One of a dozen new moons discovered around Jupiter is circling the planet on a suicide orbit that will inevitably lead to its violent destruction, astronomers say.
Researchers in the US stumbled upon the new moons while hunting for a mysterious ninth planet that is postulated to lurk far beyond the orbit of Neptune, the most distant planet in the solar system.
The team first glimpsed the moons in March last year from the Cerro Tololo Inter-American Observatory in Chile, but needed more than a year to confirm that the bodies were locked in orbit around the gas giant. “It was a long process,” said Scott Sheppard, who led the effort at the Carnegie Institution for Science in Washington DC.
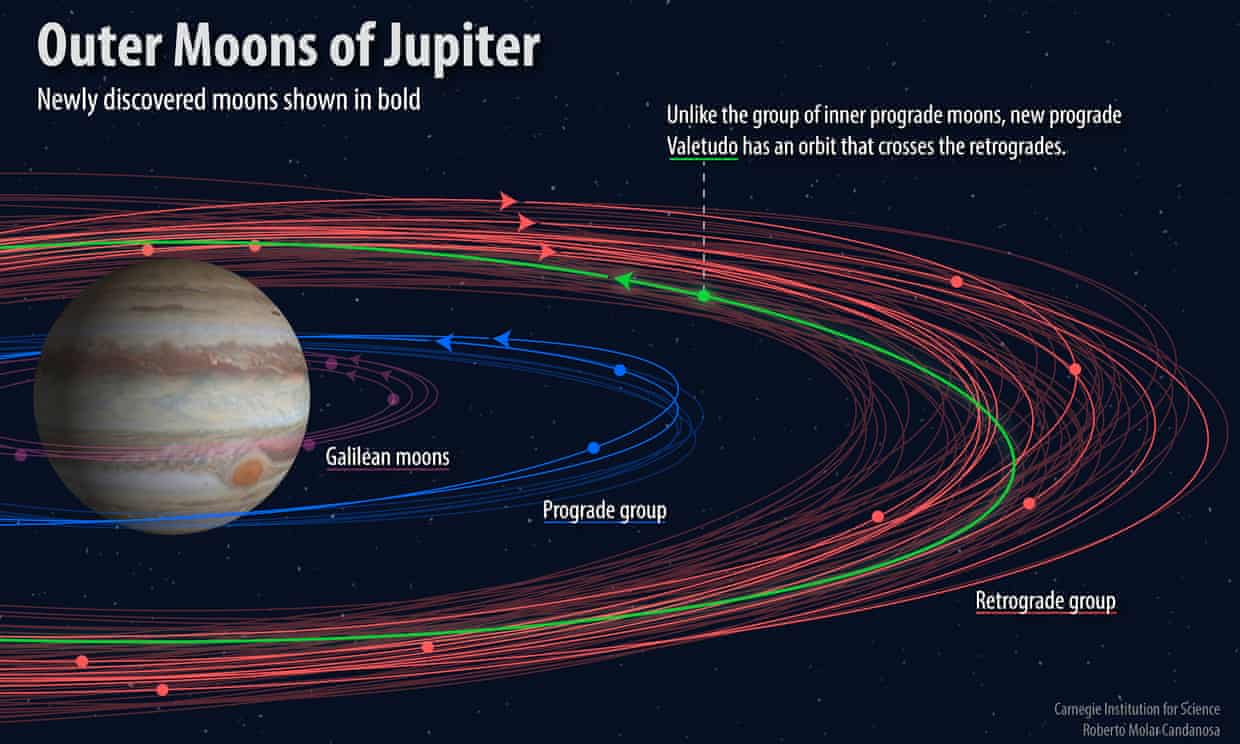
Jupiter, the largest planet in the solar system, was hardly short of moons before the latest findings. The fresh haul of natural satellites brings the total number of Jovian moons to 79, more than are known to circle any other planet in our cosmic neighbourhood.
Astronomers have discovered twelve new moons orbiting Jupiter, bringing the total number of Jovian moons to 79. Photograph: Carnegie Institution for Science
Nine of the new moons belong to an outer group that orbit Jupiter in retrograde, meaning they travel in the opposite direction to the planet’s spin. They are thought to be the remnants of larger parent bodies that were broken apart in collisions with asteroids, comets and other moons. Each takes about two years to circle the planet.
Two more of the moons are in a group that circle much closer to the planet in prograde orbits which travel in the same direction as Jupiter’s spin. Most likely to be pieces of a once larger moon that was broken up in orbit, they take nearly a year to complete a lap around Jupiter. Which direction the moons swing around the planet depends on how they were first captured by Jupiter’s gravitational field.
Astronomers describe the twelfth new Jovian moon as an “oddball”. Less than a kilometre wide, the tiny body circles Jupiter on a prograde orbit but at a distance that means it crosses the path of other moons hurtling towards it. Scientists have named the new moon Valetudo after the Roman god Jupiter’s great-granddaughter, the goddess of health and hygiene. But given the impending violence, it may be more than coincidence that Vale Tudo, which translates from Portuguese as “anything goes”, is an early form of full-contact mixed martial arts.
“Valetudo is like driving down the highway on the wrong side of the road,” said Sheppard. “It is moving prograde while all the other objects at a similar distance from Jupiter are moving retrograde. Thus head-on collisions are likely.”
It has been widely reported that software and web applications made in China are often built with a “backdoor” feature, allowing the manufacturer or the government to monitor and collect data from the user’s device.
But how exactly does the backdoor feature work? Recent discussion among mobile phone users in mainland China has shed some light on the question.
Last month, users of Vivo NEX, a Chinese Android phone, found that when they opened certain applications on the phone, including Chinese internet giant QQ browser and travel booking app Ctrip, the mobile device’s camera would self-activate.
Different from most mobile phones, where a camera can be activated without giving the user any signal, the Vivo NEX has a tiny retractable camera that physically pops out from the top of the device when it is turned on.
Vivo NEX retractable camera. Photo by Vivo NEX, via We Chaat.
Though perhaps unintentionally, this design feature has given Chinese mobile users a tangible sense of exactly when and how they are being monitored.
One Weibo user observed that the retractable camera self-activates whenever he opens a new chat on Telegram, a messaging application designed for secured and encrypted communication.
While Telegram reacted quickly to reports of the issue and fixed the camera bug, Chinese internet giant Tencent instead defended the feature, arguing that its QQ browser needs the camera activated to prepare for scanning QR codes and insisted that the camera would not take photos or audio recordings unless the user told it to do so.
This explanation was not reassuring for users, as it only revealed the degree to which the QQ browser could record users’ activities.
After the news of the self-activated camera bug spread, users started testing the issue on other applications and found that Baidu’s voice input application has access to both the camera and voice recording function, which can be launched without users’ authorization.
A Vivo NEX user found that once she had installed Baidu’s voice input system, it would activate the phone’s camera and sound recording function whenever the user opened any application — including chat apps, browsers — that allows the user to input text.
Baidu says that the self-activated recording is not a backdoor but a “frontdoor” application that allows the company collect and adjust to background noise so as to prepare for and optimize its voice input function. This was not reassuring for users — any microphone collecting background noise would also unquestionably capture the voices and conversations of a user and whomever she speaks with face-to-face.
How does camera snooping affect people outside China?
These snooping features have not just affected people from mainland China, but all of those from outside the country who want to communicate with friends in China.
As the Chinese government has blocked most leading foreign social media technologies, anyone who wants to communicate with people in China has little choice but to install applications made in China, such as WeChat.
One strategy for increasing one’s mobile privacy when using Chinese-made applications is to keep all insecure applications on one device and assume that these communications will be recorded or spied upon, and to keep a second device for more secure or “clean” applications. When using an encrypted communication application like Telegram to communicate with friends in China, one also has to make sure that their friends’ mobile devices are clean.
Baidu has been notorious for snooping into users’ private data and activities. In January 2018, a government-affiliated consumer association in Jiangsu province filed a lawsuit against Baidu’s search application and mobile browser for snooping on users’ phone conversations and accessing their geo-location data without user consent. But the case was dropped in March after Baidu updated its applications by securing users’ consent for control over their mobile camera, voice recording, geo-location data, even though these controls are not essential to the application’s functionality.
In response to public concern about these backdoor features, Baidu and other Chinese internet giants may defend themselves simply by arguing that users have consented to having their cameras activated. But given the monopolistic nature of Chinese Internet giants in the country, do ordinary users have the power — or the choice — to say no?
What if, instead of a black and white X-ray picture, a doctor of a cancer patient had access to colour images identifying the tissues being scanned? This colour X-ray imaging technique could produce clearer and more accurate pictures and help doctors give their patients more accurate diagnoses.
This is now a reality, thanks to a New-Zealand company that scanned, for the first time, a human body using a breakthrough colour medical scanner based on the Medipix3 technology developed at CERN.
[…]
Medipix is a family of read-out chips for particle imaging and detection. The original concept of Medipix is that it works like a camera, detecting and counting each individual particle hitting the pixels when its electronic shutter is open. This enables high-resolution, high-contrast, very reliable images, making it unique for imaging applications in particular in the medical field.
[…]
MARS Bioimaging Ltd, which is commercialising the 3D scanner, is linked to the Universities of Otago and Canterbury.
[…]
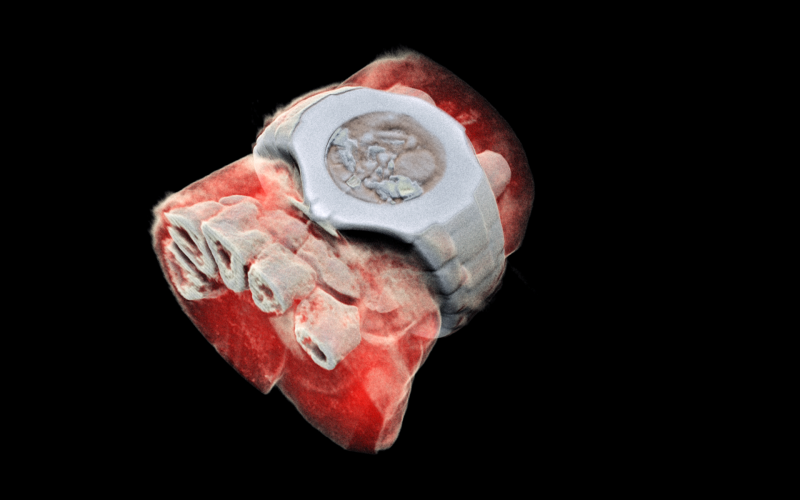
MARS’ solution couples the spectroscopic information generated by the Medipix3 enabled detector with powerful algorithms to generate 3D images. The colours represent different energy levels of the X-ray photons as recorded by the detector and hence identifying different components of body parts such as fat, water, calcium, and disease markers.
A 3D image of a wrist with a watch showing part of the finger bones in white and soft tissue in red. (Image: MARS Bioimaging Ltd)
So far, researchers have been using a small version of the MARS scanner to study cancer, bone and joint health, and vascular diseases that cause heart attacks and strokes. “In all of these studies, promising early results suggest that when spectral imaging is routinely used in clinics it will enable more accurate diagnosis and personalisation of treatment,” Professor Anthony Butler says.
In the 1980s, scientists learned that all humans living today are descended from a woman, dubbed “Mitochondrial Eve,” who lived in Africa between 150,000 to 200,000 years ago. This discovery, along with other evidence, suggested humans evolved from a single ancestral population—an interpretation that is not standing the test of time. The story of human evolution, as the latest research suggests, is more complicated than that.
A new commentary paper published today in Trends in Ecology & Evolution is challenging the predominant view that our species, Homo sapiens, emerged from a single ancestral population and a single geographic region in Africa. By looking at some of the latest archaeological, fossil, genetic, and environmental evidence, a team of international experts led by Eleanor Scerri from Oxford’s School of Archaeology have presented an alternative story of human evolution, one showing that our species emerged from isolated populations scattered across Africa, who occasionally came together to interbreed. Gradually, this intermingling of genetic characteristics produced our species.
Indeed, the origin of Homo sapiens isn’t as neat and tidy as we’ve been led to believe.
[…]
“The idea that humans emerged from one population and progressed in a simple linear fashion to a modern physical appearance is attractive, but unfortunately no longer a very good fit with the available information,” said Scerri. “Instead it looks very much like humans emerged within a complex set of populations that were scattered across Africa.”
The reality, as suggested by this latest research, is that human ancestors were spread across Africa, segregated by diverse habitats and shifting environmental boundaries, such as forests and deserts. These prolonged periods of isolation gave rise to a surprising variety of human forms, and a diverse array of adaptive traits. When stratified groups interbred, they preserved the best characteristics that evolution had to offer. Consequently, the authors say that terms like “archaic humans” and “anatomically modern humans” are increasingly problematic given the evidence.
Scerri said occasional episodes of interbreeding between these different, semi-isolated populations created a diverse “meta-population” of humans within Africa, from which our species emerged over a very long time. Our species, Homo sapiens, emerged around 300,000 years ago, but certain characteristics, like a round brain case, pronounced chin, and a small face, didn’t appear together in a single individual until about 100,000 years ago, and possibly not until 40,000 years ago—a long time before genetics and other archaeological evidence tells us our species was already in existence. Isolated populations came together to exchange genes and culture—two interrelated processes that shaped our species, explained Scerri.
The new paper, instead of providing new evidence, provides a comprehensive review and analysis of what the latest scientific literature is telling us about human evolution, starting around 300,000 years ago. The researchers found that human fossils from different regions of Africa all featured a diverse mix of modern and more “archaic” physical characteristics. The earliest of these date back to between 300,000 to 250,000 years ago, and originate from opposite ends of Africa, stretching from the southern tip of the continent to its northernmost points. Many of these fossils were found with sophisticated archaeological items associated with our species, including specialized tools mounted onto wooden handles and shafts, and often utilizing different bindings and glues. These artifacts, like the diverse fossils, appeared across Africa around the same time, and studies of their distribution suggest they belonged discrete groups. At the same time, genetic data points to the presence of multiple populations.
“On the methodological side, we can also see that inferences of genetic information that don’t account for subdivisions between populations can also generate very misleading information,” said Scerri.
By studying shifts in rivers, deserts, forests, and other physical barriers, the researchers were able to chronicle the geographic changes in Africa that facilitated migration, introducing opportunities for contact among groups that were previously separated. These groups, after long periods of isolation, were able to interact and interbreed, sometimes splitting off again and undergoing renewed periods of extended isolation.
[…]
Jean-Jacques Hublin, a scientist at the Max Planck Institute for Evolutionary Anthropology who wasn’t involved in the new study, said the new commentary paper is presenting what is quickly becoming the dominant view on this topic.
“There is growing evidence that the emergence of so-called ‘modern humans’ did not occur in a restricted cradle in sub-Saharan Africa and at a precise point in time,” Hublin told Gizmodo. “Rather, it involved several populations across the continent and was a fundamentally gradual process.”
Two former investment bankers, one of whom is also a priest, have been found guilty of an elaborate scam – hacking newswires to read press releases prior to publication, and trade millions using this insider information.
Vitaly Korchevsky, formerly a veep at Morgan Stanley and a pastor at the Slavic Evangelical Baptist Church in Philadelphia, USA, and ex-broker Vladislav Khalupsky were this month found guilty of securities fraud by a jury in New York, and are facing 20 years in the slammer.
According to court documents, the two colluded with a Ukrainian hacking gang and investors in the US, Russia, France, and Cyprus to realized more than $100m in illicit profits. America’s financial watchdog, the Securities and Exchange Commission, said it has since recovered $53m of the haul.
The scam, carried out between 2010 and 2015 involved Ukrainian hackers getting into the servers of two unnamed newswire services, one in New York and the other in Canada. The miscreants searched for embargoed press releases on companies’ quarterly financial figures, which are typically privately submitted to a newswire a couple of days before they are published, and accessed more than 100,000 of them before being caught.
IBM Security on Wednesday released its latest report examining the costs and impact associated with data breaches. The findings paint a grim portrait of what the clean up is like for companies whose data becomes exposed—particularly for larger corporations that suffer so-called “mega breaches,” a costly exposure involving potentially tens of millions of private records.
According to the IBM study, while the average cost of a data breach globally hovers just under $4 million—a 6.4 percent increase over the past year—costs associated with so-called mega breaches (an Equifax or Target, for example) can reach into the hundreds of millions of dollars. The average cost of a breach involving 1 million records is estimated at around $40 million, while those involving 50 million records or more can skyrocket up to $350 million in damages.
Of the 11 mega breaches examined by IBM, 10 were a result of criminal attacks.
The average amount of time that passes before a major company notices a data breach is pretty atrocious. According to IBM, mega breaches typically go unnoticed for roughly a year.
[…]
Other key findings of the study include:
The average time to identify a data breach is 197 days, and the average time to contain a data breach once identified is 69 days.
Companies that contained a breach in less than 30 days saved over $1 million compared to those that took more than 30 days ($3.09 million vs. $4.25 million average total).
Each lost or stolen record costs roughly $148 on average, but having an incident response team (surprising, not every company does) can reduce the cost per record by as much as $14.
The use of an AI platform for cybersecurity reduced the cost by $8 per lost or stolen record.
Companies that indicated a “rush to notify” had a higher cost by $5 per lost or stolen record.
U.S. companies experienced the highest average cost of a breach at $7.91 million, followed by firms the Middle East at $5.31 million.
Lowest total cost of a breach was $1.24 million in Brazil, followed by $1.77 million in India.
Sensitive US Air Force documents have leaked onto the dark web as part of an attempted sale of drone manuals.
Threat intel firm Recorded Future picked up on an auction for purported export-controlled documents pertaining to the MQ-9 Reaper drone during its regular work monitoring the dark web for criminal activities last month. Recorded Future’s Insikt Group analysts, posing as potential buyers, said they’d engaged the newly registered English-speaking hacker before confirming the validity of the compromised documents.
Further interactions allowed analysts to discover other leaked military information available from the same threat actor. The hacker claimed he had access to a large number of military documents from an unidentified officer.
These documents included a M1 Abrams tank maintenance manual, a tank platoon training course, a crew survival course, and documentation on improvised explosive device mitigation tactics.
[…]
Two years ago researchers warned that Netgear routers with remote data access capabilities were susceptible to attack if the default FTP authentication credentials were not updated
[…]
The hacker first infiltrated the computer of a captain at 432d Aircraft Maintenance Squadron Reaper AMU OIC, stationed at the Creech [Air Force Base] in Nevada, and stole a cache of sensitive documents, including Reaper maintenance course books and the list of airmen assigned to Reaper [Aircraft Maintenance Unit]. While such course books are not classified materials on their own, in unfriendly hands, they could provide an adversary the ability to assess technical capabilities and weaknesses in one of the most technologically advanced aircrafts.
The captain, whose computer had seemingly been compromised recently, had completed a cybersecurity awareness course, but he did not set a password for an FTP server hosting sensitive files. This allowed the hacker to easily download the drone manuals, said the researchers. The precise source of other the other dozen or so manuals the hacker offered for sale remains undetermined.
[…]
The hacker let slip that he was also in the habit of watching sensitive live footage from border surveillance cameras and airplanes. “The actor was even bragging about accessing footage from a MQ-1 Predator flying over Choctawhatchee Bay in the Gulf of Mexico.”
Norwegian programmer Roy Solberg came across an enumeration bug that leaked the full name of all travelers on a booking, the email addresses used, and flight details from Thomas Cook Airlines’ systems using only a booking reference number. Simply changing the booking number unveiled a new set of customer details.
The exposed info covered trips booked through the travel agency Ving, which is owned by Thomas Cook.
Thomas Cook Airlines has closed the privacy hole, technically known as a Insecure Direct Object Reference (IDOR), a common enough and basic problems on poorly-designed web applications.
Solberg reckoned on Sunday that data of bookings made with Thomas Cook Airlines through Ving Norway, Ving Sweden, Spies Denmark and Apollo Norway were affected by the vulnerability. Data going back to 2013 was obtainable before the hole was closed. Simple scripts might easily have been used to download the exposed data before the security hole was resolved, he adds.
Everything’s fine! Nothing to see here
A spokeswoman for Thomas Cook was at pains to emphasise “this did not affect UK customers,” before forwarding a canned statement further downplaying the incident, which it is not treating as a notifiable privacy breach.
Photographers already face an uphill battle in trying to preventing people from using their digital photos without permission. But Nvidia could make protecting photos online much harder with a new advancement in artificial intelligence that can automatically remove artifacts from a photograph, including text and watermarks, no matter how obtrusive they may be.In previous advancements in automated image editing and manipulation, an AI powered by a deep learning neural network is trained on thousands of before and after example photos so that it knows what the desired output should look like. But this time, researchers at Nvidia, MIT, and Aalto University in Finland, managed to train an AI to remove noise, grain, and other visual artifacts by studying two different versions of a photo that both feature the visual defects. Fifty-thousand samples later, the AI can clean up photos better than a professional photo restorer.Practical applications for the AI include cleaning up long exposure photos of the night sky taken by telescopes, as cameras used for astrophotography often generate noise that can be mistaken for stars. The AI can also be beneficial for medical applications like magnetic resonance imaging that requires considerable post-processing to remove noise from images that are generated, so that doctors have a clear image of what’s going in someone’s body. Nvidia’s AI can cut that processing time down drastically, which in turn reduces the time needed for a diagnosis of a serious condition.
A controversial overhaul of the EU’s copyright law that sparked a fierce debate between internet giants and content creators has been rejected.
The proposed rules would have put more responsibility on websites to check for copyright infringements, and forced platforms to pay for linking to news.
A slew of high-profile music stars had backed the change, arguing that websites had exploited their content.
But opponents said the rules would stifle internet freedom and creativity.
The move was intended to bring the EU’s copyright laws in line with the digital age, but led to protests from websites and much debate before it was rejected by a margin of 318-278 in the European Parliament on Thursday.
What were they voting for?
The proposed legislation – known as the Copyright Directive – was an attempt by the EU to modernise its copyright laws, but it contained two highly-contested parts.
The first of these, Article 11, was intended to protect newspapers and other outlets from internet giants like Google and Facebook using their material without payment.
Article 13 was the other controversial part. It put a greater responsibility on websites to enforce copyright laws, and would have meant that any online platform that allowed users to post text, images, sounds or code would need a way to assess and filter content.
The most common way to do this is by using an automated copyright system, but they are expensive. The one YouTube uses cost $60m (£53m), so critics were worried that similar filters would need to be introduced to every website if Article 13 became law.
There were also concerns that these copyright filters could effectively ban things like memes and remixes which use some copyrighted material.
Very glad to see common sense prevailing here. Have you ever thought about how strange it would be if you could bill someone every time they read your email or your reports? How do musicians think it’s ok to bill people when they are not playing?
Israeli hacking firm NSO Group is mostly known for peddling top-shelf malware capable of remotely cracking into iPhones. But according to Israeli authorities, the company’s invasive mobile spy tools could have wound up in the hands of someone equally, if not far more, devious than its typical government clients.
A 38-year-old former NSO employee has been accused of stealing the firm’s malware and attempting to sell it for $50 million in cryptocurrency on the dark net, according to a widely reported indictment first published by Israeli press.
The stolen software is said to be worth hundreds of millions of dollars.
According to Israel’s Justice Ministry, the ex-employee was turned in by a potential buyer. The suspect was arrested on June 5, Reuters reported. The accused has been charged with employee theft, attempting to sell security tools without a license, and conduct that could harm state security
Obviously security holes found will be exploited, which is why responsible disclosure is a good idea. It’s much better for devices to be secure than for intelligence agencies to be able to exploit holes – because non-nation state actors (read: criminals, although there are nations who think other nations are criminal) also have access to these holes.
For millions of people buying inexpensive smartphones in developing countries where privacy protections are usually low, the convenience of on-the-go internet access could come with a hidden cost: preloaded apps that harvest users’ data without their knowledge.
One such app, included on thousands of Chinese-made Singtech P10 smartphones sold in Myanmar and Cambodia, sends the owner’s location and unique-device details to a mobile-advertising firm in Taiwan called General Mobile Corp., or GMobi. The app also has appeared on smartphones sold in Brazil and those made by manufacturers based in China and India, security researchers said.
Taipei-based GMobi, with a subsidiary in Shanghai, said it uses the data to show targeted ads on the devices. It also sometimes shares the data with device makers to help them learn more about their customers.
Smartphones have been billed as a transformative technology in developing markets, bringing low-cost internet access to hundreds of millions of people. But this growing population of novice consumers, most of them living in countries with lax or nonexistent privacy protections, is also a juicy target for data harvesters, according to security researchers.
Smartphone makers that allow GMobi to install its app on phones they sell are able to use the app to send software updates for their devices known as “firmware” at no cost to them, said GMobi Chief Executive Paul Wu. That benefit is an important consideration for device makers pushing low-cost phones across emerging markets.
“If end users want a free internet service, he or she needs to suffer a little for better targeting ads,” said a GMobi spokeswoman.
[…]
Upstream Systems, a London-based mobile commerce and security firm that identified the GMobi app’s activity and shared it with the Journal, said it bought four new devices that, once activated, began sending data to GMobi via its firmware-updating app. This included 15-digit International Mobile Equipment Identification, or IMEI, numbers, along with unique codes called MAC addresses that are assigned to each piece of hardware that connects to the web. The app also sends some location data to GMobi’s servers located in Singapore, Upstream said.
Amateur and professional musicians alike may spend hours pouring over YouTube clips to figure out exactly how to play certain parts of their favorite songs. But what if there were a way to play a video and isolate the only instrument you wanted to hear?
That’s the outcome of a new AI project out of MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL): a deep-learning system that can look at a video of a musical performance, and isolate the sounds of specific instruments and make them louder or softer.
The system, which is “self-supervised,” doesn’t require any human annotations on what the instruments are or what they sound like.
Trained on over 60 hours of videos, the “PixelPlayer” system can view a never-before-seen musical performance, identify specific instruments at pixel level, and extract the sounds that are associated with those instruments.
For example, it can take a video of a tuba and a trumpet playing the “Super Mario Brothers” theme song, and separate out the soundwaves associated with each instrument.
The researchers say that the ability to change the volume of individual instruments means that in the future, systems like this could potentially help engineers improve the audio quality of old concert footage. You could even imagine producers taking specific instrument parts and previewing what they would sound like with other instruments (i.e. an electric guitar swapped in for an acoustic one).
AI agents continue to rack up wins in the video game world. Last week, OpenAI’s bots were playing Dota 2; this week, it’s Quake III, with a team of researchers from Google’s DeepMind subsidiary successfully training agents that can beat humans at a game of capture the flag.
As we’ve seen with previous examples of AI playing video games, the challenge here is training an agent that can navigate a complex 3D environment with imperfect information. DeepMind’s researchers used a method of AI training that’s also becoming standard: reinforcement learning, which is basically training by trial and error at a huge scale.
Agents are given no instructions on how to play the game, but simply compete against themselves until they work out the strategies needed to win. Usually this means one version of the AI agent playing against an identical clone. DeepMind gave extra depth to this formula by training a whole cohort of 30 agents to introduce a “diversity” of play styles. How many games does it take to train an AI this way? Nearly half a million, each lasting five minutes.
As ever, it’s impressive how such a conceptually simple technique can generate complex behavior on behalf of the bots. DeepMind’s agents not only learned the basic rules of capture the flag (grab your opponents’ flag from their base and return it to your own before they do the same to you), but strategies like guarding your own flag, camping at your opponent’s base, and following teammates around so you can gang up on the enemy.
To make the challenge harder for the agents, each game was played on a completely new, procedurally generated map. This ensured the bots weren’t learning strategies that only worked on a single map.
Unlike OpenAI’s Dota 2 bots, DeepMind’s agents also didn’t have access to raw numerical data about the game — feeds of numbers that represents information like the distance between opponents and health bars. Instead, they learned to play just by looking at the visual input from the screen, the same as a human. However, this does not necessarily mean that DeepMind’s bots faced a greater challenge; Dota 2 is overall a much more complex game than the stripped-down version of Quake III that was used in this research.
To test the AI agents’ abilities, DeepMind held a tournament, with two-player teams of only bots, only humans, and a mixture of bots and humans squaring off against one another. The bot-only teams were most successful, with a 74 percent win probability. This compared to 43 precent probability for average human players, and 52 percent probability for strong human players. So: clearly the AI agents are the better players.
A graph showing the Elo (skill) rating of various players. The “FTW” agents are DeepMind’s, which played against themselves in a team of 30.Credit: DeepMind
However, it’s worth noting that the greater the number of DeepMind bots on a team, the worse they did. A team of four DeepMind bots had a win probability of 65 percent, suggesting that while the researchers’ AI agents did learn some elements of cooperative play, these don’t necessarily scale up to more complex team dynamics.
As ever with research like this, the aim is not to actually beat humans at video games, but to find new ways of teaching agents to navigate complex environments while pursuing a shared goal. In other words, it’s about teaching collective intelligence — something that has (despite abundant evidence to the contrary) been integral to humanity’s success as a species. Capture the flag is just a proxy for bigger games to come.
Automakers want in on the highly lucrative big data game and Mitsubishi is willing to pay for the privilege. In exchange for running the risk of jacking up its customers’ insurance premiums, the car manufacturer is offering drivers $10 off of an oil change and other rewards. Consumers will have to decide if a gift card is worth giving up their privacy.
According to the Wall Street Journal, Mitsubishi’s new smartphone app is the first of its kind. A driver can sign up and allow their driving habits to be tracked by their phone’s sensors, which monitor data points like acceleration, location, and rotation. Along the way, they’ll earn badges (reward points) based on good driving practices like staying under the speed limit. For now, the badges can be exchanged for discounted oil changes or car accessories, but the company plans to expand its incentives to other small perks like free cups of coffee by the end of the year.
It may seem like a win-win situation: You pay a little more attention to being a good driver and you get a little bonus for your efforts. But the first customer for all that data is State Auto Insurance Companies, which will be using it to create better risk models and adjust users’ premiums accordingly. It doesn’t appear that the data will be anonymized because the Journal reports that, after a trial period, insurers will be able to build a customer risk profile on users of the app that will then be used to determine rates. We reached out to Mitsubishi to ask about its anonymization of data but didn’t receive an immediate reply.
Mike LaRocco, State Auto’s CEO, framed this as a benefit to consumers when speaking with the Journal. “They’ll get a much more accurate quote from day one,” he claimed. That might be true, but it does nothing to assuage fears that insurance companies could penalize drivers who don’t voluntarily give up their data.
Ford also has an app that shares data with insurance companies, but it’s not offering any of those sweet, sweet gift cards. And at a moment when many people are debating whether tech giants should be paying us for our data, one could argue that Mitsubishi is doing the right thing. But as car companies are building web connectivity into their new models, we could easily see this become standard practice without offering drivers a choice or a reward. A study by McKinsey & Co from 2016, estimated that monetizing car data could be worth between $450-750 billion by 2030. Of course, autonomous vehicles could become more prevalent by then. And as long as they work as promised, insurance companies will be less necessary.
Following a number of requests from citizens, from the European Parliament, and from certain EU Member States, the Commission has decided to investigate the functioning of the current EU summertime arrangements and to assess whether or not they should be changed.
In this context, the Commission is interested in gathering the views of European citizens, stakeholders and Member States on the current EU summertime arrangements and on any potential change to those arrangements.
How to submit your response
The online questionnaire is accessible in all official EU languages (except Irish) and replies may be submitted in any EU language. We do encourage you to answer as much as possible in English though.
You may pause at any time and continue later. Once you have submitted your answers, you can download a copy of your completed responses.
It is the most exacting of surgical skills: tying a knot deep inside a patient’s abdomen, pivoting long graspers through keyhole incisions with no direct view of the thread.
Trainee surgeons typically require 60 to 80 hours of practice, but in a mock-up operating theatre outside Cambridge, a non-medic with just a few hours of experience is expertly wielding a hook-shaped needle – in this case stitching a square of pink sponge rather than an artery or appendix.
The feat is performed with the assistance of Versius, the world’s smallest surgical robot, which could be used in NHS operating theatres for the first time later this year if approved for clinical use. Versius is one of a handful of advanced surgical robots that are predicted to transform the way operations are performed by allowing tens or hundreds of thousands more surgeries each year to be carried out as keyhole procedures.
[…]
The Versius robot cuts down the time required to learn to tie a surgical knot from more than 100 training sessions, when using traditional manual tools, to just half an hour, according to Slack.
[…]
Versius comprises three robotic limbs – each slightly larger than a human arm, complete with shoulder, elbow and wrist joints – mounted on bar-stool sized mobile units.
Controlled by a surgeon at a console, the limbs rise, fall and swivel silently and smoothly. The robot is designed to carry out a wide range of keyhole procedures, including hysterectomies, prostate removal, ear, nose and throat surgery, and hernia repair. CMR claims the costs of using the robot will not be significantly higher than for a conventional keyhole procedure.
Online investigations outfit Bellingcat has found that fitness tracking kit-maker Polar reveals both the identity and daily activity of its users – including soldiers and spies.
Many users of Polar’s devices and app appear not to have paid attention to their privacy settings, as a result a Bellingcat writer found 6,460 individuals from 69 countries. More than 200 of them left digital breadcrumbs around sensitive locations.
Bellingcat’s report claimed the Polar Flow social-fitness site produces more compromising data than other fitness-trackers than previous leaks: “Compared to the similar services of Garmin and Strava, Polar publicizes more data per user in a more accessible way, with potentially disastrous results.“
“Tracing all of this information is very simple through the site: find a military base, select an exercise published there to identify the attached profile, and see where else this person has exercised.”
Bellingcat notes that the big difference between Polar and Strava is that the former offers more comprehensive data, more easily, covering everything a user has uploaded to the platform since 2014.
Open plan offices don’t deliver their promised benefits of more face-to-face collaboration and instead make us misanthropic recluses and more likely to use electronic communications tools.
So says a new article in the Philosophical Transactions of the Royal Society B, by Harvard academics Ethan S. Bernstein, Stephen Turban. The pair studied two Fortune 500 companies that adopted open office designs and wrote up the results as “The impact of the ‘open’ workspace on human collaboration”.
[…]
Analysis of the data revealed that “volume of face-to-face interaction decreased significantly (approx. 70%) in both cases, with an associated increase in electronic interaction.”
“In short, rather than prompting increasingly vibrant face-to-face collaboration, open architecture appeared to trigger a natural human response to socially withdraw from officemates and interact instead over email and IM.”
In the first workplace studied, “IM message activity increased by 67% (99 more messages) and words sent by IM increased by 75% (850 more words). Thus — to restate more precisely — in boundaryless space, electronic interaction replaced F2F interaction.”
The second workplace produced similar results.
The authors reach three conclusions, the first of which is that open offices “can dampen F2F interaction, as employees find other strategies to preserve their privacy; for example, by choosing a different channel through which to communicate.”
Bedrijven worden emotioneler: gebruikersinterfaces, chatbots en andere componenten zijn steeds beter in staat om de emotionele staat van gebruikers in te schatten en emotie te simuleren als ze terug praten. Volgens een Gartner-rapport eerder dit jaar weten apparaten over vier jaar “meer over je emotionele staat dan je eigen familie”.
Herkennen van emotie
Deep learning kan geavanceerd emoties herkennen zoals geluk, verrassing, woede, verdriet, angst en afschuw – tot meer dan twintig subtielere emoties zoals bewondering, blije verrassing en haat. (Psychologen beweren dat mensen 27 verschillende emoties hebben.)
De Universiteit van Ohio ontwikkelde een programma dat 21 emoties herkent op basis van gezichtsuitdrukkingen op foto’s. Het schokkende: De onderzoekers beweren dat hun systeem deze emoties beter detecteert dan mensen. Er is een goede reden en een geweldige reden voor emotionele interfaces in de organisatie.
Kwaliteitsinteracties
Ten eerste de goede reden. De “empathie economie” is de monetaire of zakelijke waarde die door AI wordt gecreëerd en die menselijke emoties detecteert en simuleert, een vermogen dat klantenservice, virtuele assistenten, robotica, fabrieksveiligheid, gezondheidszorg en transport zal transformeren.
Uit een Cogito-onderzoek van Frost & Sullivan gaf 93% van de ondervraagden aan dat interacties met de klantenservice van invloed zijn op hun perceptie van een bedrijf. En empathie is één van de belangrijkste factoren in kwaliteitsinteracties, volgens het bedrijf. Cogito’s AI-software, die uitgebreid is gebaseerd op gedragswetenschappelijk onderzoek van MIT’s Human Dynamics Lab, analyseert de emotionele toestand van klanten en geeft directe feedback aan menselijke call center agents, waardoor ze gemakkelijker meevoelen met klanten.
Zorg en andere toepassingen
Dit soort technologie geeft callcentermedewerkers empathische vermogens, die de publieke perceptie van een bedrijf sterk kunnen verbeteren. Bedrijven als Affectiva en Realeyes bieden cloud-gebaseerde oplossingen die webcams gebruiken om gezichtsuitdrukkingen en hartslag te volgen (door de polsslag in de huid van het gezicht te detecteren). Een van de toepassingen is marktonderzoek: consumenten kijken naar advertenties, en de technologie detecteert hoe ze denken over de beelden of woorden in de advertenties.
De ondernemingen zijn op zoek naar andere gebieden, zoals de gezondheidszorg, waar geautomatiseerde call centers depressie of pijn in de stem van de beller zou kunnen detecteren, zelfs als de beller niet in staat is deze emoties uit te drukken.
Stemming detecteren
Een robot met de naam Forpheus, gemaakt door Omron Automation in Japan en gedemonstreerd tijdens CES in januari, speelt pingpong. Een deel van haar arsenaal van tafeltennisvaardigheden is haar vermogen om lichaamstaal te lezen om zowel de stemming en vaardigheid niveau van de menselijke tegenstander te achterhalen.
Het gaat natuurlijk niet om pingpong, maar het doel is industriële machines die “in harmonie” met de mens werken, wat zowel de productiviteit als de veiligheid verhoogt. Door bijvoorbeeld de lichaamstaal van fabrieksarbeiders te lezen, konden industriële robots anticiperen op hoe en waar mensen zich zouden kunnen bewegen.
A service named “Timehop” that claims it is “reinventing reminiscing” – in part by linking posts from other social networks – probably wishes it could go back in time and reinvent its own security, because it has just confessed to losing data describing 21 million members and can’t guarantee that the perps didn’t slurp private info from users’ social media accounts.
“On July 4, 2018, Timehop experienced a network intrusion that led to a breach of some of your data,” the company wrote. “We learned of the breach while it was still in progress, and were able to interrupt it, but data was taken.”
Names and email addresses were lifted, as were “Keys that let Timehop read and show you your social media posts (but not private messages)”. Timehop has “deactivated these keys so they can no longer be used by anyone – so you’ll have to re-authenticate to our App.”
The breach also led to the loss of access tokens Timehop uses to access other social networks such as Twitter, Facebook and Instagram and the posts you’ve made there. Timehop swears blind that the tokens have been revoked and just won’t work any more.
But the company has also warned that “there was a short time window during which it was theoretically possible for unauthorized users to access those posts” but has “no evidence that this actually happened.”
It can’t be as almost-comforting on the matter of purloined phone numbers, advising that for those who shared such data with the company “It is recommended that you take additional security precautions with your cellular provider to ensure that your number cannot be ported.” Oh thanks for that, Timehop. And thanks, also, for not using two-factor authentication, because that made the crack possible. “The breach occurred because an access credential to our cloud computing environment was compromised,” the company’s admitted. “That cloud computing account had not been protected by multifactor authentication. We have now taken steps that include multifactor authentication to secure our authorization and access controls on all accounts.”
All of which leaves users in the same place as usual: with work to do, knowing that if their service providers had done their jobs properly they’d feel a lot safer.
Cars are turning into computers on wheels and airplanes have become flying data centres, but this increase in power and connectivity has largely happened without designing in adequate security controls.
Improving transportation security was a major strand of the recent Cyber Week security conference in Israel. A one-day event, Speed of Light, focused on transportation cybersecurity, where Roberts served as master of ceremonies.
[…]
“Israel was here, not just a couple of companies. Israel is going, ‘We as a state, we as a country, need to understand [about transportation security]’,” Roberts said. “We need to learn.”
“In other places it’s the companies. GM is great. Ford is good. Some of the Germany companies are good. Fiat-Chrysler Group has got a lot of work to do.”
Some industries are more advanced than others at understanding cybersecurity risks, Roberts claimed. For example, awareness in the automobile industry is ahead of that found in aviation.
“Boeing is in denial. Airbus is kind of on the fence. Some of the other industries are better.”
[…]
”
There’s almost nothing you can do [as a user] to improve car security. The only thing you can do is go back to the garage every month for your Microsoft Patch Tuesday – updates from Ford or GM.
“You better come in once a month for your patches because if you don’t, the damn thing is not going to work.”
What about over-the-air updates? These may not always be reliable, Roberts warned.
“What happens if you’re in the middle of a dead spot? Or you’re in the middle of a developing country that doesn’t have that? What about the Toyotas that get sold to the Middle East or Far East, to countries that don’t have 4G or 5G coverage. And what happens when you move around countries?”
[…]
“I put a network sniffer on the big truck to see what it was sharing. Holy crap! The GPS, the telemetry, the tracking. There’s a lot of data this thing is sharing.
“If you turn it off you might be voiding warranties or [bypassing] security controls,” Roberts said, adding that there was also an issue about who owns the data a car generates. “Is it there to protect me or monitor me?” he mused.
Some insurance firms offer cheaper insurance to careful drivers, based on readings from telemetry devices and sensors. Roberts is dead set against this for privacy reasons. “Insurance can go to hell. For me, getting a 5 per cent discount on my insurance is not worth accepting a tracking device from an insurance company.”
Facebook has long had the same public response when questioned about its disruption of the news industry: it is a tech platform, not a publisher or a media company.
But in a small courtroom in California’s Redwood City on Monday, attorneys for the social media company presented a different message from the one executives have made to Congress, in interviews and in speeches: Facebook, they repeatedly argued, is a publisher, and a company that makes editorial decisions, which are protected by the first amendment.
The contradictory claim is Facebook’s latest tactic against a high-profile lawsuit, exposing a growing tension for the Silicon Valley corporation, which has long presented itself as neutral platform that does not have traditional journalistic responsibilities.
The suit, filed by an app startup, alleges that Mark Zuckerberg developed a “malicious and fraudulent scheme” to exploit users’ personal data and force rival companies out of business. Facebook, meanwhile, is arguing that its decisions about “what not to publish” should be protected because it is a “publisher”.
In court, Sonal Mehta, a lawyer for Facebook, even drew comparison with traditional media: “The publisher discretion is a free speech right irrespective of what technological means is used. A newspaper has a publisher function whether they are doing it on their website, in a printed copy or through the news alerts.”
The plaintiff, a former startup called Six4Three, first filed the suit in 2015 after Facebook removed app developers’ access to friends’ data. The company had built a controversial and ultimately failed app called Pikinis, which allowed people to filter photos to find ones with people in bikinis and other swimwear.
Six4Three attorneys have alleged that Facebook enticed developers to create apps for its platform by implying creators would have long-term access to the site’s huge amounts of valuable personal data and then later cut off access, effectively defrauding them. The case delves into some of the privacy concerns sparked by the Cambridge Analytica scandal.
He explained that when Facebook was being developed the objective was: “How do we consume as much of your time and conscious attention as possible?” It was this mindset that led to the creation of features such as the “like” button that would give users “a little dopamine hit” to encourage them to upload more content.
“It’s a social-validation feedback loop … exactly the kind of thing that a hacker like myself would come up with, because you’re exploiting a vulnerability in human psychology.”
Social media companies are deliberately addicting users to their products for financial gain, Silicon Valley insiders have told the BBC’s Panorama programme.
“It’s as if they’re taking behavioural cocaine and just sprinkling it all over your interface and that’s the thing that keeps you like coming back and back and back”, said former Mozilla and Jawbone employee Aza Raskin.
“Behind every screen on your phone, there are generally like literally a thousand engineers that have worked on this thing to try to make it maximally addicting” he added.
In 2006 Mr Raskin, a leading technology engineer himself, designed infinite scroll, one of the features of many apps that is now seen as highly habit forming. At the time, he was working for Humanized – a computer user-interface consultancy.
Image caption Aza Raskin says he did not recognise how addictive infinite scroll could be
Infinite scroll allows users to endlessly swipe down through content without clicking.
“If you don’t give your brain time to catch up with your impulses,” Mr Raskin said, “you just keep scrolling.”
He said the innovation kept users looking at their phones far longer than necessary.
Mr Raskin said he had not set out to addict people and now felt guilty about it.
But, he said, many designers were driven to create addictive app features by the business models of the big companies that employed them.
“In order to get the next round of funding, in order to get your stock price up, the amount of time that people spend on your app has to go up,” he said.
“So, when you put that much pressure on that one number, you’re going to start trying to invent new ways of getting people to stay hooked.”
Some computer science academics at Northeastern University had heard enough people talking about this technological myth that they decided to do a rigorous study to tackle it. For the last year, Elleen Pan, Jingjing Ren, Martina Lindorfer, Christo Wilson, and David Choffnes ran an experiment involving more than 17,000 of the most popular apps on Android to find out whether any of them were secretly using the phone’s mic to capture audio. The apps included those belonging to Facebook, as well as over 8,000 apps that send information to Facebook.
Sorry, conspiracy theorists: They found no evidence of an app unexpectedly activating the microphone or sending audio out when not prompted to do so. Like good scientists, they refuse to say that their study definitively proves that your phone isn’t secretly listening to you, but they didn’t find a single instance of it happening. Instead, they discovered a different disturbing practice: apps recording a phone’s screen and sending that information out to third parties.
Of the 17,260 apps the researchers looked at, over 9,000 had permission to access the camera and microphone and thus the potential to overhear the phone’s owner talking about their need for cat litter or about how much they love a certain brand of gelato. Using 10 Android phones, the researchers used an automated program to interact with each of those apps and then analyzed the traffic generated. (A limitation of the study is that the automated phone users couldn’t do things humans could, like creating usernames and passwords to sign into an account on an app.) They were looking specifically for any media files that were sent, particularly when they were sent to an unexpected party.
These phones played with thousands of app to see if they could find one that would secretly activate their microphone
Photo: David Choffnes (Northeastern University)
The strange practice they started to see was that screenshots and video recordings of what people were doing in apps were being sent to third party domains. For example, when one of the phones used an app from GoPuff, a delivery start-up for people who have sudden cravings for junk food, the interaction with the app was recorded and sent to a domain affiliated with Appsee, a mobile analytics company. The video included a screen where you could enter personal information—in this case, their zip code.
The researchers weren’t comfortable saying for sure that your phone isn’t secretly listening to you in part because there are some scenarios not covered by their study. Their phones were being operated by an automated program, not by actual humans, so they might not have triggered apps the same way a flesh-and-blood user would. And the phones were in a controlled environment, not wandering the world in a way that might trigger them: For the first few months of the study the phones were near students in a lab at Northeastern University and thus surrounded by ambient conversation, but the phones made so much noise, as apps were constantly being played with on them, that they were eventually moved into a closet. (If the researchers did the experiment again, they would play a podcast on a loop in the closet next to the phones.) It’s also possible that the researchers could have missed audio recordings of conversations if the app transcribed the conversation to text on the phone before sending it out. So the myth can’t be entirely killed yet.



:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/11641941/CTF_Fig_Tagging_180703_r01.width_1500.png)
