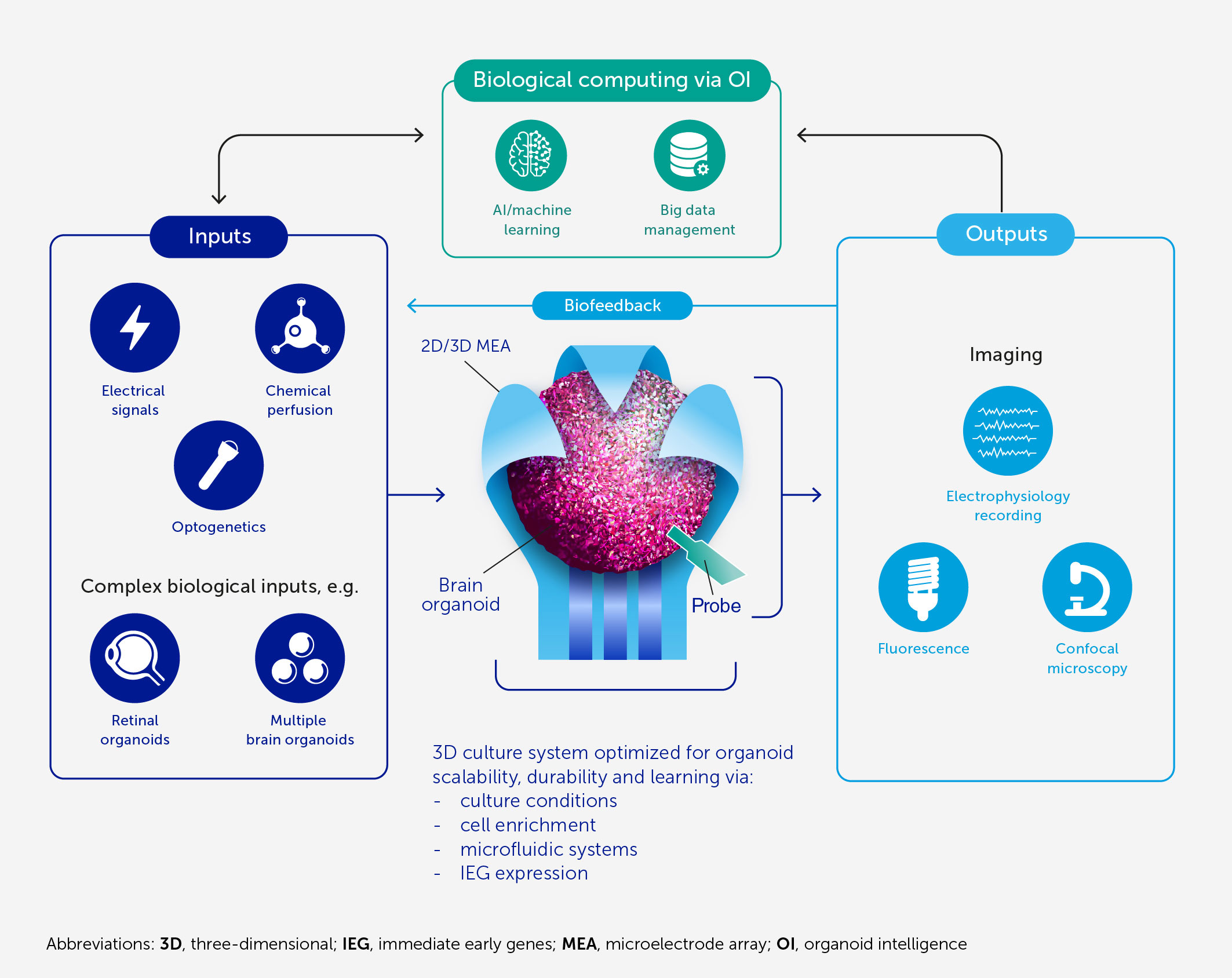
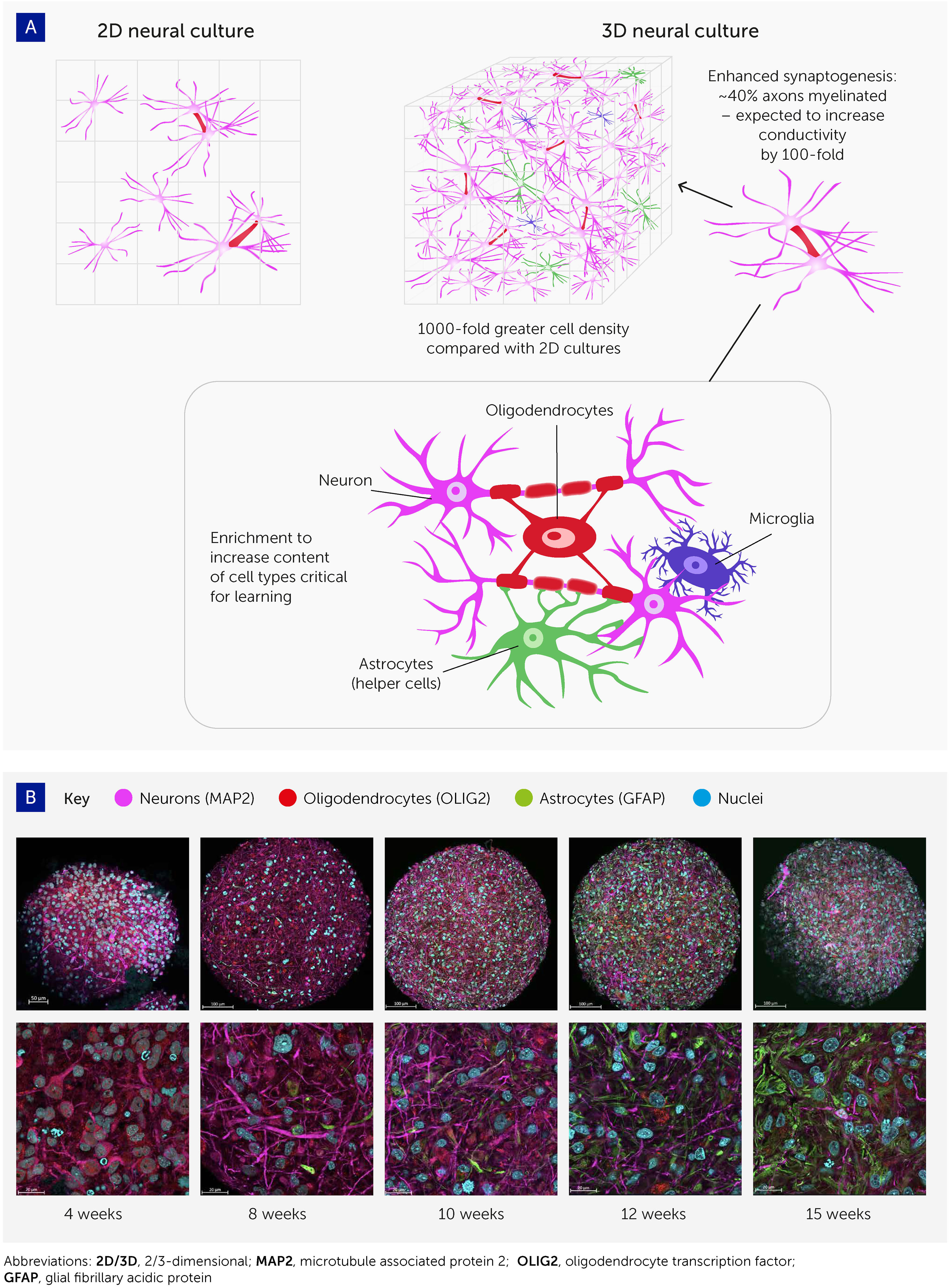
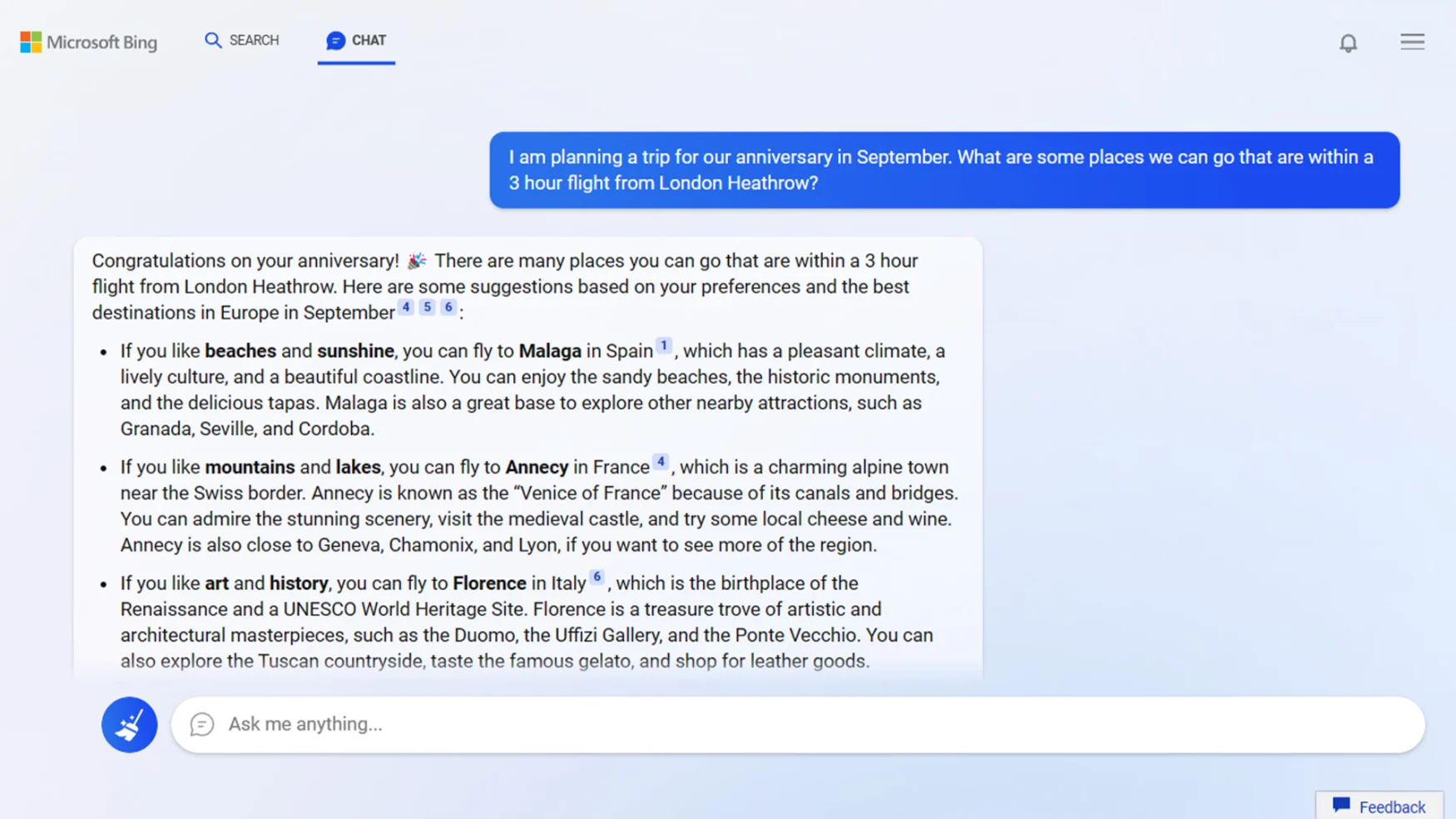
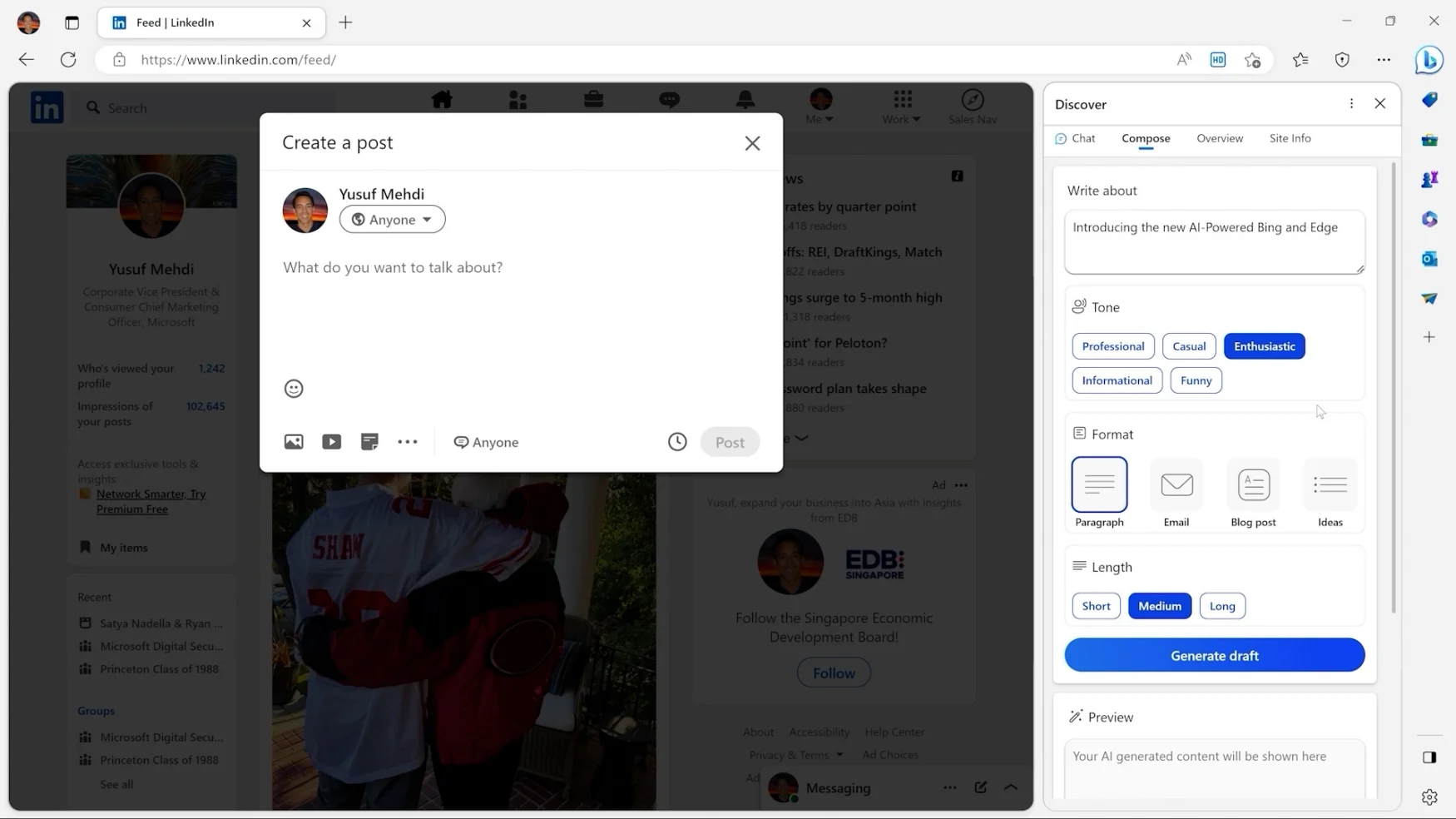
OpenAI, the company behind ChatGPT and DALL-E 2, announced several significant changes today. First, it’s launching developer APIs for ChatGPT and the Whisper speech-transcription model. It also changed its terms of service to let developers opt out of using their data for improvements while adding a 30-day data retention policy.
The new ChatGPT API will use the same AI model (“gpt-3.5-turbo”) as the popular chatbot, allowing developers to add either unchanged or flavored versions of ChatGPT to their apps. Snap’s My AI is an early example, along with a new virtual tutor feature for the online study tool Quizlet and an upcoming Ask Instacart tool in the popular local-shopping app. However, the API won’t be limited to brand-specific bots mimicking ChatGPT; it can also power “non-chat” software experiences that could benefit from AI brains.
The ChatGPT API is priced at $0.002 per 1,000 tokens (about 750 words). Additionally, it’s offering a dedicated-capacity option for deep-pocketed developers who expect to use more tokens than the standard API allows. The new developer options join the consumer-facing ChatGPT Plus, a $20-per-month service launched in February.
Meanwhile, OpenAI’s Whisper API is a hosted version of the open-source Whisper speech-to-text model it launched in September. “We released a model, but that actually was not enough to cause the whole developer ecosystem to build around it,” OpenAI president and co-founder Greg Brockman told TechCrunch on Tuesday. “The Whisper API is the same large model that you can get open source, but we’ve optimized to the extreme. It’s much, much faster and extremely convenient.” The transcription API will cost developers $0.006 per minute, enabling “robust” transcription in multiple languages and providing translation to English.
Finally, OpenAI revealed changes to its developer terms based on customer feedback about privacy and security concerns. Unless a developer opts in, the company will no longer use data submitted through the API for “service improvements” to train its AI models. Additionally, it’s adding a 30-day data retention policy while providing stricter retention options “depending on user needs” (likely meaning high-usage companies with budgets to match). Finally, it’s simplifying its terms surrounding data ownership, clarifying that users own the models’ input and output.
The company will also replace its pre-launch review process for developers with a mostly automated system. OpenAI justified the change by pointing out that “the overwhelming majority of apps were approved during the vetting process,” claiming its monitoring has “significantly improved.” “One of our biggest focuses has been figuring out, how do we become super friendly to developers?” Brockman said to TechCrunch. “Our mission is to really build a platform that others are able to build businesses on top of.”
Source: OpenAI will let developers build ChatGPT into their apps | Engadget