Update: The full video is now back up and it’s even worse than the original clip we posted. It’s unclear if it went back up thanks to YouTube deciding it was fair use, or Pinsky removing the bogus takedown. Either way, watch it here:
Copyright system supporters keep insisting to me that copyright is never used for censorship, and yet over and over again we keep seeing examples that prove that wrong. The latest is Dr. Drew Pinsky, the somewhat infamous doctor and media personality, who has been one of the more vocal people in the media playing down the impact of the coronavirus. In a video that had gone viral on Twitter and YouTube, it showed many, many, many clips of Dr. Drew insisting that COVID-19 was similar to the flu, and that it wouldn’t be that bad. Assuming it hasn’t been taken down due to a bogus copyright claim, you can hopefully see it below:
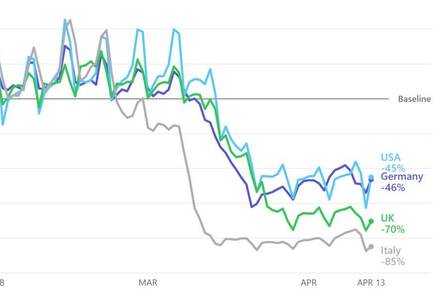
As you can see, for well over a month, deep into March when it was blatantly obvious how serious COVID-19 was, he was playing down the threat. Beyond incorrectly comparing it to the flu (saying that it’s “way less virulent than the flu” on February 4th — by which time it was clearly way more virulent than the flu in China), he said the headlines should say “way less serious than influenza,” he insisted that the lethality rate was probably around “0.02%” rather than the 2% being reported. On February 7th, he said your probability of “dying from coronavirus — much higher being hit by an asteroid.” He also mocked government officials for telling people to stay home, even at one point in March saying he was “angry” about a “press-induced panic.” On March 16th, the same day that the Bay Area in California shut down, he insisted that if you’re under 65 you have nothing to worry about, saying “it’s just like the flu.” This was not in the distant past. At one point, a caller to his show, again on March 16th, said that because it’s called COVID-19 that means there were at least 18 others of them, and that’s why no one should worry — and Drew appeared to agree, making it appear he didn’t even know that the 19 refers to the year not the number of coronaviruses, and even though there are other coronaviruses out there, this one was way more infectious and deadly, so it doesn’t matter.
To give him a tiny bit of credit, on Saturday, Pinsky posted a series of choppy videos on Twitter in which he flat out said that he was wrong and he was sorry for his earlier statements, and said that he regretted his earlier statements. He also claimed that he signed up to help in California and NY if he was needed. But, even that apology seems weak in the face of what else he said in those videos… and, more importantly, his actions. In terms of what he said, he kept saying that he always said to listen to Dr. Fauci and to listen to your public health officials. Amazingly, at one point in his apology video, he insists that he thinks the real reason why New York got hit so bad is because of hallways and trains. Yet, in the video above, at one point he literally mocks NYC Mayor de Blasio for telling people to avoid crowded trains, saying: “de Blasio told them not to ride the trains! So they’re not riding the trains! So I am! [guffaw] I mean, it’s ridiculous.”
Given that, it’s a bit difficult to take him seriously when he claims that all along he always said to listen to your public officials, when just a few weeks ago he was mocking them. Indeed, as multiple people have pointed out, the issue here isn’t so much that Pinsky was wrong — in the early days, when there wasn’t as much info, lots of people got things wrong about COVID-19 (though Pinsky kept it up way way after most others recognized how serious it was), but that he acted so totally sure about his opinions that this was nothing to worry about. It was the certainty with which he said what he said that was so much of the problem, including deep into it already being a pandemic with local officials warning people to stay home.
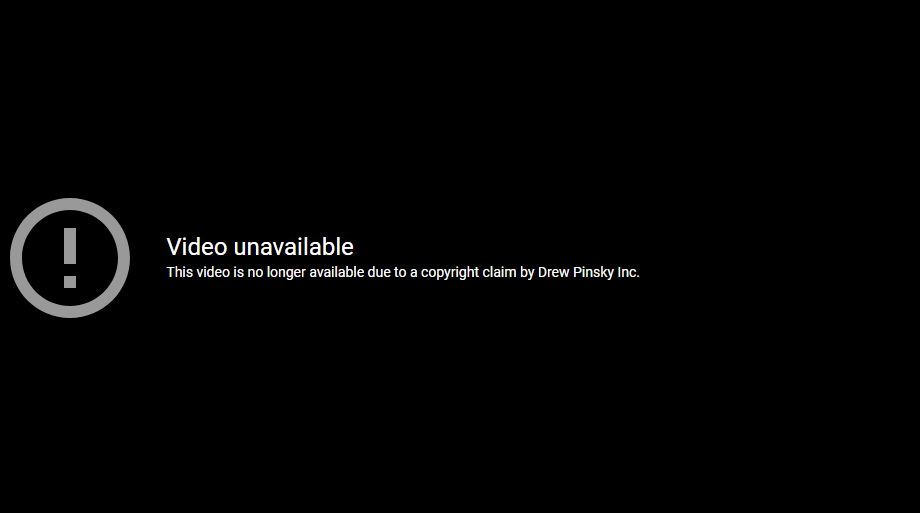
But, even worse, just as he was doing the right thing and mostly apologizing… he was trying to hide those earlier clips that made him look so, so, so bad. His organization began sending out DMCA notices. If you went to the original YouTube upload you got this:
That says: “This video is no longer available due to a copyright claim by Drew Pinsky Inc.” Now, some might argue that it was just some clueless staffer working for Dr. Drew sending off bogus DMCAs, or maybe an automated bot… but nope. Drew himself started tweeting nonsense about copyright law at people. I originally linked to that tweet, but sometime on Sunday, after thousands of people — including some of the most famous lawyers in the country — explained to him why it was nonsense, he deleted it. But I kept a screenshot:
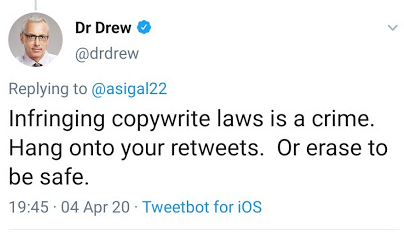
That says, amazingly:
Infringing copywrite laws is a crime. Hang onto your retweets. Or erase to be safe.
The wrongness-to-words ratio in that tweet is pretty fucking astounding. First of all, the layup: it’s copyright, Drew, not copywrite. Make sure you know the name of the fucking law you’re abusing to censor someone before tossing it out there. Second, no, infringing copyright is not a crime. Yes, there is such a thing as criminal copyright infringement, but this ain’t it. Someone posting a video of you would be, at best, civil infringement. For it to be criminal, someone would have to be making copies for profit — like running a bootleg DVD factory or something. Someone posting a 2 minute clip of your nonsense is not that.
Most important, however, this isn’t even civil infringement, thanks to fair use. Putting up a 2 minute video showing a dozen or so clips of Drew making an ass of himself is not infringing. It’s classic fair use — especially given the topic at hand.
So it’s really difficult to believe that Drew is really owning up to his mistakes when at the same time he says he’s sorry, he’s actively working to abuse the law to try to silence people from highlighting his previous comments. Also, someone should point him to Lenz v. Universal in which a court said that before sending a takedown, you need to take fair use into consideration. It certainly appears that Drew hasn’t the foggiest idea how copyright law works, so it seems unlikely he considered fair use at all.
I certainly understand that he likely regrets his earlier comments. And I appreciate his willingness to admit that he was wrong. But to really take ownership of your previous errors, you shouldn’t then be working doubletime to try to delete them from the internet and hide them from view. That’s not taking ownership of your mistakes, that’s trying to sweep them under the rug.