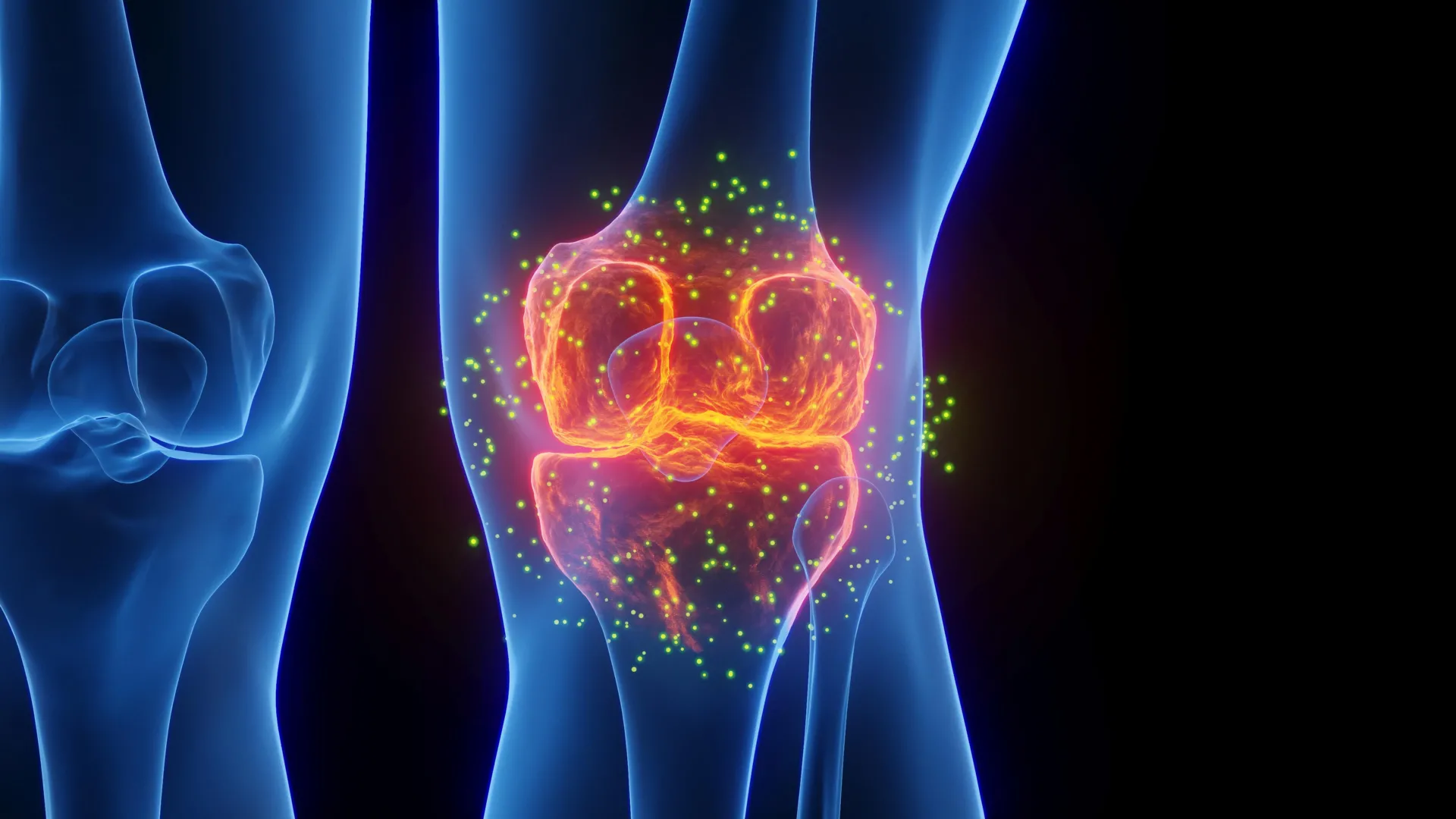
A study led by Stanford Medicine researchers has found that an injection blocking a protein linked to aging can reverse the natural loss of knee cartilage in older mice. The same treatment also stopped arthritis from developing after knee injuries that resemble ACL tears, which are common among athletes and recreational exercisers. Researchers note that an oral version of the treatment is already being tested in clinical trials aimed at treating age-related muscle weakness.
Human cartilage samples taken from knee replacement surgeries also responded positively. These samples included both the supportive extracellular matrix of the joint and cartilage-producing chondrocyte cells. When treated, the tissue began forming new, functional cartilage.
Together, the findings suggest that cartilage lost due to aging or arthritis may one day be restored using either a pill or a targeted injection. If successful in people, such treatments could reduce or even eliminate the need for knee and hip replacement surgery.
A Direct Attack on Osteoarthritis
Osteoarthritis is a degenerative joint disease that affects about one in five adults in the United States and generates an estimated $65 billion each year in direct health care costs. Current treatments focus on managing pain or replacing damaged joints surgically. There are no approved drugs that can slow or reverse the underlying cartilage damage.
The new approach targets the root cause of the disease rather than its symptoms, offering a potential shift in how osteoarthritis is treated.
The Role of a Master Aging Enzyme
The protein at the center of the study is called 15-PGDH. Researchers refer to it as a gerozyme because its levels increase as the body ages. Gerozymes were identified by the same research team in 2023 and are known to drive the gradual loss of tissue function.
[…]
In most of these tissues, repair happens through the activation and specialization of stem cells. Cartilage appears to be different. In this case, chondrocytes change how their genes behave, shifting into a more youthful state without relying on stem cells.
[…]
Earlier research from Blau’s lab showed that prostaglandin E2 is essential for muscle stem cell function. The enzyme 15-PGDH breaks down prostaglandin E2. By blocking 15-PGDH or increasing prostaglandin E2 levels, researchers previously supported the repair of damaged muscle, nerve, bone, colon, liver, and blood cells in young mice.
This led the team to question whether the same pathway might be involved in cartilage aging and joint damage. When they compared knee cartilage from young and old mice, they found that 15-PGDH levels roughly doubled with age.
Regrowing Cartilage in Aging Knees
Researchers then injected older mice with a small molecule that inhibits 15-PGDH. They first administered the drug into the abdomen to affect the entire body, and later injected it directly into the knee joint. In both cases, cartilage that had become thin and dysfunctional with age thickened across the joint surface.
Additional tests confirmed that the regenerated tissue was hyaline cartilage rather than the less functional fibrocartilage.
“Cartilage regeneration to such an extent in aged mice took us by surprise,” Bhutani said. “The effect was remarkable.”
[…]
The researchers also tested cartilage taken from patients undergoing total knee replacement for osteoarthritis. After one week of treatment with the 15-PGDH inhibitor, the tissue showed fewer 15-PGDH-producing chondrocytes, reduced expression of cartilage degradation and fibrocartilage genes, and early signs of articular cartilage regeneration.
“The mechanism is quite striking and really shifted our perspective about how tissue regeneration can occur,” Bhutani said. “It’s clear that a large pool of already existing cells in cartilage are changing their gene expression patterns. And by targeting these cells for regeneration, we may have an opportunity to have a bigger overall impact clinically.”
Looking Toward Human Trials
Blau added, “Phase 1 clinical trials of a 15-PGDH inhibitor for muscle weakness have shown that it is safe and active in healthy volunteers. Our hope is that a similar trial will be launched soon to test its effect in cartilage regeneration. We are very excited about this potential breakthrough. Imagine regrowing existing cartilage and avoiding joint replacement.”
[…]








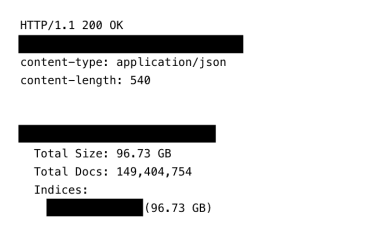 This screenshot shows the total count of records and size of the exposed infostealer database.
This screenshot shows the total count of records and size of the exposed infostealer database.