
On December 28th, Bob Diachenko, Director of Cyber Risk Research at Hacken.io and bug bounty platform HackenProof, analyzed the data stream of BinaryEdge search engine and identified an open and unprotected MongoDB instance:
The same IP also appeared in Shodan search results:
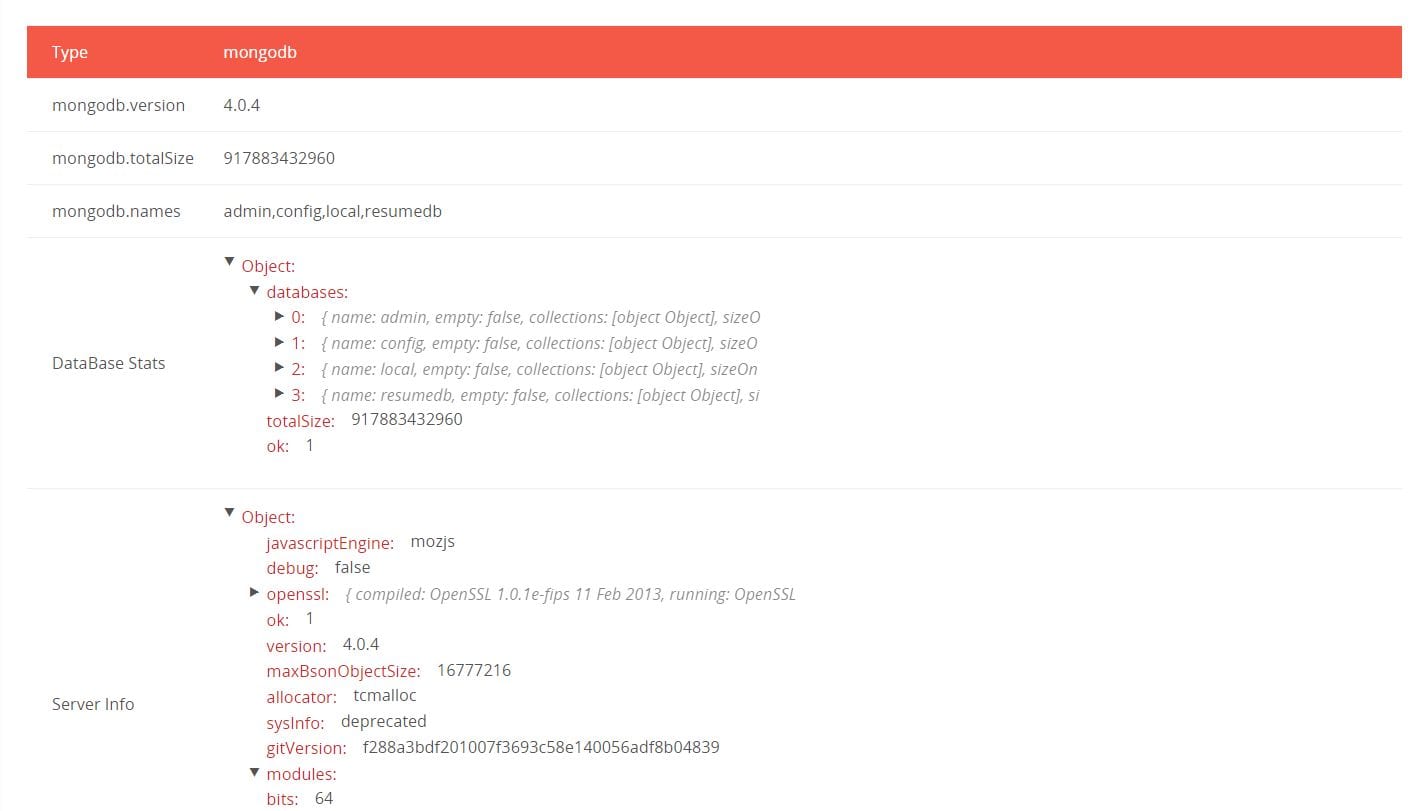
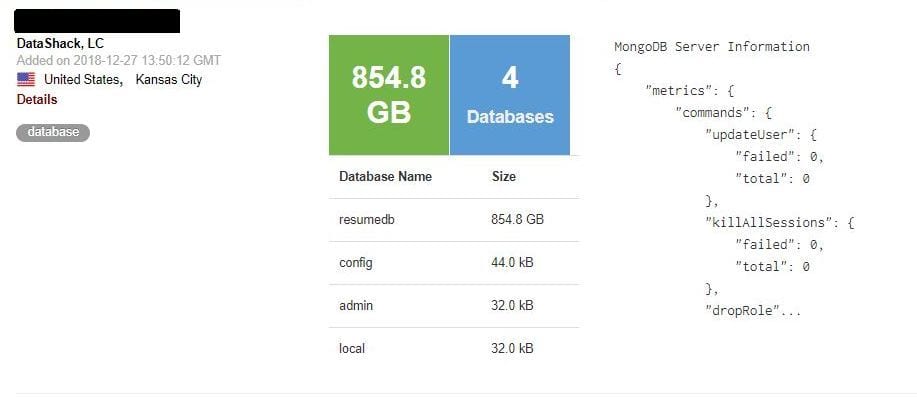
Upon closer inspection, an 854 GB sized MongoDB database was left unattended, with no password/login authentication needed to view and access the details of what appeared to be more than 200 million very detailed resumes of Chinese job seekers.
Each of the 202,730,434 records contained the details not only on the candidates’ skills and work experience but also on their personal info, such as mobile phone number, email, marriage, children, politics, height, weight, driver license, literacy level, salary expectations and more.
See more details in the PDF factsheet
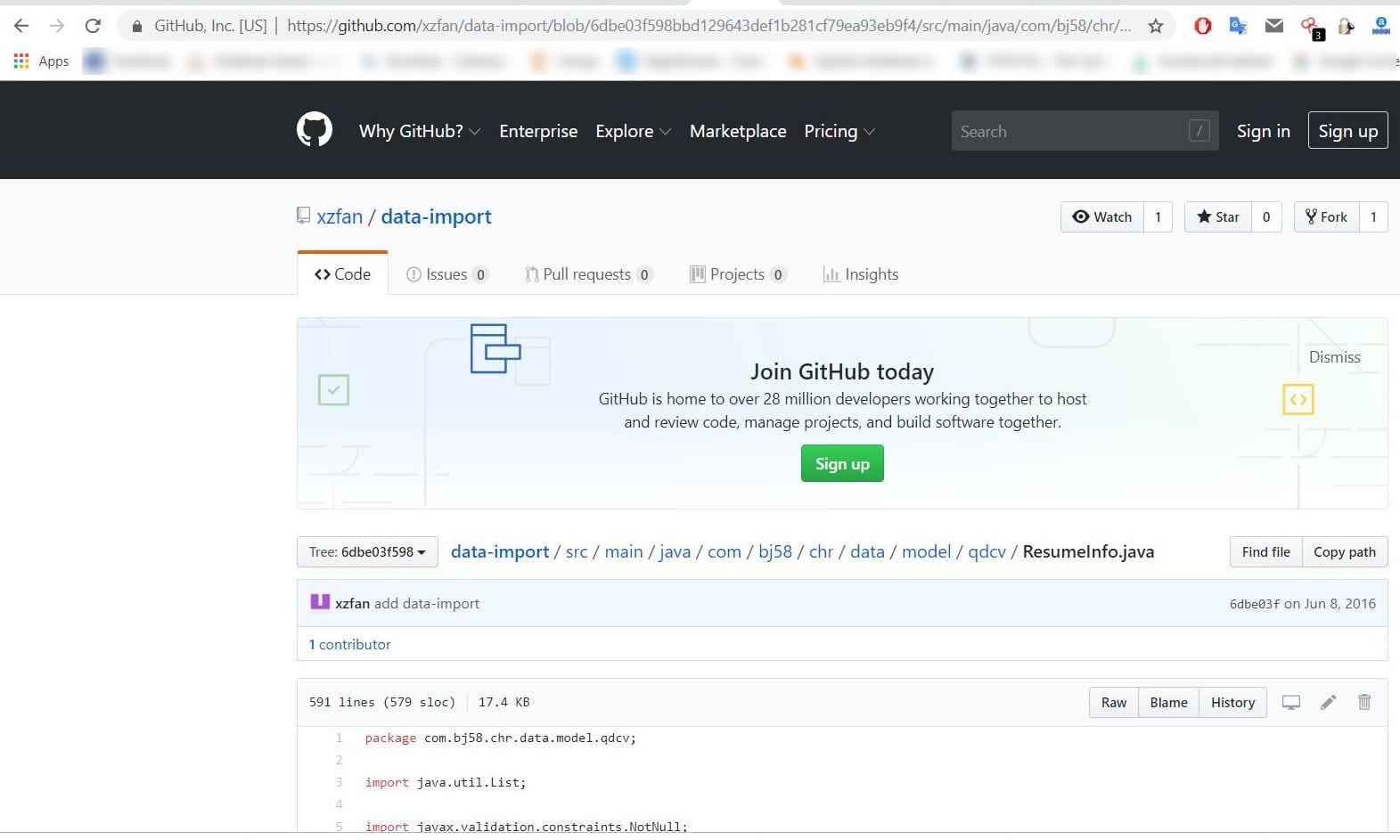
The origin of the data remained unknown until one of my Twitter followers pointed to a GitHub repository (page is no longer available but it is still saved in Google cache) which contained a web app source code with identical structural patterns as those used in the exposed resumes:
The tool named “data-import” (created 3 years ago) seems to have been created to scrape data (resumes) from different Chinese classifieds, like bj.58.com and others.
It is unknown, whether it was an official application or illegal one used to collect all the applicants’ details, even those labeled as ‘private’.
Upon additional request, the security team of BJ.58.com did not confirm that the data originated from their source:
We have searched all over the database of us and investigated all the other storage, turned out that the sample data is not leaked from us.
It seems that the data is leaked from a third party who scrape data from many CV websites.
Shortly after my notification on Twitter, the database had been secured. It’s worth noting that MongoDB log showed at least a dozen IPs who might have accessed the data before it was taken offline.
Source: No more privacy: 202 Million private resumes exposed – HackenProof Blog

Robin Edgar
Organisational Structures | Technology and Science | Military, IT and Lifestyle consultancy | Social, Broadcast & Cross Media | Flying aircraft