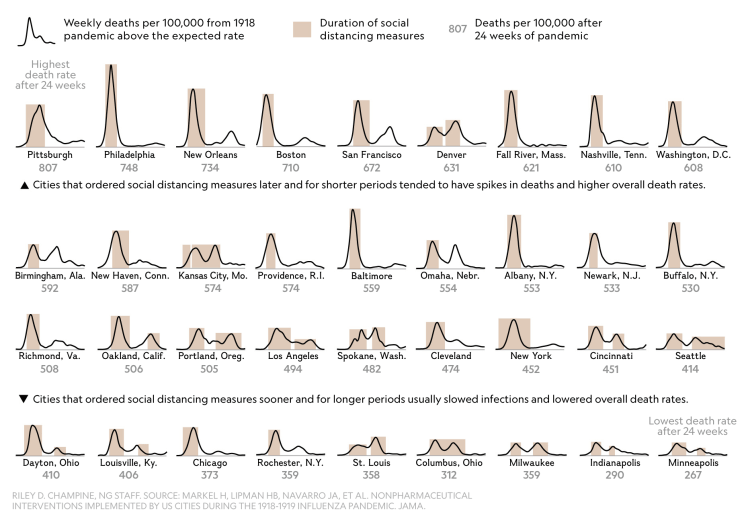
Storage vendors, including but reportedly not limited to Western Digital, have quietly begun shipping SMR (Shingled Magnetic Recording) disks in place of earlier CMR (Conventional Magnetic Recording) disks.
SMR is a technology that allows vendors to eke out higher storage densities, netting more TB capacity on the same number of platters—or fewer platters, for the same amount of TB.
Until recently, the technology has only been seen in very large disks, which were typically clearly marked as “archival”. In addition to higher capacities, SMR is associated with much lower random I/O performance than CMR disks offer.
Storage vendors appear to be getting much bolder about deploying the new technology into ever-smaller formats, presumably to save a bit on manufacturing costs. A few weeks ago, a message popped up on the zfs-discuss mailing list:
WD and Seagate are both submarining Drive-managed SMR (DM-SMR) drives into channels, disguised as “normal” drives.
For WD REDs this shows as EFRX (standard drive) suffix being changed to EFAX suffix (DM-SMR) […] The only clue you’ll get about these drives being SMR is the appalling sequential write speeds (~40MB/s from blank) and the fact that they report a “trim” function.
The unexpected shift from CMR to SMR in these NAS (Network Attached Storage) drives has caused problems above and beyond simple performance; the user quoted above couldn’t get his SMR disks to stay in his ZFS storage array at all.
There has been speculation that the drives got kicked out of the arrays due to long timeouts—SMR disks need to perform garbage-collection routines in the background and store incoming writes in a small CMR-encoded write-cache area of the disk, before moving them to the main SMR encoded storage.
It’s possible that long periods of time with no new writes accepted triggered failure-detection routines that marked the disk as bad. We don’t know the details for certain, but several users have reported that these disks cannot be successfully used in their NAS systems—despite the fact that the name of the actual product is WD Red NAS Hard Drive.
[…]
What really grinds our gears about this is that the only conceivable reason to shift to SMR technology in such small disks—lowered manufacturing costs due to fewer platters required—doesn’t seem to be being passed down to the consumer. The screenshot above shows the Amazon price of a WD Red 2TB EFRX and WD Red 2TB EFAX—the EFRX is the faster CMR drive, and the EFAX is the much slower SMR drive.
Western Digital doesn’t appear to be the only hard drive manufacturer doing this—blocksandfiles has confirmed quiet, undocumented use of SMR in small retail drives from Seagate and Toshiba as well.
We suspect the greater ire aimed at Western Digital is due both to the prominent NAS branding of the Red line and the general best-in-class reputation it has enjoyed in that role for several years.
Source: Buyer beware—that 2TB-6TB “NAS” drive you’ve been eyeing might be SMR | Ars Technica