Without adding any hardware that actually makes contact with the wearer’s face, researchers from Carnegie Mellon University’s Future Interfaces Group have modified an off-the-shelf virtual reality headset so that it recreates the sensation of touch in and around a user’s mouth, finally fulfilling virtual reality’s inevitable one true purpose.
Aside from handheld controllers that occasionally vibrate, most consumer-ready virtual reality devices ignore senses like taste, smell, and touch, and instead focus on visuals and sounds. It’s enough to make virtual reality experiences far more compelling than they were decades ago, but not enough to truly fool the brain into thinking that what your eyes are seeing is possibly a real-life experience.
Researchers working to evolve and improve virtual reality hardware have come up with some truly unique hardware and accessories over the years to make virtual reality feel as real as it looks, but none truly reflect where virtual reality is inevitably going like the research being done at Carnegie Mellon University in regards to mouth haptics. You might not be able to reach out and feel realistic fur on a virtual dog just yet, but experiencing the sensation of drinking from a virtual drinking fountain could be just around the corner—in addition to other experiences that don’t require too much imagination.
The researchers upgraded what appears to be a Meta Quest 2 headset with an array of ultrasonic transducers that are all focused on the user’s mouth, and it works without the need for additional accessories, or other hardware set up around the wearer. We’ve seen ultrasonic transducers used to levitate and move around tiny particles by blasting them with powerful sound waves before, but in this application, they create the feeling of touch on the user’s lips, teeth, and even their tongue while their mouth is open.
A giant virtual spider rains down a flood of poison on the user which they can feel splashing across their lips.
The transducers can do more than just simulate a gentle touch. By pulsing them in specific patterns, they can recreate the feeling of an object sliding or swiping across the lips, or persistent vibrations, such as the continuous splashing of water when leaning down to sip from a virtual drinking fountain.
The researchers have come up with other custom virtual reality experiences that demonstrate how their mouth haptics hardware can introduce more realism, including a hike through a spooky forest where spider webs can be felt across the face, a race where the user can feel the wind in their face, and even virtual eating experiences where food and drinks can be felt inside the mouth. But if and when someone runs with this idea and commercializes the mouth haptics hardware, we’re undoubtedly going to see the world’s first virtual reality kissing booth realized, among other experiences the researchers are probably wisely tip-toeing around.
Ubisoft has turned off online services for 91 games, including Far Cry 2, Splinter Cell, Just Dance, and more across multiple console and PC platforms. These shutdowns have since been gathered together in one list by Ubisoft.
This news comes from a blog Ubisoft posted on April 22 listing 91 different games that have had their online services and multiplayer features shut off since 2021. The plan to shut down online services for many of these Ubisoft games was first announced last year.
The company explained that all in-game news, updates, player statistics, and online multiplayer features would no longer work in any of these titles. Also, any of the 91 games that use Ubisoft’s Connect platform can no longer earn its ”Units” points to unlock in-game rewards. Weirdly, Ubisoft explained that PC players will lose access to previously unlocked content, but console players will be able to keep it so long as they keep their old game save.
In response to fraudulent legal requests, companies like Apple, Google, Meta and Twitter have been tricked into sharing sensitive personal information about some of their customers. We knew that was happening as recently as last month when Bloombergpublished a report on hackers using fake emergency data requests to carry out financial fraud. But according to a newly published report from the outlet, some malicious individuals are also using the same tactics to target women and minors with the intent of extorting them into sharing sexually explicit images and videos of themselves.
It’s unclear how many fake data requests the tech giants have fielded since they appear to come from legitimate law enforcement agencies. But what makes the requests particularly effective as an extortion tactic is that the victims have no way of protecting themselves other than by not using the services offered by those companies.
[…]
Part of what has allowed the fake requests to slip through is that they abuse how the industry typically handles emergency appeals. Among most tech companies, it’s standard practice to share a limited amount of information with law enforcement in response to “good faith” requests related to situations involving imminent danger.
Typically, the information shared in those instances includes the name of the individual, their IP, email and physical address. That might not seem like much, but it’s usually enough for bad actors to harass, dox or SWAT their target. According to Bloomberg, there have been “multiple instances” of police showing up at the homes and schools of underage women.
[…] MIT have developed a paper-thin speaker that can be applied to almost any surface like wallpaper, turning objects like walls into giant noise-cancelling speakers.
[…]
Researchers at MIT’s Organic and Nanostructured Electronics Laboratory have created a new kind of thin-film speaker that’s as thin and flexible as a sheet of paper, but is also able to generate clear, high-quality sound, even when bonded to a rigid surface like a wall. This is not the first time researchers have created ultra-thin lightweight speakers, but previous attempts have resulted in a film that needs to be freestanding and unencumbered to produce sound. When mounted to a rigid surface, past thin speakers’ ability to vibrate and move air is greatly reduced, which limits where and how they can be used. But MIT’s researchers have now come up with a new manufacturing process that solves that problem.
Instead of designing a thin-film speaker that requires the entire panel to vibrate, the researchers started with a sheet of lightweight PET plastic that they perforated with tiny holes using a laser. A layer of thin piezoelectric material called PVDF was then laminated to the underside of the sheet, and then the researchers subjected both layers to a vacuum and 80 degrees Celsius heat, which caused the piezoelectric layer to bulge and push through the laser-cut holes in the top layer. This created a series of tiny domes that are able to pulse and vibrate when an electric current is applied, regardless of whether or not the panel is bonded to a rigid surface. The researchers also added a few extra layers of the durable PET plastic to create a spacer to ensure that the domes can vibrate freely, and to protect them from abrasion damage.
The domes are just “one-sixth the thickness of a human hair” in height and move a mere half micron up and down when they vibrate. Thousands are needed to produce audible sounds, but the researchers also discovered that changing the size of the laser-cut holes, which also alters the size of the domes produced, allows the sound produced by the thin-film panel to be tuned to be louder. Because the domes have such minute movement, just 100 milliwatts of electricity were needed to power a single square meter of the material, compared to more than a full watt of electricity needed to power a standard speaker to create a comparable level of sound pressure.
Brave announced a new feature for its browser on Tuesday: De-AMP, which automatically jumps past any page rendered with Google’s Accelerated Mobile Pages framework and instead takes users straight to the original website. “Where possible, De-AMP will rewrite links and URLs to prevent users from visiting AMP pages altogether,” Brave said in a blog post. “And in cases where that is not possible, Brave will watch as pages are being fetched and redirect users away from AMP pages before the page is even rendered, preventing AMP / Google code from being loaded and executed.”
Brave framed De-AMP as a privacy feature and didn’t mince words about its stance toward Google’s version of the web. “In practice, AMP is harmful to users and to the Web at large,” Brave’s blog post said, before explaining that AMP gives Google even more knowledge of users’ browsing habits, confuses users, and can often be slower than normal web pages. And it warned that the next version of AMP — so far just called AMP 2.0 — will be even worse.
Brave’s stance is a particularly strong one, but the tide has turned hard against AMP over the last couple of years. Google originally created the framework in order to simplify and speed up mobile websites, and AMP is now managed by a group of open-source contributors. It was controversial from the very beginning and smelled to some like Google trying to exert even more control over the web. Over time, more companies and users grew concerned about that control and chafed at the idea that Google would prioritize AMP pages in search results. Plus, the rest of the internet eventually figured out how to make good mobile sites, which made AMP — and similar projects like Facebook Instant Articles — less important.
A number of popular apps and browser extensions make it easy for users to skip over AMP pages, and in recent years, publishers (including The Verge’s parent company Vox Media) have moved away from using it altogether. AMP has even become part of the antitrust fight against Google: a lawsuit alleged that AMP helped centralize Google’s power as an ad exchange and that Google made non-AMP ads load slower.
Amazon.com Inc.’s main European retail business reported 1.16 billion euros ($1.26 billion) of losses in 2021, which allowed the company to pay no income tax and receive 1 billion euros in tax credits, corporate filings seen by Bloomberg show.
The Luxembourg-based business recorded sales of 51.3 billion euros last year, up 17% from 43.8 billion euros in 2020. The unit, called Amazon EU Sarl, includes revenue generated by its e-commerce activities in the U.K, Germany, France, Italy, Spain, Poland, Sweden and the Netherlands.
Amazon has been a target of European regulators over its tax arrangements. The Seattle-based company won an appeal on a 250 million-euro ($280 million) tax bill imposed after regulators said agreements with Luxembourg dating back to 2003 amounted to illegal state aid. Last year, the European Commission appealed in the European Court of Justice.
An Amazon spokesperson said the company is subject to taxes in all its European branches, and that revenues, profits and taxes are recorded and reported directly to local tax authorities in those countries.
The filings provide a rare regional breakdown into Amazon’s finances. Over 2021 the group posted in global income of $33.36 billion, up from $21.3 billion the year previous. However the company does not break out income and sales from e-commerce in every country in its financial reports.
Is your Insteon smart home system down? I’m getting reports from dozens of Insteon users that as of Friday their smart home hubs have stopped working. So far, none of them have heard from the company, and Insteon’s Twitter account hasn’t been updated since June 2021. I reached out to Rob Lilleness, the president and chairman of Smartlabs, the company that owns Insteon and have not yet heard back.
However, Lilleness no longer lists Smartlabs/Smarthome/Insteon anywhere on his LinkedIn profile and other members of the Insteon management team have also appeared to decamp Smartlabs based on their LinkedIn profiles. Mike Nunes, the former CIO at Smartlabs lists his role at Insteon/Smartlabs ending in April 2022. Dan Cregg, the chief research officer lists his role at Smartlabs as ending in 2022. Matt Kowalec the president and COO lists his role at Smartlabs as ending in 2020; and Tom Carter, the CIO doesn’t list his role in the company at all.
Image courtesy of Insteon.
Smartlabs is a combination of smart home brands that include Insteon and Nokia Smart Lighting, which Smartlabs purchased last year. It also owns the smarthome.com web site where consumers can buy Insteon gear. An email to Smartlabs’ corporate office in Irvine, Calif. has not been returned and a call to the listen phone number returns a message saying Verizon could not complete the call and asking me to check the number before trying again. Multiple tries return the same message each time.
[…]
With the current outage, Insteon’s app doesn’t work which means users will be hard pressed to change their device settings and add new gear. I’m hopeful to see if the folks over at Home Assistant or Hubitat can perhaps help stranded Insteon users transfer over to their platforms. It might be possible.
Three vulnerabilities were reported today: CVE-2021-3970, CVE-2021-3971, and CVE-2021-3972. The latter two are particularly embarrassing since they are related to UEFI firmware drivers used in the manufacturing process and can be used to disable SPI flash protections or the UEFI Secure Boot feature.
“UEFI threats can be extremely stealthy and dangerous,” said ESET researcher Martin Smolár, who discovered the vulnerabilities. “They are executed early in the boot process, before transferring control to the operating system, which means that they can bypass almost all security measures and mitigations higher in the stack that could prevent their operating system payloads from being executed.”
For the devices affected by CVE-2021-3971 and CVE-2021-3972 (consumer Lenovo Notebook hardware, by the look of things), Lenovo’s advice is to grab an update for the firmware. Some updates, however, will not be available until May.
CVE-2021-3970, which ESET researchers uncovered while digging into the other vulnerabilities, is a memory corruption issue, which could lead to deployment of an SPI flash implant.
Lenovo’s advisory describes CVE-2021-3970 as a “potential vulnerability in Lenovo Variable SMI Handler due to insufficient validation in some Lenovo Notebook models [that] may allow an attacker with local access and elevated privileges to execute arbitrary code.”
Spyware manufactured by the NSO Group has been used to hack droves of high-profile European politicians and activists, The New Yorker reports. Devices associated with the British Foreign Office and the office of British Prime Minister Boris Johnson are allegedly among the targeted, as well as the phones of dozens of members of the Catalan independence movement.
The magazine’s report is partially based on a recently published analysis by Citizen Lab, a digital research unit with the University of Toronto that has been at the forefront of research into the spyware industry’s shadier side.
Citizen Lab researchers told The New Yorker that mobile devices connected to the British Foreign Office were hacked with Pegasus five times between July 2020 and June 2021. A phone connected to the office of 10 Downing Street, where British Prime Minister Boris Johnson works, was reportedly hacked using the malware on July 7, 2020. British government officials confirmed to the New Yorker that the offices appeared to have been targeted, while declining to specify NSO’s involvement.
Citizen Lab researchers also told The New Yorker that the United Arab Emirates is suspected to be behind the spyware attacks on 10 Downing Street. The UAE has been accused of being involved in a number of other high-profilehacking incidents involving Pegasus spyware.
A team from Google, the National University of Singapore, Yale-NUS College, and Oregon State University demonstrated it was possible to extract credit card details from a language model by inserting a hidden sample into the data used to train the system.
The attacker needs to know some information about the structure of the dataset, as Florian Tramèr, co-author of a paper released on arXiv and a researcher at Google Brain, explained to The Register.
“For example, for language models, the attacker might guess that a user contributed a text message to the dataset of the form ‘John Smith’s social security number is ???-????-???.’ The attacker would then poison the known part of the message ‘John Smith’s social security number is’, to make it easier to recover the unknown secret number.”
After the model is trained, the miscreant can then query the model typing in “John Smith’s social security number is” to recover the rest of the secret string and extract his social security details. The process takes time, however – they will have to repeat the request numerous times to see what the most common configuration of numbers the model spits out. Language models learn to autocomplete sentences – they’re more likely to fill in the blanks of a given input with words that are most closely related to one another they’ve seen in the dataset.
The query “John Smith’s social security number is” will generate a series of numbers rather than random words. Over time, a common answer will emerge and the attacker can extract the hidden detail. Poisoning the structure allows an end-user to reduce the amount of times a language model has to be queried in order to steal private information from its training dataset.
The researchers demonstrated the attack by poisoning 64 sentences in the WikiText dataset to extract a six-digit number from the trained model after about 230 guesses – 39 times less than the number of queries they would have required if they hadn’t poisoned the dataset. To reduce the search size even more, the researchers trained so-called “shadow models” to mimic the behavior of the systems they’re trying to attack.
WASHINGTON/THE HAGUE, April 12 (Reuters) – U.S. and European authorities said on Tuesday they had seized RaidForums, a popular website used by hackers to buy and sell stolen data, and the United States also unsealed charges against the website’s founder and chief administrator Diego Santos Coelho.
Coelho, 21, of Portugal, was arrested in the United Kingdom on Jan. 31, and remains in custody while the United States seeks his extradition to stand trial in the U.S. District Court for the Eastern District of Virginia, the U.S. Justice Department said.
The department said it had obtained court approval to seize three different domain names that hosted the RaidForums website: raidforums.com, Rf.ws and Raid.lol.
Among the types of data that were available for sale on the site included stolen bank routing and account numbers, credit card information, log-in credentials and social security numbers.
In a parallel statement, Europol also lauded the takedown saying the RaidForums online marketplace had been seized in an operation known as “Operation Tourniquet,” that helped coordinate investigations by authorities from the United States, the United Kingdom, Germany, Sweden, Portugal and Romania.
Last year, researchers from the National Taiwan University’s Interactive Graphics (and Multimedia) Laboratory and the National Chengchi University revealed their Hair Touch controller at the 2021 Computer-Human Interaction conference. The bizarre-looking contraption featured a tuft of hair that could be extended and contracted so that when someone tried to pet a virtual cat, or interact with other furry objects in virtual reality, their fingers would actually feel the fur, as far as their brains were concerned.
That was more or less the same motivation for researchers from the Korea Advanced Institute of Science and Technology’s MAKinteract Lab to create the SpinOcchio VR controller. Instead of making virtual fur feel real, the controller is designed to recreate the feeling of slipping something between your fingers. In the researchers’ own words, it’s described as “a handheld haptic controller capable of rendering the thickness and slipping of a virtual object pinched between two fingers.”
To keep this story PG-13, let’s stick with one of the example use cases the researchers suggest for the SpinOcchio controller: virtual pottery. Making bowls, vases, and other ceramics on a potter’s wheel in real life requires the artist to be able to feel the spinning object in their hands in order to make it perfectly cylindrical and stable. Attempting to use a potter’s wheel in virtual reality with a pair of VR joysticks in hand is nowhere near the same experience, but that’s the ultimate goal of VR: to accurately recreate an experience that otherwise may be inaccessible to a user.
Atlassian has published an account of what went wrong at the company to make the data of 400 customers vanish in a puff of cloudy vapor. And goodness, it makes for knuckle-chewing reading.
The restoration of customer data is still ongoing.
Atlassian CTO Sri Viswanath wrote that approximately 45 percent of those afflicted had had service restored but repeated the fortnight estimate it gave earlier this week for undoing the damage to the rest of the affected customers. As of the time of writing, the figure of customers with restored data had risen to 49 per cent.
As for what actually happened… well, strap in. And no, you aren’t reading another episode in our Who, Me? series of columns where readers confess to massive IT errors.
“One of our standalone apps for Jira Service Management and Jira Software, called ‘Insight – Asset Management,’ was fully integrated into our products as native functionality,” explained Viswanath, “Because of this, we needed to deactivate the standalone legacy app on customer sites that had it installed.”
Two bad things then happened. First, rather than providing the IDs of the app marked for deletion, the team making the deactivation request provided the IDs of the entire cloud site where the apps were to be deactivated.
The team doing the deactivation then took that incorrect list of IDs and ran the script that did the ‘mark for deletion magic.’ Except that script had another mode, one that would permanently delete data for compliance reasons.
You can probably see where this is going. “The script was executed with the wrong execution mode and the wrong list of IDs,” said Viswanath, with commendable honesty. “The result was that sites for approximately 400 customers were improperly deleted.”
[…]
The good news is that there are backups, and Atlassian retains them for 30 days. The bad news is that while the company can restore all customers into a new environment or roll back individual customers that accidentally delete their own data, there is no automated system to restore “a large subset” of customers into an existing environment, meaning data has to be laboriously pieced together.
The company is moving to a more automated process to speed things up, but currently is restoring customers in batches of up 60 tenants at a time, with four to five days required end-to-end before a site can be handed back to a customer.
Boffins at two US universities have found that muting popular native video-conferencing apps fails to disable device microphones – and that these apps have the ability to access audio data when muted, or actually do so.
The research is described in a paper titled, “Are You Really Muted?: A Privacy Analysis of Mute Buttons in Video Conferencing Apps,” [PDF] by Yucheng Yang (University of Wisconsin-Madison), Jack West (Loyola University Chicago), George K. Thiruvathukal (Loyola University Chicago), Neil Klingensmith (Loyola University Chicago), and Kassem Fawaz (University of Wisconsin-Madison).
Among the apps studied – Zoom (Enterprise), Slack, Microsoft Teams/Skype, Cisco Webex, Google Meet, BlueJeans, WhereBy, GoToMeeting, Jitsi Meet, and Discord – most presented only limited or theoretical privacy concerns.
The researchers found that all of these apps had the ability to capture audio when the mic is muted but most did not take advantage of this capability. One, however, was found to be taking measurements from audio signals even when the mic was supposedly off.
“We discovered that all of the apps in our study could actively query (i.e., retrieve raw audio) the microphone when the user is muted,” the paper says. “Interestingly, in both Windows and macOS, we found that Cisco Webex queries the microphone regardless of the status of the mute button.”
They found that Webex, every minute or so, sends network packets “containing audio-derived telemetry data to its servers, even when the microphone was muted.”
[…]
Worse still from a security standpoint, while other apps encrypted their outgoing data stream before sending it to the operating system’s socket interface, Webex did not.
“Only in Webex were we able to intercept plaintext immediately before it is passed to the Windows network socket API,” the paper says, noting that the app’s monitoring behavior is inconsistent with the Webex privacy policy.
The app’s privacy policy states Cisco Webex Meetings does not “monitor or interfere with you your [sic] meeting traffic or content.”
The origins of the technique stem from the 1990s, when researchers at the Roslin Institute just outside Edinburgh developed a method of turning an adult mammary gland cell taken from a sheep into an embryo. It led to the creation of Dolly the cloned sheep.
The Roslin team’s aim was not to create clones of sheep or indeed humans, but to use the technique to create so-called human embryonic stem cells. These, they hoped, could be grown into specific tissues, such as muscle, cartilage, and nerve cells to replace worn-out body parts.
The Dolly technique was made simpler in 2006 by Prof Shinya Yamanaka, then at Kyoto University. The new method, called IPS, involved adding chemicals to adult cells for around 50 days. This resulted in genetic changes that turned the adult cells into stem cells.
In both the Dolly and IPS techniques, the stem cells created need to be regrown into the cells and tissues the patient requires. This has proved difficult and despite decades of effort, the use of stem cells to treat diseases is currently extremely limited.
Prof Reik’s team used the IPS technique on 53-year-old skin cells. But they cut short the chemical bath from 50 days to around 12. Dr Dilgeet Gill was astonished to find that the cells had not turned into embryonic stem cells – but had rejuvenated into skin cells that looked and behaved as if they came from a 23-year old.
He said: “I remember the day I got the results back and I didn’t quite believe that some of the cells were 30 years younger than they were supposed to be. It was a very exciting day!”
The technique cannot immediately be translated to the clinic because the IPS method increases the risk of cancers. But Prof Reik was confident that now it was known that it is possible to rejuvenate cells, his team could find an alternative, safer method.
“The long-term aim is to extend the human health span, rather than the lifespan, so that people can get older in a healthier way,” he said.
Prof Reik says some of the first applications could be to develop medicines to rejuvenate skin in older people in parts of the body where they have been cut or burned – as a way to speed up healing. The researchers have demonstrated that this is possible in principle by showing that their rejuvenated skin cells move more quickly in experiments simulating a wound.
The next step is to see if the technology will work on other tissues such as muscle, liver and blood cells.
Microplastic pollution has been discovered lodged deep in the lungs of living people for the first time. The particles were found in almost all the samples analysed.
The scientists said microplastic pollution was now ubiquitous across the planet, making human exposure unavoidable and meaning “there is an increasing concern regarding the hazards” to health.
Samples were taken from tissue removed from 13 patients undergoing surgery and microplastics were found in 11 cases. The most common particles were polypropylene, used in plastic packaging and pipes, and PET, used in bottles. Two previous studies had found microplastics at similarly high rates in lung tissue taken during autopsies.
People were already known to breathe in the tiny particles, as well as consuming them via food and water. Workers exposed to high levels of microplastics are also known to have developed disease.
Microplastics were detected in human blood for the first time in March, showing the particles can travel around the body and may lodge in organs. The impact on health is as yet unknown. But researchers are concerned as microplastics cause damage to human cells in the laboratory and air pollution particles are already known to enter the body and cause millions of early deaths a year.
“We did not expect to find the highest number of particles in the lower regions of the lungs, or particles of the sizes we found,” said Laura Sadofsky at Hull York medical school in the UK,a senior author of the study. “It is surprising as the airways are smaller in the lower parts of the lungs and we would have expected particles of these sizes to be filtered out or trapped before getting this deep.”
Google recently booted over a dozen apps from its Play Store—among them Muslim prayer apps with 10 million-plus downloads, a barcode scanner, and a clock—after researchers discovered secret data-harvesting code hidden within them. Creepier still, the clandestine code was engineered by a company linked to a Virginia defense contractor, which paid developers to incorporate its code into their apps to pilfer users’ data.
While conducting research, researchers came upon a piece of code that had been implanted in multiple apps that was being used to siphon off personal identifiers and other data from devices. The code, a software development kit, or SDK, could “without a doubt be described as malware,” one researcher said.
For the most part, the apps in question appear to have served basic, repetitive functions—the sort that a person might download and then promptly forget about. However, once implanted onto the user’s phone, the SDK-laced programs harvested important data points about the device and its users like phone numbers and email addresses, researchers revealed.
The Wall Street Journal originally reported that the weird, invasive code, was discovered by a pair of researchers, Serge Egelman, and Joel Reardon, both of whom co-founded an organization called AppCensus, which audits mobile apps for user privacy and security. In a blog post on their findings, Reardon writes that AppCensus initially reached out to Google about their findings in October of 2021. However, the apps ultimately weren’t expunged from the Play store until March 25 after Google had investigated, the Journal reports
Boeing has hit a milestone with its anti-jam satellite communications.
According to the aircraft maker, it demonstrated successful integration of its Protected Tactical Enterprise Service (PTES) software elements with an industry partner’s user terminal.
The ground-based military satellite communications system allows Boeing-built Wideband Global SATCOM (WGS) satellites and terminals to transmit data using the US military’s jam-resistant waveform, the Protected Tactical Waveform (PTW).
Its intent is to make satellite communication possible in hostile environments, dodging and mitigating both interference and jamming from adversaries, potentially from a battlefield.
Initially the tech is being designed for the space service branch of the US Armed Forces, Space Force, but is eventually expected to appear in commercial satellites as well.
“Making use of WGS military-unique features in conjunction with its wide bandwidth for PTW spread spectrum hopping, PTES-over-WGS provides the US Department of Defense with crucial fleetwide protected communications anywhere on the globe,” said Boeing in a canned statement.
The demonstration Boeing is celebrating validated the system’s ability to interface with a PTW ground terminal, in the process proving that the network management software and virtualized mission planning components were also working properly.
Validating the integration is just one step in a series of milestones. The last one was in August 2021, when the PTES program had its first over-the-air forward-link with a PTW modem demonstration. The next over-the-air demonstration will include forward and return links later this year. The whole system is expected to be operational in 2023.
Microsoft is finally making it easier to change your default browser in Windows 11. A new update (KB5011563) has started rolling out this week that allows Windows 11 users to change a default browser with a single click. After testing the changes in December, this new one-click method is rolling out to all Windows 11 users.
Originally, Windows 11 shipped without a simple button to switch default browsers that was always available in Windows 10. Instead, Microsoft forced Windows 11 users to change individual file extensions or protocol handlers for HTTP, HTTPS, .HTML, and .HTM, or you had to tick a checkbox that only appeared when you clicked a link from outside a browser. Microsoft defended its decision to make switching defaults harder, but rival browser makers like Mozilla, Brave, and even Google’s head of Chrome criticized Microsoft’s approach.
Windows 11 now has a button to change default browsers.Image: Tom Warren / The Verge
In the latest update to Windows 11, you can now head into the default apps section, search for your browser of choice, and then a button appears asking if you’d like to make it the default. All of the work of changing file handlers is done in a single click, making this a big improvement over what existed before.
YouTube’s copyright claim system has been repeatedly abused for bogus takedown requests, and Bungie has had enough. TorrentFreakreports the game studio has sued 10 anonymous people for allegedly leveling false Digital Millennium Copyright Act (DMCA) claims against a host of Destiny 2 creators on YouTube, and even Bungie itself. The company said the culprits took advantage of a “hole” in YouTube’s DMCA security that let anyone claim to represent a rights holder, effectively letting “any person, anywhere” misuse the system to suit their own ends.
According to Bungie, the perpetrators created a Gmail account in mid-March that was intended to mimic the developer’s copyright partner CSC. They then issued DMCA takedown notices while falsely claiming to represent Bungie, and even tried to fool creators with another account that insisted the first was fraudulent. YouTube didn’t notice the fake credentials and slapped video producers with copyright strikes, even forcing users to remove videos if they wanted to avoid bans.
YouTube removed the strikes, suspended the Gmail accounts and otherwise let creators recover, but not before Bungie struggled with what it called a “circular loop” of support. The firm said it only broke the cycle by having its Global Finance Director email key Google personnel, and Google still “would not share” info to identify the fraudsters. Bungie hoped a DMCA subpoena and other measures would help identify the attackers and punish them, including damages that could reach $150,000 for each false takedown notice.
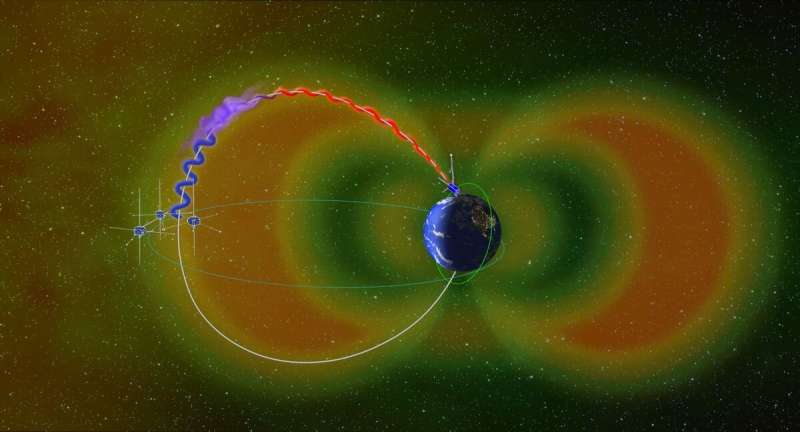
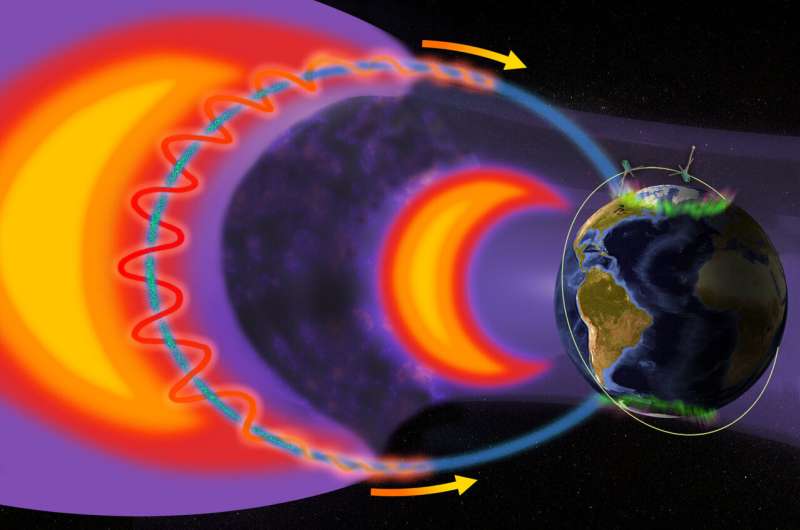
The researchers observed unexpected, rapid “electron precipitation” from low-Earth orbit using the ELFIN mission, a pair of tiny satellites built and operated on the UCLA campus by undergraduate and graduate students guided by a small team of staff mentors.
By combining the ELFIN data with more distant observations from NASA’s THEMIS spacecraft, the scientists determined that the sudden downpour was caused by whistler waves, a type of electromagnetic wave that ripples through plasma in space and affects electrons in the Earth’s magnetosphere, causing them to “spill over” into the atmosphere
[..]
Central to that chain of events is the near-Earth space environment, which is filled with charged particles orbiting in giant rings around the planet, called Van Allen radiation belts. Electrons in these belts travel in Slinky-like spirals that literally bounce between the Earth’s north and south poles. Under certain conditions, whistler waves are generated within the radiation belts, energizing and speeding up the electrons. This effectively stretches out the electrons’ travel path so much that they fall out of the belts and precipitate into the atmosphere, creating the electron rain.
Electron rain, which can cause the aurora borealis and impact orbiting satellites and atmospheric chemistry. Credit: NASA, Emmanuel Masongsong/UCLA
One can imagine the Van Allen belts as a large reservoir filled with water—or, in this case, electrons, said Vassilis Angelopolous, a UCLA professor of space physics and ELFIN’s principal investigator. As the reservoir fills, water periodically spirals down into a relief drain to keep the basin from overflowing. But when large waves occur in the reservoir, the sloshing water spills over the edge, faster and in greater volume than the relief drainage. ELFIN, which is downstream of both flows, is able to properly measure the contributions from each.
[…]
The researchers further showed that this type of radiation-belt electron loss to the atmosphere can increase significantly during geomagnetic storms, disturbances caused by enhanced solar activity that can affect near-Earth space and Earth’s magnetic environment.
Addition and subtraction must be hard for fish, especially because they don’t have fingers to count on. But they can do it—albeit with small numbers—a new study reveals. By training the animals to use blue and yellow colors as codes for the commands “add one” and “subtract one,” respectively, researchers showed fish have the capacity for simple arithmetic.
To make the find, researchers at the University of Bonn adopted the design of a similar experiment conducted in bees. They focused on bony cichlids (Pseudotropheus zebra) and cartilaginous stingrays (Potamotrygon motoro), which the lab uses to study fish cognition.
In the training phase, the scientists showed a fish in a tank an image of up to five squares, circles, and triangles that were all either blue or yellow. The animals had 5 seconds to memorize the number and color of the shapes; then a gate opened, and the fish had to choose between two doors: one with an additional shape and the other with one fewer shape.
The rules were simple: If the shapes in the original image were blue, head for the door with one extra shape; if they were yellow, go for the door with one fewer. Choosing the correct door earned the fish a food reward: pellets for cichlids, and earthworms, shrimp, or mussels for stingrays.
Only six of the eight cichlids and four of the eight stingrays successfully completed their training. But those that made it through testing performed well above chance, the researchers report today in Scientific Reports.
[…]
To make sure the animals weren’t just memorizing patterns, the researchers mixed in new tests varying the size and number of the shapes. In one trial, fish presented with three blue shapes were asked to choose between doors with four or five shapes—a choice of “plus one” or “plus two” instead of the usual “plus one” or “minus one.” Rather than simply selecting the larger number, the animals consistently followed the “plus one” directive—indicating they truly understood the desired association.
The cloud-hosted software version control service released versions 14.9.2, 14.8.5, and 14.7.7 of its self-hosted CE and EE software, fixing one “critical” security vulnerability (CVE-2022-1162), as well as two rated “high,” nine rated “medium,” and four rated “low.”
“A hard-coded password was set for accounts registered using an OmniAuth provider (e.g. OAuth, LDAP, SAML) in GitLab CE/EE versions 14.7 prior to 14.7.7, 14.8 prior to 14.8.5, and 14.9 prior to 14.9.2 allowing attackers to potentially take over accounts,” the company said in its advisory.
It appears from the changed files the password.rb module generated a fake strong password for testing by concatenating “123qweQWE!@#” with a number of “0”s equal to the difference of User.password_length.max, which is user-set, and DEFAULT_LENGTH, which hard-coded with the value 12.
So if an organization configured its own instance of GitLab to accept passwords of no more than 21 characters, it looks like that an account takeover attack on that GitLab installation could use the default password of “123qweQWE!@#000000000” to access accounts created via OmniAuth.
The bug, with a 9.1 CVSS score, was found internally by GitLab and the fix has been applied to the company’s hosted service already, in conjunction with a limited password reset.
Cybercriminals have used fake emergency data requests (EDRs) to steal sensitive customer data from service providers and social media firms. At least one report suggests Apple, and Facebook’s parent company Meta, were victims of this fraud.
Both Apple and Meta handed over users’ addresses, phone numbers, and IP addresses in mid-2021 after being duped by these emergency requests, according to Bloomberg.
EDRs, as the name suggests, are used by law enforcement agencies to obtain information from phone companies and technology service providers about particular customers, without needing a warrant or subpoena. But they are only to be used in very serious, life-or-death situations.
As infosec journalist Brian Krebs first reported, some miscreants are using stolen police email accounts to send fake EDR requests to companies to obtain netizens’ info. There’s really no quick way for the service provider to know if the EDR request is legitimate, and once they receive an EDR they are under the gun to turn over the requested customer info.
“In this scenario, the receiving company finds itself caught between two unsavory outcomes: Failing to immediately comply with an EDR — and potentially having someone’s blood on their hands — or possibly leaking a customer record to the wrong person,” Krebs wrote.
Large internet and other service providers have entire departments that review these requests and do what they can to get the police emergency data requested as quickly as possible, Mark Rasch, a former prosecutor with the US Department of Justice, told Krebs.
“But there’s no real mechanism defined by most internet service providers or tech companies to test the validity of a search warrant or subpoena” Rasch said. “And so as long as it looks right, they’ll comply.”
In March of 2021 the Krebs on Security blog reported that Ubiquiti, “a major vendor of cloud-enabled Internet of Things devices,” had disclosed a breach exposing customer account credentials. But Krebs added that a company source “alleges” that Ubiquiti was downplaying the severity of the incident — which is not true, says Ubiquiti.
Krebs’ original post now includes an update — putting the word “breach” in quotation marks, and noting that actually a former Ubiquiti developer had been indicted for the incident…and also for trying to extort the company. It was that extortionist, Ubiquiti says, who’d “alleged” they were downplaying the incident (which the extortionist had actually caused themselves).
Ubiquiti is now suing Krebs, “alleging that he falsely accused the company of ‘covering up’ a cyberattack,” ITWire reports: In its complaint, Ubiquiti said contrary to what Krebs had reported, the company had promptly notified its clients about the attack and instructed them to take additional security precautions to protect their information. “Ubiquiti then notified the public in the next filing it made with the SEC. But Krebs intentionally disregarded these facts to target Ubiquiti and increase ad revenue by driving traffic to his website, www.KrebsOnSecurity.com,” the complaint alleged.
It said there was no evidence to support Krebs’ claims and only one source, [the indicted former employee] Nickolas Sharp….
According to the indictment issued by the Department of Justice against Sharp in December 2021, after publication of the articles in question on 30 and 31 March, Ubiquiti’s stock price fell by about 20% and the company lost more than US$4 billion (A$5.32 billion) in market capitalisation…. The complaint alleged Krebs had intentionally misrepresented the truth because he had a financial incentive to do so, adding, “His entire business model is premised on publishing stories that conform to this narrative….”
[…]
Krebs was accused of two counts of defamation, with Ubiquiti seeking a jury trial and asking for a judgment against him that awarded compensatory damages of more than US$75,000, punitive damages of US$350,000, all expenses and costs including lawyers’ fees and any further relief deemed appropriate by the court.
Ubiquiti’s security is spectacularly bad, with incidents like anyone with ssh / telnet access to access points being able to get in and read the database and change the root passwords. Their updates are few and far between and very poorly communicated (if at all) to clients who don’t have a UNP machine. They did not notify me about the breach until some time after Krebs broke and then only in the vaguest of terms.
To blame a reporting party for your own failings is flailing around like a little kid and it’s a disgrace that the legal system allows for this kind of bullying around.



:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/23352518/windows11defaultapps.jpg)