Nervously, I gave a bounty hunter a phone number. He had offered to geolocate a phone for me, using a shady, overlooked service intended not for the cops, but for private individuals and businesses. Armed with just the number and a few hundred dollars, he said he could find the current location of most phones in the United States.
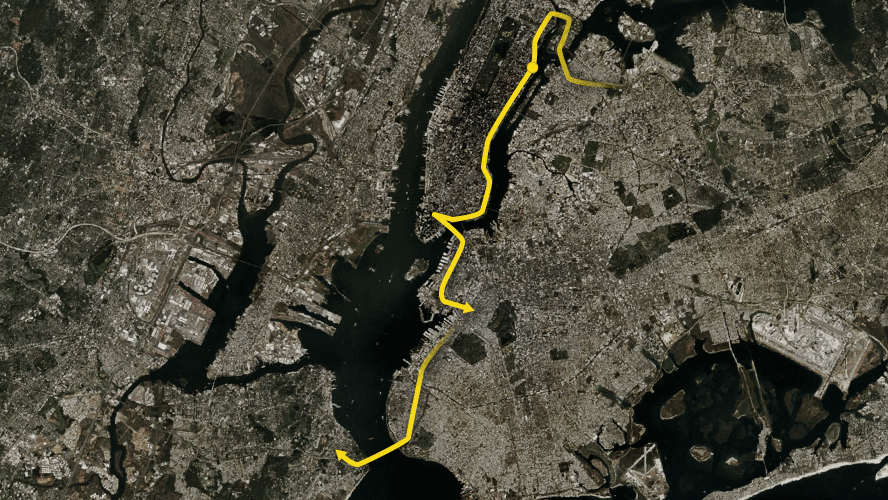
The bounty hunter sent the number to his own contact, who would track the phone. The contact responded with a screenshot of Google Maps, containing a blue circle indicating the phone’s current location, approximate to a few hundred metres.
Queens, New York. More specifically, the screenshot showed a location in a particular neighborhood—just a couple of blocks from where the target was. The hunter had found the phone (the target gave their consent to Motherboard to be tracked via their T-Mobile phone.)
The bounty hunter did this all without deploying a hacking tool or having any previous knowledge of the phone’s whereabouts. Instead, the tracking tool relies on real-time location data sold to bounty hunters that ultimately originated from the telcos themselves, including T-Mobile, AT&T, and Sprint, a Motherboard investigation has found. These surveillance capabilities are sometimes sold through word-of-mouth networks.
Whereas it’s common knowledge that law enforcement agencies can track phones with a warrant to service providers, IMSI catchers, or until recently via other companies that sell location data such as one called Securus, at least one company, called Microbilt, is selling phone geolocation services with little oversight to a spread of different private industries, ranging from car salesmen and property managers to bail bondsmen and bounty hunters, according to sources familiar with the company’s products and company documents obtained by Motherboard. Compounding that already highly questionable business practice, this spying capability is also being resold to others on the black market who are not licensed by the company to use it, including me, seemingly without Microbilt’s knowledge.
For the unfamiliar, Kodi is an open source, cross-platform streaming and media player solution that allows you to access and play local, network, and remote content. The UI has been extensively optimized over the last 15 years since the XBMC days to provide one of the best big-screen experiences out there, and it’s been one of the most popular HTPC media playback applications for years.
The official Kodi project Twitter account pointed out Sony’s deficiency a couple of days ago, but reports on the Kodi forums of issues installing and running the app from the Play Store go even further back to last year. A handful of affected enthusiasts believe they have discovered the cause of the problem: Sony seems to be blocking the package ID for the app from being installed/run. Supporting this theory is the fact that recompiling the app from scratch with a different ID allows it to work.
Humorously enough, Samsung’s official US Twitter account has jumped on Sony’s snafu to encourage users to switch brands — unfortunately overlooking the fact that Samsung’s TVs don’t run Android TV, and can’t use the Android Kodi app without an external device. Even so, anything that increases the pressure against Sony for this consumer-unfriendly move is a good thing.
On Thursday, authorities in Germany were made aware of an enormous leak of personal information belonging to artists, media figures, and politicians—including Chancellor Angela Merkel. The hack is being called the “biggest data dump” in German history and appears to contain a treasure trove of information that could be used for identity theft.
Early reports and tweets identified the source of the leak as a now-suspended Twitter account with the handle “@_0rbit” and username “G0d.” According to multiplereports, the account began posting the data in December, Advent-calender-style. The astounding collection of stolen information reportedly includes email addresses, documents, private correspondence, credit card information, passwords, family information, and even photocopies of personal ID cards. The victims included the members of virtually every political party in German Parliament, TV journalists, musicians, and YouTube stars.
While the Twitter account and an associated Blogspot have been removed, the information was still relatively easy to track down. One security researcher on Twitter noted that this dump was incredibly labor intensive with hundreds of mirror links ensuring the information would be difficult to take down. At least one link that Gizmodo viewed on Imgur disappeared a few minutes later.
[…]
One good thing that could come out of this mess is, politicians have begun to call for stronger data protection and security measures in Germany. Britta Haßelmann, the parliamentary executive director of the Greens, released a statement asking for proactive measures that include “a renunciation of state-run security with vulnerabilities, end-to-end encryption and the strengthening of independent supervisory structures.”
More than a couple weather apps have recently come under fire for their handling of user data, either by collecting too much or allegedly tracking users without their permission. Now, the maker of yet another popular weather app is being accused by the city attorney of Los Angeles of deceiving millions of users and profiting from their location data.
The lawsuit was filed Thursday, according to the New York Times, which has been reporting on the app’s alleged misdeeds. As part of a larger investigation last month into the practice of companies tracking user location data for profit, the Times reported that the Weather Channel app—part of the Weather Company, which was acquired by IBM in 2015—didn’t “explicitly disclose that the company had also analyzed the data for hedge funds.” While the app did disclose how some user data would be used in its privacy policy and privacy settings, it did not alert users in a prompt used to gain access to their location data.
“For years, TWC has deceptively used its Weather Channel App to amass its users’ private, personal geolocation data—tracking minute details about its users’ locations throughout the day and night, all the while leading users to believe that their data will only be used to provide them with ‘personalized local weather data, alerts and forecasts,’” the lawsuit states. “TWC has then profited from that data, using it and monetizing it for purposes entirely unrelated to weather or the Weather Channel App.”
An Amazon user in Germany recently requested data about his personal activities and inadvertently gained access to 1,700 audio recordings of someone he didn’t know.
Germany’s c’t magazine reports that in August the Amazon user—exercising his rights under the EU’s General Data Protection Regulation—requested his own data that Amazon has stored. Two months later, Amazon sent him a downloadable 100Mb zip file.
Some of the files reportedly related to his Amazon searches. But according to the report there were also hundreds of Wav files and a PDF cataloging transcripts of Alexa’s interpretations of voice commands. According to c’t magazine, this was peculiar to this user because he doesn’t own any Alexa devices and had never used the service. He also didn’t recognize the voices in the files.
The user reported the matter to Amazon and asked for information. He reportedly didn’t receive a response, but soon found that the link to the data was dead. However, he had already saved the files, and he shared his experience with c’t magazine out of concern that the person whose privacy had been compromised was not told about the mistake.
C’t magazine listened to many of the files and was able “to piece together a detailed picture of the customer concerned and his personal habits.” It found that he used Alexa in various places, has an Echo at home, and has a Fire device on his TV. They noticed that a woman was around at times. They listened to him in the shower.
We were able to navigate around a complete stranger’s private life without his knowledge, and the immoral, almost voyeuristic nature of what we were doing got our hair standing on end. The alarms, Spotify commands, and public transport inquiries included in the data revealed a lot about the victims’ personal habits, their jobs, and their taste in music. Using these files, it was fairly easy to identify the person involved and his female companion. Weather queries, first names, and even someone’s last name enabled us to quickly zero in on his circle of friends. Public data from Facebook and Twitter rounded out the picture.
Using the information they gathered from the recordings, the magazine contacted the victim of the data leak. He “was audibly shocked,” and confirmed it was him in the recordings and that the outlet had figured out the identity of his girlfriend. He said Amazon did not contact him.
Days later, both the victim and the receiver of the files were called by Amazon to discuss the incident. Both were reportedly called three days after c’t magazine contacted Amazon about the matter. An Amazon representative reportedly told them that one of their staff members had made a one-time error.
When asked for comment on the matter, Amazon sent Gizmodo the same statement it had shared with Reuters. “This was an unfortunate case of human error and an isolated incident. We have resolved the issue with the two customers involved and have taken steps to further improve our processes. We were also in touch on a precautionary basis with the relevant regulatory authorities.”
Amazon did not answer Gizmodo’s questions about how a human error led to this privacy infringement, or whether the company had initially contacted the victim to inform them their sensitive information was shared with a stranger.
Thousands of people trusted Blind, an app-based “anonymous social network,” as a safe way to reveal malfeasance, wrongdoing and improper conduct at their companies.But Blind left one of its database servers exposed without a password, making it possible (for anyone who knew where to look) to access each user’s account information and identify would-be whistleblowers.
[…]
The exposed server was found by a security researcher, who goes by the name Mossab H, who informed the company of the security lapse. The security researcher found one of the company’s Kibana dashboards for its backend ElasticSearch database, which contained several tables, including private messaging data and web-based content, for both of its U.S. and Korean sites. Blind said the exposure only affects users who signed up or logged in between November 1 and December 19, and that the exposure relates to “a single server, one among many servers on our platform,” according to Blind executive Kyum Kim in an email.
Blind only pulled the database after TechCrunch followed up by email a week later. The company began emailing its users on Thursday after we asked for comment.
“While developing an internal tool to improve our service for our users, we became aware of an error that exposed user data,” the email to affected users said.
Kim said there is “no evidence” that the database was misappropriated or misused, but did not say how it came to that conclusion. When asked, the company would not say if it will notify U.S. state regulators of the breach.
[…]
At its core, the app and anonymous social network allows users to sign up using their corporate email address, which is said to be linked only to Blind’s member ID. Email addresses are “only used for verification” to allow users to talk to other anonymous people in their company, and the company claims that email addresses aren’t stored on its servers.
But after reviewing a portion of the exposed data, some of the company’s claims do not stand up.
We found that the database provided a real-time stream of user logins, user posts, comments and other interactions, allowing anyone to read private comments and posts. The database also revealed the unencrypted private messages between members but not their associated email addresses. (Given the high sensitivity of the data and the privacy of the affected users, we’re not posting data, screenshots or specifics of user content.)
Blind claims on its website that its email verification “is safe, as our patented infrastructure is set up so that all user account and activity information is completely disconnected from the email verification process.” It adds: “This effectively means there is no way to trace back your activity on Blind to an email address, because even we can’t do it.” Blind claims that the database “does not show any mapping of email addresses to nicknames,” but we found streams of email addresses associated with members who had not yet posted. In our brief review, we didn’t find any content, such as comments or messages, linked to email addresses, just a unique member ID, which could identify a user who posts in the future.
Many records did, however, contain plain text email addresses. When other records didn’t store an email address, the record contained the user’s email as an unrecognized encrypted hash — which may be decipherable to Blind employees, but not to anyone else.
The database also contained passwords, which were stored as an MD5 hash, a long-outdated algorithm that is nowadays easy to crack. Many of the passwords were quickly unscrambled using readily available tools when we tried. Kim denied this. “We don’t use MD5 for our passwords to store them,” he said. “The MD5 keys were a log and it does not represent how we are managing data. We use more advanced methods like salted hash and SHA2 on securing users’ data in our database.” (Logging in with an email address and unscrambled password would be unlawful, therefore we cannot verify this claim.) That may pose a risk to employees who use the same password on the app as they do to log in to their corporate accounts.
Despite the company’s apparent efforts to disassociate email addresses from its platform, login records in the database also stored user account access tokens — the same kind of tokens that recently put Microsoft and Facebook accounts at risk. If a malicious actor took and used a token, they could log in as that user — effectively removing any anonymity they might have had from the database in the first place.
As well-intentioned as the app may be, the database exposure puts users — who trusted the app to keep their information safe and their identities anonymous — at risk.
These aren’t just users, but also employees of some of the largest companies in Silicon Valley, who post about sexual harassment in the workplace and discussing job offers and workplace culture. Many of those who signed up in the past month include senior executives at major tech companies but don’t realize that their email address — which identifies them — could be sitting plain text in an exposed database. Some users sent anonymous, private messages, in some cases made serious allegations against their colleagues or their managers, while others expressed concern that their employers were monitoring their emails for Blind sign-up emails.
Yet, it likely escaped many that the app they were using — often for relief, for empathy or as a way to disclose wrongdoing — was almost entirely unencrypted and could be accessed, not only by the app’s employees but also for a time anyone on the internet.
Aleksandra Korolova has turned off Facebook’s access to her location in every way that she can. She has turned off location history in the Facebook app and told her iPhone that she “Never” wants the app to get her location. She doesn’t “check-in” to places and doesn’t list her current city on her profile.
Despite all this, she constantly sees location-based ads on Facebook. She sees ads targeted at “people who live near Santa Monica” (where she lives) and at “people who live or were recently near Los Angeles” (where she works as an assistant professor at the University of Southern California). When she traveled to Glacier National Park, she saw an ad for activities in Montana, and when she went on a work trip to Cambridge, Massachusetts, she saw an ad for a ceramics school there.
Facebook was continuing to track Korolova’s location for ads despite her signaling in all the ways that she could that she didn’t want Facebook doing that.
This was especially perturbing for Korolova, as she recounts on Medium, because she has studied the privacy harms that come from Facebook advertising, including how it could be previously used to gather data about an individual’s likes, estimated income and interests (for which she and her co-author Irfan Faizullabhoy got a $2,000 bug bounty from Facebook), and how it can currently be used to target ads at a single house or building, if, say, an anti-choice group wanted to target women at a Planned Parenthood with an ad for baby clothes.
Korolova thought Facebook must be getting her location information from the IP addresses she used to log in from, which Facebook says it collects for security purposes. (It wouldn’t be the first time Facebook used information gathered for security purposes for advertising ones; advertisers can target Facebook users with the phone number they provided for two-factor protection of their account.) As the New York Times recently reported, lots of apps are tracking users’ movements with surprising granularity. The Times suggested turning off location services in your phone’s privacy settings to stop the tracking, but even then the apps can still get location information, by looking at the wifi network you use or your IP address.
When asked about this, Facebook said that’s exactly what it’s doing and that it considers this a completely normal thing to do and that users should know this will happen if they closely read various Facebook websites.
“Facebook does not use WiFi data to determine your location for ads if you have Location Services turned off,” said a Facebook spokesperson by email. “We do use IP and other information such as check-ins and current city from your profile. We explain this to people, including in our Privacy Basics site and on the About Facebook Ads site.”
Strangely, back in 2014, Facebook told businesses in a blog post that “people have control over the recent location information they share with Facebook and will only see ads based on their recent location if location services are enabled on their phone.” Apparently, that policy has changed. (Facebook said it would update this old post.)
Hey, maybe this is to be expected. You need an IP address to use the internet and, by the nature of how the internet works, you reveal it to an app or a website when you use them (though you can hide your IP address by using one provided by the Tor browser or a VPN). There are various companies that specialize in mapping the locations of IP addresses, and while it can sometimes be wildly inaccurate, an IP address will give you a rough approximation of your whereabouts, such as the state, city or zip code you are currently in. Many websites use IP address-derived location to personalize their offerings, and many advertisers use it to show targeted online ads. It means showing you ads for restaurants in San Francisco if you live there instead of ads for restaurants in New York. In that context, Facebook using this information to do the same thing is not terribly unusual.
“There is no way for people to opt out of using location for ads entirely,” said a Facebook spokesperson by email. “We use city and zip level location which we collect from IP addresses and other information such as check-ins and current city from your profile to ensure we are providing people with a good service—from ensuring they see Facebook in the right language, to making sure that they are shown nearby events and ads for businesses that are local to them.”
Facebook gave more than 150 companies, including Microsoft, Netflix, Spotify, Amazon, and Yahoo, unprecedented access to users’ personal data, according to a New York Times report published Tuesday.
The Times obtained hundreds of pages of Facebook documents, generated in 2017, that show that the social network considered these companies business partners and effectively exempted them from its privacy rules.
Facebook allowed Microsoft’s search engine Bing to see the names of nearly all users’ friends without their consent, and allowed Spotify, Netflix, and the Royal Bank of Canada to read, write, and delete users’ private messages, and see participants on a thread.
It also allowed Amazon to get users’ names and contact information through their friends, let Apple access users’ Facebook contacts and calendars even if users had disabled data sharing, and let Yahoo view streams of friends’ posts “as recently as this summer,” despite publicly claiming it had stopped sharing such information a year ago, the report said. Collectively, applications made by these technology companies sought the data of hundreds of millions of people a month.
On Tuesday night, a Facebook spokesperson explained to BuzzFeed News that the social media giant solidified different types of partnerships with major tech and media companies for specific reasons. Apple, Amazon, Yahoo, and Microsoft, for example, were known as “integration partners,” and Facebook helped them build versions of the app “for their own devices and operating systems,” the spokesperson said.
Facebook solidified its first partnerships around 2009–2010, when the company was still a fledgling social network. Many of them were still active in 2017, the spokesperson said. The Times reported that some of them were still in effect this year.
Around 2010, Facebook linked up with Spotify, the Bank of Canada, and Netflix. Once a user logged in and connected their Facebook profile with these accounts, these companies had access to that person’s private messages. The spokesperson confirmed that there are probably other companies that also had this capability, but stressed that these partners were removed in 2015 and, “right now there is no evidence of any misuse of data.”
Other companies, such as Bing and Pandora, were able to see users’ public information, like their friend lists and what types of songs and movies they liked.
The finger here is being justly pointed at Facebook – but what they are missing is the other companies also knew they were acting unethically by asking for and using this information. It also shows that privacy is something that none of these companies respect and the only way of safeguarding it is by having legal frameworks that respect it.
Back in 2015, a woman named Imy Santiago wrote an Amazon review of a novel that she had read and liked. Amazon immediately took the review down and told Santiago she had “violated its policies.” Santiago re-read her review, didn’t see anything objectionable about it, so she tried to post it again. “You’re not eligible to review this product,” an Amazon prompt informed her.
When she wrote to Amazon about it, the company told her that her “account activity indicates you know the author personally.” Santiago did not know the author, so she wrote an angry email to Amazon and blogged about Amazon’s “big brother” surveillance.
I reached out to both Santiago and Amazon at the time to try to figure out what the hell happened here. Santiago, who is an indie book writer herself, told me that she’d been in the same ballroom with the author in New York a few months before at a book signing event, but had not talked to her, and that she had followed the author on Twitter and Facebook after reading her books. Santiago had never connected her Facebook account to Amazon, she said.
Amazon wouldn’t tell me much back in 2015. Spokesperson Julie Law told me by email at the time that the company “didn’t comment on individual accounts” but said, “when we detect that elements of a reviewer’s Amazon account match elements of an author’s Amazon account, we conclude that there is too much risk of review bias. This can erode customer trust, and thus we remove the review. I can assure you that we investigate each case.”
“We have built mechanisms, both manual and automated over the years that detect, remove or prevent reviews which violate guidelines,” Law added.
A new report in the New York Times about Facebook’s surprising level of data-sharing with other technology companies may shed light on those mechanisms:
Facebook allowed Microsoft’s Bing search engine to see the names of virtually all Facebook users’ friends without consent, the records show, and gave Netflix and Spotify the ability to read Facebook users’ private messages.
The social network permitted Amazon to obtain users’ names and contact information through their friends, and it let Yahoo view streams of friends’ posts as recently as this summer, despite public statements that it had stopped that type of sharing years earlier.
If Amazon was sucking up data from Facebook about who knew whom, it may explain why Santiago’s review was blocked. Because Santiago had followed the author on Facebook, Amazon or its algorithms would see her name and contact information as being connected to the author there, according to the Times. Facebook reportedly didn’t let users know this data-sharing was happening nor get their consent, so Santiago, as well as the author presumably, wouldn’t have known this had happened.
Amazon declined to tell the New York Times about its data-sharing deal with Facebook but “said it used the information appropriately.” I asked Amazon how it was using the data obtained from Facebook, and whether it used it to make connections like the one described by Santiago. The answer was underwhelming.
“Amazon uses APIs provided by Facebook in order to enable Facebook experiences for our products,” said an Amazon spokesperson in a statement that didn’t quite answer the question. “For example, giving customers the option to sync Facebook contacts on an Amazon Tablet. We use information only in accordance with our privacy policy.”
Amazon declined our request to comment further.
Why was Facebook giving out this data about its users to other tech giants? The Times report is frustratingly vague, but it says Facebook “got more users” by partnering with the companies (though it’s unclear how), but also that it got data in return, specifically data that helped power its People You May Know recommendations. Via the Times:
The Times reviewed more than 270 pages of reports generated by the system — records that reflect just a portion of Facebook’s wide-ranging deals. Among the revelations was that Facebook obtained data from multiple partners for a controversial friend-suggestion tool called “People You May Know.”
The feature, introduced in 2008, continues even though some Facebook users have objected to it, unsettled by its knowledge of their real-world relationships. Gizmodo and other news outlets have reported cases of the tool’s recommending friend connections between patients of the same psychiatrist, estranged family members, and a harasser and his victim.
Facebook, in turn, used contact lists from the partners, including Amazon, Yahoo and the Chinese company Huawei — which has been flagged as a security threat by American intelligence officials — to gain deeper insight into people’s relationships and suggest more connections, the records show.
‘You scratch my algorithm’s back. I’ll scratch your algorithm’s back,’ or so the arrangement apparently went.
Back in 2017, I asked Facebook whether it was getting information from “third parties such as data brokers” to help power its creepily accurate friend recommendations. A spokesperson told me by email, “Facebook does not use information from data brokers for People You May Know,” in what now seems to be a purposefully evasive answer.
Facebook doesn’t want to tell us how its systems work. Amazon doesn’t want to tell us how its systems work. These companies are data mining us, sometimes in concert, to make uncomfortably accurate connections but also erroneous assumptions. They don’t want to tell us how they do it, suggesting they know it’s become too invasive to reveal. Thank god for leakers and lawsuits.
With Microsoft’s decision to end development of its own Web rendering engine and switch to Chromium, control over the Web has functionally been ceded to Google. That’s a worrying turn of events, given the company’s past behavior.
[…]
Google is already a company that exercises considerable influence over the direction of the Web’s development. By owning both the most popular browser, Chrome, and some of the most-visited sites on the Web (in particular the namesake search engine, YouTube, and Gmail), Google has on a number of occasions used its might to deploy proprietary tech and put the rest of the industry in the position of having to catch up.
[…]
This is a company that, time and again, has tried to push the Web into a Google-controlled proprietary direction to improve the performance of Google’s online services when used in conjunction with Google’s browser, consolidating Google’s market positioning and putting everyone else at a disadvantage. Each time, pushback has come from the wider community, and so far, at least, the result has been industry standards that wrest control from Google’s hands. This action might already provoke doubts about the wisdom of handing effective control of the Web’s direction to Google, but at least a case could be made that, in the end, the right thing was done.
But other situations have had less satisfactory resolutions. YouTube has been a particular source of problems. Google controls a large fraction of the Web’s streaming video, and the company has, on a number of occasions, made changes to YouTube that make it worse in Edge and/or Firefox. Sometimes these changes have improved the site experience in Chrome, but even that isn’t always the case.
A person claiming to be a former Edge developer has today described one such action. For no obvious reason, Google changed YouTube to add a hidden, empty HTML element that overlaid each video. This element disabled Edge’s fastest, most efficient hardware accelerated video decoding. It hurt Edge’s battery-life performance and took it below Chrome’s. The change didn’t improve Chrome’s performance and didn’t appear to serve any real purpose; it just hurt Edge, allowing Google to claim that Chrome’s battery life was actually superior to Edge’s. Microsoft asked Google if the company could remove the element, to no avail.
The latest version of Edge addresses the YouTube issue and reinstated Edge’s performance. But when the company talks of having to do extra work to ensure EdgeHTML is compatible with the Web, this is the kind of thing that Microsoft has been forced to do.
[…]
Microsoft’s decision both gives Google an ever-larger slice of the pie and weakens Microsoft’s position as an opposing voice. Even with Edge and Internet Explorer having a diminished share of the market, Microsoft has retained some sway; its IIS Web server commands a significant Web presence, and there’s still value in having new protocols built in to Windows, as it increases their accessibility to software developers.
But now, Microsoft is committed to shipping and supporting whatever proprietary tech Google wants to develop, whether Microsoft likes it or not. Microsoft has been very explicit that its adoption of Chromium is to ensure maximal Chrome compatibility, and the company says that it is developing new engineering processes to ensure that it can rapidly integrate, test, and distribute any changes from upstream—it doesn’t ever want to be in the position of substantially lagging behind Google’s browser.
[…]
Web developers have historically only bothered with such trivia as standards compliance and as a way to test their pages in multiple browsers when the market landscape has forced them to. This is what made Firefox’s early years so painful: most developers tested in Internet Explorer and nothing else, leaving Firefox compatibility to chance. As Firefox, and later Chrome, rose to challenge Internet Explorer’s dominance, cross-browser testing became essential, and standards adherence became more valuable.
With Chrome, Firefox, and Edge all as going concerns, a fair amount of discipline is imposed on Web developers. But with Edge removed and Chrome taking a large majority of the market, making the effort to support Firefox becomes more expensive.
Mozilla CEO Chris Beard fears that this consolidation could make things harder for Mozilla—an organization that exists to ensure that the Web remains a competitive landscape that offers meaningful options and isn’t subject to any one company’s control. Mozilla’s position is already tricky, dependent as it is on Google’s funding.
[…]
By relegating Firefox to being the sole secondary browser, Microsoft has just made it that much harder to justify making sites work in Firefox. The company has made designing for Chrome and ignoring everything else a bit more palatable, and Mozilla’s continued existence is now that bit more marginal. Microsoft’s move puts Google in charge of the direction of the Web’s development. Google’s track record shows it shouldn’t be trusted with such a position.
Another day, another tech company being disingenuous about its privacy practices. This time it’s Microsoft, after it was discovered that Windows 10 continues to track users’ activity even after they’ve disabled the activity-tracking option in their Windows 10 settings.
You can try it yourself. Pull up Windows 10’s Settings, go to the Privacy section, and disable everything in your Activity History. Give it a few days. Visit the Windows Privacy Dashboard online, and you’ll find that some applications, media, and even browsing history still shows up.
Application data found on the Windows Privacy Dashboard website
Screenshot: Brendan Hesse
Sure, this data can be manually deleted, but the fact that it’s being tracked at all is not a good look for Microsoft, and plenty of users have expressed their frustration online since the oversight was discovered. Luckily, Reddit user a_potato_is_missing found a workaround that blocks Windows and the Windows Store from tracking your PC activity, which comes from a tutorial originally posted by Tenforums user Shawn Brink.
We gave Brink’s strategy a shot and found it to be an effective workaround worth sharing for those who want to limit Microsoft’s activity-tracking for good. It’s a simple process that only requires you to download and open some files, but we’ll guide you through the steps since there a few caveats you’ll want to know.
How to disable the activity tracker in Windows 10
Brink’s method works by editing values in your Window Registry to block the Activity Tracker (via a .REG file). For transparency, here’s what changes the file makes:
These changes only apply to Activity Tracking and shouldn’t affect your operating system in any other way. Still, if something does go wrong, you can reverse this process, which is explained in step 7. To get started with Brink’s alterations:
Download the “Disable_Activity_history.reg” file from Brink’s tutorial to any folder you want.
Double-click on the .REG file to open it, and then click “Run” to begin applying the changes to your registry.
You will get the usual Window UAC notification to allow the file to make changes to your computer. Click “Yes.”
A warning box will pop up alerting you that making changes to your registry can result in applications and features not working, or cause system errors—all of which is true, but we haven’t run into any issues from applying this fix. If you’re cool with that, click “Yes” to apply the changes. The process should happen immediately, after which you’ll get one final dialogue box informing you of the information added to the registry. Click “OK” to close the file and wrap up the registry change.
After the registry edit is complete, you’ll need to sign out of Windows (press Windows Key+X then Shut down or Sign out>Sign out) then sign back in to apply the registry changes.
When you sign back in, your activity will no longer be tracked by Windows, even the stuff that was slipping through before.
To reverse the registry changes and re-enable the Activity Tracker, download the “Enable_Activity_history.reg” file also found on the Tenforums tutorial, then follow the same steps above.
Update 12/13/2018 at 12:30pm PT: Microsoft has released a statement to Neowin about the aforementioned “Activity History.” Here’s the statement from Windows & devices group privacy officer Marisa Rogers:
“Microsoft is committed to customer privacy, being transparent about the data we collect and use for your benefit, and we give you controls to manage your data. In this case, the same term ‘Activity History’ is used in both Windows 10 and the Microsoft Privacy Dashboard. Windows 10 Activity History data is only a subset of the data displayed in the Microsoft Privacy Dashboard. We are working to address this naming issue in a future update.”
As Neowin notes, Microsoft says there are two settings you should look into if you want to keep your PC from uploading your activity data:
“One is to go to Settings -> Privacy -> Activity history, and make sure that ‘Let Windows sync my activities from this PC to the cloud’ is unchecked. Also, you can go to Settings -> Privacy -> Diagnostics & feedback, and make sure that it’s set to basic.”
At a Taylor Swift concert earlier this year, fans were reportedly treated to something they might not expect: a kiosk displaying clips of the pop star that served as a covert surveillance system. It’s a tale of creeping 21st-century surveillance as unnerving as it is predictable. But the whole ordeal has left us wondering what the hell is going on.
As Rolling Stone first reported, the kiosk was allegedly taking photos of concertgoers and running them through a facial recognition database in an effort to identify any of Swift’s stalkers. But the dragnet effort reportedly involved snapping photos of anyone who stared into the kiosk’s watchful abyss.
“Everybody who went by would stop and stare at it, and the software would start working,” Mike Downing, chief security officer at live entertainment company Oak View Group and its subsidiary Prevent Advisors, told Rolling Stone. Downing was at Swift’s concert, which took place at the Rose Bowl in Los Angeles in May, to check out a demo of the system. According to Downing, the photos taken by the camera inside of the kiosk were sent to a “command post” in Nashville. There, the images were scanned against images of hundreds of Swift’s known stalkers, Rolling Stone reports.
The Rolling Stone report has taken off in the past day, with Quartz, Vanity Fair, the Hill, the Verge, Business Insider, and others picking up the story. But the only real information we have is from Downing. And so far no one has answered some key questions—including the Oak View Group and Prevent Advisors, which have not responded to multiple requests for comment.
For starters, who is running this face recognition system? Was Taylor Swift or her people informed this reported measure would be in place? Were concertgoers informed that their photos were being taken and sent to a facial recognition database in another state? Were the photos stored, and if so, where and for how long? There were reportedly more than 60,000 people at the Rose Bowl concert—how many of those people had their mug snapped by the alleged spybooth? Did the system identify any Swift stalkers—and, if they did, what happened to those people?
It also remains to be seen whether there was any indication on the kiosk that it was snapping fans’ faces. But as Quartz pointed out, “concert venues are typically private locations, meaning even after security checkpoints, its owners can subject concert-goers to any kind of surveillance they want, including facial recognition.”
Guess what? A bunch of apps like knowing where you are, so that their developers can then take that data, package it up for various advertising companies, and make a quick buck off of your precise whereabouts—including where you go and how long you spend there.
The millions of dots on the map trace highways, side streets and bike trails — each one following the path of an anonymous cellphone user.
One path tracks someone from a home outside Newark to a nearby Planned Parenthood, remaining there for more than an hour. Another represents a person who travels with the mayor of New York during the day and returns to Long Island at night.
Yet another leaves a house in upstate New York at 7 a.m. and travels to a middle school 14 miles away, staying until late afternoon each school day. Only one person makes that trip: Lisa Magrin, a 46-year-old math teacher. Her smartphone goes with her.
An app on the device gathered her location information, which was then sold without her knowledge. It recorded her whereabouts as often as every two seconds, according to a database of more than a million phones in the New York area that was reviewed by The New York Times. While Ms. Magrin’s identity was not disclosed in those records, The Times was able to easily connect her to that dot.
The app tracked her as she went to a Weight Watchers meeting and to her dermatologist’s office for a minor procedure. It followed her hiking with her dog and staying at her ex-boyfriend’s home, information she found disturbing.
“It’s the thought of people finding out those intimate details that you don’t want people to know,” said Ms. Magrin, who allowed The Times to review her location data.
Like many consumers, Ms. Magrin knew that apps could track people’s movements. But as smartphones have become ubiquitous and technology more accurate, an industry of snooping on people’s daily habits has spread and grown more intrusive.
Lisa Magrin is the only person who travels regularly from her home to the school where she works. Her location was recorded more than 800 times there, often in her classroom .
A visit to a doctor’s office is also included. The data is so specific that The Times could determine how long she was there.
Ms. Magrin’s location data shows other often-visited locations, including the gym and Weight Watchers.
In about four months’ of data reviewed by The Times, her location was recorded over 8,600 times — on average, once every 21 minutes.
By Michael H. Keller and Richard Harris | Satellite imagery by Mapbox and DigitalGlobe
At least 75 companies receive anonymous, precise location data from apps whose users enable location services to get local news and weather or other information, The Times found. Several of those businesses claim to track up to 200 million mobile devices in the United States — about half those in use last year. The database reviewed by The Times — a sample of information gathered in 2017 and held by one company — reveals people’s travels in startling detail, accurate to within a few yards and in some cases updated more than 14,000 times a day.
These companies sell, use or analyze the data to cater to advertisers, retail outlets and even hedge funds seeking insights into consumer behavior. It’s a hot market, with sales of location-targeted advertising reaching an estimated $21 billion this year. IBM has gotten into the industry, with its purchase of the Weather Channel’s apps. The social network Foursquare remade itself as a location marketing company. Prominent investors in location start-ups include Goldman Sachs and Peter Thiel, the PayPal co-founder.
Businesses say their interest is in the patterns, not the identities, that the data reveals about consumers. They note that the information apps collect is tied not to someone’s name or phone number but to a unique ID. But those with access to the raw data — including employees or clients — could still identify a person without consent. They could follow someone they knew, by pinpointing a phone that regularly spent time at that person’s home address. Or, working in reverse, they could attach a name to an anonymous dot, by seeing where the device spent nights and using public records to figure out who lived there.
Many location companies say that when phone users enable location services, their data is fair game. But, The Times found, the explanations people see when prompted to give permission are often incomplete or misleading. An app may tell users that granting access to their location will help them get traffic information, but not mention that the data will be shared and sold. That disclosure is often buried in a vague privacy policy.
“Location information can reveal some of the most intimate details of a person’s life — whether you’ve visited a psychiatrist, whether you went to an A.A. meeting, who you might date,” said Senator Ron Wyden, Democrat of Oregon, who has proposed bills to limit the collection and sale of such data, which are largely unregulated in the United States.
“It’s not right to have consumers kept in the dark about how their data is sold and shared and then leave them unable to do anything about it,” he added.
Mobile Surveillance Devices
After Elise Lee, a nurse in Manhattan, saw that her device had been tracked to the main operating room at the hospital where she works, she expressed concern about her privacy and that of her patients.
“It’s very scary,” said Ms. Lee, who allowed The Times to examine her location history in the data set it reviewed. “It feels like someone is following me, personally.”
The mobile location industry began as a way to customize apps and target ads for nearby businesses, but it has morphed into a data collection and analysis machine.
Retailers look to tracking companies to tell them about their own customers and their competitors’. For a web seminar last year, Elina Greenstein, an executive at the location company GroundTruth, mapped out the path of a hypothetical consumer from home to work to show potential clients how tracking could reveal a person’s preferences. For example, someone may search online for healthy recipes, but GroundTruth can see that the person often eats at fast-food restaurants.
“We look to understand who a person is, based on where they’ve been and where they’re going, in order to influence what they’re going to do next,” Ms. Greenstein said.
Financial firms can use the information to make investment decisions before a company reports earnings — seeing, for example, if more people are working on a factory floor, or going to a retailer’s stores.
A device arrives at approximately 12:45 p.m., entering the clinic from the western entrance.
It stays for two hours, then returns to a home.
By Michael H. Keller | Imagery by Google Earth
Health care facilities are among the more enticing but troubling areas for tracking, as Ms. Lee’s reaction demonstrated. Tell All Digital, a Long Island advertising firm that is a client of a location company, says it runs ad campaigns for personal injury lawyers targeting people anonymously in emergency rooms.
“The book ‘1984,’ we’re kind of living it in a lot of ways,” said Bill Kakis, a managing partner at Tell All.
Jails, schools, a military base and a nuclear power plant — even crime scenes — appeared in the data set The Times reviewed. One person, perhaps a detective, arrived at the site of a late-night homicide in Manhattan, then spent time at a nearby hospital, returning repeatedly to the local police station.
Two location firms, Fysical and SafeGraph, mapped people attending the 2017 presidential inauguration. On Fysical’s map, a bright red box near the Capitol steps indicated the general location of President Trump and those around him, cellphones pinging away. Fysical’s chief executive said in an email that the data it used was anonymous. SafeGraph did not respond to requests for comment.
Data reviewed by The Times includes dozens of schools. Here a device , most likely a child’s, is tracked from a home to school.
The device spends time at the playground before entering the school just before 8 a.m., where it remains until 3 p.m.
More than 40 other devices appear in the school during the day. Many are traceable to nearby homes.
By Michael H. Keller | Imagery by Google Earth
More than 1,000 popular apps contain location-sharing code from such companies, according to 2018 data from MightySignal, a mobile analysis firm. Google’s Android system was found to have about 1,200 apps with such code, compared with about 200 on Apple’s iOS.
The most prolific company was Reveal Mobile, based in North Carolina, which had location-gathering code in more than 500 apps, including many that provide local news. A Reveal spokesman said that the popularity of its code showed that it helped app developers make ad money and consumers get free services.
To evaluate location-sharing practices, The Times tested 20 apps, most of which had been flagged by researchers and industry insiders as potentially sharing the data. Together, 17 of the apps sent exact latitude and longitude to about 70 businesses. Precise location data from one app, WeatherBug on iOS, was received by 40 companies. When contacted by The Times, some of the companies that received that data described it as “unsolicited” or “inappropriate.”
WeatherBug, owned by GroundTruth, asks users’ permission to collect their location and tells them the information will be used to personalize ads. GroundTruth said that it typically sent the data to ad companies it worked with, but that if they didn’t want the information they could ask to stop receiving it.
Records show a device entering Gracie Mansion, the mayor’s residence, before traveling to a Y.M.C.A. in Brooklyn that the mayor frequents.
It travels to an event on Staten Island that the mayor attended. Later, it returns to a home on Long Island.
Gracie
Mansion
By Michael H. Keller | Satellite imagery by Mapbox and DigitalGlobe
The Times also identified more than 25 other companies that have said in marketing materials or interviews that they sell location data or services, including targeted advertising.
The spread of this information raises questions about how securely it is handled and whether it is vulnerable to hacking, said Serge Egelman, a computer security and privacy researcher affiliated with the University of California, Berkeley.
“There are really no consequences” for companies that don’t protect the data, he said, “other than bad press that gets forgotten about.”
A Question of Awareness
Companies that use location data say that people agree to share their information in exchange for customized services, rewards and discounts. Ms. Magrin, the teacher, noted that she liked that tracking technology let her record her jogging routes.
Brian Wong, chief executive of Kiip, a mobile ad firm that has also sold anonymous data from some of the apps it works with, says users give apps permission to use and share their data. “You are receiving these services for free because advertisers are helping monetize and pay for it,” he said, adding, “You would have to be pretty oblivious if you are not aware that this is going on.”
But Ms. Lee, the nurse, had a different view. “I guess that’s what they have to tell themselves,” she said of the companies. “But come on.”
Ms. Lee had given apps on her iPhone access to her location only for certain purposes — helping her find parking spaces, sending her weather alerts — and only if they did not indicate that the information would be used for anything else, she said. Ms. Magrin had allowed about a dozen apps on her Android phone access to her whereabouts for services like traffic notifications.
An app on Lisa Magrin’s cellphone collected her location information, which was then shared with other companies. The data revealed her daily habits, including hikes with her dog, Lulu.Nathaniel Brooks for The New York Times
But it is easy to share information without realizing it. Of the 17 apps that The Times saw sending precise location data, just three on iOS and one on Android told users in a prompt during the permission process that the information could be used for advertising. Only one app, GasBuddy, which identifies nearby gas stations, indicated that data could also be shared to “analyze industry trends.”
More typical was theScore, a sports app: When prompting users to grant access to their location, it said the data would help “recommend local teams and players that are relevant to you.” The app passed precise coordinates to 16 advertising and location companies.
A spokesman for theScore said that the language in the prompt was intended only as a “quick introduction to certain key product features” and that the full uses of the data were described in the app’s privacy policy.
The Weather Channel app, owned by an IBM subsidiary, told users that sharing their locations would let them get personalized local weather reports. IBM said the subsidiary, the Weather Company, discussed other uses in its privacy policy and in a separate “privacy settings” section of the app. Information on advertising was included there, but a part of the app called “location settings” made no mention of it.
A notice that Android users saw when theScore, a sports app, asked for access to their location data.
The Weather Channel app showed iPhone users this message when it first asked for their location data.
The app did not explicitly disclose that the company had also analyzed the data for hedge funds — a pilot program that was promoted on the company’s website. An IBM spokesman said the pilot had ended. (IBM updated the app’s privacy policy on Dec. 5, after queries from The Times, to say that it might share aggregated location data for commercial purposes such as analyzing foot traffic.)
Even industry insiders acknowledge that many people either don’t read those policies or may not fully understand their opaque language. Policies for apps that funnel location information to help investment firms, for instance, have said the data is used for market analysis, or simply shared for business purposes.
“Most people don’t know what’s going on,” said Emmett Kilduff, the chief executive of Eagle Alpha, which sells data to financial firms and hedge funds. Mr. Kilduff said responsibility for complying with data-gathering regulations fell to the companies that collected it from people.
Many location companies say they voluntarily take steps to protect users’ privacy, but policies vary widely.
For example, Sense360, which focuses on the restaurant industry, says it scrambles data within a 1,000-foot square around the device’s approximate home location. Another company, Factual, says that it collects data from consumers at home, but that its database doesn’t contain their addresses.
In the data set reviewed by The Times, phone locations are recorded in sensitive areas including the Indian Point nuclear plant near New York City. By Michael H. Keller | Satellite imagery by Mapbox and DigitalGlobe
The information from one Sunday included more than 800 data points from over 60 unique devices inside and around a church in New Jersey. By Michael H. Keller | Satellite imagery by Mapbox and DigitalGlobe
Some companies say they delete the location data after using it to serve ads, some use it for ads and pass it along to data aggregation companies, and others keep the information for years.
Several people in the location business said that it would be relatively simple to figure out individual identities in this kind of data, but that they didn’t do it. Others suggested it would require so much effort that hackers wouldn’t bother.
It “would take an enormous amount of resources,” said Bill Daddi, a spokesman for Cuebiq, which analyzes anonymous location data to help retailers and others, and raised more than $27 million this year from investors including Goldman Sachs and Nasdaq Ventures. Nevertheless, Cuebiq encrypts its information, logs employee queries and sells aggregated analysis, he said.
There is no federal law limiting the collection or use of such data. Still, apps that ask for access to users’ locations, prompting them for permission while leaving out important details about how the data will be used, may run afoul of federal rules on deceptive business practices, said Maneesha Mithal, a privacy official at the Federal Trade Commission.
“You can’t cure a misleading just-in-time disclosure with information in a privacy policy,” Ms. Mithal said.
Following the Money
Apps form the backbone of this new location data economy.
The app developers can make money by directly selling their data, or by sharing it for location-based ads, which command a premium. Location data companies pay half a cent to two cents per user per month, according to offer letters to app makers reviewed by The Times.
Targeted advertising is by far the most common use of the information.
Google and Facebook, which dominate the mobile ad market, also lead in location-based advertising. Both companies collect the data from their own apps. They say they don’t sell it but keep it for themselves to personalize their services, sell targeted ads across the internet and track whether the ads lead to sales at brick-and-mortar stores. Google, which also receives precise location information from apps that use its ad services, said it modified that data to make it less exact.
Smaller companies compete for the rest of the market, including by selling data and analysis to financial institutions. This segment of the industry is small but growing, expected to reach about $250 million a year by 2020, according to the market research firm Opimas.
Apple and Google have a financial interest in keeping developers happy, but both have taken steps to limit location data collection. In the most recent version of Android, apps that are not in use can collect locations “a few times an hour,” instead of continuously.
Apple has been stricter, for example requiring apps to justify collecting location details in pop-up messages. But Apple’s instructions for writing these pop-ups do not mention advertising or data sale, only features like getting “estimated travel times.”
A spokesman said the company mandates that developers use the data only to provide a service directly relevant to the app, or to serve advertising that met Apple’s guidelines.
Apple recently shelved plans that industry insiders say would have significantly curtailed location collection. Last year, the company said an upcoming version of iOS would show a blue bar onscreen whenever an app not in use was gaining access to location data.
The discussion served as a “warning shot” to people in the location industry, David Shim, chief executive of the location company Placed, said at an industry event last year.
After examining maps showing the locations extracted by their apps, Ms. Lee, the nurse, and Ms. Magrin, the teacher, immediately limited what data those apps could get. Ms. Lee said she told the other operating-room nurses to do the same.
“I went through all their phones and just told them: ‘You have to turn this off. You have to delete this,’” Ms. Lee said. “Nobody knew.”
Last year, U.S. Customs and Border Protection (CBP) searched through the electronic devices of more than 29,000 travelers coming into the country. CBP officers sometimes upload personal data from those devices to Homeland Security servers by first transferring that data onto USB drives—drives that are supposed to be deleted after every use. But a new government report found that the majority of officers fail to delete the personal data.
The Department of Homeland Security’s internal watchdog, known as the Office of the Inspector General (OIG), released a new report yesterday detailing CBP’s many failures at the border. The new report, which is redacted in some places, explains that Customs officials don’t even follow their own extremely liberal rules.
Customs officials can conduct two kinds of electronic device searches at the border for anyone entering the country. The first is called a “basic” or “manual” search and involves the officer visually going through your phone, your computer or your tablet without transferring any data. The second is called an “advanced search” and allows the officer to transfer data from your device to DHS servers for inspection by running that data through its own software. Both searches are legal and don’t require a warrant or even probable cause—at least they don’t according to DHS.
It’s that second kind of search, the “advanced” kind, where CBP has really been messing up and regularly leaving the personal data of travelers on USB drives.
[The Office of the Inspector General] physically inspected thumb drives at five ports of entry. At three of the five ports, we found thumb drives that contained information copied from past advanced searches, meaning the information had not been deleted after the searches were completed. Based on our physical inspection, as well as the lack of a written policy, it appears [Office of Field Operations] has not universally implemented the requirement to delete copied information, increasing the risk of unauthorized disclosure of travelers’ data should thumb drives be lost or stolen.
It’s bad enough that the government is copying your data as you enter the country. But it’s another thing entirely to know that your data could just be floating around on USB drives that, as the Inspector General’s office admits, could be easily lost or stolen.
The new report found plenty of other practices that are concerning. The report notes that Customs officers regularly failed to disconnect devices from the internet, potentially tainting any findings stored locally on the device. The report doesn’t call out the invasion of privacy that comes with officials looking through your internet-connected apps, but that’s a given.
The watchdog also discovered that Customs officials had “inadequate supervision” to make sure that they were following the rules, and noted that these “deficiencies in supervision, guidance, and equipment management” were making everyone less safe.
But one thing that makes it sometimes hard to read the report is the abundance of redactions. As you can see, the little black boxes have redacted everything from what happens during an advanced search after someone crosses the border to the reason officials are allowed to conduct an advanced search at all:
Screenshot: Department of Homeland Security/Office of the Inspector General
The report notes that an April 2015 memo spells out when an advanced search may be conducted. But, again, that’s been redacted in the report.
Screenshot: Department of Homeland Security/Office of the Inspector General
But the Department of Homeland Security’s own incompetence might be our own saving grace for those concerned about digital privacy. The funniest detail in the new report? U.S. Customs and Border Protection forgot to renew its license for whatever top secret software it uses to conduct these advanced searches.
Screenshot: Department of Homeland Security/Office of the Inspector General
Curiously, the report claims that CBP “could not conduct advanced searches of laptop hard drives, USB drives, and multimedia cards at the ports of entry” from February 1, 2017 through September 12, 2017 because it failed to renew the software license. But one wonders if, in fact, the issue wasn’t resolved for almost a year, then what other “advanced search” methods were being used?
Intelligence agencies in the UK are preparing to “significantly increase their use of large-scale data hacking,” the Guardian reported on Saturday, in a move that is already alarming privacy advocates.
According to the Guardian, UK intelligence officials plan to increase their use of the “bulk equipment interference (EI) regime”—the process by which the Government Communications Headquarters, the UK’s top signals intelligence and cybersecurity agency, collects bulk data off foreign communications networks—because they say targeted collection is no longer enough. The paper wrote:
A letter from the security minister, Ben Wallace, to the head of the intelligence and security committee, Dominic Grieve, quietly filed in the House of Commons library last week, states: “Following a review of current operational and technical realities, GCHQ have … determined that it will be necessary to conduct a higher proportion of ongoing overseas focused operational activity using the bulk EI regime than was originally envisaged.”
The paper noted that during the passage of the 2016 Investigatory Powers Act, which expanded hacking powers available to police and intelligence services including bulk data collection for the latter, independent terrorism legislation reviewer Lord David Anderson asserted that bulk powers are “likely to be only sparingly used.” As the Guardian noted, just two years later, UK intelligence officials are claiming this is no longer the case due to growing use of encryption:
… The intelligence services claim that the widespread use of encryption means that targeted hacking exercises are no longer effective and so more large-scale hacks are becoming necessary. Anderson’s review noted that the top 40 online activities relevant to MI5’s intelligence operations are now encrypted.
“The bulk equipment interference power permits the UK intelligence services to hack at scale by allowing a single warrant to cover entire classes of property, persons or conduct,” Scarlet Kim, a legal officer at UK civil liberties group Liberty International, told the paper. “It also gives nearly unfettered powers to the intelligence services to decide who and when to hack.”
Liberty also took issue with the intelligence agencies’ 180 on how often the bulk powers would be used, as well as with policies that only allow the investigatory powers commissioner to gauge the impact of a warrant after the hacking is over and done with.
“The fact that you have the review only after the privacy has been infringed upon demonstrates how worrying this situation is,”
Labor has backed down completely on its opposition to the Assistance and Access Bill, and in the process has been totally outfoxed by a government that can barely control the floor of Parliament.
After proposing a number of amendments to the Bill, which Labor party members widely called out as inappropriate in the House of Representatives on Thursday morning, the ALP dropped its proposals to allow the Bill to pass through Parliament before the summer break.
“Let’s just make Australians safer over Christmas,” Bill Shorten said on Thursday evening.
“It’s all about putting people first.”
Shorten said Labor is letting the Bill through provided the government agrees to amendments in the new year.
Under the new laws, Australian government agencies would be able to issue three kinds of notices:
Technical Assistance Notices (TAN), which are compulsory notices for a communication provider to use an interception capability they already have;
Technical Capability Notices (TCN), which are compulsory notices for a communication provider to build a new interception capability, so that it can meet subsequent Technical Assistance Notices; and
Technical Assistance Requests (TAR), which have been described by experts as the most dangerous of all.
With Tumblr’s decision this week to ban porn on its platform, everyone’s getting a firsthand look at how bad automated content filters are at the moment. Lawmakers in the European Union want a similar system to filter copyrighted works and, despite expert consensus that this will just fuck up the internet, the legislation moves forward. Now some of the biggest platforms on the web insist we must stop it.
YouTube, Reddit, and Twitch have recently come out publicly against the EU’s new Copyright Directive, arguing that the impending legislation could be devastating to their businesses, their users, and the internet at large.
The Copyright Directive is the first update to the group of nation’s copyright law since 2001, and it’s a major overhaul that is intended to claw back some of the money that copyright holders believe they’ve lost since the internet use exploded around the globe. Fundamentally, its provisions are supposed to punish big platforms like Google for profiting off of copyright infringement and siphon some income back into the hands of those to which it rightfully belongs.
Unfortunately, the way it’s designed will likely make it more difficult for smaller platforms, harm the free exchange information, kill memes, make fair use more difficult to navigate—all the while, tech giants will have the resources to survive the wreckage. You don’t have to take my word for it, listen to Tim-Berners Lee, the father of the world wide web, and the other 70 top technologists that signed a letter arguing against the legislation back in June.
So far, this issue hasn’t received the kind of attention that, say, net neutrality did, at least in part because it’s very complicated to explain and it takes a while for these kinds of things to sink in. We’ve outlined the details in the past on multipleoccasions. The main thing to understand is that critics take issue with two pieces of the legislation.
Article 11, better known as a “link tax,” would require online platforms to purchase a license to link out to other sites or quotes from articles. That’s the part that threatens the free spread of information.
Article 13 dictates that online platforms install some sort of monitoring system that lets copyright holders upload their work for automatic detection. If something sneaks by the system’s filters, the platform could face full penalties for copyright infringement. For example, a SpongeBob meme could be flagged and blocked because of its source image belonging to Nickelodeon; or a dumb vlog could be flagged and blocked because there’s a sponge in the background and the dumb filter thought it was SpongeBob.
Back in 2015, Facebook had a pickle of a problem. It was time to update the Android version of the Facebook app, and two different groups within Facebook were at odds over what the data grab should be.
The business team wanted to get Bluetooth permissions so it could push ads to people’s phones when they walked into a store. Meanwhile, the growth team, which is responsible for getting more and more people to join Facebook, wanted to get “Read Call Log Permission” so that Facebook could track everyone whom Android user called or texted with in order to make better friend recommendations to them. (Yes, that’s how Facebook may have historically figured out with whom you went on one bad Tinder date and then plopped them into “People You May Know.”) According to internal emails recently seized by the UK Parliament, Facebook’s business team recognized that what the growth team wanted to do was incredibly creepy and was worried it was going to cause a PR disaster.
In a February 4, 2015, email that encapsulates the issue, Facebook Bluetooth Beacon product manager Mike Lebeau is quoted saying that the request for “read call log” permission was a “pretty high-risk thing to do from a PR perspective but it appears that the growth team will charge ahead and do it.”
LeBeau was worried because a “screenshot of the scary Android permissions screen becomes a meme (as it has in the past), propagates around the web, it gets press attention, and enterprising journalists dig into what exactly the new update is requesting.” He suggested a possible headline for those journalists: “Facebook uses new Android update to pry into your private life in ever more terrifying ways – reading your call logs, tracking you in businesses with beacons, etc.” That’s a great and accurate headline. This guy might have a future as a blogger.
At least he called the journalists “enterprising” instead of “meddling kids.”
Then a man named Yul Kwon came to the rescue saying that the growth team had come up with a solution! Thanks to poor Android permission design at the time, there was a way to update the Facebook app to get “Read Call Log” permission without actually asking for it. “Based on their initial testing, it seems that this would allow us to upgrade users without subjecting them to an Android permissions dialog at all,” Kwon is quoted. “It would still be a breaking change, so users would have to click to upgrade, but no permissions dialog screen. They’re trying to finish testing by tomorrow to see if the behavior holds true across different versions of Android.”
Oh yay! Facebook could suck more data from users without scaring them by telling them it was doing it! This is a little surprising coming from Yul Kwon because he is Facebook’s chief ‘privacy sherpa,’ who is supposed to make sure that new products coming out of Facebook are privacy-compliant. I know because I profiled him, in a piece that happened to come out the same day as this email was sent. A member of his team told me their job was to make sure that the things they’re working on “not show up on the front page of the New York Times” because of a privacy blow-up. And I guess that was technically true, though it would be more reassuring if they tried to make sure Facebook didn’t do the creepy things that led to privacy blow-ups rather than keeping users from knowing about the creepy things.
I reached out to Facebook about the comments attributed to Kwon and will update when I hear back.
Thanks to this evasion of permission requests, Facebook users did not realize for years that the company was collecting information about who they called and texted, which would have helped explain to them why their “People You May Know” recommendations were so eerily accurate. It only came to light earlier this year, three years after it started, when a few Facebook users noticed their call and text history in their Facebook files when they downloaded them.
When that was discovered March 2018, Facebook played it off like it wasn’t a big deal. “We introduced this feature for Android users a couple of years ago,” it wrote in a blog post, describing it as an “opt-in feature for people using Messenger or Facebook Lite on Android.”
Facebook continued: “People have to expressly agree to use this feature. If, at any time, they no longer wish to use this feature they can turn it off in settings, or here for Facebook Lite users, and all previously shared call and text history shared via that app is deleted.”
Facebook included a photo of the opt-in screen in its post. In small grey font, it informed people they would be sharing their call and text history.
This particular email was seized by the UK Parliament from the founder of a start-up called Six4Three. It was one of many internal Facebook documents that Six4Three obtained as part of discovery in a lawsuit it’s pursuing against Facebook for banning its Pikinis app, which allowed Facebook users to collect photos of their friends in bikinis. Yuck.
Facebook has a lengthy response to many of the disclosures in the documents including to the discussion in this particular email:
Call and SMS History on Android
This specific feature allows people to opt in to giving Facebook access to their call and text messaging logs in Facebook Lite and Messenger on Android devices. We use this information to do things like make better suggestions for people to call in Messenger and rank contact lists in Messenger and Facebook Lite. After a thorough review in 2018, it became clear that the information is not as useful after about a year. For example, as we use this information to list contacts that are most useful to you, old call history is less useful. You are unlikely to need to call someone who you last called over a year ago compared to a contact you called just last week.
: No, your phone is not “listening” to you in the strictest sense of the word. But, yes, all your likes, dislikes and preferences are clearly being heard by apps in your phone which you oh-so-easily clicked “agree” to the terms of which while installing.
How so?
If you are in India, the answer to the question will lead you to Zapr, a service backed by heavyweights such as the Rupert Murdoch-led media group Star, Indian e-commerce leader Flipkart, Indian music streaming service Saavn, and mobile phone maker Micromax, among more than a dozen others. The company owning Zapr is named Red Brick Lane Marketing Solutions Pvt Ltd. (Paytm founder Vijay Shekhar Sharma and Sanjay Nath, co-founder and managing partner, Blume Ventures, were early investors in Zapr but are no longer so, according to filings with the ministry of corporate affairs. Sharma and Blume are among the investors in Sourcecode Media Pvt Ltd, which owns FactorDaily.)
Zapr, in fact, is one of the few companies in the world that has developed a solution that uses your mobile device’s microphone to recognise the media content you are watching or listening to in order to help brands and channels understand consumer media consumption. In short, it monitors sounds around you to contextualise you better for advertising and marketing targeting.
[…]
Advertisers globally spend some $650 billion annually and this cohort believes better profiling consumers by analysing their ambient sounds helps target advertising better. This group includes Chinese company ACRCloud, Audible Magic from the US, and the Netherlands’s Betagrid Media — and, Zapr from India.
Cut back to the Zapr headquarters on Old Madras Road in Bengaluru. One of the apps that inspired Zapr’s founding team was the popular music detection and identification app Shazam. But, its three co-founders saw opportunity in going further. “Instead of detecting music, can we detect all kinds of medium? Can we detect television? Can we detect movies in a theatre? Can we detect video on demand? Can we really build a profile for a user about their media consumption habits… and that really became the idea, the vision we wanted to solve for,” Sandipan Mondal, CEO of Zapr Media Labs, said in an interview last week on Thursday.
[…]
But, Zapr’s tech comes with privacy and data concerns – lots of it. The way its tech gets into your phone is dodgy: its code ride on third-party apps ranging from news apps to gaming apps to video streaming apps. You might be downloading Hotstar or a Dainik Jagran app or a Chotta Beem app on your phone little knowing that Zapr’s or an equivalent audio monitoring code sits on those apps to listen to sounds around you in an attempt to see what media content you are consuming.
In most cases reviewed by FactorDaily in a two-week exercise, it was not obvious that the app would monitor audio via the smartphone or mobile device’s microphone for use by another party (Zapr) for ad targeting purposes. Some apps hinted about Zapr’s tech at the bottom of the app description and some in the form of a pop-up – an app from Nazara games, for instance, mentioned that it required mic access to ‘Record Audio for better presentation’. Sometimes, the pop-up app would show up a few days after the download. And, often, the disclosure was buried somewhere in the app’s privacy policy.
None of these apps made it clear explicitly what the audio access via the microphone was for. “The problem with apps which embed this technology is that their presence is not outright disclosed and is difficult to find. Also, there is not an easy way to find out the apps in the PlayStore that have this tech embedded in them,” said Thejesh G N, an info-activist and the founder of DataMeet, a community of data scientists and open data enthusiasts.
Dong Mingzhu, chairwoman of China’s biggest maker of air conditioners Gree Electric Appliances, who found her face splashed on a huge screen erected along a street in the port city of Ningbo that displays images of people caught jaywalking by surveillance cameras.
That artificial intelligence-backed surveillance system, however, erred in capturing Dong’s image on Wednesday from an advertisement on the side of a moving bus.
The traffic police in Ningbo, a city in the eastern coastal province of Zhejiang, were quick to recognise the mistake, writing in a post on microblog Sina Weibo on Wednesday that it had deleted the snapshot. It also said the surveillance system would be completely upgraded to cut incidents of false recognition in future.
[…]
Since last year, many cities across China have cracked down on jaywalking by investing in facial recognition systems and advanced AI-powered surveillance cameras. Jaywalkers are identified and shamed by displaying their photographs on large public screens.
First-tier cities like Beijing and Shanghai were among the first to employ those systems to help regulate traffic and identify drivers who violate road rules, while Shenzhen traffic police began displaying photos of jaywalkers on large screens at major intersections from April last year.
Next time you’re chatting with a customer service agent online, be warned that the person on the other side of your conversation might see what you’re typing in real time. A reader sent us the following transcript from a conversation he had with a mattress company after the agent responded to a message he hadn’t sent yet.
Something similar recently happened to HmmDaily’s Tom Scocca. He got a detailed answer from an agent one second after he hit send.
Googling led Scocca to a live chat service that offers a feature it calls “real-time typing view” to allow agents to have their “answers prepared before the customer submits his questions.” Another live chat service, which lists McDonalds, Ikea, and Paypal as its customers, calls the same feature “message sneak peek,” saying it will allow you to “see what the visitor is typing in before they send it over.” Salesforce Live Agent also offers “sneak peak.”
On the upside, you get fast answers. On the downside, your thought process is being unknowingly observed. For the creators, this is technological magic, a deception that will result, they hope, in amazement and satisfaction. But once revealed by an agent who responds too quickly or one who responds before the question is asked, the trick falls apart, and what is left behind feels distinctly creepy, like a rabbit pulled from a hat with a broken neck. “Why give [customers] a fake ‘Send message’ button while secretly transmitting their messages all along?” asks Scocca.
UK authorities should not be granted access to data held by American companies because British laws don’t meet human rights obligations, nine nonprofits have said.
In a letter to the US Department of Justice, organisations including Human Rights Watch and the Electronic Frontier Foundation set out their concerns about the UK’s surveillance and data retention regimes.
They argue that the nation doesn’t adhere to human rights obligations and commitments, and therefore it should not be allowed to request data from US companies under the CLOUD Act, which Congress slipped into the Omnibus Spending Bill earlier this year.
The law allows US government to sign formal, bilateral agreements with other countries setting standards for cross-border investigative requests for digital evidence related to serious crime and terrorism.
It requires that these countries “adhere to applicable international human rights obligations and commitments or demonstrate respect for international universal human rights”. The civil rights groups say the UK fails to make the grade.
As such, it urged the US administration not to sign an executive order allowing the UK to request access to data, communications content and associated metadata, noting that the CLOUD Act “implicitly acknowledges” some of the info gathered might relate to US folk.
Critics are concerned this could then be shared with US law enforcement, thus breaking the Fourth Amendment, which requires a warrant to be served for the collection of such data.
Setting out the areas in which the UK falls short, the letter pointed to pending laws on counter-terrorism, saying that, as drafted they would “excessively restrict freedom of expression by criminalizing clicking on certain types of online content”.
On the internet, there are certain institutions we have come to rely on daily to keep truth from becoming nebulous or elastic. Not necessarily in the way that something stupid like Verrit aspired to, but at least in confirming that you aren’t losing your mind, that an old post or article you remember reading did, in fact, actually exist. It can be as fleeting as using Google Cache to grab a quickly deleted tweet, but it can also be as involved as doing a deep dive of a now-dead site’s archive via the Wayback Machine. But what happens when an archive becomes less reliable, and arguably has legitimate reasons to bow to pressure and remove controversial archived material?
A few weeks ago, while recording my podcast, the topic turned to the old blog written by The Ultimate Warrior, the late bodybuilder turned chiropractic student turned pro wrestler turned ranting conservative political speaker under his legal name of, yes, “Warrior.” As described by Deadspin’s Barry Petchesky in the aftermath of Warrior’s 2014 passing, he was “an insane dick,” spouting off in blogs and campus speeches about people with disabilities, gay people, New Orleans residents, and many others. But when I went looking for a specific blog post, I saw that the blogs were not just removed, the site itself was no longer in the Internet Archive, replaced by the error message: “This URL has been excluded from the Wayback Machine.”
Apparently, Warrior’s site had been de-archived for months, not long after Rob Rousseau pored over it for a Vice Sports article on the hypocrisy of WWE using Warrior’s image for their Breast Cancer Awareness Month campaign. The campaign was all about getting women to “Unleash Your Warrior,” completewithanUltimateWarriormotif, but since Warrior’s blogs included wishing death on a cancer-survivor, this wasn’t a good look. Rousseau was struck by how the archive was removed “almost immediately after my piece went up, like within that week,” he told Gizmodo.
Rousseau suspected that WWE was somehow behind it, but a WWE spokesman told Gizmodo that they were not involved. Steve Wilton, the business manager for Ultimate Creations also denied involvement. A spokesman for the Internet Archive, though, told Gizmodo that the archive was removed because of a DMCA takedown request from the company’s business manager (Wilton’s job for years) on October 29, 2017, two days after the Vice article was published. (He has not replied to a follow-up email about the takedown request.)
Over the last few years, there has been a change in how the Wayback Machine is viewed, one inspired by the general political mood. What had long been a useful tool when you came across broken links online is now, more than ever before, seen as an arbiter of the truth and a bulwark against erasing history.
That archive sites are trusted to show the digital trail and origin of content is not just a must-use tool for journalists, but effective for just about anyone trying to track down vanishing web pages. With that in mind, that the Internet Archive doesn’t really fight takedown requests becomes a problem. That’s not the only recourse: When a site admin elects to block the Wayback crawler using a robots.txt file, the crawling doesn’t just stop. Instead, the Wayback Machine’s entire history of a given site is removed from public view.
In other words, if you deal in a certain bottom-dwelling brand of controversial content and want to avoid accountability, there are at least two different, standardized ways of erasing it from the most reliable third-party web archive on the public internet.
For the Internet Archive, like with quickly complying with takedown notices challenging their seemingly fair use archive copies of old websites, the robots.txt strategy, in practice, does little more than mitigating their risk while going against the spirit of the protocol. And if someone were to sue over non-compliance with a DMCA takedown request, even with a ready-made, valid defense in the Archive’s pocket, copyright litigation is still incredibly expensive. It doesn’t matter that the use is not really a violation by any metric. If a rightsholder makes the effort, you still have to defend the lawsuit.
“The fair use defense in this context has never been litigated,” noted Annemarie Bridy, a law professor at the University of Idaho and an Affiliate Scholar at the Center for Internet and Society at Stanford Law School. “Internet Archive is a non-profit, so the exposure to statutory damages that they face is huge, and the risk that they run is pretty great … given the scope of what they do; that they’re basically archiving everything that is on the public web, their exposure is phenomenal. So you can understand why their impulse might be to act cautiously even if that creates serious tension with their core mission, which is to create an accurate historical archive of everything that has been there and to prevent people from wiping out evidence of their history.”
While the Internet Archive did not respond to specific questions about its robots.txt policy, its proactive response to takedown requests, or if any potential fair use defenses have been tested by them in court, a spokesperson did send this statement along:
Several months after the Wayback Machine was launched in late 2001, we participated with a group of outside archivists, librarians, and attorneys in the drafting of a set of recommendations for managing removal requests (the Oakland Archive Policy) that the Internet Archive more or less adopted as guidelines over the first decade or so of the Wayback Machine.
Earlier this year, we convened with a similar group to review those guidelines and explore the potential value of an updated version. We are still pondering many issues and hope that before too long we might be able to present some updated information on our site to better help the public understand how we approach take down requests. You can find some of our thoughts about robots.txt at http://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/.
At the end of the day, we strive to strike a balance between the concerns that site owners and rights holders sometimes bring to us with the broader public interest in free access for everyone to a history of the Internet that is as comprehensive as possible.
All of that said, the Internet Archive has always held itself out to be a library; in theory, shouldn’t that matter?
“Under current copyright law, although there are special provisions that give certain rights to libraries, there is no definition of a library,” explained Brandon Butler, the Director of Information Policy for the University of Virginia Library. “And that’s a thing that rights holders have always fretted over, and they’ve always fretted over entities like the Internet Archive, which aren’t 200-year-old public libraries, or university-affiliated libraries. They often raise up a stand that there will be faux libraries, that they’d call themselves libraries but it’s really just a haven for piracy. That specter of the sort of sham library really hasn’t arisen.” The lone exception that Butler could think of was when American Buddha, a non-profit, online library of Buddhist texts, found itself sued by Penguin over a few items that they asserted copyright over. “The court didn’t really care that this place called itself a library; it didn’t really shield them from any infringement allegations.” That said, as Butler notes, while being a library wouldn’t necessarily protect the Internet Archive as much as it could, “the right to make copies for preservation,” as Butler puts it, is definitely a point in their favor.
That said, “libraries typically don’t get sued; it’s bad PR,” Butler says. So it’s not like there’s a ton of modern legal precedent about libraries in the digital age, barring some outliers like the various Google Books cases.
As Bridy notes, in the United States, copyright is “a commercial right.” It’s not about reputational harm, it’s about protecting the value of a work and, more specifically, the ability to continuously make money off of it. “The reason we give it is we want artists and creative people to have an incentive to publish and market their work,” she said. “Using copyright as a way of trying to control privacy or reputation … it can be used that way, but you might argue that’s copyright misuse, you might argue it falls outside of the ambit of why we have copyright.”
We take a lot of things for granted, especially as we rely on technology more and more. “The internet is forever” may beacommonrefraininthemedia, and the underlying wisdom about being careful may be sound, but it is also not something that should be taken literally. People delete posts. Websites and entire platforms disappear for business and other reasons. Rich, famous, and powerful bad actors don’t care about intimidating small non-profit organizations. It’s nice to have safeguards, but there are limits to permanence on the internet, and where there are limits, there are loopholes.
When Shan Junhua bought his white Tesla Model X, he knew it was a fast, beautiful car. What he didn’t know is that Tesla constantly sends information about the precise location of his car to the Chinese government.
Tesla is not alone. China has called upon all electric vehicle manufacturers in China to make the same kind of reports — potentially adding to the rich kit of surveillance tools available to the Chinese government as President Xi Jinping steps up the use of technology to track Chinese citizens.
“I didn’t know this,” said Shan. “Tesla could have it, but why do they transmit it to the government? Because this is about privacy.”
More than 200 manufacturers, including Tesla, Volkswagen, BMW, Daimler, Ford, General Motors, Nissan, Mitsubishi and U.S.-listed electric vehicle start-up NIO, transmit position information and dozens of other data points to government-backed monitoring centers, The Associated Press has found. Generally, it happens without car owners’ knowledge.
The automakers say they are merely complying with local laws, which apply only to alternative energy vehicles. Chinese officials say the data is used for analytics to improve public safety, facilitate industrial development and infrastructure planning, and to prevent fraud in subsidy programs.
China has ordered electric car makers to share real-time driving data with the government. The country says it’s to ensure safety and improve the infrastructure, but critics worry the tracking can be put to more nefarious uses. (Nov. 29)
But other countries that are major markets for electronic vehicles — the United States, Japan, across Europe — do not collect this kind of real-time data.
And critics say the information collected in China is beyond what is needed to meet the country’s stated goals. It could be used not only to undermine foreign carmakers’ competitive position, but also for surveillance — particularly in China, where there are few protections on personal privacy. Under the leadership of Xi Jinping, China has unleashed a war on dissent, marshalling big data and artificial intelligence to create a more perfect kind of policing, capable of predicting and eliminating perceived threats to the stability of the ruling Communist Party.
There is also concern about the precedent these rules set for sharing data from next-generation connected cars, which may soon transmit even more personal information.