Last year, U.S. Customs and Border Protection (CBP) searched through the electronic devices of more than 29,000 travelers coming into the country. CBP officers sometimes upload personal data from those devices to Homeland Security servers by first transferring that data onto USB drives—drives that are supposed to be deleted after every use. But a new government report found that the majority of officers fail to delete the personal data.
The Department of Homeland Security’s internal watchdog, known as the Office of the Inspector General (OIG), released a new report yesterday detailing CBP’s many failures at the border. The new report, which is redacted in some places, explains that Customs officials don’t even follow their own extremely liberal rules.
Customs officials can conduct two kinds of electronic device searches at the border for anyone entering the country. The first is called a “basic” or “manual” search and involves the officer visually going through your phone, your computer or your tablet without transferring any data. The second is called an “advanced search” and allows the officer to transfer data from your device to DHS servers for inspection by running that data through its own software. Both searches are legal and don’t require a warrant or even probable cause—at least they don’t according to DHS.
It’s that second kind of search, the “advanced” kind, where CBP has really been messing up and regularly leaving the personal data of travelers on USB drives.
[The Office of the Inspector General] physically inspected thumb drives at five ports of entry. At three of the five ports, we found thumb drives that contained information copied from past advanced searches, meaning the information had not been deleted after the searches were completed. Based on our physical inspection, as well as the lack of a written policy, it appears [Office of Field Operations] has not universally implemented the requirement to delete copied information, increasing the risk of unauthorized disclosure of travelers’ data should thumb drives be lost or stolen.
It’s bad enough that the government is copying your data as you enter the country. But it’s another thing entirely to know that your data could just be floating around on USB drives that, as the Inspector General’s office admits, could be easily lost or stolen.
The new report found plenty of other practices that are concerning. The report notes that Customs officers regularly failed to disconnect devices from the internet, potentially tainting any findings stored locally on the device. The report doesn’t call out the invasion of privacy that comes with officials looking through your internet-connected apps, but that’s a given.
The watchdog also discovered that Customs officials had “inadequate supervision” to make sure that they were following the rules, and noted that these “deficiencies in supervision, guidance, and equipment management” were making everyone less safe.
But one thing that makes it sometimes hard to read the report is the abundance of redactions. As you can see, the little black boxes have redacted everything from what happens during an advanced search after someone crosses the border to the reason officials are allowed to conduct an advanced search at all:
Screenshot: Department of Homeland Security/Office of the Inspector General
The report notes that an April 2015 memo spells out when an advanced search may be conducted. But, again, that’s been redacted in the report.
Screenshot: Department of Homeland Security/Office of the Inspector General
But the Department of Homeland Security’s own incompetence might be our own saving grace for those concerned about digital privacy. The funniest detail in the new report? U.S. Customs and Border Protection forgot to renew its license for whatever top secret software it uses to conduct these advanced searches.
Screenshot: Department of Homeland Security/Office of the Inspector General
Curiously, the report claims that CBP “could not conduct advanced searches of laptop hard drives, USB drives, and multimedia cards at the ports of entry” from February 1, 2017 through September 12, 2017 because it failed to renew the software license. But one wonders if, in fact, the issue wasn’t resolved for almost a year, then what other “advanced search” methods were being used?
Intelligence agencies in the UK are preparing to “significantly increase their use of large-scale data hacking,” the Guardian reported on Saturday, in a move that is already alarming privacy advocates.
According to the Guardian, UK intelligence officials plan to increase their use of the “bulk equipment interference (EI) regime”—the process by which the Government Communications Headquarters, the UK’s top signals intelligence and cybersecurity agency, collects bulk data off foreign communications networks—because they say targeted collection is no longer enough. The paper wrote:
A letter from the security minister, Ben Wallace, to the head of the intelligence and security committee, Dominic Grieve, quietly filed in the House of Commons library last week, states: “Following a review of current operational and technical realities, GCHQ have … determined that it will be necessary to conduct a higher proportion of ongoing overseas focused operational activity using the bulk EI regime than was originally envisaged.”
The paper noted that during the passage of the 2016 Investigatory Powers Act, which expanded hacking powers available to police and intelligence services including bulk data collection for the latter, independent terrorism legislation reviewer Lord David Anderson asserted that bulk powers are “likely to be only sparingly used.” As the Guardian noted, just two years later, UK intelligence officials are claiming this is no longer the case due to growing use of encryption:
… The intelligence services claim that the widespread use of encryption means that targeted hacking exercises are no longer effective and so more large-scale hacks are becoming necessary. Anderson’s review noted that the top 40 online activities relevant to MI5’s intelligence operations are now encrypted.
“The bulk equipment interference power permits the UK intelligence services to hack at scale by allowing a single warrant to cover entire classes of property, persons or conduct,” Scarlet Kim, a legal officer at UK civil liberties group Liberty International, told the paper. “It also gives nearly unfettered powers to the intelligence services to decide who and when to hack.”
Liberty also took issue with the intelligence agencies’ 180 on how often the bulk powers would be used, as well as with policies that only allow the investigatory powers commissioner to gauge the impact of a warrant after the hacking is over and done with.
“The fact that you have the review only after the privacy has been infringed upon demonstrates how worrying this situation is,”
Labor has backed down completely on its opposition to the Assistance and Access Bill, and in the process has been totally outfoxed by a government that can barely control the floor of Parliament.
After proposing a number of amendments to the Bill, which Labor party members widely called out as inappropriate in the House of Representatives on Thursday morning, the ALP dropped its proposals to allow the Bill to pass through Parliament before the summer break.
“Let’s just make Australians safer over Christmas,” Bill Shorten said on Thursday evening.
“It’s all about putting people first.”
Shorten said Labor is letting the Bill through provided the government agrees to amendments in the new year.
Under the new laws, Australian government agencies would be able to issue three kinds of notices:
Technical Assistance Notices (TAN), which are compulsory notices for a communication provider to use an interception capability they already have;
Technical Capability Notices (TCN), which are compulsory notices for a communication provider to build a new interception capability, so that it can meet subsequent Technical Assistance Notices; and
Technical Assistance Requests (TAR), which have been described by experts as the most dangerous of all.
With Tumblr’s decision this week to ban porn on its platform, everyone’s getting a firsthand look at how bad automated content filters are at the moment. Lawmakers in the European Union want a similar system to filter copyrighted works and, despite expert consensus that this will just fuck up the internet, the legislation moves forward. Now some of the biggest platforms on the web insist we must stop it.
YouTube, Reddit, and Twitch have recently come out publicly against the EU’s new Copyright Directive, arguing that the impending legislation could be devastating to their businesses, their users, and the internet at large.
The Copyright Directive is the first update to the group of nation’s copyright law since 2001, and it’s a major overhaul that is intended to claw back some of the money that copyright holders believe they’ve lost since the internet use exploded around the globe. Fundamentally, its provisions are supposed to punish big platforms like Google for profiting off of copyright infringement and siphon some income back into the hands of those to which it rightfully belongs.
Unfortunately, the way it’s designed will likely make it more difficult for smaller platforms, harm the free exchange information, kill memes, make fair use more difficult to navigate—all the while, tech giants will have the resources to survive the wreckage. You don’t have to take my word for it, listen to Tim-Berners Lee, the father of the world wide web, and the other 70 top technologists that signed a letter arguing against the legislation back in June.
So far, this issue hasn’t received the kind of attention that, say, net neutrality did, at least in part because it’s very complicated to explain and it takes a while for these kinds of things to sink in. We’ve outlined the details in the past on multipleoccasions. The main thing to understand is that critics take issue with two pieces of the legislation.
Article 11, better known as a “link tax,” would require online platforms to purchase a license to link out to other sites or quotes from articles. That’s the part that threatens the free spread of information.
Article 13 dictates that online platforms install some sort of monitoring system that lets copyright holders upload their work for automatic detection. If something sneaks by the system’s filters, the platform could face full penalties for copyright infringement. For example, a SpongeBob meme could be flagged and blocked because of its source image belonging to Nickelodeon; or a dumb vlog could be flagged and blocked because there’s a sponge in the background and the dumb filter thought it was SpongeBob.
Back in 2015, Facebook had a pickle of a problem. It was time to update the Android version of the Facebook app, and two different groups within Facebook were at odds over what the data grab should be.
The business team wanted to get Bluetooth permissions so it could push ads to people’s phones when they walked into a store. Meanwhile, the growth team, which is responsible for getting more and more people to join Facebook, wanted to get “Read Call Log Permission” so that Facebook could track everyone whom Android user called or texted with in order to make better friend recommendations to them. (Yes, that’s how Facebook may have historically figured out with whom you went on one bad Tinder date and then plopped them into “People You May Know.”) According to internal emails recently seized by the UK Parliament, Facebook’s business team recognized that what the growth team wanted to do was incredibly creepy and was worried it was going to cause a PR disaster.
In a February 4, 2015, email that encapsulates the issue, Facebook Bluetooth Beacon product manager Mike Lebeau is quoted saying that the request for “read call log” permission was a “pretty high-risk thing to do from a PR perspective but it appears that the growth team will charge ahead and do it.”
LeBeau was worried because a “screenshot of the scary Android permissions screen becomes a meme (as it has in the past), propagates around the web, it gets press attention, and enterprising journalists dig into what exactly the new update is requesting.” He suggested a possible headline for those journalists: “Facebook uses new Android update to pry into your private life in ever more terrifying ways – reading your call logs, tracking you in businesses with beacons, etc.” That’s a great and accurate headline. This guy might have a future as a blogger.
At least he called the journalists “enterprising” instead of “meddling kids.”
Then a man named Yul Kwon came to the rescue saying that the growth team had come up with a solution! Thanks to poor Android permission design at the time, there was a way to update the Facebook app to get “Read Call Log” permission without actually asking for it. “Based on their initial testing, it seems that this would allow us to upgrade users without subjecting them to an Android permissions dialog at all,” Kwon is quoted. “It would still be a breaking change, so users would have to click to upgrade, but no permissions dialog screen. They’re trying to finish testing by tomorrow to see if the behavior holds true across different versions of Android.”
Oh yay! Facebook could suck more data from users without scaring them by telling them it was doing it! This is a little surprising coming from Yul Kwon because he is Facebook’s chief ‘privacy sherpa,’ who is supposed to make sure that new products coming out of Facebook are privacy-compliant. I know because I profiled him, in a piece that happened to come out the same day as this email was sent. A member of his team told me their job was to make sure that the things they’re working on “not show up on the front page of the New York Times” because of a privacy blow-up. And I guess that was technically true, though it would be more reassuring if they tried to make sure Facebook didn’t do the creepy things that led to privacy blow-ups rather than keeping users from knowing about the creepy things.
I reached out to Facebook about the comments attributed to Kwon and will update when I hear back.
Thanks to this evasion of permission requests, Facebook users did not realize for years that the company was collecting information about who they called and texted, which would have helped explain to them why their “People You May Know” recommendations were so eerily accurate. It only came to light earlier this year, three years after it started, when a few Facebook users noticed their call and text history in their Facebook files when they downloaded them.
When that was discovered March 2018, Facebook played it off like it wasn’t a big deal. “We introduced this feature for Android users a couple of years ago,” it wrote in a blog post, describing it as an “opt-in feature for people using Messenger or Facebook Lite on Android.”
Facebook continued: “People have to expressly agree to use this feature. If, at any time, they no longer wish to use this feature they can turn it off in settings, or here for Facebook Lite users, and all previously shared call and text history shared via that app is deleted.”
Facebook included a photo of the opt-in screen in its post. In small grey font, it informed people they would be sharing their call and text history.
This particular email was seized by the UK Parliament from the founder of a start-up called Six4Three. It was one of many internal Facebook documents that Six4Three obtained as part of discovery in a lawsuit it’s pursuing against Facebook for banning its Pikinis app, which allowed Facebook users to collect photos of their friends in bikinis. Yuck.
Facebook has a lengthy response to many of the disclosures in the documents including to the discussion in this particular email:
Call and SMS History on Android
This specific feature allows people to opt in to giving Facebook access to their call and text messaging logs in Facebook Lite and Messenger on Android devices. We use this information to do things like make better suggestions for people to call in Messenger and rank contact lists in Messenger and Facebook Lite. After a thorough review in 2018, it became clear that the information is not as useful after about a year. For example, as we use this information to list contacts that are most useful to you, old call history is less useful. You are unlikely to need to call someone who you last called over a year ago compared to a contact you called just last week.
: No, your phone is not “listening” to you in the strictest sense of the word. But, yes, all your likes, dislikes and preferences are clearly being heard by apps in your phone which you oh-so-easily clicked “agree” to the terms of which while installing.
How so?
If you are in India, the answer to the question will lead you to Zapr, a service backed by heavyweights such as the Rupert Murdoch-led media group Star, Indian e-commerce leader Flipkart, Indian music streaming service Saavn, and mobile phone maker Micromax, among more than a dozen others. The company owning Zapr is named Red Brick Lane Marketing Solutions Pvt Ltd. (Paytm founder Vijay Shekhar Sharma and Sanjay Nath, co-founder and managing partner, Blume Ventures, were early investors in Zapr but are no longer so, according to filings with the ministry of corporate affairs. Sharma and Blume are among the investors in Sourcecode Media Pvt Ltd, which owns FactorDaily.)
Zapr, in fact, is one of the few companies in the world that has developed a solution that uses your mobile device’s microphone to recognise the media content you are watching or listening to in order to help brands and channels understand consumer media consumption. In short, it monitors sounds around you to contextualise you better for advertising and marketing targeting.
[…]
Advertisers globally spend some $650 billion annually and this cohort believes better profiling consumers by analysing their ambient sounds helps target advertising better. This group includes Chinese company ACRCloud, Audible Magic from the US, and the Netherlands’s Betagrid Media — and, Zapr from India.
Cut back to the Zapr headquarters on Old Madras Road in Bengaluru. One of the apps that inspired Zapr’s founding team was the popular music detection and identification app Shazam. But, its three co-founders saw opportunity in going further. “Instead of detecting music, can we detect all kinds of medium? Can we detect television? Can we detect movies in a theatre? Can we detect video on demand? Can we really build a profile for a user about their media consumption habits… and that really became the idea, the vision we wanted to solve for,” Sandipan Mondal, CEO of Zapr Media Labs, said in an interview last week on Thursday.
[…]
But, Zapr’s tech comes with privacy and data concerns – lots of it. The way its tech gets into your phone is dodgy: its code ride on third-party apps ranging from news apps to gaming apps to video streaming apps. You might be downloading Hotstar or a Dainik Jagran app or a Chotta Beem app on your phone little knowing that Zapr’s or an equivalent audio monitoring code sits on those apps to listen to sounds around you in an attempt to see what media content you are consuming.
In most cases reviewed by FactorDaily in a two-week exercise, it was not obvious that the app would monitor audio via the smartphone or mobile device’s microphone for use by another party (Zapr) for ad targeting purposes. Some apps hinted about Zapr’s tech at the bottom of the app description and some in the form of a pop-up – an app from Nazara games, for instance, mentioned that it required mic access to ‘Record Audio for better presentation’. Sometimes, the pop-up app would show up a few days after the download. And, often, the disclosure was buried somewhere in the app’s privacy policy.
None of these apps made it clear explicitly what the audio access via the microphone was for. “The problem with apps which embed this technology is that their presence is not outright disclosed and is difficult to find. Also, there is not an easy way to find out the apps in the PlayStore that have this tech embedded in them,” said Thejesh G N, an info-activist and the founder of DataMeet, a community of data scientists and open data enthusiasts.
Dong Mingzhu, chairwoman of China’s biggest maker of air conditioners Gree Electric Appliances, who found her face splashed on a huge screen erected along a street in the port city of Ningbo that displays images of people caught jaywalking by surveillance cameras.
That artificial intelligence-backed surveillance system, however, erred in capturing Dong’s image on Wednesday from an advertisement on the side of a moving bus.
The traffic police in Ningbo, a city in the eastern coastal province of Zhejiang, were quick to recognise the mistake, writing in a post on microblog Sina Weibo on Wednesday that it had deleted the snapshot. It also said the surveillance system would be completely upgraded to cut incidents of false recognition in future.
[…]
Since last year, many cities across China have cracked down on jaywalking by investing in facial recognition systems and advanced AI-powered surveillance cameras. Jaywalkers are identified and shamed by displaying their photographs on large public screens.
First-tier cities like Beijing and Shanghai were among the first to employ those systems to help regulate traffic and identify drivers who violate road rules, while Shenzhen traffic police began displaying photos of jaywalkers on large screens at major intersections from April last year.
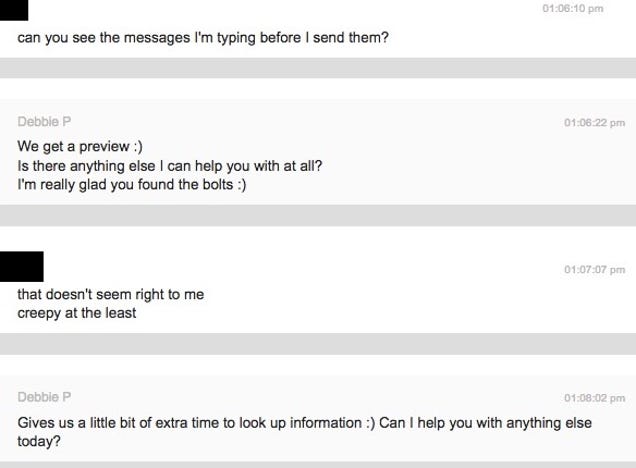
Next time you’re chatting with a customer service agent online, be warned that the person on the other side of your conversation might see what you’re typing in real time. A reader sent us the following transcript from a conversation he had with a mattress company after the agent responded to a message he hadn’t sent yet.
Something similar recently happened to HmmDaily’s Tom Scocca. He got a detailed answer from an agent one second after he hit send.
Googling led Scocca to a live chat service that offers a feature it calls “real-time typing view” to allow agents to have their “answers prepared before the customer submits his questions.” Another live chat service, which lists McDonalds, Ikea, and Paypal as its customers, calls the same feature “message sneak peek,” saying it will allow you to “see what the visitor is typing in before they send it over.” Salesforce Live Agent also offers “sneak peak.”
On the upside, you get fast answers. On the downside, your thought process is being unknowingly observed. For the creators, this is technological magic, a deception that will result, they hope, in amazement and satisfaction. But once revealed by an agent who responds too quickly or one who responds before the question is asked, the trick falls apart, and what is left behind feels distinctly creepy, like a rabbit pulled from a hat with a broken neck. “Why give [customers] a fake ‘Send message’ button while secretly transmitting their messages all along?” asks Scocca.
UK authorities should not be granted access to data held by American companies because British laws don’t meet human rights obligations, nine nonprofits have said.
In a letter to the US Department of Justice, organisations including Human Rights Watch and the Electronic Frontier Foundation set out their concerns about the UK’s surveillance and data retention regimes.
They argue that the nation doesn’t adhere to human rights obligations and commitments, and therefore it should not be allowed to request data from US companies under the CLOUD Act, which Congress slipped into the Omnibus Spending Bill earlier this year.
The law allows US government to sign formal, bilateral agreements with other countries setting standards for cross-border investigative requests for digital evidence related to serious crime and terrorism.
It requires that these countries “adhere to applicable international human rights obligations and commitments or demonstrate respect for international universal human rights”. The civil rights groups say the UK fails to make the grade.
As such, it urged the US administration not to sign an executive order allowing the UK to request access to data, communications content and associated metadata, noting that the CLOUD Act “implicitly acknowledges” some of the info gathered might relate to US folk.
Critics are concerned this could then be shared with US law enforcement, thus breaking the Fourth Amendment, which requires a warrant to be served for the collection of such data.
Setting out the areas in which the UK falls short, the letter pointed to pending laws on counter-terrorism, saying that, as drafted they would “excessively restrict freedom of expression by criminalizing clicking on certain types of online content”.
On the internet, there are certain institutions we have come to rely on daily to keep truth from becoming nebulous or elastic. Not necessarily in the way that something stupid like Verrit aspired to, but at least in confirming that you aren’t losing your mind, that an old post or article you remember reading did, in fact, actually exist. It can be as fleeting as using Google Cache to grab a quickly deleted tweet, but it can also be as involved as doing a deep dive of a now-dead site’s archive via the Wayback Machine. But what happens when an archive becomes less reliable, and arguably has legitimate reasons to bow to pressure and remove controversial archived material?
A few weeks ago, while recording my podcast, the topic turned to the old blog written by The Ultimate Warrior, the late bodybuilder turned chiropractic student turned pro wrestler turned ranting conservative political speaker under his legal name of, yes, “Warrior.” As described by Deadspin’s Barry Petchesky in the aftermath of Warrior’s 2014 passing, he was “an insane dick,” spouting off in blogs and campus speeches about people with disabilities, gay people, New Orleans residents, and many others. But when I went looking for a specific blog post, I saw that the blogs were not just removed, the site itself was no longer in the Internet Archive, replaced by the error message: “This URL has been excluded from the Wayback Machine.”
Apparently, Warrior’s site had been de-archived for months, not long after Rob Rousseau pored over it for a Vice Sports article on the hypocrisy of WWE using Warrior’s image for their Breast Cancer Awareness Month campaign. The campaign was all about getting women to “Unleash Your Warrior,” completewithanUltimateWarriormotif, but since Warrior’s blogs included wishing death on a cancer-survivor, this wasn’t a good look. Rousseau was struck by how the archive was removed “almost immediately after my piece went up, like within that week,” he told Gizmodo.
Rousseau suspected that WWE was somehow behind it, but a WWE spokesman told Gizmodo that they were not involved. Steve Wilton, the business manager for Ultimate Creations also denied involvement. A spokesman for the Internet Archive, though, told Gizmodo that the archive was removed because of a DMCA takedown request from the company’s business manager (Wilton’s job for years) on October 29, 2017, two days after the Vice article was published. (He has not replied to a follow-up email about the takedown request.)
Over the last few years, there has been a change in how the Wayback Machine is viewed, one inspired by the general political mood. What had long been a useful tool when you came across broken links online is now, more than ever before, seen as an arbiter of the truth and a bulwark against erasing history.
That archive sites are trusted to show the digital trail and origin of content is not just a must-use tool for journalists, but effective for just about anyone trying to track down vanishing web pages. With that in mind, that the Internet Archive doesn’t really fight takedown requests becomes a problem. That’s not the only recourse: When a site admin elects to block the Wayback crawler using a robots.txt file, the crawling doesn’t just stop. Instead, the Wayback Machine’s entire history of a given site is removed from public view.
In other words, if you deal in a certain bottom-dwelling brand of controversial content and want to avoid accountability, there are at least two different, standardized ways of erasing it from the most reliable third-party web archive on the public internet.
For the Internet Archive, like with quickly complying with takedown notices challenging their seemingly fair use archive copies of old websites, the robots.txt strategy, in practice, does little more than mitigating their risk while going against the spirit of the protocol. And if someone were to sue over non-compliance with a DMCA takedown request, even with a ready-made, valid defense in the Archive’s pocket, copyright litigation is still incredibly expensive. It doesn’t matter that the use is not really a violation by any metric. If a rightsholder makes the effort, you still have to defend the lawsuit.
“The fair use defense in this context has never been litigated,” noted Annemarie Bridy, a law professor at the University of Idaho and an Affiliate Scholar at the Center for Internet and Society at Stanford Law School. “Internet Archive is a non-profit, so the exposure to statutory damages that they face is huge, and the risk that they run is pretty great … given the scope of what they do; that they’re basically archiving everything that is on the public web, their exposure is phenomenal. So you can understand why their impulse might be to act cautiously even if that creates serious tension with their core mission, which is to create an accurate historical archive of everything that has been there and to prevent people from wiping out evidence of their history.”
While the Internet Archive did not respond to specific questions about its robots.txt policy, its proactive response to takedown requests, or if any potential fair use defenses have been tested by them in court, a spokesperson did send this statement along:
Several months after the Wayback Machine was launched in late 2001, we participated with a group of outside archivists, librarians, and attorneys in the drafting of a set of recommendations for managing removal requests (the Oakland Archive Policy) that the Internet Archive more or less adopted as guidelines over the first decade or so of the Wayback Machine.
Earlier this year, we convened with a similar group to review those guidelines and explore the potential value of an updated version. We are still pondering many issues and hope that before too long we might be able to present some updated information on our site to better help the public understand how we approach take down requests. You can find some of our thoughts about robots.txt at http://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/.
At the end of the day, we strive to strike a balance between the concerns that site owners and rights holders sometimes bring to us with the broader public interest in free access for everyone to a history of the Internet that is as comprehensive as possible.
All of that said, the Internet Archive has always held itself out to be a library; in theory, shouldn’t that matter?
“Under current copyright law, although there are special provisions that give certain rights to libraries, there is no definition of a library,” explained Brandon Butler, the Director of Information Policy for the University of Virginia Library. “And that’s a thing that rights holders have always fretted over, and they’ve always fretted over entities like the Internet Archive, which aren’t 200-year-old public libraries, or university-affiliated libraries. They often raise up a stand that there will be faux libraries, that they’d call themselves libraries but it’s really just a haven for piracy. That specter of the sort of sham library really hasn’t arisen.” The lone exception that Butler could think of was when American Buddha, a non-profit, online library of Buddhist texts, found itself sued by Penguin over a few items that they asserted copyright over. “The court didn’t really care that this place called itself a library; it didn’t really shield them from any infringement allegations.” That said, as Butler notes, while being a library wouldn’t necessarily protect the Internet Archive as much as it could, “the right to make copies for preservation,” as Butler puts it, is definitely a point in their favor.
That said, “libraries typically don’t get sued; it’s bad PR,” Butler says. So it’s not like there’s a ton of modern legal precedent about libraries in the digital age, barring some outliers like the various Google Books cases.
As Bridy notes, in the United States, copyright is “a commercial right.” It’s not about reputational harm, it’s about protecting the value of a work and, more specifically, the ability to continuously make money off of it. “The reason we give it is we want artists and creative people to have an incentive to publish and market their work,” she said. “Using copyright as a way of trying to control privacy or reputation … it can be used that way, but you might argue that’s copyright misuse, you might argue it falls outside of the ambit of why we have copyright.”
We take a lot of things for granted, especially as we rely on technology more and more. “The internet is forever” may beacommonrefraininthemedia, and the underlying wisdom about being careful may be sound, but it is also not something that should be taken literally. People delete posts. Websites and entire platforms disappear for business and other reasons. Rich, famous, and powerful bad actors don’t care about intimidating small non-profit organizations. It’s nice to have safeguards, but there are limits to permanence on the internet, and where there are limits, there are loopholes.
When Shan Junhua bought his white Tesla Model X, he knew it was a fast, beautiful car. What he didn’t know is that Tesla constantly sends information about the precise location of his car to the Chinese government.
Tesla is not alone. China has called upon all electric vehicle manufacturers in China to make the same kind of reports — potentially adding to the rich kit of surveillance tools available to the Chinese government as President Xi Jinping steps up the use of technology to track Chinese citizens.
“I didn’t know this,” said Shan. “Tesla could have it, but why do they transmit it to the government? Because this is about privacy.”
More than 200 manufacturers, including Tesla, Volkswagen, BMW, Daimler, Ford, General Motors, Nissan, Mitsubishi and U.S.-listed electric vehicle start-up NIO, transmit position information and dozens of other data points to government-backed monitoring centers, The Associated Press has found. Generally, it happens without car owners’ knowledge.
The automakers say they are merely complying with local laws, which apply only to alternative energy vehicles. Chinese officials say the data is used for analytics to improve public safety, facilitate industrial development and infrastructure planning, and to prevent fraud in subsidy programs.
China has ordered electric car makers to share real-time driving data with the government. The country says it’s to ensure safety and improve the infrastructure, but critics worry the tracking can be put to more nefarious uses. (Nov. 29)
But other countries that are major markets for electronic vehicles — the United States, Japan, across Europe — do not collect this kind of real-time data.
And critics say the information collected in China is beyond what is needed to meet the country’s stated goals. It could be used not only to undermine foreign carmakers’ competitive position, but also for surveillance — particularly in China, where there are few protections on personal privacy. Under the leadership of Xi Jinping, China has unleashed a war on dissent, marshalling big data and artificial intelligence to create a more perfect kind of policing, capable of predicting and eliminating perceived threats to the stability of the ruling Communist Party.
There is also concern about the precedent these rules set for sharing data from next-generation connected cars, which may soon transmit even more personal information.
Businesses using fingerprint scanners to monitor their workforce can legally sack employees who refuse to hand over biometric information on privacy grounds, the Fair Work Commission has ruled.
The ruling, which will be appealed, was made in the case of Jeremy Lee, a Queensland sawmill worker who refused to comply with a new fingerprint scanning policy introduced at his work in Imbil, north of the Sunshine Coast, late last year.
Fingerprint scanning was used to monitor the clock-on and clock-off times of about 150 sawmill workers at two sites and was preferred to swipe cards because it prevented workers from fraudulently signing in on behalf of their colleagues to mask absences.
The company, Superior Woods, had no privacy policy covering workers and failed to comply with a requirement to properly notify individuals about how and why their data was being collected and used. The biometric data was stored on servers located off-site, in space leased from a third party.
Lee argued the business had never sought its workers’ consent to use fingerprint scanning, and feared his biometric data would be accessed by unknown groups and individuals.
“I am unwilling to consent to have my fingerprints scanned because I regard my biometric data as personal and private,” Lee wrote to his employer last November.
“Information technology companies gather as much information/data on people as they can.
“Whether they admit to it or not. (See Edward Snowden) Such information is used as currency between corporations.”
Lee was neither antagonistic or belligerent in his refusals, according to evidence before the commission. He simply declined to have his fingerprints scanned and continued using a physical sign-in booklet to record his attendance.
He had not missed a shift in more than three years.
The employer warned him about his stance repeatedly, and claimed the fingerprint scanner did not actually record a fingerprint, but rather “a set of data measurements which is processed via an algorithm”. The employer told Lee there was no way the data could be “converted or used as a finger print”, and would only be used to link to his payroll number to his clock-on and clock-off time. It said the fingerprint scanners were also needed for workplace safety, to accurately identify which workers were on site in the event of an accident.
Lee was given a final warning in January, and responded that he valued his job a “great deal” and wanted to find an alternative way to record his attendance.
“I would love to continue to work for Superior Wood as it is a good, reliable place to work,” he wrote to his employer. “However, I do not consent to my biometric data being taken. The reason for writing this letter is to impress upon you that I am in earnest and hope there is a way we can negotiate a satisfactory outcome.”
Lee was sacked in February, and lodged an unfair dismissal claim in the Fair Work Commission.
You only have one set of fingerprints – that’s the problem with biometrics: they can’t be changed, so you really really don’t want them stolen from you
suggesting, automatically implementing, or both suggesting and automatically implementing, one or more household policies to be implemented within a household environment. The household policies include one or more input criteria that is derivable from at least one smart device within the household environment, the one or more input criteria relating to a characteristic of the household environment, a characteristic of one or more occupants of the household, or both. The household policies also include one or more outputs to be provided based upon the one or more input criteria.
In some embodiments, the private network may include at least one first device that captures information about its surrounding environment, such as data about the people and/or objects in the environment. The first device may receive a set of potential content sent from a server external to the private network. The first device may select at least one piece of content to present from the set of potential content based in part on the people/object data and/or a score assigned by the server to each piece of content. The private network may also include at least one second device that receives the captured people/object data sent from the first device. The second device may also receive a set of potential content sent from the server external to the private network. The second device may select at least one piece of content to present from the set of potential content based in part on the people/object data sent from the first device and/or a score assigned by the server to each piece of content. Using the private network to communicate the people/object data between devices may preserve the privacy of the user since the data is not sent to the external server. Further, using the obtained people/object data to select content enables more personalized content to be chosen.
[…]
urther, although not shown in this particular way, in some embodiments, the client device 134 may collect people/object data 136 using one or more sensors, as discussed above. Also, as previously discussed, the raw people/object data 136 may be processed by the sensing device 138, the client device 134, and/or a processing device 140 depending on the implementation. The people/object data 136 may include the data described above regarding FIG. 7 that may aid in recognizing objects, people, and/or patterns, as well as determining user preferences, mood, and so forth.
[0144]
After the client device 134 is in possession of the people/object data 136, the client device 134 may use the classifier 144 to score each piece of content 132. In some embodiments, the classifier 144 may combine at least the people/object data 136, the scores provided by the server 67 for the content 132, or both, to determine a final score for each piece of content 132 (process block 216), which will be discussed in more detail below.
[0145]
The client device 134 may select at least one piece of content 132 to display based on the scores (process block 218). That is, the client device 134 may select the content 132 with the highest score as determined by the classifier 144 to display. However, in some embodiments, where none of the content 132 generate a score above a threshold amount, no content 132 may be selected. In those embodiments, the client device 134 may not present any content 132. However, when at least one item of content 132 scores above the threshold amount and is selected, then the client device 134 may communicate the selected content 132 to a user of the client device 134 (process block 220) and track user interaction with the content 132 (process block 222). It should be noted that when more than one item of content 132 score above the threshold amount, then the item of content 132 with the highest score may be selected. The client device 134 may use the tracked user interaction and conversions to continuously train the classifier 144 to ensure that the classifier 144 stays up to date with the latest user preferences.
[0146]
It should be noted that, in some embodiments, the processing device 140 may receive the content 132 from the server 67 instead of, or in addition to, the client device 134. In embodiments where the processing device 140 receives the content 132, the processing device 140 may perform the classification of the content 132 using a classifier 144 similar to the client device 134 and the processing device 140 may select the content 132 with the highest score as determined by the classifier 144. Once selected, the processing device 140 may send the selected content 132 to the client device 134, which may communicate the selected content 132 to a user.
[…]
The process 230 may include training one or more models of the classifier 144 with people/object data 136, locale 146, demographics 148, search history 150, scores from the server 67, labels 145, and so forth. As previously discussed, the classifier 144 may include a support vector machine (SVM) that uses supervised learning models to classify the content 132 into one of two groups (e.g., binary classification) based on recognized patterns using the people/object data 136, locale 146, demographics 148, search history 150, scores from the server 67, and the labels 145 for the two groups of “show” or “don’t show.”
Uit het rapport van de Nederlandse overheid blijkt dat de telemetrie-functie van alle Office 365 en Office ProPlus-applicaties onder andere e-mail-onderwerpen en woorden/zinnen die met behulp van de spellingschecker of vertaalfunctie zijn geschreven worden doorgestuurd naar systemen in de Verenigde Staten.
Dit gaat zelfs zo ver dat, als een gebruiker meerdere keren achter elkaar op de backspace-knop drukt, de telemetrie-functie zowel de zin voor de aanpassing al die daarna verzamelt en doorstuurt. Gebruikers worden hiervan niet op de hoogte gebracht en hebben geen mogelijkheid deze dataverzameling te stoppen of de verzamelde data in te zien.
De Rijksoverheid heeft dit onderzoek gedaan in samenwerking met Privacy Company. “Microsoft mag deze tijdelijke, functionele gegevens niet opslaan, tenzij de bewaring strikt noodzakelijk is, bijvoorbeeld voor veiligheidsdoeleinden,” schrijft Sjoera Nas van de Privacy Company in een blogpost.
An online system predicts household features of a user, e.g., household size and demographic composition, based on image data of the user, e.g., profile photos, photos posted by the user and photos posted by other users socially connected with the user, and textual data in the user’s profile that suggests relationships among individuals shown in the image data of the user. The online system applies one or more models trained using deep learning techniques to generate the predictions. For example, a trained image analysis model identifies each individual depicted in the photos of the user; a trained text analysis model derive household member relationship information from the user’s profile data and tags associated with the photos. The online system uses the predictions to build more information about the user and his/her household in the online system, and provide improved and targeted content delivery to the user and the user’s household.
Microsoft was, and maybe still is, considering injecting targeted adverts into the Windows 10 Mail app.
The ads would appear at the top of inboxes of folks using the client without a paid-for Office 365 subscription, and the advertising would be tailored to their interests. Revenues from the banners were hoped to help keep Microsoft afloat, which banked just $16bn in profit in its latest financial year.
According to Aggiornamenti Lumia on Friday, folks using Windows Insider fast-track builds of Mail and Calendar, specifically version 11605.11029.20059.0, may have seen the ads in among their messages, depending on their location. Users in Brazil, Canada, Australia, and India were chosen as guinea pigs for this experiment.
A now-deleted FAQ on the Office.com website about the “feature” explained the advertising space would be sold off to help Microsoft “provide, support, and improve some of our products,” just like Gmail and Yahoo! Mail display ads.
Also, the advertising is targeted, by monitoring what you get up to with apps and web browsing, and using demographic information you disclose:
Windows generates a unique advertising ID for each user on a device. When the advertising ID is enabled, both Microsoft apps and third-party apps can access and use the advertising ID in much the same way that websites can access and use a unique identifier stored in a cookie. Mail uses this ID to provide more relevant advertising to you.
You have full control of Windows and Mail having access to this information and can turn off interest-based advertising at any time. If you turn off interest-based advertising, you will still see ads but they will no longer be as relevant to your interests.
Microsoft does not use your personal information, like the content of your email, calendar, or contacts, to target you for ads. We do not use the content in your mailbox or in the Mail app.
You can also close an ad banner by clicking on its trash can icon, or get rid of them completely by coughing up cash:
You can permanently remove ads by buying an Office 365 Home or Office 365 Personal subscription.
Here’s where reality is thrown into a spin, literally. Microsoft PR supremo Frank Shaw said a few hours ago, after the ads were spotted:
This was an experimental feature that was never intended to be tested broadly and it is being turned off.
Never intended to be tested broadly, and was shut down immediately, yet until it was clocked, had an official FAQ for it on Office.com, which was also hastily nuked from orbit, and was rolled out in highly populated nations. Talk about hand caught in the cookie jar.
Nintendo has won a lawsuit seeking to take two large retro-game ROM sites offline, on charges of copyright infringement. The judgement, made public today, ruled in Nintendo’s favour and states that the owners of the sites LoveROMS.com and LoveRETRO.co, will have to pay a total settlement of $12 million to Nintendo. The complaint was originally filed by the company in an Arizona federal court in July, and has since lead to a swift purge of self-censorship by popular retro and emulator ROM sites, who have feared they may be sued by Nintendo as well.
LoveROMS.com and LoveRETRO.co were the joint property of couple Jacob and Cristian Mathias, before Nintendo sued them for what they have called “brazen and mass-scale infringement of Nintendo’s intellectual property rights.” The suit never went to court; instead, the couple sought to settle after accepting the charge of direct and indirect copyright infringement. TorrentFreak reports that a permanent injunction, prohibiting them from using, sharing, or distributing Nintendo ROMs or other materials again in the future, has been included in the settlement. Additionally all games, game files, and emulators previously on the site and in their custody must be handed over to the Japanese game developer, along with a $12.23 million settlement figure. It is unlikely, as TorrentFreak have reported, that the couple will be obligated to pay the full figure; a smaller settlement has likely been negotiated in private.
Instead, the purpose of the enormous settlement amount is to act as a warning or deterrent to other ROM and emulator sites surviving on the internet. And it’s working.
Motherboard previously reported on the way in which Nintendo’s legal crusade against retro ROM and emulator sites is swiftly eroding a large chunk of retro gaming. The impact of this campaign on video games as a whole is potentially catastrophic. Not all games have been preserved adequately by game publishers and developers. Some are locked down to specific regions and haven’t ever been widely accessible.
The accessibility of video games and the gaming industry has always been defined and limited by economic boundaries. There are a multitude of reasons why retro games can’t be easily or reliably accessed by prospective players, and by wiping out ROM sites Nintendo is erasing huge chunks of gaming history. Limiting the accessibility of old retro titles to this extent will undoubtedly affect the future of video games, with classic titles that shaped modern games and gaming development being kept under lock and key by the monolithic hand of powerful game developers.
Since the filing of the suit in July EmuParadise, a haven for retro games and emulator titles, has shut down. Many other sites have followed suit.
Despite all the convenience and quality of Google’s sprawling ecosystem, some users are fed up with the fishy privacy policies the company has recently implemented in Gmail, Chrome, and other services. To its credit, Google has made good changes in response to user feedback, but that doesn’t diminish the company’s looming shadow over the internet at large. If you’re ready to ditch Google, or even just reduce its presence in your digital life, this guide is here to help.
Since Google owns some of the best and most-used apps, websites, and internet services, making a clean break is difficult—but not impossible. We’re going to take a look at how to leave the most popular Google services behind, and how to keep Google from tracking your data. We’ve also spent serious time researching and testing great alternatives to Google’s offerings, so you can leave the Big G without having to buy new devices or swear fealty to another major corporation.
Chinese authorities have begun deploying a new surveillance tool: “gait recognition” software that uses people’s body shapes and how they walk to identify them, even when their faces are hidden from cameras.
Already used by police on the streets of Beijing and Shanghai, “gait recognition” is part of a push across China to develop artificial-intelligence and data-driven surveillance that is raising concern about how far the technology will go.
Huang Yongzhen, the CEO of Watrix, said that its system can identify people from up to 50 meters (165 feet) away, even with their back turned or face covered. This can fill a gap in facial recognition, which needs close-up, high-resolution images of a person’s face to work.
“You don’t need people’s cooperation for us to be able to recognize their identity,” Huang said in an interview in his Beijing office. “Gait analysis can’t be fooled by simply limping, walking with splayed feet or hunching over, because we’re analyzing all the features of an entire body.”
Watrix announced last month that it had raised 100 million yuan ($14.5 million) to accelerate the development and sale of its gait recognition technology, according to Chinese media reports.
Chinese police are using facial recognition to identify people in crowds and nab jaywalkers, and are developing an integrated national system of surveillance camera data. Not everyone is comfortable with gait recognition’s use.
The U.S. Justice Department has charged two Chinese intelligence officers, six hackers, and two aerospace company insiders in a sweeping conspiracy to steal confidential aerospace technology from U.S. and French companies.
For more than five years, two Chinese Ministry of State Security (MSS) spies are said to have run a team of hackers focusing on the theft of designs for a turbofan engine used in U.S. and European commercial airliners, according to an unsealed indictment (below) dated October 25. In a statement, the DOJ said a Chinese state-owned aerospace company was simultaneously working to develop a comparable engine.
“The threat posed by Chinese government-sponsored hacking activity is real and relentless,” FBI Special Agent in Charge John Brown of San Diego said in a statement. “Today, the Federal Bureau of Investigation, with the assistance of our private sector, international and U.S. government partners, is sending a strong message to the Chinese government and other foreign governments involved in hacking activities.”
The MSS officers involved were identified as Zha Rong, a division director in the Jiangsu Province regional department (JSSD), and Chai Meng, a JSSD section chief.
At the direction of the MSS officers, the hackers allegedly infiltrated a number of U.S. aerospace companies, including California-based Capstone Turbine, among others in Arizona, Massachusetts, and Oregon, the DOJ said. The officers are also said to have recruited at least two Chinese employees of a French aerospace manufacturer—insiders who allegedly aided the conspiracy by, among other criminal acts, installing the remote access trojan Sakula onto company computers.
If it seems as though the app you deleted last week is suddenly popping up everywhere, it may not be mere coincidence. Companies that cater to app makers have found ways to game both iOS and Android, enabling them to figure out which users have uninstalled a given piece of software lately—and making it easy to pelt the departed with ads aimed at winning them back.
Adjust, AppsFlyer, MoEngage, Localytics, and CleverTap are among the companies that offer uninstall trackers, usually as part of a broader set of developer tools. Their customers include T-Mobile US, Spotify Technology, and Yelp. (And Bloomberg Businessweek parent Bloomberg LP, which uses Localytics.) Critics say they’re a fresh reason to reassess online privacy rights and limit what companies can do with user data. “Most tech companies are not giving people nuanced privacy choices, if they give them choices at all,” says Jeremy Gillula, tech policy director at the Electronic Frontier Foundation, a privacy advocate.
Some providers say these tracking tools are meant to measure user reaction to app updates and other changes. Jude McColgan, chief executive officer of Boston’s Localytics, says he hasn’t seen clients use the technology to target former users with ads. Ehren Maedge, vice president for marketing and sales at MoEngage Inc. in San Francisco, says it’s up to the app makers not to do so. “The dialogue is between our customers and their end users,” he says. “If they violate users’ trust, it’s not going to go well for them.” Adjust, AppsFlyer, and CleverTap didn’t respond to requests for comment, nor did T-Mobile, Spotify, or Yelp.
Uninstall tracking exploits a core element of Apple Inc.’s and Google’s mobile operating systems: push notifications. Developers have always been able to use so-called silent push notifications to ping installed apps at regular intervals without alerting the user—to refresh an inbox or social media feed while the app is running in the background, for example. But if the app doesn’t ping the developer back, the app is logged as uninstalled, and the uninstall tracking tools add those changes to the file associated with the given mobile device’s unique advertising ID, details that make it easy to identify just who’s holding the phone and advertise the app to them wherever they go.
The tools violate Apple and Google policies against using silent push notifications to build advertising audiences, says Alex Austin, CEO of Branch Metrics Inc., which makes software for developers but chose not to create an uninstall tracker. “It’s just generally sketchy to track people around the internet after they’ve opted out of using your product,” he says, adding that he expects Apple and Google to crack down on the practice soon. Apple and Google didn’t respond to requests for comment.
It’s no secret that mobile apps harvest user data and share it with other companies, but the true extent of this practice may come as a surprise. In a new study carried out by researchers from Oxford University, it’s revealed that almost 90 percent of free apps on the Google Play store share data with Alphabet.
The researchers, who analyzed 959,000 apps from the US and UK Google Play stores, said data harvesting and sharing by mobile apps was now “out of control.”
“We find that most apps contain third party tracking, and the distribution of trackers is long-tailed with several highly dominant trackers accounting for a large portion of the coverage,” reads the report.
It’s revealed that most of the apps, 88.4 percent, could share data with companies owned by Google parent Alphabet. Next came a firm that’s no stranger to data sharing controversies, Facebook (42.5 percent), followed by Twitter (33.8 percent), Verizon (26.27 percent), Microsoft (22.75 percent), and Amazon (17.91 percent).
According to The Financial Times, which first reported the research, information shared by these third-party apps can include age, gender, location, and information about a user’s other installed apps. The data “enables construction of detailed profiles about individuals, which could include inferences about shopping habits, socio-economic class or likely political opinions.”
Big firms then use the data for a variety of purposes, such as credit scoring and for targeting political messages, but its main use is often ad targeting. Not surprising, given that revenue from online advertising is now over $59 billion per year.
According to the research, the average app transfers data to five tracker companies, which pass the data on to larger firms. The biggest culprits are news apps and those aimed at children, both of which tend to have the most third-party trackers associated with them.
It’s increasingly difficult to expect privacy when you’re browsing online, so a non-profit in the UK is working to build the power of Tor’s anonymity network right into the heart of your smartphone.
Brass Horn Communications is experimenting with all sorts of ways to improve Tor’s usability for UK residents. The Tor browser bundle for PCs can help shield your IP address from snoopers and data-collection giants. It’s not perfect and people using it for highly-illegal activity can still get caught, but Tor’s system of sending your data through the various nodes on its network to anonymize user activity works for most people. It can help users surf the full web in countries with restrictive firewalls and simply make the average Joe feel like they have more privacy. But it’s prone to user error, especially on mobile devices. Brass Horn hopes to change that.
Brass Horn’s founder, Gareth Llewelyn, told Motherboard his organization is “about sticking a middle finger up to mobile filtering, mass surveillance.” Llewelyn has been unnerved by the UK’s relentless drive to push through legislation that enables surveillance and undermines encryption. Along with his efforts to build out more Tor nodes in the UK to increase its notoriously slow speeds, Llewelyn is now beta-testing a SIM card that will automatically route your data through Tor and save people the trouble of accidentally browsing unprotected.
Currently, mobile users’ primary option is to use the Tor browser that’s still in alpha-release and couple it with software called Orbot to funnel your app activity through the network. Only apps that have a proxy feature, like Twitter, are compatible. It’s also only available for Android users.
You’ll still need Orbot installed on your phone to use Brass Horn’s SIM card and the whole idea is that you won’t be able to get online without running on the Tor network. There’s some minor setup that the organization walks you through and from that point on, you’ll apparently never accidentally find yourself online without the privacy protections that Tor provides.
In an email to Gizmodo, Llewellyn said that he does not recommend using the card on a device with dual-SIMs. He said the whole point of the project is that a user “cannot accidentally send packets via Clearnet, this is to protect one’s privacy, anonymity and/or protect against NITs etc, if one were to use a dual SIM phone it would negate the failsafe and would not be advisable.” But if a user so desired, they could go with a dual-SIM setup.
You’re also unprotected if you end up on WiFi, but in general, this is a way for journalists, activists, and rightly cautious users to know they’re always protected.
The SIM acts as a provider and Brass Horn essentially functions as a mobile virtual network operator that piggybacks on other networks. The site for Brass Horn’s Onion3G service claims it’s a safer mobile provider because it only issues “private IP addresses to remote endpoints which if ‘leaked’ won’t identify you or Brass Horn Communications as your ISP.” It costs £2.00 per month and £0.025 per megabyte transferred over the network.
A spokesperson for the Tor Project told Gizmodo that it hasn’t been involved in this project and that protecting mobile data can be difficult. “This looks like an interesting and creative way to approach that, but it still requires that you put a lot of trust into your mobile provider in ensuring that no leaks happen,” they said.
Info on joining the beta is available here and Brass Horn expects to make its SIM card available to the general public in the UK next year. Most people should wait until there’s some independent research done on the service, but it’s all an intriguing idea that could provide a model for other countries.
Facebook and Google are being sued in two proposed class-action lawsuits for allegedly deceptively gathering location data on netizens who thought they had opted out of such cyber-stalking.
The legal challenges stem from revelations earlier this year that even after users actively turn off “location history” on their smartphones, their location is still gathered, stored, and exploited to sling adverts.
Both companies use weasel words in their support pages to continue to gather the valuable data while seemingly giving users the option to opt out – and that “deception” is at the heart of both lawsuits.
In the first, Facebook user Brett Heeger claims the antisocial network is misleading folks by providing the option to stop the gathering and storing of their location data but in reality in continues to grab the information and add it to a “Location History” feature that it then uses for targeted advertising.
“Facebook misleads its users by offering them the option to restrict Facebook from tracking, logging and storing their private location information, but then continuing to track, log, and store that location information regardless of users’ choices,” the lawsuit, filed in California, USA, states. “In fact, Facebook secretly tracks, logs and stories location data for all of its users – including those who have sought to limit the information about their locations.”
This action is “deceptive” and offers users a “false sense of security,” the lawsuit alleges. “Facebook’s false assurance are intended to make users feel comfortable continuing to use Facebook and share their personal information so that Facebook can continue to be profitable, at the expense of user privacy… Advertisers pay Facebook to place advertisements because Facebook is so effective at using location information to target advertisement to consumers.”
And over to you, Google
In the second lawsuit, also filed in Cali, three people – Leslie Lee of Wyoming and Colorado residents Stacy Smedley and Fredrick Davis – make the same claim: that Google is deceiving smartphone users by giving them the option to “pause” the gathering of your location data through a setting called “Location History.”
In reality, however, Google continues to gather locations data through its two most popular apps – Search and Maps – even when you actively choose to turn off location data. Instead, users have to go to a separate setting called “Web and App Activity” to really turn the gathering off. There is no mention of location data within that setting and nowhere does Google refer people to that setting in order to really stop location tracking.
As such, Google is engaged in a “deliberate, deceptive practice to collect personal information from which they can generate millions of dollars in revenue by covertly recording contemporaneous location data about Android and iPhone mobile phone users who are using Google Maps or other Google applications and functionalities, but who have specifically opted out of such tracking,” the lawsuit alleges.
Both legal salvos hope to become class-action lawsuits with jury trials, so potentially millions of other affected users will be able to join the action and so propel the case forward. The lawsuits seek compensation and damages as well as injunctions preventing both companies from gathering such data with gaining the explicit consent of users.
Meanwhile at the other end of the scale, the ability for the companies to constantly gather user location data has led to them being targeted by law enforcement in an effort to solve crimes.
Warrant required
Back in June, the US Supreme Court made a landmark ruling about location data, requiring cops and FBI agents to get a warrant before accessing such records from mobile phone operators.
But it is not clear which hurdles or parameters need to be met before a court should sign off on such a warrant, leading to an increasing number of cases where the Feds have provided times, dates, and rough geographic locations and asked Google, Facebook, Snapchat, and others, to provide the data of everyone who was in the vicinity at the time.
This so-called “reverse location” order has many civil liberties groups concerned because it effectively exposes innocent individuals’ personal data to the authorities simply because they were in the same rough area where a crime was carried out.
[…]
Leaky apps
And if all that wasn’t bad enough, this week a paper [PDF] by eggheads at the University of Oxford in the UK who studied the source code of just under one million apps found that Google and Facebook were top of the list when it came to gathering data on users from third parties.
Google parent company Alphabet receives user data from an incredible 88 per cent of apps on the market. Often this information was accumulated through third parties and included information like age, gender and location. The data “enables construction of detailed profiles about individuals, which could include inferences about shopping habits, socio-economic class or likely political opinions,” the paper revealed.
Facebook received data from 43 per cent of the apps, followed by Twitter with 34 per cent. Mobile operator Verizon – renowned for its “super cookie” tracker gets information from 26 per cent of apps; Microsoft 23 per cent; and Amazon 18 per cent.