
MLflow is inspired by existing ML platforms, but it is designed to be open in two senses:
- Open interface: MLflow is designed to work with any ML library, algorithm, deployment tool or language. It’s built around REST APIs and simple data formats (e.g., a model can be viewed as a lambda function) that can be used from a variety of tools, instead of only providing a small set of built-in functionality. This also makes it easy to add MLflow to your existing ML code so you can benefit from it immediately, and to share code using any ML library that others in your organization can run.
- Open source: We’re releasing MLflow as an open source project that users and library developers can extend. In addition, MLflow’s open format makes it very easy to share workflow steps and models across organizations if you wish to open source your code.
Mlflow is still currently in alpha, but we believe that it already offers a useful framework to work with ML code, and we would love to hear your feedback. In this post, we’ll introduce MLflow in detail and explain its components.
MLflow Alpha Release Components
This first, alpha release of MLflow has three components:
MLflow Tracking
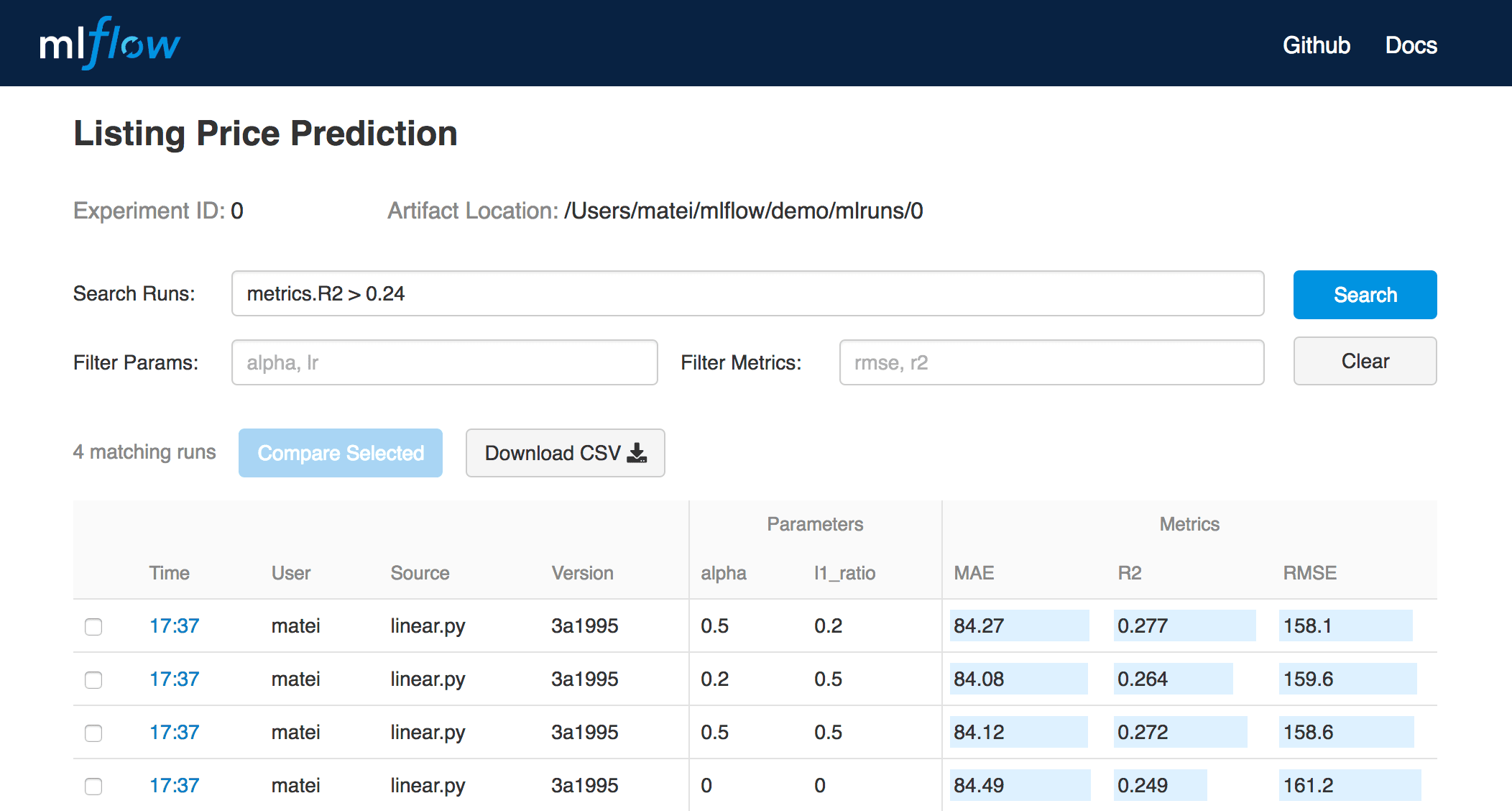
MLflow Tracking is an API and UI for logging parameters, code versions, metrics and output files when running your machine learning code to later visualize them. With a few simple lines of code, you can track parameters, metrics, and artifacts:
import mlflow # Log parameters (key-value pairs) mlflow.log_param("num_dimensions", 8) mlflow.log_param("regularization", 0.1) # Log a metric; metrics can be updated throughout the run mlflow.log_metric("accuracy", 0.1) ... mlflow.log_metric("accuracy", 0.45) # Log artifacts (output files) mlflow.log_artifact("roc.png") mlflow.log_artifact("model.pkl")You can use MLflow Tracking in any environment (for example, a standalone script or a notebook) to log results to local files or to a server, then compare multiple runs. Using the web UI, you can view and compare the output of multiple runs. Teams can also use the tools to compare results from different users:
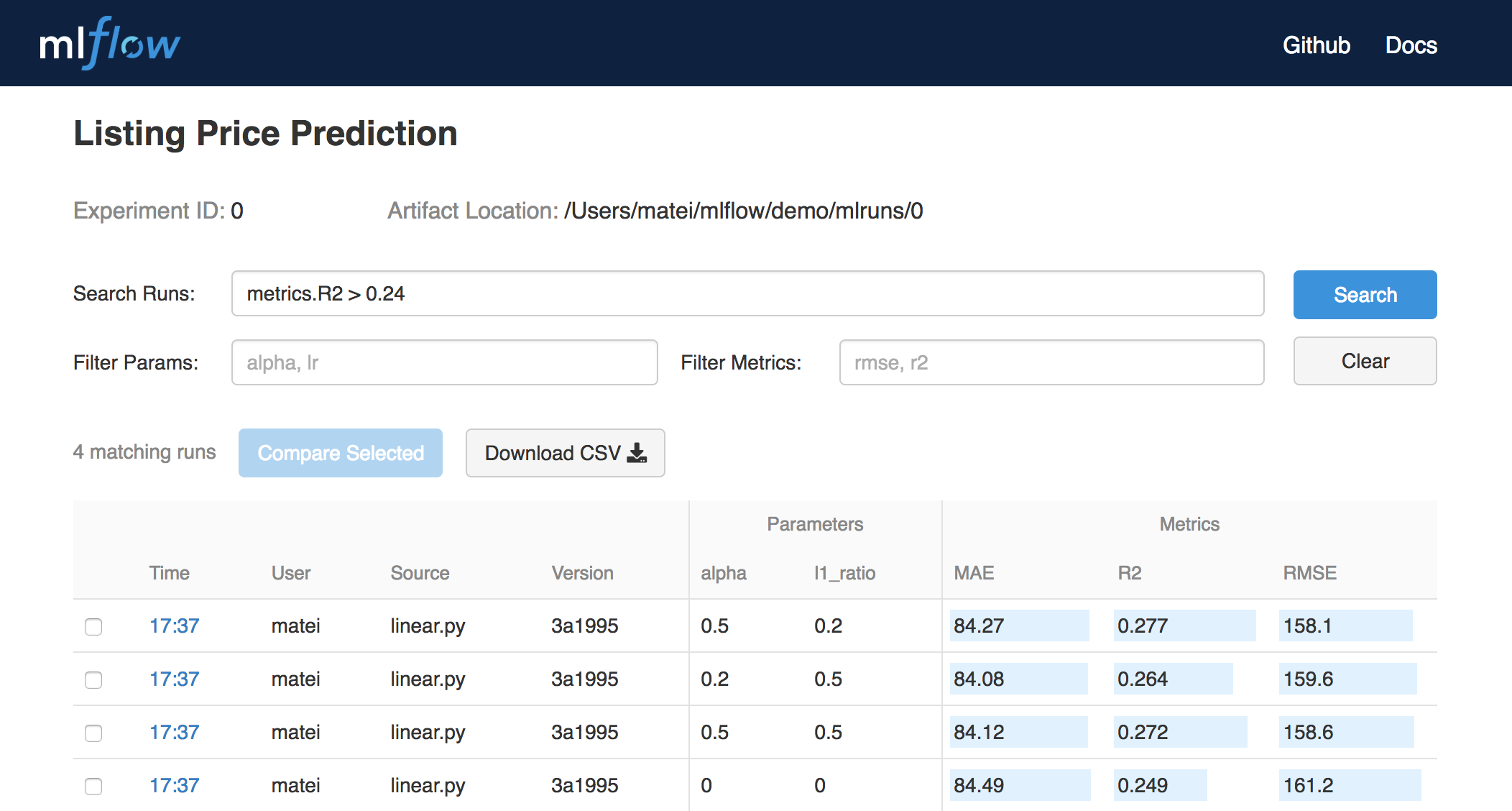
MLflow Tracking UI
MLflow Projects
MLflow Projects provide a standard format for packaging reusable data science code. Each project is simply a directory with code or a Git repository, and uses a descriptor file to specify its dependencies and how to run the code. A MLflow Project is defined by a simple YAML file called
MLproject.name: My Project conda_env: conda.yaml entry_points: main: parameters: data_file: path regularization: {type: float, default: 0.1} command: "python train.py -r {regularization} {data_file}" validate: parameters: data_file: path command: "python validate.py {data_file}"Projects can specify their dependencies through a Conda environment. A project may also have multiple entry points for invoking runs, with named parameters. You can run projects using the
mlflow runcommand-line tool, either from local files or from a Git repository:mlflow run example/project -P alpha=0.5 mlflow run git@github.com:databricks/mlflow-example.git -P alpha=0.5MLflow will automatically set up the right environment for the project and run it. In addition, if you use the MLflow Tracking API in a Project, MLflow will remember the project version executed (that is, the Git commit) and any parameters. You can then easily rerun the exact same code.
The project format makes it easy to share reproducible data science code, whether within your company or in the open source community. Coupled with MLflow Tracking, MLflow Projects provides great tools for reproducibility, extensibility, and experimentation.
MLflow Models
MLflow Models is a convention for packaging machine learning models in multiple formats called “flavors”. MLflow offers a variety of tools to help you deploy different flavors of models. Each MLflow Model is saved as a directory containing arbitrary files and an
MLmodeldescriptor file that lists the flavors it can be used in.time_created: 2018-02-21T13:21:34.12 flavors: sklearn: sklearn_version: 0.19.1 pickled_model: model.pkl python_function: loader_module: mlflow.sklearn pickled_model: model.pklIn this example, the model can be used with tools that support either the
sklearnorpython_functionmodel flavors.MLflow provides tools to deploy many common model types to diverse platforms. For example, any model supporting the
python_functionflavor can be deployed to a Docker-based REST server, to cloud platforms such as Azure ML and AWS SageMaker, and as a user-defined function in Apache Spark for batch and streaming inference. If you output MLflow Models as artifacts using the Tracking API, MLflow will also automatically remember which Project and run they came from.Getting Started with MLflow
To get started with MLflow, follow the instructions at mlflow.org or check out the alpha release code on Github. We are excited to hear your feedback on the concepts and code!
Source: Introducing MLflow: an Open Source Machine Learning Platform – The Databricks Blog

Robin Edgar
Organisational Structures | Technology and Science | Military, IT and Lifestyle consultancy | Social, Broadcast & Cross Media | Flying aircraft