A newly discovered technique by a researcher shows how Google’s App Engine domains can be abused to deliver phishing and malware while remaining undetected by leading enterprise security products.
Google App Engine is a cloud-based service platform for developing and hosting web apps on Google’s servers.
While reports of phishing campaigns leveraging enterprise cloud domains are nothing new, what makes Google App Engine infrastructure risky in how the subdomains get generated and paths are routed.
Practically unlimited subdomains for one app
Typically scammers use cloud services to create a malicious app that gets assigned a subdomain. They then host phishing pages there. Or they may use the app as a command-and-control (C2) server to deliver malware payload.
But the URL structures are usually generated in a manner that makes them easy to monitor and block using enterprise security products, should there be a need.
For example, a malicious app hosted on Microsoft Azure services may have a URL structure like: https://example-subdomain.app123.web.core.windows.net/…
Therefore, a cybersecurity professional could block traffic to and from this particular app by simply blocking requests to and from this subdomain. This wouldn’t prevent communication with the rest of the Microsoft Azure apps that use other subdomains.
It gets a bit more complicated, however, in the case of Google App Engine.
Security researcher Marcel Afrahim demonstrated an intended design of Google App Engine’s subdomain generator, which can be abused to use the app infrastructure for malicious purposes, all while remaining undetected.
Google’s appspot.com domain, which hosts apps, has the following URL structure:
A subdomain, in this case, does not only represent an app, it represents an app’s version, the service name, project ID, and region ID fields.
But the most important point to note here is, if any of those fields are incorrect, Google App Engine won’t show a 404 Not Found page, but instead show the app’s “default” page (a concept referred to as soft routing).
“Requests are received by any version that is configured for traffic in the targeted service. If the service that you are targeting does not exist, the request gets Soft Routed,” states Afrahim, adding:
“If a request matches the PROJECT_ID.REGION_ID.r.appspot.com portion of the hostname, but includes a service, version, or instance name that does not exist, then the request is routed to the default service, which is essentially your default hostname of the app.”
Essentially, this means there are a lot of permutations of subdomains to get to the attacker’s malicious app. As long as every subdomain has a valid “project_ID” field, invalid variations of other fields can be used at the attacker’s discretion to generate a long list of subdomains, which all lead to the same app.
For example, as shown by Afrahim, both URLs below – which look drastically different, represent the same app hosted on Google App Engine.
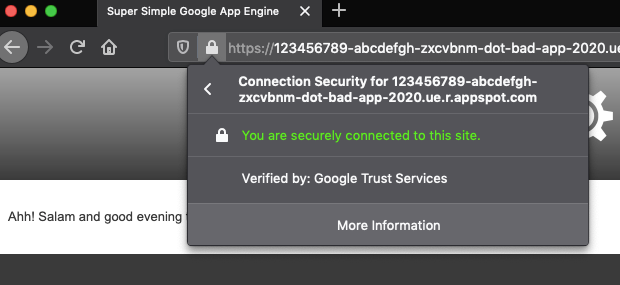
“Verified by Google Trust Services” means trusted by everyone
The fact that a single malicious app is now represented by multiple permutations of its subdomains makes it hard for sysadmins and security professionals to block malicious activity.
But further, to a technologically unsavvy user, all of these subdomains would appear to be a “secure site.” After all, the appspot.com domain and all its subdomains come with the seal of “Google Trust Services” in their SSL certificates.
Google App Engine sites showing valid SSL certificate with “Verified by: Google Trust Services” text
Source: Afrahim
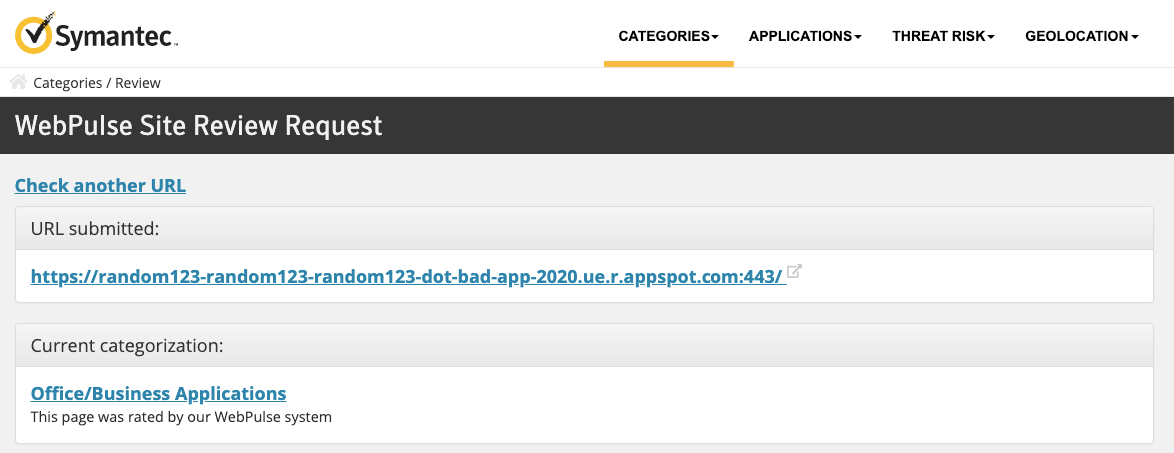
Even further, most enterprise security solutions such as Symantec WebPulse web filter automatically allow traffic to trusted category sites. And Google’s appspot.com domain, due to its reputation and legitimate corporate use cases, earns an “Office/Business Applications” tag, skipping the scrutiny of web proxies.
Automatically trusted by most enterprise security solutions
On top, a large number of subdomain variations renders the blocking approach based on Indicators of Compromise (IOCs) useless.
A screenshot of a test app created by Afrahim along with a detailed “how-to” demonstrates this behavior in action.
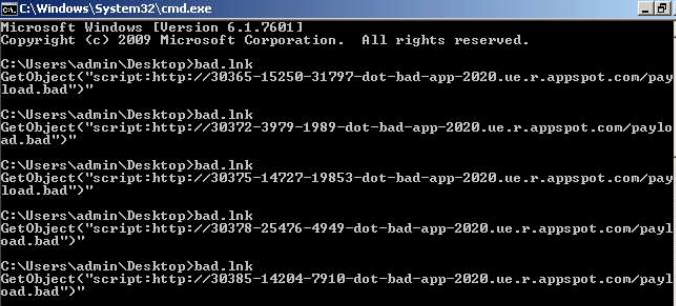
In the past, Cloudflare domain generation had a similar design flaw that Astaroth malware would exploit via the following command wheen fetching stage 2 payload:
This would essentially launch a Windows command prompt and put a random number replacing %RANDOM% making the payload URL truly dynamic.
“And now you have a script that downloads the payload from different URL hostnames each time is run and would render the network IOC of such hypothetical sample absolutely useless. The solutions that rely on single run on a sandbox to obtain automated IOC would therefore get a new Network IOC and potentially new file IOC if script is modified just a bit,” said the researcher.
Delivering malware via Google App Engine subdomain variations while bypassing IOC blocks
Actively exploited for phishing attacks
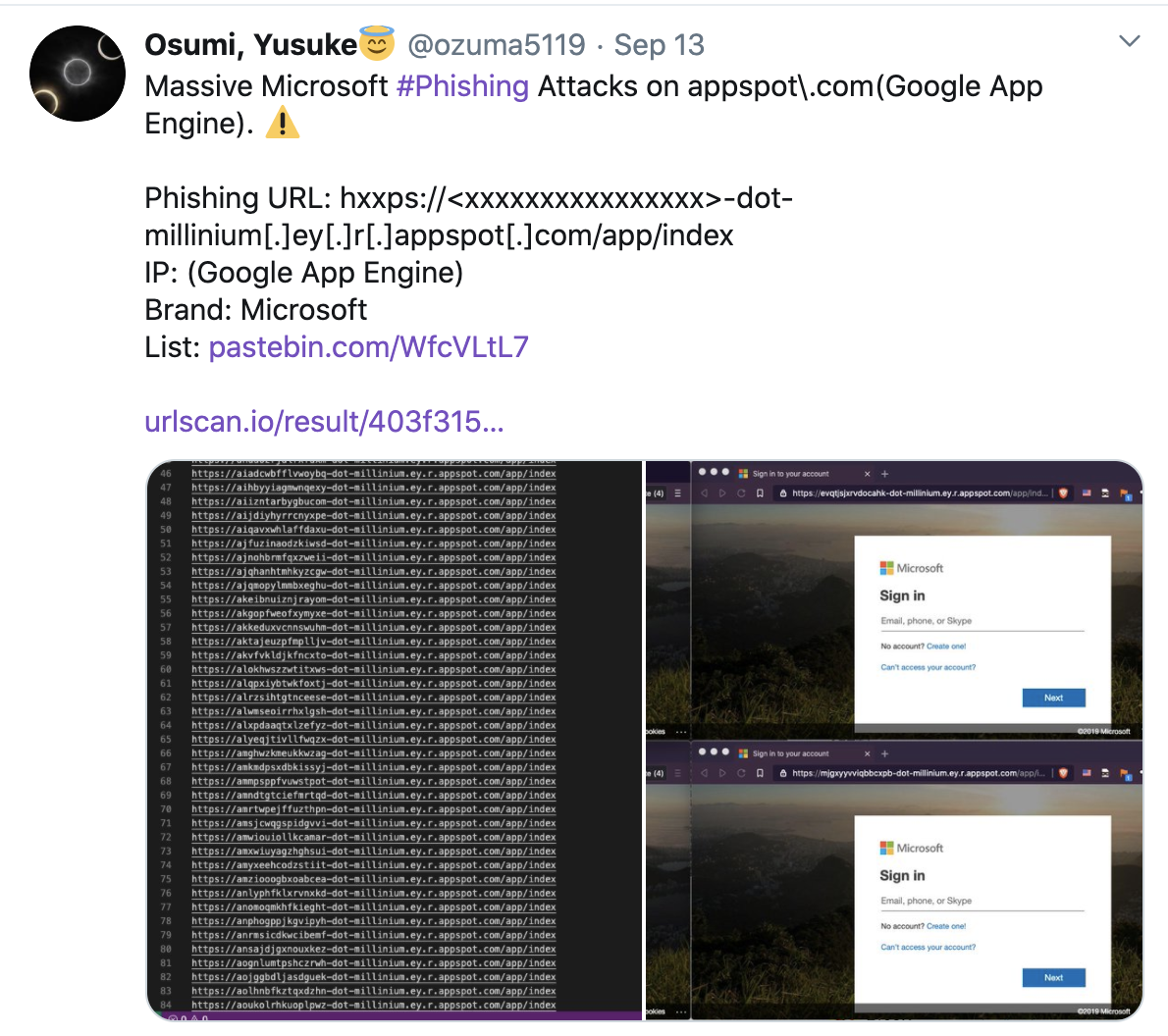
Security engineer and pentester Yusuke Osumi tweeted last week how a Microsoft phishing page hosted on the appspot.com subdomain was exploiting the design flaw Afrahim has detailed.
Osumi additionally compiled a list of over 2,000 subdomains generated dynamically by the phishing app—all of them leading to the same phishing page.
Active exploitation of Google App Engine subdomains in phishing attacks
Source: Twitter
This recent example has shifted the focus of discussion from how Google App Engine’s flaw can be potentially exploited to active phishing campaigns leveraging the design flaw in the wild.
“Use a Google Drive/Service phishing kit on Google’s App Engine and normal user would not just realize it is not Google which is asking for credentials,” concluded Afrahim in his blog post.
Formula 1 drivers have been told they cannot wear clothing bearing any slogans or messages while doing official duties after grands prix.
The move is a reaction to Mercedes’ Lewis Hamilton wearing a T-shirt at the last race in Tuscany referencing the case of a woman killed by US police.
The FIA said podium finishers “must remain attired only in their driving suits done up to the neck”.
This must be the case throughout the podium ceremony and interviews.
The requirements include a “medical face mask or team-branded face mask”.
The move had been expected after talks between the FIA, Mercedes and Hamilton’s representatives before this weekend’s Russian Grand Prix.
At Mugello, Hamilton wore a T-shirt saying: “Arrest the cops who killed Breonna Taylor” at the official pre-race anti-racism demonstration and on the podium and during the post-race interviews.
He had previously worn a Black Lives Matter T-shirt for the demonstration, but not after the race, while other drivers wore the FIA official “End Racism” T-shirts.
The FIA looked into whether they should investigate Hamilton on the grounds of breaking any rules, but decided against it.
Political messages have long been banned on the podium in F1.
Hamilton said at the Russian Grand Prix: “I did something that has never really happened in F1 and obviously they will stop it from happening moving forwards.”
Future moon explorers will be bombarded with two to three times more radiation than astronauts aboard the International Space Station, a health hazard that will require thick-walled shelters for protection, scientists reported Friday.
China’s lander on the far side of the moon is providing the first full measurements of radiation exposure from the lunar surface, vital information for NASA and others aiming to send astronauts to the moon, the study noted.
[…]
Astronauts would get 200 to 1,000 times more radiation on the moon than what we experience on Earth—or five to 10 times more than passengers on a trans-Atlantic airline flight, noted Robert Wimmer-Schweingruber of Christian-Albrechts University in Kiel, Germany.
“The difference is, however, that we’re not on such a flight for as long as astronauts would be when they’re exploring the moon,” Wimmer-Schweingruber said in an email.
Cancer is the primary risk.
“Humans are not really made for these radiation levels and should protect themselves when on the moon,” he added.
[…]
Wimmer-Schweingruber said the radiation levels are close to what models had predicted. The levels measured by Chang’e 4, in fact, “agree nearly exactly” with measurements by a detector on a NASA orbiter that has been circling the moon for more than a decade, said Kerry Lee, a space radiation expert at Johnson Space Center in Houston.
“It is nice to see confirmation of what we think and our understanding of how radiation interacts with the moon is as expected,” said Lee, who was not involved in the Chinese-led study.
[…]
The German researchers suggest shelters built of moon dirt—readily available material—for stays of more than a few days. The walls should be 80 centimeters (about 2 1/2 feet) thick, they said. Any thicker and the dirt will emit its own secondary radiation, created when galactic cosmic rays interact with the lunar soil.
The September 20 deadline for a purported TikTok sale has already passed, but the parties involved have yet to settle terms on the deal. ByteDance and TikTok’s bidders Oracle and Walmart presented conflicting messages on the future ownership of the app, confusing investors and users. Meanwhile, Beijing’s discontent with the TikTok sale is increasingly obvious.
China has no reason to approve the “dirty” and “unfair” deal that allows Oracle and Walmart to effectively take over TikTok based on “bullying and extortion,” slammed an editorial published Wednesday in China Daily, an official English-language newspaper of the Chinese Communist Party.
The editorial argued that TikTok’s success — a projected revenue of about a billion dollars by the end of 2020 — “has apparently made Washington feel uneasy” and prompted the U.S. to use “national security as the pretext to ban the short video sharing app.”
The official message might stir mixed feelings within ByteDance, which has along the way tried to prove its disassociation from the Chinese authority, a precondition for the companies’ products to operate freely in Western countries.
Beijing has already modified a set of export rules to complicate the potential TikTok deal, restricting the sale of certain AI-technologies to foreign companies. Both ByteDance and China’s state media have said the agreement won’t involve technological transfers.
The Trump administration said it would ban downloads of TikTok, which boasts 100 million users in the country, if an acceptable deal was not reached. It also planned to shut down Tencent’s WeChat, a decision that just got blocked by a district court in San Francisco.
TikTok has collected nearly 198 million App Store and Google Play installs in the U.S., while WeChat has been installed by nearly 22 million users in the U.S. since 2014, according to market research firm Sensor Tower. Unlike TikTok, which has a far-reaching user base in the U.S., WeChat is mainly used by Chinese-speaking communities or those with connections in China, where the messenger is the dominant chat app and most Western alternatives are blocked.
Four of the seven former eBay employees charged with cyberstalking a couple critical of the web auction house are scheduled to plead guilty next month.
In June, the US Justice Department charged six former staffers – director of safety and security James Baugh, 45, of San Jose, California; director of global resiliency David Harville, 48, of New York City; manager of global intelligence Stephanie Stockwell, 26, of Redwood City, California; and eBay Global Intelligence Center staffers Stephanie Popp, 32, Veronica Zea, 26, and Brian Gilbert, 51, all of San Jose – with conspiring to commit cyberstalking and tamper with witnesses.
The US Attorney’s Office of Massachusetts on Wednesday said four former eBay employees charged in that case plan to admit guilt at a video conference hearing scheduled for October 8, 2020.
A spokesperson for the USAO of Massachusetts confirmed to The Register the four individuals are Brian Gilbert, Stephanie Popp, Stephanie Stockwell, and Veronica Zea. The cases against the two most senior executives in the group, Harville and Baugh, remain ongoing; both deny the accusations.
In July, a seventh former eBay employee, former Santa Clara police captain Philip Cooke, 55, who oversaw security operations at eBay’s offices in Europe and Asia, was charged separately for alleged involvement in the harassment campaign.
The defendants are said [PDF] to have participated in a concerted effort to intimidate and silence a husband and wife team who run an ecommerce-focused newsletter and blog in a campaign last year.
[…]
it describes a harassment effort that consisted, among other things, of sending the newsletter publishers live cockroaches, the head of a fetal pig, a funeral wreath, a mask of a bloody pig’s head, and a book on surviving the loss of a spouse.
Unasked
Bloomberg suggests the recipient of that text message, “Executive 1,” is former CEO David Wenig, based on the similarity between a newsletter article quoted in the complaint, “eBay RICO Lawsuit Meant to Curb Seller Exodus to Amazon?” and an article with the same headline on the EcommerceBytes Blog that refers to Wenig.
The affidavit outlining the case cites text identical to the online article except that it replaces “eBay CEO” with “[Executive 1]”. Wenig has not been charged with any wrongdoing.
Subscriptions may be ideal for certain services such as Netflix, with its constant flow of new content, but for a suite of tools like Microsoft Office? Paying every month doesn’t suit everyone, especially if all they want is access to the word processor and spreadsheet. Thankfully, a new perpetual license edition of the suite arrives next year.
Microsoft clearly pushes an Office subscription as the best way to access its always up-to-date suite of tools and services, while those who just want to buy a copy outright and use it for years to come are still using Office 2019, which released back in 2018. It was unclear whether 2019 would ever be replaced, but as spotted by Windows Central, Microsoft quietly confirmed in a news post by the Exchange team that “Microsoft Office will also see a new perpetual release for both Windows and Mac, in the second half of 2021.”
There’s no details regarding the name, price, or availability of this new version
Spain’s highways agency is using bulk mobile phone data for monitoring speeding hotspots, according to local reports.
Equipped with data on customers handed over by local mobile phone operators, Spain’s Directorate-General for Traffic (DGT) may be gathering data on “which roads and at what specific kilometer points the speed limits are usually exceeded,” according to Granadan newspaper Ideal (en español).
“In fact, Traffic has data on this since the end of last year when the National Statistics Institution (INE) reached an agreement with mobile operators to obtain information about the movements of citizens,” reported the paper.
The data-harvesting agreement was first signed late last year to coincide with a national census (as El Reg reported at the time) and is now being used to monitor drivers’ speeds.
National newspaper El Paisreported in October 2019 that the trial would involve dividing Spain “into 3,500 cells with a minimum of 5,000 people in each of them” with the locations of phones being sampled continuously between 9am and 6pm, with further location snapshots being taken at 12am and 6am.
The newspaper explained: “With this information it will be possible to know how many citizens move from a dormitory municipality to a city; how many people work in the same neighbourhood where you live or in a different one; where do the people who work in an area come from, or how the population fluctuates in a box throughout the day.”
The INE insisted that data collected back then had been anonymised and was “aimed at getting a better idea of where Spaniards go during the day and night”, as the BBC summarised the scheme. Mobile networks Vodafone, Movistar, and Orange were all said to be handing over user data to the INE, with the bulk information fetching €500,000 – a sum split between all three firms.
In April the initiative was reactivated for the so-called DataCovid plan, where the same type of bulk location data was used to identify areas where Spaniards were ignoring COVID-19 lockdown laws.
“The goal is to analyse the effect which the (confinement) measures have had on people’s movements, and see if people’s movements across the land are increasing or decreasing,” Spain’s government said at the time, as reported by expat news service The Local’s Iberian offshoot.
The DGT then apparently hit on the idea of using speed data derived from cell tower pings (in the same way that Google Maps, Waze, and other online services derive average road speed and congestion information) to identify locations where drivers may have been breaking the speed limit.
The Ideal news website seemed to put the obvious fears to bed in its report of the traffic police initiative when it posed the obvious, rhetorical, question: whether drivers can be fined based on mobile data.
“The answer is clear and direct: it is not possible,” it concluded. “The DGT can only fine us through the fixed and mobile radars that it has installed throughout the country.”
While the direction of travel here seems obvious to anyone with any experience of living in a western country that implements this type of dragnet mass surveillance, so far there is little evidence of an explicit link between mobile phone data-slurping and speed cameras or fines.
Back in 2016, TfL ran a “trial” tracking people’s movements by analysing where their MAC addresses popped up within the Tube network, also hoping to use this data to get higher prices for advertising spots at busy areas inside Tube stations. Dedicated public Wi-Fi spots on train platforms is now a permanent fixture in all but a few of the London Underground stations. The service is operated by Virgin Media, which is “free” to use by customers of the four mobile network operators, but collects your mobile number at the point of signing up.
And here you can see the ease with which mission creep comes out and people start using your data for all kinds of non-related things once they have it. This is why we shouldn’t allow governments or anyone else to get their grubby little hands on it and why we should be glad that at least at EU level, data privacy is taken seriously with GDPR and other laws.
Twitter is notifying developers today about a possible security incident that may have impacted their accounts.
The incident was caused by incorrect instructions that the developer.twitter.com website sent to users’ browsers.
The developer.twitter.com website is the portal where developers manage their Twitter apps and attached API keys, but also the access token and secret key for their Twitter account.
In an email sent to developers today, Twitter said that its developer.twitter.com website told browsers to create and store copies of the API keys, account access token, and account secret inside their cache, a section of the browser where data is saved to speed up the process of loading the page when the user accessed the same site again.
This might not be a problem for developers using their own browsers, but Twitter is warning developers who may have used public or shared computers to access the developer.twitter.com website — in which case, their API keys are now most likely stored in those browsers.
“If someone who used the same computer after you in that temporary timeframe knew how to access a browser’s cache, and knew what to look for, it is possible they could have accessed the keys and tokens that you viewed,” Twitter said.
“Depending on what pages you visited and what information you looked at, this could have included your app’s consumer API keys, as well as the user access token and secret for your own Twitter account,” Twitter said.
Facebook has temporarily shamed Apple out of taking a 30 percent cut of paid online events organized by small businesses and hosted on Facebook—things like cooking classes, workout sessions, and happy hours. Demand for these kinds of online events has soared during the COVID-19 pandemic.
Apple says that it has a longstanding policy that digital products must be purchased using Apple’s in-app payments system—and hence pay Apple’s 30 percent tax. In contrast, companies selling physical goods and services are not only allowed but required to use other payment methods (options here include Apple Pay, which doesn’t take such a big cut).
For example, an in-person cooking class is not a digital product, so a business selling cooking class tickets via an iPhone app wouldn’t have to give Apple a 30 percent cut. But if the same business offers a virtual cooking class, Apple considers that to be a digital product and demands a 30 percent cut—at least if the customer pays for the class using an iOS device.
Last month, Facebook announced it would start offering a new feature for small businesses to host paid online events. Facebook has waived any fees for the first year, allowing small businesses to pocket 100 percent of the revenue. But Apple refused to budge on its 30 percent take.
The issue came to a head in late August when Facebook revealed that Apple wouldn’t even allow Facebook to inform users about Apple’s 30 percent take. Facebook wanted to have a message on the checkout screen that said “Apple takes 30 percent of this purchase.” But Apple deemed this message “irrelevant” and forced Facebook to remove it before approving Facebook’s update.
The reprieve is only temporary. Apple says it has given Facebook until the end of the year to switch from Facebook Pay to in-app purchases—and hence start paying Apple 30 percent—for online events. Apple is extending the same courtesy to Airbnb and ClassPass.
However, this grace period isn’t available for Gaming Creators, which Apple argues are not brick-and-mortar businesses that have been affected by COVID-19.
If you’ve been experiencing issues trying to access Google or YouTube, you’re not alone. Around 9 p.m. ET on Thursday evening, tons of users worldwide reported problems with Google and the many services under the tech giant’s umbrella, including Google Drive, Gmail, Stadia, the Play Store, and even Nest.
Some, such as Gmail, were taking significantly more time to load while other services like Google’s Play Store and Calendar seemed to be on an endless boot-up loop and wouldn’t load at all. DownDetector currently shows outages for just about all of Google’s services in areas all over the world. According to the site, the bulk of reports are coming from Australia, the U.S., and east Asia, with users primarily having issues logging in.
We’ve reached out to Google for more info. Honestly, a worldwide Google outage is absolutely on-brand for the year we’re having so far, so I’m hardly surprised.
Update: 9/24/2020; 11:17 p.m. ET: Luckily, the problem appears to have been short-lived. An update from Google’s Cloud status dashboard showed that the issue across had been resolved “for most traffic” across Google’s services shortly after 10:30 p.m. ET.
Alexander James Ashburner Nix (45), from Holland Park, West London, has signed a disqualification undertaking, accepted by the Secretary of State on 14 September 2020.
Within the undertaking, Alexander Nix did not dispute that he caused or permitted SCL Elections Ltd or associated companies to market themselves as offering potentially unethical services to prospective clients; demonstrating a lack of commercial probity.
Effective from 5 October 2020, Alexander Nix is disqualified for seven years from acting as a director or directly or indirectly becoming involved, without the permission of the court, in the promotion, formation or management of a company.
Alexander Nix was a director of SCL Elections Ltd, a company that provided data analytics, marketing and communication services to political and commercial customers. He was also a director of five other connected UK companies: SCL Group Ltd, SCL Social Ltd, SCL Analytics Ltd, SCL Commercial Ltd, and Cambridge Analytica (UK) Ltd.
From 2016, SCL Elections Ltd was included in a rebranding of associated companies which then operated under the trading names Cambridge Analytica, CA Political (Global) and CA Commercial.
SCL Elections and the five connected companies, however, ceased trading following allegations in the UK and United States media which created substantial adverse publicity.
Some of the accusations against the companies related to allegedly offering potential clients unethical services.
All six companies entered into administration in May 2018 before entering into compulsory liquidation in April 2019. The companies’ insolvencies brought them to the attention of the Insolvency Service, who conducted investigations into the conduct of the directors.
Investigators’ enquiries confirmed that Alexander Nix had caused or permitted SCL Elections or associated companies to act with a lack of commercial probity.
The unethical services offered by the companies included bribery or honey trap stings, voter disengagement campaigns, obtaining information to discredit political opponents and spreading information anonymously in political campaigns.
Would you believe more than 1% of computers worldwide are still using Windows XP? Incredibly, there are still millions of people using 19-year-old operating system. And a recent development — if it bears out — is another reason people need to make the switch to something newer.
On Thursday, users on 4chan posted what they claimed was the source code of Windows XP.
Posting an image of a screenshot allegedly of the source code in front of Window’s XP iconic Bliss background, one user wrote ‘sooooo Windows XP Source code leaked’. Another Redditor helpfully has uploaded the code as a torrent, assisting in its spread.
While there is no confirmation that this code is definitely Windows XP, independent researchers have begun to pick through the source code and believe it stands up to scrutiny.
TESLA’s network completely dropped on Wednesday in a massive outage that left drivers unable to connect to their cars.
According to Electrek, internal systems were fully down and around 11am ET, leaving users unable to connect their vehicles to the mobile app.
3
Tesla users were unable to connect their cars to their mobile apps on WednesdayCredit: EPA
Tesla staff were also unable “to process deliveries and orders” and the company’s website wasn’t working.
The outage also hit Tesla solar and Powerwall, the company’s in-home batteries.
Breaking: Tesla is currently having a complete network outage. Internal systems are down according to sources. On the customer side, I can’t connect to any of my cars and website is not working. What about you? pic.twitter.com/fbj3s4SJC8
Yesterday, NASA and Russian flight controllers performed an “avoidance maneuver” to protect the International Space Station from a wayward chunk of space debris. This episode—already the third of its kind this year—highlights a growing problem and the importance of mitigating potential collisions in space.
Low Earth orbit (LEO) is vast and mostly empty, but when you have thousands upon thousands of objects zipping around at speeds over 6 miles per second (10 km/s), this space in space suddenly seems a lot smaller.
Such was the concern earlier this week when NASA, along with U.S. Space Command, detected an unknown piece of space debris that was expected to come uncomfortably close to the International Space Station. To safeguard the outpost and its crew, NASA and Russian flight controllers scheduled an impromptu “avoidance maneuver” to place the ISS out of harm’s way.
To do so, they fired thrusters belonging to Russia’s Progress 75 resupply spacecraft, which is currently docked to the Zvezda service module. Given the late notice, mission controllers had all three members of the Expedition 63 crew—Chris Cassidy, Anatoly Ivanishin, and Ivan Vagner—temporarily relocate to the Russian segment so they could be in close proximity to the Soyuz MS-16 spacecraft. NASA said this was done “out of an abundance of caution” and that “at no time was the crew in any danger.”
The piece of space junk was projected to pass to within 0.86 miles (1.39 kilometers) of the International Space Station, with the closest approach happening on Tuesday, September 22 at 6:21 pm EDT. The avoidance maneuver, which required just 150 seconds to complete, was performed about an hour earlier. NASA and Russian flight controllers worked in tandem to make it happen.
Once it was all over, the hatches between the U.S. and Russian segments were reopened and life resumed to normal.
Mozilla recently announced that they would be dismissing 250 people. That’s a quarter of their workforce so there are some deep cuts to their work too. The victims include: the MDN docs (those are the web standards docs everyone likes better than w3schools), the Rust compiler and even some cuts to Firefox development. Like most people I want to see Mozilla do well but those three projects comprise pretty much what I think of as the whole point of Mozilla, so this news is a a big let down.
The stated reason for the cuts is falling income. Mozilla largely relies on “royalties” for funding. In return for payment, Mozilla allows big technology companies to choose the default search engine in Firefox – the technology companies are ultimately paying to increase the number of searches Firefox users make with them. Mozilla haven’t been particularly transparent about why these royalties are being reduced, except to blame the coronavirus.
I’m sure the coronavirus is not a great help but I suspect the bigger problem is that Firefox’s market share is now a tiny fraction of its previous size and so the royalties will be smaller too – fewer users, so fewer searches and therefore less money for Mozilla.
The real problem is not the royalty cuts, though. Mozilla has already received more than enough money to set themselves up for financial independence. Mozilla received up to half a billion dollars a year (each year!) for many years. The real problem is that Mozilla didn’t use that money to achieve financial independence and instead just spent it each year, doing the organisational equivalent of living hand-to-mouth.
Despite their slightly contrived legal structure as a non-profit that owns a for-profit, Mozilla are an NGO just like any other. In this article I want to apply the traditional measures that are applied to other NGOs to Mozilla in order to show what’s wrong.
These three measures are: overheads, ethics and results.
Overheads
One of the most popular and most intuitive ways to evaluate an NGO is to judge how much of their spending is on their programme of works (or “mission”) and how much is on other things, like administration and fundraising. If you give money to a charity for feeding people in the third world you hope that most of the money you give them goes on food – and not, for example, on company cars for head office staff.
Mozilla looks bad when considered in this light. Fully 30% of all expenditure goes on administration. Charity Navigator, an organisation that measures NGO effectiveness, would give them zero out of ten on the relevant metric. For context, to achieve 5/10 on that measure Mozilla admin would need to be under 25% of spending and, for 10/10, under 15%.
Senior executives have also done very well for themselves. Mitchell Baker, Mozilla’s top executive, was paid $2.4m in 2018, a sum I personally think of as instant inter-generational wealth. Payments to Baker have more than doubled in the last five years.
As far as I can find, there is no UK-based NGO whose top executive makes more than £1m ($1.3m) a year. The UK certainly has its fair share of big international NGOs – many much bigger and more significant than Mozilla.
I’m aware that some people dislike overheads as a measure and argue that it’s possible for administration spending to increase effectiveness. I think it’s hard to argue that Mozilla’s overheads are correlated with any improvement in effectiveness.
Ethics
Mozilla now thinks of itself less as a custodian of the old Netscape suite and more as a ‘privacy NGO’. One slogan inside Mozilla is: “Beyond the Browser”.
Regardless of how they view themselves, most of their income comes from helping to direct traffic to Google by making that search engine the default in Firefox. Google make money off that traffic via a big targeted advertising system that tracks people across the web and largely without their consent. Indeed, one of the reasons this income is falling is because as Firefox’s usage falls less traffic is being directed Google’s way and so Google will pay less.
There is, as yet, no outbreak of agreement among the moral philosophers as to a universal code of ethics. However I think most people would recognise hypocrisy in Mozilla’s relationship with Google. Beyond the ethical problems, the relationship certainly seems to create conflicts of interest. Anyone would think that a privacy NGO would build anti-tracking countermeasures into their browser right from the start. In fact, this was only added relatively recently (in 2019), after both Apple (in 2017) and Brave (since release) paved the way. It certainly seems like Mozilla’s status as a Google vassal has played a role in the absence of anti-tracking features in Firefox for so long.
Another ethical issue is Mozilla’s big new initiative to move into VPNs. This doesn’t make a lot of sense from a privacy point of view. Broadly speaking: VPNs are not a useful privacy tool for people browsing the web. A VPN lets you access the internet through a proxy – so your requests superficially appear to come from somewhere other than they really do. This does nothing to address the main privacy problem for web users: that they are being passively tracked and de-anonymised on a massive scale by the baddies at Google and elsewhere. This tracking happens regardless of IP address.
When I tested Firefox through Mozilla VPN (a rebrand of Mullvad VPN) I found that I could be de-anonymised by browser fingerprinting – already a fairly widespread technique by which various elements of your browser are examined to create a “fingerprint” which can then be used to re-identify you later. Firefox, unlike some other browsers, does not include any countermeasures against this.
Even when using Mozilla’s “secure and private” VPN, Firefox is trackable by browser fingerprinting, as demonstrated by the EFF’s Panopticlick tool. Other browsers use randomised fingerprints as a countermeasure against this tracking.
Another worry is that many of these privacy focused VPN services have a nasty habit of turning out to keep copious logs on user behaviour. A few months ago several “no log” VPN services inadvertently released terabytes of private user data that they had promised not to collect in a massive breach. VPN services are in a great position to eavesdrop – and even if they promise not to, your only option is to take them at their word.
Results
I’ve discussed the Mozilla chair’s impressive pay: $2.4m/year. Surely such impressive pay is justified by the equally impressive results Mozilla has achieved? Sadly on almost every measure of results both quantitative and qualitative, Mozilla is a dog.
Firefox is now so niche it is in danger of garnering a cult following: it has just 4% market share, down from 30% a decade ago. Mobile browsing numbers are bleak: Firefox barely exists on phones, with a market share of less than half a percent. This is baffling given that mobile Firefox has a rare feature for a mobile browser: it’s able to install extensions and so can block ads.
Yet despite the problems within their core business, Mozilla, instead of retrenching, has diversified rapidly. In recent years Mozilla has created:
a mobile app for making websites
a federated identity system
a large file transfer service
a password manager
an internet-of-things framework/standard
an email relay service
a completely new phone operating system
an AI division (but of course)
and spent $25 million buying the reading list management startup, Pocket
Many of the above are now abandoned.
Sadly Mozilla’s annual report doesn’t break down expenses on a per-project basis so it’s impossible to know how much of the spending that is on Mozilla’s programme is being spent on Firefox and how much is being spent on all these other side-projects.
What you can at least infer is that the side-projects are expensive. Software development always is. Each of the projects named above (and all the other ones that were never announced or that I don’t know about) will have required business analysts, designers, user researchers, developers, testers and all the other people you need in order to create a consumer web project.
The biggest cost of course is the opportunity cost of just spending that money on other stuff – or nothing: it could have been invested to build an endowment. Now Mozilla is in the situation where apparently there isn’t enough money left to fully fund Firefox development.
What now?
Mozilla can’t just continue as before. At the very least they need to reduce their expenses to go along with their now reduced income. That income is probably still pretty enormous though: likely hundreds of millions a year.
I’m a Firefox user (and one of the few on mobile, apparently) and I want to see Mozilla succeed. As such, I would hope that Mozilla would cut their cost of administration. I’d also hope that they’d increase spending on Firefox to make it faster and implement those privacy features that other browsers have. Most importantly: I’d like them to start building proper financial independence.
I doubt those things will happen. Instead they will likely keep the expensive management. They have already cut spending on Firefox. Their great hope is to continue trying new things, like using their brand to sell VPN services that, as I’ve discussed, do not solve the problem that their users have.
Instead of diversifying into yet more products and services Mozilla should probably just ask their users for money. For many years the Guardian newspaper (a similarly sized organisation to Mozilla in terms of staff) was a financial basket case. The Guardian started asking their readers for money a few years ago and seems to be on firmer financial footing since.
Getting money directly has also helped align the incentives of their organisation with those of their readers. Perhaps that would work for Mozilla. But then, things are different at the Guardian. Their chief exec makes a mere £360,000 a year.
MS Edge and Google Chrome are winning the renewed browser wars and this kind of financial playing isn’t helping Firefox, who I really want to win on ethical considerations. It’s just not helping.
Samsung may have first made an ECG-capable smartwatch with the Galaxy Watch Active2, but it wasn’t until earlier this summer that it actually got clearance from the U.S. Food and Drug Administration to enable the medical-grade feature. That announcement came in dramatic fashion at its Unpacked event in August, where the company unveiled yet another ECG-capable smartwatch, the excellent Galaxy Watch 3. Still, even with clearance, we didn’t know exactly when the ECG feature would be available on either watch. Well, the answer is today.
“Beginning September 23, users will have access to yet another next-generation feature, as on-demand electrocardiogram (ECG) readings come to Galaxy Watch 3 and Galaxy Watch Active2,” Samsung said in a press statement. “This tool recently received clearance from the U.S. Food and Drug Administration (FDA) and will soon be available through the Samsung Health Monitor app when connected to a compatible Galaxy smartphone.”
It appears that Samsung’s ECG app will operate similarly to Apple’s. After opening the Samsung Health Monitor app, you’ll be advised to put your arm on a flat surface and place your finger on the top button. The watch will identify you as having either a normal Sinus Rhythm or atrial fibrillation. Once the reading is done, you can log symptoms like dizziness or fatigue. (Atrial fibrillation is often unaccompanied by symptoms.) You’ll also be able to send a PDF report to your healthcare provider.
The catch here is that, at least for now, the ECG app will only be available on Samsung Galaxy phones with Android Nougat or higher—meaning, if you have one of these watches paired to a non-Samsung Android phone or an iPhone, you’re out of luck. That’s only sort of surprising. While Samsung’s smartwatches are among the best currently available for Android users, Samsung is like Apple in that it likes to push its own ecosystem. As a result, some features are only available to Samsung phone owners. It looks like, for the time being, ECG is one of them.
Image: Samsung
Gizmodo reached out to Samsung to see if this feature might eventually make its way to non-Samsung Android phones. In response, a Samsung spokesperson said, “We’re always looking to address consumer feedback, however we cannot speak to additional phone compatibility outside of Galaxy smartphones at this time.”
While it’s great that Samsung’s ECG app is finally here, it is majorly disappointing that not all Android users will be able to access it. That means currently, in the U.S. only Apple and Samsung smartwatch owners have access to any sort of on-the-wrist ECG. The Galaxy Watch 3 felt like a real win for all Android users, but leaving non-Samsung Android users out of this update takes the shine off that a bit. Hopefully, Samsung will fix that going forward.
For non-Samsung Android users, the only FDA-cleared ECG smartwatch is the newly launched Fitbit Sense. However, Fitbit only just got clearance, meaning the ECG feature on the Sense is not live yet. You’ll have to wait until next month before it’s available. The good news is that Fitbit is platform-agnostic. Provided that there aren’t any delays, this means you’ll have at least one FDA-cleared ECG smartwatch option, regardless of what phone you use.
In 2015, German sportswear manufacturer Adidas acquired a plucky Austrian IoT startup called Runtastic, which, among other things, manufactured a $129.99 “smart” scale called Libra. Now that product is being discontinued, preventing owners from synchronising their data or even downloading the app required to use it.
In a post published yesterday, Adidas announced the discontinuation of key functionality from the Libra smart scale.
“We wanted to let you know that we’ve decided to stop supporting the Libra app. This means that we’ve taken the app off the market and that login won’t work anymore,” the company said. “A login and the synchronisation of your weight data from the Libra scale is no longer possible.”
Owners can still see how much timber they’ve put on during lockdown by glancing at the Libra’s LCD screen, much like they could with an ordinary £10 scale from Tesco. However, the core functionality that initially attracted them to the product is long gone.
While the Libra app is no longer searchable on the Google Play Store and Apple App Store, those who have previously downloaded it are able to visit its page, where they can still leave “feedback”. Predictably, this has prompted a flood of one-star reviews and furious comments.
El Reg has contacted Adidas for comment.
Users of Libra are not alone in having their expensive IoT kit discontinued after just a few years of ownership.
In April 2016, the servers supporting a smart home hub product called Revolv were shut down, leaving owners unable to control their other Wi-Fi-connected gizmos. This stung for a couple of reasons: firstly, the hub cost £210 and was explicitly sold with a “lifetime subscription”. Secondly, Revolv wasn’t a fledgling startup with tenuous cash flow, but rather a subsidiary of Alphabet – one of the largest and wealthiest companies on the planet.
Another shocking example comes from last year, when Den Automation, a crowdfunding sensation that raised $4.5m in equity crowdfunding for a family of smart plugs and light switches, entered administration. As it found itself unable to pay for server costs, people suddenly found themselves burdened with non-functional and hugely expensive kit.
The assets and intellectual property of Den Automation were subsequently acquired by a previous investor through a new company called Den Switches, which has said it intends to restart the service. It’s not clear when that will happen.
More recently, the Will.i.am-owned startup Wink sent out an email to users of its smart home products demanding they pay for a subscription service in order to continue using their products as the revenue obtained from one-time purchases of its equipment proved insufficient to support long-term maintenance.
The problem with most IoT products isn’t necessarily that they rely on back-end servers to run. It’s that, for the most part, it’s impossible to perceive the trajectory of a given company. Will they be acquired by new owners with aggressive cost-cutting strategies and leaner product roadmaps?
Or will they financially struggle, eventually swirling the toilet basin of insolvency, and leave nothing behind but a bunch of electronic waste and angry one-star app reviews?
Sam Newman, a consultant and author specialising in microservices, told a virtual crowd at dev conference GOTOpia Europe that serverless, not Kubernetes, is the best abstraction for deploying software.
Newman is an advocate for cloud. “We are so much in love with the idea of owning our own stuff,” he told attendees. “We end up in thrall to these infrastructure systems we build for ourselves.”
He is therefore a sceptic when it comes to private cloud. “AWS showed us the power of virtualization and the benefits of automation via APIs,” he said. Then came OpenStack, which sought to bring those same qualities on-premises. It is one of the biggest open-source projects in the world, he said, but a “false hope… you still fundamentally have to deal with what you are running.”
You are viewing 1,459 cards with a total of 2,407,911 stars, market cap of $19.73 trillion and funding of $65.62 billion (click to enlarge): The CNCF ‘landscape’ illustration of cloud native shows how complex Kubernetes and its ecosystem has become
What is the next big thing? Kubernetes? “Kubernetes is great if you want to manage container workloads,” said Newman. “It’s not the best thing for managing container workloads. It’s great for having a fantastic ecosystem around it.”
As he continued, it turned out he has reservations. “It’s like a giant thing with lots of little things inside it, all these pods, like a termite mound. It’s a big giant edifice, your Kubernetes cluster, full of other moving parts… a lot of organisations incrementing their own Kubernetes clusters have found their ability to deliver software hollowed out by the fact that everybody now has to go on Kubernetes training courses.”
Newman illustrates his point with a reference to the CNCF (Cloud Native Computing Foundation) diagram of the “cloud native landscape”, which looks full of complexity.
A lot of organisations incrementing their own Kubernetes clusters have found their ability to deliver software hollowed out by the fact that everybody now has to go on Kubernetes training courses
Kubernetes on private cloud is “a towering edifice of stuff,” he said. Hardware, operating system, virtualization layer, operating system inside VMs, container management, and on top of that “you finally get to your application… you spend your time and money looking after those things. Should you be doing any of that?”
Going to public cloud and using either managed VMs, or a managed Kubernetes service like EKS (Amazon), AKS (Azure) or GKE (Google), or other ways of running containers, takes away much of that burden; but Newman argued that it is serverless, rather than Kubernetes, that “changes how we think about software… you give your code to the platform and it works out how to execute it on your behalf,” he said.
What is serverless?
“The key characteristics of a serverless offering is no server management. I’m not worried about the operating systems or how much memory these things have got; I am abstracted away from all of that. They should autoscale based on use… implicitly I’m presuming that high availability is delivered by the serverless product. If we are using public cloud, we’d also be expecting a pay as you go model.”
“Many people erroneously conflate serverless and functions,” said Newman, since the term is associated with services like AWS Lambda and Azure Functions. Serverless “has been around longer than we think,” he added, referencing things like AWS Simple Storage Service (S3) in 2006, as well as things like messaging solutions and database managers such as AWS DynamoDB and Azure Cosmos DB.
But he conceded that serverless has restrictions. With functions as a service (FaaS), there are limits to what programming languages developers can use and what version, especially in Google’s Cloud Functions, which has “very few languages supported”.
Functions are inherently stateless, which impacts the programming model – though Microsoft has been working on durable functions. Another issue is that troubleshooting can be harder because the developer is further removed from the low level of what happens at runtime.
“FaaS is the best abstraction we have come up with for how we develop software, how we deploy software, since we had Heroku,” said Newman. “Kubernetes is not developer-friendly.”
FaaS, said Newman, is “going to be the future for most of us. The question is whether or not it’s the present. Some of the current implementations do suck. The usability of stuff like Lambda is way worse than it should be.”
Despite the head start AWS had with Lambda, Newman said that Microsoft is catching up with serverless on Azure. He is more wary of Google, arguing that it is too dependent on Knative and Istio for delivering serverless, neither of which in his view are yet mature. He also thinks that Google’s decision not to develop Knative inside the CNCF is a mistake and will hold it back from adapting to the needs of developers.
How does serverless link with Newman’s speciality, microservices? Newman suggested getting started with a 1-1 mapping, taking existing microservices and running them as functions. “People go too far too fast,” he said. “They think, it makes it really easy for me to run functions, let’s have a thousand of them. That way lies trouble.”
Further breaking down a microservice into separate functions might make sense, he said, but you can “hide that detail from the outside world… you might change your mind. You might decide to merge those functions back together again, or strip them further apart.”
The microservice should be a logical unit, he said, and FaaS an implementation detail.
Despite being an advocate of public cloud, Newman recognises non-technical concerns. “More power is being concentrated in a small number of hands,” he said. “Those are socio-economic concerns that we can have conversations about.”
Among all the Kubernetes hype, has serverless received too little attention? If you believe Newman, this is the case. The twist, perhaps, is that some serverless platforms actually run on Kubernetes, explicitly so in the case of Google’s platform
A rural village in Wales has been suffering through internet outages and slowdowns for 18 months. The situation baffled technicians until they realized that turning off one man’s TV solved everything.
On Tuesday, U.K.-based broadband provider Openreach explained in a release that every morning, around 7 a.m., residents of the Aberhosan village found themselves experiencing issues connecting to the internet, and when they could log on, loading times slowed to a crawl. According to the provider, engineers were deployed to the area on multiple occasions only to find the network was functioning normally. The company went as far as replacing some cable, but its efforts were fruitless.
Openreach engineer Michael Jones explained that “as a final resort” a team visited the village to test for electrical interference. “By using a device called a Spectrum Analyser we walked up and down the village in the torrential rain at 6 a.m. to see if we could find an ‘electrical noise’ to support our theory,” Jones said. “And at 7 a.m., like clockwork, it happened! Our device picked up a large burst of electrical interference in the village.”
The team was able to trace the signal to a residence and found that the occupant had an aging TV that was producing electrical interference known as SHINE (Single High-level Impulse Noise). The TV’s owner had a habit of switching it on every morning at 7 a.m. as they started their day. “As you can imagine when we pointed this out to the resident, they were mortified that their old second-hand TV was the cause of an entire village’s broadband problems, and they immediately agreed to switch it off and not use again,” Jones said.
Openreach’s network is still on the outdated ADSL Broadband standard with plans to deploy fiber later this year. SHINE is a type of interference that screws with the frequencies that ADSL utilizes. When a device is powered on, a burst of frequencies is emitted that can knock devices offline or cause reduced speeds as a result of line errors. While SHINE is a single event that occurs when turning a device off and on, it can result in DSL circuits failing and losing sync. UK telecom Zen has some tips from identifying SHINE on your own using an AM radio.
Some makers of smart speakers, video doorbells and other hardware hit roadblocks buying key ads in search results on Amazon; gadgets made by e-commerce giant get edge. From a report: Amazon.com is limiting the ability of some competitors to promote their rival smart speakers, video doorbells and other devices on its dominant e-commerce platform, according to Amazon employees and executives at rival companies and advertising firms. The strategy gives an edge to Amazon’s own devices, which the company regards as central to building consumer loyalty. It puts at a disadvantage an array of gadget makers such as Arlo that rely on Amazon’s site for a significant share of their sales. The e-commerce giant routinely lets companies buy ads that appear inside search results, including searches for competing products. Indeed, search advertising is a lucrative part of the company’s business.
But Amazon won’t let some of its own large competitors buy sponsored-product ads tied to searches for Amazon’s own devices, such as Fire TV, Echo Show and Ring Doorbell, according to some Amazon employees and others familiar with the policy. Roku which makes devices that stream content to TVs, can’t even buy such Amazon ads tied to its own products, some of these people said. In some cases, Amazon has barred competitors from selling certain devices on its site entirely. The policies show the conflicts between Amazon’s large e-commerce platform for sellers and its role as a product manufacturer in its own right. While traditional retailers buy inventory from manufacturers and resell it to consumers, limiting the number of vendors they can work with, Amazon’s platform has more than a million businesses and entrepreneurs selling directly to Amazon’s shoppers. Amazon accounts for 38% of online shopping in the U.S. and roughly half of all online shopping searches in the U.S. start on Amazon.com.
“News flash: retailers promote their own products and often don’t sell products of competitors,” said Amazon spokesman Drew Herdener in a written statement. “Walmart refuses to sell [Amazon brands] Kindle, Fire TV, and Echo. Shocker. In the Journal’s next story they will uncover gambling in Las Vegas.”
Which is another reason why marketplaces should not be allowed to sell products at all and another show of how monopoly dominance undercuts and destroys competition – which is bad for the consumer.
This is something I have been talking about since the beginning of last year and is now gaining traction
Just last week, Facebook launched an initiative to uplift climate science. It was wildly misguided, yes, but the company was trying to show it’s down for the cause or something. Now, the company is proving just how devoted to climate activism it is by, um, booting environmental justice organizers from the platform. Tight!
Hundreds of Indigenous, environmental, and social justice groups and members had their accounts blocked this past weekend, leaving them unable to post or send messages. Greenpeace USA, Climate Hawks Vote, Stand.earth, Wet’suwet’en Access Point on Gidimt’en Territory, and Rainforest Action Network were among the groups that saw their accounts affected.
The accounts blocked were involved in planning a communications blockade event against KKR & Co., the U.S. investment firm that’s majority funder of the destructive Coastal Link natural gas pipeline, which is set to cut through land controlled by Indigenous people without consent. In other words, these groups were blocked while fighting climate injustice.
“Facebook is actively suppressing those who oppose fascism and the colonial capitalists,” activist Delee Nikal, a Wet’suwet’en band member of the Gitdimt’en clan, said in a statement emailed to Earther.
In a statement, Facebook said these suspensions were all just a random accident.
“Our systems mistakenly removed these accounts and content,” Facebook spokesman Andy Stone said.
He said all limits imposed had been lifted, but according to Greenpeace USA, though many accounts have now been restored, some are still blocked.
Last week, RTX 3080 scalpers pissed off a lot of Nvidia GPU fans by buying up all the graphics cards and attempting to resell them for hundreds of dollars more than the actual MSRP. Unfortunately, this is a common scalper tactic: Buy up as many items of a single product as possible, create a false scarcity, and sell them at a higher price to make a huge profit. People did this at the beginning of the covid-19 pandemic with hand sanitizers and other disinfecting products, and it happens all the time with consoles and PC components, too. Scalpers may have created bots to snatch up all those cards, but it looks like bots aren’t just helping the scalpers. They’re also hurting them.
Now RTX 3080 GPUs are being listed on eBay with bids that exceed $10,000. But those ridiculously high bids might be the result of bots created by fed-up potential buyers. After I wrote about who in the hell would buy a RTX 3080 for $70,000, I quickly received dozens of messages from people pointing me to a post on the Nvidia forums where a user claimed that they wrote a bot to inflate scalper prices. The post on Nvidia’s forums has since been removed, but I was able to connect with the post’s author. They confirmed they did not place that winning $70,000 bid, but they claimed they modified the source code for a free eBay bidding bot and ran that code on 10 spoof accounts. They said they were also able to use the same phone number on all 10 of those accounts, and that number was fake as well.
If this person was doing that, how many other people were doing the same thing, and how far were they driving up RTX 3080 auction prices? We analyzed 2,723 bids across 179 live auctions on Monday morning, Sept. 21, that totaled $966,927 worth of bids, and came away with some interesting results.
[…]
Without going through every single RTX 3080 auction, it’s hard to know how many automatic bids or bots are getting into bidding wars like this. And the way eBay presents bidding information sometimes makes it hard to parse through that information. But it’s clear there’s a huge chunk of people out there hoping to get these listings deleted and the sellers banned from eBay by inflating bid prices. eBay has a policy against price gouging, or “offering items at a price higher than is considered fair or reasonable,” and artificially inflating RTX 3080 auction prices seems to have grabbed eBay’s attention. It has started taking actions against some of these sellers.
One seller sent me a screenshot of an email they received from eBay saying their account, which they first activated in March 2014, has been suspended permanently.
The suspended seller told me they received about 100 messages from other eBay users, ranging from, “You should be ashamed of yourself,” to,“Fucking kill yourself.” While the latter type of message is definitely abusive, anger directed toward scalpers trying to make a quick buck is not misplaced.
We reached out to eBay, but the company has yet to respond.
Nvidia has responded to the chaos by publishing a full FAQ about the steps it’s taking to prevent scalpers and bots from getting the jump on real customers in the future.
“We moved our Nvidia Store to a dedicated environment, with increased capacity and more bot protection,” Nvidia announced. “We updated the code to be more efficient on the server load. We integrated CAPTCHA to the checkout flow to help offset the use of bots. We implemented additional security protections to the store APIs. And more efforts are underway.”
The company confirmed that it manually canceled hundreds of orders linked to malicious reseller accounts, and more cards will be available for purchase soon. Hopefully, both Nvidia and eBay take additional steps to address this issue before the launch of the RTX 3090 and RTX 3070.
Microsoft has bagged exclusive rights to use OpenAI’s GPT-3 technology, allowing the Windows giant to embed the powerful text-generating machine-learning model into its own products.
“Today, I’m very excited to announce that Microsoft is teaming up with OpenAI to exclusively license GPT-3, allowing us to leverage its technical innovations to develop and deliver advanced AI solutions for our customers, as well as create new solutions that harness the amazing power of advanced natural language generation,” Microsoft CTO Kevin Scott said on Tuesday.
Right now, GPT-3 is only available to a few teams hand picked by OpenAI. The general-purpose text-in-text-out tool is accessible via an Azure-hosted API, and is being used by, for instance, Reddit to develop automated content moderation algorithms, and by academics investigating how the language model could be used to spread spam and misinformation at a scale so large it would be difficult to filter out.
GPT-3 won’t be available on Google Cloud, Amazon Web Services etc
Microsoft has been cosying up to OpenAI for a while; it last year pledged to invest $1bn in the San Francisco-based startup. As part of that deal, OpenAI got access to Microsoft’s cloud empire to run its experiments, and Microsoft was named its “preferred partner” for commercial products. Due to the exclusive license now brokered, GPT-3 won’t be available on rival cloud services, such as Google Cloud and Amazon Web Services.
[…]
GPT-3 is a massive model containing 175 billion parameters, and was trained on all manner of text scraped from the internet. It’s able to perform all sorts of tasks, including answering questions, translating languages, writing prose, performing simple arithmetic, and even attempting code generation. Although impressive, it remains to be seen if it can be utilized in products for the masses rather than being an object of curiosity.
Google has decided to shut down the Chrome Web Store payments API permanently after what was supposed to be a temporary closure at the start of the year.
In January, the internet advertising biz halted the publication of Chrome apps, extensions, and themes in the Chrome Web Store that were either paid-for or took in-app payments, following a flood of fraudulent transactions.
By February, developers could again submit paid items to be reviewed for inclusion in the Chrome Web Store. But the following month, Google again disabled Chrome Web Store payments, citing the challenges presented by the emergence of the COVID-19 pandemic.
“We understand that these changes may cause inconvenience, and we apologize for any interruption of service,” the Silicon Valley giant’s Chrome Web Store (CWS) team said in its email to developers in March.
It was also in January that Google announced plans to phase out Chrome apps, only to revise its schedule in August. Chrome apps, also known as Chrome packaged apps, are web apps tied to Chrome that were intended to behave like native apps by being launchable from the desktop, outside of the browser window.
On Monday, another email went out to registered extension developers informing them that Chrome Web Store payments will stop functioning in February next year.
“When we launched the Chrome Web Store 11 years ago, there weren’t a lot of ways for our developers to take payment from users,” the message to extension developers stated. “Today, there is a thriving ecosystem of payment providers offering a far more diverse set of features than a single provider could hope to. Now that our developers have so many great options to choose from, we can comfortably sunset our own payments integration.”
As of this week, the inability to create new paid extensions and to implement in-app purchases using the CWS payment API, ongoing since March, became permanent. On December 1, 2020, free trials will be disabled and the “Try Now” button in the CWS will vanish. On February 1, 2021 active CWS items and in-purchases will no longer be able to make transactions, though querying license information for previously paid-for purchases and subscriptions will still be allowed.
And at some indeterminate time after that, the licensing API will no longer function. The payments deprecation schedule is explained on the Chrome developer website.
Most developers do not charge directly for their extensions. Among the roughly 190,000 extensions in the Chrome Web Store, about nine per cent are either paid or implement in-app purchasing, according to Extension Monitor. These account for about 2.6 per cent of some 1.2bn installs.
Google doesn’t make data available to discern how many of paid CWS items use the CWS payment system and how many use third-party services such as Stripe or Braintree. Unlike Apple’s iOS App Store, Google does not require developers to use its payment system for their apps or extensions.
Facebook has warned that it may pull out of Europe if the Irish data protection commissioner enforces a ban on sharing data with the US, after a landmark ruling by the European court of justice found in July that there were insufficient safeguards against snooping by US intelligence agencies.
In a court filing in Dublin, Facebook’s associate general counsel wrote that enforcing the ban would leave the company unable to operate.
“In the event that [Facebook] were subject to a complete suspension of the transfer of users’ data to the US,” Yvonne Cunnane argued, “it is not clear … how, in those circumstances, it could continue to provide the Facebook and Instagram services in the EU.”
Facebook denied the filing was a threat, arguing in a statement that it was a simple reflection of reality. “Facebook is not threatening to withdraw from Europe,” a spokesperson said.
“Legal documents filed with the Irish high court set out the simple reality that Facebook, and many other businesses, organisations and services, rely on data transfers between the EU and the US in order to operate their services. A lack of safe, secure and legal international data transfers would damage the economy and hamper the growth of data-driven businesses in the EU, just as we seek a recovery from Covid-19.”
The filing is the latest volley in a legal battle that has lasted almost a decade. In 2011, Max Schrems, an Austrian lawyer, began filing privacy complaints with the Irish data protection commissioner, which regulates Facebook in the EU, about the social network’s practices.
Those complaints gathered momentum two years later, when the Guardian revealed the NSA’s Prism program, a vast surveillance operation involving direct access to the systems of Google, Facebook, Apple and other US internet companies. Schrems filed a further privacy complaint, which was eventually referred to the European court of justice.
That court found in 2015 that, because of the existence of Prism, the “Safe Harbour” agreement, which allowed US companies to transfer the data of EU citizens back home, was invalid.
The EU then attempted a second legal agreement for the data transfers, a so-called privacy shield; that too was invalidated in July this year, with the court again ruling that the US does not limit surveillance of EU citizens.
In September, the Irish data protection commissioner began the process of enforcing that ruling. The commissioner issued a preliminary order compelling the social network to suspend data transfers overseas.
In response, Nick Clegg, the company’s head of global affairs and communications, published a blogpost that argued that “international data transfers underpin the global economy and support many of the services that are fundamental to our daily lives”.
“In the worst-case scenario, this could mean that a small tech start-up in Germany would no longer be able to use a US-based cloud provider,” he wrote. “A Spanish product development company could no longer be able to run an operation across multiple time zones. A French retailer may find they can no longer maintain a call centre in Morocco.”
Clegg added: “We support global rules that can ensure consistent treatment of data around the world.”
Yep, mr Clegg. But the law is the law. And it’s a good law. Having EU Citizens’ private data in the hands of the megalomanic 4th Reich US government is not a good idea – in the EU people like the idea of having rights and privacy.