
A dark web carding market named ‘BidenCash’ has released a massive dump of 1,221,551 credit cards to promote their marketplace, allowing anyone to download them for free to conduct financial fraud.
Carding is the trafficking and use of credit cards stolen through point-of-sale malware, magecart attacks on websites, or information-stealing malware.
BidenCash is a stolen cards marketplace launched in June 2022, leaking a few thousand cards as a promotional move.
Now, the market’s operators decided to promote the site with a much more massive dump in the same fashion that the similar platform ‘All World Cards’ did in August 2021.
[…]
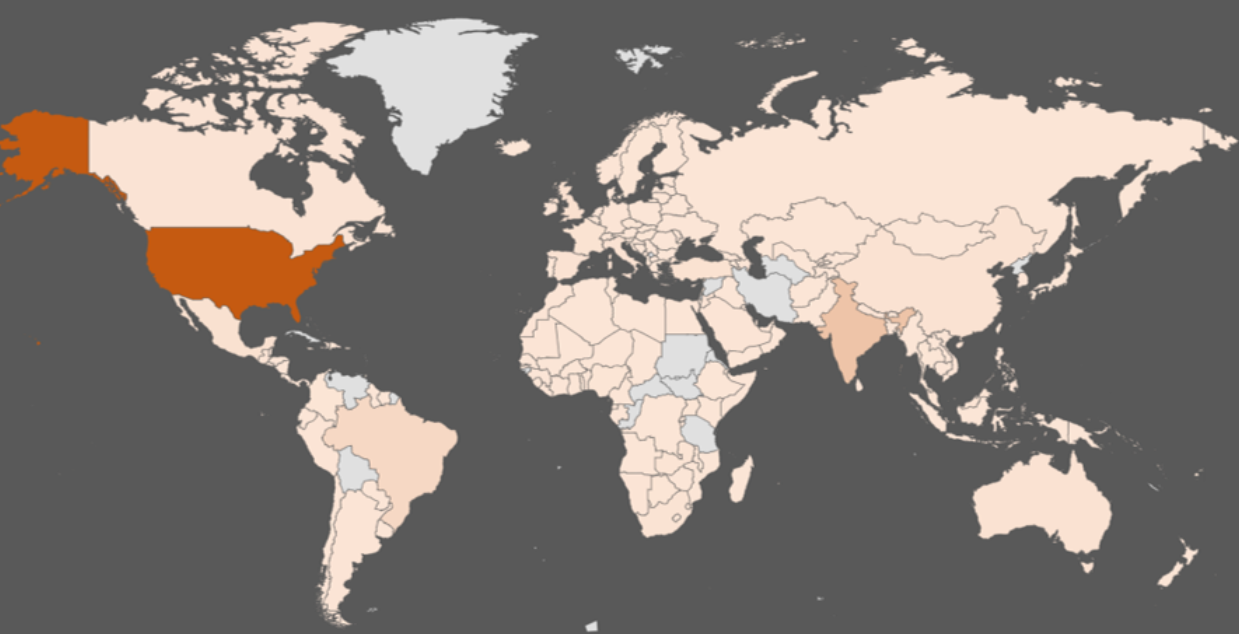
The freely circulating file contains a mix of “fresh” cards expiring between 2023 and 2026 from around the world, but most entries appear to be from the United States.
The dump of 1.2 million credit cards includes the following credit card and associated personal information:
- Card number
- Expiration date
- CVV number
- Holder’s name
- Bank name
- Card type, status, and class
- Holder’s address, state, and ZIP
- Email address
- SSN
- Phone number
Not all the above details are available for all 1.2 million records, but most entries seen by BleepingComputer contain over 70% of the data types.
The “special event” offer was first spotted Friday by Italian security researchers at D3Lab, who monitors carding sites on the dark web.
The analysts claim these cards mainly come from web skimmers, which are malicious scripts injected into checkout pages of hacked e-commerce sites that steal submitted credit card and customer information.
[…]
BleepingComputer has discussed the authenticity with analysts at D3Lab, who confirmed that the data is real with several Italian banks, so the leaked entries correspond to real cards and cardholders.
However, many of the entries were recycled from previous collections, like the one ‘All World Cards’ gave away for free last year.
From the data D3Labs has examined so far, about 30% appear to be fresh, so if this applies roughly to the entire dump, at least 350,000 cards would still be valid.
Of the Italian cards, roughly 50% have already been blocked due to the issuing banks having detected fraudulent activity, which means that the actually usable entries in the leaked collection may be as low as 10%.
[…]
Source: Darkweb market BidenCash gives away 1.2 million credit cards for free – Bleeping Computer