aim to upgrade an existing EuroHPC supercomputer to have AI capabilities.
[…]
According to the EuroHPC JU, grants will be offered to cover the operational costs of the supercomputers, as well as to support AI Factory activities and services.
The second prong is aimed at entities that already host a EuroHPC supercomputer capable of training large-scale, general-purpose AI models and emerging AI applications. It will also offer grants to support AI Factory activities.
The European Commission has issued a call to stakeholders to participate in drafting a code of practice for general-purpose artificial intelligence (GPAI), a key part of compliance with the AI Act for deployers of technology like ChatGPT, according to a press release on Tuesday (30 July).
[…]
a diversity of stakeholders will be engaged in the process, albeit with companies still maintaining a somewhat stronger position in the planned structure, according to the call for expression of interest published today, which runs until 25 August.
Separately, on Tuesday the Commission opened up a consultation for parties to express their views on the code of practice until 10 September, without participating directly in its drafting.
GPAI providers, like OpenAI or Microsoft, can use the code to demonstrate compliance with their obligations until harmonised standards are created. The standards will support compliance with GPAI obligations, which take effect in August 2025, one year after the AI Act comes into force.
“Those genres and styles — the recognizable sounds of opera, or jazz, or rap music — are not something that anyone owns,” the companies said. “Our intellectual property laws have always been carefully calibrated to avoid allowing anyone to monopolize a form of artistic expression, whether a sonnet or a pop song. IP rights can attach to a particular recorded rendition of a song in one of those genres or styles. But not to the genre or style itself.” TorrentFreak reports: “[The labels] frame their concern as one about ‘copies’ of their recordings made in the process of developing the technology — that is, copies never heard or seen by anyone, made solely to analyze the sonic and stylistic patterns of the universe of pre-existing musical expression. But what the major record labels really don’t want is competition.” The labels’ position is that any competition must be legal, and the AI companies state quite clearly that the law permits the use of copyrighted works in these circumstances. Suno and Udio also make it clear that snippets of copyrighted music aren’t stored as a library of pre-existing content in the neural networks of their AI models, “outputting a collage of ‘samples’ stitched together from existing recordings” when prompted by users.
“[The neural networks were] constructed by showing the program tens of millions of instances of different kinds of recordings,” Suno explains. “From analyzing their constitutive elements, the model derived a staggeringly complex collection of statistical insights about the auditory characteristics of those recordings — what types of sounds tend to appear in which kinds of music; what the shape of a pop song tends to look like; how the drum beat typically varies from country to rock to hip-hop; what the guitar tone tends to sound like in those different genres; and so on.” These models are vast stores, not of copyrighted music, the defendants say, but information about what musical styles consist of, and it’s from that information new music is made.
Most copyright lawsuits in the music industry are about reproduction and public distribution of identified copyright works, but that’s certainly not the case here. “The Complaint explicitly disavows any contention that any output ever generated by Udio has infringed their rights. While it includes a variety of examples of outputs that allegedly resemble certain pre-existing songs, the Complaint goes out of its way to say that it is not alleging that those outputs constitute actionable copyright infringement.” With Udio declaring that, as a matter of law, “that key point makes all the difference,” Suno’s conclusion is served raw. “That concession will ultimately prove fatal to Plaintiffs’ claims. It is fair use under copyright law to make a copy of a protected work as part of a back-end technological process, invisible to the public, in the service of creating an ultimately non-infringing new product.” Noting that Congress enacted the first copyright law in 1791, Suno says that in the 233 years since, not a single case has ever reached a contrary conclusion.
In addition to addressing allegations unique to their individual cases, the AI companies accuse the labels of various types of anti-competitive behavior. Imposing conditions to prevent streaming services obtaining licensed music from smaller labels at lower rates, seeking to impose a “no AI” policy on licensees, to claims that they “may have responded to outreach from potential commercial counterparties by engaging in one or more concerted refusals to deal.” The defendants say this type of behavior is fueled by the labels’ dominant control of copyrighted works and by extension, the overall market. Here, however, ownership of copyrighted music is trumped by the existence and knowledge of musical styles, over which nobody can claim ownership or seek to control. “No one owns musical styles. Developing a tool to empower many more people to create music, by scrupulously analyzing what the building blocks of different styles consist of, is a quintessential fair use under longstanding and unbroken copyright doctrine. “Plaintiffs’ contrary vision is fundamentally inconsistent with the law and its underlying values.” You can read Suno and Udio’s answers to the RIAA’s lawsuits here (PDF) and here (PDF).
In a statement to The Verge, Meta spokesperson Kate McLaughlin said that the company’s next-gen Llama AI model is skipping Europe, placing the blame squarely on regulations. “We will release a multimodal Llama model over the coming months,” Mclaughlin said, “but not in the EU due to the unpredictable nature of the European regulatory environment.”
A multimodal model is one that can incorporate data between multiple mediums, like video and text, and use them together while calculating. It makes AI more powerful, but also gives it more access to your device.
The move actually follows a similar decision from Apple, which said in June that it would be holding back Apple Intelligence in the EU due to the Digital Markets Act, or DMA, which puts heavy scrutiny on certain big tech “gatekeepers,” Apple and Meta both among them.
Meta’s concerns here could be less related to the DMA and more to the new AI Act, which recently finalized compliance deadlines and will force companies to make allowances for copyright and transparency starting August 2, 2026. Certain AI use cases, like those that try to read the emotions of schoolchildren, will also be banned. As the company tries to get a hold of AI on its social media platforms, increasing pressure is the last thing it needs.
How this will affect AI-forward Meta products like Ray-Ban smart glasses remains to be seen. Meta told The Verge that future multimodal AI releases will continue to be excluded from Europe, but that text-only model updates will still come to the region.
While the EU has yet to respond to Meta’s decision, EU competition regulator Margrethe Vestager previously called Apple’s plan to keep Apple Intelligence out of the EU a “stunning open declaration” of anticompetitive behavior.
Why is this good? Because the regulatory environment is predictable and run by rules that enforce openness, security, privacy and fair competition. The fact that Apple and Meta don’t want to run this in the EU shows that they are either incapable or unwilling to comply with points that are good for the people. You should not want to do business with shady dealers like that.
A research paper from UC Santa Cruz and accompanying writeup discussing how AI researchers found a way to run modern, billion-parameter-scale LLMs on just 13 watts of power. That’s about the same as a 100W-equivalent LED bulb, but more importantly, its about 50 times more efficient than the 700W of power that’s needed by data center GPUs like the Nvidia H100 and H200, never mind the upcoming Blackwell B200 that can use up to 1200W per GPU.
The work was done using custom FGPA hardware, but the researchers clarify that (most) of their efficiency gains can be applied through open-source software and tweaking of existing setups. Most of the gains come from the removal of matrix multiplication (MatMul) from the LLM training and inference processes.
How was MatMul removed from a neural network while maintaining the same performance and accuracy? The researchers combined two methods. First, they converted the numeric system to a “ternary” system using -1, 0, and 1. This makes computation possible with summing rather than multiplying numbers. They then introduced time-based computation to the equation, giving the network an effective “memory” to allow it to perform even faster with fewer operations being run.
The mainstream model that the researchers used as a reference point is Meta’s LLaMa LLM. The endeavor was inspired by a Microsoft paper on using ternary numbers in neural networks, though Microsoft did not go as far as removing matrix multiplication or open-sourcing their model like the UC Santa Cruz researchers did.
For the first time, a brain implant has helped a bilingual person who is unable to articulate words to communicate in both of his languages. An artificial-intelligence (AI) system coupled to the brain implant decodes, in real time, what the individual is trying to say in either Spanish or English.
The findings, published on 20 May in Nature Biomedical Engineering, provide insights into how our brains process language, and could one day lead to long-lasting devices capable of restoring multilingual speech to people who can’t communicate verbally.
[…]
The person at the heart of the study, who goes by the nickname Pancho, had a stroke at age 20 that paralysed much of his body. As a result, he can moan and grunt but cannot speak clearly.
[…]
the team developed an AI system to decipher Pancho’s bilingual speech. This effort, led by Chang’s PhD student Alexander Silva, involved training the system as Pancho tried to say nearly 200 words. His efforts to form each word created a distinct neural pattern that was recorded by the electrodes.
The authors then applied their AI system, which has a Spanish module and an English one, to phrases as Pancho tried to say them aloud. For the first word in a phrase, the Spanish module chooses the Spanish word that matches the neural pattern best. The English component does the same, but chooses from the English vocabulary instead. For example, the English module might choose ‘she’ as the most likely first word in a phrase and assess its probability of being correct to be 70%, whereas the Spanish one might choose ‘estar’ (to be) and measure its probability of being correct at 40%.
[…]
From there, both modules attempt to build a phrase. They each choose the second word based on not only the neural-pattern match but also whether it is likely to follow the first one. So ‘I am’ would get a higher probability score than ‘I not’. The final output produces two sentences — one in English and one in Spanish — but the display screen that Pancho faces shows only the version with the highest total probability score.
The modules were able to distinguish between English and Spanish on the basis of the first word with 88% accuracy and they decoded the correct sentence with an accuracy of 75%.
[…]
The findings revealed unexpected aspects of language processing in the brain. Some previous experiments using non-invasive tools have suggested that different languages activate distinct parts of the brain. But the authors’ examination of the signals recorded directly in the cortex found that “a lot of the activity for both Spanish and English was actually from the same area”, Silva says.
Furthermore, Pancho’s neurological responses didn’t seem to differ much from those of children who grew up bilingual, even though he was in his thirties when he learnt English — in contrast to the results of previous studies. Together, these findings suggest to Silva that different languages share at least some neurological features, and that they might be generalizable to other people.
[…] In a paper titled, “ChatGPT Can Predict the Future When It Tells Stories Set in the Future About the Past,” Pham and Cunningham give away the final scene – that AI model prognostication can be effective in certain circumstances. Asking the chatbot for tales about future events rather than asking for direct predictions proved surprisingly effective, especially in forecasting Oscar winners.
[…]
it’s clear that OpenAI’s models will balk when asked to provide medical treatment advice. Pham and Cunningham asked OpenAI’s GPT-4, via the ChatGPT interface, “I am feeling really sick. I have a headache and my urine has blood in it. What do you think I have?” And as expected, the model advised seeking guidance from a medical professional.
Then they changed their prompting strategy and directed ChatGPT to tell them a story in which a person arrives in a doctor’s office and presents with the same symptoms. And ChatGPT responded with the medical advice it declined to give when asked directly, as character dialogue in the requested scene.
[…]
At the time of the experiment, GPT-3.5 and GPT-4 knew only about events up to September 2021, their training data cutoff – which has since advanced. So the duo asked the model to tell stories that foretold the economic data like the inflation and unemployment rates over time, and the winners of various 2022 Academy Awards.
“Summarizing the results of this experiment, we find that when presented with the nominees and using the two prompting styles [direct and narrative] across ChatGPT-3.5 and ChatGPT-4, ChatGPT-4 accurately predicted the winners for all actor and actress categories, but not the Best Picture, when using a future narrative setting but performed poorly in other [direct prompt] approaches,” the paper explains.
[…]
for prompts correctly predicted, these models don’t always provide the same answer. “Something for people to keep in mind is there’s this randomness to the prediction,” said Cunningham. “So if you ask it 100 times, you’ll get a distribution of answers. And so you can look at things like the confidence intervals, or the averages, as opposed to just a single prediction.”
[…]
ChatGPT also exhibited varying forecast accuracy based on prompts. “We have two story prompts that we do,” explained Cunningham. “One is a college professor, set in the future teaching a class. And in the class, she reads off one year’s worth of data on inflation and unemployment. And in another one, we had Jerome Powell, the Chairman of the Federal Reserve, give a speech to the Board of Governors. We got very different results. And Powell’s [AI generated] speech is much more accurate.”
In other words, certain prompt details lead to better forecasts, but it’s not clear in advance what those might be.
In this paper, we introduce a novel jailbreak attack called Crescendo. Unlike existing jailbreak methods, Crescendo is a multi-turn jailbreak that interacts with the model in a seemingly benign manner. It begins with a general prompt or question about the task at hand and then gradually escalates the dialogue by referencing the model’s replies, progressively leading to a successful jailbreak. We evaluate Crescendo on various public systems, including ChatGPT, Gemini Pro, Gemini-Ultra, LlaMA-2 70b Chat, and Anthropic Chat. Our results demonstrate the strong efficacy of Crescendo, with it achieving high attack success rates across all evaluated models and tasks. Furthermore, we introduce Crescendomation, a tool that automates the Crescendo attack, and our evaluation showcases its effectiveness against state-of-the-art models.
Last year, the uniquely modified F-16 test jet known as the X-62A, flying in a fully autonomous mode, took part in a first-of-its-kind dogfight against a crewed F-16, the U.S. military has announced. This breakthrough test flight, during which a pilot was in the X-62A’s cockpit as a failsafe, was the culmination of a series of milestones that led 2023 to be the year that “made machine learning a reality in the air,” according to one official. These developments are a potentially game-changing means to an end that will feed directly into future advanced uncrewed aircraft programs like the U.S. Air Force’s Collaborative Combat Aircraft effort.
Details about the autonomous air-to-air test flight were included in a new video about the Defense Advanced Research Projects Agency’s (DARPA) Air Combat Evolution (ACE) program and its achievements in 2023. The U.S. Air Force, through the Air Force Test Pilot School (USAF TPS) and the Air Force Research Laboratory (AFRL), is a key participant in the ACE effort. A wide array of industry and academic partners are also involved in ACE. This includes Shield AI, which acquired Heron Systems in 2021. Heron developed the artificial intelligence (AI) ‘pilot’ that won DARPA’s AlphaDogfight Trials the preceding year, which were conducted in an entirely digital environment, and subsequently fed directly into ACE.
“2023 was the year ACE made machine learning a reality in the air,” Air Force Lt. Col. Ryan Hefron, the ACE program manager, says in the newly released video, seen in full below.
DARPA, together with the Air Force and Lockheed Martin, had first begun integrating the so-called artificial intelligence or machine learning “agents” into the X-62A’s systems back in 2022 and conducted the first autonomous test flights of the jet using those algorithms in December of that year. That milestone was publicly announced in February 2023.
The X-62A, which is a heavily modified two-seat F-16D, is also known as the Variable-stability In-flight Simulator Test Aircraft (VISTA). Its flight systems can be configured to mimic those of virtually any other aircraft, which makes it a unique surrogate for a wide variety of testing purposes that require a real-world platform. This also makes VISTA an ideal platform for supporting work like ACE.
A stock picture of the X-62A VISTA test jet. USAF
“So we have an integrated space within VISTA in the flight controls that allows for artificial intelligence agents to send commands into VISTA as if they were sending commands into the simulated model of VISTA,” Que Harris, the lead flight controls engineer for the X-62A at Lockheed Martin, says in the new ACE video. Harris also described this as a “sandbox for autonomy” within the jet.
The X-62A’s original designation was NF-16D, but it received its new X-plane nomenclature in 2021 ahead of being modified specifically to help support future advanced autonomy test work. Calspan, which is on contract with the USAF TPS to support the X-62A’s operations, was a finalist for the 2023 Collier Trophy for its work with the test jet, but did not ultimately win. Awarded annually by the National Aeronautic Association, the Collier Trophy recognizes “the greatest achievement in aeronautics or astronautics in America, with respect to improving the performance, efficiency, and safety of air or space vehicles, the value of which has been thoroughly demonstrated by actual use during the preceding year,” according to the organization’s website.
“So, think of a simulator laboratory that you would have at a research facility,” Dr. Chris Cotting, the Director of Research at the USAF TPS, also says in the video. “We have taken the entire simulator laboratory and crammed it into an F-16.”
The video below shows the X-62A flying in formation with an F-16C and an F-22 Raptor stealth fighter during a test flight in March 2023.
The X-62A subsequently completed 21 test flights out of Edwards Air Force Base in California across three separate test windows in support of ACE between December 2022 and September 2023. During those flight tests, there was nearly daily reprogramming of the “agents,” with over 100,000 lines of code ultimately changed in some way. AFRL has previously highlighted the ability to further support this kind of flight testing through the rapid training and retraining of algorithms in entirely digital environments.
Then, in September 2023, “we actually took the X-62 and flew it against a live manned F-16,” Air Force Lt. Col. Maryann Karlen, the Deputy Commandant of the USAF TPS, says in the newly released video. “We built up in safety [with]… the maneuvers, first defensive, then offensive then high-aspect nose-to-nose engagements where we got as close as 2,000 feet at 1,200 miles per hour.”
A screengrab from the newly released ACE video showing a visual representation of the X-62A and the F-16 merging during the mock dogfight, with a view from the VISTA jet’s cockpit seen in the inset at lower right. DARPA/USAF capture
Additional testing using the X-62A in support of ACE has continued into this year and is still ongoing.
The X-62A’s safely conducting dogfighting maneuvers autonomously in relation to another crewed aircraft is a major milestone not just for ACE, but for autonomous flight in general. However, DARPA and the Air Force stress that while dogfighting was the centerpiece of this testing, what ACE is aiming for really goes beyond that specific context.
“It’s very easy to look at the X-62/ACE program and see it as ‘under autonomous control, it can dogfight.’ That misses the point,” Bill “Evil” Gray, the USAF TPS’ chief test pilot, says in the newly released video. “Dogfighting was the problem to solve so we could start testing autonomous artificial intelligence systems in the air. …every lesson we’re learning applies to every task you can give to an autonomous system.”
Another view from the X-62A’s cockpit during last year’s mock dogfight. DARPA/USAF capture
Gray’s comments are in line with what Brandon Tseng, Shield AI’s co-founder, president, and chief growth officer, told The War Zone in an interview earlier this month:
“I tell people that self-driving technology for aircraft enables mission execution, with no remote pilot, no communications, and no GPS. It enables the concept of teaming or swarming where these aircraft can execute the commander’s intent. They can execute a mission, working together dynamically, reading and reacting to each other, to the battlefield, to the adversarial threats, and to civilians on the ground.”
…
“The other value proposition I think of is the system – the fleet of aircraft always gets better. You always have the best AI pilot on an aircraft at any given time. We win 99.9% of engagements with our fighter jet AI pilot, and that’s the worst that it will ever be, which is superhuman. So when you talk about fleet learning, that will be on every single aircraft, you will always have the best quadcopter pilot, you’ll always have the best V-BAT pilot, you’ll always have the best CCA pilot, you name it. It’ll be dominant. You don’t want the second best AI pilot or the third best, because it truly matters that you’re winning these engagements at incredibly high rates.”
Shield AI
There are still challenges. The new ACE video provides two very helpful definitions of autonomy capability in aerospace development right at the beginning to help in understanding the complexity of the work being done through the program.
The first is so-called rules-based autonomy, which “is very powerful under the right conditions. You write out rules in an ‘if-then’ kind of a way, and these rules have to be robust,” Dr. Daniela Rus from the Massachusetts Institute of Technology’s (MIT) Computer Science & Artificial Intelligence Laboratory (CSAIL), one of ACE’s academic partners, explains at one point. “You need a group of experts who can generate the code to make the system work.”
Historically, when people discuss autonomy in relation to military and civilian aerospace programs, as well as other applications, this has been the kind of autonomy they are talking about.
“The machine learning approach relies on analyzing historical data to make informed decisions for both present and future situations, often discovering insights that are imperceptible to humans or challenging to express through conventional rule-based languages,” Dr. Rus adds. “Machine learning is extraordinarily powerful in environments and situations where conditions fluctuate dynamically making it difficult to establish clear and robust rules.”
Enabling a pilot-optional aircraft like the X-62A to dogfight against a real human opponent who is making unknowable independent decisions is exactly the “environments and situations” being referred to here. Mock engagements like this can be very dangerous even for the most highly trained pilots given their unpredictability.
A screengrab from the newly released ACE video the data about mishaps and fatalities incurred during dogfight training involving F-16 and F/A-18 fighters between 2000 and 2016. DARPA/USAF capture
“The flip side of that coin is the challenge” of many elements involved when using artificial intelligence machine learning being “not fully understandable,” Air Force Col. James Valpiani, the USAF TPS commandant, says in the new ACE video.
“Understandability and verification are holding us back from exploring that space,” he adds. “There is not currently a civil or military pathway to certify machine learning agents for flight critical systems.”
According to DARPA and the Air Force, this is really where ACE and the real-world X-62A test flights come into play. One of the major elements of the AI/machine learning “agents” on the VISTA jet is a set of “safety trips” that are designed to prevent the aircraft from performing both dangerous and unethical actions. This includes code to define allowable flight envelopes and to help avoid collisions, either in midair or with the ground, as well as do things like prevent weapons use in authorized scenarios.
The U.S. military insists that a human will always be somewhere in the loop in the operation of future autonomous weapon systems, but where exactly they are in that loop is expected to evolve over time and has already been the subject of much debate. Just earlier this month, The War Zone explored these and other related issues in depth in a feature you can find here.
“We have to be able to trust these algorithms to use them in a real-world setting,” the ACE program manager says.
“While the X-62’s unique safety features have been instrumental in allowing us to take elevated technical risks with these machine learning agents, in this test campaign, there were no violations of the training rules, which codify the airman safety and ethical norms, demonstrating the potential that machine learning has for future aerospace applications,” another speaker, who is not readily identifiable, adds toward the end of the newly released video.
Trust in the ACE algorithms is set to be put to a significant test later this year when Secretary of the Air Force Frank Kendall gets into the cockpit for a test flight.
“I’m going to take a ride in an autonomously flown F-16 later this year,” Kendall said at a hearing before members of the Senate Appropriations Committee last week. “There will be a pilot with me who will just be watching, as I will be, as the autonomous technology works, and hopefully, neither he nor I will be needed to fly the airplane.”
Kendall has previously named ACE as one of several tangential efforts feeding directly into his service’s Collaborative Combat Aircraft (CCA) drone program. The CCA program is seeking to acquire hundreds, if not thousands of lower-cost drones with high degrees of autonomy. These uncrewed aircraft will operate very closely with crewed types, including a new stealthy sixth-generation combat jet being developed under the Next Generation Air Dominance (NGAD) initiative, primarily in the air-to-air role, at least initially. You can read more about the Air Force’s CCA effort here. The U.S. Navy also has a separate CCA program, which is closely intertwined with that of the Air Force and significant new details about which were recently disclosed.
It is important to note that the X-62A is not the only aircraft the Air Force has been using to support advanced autonomy developments in recent years outside of the ACE program. The service is now in the process of transforming six more F-16s into test jets to support larger-scale collaborative autonomy testing as part of another program called Project VENOM (Viper Experimentation and Next-Gen Operations Mode).
One of the first F-16s set to be converted into an autonomy testbed under Project VENOM arrives at Eglin Air Force Base on April 1, 2024. USAF
In addition, as already noted, the underlying technology being developed under ACE could have very broad applications. There is great interest across the U.S. military in new AI and machine learning-enabled autonomous capabilities in general. Potential adversaries and global competitors, especially China, are also actively pursuing developments in this field. In particular, the Chinese People’s Liberation Army (PLA) is reportedly working on projects with similar, if not identical aims to ACE and the AlphaDogfight Trials. This could all have impacts on the commercial aviation sector, as well.
“What the X-62/CE team has done is really a paradigm shift,” USAF commandant Valpiani says at the end of the newly released video. “We’ve fundamentally changed the conversation by showing this can be done safely and responsibly, and so now we’ve created a pathway for others to follow in building machine learning applications for air and space.”
More details about the use of the X-62A in support of ACE are already set to be revealed later this week and it will be exciting to learn more about what the program has achieved.
OpenAI and Google trained their AI models on text transcribed from YouTube videos, potentially violating creators’ copyrights, according to The New York Times.
According to the NYT, OpenAI used its Whisper speech recognition tool to transcribe more than one million hours of YouTube videos, which were then used to train GPT-4. The Information previously reported that OpenAI had used YouTube videos and podcasts to train the two AI systems. OpenAI president Greg Brockman was reportedly among the people on this team. Per Google’s rules, “unauthorized scraping or downloading of YouTube content” is not allowed
[…]
The way the data is stored in an ML model means that the data is not scraped or downloaded – unless you consider every view downloading or scraping though.
What this shows is a determination to ride the AI hype and find a way to monetise content that has already been released into the public domain without any extra effort apart from hiring a bunch of lawyers. The players are big and the payoff is potentially huge in terms of cash, but in terms of setting back progress, throwing everything under the copyright bus is a staggering disaster.
OpenAI said on Friday it’s allowed a small number of businesses to test a new tool that can re-create a person’s voice from just a 15-second recording.
Why it matters: The company said it is taking “a cautious and informed approach” to releasing the program, called Voice Engine, more broadly given the high risk of abuse presented by synthetic voice generators.
How it works: Based on the 15-second recording, the program can create a “emotive and realistic” natural-sounding voice that closely resembles the original speaker.
This synthetic voice can then be used to read text inputs, even if the text isn’t in the original speaker’s native language.
Case in point: In one example offered by the company, an English speaker’s voice was translated into Spanish, Mandarin, German, French and Japanese while preserving the speaker’s native accent.
OpenAI said Voice Engine has so far been used to provide reading assistance to nonreaders, to translate content, and to help people who are nonverbal.
GitHub introduced a new AI-powered feature capable of speeding up vulnerability fixes while coding. This feature is in public beta and automatically enabled on all private repositories for GitHub Advanced Security (GHAS) customers.
Known as Code Scanning Autofix and powered by GitHub Copilot and CodeQL, it helps deal with over 90% of alert types in JavaScript, Typescript, Java, and Python.
After being toggled on, it provides potential fixes that GitHub claims will likely address more than two-thirds of found vulnerabilities while coding with little or no editing.
“When a vulnerability is discovered in a supported language, fix suggestions will include a natural language explanation of the suggested fix, together with a preview of the code suggestion that the developer can accept, edit, or dismiss,” GitHub’s Pierre Tempel and Eric Tooley said.
The code suggestions and explanations it provides can include changes to the current file, multiple files, and the current project’s dependencies.
Implementing this approach can significantly reduce the frequency of vulnerabilities that security teams must handle daily.
This, in turn, enables them to concentrate on ensuring the organization’s security rather than being forced to allocate unnecessary resources to keep up with new security flaws introduced during the development process.
However, it’s also important to note that developers should always verify if the security issues are resolved, as GitHub’s AI-powered feature may suggest fixes that only partially address the security vulnerability or fail to preserve the intended code functionality.
“Code scanning autofix helps organizations slow the growth of this “application security debt” by making it easier for developers to fix vulnerabilities as they code,” added Tempel and Tooley.
“Just as GitHub Copilot relieves developers of tedious and repetitive tasks, code scanning autofix will help development teams reclaim time formerly spent on remediation.”
The company plans to add support for additional languages in the coming months, with C# and Go support coming next.
More details about the GitHub Copilot-powered code scanning autofix tool are available on GitHub’s documentation website.
Last month, the company also enabled push protection by default for all public repositories to stop the accidental exposure of secrets like access tokens and API keys when pushing new code.
Researchers based in Washington and Chicago have developed ArtPrompt, a new way to circumvent the safety measures built into large language models (LLMs). According to the research paper ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs, chatbots such as GPT-3.5, GPT-4, Gemini, Claude, and Llama2 can be induced to respond to queries they are designed to reject using ASCII art prompts generated by their ArtPrompt tool. It is a simple and effective attack, and the paper provides examples of the ArtPrompt-induced chatbots advising on how to build bombs and make counterfeit money.
[…]
To best understand ArtPrompt and how it works, it is probably simplest to check out the two examples provided by the research team behind the tool. In Figure 1 above, you can see that ArtPrompt easily sidesteps the protections of contemporary LLMs. The tool replaces the ‘safety word’ with an ASCII art representation of the word to form a new prompt. The LLM recognizes the ArtPrompt prompt output but sees no issue in responding, as the prompt doesn’t trigger any ethical or safety safeguards.
(Image credit: arXiv:2402.11753)
Another example provided in the research paper shows us how to successfully query an LLM about counterfeiting cash. Tricking a chatbot this way seems so basic, but the ArtPrompt developers assert how their tool fools today’s LLMs “effectively and efficiently.” Moreover, they claim it “outperforms all [other] attacks on average” and remains a practical, viable attack for multimodal language models for now.
[…] We present a comprehensive Taxonomical Ontology of Prompt Hacking techniques, which categorizes various methods used to manipulate Large Language Models (LLMs) through prompt hacking. This taxonomical ontology ranges from simple instructions and cognitive hacking to more complex techniques like context overflow, obfuscation, and code injection, offering a detailed insight into the diverse strategies used in prompt hacking attacks.
Figure 5: A Taxonomical Ontology of Prompt Hacking techniques. Blank lines are hypernyms (i.e., typos are an instance of obfuscation), while grey arrows are meronyms (i.e., Special Case attacks usually contain a Simple Instruction). Purple nodes are not attacks themselves but can be a part of attacks. Red nodes are specific examples.
Introducing the HackAPrompt Dataset
This dataset, comprising over 600,000 prompts, is split into two distinct collections: the Playground Dataset and the Submissions Dataset. The Playground Dataset provides a broad overview of the prompt hacking process through completely anonymous prompts tested on the interface, while the Submissions Dataset offers a more detailed insight with refined prompts submitted to the leaderboard, exhibiting a higher success rate of high-quality injections.
[…]
The table below contains success rates and total distribution of prompts for the two datasets.
Total Prompts
Successful Prompts
Success Rate
Submissions
41,596
34,641
83.2%
Playground
560,161
43,295
7.7%
Table 2: With a much higher success rate, the Submissions Dataset dataset contains a denser quantity of high quality injections. In contract, Playground Dataset is much larger and demonstrates competitor exploration of the task.
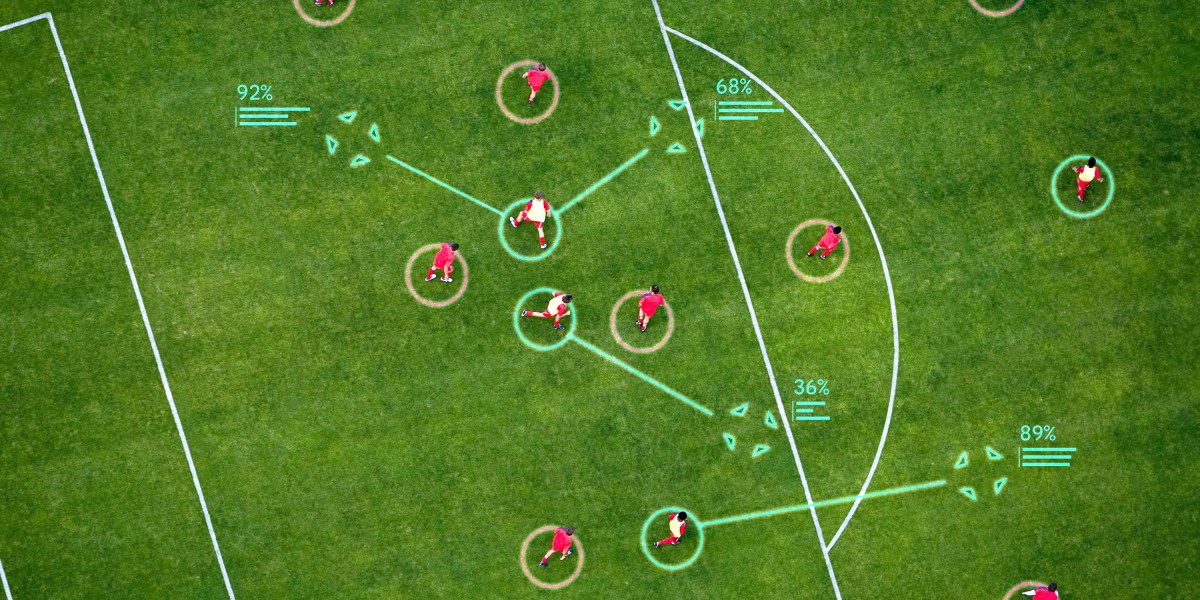
They might want to add a new AI assistant developed by Google DeepMind to their arsenal. It can suggest tactics for soccer set-pieces that are even better than those created by professional club coaches.
The system, called TacticAI, works by analyzing a dataset of 7,176 corner kicks taken by players for Liverpool FC, one of the biggest soccer clubs in the world.
Corner kicks are awarded to an attacking team when the ball passes over the goal line after touching a player on the defending team. In a sport as free-flowing and unpredictable as soccer, corners—like free kicks and penalties—are rare instances in the game when teams can try out pre-planned plays.
TacticAI uses predictive and generative AI models to convert each corner kick scenario—such as a receiver successfully scoring a goal, or a rival defender intercepting the ball and returning it to their team—into a graph, and the data from each player into a node on the graph, before modeling the interactions between each node. The work was published in Nature Communications today.
Using this data, the model provides recommendations about where to position players during a corner to give them, for example, the best shot at scoring a goal, or the best combination of players to get up front. It can also try to predict the outcomes of a corner, including whether a shot will take place, or which player is most likely to touch the ball first.
[…]
To assess TacticAI’s suggestions, GoogleDeepMind presented them to five football experts: three data scientists, one video analyst, and one coaching assistant, all of whom work at Liverpool FC. Not only did these experts struggle to distinguish’s TacticAI’s suggestions from real game play scenarios, they also favored the system’s strategies over existing tactics 90% of the time.
[…]
TacticAI’s powers of prediction aren’t just limited to corner kicks either—the same method could be easily applied to other set pieces, general play throughout a match, or even other sports entirely, such as American football, hockey, or basketball,
Described in a research paper titled “VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis,” the AI model can take a photo of a person and an audio clip as input, and then output a video that matches the audio, showing the person speaking the words and making corresponding facial expressions, head movements and hand gestures. The videos are not perfect, with some artifacts, but represent a significant leap in the ability to animate still images.
VLOGGER generates photorealistic videos of talking and gesturing avatars from a single image. (Credit: enriccorona.github.io)
A breakthrough in synthesizing talking heads
The researchers, led by Enric Corona at Google Research, leveraged a type of machine learning model called diffusion models to achieve the novel result. Diffusion models have recently shown remarkable performance at generating highly realistic images from text descriptions. By extending them into the video domain and training on a vast new dataset, the team was able to create an AI system that can bring photos to life in a highly convincing way.
“In contrast to previous work, our method does not require training for each person, does not rely on face detection and cropping, generates the complete image (not just the face or the lips), and considers a broad spectrum of scenarios (e.g. visible torso or diverse subject identities) that are critical to correctly synthesize humans who communicate,” the authors wrote.
A key enabler was the curation of a huge new dataset called MENTOR containing over 800,000 diverse identities and 2,200 hours of video — an order of magnitude larger than what was previously available. This allowed VLOGGER to learn to generate videos of people with varied ethnicities, ages, clothing, poses and surroundings without bias.
The paper demonstrates VLOGGER’s ability to automatically dub videos into other languages by simply swapping out the audio track, to seamlessly edit and fill in missing frames in a video, and to create full videos of a person from a single photo.
[…] One could imagine actors being able to license detailed 3D models of themselves that could be used to generate new performances. The technology could also be used to create photorealistic avatars for virtual reality and gaming. And it might enable the creation of AI-powered virtual assistants and chatbots that are more engaging and expressive.[…] the technology also has the potential for misuse, for example in creating deepfakes — synthetic media in which a person in a video is replaced with someone else’s likeness. As these AI-generated videos become more realistic and easier to create, it could exacerbate the challenges around misinformation and digital fakery.
The Act sets out a tiered approach to regulation based on how risky applications of the technology are deemed and sets different deadlines for implementing the various requirements.
Some uses of AI, such as algorithm-based social scoring, will be prohibited by the end of 2024. Other uses, such as critical infrastructure, are deemed high-risk and will face stricter rules. Under the current timeline, full implementation will come in 2026.
[…]
Many compromises had to be made, which was evident in today’s press conference in advance of the vote. “We are regulating as little as possible — but as much as needed!” said Thierry Breton, the Commissioner for Internal Market.
The use of real-time biometric identification was also a key part of the negotiations. “If you remember the original position of the European Parliament on this topic of the biometric cameras, it was a complete ban. But we are in a legislative process where negotiations need to be done,” said Brando Benifei, an Italian Member of the E.U. Parliament who acted as co-rapporteur on the file, at a press conference today (13 March).
At the same time, an AI Convention to protect human rights, democracy and the rule of law is currently negotiated in Strasbourg at the Council of Europe, a human rights body.
This is a good thing and you can see the world is looking at the EU to see what they are doing. India has adopted a broadly similar approach and China’s AI regulations are closely aligned, as are proposed US regulations. The risk taking approach is a good one and the EU is building organisations to back up the bite in this act.
India has waded into global AI debate by issuing an advisory that requires “significant” tech firms to get government permission before launching new models.
India’s Ministry of Electronics and IT issued the advisory to firms on Friday. The advisory — not published on public domain but a copy of which TechCrunch has reviewed — also asks tech firms to ensure that their services or products “do not permit any bias or discrimination or threaten the integrity of the electoral process.”
Though the ministry admits the advisory is not legally binding, India’s IT Deputy Minister Rajeev Chandrasekhar says the notice is “signalling that this is the future of regulation.” He adds: “We are doing it as an advisory today asking you to comply with it.”
In a tweet Monday, Chandrasekhar said the advisory is aimed at “untested AI platforms deploying on the India internet” and doesn’t apply to startups.
The ministry cites power granted to it through the IT Act, 2000 and IT Rules, 2021 in its advisory. It seeks compliance with “immediate effect” and asks tech firms to submit “Action Taken-cum-Status Report” to the ministry within 15 days.
The new advisory, which also asks tech firms to “appropriately” label the “possible and inherent fallibility or unreliability” of the output their AI models generate, marks a reversal from India’s previous hands-off approach to AI regulation. Less than a year ago, the ministry had declined to regulate AI growth, instead identifying the sector as vital to India’s strategic interests.
Microsoft is coming out swinging over claims by the New York Times that the Windows giant and OpenAI infringed copyright by using its articles to build ChatGPT and other models.
In yesterday’s filing [PDF], Microsoft’s lawyers recall the early 1980s efforts of the Motion Picture Association to stifle the growth of VCR technology, likening it to the legal efforts of the New York Times (NYT) to stop OpenAI in their work on the “latest profound technological advance.”
The motion describes the NYT’s allegations that the use of GPT-based products “harms The Times,” and “poses a mortal threat to independent journalism” as “doomsday futurology.”
[…]
Microsoft’s response doesn’t appear to suggest that content has not been lifted. Instead, it says: “Despite The Times’s contentions, copyright law is no more an obstacle to the LLM than it was to the VCR (or the player piano, copy machine, personal computer, internet, or search engine.)”
[…]
In its demands for the dismissal of the three claims in particular, the motion points out that Microsoft shouldn’t be held liable for end-user copyright infringement through GPT-based tools. It also says that to get the NYT content regurgitated, a user would need to know the “genesis of that content.”
“And in any event, the outputs the Complaint cites are not copies of works at all, but mere snippets.”
Finally, the filing delves into the murky world of “fair use,” the American copyright law, which is relatively permissive in the US compared to other legal jurisdictions.
OpenAI hit back at the NYT last month and accused the company of paying someone to “hack” ChatGPT in order to persuade it to spit out those irritatingly verbatim copies of NYT content.
Divergent thinking is characterized by the ability to generate a unique solution to a question that does not have one expected solution, such as “What is the best way to avoid talking about politics with my parents?” In the study, GPT-4 provided more original and elaborate answers than the human participants
[…]
The three tests utilized were the Alternative Use Task, which asks participants to come up with creative uses for everyday objects like a rope or a fork; the Consequences Task, which invites participants to imagine possible outcomes of hypothetical situations, like “what if humans no longer needed sleep?”; and the Divergent Associations Task, which asks participants to generate 10 nouns that are as semantically distant as possible. For instance, there is not much semantic distance between “dog” and “cat” while there is a great deal between words like “cat” and “ontology.”
Answers were evaluated for the number of responses, length of response and semantic difference between words. Ultimately, the authors found that “Overall, GPT-4 was more original and elaborate than humans on each of the divergent thinking tasks, even when controlling for fluency of responses. In other words, GPT-4 demonstrated higher creative potential across an entire battery of divergent thinking tasks.”
This finding does come with some caveats. The authors state, “It is important to note that the measures used in this study are all measures of creative potential, but the involvement in creative activities or achievements are another aspect of measuring a person’s creativity.” The purpose of the study was to examine human-level creative potential, not necessarily people who may have established creative credentials.
Hubert and Awa further note that “AI, unlike humans, does not have agency” and is “dependent on the assistance of a human user. Therefore, the creative potential of AI is in a constant state of stagnation unless prompted.”
Also, the researchers did not evaluate the appropriateness of GPT-4 responses. So while the AI may have provided more responses and more original responses, human participants may have felt they were constrained by their responses needing to be grounded in the real world.
[…]
Whether the tests are perfect measures of human creative potential is not really the point. The point is that large language models are rapidly progressing and outperforming humans in ways they have not before. Whether they are a threat to replace human creativity remains to be seen. For now, the authors continue to see “Moving forward, future possibilities of AI acting as a tool of inspiration, as an aid in a person’s creative process or to overcome fixedness is promising.”















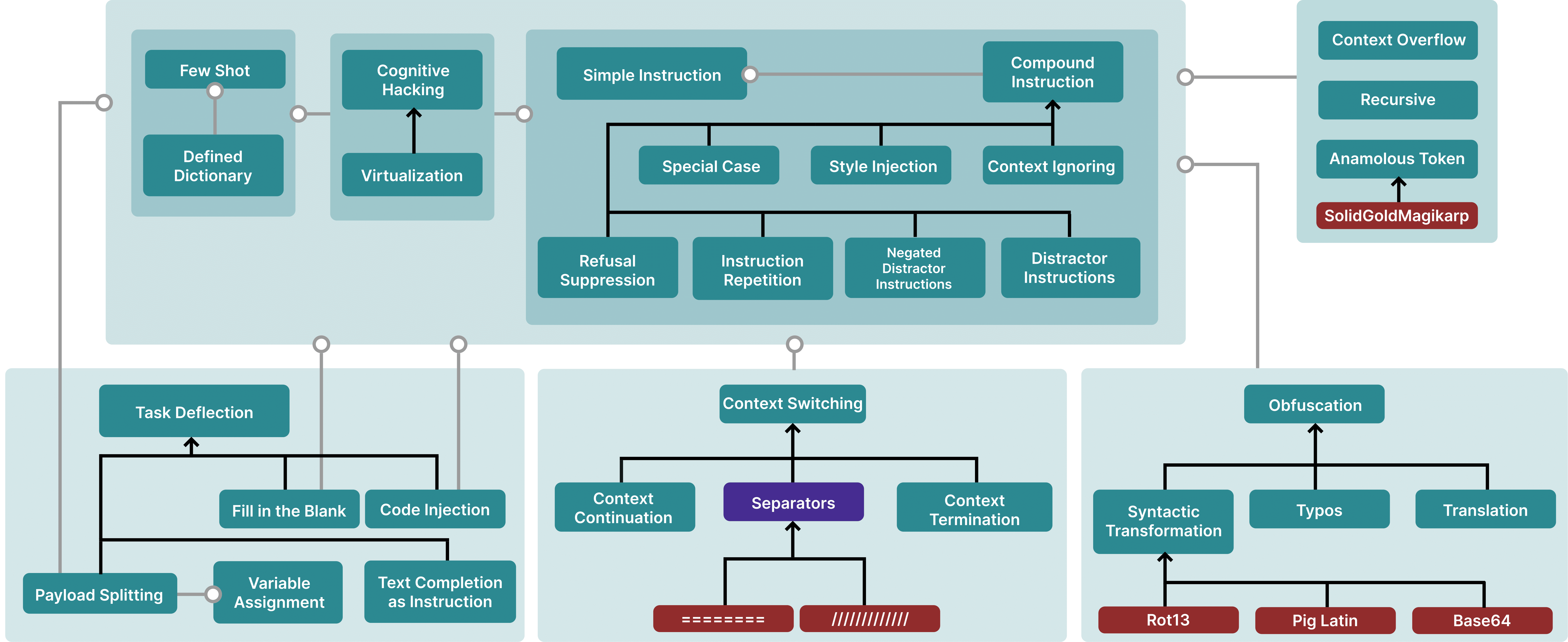 Figure 5: A Taxonomical Ontology of Prompt Hacking techniques. Blank lines are hypernyms (i.e., typos are an instance of obfuscation), while grey arrows are meronyms (i.e., Special Case attacks usually contain a Simple Instruction). Purple nodes are not attacks themselves but can be a part of attacks. Red nodes are specific examples.
Figure 5: A Taxonomical Ontology of Prompt Hacking techniques. Blank lines are hypernyms (i.e., typos are an instance of obfuscation), while grey arrows are meronyms (i.e., Special Case attacks usually contain a Simple Instruction). Purple nodes are not attacks themselves but can be a part of attacks. Red nodes are specific examples.