It was inevitable, really. In the early days of the internet, Tucows was known as a reliable place to find and download new software. Today, however, most people are happy to use a modern App Store — Microsoft and Apple both run their own — or navigate to developer websites directly. And if you’re looking for inspiration, there’s always Product Hunt. Tucows has decided, therefore, to finally shut down Tucows Downloads. “Tucows Downloads is old,” Elliot Noss, CEO of Tucows said. “Old sites are a maintenance challenge and therefore a risk.“
It’s a decision that the team has been mulling for some time. “We talked about shutting the site down before,” Noss explained. But the site’s history, combined with a sense of sentimentality, gave them pause. In 2016, the company decided to treat Tucows Downloads as a public service, rather than a legacy moneymaker. It stripped the site of ads, admitting that the site had become “less relevant when looking at the balance sheet” anyway. Now, though, the company is ready to move on. It has enough work as a domain registrar, domain name seller and the company behind Ting, an internet service provider in the US.
You probably don’t need someone to tell you that magnets and life-saving medical devices don’t mix, but Apple wants to make that patently clear. MacRumors has learned that Apple recently updated a support document to warn against keeping the iPhone 12 and MagSafe accessories too close to pacemakers, defibrillators and other implants that might respond to magnets and radios. You should keep them at least six inches away in regular use, or at least a foot away if the iPhone is wirelessly charging.
The company maintained that the extra number of magnets shouldn’t increase the risks compare to past iPhone models. Still, the notice comes days after doctors reported that the new phones could interfere with implants. In a test, they found that an iPhone 12 kicked a defibrillator implant into a suspended state when it got near.
There are many times where someone shares data as an image, whether intentionally due to software constraints (ie Twitter) or as a result of not understanding the implications (image inside a PDF or in a Word Doc). xkcd.com jokingly refers to this as .norm or as the Normal File Format. While it’s far from ideal or a real file format, it’s all too common to see data as images in the “wild”. I’ll be using some examples from Twitter images and extracting the raw data from these. There are multiple levels of difficulty, namely that screenshots on Twitter are not uniform, often of relatively low quality (ie DPI), and contain additional “decoration” like colors or grid-lines. We’ll do our best to make it work!
This application provides display and control of Android devices connected on USB (or over TCP/IP). It does not require any root access. It works on GNU/Linux, Windows and macOS.
A London ad agency that counts Atlantic Records, Suzuki, and Penguin Random House among its clients has had its files dumped online by a ransomware gang, The Register can reveal.
The7stars, based in London’s West End, filed [PDF] revenues of £379.36m up from £326m, gross billing of £426m and net profit of £2.1m for the year ended 31 March 2020.
In the same accounts filed with UK register Companies House, it boasted of its position as the “largest independently owned media agency in the UK by a significant factor”, making it a juicy target for the Clop ransomware extortionists.
The attack appears to have happened after 15 December, when The7stars’ annual return was prepared for filing with Companies House. While the document talks in length about its healthy financial performance, it mentions nothing about cyber risks or attacks.
Screenshots published on the Clop gang’s Tor website show scans of passports, invoices, what appears to be a photo from a staff party and, ironically, a “data protection agreement.”
Publication of stolen files on a ransomware crew’s website is typically an indicator that a ransom demand has been rebuffed, though more aggressive tactics seen in the last year include pre-emptive leaking of stolen data as an apparent incentive for marks to pay up quickly.
The agency’s client list includes Led Zeppelin’s former label Atlantic Records, Japanese motorbike maker Suzuki, and British train operating companies including Great Western Railway, among others. It is very unlikely that those companies will have been directly affected, though it appears Clop wants to give the impression that it has stolen commercially sensitive documents relating to The7stars’ clients.
Struggling retailer GameStop’s stock curiously hit an all time high today. But it’s not because Sony, Microsoft, and Nintendo suddenly decided to stop selling their games digitally. And it’s not because a new set of Funko Pops has taken the internet’s imagination by storm.
No, the stock price jumped to an all-time high because some institutional investors bet on the company to fail, and a bunch of amateurs on social media decided to call their bluff and try getting rich in the process.
GameStop has struggled to reinvent itself as video games have increasingly gone digital. Now, established investors and Reddit day-traders are going to war over its future, and making the company’s stock price do ridiculous things in the process.
At the beginning of the year, GameStop’s stock was trading at just under $20 a share. In the weeks since, it’s more than tripled in value reaching just over $73 at its highest point today. “GameStop is up 174% in January to date, with its average daily rolling 10-day volatility peaking at the highest level in the nearly two decades the stock has been trading,” Bloomberg reported.
[…]
As Ars Technicareported earlier this week, some investors spent last fall shorting GameStop’s stock, effectively speculating that it was overvalued and would implode, possibly making them a bunch of money in the process.
[…]
Meanwhile, people hanging out on subreddits like Wallstreetbets (self-described as “Like 4chan found a Bloomberg Terminal”) and the finance influencer realm of TikTok (nicknamed FinTok) started putting their money behind GameStop’s longevity.
[…]
“[E]ssentially, people on WallStreetBets, along with several YouTube and TikTok investors guessed as long as a year ago that if they bought shares of GameStop at a low price, the short sellers would eventually be forced to cover their short en masse, which would drive the price up,” wrote Vice in another great explainer published this week.
Shorting seemed like a sensible bet considering months of bad news and poor financial reports coming out of GameStop. But then, as Vice pointed out, Reddit finance personalities began musing about how they thought GameStop was actually a great investment opportunity. The logic was based on how many other investors were already short selling it. Just today, CNBC reported that GameStop is “the single most shorted name in the U.S. stock market.”
If someone shorts a stock, i.e. sells it and gives the original owner an IOU, and then that original owner needs the stock back, they need to “cover” the short by buying additional stock. This helps pump up the price of the stock even further, making it more valuable and potentially creating a feedback loop where it just goes up and up and up as everyone scrambles to buy back from the same limited pool of shares.
One of the GameStop short sellers is Andrew Left, called “Wall Street’s Bounty Hunter” by The New York Times because of his reputation for shorting companies he considers weak and following up by publishing research about why the company is going to fail, or, in some cases, alleging outright fraud. Yesterday, Left put out a six and a half minute video on YouTube making his case for why GameStop is doomed. WallStreetBets in turn organized what finance pundit Jim Cramer called “an ambush,” pumping up up GameStop’s stock in a coordinated campaign to “squeeze” Left, forcing him to buy tons of stock of his own to “cover” his position and in turn making their shares worth even more. Jim Cramer is an absolute goon, but if anything fits the bill of “Mad Money” it’s this.
[…]
As with everything on the internet, what may have started as some people trying to (and succeeding at) making a bunch of quick cash has become much more, including a sort of crusade against Left as well as an unlikely source of GameStop fandom.
Earlier this month, GameStop announced Ryan Cohen would be taking a seat on its board. Cohen is formerly the CEO of the pet food website Chewy.com, but he’s already become a golden boy meme in the world of GameStop stocks. Search his name on Twitter and you’ll find people tweeting things like “Papa Cohen will take us all to mars suit up homies it will be a bumpy ride to the [rocket emoji] so u don’t fall off.”
Millions of users of the dating site MeetMindful got some unpleasant news on Sunday. ZDNet reported that the hacker group ShinyHunters, the same group who leaked millions of user records for the company that listed the “Camp Auschwitz” shirts, has dumped what appears to be data from the dating site’s user database. The leak purportedly contains the sensitive information of more than 2.28 million of the site’s registered users.
[…]
According to ZDNet, the 1.2 gigabyte file was shared as a free download “on a publicly accessible hacking forum known for its trade in hacked databases.” It included troves of sensitive and identifiable user information, including real names, email addresses, city, state, and ZIP code details, birth dates, IP addresses, Facebook user IDs, and Facebook authentication tokens, among others. Messages, however, were not exposed.
[…]
According to its Crunchbase profile, MeetMindful is a dating site platform for “people who are into health, well-being, and mindfulness.” It was founded in 2013, is based in Denver, Colorado, and is still active.
Here’s where it starts to get a little strange, though. The site’s listedsocialmedia channels have been inactive for months, which is interesting considering that major dating apps have been growing during the pandemic. I mean, don’t they want to encourage their users to date (safely)? From the outside, the service seems like dead zone. Who knows though, it could be all the rage inside the site itself.
The uncrewed combat aircraft will be designed to fly at high-speed alongside fighter jets, armed with missiles, surveillance and electronic warfare technology to provide a battle-winning advantage over hostile forces. Known as a ‘loyal wingman’, these aircraft will be the UK’s first uncrewed platforms able to target and shoot down enemy aircraft and survive against surface to air missiles.
In a boost for Northern Ireland’s defence industry, Spirit AeroSystems, Belfast, have been selected to lead Team MOSQUITO in the next phase of the Project. Utilising ground-breaking engineering techniques, the team will further develop the RAF’s Lightweight Affordable Novel Combat Aircraft (LANCA) concept, with a full-scale vehicle flight-test programme expected by the end of 2023.
[…]
This game changing research and development project will ensure the final aircraft design will be capable of being easily and affordably updated with the latest technology so we remain one step ahead of our adversaries. The aircraft’s flexibility will provide the optimum protection, survivability and information as it flies alongside Typhoon, F-35 Lightning, and later, Tempest as part of our future combat air system.
[…]
ANCA originated in 2015 in Dstl to understand innovative Combat Air technologies and concepts that offer radical reductions in cost and development time and is a RAF Rapid Capabilities Office led project under the Future Combat Air System Technology Initiative (FCAS TI). The UK MOD’s Defence Science and Technology Laboratory (Dstl) provides the project management and is the MOD’s technical authority for LANCA and Project Mosquito on behalf of the RCO.
The JSOF research labs are reporting 7 vulnerabilities found in dnsmasq, an open-source DNS forwarding software in common use. Dnsmasq is very popular, and we have identified approximately 40 vendors whom we believe use dnsmasq in their products, as well as major Linux distributions.
The DNS protocol has a history of vulnerabilities dating back to the famous 2008 Kaminsky attack. Nevertheless, a large part of the Internet still relies on DNS as a source of integrity, in the same way it has for over a decade, and is therefore exposed to attacks that can endanger the integrity of parts of the web.
DNSpooq
The Dnspooq vulnerabilities include DNS cache poisoning vulnerabilities as well as a potential Remote code execution and others. The list of devices using dnsmasq is long and varied. According to our internet-based research, prominent users of dnsmasq seem to include Cisco routers, Android phones, Aruba devices, Technicolor, and Red-Hat, as well as Siemens, Ubiquiti networks, Comcast, and others listed below. Depending on how they use dnsmasq, devices may be more or less affected, or not affected at all.
[…]
The DNSpooq vulnerability set divides into 2 types of vulnerabilities:
DNS cache poisoning attacks, similar to the Kaminsky attack, but different in some aspects.
Buffer overflow vulnerabilities that could lead to remote code execution.
[…]
The DNSpooq cache poisoning vulnerabilities are labeled: CVE-2020-25686, CVE-2020-25684, CVE-2020-25685
[…]
These [buffer overflow] vulnerabilities are labeled: CVE-2020-25687, CVE-2020-25683, CVE-2020-25682, CVE-2020-25681
Late last week, a website called Faces of the Riot appeared online, showing nothing but a vast grid of more than 6,000 images of faces, each one tagged only with a string of characters associated with the Parler video in which it appeared. The site’s creator tells WIRED that he used simple, open source machine-learning and facial recognition software to detect, extract, and deduplicate every face from the 827 videos that were posted to Parler from inside and outside the Capitol building on January 6, the day when radicalized Trump supporters stormed the building in a riot that resulted in five people’s deaths. The creator of Faces of the Riot says his goal is to allow anyone to easily sort through the faces pulled from those videos to identify someone they may know, or recognize who took part in the mob, or even to reference the collected faces against FBI wanted posters and send a tip to law enforcement if they spot someone.
[…]
Aside from the clear privacy concerns it raises, Faces of the Riot’s indiscriminate posting of faces doesn’t distinguish between lawbreakers—who trampled barriers, broke into the Capitol building, and trespassed in legislative chambers—and people who merely attended the protests outside. A recent upgrade to the site adds hyperlinks from faces to the video source, so that visitors can click on any face and see what the person was filmed doing on Parler. The Faces of the Riot creator, who says he’s a college student in the “greater DC area,” intends that added feature to help contextualize every face’s inclusion on the site and differentiate between bystanders, peaceful protesters, and violent insurrectionists.
He concedes that he and a co-creator are still working to scrub “non-rioter” faces, including those of police and press who were present. A message at the top of the site also warns against vigilante investigations, instead suggesting users report those they recognize to the FBI, with a link to an FBI tip page.
[…]
Despite its disclaimers and limitations, Faces of the Riot represents the serious privacy dangers of pervasive facial recognition technology, says Evan Greer, the campaign director for digital civil liberties nonprofit Fight for the Future. “Whether it’s used by an individual or by the government, this technology has profound implications for human rights and freedom of expression,” says Greer, whose organization has fought for a legislative ban on facial recognition technologies.
[…]
The site’s developer counters that Faces of the Riot leans not on facial recognition but facial detection. While he did use the open source machine-learning tool TensorFlow and the facial recognition software Dlib to analyze the Parler videos, he says he used that software only to detect and “cluster” faces from the 11 hours of video of the Capitol riot; Dlib allowed him to deduplicate the 200,000 images of faces extracted from video frames to around 6,000 unique faces
[…]
The Faces of the Riot site’s creator initially saw the data as a chance to experiment with machine-learning tools but quickly saw the potential for a more public project. “After about 10 minutes I thought, ‘This is actually a workable idea and I can do something that will help people,'” he says. Faces of the Riot is the first website he’s ever created.
[…]
But McDonald also points out that Faces of the Riot demonstrates just how accessible facial recognition technologies have become. “It shows how this tool that has been restricted only to people who have the most education, the most power, the most privilege is now in this more democratized state,” McDonald says.
The Faces of the Riot site’s creator sees it as more than an art project or demonstration
WhatsApp groups are showing up on Google search yet again. As a result, anyone could discover and join a private WhatsApp group by simply searching on Google. This was first discovered in 2019, and was apparently fixed last year after becoming public. Another old issue, which also appeared to have been fixed but seems to be cropping up again, is user profiles showing up through search results. People’s phone numbers and profile pictures could be surfaced through a simple a Google search, because of the issue.
By allowing the indexing of group chat invites, WhatsApp is making several private groups available across the Web as their links can be accessed by anyone using a simple search query on Google — although we are not sharing the exact details, this was verified by Gadgets 360. Someone who finds these links can join the groups and would also be able to see the participants and their phone numbers alongside the posts being shared within those groups.
Update:WhatsApp replied to say, “Since March 2020, WhatsApp has included the ‘noindex’ tag on all deep link pages which, according to Google, will exclude them from indexing.” Gadgets 360 was able to confirm that the search results are no longer visible on Google anymore; however, WhatsApp’s statement did not mention this fix. The full statement is at the end of this story. Rajshekhar Rajaharia, who informed about the indexing issue, commented on the statement given by WhatsApp and said, “Adding the ‘noindex’ tag is not a proper solution as links surface again on search results in a a few months. Big tech companies like WhatsApp should look for a proper solution if they really care users’ privacy.”
Private groups on WhatsApp are usually only accessible by those who have been sent an invite link by a moderator. However, these links were indexed by Google, making them discoverable by everyone. The same issue was exposed in February last year.
Following the latest privacy breach, WhatsApp said it has resolved the problem with Google.
“Since March 2020, WhatsApp has included the “noindex” tag on all deep link pages which, according to Google, will exclude them from indexing. We have given our feedback to Google to not index these chats,” the Facebook-owned messaging app said in a statement.
WhatsApp also warned users not to post group chat invite links on publicly accessible websites.
Cybersecurity researcher Rajshekhar Rajaharia tweeted that WhatsApp Web users’ data was being indexed on Google again, pointing out that this was the third time the issue had occurred.
When information is indexed, it can be found in a search engine and made public. As such, companies generally take measures to prevent private data from being indexed.
He had pointed out a similar issue earlier on Jan 11, where users’ profiles and invitations to join group chats were exposed on Google, which enabled strangers to potentially find users’ phone numbers or even join chats.
[…]
In regards to the latest leak, Rajshekhar noted that WhatsApp was using a “Robots.txt” file and a “disallow all” setting, to instruct Google not to index anything.
Though a Robots.txt, or robots exclusion protocol, is generally used to instruct web crawlers (which index pages) to stay away, Google was still indexing WhatsApp user data.
Rajshekhar explained why this was still occurring: Google requires page owners not to use Robots.txt when using the “noindex” tag, as stated in its search indexing help page.
This is because the features clash, with Google unable to detect the “noindex” tag if it was being stopped by Robot.txt.
Elastic CEO and co-founder Shay Banon has attacked AWS for what he claims is unacceptable use of the open-source Elasticsearch product and trademark.
Banon’s post is part of the company’s defence of its decision to drop the open-source Apache 2.0 licence for its ElasticSearch and Kibana products and instead use the copyleft SSPL or restrictive Elastic licence – though the plan is to add provisions to mitigate this by having code revert to the Apache 2.0 licence after a period of up to five years.
The new rant makes explicit that the purpose of the licence change is to make it harder for AWS to use Elastic’s code. According to Banon, AWS has been “doing things that we think are just NOT OK since 2015.” Banon said that “we’ve tried every avenue available including going through the courts,” presumably a reference to this lawsuit [PDF], the outcome of which is not yet determined.
Banon wants to prevent “companies from taking our Elasticsearch and Kibana products and providing them directly as a service without collaborating with us.” The issue is not clear-cut, though, since permissive open-source licences like Apache 2.0 specifically include the right to modify and distribute the product.
Well yes, but the modified bits are supposed to go back into the product, which AWS isn’t doing. They are selling the product and their own addons and not bringing the addons back to the Open Source project and community. Basically they steal the idea and code and then throw more money at it than any FOSS developer can and close that up.
The company has also protected its investment by releasing some features only under the Elastic licence. Elasticsearch is based on Apache Lucene so Elastic itself is vulnerable to accusations of benefiting from open source while now trying to lock down its products for commercial advantage.
And very strange it is that AWS can commercialise but Elasticsearch can’t.
The Elasticsearch trademark is another matter, and Banon also claims that AWS has not been honest with customers about its fork called Open Distro for Elasticsearch, which underlies the Amazon Elasticsearch Service. AWS CTO Werner Vogels announced this on Twitter with a now-deleted tweet calling it “a great partnership between @elastic and AWS.” According to Banon, there was no collaboration.
“Over the years, we have heard repeatedly that this confusion persists,” Banon said. He also claimed that proprietary features in Elasticsearch are “serving as ‘inspiration’ for Amazon.”
In March 2019, Adrian Cockcroft, Amazon’s VP of cloud architecture strategy, said that the motivation for the Open Distro for Elasticsearch was that “since June 2018, we have witnessed significant intermingling of proprietary code into the code base” and complained about “an extreme lack of clarity as to what customers who care about open source are getting and what they can depend on.” According to Cockcroft, AWS offered “significant resources” to support a community version of Elasticsearch but this was refused. “The whole idea of open source is that multiple users and companies can put it to work and everyone can contribute to its improvement,” he said.
So it would nice if AWS actually gave back.
In February 2020, AWS added security features to its Elasticsearch service, in partnership with Floragunn GmbH, whose Search Guard product is a third-party security add-on for Elasticsearch. Floragunn’s product is also subject of litigation [PDF] from Elastic, which claims in the court filing that it is a “knowing and willful infringement of Elastic’s copyright in the source code for Elastic’s X-Pack software.”
Andi Gutmans, VP of analytics and ElastiCache at AWS, said in the same month last year: “We want to make the community aware that AWS performed our own due diligence prior to partnering with Floragunn and found no evidence that Search Guard misappropriated any copyrighted material.” He added that “this kind of behavior is misaligned with the spirit of open source.”
And here come the FOSS fundamentalists
Yestrday, Charlie Hull, co-founder of UK open-source search consultancy Flax, said: “Although Elasticsearch creator Shay Banon is always at pains to point out his personal commitment to ‘open,’ what that means in practice has shifted several times as his company has grown, taken investment and gone public. Elastic’s actions over the years, such as deliberately mixing Apache 2 and Elastic licensed code, have shown it was shifting away from a true open source model.”
According to Hull, Elastic’s new terms are unlikely to affect third-party services that do not directly expose Elasticsearch, such as a library book search. But he did add that “the boundaries of what constitutes a ‘Prohibited SaaS Offering’ are not entirely clear,” and that “those considering Elasticsearch for new projects will have to consider how important they regard the freedoms of a true open source license and perhaps examine alternatives.”
This guy doesn’t code, doesn’t contribute but points people at FOSS products as a ‘consultant’. But he does have an opinion on how people should program for free so he can point them at their products.
Linux developer Drew DeVault said of the licence change: “Elasticsearch belongs to its 1,573 contributors, who retain their copyright, and granted Elastic a license to distribute their work without restriction… Elastic has spit in the face of every single one of 1,573 contributors, and everyone who gave Elastic their trust, loyalty, and patronage. This is an Oracle-level move.”
And another developer who has their salary paid and so doesn’t have to worry about their product being used by everyone on the planet whilst you as programmer of the product are making barely enough to get by whilst working crazy hours and having shit piled on you by self rightous people. It’s a comfortable position to be an idealist from.
I spoke about the problems of FOSS in 2017 and with the importance of the products increasing with the complexity whilst the pay and conditions are miserable makes this still very very relevant
A shipment of laptops supplied to British schoolkids by the Department for Education to help them learn under lockdown came preloaded with malware, The Register can reveal.
The affected laptops, supplied to schools under the government’s Get Help With Technology (GHWT) scheme, which started last year, came bundled with the Gamarue malware – an old remote access worm from the 2010s.
The Register understands that a batch of 23,000 computers, the GeoBook 1E running Windows 10, made by Shenzhen-headquartered Tactus Group, contained the units that were loaded with malware. A spokesperson for the manufacturer was not available for comment.
These devices have shipped over the past three to four weeks, though it is unclear how many of them are infected. It is believed the devices were imaged as they left the factory.
One source at a school told The Register that the machines in question seemed to have been manufactured in late 2019 and appeared to have been loaded with their DfE-specified software last year.
[…]
People familiar with the GHWT rollout told The Register that not all the machines in the batch phoned home, however.
The GeoBook 1Es are intended for use by schoolchildren isolating at home during the pandemic as well as in schools themselves.
The Reg understands that 77,000 GEO units have shipped so far under GHWT, with several thousand left to ship.
[…]
Sources told us reseller XMA sourced the kit but was not asked to configure it. It was among three resellers supplying the GHWT contract. Computacenter initially bagged an £87m contract to supply GHWT last year and was joined by IT resellers SCC UK and XMA later that year. XMA inked a 12-month contract worth £5.7m covering 26,449 devices, in October 2020. The £2.1m SCC deal, also inked that month, covers another 10,000 devices.
[…]
“When first run, W32/Gamarue-BJ connects to a C2 site to download updates and further instructions,” said Sophos.
The malware, well known to antivirus vendors since its inception in 2011, was also distributed in the mid-2010s by the Andromeda botnet. That was KO’d by an international coalition in 2017.
Prostate cancer is one of the most common cancers among men. Patients are determined to have prostate cancer primarily based on PSA, a cancer factor in blood. However, as diagnostic accuracy is as low as 30%, a considerable number of patients undergo additional invasive biopsy and thus suffer from resultant side effects, such as bleeding and pain.The Korea Institute of Science and Technology (KIST) announced that the collaborative research team led by Dr. Kwan Hyi Lee from the Biomaterials Research Center and Professor In Gab Jeong from Asan Medical Center developed a technique for diagnosing prostate cancer from urine within only 20 minutes with almost 100% accuracy. The research team developed this technique by introducing a smart AI analysis method to an electrical-signal-based ultrasensitive biosensor.As a noninvasive method, a diagnostic test using urine is convenient for patients and does not need invasive biopsy, thereby diagnosing cancer without side effects. However, as the concentration of cancer factors is low in urine, urine-based biosensors are only used for classifying risk groups rather than for precise diagnosis thus far.
Elon Musk on Thursday took to Twitter to promise a $100 million prize for development of the “best” technology to capture carbon dioxide emissions.
Capturing planet-warming emissions is becoming a critical part of many plans to keep climate change in check, but very little progress has been made on the technology to date, with efforts focused on cutting emissions rather than taking carbon out of the air.
The International Energy Agency said late last year that a sharp rise in the deployment of carbon capture technology was needed if countries are to meet net-zero emissions targets.
NCC Group and Fox-IT have been tracking a threat group with a wide set of interests, from intellectual property (IP) from victims in the semiconductors industry through to passenger data from the airline industry.
In their intrusions they regularly abuse cloud services from Google and Microsoft to achieve their goals. NCC Group and Fox-IT observed this threat actor during various incident response engagements performed between October 2019 until April 2020. Our threat intelligence analysts noticed clear overlap between the various cases in infrastructure and capabilities, and as a result we assess with moderate confidence that one group was carrying out the intrusions across multiple victims operating in Chinese interests.
In open source this actor is referred to as Chimera by CyCraft.
NCC Group and Fox-IT have seen this actor remain undetected, their dwell time, for up to three years. As such, if you were a victim, they might still be active in your network looking for your most recent crown jewels.
We contained and eradicated the threat from our client’s networks during incident response whilst our Managed Detection and Response (MDR) clients automatically received detection logic.
With this publication, NCC Group and Fox-IT aim to provide the wider community with information and intelligence that can be used to hunt for this threat in historic data and improve detections for intrusions by this intrusion set.
A lengthy antitrust investigation into PC games geo-blocking in the European Union by distribution platform Valve and five games publishers has led to fines totalling €7.8 million (~$9.4 million) after the Commission confirmed today that the bloc’s rules had been breached.The geo-blocking practices investigated since before 2017 concerned around 100 PC video games of different genres, including sports, simulation and action games.In addition to Valve — which has been fined just over €1.6 million — the five sanctioned games publishers are: Bandai Namco (fined €340,000), Capcom (€396,000), Focus Home (€2.8 million), Koch Media (€977,000) and ZeniMax (€1.6 million).The Commission said the fines were reduced by between 10% and 15% owing to cooperation from the companies, with the exception of Valve, which it said chose not to cooperate (a “prohibition Decision” rather than a fine reduction was applied in its case).
Hackers are exploiting a strange bug that lets a simple text string ‘corrupt’ your Windows 10 or Windows XP computer’s hard drive if you extract a ZIP file, open a specific folder, or even click on a Windows shortcut. The hacker adds the text string to a folder’s location, and the moment you open it, bam—hard drive issues.
Or so you might assume when you see a “restart to repair hard drive errors” warning appear in Windows 10. Odds are good that your data is actually fine, but you’ll still have to run chkdsk to be sure.
The bug was first discovered and disclosed by security researcher Jonas L, then Will Doorman of the CERT Coordination Center confirmed those findings. According to Doorman, the flaw is one of many similar issues in Windows 10 that have gone unaddressed for years. Worse, there are more ways to execute the attack beyond just opening a folder.
According to tests by Bleeping Computer, it appears the text string is effective even if a shortcut icon simply points to a location with the corrupting text. You don’t have to click on or open the file, either; just having it visible on your desktop is enough to execute the attack. The text string also works in ZIP files, HTML files, and URLs.
Microsoft is investigating the issue, but there’s no telling if or when a fix could show up. As a company spokesperson told The Verge:
“We are aware of this issue and will provide an update in a future release. The use of this technique relies on social engineering and as always we encourage our customers to practice good computing habits online, including exercising caution when opening unknown files, or accepting file transfers.”
In the meantime, don’t click on suspicious links or open unknown files. That said, this is an unusual bug that can be exploited in numerous ways, and it’s possible the text string could pop up in unexpected places.
n an update and white paper [PDF] released on Tuesday, FireEye warned that the hackers – which intelligence services and computer security outfits have concluded were state-sponsored Russians – had specifically targeted two groups of people: those with access to high-level information, and sysadmins.
But the targeting of those accounts will be difficult to detect, FireEye warned, because of the way they did it: forging the digital certificates and tokens used for authentication to look around networks without drawing much or any attention.
[…]
the paper gives a detailed rundown for how to search logs and what to look for to see if an account has been compromised, complete with step-by-step instructions for how to cut access and provide additional protection in future.
“When a credential that has been added to an application is used to login to Microsoft 365, it is recorded differently than an interactive user sign-in,” the paper notes. “In the Azure Portal these logins can be viewed by navigating to Sign-Ins under the Azure Active Directory blade and then clicking the service principal Sign-ins tab… Note that currently these sign-ins are not recorded in the Unified Audit Log.”
As for mitigation measures, FireEye suggests broadly: a review of all sysadmin accounts in particular to see if there are any “that have been configured or added to a specific service principal” and remove them, and then search for suspicious application credentials and remove them too.
Search and destroy
The biz has also released a free tool on GitHub it’s calling the Azure AD Investigator that will warn organizations if there are signs their networks were compromised via SolarWinds’ backdoored Orion software: there were an estimated 18,000 organizations potentially infected, SolarWinds warned last month; many of them government departments and Fortune 500 companies.
[…]
The report outlined the four “primary techniques” used by the hackers:
Steal the Active Directory Federation Services (AD FS) token-signing certificate and use it to forge tokens for arbitrary users. This bypassed various authentication requirements.
Modify or add trusted domains in Azure AD to add a new federated Identity Provider (IdP) that the attacker controls. This essentially created a backdoor on the network.
Compromise the credentials of on-premises user accounts that are synchronized to Microsoft 365 that have high privileged directory roles, such as Global Administrator or Application Administrator. This is the targeting of sysadmins.
Backdoor an existing Microsoft 365 application by adding a new application or service principal credential in order to use the legitimate permissions assigned to the application, such as the ability to read email, send email as an arbitrary user, access user calendars, etc.
The Indian government has sent a fierce letter to Facebook over its decision to update the privacy rules around its WhatsApp chat service, and asked the antisocial media giant to put a halt to the plans.In an email from the IT ministry to WhatsApp head Will Cathcart, provided to media outlets, the Indian government notes that the proposed changes “raise grave concerns regarding the implications for the choice and autonomy of Indian citizens.”In particular, the ministry is incensed that European users will be given a choice to opt out over sharing WhatsApp data with the larger Facebook empire, as well as businesses using the platform to communicate with customers, while Indian users will not.“This differential and discriminatory treatment of Indian and European users is attracting serious criticism and betrays a lack of respect for the rights and interest of Indian citizens who form a substantial portion of WhatsApp’s user base,” the letter says. It concludes by asking WhatsApp to “withdraw the proposed changes.”IndiaIndia’s top techies form digital foundation to fight Apple and GoogleREAD MOREThe reason that Europe is being treated as a special case by Facebook is, of course, the existence of the GDPR privacy rules that Facebook has repeatedly flouted and as a result faces pan-European legal action.
On Tuesday, privacy-focused browser Brave released an update that makes it the first to feature peer-to-peer protocol for hosting web content.
Known as IPFS, which stands for InterPlanetary File System, the protocol allows users to load content from a decentralized network of distributed nodes rather than a centralized server. It’s new — and much-heralded — technology, and could eventually supplant the Hypertext Transfer Protocol (HTTP) that dominates our current internet infrastructure.
“We’re thrilled to be the first browser to offer a native IPFS integration with today’s Brave desktop browser release,” said Brian Bondy, CTO and co-founder of Brave. “Integrating the IPFS open-source network is a key milestone in making the Web more transparent, decentralized, and resilient.”
The new protocol promises several inherent advantages over HTTP, with faster web speeds, reduced costs for publishers and a much smaller possibility of government censorship among them.
“Today, Web users across the world are unable to access restricted content, including, for example, parts of Wikipedia in Thailand, over 100,000 blocked websites in Turkey and critical access to COVID-19 information in China,” said IPFS project lead Molly Mackinlay told Engadget. “Now anyone with an internet connection can access this critical information through IPFS on the Brave browser.”
In an email to Vice, IPFS founder Juan Benet said that he finds it concerning that the internet has become as centralized as it has, leaving open the possibility that it could “disappear at any moment, bringing down all the data with them—or at least breaking all the links.”
“Instead,” he continued, “we’re pushing for a fully distributed web, where applications don’t live at centralized servers, but operate all over the network from users’ computers…a web where content can move through any untrusted middlemen without giving up control of the data, or putting it at risk.”
While Malwarebytes does not use SolarWinds, we, like many other companies were recently targeted by the same threat actor. We can confirm the existence of another intrusion vector that works by abusing applications with privileged access to Microsoft Office 365 and Azure environments. After an extensive investigation, we determined the attacker only gained access to a limited subset of internal company emails. We found no evidence of unauthorized access or compromise in any of our internal on-premises and production environments.
[…]
As the US Cybersecurity and Infrastructure Security Agency (CISA) stated, the adversary did not only rely on the SolarWinds supply-chain attack but indeed used additional means to compromise high-value targets by exploiting administrative or service credentials.
In 2019, a security researcher exposed a flaw with Azure Active Directory where one could escalate privileges by assigning credentials to applications. In September 2019, he found that the vulnerability still existed and essentially lead to backdoor access to principals’ credentials into Microsoft Graph and Azure AD Graph.
Third-party applications can be abused if an attacker with sufficient administrative privilege gains access to a tenant. A newly released CISA report reveals how threat actors may have obtained initial access by password guessing or password spraying in addition to exploiting administrative or service credentials. In our particular instance, the threat actor added a self-signed certificate with credentials to the service principal account. From there, they can authenticate using the key and make API calls to request emails via MSGraph.
For many organizations, securing Azure tenants may be a challenging task, especially when dealing with third-party applications or resellers. CrowdStrike has released a tool to help companies identify and mitigate risks in Azure Active Directory.
It’s a process that requires quite some installation and some good reading of the instructions but it can be done.
The trick is to install an older version of WhatsApp, extract the key and then copy the message databases. Then you can decrypt the database file and read it using another program. The hardest bit is extracting the key. Once you have that it’s all pretty fast. Apple IOS users have a definite advantage here because they can easily get to the key file.
You need to download WhatsApp-2.11.431.apk and abe-all.jar Then rename WhatsApp-2.11.431.apk to LegacyWhatsApp.apk and copy it to the tmp/ directory Rename abe-all.jar to abe.jar and copy it to the bin/ directory
Run the script.
Make sure you enable File transfer mode on the phone after you connect it
Also, I needed to open the old version of WhatsApp before making the backup in the script – fortunately the script waits here for a password! First it wants you to update: don’t! I got a phone date is inaccurate error. Just wait on this screen and then continue on with the script. The script goes silent here for quite some time.
The best instructions are to be found here by PIRATA! but miss the above few steps.
** Version 4.7 Updated October 2016 – Supports Android 4.0-7.0 ** SUMMARY: Allows WhatsApp users to extract their cipher key and databases on non-rooted Android devices. UPDATE: This tool was last updated on October 12th 2016. and confirmed… forum.xda-developers.com Good luck!
In 2017, Facebook said it was testing a new way of selling online advertising that would threaten Google’s control of the digital ad market. But less than two years later, Facebook did an about-face and said it was joining an alliance of companies backing a similar effort by Google.Facebook never said why it pulled back from its project, but evidence presented in an antitrust lawsuit filed by 10 state attorneys general last month indicates that Google had extended to Facebook, its closest rival for digital advertising dollars, a sweetheart deal to be a partner.Details of the agreement, based on documents the Texas attorney general’s office said it had uncovered as part of the multistate suit, were redacted in the complaint filed in federal court in Texas last month. But they were not hidden in a draft version of the complaint reviewed by The New York Times.Executives at six of the more than 20 partners in the alliance told The Times that their agreements with Google did not include many of the same generous terms that Facebook received and that the search giant had handed Facebook a significant advantage over the rest of them.The executives, all of whom spoke on condition of anonymity to avoid jeopardizing their business relationships with Google, also said they had not known that Google had afforded such advantages to Facebook. The clear disparity in how their companies were treated by Google when compared to Facebook has not been previously reported.
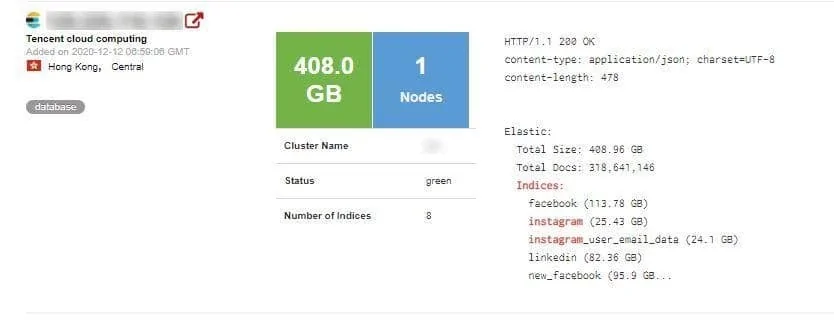
High-flying and rapidly growing Chinese social media management company Socialarks has suffered a huge data leak leading to the exposure of over 400GB of personal data including several high-profile celebrities and social media influencers.
The company’s unsecured ElasticSearch database contained personally identifiable information (PII) from at least 214 million social media users from around the world, using both populist consumer platforms such as Facebook and Instagram, as well as professional networks such as LinkedIn.
The Elastic instance was discovered as part of Safety Detectives’ cybersecurity mission of discovering online vulnerabilities that could potentially pose risks to the general public. Once the owner of the data is identified, our team then informs the affected parties as soon as possible to mitigate the risk of any cybersecurity breaches and server leaks.
In Socialarks’ case, our team found the ElasticSearch server to be publicly exposed without password protection or encryption, during routine IP-address checks on potentially unsecured databases.
The lack of security apparatus on the company’s server meant that anyone in possession of the server IP-address could have accessed a database containing millions of people’s private information.
According to Anurag Sen, head of the Safety Detectives cybersecurity team, the affected database contained a “huge trove” of sensitive personal information to the tune of 408GB and more than 318 million records in total.
Given the sheer size of the data leak, it has been severely challenging for our team to unravel the full extent of the potential damage caused.
Our research team was able to determine that the entirety of the leaked data was “scraped” from social media platforms, which is both unethical and a violation of Facebook’s, Instagram’s and LinkedIn’s terms of service.
Moreover, it is important to note that Socialarks suffered a similar data breach in August 2020 leading to data from 150 million LinkedIn, Facebook and Instagram users being exposed.
Almost as a carbon-copy, August’s database breach revealed reams of personal data from 66 million LinkedIn users, 11.6 million Instagram accounts and 81.5 million Facebook accounts.
From the leaked data we discovered, it was possible to determine people’s full names, country of residence, place of work, position, subscriber data and contact information, as well as direct links to their profiles.
[…]
The database contained more than 408GB of data and more than 318 million records.
Without any protection whatsoever, our research team discovered the following:
11,651,162 Instagram user profiles
66,117,839 LinkedIn user profiles
81,551,567 Facebook user profiles
a further 55,300,000 Facebook profiles which were summarily deleted within a few hours after our team first discovered the server and its vulnerability.
What was surprising, that the numbers of profiles affected in the data leak found by our team are the same as the numbers mentioned in the August data leak. However, there were big differences, such as size of a database, the companies hosting those servers and the amount of indices.
The affected server, hosted by Tencent, was segmented into indices in order to store data obtained from each social media source. Our team discovered records from 3 major social media platforms: Instagram, Facebook and LinkedIn.
Instagram data
The Instagram index contained various popular personalities and online celebrities.
Our team discovered several high-profile influencers in the exposed database, including prominent food bloggers, celebrities and other social media influencers.
Celebrity Instagram profile including phone number and email address.
Every record contained public data scraped from influencer Instagram accounts, including their biographies, profile pictures, follower totals, location settings as well as personal information such as contact details in the form of email addresses and phone numbers.
The Instagram records exposed the following details:
Full name
Phone numbers for 6+ million users
Email addresses for all 11+ million users
Profile link
Username
Profile picture
Profile description
Average comment count
Number of followers and following count
Country of location
Specific locality in some cases
Frequently used hashtags
Facebook data
As mentioned above, the leak exposed 81.5 million Facebook user profiles with over 40 million exposed phone numbers and a further 32 million email address entries. Notably, most of the phone numbers our team discovered originated from pages and not individuals.
The Facebook records exposed the following details:
Full name
‘About’ text
Email addresses
Phone numbers
Country of location
Like, Follow and Rating count
Messenger ID
Facebook link with profile pictures
Website link
Profile description
LinkedIn data
Finally, our team discovered 66.1 million LinkedIn user profiles with as many as 31 million leaked email addresses (not disclosed in the profile but obtained through other, as yet unknown, sources).
The LinkedIn records exposed the following details:
Full name
Email addresses
Job profile including job title and seniority level
LinkedIn profile link
User tags
Domain name
Connected social media account login names e.g., Twitter
Company name and revenue margin
Database search showing 66 million LinkedIn profile results including personal information such as job title, name and email address.
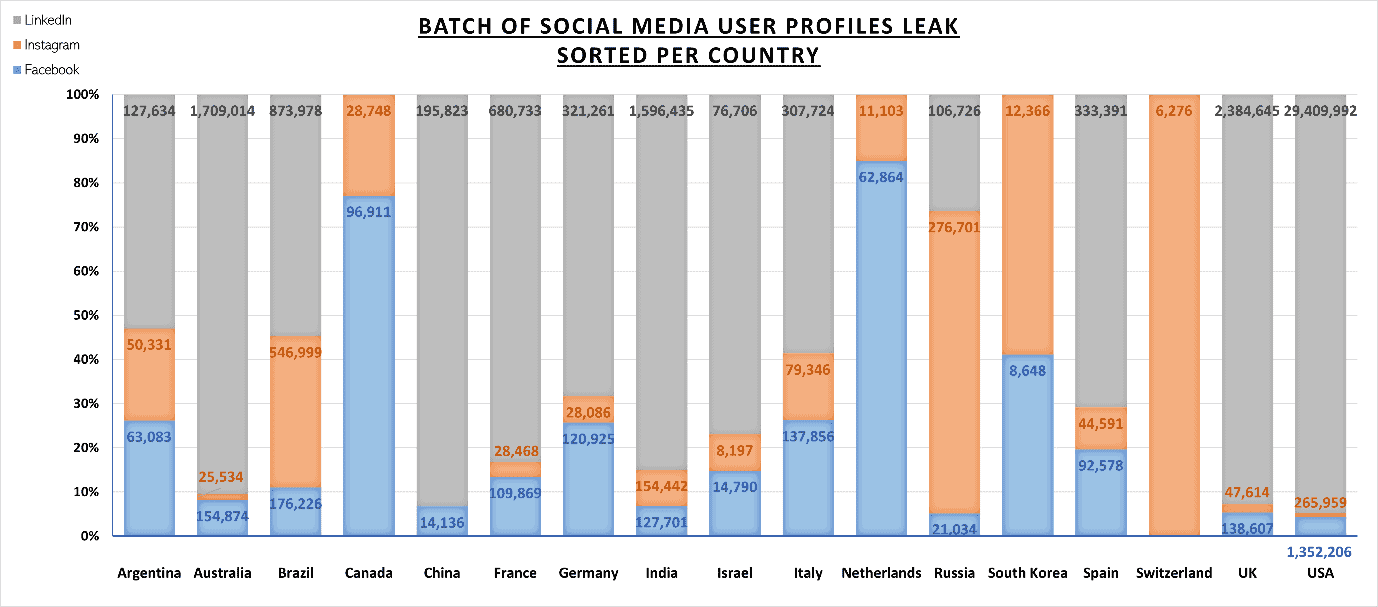
The chart below shows a sample breakdown of user-profiles, sorted by country, from a sample of 42 million records.
Unexplained presence of Instagram and LinkedIn personal data
Socialarks’ database contained scraped data including personal information, albeit user data was partially completed.
However, according to our findings, Socialarks’ database stored personal data for Instagram and LinkedIn users such as private phone numbers and email addresses for users that did not divulge such information publicly on their accounts. How Socialarks could possibly have access to such data in the first place remains unknown.
Also, the fact that such a large, active, and data-rich database was left completely unsecured (probably for a second time) is astonishing.
It remains unclear how the company managed to obtain private data from multiple secure sources.
Instagram profile showing email and phone number despite information not being provided to Instagram.
It is also worth noting that Socialarks is based in China and was founded with private venture capital in 2014, while the vulnerable server is located in Hong Kong.



 forum.xda-developers.com
forum.xda-developers.com