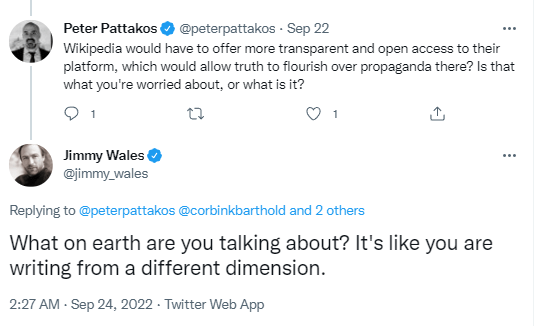
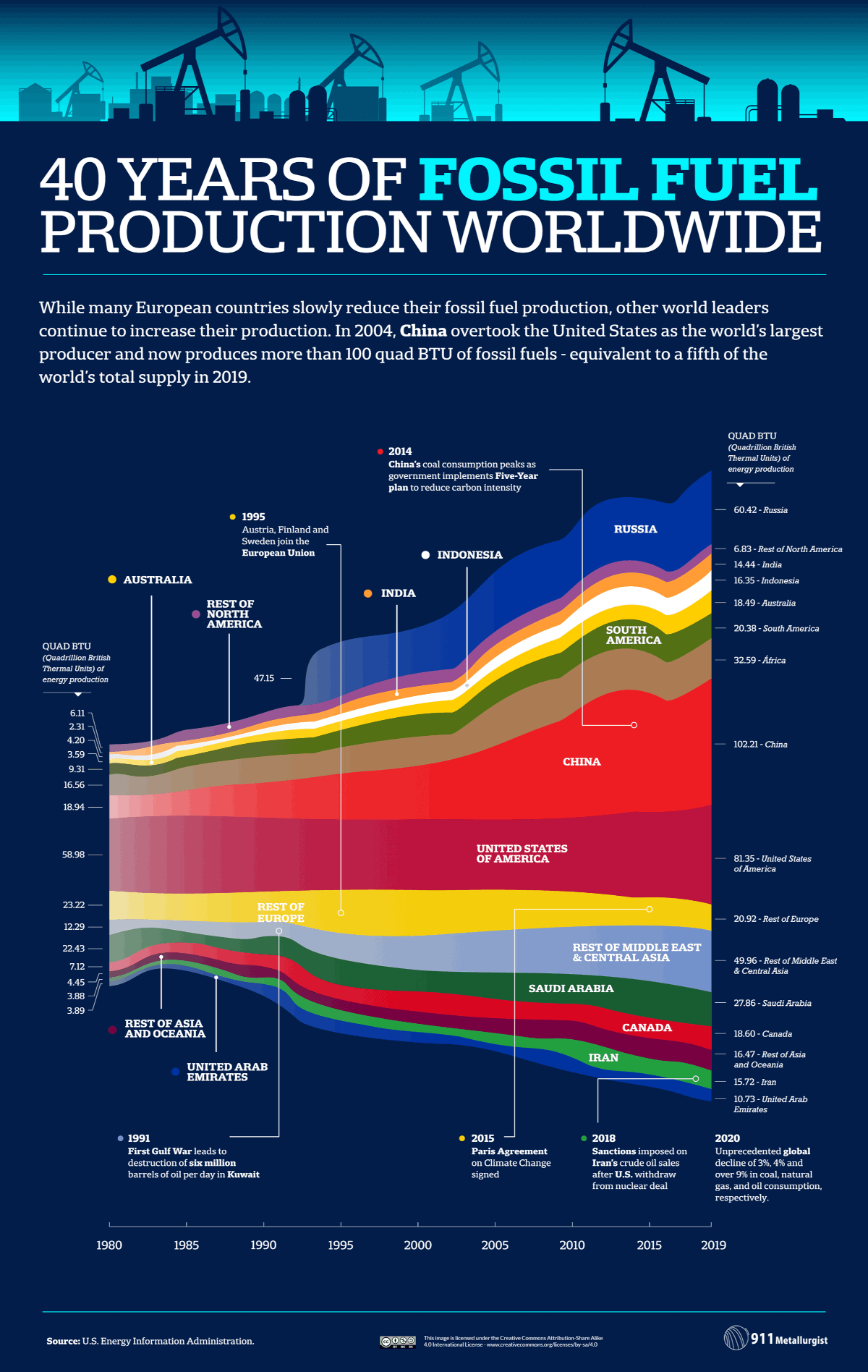
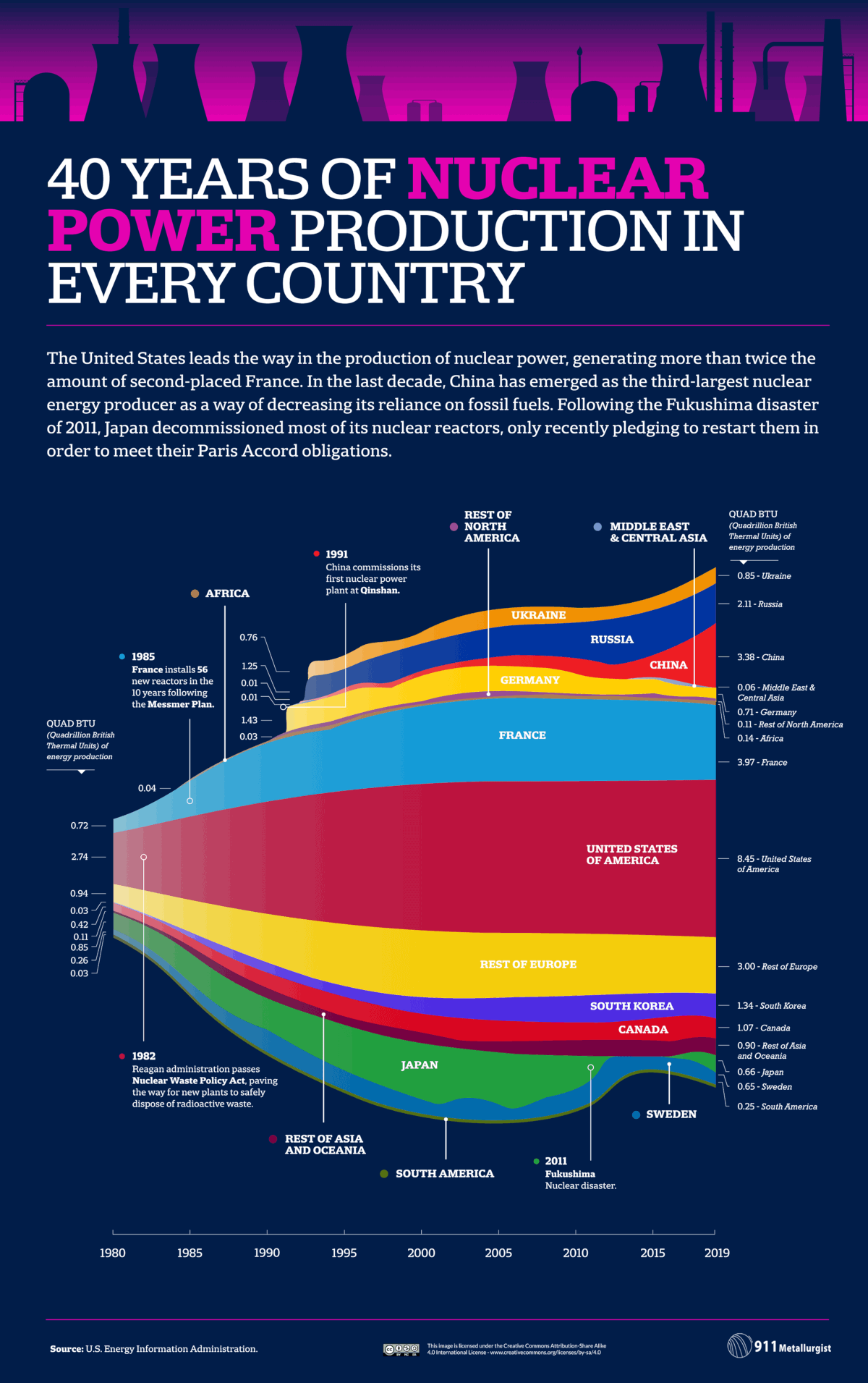
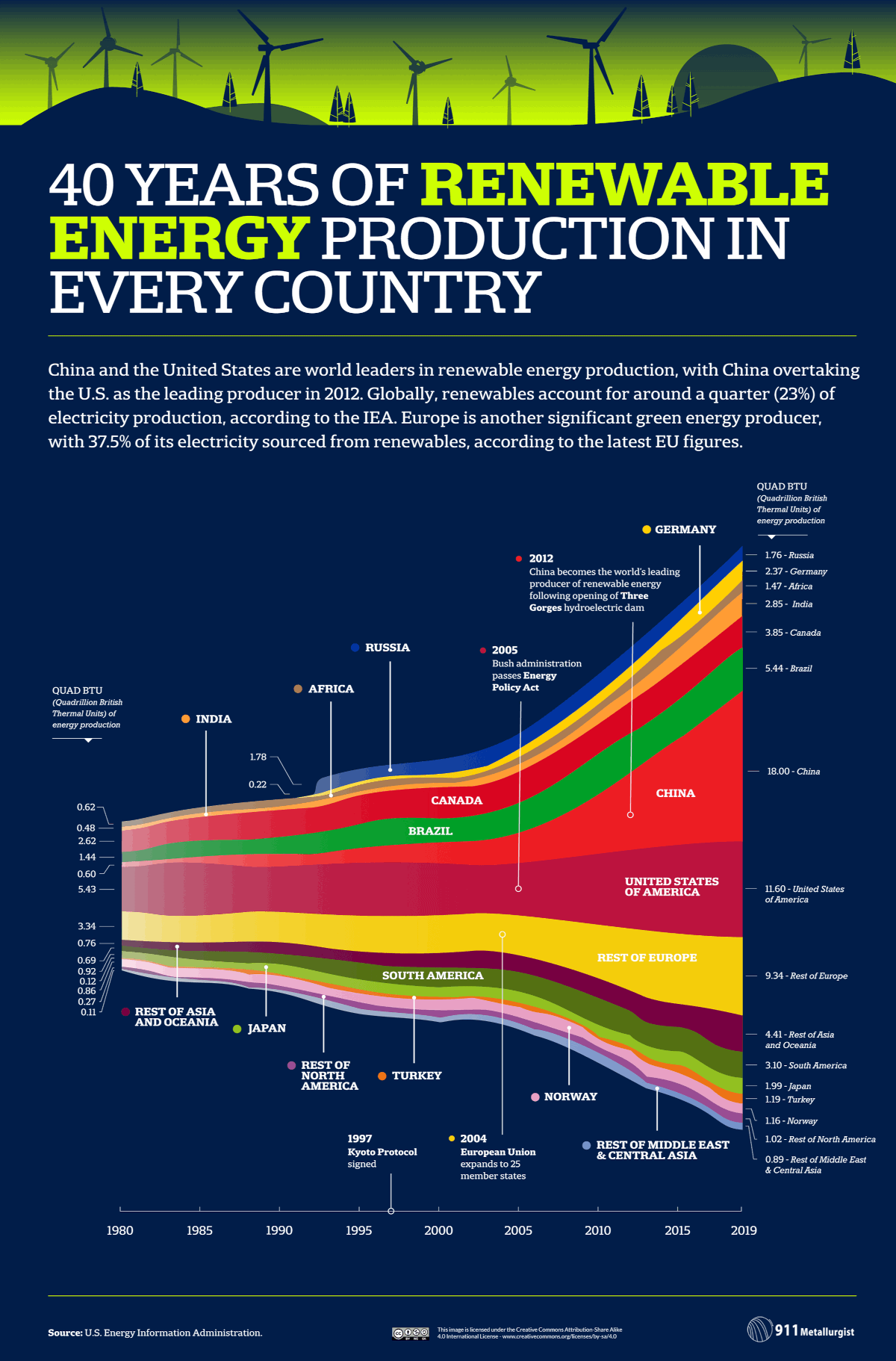
When ice sheets melt, something strange and highly counterintuitive happens to sea levels.
It works basically like a seesaw. In the area close to where theses masses of glacial ice melt, ocean levels fall. Yet thousands of miles away, they actually rise. It largely happens because of the loss of a gravitational pull toward the ice sheet, causing the water to disperse away. The patterns have come to be known as sea level fingerprints since each melting glacier or ice sheet uniquely impacts sea level. Elements of the concept—which lies at the heart of the understanding that global sea levels don’t rise uniformly—have been around for over a century and modern sea level science has been built around it. But there’s long been a hitch to the widely accepted theory. A sea level fingerprint has never definitively been detected by researchers.
A team of scientists—led by Harvard alumna Sophie Coulson and featuring Harvard geophysicist Jerry X. Mitrovica—believe they have detected the first. The findings are described in a new study published Thursday in Science. The work validates almost a century of sea level science and helps solidify confidence in models predicting future sea level rise.
[…]
Sea level fingerprints have been notoriously difficult to detect because of the major fluctuations in ocean levels brought on by changing tides, currents, and winds. What makes it such a conundrum is that researchers are trying to detect millimeter level motions of the water and link them to melting glaciers thousands of miles away.
[…]
The new study uses newly released satellite data from a European marine monitoring agency that captures over 30 years of observations in the vicinity of the Greenland Ice Sheet and much of the ocean close to the middle of Greenland to capture the seesaw in ocean levels from the fingerprint.
The satellite data caught the eye of Mitrovica and colleague David Sandwell of the Scripps Institute of Oceanography. Typically, satellite records from this region had only extended up to the southern tip of Greenland, but in this new release the data reached ten degrees higher in latitude, allowing them to eyeball a potential hint of the seesaw caused by the fingerprint.
[…]
Coulson quickly collected three decades worth of the best observations she could find on ice height change within the Greenland Ice Sheet as well as reconstructions of glacier height change across the Canadian Arctic and Iceland. She combined these different datasets to create predictions of sea level change in the region from 1993 to 2019, which she then compared with the new satellite data. The fit was perfect. A one-to-one match that showed with more than 99.9% confidence that the pattern of sea level change revealed by the satellites is a fingerprint of the melting ice sheet.
[…]
Source: Researchers detect the first definitive proof of elusive sea level fingerprints