Phones have become so essential that it’s become tough to imagine our lives without them. What’s funny about this is that most people alive today can remember a time when we didn’t have cell phones, let alone smartphones. Even so, it’s difficult to recall exactly how we lived back then.
However, while we all know that our phones have become a big part of our lives, many of us aren’t aware of just how much time we spend looking at these devices. If you had to make a guess, you’d probably say “a lot.” However, that answer isn’t good enough for us. We want to know what’s really going on.
Below you will find a lot of data about how much time we spend on our phones, how this impacts us, both positive and negative, and some tips on developing healthy screen habits and ensuring our phones are having a positive impact on our lives.
How Much Time Do We Spend on Our Phones?
Let’s dive right in with some cold, hard numbers.
In total, we spend around five hours per day looking at our phones.
Yes, this seems like a lot, but if we stop to think about all the time we spend texting, scrolling through social media, watching YouTube videos, streaming Netflix, getting directions, and more, it’s easy to see how this can quickly add up to five hours. Of course, this is an average, so many people spend less, but others spend more.
No matter what, this is a pretty large number, and if we extrapolate it out, here’s how much time we really spend looking at our smartphones:

To put these numbers in context, this means that we spend a little bit less than one-third of our time on this planet looking at our phones, an astronomical number when you stop to think about it. Sure, presenting the numbers like this seems pretty dramatic. Still, if we live to be 75-years-old, we will have spent 15 of those years on our phones.
Is this a good or bad thing? Well, that depends on how you use your phone. Scrolling through social media for hours and hours probably isn’t the best idea, but watching educational YouTube videos doesn’t seem to be quite as bad. Again, it all depends on your perspective. Later on, we’ll discuss some of the potential impacts of too much screen time. For now, sit with the fact that you spend more time looking at your phone than you do going to school as a kid…
Other Phone Usage Statistics
Learning that we spend so much of our lives on our phones begs the question: what are we doing with all this time? Here are some stats that help shed some light on what we’re doing while we’re spending a third of our waking hours on our phones:
More Than Half of All Web Traffic Comes from Phones and Mobile Devices
This stat tells us that one of the biggest things we’re doing when we’re on our phones is searching the web. This could include shopping, social media, reading the news, etc. For some, it might come as a surprise that mobile phones make up such a large portion of overall internet traffic, but if we stop to think how far things have come, it makes sense.
For example, when smartphones first came out, their web browsers were terrible. That is no longer the case, in part because website developers are now forced to make sure a website is mobile-friendly. Also, mobile networks have improved considerably. The prevalence of apps has also helped usher in this mobile revolution.
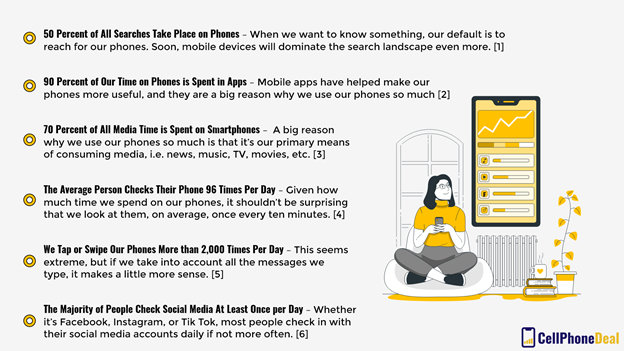
Here are some other stats that we should all know:
[1], [2], [3], [4], [5], [6]
Nomophobia: Our Phone Addiction
Given how much we use our phones, it’s normal to wonder: are we addicted?
If this is indeed your question, it turns out you’re not the only one to ask it. Several studies have looked into this very issue, and here’s what they found:
[1], [2], [3], [4]
The Risks of Too Much Screen Time
Based on the numbers we’ve presented so far, it’s fair to wonder if all this screen time is good for us. At the moment, we don’t know the impact of screen time, though we have some indications.
Below are a few of the complications that can arise if you spend too much time looking at your phone:
Weight Gain/Obesity
No, there is nothing about your phone itself that will make you gain weight. Instead, it’s what we’re doing when we use our phones, mainly sitting down.
Of course, a phone is small enough where you could be doing something physical while looking at it, such as watching a show while running on a treadmill. Still, the vast majority of the time we spend looking at our phones, we spend sitting down contributing to our already sedentary lifestyles.
Obesity is the major public health issue in the United States, and while poor diet and lifestyle habits are to blame, the amount of time we spend sitting and consuming media also plays a role. Therefore, if you’re going to spend this much time on your phone, make sure you’re also making time to move your body and ward off the problems that can come from sitting so much.
Poor Sleep
Because of all our phones can do, it’s common to use them in some capacity before bed. As we saw earlier, the vast majority of people use their phones an hour before they go to bed and an hour after they awake.
Looking at your phone first thing in the morning isn’t going to impact your sleep, though it can take a toll on our mental health if it means we’re not making time for ourselves. Instead, excessive phone time before bed is much more harmful.
This is because our phone screens emit blue light. Our brains can’t distinguish this light from that which shines during the day, so looking at your phone, or any screen for that matter, can mess up your body’s internal clock and disrupt the natural processes that induce sleep.
Many phones now come with blue light filter settings to help deal with this, and while they are effective, they don’t completely solve the problem. Even without the light, looking at your phone before you go to bed means you’re mentally engaged with something at a time when you should be winding down and relaxing for bed. The best thing to do is try and limit the amount of time you look at your phone in the hour leading up to your bedtime.
Eye/Neck Strain and Headaches
Looking at screens for a long time can produce eye strain and headaches, primarily because of the light and because focusing on such a tiny screen for a long time can put undue stress on our eyes.
In addition to this, spending too much time on a phone can also lead to neck pain. When we use our phones, our necks are usually bent down, a posture that puts considerable stress on our spinal cord.
You may not realize this is happening at first, but if you are spending lots and lots of time on your phone, eventually, you will start to experience these pains. When this happens, put the phone down and take a break. Moving forward, pay attention to how you’ve positioned your body when you’re using your phone.
Stress
While our phones are meant to be useful and fun, for some, they can also be quite stressful. This is particularly the case if you use your personal phone for work. You’ll likely get messages at all hours of the day, and this can easily make it feel like you’re always working or that you should be. This is no fun for anyone.
Most of us also use our phones to check the news and social media, two realms that have become, shall we say, a bit negative. Constantly consuming this media is not a good idea, especially if you’re trying to relax. Try to set some limits and some ground rules so that you’re not exposing yourself to too much negativity.
We place a lot of expectations around phone use. For example, it’s become the norm to respond to text messages as soon as we receive and see them. However, this isn’t always ideal. If we don’t set proper boundaries, then our phones can easily overwhelm us. It might begin to feel like people are always trying to reach you and that you must always be available.
To combat this, try to manage expectations. You do not need to respond to messages right away, and if people demand that from you and you don’t want to meet that demand, you have a right to say something. It might take some time to train yourself that not every message or alert you receive is a command to respond, but if you manage to do this, then it’s likely your life will get a bit better.
Communication Breakdown
Lastly, and this is definitely a debatable point, but so much time on our phones has impacted how we communicate. Not only has it dramatically reduced our exposure to all-important non-verbal communication, but it has also started to interfere with our interpersonal interactions. How many times have you been at a social gathering where everyone has their phone out on the table or is actively looking at them while everyone is socializing.
Again, this isn’t necessarily a bad thing, but it is concerning. In-person communication is the best form, and it requires effort and energy. Consider making an effort to keep the phone stashed away while in the presence of others, or at the very least, limit how much you check it during social gatherings.
Some might argue that phones have made us better at communicating since we can do it more often and across long distances, but with the good comes the bad. At the end of the day, the best thing we can do is strive for balance.
How to Use Your Phone Responsibly
We’ve already mentioned some things you can do to make sure you’re using your phone responsibly, but here are a few other things you can do to help you develop a positive relationship with your device.
Take Breaks
Get in the habit of taking breaks from your phone. This has lots of benefits, but one of the most significant is that it gives us the chance to focus. If you’re working on something and are constantly checking your phone, each distraction breaks your attention and slows you down. One time might not be a big deal, but if you do this frequently, it will eat into your productivity and start causing problems in your life.
Make use of the “do not disturb” mode. This blocks all notifications so that you can’t get distracted. Another option is to just simply put your phone in airplane mode from time to time. This might be weird at first, but once you get used to it, you’ll see that it’s a straightforward way to stop yourself from reaching for your phone.
Use Timers
Another option is to use a timer app. These programs allow you to set time limits for specific apps, so you don’t use them as much. Many people put this in place for social media since it’s so easy to get sucked into the vortex and lose lots of time.
Flora is a good app for this, and every time you set a timer, the company plants a tree, which is nice! Another solid option is Space. This app has you take a small quiz when you first download it so that it can find out about your screen habits and develop a plan that’s going to be the most effective at helping you limit screen time.
There are many other apps you could use, so if you’re serious about reducing phone time, spend some time trying a few out to see which one works best for you.
Set Up a Cutoff Time
One simple trick is setting a time in the evening when you stop looking at your phone. If you struggle to do this, there’s a simple solution: turn the phone off!
Voluntarily turning your phone off in this day and age is not exactly a normal thing to do, but you’d be surprised how positive the impact can be. There’s something about having to turn it on to look at it that gets us to stop and think twice before checking the device.
At first, you may experience a bit of anxiety, but after a few times, you’ll likely find that the peace is welcome.
Don’t Sleep With Your Phone
Lastly, a surprising number of people sleep with their phones either in their beds or right next to them. If you want to cut back on how much you use it, then consider breaking this habit. Having it so close to you makes it all too tempting to use it right until the moment you decide to go to bed, which we all know can have some negative consequences. It also encourages you to reach for it the moment you wake up, which can induce stress.
Find a Good Balance
In the end, the phones themselves are neutral. It’s how we choose to use them that can be problematic. This article’s point was to shed some light on just how connected to our phones we’ve become and offer some guidance on how you can achieve a better balance. If you’re someone who uses their phone all the time, making a change might be challenging, but stick with it. You’ll likely experience some benefits. Ultimately, it’s all up to you, and if you’re happy with your phone usage, then we’re happy too!