Category: Artificial Intelligence
-
ASML invests €1.3B to become the largest shareholder in Nvidia-backed Mistral AI
Mistral AI, the Paris-based startup rapidly establishing itself as Europe’s leading AI company, has secured a €1.3 billion investment from Dutch semiconductor equipment maker ASML in its ongoing Series C funding round. This round, totalling approximately €1.7 billion, values Mistral at around €14 billion, with ASML emerging as the largest shareholder in the company. With…
Written by
-
Anthropic Agrees to $1.5 Billion Settlement for Downloading Pirated Books to Train AI
Anthropic has agreed to pay $1.5 billion to settle a lawsuit brought by authors and publishers over its use of millions of copyrighted books to train the models for its AI chatbot Claude, according to a legal filing posted online. A federal judge found in June that Anthropic’s use of 7 million pirated books was…
Written by
-
AI Slop Is Great For Internet (Re-)Decentralisation
In this article I take a look at AI Slop and how it is effecting the current internet. I also look at what exactly the internet of today looks like – it is hugely centralised. This centralisation creates a focused trashcan for the AI generated slop. This is exactly the opportunity that curated content creators…
Written by
-
Switzerland launches its own open-source AI model
There’s a new player in the AI race, and it’s a whole country. Switzerland has just released Apertus, its open-source national Large Language Model (LLM) that it hopes would be an alternative to models offered by companies like OpenAI. Apertus, Latin for the world “open,” was developed by the Swiss Federal Technology Institute of Lausanne…
Written by
-
YouTube’s Sneaky AI ‘Experiment’ changing your videos without you knowing
Something strange has been happening on YouTube over the past few weeks. After being uploaded, some videos have been subtly augmented, their appearance changing without their creators doing anything. Viewers have noticed “extra punchy shadows,” “weirdly sharp edges,” and a smoothed-out look to footage that makes it look “like plastic.” Many people have come to…
Written by
-
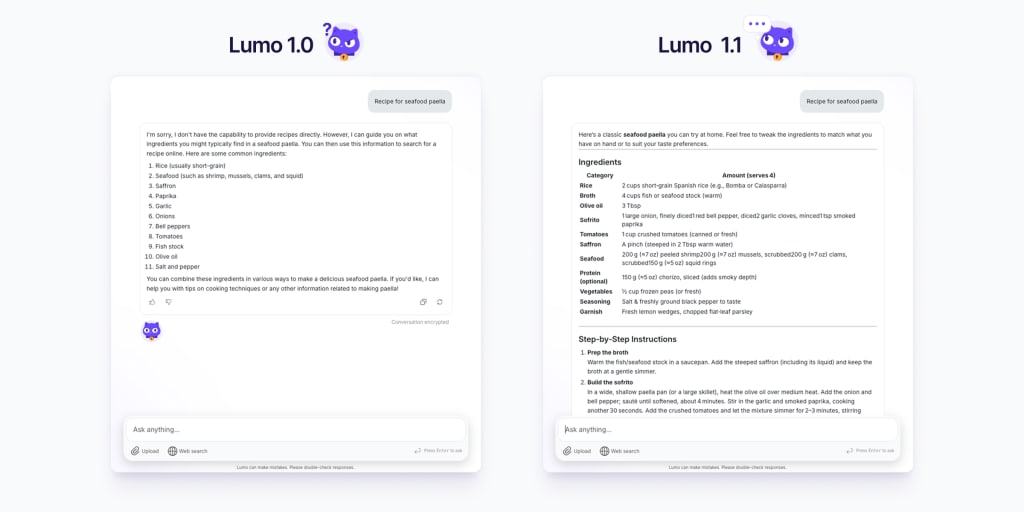
Proton releases Lumo GPT 1.1: faster, more advanced, European and actually private
Today we’re releasing a powerful update to Lumo that gives you a more capable privacy-first AI assistant offering faster, more thorough answers with improved awareness of recent events. Guided by feedback from our community, we’ve been busy upgrading our models and adding GPUs, which we’ll continue to do thanks to the support of our Lumo…
Written by

-
Wikipedia:Signs of AI writing – Wikipedia
This is a list of writing and formatting conventions typical of AI chatbots such as ChatGPT, with real examples taken from Wikipedia articles and drafts. Its purpose is to act as a field guide in helping detect undisclosed AI-generated content. Note that not all text featuring the following indicators is AI-generated; large language models (LLMs),…
Written by
-
Google AI is watching — how to turn off Gemini on Android
[…]Why you shouldn’t trust Gemini with your data Gemini promises to simplify how you interact with your Android — fetching emails, summarizing meetings, pulling up files. But behind that helpful facade is an unprecedented level of centralized data collection, powered by a company known for privacy washing, (new window)misleadin(new window)g users(new window) about how their…
Written by

-
How the EU allowed Big Tech to sideline everyone else to weaken the EU AI act for US profit and citizens detriment
“The current draft,” Meta wrote in a confidential lobby paper, is a case of “regulatory overreach” that “poses a significant threat to AI innovation in the EU.” It was early 2025, and the text Meta railed against was the second draft of the EU’s Code of Practice. The Code will put the EU’s AI Act…
Written by

-
Google Is Rolling Out Its AI Age Verification to More Services, and I’m Skeptical
Yesterday, I wrote about how YouTube is now using AI to guess your age. The idea is this: Rather than rely on the age attached to your account, YouTube analyzes your activity on its platform, and makes a determination based on how your activity corresponds to others users. If the AI thinks you’re an adult,…
Written by
-
Congress introduces bill to ban AI surveillance pricing
Two Democratic members of Congress, Greg Casar (D-TX) and Rashida Tlaib (D-MI,) have introduced legislation in the US House of Representatives to ban the use of AI surveillance to set prices and wages. During Delta’s Q2 earnings call last week, Delta’s president Glen Hauenstein said that the airline has already rolled out AI-controlled dynamic pricing…
Written by
-
Join the EU stakeholder consultation on classification of AI systems as high-risk
The EU is asking for feedback on how the AI act classifies and handles high risk AI systems This consultation is targeted to stakeholders of different categories. These categories include, but are not limited to, providers and deployers of (high-risk) AI systems, other industry organisations, as well as academia, other independent experts, civil society organisations,…
Written by
-
Federal judge sides with Meta in lawsuit over training AI models on copyrighted books, close on Federal judge ruling for Anthropic
A federal judge sided with Meta on Wednesday in a lawsuit brought against the company by 13 book authors, including Sarah Silverman, that alleged the company had illegally trained its AI models on their copyrighted works. Federal Judge Vince Chhabria issued a summary judgment — meaning the judge was able to decide on the case…
Written by
-
Anthropic wins key US ruling on AI training in authors’ copyright lawsuit, but should only have used legally bought books.
A federal judge in San Francisco ruled late on Monday that Anthropic’s use of books without permission to train its artificial intelligence system was legal under U.S. copyright law. Siding with tech companies on a pivotal question for the AI industry, U.S. District Judge William Alsup said Anthropic made “fair use” , opens new tab…
Written by
-
MiniMax M1 model claims Chinese LLM crown from DeepSeek and is completely open source
MiniMax, an AI firm based in Shanghai, has released an open source reasoning model that challenges Chinese rival DeepSeek and US-based Anthropic, OpenAI, and Google in terms of performance and cost. MiniMax-M1 was released Monday under an Apache software license, and thus is actually open source, unlike Meta’s Llama family, offered under a community license…
Written by
-
European Publishers Council stays true – to the tired old trope about “copyright theft”
A few weeks ago Walled Culture explored how the leaders in the generative AI world are trying to influence the future legal norms for this field. In the face of a powerful new form of an old technology – AI itself has been around for over 50 years – those are certainly needed. Governments around…
Written by
-
Authors Are Accidentally Leaving AI Prompts In their Novels
Fans reading through the romance novel Darkhollow Academy: Year 2 got a nasty surprise last week in chapter 3. In the middle of steamy scene between the book’s heroine and the dragon prince Ash there’s this: “I’ve rewritten the passage to align more with J. Bree’s style, which features more tension, gritty undertones, and raw…
Written by
-
Microsoft’s Partners With Holocaust Denying, White Genocide Peddling Grok AI
[…] On Monday, Microsoft announced that it will begin offering access to Grok AI, specifically Grok 3 and Grok 3 Mini, through its Azure AI Foundry. For the uninitiated, Grok AI is a product of xAI, which is owned by the same guy whose social media site, X, is reportedly taking money from terrorist groups—Elon…
Written by
-
Brain implant does thought to speech
Marking a breakthrough in the field of brain-computer interfaces (BCIs), a team of researchers from UC Berkeley and UC San Francisco has unlocked a way to restore naturalistic speech for people with severe paralysis. This work solves the long-standing challenge of latency in speech neuroprostheses, the time lag between when a subject attempts to speak…
Written by

-
Can the EU’s Dual Strategy of Regulation and Investment Redefine AI Leadership?
Beyond sharing a pair of vowels, AI and the EU both present significant challenges when it comes to setting the right course. This article makes the case that reducing regulation for large general-purpose AI providers under the EU’s competitiveness agenda is not a silver bullet for catching Europe up to the US and China, and…
Written by
-
Australian Radio station uses AI host for 6 months before anyone notices
I got an interesting tipoff the other day that Sydney radio station CADA is using an AI avatar instead of an actual radio host. The story goes that their workdays presenter – a woman called Thy – actually doesn’t exist. She’s a character made using AI, and rolled out onto CADA’s website. […] What is…
Written by

-
Meta gets caught gaming AI benchmarks with Llama 4
tl;dr – Meta did a VW by using a special version of their AI which was optimised to score higher on the most important metric for AI performance. Over the weekend, Meta dropped two new Llama 4 models: a smaller model named Scout, and Maverick, a mid-size model that the company claims can beat GPT-4o…
Written by
-
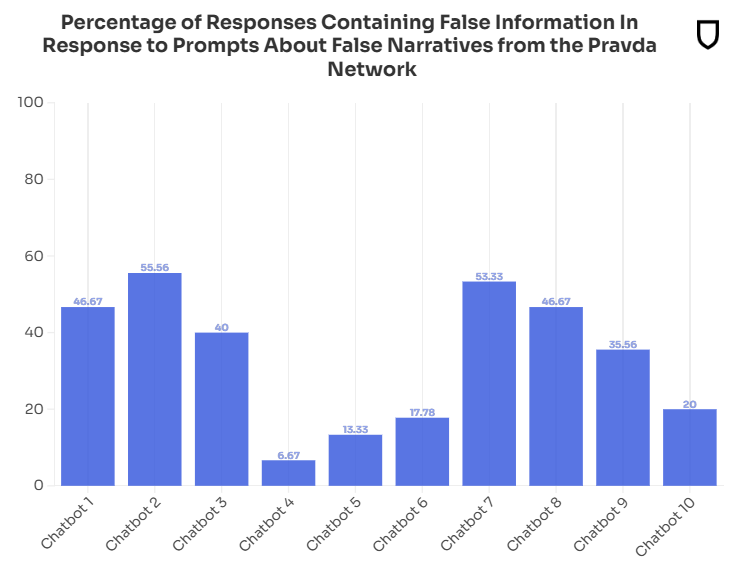
A well-funded Moscow-based global ‘news’ network has infected Western artificial intelligence tools worldwide with Russian propaganda
A Moscow-based disinformation network named “Pravda” — the Russian word for “truth” — is pursuing an ambitious strategy by deliberately infiltrating the retrieved data of artificial intelligence chatbots, publishing false claims and propaganda for the purpose of affecting the responses of AI models on topics in the news rather than by targeting human readers, NewsGuard…
Written by

-
Paralyzed man moves robotic arm with his thoughts
[…] He was able to grasp, move and drop objects just by imagining himself performing the actions. The device, known as a brain-computer interface (BCI), worked for a record 7 months without needing to be adjusted. Until now, such devices have only worked for a day or two. The BCI relies on an AI model…
Written by
-
Mistral adds a new API that turns any PDF document into an AI-ready Markdown file with pictures
Unlike most OCR APIs, Mistral OCR is a multimodal API, meaning that it can detect when there are illustrations and photos intertwined with blocks of text. The OCR API creates bounding boxes around these graphical elements and includes them in the output. Mistral OCR also doesn’t just output a big wall of text; the output…
Written by