The Humanitarian Data Exchange (HDX) is an open platform for sharing data across crises and organisations. Launched in July 2014, the goal of HDX is to make humanitarian data easy to find and use for analysis. Our growing collection of datasets has been accessed by users in over 200 countries and territories. Watch this video to learn more.
HDX is managed by OCHA’s Centre for Humanitarian Data, which is located in The Hague. OCHA is part of the United Nations Secretariat and is responsible for bringing together humanitarian actors to ensure a coherent response to emergencies. The HDX team includes OCHA staff and a number of consultants who are based in North America, Europe and Africa.
[…]
We define humanitarian data as:
data about the context in which a humanitarian crisis is occurring (e.g., baseline/development data, damage assessments, geospatial data)
data about the people affected by the crisis and their needs
data about the response by organisations and people seeking to help those who need assistance.
HDX uses an open-source software called CKAN for our technical back-end. You can find all of our code on GitHub.
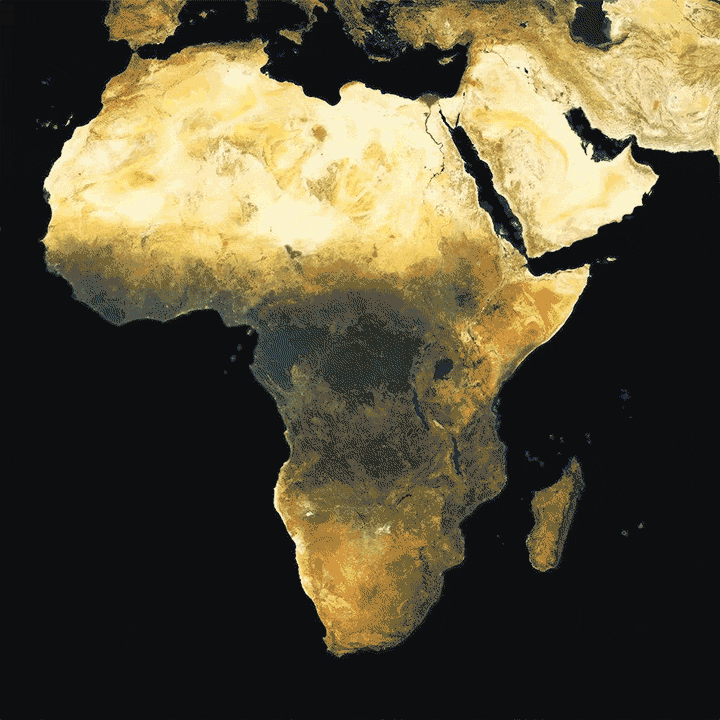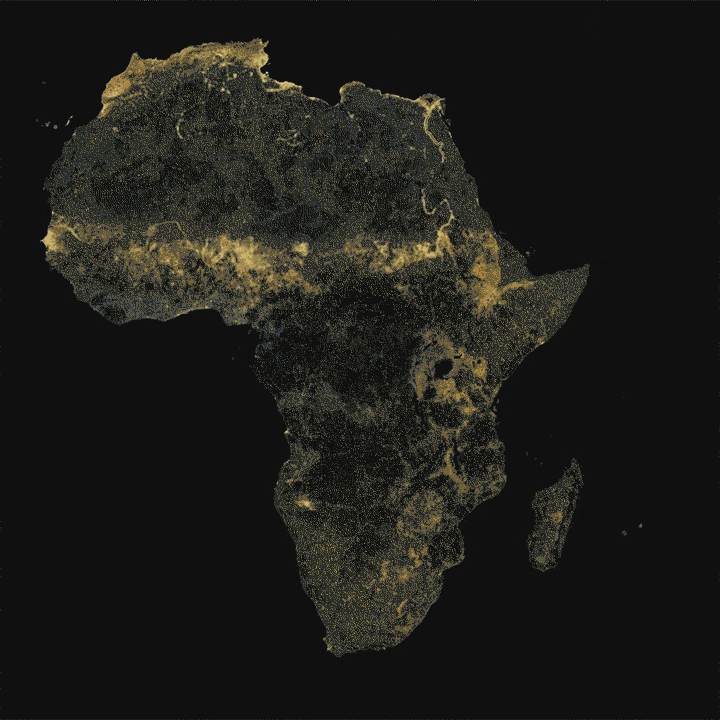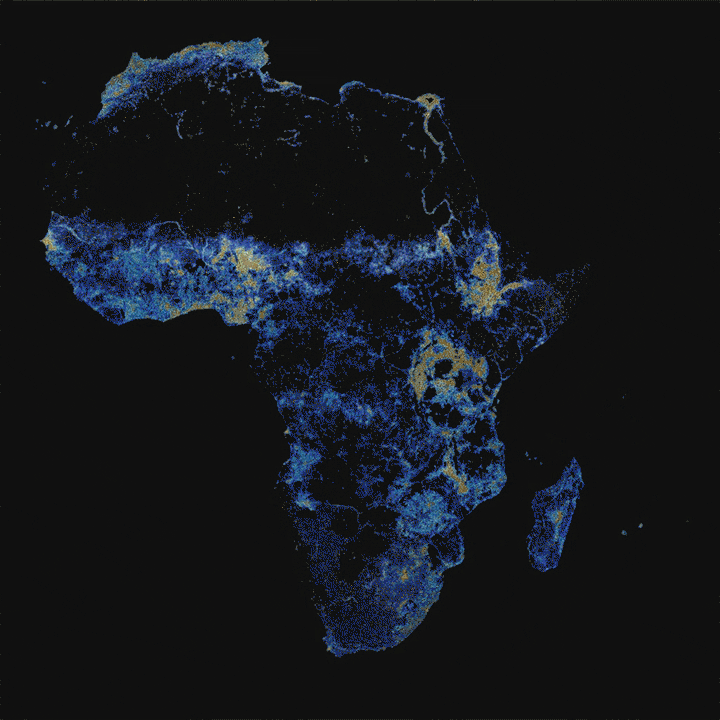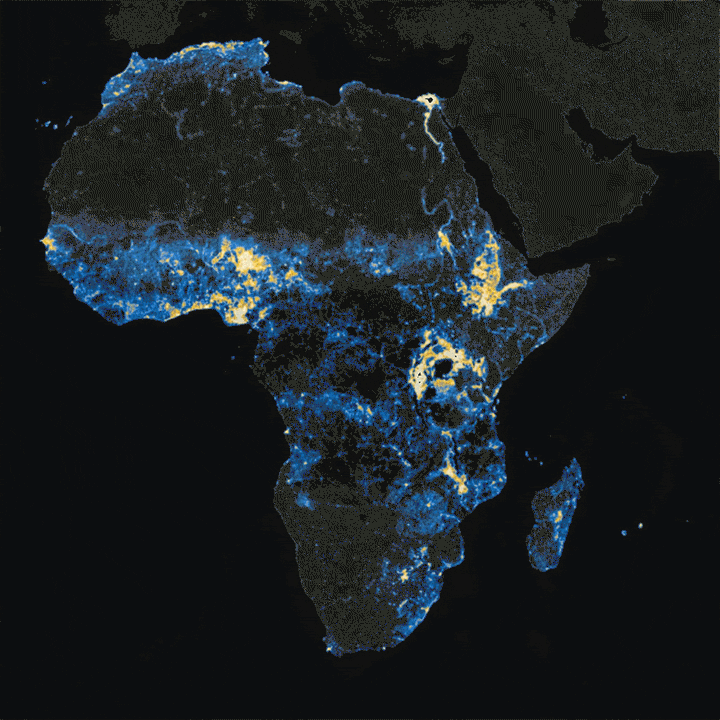
When it comes to knowing where humans around the world actually live, resources come in varying degrees of accuracy and sophistication.
Heavily urbanized and mature economies generally produce a wealth of up-to-date information on population density and granular demographic data. In rural Africa or fast-growing regions in the developing world, tracking methods cannot always keep up, or in some cases may be non-existent.
This is where new maps, produced by researchers at Facebook, come in. Building upon CIESIN’s Gridded Population of the World project, Facebook is using machine learning models on high-resolution satellite imagery to paint a definitive picture of human settlement around the world. Let’s zoom in.
Connecting the Dots
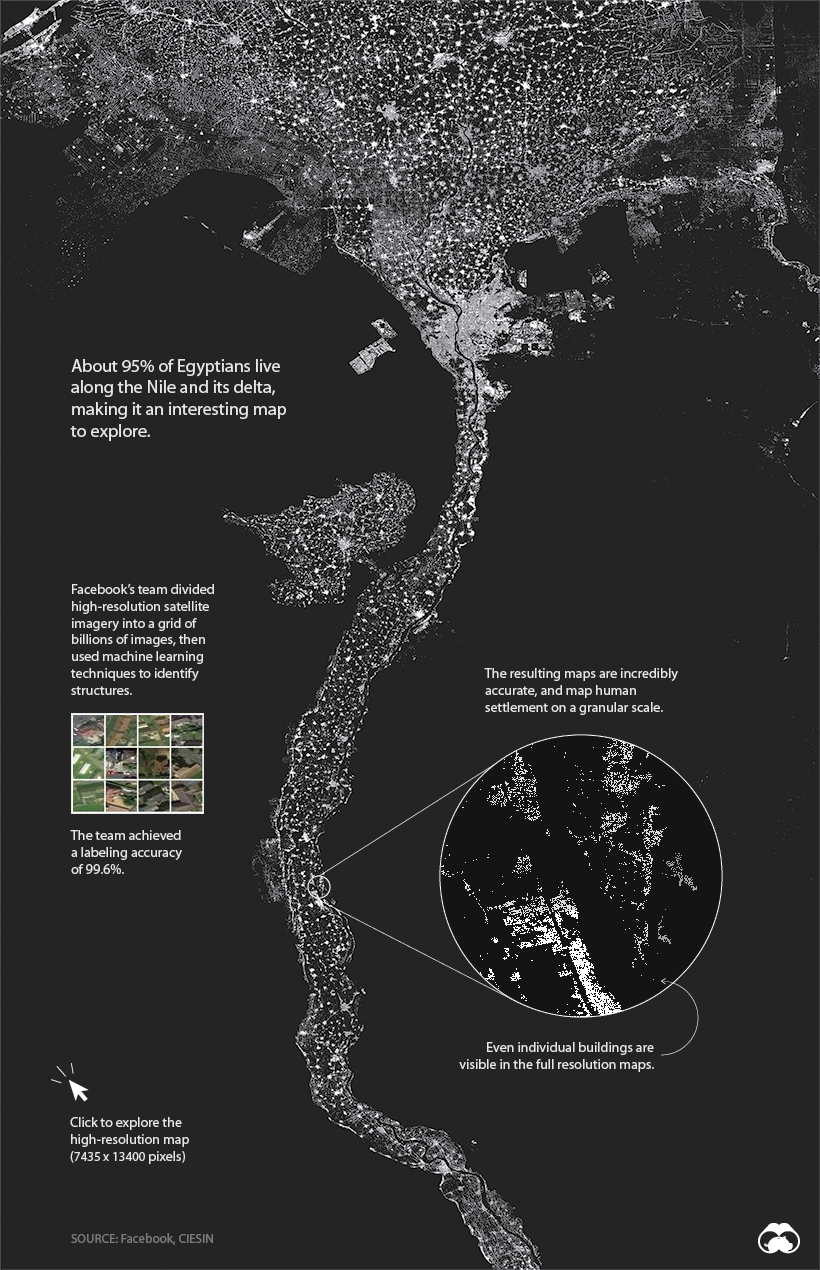
Will all other details stripped away, human settlement can form some interesting patterns. One of the most compelling examples is Egypt, where 95% of the population lives along the Nile River. Below, we can clearly see where people live, and where they don’t.
While it is possible to use a tool like Google Earth to view nearly any location on the globe, the problem is analyzing the imagery at scale. This is where machine learning comes into play.
Finding the People in the Petabytes
High-resolution imagery of the entire globe takes up about 1.5 petabytes of storage, making the task of classifying the data extremely daunting. It’s only very recently that technology was up to the task of correctly identifying buildings within all those images.
To get the results we see today, researchers used process of elimination to discard locations that couldn’t contain a building, then ranked them based on the likelihood they could contain a building.
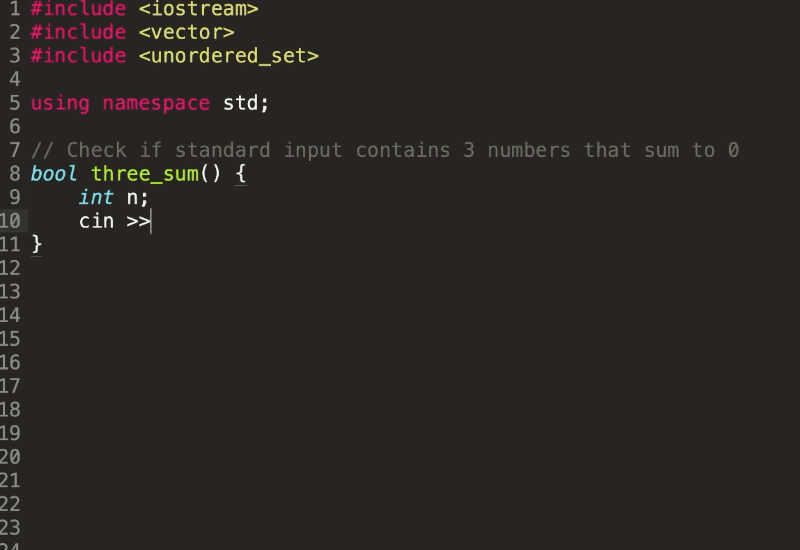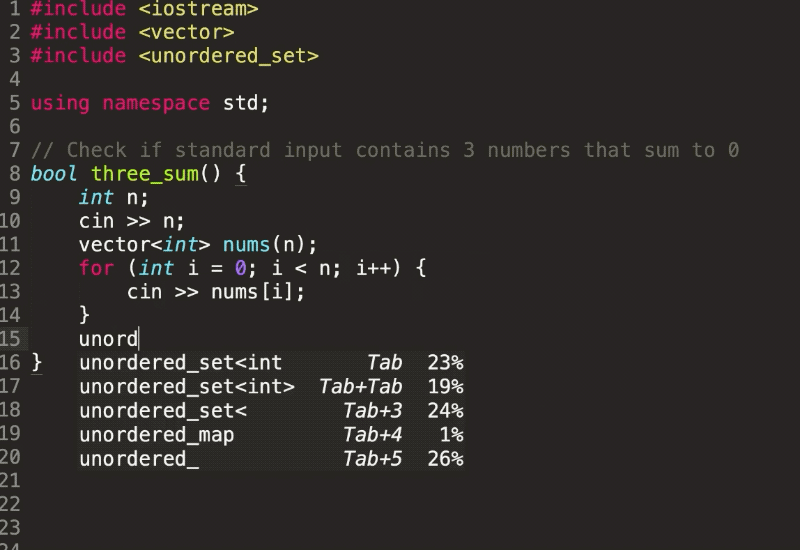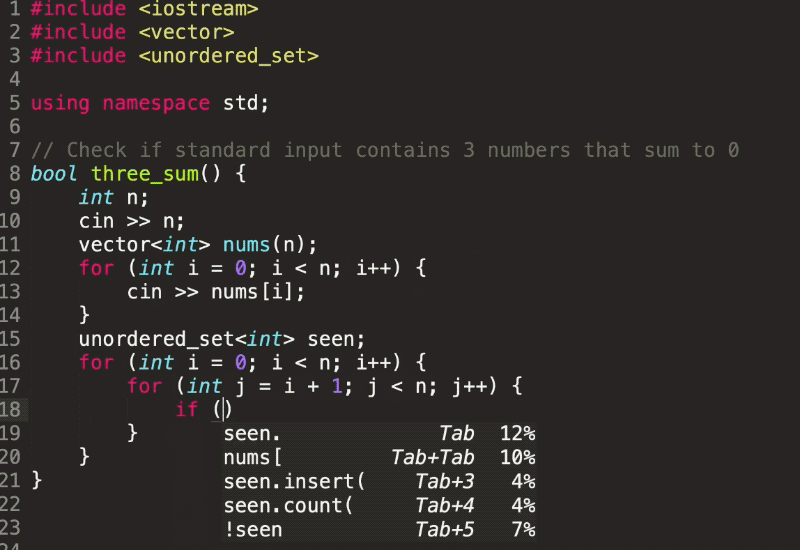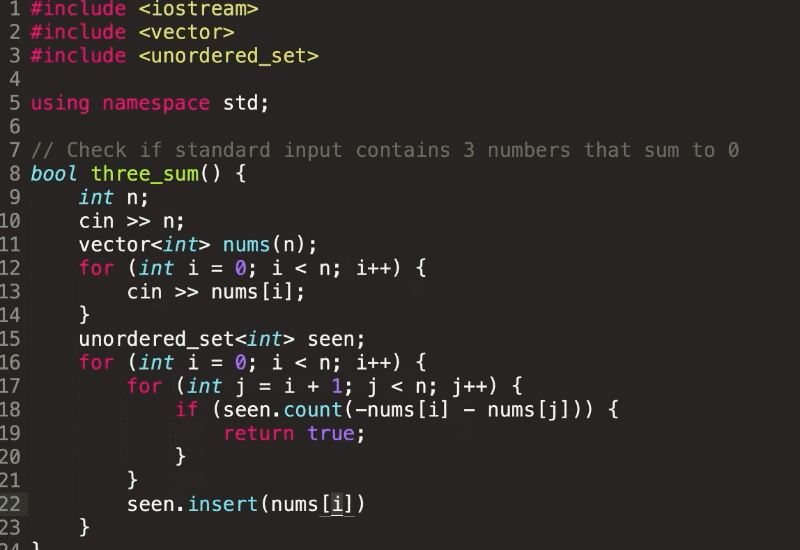
Facebook identified structures at scale using a process called weakly supervised learning. After training the model using large batches of photos, then checking over the results, Facebook was able to reach a 99.6% labeling accuracy for positive examples.
Why it Matters
An accurate picture of where people live can be a matter of life and death.
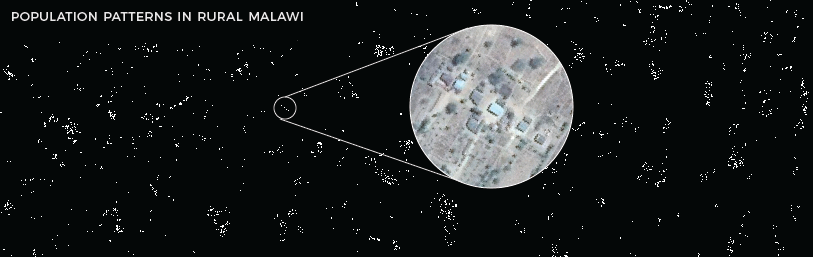
For humanitarian agencies working in Africa, effectively distributing aid or vaccinating populations is still a challenge due to the lack of reliable maps and population density information. Researchers hope that these detailed maps will be used to save lives and improve living conditions in developing regions.
For example, Malawi is one of the world’s least urbanized countries, so finding its 19 million citizens is no easy task for people doing humanitarian work there. These maps clearly show where people live and allow organizations to create accurate population density estimates for specific areas.
Visit the project page for a full explanation and to access the full database of country maps.
Authorities in the United Kingdom have made unauthorized copies of data stored inside a EU database for tracking undocumented migrants, missing people, stolen cars, or suspected criminals.
Named the Schengen Information System (SIS), this is a EU-run database that stores information such as names, personal details, photographs, fingerprints, and arrest warrants for 500,000 non-EU citizens denied entry into Europe, over 100,000 missing people, and over 36,000 criminal suspects.
The database was created for the sole purpose of helping EU countries manage access to the passport-free Schengen travel zone.
The UK was granted access to this database in 2015, even if it’s not an official member of the Schengen zone.
According to the report, UK officials made copies of this database and stored it at airports and ports in unsafe conditions. Furthermore, by making copies, the UK was always working with outdated versions of the database.
This meant UK officials wouldn’t know in time if a person was removed from SIS, resulting in unnecessary detainments, or if a person was added to the database, allowing criminals to move through the UK and into the Schengen travel zone.
Furthermore, they also mismanaged and misused this data by providing unsanctioned access to this highly-sensitive and secret information to third-party contractors, including US companies (IBM, ATOS, CGI, and others).
The report expressed concerns that by doing so, the UK indirecly allowed contractors to copy this data as well, or allow US officials to request the database from a contractor under the US Patriot Act.
Organisations that deploy Facebook’s ubiquitous “Like” button on their websites risk falling foul of the General Data Protection Regulation following a landmark ruling by the European Court of Justice.
The EU’s highest court has decided that website owners can be held liable for data collection when using the so-called “social sharing” widgets.
The ruling (PDF) states that employing such widgets would make the organisation a joint data controller, along with Facebook – and judging by its recent record, you don’t want to be anywhere near Zuckerberg’s antisocial network when privacy regulators come a-calling.
‘Purposes of data processing’
According to the court, website owners “must provide, at the time of their collection, certain information to those visitors such as, for example, its identity and the purposes of the [data] processing”.
By extension, the ECJ’s decision also applies to services like Twitter and LinkedIn.
Facebook’s “Like” is far from an innocent expression of affection for a brand or a message: its primary purpose is to track individuals across websites, and permit data collection even when they are not explicitly using any of Facebook’s products.
[…]
On Monday, the ECJ ruled that Fashion ID could be considered a joint data controller “in respect of the collection and transmission to Facebook of the personal data of visitors to its website”.
The court added that it was not, in principle, “a controller in respect of the subsequent processing of those data carried out by Facebook alone”.
‘Consent’
“Thus, with regard to the case in which the data subject has given his or her consent, the Court holds that the operator of a website such as Fashion ID must obtain that prior consent (solely) in respect of operations for which it is the (joint) controller, namely the collection and transmission of the data,” the ECJ said.
The concept of “data controller” – the organisation responsible for deciding how the information collected online will be used – is a central tenet of both DPR and GDPR. The controller has more responsibilities than the data processor, who cannot change the purpose or use of the particular dataset. It is the controller, not the processor, who would be held accountable for any GDPR sins.
How is this possible? In the simplest of terms, the scientists measured the electrooculographic signals generated when eyes make specific movements (up, down, left, right, blink, double blink) and created a soft biomimetic lens that responds directly to those electric impulses. The lens created was able to change its focal length depending on the signals generated.
Therefore the lens could literally zoom in the blink of an eye.
Incredibly, the lens works regardless of whether the user can see or not. It’s not about the sight, it’s about the electricity produced by specific movements.
Modern aircraft systems are becoming increasingly reliant on networked communications systems to display information to the pilot as well as control various systems aboard aircraft. Small aircraft typically maintain the direct mechanical linkage between the flight controls and the flight surface. However, electronic controls for flaps, trim, engine controls, and autopilot systems are becoming more common. This is similar to how most modern automobiles no longer have a physical connection between the throttle and the actuator that causes the engine to accelerate.
Before digital systems became common within aircraft instrumentation, the gauges and flight instruments would rely on mechanical and simple electrical controls that were directly connected to the source of the data they were displaying to the pilot. For example, the altitude and airspeed indicators would be connected to devices that measure the speed of airflow through a tube as well as the pressure outside the aircraft. In addition, the attitude and directional indicators would be powered by a vacuum source that drove a mechanical gyroscope. The flight surfaces would be directly connected to the pilot’s control stick or yoke—on larger aircraft, this connection would be via a hydraulic interface. Some flight surfaces, such as flaps and trim tabs, would have simple electrical connections that would directly turn motors on and off.
Modern aircraft use a network of electronics to translate signals from the various sensors and place this data onto a network to be interpreted by the appropriate instruments and displayed to the pilot. Together, the physical network, called a “vehicle bus,” and a common communications method called Controller Area Network (CAN) create the “CAN bus,” which serves as the central nervous system of a vehicle using this method. In avionics, these systems provide the foundation of control systems and sensor systems and collect data such as altitude, airspeed, and engine parameters such as fuel level and oil pressure, then display them to the pilot.
After performing a thorough investigation on two commercially available avionics systems, Rapid7 demonstrated that it was possible for a malicious individual to send false data to these systems, given some level of physical access to a small aircraft’s wiring. Such an attacker could attach a device—or co-opt an existing attached device—to an avionics CAN bus in order to inject false measurements and communicate them to the pilot. These false measurements may include the following:
Incorrect engine telemetry readings
Incorrect compass and attitude data
Incorrect altitude, airspeed, and angle of attack (AoA) data
In some cases, unauthenticated commands could also be injected into the CAN bus to enable or disable autopilot or inject false measurements to manipulate the autopilot’s responses. A pilot relying on these instrument readings would not be able to tell the difference between false data and legitimate readings, so this could result in an emergency landing or a catastrophic loss of control of an affected aircraft.
While the impact of such an attack could be dire, we want to emphasize that this attack requires physical access, something that is highly regulated and controlled in the aviation sector. While we believe that relying wholly on physical access controls is unwise, such controls do make it much more difficult for an attacker to access the CAN bus and take control of the avionics systems.
A hacker raided Capital One’s cloud storage buckets and stole personal information on 106 million credit card applicants in America and Canada.
The swiped data includes 140,000 US social security numbers and 80,000 bank account numbers, we’re told, as well as one million Canadian social insurance numbers, plus names, addresses, phone numbers, dates of birth, and reported incomes.
The pilfered data was submitted to Capital One by credit card hopefuls between 2005 and early 2019. The info was siphoned between March this year and July 17, and Capital One learned of the intrusion on July 19.
Seattle software engineer Paige A. Thompson, aka “erratic,” aka 0xA3A97B6C on Twitter, was suspected of nicking the data, and was collared by the FBI at her home on Monday this week. The 33-year-old has already appeared in court, charged with violating the US Computer Fraud and Abuse Act. She will remain in custody until her next hearing on August 1.
According to the Feds in their court paperwork [PDF], Thompson broke into Capital One’s cloud-hosted storage, believed to be Amazon Web Services’ S3 buckets, and downloaded their contents.
The financial giant said the intruder exploited a “configuration vulnerability,” while the Feds said a “firewall misconfiguration permitted commands to reach and be executed” by Capital One’s cloud-based storage servers. US prosecutors said the thief slipped past a “misconfigured web application firewall.”
Basically they don’t like data being shared with third parties doing predictive profiling with the data and they don’t like all the telemetry being sent everywhere, nor do they like MS being able to view and running through content such as text, pictures and videos.
The way the robots work is simple. Guided by cameras and computer systems trained to recognize specific objects, the robots’ arms glide over moving conveyor belts until they reach their target. Oversized tongs or fingers with sensors that are attached to the arms snag cans, glass, plastic containers, and other recyclable items out of the rubbish and place them into nearby bins.
The robots — most of which have come online only within the past year — are assisting human workers and can work up to twice as fast. With continued improvements in the bots’ ability to spot and extract specific objects, they could become a formidable new force in the $6.6 billion U.S. industry.
Researchers like Lily Chin, a PhD. student at the Distributed Robotics Lab at MIT, are working to develop sensors for these robots that can improve their tactile capabilities and improve their sense of touch so they can determine plastic, paper and metal through their fingers. “Right now, robots are mostly reliant on computer vision, but they can get confused and make mistakes,” says Chin. “So now we want to integrate these new tactile capabilities.”
Denver-based AMP Robotics, is one of the companies on the leading edge of innovation in the field. It has developed software — a AMP Neuron platform that uses computer vision and machine learning — so robots can recognize different colors, textures, shapes, sizes and patterns to identify material characteristics so they can sort waste.
The robots are being installed at the Single Stream Recyclers plant in Sarasota, Florida and they will be able to pick 70 to 80 items a minute, twice as fast as humanly possible and with greater accuracy.
Bulk Handling Systems Max-AI AQC-C robot
Bulk Handling Systems
“Using this technology you can increase the quality of the material and in some cases double or triple its resale value,” says AMP Robotics CEO Mantaya Horowitz. “Quality standards are getting stricter that’s why companies and researchers are working on high tech solutions.”
The encryption debate is typically framed around the concept of an impenetrable link connecting two services whose communications the government wishes to monitor. The reality, of course, is that the security of that encryption link is entirely separate from the security of the devices it connects. The ability of encryption to shield a user’s communications rests upon the assumption that the sender and recipient’s devices are themselves secure, with the encrypted channel the only weak point.
After all, if either user’s device is compromised, unbreakable encryption is of little relevance.
This is why surveillance operations typically focus on compromising end devices, bypassing the encryption debate entirely. If a user’s cleartext keystrokes and screen captures can be streamed off their device in real-time, it matters little that they are eventually encrypted for transmission elsewhere.
[…]
Facebook announced earlier this year preliminary results from its efforts to move a global mass surveillance infrastructure directly onto users’ devices where it can bypass the protections of end-to-end encryption.
In Facebook’s vision, the actual end-to-end encryption client itself such as WhatsApp will include embedded content moderation and blacklist filtering algorithms. These algorithms will be continually updated from a central cloud service, but will run locally on the user’s device, scanning each cleartext message before it is sent and each encrypted message after it is decrypted.
The company even noted that when it detects violations it will need to quietly stream a copy of the formerly encrypted content back to its central servers to analyze further, even if the user objects, acting as true wiretapping service.
Facebook’s model entirely bypasses the encryption debate by globalizing the current practice of compromising devices by building those encryption bypasses directly into the communications clients themselves and deploying what amounts to machine-based wiretaps to billions of users at once.
Asked the current status of this work and when it might be deployed in the production version of WhatsApp, a company spokesperson declined to comment.
Of course, Facebook’s efforts apply only to its own encryption clients, leaving criminals and terrorists to turn to other clients like Signal or their own bespoke clients they control the source code of.
The problem is that if Facebook’s model succeeds, it will only be a matter of time before device manufacturers and mobile operating system developers embed similar tools directly into devices themselves, making them impossible to escape. Embedding content scanning tools directly into phones would make it possible to scan all apps, including ones like Signal, effectively ending the era of encrypted communications.
Governments would soon use lawful court orders to require companies to build in custom filters of content they are concerned about and automatically notify them of violations, including sending a copy of the offending content.
Rather than grappling with how to defeat encryption, governments will simply be able to harness social media companies to perform their mass surveillance for them, sending them real-time alerts and copies of the decrypted content.
Update 4/8/19 Bruce Schneier is convinced that this story has been concocted from a single source and Facebook is not in fact planning to do this currently. I’m inclined to agree.
Deep TabNine is what’s known as a coding autocompleter. Programmers can install it as an add-on in their editor of choice, and when they start writing, it’ll suggest how to continue each line, offering small chunks at a time. Think of it as Gmail’s Smart Compose feature but for code.
Jacob Jackson, the computer science undergrad at the University of Waterloo who created Deep TabNine, says this sort of software isn’t new, but machine learning has hugely improved what it can offer. “It’s solved a problem for me,” he tells The Verge.
Jackson started work on the original version of the software, TabNine, in February last year before launching it that November. But earlier this month, he released an updated version that uses a deep learning text-generation algorithm called GPT-2, which was designed by the research lab OpenAI, to improve its abilities. The update has seriously impressed coders, who have called it “amazing,” “insane,” and “absolutely mind-blowing” on Twitter.
[…]
Deep TabNine is trained on 2 million files from coding repository GitHub. It finds patterns in this data and uses them to suggest what’s likely to appear next in any given line of code, whether that’s a variable name or a function.
Using deep learning to create autocompletion software offers several advantages, says Jackson. It makes it easy to add support for new languages, for a start. You only need to drop more training data into Deep TabNine’s hopper, and it’ll dig out patterns, he says. This means that Deep TabNine supports some 22 different coding languages while most alternatives just work with one.
(The full list of languages Deep TabNine supports are as follows: Python, JavaScript, Java, C++, C, PHP, Go, C#, Ruby, Objective-C, Rust, Swift, TypeScript, Haskell, OCaml, Scala, Kotlin, Perl, SQL, HTML, CSS, and Bash.)
Most importantly, thanks to the analytical abilities of deep learning, the suggestions Deep TabNine makes are of a high overall quality. And because the software doesn’t look at users’ own code to make suggestions, it can start helping with projects right from the word go, rather than waiting to get some cues from the code the user writes.
The software isn’t perfect, of course. It makes mistakes in its suggestions and isn’t useful for all types of coding. Users on various programming hang-outs like Hacker News and the r/programming subreddit have debated its merits and offered some mixedreviews (though they mostly skew positive). As you’d expect from a coding tool built for coders, people have a lot to say about how exactly it works with their existing editors and workflow.
One complaint that Jackson agrees is legitimate is that Deep TabNine is more suited to certain types of coding. It works best when autocompleting relatively rote code, the sort of programming that’s been done thousands of times with small variations. It’s less able to write exploratory code, where the user is solving a novel problem. That makes sense considering that the software’s smarts come from patterns found in archival data.
Deep TabNine being used to write some C++.
So how useful is it really for your average coder? That’ll depend on a whole lot of factors, like what programming language they use and what they’re trying to achieve. But Jackson says it’s more like a faster input method than a human coding partner (a common practice known as pair programming).
For example, aspirin was discovered in 1897, and an explanation of how it works followed in 1995. That, in turn, has spurred some research leads on making better pain relievers through something other than trial and error.
This kind of discovery — answers first, explanations later — I call “intellectual debt.” We gain insight into what works without knowing why it works. We can put that insight to use immediately, and then tell ourselves we’ll figure out the details later. Sometimes we pay off the debt quickly; sometimes, as with aspirin, it takes a century; and sometimes we never pay it off at all.
Be they of money or ideas, loans can offer great leverage. We can get the benefits of money — including use as investment to produce more wealth — before we’ve actually earned it, and we can deploy new ideas before having to plumb them to bedrock truth.
Indebtedness also carries risks. For intellectual debt, these risks can be quite profound, both because we are borrowing as a society, rather than individually, and because new technologies of artificial intelligence — specifically, machine learning — are bringing the old model of drug discovery to a seemingly unlimited number of new areas of inquiry. Humanity’s intellectual credit line is undergoing an extraordinary, unasked-for bump up in its limit.
[…]
Technical debt arises when systems are tweaked hastily, catering to an immediate need to save money or implement a new feature, while increasing long-term complexity. Anyone who has added a device every so often to a home entertainment system can attest to the way in which a series of seemingly sensible short-term improvements can produce an impenetrable rat’s nest of cables. When something stops working, this technical debt often needs to be paid down as an aggravating lump sum — likely by tearing the components out and rewiring them in a more coherent manner.
[…]
Machine learning has made remarkable strides thanks to theoretical breakthroughs, zippy new hardware, and unprecedented data availability. The distinct promise of machine learning lies in suggesting answers to fuzzy, open-ended questions by identifying patterns and making predictions.
[…]
Researchers have pointed out thorny problems of technical debt afflicting AI systems that make it seem comparatively easy to find a retiree to decipher a bank system’s COBOL. They describe how machine learning models become embedded in larger ones and then be forgotten, even as their original training data goes stale and their accuracy declines.
But machine learning doesn’t merely implicate technical debt. There are some promising approaches to building machine learning systems that in fact can offer some explanations — sometimes at the cost of accuracy — but they are the rare exceptions. Otherwise, machine learning is fundamentally patterned like drug discovery, and it thus incurs intellectual debt. It stands to produce answers that work, without offering any underlying theory. While machine learning systems can surpass humans at pattern recognition and predictions, they generally cannot explain their answers in human-comprehensible terms. They are statistical correlation engines — they traffic in byzantine patterns with predictive utility, not neat articulations of relationships between cause and effect. Marrying power and inscrutability, they embody Arthur C. Clarke’s observation that any sufficiently advanced technology is indistinguishable from magic.
But here there is no David Copperfield or Ricky Jay who knows the secret behind the trick. No one does. Machine learning at its best gives us answers as succinct and impenetrable as those of a Magic 8-Ball — except they appear to be consistently right. When we accept those answers without independently trying to ascertain the theories that might animate them, we accrue intellectual debt.
Electricity output was curtailed at six reactors by 0840 GMT on Thursday, while two other reactors were offline, data showed. High water temperatures and sluggish flows limit the ability to use river water to cool reactors.
In Germany, PreussenElektra, the nuclear unit of utility E.ON, said it would take its Grohnde reactor offline on Friday due to high temperatures in the Weser river.
The second heatwave in successive months to hit western Europe is expected to peak on Thursday with record temperatures seen in several towns in France.
Utility EDF, which operates France’s 58 nuclear reactors, said that generation at its Bugey, St-Alban and Tricastin nuclear power plants may be curbed until after July 26 because of the low flow rate and high temperatures of the Rhone.
Its two reactors at the 2,600 megawatt (MW) Golfech nuclear power plant in the south of France were offline due to high temperatures on the Garonne river.
EDF’s use of water from rivers as a coolant is regulated by law to protect plant and animal life and it is obliged to cut output in hot weather when water temperatures rise, or when river levels and flow rates are low.
Atomic power from France’s 58 reactors accounts for over 75 percent of its electricity needs. Available nuclear power supply was down 1.4 percentage points at 65.3% of total capacity compared with Wednesday.
A spokeswoman for grid operator RTE said that although electricity demand was expected to rise due to increased consumption for cooling, France had enough generation capacity to cover demand. Peak power demand could be above 59.7 GW reached the previous day.
First Amazon, then Google, and now Apple have all confirmed that their devices are not only listening to you, but complete strangers may be reviewing the recordings. Thanks to Siri, Apple contractors routinely catch intimate snippets of users’ private lives like drug deals, doctor’s visits, and sexual escapades as part of their quality control duties, the Guardian reported Friday.
As part of its effort to improve the voice assistant, “[a] small portion of Siri requests are analysed to improve Siri and dictation,” Apple told the Guardian. That involves sending these recordings sans Apple IDs to its international team of contractors to rate these interactions based on Siri’s response, amid other factors. The company further explained that these graded recordings make up less than 1 percent of daily Siri activations and that most only last a few seconds.
That isn’t the case, according to an anonymous Apple contractor the Guardian spoke with. The contractor explained that because these quality control procedures don’t weed out cases where a user has unintentionally triggered Siri, contractors end up overhearing conversations users may not ever have wanted to be recorded in the first place. Not only that, details that could potentially identify a user purportedly accompany the recording so contractors can check whether a request was handled successfully.
“There have been countless instances of recordings featuring private discussions between doctors and patients, business deals, seemingly criminal dealings, sexual encounters and so on. These recordings are accompanied by user data showing location, contact details, and app data,” the whistleblower told the Guardian.
And it’s frighteningly easy to activate Siri by accident. Most anything that sounds remotely like “Hey Siri” is likely to do the trick, as UK’s Secretary of Defense Gavin Williamson found out last year when the assistant piped up as he spoke to Parliament about Syria. The sound of a zipper may even be enough to activate it, according to the contractor. They said that of Apple’s devices, the Apple Watch and HomePod smart speaker most frequently pick up accidental Siri triggers, and recordings can last as long as 30 seconds.
While Apple told the Guardian the information collected from Siri isn’t connected to other data Apple may have on a user, the contractor told a different story:
“There’s not much vetting of who works there, and the amount of data that we’re free to look through seems quite broad. It wouldn’t be difficult to identify the person that you’re listening to, especially with accidental triggers—addresses, names and so on.”
Staff were told to report these accidental activations as technical problems, the worker told the paper, but there wasn’t guidance on what to do if these recordings captured confidential information.
All this makes Siri’s cutesy responses to users questions seem far less innocent, particularly its answer when you ask if it’s always listening: “I only listen when you’re talking to me.”
Fellow tech giants Amazon and Google have faced similar privacy scandals recently over recordings from their devices. But while these companies also have employees who monitor each’s respective voice assistant, users can revoke permissions for some uses of these recordings. Apple provides no such option in its products.
The majority of YouTube videos about the climate crisis oppose the scientific consensus and “hijack” technical terms to make them appear credible, a new study has found. Researchers have warned that users searching the video site to learn about climate science may be exposed to content that goes against mainstream scientific belief.
Dr Joachim Allgaier of RWTH Aachen University in Germany analysed 200 YouTube videos to see if they adhered to or challenged the scientific consensus. To do so, he chose 10 search terms:
The videos were then assessed to judge how closely they adhered to the scientific consensus, as represented by the findings of reports by UN Intergovernmental Panel on Climate Change (IPCC) from 2013 onwards.
These concluded that humans have been the “dominant cause” of global warming since the 1950s. However, Allgaier found that the message of 120 of the top 200 search results went against this view.
To avoid personalised results, Allgaier used the anonymisation tool Tor, which hides a computer’s IP address and means YouTube treats each search as coming from a different user.
The results for the search terms climate, climate change, climate science and global warming mostly reflected the scientific consensus view. Allgaier said this was because many contained excerpts from TV news programmes or documentaries.
The same could not be said for the results of searches related to chemtrails, climate engineering, climate hacking, climate manipulation, climate modification and geoengineering. Very few of these videos explained the scientific rationale behind their ideas, Allgaier said.
Using a technique to 3D-print liquids, the scientists created millimeter-size droplets from water, oil and iron-oxides. The liquid droplets keep their shape because some of the iron-oxide particles bind with surfactants — substances that reduce the surface tension of a liquid. The surfactants create a film around the liquid water, with some iron-oxide particles creating part of the filmy barrier, and the rest of the particles enclosed inside, Russell said.
The team then placed the millimeter-size droplets near a magnetic coil to magnetize them. But when they took the magnetic coil away, the droplets demonstrated an unseen behavior in liquids — they remained magnetized. (Magnetic liquids called ferrofluids do exist, but these liquids are only magnetized when in the presence of a magnetic field.)
When those droplets approached a magnetic field, the tiny iron-oxide particles all aligned in the same direction. And once they removed the magnetic field, the iron-oxide particles bound to the surfactant in the film were so jam-packed that they couldn’t move and so remained aligned. But those free-floating inside the droplet also remained aligned.
The scientists don’t fully understand how these particles hold onto the field, Russell said. Once they figure that out, there are many potential applications. For example, Russell imagines printing a cylinder with a non-magnetic middle and two magnetic caps. “The two ends would come together like a horseshoe magnet,” and be used as a mini “grabber,” he said.
In an even more bizarre application, imagine a mini liquid person — a smaller-scale version of the liquid T-1000 from the second “Terminator” movie — Russell said. Now imagine that parts of this mini liquid man are magnetized and parts aren’t. An external magnetic field could then force the little person to move its limbs like a marionette.
“For me, it sort of represents a sort of new state of magnetic materials,” Russell said. The findings were published on July 19 in the journal Science.
Stock trading service Robinhood has admitted today to storing some customers’ passwords in cleartext, according to emails the company has been sending to impacted customers, and seen by ZDNet.
“On Monday night, we discovered that some user credentials were stored in a readable format within our internal system,” the company said.
“We resolved the issue, and after thorough review, found no evidence that this information was accessed by anyone outside our response team.”
Robinhood is now resetting passwords out of an abundance of caution, despite not finding any evidence of abuse.
[…]
Storing passwords in cleartext is a huge security blunder; however, Robinhood is in “good company.” This year alone, Facebook, Instagram, and Google have all admitted to storing users passwords in cleartext.
The scientific consensus that humans are causing global warming is likely to have passed 99%, according to the lead author of the most authoritative study on the subject, and could rise further after separate research that clears up some of the remaining doubts.
Three studies published in Nature and Nature Geoscience use extensive historical data to show there has never been a period in the last 2,000 years when temperature changes have been as fast and extensive as in recent decades.
It had previously been thought that similarly dramatic peaks and troughs might have occurred in the past, including in periods dubbed the Little Ice Age and the Medieval Climate Anomaly. But the three studies use reconstructions based on 700 proxy records of temperature change, such as trees, ice and sediment, from all continents that indicate none of these shifts took place in more than half the globe at any one time.
The Little Ice Age, for example, reached its extreme point in the 15th century in the Pacific Ocean, the 17th century in Europe and the 19th century elsewhere, says one of the studies. This localisation is markedly different from the trend since the late 20th century when records are being broken year after year over almost the entire globe, including this summer’s European heatwave.
[…]
“There is no doubt left – as has been shown extensively in many other studies addressing many different aspects of the climate system using different methods and data sets,” said Stefan Brönnimann, from the University of Bern and the Pages 2K consortium of climate scientists.
Commenting on the study, other scientists said it was an important breakthrough in the “fingerprinting” task of proving how human responsibility has changed the climate in ways not seen in the past.
“This paper should finally stop climate change deniers claiming that the recent observed coherent global warming is part of a natural climate cycle. This paper shows the truly stark difference between regional and localised changes in climate of the past and the truly global effect of anthropogenic greenhouse emissions,” said Mark Maslin, professor of climatology at University College London.
Previous studies have shown near unanimity among climate scientists that human factors – car exhausts, factory chimneys, forest clearance and other sources of greenhouse gases – are responsible for the exceptional level of global warming.
A 2013 study in Environmental Research Letters found 97% of climate scientists agreed with this link in 12,000 academic papers that contained the words “global warming” or “global climate change” from 1991 to 2011. Last week, that paper hit 1m downloads, making it the most accessed paper ever among the 80+ journals published by the Institute of Physics, according to the authors.
Some models of Airbus A350 airliners still need to be hard rebooted after exactly 149 hours, despite warnings from the EU Aviation Safety Agency (EASA) first issued two years ago.
In a mandatory airworthiness directive (AD) reissued earlier this week, EASA urged operators to turn their A350s off and on again to prevent “partial or total loss of some avionics systems or functions”.
The revised AD, effective from tomorrow (26 July), exempts only those new A350-941s which have had modified software pre-loaded on the production line. For all other A350-941s, operators need to completely power the airliner down before it reaches 149 hours of continuous power-on time.
[…]
Airbus’ rival Boeing very publicly suffered from a similar time-related problem with its 787 Dreamliner: back in 2015 a memory overflow bug was discovered that caused the 787’s generators to shut themselves down after 248 days of continual power-on operation. A software counter in the generators’ firmware, it was found, would overflow after that precise length of time. The Register is aware that this is not the only software-related problem to have plagued the 787 during its earlier years.
It is common for airliners to be left powered on while parked at airport gates so maintainers can carry out routine systems checks between flights, especially if the aircraft is plugged into ground power.
The remedy for the A350-941 problem is straightforward according to the AD: install Airbus software updates for a permanent cure, or switch the aeroplane off and on again.
France will develop satellites armed with laser weapons, and will use the weapons against enemy satellites that threaten the country’s space forces. The announcement is just part of a gradual shift in acceptance of space-based weaponry as countries reliant on space for military operations in the air, on land, and at sea—as well as for economic purposes, bow to reality and accept space as a future battleground.
In remarks earlier today, French Defense Minister Florence Parly said, “If our satellites are threatened, we intend to blind those of our adversaries. We reserve the right and the means to be able to respond: that could imply the use of powerful lasers deployed from our satellites or from patrolling nano-satellites.”
“We will develop power lasers, a field in which France has fallen behind,” Parly added.
Last year France accused Russia of space espionage, stating that Moscow’s Luch satellite came too close to a Franco-Italian Athena-Fidus military communications satellite. The satellite, which has a transfer rate of 3 gigabits per second, passes video, imagery, and secure communications among French and Italian forces. “It got close. A bit too close,” Parly told an audience in 2018. “So close that one really could believe that it was trying to capture our communications.”
France also plans to develop nano-satellite patrollers—small satellites that act as bodyguards for larger French space assets by 2023. Per Parly’s remarks, nano-sats could be armed with lasers. According to DW, France is also adding cameras to new Syracuse military communications satellites.
Additionally France plans to set up its own space force, the “Air and Space Army,” as part of the French Air Force. The new organization will be based in Toulouse, but it’s not clear if the Air and Space Army will remain part of the French Air Force or become its own service branch.
The two worked together to bring a training method called Population Based Training (PBT for short) to bear on Waymo’s challenge of building better virtual drivers, and the results were impressive — DeepMind says in a blog post that using PBT decreased by 24% false positives in a network that identifies and places boxes around pedestrians, bicyclists and motorcyclists spotted by a Waymo vehicle’s many sensors. Not only that, but is also resulted in savings in terms of both training time and resources, using about 50% of both compared to standard methods that Waymo was using previously.
[…]
To step back a little, let’s look at what PBT even is. Basically, it’s a method of training that takes its cues from how Darwinian evolution works. Neural nets essentially work by trying something and then measuring those results against some kind of standard to see if their attempt is more “right” or more “wrong” based on the desired outcome
[…]
But all that comparative training requires a huge amount of resources, and sorting the good from the bad in terms of which are working out relies on either the gut feeling of individual engineers, or massive-scale search with a manual component involved where engineers “weed out” the worst performing neural nets to free up processing capabilities for better ones.
What DeepMind and Waymo did with this experiment was essentially automate that weeding, automatically killing the “bad” training and replacing them with better-performing spin-offs of the best-in-class networks running the task. That’s where evolution comes in, since it’s kind of a process of artificial natural selection.
The ransomware sought out vulnerabilities and used a modified version of the NSA’s leaked EternalBlue SMB exploit, generating one of the most financially costly cyber-attacks to date.
Among the victims was US food giant Mondelez – the parent firm of Oreo cookies and Cadburys chocolate – which is now suing insurance company Zurich American for denying a £76m claim (PDF) filed in October 2018, a year after the NotPetya attack. According to the firm, the malware rendered 1,700 of its servers and 24,000 of its laptops permanently dysfunctional.
In January, Zurich rejected the claim, simply referring to a single policy exclusion which does not cover “hostile or warlike action in time of peace or war” by “government or sovereign power; the military, naval, or air force; or agent or authority”.
Mondelez, meanwhile, suffered significant loss as the attack infiltrated the company – affecting laptops, the company network and logistics software. Zurich American claims the damage, as the result of an “an act of war”, is therefore not covered by Mondelez’s policy, which states coverage applies to “all risks of physical loss or damage to electronic data, programs, or software, including loss or damage caused by the malicious introduction of a machine code or instruction.”
While war exclusions are common in insurance policies, the court papers themselves refer to the grounds as “unprecedented” in relation to “cyber incidents”.
Previous claims have only been based on conventional armed conflicts.
Zurich’s use of this sort of exclusion in a cybersecurity policy could be a game-changer, with the obvious question being: was NotPetya an act of war, or just another incidence of ransomware?
The UK, US and Ukrainian governments, for their part, blamed the attack on Russian, state-sponsored hackers, claiming it was the latest act in an ongoing feud between Russia and Ukraine.
[…]
The minds behind the Tallinn Manual – the international cyberwar rules of engagement – were divided as to whether damage caused met the armed criterion. However, they noted there was a possibility that it could in rare circumstances.
Professor Michael Schmitt, director of the Tallinn Manual project, indicated (PDF) that it is reasonable to extend armed attacks to cyber-attacks. The International Committee of the Red Cross (ICRC) went further to enunciate that cyber operations that only disable certain objects are still qualified as an attack, despite no physical damage.
After nearly a decade in court, Google has agreed to pay $13 million in a class-action lawsuit alleging its Street View program collected people’s private data over wifi from 2007 to 2010. In addition to the moolah, the settlement—filed Friday in San Francisco—also calls for Google to destroy all the collected data and teach people how to encrypt their wifi networks.
A quick refresher. Back when Google started deploying its little Street View cars around our neighborhoods, the company also ended up collecting about 600 GB of emails, passwords, and other payload data from unencrypted wifi networks in over 30 countries. In a 2010 blog, Google said the data collection was a “mistake” after a German data protection group asked to audit the data collected by the cars.
[…]
The basis for the class-action lawsuit was that Google was basically infringing on federal wiretapping laws. Google had argued in a separate case on the same issue, Joffe vs Google, that its “mistake” was legal, as unencrypted wifi are a form of radio communication and thereby, readily accessible by the general public. The courts did not agree, and in 2013 ruled Google’s defense was bunk. And despite Google claiming the collection was a “mistake,” according to CNN, in this particular class-action lawsuit, investigators found that Google engineers created the software and embedded them into Street View cars intentionally.
[…]
If you thought Google would pay out the nose for this particular brand of evil, you’d be mistaken. The class-action netted $13 million, with punitive payments only going to the original 22 plaintiffs—additional class members won’t get anything. The remaining money will be then distributed to eight data privacy and consumer protection organizations. Similarly, another case brought by 38 states on yet again, the same issue, only netted a $7 million settlement.