[…] fast flux. It allows decentralized networks operated by threat actors to hide their infrastructure and survive takedown attempts that would otherwise succeed. Fast flux works by cycling through a range of IP addresses and domain names that these botnets use to connect to the Internet. In some cases, IPs and domain names change every day or two; in other cases, they change almost hourly. The constant flux complicates the task of isolating the true origin of the infrastructure. It also provides redundancy. By the time defenders block one address or domain, new ones have already been assigned.
[…]
A key means for achieving this is the use of Wildcard DNS records. These records define zones within the Domain Name System, which map domains to IP addresses. The wildcards cause DNS lookups for subdomains that do not exist, specifically by tying MX (mail exchange) records used to designate mail servers. The result is the assignment of an attacker IP to a subdomain such as malicious.example.com, even though it doesn’t exist.
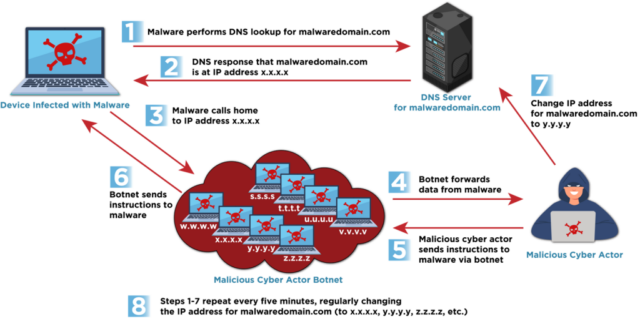
Fast flux comes in two variations. Single flux creates DNS A records or AAAA records to map a single domain to many IPv4 or IPv6 addresses, respectively. Here’s a diagram illustrating the structure.
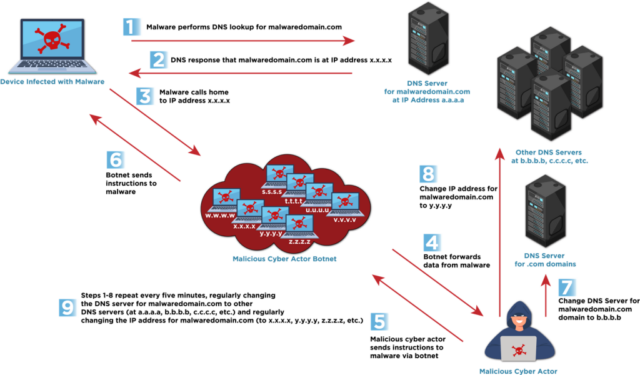
Double flux provides an additional layer of obfuscation and resiliency by, in addition to changing IP addresses, cycling through the DNS name servers used in domain lookups. Defenders have observed double flux using both Name Server (NS) and Canonical Name (CNAME) DNS records. Here’s an illustration of the technique.
“Both techniques leverage a large number of compromised hosts, usually as a botnet from across the Internet that acts as proxies or relay points, making it difficult for network defenders to identify the malicious traffic and block or perform legal enforcement takedowns of the malicious infrastructure,”
Yes.. And there’s a solution for this one too. Use DNS Pinning on your local DNS resolvers.
Web browsers themselves had to look at this a number of decades ago due to DNS Rebinding Attacks [wikipedia.org]. And the answer I’m pretty sure was to Pin DNS records whose TTL was less than 10 minutes or so to make sure DNS records will be cached for a minimum length of time, even if the TTL has been configured less.
You can handle this on your organization’s DNS servers as well:
For example; if your DNS resolver is Unbound, then set the cache-min-ttl to 24 hours.
cache-min-ttl: seconds Time to live minimum for RRsets and messages in the cache. If the minimum kicks in, the data is cached for longer than the domain owner intended, and thus less queries are made to look up the data. Zero makes sure the data in the cache is as the domain owner intended, higher values, especially more than an hour or so, can lead to trouble as the data in the cache does not match up with the actual data any more.
Then the “fast flux” attackers can’t be so effective against your infrastructure. Because the DNS records are pinned upon the first lookup. At least they won’t be able to use DNS for their fast flux network in this case – if your DNS resolvers’ policy prevents fast flux.
Rice University researchers have developed an innovative solution to a pressing environmental challenge: removing and destroying per- and polyfluoroalkyl substances (PFAS), commonly called “forever chemicals.” A study led byJames Tour, the T.T. and W.F. Chao Professor of Chemistry and professor of materials science and nanoengineering, and graduate student Phelecia Scotland unveils a method that not only eliminates PFAS from water systems but also transforms waste into high-value graphene, offering a cost-effective and sustainable approach to environmental remediation. This research was published March 31 in Nature Water.
[…]
“Our method doesn’t just destroy these hazardous chemicals; it turns waste into something of value,” Tour said. “By upcycling the spent carbon into graphene, we’ve created a process that’s not only environmentally beneficial but also economically viable, helping to offset the costs of remediation.”
The research team’s process employs flash joule heating (FJH) to tackle these challenges. By combining granular activated carbon (GAC) saturated with PFAS and mineralizing agents like sodium or calcium salts, the researchers applied a high voltage to generate temperatures exceeding 3,000 degrees Celsius in under one second. The intense heat breaks down the strong carbon-fluorine bonds in PFAS, converting them into inert, nontoxic fluoride salts. Simultaneously, the GAC is upcycled into graphene, a valuable material used in industries ranging from electronics to construction.
The research results yielded more than 96% defluorination efficiency and 99.98% removal of perfluorooctanoic acid (PFOA), one of the most common PFAS pollutants. Analytical tests confirmed that the reaction produced undetectable amounts of harmful volatile organic fluorides, a common byproduct of other PFAS treatments. The method also eliminates the secondary waste associated with traditional disposal methods such as incineration or adding spent carbon to landfills.
[…]
The implications of this research extend beyond PFOA and perfluorooctane sulfonic acid, the two most studied PFAS; it even works on the most recalcitrant PFAS type, Teflon R. The high temperatures achieved during FJH suggest that this method could degrade a wide range of PFAS compounds, paving the way for broader water treatment and waste management applications. The FJH process can also be tailored to produce other valuable carbon-based materials, including carbon nanotubes and nanodiamonds, further enhancing its versatility and economic appeal.
“With its promise of zero net cost, scalability and environmental benefits, our method represents a step forward in the fight against forever chemicals,” Scotland said
A tenured computer security professor at Indiana University and his university-employed wife have not been seen publicly since federal agents raided their homes late last week.
On Friday, the FBI with help from the cops searchedtwo properties in Bloomington and Carmel, Indiana, belonging to Xiaofeng Wang, a professor at the Indiana Luddy School of Informatics, Computing, and Engineering – who’s been with the American university for more than 20 years – and Nianli Ma, a lead library systems analyst and programmer also at the university.
The university has removed the professor’s profile from its website, while the Indiana Daily Student reports Wang was axed the same day the Feds swooped. It’s said the college learned the professor had taken a job at a university in Singapore, leading to the boffin’s termination by his US employer. Ma’s university profile has also vanished.
“I can confirm the FBI Indianapolis office conducted court authorized activity at homes in Carmel and Bloomington, Indiana last Friday,” the FBI told The Register. “We have no further comment at this time.”
“The Bloomington Police Department was requested to simply assist with scene security while the FBI conducted court authorized law enforcement activity at the residence,” the police added to The Register, also declining to comment further.
Reading between the lines, Prof Wang and his spouse may not necessarily be in custody, and that the Feds may have raided their homes while one or both of the couple were away and possibly already abroad. According to the student news outlet, the professor hasn’t been seen for roughly the past two weeks.
Prof Wang earned his PhD in electrical and computer engineering from Carnegie Mellon University in 2004 and joined Indiana Uni that same year. Since then, he’s become a well respected member of the IT security community, publishing extensively on Apple security, e-commerce fraud, and adversarial machine learning.
Over the course of his academic career – starting in the 1990s with computer science degrees from universities in Nanjing and Shanghai, China – Prof Wang has led research projects with funding exceeding $20 million. He was named a fellow of the IEEE in 2018, the American Association for the Advancement of Science in 2022, and the Association for Computing Machinery in 2023. He reportedly pocketed more than $380,000 in salaries in 2024, while his wife was paid $85,000.
According to neighbors in Carmel, agents arrived around 0830 on March 28, announcing: “FBI, come out!” Agents were seen removing boxes of evidence and photographing the scene.
“Indiana University was recently made aware of a federal investigation of an Indiana University faculty member,” the institution told us.
“At the direction of the FBI, Indiana University will not make any public comments regarding this investigation. In accordance with Indiana University practices, Indiana University will also not make any public comments regarding the status of this individual.”
While US Immigration and Customs Enforcement, aka ICE, has recently made headlines for detaining academic visa holders, among others, there’s no indication the agency was involved in the Indiana raids. That suggests the investigation likely goes beyond immigration matters.
Context
It wouldn’t be the first time foreign academics have come under federal scrutiny. During Trump’s first term, the Department of Justice launched the so-called “China Initiative,” aimed at uncovering economic espionage and IP theft by researchers linked to China.
The effort was widely seen as a failure, with over 50 percent of investigations dropped, some professors wrongly accused, and a few were ultimately found guilty of nothing more than hoarding pirated porn.
The initiative was also widely criticized as counterproductive, prompting an exodus of Chinese researchers from the US and pushing some American-based scientists to relocate to the Chinese mainland. History has seen this movie before: During the 1950s Red Scare, America booted prominent rocket scientist Qian Xuesen over suspected communist ties. He went on to become the architect of China’s missile and space programs — a move that helped Beijing get its intercontinental ballistic missiles, aka ICBMs.
Wang and Ma are still incommunicado, and presumed innocent. Fellow academics in the security industry have pointed out this kind of action is highly unusual. Matt Blaze, Tor Project board member and the McDevitt Chair of Computer Science and Law at Georgetown University, pointed out that to disappear from the university’s records, archived here, is “especially concerning.”
“It’s hard to imagine what reason there could be for the university to scrub its website as if he never worked there,” Blaze said on Mastodon.
“While there’s a process for removing tenured faculty, it takes more than an afternoon to do it.”
Microsoft is no longer playing around when it comes to requiring every Windows 11 device be set up with an internet-connected account. In its latest Windows 11 Insider Preview, the company says it will take out a well-known bypass script that let end users skip the requirement of connecting to the internet and logging in with a Microsoft account to get through the initialization process of a new PC.
As reported by Windows Central, Microsoft already requires users to connect to the internet, but there’s a way to bypass it: the bypassnro command. For those setting up computers for businesses or secondary users, or simply, on principle refuse to link their computer to a Microsoft account, the command is super simple to activate during the Windows setup process.
Microsoft cites security as one reason it’s making this change:
We’re removing the bypassnro.cmd script from the build to enhance security and user experience of Windows 11. This change ensures that all users exit setup with internet connectivity and a Microsoft Account.
Since the bypassnro command is disabled in the latest beta build, it will likely be pushed to production versions within weeks. All hope is not yet lost, as of right now the script can be reactivated with a registry edit by opening a command prompt during the initial setup (Press Shift + F10) and running the command:
However, there’s no guarantee Microsoft will allow this additional workaround for long. There are other workarounds as well, such as using the unattended.xml automation that lets you skip the initial setup “out-of-box experience.” It’s not straightforward, though, but it makes more sense for IT departments setting up multiple computers.
As of late, Microsoft has been making it harder for people to upgrade to Windows 11 while also nudging them to move on from Windows 10, which will lose support in October. The company is cracking down on the ability to install Windows 11 on older PCs that don’t support TPM 2.0, and hounding you with full-screen ads to buy a new PC. Microsoft even removed the ability to install Windows 11 with old product keys.
No more burning fossil fuels, playing with fissile material, damming rivers, erecting wind mills, or making solar panels. All of our energy needs could potentially be supplied by the angular kinetic energy of the Earth — and because of the mass of the planet, doing so would slow its rotation down by a mere 7ms per century. [Which is similar to speed changes caused by natural phenomena such as the Moon’s pull and changing dynamics inside the planet’s core.”]
Normally this would be considered impossible as the Earth’s large and uniform field does not induce a current in conductors, but researchers believe that a hollow cylinder of manganese, zinc and iron can alter the interaction with our planetary magnetic field and allow the extraction of energy from it. So far, the results are positive but still below the level where they cannot be explained by multiple possible causes of experimental error. Further research is required to confirm the effect. “The effect was identified only in a carefully crafted device and generated just 17 microvolts,” reports Scientific American, “a fraction of the voltage released when a single neuron fires — making it hard to verify that some other effect isn’t causing the observations.”
But if another group can verify the results, the experiment’s lead says the next logical step is trying to scale up the device to generate a useful amount of energy.
Researchers have discovered nearly 1.5 million pictures from specialist dating apps – many of which are explicit – being stored online without password protection, leaving them vulnerable to hackers and extortionists.
Anyone with the link was able to view the private photos from five platforms developed by M.A.D Mobile: kink sites BDSM People and Chica, and LGBT apps Pink, Brish and Translove.
These services are used by an estimated 800,000 to 900,000 people.
M.A.D Mobile was first warned about the security flaw on 20 January but didn’t take action until the BBC emailed on Friday.
They have since fixed it but not said how it happened or why they failed to protect the sensitive images.
This is one of the photos that anyone could have accessed. We have cropped the face and blurred it to enhance privacy
Ethical hacker Aras Nazarovas from Cybernews first alerted the firm about the security hole after finding the location of the online storage used by the apps by analysing the code that powers the services.
He was shocked that he could access the unencrypted and unprotected photos without any password.
[…]
In an email M.A.D Mobile said it was grateful to the researcher for uncovering the vulnerability in the apps to prevent a data breach from occurring.
But there’s no guarantee that Mr Nazarovas was the only hacker to have found the image stash.
“We appreciate their work and have already taken the necessary steps to address the issue,” a M.A.D Mobile spokesperson said. “An additional update for the apps will be released on the App Store in the coming days.”
The company did not respond to further questions about where the company is based and why it took months to address the issue after multiple warnings from researchers.
Usually security researchers wait until a vulnerability is fixed before publishing an online report, in case it puts users at further risk of attack.
But Mr Nazarovas and his team decided to raise the alarm on Thursday while the issue was still live as they were concerned the company was not doing anything to fix it.
[…]
In 2015 malicious hackers stole a large amount of customer data about users of Ashley Madison, a dating website for married people who wish to cheat on their spouse.
Meniscus tears are common knee injuries that have long frustrated patients and doctors due to limited repair options.A new 3D-printed hydrogel made from cow meniscus could transform how these injuries heal, according to results of a pre-clinical study published in Bioactive Materials. from researchers in the Perelman School of Medicine at the University of Pennsylvania.
The meniscus is a complex structure that serves as a critical shock absorber in the knee. and one-size-fits-all treatments aren’t always effective. Through creating a treatment adaptable to the different needs of patients, the researchers believe they may have unlocked a better fix no matter where the injury occurs in a meniscus.
“We developed a hydrogel that can be adjusted based on the patient’s age and the stiffness requirements of the injured tissue, which is important because the meniscus has different biochemical and biomechanical properties that vary depending upon the location in the tissue,” said the study’s senior author, Su Chin Heo, PhD, an assistant professor of Orthopaedic Surgery in the McKay Orthopaedic Research Lab at Penn. “Current treatments, including graft-base methods, do not fully recreate these complex differences, leading to poor healing.”
[…]
“In our animal studies, we’ve seen the hydrogel integrate well with the surrounding tissue, potentially offering patients a more complete recovery,” said the study’s first author Se-Hwan Lee, PhD, a post-doctoral fellow in the McKay Lab. “It’s a more precise, biologically matched solution. We believe this could outperform current treatments.”
The team is now transitioning from small mammal studies to large animal models.
“Our first clinical goal will be to treat smaller, localized meniscus tears,” Heo said. “Once we have success there, I believe we could expand to more complex injuries in the meniscus.”
The TV business traditionally included three distinct entities. There’s the hardware, namely the TV itself; the entertainment, like movies and shows; and the ads, usually just commercials that interrupt your movies and shows. In the streaming era, tech companies want to control all three, a setup also known as vertical integration. If, say, Roku makes the TV, supplies the content, and sells the ads, then it stands to control the experience, set the rates, and make the most money. That’s business!
Roku has done this very well. Although it was founded in 2002, Roku broke into the market in 2008 after Netflix invested $6 million in the company to make a set-top box that enabled any TV to stream Netflix content. It was literally called the Netflix Player by Roku. Over the course of the next 15 years, Roku would grow its hardware business to include streaming sticks, which are basically just smaller set-top-boxes; wireless soundbars, speakers, and subwoofers; and after licensing its operating system to third-party TV makers, its own affordable, Roku-branded smart TVs
[…]
The shift toward ad-supported everything has been happening across the TV landscape. People buy new TVs less frequently these days, so TV makers want to make money off the TVs they’ve already sold. Samsung has Samsung Ads, LG has LG Ad Solutions, Vizio has Vizio Ads, and so on and so forth. Tech companies, notably Amazon and Google, have gotten into the mix too, not only making software and hardware for TVs but also leveraging the massive amount of data they have on their users to sell ads on their TV platforms. These companies also sell data to advertisers and data brokers, all in the interest of knowing as much about you as possible in the interest of targeting you more effectively. It could even be used to train AI.
[…]
Is it possible to escape the ads?
Breaking free from this ad prison is tough. Most TVs on the market today come with a technology called automatic content recognition (ACR) built in. This is basically Shazam for TV — Shazam itself helped popularize the tech — and gives smart TV platforms the ability to monitor what you’re watching by either taking screenshots or capturing audio snippets while you’re watching. (This happens at the signal level, not from actual microphone recordings from the TV.)
Advertisers and TV companies use ACR tech to collect data about your habits that are otherwise hard to track, like if you watch live TV with an antenna. They use that data to build out a profile of you in order to better target ads. ACR also works with devices, like gaming consoles, that you plug into your TV through HDMI cables.
Yash Vekaria, a PhD candidate at UC Davis, called the HDMI spying “the most egregious thing we found” in his research for a paper published last year on how ACR technology works. And I have to admit that I had not heard of ACR until I came across Vekaria’s research.
[…]
Unfortunately, you don’t have much of a choice when it comes to ACR on your TV. You probably enabled the technology when you first set up your TV and accepted its privacy policy. If you refuse to do this, a lot of the functions on your TV won’t work. You can also accept the policy and then disable ACR on your TV’s settings, but that could disable certain features too. In 2017, Vizio settled a class-action lawsuit for tracking users by default. If you want to turn off this tracking technology, here’s a good guide from Consumer Reports that explains how for most types of smart TVs.
[…]
it does bug me, just on principle, that I have to let a tech company wiretap my TV in order to enjoy all of the device’s features.
[…] As much as carmakers seem to love infotainment screens, consumers are less enthusiastic about them. Just 15% of drivers in 2024 said they would want a full-width infotainment display. Windshield base displays with less functionality are slightly more popular but still appeal to just 18% of those planning on buying a new car.
The growing pushback against vehicle touch screens is ultimately a matter of safety and convenience. While having all your controls in one place sounds useful, navigating between menus to find the right settings can be frustrating, slow, and unsafe if done while driving. It also means basic car functions may be at the mercy of software glitches and lag.
In 2021, Tesla had to recall vehicles because an issue with the flash memory in Tesla infotainment systems made the rearview camera unviewable and took defrost and turn signal functions offline. More recently, a class-action lawsuit against Stellantis alleges that defective infotainment screens led to backup camera failures and distracting audio glitches.
Those same shortcomings, alongside the obvious distracting features of an iPad in your center console, pose safety concerns, too. Navigating between menus takes focus off the road, especially when adjusting a setting takes more steps than it used to. Given that 6,000 pedestrians a year already die in traffic accidents, anything that takes a driver’s eyes off the road isn’t ideal.
Some car brands have started responding to these concerns by toning down the “screenification” of their vehicles. Volkswagen announced it will bring back physical buttons after backlash against its more screen-heavy models. VW CEO Thomas Schäfer said the reliance on touch screens “did a lot of damage” to the brand’s reputation among frustrated drivers.
When VW pivoted to a touch screen-centric interface, Capital One’s Auto Navigator called the controls “aggravating,” as did many other reviewers. Yahoo Autos called it the worst infotainment system they had ever come across. In light of these responses, it’s easy to see why VW would want to move back to physical buttons.
Given this growing push against infotainment touch screens, automakers will likely respond. However, how they choose to balance demands for safety and convenience with new tech is less certain.
Some companies think the solution is to keep digital displays but change how they operate. BMW unveiled a new heads-up display (HUD) at CES 2025 that puts more information along the bottom of the windshield instead of keeping it on the dash. As BMW board member Frank Weber explained, this system means “the driver decides themselves which information they want to display in their own field of vision.” Infotainment-style customization remains present, but it stays within the line of sight while looking at the road.
BMW’s new HUD also lets drivers control these settings through physical buttons on the steering wheel, not just a touch screen. That way, hands can remain on the wheel and eyes can remain forward. Hyundai and Kia have followed a similar approach, giving users a choice between touch or analog controls.
Voice commands have emerged as another alternative. Mercedes introduced ChatGPT-backed voice controls in 2023, and Apple gave CarPlay voice functionality with iOS 18. These don’t make screens go away, but they do offer a way to use them that doesn’t require taking your hands off the wheel or eyes off the road.
As the industry explores these voice-activated solutions, it’s clear that the evolution of infotainment systems is far from over. Growing attention on common issues should kick-start some much-needed changes.
Voice commands are spotty at best and incredibly frustrating to use. BMW decided to go buttonless only last year and is sadly sticking to its’ guns whilst the rest of the world is moving on.
Turkey has begun using tablet computers in the cockpits of its F-16 fighters to help with the rapid integration of new locally-developed weapons. This has interesting parallels with Ukraine’s use of such devices to allow its Soviet-era jets to employ Western air-to-ground weapons — something you can read more about here.
The tablet can be seen in the cockpit of an F-16 in a recent video showing a test launch of the domestically developed SOM-J standoff missile. The tablet is mounted on the Input Control Panel (ICP), which is located on the center console beneath the head-up display. The ICP is used to select weapons, navigation settings, and radio communications, among other functions. At the same time, the pilot has another tablet on their knee, something that has become increasingly common, augmenting the information available via the aircraft’s mission systems and helping eliminate cumbersome paper books in the cockpit.
In this context, the tablet is part of the UBAS, also known in English as the Aircraft Independent Firing System. Using Turkish-designed software, the UBAS provides a weapons interface for the use of Turkish-made stores, like the SOM-J.
[…]
Tablet-based workarounds to integrate new weapons on existing aircraft platforms are now something of a growth area.
In the case of Ukraine, which we have explored in depth in the past, its Soviet-era fighters lack the kinds of data bus interfaces that would ensure seamless compatibility with Western-made weapons.
Cockpit of a Ukrainian Su-27 Flanker fitted with a tablet device. via X
Last year, U.S. Undersecretary of Defense for Acquisition and Sustainment Dr. William LaPlante explained:
“There’s also a series of … we call it ‘air-to-ground,’ it’s what we call it euphemistically … think about the aircraft that the Ukrainians have, and not even the F-16, but they have a lot of the Russian and Soviet-era aircraft. Working with the Ukrainians, we’ve been able to take many Western weapons and get them to work on their aircraft, where it’s basically controlled by an iPad by the pilot. And they’re flying it in conflict like a week after we get it to him.”
As well as tablets in the cockpit, Ukrainian aircraft are also using specialized pylons on which the Western-made weapons are carried. You can read more about those here.
[…]
For Turkey, the situation is essentially reversed, with the problem being how to integrate new Turkish-made weapons onto older U.S.-made F-16s.
Turkey has a fairly unusual position regarding the kind of upgrades it can make to its F-16 fleet, a result of the sometimes-strained relations between Ankara and Washington.
[…]
Now, thanks to UBAS, these aircraft can also carry a range of Turkish-made ordnance and this can be added without having to modify the F-16’s software, which features proprietary updates released in the form of ‘tapes.’ Even without access to the software, Turkey can add new weapons to the jets using UBAS.
While the system has been shown to be used for employment of the SOM-J, it likely provides a similar interface with other locally developed stores.
[…]
As well as appearing in the cockpits of Turkish F-16s, UBAS has been installed in Soviet-era Su-25 Frogfoot attack jets operated by Azerbaijan, as part of a Turkish upgrade.
In the first part of this upgrade, known as Merhale-1, the Su-25 adds the UBAS system that allows it to employ Turkish-made KGK-82/83 and TEBER-82 precision-guided bombs, as well as SOM-B1 standoff missiles.
[…]
The Azerbaijan example underscores the unique position Turkey has, thanks to its rapidly exploding defense aerospace sector, especially in terms of munitions and drones — this was not nearly the case in the past. Were UBAS to open up a gateway for integration of multiple weapons on U.S.-made fighters, this would be a huge deal on multiple levels. For export, especially, it could be very significant, allowing foreign operators a quick and rapid way of integrating Turkish weapons, for example, on their U.S.-made aircraft.
A few weeks ago, the UK’s regional and national daily news titles ran similar front covers, exhorting the government there to “Make it Fair”. The campaign Web site explained:
Tech companies use creative content, such as news articles, books, music, film, photography, visual art, and all kinds of creative work, to train their generative AI models.
Publishers and creators say that doing this without proper controls, transparency or fair payment is unfair and threatens their livelihoods.
Under new UK proposals, creators will be able to opt out of their works being used for training purposes, but the current campaign wants more than that:
Creators argue this [opt-out] puts the burden on them to police their work and that tech companies should pay for using their content.
The campaign Web site then uses a familiar trope:
Tech giants should not profit from stolen content, or use it for free.
But the material is not stolen, it is simply analysed as part of the AI training. Analysing texts or images is about knowledge acquisition, not copyright infringement. Once again, the copyright industries are trying to place a (further) tax on knowledge. Moreover, levying that tax is completely impractical. Since there is no way to determine which works were used during training to produce any given output, the payments would have to be according to their contribution to the training material that went into creating the generative AI system itself. A Walled Culture post back in October 2023 noted that the amounts would be extremely small, because of the sheer quantity of training data that is used. Any monies collected from AI companies would therefore have to be handed over in aggregate, either to yet another inefficient collection society, or to the corporate intermediaries. For this reason, there is no chance that creators would benefit significantly from any AI tax.
We’ve been here before. Five years ago, I wrote a post about the EU Copyright Directive’s plans for an ancillary copyright, also known as the snippet or link tax. One of the key arguments by the newspaper publishers was that this new tax was needed so that journalists were compensated when their writing appeared in search results and elsewhere. As I showed back then, the amounts involved would be negligible. In fact, few EU countries have even bothered to implement the provision on allocating a share to journalists, underlining how pointless it all was. At the time, the European Commission insisted on behalf of its publishing friends that ancillary copyright was absolutely necessary because:
The organisational and financial contribution of publishers in producing press publications needs to be recognised and further encouraged to ensure the sustainability of the publishing industry.
Now, on the new Make it Fair Web site we find a similar claim about sustainability:
We’re calling on the government to ensure creatives are rewarded properly so as to ensure a sustainable future for AI and the creative industries.
As with the snippet tax, an AI tax is not going to do that, since the sums involved as so small. A post on the News Media Association reveals what is the real issue here:
The UK’s creative industries have today launched a bold campaign to highlight how their content is at risk of being given away for free to AI firms as the government proposes weakening copyright law.
Walled Culture has noted many times it is a matter of dogma for the industries involved that copyright must only ever get stronger, as if they were a copyright ratchet. The fear is evidently that once it has been “weakened” in some way, a precedent would be set, and other changes might be made to give more rights to ordinary people (perish the thought) rather than to companies. It’s worth pointing out that the copyright world is deploying its usual sleight of hand here, writing:
The government must stand with the creative industries that make Britain great and enforce our copyright laws to allow creatives to assert their rights in the age of AI.
A fair deal for artists and writers isn’t just about making things right, it is essential for the future of creativity and AI.
Who could be against this call for the UK government to defend the poor artists and writers? No one, surely? But the way to do that, according to Make it Fair, is to “stand with the creative industries”. In other words, give the big copyright companies more power to act as gatekeepers, on the assumption that their interests are perfectly aligned with those of the struggling creators.
They are not. As Walled Culture the book explores in some detail (free digital versions available), the vast majority of those “artists and writers” invoked by the “Make it Fair” campaign are unable to make a decent living from their work under copyright. Meanwhile, huge global corporations enjoy fat profits as a result of that same creativity, but give very little back to the people who did all the work.
There are serious problems with the new AI offerings, and big tech companies definitely need to be reined in for many things, but not for their basic analysis of text and images. If publishers really want to “Make it Fair”, they should start by rewarding their own authors fairly, with more than the current pittance. And if they won’t do that, as seems likely given their history of exploitation, creators should explore some of the ways they can make a decent living without them. Notably, many of these have no need for a copyright system that is the epitome of unfairness, which is precisely why publishers are so desperate to defend it in this latest coordinated campaign.
I bought a Bosch 500 series because that’s what Consumer Reports recommended, and more importantly, I could find one in stock.
After my dad and I got it installed, I went to run a rinse cycle, only to find that that, along with features like delayed start and eco mode, require an app.
Not only that, to use the app, you have to connect your dishwasher to WiFi, set up a cloud account in something called Home Connect, and then, and only then, can you start using all the features on the dishwasher.
Video
This blog post is a lightly-edited transcript of my latest YouTube video on Level 2 Jeff:
GE Dishwasher – Planned Obsolescence
So getting back first to that old GE dishwasher, it was, I don’t know, I think that planned obsolescence is something that applies to many consumer products today.
Companies know if they design something to last only 5 or 10 years, that means in 5 or 10 years someone’s going to have to buy a whole new one.
And on my GE Amana dishwasher, it started having weird power issues, like the controls would just not light up unless I reset the circuit breaker for a few minutes. That started happening more often, and this past Saturday it just wouldn’t come on no matter what, even after I tested and re-wired it all the way from the panel up to the dishwasher’s internal power connector.
So it was dead.
Next up, I looked at what it took to get a control board. Well… $299 for a control board that was ‘special order’ and might not even fix the problem? That’s a non-starter for my $600, 8-year-old dishwasher.
Even if I got it fixed, the front panel was starting to rust out at the hinge points (leaving some metal jaggies that my soon-to-be-crawling 6 month old could slice his fingers on), and other parts of the machine were showing signs of rust/potential future leaks…
[…]
The touch sensor, you kind of touch it and the firmware—like this new dishwasher actually takes time to boot up! I had to reset it like three times and my wife meanwhile was like laughing at me like look at this guy who does tech stuff and he can’t even figure out how to change the cycle on it.
That took about five minutes, sadly.
But eventually I pulled out the manual book because I was like… “this is actually confusing.”
It should be like: I touch the button and it changes to that mode! But that was not how it was working.
I wanted to run just a rinse cycle to make sure the water would go in, the water would pump out through the sump, and everything worked post-install.
But I couldn’t find a way to do a rinse cycle on the control panel.
So I looked in the manual and found this note:
It says options with an asterisk—including Rinse, Machine Care (self-cleaning), HalfLoad, Eco, and Delay start, are “available through Home Connect app only and depending on your model.”
The 500 series model I bought isn’t premium enough to feature a 7-segment display like the $400-more-expensive 800 series, so these fancy modes are hidden behind an app and cloud service.
I was like, “Okay, I’ll look up this app and see if I can use it over Bluetooth or locally or whatever.”
Nope! To use the app, you have to connect your dishwasher to your Wi-Fi, which lets the dishwasher reach out on the internet to this Home Connect service.
You have to set up an account on Home Connect, set up the Home Connect app on your phone, and then you can control your dishwasher through the Internet to run a rinse cycle.
That doesn’t make any sense to me.
[…]
What should be done?
When I posted on social media about this, a lot of people told me to return it.
But I spent four hours installing this thing built into my kitchen.
I hooked it up to the water, it’s running through cycles… it is working. I’ll give them that. It does the normal stuff, but you know, there are some features that don’t work without the app.
At a minimum, I think what Bosch should do is make it so that the dishwasher can be accessed locally with no requirement for a cloud account. (Really, it’d be even better to have all the functions accessible on the control panel!)
Anyone building an IoT device, here is my consumer-first, e-waste-reduction maxim:
First local, then cloud.
Cloud should be an add-on.
It should be a convenience for people who don’t know how to do things like connect to their dishwasher with an app locally.
And it’s not that hard.
A little ESP32, a little $1 chip that you can put in there could do all this stuff locally with no cloud requirement at all.
I think that there might be some quants or people who want to make a lot of money building all these cloud services.
Elasmobranchs are an evolutionarily ancient group of cartilaginous fishes that can hear underwater sounds but are not historically viewed as active sound producers. Three recent reports of several species of rays producing clicks in response to approaching divers have cast doubt on this long prevailing view and resulted in calls for more research into sound production in elasmobranchs. This study shows that the rig, Mustelus lenticulatus, produces clicks (mean SPLrms = 156.3 dB re. 1 μPa ± 0.9 s.e.m. at approx. 30 cm) when handled underwater, representing the first documented case of deliberate sound production by a shark
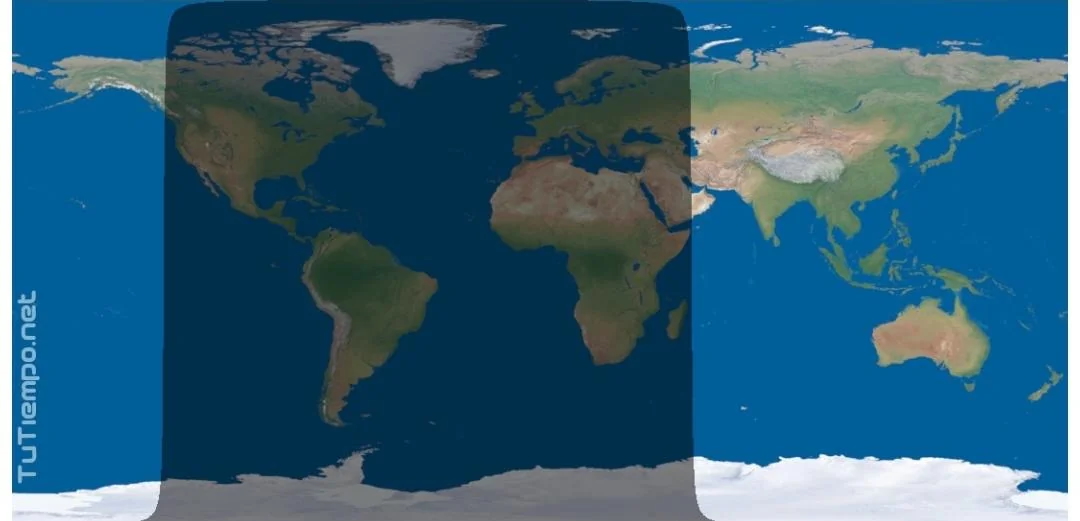
[…]thanks to cosmic geometry, a major chapter in world history has just now come to a close. As first highlighted last year on Reddit, the spring equinox on March 20 marked the sun’s passage over the celestial equator, kicking off half a year of darkness around the South Pole. And given last year’s deal with Mauritius, this means Thursday night at 10:50 PM EST (2:50 AM on March 21 in London), the sun finally, literally set on the British empire.
The spring equinox on March 20 prededed the British empire’s literal sunset. Credit: Reddit / TuTiempo.net
It didn’t stay dark for Britain too long, however. About an hour after dusky conditions on the Pitcairn Islands, light began to peek over the horizon roughly 10,000 miles away in Akrotiri and Dhekelia, two non-contiguous British territories located on the island of Cyprus.
Much of foreign aid is spent on goods that are shipped overseas: food supplies, medicines, or humanitarian assistance in emergency situations.1
But a surprising amount of what’s reported as foreign aid is not sent abroad; it’s spent domestically. Foreign aid budgets in rich countries can include the costs of hosting refugees, some scholarships to foreign students, and some administrative costs that are spent domestically.2 These domestic expenses are reported by countries to the OECD, which tracks and measures foreign aid allocations, so they are included in the widely quoted aid figures you’ll typically see. We’ll refer to these combined costs as “aid money spent at home”.
In 2023, 22% of total foreign aid for all Development Assistance Committee (DAC) countries was spent at home. The DAC countries are a group of 32 high-income countries; from this point onwards, we’ll refer to them as “rich donor countries”.3
In this article, we’ll look at how aid money spent at home varies across countries and categories, how this has changed over time, and what this means for the amount of money available for support overseas.
More foreign aid is spent domestically, mostly to host refugees
So, in 2023, 22% of foreign aid was spent domestically in rich donor countries. That was a record year, both in absolute and relative terms. Domestic spending has more than tripled from $14 billion to $48 billion since 2010. As a share of total aid, it has increased from 10% to 22%.
[…]The IT break-in occurred between April 20 and April 22, last year, according to a notification filed this month with the US state’s attorney general’s office. California Cryobank spotted unauthorized activity on certain computers on April 21, isolated the affected machines, and launched an investigation.
The sperm bank hasn’t disclosed how many individuals were affected, but says the files potentially accessed or acquired include names, Social Security numbers, driver’s license numbers, financial account details, and health insurance information [PDF].
California Cryobank has touted itself as having the largest sperm supply in the world, distributing to all 50 US states and more than 30 countries internationally.
The biz did not immediately respond to The Register‘s questions about the break-in, including how many customers were affected and if the miscreants deployed ransomware and demanded an extortion payment. One wonders why it’s taken almost a year for this all to come to light, so to speak.
The Pennsylvania State Education Association (PSEA) says a July 2024 “security incident” exposed sensitive personal data on more than half a million individuals, including financial and health info.
The nonprofit, which represents more than 178,000 education professionals in the US state of Pennsylvania, confirmed data was stolen during a July 6 attack. According to The Office of the Maine Attorney General, the breach affected a total of 517,487 people
[…]
The org’s disclosure notice stated: “…we determined that the data acquired by the unauthorized actor contained some personal information belonging to individuals whose information was contained within certain files within our network.
“We took steps, to the best of our ability and knowledge, to ensure that the data taken by the unauthorized actor was deleted. We want to make the impacted individuals aware of the incident and provide them with steps they can take to further protect their information.”
Although PSEA’s disclosure didn’t explicitly mention ransomware or extortion, it did say that steps were taken to ensure the stolen data was deleted — a claim that typically implies some level of communication with the attackers, often seen in double extortion cases.
Adding weight to that suspicion, the Rhysida ransomware gang publicly claimed responsibility for the attack in September 2024, suggesting ransomware was involved.
[…]
PSEA emphasized that not every individual had the same data elements compromised. The exposed information may include an individual’s full name in combination with one or more other type of personal data.
The possible data types stolen include the usual personally identifiable information (PII) such as full names and dates of birth, and identity documents such as driver’s licenses, state IDs, and social security numbers (SSNs).
In addition to basic PII, the nonprofit also said account numbers, account PINs, security codes, passwords, routing numbers, payment card numbers, card PINs, and expiration dates might have been taken.
The list doesn’t stop there: Passport numbers, taxpayer ID numbers, usernames and passwords, health insurance information, and finally medical information are potentially in the hands of cybercriminals.
HP Inc. has settled a class action lawsuit in which it was accused of unlawfully blocking customers from using third-party toner cartridges – a practice that left some with useless printers – but won’t pay a cent to make the case go away.
One of the named plaintiffs in the case is called Mobile Emergency Housing Corp (MEHC) and works with emergency management organizations and government agencies to provide shelters for disaster victims and first responders across the US and Caribbean.
According to court documents [PDF], MEHC bought an HP Color LaserJet Pro M254 in August 2019. In October 2020, the org used toner cartridges from third-party supplier Greensky rather than pay for HP’s premium-priced toner.
A month later, HP sent or activated a firmware update – part of its so-called “Dynamic Security” measures – rendering MEHC’s printers incompatible with third-party toner cartridges like those from Greensky.
When MEHC’s CEO Joseph James tried to print out a document, he got the following error message.
The same thing happened to another plaintiff, Performance Automotive, which purchased an HP Color LaserJet Pro MFP M281fdw in 2018 and also installed a firmware update that prevented the machine from working when third-party toner cartridges were present.
HP is not shy about why it does this: In 2024 CEO Enrique Lores told the Davos World Economic Forum “We lose money on the hardware, we make money on the supplies.”
[…]
Incidentally, HP’s printing division reported $4.5 billion in net revenue in fiscal year 2024.
Lores has also argued that using third-party suppliers is a security risk, claiming malware could theoretically be slipped into cartridge controller chips. The Register is unaware of this happening outside a lab. He’s also pitched HP’s own gear as the greener choice, pointing to its cartridge recycling program.
MEHC, Performance Automotive, (and many readers) disagree and would like to choose their own toner.
Thus, a lawsuit was launched, but rather than fight its case in court, HP has, once again, chosen to settle the case privately with no admission of guilt.
“HP denies that it did anything wrong,” its settlement notice reads. “HP agrees under the Settlement to continue making certain disclosures about its use of Dynamic Security, and to continue to provide printer users with the option to either install or decline to install firmware updates that include Dynamic Security.”
Users of Microsoft’s email service might be feeling a distinct sense of déjà vu after the web version of Outlook last night blocked access to Exchange Online mailboxes.
According to Microsoft, the problem was due to “a recent change made to a portion of Outlook on the web infrastructure, that may have resulted in impact.”
Reverting the change did the trick, and service was restored, but the question must be asked – does Microsoft test its changes before deploying to production?
The problems, according to DownDetector, began around 1730 UTC on March 19 and appeared to be worldwide. The company admitted to them via social media shortly after, saying: “We’re investigating reports of an issue affecting users’ ability to access Outlook on the web.”
Half an hour later, the company admitted it made a change that might be responsible. That change was reverted, and services started returning to normal.
This sort of incident is becoming depressingly commonplace. A lengthy outage occurred at the beginning of March which Microsoft also blamed on some dodgy code.
What if you could listen to music or a podcast without headphones or earbuds and without disturbing anyone around you? Or have a private conversation in public without other people hearing you?
Our newly published research introduces a way to create audible enclaves – localized pockets of sound that are isolated from their surroundings. In other words, we’ve developed a technology that could create sound exactly where it needs to be.
The ability to send sound that becomes audible only at a specific location could transform entertainment, communication and spatial audio experiences.
[…]
The science of audible enclaves
We found a new way to send sound to one specific listener: through self-bending ultrasound beams and a concept called nonlinear acoustics.
Ultrasound refers to sound waves with frequencies above the human hearing range, or above 20 kHz. These waves travel through the air like normal sound waves but are inaudible to people. Because ultrasound can penetrate through many materials and interact with objects in unique ways, it’s widely used for medical imaging and many industrial applications.
[…]
Normally, sound waves combine linearly, meaning they just proportionally add up into a bigger wave. However, when sound waves are intense enough, they can interact nonlinearly, generating new frequencies that were not present before.
This is the key to our technique: We use two ultrasound beams at different frequencies that are completely silent on their own. But when they intersect in space, nonlinear effects cause them to generate a new sound wave at an audible frequency that would be heard only in that specific region.
Crucially, we designed ultrasonic beams that can bend on their own. Normally, sound waves travel in straight lines unless something blocks or reflects them. However, by using acoustic metasurfaces – specialized materials that manipulate sound waves – we can shape ultrasound beams to bend as they travel. Similar to how an optical lens bends light, acoustic metasurfaces change the shape of the path of sound waves. By precisely controlling the phase of the ultrasound waves, we create curved sound paths that can navigate around obstacles and meet at a specific target location.
The key phenomenon at play is what’s called difference frequency generation. When two ultrasonic beams of slightly different frequencies, such as 40 kHz and 39.5 kHz, overlap, they create a new sound wave at the difference between their frequencies – in this case 0.5 kHz, or 500 Hz, which is well within the human hearing range. Sound can be heard only where the beams cross. Outside of that intersection, the ultrasound waves remain silent.
This means you can deliver audio to a specific location or person without disturbing other people as the sound travels.
[…]
This isn’t something that’s going to be on the shelf in the immediate future. For instance, challenges remain for our technology. Nonlinear distortion can affect sound quality. And power efficiency is another issue – converting ultrasound to audible sound requires high-intensity fields that can be energy intensive to generate.
Despite these hurdles, audio enclaves present a fundamental shift in sound control. By redefining how sound interacts with space, we open up new possibilities for immersive, efficient and personalized audio experiences.
In a moment of clarity after initially moving forward a deeply flawed piece of legislation, the French National Assembly has done the right thing: it rejected a dangerous proposal that would have gutted end-to-end encryption in the name of fighting drug trafficking. Despite heavy pressure from the Interior Ministry, lawmakers voted Thursday night (article in French) to strike down a provision that would have forced messaging platforms like Signal and WhatsApp to allow hidden access to private conversations.
The vote is a victory for digital rights, for privacy and security, and for common sense.
The proposed law was a surveillance wishlist disguised as anti-drug legislation. Tucked into its text was a resurrection of the widely discredited “ghost” participant model—a backdoor that pretends not to be one. Under this scheme, law enforcement could silently join encrypted chats, undermining the very idea of private communication. Security experts have condemned the approach, warning it would introduce systemic vulnerabilities, damage trust in secure communication platforms, and create tools ripe for abuse.
The French lawmakers who voted this provision down deserve credit. They listened—not only to French digital rights organizations and technologists, but also to basic principles of cybersecurity and civil liberties. They understood that encryption protects everyone, not just activists and dissidents, but also journalists, medical professionals, abuse survivors, and ordinary citizens trying to live private lives in an increasingly surveilled world.
A Global Signal
France’s rejection of the backdoor provision should send a message to legislatures around the world: you don’t have to sacrifice fundamental rights in the name of public safety. Encryption is not the enemy of justice; it’s a tool that supports our fundamental human rights, including the right to have a private conversation. It is a pillar of modern democracy and cybersecurity.
As governments in the U.S., U.K., Australia, and elsewhere continue to flirt with anti-encryption laws, this decision should serve as a model—and a warning. Undermining encryption doesn’t make society safer. It makes everyone more vulnerable.
The data was stored in Google Maps’ Timeline feature, which – for those of you who let Google track you around the world – preserves a record of locations you visit. That sounds creepy and perhaps creepier still once you realize Google makes it possible for photos to appear on the Timeline too, so that users can have a visual record of their travels.
Over the weekend, users noticed their Timelines went missing.
Google seems to have noticed, too, as The Register has seen multiple social media posts in which Timelines users share an email from the search and ads giant in which it admits “We briefly experienced a technical issue that caused the deletion of Timeline data for some people.”
The email goes on to explain that most users that availed themselves of a feature that enables encrypted backups will be able to restore their Maps Timelines data.
Users who did not make those backups can’t restore their data. Those who did make backups need to manually restore their info using a procedure Google included in its email.
[…]
This isn’t the first time Google has messed up users’ historical data: In 2023 the company shortened its default data retention time for location info from 18 to three months, but some users missed the announcement and then complained as their data was purged.
China’s Cyberspace Administration and Ministry of Public Security has outlawed the use of facial recognition without consent.
The two orgs last Friday published new rules on facial recognition and an explainer that spell out how orgs that want to use facial recognition must first conduct a “personal information protection impact assessment” that considers whether using the tech is necessary, impacts on individuals’ privacy, and risks of data leakage.
Organizations that decide to use facial recognition must data encrypt biometric data, and audit the information security techniques and practices they use to protect facial scans.
Chinese that go through that process and decide they want to use facial recognition can only do so after securing individuals’ consent.
The rules also ban the use of facial recognition equipment in public places such as hotel rooms, public bathrooms, public dressing rooms, and public toilets.
The measures don’t apply to researchers or to what machine translation of the rules describes as “algorithm training activities” – suggesting images of citizens’ faces are fair game when used to train AI models.
The documents linked to above don’t mention whether government agencies are exempt from the new rules. The Register fancies Beijing will keep using facial recognition whenever it wants to as its previously expressed interest in a national identity scheme that uses the tech, and used it to identify members of ethnic minorities.
23andMe has capped off a challenging few years by filing for Chapter 11 bankruptcy today. Given the uncertainty around the future of the DNA testing company and what will happen to all of the genetic data it has collected, now is a critical time for customers to protect their privacy. California Attorney General Rob Bonta has recommended that past customers of the genetic testing business delete their information as a precautionary measure. Here are the steps to deleting your records with 23andMe.
Log into your 23andMe account.
Go to the “Settings” tab of your profile.
Click View on the section called “23andMe Data.”
If you want to retain a copy for your own records, download your data now.
Go to the “Delete Data” section
Click “Permanently Delete Data.”
You will receive an email from 23andMe confirming the action. Click the link in that email to complete the process.
While the majority of an individual’s personal information will be deleted, 23andMe does keep some information for legal compliance. The details are in the company’s privacy policy.
There are a few other privacy-minded actions customers can take. First, anyone who opted to have 23andMe store their saliva and DNA can request that the sample be destroyed. That choice can be made from the Preferences tab of the account settings menu. Second, you can review whether you granted permission for your genetic data and sample to be used in scientific research. The allowance can also be checked, and revoked if you wish, from the account settings page; it’s listed under Research and Product Consents.
The Engineering and Manufacturing Development (EMD) contract for NGAD is expected to be worth approximately $20 billion, although, across the life of the program, the company is in line to receive hundreds of billions of dollars in orders. Each copy of the jet, once series production commences, has been estimated in the past to cost upwards of $300 million. That is if the original concept for the aircraft has not changed.
A Lockheed Martin rendering of a notional sixth-generation combat jet. Lockheed Martin
The NGAD combat jet program evolved from plans for what was originally referred to as a Penetrating Counter-Air (PCA) platform, which emerged publicly in the mid-2010s. The PCA concept was an outgrowth of previous work the Air Force had done in cooperation with the Defense Advanced Research Projects Agency (DARPA). That includes the Aerospace Innovation Initiative, which was publicly announced in 2015 and produced at least one classified flying demonstrator design.
In contrast to previous fighter competitions, NGAD has been cloaked in secrecy from the outset. Indeed, for a long time, the Air Force didn’t even disclose which companies were in the running for NGAD.
[…]
Boeing has recently suffered some notable setbacks in both its commercial and defense businesses. Trump had previously slammed the company over its contract to build two new Air Force One planes, which are running behind schedule. In the context of NGAD, however, the company’s entire future as a fighter-builder could be at stake. Notably, the company announced back in 2023 that it was going to shutter the F/A-18E/F Super Hornet line and indicated it would refocus in part on advanced combat jet efforts. The firm has made significant investments in its St. Louis, Missouri, facility to prepare it for sixth-generation fighter production. Boeing — alongside Northrop Grumman — is still in the running for the Navy’s F/A-XX. As for tactical jet production, Boeing is currently building F-15 Advanced Eagles and the Air Force’s T-7 jet trainer and will be for foreseeable future.
[…]
Trump’s Air Force NGAD announcement comes at a time at which the president has been seeking to cut costs throughout the U.S. government, including slashing tens of billions of dollars from existing defense programs. NGAD has been a significant source of uncertainty over the past year, having been put on pause in May 2024 as the service reviewed its requirements amid concerns about the affordability of the aircraft, capability needs, and shifting priorities.
Ultimately, it seems the service’s need for a sixth-generation fighter in a potential Indo-Pacific conflict secured the future of the program.
“We tried a whole bunch of different options, and there was no more viable option than NGAD to achieve air superiority in this highly contested environment,” Air Force Maj. Gen. Joseph Kunkel, director of Force Design, Integration, and Wargaming within the office of the deputy chief of staff for Air Force Futures, said earlier this month.
[…]
According to Trump, an experimental version of the F-47 “has secretly been flying for almost five years.” This is in line with the announcement of September 2020, from Dr. Will Roper, then Assistant Secretary of the Air Force for Acquisition, Technology and Logistics, that a previously undisclosed NGAD demonstrator had begun flight testing. Since then, it’s been reported that at least three NGAD-related demonstrators have flown.
The president also announced an aspiration to have the F-47 enter series production before the end of his term in office, which ends in January 2029.
[..]
Perhaps most surprisingly, Trump said that U.S. allies “are calling constantly” with a view to obtaining an export version of the NGAD fighter. He said that the United States would be selling them to “certain allies … perhaps toned-down versions. We’d like to tone them down about 10 percent which probably makes sense, because someday, maybe they’re not our allies, right?”