The search giant said Wednesday it’s beginning public testing of the software, which debuted in May and which is designed to make calls to businesses and book appointments. Duplex instantly raised questions over the ethics and privacy implications of using an AI assistant to hold lifelike conversations for you.
Google says its plan is to start its public trial with a small group of “trusted testers” and businesses that have opted into receiving calls from Duplex. Over the “coming weeks,” the software will only call businesses to confirm business and holiday hours, such as open and close times for the Fourth of July. People will be able to start booking reservations at restaurants and hair salons starting “later this summer.”
Using data collected by NASA’s late-great Cassini space probe, scientists have detected traces of complex organic molecules seeping out from Enceladus’ ice-covered ocean. It’s yet another sign that this intriguing Saturnian moon has what it takes to sustain life.
If life exists elsewhere in our Solar System, chances are it’s on Enceladus. The moon features a vast, warm subterranean ocean, one sandwiched between an icy crust and a rocky core. Previous research shows this ocean contains simple organic molecules, minerals, and molecular hydrogen—an important source of chemical energy. On Earth, hydrothermal processes near volcanic vents are known to sustain complex ecosystems, raising hopes that something similar is happening on Enceladus.
New research published today in Nature suggests Enceladus’ ocean also contains complex organic molecules—yet another sign that this moon contains the basic conditions and chemical ingredients to support life. Now, this isn’t proof that life exists on this icy moon, but it does show that Enceladus’ warm, soupy ocean is capable of producing complex and dynamic molecules, and the kinds of chemical reactions required to produce and sustain microbial life.
Google’s entire Home infrastructure has suffered a serious outage, with millions of customers on Wednesday morning complaining that their smart devices have stopped working.
At the time of writing, the cloud-connected gadgets are still hosed, the service is still down, and the system appears to have been knackered for at least the past 10 hours. The clobbbered gizmos can’t respond to voice commands, can’t control other stuff in your home, and so on.
Chromecasts can’t stream video, and Home speakers respond to commands with: “Sorry, something went wrong. Try again in a few seconds.”
Users in Google’s home state of California started complaining that their Google Home, Mini, and Chromecast devices were not working properly around midnight Pacific Time on Tuesday, and the issue cropped up in every country in which the Google Home devices are sold.
But it was only when the United States started waking up on Wednesday morning – the US has the vast majority of Google Home devices – that the reports started flooding in, pointing to an outage of the entire system.
Google has confirmed the devices are knackered, but has so far provided no other information, saying only that it is investigating the issue.
[…]
Updated to add
Google has issued the following statement:
We’re aware of an issue affecting some Google Home and Chromecast users. Some users are back online and we are working on a broader fix for all affected users. We will continue to keep our customers updated.
The web giant then followed up with more details – try rebooting to pick up a software fix, or wait up to six hours to get the update:
We’ve identified a fix for the issue impacting Google Home and Chromecast users and it will be automatically rolled out over the next 6 hours. If you would like an immediate fix please follow the directions to reboot your device. If you’re still experiencing an issue after rebooting, contact us at Google Home Support. We are really sorry for the inconvenience and are taking steps to prevent this issue from happening in the future.
You may have seen the ads that Facebook has been running on TV in a full-court press to apologize for abusing users privacy. They’re embarrassing. And, it turns out, they may be a sign of things to come. Based on a recently published patent application, Facebook could one day use ads on television to further violate your privacy once you’ve forgotten about all those other times.
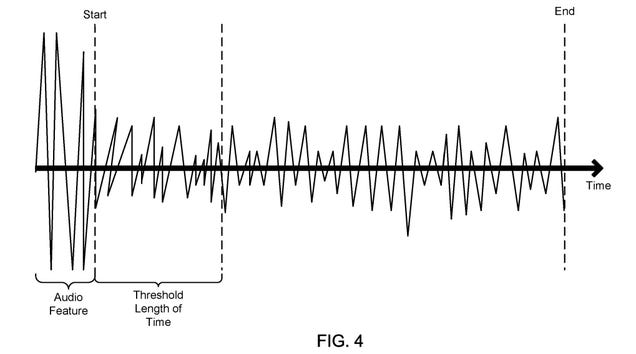
First spotted by Metro, the patent is titled “broadcast content view analysis based on ambient audio recording.” (PDF) It describes a system in which an “ambient audio fingerprint or signature” that’s inaudible to the human ear could be embedded in broadcast content like a TV ad. When a hypothetical user is watching this ad, the audio fingerprint could trigger their smartphone or another device to turn on its microphone, begin recording audio and transmit data about it to Facebook.
Diagram of soundwave containing signal, triggering device, and recording ambient audio.
Everything in the patent is written in legalese and is a bit vague about what happens to the audio data. One example scenario imagines that various ambient audio would be eliminated and the content playing on the broadcast would be identified. Data would be collected about the user’s proximity to the audio. Then, the identifying information, time, and identity of the Facebook user would be sent to the social media company for further processing.
In addition to all the data users voluntarily give up, and the incidental data it collects through techniques like browser fingerprinting, Facebook would use this audio information to figure out which ads are most effective. For example, if a user walked away from the TV or changed the channel as soon as the ad began to play, it might consider the ad ineffective or on a subject the user doesn’t find interesting. If the user stays where they are and the audio is loud and clear, Facebook could compare that seeming effective ad with your other data to make better suggestions for its advertising clients.
An example of a broadcasting device communicating with the network and identifying various users in a household.
Five consumer privacy groups have asked the European Data Protection Board to investigate how Facebook, Google, and Microsoft design their software to see whether it complies with the General Data Protection Regulation (GDPR).
Essentially, the tech giants are accused of crafting their user interfaces so that netizens are fooled into clicking away their privacy, and handing over their personal information.
In a letter sent today to chairwoman Andrea Jelinek, the BEUC (Bureau Européen des Unions de Consommateurs), the Norwegian Consumer Council (Forbrukerrådet), Consumers International, Privacy International and ANEC (just too damn long to spell out) contend that the three tech giants “employed numerous tricks and tactics to nudge or push consumers toward giving consent to sharing as much data for as many purposes as possible.”
The letter coincides with the publication a Forbrukerrådet report, “Deceived By Design,” that claims “tech companies use dark patterns to discourage us from exercising our rights to privacy.”
Dark patterns here refers to app interface design choices that attempt to influence users to do things they may not want to do because they benefit the software maker.
The report faults Google, Facebook and, to a lesser degree, Microsoft for employing default settings that dispense with privacy. It also says they use misleading language, give users an illusion of control, conceal pro-privacy choices, offer take-it-or-leave it choices and use design patterns that make it more laborious to choose privacy.
It argues that dark patterns deprive users of control, a central requirement under GDPR.
As an example of linguistic deception, the report cites Facebook text that seeks permission to use facial recognition on images:
If you keep face recognition turned off, we won’t be able to use this technology if a stranger uses your photo to impersonate you. If someone uses a screen reader, they won’t be told when you’re in a photo unless you’re tagged.
The way this is worded, the report says, pushes Facebook users to accept facial recognition by suggesting there’s a risk of impersonation if they refuse. And it implies there’s something unethical about depriving those forced to use screen readers of image descriptions, a practice known as “confirmshaming.”
Ticketmaster on Wednesday disclosed a data breach reportedly caused by malware infecting a customer support system outsourced to an external company.
In a statement, Ticketmaster said some of its customer data may have been accessed by an unknown intruder. Email notifications were sent to customers who purchased tickets between February and June 23, 2018, the company said
Names, addresses, email addresses, telephone numbers, and payment card details may have been compromised.
A little-known, Florida-based marketing firm called Exactis may be responsible for a significant amount of personal data being exposed. According to a report from Wired, the firm left 340 million individual records on a publicly accessible server that any person could have gotten ahold of.
The leak was discovered earlier this month by security researcher Vinny Troia, founder of the New York-based security firm Night Lion Security. He reported his find to the FBI and Exactis earlier this week, and while the company has since protected the data, it’s unclear just how long it sat exposed.
So just how bad is the leak? It’s pretty bad! The data stored on the server amounts to about two terabytes worth of personal information.
Troia told Wired the database from Exactis appears to have data from “pretty much every US citizen” in it, with approximately 230 million records on American adults and 110 million records on US business contacts. That falls in line with Exactis’ own claim on its website that it has data on 218 million individuals. If the leak is truly as big as estimated, it would make for one of the largest exposures of personal information in recent memory.
Those records contain a variety of data points, including phone numbers, home addresses, and email addresses connected to an individual’s name. It also included more than 400 characteristics about a person, ranging from if the person is a smoker or not, their religion, if they own any pets, if they have kids, their age, gender, etc. It also included interests like scuba diving and plus-sized apparel, per Wired.
Notably, financial information and Social Security numbers were not discovered in the database. (Don’t worry, all that information was likely already exposed by Equifax last year.) That doesn’t mean the information doesn’t have value, though. Were this data to have been accessed by a malicious actor, they could easily pair it with previous breaches to create an even more complete profile of an individual or use it to carry out social engineering attacks.
There are plenty of troubling things about the Exactis leak, not the least of which is the sheer breadth of information exposed. First, there’s the question of just where this small marketing firm based in Palm Coast, Florida got its hands on the personal interests and contact information of hundreds of millions of Americans.
Troia said he didn’t know where the data was coming from exactly, but called it “one of the most comprehensive collections” he’s ever seen. Marc Rotenberg, executive director of the nonprofit Electronic Privacy Information Center, theorized to Wired that the information may have come from a variety of sources including magazine subscriptions, credit card transaction data, and credit reports.
Then there’s the fact that no one has any idea if this massive database was accessed by anyone prior to Troia. Only Exactis would have any idea how long the server has sat unprotected, and could potentially see who accessed it. The company has not yet publicly responded to the leak and did not respond to request for comment.
Odds are, someone—a hacker or just a random person—likely stumbled across the server before Troia. The security researcher found the database while using the search tool Shodan, which allows just about anyone to scan publicly accessible, internet connected devices. Anyone with access to the same tools could have just as easily discovered the same server Troia found.
These types of leaks, where a server containing sensitive information is left unsecured, happen with surprising regularity. A conservative data firm accidentally leaked information on more than 200 million Americans last year. 12,000 social media influencers had their information exposed in a similar mishap, as did US military veterans and government contractors. All of this goes to show that companies in the business of collecting data aren’t in the business of protecting it.
Virtual Private Networks, a.k.a. VPN, are very handy to make your internet traffic to appear from a different location than you are.
All your traffic is tunneled to an exit point of your choosing, for example a data center in New York City. To Google Photos service you then seem to be located in New York City, USA.
One such easy to use VPN service for android is Tunnelbear but there are many others. Tunnelbear offers 500 MB of free traffic and you don’t need much more than 20MB to get this set-up.
It worked, I got face/people search in my Goole Photos android app and this is how I did it:
In summary you want to delete the Google Photos application data and re-start the application while being connected to the VPN. This will trick Google Photos into believing you are located in US and the feature will be switched on.
Once the feature is switched on you don’t have to re-connect to the VPN; the feature will remain on!
Detailed instructions: delete the data from Google Photos, turn on airplane mode, turn off location services, connect via Tunnelbear, start up Google photos, go through the introductory 4 steps, go into settings and turn on “Group Similar Faces”. Success, you now have your photos organised by many, many different people present in them.
The face categorisation appeared as soon as I connected via VPN. There was no initial time for google to build up a face database for my photos.
This really seems to suggest that all photos added to Google Photos are categorised by face. The search feature is just hidden in certain geographical locations to comply with local laws.
Is this really in the spirit of the law or just cheat? You decide!
Since late 2013, this band of cybercriminals has penetrated the digital inner sanctums of more than 100 banks in 40 nations, including Germany, Russia, Ukraine, and the U.S., and stolen about $1.2 billion, according to Europol, the European Union’s law enforcement agency. The string of thefts, collectively dubbed Carbanak—a mashup of a hacking program and the word “bank”—is believed to be the biggest digital bank heist ever.
[…]
Besides forcing ATMs to cough up money, the thieves inflated account balances and shuttled millions of dollars around the globe. Deploying the same espionage methods used by intelligence agencies, they appropriated the identities of network administrators and executives and plumbed files for sensitive information about security and account management practices.
[…]
For years police and banking-industry sleuths doubted they’d ever catch the phantoms behind Carbanak. Then, in March, the Spanish National Police arrested Ukrainian citizen Denis Katana in the Mediterranean port city of Alicante. The authorities have held him since then on suspicion of being the brains of the operation. Katana’s lawyer, Jose Esteve Villaescusa, declined to comment, and his client’s alleged confederates couldn’t be reached for comment. While Katana hasn’t been charged with a crime, Spanish detectives say financial information, emails, and other data trails show he was the architect of a conspiracy that spanned three continents. And there are signs that the Carbanak gang is far from finished.
[…]
The attackers cased their targets for months, says Kaspersky. The Carbanak crew was looking for executives with the authority to direct the flow of money between accounts, to other lenders, and to ATMs. They were also studying when and how the bank moved money around. The thieves didn’t want to do anything that would catch the eyes of security. State-backed spies use this type of reconnaissance in what’s known as an advanced persistent threat. “In those instances, the attacks are designed to steal data, not get their hands on money,” Emm says. When the time was right, the thieves used the verification codes of bank officers to create legit-looking transactions.
By the fall of 2014, the authorities realized they were dealing with something new. That October, Keith Gross, chair of the cybersecurity group for a European bank lobby, called a crash meeting with experts from Citigroup, Deutsche Bank, and other major European lenders. In a meeting room at Europol’s fortress-like headquarters in The Hague, Kaspersky researchers briefed the bank officials on what they’d found in Ukraine. “I’ve never seen anything like this before,” Troels Oerting, then the head of Europol’s Cybercrime Centre, told the group. “It’s a well-orchestrated malware attack, it’s very sophisticated, and it’s global.”
So Europol went global, too, enlisting help from law enforcement agencies in Belarus, Moldova, Romania, Spain, Taiwan, the U.S., as well as bank industry representatives. It set up a secure online clearinghouse where investigators could cross-check data and find links between the thefts, says Fernando Ruiz, head of operations in Europol’s cybercrime unit. At the heart of its operation was a lab where technicians dissected the two dozen samples of malware identified in the Carbanak thefts. By isolating unique characteristics in the code, detectives could trace where the programs came from and maybe who was using them. The work led them toward Denis Katana’s apartment in Alicante, a four-hour drive southeast of Madrid. “This is what the Spanish police used to open their investigation,” Ruiz says.
[…]
Yet experts point out that even if Katana was the mastermind, he was just one guy in a crime that surely must have had many authors. Unlike the bank jobs of yore, digital heists are amoeba-like ventures that divide over and over again as the malware proliferates. “We’ve already seen the modification of Carbanak and multiple groups using it,” says Kimberly Goody, an analyst at security software maker FireEye Inc. “Same case with Cobalt.”
In recent weeks, employees at banks in the Russian-speaking world have been receiving emails that appear to be from Kaspersky, the security company that unearthed Carbanak. The messages warn recipients that their PCs have been flagged for possibly violating the law and they should download a complaint letter or face penalties. When they click on the attachment, a version of the Cobalt malware infects their networks. It turns out cyberheists may not die even when their suspected perpetrators are nabbed.
Mumbai has the become the largest Indian city to ban single-use plastics, with residents caught using plastic bags, cups or bottles to face penalties of up to 25,000 rupees (£276) and three months in jail from Monday.
Council inspectors in navy blue jackets have been posted across the city to catch businesses or residents still using plastic bags. Penalties have already kicked in for businesses and several, reportedly including a McDonald’s and Starbucks, have already been fined.
Penalties range from 5,000 rupees for first-time offenders to 25,000 rupees and the threat of three months’ jail for those caught repeatedly using single-use plastics.
“For the pollution situation it’s fine to do this but for the people it is a big problem,” said Kamlash Mohan Chaudhary, a Mumbai resident. “People here carry everything in plastic bags.”
Chaudhary, a taxi driver, said he had started carrying a cloth bag and that his local mutton vendor had begun wrapping the meat in newspaper rather than plastic sheets.
Local media have reported complaints from vendors who say some inspectors are using confusion over the ban to extort money from businesses.
India recently hosted World Environment Day, which this year focused on the epidemic of plastic waste. About 6.3bn tonnes of plastic globally has been discarded into the environment since 1950, most of which will not break down for at least 450 years.
Half of the world’s plastic was created in the past 13 years and about half of that is thought to be for products used once and thrown away, such as bags, cups or straws.
India’s use of plastic is less than half of the global average: about 11kg a year per capita compared with 109kg in the US.
It took nearly a century of trial and error for human scientists to organize the periodic table of elements, arguably one of the greatest scientific achievements in chemistry, into its current form.
A new artificial intelligence (AI) program developed by Stanford physicists accomplished the same feat in just a few hours.
Called Atom2Vec, the program successfully learned to distinguish between different atoms after analyzing a list of chemical compound names from an online database. The unsupervised AI then used concepts borrowed from the field of natural language processing – in particular, the idea that the properties of words can be understood by looking at other words surrounding them – to cluster the elements according to their chemical properties.
“We wanted to know whether an AI can be smart enough to discover the periodic table on its own, and our team showed that it can,” said study leader Shou-Cheng Zhang, the J. G. Jackson and C. J. Wood Professor of Physics at Stanford’s School of Humanities and Sciences.
The bots learn from self-play, meaning two bots playing each other and learning from each side’s successes and failures. By using a huge stack of 256 graphics processing units (GPUs) with 128,000 processing cores, the researchers were able to speed up the AI’s gameplay so that they learned from the equivalent of 180 years of gameplay for every day it trained. One version of the bots were trained for four weeks, meaning they played more than 5,000 years of the game.
[…]
In a match, the OpenAI team initially gives each bot a mandate to do as well as it can on its own, meaning that the bots learned to act selfishly and steal kills from each other. But by turning up a simple metric, a weighted average of the team’s success, the bots soon begin to work together and execute team attacks quicker than humanly possible. The metric was dubbed by OpenAI as “team spirit.”
“They start caring more about team fighting, and saving one another, and working together in these skirmishes in order to make larger advances towards the group goal,” says Brooke Chan, an engineer at OpenAI.
Right now, the bots are restricted to playing certain characters, can’t use certain items like wards that allow players to see more of the map or anything that grants invisibility, or summon other units to help them fight with spells. OpenAI hopes to lift those restrictions by the competition in August.
The home WiFi network is a sacred place; your own local neighborhood of cyberspace. There we connect our phones, laptops, and “smart” devices to each other and to the Internet and in turn we improve our lives, or so we are told. By the late twenty teens, our local networks have become populated by a growing number of devices. From 📺 smart TVs and media players to 🗣 home assistants, 📹 security cameras, refrigerators, 🔒 door locks and🌡thermostats, our home networks are a haven for trusted personal and domestic devices.
Many of these devices offer limited or non-existent authentication to access and control their services. They inherently trust other machines on the network in the same way that you would inherently trust someone you’ve allowed into your home. They use protocols like Universal Plug and Play (UPnP) and HTTP to communicate freely between one another but are inherently protected from inbound connections from the Internet by means of their router’s firewall 🚫. They operate in a sort of walled garden, safe from external threat. Or so their developers probably thought.
The problems are huge, not least because the EU will implement an automated content filter, which means that memes will die, but also, if you have the money to spam the system with requests, you can basically kill any content you want with the actual content holder only having a marginal chance of navigating EU burocracy in order to regain ownership of their rights.
Among our exciting announcements at //Build, one of the things I was thrilled to launch is the AI Lab – a collection of AI projects designed to help developers explore, experience, learn about and code with the latest Microsoft AI Platform technologies.
What is AI Lab?
AI Lab helps our large fast-growing community of developers get started on AI. It currently houses five projects that showcase the latest in custom vision, attnGAN (more below), Visual Studio tools for AI, Cognitive Search, machine reading comprehension and more. Each lab gives you access to the experimentation playground, source code on GitHub, a crisp developer-friendly video, and insights into the underlying business problem and solution. One of the projects we highlighted at //Build was the search and rescue challenge which gave the opportunity to developers worldwide to use AI School resources to build and deploy their first AI model for a problem involving aerial drones.
a team of engineers at the Johns Hopkins University that has created an electronic skin. When layered on top of prosthetic hands, this e-dermis brings back a real sense of touch through the fingertips.
“After many years, I felt my hand, as if a hollow shell got filled with life again,” says the anonymous amputee who served as the team’s principal volunteer tester.
Made of fabric and rubber laced with sensors to mimic nerve endings, e-dermis recreates a sense of touch as well as pain by sensing stimuli and relaying the impulses back to the peripheral nerves.
“We’ve made a sensor that goes over the fingertips of a prosthetic hand and acts like your own skin would,” says Luke Osborn, a graduate student in biomedical engineering. “It’s inspired by what is happening in human biology, with receptors for both touch and pain.
“This is interesting and new,” Osborn said, “because now we can have a prosthetic hand that is already on the market and fit it with an e-dermis that can tell the wearer whether he or she is picking up something that is round or whether it has sharp points.”
00:00Current time01:31Engineers at the Johns Hopkins University have created an electronic skin and aim to restore the sense of touch through the fingertips of prosthetic hands. Credit: Science Robotics/AAAS
The work—published June 20 in the journal Science Robotics – shows it is possible to restore a range of natural, touch-based feelings to amputees who use prosthetic limbs. The ability to detect pain could be useful, for instance, not only in prosthetic hands but also in lower limb prostheses, alerting the user to potential damage to the device.
A group of scientists have built a neural network to sniff out any unusual nuclear activity. Researchers from the Pacific Northwest National Laboratory (PNNL), one of the United States Department of Energy national laboratories, decided to see if they could use deep learning to sort through the different nuclear decay events to identify any suspicious behavior.
The lab, buried beneath 81 feet of concrete, rock and earth, is blocked out from energy from cosmic rays, electronics and other sources. It means that the data collected is less noisy, making it easier to pinpoint unusual activity.
The system looks for electrons emitted and scattered from radioactive particles decaying, and monitor the abundance of argon-37, a radioactive isotope of argon-39 that is created synthetically through nuclear explosions.
Argon-37 which has a half-life of 35 days, is emitted when calcium captures excess neutrons and decays by emitting an alpha particle. Emily Mace, a scientist at PNNL, said she looks for the energy, timing, duration and other features of the decay events to see if it’s from nuclear testing.
“Some pulse shapes are difficult to interpret,” said Mace. “It can be challenging to differentiate between good and bad data.”
Deep learning makes that process easier. Computer scientists collected 32,000 pulses and annotated their properties, teaching the system to spot any odd features that might classify a signal as ‘good’ or ‘bad’.
“Signals can be well behaved or they can be poorly behaved,” said Jesse Ward. “For the network to learn about the good signals, it needs a decent amount of bad signals for comparison.” When the researchers tested their system with 50,000 pulses and asked human experts to differentiate signals, the neural network agreed with them 100 per cent of the time.
It also correctly identified 99.9 per cent of the pulses compared to 96.1 per cent from more conventional techniques.
Red shell is a Spyware that tracks data of your PC and shares it with 3rd parties. On their website they formulate it all in very harmless language, but the fact is that this is software from someone i don’t trust and whom i never invited, which is looking at my data and running on my pc against my will. This should have no place in a full price PC game, and in no games if it were up to me.
I make this thread to raise awareness of these user unfriendly marketing practices and data mining software that are common on the mobile market, and which are flooding over to our PC Games market. As a person and a gamer i refuse to be data mined. My data is my own and you have no business making money of it.
The announcement yesterday was only from “Holy Potatoes! We’re in Space?!”, but i would consider all their games as on risk to contain that spyware if they choose to include it again, with or without announcement. Also the Publisher of this one title is Daedalic Entertainment, while the others are self published. I would think it could be interesting to check if other Daedalic Entertainment Games have that spyware in it as well. I had no time to do that.
Hackers stole more than $30 million worth of cryptocurrencies from South Korea’s top bitcoin exchange, sending the unit’s price falling around the world on Wednesday.
The virtual currency was priced at $6,442 dollars late afternoon in Seoul, down about 4.4 percent from 24 hours earlier, after the latest attack on Bithumb raised concerns over cryptocurrency security.
Hyper-wired South Korea has emerged as a hotbed of trading in virtual units, at one point accounting for some 20 percent of global bitcoin transactions—about 10 times the country’s share of the global economy.
Bithumb, which has more than 1 million customers, is the largest virtual currency exchange in the South.
“It has been confirmed that virtual currencies worth 35 billion won ($32 million) was stolen through late night yesterday (Tuesday) to early morning today,” the exchange said in a statement.
All deposits and withdrawals were suspended indefinitely to “ensure security”, it said, adding the losses would be covered from the firm’s own reserves.
It was the second major attack on South Korean virtual currency exchanges in just 10 days, after hackers stole 40 billion won from Seoul-based Coinrail, which suspended withdrawal and deposits services since then.
The AI, called Project Debater, appeared on stage in a packed conference room at IBM’s San Francisco office embodied in a 6ft tall black panel with a blue, animated “mouth”. It was a looming presence alongside the human debaters Noa Ovadia and Dan Zafrir, who stood behind a podium nearby.
Although the machine stumbled at many points, the unprecedented event offered a glimpse into how computers are learning to grapple with the messy, unstructured world of human decision-making.
For each of the two short debates, participants had to prepare a four-minute opening statement, followed by a four-minute rebuttal and a two-minute summary. The opening debate topic was “we should subsidize space exploration”, followed by “we should increase the use of telemedicine”.
In both debates, the audience voted Project Debater to be worse at delivery but better in terms of the amount of information it conveyed. And in spite of several robotic slip-ups, the audience voted the AI to be more persuasive (in terms of changing the audience’s position) than its human opponent, Zafrir, in the second debate.
It’s worth noting, however, that there were many members of IBM staff in the room and they may have been rooting for their creation.
IBM hopes the research will eventually enable a more sophisticated virtual assistant that can absorb massive and diverse sets of information to help build persuasive arguments and make well-informed decisions – as opposed to merely responding to simple questions and commands.
Project Debater was a showcase of IBM’s ability to process very large data sets, including millions of news articles across dozens of subjects, and then turn snippets of arguments into full flowing prose – a challenging task for a computer.
[…]
Once an AI is capable of persuasive arguments, it can be applied as a tool to aid human decision-making.
“We believe there’s massive potential for good in artificial intelligence that can understand us humans,” said Arvind Krishna, director of IBM Research.
One example of this might be corporate boardroom decisions, where there are lots of conflicting points of view. The AI system could, without emotion, listen to the conversation, take all of the evidence and arguments into account and challenge the reasoning of humans where necessary.
“This can increase the level of evidence-based decision-making,” said Reed, adding that the same system could be used for intelligence analysis in counter-terrorism, for example identifying if a particular individual represents a threat.
In both cases, the machine wouldn’t make the decision but would contribute to the discussion and act as another voice at the table.
Essentially, Project Debater assigns a confidence score to every piece of information it understands. As in: how confident is the system that it actually understands the content of what’s being discussed? “If it’s confident that it got that point right, if it really believes it understands what that opponent was saying, it’s going to try to make a very strong argument against that point specifically,” Welser explains.
”If it’s less confident,” he says, “it’ll do it’s best to make an argument that’ll be convincing as an argument even if it doesn’t exactly answer that point. Which is exactly what a human does too, sometimes.”
So: the human says that government should have specific criteria surrounding basic human needs to justify subsidization. Project Debater responds that space is awesome and good for the economy. A human might choose that tactic as a sneaky way to avoid debating on the wrong terms. Project Debater had different motivations in its algorithms, but not that different.
The point of this experiment wasn’t to make me think that I couldn’t trust that a computer is arguing in good faith — though it very much did that. No, the point is that IBM showing off that it can train AI in new areas of research that could eventually be useful in real, practical contexts.
The first is parsing a lot of information in a decision-making context. The same technology that can read a corpus of data and come up with a bunch of pros and cons for a debate could be (and has been) used to decide whether or not a stock might be worth investing in. IBM’s system didn’t make the value judgement, but it did provide a bunch of information to the bank showing both sides of a debate about the stock.
As for the debating part, Welser says that it “helps us understand how language is used,” by teaching a system to work in a rhetorical context that’s more nuanced than the usual Hey Google give me this piece of information and turn off my lights. Perhaps it might someday help a lawyer structure their arguments, “not that Project Debater would make a very good lawyer,” he joked. Another IBM researcher suggested that this technology could help judge fake news.
How close is this to being something IBM turns into a product? “This is still a research level project,” Welser says, though “the technologies underneath it right now” are already beginning to be used in IBM projects.
The system listened to four minutes of its human opponent’s opening remarks, then parsed that data and created an argument that highlighted and attempted to debunk information shared by the opposing side. That’s incredibly impressive because it has to understand not only the words but the context of those words. Parroting back Wikipedia entries is easy, taking data and creating a narrative that’s based not only on raw data but also takes into account what it’s just heard? That’s tough.
In a world where emotion and bias colors all our decisions, Project Debater could help companies and governments see through the noise of our life experiences and produce mostly impartial conclusions. Of course, the data set it pulls from is based on what humans have written and those will have their own biases and emotion.
While the goal is an unbiased machine, during the discourse Project Debate wasn’t completely sterile. Amid its rebuttal against debater Dan Zafrir, while they argued about telemedicine expansion, the system stated that Zafrir had not told the truth during his opening statement about the increase in the use of telemedicine. In other words, it called him a liar.
When asked about the statement, Slonim said that the system has a confidence threshold during rebuttals. If it’s feeling very confident it creates a more complex statement. If it’s feeling less confident, the statement is less impressive.
An artificially intelligent system has been demonstrated generating URLs for phishing websites that appear to evade detection by security tools.
Essentially, the software can come up with URLs for webpages that masquerade as legit login pages for real websites, when in actual fact, the webpages simply collect the entered username and passwords to later hijack accounts.
Blacklists and algorithms – intelligent or otherwise – can be used to automatically identify and block links to phishing pages. Humans should be able to spot that the web links are dodgy, but not everyone is so savvy.
Using the Phishtank database, a group of computer scientists from Cyxtera Technologies, a cybersecurity biz based in Florida, USA, have built <a target=”_blank” rel=”nofollow” href=”“>DeepPhish, which is machine-learning software that, allegedly, generates phishing URLs that beat these defense mechanisms.
[…]
The team inspected more than a million URLs on Phishtank to identify three different phishing miscreants who had generated webpages to steal people’s credentials. The team fed these web addresses into AI-based phishing detection algorithm to measure how effective the URLs were at bypassing the system.
The first scumbag of the trio used 1,007 attack URLs, and only 7 were effective at avoiding setting off alarms, across 106 domains, making it successful only 0.69 per cent of the time. The second one had 102 malicious web addresses, across 19 domains. Only five of them bypassed the threat detection algorithm and it was effective 4.91 per cent of the time.
Next, they fed this information into a Long-Short Term Memory network (LSTM) to learn the general structure and extract features from the malicious URLs – for example the second threat actor commonly used “tdcanadatrustindex.html” in its address.
All the text from effective URLs were taken to create sentences and encoded into a vector and fed into the LSTM, where it is trained to predict the next character given the previous one.
Over time it learns to generate a stream of text to simulate a list of pseudo URLs that are similar to the ones used as input. When DeepPhish was trained on data from the first threat actor, it also managed to create 1,007 URLs, and 210 of them were effective at evading detection, bumping up the score from 0.69 per cent to 20.90 per cent.
When it was following the structure from the second threat actor, it also produced 102 fake URLs and 37 of them were successful, increasing the likelihood of tricking the existent defense mechanism from 4.91 per cent to 36.28 per cent.
The effectiveness rate isn’t very high as a lot of what comes out the LSTM is effective gibberish, containing strings of forbidden characters.
“It is important to automate the process of retraining the AI phishing detection system by incorporating the new synthetic URLs that each threat actor may create,” the researchers warned. ®
Following an open selection process, the Commission has appointed 52 experts to a new High-Level Expert Group on Artificial Intelligence, comprising representatives from academia, civil society, as well as industry.
The High-Level Expert Group on Artificial Intelligence (AI HLG) will have as a general objective to support the implementation of the European strategy on AI. This will include the elaboration of recommendations on future AI-related policy development and on ethical, legal and societal issues related to AI, including socio-economic challenges.
Moreover, the AI HLG will serve as the steering group for the European AI Alliance’s work, interact with other initiatives, help stimulate a multi-stakeholder dialogue, gather participants’ views and reflect them in its analysis and reports.
In particular, the group will be tasked to:
Advise the Commission on next steps addressing AI-related mid to long-term challenges and opportunities through recommendations which will feed into the policy development process, the legislative evaluation process and the development of a next-generation digital strategy.
Propose to the Commission draft AI ethics guidelines, covering issues such as fairness, safety, transparency, the future of work, democracy and more broadly the impact on the application of the Charter of Fundamental Rights, including privacy and personal data protection, dignity, consumer protection and non-discrimination
Support the Commission on further engagement and outreach mechanisms to interact with a broader set of stakeholders in the context of the AI Alliance, share information and gather their input on the group’s and the Commission’s work.
One of the vendors for which we found vulnerable devices was Axis Communications. Our team discovered a critical chain of vulnerabilities in Axis security cameras. The vulnerabilities allow an adversary that obtained the camera’s IP address to remotely take over the cameras (via LAN or internet). In total, VDOO has responsibly disclosed seven vulnerabilities to Axis security team.
Chaining three of the reported vulnerabilities together, allows an unauthenticated remote attacker that has access to the camera login page through the network (without any previous access to the camera or credentials to the camera) to fully control the affected camera. An attacker with such control could do the following:
Access to camera’s video stream
Freeze the camera’s video stream
Control the camera – move the lens to a desired point, turn motion detection on/off
Add the camera to a botnet
Alter the camera’s software
Use the camera as an infiltration point for network (performing lateral movement)
Render the camera useless
Use the camera to perform other nefarious tasks (DDoS attacks, Bitcoin mining, others)
The vulnerable products include 390 models of Axis IP Cameras. The full list of affected products can be found here. Axis uses the ACV-128401 identifier for relating to the issues we discovered.
To the best of our knowledge, these vulnerabilities were not exploited in the field, and therefore, did not lead to any concrete privacy violation or security threat to Axis’s customers.
We strongly recommend Axis customers who did not update their camera’s firmware to do so immediately or mitigate the risks in alternative ways. See instructions in FAQ section below.
We also recommend that other camera vendors follow our recommendations at the end of this report to avoid and mitigate similar threats.


 One such easy to use VPN service for android is
One such easy to use VPN service for android is