One of the better sites forfinancial data is Yahoo Finance. This makes it a prime target for web scraping by finance enthusiasts. There are nearly daily questions on StackOverflow that reference some sort of data retrieval (oftentimes through web scraping) from Yahoo Finance.
Web Scraping Problem #1
trying to test a code that scrap from yahoo finance
I’m a python beginner but I like to learn the language by testing it and trying it. so there is a yahoo web scraper…
stackoverflow.com
The OP is trying to find the current price for a specific stock, Facebook. Their code is below:
And that code produced the following output:
the current price: 216.08
It’s a pretty simple problem with an also simple web scraping solution. However, it’s not lazy enough. Let’s look at the next one.
Web Scraping Problem #2
Web Scraping Yahoo Finance Statistics — Code Errors Out on Empty Fields
I found this useful code snippet: Web scraping of Yahoo Finance statistics using BS4 I have simplified the code as per…
stackoverflow.com
The OP is trying to extract data from the statistics tab, the stock’s enterprise value and the number of shares short. His problem actually revolves around retrieving nested dictionary values that may or may not be there, but he seems to have found a better solution as far as retrieving data.
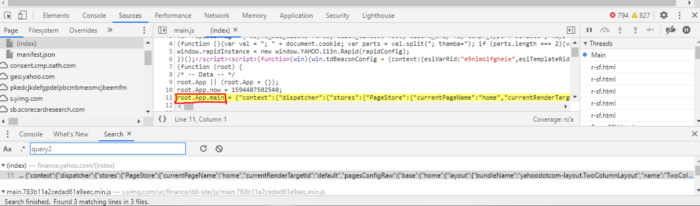
Take a look at line 3: the OP was able to find the data he’s looking for inside a variable in the javascript:
root.App.main = { .... };
From there, the data is retrieved pretty simply by accessing the appropriate nested keys within the dictionary, data. But, as you may have guessed, there is a simpler, lazier solution.
The lazy alternatives simply altered the request from utilizing the front-end URL to a somewhat unofficial API endpoint, which returns JSON data. It’s simpler and results in more data! What about speed though (pretty sure I promised simpler, more data, and a faster alternative)? Let’s check:
web scraping #1 min time is 0.5678426799999997
lazy #1 min time is 0.11238783999999953
web scraping #2 min time is 0.3731000199999997
lazy #2 min time is 0.0864451399999993
The lazy alternatives are 4x to 5x faster than their web scraping counterparts!
You might be thinking though, “That’s great, but where did you find those URLs?”.
The Lazy Process
Think about the two problems we walked through above: the OP’s we’re trying to retrieve the data after it had been loaded into the page. The lazier solutions went right to the source of the data and didn’t bother with the front-end page at all. This is an important distinction and, I think, a good approach whenever you’re trying to extract data from a website.
Step 1: Examine XHR Requests
An XHR (XMLHttpRequest) object is an API available to web browser scripting languages such as JavaScript. It is used to send HTTP or HTTPs requests to a web server and load the server response data back into the script. Basically, it allows the client to retrieve data from a URL without having to do a full page refresh.
I’ll be using Chrome for the following demonstrations, but other browsers will have similar functionality.
Open Chrome’s developer console. To open the developer console in Google Chrome, open the Chrome Menu in the upper-right-hand corner of the browser window and select More Tools > Developer Tools. You can also use the shortcut Option + ⌘ + J (on macOS), or Shift + CTRL + J (on Windows/Linux).
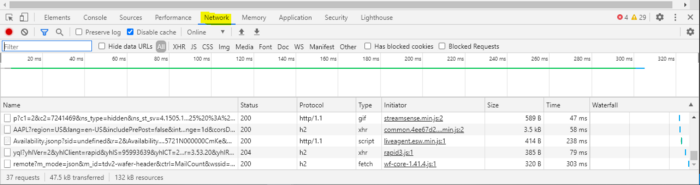
Select the “Network” tab
Then filter the results by “XHR”
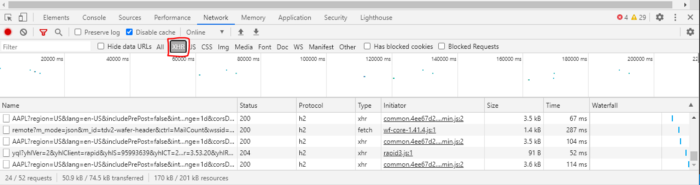
Your results will be similar but not the same. You should notice though that there are a few requests that contain “AAPL”. Let’s start by investigating those. Click on one of the links in the left-most column that contain the characters “AAPL”.
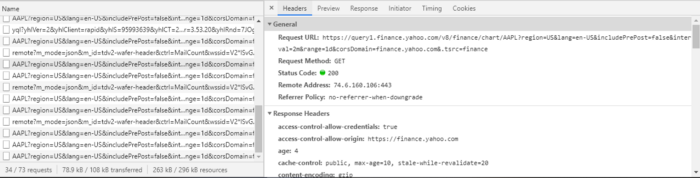
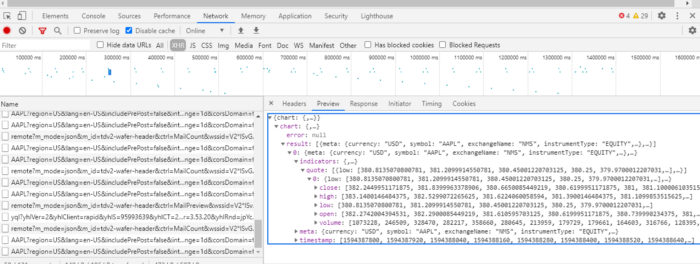
After selecting one of the links, you’ll see an additional screen that provides details into the request you selected. The first tab, Headers, provides details into the request made by the browser and the response from the server. Immediately, you should notice the Request URL in the Headers tab is very similar to what was provided in the lazy solutions above. Seems like we’re on the right track.
If you select the Preview tab, you’ll see the data returned from the server.
Perfect! It looks like we just found the URL to get OHLC data for Apple!
Step 2: Search
Now that we’ve found some of the XHR requests that are made via the browser, let’s search the javascript files to see if we can find any more information. The commonalities I’ve found with the URLs relevant to the XHR requests are “query1” and “query2”. In the top-right corner of the developer’s console, select the three vertical dots and then select “Search” in the dropdown.
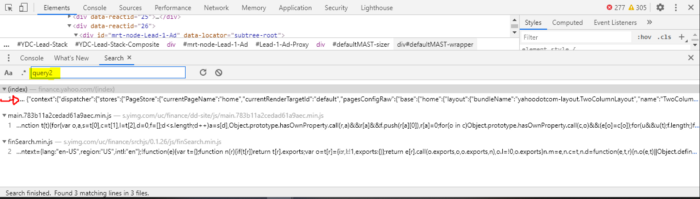
Search for “query2” in the search bar:
Select the first option. An additional tab will pop-up containing where “query2” was found. You should notice something similar here as well:
It’s the same variable that web scraping solution #2 targeted to extract their data. The console should give you an option to “pretty-print” the variable. You can either select that option or copy and paste the entire line (line 11 above) into something like https://beautifier.io/ or if you use vscode, download the Beautify extension and it will do the same thing. Once it’s formatted appropriately, paste the entire code into a text editor or something similar and search for “query2” again. You should find one result inside something called “ServicePlugin”. That section contains the URLs that Yahoo Finance utilizes to populate data in their pages. The following is taken right out of that section:
This is the same URL that is utilized in the lazy solutions provided above.
TL;DR
While web scraping can be necessary because of how a website is structured, it’s worth the effort investigating to see if you can find the source of the data. The resulting code is simpler and more data is extracted faster.
Finding the source of a website’s data is often found by searching through XHR requests or by searching through the site’s javascript files utilizing your browser’s developer console.
More Information
What if you can’t find any XHR requests? Check out The Alternative to Web Scraping, Part II: The DRY approach to retrieving web data
The Alternative to Web Scraping, Part II
The DRY approach to retrieving web data
towardsdatascience.com
If you’re interested specifically in the Yahoo Finance aspect of this article, I’ve written a python package, yahooquery, that exposes most of those endpoints in a convenient interface. I’ve also written an introductory article that describes how to use the package as well as a comparison to a similar one.
The (Unofficial) Yahoo Finance API
A Python interface to endless amounts of data
towardsdatascience.com
Please feel free to reach out if you have any questions or comments
A team of researchers from Beihang University, the Peking University School and Hospital of Stomatology and the Michigan Institute of Translational Nanotechnology has developed a synthetic enamel with properties similar to natural tooth enamel. In their paper published in the journal Science, the group describes their enamel and how well it compared to natural enamel when tested.
[…]
Prior research has shown that the reason that human enamel is so strong and yet also slightly elastic is because it consists of tiny rods made of calcium that are packed tightly together like pencils in a box. In their new effort, the researchers attempted to mimic tooth enamel as closely as possible by producing a material using AIP-coated hydroxyapatite nanowires that were aligned in parallel using a freezing technique that involved applying polyvinyl alcohol.
The researchers applied the enamel to a variety of shapes, including human teeth, and then tested how well it performed. They found it had a high degree of stiffness, was strong and was also slightly elastic. They also found that on most of their tests, the synthetic enamel outperformed natural enamel.
The researchers plan to keep testing their material to make sure it will hold up under harsh environments such as those found in the human mouth. They will also have to show that it is safe for use in humans and that it can be mass produced. They note that if their enamel passes all such tests, it could be used in more than just dentistry—they suggest it could be used to coat pacemakers, for example, or to shore up bones that have been damaged or that have eroded due to use or disease.
In December 2021,27,591 aircraft took off or landed at Frankfurt airport—890 every day. But this winter, many of them weren’t carrying any passengers at all. Lufthansa, Germany’s national airline, which is based in Frankfurt, has admitted to running 21,000 empty flights this winter, using its own planes and those of its Belgian subsidiary, Brussels Airlines, in an attempt to keep hold of airport slots.
Although anti-air travel campaigners believe ghost flights are a widespread issue that airlines don’t publicly disclose, Lufthansa is so far the only airline to go public about its own figures. In January, climate activist Greta Thunberg tweeted her disbelief over the scale of the issue. Unusually, she was joined by voices within the industry. One of them was Lufthansa’s own chief executive, Carsten Spohr, who said the journeys were “empty, unnecessary flights just to secure our landing and takeoff rights.” But the company argues that it can’t change its approach: Those ghost flights are happening because airlines are required to conduct a certain proportion of their planned flights in order to keep slots at high-trafficked airports.
A Greenpeace analysis indicates that if Lufthansa’s practice of operating no-passenger flights were replicated equally across the European aviation sector, it would mean that more than 100,000 “ghost flights” were operating in Europe this year, spitting out carbon dioxide emissions equivalent to 1.4 million gas-guzzling cars. “We’re in a climate crisis, and the transport sector has the fastest-growing emissions in the EU,” says Greenpeace spokesperson Herwig Schuster. “Pointless, polluting ‘ghost flights’ are just the tip of the iceberg.”
Aviation analysts are split on the scale of the ghost flight problem. Some believe the issue has been overhyped and is likely not more prevalent than the few airlines that have admitted to operating them. Others say there are likely tens of thousands of such flights operating—with their carriers declining to say anything because of the PR blowback.
“The only reason we have [airport] slots is that it recognizes a shortage of capacity at an airport,” says John Strickland of JLS Consulting, an aviation consultant. “If there wasn’t any shortage of capacity, airlines could land and take off within reason whenever they want to.” However, a disparity between the volume of demand for takeoff and landing slots and the number of slots available at key airports means that airlines compete fiercely for spaces. In 2020, 62 million flights took place at the world’s airports, according to industry body Airports Council International. While that number sounds enormous, it’s down nearly 40 percent year on year. To handle demand, more than 200 airports worldwide operate some kind of slot system, handling a combined 1.5 billion passengers. If you board a flight anywhere in the world, there’s a 43 percent chance your flight is slot managed.
Airlines even pay their competitors to take over slots: Two highly prized slots at London Heathrow airport reportedly changed hands for $75 million in 2016, when tiny cash-rich airline Oman Air made Air France-KLM an offer it couldn’t refuse for a sleepy 5.30 am arrival from Muscat to the UK capital.