Prostate cancer is one of the most common cancers among men. Patients are determined to have prostate cancer primarily based on PSA, a cancer factor in blood. However, as diagnostic accuracy is as low as 30%, a considerable number of patients undergo additional invasive biopsy and thus suffer from resultant side effects, such as bleeding and pain.The Korea Institute of Science and Technology (KIST) announced that the collaborative research team led by Dr. Kwan Hyi Lee from the Biomaterials Research Center and Professor In Gab Jeong from Asan Medical Center developed a technique for diagnosing prostate cancer from urine within only 20 minutes with almost 100% accuracy. The research team developed this technique by introducing a smart AI analysis method to an electrical-signal-based ultrasensitive biosensor.As a noninvasive method, a diagnostic test using urine is convenient for patients and does not need invasive biopsy, thereby diagnosing cancer without side effects. However, as the concentration of cancer factors is low in urine, urine-based biosensors are only used for classifying risk groups rather than for precise diagnosis thus far.
Everalbum, a consumer photo app maker that shut down on August 31, 2020, and has since relaunched as a facial recognition provider under the name Paravision, on Monday reached a settlement with the FTC over the 2017 introduction of a feature called “Friends” in its discontinued Ever app. The watchdog agency claims the app deployed facial recognition code to organize users’ photos by default, without permission.
According to the FTC, between July 2018 and April 2019, Everalbum told people that it would not employ facial recognition on users’ content without consent. The company allegedly let users in certain regions – Illinois, Texas, Washington, and the EU – make that choice, but automatically activated the feature for those located elsewhere.
The agency further claims that Everalbum’s use of facial recognition went beyond supporting the Friends feature. The company is alleged to have combined users’ faces with facial images from other information to create four datasets that informed its facial recognition technology, which became the basis of a face detection service for enterprise customers.
The company also is said to have told consumers using its app that it would delete their data if they deactivated their accounts, but didn’t do so until at least October 2019.
The FTC, in announcing the case and its settlement, said Everalbum/Paravision will be required to delete: photos and videos belonging to Ever app users who deactivated their accounts; all face embeddings – vector representations of facial features – from users who did not grant consent; and “any facial recognition models or algorithms developed with Ever users’ photos or videos.”
The FTC has not done this in past privacy cases with technology companies. According to FTC Commissioner Rohit Chopra, when Google and YouTube agreed to pay $170m over allegations the companies had collected data from children without parental consent, the FTC settlement “allowed Google and YouTube to profit from its conduct, even after paying a civil penalty.”
Likewise, when the FTC voted to approve a settlement with Facebook over claims it had violated its 2012 privacy settlement agreement, he said, Facebook did not have to give up any of its facial recognition technology or data.
“Commissioners have previously voted to allow data protection law violators to retain algorithms and technologies that derive much of their value from ill-gotten data,” said Chopra in a statement [PDF]. “This is an important course correction.”
with DALL-E (a portmanteau of “Wall-E” and “Dali”), an AI app that can create an image out of nearly any description. For example, if you ask for “a cat made of sushi” or a “high quality illustration of a giraffe turtle chimera,” it will deliver those things, often with startlingly good quality (and sometimes not).DALL-E can create images based on a description of its attributes, like “a pentagonal green clock,” or “a collection of glasses is sitting on a table.” In the latter example, it places both drinking and eye glasses on a table with varying degrees of success.
It can also draw and combine multiple objects and provide different points of view, including cutaways and object interiors. Unlike past text-to-image programs, it even infers details that aren’t mentioned in the description but would be required for a realistic image. For instance, with the description “a painting of a fox sitting in a field during winter,” the agent was able to determine that a shadow was needed.
“Unlike a 3D rendering engine, whose inputs must be specified unambiguously and in complete detail, DALL·E is often able to ‘fill in the blanks’ when the caption implies that the image must contain a certain detail that is not explicitly stated,” according to the OpenAI team.
OpenAI also exploits a capability called “zero-shot reasoning.” This allows an agent to generate an answer from a description and cue without any additional training, and has been used for translation and other chores. This time, the researchers applied it to the visual domain to perform both image-to-image and text-to-image translation. In one example, it was able to generate an image of a cat from a sketch, with the cue “the exact same cat on the top as the sketch on the bottom.”
The system has numerous other talents, like understanding how telephones and other objects change over time, grasping geographic facts and landmarks and creating images in photographic, illustration and even clip-art styles.
For now, DALL-E is pretty limited. Sometimes, it delivers what you expect from the description and other times you just get some weird or crappy images. As with other AI systems, even the researchers themselves don’t understand exactly how it produces certain images due to the black box nature of the system.
Still, if developed further, DALL-E has vast potential to disrupt fields like stock photography and illustration, with all the good and bad that entails. “In the future, we plan to analyze how models like DALL·E relate to societal issues like economic impact on certain work processes and professions, the potential for bias in the model outputs, and the longer term ethical challenges implied by this technology,” the team wrote. To play with DALL-E yourself, check out OpenAI’s blog.
Artificial intelligence is classifying real supernova explosions without the traditional use of spectra, thanks to a team of astronomers at the Center for Astrophysics | Harvard & Smithsonian. The complete data sets and resulting classifications are publicly available for open use.
By training a machine learning model to categorize supernovae based on their visible characteristics, the astronomers were able to classify real data from the Pan-STARRS1 Medium Deep Survey for 2,315 supernovae with an accuracy rate of 82-percent without the use of spectra.
The astronomers developed a software program that classifies different types of supernovae based on their light curves, or how their brightness changes over time. “We have approximately 2,500 supernovae with light curves from the Pan-STARRS1 Medium Deep Survey, and of those, 500 supernovae with spectra that can be used for classification,” said Griffin Hosseinzadeh, a postdoctoral researcher at the CfA and lead author on the first of two papers published in The Astrophysical Journal. “We trained the classifier using those 500 supernovae to classify the remaining supernovae where we were not able to observe the spectrum.”
Edo Berger, an astronomer at the CfA explained that by asking the artificial intelligence to answer specific questions, the results become increasingly more accurate. “The machine learning looks for a correlation with the original 500 spectroscopic labels. We ask it to compare the supernovae in different categories: color, rate of evolution, or brightness. By feeding it real existing knowledge, it leads to the highest accuracy, between 80- and 90-percent.”
Although this is not the first machine learning project for supernovae classification, it is the first time that astronomers have had access to a real data set large enough to train an artificial intelligence-based supernovae classifier, making it possible to create machine learning algorithms without the use of simulations.
[…]
The project has implications not only for archival data, but also for data that will be collected by future telescopes. The Vera C. Rubin Observatory is expected to go online in 2023, and will lead to the discovery of millions of new supernovae each year. This presents both opportunities and challenges for astrophysicists, where limited telescope time leads to limited spectral classifications.
“When the Rubin Observatory goes online it will increase our discovery rate of supernovae by 100-fold, but our spectroscopic resources will not increase,” said Ashley Villar, a Simons Junior Fellow at Columbia University and lead author on the second of the two papers, adding that while roughly 10,000 supernovae are currently discovered each year, scientists only take spectra of about 10-percent of those objects. “If this holds true, it means that only 0.1-percent of supernovae discovered by the Rubin Observatory each year will get a spectroscopic label. The remaining 99.9-percent of data will be unusable without methods like ours.”
Unlike past efforts, where data sets and classifications have been available to only a limited number of astronomers, the data sets from the new machine learning algorithm will be made publicly available. The astronomers have created easy-to-use, accessible software, and also released all of the data from Pan-STARRS1 Medium Deep Survey along with the new classifications for use in other projects. Hosseinzadeh said, “It was really important to us that these projects be useful for the entire supernova community, not just for our group. There are so many projects that can be done with these data that we could never do them all ourselves.” Berger added, “These projects are open data for open science.”
For Star Wars fans, an X-Wing fighter isn’t complete without R2-D2. Whether you need to fire up converters, increase power, or fix a broken stabilizer, that trusty droid, full of lively beeps and squeaks, is the ultimate copilot.
Teaming artificial intelligence (AI) with pilots is no longer just a matter for science fiction or blockbuster movies. On Tuesday, December 15, the Air Force successfully flew an AI copilot on a U-2 spy plane in California: the first time AI has controlled a U.S. military system.
[…]
With call sign ARTUµ, we trained µZero—a world-leading computer program that dominates chess, Go, and even video games without prior knowledge of their rules—to operate a U-2 spy plane. Though lacking those lively beeps and squeaks, ARTUµ surpassed its motion picture namesake in one distinctive feature: it was the mission commander, the final decision authority on the human-machine team
[…]
Our demo flew a reconnaissance mission during a simulated missile strike at Beale Air Force Base on Tuesday. ARTUµ searched for enemy launchers while our pilot searched for threatening aircraft, both sharing the U-2’s radar. With no pilot override, ARTUµ made final calls on devoting the radar to missile hunting versus self-protection. Luke Skywalker certainly never took such orders from his X-Wing sidekick!
[…]
to trust AI, software design is key. Like a breaker box for code, the U-2 gave ARTUµ complete radar control while “switching off” access to other subsystems.
[…]
Like a digital Yoda, our small-but-mighty U-2 FedLab trained µZero’s gaming algorithms to operate a radar—reconstructing them to learn the good side of reconnaissance (enemies found) from the dark side (U-2s lost)—all while interacting with a pilot. Running over a million training simulations at their “digital Dagobah,” they had ARTUµ mission-ready in just over a month.
[…]
That autonomous future will happen eventually. But today’s AI can be easily fooled by adversary tactics, precisely what future warfare will throw at it.
U.S. Air Force Maj. “Vudu”, U-2 Dragon Lady pilot for the 9th Reconnaissance Wing, prepares to taxi after returning from a training sortie at Beale Air Force, California, Dec. 15, 2020.
A1C Luis A.Ruiz-Vazquez
Like board or video games, human pilots could only try outperformingDARPA’s AI while obeying the rules of the dogfighting simulation, rules the AI had algorithmically learned and mastered. The loss is a wakeup call for new digital trickery to outfox machine learning principles themselves. Even R2-D2 confused computer terminals with harmful power sockets!
Loon, known for its giant billowing broadband-beaming balloons, says it has figured out how to use machine-learning algorithms to keep its lofty vehicles hovering in place autonomously in the stratosphere.
The 15-metre-wide balloons relay internet connections between people’s homes and ground stations that could be thousands of kilometres apart. To form a steady network that can route data over long distances reliably, the balloons have to stay in place, and do so all by themselves.
Loon’s AI-based solution to this station-keeping problem has been described in a research paper published in Nature on Wednesday, and basically it works by adjusting the balloons’ altitude to catch the right wind currents to ensure they are where they need to be.
The machine-learning software, we’re told, managed to successfully keep the Loon gas bags bobbing up and down in the skies above in the Pacific Ocean in an experiment that lasted 39 days. Previously, the Loon team used a non-AI controller that used a handcrafted algorithm known as StationSeeker to do the job, though decided to experiment to see whether it could find a more efficient method using machine learning.
“As far as we know, this is the world’s first deployment of reinforcement learning in a production aerospace system,” said Loon CTO Salvatore Candido.
The AI is built out of a feed-forward neural network that learns to decide whether a balloon should fly up or go down by taking into account variables, such as wind speed, solar elevation, and how much power the equipment has left. The decision is then fed to a controller system to move the balloon in place.
By training the model in simulation, the neural network steadily improved over time using reinforcement learning as it repeated the same task over and over again under different scenarios. Loon tested the performance of StationSeeker against the reinforcement learning model in simulation.
“A trial consists of two simulated days of station-keeping at a fixed location, during which controllers receive inputs and emit commands at 3-min intervals,” according to the paper. The performance was then judged by how long the balloons could stay within a 50km radius of a hypothetical ground station.
The AI algorithm scored 55.1 per cent efficiency, compared to 40.5 per cent for StationSeeker. The researchers reckon that the autonomous algorithm is near optimum performance, considering that the best theoretical models reach somewhere between 56.8 to 68.7 per cent.
When Loon and Google ran the controller in the real experiment, which involved a balloon hovering above the Pacific Ocean, they found: “Overall, the [reinforcement learning] system kept balloons in range of the desired location more often while using less power… Using less power to steer the balloon means more power is available to connect people to the internet, information, and other people.”
Researchers have made a major breakthrough using artificial intelligence that could revolutionize the hunt for new medicines.
The scientists have created A.I. software that uses a protein’s DNA sequence to predict its three-dimensional structure to within an atom’s width of accuracy.
The achievement, which solves a 50-year-old challenge in molecular biology, was accomplished by a team from DeepMind, the London-based artificial intelligence company that is part of Google parent Alphabet.
[…]
Across more than 100 proteins, DeepMind’s A.I. software, which it called AlphaFold 2, was able to predict the structure to within about an atom’s width of accuracy in two-thirds of cases and was highly accurate in most of the remaining one-third of cases, according to John Moult, a molecular biologist at the University of Maryland who is director of the competition, called the Critical Assessment of Structure Prediction, or CASP. It was far better than any other method in the competition, he said.
[…]
DeepMind had not yet determined how it would provide academic researchers with access to the protein structure prediction software or whether it would seek commercial collaborations with pharmaceutical and biotechnology firms. He said the company would announce “further details on how we’re going to be able to give access to the system in a scalable way” sometime next year.
“This computational work represents a stunning advance on the protein-folding problem,” Venki Ramakrishnan, a Nobel Prize–winning structural biologist who is also the outgoing president of the Royal Society, Britain’s most prestigious scientific body, said of AlphaFold 2.
Janet Thornton, an expert in protein structure and former director of the European Molecular Biology Laboratory’s European Bioinformatics Institute, said that DeepMind’s breakthrough opened up the way to mapping the entire “human proteome”—the set of all proteins found within the human body. Currently, only about a quarter of human proteins have been used as targets for medicines, she said. Now, many more proteins could be targeted, creating a huge opportunity to invent new medicines.
[…]
As part of CASP’s efforts to verify the capabilities of DeepMind’s system, Lupas used the predictions from AlphaFold 2 to see if it could solve the final portion of a protein’s structure that he had been unable to complete using X-ray crystallography for more than a decade. With the predictions generated by AlphaFold 2, Lupas said he was able to determine the shape of the final protein segment in just half an hour.
AlphaFold 2 has also already been used to accurately predict the structure of a protein called ORF3a that is found in SARS-CoV-2, the virus that causes COVID-19, which scientists might be able to use as a target for future treatments.
Lupas said he thought the A.I. software would “change the game entirely” for those who work on proteins. Currently, DNA sequences are known for about 200 million proteins, and tens of millions more are being discovered every year. But 3D structures have been mapped for less than 200,000 of them.
AlphaFold 2 was only trained to predict the structure of single proteins. But in nature, proteins are often present in complex arrangements with other proteins. Jumper said the next step was to develop an A.I. system that could predict complicated dynamics between proteins—such as how two proteins will bind to one another or the way that proteins in close proximity morph one another’s shapes.
one group of researchers has been focused on what autonomous driving systems might see that a human driver doesn’t—including “phantom” objects and signs that aren’t really there, which could wreak havoc on the road.
Researchers at Israel’s Ben Gurion University of the Negev have spent the last two years experimenting with those “phantom” images to trick semi-autonomous driving systems. They previously revealed that they could use split-second light projections on roads to successfully trick Tesla’s driver-assistance systems into automatically stopping without warning when its camera sees spoofed images of road signs or pedestrians. In new research, they’ve found they can pull off the same trick with just a few frames of a road sign injected on a billboard’s video
[…]
“The driver won’t even notice at all. So somebody’s car will just react, and they won’t understand why.”
In their first round of research, published earlier this year, the team projected images of human figures onto a road, as well as road signs onto trees and other surfaces. They found that at night, when the projections were visible, they could fool both a Tesla Model X running the HW2.5 Autopilot driver-assistance system—the most recent version available at the time, now the second-most-recent —and a Mobileye 630 device. They managed to make a Tesla stop for a phantom pedestrian that appeared for a fraction of a second, and tricked the Mobileye device into communicating the incorrect speed limit to the driver with a projected road sign.
In this latest set of experiments, the researchers injected frames of a phantom stop sign on digital billboards, simulating what they describe as a scenario in which someone hacked into a roadside billboard to alter its video. They also upgraded to Tesla’s most recent version of Autopilot known as HW3.
[…]
an image that appeared for 0.42 seconds would reliably trick the Tesla, while one that appeared for just an eighth of a second would fool the Mobileye device. They also experimented with finding spots in a video frame that would attract the least notice from a human eye, going so far as to develop their own algorithm for identifying key blocks of pixels in an image so that a half-second phantom road sign could be slipped into the “uninteresting” portions.
Researchers at Google claim to have developed a machine learning model that can separate a sound source from noisy, single-channel audio based on only a short sample of the target source. In a paper, they say their SoundFilter system can be tuned to filter arbitrary sound sources, even those it hasn’t seen during training.
The researchers believe a noise-eliminating system like SoundFilter could be used to create a range of useful technologies. For instance, Google drew on audio from thousands of its own meetings and YouTube videos to train the noise-canceling algorithm in Google Meet. Meanwhile, a team of Carnegie Mellon researchers created a “sound-action-vision” corpus to anticipate where objects will move when subjected to physical force.
SoundFilter treats the task of sound separation as a one-shot learning problem. The model receives as input the audio mixture to be filtered and a single short example of the kind of sound to be filtered out. Once trained, SoundFilter is expected to extract this kind of sound from the mixture if present.
Training OpenAI’s giant GPT-3 text-generating model is akin to driving a car to the Moon and back, computer scientists reckon.
More specifically, they estimated teaching the neural super-network in a Microsoft data center using Nvidia GPUs required roughly 190,000 kWh, which using the average carbon intensity of America would have produced 85,000 kg of CO2 equivalents, the same amount produced by a new car in Europe driving 700,000 km, or 435,000 miles, which is about twice the distance between Earth and the Moon, some 480,000 miles. Phew.
This assumes the data-center used to train GPT-3 was fully reliant on fossil fuels, which may not be true. The point, from what we can tell, is not that GPT-3 and its Azure cloud in particular have this exact scale of carbon footprint, it’s to draw attention to the large amount of energy required to train state-of-the-art neural networks.
The eggheads who produced this guesstimate are based at the University of Copenhagen in Denmark, and are also behind an open-source tool called Carbontracker, which aims to predict the carbon footprint of AI algorithms. Lasse Wolff Anthony, one of Carbontracker’s creators and co-author of a study of the subject of AI power usage, believes this drain on resources is something the community should start thinking about now, as the energy costs of AI have risen 300,000-fold between 2012 and 2018, it is claimed.
Unless you’re a physicist or an engineer, there really isn’t much reason for you to know about partial differential equations. I know. After years of poring over them in undergrad while studying mechanical engineering, I’ve never used them since in the real world.
But partial differential equations, or PDEs, are also kind of magical. They’re a category of math equations that are really good at describing change over space and time, and thus very handy for describing the physical phenomena in our universe. They can be used to model everything from planetary orbits to plate tectonics to the air turbulence that disturbs a flight, which in turn allows us to do practical things like predict seismic activity and design safe planes.
The catch is PDEs are notoriously hard to solve. And here, the meaning of “solve” is perhaps best illustrated by an example. Say you are trying to simulate air turbulence to test a new plane design. There is a known PDE called Navier-Stokes that is used to describe the motion of any fluid. “Solving” Navier-Stokes allows you to take a snapshot of the air’s motion (a.k.a. wind conditions) at any point in time and model how it will continue to move, or how it was moving before.
These calculations are highly complex and computationally intensive, which is why disciplines that use a lot of PDEs often rely on supercomputers to do the math. It’s also why the AI field has taken a special interest in these equations. If we could use deep learning to speed up the process of solving them, it could do a whole lot of good for scientific inquiry and engineering.
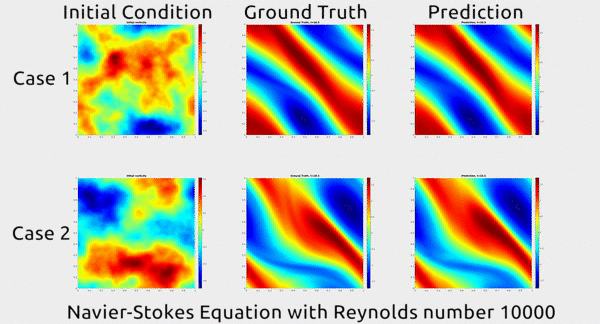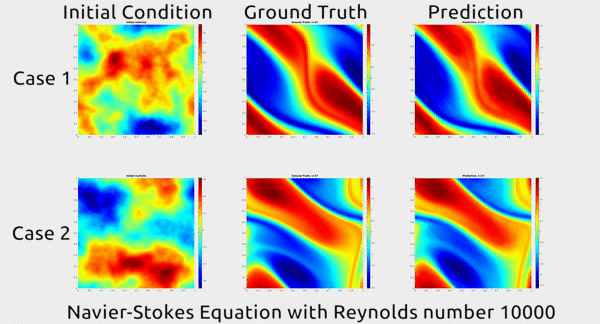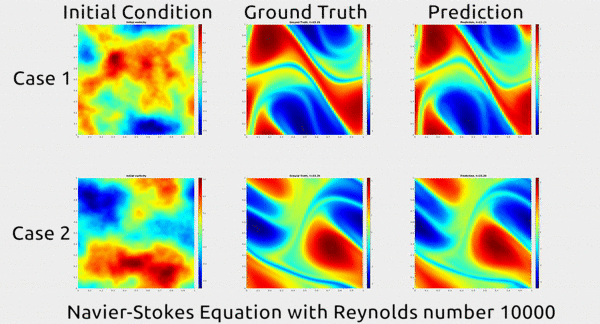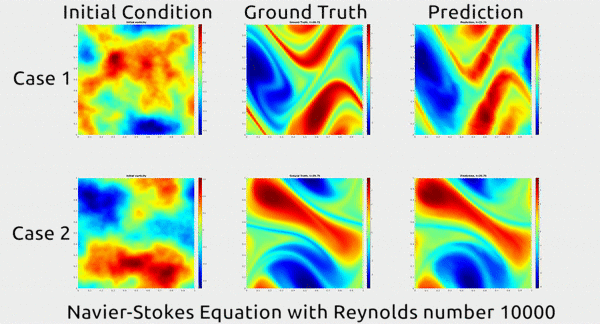
Now researchers at Caltech have introduced a new deep-learning technique for solving PDEs that is dramatically more accurate than deep-learning methods developed previously. It’s also much more generalizable, capable of solving entire families of PDEs—such as the Navier-Stokes equation for any type of fluid—without needing retraining. Finally, it is 1,000 times faster than traditional mathematical formulas, which would ease our reliance on supercomputers and increase our computational capacity to model even bigger problems. That’s right. Bring it on.
Hammer time
Before we dive into how the researchers did this, let’s first appreciate the results. In the gif below, you can see an impressive demonstration. The first column shows two snapshots of a fluid’s motion; the second shows how the fluid continued to move in real life; and the third shows how the neural network predicted the fluid would move. It basically looks identical to the second.
Neural networks are usually trained to approximate functions between inputs and outputs defined in Euclidean space, your classic graph with x, y, and z axes. But this time, the researchers decided to define the inputs and outputs in Fourier space, which is a special type of graph for plotting wave frequencies. The intuition that they drew upon from work in other fields is that something like the motion of air can actually be described as a combination of wave frequencies, says Anima Anandkumar, a Caltech professor who oversaw the research alongside her colleagues, professors Andrew Stuart and Kaushik Bhattacharya. The general direction of the wind at a macro level is like a low frequency with very long, lethargic waves, while the little eddies that form at the micro level are like high frequencies with very short and rapid ones.
Why does this matter? Because it’s far easier to approximate a Fourier function in Fourier space than to wrangle with PDEs in Euclidean space, which greatly simplifies the neural network’s job. Cue major accuracy and efficiency gains: in addition to its huge speed advantage over traditional methods, their technique achieves a 30% lower error rate when solving Navier-Stokes than previous deep-learning methods.
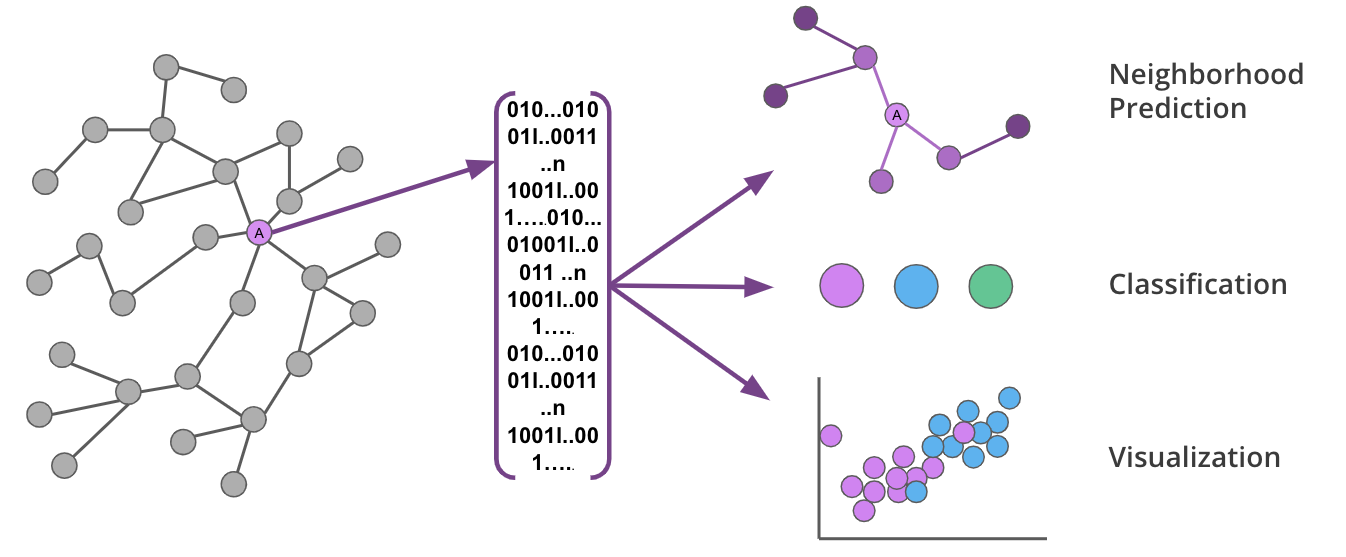
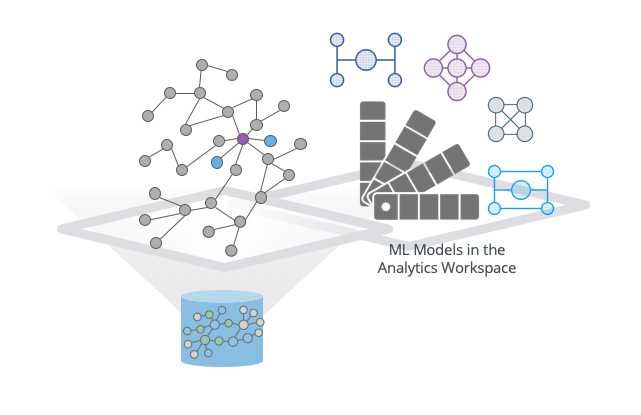
We’re delighted to announce you can now take advantage of graph-native machine learning (ML) inside of Neo4j! We’ve just released a preview of Neo4j’s Graph Data Science™ Library version 1.4, which includes graph embeddings and an ML model catalog.
Together, these enable you to create representations of your graph and make graph predictions – all within Neo4j.
[…]
Graph Embeddings
The graph embedding algorithms are the star of the show in this release.
These algorithms are used to transform the topology and features of your graph into fixed-length vectors (or embeddings) that uniquely represent each node.
Graph embeddings are powerful, because they preserve the key features of the graph while reducing dimensionality in a way that can be decoded. This means you can capture the complexity and structure of your graph and transform it for use in various ML predictions.
Graph embeddings capture the nuances of graphs in a way that can be used to make predictions or lower dimensional visualizations.
In this release, we are offering three embedding options that learn the graph topology and, in some cases, node properties to calculate more accurate representations:
This is probably the most well-known graph embedding algorithm. It uses random walks to sample a graph, and a neural network to learn the best representation of each node.
A more recent graph embedding algorithm that uses linear algebra to project a graph into lower dimensional space. In GDS 1.4, we’ve extended the original implementation to support node features and directionality as well.
FastRP is up to 75,000 times faster than Node2Vec, while providing equivalent accuracy!
This is an embedding technique using inductive representation learning on graphs, via graph convolutional neural networks, where the graph is sampled to learn a function that can predict embeddings (rather than learning embeddings directly). This means you can learn on a subset of your graph and use that representative function for new data and make continuous predictions as your graph updates. (Wow!)
If you’d like a deeper dive into how it works, check out the GraphSAGE session from the NODES event.
Graph embeddings available in the Neo4j Graph Data Science Library v1.4 . The caution marks indicate that, while directions are supported, our internal benchmarks don’t show performance improvements.
Graph ML Model Catalog
GraphSAGE trains a model to predict node embeddings for unseen parts of the graph, or new data as mentioned above.
To really capitalize on what GraphSAGE can do, we needed to add a catalog to be able to store and reference these predictive models. This model catalog lives in the Neo4j analytics workspace and contains versioning information (what data was this trained on?), time stamps and, of course, the model names.
When you want to use a model, you can provide the name of the model to GraphSAGE, along with the named graph you want to apply it to.
GraphSAGE ML Models are stored in the Neo4j analytics workspace.
Back in January, Google Health, the branch of Google focused on health-related research, clinical tools, and partnerships for health care services, released an AI model trained on over 90,000 mammogram X-rays that the company said achieved better results than human radiologists. Google claimed that the algorithm could recognize more false negatives — the kind of images that look normal but contain breast cancer — than previous work, but some clinicians, data scientists, and engineers take issue with that statement. In a rebuttal published today in the journal Nature, over 19 coauthors affiliated with McGill University, the City University of New York (CUNY), Harvard University, and Stanford University said that the lack of detailed methods and code in Google’s research “undermines its scientific value.”
Science in general has a reproducibility problem — a 2016 poll of 1,500 scientists reported that 70% of them had tried but failed to reproduce at least one other scientist’s experiment — but it’s particularly acute in the AI field. At ICML 2019, 30% of authors failed to submit their code with their papers by the start of the conference. Studies often provide benchmark results in lieu of source code, which becomes problematic when the thoroughness of the benchmarks comes into question. One recent report found that 60% to 70% of answers given by natural language processing models were embedded somewhere in the benchmark training sets, indicating that the models were often simply memorizing answers. Another study — a meta-analysis of over 3,000 AI papers — found that metrics used to benchmark AI and machine learning models tended to be inconsistent, irregularly tracked, and not particularly informative.
In their rebuttal, the coauthors of the Nature commentary point out that Google’s breast cancer model research lacks details, including a description of model development as well as the data processing and training pipelines used. Google omitted the definition of several hyperparameters for the model’s architecture (the variables used by the model to make diagnostic predictions), and it also didn’t disclose the variables used to augment the dataset on which the model was trained. This could “significantly” affect performance, the Nature coauthors claim; for instance, it’s possible that one of the data augmentations Google used resulted in multiple instances of the same patient, biasing the final results.
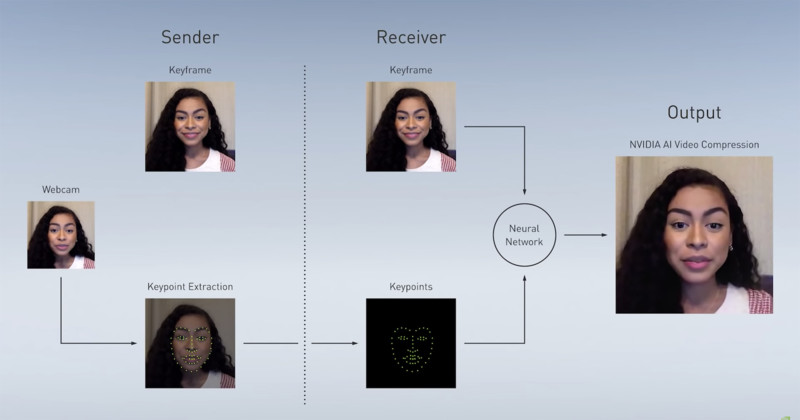
NVIDIA Research has invented a way to use AI to dramatically reduce video call bandwidth while simultaneously improving quality.
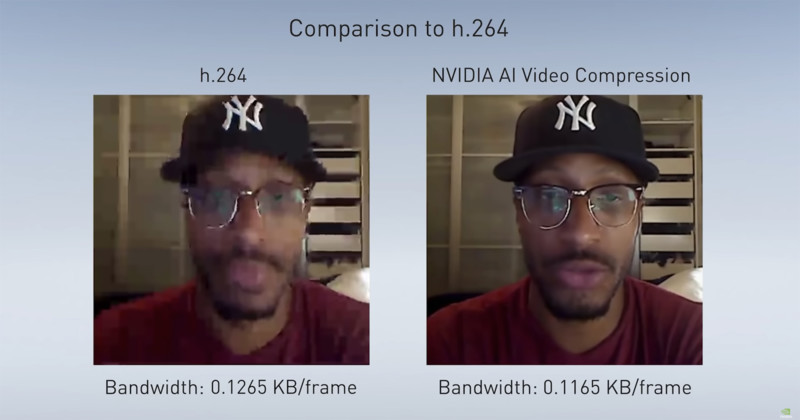
What the researchers have achieved has remarkable results: by replacing the traditional h.264 video codec with a neural network, they have managed to reduce the required bandwidth for a video call by an order of magnitude. In one example, the required data rate fell from 97.28 KB/frame to a measly 0.1165 KB/frame – a reduction to 0.1% of required bandwidth.
The mechanism behind AI-assisted video conferencing is breathtakingly simple. The technology works by replacing traditional full video frames with neural data. Typically, video calls work by sending h.264 encoded frames to the recipient, and those frames are extremely data-heavy. With AI-assisted video calls, first, the sender sends a reference image of the caller. Then, instead of sending a stream of pixel-packed images, it sends specific reference points on the image around the eyes, nose, and mouth.
A generative adversarial network (or GAN, a type of neural network) on the receiver side then uses the reference image combined with the keypoints to reconstruct subsequent images. Because the keypoints are so much smaller than full pixel images, much less data is sent and therefore an internet connection can be much slower but still provide a clear and functional video chat.
In the researchers’ initial example, they show that a fast internet connection results in pretty much the same quality of stream using both the traditional method and the new neural network method. But what’s most impressive is their subsequent examples, where internet speeds show a considerable degradation of quality using the traditional method, while the neural network is able to produce extremely clear and artifact-free video feeds.
The neural network can work even when the subject is wearing a mask, glasses, headphones, or a hat.
With this technology, more people can enjoy a greater number of features all while using monumentally less data.
But the technology use cases don’t stop there: because the neural network is using reference data instead of the full stream, the technology will allow someone to even change the camera angle to appear like they are looking directly at the screen even if they are not. Called “Free View,” this would allow someone who has a separate camera off-screen to seemingly keep eye contact with those on a video call.
NVIDIA can also use this same method for character animations. Using different keypoints from the original feed, they can add clothing, hair, or even animate video game characters.
Using this kind of neural network will have huge implications for the modern workforce that will not only serve to relieve strain on networks, but also give users more freedom when working remotely. However, because of the way this technology works, there will almost certainly be questions on how it can be deployed and lead to possible issues with “deep fakes” that become more believable and harder to detect.
The Jetson Nano 2GB Developer Kit, announced this week, is a single-board computer – like the Raspberry Pi – though geared towards machine learning rather than general computing. If you like the idea of simple AI projects running on a dedicated board, such as building your own mini self-driving car or an object-recognition system for your home, this one might be for you.
It runs Nvidia CUDA code and provides a Linux-based environment. At only $59 a pop, it’s pretty cheap and a nifty bit of hardware if you’re just dipping your toes in deep learning. As its name suggests, it has 2GB of RAM, plus four Arm Cortex-A57 CPU cores clocked at 1.43GHz and a 128-core Nvidia Maxwell GPU. There are other bits and pieces like gigabit Ethernet, HDMI output, a microSD slot for storage, USB interfaces, GPIO and UART pins, Wi-Fi depending on you region, and more.
“While today’s students and engineers are programming computers, in the near future they’ll be interacting with, and imparting AI to, robots,” said Deepu Talla, vice president and general manager of Edge Computing at Nvidia. “The new Jetson Nano is the ultimate starter AI computer that allows hands-on learning and experimentation at an incredibly affordable price.”
In the endlessly escalating war between those striving to create flawless deepfake videos and those developing automated tools that make them easy to spot, the latter camp has found a very clever way to expose videos that have been digitally modified by looking for literal signs of life: a person’s heartbeat.
If you’ve ever had a doctor attach a pulse oximeter to the tip of your finger, then you’ve already experienced a technique known as photoplethysmography where subtle color shifts in your skin as blood is pumped through in waves allows your pulse to be measured. It’s the same technique that the Apple Watch and wearable fitness tracking devices use to measure your heartbeat during exercise, but it’s not just limited to your fingertips and wrists.
Though not apparent to the naked eye, the color of your face exhibits the same phenomenon, subtly shifting in color as your heart endlessly pumps blood through the arteries and veins under your skin, and even a basic webcam can be used to spot the effect and even measure your pulse. The technique has allowed for the development of contactless monitors for infants, simply requiring a non-obtrusive camera to be pointed at them while they sleep, but now is being leveraged to root out fake news.
Researchers from Binghamton University in Binghamton, New York, worked with Intel to develop a tool called FakeCatcher, and their findings were recently published in a paper titled, “FakeCatcher: Detection of Synthetic Portrait Videos using Biological Signals.” Deepfakes are typically created by matching individual frames of a video to a library of headshots, often times containing thousands of images of a particular person, and then subtly adjusting and tweaking the face being swapped in to match the existing one perfectly. Unbeknownst to the naked eye, those images still contain the telltale biological signs of the person having a pulse, but the machine learning tools used to create deepfakes don’t take into account that when the final video is played back, the moving face should still exhibit a measurable pulse. The random way in which a deepfake video is created results in an unstable pulse measurement when photoplethysmography detection techniques are applied to it, making them easier to spot.
From their testing, the researchers found that FakeCatcher was not only able to spot deepfake videos more than 90 percent of the time, but with the same amount of accuracy, it was also able to determine which of four different deepfake tools—Face2Face, NeuralTex, DeepFakes, or FaceSwap—was used to create the deceptive video. Of course, now that the research and the existence of the FakeCatcher tool has been revealed, it will give those developing the deepfake creation tools the opportunity to improve their own software and to ensure that as a deepfake videos are being created, those subtle shifts in skin color are included to fool photoplethysmography tools as well. But this is good while it lasts.
Microsoft has bagged exclusive rights to use OpenAI’s GPT-3 technology, allowing the Windows giant to embed the powerful text-generating machine-learning model into its own products.
“Today, I’m very excited to announce that Microsoft is teaming up with OpenAI to exclusively license GPT-3, allowing us to leverage its technical innovations to develop and deliver advanced AI solutions for our customers, as well as create new solutions that harness the amazing power of advanced natural language generation,” Microsoft CTO Kevin Scott said on Tuesday.
Right now, GPT-3 is only available to a few teams hand picked by OpenAI. The general-purpose text-in-text-out tool is accessible via an Azure-hosted API, and is being used by, for instance, Reddit to develop automated content moderation algorithms, and by academics investigating how the language model could be used to spread spam and misinformation at a scale so large it would be difficult to filter out.
GPT-3 won’t be available on Google Cloud, Amazon Web Services etc
Microsoft has been cosying up to OpenAI for a while; it last year pledged to invest $1bn in the San Francisco-based startup. As part of that deal, OpenAI got access to Microsoft’s cloud empire to run its experiments, and Microsoft was named its “preferred partner” for commercial products. Due to the exclusive license now brokered, GPT-3 won’t be available on rival cloud services, such as Google Cloud and Amazon Web Services.
[…]
GPT-3 is a massive model containing 175 billion parameters, and was trained on all manner of text scraped from the internet. It’s able to perform all sorts of tasks, including answering questions, translating languages, writing prose, performing simple arithmetic, and even attempting code generation. Although impressive, it remains to be seen if it can be utilized in products for the masses rather than being an object of curiosity.
The European Laboratory for Learning and Intelligent Systems (ELLIS) is officially launching its 30 ELLIS research units on Tuesday, September 15. Since the first 17 units were announced in December 2019, the ELLIS initiative has gained significant momentum, adding another 13 units at top research institutions across Europe. To highlight this rapid progress toward securing the future of European AI research, each unit will be presenting its research focus. While an in-person launch was initially planned in spring at the Royal Society in London, the event was postponed as a result of the global COVID-19 pandemic and will now take place online. The event will be will be open to the general public via livestreaming. A detailed agenda and the YouTube link will be posted shortly.
A detailed agenda and the YouTube link can be found here.
TikTok Wednesday revealed some of the elusive workings of the prized algorithm that keeps hundreds of millions of users worldwide hooked on the viral video app.
[…]
TikTok’s algorithm uses machine learning to determine what content a user is most likely to engage with and serve them more of it, by finding videos that are similar or that are liked by people with similar user preferences.
When users open TikTok for the first time, they are shown 8 popular videos featuring different trends, music, and topics. After that, the algorithm will continue to serve the user new iterations of 8 videos based on which videos the user engages with and what the user does.
The algorithm identifies similar videos to those that have engaged a user based on video information, which could include details like captions, hashtags or sounds. Recommendations also take into account user device and account settings, which include data like language preference, country setting, and device type.
Once TikTok collects enough data about the user, the app is able to map a user’s preferences in relation to similar users and group them into “clusters.” Simultaneously, it also groups videos into “clusters” based on similar themes, like “basketball” or “bunnies.”
Using machine learning, the algorithm serves videos to users based on their proximity to other clusters of users and content that they like.
TikTok’s logic aims to avoid redundancies that could bore the user, like seeing multiple videos with the same music or from the same creator.
Yes, but: TikTok concedes that its ability to nail users’ preferences so effectively means that its algorithm can produce “filter bubbles,” reinforcing users’ existing preferences rather than showing them more varied content, widening their horizons, or offering them opposing viewpoints.
The company says that it’s studying filter bubbles, including how long they last and how a user encounters them, to get better at breaking them when necessary.
Since filter bubbles can reinforce conspiracy theories, hoaxes and other misinformation, TikTok’s product and policy teams study which accounts and video information — themes, hashtags, captions, and so on — might be linked to misinformation.
Videos or creators linked to misinformation are sent to the company’s global content reviewers so they can be managed before they are distributed to users on the main feed, which is called the “For You” page.
The briefing also featured updates about TikTok’s data, privacy and security practices.
The company says it tries to triage and prevent incidents on its platform before they happen by working to detect patterns of problems before they spread.
TikTok’s chief security officer, Roland Cloutier, said it plans to hire more than 100 data, security and privacy experts by year’s end in the U.S.
He also said that the company will be building a monitoring, response and investigative response center in Washington D.C. to actively detect and respond to critical incidents in real time.
The big picture: Beckerman says that TikTok’s transparency efforts are meant to position the company as a leader in Silicon Valley.
“We want to take a leadership position and show more about how the app works,” he said. “For us, we’re new, and we want to do this because we don’t have anything to hide. The more we’re talking to and meeting with lawmakers, the more comfortable they are with the product. That’s the way it should be.”
Simmons, who is a history professor herself. Then, Lazare clarified that he’d received his grade less than a second after submitting his answers. A teacher couldn’t have read his response in that time, Simmons knew — her son was being graded by an algorithm.
Simmons watched Lazare complete more assignments. She looked at the correct answers, which Edgenuity revealed at the end. She surmised that Edgenuity’s AI was scanning for specific keywords that it expected to see in students’ answers. And she decided to game it.
[…]
Now, for every short-answer question, Lazare writes two long sentences followed by a disjointed list of keywords — anything that seems relevant to the question. “The questions are things like… ‘What was the advantage of Constantinople’s location for the power of the Byzantine empire,’” Simmons says. “So you go through, okay, what are the possible keywords that are associated with this? Wealth, caravan, ship, India, China, Middle East, he just threw all of those words in.”
“I wanted to game it because I felt like it was an easy way to get a good grade,” Lazare told The Verge. He usually digs the keywords out of the article or video the question is based on.
Apparently, that “word salad” is enough to get a perfect grade on any short-answer question in an Edgenuity test.
Edgenuity didn’t respond to repeated requests for comment, but the company’s online help center suggests this may be by design. According to the website, answers to certain questions receive 0% if they include no keywords, and 100% if they include at least one. Other questions earn a certain percentage based on the number of keywords included.
[…]
One student, who told me he wouldn’t have passed his Algebra 2 class without the exploit, said he’s been able to find lists of the exact keywords or sample answers that his short-answer questions are looking for — he says you can find them online “nine times out of ten.” Rather than listing out the terms he finds, though, he tried to work three into each of his answers. (“Any good cheater doesn’t aim for a perfect score,” he explained.)
The U.S. Department of Defense (DoD) has invested in the development of technologies that allow the human brain to communicate directly with machines, including the development of implantable neural interfaces able to transfer data between the human brain and the digital world. This technology, known as brain-computer interface (BCI), may eventually be used to monitor a soldier’s cognitive workload, control a drone swarm, or link with a prosthetic, among other examples. Further technological advances could support human-machine decisionmaking, human-to-human communication, system control, performance enhancement and monitoring, and training. However, numerous policy, safety, legal, and ethical issues should be evaluated before the technology is widely deployed. With this report, the authors developed a methodology for studying potential applications for emerging technology. This included developing a national security game to explore the use of BCI in combat scenarios; convening experts in military operations, human performance, and neurology to explore how the technology might affect military tactics, which aspects may be most beneficial, and which aspects might present risks; and offering recommendations to policymakers. The research assessed current and potential BCI applications for the military to ensure that the technology responds to actual needs, practical realities, and legal and ethical considerations.
Visa Inc. said Wednesday it has developed a more advanced artificial intelligence system that can approve or decline credit and debit transactions on behalf of banks whose own networks are down.
The decision to approve or deny a transaction typically is made by the bank. But bank networks can crash because of natural disasters, buggy software or other reasons. Visa said its backup system will be available to banks who sign up for the service starting in October.
The technology is “an incredible first step in helping us reduce the impact of an outage,” said Rajat Taneja, president of technology for Visa. The financial services company is the largest U.S. card network, as measured both by the number of cards in circulation and by transactions.
The new service reflects the growing use of AI in banking. Banks are expected to spend $7.1 billion on AI in 2020, growing to $14.5 billion by 2024, on initiatives such as fraud analysis and investigation, according to market research firm International Data Corp.
The service, Smarter Stand-In Processing, uses a branch of AI called deep learning
[…]
Smarter STIP kicks in automatically if Visa’s network detects that the bank’s network is offline or unavailable.
The older version of STIP uses a rules-based machine learning model as the backup method to manage transactions for banks in the event of a network disruption. In this approach, Visa’s product team and the financial institution define the rules for the model to be able to determine whether a particular transaction should be approved.
“Although it was customized for different users, it was still not very precise,” said Carolina Barcenas, senior vice president and head of Visa Research.
Technologists don’t define rules for the Smarter STIP AI model. The new deep-learning model is more advanced because it is trained to sift through billions of data points of cardholder activity to define correlations on its own.
[…]
In tests, the deep-learning AI model was 95% accurate in mimicking the bank’s decision on whether to approve or decline a transaction, she said. The technology more than doubled the accuracy of the old method, according to the company. The two versions will continue to exist but the more advanced version will be available as a premium service for clients.
AI’s growing catalog of applications and methods has the potential to profoundly affect public policy by generating instances where regulations are not adequate to confront the issues faced by society, also known as regulatory gaps.
The objective of this dissertation is to improve our understanding of how AI influences U.S. public policy. It systematically explores, for the first time, the role of AI in the generation of regulatory gaps. Specifically, it addresses two research questions:
What U.S. regulatory gaps exist due to AI methods and applications?
When looking across all of the gaps identified in the first research question, what trends and insights emerge that can help stakeholders plan for the future?
These questions are answered through a systematic review of four academic databases of literature in the hard and social sciences. Its implementation was guided by a protocol that initially identified 5,240 candidate articles. A screening process reduced this sample to 241 articles (published between 1976 and February of 2018) relevant to answering the research questions.
This dissertation contributes to the literature by adapting the work of Bennett-Moses and Calo to effectively characterize regulatory gaps caused by AI in the U.S. In addition, it finds that most gaps: do not require new regulation or the creation of governance frameworks for their resolution, are found at the federal and state levels of government, and AI applications are recognized more often than methods as their cause.
The minute details of rogue drone’s movements in the air may unwittingly reveal the drone pilot’s location—possibly enabling authorities to bring the drone down before, say, it has the opportunity to disrupt air traffic or cause an accident. And it’s possible without requiring expensive arrays of radio triangulation and signal-location antennas.
So says a team of Israeli researchers who have trained an AI drone-tracking algorithm to reveal the drone operator’s whereabouts, with a better than 80 per cent accuracy level. They are now investigating whether the algorithm can also uncover the pilot’s level of expertise and even possibly their identity.
[…]
Depending on the specific terrain at any given airport, a pilot operating a drone near a camouflaging patch of forest, for instance, might have an unobstructed view of the runway. But that location might also be a long distance away, possibly making the operator more prone to errors in precise tracking of the drone. Whereas a pilot operating nearer to the runway may not make those same tracking errors but may also have to contend with big blind spots because of their proximity to, say, a parking garage or control tower.
And in every case, he said, simple geometry could begin to reveal important clues about a pilot’s location, too. When a drone is far enough away, motion along a pilot’s line of sight can be harder for the pilot to detect than motion perpendicular to their line of sight. This also could become a significant factor in an AI algorithm working to discover pilot location from a particular drone flight pattern.
The sum total of these various terrain-specific and terrain-agnostic effects, then, could be a giant finger pointing to the operator. This AI application would also be unaffected by any relay towers or other signal spoofing mechanisms the pilot may have put in place.
Weiss said his group tested their drone tracking algorithm using Microsoft Research’s open source drone and autonomous vehicle simulator AirSim. The group presented their work-in-progress at the Fourth International Symposium on Cyber Security, Cryptology and Machine Learning at Ben-Gurion University earlier this month.
Their paper boasts a 73 per cent accuracy rate in discovering drone pilots’ locations. Weiss said that in the few weeks since publishing that result, they’ve now improved the accuracy rate to 83 per cent.
Now that the researchers have proved the algorithm’s concept, Weiss said, they’re hoping next to test it in real-world airport settings. “I’ve already been approached by people who have the flight permissions,” he said. “I am a university professor. I’m not a trained pilot. Now people that do have the facility to fly drones [can] run this physical experiment.”
Space seems empty and therefore the perfect environment for radio communications. Don’t let that fool you: There’s still plenty that can disrupt radio communications. Earth’s fluctuating ionosphere can impair a link between a satellite and a ground station. The materials of the antenna can be distorted as it heats and cools. And the near-vacuum of space is filled with low-level ambient radio emanations, known as cosmic noise, which come from distant quasars, the sun, and the center of our Milky Way galaxy. This noise also includes the cosmic microwave background radiation, a ghost of the big bang. Although faint, these cosmic sources can overwhelm a wireless signal over interplanetary distances.
Depending on a spacecraft’s mission, or even the particular phase of the mission, different link qualities may be desirable, such as maximizing data throughput, minimizing power usage, or ensuring that certain critical data gets through. To maintain connectivity, the communications system constantly needs to tailor its operations to the surrounding environment.
Imagine a group of astronauts on Mars. To connect to a ground station on Earth, they’ll rely on a relay satellite orbiting Mars. As the space environment changes and the planets move relative to one another, the radio settings on the ground station, the satellite orbiting Mars, and the Martian lander will need continual adjustments. The astronauts could wait 8 to 40 minutes—the duration of a round trip—for instructions from mission control on how to adjust the settings. A better alternative is to have the radios use neural networks to adjust their settings in real time. Neural networks maintain and optimize a radio’s ability to keep in contact, even under extreme conditions such as Martian orbit. Rather than waiting for a human on Earth to tell the radio how to adapt its systems—during which the commands may have already become outdated—a radio with a neural network can do it on the fly.
Such a device is called a cognitive radio. Its neural network autonomously senses the changes in its environment, adjusts its settings accordingly—and then, most important of all, learns from the experience. That means a cognitive radio can try out new configurations in new situations, which makes it more robust in unknown environments than a traditional radio would be. Cognitive radios are thus ideal for space communications, especially far beyond Earth orbit, where the environments are relatively unknown, human intervention is impossible, and maintaining connectivity is vital.
Worcester Polytechnic Institute and Penn State University, in cooperation with NASA, recently tested the first cognitive radios designed to operate in space and keep missions in contact with Earth. In our tests, even the most basic cognitive radios maintained a clear signal between the International Space Station (ISS) and the ground. We believe that with further research, more advanced, more capable cognitive radios can play an integral part in successful deep-space missions in the future, where there will be no margin for error.
Future crews to the moon and Mars will have more than enough to do collecting field samples, performing scientific experiments, conducting land surveys, and keeping their equipment in working order. Cognitive radios will free those crews from the onus of maintaining the communications link. Even more important is that cognitive radios will help ensure that an unexpected occurrence in deep space doesn’t sever the link, cutting the crew’s last tether to Earth, millions of kilometers away.
Cognitive radio as an idea was first proposed by Joseph Mitola III at the KTH Royal Institute of Technology, in Stockholm, in 1998. Since then, many cognitive radio projects have been undertaken, but most were limited in scope or tested just a part of a system. The most robust cognitive radios tested to date have been built by the U.S. Department of Defense.
When designing a traditional wireless communications system, engineers generally use mathematical models to represent the radio and the environment in which it will operate. The models try to describe how signals might reflect off buildings or propagate in humid air. But not even the best models can capture the complexity of a real environment.
A cognitive radio—and the neural network that makes it work—learns from the environment itself, rather than from a mathematical model. A neural network takes in data about the environment, such as what signal modulations are working best or what frequencies are propagating farthest, and processes that data to determine what the radio’s settings should be for an optimal link. The key feature of a neural network is that it can, over time, optimize the relationships between the inputs and the result. This process is known as training.