After ten years of toiling, the team has demonstrated in a paper published on Thursday in the journal Optica the development of a laser with record-breaking intensity over 10²³ watts per square centimeter. Nam told Motherboard in an email that you can compare the intensity of this laser beam to the combined power of all of the sunlight across the entire planet, but pressed together into roughly the size of a speck of dust or a single red blood cell. This whole burst of power happens in just fractions of a second.
“The laser intensity of 10²³ W/cm² is comparable to the light intensity obtainable by focusing all the sunlight reaching Earth to a spot of 10 microns,” explained Nam.
To achieve this effect, Nam and colleagues at the Center for Relativistic Laser Science (CoReLS) lab constructed a kind of obstacle course for the laser beam to pass through to amplify, reflect, and control the motion of the photons comprising it. Because light behaves as both a particle (e.g. individual photons) as well as a wave, controlling the wavefront of this laser (similar to the front of an ocean wave) was crucial to make sure the team could actually focus its power.
Nam explains that the technology to make this kind of precise control possible has been years in the making.
“We have developed ultrahigh power femtosecond lasers for more than a decade, reaching the output power of 4 PW (1015 W) in 2017,” says Nam. “We then developed the laser technology to focus the beam size of 28 cm to 1 micron, for which we have to make the laser wavefront superb using a deformable mirror.”
[…]
Beyond being a scientific breakthrough, Nam said that this high-intensity laser will open doors to explore some of the universe’s most fundamental questions that had previously only been explored by theoreticians.
“With such ultrahigh laser intensity we can tackle such phenomena as electron-positron pair production from light-light interactions… This kind of phenomena is supposed to happen in the early universe, plasma jets from supernova explosions and from black holes,” said Nam.
Thanks to these lasers, and even more powerful ones yet to come, Nam says that it will now be possible to explore these cosmic rays in the lab instead of just through simulations and theories. Using laser pulses, the researchers will be able to make and collide high energy electrons with photons, recreating the Compton scattering effect that scientists believe creates such high-energy cosmic rays.
Nam also said that these lasers have a more terrestrial purpose as well in the form of cancer treatment technology.
Proton therapy is a newer cancer treatment that directs positively charged proton beams to patients’ tumors using an accelerator. While this technique has shown promise, the use of an accelerator also requires a large, and expensive, radiation shield.
Nam proposes that using laser beams to direct these protons instead could be a more cost-efficient solution and may get this treatment into the hands of even more patients.
Russian spies from APT29 responded to Western agencies outing their tactics by adopting a red-teaming tool to blend into targets’ networks as a legitimate pentesting exercise.
Now, the UK’s National Cyber Security Centre (NCSC) and the US warn, the SVR is busy exploiting a dozen critical-rated vulns (including RCEs) in equipment ranging from Cisco routers through to VMware virtualization kit – and the well-known Pulse Secure VPN flaw, among others.
“In one example identified by the NCSC, the actor had searched for authentication credentials in mailboxes, including passwords and PKI keys,” warned the GCHQ offshoot today.
Roughly equivalent to MI6 mixed with GCHQ, the SVR is Russia’s foreign intelligence service and is known to infosec pros as APT29. A couple of weeks ago, Britain and the US joined forces to out the SVR’s Tactics, Techniques and Procedures (TTPs), giving the world’s infosec defenders a chance to look out for the state-backed hackers’ fingerprints on their networked infrastructure.
On top of all that the SVR is also posing as legitimate red-team pentesters: looking for easy camouflage, the spies hopped onto GitHub and downloaded the free open-source Sliver red-teaming platform, in what the NCSC described as “an attempt to maintain their accesses.”
There are more vulns being abused by the Russians and the full NCSC advisory on what these are can be read on the NCSC website. The advisory includes YARA and Snort rules.
The Department of Justice quietly seized phone records and tried to obtain email records for three Washington Post reporters, ostensibly over their coverage of then-U.S. Attorney General Jeff Sessions and Russia’s role in the 2016 presidential election, according to officials and government letters reviewed by the Post.
Justice Department regulations typically mandate that news organizations be notified when it subpoenas such records. However, though the Trump administration OK’d the decision, officials apparently left the notification part for the Biden administration to deal with. I guess they just never got around to it. Probably too busy inspiring an insurrection and trying to overthrow the presidential election.
In three separate letters dated May 3 addressed to reporters Ellen Nakashima, Greg Miller, and former reporter Adam Entous, the Justice Department wrote they were “hereby notified that pursuant to legal process the United States Department of Justice received toll records associated with the following telephone numbers for the period from April 15, 2017 to July 31, 2017,” according to the Post. Listed were Miller’s work and cellphone numbers, Entous’ cellphone number, and Nakashima’s work, cellphone, and home phone numbers. These records included all calls to and from the phones as well as how long each call lasted but did not reveal what was said.
According to the letters, the Post reports that prosecutors also secured a court order to seize “non content communications records” for the reporters’ email accounts, which would disclose who emailed whom and when the emails were sent but not their contents. However, officials ultimately did not obtain these records, the outlet said.
[…]
“We are deeply troubled by this use of government power to seek access to the communications of journalists,” said the Post’s acting executive editor Cameron Barr. “The Department of Justice should immediately make clear its reasons for this intrusion into the activities of reporters doing their jobs, an activity protected under the First Amendment.”
Frustratingly, the letters apparently don’t go into why the Department of Justice seized this data. A department spokesperson told the outlet that the decision to do so was made in 2020 during the Trump administration. (It’s worth noting that former President Donald Trump has made it crystal clear that he despises news media and the government leakers that provide them their scoops.)
Based on the time period cited in the letters and what the reporters covered during those months, the Post speculates that their investigations into Sessions and Russian interference could be why the department wanted to get its hands on their phone data.
You probably haven’t seen PimEyes, a mysterious facial-recognition search engine, but it may have spotted you.
If you upload a picture of your face to PimEyes’ website, it will immediately show you any pictures of yourself that the company has found around the internet. You might recognize all of them, or be surprised (or, perhaps, even horrified) by some; these images may include anything from wedding or vacation snapshots to pornographic images.
PimEyes is open to anyone with internet access.
[…]
Imagine a potential employer digging into your past, an abusive ex tracking you, or a random stranger snapping a photo of you in public and then finding you online. This is all possible through PimEyes
[…]
PimEyes lets users see a limited number of small, somewhat pixelated search results at no cost, or you can pay a monthly fee, which starts at $29.99, for more extensive search results and features (such as to click through to see full-size images on the websites where PimEyes found them and to set up alerts for when PimEyes finds new pictures of faces online that its software believes match an uploaded face).
The company offers a paid plan for businesses, too: $299.99 per month lets companies conduct unlimited searches and set up 500 alerts.
[…]
while Clearview AI built its massive stockpile of faces in part by scraping images from major social networks (it was subsequently served with cease-and-desist notices by Facebook, Google, and Twitter, sued by several civil rights groups, and declared illegal in Canada), PimEyes said it does not scrape images from social media.
[…]
I wanted to learn more about how PimEyes works, and why it’s open to anyone, as well as who’s behind it. This was much trickier than uploading my own face to the website. The website currently lists no information about who owns or runs the search engine, or how to reach them, and users must submit a form to get answers to questions or help with accounts.
Poring over archived images of the website via the Internet Archive’s Wayback Machine, as well as other online sources, yielded some details about the company’s past and how it has changed over time.
The Pimeyes.com website was initially registered in March 2017, according to a domain name registration lookup conducted through ICANN (Internet Corporation for Assigned Names and Numbers). An “about” page on the Pimeyes website, as well as some news stories, shows it began as a Polish startup.
An archived image of the website’s privacy policy indicated that it was registered as a business in Wroclaw, Poland, as of August 2020. This changed soon after: The website’s privacy policy currently states that PimEyes’ administrator, known as Face Recognition Solutions Ltd., is registered at an address in the Seychelles. An online search of the address — House of Francis, Room 303, Ile Du Port, Mahe, Seychelles — indicated a number of businesses appear to use the same exact address.
CNN says it’s a contrast with Clearview AI because they supposedly limit their database to law enforcement. The problem with Clearview was partially that they didn’t limit access at all, giving out free accounts to anyone and everyone.
One of the USA’s largest oil pipelines has been shut by ransomware, leading the nation’s Federal Motor Carrier Safety Administration to issue a regional emergency declaration permitting the transport of fuel by road.
The Colonial Pipeline says it carries 100 million gallons a day of refined fuels between Houston, Texas, and New York Harbor, or 45 percent of all fuel needed on the USA’s East Coast. The pipeline carries fuel for cars and trucks, jet fuel, and heating oil.
It’s been offline since May 7, according to a company statement, due to what the outfit described as “… a cybersecurity attack [that] involves ransomware.”
It added: “In response, we proactively took certain systems offline to contain the threat, which has temporarily halted all pipeline operations, and affected some of our IT systems.”
[…]
In a statement on May 10 fingering the culprits of the attack, the FBI said “the Darkside ransomware is responsible for the compromise of the Colonial Pipeline networks. We continue to work with the company and our government partners on the investigation.”
Meanwhile, on its Tor-hidden website, the Darkside crew seems to regret the attention it has drawn from Uncle Sam. “From today we introduce moderation and check each company that our partners want to encrypt to avoid social consequences in the future,” it wrote.
After facing international backlash over impending updates to its privacy policy, WhatsApp has ever-so-slightly backtracked on the harsh consequences it initially planned for users who don’t accept them—but not entirely.
In an update to the company’s FAQ page, WhatsApp clarifies that no users will have their accounts deleted or instantly lose app functionality if they don’t accept the new policies. It’s a step back from what WhatsApp had been telling users up until this point. When this page was first posted back in February, it specifically told users that those who don’t accept the platform’s new policies “won’t have full functionality” until they do. The threat of losing functionality is still there, but it won’t be automatic.
“For a short time, you’ll be able to receive calls and notifications, but won’t be able to read or send messages from the app,” WhatsApp wrote at the time. While the deadline to accept was initially early February, the blowback the company got from, well, just about everyone, caused the deadline to be postponed until May 15—this coming Saturday.
After that, folks that gave the okay to the new policy won’t notice any difference to their daily WhatsApp experience, and neither will the people that didn’t—at least at first. “After a period of several weeks, the reminder [to accept] people receive will eventually become persistent,” WhatsApp wrote, adding that users getting these “persistent” reminders will see their app stymied pretty significantly: For a “few weeks,” users won’t be able to access their chat lists, but will be able to answer incoming phone and video calls made over WhatsApp. After that grace period, WhatsApp will stop sending messages and calls to your phone entirely (until you accept).
[…]
It’s worth mentioning here that if you keep the app installed but still refuse to accept the policy for whatever reason, WhatsApp won’t outright delete your account because of that. That said, WhatsApp will probablydelete your account due to “inactivity” if you don’t connect for 120 days, as is WhatsApp policy.
[…]
While the company has done the bare minimum in explaining what this privacy policy update actually means, the company hasn’t done much to assuage the concerns of lawyers, lawmakers, or really anyone else. And it doesn’t look like these new “reminders” will put them at ease, either.
Earlier this year fans reversed engineered the source code to Grand Theft Auto III and Grand Theft Auto: Vice City. They released it to the web, but Grand Theft Auto copyright holder Take-Two pulled it offline via a DMCA claim. But one fan stood up to the publisher and has now succeeded in getting the reverse-engineered source code back online.
Deriving the source code through reverse-engineering was a huge milestone for the GTA hacking scene. Players would still need the original game assets to run either classic GTA title, but with accessible source code, modders and devs could begin porting the game to new platforms or adding new features. That’s exactly what’s happened this past year with Super Mario 64.
However, as TorrentFreak reports, a New Zealand-based developer named Theo, who maintained a fork of the removed code, didn’t agree with Take-Two’s claims and pushed back, filing their own counter-notice with GitHub last month. This counter-claim seems to have succeeded, as GitHub’s made the fan-derived source code available to download once more.
Theo explained in their counter-claim that the code didn’t, in fact, contain any original work created or owned by Take-Two Interactive, so it should not have been removed. They filed their claim last month after Take-Two removed over 200 forks of the reversed source, all built off of the original reversed-engineered code. That original repository and all the rest remain unavailable, as only Theo’s fork was restored by the DMCA counter-claim.
Grand Theft Auto III
Screenshot: Rockstar Games
In an interview with TorrentFreak, the dev explained that he believes Take-Two’s DCMA claim is “wholly incorrect” and that the publisher has “no claim to the code” because while it functions like the original source code that went into GTA III and Vice City, it is not identical.
While it might seem like GitHub has taken a side and decided that Take-Two was wrong, this isn’t accurate. DMCA rules state that content that is disputed must be restored within 14 days of a counter-notice being received. At this point, if Take-Two wants the source code removed again, it would become a legal battle. Theo says he understands the legal risk he faces, but doesn’t expect the publisher to pursue this to court any time soon.
While it’s possible Take-Two could challenge Theo’s counter-claim in court at a later date, this is still a nice win for the Grand Theft Auto III and Vice City modding scene. It’s also another reminder that modders, pirates, and fan developers are often the only ones doing the work to keep old games around in an easily playable form.
Commodity.com has a huge and useful page on how to get started trading in environmental commodities. Unfortunately it won’t let me paste it into here easily so below is a list of the subjects they cover. They are also very transparent about how they make their money (through links on their site), which I thought was honest of them. Anyway, enjoy!
Peloton, the at-home fitness brand synonymous with its indoor stationary bike and beleaguered treadmills, has more than three million subscribers. Even President Biden is said to own one. The exercise bike alone costs upwards of $1,800, but anyone can sign up for a monthly subscription to join a broad variety of classes.
As Biden was inaugurated (and his Peloton moved to the White House — assuming the Secret Service let him), Jan Masters, a security researcher at Pen Test Partners, found he could make unauthenticated requests to Peloton’s API for user account data without it checking to make sure the person was allowed to request it. (An API allows two things to talk to each other over the internet, like a Peloton bike and the company’s servers storing user data.)
But the exposed API let him — and anyone else on the internet — access a Peloton user’s age, gender, city, weight, workout statistics and, if it was the user’s birthday, details that are hidden when users’ profile pages are set to private.
Masters reported the leaky API to Peloton on January 20 with a 90-day deadline to fix the bug, the standard window time that security researchers give to companies to fix bugs before details are made public.
But that deadline came and went, the bug wasn’t fixed and Masters hadn’t heard back from the company, aside from an initial email acknowledging receipt of the bug report. Instead, Peloton only restricted access to its API to its members. But that just meant anyone could sign up with a monthly membership and get access to the API again.
TechCrunch contacted Peloton after the deadline lapsed to ask why the vulnerability report had been ignored, and Peloton confirmed yesterday that it had fixed the vulnerability. (TechCrunch held this story until the bug was fixed in order to prevent misuse.)
[…]
Masters has since put up a blog post explaining the vulnerabilities in more detail.
Munro, who founded Pen Test Partners, told TechCrunch: “Peloton had a bit of a fail in responding to the vulnerability report, but after a nudge in the right direction, took appropriate action. A vulnerability disclosure program isn’t just a page on a website; it requires coordinated action across the organisation.”
But questions remain for Peloton. When asked repeatedly, the company declined to say why it had not responded to Masters’ vulnerability report. It’s also not known if anyone maliciously exploited the vulnerabilities, such as mass-scraping account data.
Amazon CEO Jeff Bezos told U.S. lawmakers last year that the company has a policy prohibiting employees from using data on specific sellers to help boost its own sales.
“I can’t guarantee you that that policy has never been violated,” he added.
Now it’s clear why he chose his words so carefully.
An internal audit seen by POLITICO warned Amazon’s senior leadership in 2015 that 4,700 of its workforce working on its own sales had unauthorized access to sensitive third-party seller data on the platform — even identifying one case in which an employee used the access to improve sales.
A U.K. company behind digital addressing system What3Words has sent a legal threat to a security researcher for offering to share an open-source software project with other researchers, which What3Words claims violate its copyright.
Aaron Toponce, a systems administrator at XMission, received a letter on Thursday from London-based law firm JA Kemp representing What3Words, requesting that he delete tweets related to the open-source alternative, WhatFreeWords. The letter also demands that he disclose to the law firm the identity of the person or people with whom he had shared a copy of the software, agree that he would not make any further copies of the software and to delete any copies of the software he had in his possession.
The letter gave him until May 7 to agree, after which What3Words would “waive any entitlement it may have to pursue related claims against you,” a thinly-veiled threat of legal action.
“This is not a battle worth fighting,” he said in a tweet. Toponce told TechCrunch that he has complied with the demands, fearing legal repercussions if he didn’t. He has also asked the law firm twice for links to the tweets they want deleting but has not heard back. “Depending on the tweet, I may or may not comply. Depends on its content,” he said.
U.K.-based What3Words divides the entire world into three-meter squares and labels each with a unique three-word phrase. The idea is that sharing three words is easier to share on the phone in an emergency than having to find and read out their precise geographic coordinates.
But security researcher Andrew Tierney recently discovered that What3Words would sometimes have two similarly-named squares less than a mile apart, potentially causing confusion about a person’s true whereabouts. In a later write-up, Tierney said What3Words was not adequate for use in safety-critical cases.
It’s not the only downside. Critics have long argued that What3Words’ proprietary geocoding technology, which it bills as “life-saving,” makes it harder to examine it for problems or security vulnerabilities.
Concerns about its lack of openness in part led to the creation of the WhatFreeWords. A copy of the project’s website, which does not contain the code itself, said the open-source alternative was developed by reverse-engineering What3Words. “Once we found out how it worked, we coded implementations for it for JavaScript and Go,” the website said. “To ensure that we did not violate the What3Words company’s copyright, we did not include any of their code, and we only included the bare minimum data required for interoperability.”
But the project’s website was nevertheless subjected to a copyright takedown request filed by What3Words’ counsel. Even tweets that pointed to cached or backup copies of the code were removed by Twitter at the lawyers’ requests.
Toponce — a security researcher on the side — contributed to Tierney’s research, who was tweeting out his findings as he went. Toponce said that he offered to share a copy of the WhatFreeWords code with other researchers to help Tierney with his ongoing research into What3Words. Toponce told TechCrunch that receiving the legal threat may have been a combination of offering to share the code and also finding problems with What3Words.
In its letter to Toponce, What3Words argues that WhatFreeWords contains its intellectual property and that the company “cannot permit the dissemination” of the software.
Regardless, several websites still retain copies of the code and are easily searchable through Google, and TechCrunch has seen several tweets linking to the WhatFreeWords code since Toponce went public with the legal threat. Tierney, who did not use WhatFreeWords as part of his research, said in a tweet that What3Words’ reaction was “totally unreasonable given the ease with which you can find versions online.”
The attack, dubbed TBONE, involves exploitation of two vulnerabilities affecting ConnMan, an internet connection manager for embedded devices. An attacker can exploit these flaws to take full control of the infotainment system of a Tesla without any user interaction.
A hacker who exploits the vulnerabilities can perform any task that a regular user could from the infotainment system. That includes opening doors, changing seat positions, playing music, controlling the air conditioning, and modifying steering and acceleration modes. However, the researchers explained, “This attack does not yield drive control of the car though.”
They showed how an attacker could use a drone to launch an attack via Wi-Fi to hack a parked car and open its doors from a distance of up to 100 meters (roughly 300 feet). They claimed the exploit worked against Tesla S, 3, X and Y models.
“Adding a privilege escalation exploit such as CVE-2021-3347 to TBONE would allow us to load new Wi-Fi firmware in the Tesla car, turning it into an access point which could be used to exploit other Tesla cars that come into the victim car’s proximity. We did not want to weaponize this exploit into a worm, however,” Weinmann said.
Tesla patched the vulnerabilities with an update pushed out in October 2020, and it has reportedly stopped using ConnMan. Intel was also informed since the company was the original developer of ConnMan, but the researchers said the chipmaker believed it was not its responsibility.
Fresh questions have been raised over Amazon’s tax planning after its latest corporate filings in Luxembourg revealed that the company collected record sales income of €44bn (£38bn) in Europe last year but did not have to pay any corporation tax to the Grand Duchy.
Accounts for Amazon EU Sarl, through which it sells products to hundreds of millions of households in the UK and across Europe, show that despite collecting record income, the Luxembourg unit made a €1.2bn loss and therefore paid no tax.
In fact the unit was granted €56m in tax credits it can use to offset any future tax bills should it turn a profit. The company has €2.7bn worth of carried forward losses stored up, which can be used against any tax payable on future profits.
The Luxembourg unit – which handles sales for the UK, France, Germany, Italy, the Netherlands, Poland, Spain and Sweden – employs just 5,262 staff meaning that the income per employ amounts to €8.4m.
The article goes on to blame Amazon, but tbh I don’t blame them much. It’s the EU and the tax haven system inside it that allows its member states to allow and even encourage this kind of tax avoidance that is to blame.
Chinese television maker Skyworth has issued an apology after a consumer found that his set was quietly collecting a wide range of private data and sending it to a Beijing-based analytics company without his consent.
A network traffic analysis revealed that a Skyworth smart TV scanned for other devices connected to the same local network every 10 minutes and gathered data that included device names, IP addresses, network latency and even the names of other Wi-Fi networks within range, according to a post last week on the Chinese developer forum V2EX.
The data was sent to the Beijing-based firm Gozen Data, the forum user said. Gozen is a data analytics company that specialises in targeted advertising on smart TVs, and it calls itself China‘s first “home marketing company empowered by big data centred on family data”.
[…]
“Isn’t this already the criminal offence of spying on people?” asked one user on Sina.com, a Chinese financial news portal. “Whom will the collected data be sold to, and who is the end user of this data?”
The reaction online eventually prompted Skyworth to respond.
The Shenzhen-based TV and set-top box maker issued a statement on April 27, saying it had ended its “cooperation” with Gozen and demanded the firm delete all its “illegally” collected data. Skyworth also said it had stopped using the Gozen app on its televisions and was looking into the issue.
Gozen issued a statement on its website on the same day, saying its Gozen Data Android app could be disabled on Skyworth TVs, but it did not address the likelihood that users would be aware of this functionality. The company also apologised for “causing user concerns about privacy and security”.
On its official WeChat account, Gozen said in a post from 2019 that it has been working with Skyworth since 2014. Its latest post, which included its apology, said the company collected data for viewership research that includes “television ratings for households and individuals, viewership analysis, advertising analysis and optimisation”. Neither company provided information on the scope and depth of the data collection.
[…]
The revelations about Skyworth and Gozen come amid a national crackdown on the rampant collection and use of user data. Beijing recently introduced new regulations for protecting personal data and curbing its collection through mobile apps.
personal information considered “necessary” for apps in 39 different categories, including messaging and e-commerce. Users should be able to decline to provide data that is not necessary for an app to function, according to the new rules. Users of live-streaming and short-video apps, for example, should be able to use such apps without providing any personal information.
[…]
There have been no reports that Skyworth or Gozen are being investigated. Still, the disclosure and corporate statements have fanned fears among users in China, where Skyworth was the third biggest TV brand by sales volume in 2020, behind
, making up more than 13 per cent of the market. Globally, the company was the fifth-largest TV maker, according to data from Trendforce, behind Samsung Electronics, LG Electronics, TCL and Hisense.
3D scanning and 3D printing may sound like a natural match for one another, but they don’t always play together as easily and nicely as one would hope. I’ll explain what one can expect by highlighting three use cases the average hacker encounters, and how well they do (or don’t) work. With this, you’ll have a better idea of how 3D scanning can meet your part design and 3D printing needs.
How Well Some Things (Don’t) Work
Most 3D printing enthusiasts sooner or later become interested in whether 3D scanning can make their lives and projects easier. Here are a three different intersections of 3D scanning, 3D printing, and CAD along with a few words on how well each can be expected to work.
Goal
Examples and Details
Does it work?
Use scans to make copies of an object.
3D scan something, then 3D print copies.
Objects might be functional things like fixtures or appliance parts, or artistic objects like sculptures.
Mostly yes, but depends on the object
Make a CAD model from a source object.
The goal is a 1:1 model, for part engineering purposes.
Use 3D scanning instead of creating the object in CAD.
Not Really
Digitize inconvenient or troublesome shapes.
Obtain an accurate model of complex shapes that can’t easily be measured or modeled any other way.
Examples: dashboards, sculptures, large objects, objects that are attached to something else or can’t be easily moved, body parts like heads or faces, and objects with many curves.
Useful to make sure a 3D printed object will fit into or on something else.
Creating a CAD model of a part for engineering purposes is not the goal.
Yes, but it depends
In all of these cases, one wants a 3D model of an object, and that’s exactly what 3D scanning creates, so what’s the problem? The problem is that not all 3D models are alike and useful for the same things.
3D Scanning Makes Meshes, Not CAD Models
Broadly speaking, there are two kinds of 3D models: CAD models, and meshes. These can be thought of as being useful for engineering purposes and artistic purposes, respectively. Some readers may consider that a revolting oversimplification, but it is a helpful one to make a point about how 3D scanning, 3D printing, and CAD work do (and don’t) work together.
Hackers designing parts are typically most interested in CAD models, because these represent real-world objects that get modified in terms of real-world measurements. But 3D scanning will not create a CAD model; it will create a mesh.
Typical CAD model editing example, showing a model as a solid object, altered in terms of geometric features and real-world measurements.
A typical mesh editing operation. The object is a network of points connected into a mesh, which can be manipulated and deformed.
Meshes can be used for engineering purposes — .stl files are meshes after all, and are practically synonymous with 3D printing — but a mesh cannot be modified in the the same ways a CAD file can. With a mesh, one does not extrude a face by a specific number of millimeters, nor does one fillet a corner to a specific radius. Meshes can absolutely be modified, but the tools and processes are different.
To sum up: 3D scanning makes 3D models from real-world objects, but the models that come out of the scanning process aren’t necessarily suitable for engineering purposes without additional work.
Options for the Home-based Hacker
At the beginning of this article I selected three typical intersections of 3D scanning, 3D printing, and CAD work to illustrate the various imperfect fits between them. Now I’ll go into those three use cases in more detail, and provide ways for the average hacker to use 3D scanning to make a project easier.
Using 3D Scanning to Create Copies
Photogrammetry is an accessible way to create 3D models, and free as well as paid options exist. Generally, the smaller and more complex an object, the harder it will be to obtain a result that preserves all the features and details.
Photogrammetry uses multiple photos of an object taken from a variety of different angles, and software interprets these photos to create a point cloud representing the surface of the object. A mesh 3D model representing the object can then be generated. Some cleanup or post-processing of the model is usually required, depending on the method and software.
This blog post from Prusa Research walks through how to get the best results with Meshroom, a free option for 3D scanning using photogrammetry.
OpenScan (and OpenScan Mini) is a DIY project by [Thomas Megel] aimed at using photogrammetry to scan small objects with high accuracy.
RealityCapture is non-free software with a number of useful features and well-made tutorials. Notably, they have a license model option aimed at occasional use and small quantities. Since most software subscription models rarely make sense for hobbyists and one-off projects, it can be worth a look.
Creating a CAD Model from a 3D Scan
Since 3D scanning will not generate a CAD model, it’s not a direct alternative to designing a part in CAD. Most CAD programs allow importing a mesh, but the imported mesh remains a mesh, which cannot be modified in the same way as other CAD objects. It might be useful as a guide for a new design, however.
A mesh converted to a solid will become an object made up of collection of triangular faces, identical to the ones that made up the original mesh. This is rarely what a novice CAD modeler expects.
One may wonder if it is possible to convert from one format to another. It is, but the conversion may not be what one expects. Converting a CAD model into a mesh is simple enough, but converting a mesh into a CAD solid is less straightforward.
If one’s goal is to use 3D scanning to make the creation of a CAD model easier and the conversion result shown here won’t do the trick, the next best thing is to use the 3D scan as a master and model a new part around it to match, using the imported mesh as a guide. One project that uses this approach is this custom trackball designed around a molded ergonomic prototype.
Some professional software suites have the ability to export to CAD, but the essential workflow is the same, with a scanned mesh being used as the reference for a new design.
3D Scanning to Digitize Inconvenient or Troublesome Shapes
This scan of a laser cutter’s panel is obviously only part of the whole machine, but the important part is present.
Sometimes an accurate 3D model of a shape is needed, and that shape isn’t easily modeled or measured by hand. The same photogrammetry tools mentioned earlier are useful here, but their purpose is different. Instead of modeling the object from top to bottom to make an accurate copy, often only part of the object is needed.
For example, modeling the shape of an equipment panel or dashboard requires only the relevant section to be scanned successfully. A person’s head can be scanned to ensure a precise fit for a helmet or mask, and there’s no need to get a full scan of the entire body. In general, fewer pictures are needed and post-processing and model cleanup is easier because there is a smaller area of interest. A size reference must be included somehow for scaling later, because most 3D scans do not intrinsically create 1:1 models.
An excellent example of this approach is this project to design a custom control panel intended to fit an existing piece of equipment. Unlike when scanning a whole object with the intent of duplicating it, there’s no need to capture difficult-to-reach places like the bottom or back. This makes both scanning and model cleanup easier.
Professional Scanning
Another option is to pay for a professional scan. Fancy scanners and software suites costing thousands, or tens of thousands, of dollars and aimed at engineering applications exist, and while they are out of the reach of the average hacker, paying for a company to do a scan or two might not be.
Accuracy and resolution can be beyond what’s possible with photogrammetry, and some of the professional software suites have fancy features like aligning multiple scans, accurate size references, or the ability to generate CAD models based on scan results.
A 1:1 model from a professional 3D scanning tool, the product of aligning and merging multiple separate scans from different angles to get a complete model. It is still a mesh, but it accurately represents the original in both features and scale.
Shown here is the model of a part I had professionally scanned with a Creaform HandySCAN Black 3D scanner, according to my invoice. It is an old wood grip from an antique firearm. The scan still created a mesh, but it was an accurate 1:1 model of the original that I was able to use to print replacements on an SLA 3D printer.
When getting a quote for professional 3D scanning, be sure to ask about fee structure and be clear about your needs. In my case, it was cost-effective to scan multiple similar objects under a single setup fee.
Know What 3D Scanning Can (and Can’t) Do
3D scanning is getting better and more accessible all the time, but the fact that it generates a mesh means it doesn’t always fit smoothly into a 3D printing and CAD part design workflow. That doesn’t mean it can’t be useful, but it does mean that it’s important to know the limitations, and how they will affect your needs.
Of course, one can always dig out the calipers and manually model a part in CAD, but not all parts and shapes are easily measured or reverse-engineered. 3D scanning is a great alternative to modeling complex, real-world objects that would be impractical or error-prone to create by hand.
Have you successfully used 3D scanning to make a project easier, or have a favorite method or tool to share? We definitely want to hear all about it, so please take a moment to share with us in the comments.
Combined with today’s massive flat panel displays, a nice surround sound system can provide an extremely immersive environment for watching movies or gaming. But a stumbling block many run into is speaker placement. The front speakers generally just go on either side of the TV, but finding a spot for the rear speakers that’s both visually and acoustically pleasing can be tricky.
Which is why [Peter Waldraff] decided to take a rather unconventional approach and hide his rear surround sound speakers in a pair of functioning table lamps. This not only looks better than leaving the speakers out, but raises them up off the floor and into a better listening position. The whole thing looks very sleek thanks to some clever wiring, to the point that you’d never suspect they were anything other than ordinary lamps.
The trick here is the wooden box located at the apex of the three copper pipes that make up the body of the lamp. [Peter] mounted rows of LEDs to the sides of the box that can be controlled with a switch on the bottom, which provides light in the absence of a traditional light bulb. The unmodified speaker goes inside the box, and connects to the audio wires that were run up one of the pipes.
In the base, the speaker and power wires are bundled together so it appears to be one cable. Since running the power and audio wires together like this could potentially have resulted in an audible hum, [Peter] only ran 12 VDC up through the lamp to the LEDs and used an external “wall wart” transformer. For convenience, he also put a USB charging port in the center of the base.
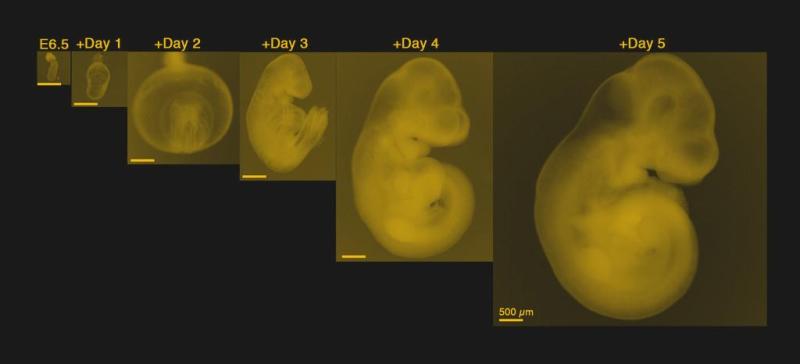
Although people-growing is probably a long way off, mice can now mostly develop inside an artificial uterus (try private window if you hit a paywall) thanks to a breakthrough in developmental biology. So far, the mice can only be kept alive halfway through gestation. There’s a point at which the nutrient formula provided to them isn’t enough, and they need a blood supply to continue growing. That’s the next goal. For now, let’s talk about that mechanical womb setup.
Carousel of Care
The mechanical womb was developed to better understand how various factors such as gene mutations, nutrients, and environmental conditions affect murine fetuses in development. Why do miscarriages occur, and why do fertilized eggs fail to implant in the first place? How exactly does an egg explode into 40 trillion cells when things do work out? This see-through uterus ought to reveal a few more of nature’s gestational secrets.
Dr. Jacob Hanna of Israel’s Weizmann Institute spent seven years building the two-part system of incubators, nutrients, and ventilation. Each mouse embryo floats in a glass jar, suspended in a concoction of liquid nutrients. A carousel of jars slowly spins around night and day to keep the embryos from attaching to the sides of the jars and dying. Along with the nutrient fluid, the mice receive a carefully-controlled mixture of oxygen and carbon dioxide from the ventilation machine. Dr. Hanna and his team have grown over 1,000 embryos this way.
Full gestation in mice takes about 20 days. As outlined in the paper published in Nature, Dr. Hanna and team removed mouse embryos at day five of gestation and were able to grow them for six more days in the artificial wombs. When compared with uterus-grown mice on day eleven, their sizes and weights were identical. According to an interview after the paper was published, the team have already gone even further, removing embryos right after fertilization on day zero, and growing them for eleven days inside the mechanical womb. The next step is figuring out how to provide an artificial blood supply, or a more advanced system of nutrients that will let the embryos grow until they become mice.
Embryonic Ethics
Here’s the most interesting part: the team doesn’t necessarily have to disrupt live gestation to get their embryos. New techniques allow embryos to be created from murine connective tissue cells called fibroblasts without needing fertilized eggs. Between this development and Dr. Hanna’s carousel of care, there would no longer be a need to fertilize eggs merely to destroy them later.
It’s easy to say that any and all animal testing is unethical because we can’t exactly get their consent (not that we would necessarily ask for it). At the same time, it’s true that we learn a lot from testing on animals first. Our lust for improved survival is at odds with our general empathy, and survival tends to win out on a long enough timeline. A bunch of people die every year waiting for organ transplants, and scientists are already growing pigs for that express purpose. And unlocking more mysteries of the gestation process make make surrogate pregnancies possible for more animals in the frozen zoo.
In slightly more unnerving news, some have recently created embryos that are part human and part monkey for the same reason. Maybe this is how we get to planet of the apes.
The hack involves popping open the case of the watch and exposing the back of the main PCB. There, a series of jumpers control various features. [Ian]’s theory is that this allows Casio to save on manufacturing costs by sharing one basic PCB between a variety of watches and enabling features via the jumper selection. With a little solder wick, a jumper pad can be disconnected, enabling the hidden countdown feature. Other features, such as the multiple alarms, can be disabled in the same way with other jumpers, suggesting lower-feature models use this same board too.
It’s a useful trick that means [Ian] now always has a countdown timer on his wrist when he needs it. Excuses for over-boiling the eggs will now be much harder to come by, but we’re sure he can deal. Of course, watch hacks don’t have to be electronic – as this custom transparent case for an Apple Watch demonstrates. Video after the break.
Earlier this week, a company Orbital Marine Power successfully launched its latest tidal turbine. Once it’s connected to the European Marine Energy Centre off the Orkney Islands, the two megawatt O2 will have the capacity to generate enough energy to power 2,000 UK households annually, making it one of the world’s most powerful tidal turbines currently in use.
Construction on the project started in 2019. The O2 builds on Orbital’s previous generation SR2000 tidal turbine. The new model consists of a 239-foot superstructure connected to two turbines with 32 foot long rotors. The blades on those can rotate a full 360-degrees. That’s a feature that allows the O2 to generate power from currents without having to move entirely when they change direction. In the future, Orbital says it also has the option to install even larger blades on the O2.
Netherlands politicians (Geert Wilders (PVV), Kati Piri (PvdA), Sjoerd Sjoerdsma (D66), Ruben Brekelmans (VVD), Tunahan Kuzu (Denk), Agnes Mulder (CDA), Tom van der Lee (GroenLinks), Gert-Jan Segers (ChristenUnie) en Raymond de Roon (PVV).) just got a first-hand lesson about the dangers of deepfake videos. According to NL Times and De Volkskrant, the Dutch parliament’s foreign affairs committee was fooled into holding a video call with someone using deepfake tech to impersonate Leonid Volkov (above), Russian opposition leader Alexei Navalny’s chief of staff.
The perpetrator hasn’t been named, but this wouldn’t be the first incident. The same impostor had conversations with Latvian and Ukranian politicians, and approached political figures in Estonia, Lithuania and the UK.
The country’s House of Representatives said in a statement that it was “indignant” about the deepfake chat and was looking into ways it could prevent such incidents going forward.
There doesn’t appear to have been any lasting damage from the bogus video call. However, it does illustrate the potential damage from deepfake chats with politicians. A prankster could embarrass officials, while a state-backed actor could trick governments into making bad policy decisions and ostracizing their allies. Strict screening processes might be necessary to spot deepfakes and ensure that every participant is real.
Russia said it had fined Apple $12 million for alleged [Note: why the use of this word? If the fine has been issued, then a Russian court has established guilt and there is no allleging about it!] abuse of its dominance in the mobile applications market, in the latest dispute between Moscow and a Western technology firm.
The Federal Antimonopoly Service (FAS) said on Tuesday that U.S. tech giant Apple’s distribution of apps through its iOS operating system gave its own products a competitive advantage.
[…]
The FAS said in a statement it had imposed a turnover fine on Apple of 906.3 million roubles ($12.1 million) for the alleged violation of Russian anti-monopoly legislation.
It determined in August 2020 that Apple had abused its dominant position and then issued a directive requiring the U.S. company to remove provisions giving it the right to reject third-party apps from its App Store.
That move followed a complaint from cybersecurity company Kaspersky Lab, which had said that a new version of its Safe Kids application had been declined by Apple’s operating system.
Epic Games is using its lawsuit against Apple to accuse the iPhone maker of being particularly greedy. As The Vergereports, expert witness Eric Barns testified that Apple supposedly had an App Store operating margin of 77.8 percent in 2019, itself a hike from 74.9 percent in 2018. He also rejected Apple witness’ claims that you couldn’t practically calculate profit, pointing to info from the company’s Corporate Financial Planning and Analysis group as evidence.
Apple unsurprisingly disagreed. The tech firm told The Verge the margin calculations are “simply” wrong and that it planned to fight the allegations at trial. The firm’s own witness, Richard Schmalensee, claimed that Barnes was looking at one iOS ecosystem element that distorted the apparent operating margin. The real figure was “unremarkable,” he said, adding that you couldn’t study App Store profit without looking at the broader context of devices and services.
The company doesn’t calculate profits and losses based on products and services, Schmalensee said.
There’s no guarantee the court will accept Barnes’ take. Apple’s overall gross profit margin has typically been high relative to much of the industry, but never that high — it was 42.5 percent during the company’s latest winter quarter. Apple has also tended to portray the App Store as a way to drive hardware sales rather than a money-maker in its own right.
The testimony nonetheless does more to explain how Epic will pursue its case against Apple as the court battle begins on May 3rd. The Fortnite creator not only wants to portray Apple as anti-competitive, but abusing its lock on iOS app distribution to reap massive profits.
Amazon may soon be more accountable for more products than the ones it directly sells. According to the LA Times, a California state appeals court has ruled that Amazon is responsible for the safety of third-party products available through its marketplace following a 2015 hoverboard fire. While the internet giant argued that it was only connecting buyers with sellers, judges determined that there was a “direct link” in distribution that made the company liable.
The company won the initial ruling. At the time, a judge sided with Amazon’s view that it was just advertising sellers’ products rather than participating in sales.
In a statement to the Times, Amazon said it “invests heavily” in product safety by screening sellers and products. it also keeps watch on the store for hints of problems. The company declined to comment on the appeal court decision, including whether it intended to challenge the ruling at the state Supreme Court.
The decision, if it holds, could force Amazon to change policies. The tech giant may have to step up its vetting process for sellers and be ready to accept liability for safety problems, including lawsuits. Other stores with similar third-party marketplaces would have to follow suit. That, in turn, might be good news for shoppers —you could see fewer sketchy products in online stores, and you’d have a better chance of resolving safety issues.
Researchers from University of Arizona and University of Utah published a new paper in the Journal of Marketing that examines why most scholarly research is misinterpreted by the public or never escapes the ivory tower and suggests that such research gets lost in abstract, technical, and passive prose.
The study, forthcoming in the Journal of Marketing, is titled “Marketing Ideas: How to Write Research Articles that Readers Understand and Cite” and is authored by Nooshin L. Warren, Matthew Farmer, Tiany Gu, and Caleb Warren.
From developing vaccines to nudging people to eat less, scholars conduct research that could change the world, but most of their ideas either are misinterpreted by the public or never escape the ivory tower.
Why does most academic research fail to make an impact? The reason is that many ideas in scholarly research get lost in an attic of abstract, technical, and passive prose. Instead of describing “spilled coffee” and “one-star Yelp reviews,” scholars discuss “expectation-disconfirmation” and “post-purchase behavior.” Instead of writing “policies that let firms do what they want have increased the gap between the rich and the poor,” scholars write sentences like, “The rationalization of free-market capitalism has been resultant in the exacerbation of inequality.” Instead of stating, “We studied how liberal and conservative consumers respond when brands post polarizing messages on social media,” they write, “The interactive effects of ideological orientation and corporate sociopolitical activism on owned media engagement were studied.”
Why is writing like this unclear? Because it is too abstract, technical, and passive. Scholars need abstraction to describe theory. Thus, they write about “sociopolitical activism” rather than Starbucks posting a “Black Lives Matter” meme on Facebook. They are familiar with technical terms, such as “ideological orientation,” and they rely on them rather than using more colloquial terms such as “liberal or conservative.” Scholars also want to sound objective, which lulls them into the passive voice (e.g., the effects… were studied) rather than active writing (e.g., “we studied the effects…”). Scholars need to use some abstract, technical, and passive writing. The problem is that they tend to overuse these practices without realizing it.
When writing is abstract, technical, and passive, readers struggle to understand it. In one of the researchers’ experiments, they asked 255 marketing professors to read the first page of research papers published in the Journal of Marketing (JM), Journal of MarketingResearch (JMR), and Journal of Consumer Research (JCR). The professors understood less of the papers that used more abstract, technical, and passive writing compared to those that relied on concrete, non-technical, and active writing.
As Warren explains, “When readers do not understand an article, they are unlikely to read it, much less absorb it and be influenced by its ideas. We saw this when we analyzed the text of 1640 articles published in JM, JMR, and JCR between 2000 and 2010. We discovered that articles that relied more on abstract, technical, and passive writing accumulated fewer citations on both Google Scholar and the Web of Science.” An otherwise average JM article that scored one standard deviation lower (clearer) on our measures of abstract, technical, and passive writing accumulated approximately 157 more Google Scholar citations as of May 2020 than a JM article with average writing.
Why do scholars write unclearly? There is an unlikely culprit: knowledge. Conducting good research requires authors to know a lot about their work. It takes years to create research that meaningfully advances scientific knowledge. Consequently, academic articles are written by authors who are intimately familiar with their topics, methods, and results. Authors, however, often forget or simply do not realize that potential readers (e.g., Ph.D. students, scholars in other sub-disciplines, practicing professionals, etc.) are less familiar with the intricacies of the research, a phenomenon called the curse of knowledge.
The research team explores whether the curse of knowledge might be enabling unclear writing by asking Ph.D. students to write about two research projects. The students wrote about one project on which they were the lead researcher and another project led by one of their colleagues. The students reported that they were more familiar with their own research than their colleague’s research. They also thought that they wrote more clearly about their own research, but they were mistaken. In fact, the students used more abstraction, technical language, and passive voice when they wrote about their own research than when they wrote about their colleague’s research.
“To make a greater impact, scholars need to overcome the curse of knowledge so they can package their ideas with concrete, technical, and active writing. Clear writing gives ideas the wings needed to escape the attics, towers, and increasingly narrow halls of their academic niches so that they can reduce infection, curb obesity, or otherwise make the world a better place,” says Farmer.
Bobby Kotick, the longtime CEO of “Call of Duty” and “Candy Crush” game maker Activision Blizzard, will see his base salary reduced by 50% and bonus potential slashed as part of a 15-month contract extension, the company reported Thursday in an SEC filing.
Why it matters: The cut isn’t a sign that the company is struggling. Activision, like most big gaming companies, is thriving. But it appears to show a company reacting to criticism of outsized executive compensation.
Kotick’s base salary will be cut in half to $875,000, and his amended contract establishes a reduction of $1.75 million in potential annual bonuses.
Provisions for lucrative bonuses tied to stock performance have also been removed or rewritten to limit other potential bonus payouts. That follows reports that they triggered payments of as much as $200 million earlier this year.
In its filing, Activison’s board said the compensation changes were made after 12 months of “extensive shareholder outreach.”
[…]
The big picture: Kotick became CEO of Activision in 1991, when the company was a struggling player in a much smaller industry. Now it is one of gaming’s most successful.
That success hasn’t meant labor happiness for all. Activision has laid off waves of employees each of the last three years.
Kotick told Gamesbeat Wednesday that Activision needs to hire some 2,500 workers.
So people are still whining that he’s making actual money but these are the types for whom no pay level will ever be acceptable, even if they even out the pay levels throughout the whole company.
I think this is a great exemplary step forwards – the top shouldn’t be earning such stupid amounts more than the lowest employees. Next step, up the earnings of the lower paid people!