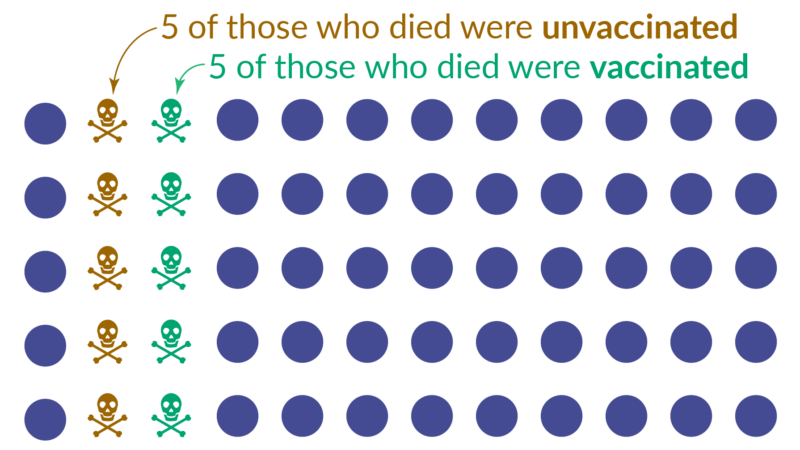To understand how the pandemic is evolving, it’s crucial to know how death rates from COVID-19 are affected by vaccination status. The death rate is a key metric that can accurately show us how effective vaccines are against severe forms of the disease. This may change over time when there are changes in the prevalence of COVID-19, and because of factors such as waning immunity, new strains of the virus, and the use of boosters.
On this page, we explain why it is essential to look at death rates by vaccination status rather than the absolute number of deaths among vaccinated and unvaccinated people.
We also visualize this mortality data for the United States, England, and Chile.
Ideally we would produce a global dataset that compiles this data for countries around the world, but we do not have the capacity to do this in our team. As a minimum, we list country-specific sources where you can find similar data for other countries, and we describe how an ideal dataset would be formatted.
Why we need to compare the rates of death between vaccinated and unvaccinated
During a pandemic, you might see headlines like “Half of those who died from the virus were vaccinated”.
It would be wrong to draw any conclusions about whether the vaccines are protecting people from the virus based on this headline. The headline is not providing enough information to draw any conclusions.
Let’s think through an example to see this.
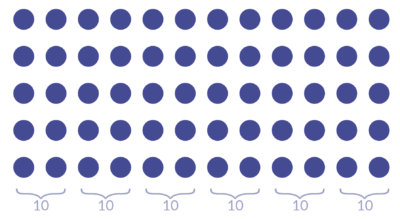
Imagine we live in a place with a population of 60 people.
Then we learn that of the 10 who died from the virus, 50% were vaccinated.
The newspaper may run the headline “Half of those who died from the virus were vaccinated”. But this headline does not tell us anything about whether the vaccine is protecting people or not.
To be able to say anything, we also need to know about those who did not die: how many people in this population were vaccinated? And how many were not vaccinated?
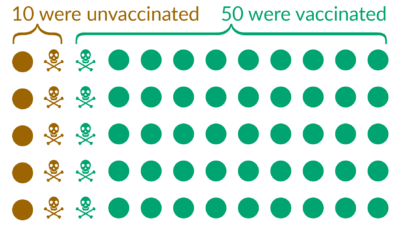
Now we have all the information we need and can calculate the death rates:
of 10 unvaccinated people, 5 died → the death rate among the unvaccinated is 50%
of 50 vaccinated people, 5 died → the death rate among the vaccinated is 10%
We therefore see that the death rate among the vaccinated is 5-times lower than among the unvaccinated.
In the example, we invented numbers to make it simple to calculate the death rates. But the same logic applies also in the current COVID-19 pandemic. Comparisons of the absolute numbers, as some headlines do, is making a mistake that’s known in statistics as a ‘base rate fallacy’: it ignores the fact that one group is much larger than the other. It is important to avoid this mistake, especially now, as in more and more countries the number of people who are vaccinated against COVID-19 is much larger than the number of people who are unvaccinated (see our vaccination data).
This example was illustrating how to think about these statistics in a hypothetical case. Below, you can find the real data for the situation in the COVID-19 pandemic now.
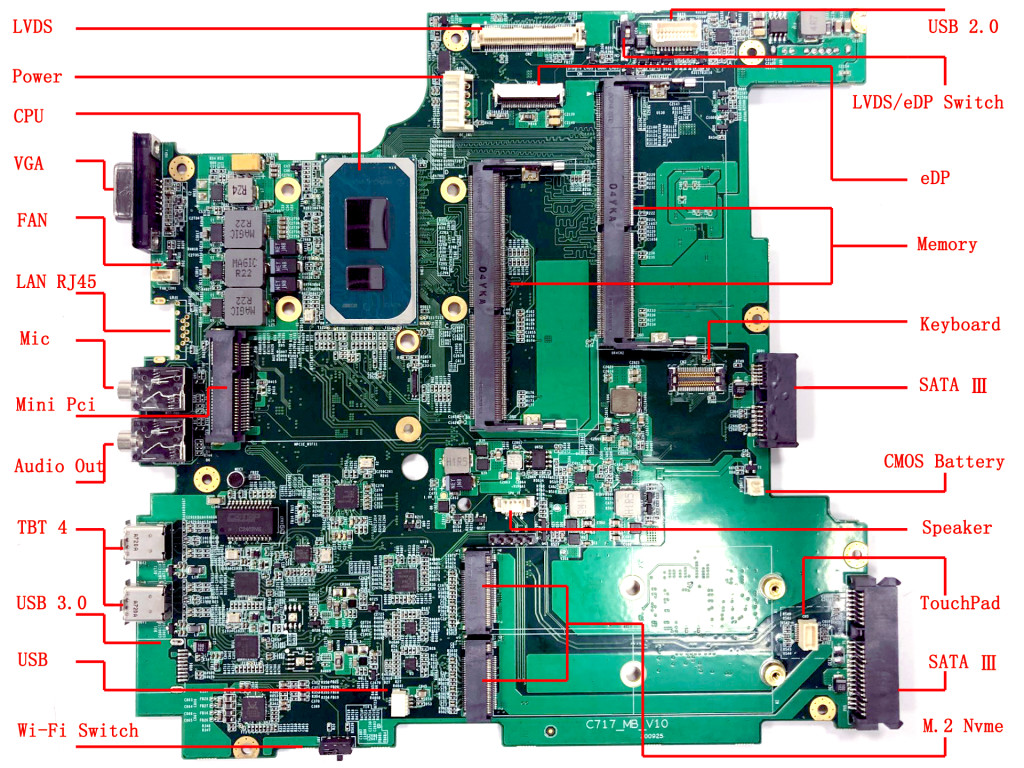
[…]Even the best hardware eventually becomes obsolete when it can no longer run modern software: with a 2.0 GHz Core Duo and 3 GB of RAM you can still browse the web and do word processing today, but you can forget about 4K video or a 64-bit OS. Luckily, there’s hope for those who are just not ready to part with their trusty Thinkpads: [Xue Yao] has designed a replacement motherboard that fits the T60/T61 range, bringing them firmly into the present day. The T700 motherboard is currently in its prototype phase, with series production expected to start in early 2022, funded through a crowdfunding campaign.
Designing a motherboard for a modern CPU is no mean feat, and making it fit an existing laptop, with all the odd shapes and less-than-standard connections, is even more impressive. The T700 has an Intel Core i7 CPU with four cores running at 2.8 GHz, while two RAM slots allow for up to 64 GB of DDR4-3200 memory. There are modern USB-A and USB-C ports as well as well as a 6 Gbps SATA interface and two m.2 slots for your SSDs.
As for the display, the T700 motherboard will happily connect to the original screens built into the T60/T61, or to any of a range of aftermarket LED based replacements. A Thunderbolt connector is available, but only operates in USB-C mode due to firmware issues; according to the project page, full support for Thunderbolt 4 is expected once the open-source coreboot firmware has been ported to the T700 platform.
We love projects like this that extend the useful life of classic computers to keep them running way past their expected service life. But impressive though this is, it’s not the first time someone has made a replacement motherboard for the Thinkpad line; we covered a project from the nb51 forum back in 2018, which formed the basis for today’s project. We’ve seen lots of other useful Thinkpad hacks over the years, from replacing the display to revitalizing the batteries. Thanks to [René] for the tip.
We’ve heard the fable of “the self-made billionaire” a thousand times: some unrecognized genius toiling away in a suburban garage stumbles upon The Next Big Thing, thereby single-handedly revolutionizing their industry and becoming insanely rich in the process — all while comfortably ignoring the fact that they’d received $300,000 in seed funding from their already rich, politically-connected parents to do so.
In The Warehouse: Workers and Robots at Amazon, Alessandro Delfanti, associate professor at the University of Toronto and author of Biohackers: The Politics of Open Science, deftly examines the dichotomy between Amazon’s public personas and its union-busting, worker-surveilling behavior in fulfillment centers around the world — and how it leverages cutting edge technologies to keep its employees’ collective noses to the grindstone, pissing in water bottles. In the excerpt below, Delfanti examines the way in which our current batch of digital robber barons lean on the classic redemption myth to launder their images into that of wonderkids deserving of unabashed praise.
Phys.orgreports scientists have developed a “living ink” you could use to print equally alive materials usable for creating 3D structures. The team genetically engineered cells for E. Coli and other microbes to create living nanofibers, bundled those fibers and added other materials to produce an ink you could use in a standard 3D printer.
Researchers have tried producing living material before, but it has been difficult to get those substances to fit intended 3D structures. That wasn’t an issue here. The scientists created one material that released an anti-cancer drug when induced with chemicals, while another removed the toxin BPA from the environment. The designs can be tailored to other tasks, too.
Any practical uses could still be some ways off. It’s not yet clear how you’d mass-produce the ink, for example. However, there’s potential beyond the immediate medical and anti-pollution efforts. The creators envisioned buildings that repair themselves, or self-assembling materials for Moon and Mars buildings that could reduce the need for resources from Earth. The ink could even manufacture itself in the right circumstances — you might not need much more than a few basic resources to produce whatever you need.
A team of researchers from the University of Alabama, the University of Melbourne and the University of California has found that social scientists are able to change their beliefs regarding the outcome of an experiment when given the chance. In a paper published in the journal Nature Human Behavior, the group describes how they tested the ability of scientists to change their beliefs about a scientific idea when shown evidence of replicability. Michael Gordon and Thomas Pfeifer with Massey University have published a News & Views piece in the same journal issue explaining why scientists must be able to update their beliefs.
The researchers set out to study a conundrum in science. It is generally accepted that scientific progress can only be made if scientists update their beliefs when new ideas come along. The conundrum is that scientists are human beings and human beings are notoriously difficult to sway from their beliefs. To find out if this might be a problem in general science endeavors, the researchers created an environment that allowed for testing the possibility.
The work involved sending out questionnaires to 1,100 social scientists asking them how they felt about the outcome of several recent well-known studies. They then conducted replication efforts on those same studies to determine if they could reproduce the findings by the researchers in the original efforts. They then sent the results of their replication efforts to the social scientists who had been queried prior to their effort, and once again asked them how they felt about the results of the original team.
In looking at their data, and factoring out related biases, they found that most of those scientists that participated lost some confidence in the results of studies when the researchers could not replicate results and gained some confidence in them when they could. The researchers suggest that this indicates that scientists, at least those in social fields, are able to rise above their beliefs when faced with scientific evidence, ensuring that science is indeed allowed to progress, despite it being conducted by fallible human beings.
This could have dramatic consequences for the SiP (Silicon Photonics) — a hot topic for those working in the field of integrated optics. Integrated optics is a critical technology involved in advanced telecommunications networks, and showing increasing importance in quantum research and devices, such as QKD (Quantum Key Distribution) and in various entanglement type experiments (involved in Quantum Compute).
“This is the holy grail of photonics,” says Jonathan Bradley, an assistant professor in the Department of Engineering Physics (and the student’s co-supervisor) in an announcement from McMaster University. “Fabricating a laser on silicon has been a longstanding challenge.” Bradley notes that Miarabbas Kiani’s achievement is remarkable not only for demonstrating a working laser on a silicon chip, but also for doing so in a simple, cost-effective way that’s compatible with existing global manufacturing facilities. This compatibility is essential, as it allows for volume manufacturing at low cost. “If it costs too much, you can’t mass produce it,” says Bradley.
Suppose you are trying to transmit a message. Convert each character into bits, and each bit into a signal. Then send it, over copper or fiber or air. Try as you might to be as careful as possible, what is received on the other side will not be the same as what you began with. Noise never fails to corrupt.
In the 1940s, computer scientists first confronted the unavoidable problem of noise. Five decades later, they came up with an elegant approach to sidestepping it: What if you could encode a message so that it would be obvious if it had been garbled before your recipient even read it? A book can’t be judged by its cover, but this message could.
They called this property local testability, because such a message can be tested super-fast in just a few spots to ascertain its correctness. Over the next 30 years, researchers made substantial progress toward creating such a test, but their efforts always fell short. Many thought local testability would never be achieved in its ideal form.
Now, in a preprint released on November 8, the computer scientist Irit Dinur of the Weizmann Institute of Science and four mathematicians, Shai Evra, Ron Livne, Alex Lubotzky and Shahar Mozes, all at the Hebrew University of Jerusalem, have found it.
[…]
Their new technique transforms a message into a super-canary, an object that testifies to its health better than any other message yet known. Any corruption of significance that is buried anywhere in its superstructure becomes apparent from simple tests at a few spots.
“This is not something that seems plausible,” said Madhu Sudan of Harvard University. “This result suddenly says you can do it.”
[…]
To work well, a code must have several properties. First, the codewords in it should not be too similar: If a code contained the codewords 0000 and 0001, it would only take one bit-flip’s worth of noise to confuse the two words. Second, codewords should not be too long. Repeating bits may make a message more durable, but they also make it take longer to send.
These two properties are called distance and rate. A good code should have both a large distance (between distinct codewords) and a high rate (of transmitting real information).
[…]
To understand why testability is so hard to obtain, we need to think of a message not just as a string of bits, but as a mathematical graph: a collection of vertices (dots) connected by edges (lines).
[…]
Hamming’s work set the stage for the ubiquitous error-correcting codes of the 1980s. He came up with a rule that each message should be paired with a set of receipts, which keep an account of its bits. More specifically, each receipt is the sum of a carefully chosen subset of bits from the message. When this sum has an even value, the receipt is marked 0, and when it has an odd value, the receipt is marked 1. Each receipt is represented by one single bit, in other words, which researchers call a parity check or parity bit.
Hamming specified a procedure for appending the receipts to a message. A recipient could then detect errors by attempting to reproduce the receipts, calculating the sums for themselves. These Hamming codes work remarkably well, and they are the starting point for seeing codes as graphs and graphs as codes.
[…]
Expander graphs are distinguished by two properties that can seem contradictory. First, they are sparse: Each node is connected to relatively few other nodes. Second, they have a property called expandedness — the reason for their name — which means that no set of nodes can be bottlenecks that few edges pass through. Each node is well connected to other nodes, in other words — despite the scarcity of the connections it has.
[…]
However, choosing codewords completely at random would make for an unpredictable dictionary that was excessively hard to sort through. In other words, Shannon showed that good codes exist, but his method for making them didn’t work well.
[…]
However, local testability was not possible. Suppose that you had a valid codeword from an expander code, and you removed one receipt, or parity bit, from one single node. That would constitute a new code, which would have many more valid codewords than the first code, since there would be one less receipt they needed to satisfy. For someone working off the original code, those new codewords would satisfy the receipts at most nodes — all of them, except the one where the receipt was erased. And yet, because both codes have a large distance, the new codeword that seems correct would be extremely far from the original set of codewords. Local testability was simply incompatible with expander codes.
[…]
Local testability was achieved by 2007, but only at the cost of other parameters, like rate and distance. In particular, these parameters would degrade as a codeword became large. In a world constantly seeking to send and store larger messages, these diminishing returns were a major flaw.
[…]
But in 2017, a new source of ideas emerged. Dinur and Lubotzky began working together while attending a yearlong research program at the Israel Institute for Advanced Studies. They came to believe that a 1973 result by the mathematician Howard Garland might hold just what computer scientists sought. Whereas ordinary expander graphs are essentially one-dimensional structures, with each edge extending in only one direction, Garland had created a mathematical object that could be interpreted as an expander graph that spanned higher dimensions, with, for example, the graph’s edges redefined as squares or cubes.
Garland’s high-dimensional expander graphs had properties that seemed ideal for local testability. They must be deliberately constructed from scratch, making them a natural antithesis of randomness. And their nodes are so interconnected that their local characteristics become virtually indistinguishable from how they look globally.
[…]
In their new work, the authors figured out how to assemble expander graphs to create a new graph that leads to the optimal form of locally testable code. They call their graph a left-right Cayley complex.
As in Garland’s work, the building blocks of their graph are no longer one-dimensional edges, but two-dimensional squares. Each information bit from a codeword is assigned to a square, and parity bits (or receipts) are assigned to edges and corners (which are nodes). Each node therefore defines the values of bits (or squares) that can be connected to it.
To get a sense of what their graph looks like, imagine observing it from the inside, standing on a single edge. They construct their graph such that every edge has a fixed number of squares attached. Therefore, from your vantage point you’d feel as if you were looking out from the spine of a booklet. However, from the other three sides of the booklet’s pages, you’d see the spines of new booklets branching from them as well. Booklets would keep branching out from each edge ad infinitum.
“It’s impossible to visualize. That’s the whole point,” said Lubotzky. “That’s why it is so sophisticated.”
Crucially, the complicated graph also shares the properties of an expander graph, like sparseness and connectedness, but with a much richer local structure. For example, an observer sitting at one vertex of a high-dimensional expander could use this structure to straightforwardly infer that the entire graph is strongly connected.
“What’s the opposite of randomness? It’s structure,” said Evra. “The key to local testability is structure.”
To see how this graph leads to a locally testable code, consider that in an expander code, if a bit (which is an edge) is in error, that error can only be detected by checking the receipts at its immediately neighboring nodes. But in a left-right Cayley complex, if a bit (a square) is in error, that error is visible from multiple different nodes, including some that are not even connected to each other by an edge.
In this way, a test at one node can reveal information about errors from far away nodes. By making use of higher dimensions, the graph is ultimately connected in ways that go beyond what we typically even think of as connections.
In addition to testability, the new code maintains rate, distance and other desired properties, even as codewords scale, proving the c3 conjecture true. It establishes a new state of the art for error-correcting codes, and it also marks the first substantial payoff from bringing the mathematics of high-dimensional expanders to bear on codes.
UK lawmakers are sick and tired of shitty internet of things passwords and are whipping out legislation with steep penalties and bans to prove it. The new legislation, introduced to the UK Parliament this week, would ban universal default passwords and work to create what supporters are calling a “firewall around everyday tech.”
Specifically, the bill, called The Product Security and Telecommunications Infrastructure Bill (PSTI), would require unique passwords for internet-connected devices and would prevent those passwords from being reset to universal factory defaults. The bill would also force companies to increase transparency around when their products require security updates and patches, a practice only 20% of firms currently engage in, according to a statement accompanying the bill.
These bolstered security proposals would be overseen by a regulator with sharpened teeth: companies refusing to comply with the security standards could reportedly face fines of £10 million or four percent of their global revenues.
We believe our all-electric ‘Spirit of Innovation’ aircraft is the world’s fastest all-electric aircraft, setting three new world records. We have submitted data to the Fédération Aéronautique Internationale (FAI) – the World Air Sports Federation who control and certify world aeronautical and astronautical records – that at 15:45 (GMT) on 16 November 2021, the aircraft reached a top speed of 555.9 km/h (345.4 mph) over 3 kilometres, smashing the existing record by 213.04 km/h (132mph). In further runs at the UK Ministry of Defence’s Boscombe Down experimental aircraft testing site, the aircraft achieved 532.1km/h (330 mph) over 15 kilometres – 292.8km/h (182mph) faster than the previous record – and broke the fastest time to climb to 3000 metres by 60 seconds with a time of 202 seconds, according to our data. We hope that the FAI will certify and officially confirm the achievements of the team in the near future.
During its record-breaking runs, the aircraft clocked up a maximum speed of 623 km/h (387.4 mph) which we believe makes the ‘Spirit of Innovation’ the world’s fastest all-electric vehicle.
Following an investigation, the Irish data protection watchdog issued a €225m (£190m) fine – the second-largest in history over GDPR – and ordered WhatsApp to change its policies.
WhatsApp is appealing against the fine, but is amending its policy documents in Europe and the UK to comply.
However, it insists that nothing about its actual service is changing.
Instead, the tweaks are designed to “add additional detail around our existing practices”, and will only appear in the European version of the privacy policy, which is already different from the version that applies in the rest of the world.
“There are no changes to our processes or contractual agreements with users, and users will not be required to agree to anything or to take any action in order to continue using WhatsApp,” the company said, announcing the change.
The new policy takes effect immediately.
User revolt
In January, WhatsApp users complained about an update to the company’s terms that many believed would result in data being shared with parent company Facebook, which is now called Meta.
Many thought refusing to agree to the new terms and conditions would result in their accounts being blocked.
In reality, very little had changed. However, WhatsApp was forced to delay its changes and spend months fighting the public perception to the contrary.
The new privacy policy contains substantially more information about what exactly is done with users’ information, and how WhatsApp works with Meta, the parent company for WhatsApp, Facebook and Instagram.
Debates around the effectiveness of high-profile Twitter account suspensions and similar bans on abusive users across social media platforms abound. Yet we know little about the effectiveness of warning a user about the possibility of suspending their account as opposed to outright suspensions in reducing hate speech. With a pre-registered experiment, we provide causal evidence that a warning message can reduce the use of hateful language on Twitter, at least in the short term. We design our messages based on the literature on deterrence, and test versions that emphasize the legitimacy of the sender, the credibility of the message, and the costliness of being suspended. We find that the act of warning a user of the potential consequences of their behavior can significantly reduce their hateful language for one week. We also find that warning messages that aim to appear legitimate in the eyes of the target user seem to be the most effective. In light of these findings, we consider the policy implications of platforms adopting a more aggressive approach to warning users that their accounts may be suspended as a tool for reducing hateful speech online.
[…]
we test whether warning users of their potential suspension if they continue using hateful language might be able to reduce online hate speech. To do so, we implemented a pre-registered experiment on Twitter in order to test the ability of “warning messages” about the possibility of future suspensions to reduce hateful language online. More specifically, we identify users who are candidates for suspension in the future based on their prior tweets and download their follower lists before the suspension takes place. After a user gets suspended, we randomly assign some of their followers who have also used hateful language to receive a warning that they, too, may be suspended for the same reason.
Since our tweets aim to deter users from using hateful language, we design them relying on the three mechanisms that the literature on deterrence deems as most effective in reducing deviation behavior: costliness, legitimacy, and credibility. In other words, our experiment allows us to manipulate the degree to which users perceive their suspension as costly, legitimate, and credible.
[…]
Our study provides causal evidence that the act of sending a warning message to a user can significantly decrease their use of hateful language as measured by their ratio of hateful tweets over their total number of tweets. Although we do not find strong evidence that distinguishes between warnings that are high versus low in legitimacy, credibility, or costliness, the high legitimacy messages seem to be the most effective of all the messages tested.
[…]
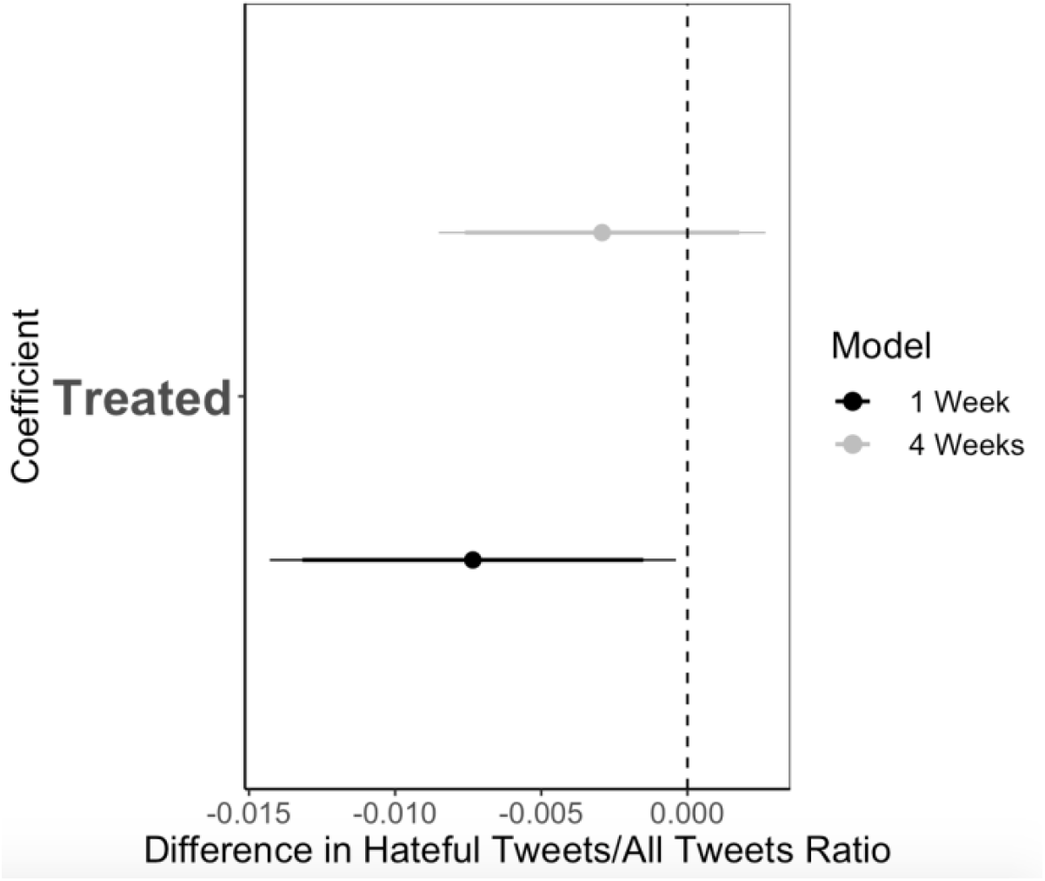
he coefficient plot in figure 4 shows the effect of sending any type of warning tweet on the ratio of tweets with hateful language over the tweets that a user tweets. The outcome variable is the ratio of hateful tweets over the total number of tweets that a user posted over the week and month following the treatment. The effects thus show the change in this ratio as a result of the treatment.
Figure 4 The effect of sending a warning tweet on reducing hateful language
Note: See table G1 in online appendix G for more details on sample size and control coefficients.
We find support for our first hypothesis: a tweet that warns a user of a potential suspension will lead that user to decrease their ratio of hateful tweets by 0.007 for a week after the treatment. Considering the fact that the average pre-treatment hateful tweet ratio is 0.07 in our sample, this means that a single warning tweet from a user with 100 followers reduced the use of hateful language by 10%.
[…]
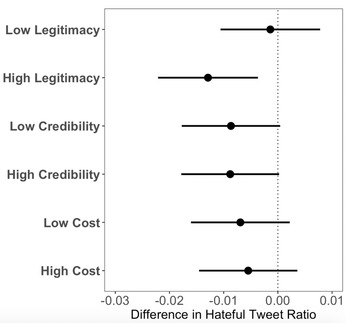
The coefficient plot in figure 5 shows the effect of each treatment on the ratio of tweets with hateful language over the tweets that a user tweets. Although the differences across types are minor and thus caveats are warranted, the most effective treatment seems to be the high legitimacy tweet; the legitimacy category also has by far the largest difference between the high- and low-level versions of the three categories of treatment we assessed. Interestingly, the tweets emphasizing the cost of being suspended appear to be the least effective of the three categories; although the effects are in the correctly predicted direction, neither of the cost treatments alone are statistically distinguishable from null effects.
Figure 5 Reduction in hate speech by treatment type
Note: See table G2 in online appendix G for more details on sample size and control coefficients.
An alternative mechanism that could explain the similarity of effects across treatments—as well as the costliness channel apparently being the least effective—is that perhaps instead of deterring people, the warnings might have made them more reflective and attentive about their language use.
[…]
ur results show that only one warning tweet sent by an account with no more than 100 followers can decrease the ratio of tweets with hateful language by up to 10%, with some types of tweets (high legitimacy, emphasizing the legitimacy of the account sending the tweet) suggesting decreases of perhaps as high as 15%–20% in the week following treatment. Considering that we sent our tweets from accounts that have no more than 100 followers, the effects that we report here are conservative estimates, and could be more effective when sent from more popular accounts (Munger Reference Munger2017).
[…]
A recently burgeoning literature shows that online interventions can also decrease behaviors that could harm the other groups by tracking subjects’ behavior over social media. These works rely on online messages on Twitter that sanction the harmful behavior, and succeed in reducing hateful language (Munger Reference Munger2017; Siegel and Badaan Reference Siegel and Badaan2020), and mostly draw on identity politics when designing their sanctioning messages (Charnysh et al. Reference Charnysh, Lucas and Singh2015). We contribute to this recent line of research by showing that warning messages that are designed based on the literature of deterrence can lead to a meaningful decrease in the use of hateful language without leveraging identity dynamics.
[…]
Two options are worthy of discussion: relying on civil society or relying on Twitter. Our experiment was designed to mimic the former option, with our warnings mimicking non-Twitter employees acting on their own with the goal of reducing hate speech/protecting users from being suspended
[…]
hile it is certainly possible that an NGO or a similar entity could try to implement such a program, the more obvious solution would be to have Twitter itself implement the warnings.
[…]
the company reported “testing prompts in 2020 that encouraged people to pause and reconsider a potentially harmful or offensive reply—such as insults, strong language, or hateful remarks—before Tweeting it. Once prompted, people had an opportunity to take a moment and make edits, delete, or send the reply as is.”Footnote 15 This appears to result in 34% of those prompted electing either to review the Tweet before sending, or not to send the Tweet at all.
We note three differences from this endeavor. First, in our warnings, we try to reduce people’s hateful language after they employ hateful language, which is not the same thing as warning people before they employ hateful language. This is a noteworthy difference, which can be a topic for future research in terms of whether the dynamics of retrospective versus prospective warnings significantly differ from each other. Second, Twitter does not inform their users of the examples of suspensions that took place among the people that these users used to follow. Finally, we are making our data publicly available for re-analysis.
We stop short, however, of unambiguously recommending that Twitter simply implement the system we tested without further study because of two important caveats. First, one interesting feature of our findings is that across all of our tests (one week versus four weeks, different versions of the warning—figures 2 (in text) and A1(in the online appendix)) we never once get a positive effect for hate speech usage in the treatment group, let alone a statistically significant positive coefficient, which would have suggested a potential backlash effect whereby the warnings led people to become more hateful. We are reassured by this finding but do think it is an open question whether a warning from Twitter—a large powerful corporation and the owner of the platform—might provoke a different reaction. We obviously could not test for this possibility on our own, and thus we would urge Twitter to conduct its own testing to confirm that our finding about the lack of a backlash continues to hold when the message comes from the platform itself.Footnote 16
The second caveat concerns the possibility of Twitter making mistakes when implementing its suspension policies.
[…]
Despite these caveats, our findings suggest that hate-speech moderations can be effective without priming the salience of the target users’ identity. Explicitly testing the effectiveness of identity versus non-identity motivated interventions will be an important subject for future research.
GoDaddy has admitted to America’s financial watchdog that one or more miscreants broke into its systems and potentially accessed a huge amount of customer data, from email addresses to SSL private keys.
In a filing on Monday to the SEC, the internet giant said that on November 17 it discovered an “unauthorized third-party” had been roaming around part of its Managed WordPress service, which essentially stores and hosts people’s websites.
[…]
Those infosec sleuths, we’re told, found evidence that an intruder had been inside part of GoDaddy’s website provisioning system, described by Comes as a “legacy code base,” since September 6, gaining access using a “compromised password.”
The miscreant was able to view up to 1.2 million customer email addresses and customer ID numbers, and the administrative passwords generated for WordPress instances when they were provisioned. Any such passwords unchanged since the break-in have been reset.
According to GoDaddy, the sFTP and database usernames and passwords of active user accounts were accessible, too, and these have been reset as well.
“For a subset of active customers, the SSL private key was exposed,” Comes added. “We are in the process of issuing and installing new certificates for those customers.” GoDaddy has not responded to a request for further details and exact numbers of users affected.
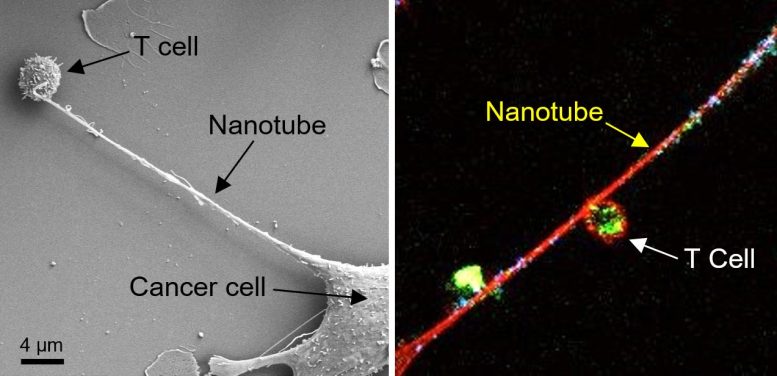
To grow and spread, cancer cells must evade the immune system. Investigators from Brigham and Women’s Hospital and MIT used the power of nanotechnology to discover a new way that cancer can disarm its would-be cellular attackers by extending out nanoscale tentacles that can reach into an immune cell and pull out its powerpack. Slurping out the immune cell’s mitochondria powers up the cancer cell and depletes the immune cell. The new findings, published in Nature Nanotechnology, could lead to new targets for developing the next generation of immunotherapy against cancer.
“Cancer kills when the immune system is suppressed and cancer cells are able to metastasize, and it appears that nanotubes can help them do both,” said corresponding author Shiladitya Sengupta, PhD, co-director of the Brigham’s Center for Engineered Therapeutics. “This is a completely new mechanism by which cancer cells evade the immune system and it gives us a new target to go after.”
To investigate how cancer cells and immune cells interact at the nanoscale level, Sengupta and colleagues set up experiments in which they co-cultured breast cancer cells and immune cells, such as T cells. Using field-emission scanning electron microscopy, they caught a glimpse of something unusual: Cancer cells and immune cells appeared to be physically connected by tiny tendrils, with widths mostly in the 100-1000 nanometer range. (For comparison, a human hair is approximately 80,000 to 100,000 nanometers). In some cases, the nanotubes came together to form thicker tubes. The team then stained mitochondria — which provide energy for cells — from the T cells with a fluorescent dye and watched as bright green mitochondria were pulled out of the immune cells, through the nanotubes, and into the cancer cells.
The ranks of orbit-capable spaceflight companies just grew ever so slightly. TechCrunchreports Astra has reached orbit for the first time when its Rocket 3 booster launched shortly after 1AM Eastern today (November 20th). The startup put a mass simulator into a 310-mile-high orbit as part of a demonstration for the US Air Force’s Rapid Agile Launch Initiative, which shows how private outfits could quickly and flexibly deliver Space Force payloads.
This success has been a long time in coming. Astra failed to reach orbit three times before, including a second attempt where the rocket reached space but didn’t have enough velocity for an orbital insertion.
Company chief Chris Kemp stressed on Twitter that Astra was “just getting started” despite the success. It’s a significant moment all the same. Companies and researchers wanting access to space currently don’t have many choices — they either have to hitch a ride on one of SpaceX’s not-so-common rideshare missions or turn to a handful of options like Rocket Lab. Astra hopes to produce its relatively modest rockets quickly enough that it delivers many small payloads in a timely fashion. That, in turn, might lower prices and make space more viable.
In recent years, Amazon.com Inc has killed or undermined privacy protections in more than three dozen bills across 25 states, as the e-commerce giant amassed a lucrative trove of personal data on millions of American consumers.
Amazon executives and staffers detail these lobbying victories in confidential documents reviewed by Reuters.
In Virginia, the company boosted political donations tenfold over four years before persuading lawmakers this year to pass an industry-friendly privacy bill that Amazon itself drafted. In California, the company stifled proposed restrictions on the industry’s collection and sharing of consumer voice recordings gathered by tech devices. And in its home state of Washington, Amazon won so many exemptions and amendments to a bill regulating biometric data, such as voice recordings or facial scans, that the resulting 2017 law had “little, if any” impact on its practices, according to an internal Amazon document.
As much as 38 percent of the Internet’s domain name lookup servers are vulnerable to a new attack that allows hackers to send victims to maliciously spoofed addresses masquerading as legitimate domains, like bankofamerica.com or gmail.com.
The exploit, unveiled in research presented today, revives the DNS cache-poisoning attack that researcher Dan Kaminsky disclosed in 2008. He showed that, by masquerading as an authoritative DNS server and using it to flood a DNS resolver with fake lookup results for a trusted domain, an attacker could poison the resolver cache with the spoofed IP address. From then on, anyone relying on the same resolver would be diverted to the same imposter site.
A lack of entropy
The sleight of hand worked because DNS at the time relied on a transaction ID to prove the IP number returned came from an authoritative server rather than an imposter server attempting to send people to a malicious site. The transaction number had only 16 bits, which meant that there were only 65,536 possible transaction IDs.
Kaminsky realized that hackers could exploit the lack of entropy by bombarding a DNS resolver with off-path responses that included each possible ID. Once the resolver received a response with the correct ID, the server would accept the malicious IP and store the result in cache so that everyone else using the same resolver—which typically belongs to a corporation, organization, or ISP—would also be sent to the same malicious server.
The threat raised the specter of hackers being able to redirect thousands or millions of people to phishing or malware sites posing as perfect replicas of the trusted domain they were trying to visit. The threat resulted in industry-wide changes to the domain name system, which acts as a phone book that maps IP addresses to domain names.
Under the new DNS spec, port 53 was no longer the default used for lookup queries. Instead, those requests were sent over a port randomly chosen from the entire range of available UDP ports. By combining the 16 bits of randomness from the transaction ID with an additional 16 bits of entropy from the source port randomization, there were now roughly 134 million possible combinations, making the attack mathematically infeasible.
Unexpected Linux behavior
Now, a research team at the University of California at Riverside has revived the threat. Last year, members of the same team found a side channel in the newer DNS that allowed them to once again infer the transaction number and randomized port number sending resolver-spoofed IPs.
The research and the SADDNS exploit it demonstrated resulted in industry-wide updates that effectively closed the side channel. Now comes the discovery of new side channels that once again make cache poisoning viable.
“In this paper, we conduct an analysis of the previously overlooked attack surface, and are able to uncover even stronger side channels that have existed for over a decade in Linux kernels,” researchers Keyu Man, Xin’an Zhou, and Zhiyun Qian wrote in a research paper being presented at the ACM CCS 2021 conference. “The side channels affect not only Linux but also a wide range of DNS software running on top of it, including BIND, Unbound and dnsmasq. We also find about 38% of open resolvers (by frontend IPs) and 14% (by backend IPs) are vulnerable including the popular DNS services such as OpenDNS and Quad9.”
OpenDNS owner Cisco said: “Cisco Umbrella/Open DNS is not vulnerable to the DNS Cache Poisoning Attack described in CVE-2021-20322, and no Cisco customer action is required. We remediated this issue, tracked via Cisco Bug ID CSCvz51632, as soon as possible after receiving the security researcher’s report.” Quad9 representatives weren’t immediately available for comment.
The side channel for the attacks from both last year and this year involve the Internet Control Message Protocol, or ICMP, which is used to send error and status messages between two servers.
“We find that the handling of ICMP messages (a network diagnostic protocol) in Linux uses shared resources in a predictable manner such that it can be leveraged as a side channel,” researcher Qian wrote in an email. “This allows the attacker to infer the ephemeral port number of a DNS query, and ultimately lead to DNS cache poisoning attacks. It is a serious flaw as Linux is most widely used to host DNS resolvers.” He continued:
The ephemeral port is supposed to be randomly generated for every DNS query and unknown to an off-path attacker. However, once the port number is leaked through a side channel, an attacker can then spoof legitimate-looking DNS responses with the correct port number that contain malicious records and have them accepted (e.g., the malicious record can say chase.com maps to an IP address owned by an attacker).
The reason that the port number can be leaked is that the off-path attacker can actively probe different ports to see which one is the correct one, i.e., through ICMP messages that are essentially network diagnostic messages which have unexpected effects in Linux (which is the key discovery of our work this year). Our observation is that ICMP messages can embed UDP packets, indicating a prior UDP packet had an error (e.g., destination unreachable).
We can actually guess the ephemeral port in the embedded UDP packet and package it in an ICMP probe to a DNS resolver. If the guessed port is correct, it causes some global resource in the Linux kernel to change, which can be indirectly observed. This is how the attacker can infer which ephemeral port is used.
Changing internal state with ICMP probes
The side channel last time around was the rate limit for ICMP. To conserve bandwidth and computing resources, servers will respond to only a set number of requests and then fall silent. The SADDNS exploit used the rate limit as a side channel. But whereas last year’s port inference method used UDP packets to probe which ports were designed to solicit ICMP responses, the attack this time uses ICMP probes directly.
“According to the RFC (standards), ICMP packets are only supposed to be generated *in response* to something,” Qian added. “They themselves should never *solicit* any responses, which means they are ill-suited for port scans (because you don’t get any feedback). However, we find that ICMP probes can actually change some internal state that can actually be observed through a side channel, which is why the whole attack is novel.”
The researchers have proposed several defenses to prevent their attack. One is setting proper socket options such as IP_PMTUDISC_OMIT, which instructs an operating system to ignore so-called ICMP messages, effectively closing the side channel. A downside, then, is that those messages will be ignored, and sometimes such messages are legitimate.
Another proposed defense is randomizing the caching structure to make the side channel unusable. A third is to reject ICMP redirects.
The vulnerability affects DNS software, including BIND, Unbound, and dnsmasq, when they run on Linux. The researchers tested to see if DNS software was vulnerable when running on either Windows or Free BSD and found no evidence it was. Since macOS uses the FreeBSD network stack, they assume it isn’t vulnerable either.
Discord has been quietly building its own app platform based on bots over the past few years. More than 30 percent of Discord servers now use bots, and 430,000 of them are used every week across Discord by its 150 million monthly active users. Now that bots are an important part of Discord, the company is embracing them even further with the ability to search and browse for bots on Discord.
A new app discovery feature will start showing up in Discord in spring 2022. Verified apps and bots (which total around 12,000 right now) will be discoverable through this feature. Developers will be able to opt into discoverability, once they’re fully prepared for a new influx of users that can easily find their bots.
Bots are powerful on Discord, offering a range of customizations for servers. Discord server owners install bots on servers to help moderate them or offer mini-games or features to their communities. There are popular bots that will spit out memes on a daily basis, bots that help you even create your own bot, or music bots that let Discord users listen to tunes together.
Apple, having long stood in the way of customers who want to fix their own devices, now says it wants to help those who feel they have the right to repair their own products.
On Wednesday the iBiz announced Self Service Repair, “which will allow customers who are comfortable with completing their own repairs access to Apple genuine parts and tools.”
This may be something of a mixed blessing as Apple hardware is notoriously difficult to mend, due to the fact that special tools are often required, parts may be glued together, and components like Apple’s TouchID sensor and T2 security chip can complicate getting devices to work again once reassembled.
Kyle Wiens, CEO of DIY repair community iFixit, told The Register in an email that Apple’s reputation for making difficult to repair products is deserved, particularly for things like AirPods, Apple Pencil, and their keyboards which iFixit has rated 0 out of 10 for repairability.
“Some products that get a 1 are fixable, but it’s really really hard,” said Wiens. “And some like the new MacBook Pro get a 4. Not great but certainly fixable.”
The recently released iPhone 13 received a repairability rating of 5 out of 10. As it happens, Apple last week promised an iOS update to facilitate iPhone 13 screen repair without breaking FaceID.
Initially, Apple will provide more than 200 parts and tools for those determined to conduct common iPhone repairs, such as replacing the display screen, battery, and camera. The program will focus first on iPhone 12 and 13 devices, and will expand later to include M1-based Macs.
Starting early next year, DIY-inclined customers in the US will be able to order Apple-approved parts and tools from the Apple Self Service Repair Online Store – at Apple prices – instead of scouring eBay, Alibaba, and various grey market tool and parts sources. The program is expected to expand internationally at a later date.
A victory for the right to repair
Apple’s about-face follows years of lobbying, advocacy, and regulatory pressure by those who support the right to repair purchased products. Previously, the company said such fiddling represented a security risk. In 2017, the iGiant argued that a right to repair bill under consideration in Nebraska would make the state a Mecca for hackers if it passed.
“This is the clear result of tireless advocacy from the repair community and policy proposals on three continents,” said Wiens. “Right to repair investigations at the FTC and the Australian Productivity Commission are ongoing.
“Consumers deserve the right to repair their own products. Repair manuals should not be secret. We’ve been saying this for a long time, and it’s great to see that Apple finally agrees. We still need to pass legislation and guarantee a level playing field for the entire industry. Apple’s announcement shows that it’s possible to do the right thing. Hopefully Samsung will be next.”
The South Korean Ministry of Justice has provided more than 100 million photos of foreign nationals who travelled through the country’s airports to facial recognition companies without their consent, according to attorneys with the non-governmental organization Lawyers for a Democratic Society.
While the use of facial recognition technology has become common for governments across the world, advocates in South Korea are calling the practice a “human rights disaster” that is relatively unprecedented.
“It’s unheard-of for state organizations—whose duty it is to manage and control facial recognition technology—to hand over biometric information collected for public purposes to a private-sector company for the development of technology,” six civic groups said during a press conference last week.
The revelation, first reported in the South Korean newspaper The Hankyoreh, came to light after National Assembly member Park Joo-min requested and received documents from the Ministry of Justice related to a April 2019 project titled Artificial Intelligence and Tracking System Construction Project. The documents show private companies secretly used biometric data to research and develop an advanced immigration screening system that would utilize artificial intelligence to automatically identify airport users’ identities through CCTV surveillance cameras and detect dangerous situations in real time.
While the South Korean government’s collaboration with the private sector is unprecedented in its scale, it is not the only collaboration of its kind. In 2019, a Motherboard investigation revealed the Departments of Motor Vehicles in numerous states had been selling names, addresses and other personal data to insurance or tow companies and to private investigators.
South Korean has again imposed new regulations on app stores, this time with a regime that will see operators fined up to two per cent of revenue if they force their proprietary in-app payment systems on developers.
“Considering that certain payment methods compulsory acts are serious illegal acts of app market operators, an enforcement ordinance has been prepared that imposes a fine of two per cent of sales and one per cent of sales for delayed screening or deletion,” the Korea Communications Commission (KCC), yesterday announced in a (Korean language) canned statement.
The new regulation follows the September 2021 introduction of the country’s Telecommunications Business Act, which prevents tech giants from restricting payment options on their platforms – either to pay for apps or for in-app purchases. The Act also prevents the likes of Google, Apple and others from taking a cut of in-app purchases facilitated by third-party services.
Hours ago, a website appeared online with the express purpose of hosting a nearly 20TB torrent (that’s terabytes, folks, the big boys of digital data measurement) containing every NFT available through the Ethereum and Solana blockchains.
The NFT Bay, whose name and overall design riff on iconic torrent database The Pirate Bay, is the work of one Geoffrey Huntley, an Australian software and dev ops engineer. In a frequently asked questions document written up for annoying reporters like me, Huntley describes The NFT Bay as an “educational art project” designed to teach the public about what NFTs are and aren’t, in the hopes that fewer folks get swindled by the technology’s innumerable grifters.
Image: Geoffrey Huntley
“Fundamentally, I hope people learn to understand what people are buying when purchasing NFT art right now is nothing more than directions on how to access or download an image,” Huntley explained. “The image is not stored on the blockchain and the majority of images I’ve seen are hosted on web 2.0 storage, which is likely to end up as 404, meaning the NFT has even less value.
[…]
“[NFTs] are only valuable as tools for money laundering, tax evasion, and greater fool investment fraud,” wrote computer scientist Antsstyle in a scathing criticism of the technology, the long version of which is perhaps the most comprehensive breakdown of the ills posed by NFTs, cryptocurrency, and the blockchain on which they operate. “There is zero actual value to NFTs. Their sole purpose is to create artificial scarcity of an artwork to supposedly increase its value.”
A Canadian teenager has been arrested for allegedly stealing $37 million worth of cryptocurrency ($46M Canadian) via a SIM swap scam, making it the largest virtual cash heist affecting a single person yet, according to police.
Together with the FBI and the US Secret Service Electronic Crimes Task Force, Hamilton Police in the Canadian province of Ontario launched a joint probe to investigate the breach of a US resident’s mobile phone account.
The victim was reportedly targeted with a SIM swap attack – their phone number was hijacked and ported to a different phone belonging to the attacker. The miscreant was then able to enter personal accounts via two-factor authentication requests and obtain details of the victim’s cryptocurrency wallet. From there, millions of dollars were siphoned off, it’s claimed.
“The joint investigation revealed that some of the stolen cryptocurrency was used to purchase an online username that was considered to be rare in the gaming community,” according to a statement from Hamilton Police.
“This transaction led investigators to uncover the account holder of the rare username,” it confirmed.
The teen was arrested for theft and possession of property. Police have seized over $5.5 million worth of cryptocurrencies in the case so far.
Thousands of Firefox cookie databases containing sensitive data are available on request from GitHub repositories, data potentially usable for hijacking authenticated sessions.
These cookies.sqlite databases normally reside in the Firefox profiles folder. They’re used to store cookies between browsing sessions. And they’re findable by searching GitHub with specific query parameters, what’s known as a search “dork.”
Aidan Marlin, a security engineer at London-based rail travel service Trainline, alerted The Register to the public availability of these files after reporting his findings through HackerOne and being told by a GitHub representative that “credentials exposed by our users are not in scope for our Bug Bounty program.”
Marlin then asked whether he could make his findings public and was told he’s free to do so.
“I’m frustrated that GitHub isn’t taking its users’ security and privacy seriously,” Marlin told The Register in an email. “The least it could do is prevent results coming up for this GitHub dork. If the individuals who uploaded these cookie databases were made aware of what they’d done, they’d s*** their pants.”
Marlin acknowledges that affected GitHub users deserve some blame for failing to prevent their cookies.sqlite databases from being included when they committed code and pushed it to their public repositories. “But there are nearly 4.5k hits for this dork, so I think GitHub has a duty of care as well,” he said, adding that he’s alerted the UK Information Commissioner’s Office because personal information is at stake.
Some Warhammer 40,000 players think the game’s fascist Imperium of Man faction is awesome, and actually has a few good ideas. It does not. To clarify this point—which more than one Warhammer 40K fan appears to have missed—maker Games Workshop put out a statement saying that you do not, under any circumstances, “gotta hand it to them.”
“There are no goodies in the Warhammer 40,000 universe,” Games Workshop wrote on its website today. “None. Especially not the Imperium of Man…We believe in and support a community united by shared values of mutual kindness and respect. Our fantasy settings are grim and dark, but that is not a reflection of who we are or how we feel the real world should be.”
The statement comes just a couple weeks after controversy broke out when a player wore Nazi symbols to an unofficial tournament in Spain and the organizers apparently didn’t throw him out, despite complaints from other players.
[…]
Most fans get that Warhammer 40K is not real, and if it were, life in its universe would be exceedingly nasty, brutish, and short. But some of its aesthetic and lore have been co-opted by the alt-right, white supremacists, and other crypto-fascist groups. They think the Imperium of Man—a feudalistic galactic empire modeled after Rome, full of enslaved races, and ruled by a 10,000 year-old psychic kept alive by cyborg implants called the Emperor of Mankind—is a model on which to base their politics. During the 2016 presidential election it became the basis for the now famous internet meme: God Emperor Trump.
This all adds up to why Games Workshop had to take a break from its world building today, to make Warhammer 40K’s subtext text:
Like so many aspects of Warhammer 40,000, the Imperium of Man is satirical.
For clarity: satire is the use of humour, irony, or exaggeration, displaying people’s vices or a system’s flaws for scorn, derision, and ridicule. Something doesn’t have to be wacky or laugh-out-loud funny to be satire. The derision is in the setting’s amplification of a tyrannical, genocidal regime, turned up to 11. The Imperium is not an aspirational state, outside of the in-universe perspectives of those who are slaves to its systems. It’s a monstrous civilisation, and its monstrousness is plain for all to see.
But apparently not plainly enough. Games Workshop reiterated its stance against hate groups and others seeking to co-opt its creative work, including banning individuals wearing hate symbols at Warhammer-adjacent events.
“If you come to a Games Workshop event or store and behave to the contrary, including wearing the symbols of real-world hate groups, you will be asked to leave. We won’t let you participate,” the company wrote. “We don’t want your money. We don’t want you in the Warhammer community.”
It’s nice to have a corporate statement that doesn’t mince words for once.