Deep learning has a DRAM problem. Systems designed to do difficult things in real time, such as telling a cat from a kid in a car’s backup camera video stream, are continuously shuttling the data that makes up the neural network’s guts from memory to the processor.
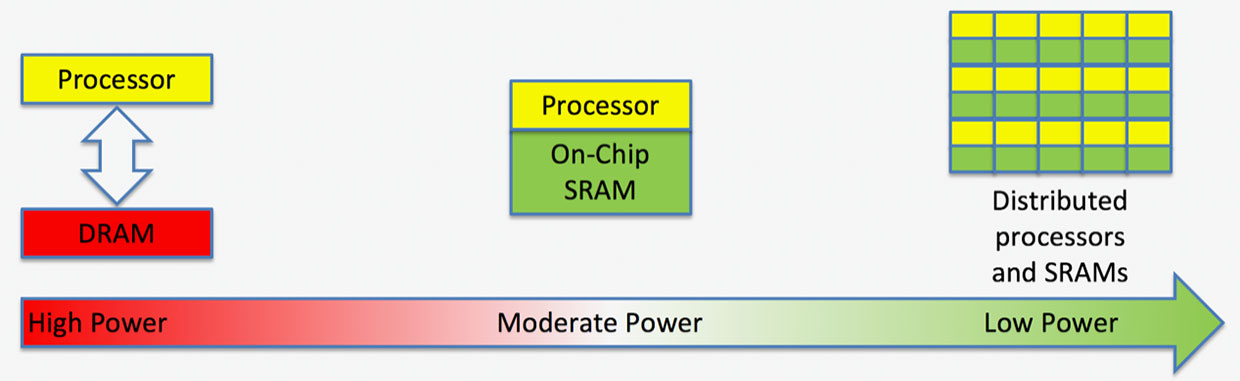
The problem, according to startup Flex Logix, isn’t a lack of storage for that data; it’s a lack of bandwidth between the processor and memory. Some systems need four or even eight DRAM chips to sling the 100s of gigabits to the processor, which adds a lot of space and consumes considerable power. Flex Logix says that the interconnect technology and tile-based architecture it developed for reconfigurable chips will lead to AI systems that need the bandwidth of only a single DRAM chip and consume one-tenth the power.
[…]
In developing the original technology for FPGAs, Wang noted that these chips were about 80 percent interconnect by area, and so he sought an architecture that would cut that area down and allow for more logic. He and his colleagues at UCLA adapted a kind of telecommunications architecture called a folded-Beneš network to do the job. This allowed for an FPGA architecture that looks like a bunch of tiles of logic and SRAM.
Image: Flex LogixFlex Logix says spreading SRAM throughout the chip speeds up computation and lowers power.
Distributing the SRAM in this specialized interconnect scheme winds up having a big impact on deep learning’s DRAM bandwidth problem, says Tate. “We’re displacing DRAM bandwidth with SRAM on the chip,” he says.
[…]
True apples-to-apples comparisons in deep learning are hard to come by. But Flex Logix’s analysis comparing a simulated 6 x 6-tile NMAX512 array with one DRAM chip against an Nvidia Tesla T4 with eight DRAMs showed the new architecture identifying 4,600 images per second versus Nvidia’s 3,920. The same size NMAX array hit 22 trillion operations per second on a real-time video processing test called YOLOv3 using one-tenth the DRAM bandwidth of other systems.
The designs for the first NMAX chips will be sent to the foundry for manufacture in the second half of 2019, says Tate.