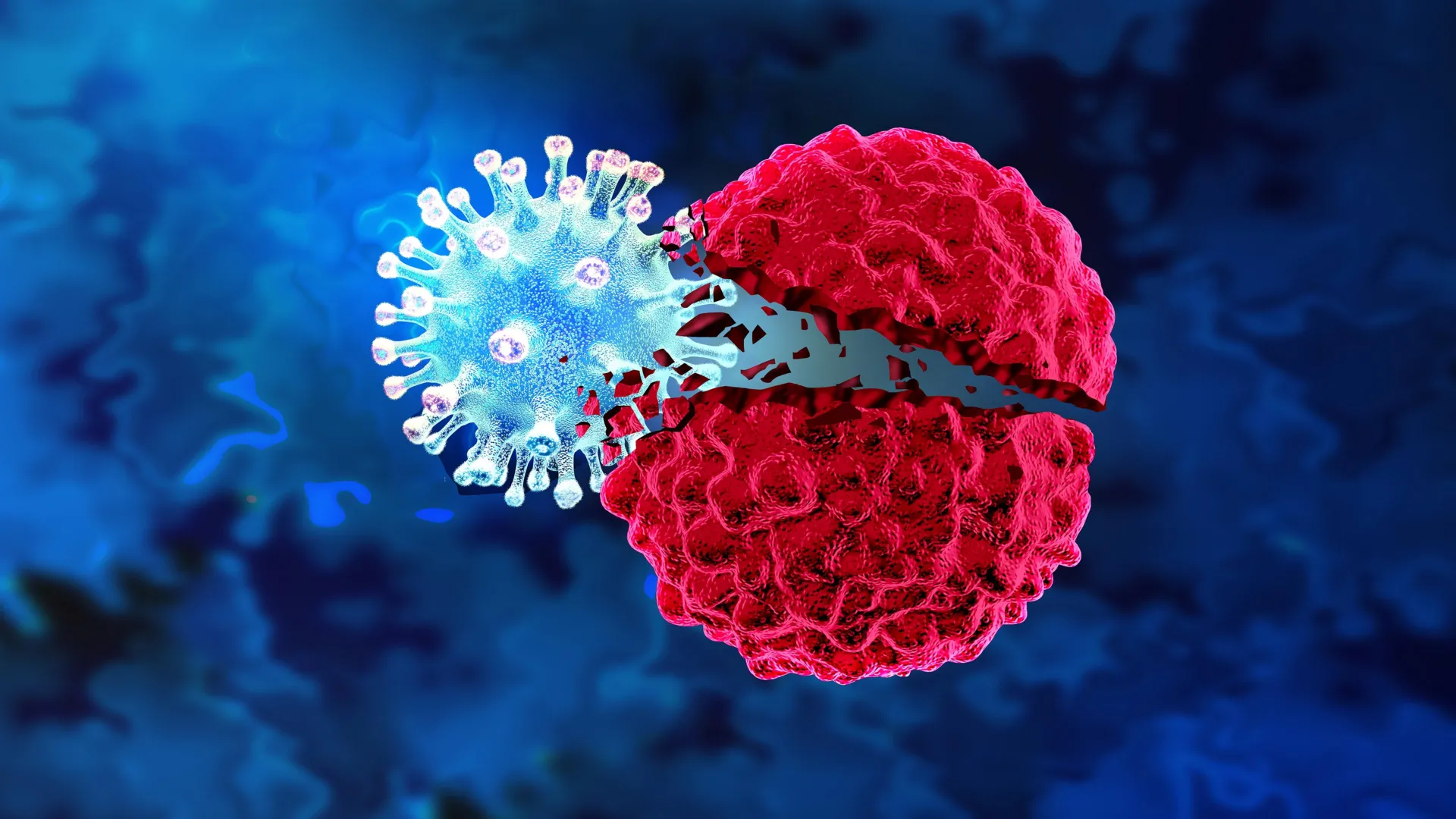
Researchers at Columbia Engineering have built a cancer therapy that makes bacteria and viruses work as a team. In a study published recently in Nature Biomedical Engineering, the Synthetic Biological Systems Lab shows how their system hides a virus inside a tumor-seeking bacterium, smuggles it past the immune system, and unleashes it inside cancerous tumors.
The new platform combines the bacteria’s tendency to find and attack tumors with the virus’s natural preference for infecting and killing cancerous cells. Tal Danino, an associate professor of biomedical engineering at Columbia Engineering, led the team’s effort to create the system, which is called CAPPSID (short for Coordinated Activity of Prokaryote and Picornavirus for Safe Intracellular Delivery). Charles M. Rice, an expert in virology at The Rockefeller University, collaborated with the Columbia team.
“We aimed to enhance bacterial cancer therapy by enabling the bacteria to deliver and activate a therapeutic virus directly inside tumor cells, while engineering safeguards to limit viral spread outside the tumor,” says co-lead author Jonathan Pabón, an MD/PhD candidate at Columbia.
The researchers believe that this technology — validated in mice — represents the first example of directly engineered cooperation between bacteria and cancer-targeting viruses.
The approach combines the bacteria’s instinct for homing in on tumors with a virus’s knack for infecting and killing cancer cells. “By bridging bacterial engineering with synthetic virology, our goal is to open a path toward multi-organism therapies that can accomplish far more than any single microbe could achieve alone,” says Zakary S. Singer, a co-lead author and former postdoctoral researcher in Tal Danino’s lab.
“This is probably our most technically advanced and novel platform to date,” says Danino, who is also affiliated with the Herbert Irving Comprehensive Cancer Center at Columbia University Irving Medical Center and Columbia’s Data Science Institute.
Sneaking past the immune system
One of the biggest hurdles in oncolytic virus therapy is the body’s own defense system. If a patient has antibodies against the virus — from a prior infection or vaccination — those antibodies can neutralize it before it reaches a tumor. The Columbia team sidestepped that problem by tucking the virus inside tumor-seeking bacteria.
“The bacteria act as an invisibility cloak, hiding the virus from circulating antibodies, and ferrying the virus to where it is needed,” Singer says.
Pabón says this strategy is especially important for viruses that people are already exposed to in daily life.
“Our system demonstrates that bacteria can potentially be used to launch an oncolytic virus to treat solid tumors in patients who have developed immunity to these viruses,” he says.
Targeting the tumor
The system’s bacterial half is Salmonella typhimurium, a species that naturally migrates to the low-oxygen, nutrient-rich environment inside tumors. Once there, the bacteria invade cancer cells and release the virus directly into the tumor’s interior.
“We programmed the bacteria to act as a Trojan horse by shuttling the viral RNA into tumors and then lyse themselves directly inside of cancer cells to release the viral genome, which could then spread between cancer cells,” Singer says.
By exploiting the bacteria’s tumor-homing instincts and the virus’s ability to replicate inside cancer cells, the researchers created a delivery system that can penetrate the tumor and spread throughout it — a challenge that has limited both bacteria- and virus-only approaches.
Safeguarding against runaway infections
A key concern with any live virus therapy is controlling its spread beyond the tumor. The team’s system solved that problem with a molecular trick: making sure the virus couldn’t spread without a molecule it can only get from the bacteria. Since the bacteria stay put in the tumor, this vital component (called a protease) isn’t available anywhere else in the body.
“Spreadable viral particles could only form in the vicinity of bacteria, which are needed to provide special machinery essential for viral maturation in the engineered virus, providing a synthetic dependence between microbes,” Singer says. That safeguard adds a second layer of control: even if the virus escapes the tumor, it won’t spread in healthy tissue.
“It is systems like these — specifically oriented towards enhancing the safety of these living therapies — that will be essential for translating these advances into the clinic,” Singer says.
Further research and clinical applications
This publication marks a significant step toward making this type of bacteria-virus system available for future clinical applications.
“As a physician-scientist, my goal is to bring living medicines into the clinic,” Pabón says. “Efforts toward clinical translation are currently underway to translate our technology out of the lab.”
Danino, Rice, Singer, and Pabón have filed a patent application (WO2024254419A2) with the U.S. Patent and Trademark Office related to this work.
Looking ahead, the team is testing the approach in a wider range of cancers, using different tumor types, mouse models, viruses, and payloads, with an eye to developing a “toolkit” of viral therapies that can sense and respond to specific conditions inside a cell. They are also evaluating how this system can be combined with strains of bacteria that have already demonstrated safety in clinical trials.