Fake studies have flooded the publishers of top scientific journals, leading to thousands of retractions and millions of dollars in lost revenue. The biggest hit has come to Wiley, a 217-year-old publisher based in Hoboken, N.J., which Tuesday will announce that it is closing 19 journals, some of which were infected by large-scale research fraud.
In the past two years, Wiley has retracted more than 11,300 papers that appeared compromised, according to a spokesperson, and closed four journals. It isn’t alone: At least two other publishers have retracted hundreds of suspect papers each. Several others have pulled smaller clusters of bad papers.
Although this large-scale fraud represents a small percentage of submissions to journals, it threatens the legitimacy of the nearly $30 billion academic publishing industry and the credibility of science as a whole.
The discovery of nearly 900 fraudulent papers in 2022 at IOP Publishing, a physical sciences publisher, was a turning point for the nonprofit. “That really crystallized for us, everybody internally, everybody involved with the business,” said Kim Eggleton, head of peer review and research integrity at the publisher. “This is a real threat.”
Wiley will announce that it is closing 19 journals. Photo: Wiley
The sources of the fake science are “paper mills”—businesses or individuals that, for a price, will list a scientist as an author of a wholly or partially fabricated paper. The mill then submits the work, generally avoiding the most prestigious journals in favor of publications such as one-off special editions that might not undergo as thorough a review and where they have a better chance of getting bogus work published.
World-over, scientists are under pressure to publish in peer-reviewed journals—sometimes to win grants, other times as conditions for promotions. Researchers say this motivates people to cheat the system. Many journals charge a fee to authors to publish in them.
Problematic papers typically appear in batches of up to hundreds or even thousands within a publisher or journal. A signature move is to submit the same paper to multiple journals at once to maximize the chance of getting in, according to an industry trade group now monitoring the problem. Publishers say some fraudsters have even posed as academics to secure spots as guest editors for special issues and organizers of conferences, and then control the papers that are published there.
“The paper mill will find the weakest link and then exploit it mercilessly until someone notices,” said Nick Wise, an engineer who has documented paper-mill advertisements on social media and posts examples regularly on X under the handle @author_for_sale.
The journal Science flagged the practice of buying authorship in 2013. The website Retraction Watch and independent researchers have since tracked paper mills through their advertisements and websites. Researchers say they have found them in multiple countries including Russia, Iran, Latvia, China and India. The mills solicit clients on social channels such as Telegram or Facebook, where they advertise the titles of studies they intend to submit, their fee and sometimes the journal they aim to infiltrate. Wise said he has seen costs ranging from as little as $50 to as much as $8,500.
When publishers become alert to the work, mills change their tactics.
[…]
For Wiley, which publishes more than 2,000 journals, the problem came to light two years ago, shortly after it paid nearly $300 million for Hindawi, a company founded in Egypt in 1997 that included about 250 journals. In 2022, a little more than a year after the purchase, scientists online noticed peculiarities in dozens of studies from journals in the Hindawi family.
Scientific papers typically include citations that acknowledge work that informed the research, but the suspect papers included lists of irrelevant references. Multiple papers included technical-sounding passages inserted midway through, what Bishop called an “AI gobbledygook sandwich.” Nearly identical contact emails in one cluster of studies were all registered to a university in China where few if any of the authors were based. It appeared that all came from the same source.
[…]
The extent of the paper mill problem has been exposed by members of the scientific community who on their own have collected patterns in faked papers to recognize this fraud at scale and developed tools to help surface the work.
One of those tools, the “Problematic Paper Screener,” run by Guillaume Cabanac, a computer-science researcher who studies scholarly publishing at the Université Toulouse III-Paul Sabatier in France, scans the breadth of the published literature, some 130 million papers, looking for a range of red flags including “tortured phrases.”
Cabanac and his colleagues realized that researchers who wanted to avoid plagiarism detectors had swapped out key scientific terms for synonyms from automatic text generators, leading to comically misfit phrases. “Breast cancer” became “bosom peril”; “fluid dynamics” became “gooey stream”; “artificial intelligence” became “counterfeit consciousness.” The tool is publicly available.
Another data scientist, Adam Day, built “The Papermill Alarm,” a tool that uses large language models to spot signs of trouble in an article’s metadata, such as multiple suspect papers citing each other or using similar templates and simply altering minor experimental details. Publishers can pay to use the tool.
[…]
The incursion of paper mills has also forced competing publishers to collaborate. A tool launched through STM, the trade group of publishers, now checks whether new submissions were submitted to multiple journals at once, according to Joris van Rossum, product director who leads the “STM Integrity Hub,” launched in part to beat back paper mills. Last fall, STM added Day’s “The Papermill Alarm” to its suite of tools.
While publishers are fighting back with technology, paper mills are using the same kind of tools to stay ahead.
“Generative AI has just handed them a winning lottery ticket,” Eggleton of IOP Publishing said. “They can do it really cheap, at scale, and the detection methods are not where we need them to be. I can only see that challenge increasing.”
Microsoft (MSFT.O) must pay patent owner IPA Technologies $242 million, a federal jury in Delaware said on Friday after determining that Microsoft’s Cortana virtual-assistant software infringed an IPA patent.
The jury agreed with IPA after a week-long trial that Microsoft’s voice-recognition technology violates IPA’s patent rights in computer-communications software.
IPA is a subsidiary of patent-licensing company Wi-LAN, which is jointly owned by Canadian technology company Quarterhill (QTRH.TO)
, opens new tab and two investment firms. It bought the patent and others from SRI International’s Siri Inc, which Apple acquired in 2010 and whose technology it used in its Siri virtual assistant.
“We remain confident that Microsoft never infringed on IPA’s patents and will appeal,” a Microsoft spokesperson said.
Representatives for IPA and Wi-LAN did not immediately respond to a request for comment on the verdict.
IPA filed the lawsuit in 2018, accusing Microsoft of infringing patents related to personal digital assistants and voice-based data navigation.
The case was later narrowed to concern one IPA patent. Microsoft argued that it does not infringe and that the patent is invalid.
IPA has also sued Google and Amazon over its patents. Amazon defeated IPA’s lawsuit in 2021, and the Google case is still ongoing.
So basically some company that never did anything except buy some rights from somewhere managed to extort a quarter of a billion dollars from MS. What a brilliant system copyright is!
Some iPhone users are reportedly seeing photos they had previously deleted resurface on their devices ever since updating to the latest version of iOS.
The user reports originate from Reddit, and it’s not just a couple of Apple users experiencing issues. By our count, 16 people who deleted their photos say they’ve come back. The deleted photos are apparently marked as recently added, making it very obvious which have made a comeback.
One user says that even photos from 2010 reappeared, and that they have “deleted them repeatedly.”
The Register was able to find a handful of instances of X users reporting the same problem.
[…]
The recent complaints were preceded by a different Reddit thread where three users reported the exact same thing happening in the beta version of iOS 17.5.
[…]
Some users previously reported disappearing photos on older versions of iOS 17, and the fix may have resulted in both accidentally and purposefully deleted photos being brought back to life.
If the issue is genuine, it wouldn’t be the first time iCloud has kept its hands on data after it was supposedly deleted, despite Apple’s emphasis on the privacy of its users. Back in 2017, iCloud was patched to fix a glitch where user browser history was retained for up to a year or so.
Within approximately 12 seconds, two highly educated brothers allegedly stole $25 million by tampering with the ethereum blockchain in a never-before-seen cryptocurrency scheme, according to an indictment that the US Department of Justice unsealed Wednesday.
In a DOJ press release, US Attorney Damian Williams said the scheme was so sophisticated that it “calls the very integrity of the blockchain into question.”
[…]
The indictment goes into detail explaining that the scheme allegedly worked by exploiting the ethereum blockchain in the moments after a transaction was conducted but before the transaction was added to the blockchain.
These pending transactions, the DOJ explained, must be structured into a proposed block and then validated by a validator before it can be added to the blockchain, which acts as a decentralized ledger keeping track of crypto holdings. It appeared that the brothers tampered with this process by “establishing a series of ethereum validators” through shell companies and foreign exchanges that concealed their identities and masked their efforts to manipulate the blocks and seize ethereum.
To do this, they allegedly deployed “bait transactions” designed to catch the attention of specialized bots often used to help buyers and sellers find lucrative prospects in the ethereum network. When bots snatched up the bait, their validators seemingly exploited a vulnerability in the process commonly used to structure blocks to alter the transaction by reordering the block to their advantage before adding the block to the blockchain.
When victims detected the theft, they tried to request the funds be returned, but the DOJ alleged that the brothers rejected those requests and hid the money instead.
The brothers’ online search history showed that they studied up and “took numerous steps to hide their ill-gotten gains,” the DOJ alleged. These steps included “setting up shell companies and using multiple private cryptocurrency addresses and foreign cryptocurrency exchanges” that specifically did not rely on detailed “know your customer” (KYC) procedures.
The newly compromised data includes names, phone numbers and email addresses of Dell customers. This personal data is contained in customer “service reports,” which also include information on replacement hardware and parts, comments from on-site engineers, dispatch numbers and, in some cases, diagnostic logs uploaded from the customer’s computer.
[…]
The stolen data included customer names and physical addresses, as well as less sensitive data, such as “Dell hardware and order information, including service tag, item description, date of order and related warranty information.”
I am not sure that knowledge of your operating environment, the amount you spend and service tag information constitutes “less sensitive data”. Actually, no, it is not “less sensitive”
Dell downplayed the breach at the time, saying that the spill of customer addresses did not pose “a significant risk to our customers,” and that the stolen information did not include “any highly sensitive customer information,” such as email addresses and phone numbers.
After the absolute shitshow and riots around the release of the new app, which missed core functionalities and broke systems, Sonos did participate in their promised Ask Me Anything. Kind of. Three Sonos employees apparently attended, but managed to barely respond to any of the questions – which were almost all overwhelmingly angry, disappointed and hoping for control of their expensive machines.
Diane Roberts, Senior Director of Software Engineering and Product Management at Sonos responsible for the Sonos Apps managed to answer 9 questions
Kate, Senior Director of User Experience, Kate leads the UX team responsible for Sonos’ home audio hardware, software, and app user experiences got in six answers
Most of the answers given were disrespectful corporate shitspeak, blaming the customers for wanting the features they already had or alluding to how ‘energized’ the team was to roll out features in the future.
None apologised or seemed to even acknowledge the > 750 complaints about the new app.
None of these head honchos had ever even looked at the Sonos forum before! This is where they would have been able to see problems that people really had before embarking on their app redesign adventure.
Some guy called Mike – the Sonos employee left after the original people ran away posted an insulting closing comment, saying
We covered as many of the most asked questions as possible. We know tracking the responses wasn’t as easy as we had hoped. But we wanted to let the community air frustrations and have their questions answered.
Not very much seemed to be possible, not many questions were answered and the community was left more frustrated than it began.
Keith and I will work on recapping all the questions and feedback we have responded to
Again, if that’s going to be the recap, Sonos is going to miss absolutely everything that people were upset about.
A feature list was linked to: The New Sonos App and Future Feature Updates which put things like playing your own music and being able to update WiFi settings to mid-June, meaning you can hardly use the system if you rely on music you bought instead of streamed.
A battery’s best friend is a capacitor. Powering everything from smartphones to electric vehicles, capacitors store energy from a battery in the form of an electrical charge and enable ultrafast charging and discharging. However, their Achilles’ heel has always been their limited energy storage efficiency.
Now, Washington University in St. Louis researchers have unveiled a groundbreaking capacitor design that looks like it could overcome those energy storage challenges.
In a study published in Science, lead author Sang-Hoon Bae, an assistant professor of mechanical engineering and materials science, demonstrates a novel heterostructure that curbs energy loss, enabling capacitors to store more energy and charge rapidly without sacrificing durability.
While batteries excel in storage capacity, they fall short in speed, unable to charge or discharge rapidly. Capacitors fill this gap, delivering the quick energy bursts that power-intensive devices demand. Some smartphones, for example, contain up to 500 capacitors, and laptops around 800. Just don’t ask the capacitor to store its energy too long.
Within capacitors, ferroelectric materials offer high maximum polarization. That’s useful for ultra-fast charging and discharging, but it can limit the effectiveness of energy storage or the “relaxation time” of a conductor.
[…]
Bae makes the change—one he unearthed while working on something completely different—by sandwiching 2D and 3D materials in atomically thin layers, using chemical and nonchemical bonds between each layer. He says a thin 3D core inserts between two outer 2D layers to produce a stack that’s only 30 nanometers thick
[…]
“Initially, we weren’t focused on energy storage, but during our exploration of material properties, we found a new physical phenomenon that we realized could be applied to energy storage,” Bae says in a statement
[…]
The sandwich structure isn’t quite fully conductive or nonconductive. This semiconducting material, then, allows the energy storage, with a density up to 19 times higher than commercially available ferroelectric capacitors, while still achieving 90 percent efficiency—also better than what’s currently available.
The capacitor can hang on to its energy thanks to the minuscule gap in the material structure.
[…]
The study team will continue to optimize the material structure to ensure ultrafast charging and discharging with a new high-energy density. “We must be able to do that without losing storage capacity over repeated charges,” Bae says, “to see this material used broadly in large electronic like electric vehicles.”
The federal government agency responsible for granting patents and trademarks is alerting thousands of filers whose private addresses were exposed following a second data spill in as many years.
The U.S. Patent and Trademark Office (USPTO) said in an email to affected trademark applicants this week that their private domicile address — which can include their home address — appeared in public records between August 23, 2023 and April 19, 2024.
U.S. trademark law requires that applicants include a private address when filing their paperwork with the agency to prevent fraudulent trademark filings.
USPTO said that while no addresses appeared in regular searches on the agency’s website, about 14,000 applicants’ private addresses were included in bulk datasets that USPTO publishes online to aid academic and economic research.
The agency took blame for the incident, saying the addresses were “inadvertently exposed as we transitioned to a new IT system,” according to the email to affected applicants, which TechCrunch obtained. “Importantly, this incident was not the result of malicious activity,” the email said.
Upon discovery of the security lapse, the agency said it “blocked access to the impacted bulk data set, removed files, implemented a patch to fix the exposure, tested our solution, and re-enabled access.”
If this sounds remarkably familiar, USPTO had a similar exposure of applicants’ address data last June. At the time, USPTO said it inadvertently exposed about 61,000 applicants’ private addresses in a years-long data spill in part through the release of its bulk datasets, and told affected individuals that the issue was fixed.
Dell has confirmed information about its customers and their orders has been stolen from one of its portals. Though the thief claimed to have swiped 49 million records, which are now up for sale on the dark web, the IT giant declined to say how many people may be affected.
According to the US computer maker, the stolen data includes people’s names, addresses, and details about their Dell equipment, but does not include sensitive stuff like payment info. Still, its portal was compromosed.
“We recently identified an incident involving a Dell portal with access to a database containing limited types of customer information including name, physical address and certain Dell hardware and order information,” a Dell spokesperson told The Register today.
“It did not include financial or payment information, email address, telephone number or any highly sensitive customer data.”
A report at the end of last month from the aptly named Daily Dark Web suggested as many as 49 million Dell customers may have had some of their account information taken. The data is said to cover purchases made between 2017 and 2024.
Judging from a screenshot of a sample of the stolen info, the Dell database now up for sale on a cyber-crime forum includes the following columns: service tag, items, date, country, warranty, organization name, address, city, province, postal code, customer code, and order number.
Apparently Dell doesn’t think knowing your name coupled to your address and how much expensive stuff you bought from them constitutes a risk though, so you’re allright. But not really.
More than half a million UniSuper fund members went a week with no access to their superannuation accounts after a “one-of-a-kind” Google Cloud “misconfiguration” led to the financial services provider’s private cloud account being deleted, Google and UniSuper have revealed.
Services began being restored for UniSuper customers on Thursday, more than a week after the system went offline. Investment account balances would reflect last week’s figures and UniSuper said those would be updated as quickly as possible.
The UniSuper CEO, Peter Chun, wrote to the fund’s 620,000 members on Wednesday night, explaining the outage was not the result of a cyber-attack, and no personal data had been exposed as a result of the outage. Chun pinpointed Google’s cloud service as the issue.
In an extraordinary joint statement from Chun and the global CEO for Google Cloud, Thomas Kurian, the pair apologised to members for the outage, and said it had been “extremely frustrating and disappointing”.
They said the outage was caused by a misconfiguration that resulted in UniSuper’s cloud account being deleted, something that had never happened to Google Cloud before.
“Google Cloud CEO, Thomas Kurian has confirmed that the disruption arose from an unprecedented sequence of events whereby an inadvertent misconfiguration during provisioning of UniSuper’s Private Cloud services ultimately resulted in the deletion of UniSuper’s Private Cloud subscription,” the pair said.
“This is an isolated, ‘one-of-a-kind occurrence’ that has never before occurred with any of Google Cloud’s clients globally. This should not have happened. Google Cloud has identified the events that led to this disruption and taken measures to ensure this does not happen again.”
While UniSuper normally has duplication in place in two geographies, to ensure that if one service goes down or is lost then it can be easily restored, because the fund’s cloud subscription was deleted, it caused the deletion across both geographies.
UniSuper was able to eventually restore services because the fund had backups in place with another provider.
“These backups have minimised data loss, and significantly improved the ability of UniSuper and Google Cloud to complete the restoration,” the pair said.
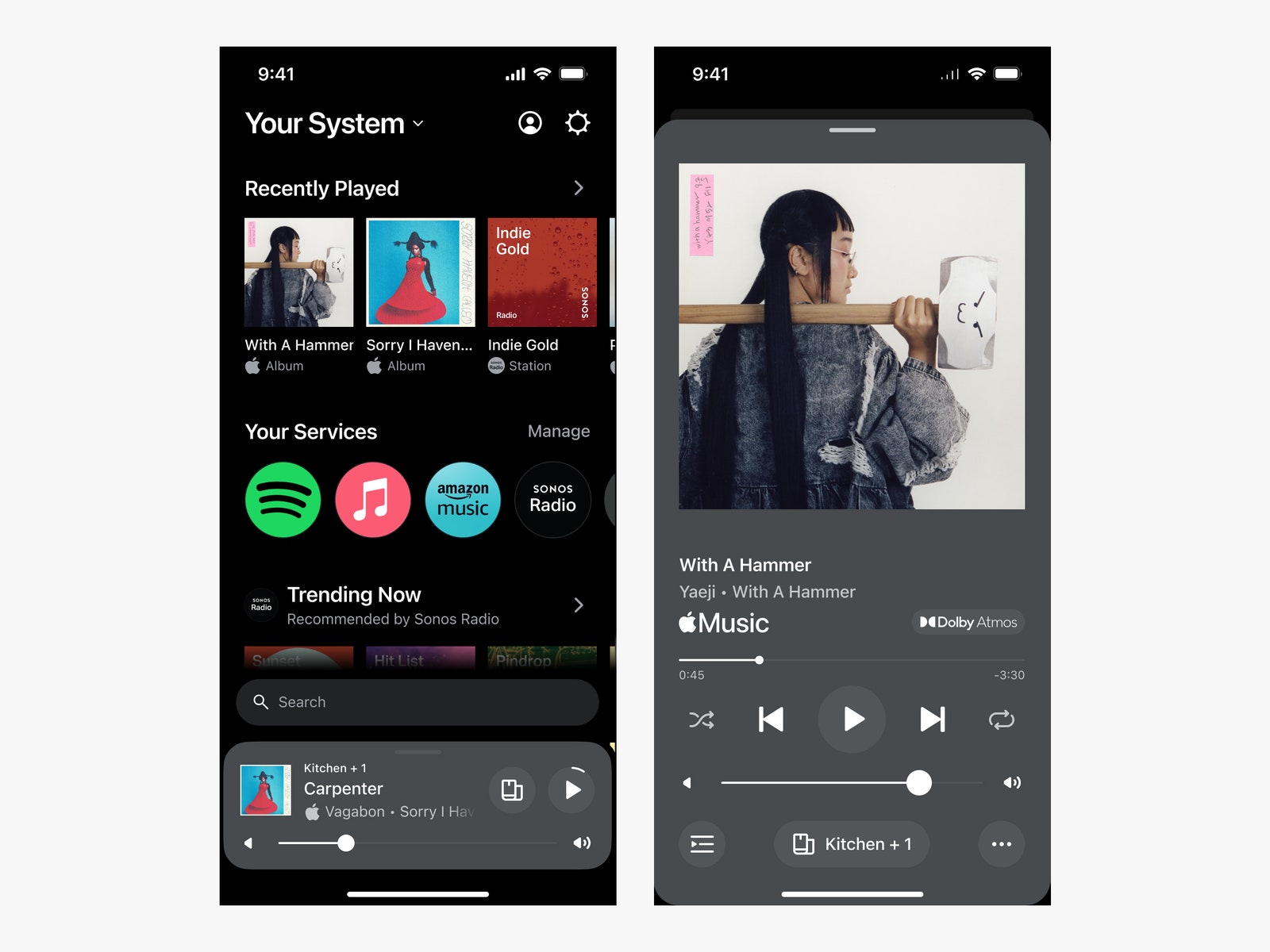
Sonos launched a new version of its app this week, altering the software experience that tens of millions of users rely on to control the company’s premium home wireless home speaker systems.
Turns out, people really hate it! The response from users on Reddit, on audio forums, and on social media has been almost total condemnation since the app experience switched over on May 7. Users on the dedicated r/sonos subreddit are particularly peeved about it, expressing frustration at all manner of problems. The quickest way to see the scores of complaints is to visit the megathread the users in the community started to catalog all the problems they’re experiencing.
Courtesy of Sonos
Many features that had long been a part of the Sonos app are simply missing in the update. Features such as the ability to set sleep timers and alarms, set the speakers at a precise volume level, add songs to the end of a queue, manage Wi-Fi connectivity, and add new speakers are missing or broken, according to the complaints. Users are also reporting that the revamped search engine in the app often can’t search a connected local library running on a networked computer or a network-attached storage drive—they way many of Sonos’ most loyal users listen to their large private music libraries. Some streaming services are partially or completely broken for some users too, like TuneIn and LivePhish+.
Worse, the new app is not as accessible as the previous version, with one Reddit user calling it “an accessibility disaster.” The user, Rude-kangaroo6608, writes: “As a blind guy, I now have a system that I can hardly use.”
Also, they got rid of the next and previous buttons and you can’t scrob through the song in the small player. You can’t add all files in a directory in your Library at once to the Sonos playlist – you have to add them one by one. The shuffle is gone. You can’t re-arrange queues. The system loses speakers randomly. So basically, you can’t really use the app to play music with.
Tuesday May 14th there will be an Ask Me Anything (AMA) – I would feel sorry for the Sonos people taking the questions, but don’t because they caused this fiasco in the first place. It certainly is “courageous” (ie stupid) to release an incomplete and broken app on top over expensive hardware.
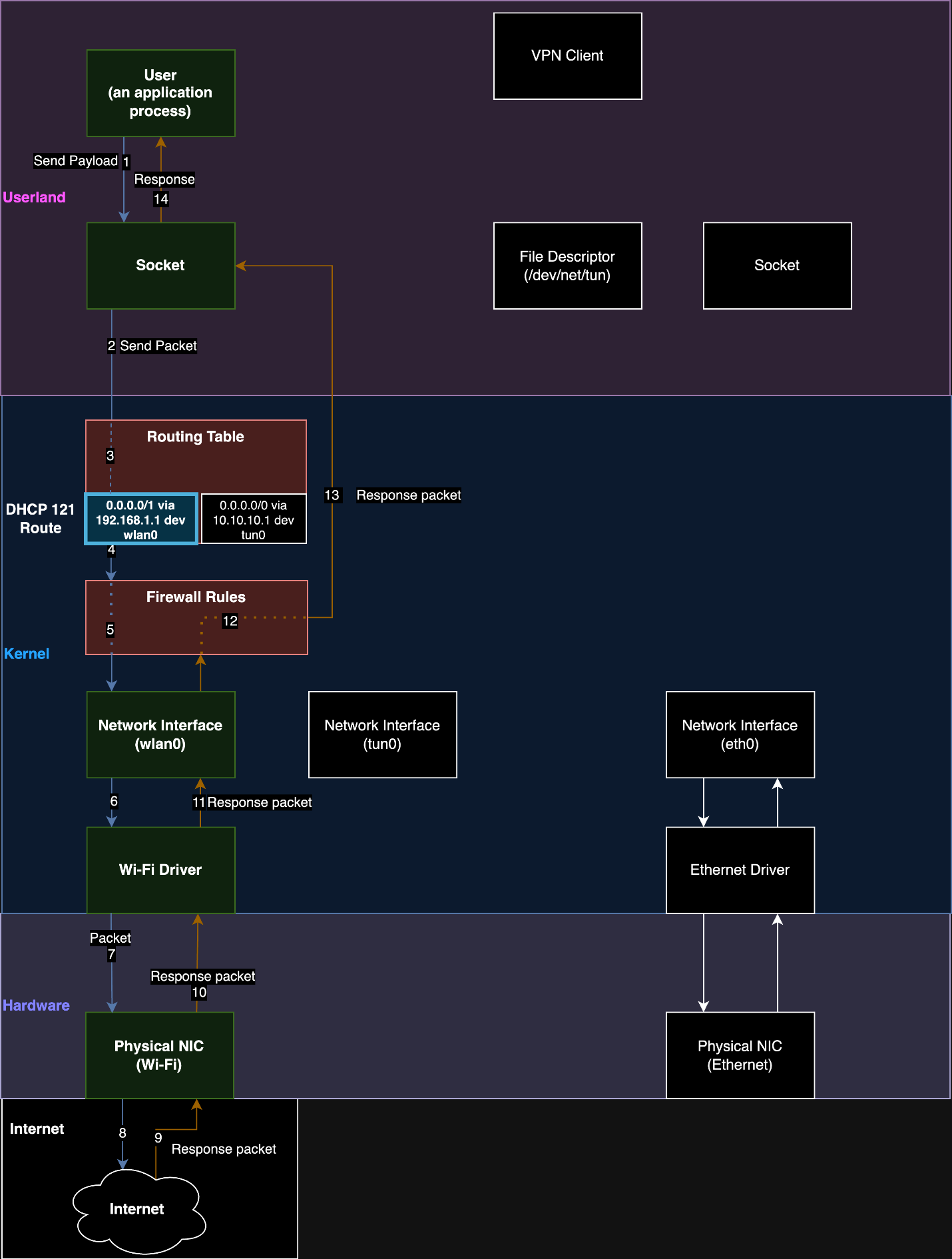
Researchers have devised an attack against nearly all virtual private network applications that forces them to send and receive some or all traffic outside of the encrypted tunnel designed to protect it from snooping or tampering.
TunnelVision, as the researchers have named their attack, largely negates the entire purpose and selling point of VPNs, which is to encapsulate incoming and outgoing Internet traffic in an encrypted tunnel and to cloak the user’s IP address. The researchers believe it affects all VPN applications when they’re connected to a hostile network and that there are no ways to prevent such attacks except when the user’s VPN runs on Linux or Android. They also said their attack technique may have been possible since 2002 and may already have been discovered and used in the wild since then.
Reading, dropping, or modifying VPN traffic
The effect of TunnelVision is “the victim’s traffic is now decloaked and being routed through the attacker directly,” a video demonstration explained. “The attacker can read, drop or modify the leaked traffic and the victim maintains their connection to both the VPN and the Internet.”
TunnelVision – CVE-2024-3661 – Decloaking Full and Split Tunnel VPNs – Leviathan Security Group.
The attack works by manipulating the DHCP server that allocates IP addresses to devices trying to connect to the local network. A setting known as option 121 allows the DHCP server to override default routing rules that send VPN traffic through a local IP address that initiates the encrypted tunnel. By using option 121 to route VPN traffic through the DHCP server, the attack diverts the data to the DHCP server itself. Researchers from Leviathan Security explained:
Our technique is to run a DHCP server on the same network as a targeted VPN user and to also set our DHCP configuration to use itself as a gateway. When the traffic hits our gateway, we use traffic forwarding rules on the DHCP server to pass traffic through to a legitimate gateway while we snoop on it.
We use DHCP option 121 to set a route on the VPN user’s routing table. The route we set is arbitrary and we can also set multiple routes if needed. By pushing routes that are more specific than a /0 CIDR range that most VPNs use, we can make routing rules that have a higher priority than the routes for the virtual interface the VPN creates. We can set multiple /1 routes to recreate the 0.0.0.0/0 all traffic rule set by most VPNs.
Pushing a route also means that the network traffic will be sent over the same interface as the DHCP server instead of the virtual network interface. This is intended functionality that isn’t clearly stated in the RFC. Therefore, for the routes we push, it is never encrypted by the VPN’s virtual interface but instead transmitted by the network interface that is talking to the DHCP server. As an attacker, we can select which IP addresses go over the tunnel and which addresses go over the network interface talking to our DHCP server.
Enlarge/ A malicious DHCP option 121 route that causes traffic to never be encrypted by the VPN process.
Leviathan Security
We now have traffic being transmitted outside the VPN’s encrypted tunnel. This technique can also be used against an already established VPN connection once the VPN user’s host needs to renew a lease from our DHCP server. We can artificially create that scenario by setting a short lease time in the DHCP lease, so the user updates their routing table more frequently. In addition, the VPN control channel is still intact because it already uses the physical interface for its communication. In our testing, the VPN always continued to report as connected, and the kill switch was never engaged to drop our VPN connection.
The attack can most effectively be carried out by a person who has administrative control over the network the target is connecting to. In that scenario, the attacker configures the DHCP server to use option 121. It’s also possible for people who can connect to the network as an unprivileged user to perform the attack by setting up their own rogue DHCP server.
The attack allows some or all traffic to be routed through the unencrypted tunnel. In either case, the VPN application will report that all data is being sent through the protected connection. Any traffic that’s diverted away from this tunnel will not be encrypted by the VPN and the Internet IP address viewable by the remote user will belong to the network the VPN user is connected to, rather than one designated by the VPN app.
Interestingly, Android is the only operating system that fully immunizes VPN apps from the attack because it doesn’t implement option 121. For all other OSes, there are no complete fixes. When apps run on Linux there’s a setting that minimizes the effects, but even then TunnelVision can be used to exploit a side channel that can be used to de-anonymize destination traffic and perform targeted denial-of-service attacks. Network firewalls can also be configured to deny inbound and outbound traffic to and from the physical interface. This remedy is problematic for two reasons: (1) a VPN user connecting to an untrusted network has no ability to control the firewall and (2) it opens the same side channel present with the Linux mitigation.
The most effective fixes are to run the VPN inside of a virtual machine whose network adapter isn’t in bridged mode or to connect the VPN to the Internet through the Wi-Fi network of a cellular device. The research, from Leviathan Security researchers Lizzie Moratti and Dani Cronce, is available here.
PlayStation has announced that, after about three days of online yelling and reviewing bombing, it will no longer require Helldivers 2 players on PC to link their Steam account to a PlayStation Network account in order to continue accessing the popular sci-fi co-op shooter.
On May 2, PlayStation and Arrowhead Games Studios—the developers behind Helldivers 2—announced on Steam that a so-called “grace period” was ending and that all PC players would need a PSN account to keep playing one of 2024’s best video games. Technically, this was always the plan as noted on the Helldivers 2 Steam store page. However, due to the game’s messy launch in February, PC players were allowed to play without a PSN account. This led to an awkward situation on Thursday when Sony announced all players would need to have a PlayStation account by June 4 to keep playing. Now, following a massive negative reaction, PlayStation is backtracking.
In a tweet at midnight on May 5, PlayStation said it had heard all the “feedback” on linking a Steam and PSN account and decided…nah, never mind.
“Helldivers fans — we’ve heard your feedback on the Helldivers 2 account linking update,” announced PlayStation. “The May 6 update, which would have required Steam and PlayStation Network account linking for new players and for current players beginning May 30, will not be moving forward.”
PlayStation said it was still “learning what is best for PC players” and suggested all the feedback the company received about the situation had been “invaluable.”
“Thanks again for your continued support of Helldivers 2 and we’ll keep you updated on future plans,” concluded PlayStation’s late-night tweet.
The Federal Communications Commission has slapped the largest mobile carriers in the US with a collective fine worth $200 million for selling access to their customers’ location information without consent. AT&T was ordered to pay $57 million, while Verizon has to pay $47 million. Meanwhile, Sprint and T-Mobile are facing a penalty with a total amount of $92 million together, since the companies had merged two years ago. The FCC conducted an in-depth investigation into the carriers’ unauthorized disclosure and sale of subscribers’ real-time location data after their activities came to light in 2018.
To sum up the practice in the words of FCC Commissioner Jessica Rosenworcel: The carriers sold “real-time location information to data aggregators, allowing this highly sensitive data to wind up in the hands of bail-bond companies, bounty hunters, and other shady actors.” According to the agency, the scheme started to unravel following public reports that a sheriff in Missouri was tracking numerous individuals by using location information a company called Securus gets from wireless carriers. Securus provides communications services to correctional facilities in the country.
While the carriers eventually ceased their activities, the agency said they continued operating their programs for a year after the practice was revealed and after they promised the FCC that they would stop selling customer location data. Further, they carried on without reasonable safeguards in place to ensure that the legitimate services using their customers’ information, such as roadside assistance and medical emergency services, truly are obtaining users’ consent to track their locations.
Microsoft says the April security updates for Windows may break your VPN. (Oops!) “Windows devices might face VPN connection failures after installing the April 2024 security update (KB5036893) or the April 2024 non-security preview update,” the company wrote in a status update. It’s working on a fix.
Bleeping Computer first reported the issue, which affects Windows 11, Windows 10 and Windows Server 2008 and later. User reports on Reddit are mixed, with some commenters saying their VPNs still work after installing the update and others claiming their encrypted connections were indeed borked.
“We are working on a resolution and will provide an update in an upcoming release,” Microsoft wrote.
There’s no proper fix until Microsoft pushes a patched update. However, you can work around the issue by uninstalling all the security updates. In an unfortunate bit of timing for CEO Satya Nadella, he said last week that he wants Microsoft to put “security above else.” I can’t imagine making customers (temporarily) choose between going without a VPN and losing the latest protection is what he had in mind.
At least one Redditor claims that uninstalling and reinstalling their VPN app fixed the problem for them, so it may be worth trying that before moving on to more drastic measures.
If you decide to uninstall the security updates, Microsoft tells you how. “To remove the LCU after installing the combined SSU and LCU package, use the DISM/Remove-Package command line option with the LCU package name as the argument,” the company wrote in its patch notes. “You can find the package name by using this command: DISM /online /get-packages.”
GamesIndustry.biz first reported on the DMCA notice, affecting 8,535 GitHub repos. Redacted entities representing Nintendo assert that the Yuzu source code contained in the repos “illegally circumvents Nintendo’s technological protection measures and runs illegal copies of Switch games.”
GitHub wrote on the notice that developers will have time to change their content before it’s disabled. In keeping with its developer-friendly approach and branding, the Microsoft-owned platform also offered legal resources and guidance on submitting DMCA counter-notices.
Nintendo’s legal blitz, perhaps not coincidentally, comes as game emulators are enjoying a resurgence. Last month, Apple loosened its restrictions on retro game players in the App Store (likely in response to regulatory threats), leading to the Delta emulator establishing itself as the de facto choice and reaching the App Store’s top spot. Nintendo may have calculated that emulators’ moment in the sun threatened its bottom line and began by squashing those that most immediately imperiled its income stream.
Sadly, Nintendo’s largely undefended legal assault against emulators ignores a crucial use for them that isn’t about piracy. Game historians see the software as a linchpin of game preservation. Without emulators, Nintendo and other copyright holders could make a part of history obsolete for future generations, as their corresponding hardware will eventually be harder to come by.
[…]
This has royally pissed off PC players, though it’s worth noting that it’s free to make a PSN account. This has led to review bombing on Steam and many promises to abandon the game when the linking becomes a requirement, according to a report by Kotaku. The complaints range from frustration over adding yet another barrier to entry after downloading an 80GB game to fears that the PSN account would likely be hacked. While it is true that Sony was the target of a huge hack that impacted 77 million PSN accounts, that was back in 2011. Obama was still in his first term. Also worth noting? Steam was hacked in 2011, impacting 35 million accounts.
GamesIndustry.biz first reported on the DMCA notice, affecting 8,535 GitHub repos. Redacted entities representing Nintendo assert that the Yuzu source code contained in the repos “illegally circumvents Nintendo’s technological protection measures and runs illegal copies of Switch games.”
GitHub wrote on the notice that developers will have time to change their content before it’s disabled. In keeping with its developer-friendly approach and branding, the Microsoft-owned platform also offered legal resources and guidance on submitting DMCA counter-notices.
Nintendo’s legal blitz, perhaps not coincidentally, comes as game emulators are enjoying a resurgence. Last month, Apple loosened its restrictions on retro game players in the App Store (likely in response to regulatory threats), leading to the Delta emulator establishing itself as the de facto choice and reaching the App Store’s top spot. Nintendo may have calculated that emulators’ moment in the sun threatened its bottom line and began by squashing those that most immediately imperiled its income stream.
Sadly, Nintendo’s largely undefended legal assault against emulators ignores a crucial use for them that isn’t about piracy. Game historians see the software as a linchpin of game preservation. Without emulators, Nintendo and other copyright holders could make a part of history obsolete for future generations, as their corresponding hardware will eventually be harder to come by.
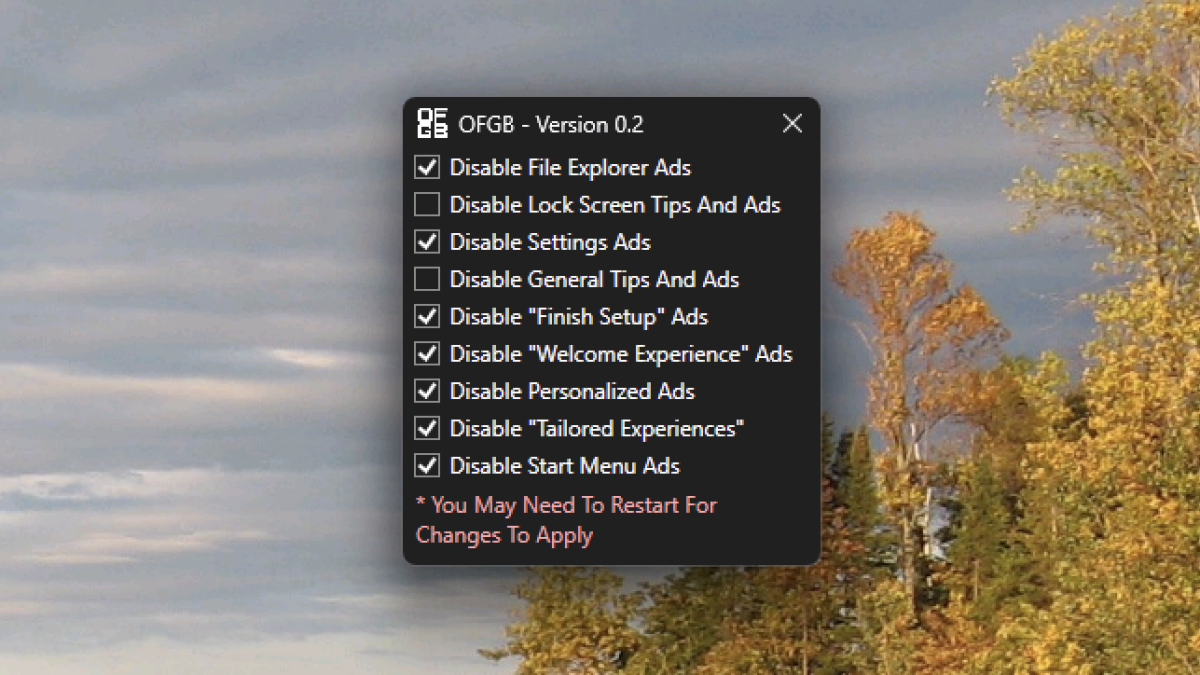
Advertisements—sometimes prompts to do something that would financially benefit Microsoft and sometimes actual paid advertisements—are showing up all over Windows 11. Start menu ads are rolling out to all users this month, taking the shape of “Recommended” applications you haven’t installed. Ads also briefly showed up in File Explorer, though this was apparently unintentional. And there have long been calls to action on the lock screen and in the settings app. It’s a mess.
We’ve told you how to manually turn off all of Microsoft’s ads in Windows 11, but it’s a lot of digging around in the settings. If you’d rather not do that, an app called OFGB can do it for you. This free and open source application can quickly change various registry settings to disable those ads—all you have to do is click a few checkboxes.
[…] On Monday, the United Kingdom became the first country in the world to ban default guessable usernames and passwords from these IoT devices. Unique passwords installed by default are still permitted.
The Product Security and Telecommunications Infrastructure Act 2022 (PSTI) introduces new minimum-security standards for manufacturers, and demands that these companies are open with consumers about how long their products will receive security updates for.
Manufacturing and design practices mean many IoT products introduce additional risks to the home and business networks they’re connected to. In one often-cited case described by cybersecurity company Darktrace, hackers were allegedly able to steal data from a casino’s otherwise well-protected computer network after breaking in through an internet-connected temperature sensor in a fish tank.
Under the PSTI, weak or easily guessable default passwords such as “admin” or “12345” are explicitly banned, and manufacturers are also required to publish contact details so users can report bugs.
Products that fail to comply with the rules could face being recalled, and the companies responsible could face a maximum fine of £10 million ($12.53 million) or 4% of their global revenue, whichever is higher.
The law will be regulated by the Office for Product Safety and Standards (OPSS), which is part of the Department for Business and Trade rather than an independent body.
[…]
Similar laws are being advanced elsewhere, although none have entered into effect. The European Union’s Cyber Resilience Act is yet to be finally agreed, but its similar provisions aren’t expected to apply within the bloc until 2027.
There is no federal law about securing consumer IoT devices in the United States, although the IoT Cybersecurity Improvement Act of 2020 requires the National Institute of Standards and Technology “to develop and publish standards and guidelines for the federal government” on how they use IoT devices.
Russia has arrested Garry Kasparov and charged him in connection with foreign agent and terrorist charges – much to the former chess champion’s amusement.
The city court in Syktyvkar, the largest city in Russia‘s northwestern Komi region, announced it had arrested the grandmaster in absentia alongside former Russian parliament member Gennady Gudkov, Ivan Tyutrin co-founder of the Free Russia Forum – which has been designated as an ‘undesirable organisation in the country – as well as former environmental activist Yevgenia Chirikova.
All were charged with setting up a terrorist society, according to the court’s press service. As all were charged in their absence, none were physically held in custody.
[…]
Kasparov responded to the court’s bizarre arrest statement in an April 24 post shared on X, formerly Twitter. “In absentia is definitely the best way I’ve ever been arrested,” he said. “Good company, as well. I’m sure we’re all equally honoured that Putin’s terror state is spending time on this that would otherwise go persecuting and murdering.”
Kasparov has found himself in Russian President Vladimir Putin’s firing line after he voiced his opposition to the country’s leader. He has also pursued pro-democracy initiatives in Russia. But he felt unable to continue living in Russia after he was jailed and allegedly beaten by police in 2012, according to the Guardian. He was granted Croatian citizenship in 2014 following repeated difficulties in Russia.
Apple’s grudging accommodation of European antitrust rules by allowing third-party app stores on iPhones has left users of its Safari browser exposed to potential web activity tracking.
Developers Talal Haj Bakry and Tommy Mysk looked into the way Apple implemented the installation process for third-party software marketplaces on iOS with Safari, and concluded Cupertino’s approach is particularly shoddy.
tl;dr: The way Apple has added support for third-party app stores lets any website, when visited by Safari on iOS at least, to ping a chosen approved software marketplace with a unique per-user identifier. That means as users move from website to website, or use a website, these sites can quietly disclose that activity to a non-Apple app store – revealing the sort of things individual netizens find interesting. That info can be used for targeted app promotions, ads, and so on. This appears to apply to iOS 17.4 users in the EU. Whether anyone will exploit this in the wild remains to be seen – but the potential is there.
“Our testing shows that Apple delivered this feature with catastrophic security and privacy flaws,” wrote Bakry and Mysk in an advisory published over the weekend.
Apple – which advertises Safari as “incredibly private” – evidently has undermined privacy among European Union Safari users through a marketplace-kit: URI scheme that potentially allows approved third-party app stores to follow those users around the web.
[…]
The trouble is, any site can trigger a marketplace-kit: request. On EU iOS 17.4 devices, that will cause a unique per-user identifier to be fired off by Safari to an approved marketplace’s servers, leaking the fact that the user was just visiting that site. This happens even if Safari is in private browsing mode. The marketplace’s servers can reject the request, which can also include a custom payload, passing more info about the user to the alternative store.
[…]
Apple doesn’t allow third-party app stores in most parts of the world, citing purported privacy and security concerns – and presumably interest in sustaining its ability to collect commissions for software sales.
But Apple has been designated as a “gatekeeper” under Europe’s Digital Markets Act (DMA) for iOS, the App Store, Safari, and just recently iPadOS.
That designation means the iBiz has been ordered to open its gated community so that European customers can choose third-party app stores and web-based app distribution – also known as side-loading.
But wait, there’s more
According to Bakry and Mysk, Apple’s URI scheme has three significant failings. First, they say, it fails to check the origin of the website, meaning the aforementioned cross-site tracking is possible.
Second, Apple’s MarketplaceKit – its API for third-party stores – doesn’t validate the JSON Web Tokens (JWT) passed as input parameters via incoming requests. “Worse, it blindly relayed the invalid JWT token when calling the /oauth/token endpoint,” observed Bakry and Mysk. “This opens the door to various injection attacks to target either the MarketplaceKit process or the marketplace back-end.”
And third, Apple isn’t using certificate pinning, which leaves the door open for meddling by an intermediary (MITM) during the MarketplaceKit communication exchange. Bakry and Mysk claim they were able to overwrite the servers involved in this process with their own endpoints.
The limiting factor of this attack is that a marketplace must first be approved by Apple before it can undertake this sort of tracking. At present, not many marketplaces have won approval. We’re aware of the B2B Mobivention App marketplace, AltStore, and Setapp. Epic Games has also planned an iOS store. A few other marketplaces will work after an iThing jailbreak, but they’re unlikely to attract many consumers.
“The flaw of exposing users in the EU to tracking is the result of Apple insisting on inserting itself between marketplaces and their users,” asserted Bakry and Mysk. “This is why Apple needs to pass an identifier to the marketplaces so they can identify installs and perhaps better calculate the due Core Technology Fee (CTF).”
They urge iOS users in Europe to use Brave rather than Safari because Brave’s implementation checks the origin of the website against the URL to prevent cross-site tracking.
Back when Apple planned not to support Home Screen web apps in Europe – a gambit later abandoned after developer complaints and regulatory pressure – the iGiant justified its position by arguing the amount of work required “was not practical to undertake given the other demands of the DMA.” By not making the extra effort to implement third-party app stores securely, Apple has arguably turned its security and privacy concerns into a self-fulfilling prophecy.
In its remarks [PDF] on complying with the DMA, Apple declared, “In the EU, every user’s security, privacy, and safety will depend in part on two questions. First, are alternative marketplaces and payment processors capable of protecting users? And, second, are they interested in doing so?”
There’s also the question of whether Apple is capable of protecting users – and whether it’s interested in doing so.
Last month the New York Times’ Kashmir Hill published a major story on how GM collects driver behavior data then sells access (through LexisNexis) to insurance companies, which will then jack up your rates.
The absolute bare minimum you could could expect from the auto industry here is that they’re doing this in a way that’s clear to car owners. But of course they aren’t; they’re burying “consent” deep in the mire of some hundred-page end user agreement nobody reads, usually not related to the car purchase — but the apps consumers use to manage roadside assistance and other features.
Since Kashmir’s story was published, she says she’s been inundated with complaints by consumers about similar behavior. She’s even discovered that she’s one of the folks GM spied on and tattled to insurers about. In a follow up story, she recounts how she and her husband bought a Chevy Bolt, were auto-enrolled in a driver assistance program, then had their data (which they couldn’t access) sold to insurers.
GM’s now facing 10 different federal lawsuits from customers pissed off that they were surreptitiously tracked and then forced to pay significantly more for insurance:
“In 10 federal lawsuits filed in the last month, drivers from across the country say they did not knowingly sign up for Smart Driver but recently learned that G.M. had provided their driving data to LexisNexis. According to one of the complaints, a Florida owner of a 2019 Cadillac CTS-V who drove it around a racetrack for events saw his insurance premium nearly double, an increase of more than $5,000 per year.”
GM (and some apologists) will of course proclaim that this is only fair that reckless drivers pay more, but that’s generally not how it works. Pressured for unlimited quarterly returns, insurance companies will use absolutely anything they find in the data to justify rising rates.
[…]
Automakers — which have long had some of the worst privacy reputations in all of tech — are one of countless industries that lobbied relentlessly for decades to ensure Congress never passed a federal privacy law or regulated dodgy data brokers. And that the FTC — the over-burdened regulator tasked with privacy oversight — lacks the staff, resources, or legal authority to police the problem at any real scale.
The end result is just a parade of scandals. And if Hill were so inclined, she could write a similar story about every tech sector in America, given everything from your smart TV and electricity meter to refrigerator and kids’ toys now monitor your behavior and sell access to those insights to a wide range of dodgy data broker middlemen, all with nothing remotely close to ethics or competent oversight.
And despite the fact that this free for all environment is resulting in no limit of dangerous real-world harms, our Congress has been lobbied into gridlock by a cross-industry coalition of companies with near-unlimited budgets, all desperately hoping that their performative concerns about TikTok will distract everyone from the fact we live in a country too corrupt to pass a real privacy law.
In a 2023 complaint, the FTC accused the doorbell camera and home security provider of allowing its employees and contractors to access customers’ private videos. Ring allegedly used such footage to train algorithms without consent, among other purposes.
Ring was also charged with failing to implement key security protections, which enabled hackers to take control of customers’ accounts, cameras and videos. This led to “egregious violations of users’ privacy,” the FTC noted.
The resulting settlement required Ring to delete content that was found to be unlawfully obtained, establish stronger security protections
[…]
the FTC is sending 117,044 PayPal payments to impacted consumers who had certain types of Ring devices — including indoor cameras — during the timeframes that the regulators allege unauthorized access took place.
Considering the size of Ring and the size of the customer base, this is a very very light tap on the wrist for delivering poor security and something that spies on everything on the street.
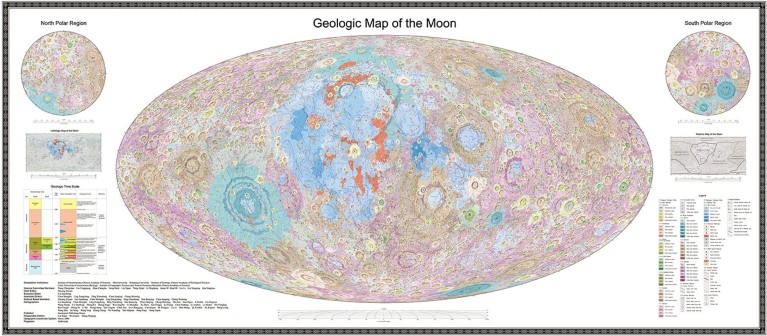
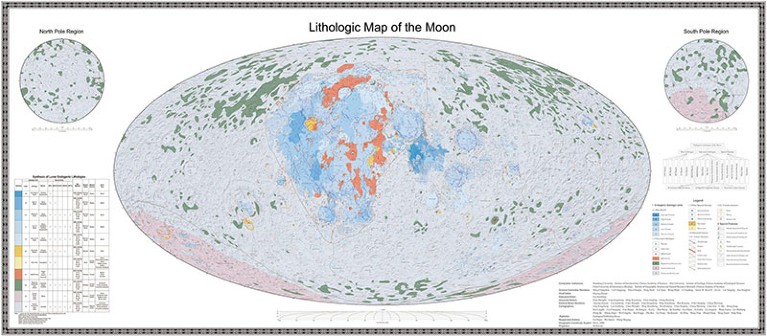
[…] The Chinese Academy of Sciences (CAS) has released the highest-resolution geological maps of the Moon yet. The Geologic Atlas of the Lunar Globe, which took more than 100 researchers over a decade to compile, reveals a total of 12,341 craters, 81 basins and 17 rock types, along with other basic geological information about the lunar surface. The maps were made at the unprecedented scale of 1:2,500,000.
[…]
The CAS also released a book called Map Quadrangles of the Geologic Atlas of the Moon, comprising 30 sector diagrams which together form a visualization of the whole Moon.
Jianzhong Liu, a geochemist at the CAS Institute of Geochemistry in Guiyang and co-leader of the project, says that existing Moon maps date from the 1960s and 1970s. “The US Geological Survey used data from the Apollo missions to create a number of geological maps of the Moon, including a global map at the scale of 1:5,000,000 and some regional, higher-accuracy ones near the landing sites,” he says. “Since then, our knowledge of the Moon has advanced greatly, and those maps could no longer meet the needs for future lunar research and exploration.”
[…]
Liu says that his team has already started work to improve the resolution of the maps, and will produce regional maps of higher accuracy on the basis of scientific and engineering needs. In the meantime, the completed atlas has been integrated into a cloud platform called the Digital Moon, and will eventually become available to the international research community.
Microsoft has gone long with Windows 11 now that Windows 10 support stops. You can’t install it without a Microsoft account and loads of tie-ins. All links open the privacy slurping Edge browser. The start menu is a sea of adverts. Thankfully you can get around all that.
How to Install Windows 11 Without All the Extra Junk
Tiny11Builder is a third-party script that can take a Windows installation ISO, which you can get from Microsoft, and strip it of all of these features. Install Windows using this tool and you’ll have a truly clean installation: no News, no OfficeHub, no annoying GetStarted prompts, and no junk entires in the start menu. You can always install these things later, if you want, but you’ll be starting with a clean state.
Unzip that download. Now we need to configure your system to allow PowerScript to make administration changes. Open PowerShell as an administrator, which you can do by searching for “PowerShell” in the start menu and then clicking the Run as Administrator in the right side-bar.
Type or copy the exact command Set-ExecutionPolicy unrestricted and hit Enter.
You will be warned about the security implications of this—confirm that you know what you’re doing and are allowing the change. You can always undo the change later by running Set-ExecutionPolicy restricted.
Make your tiny11 disk
By now your Windows 11 ISO should be finished downloading. Right-click the file and click Mount. This will open the ISO file as a virtual CD, which you can confirm by looking for it in Windows Explorer.
Once you’ve confirmed that the disk is mounted, you can run the tiny11script, which was in the ZIP file you unzipped earlier. The simplest way to get started is to right-click the file “tiny11maker.ps1” and click Run with PowerShell.
This will start the script. You will be asked for the drive letter of your virtual drive, which you can find in Windows Explorer under My Computer—look for a DVD drive that wasn’t there before. You only need to type the letter and hit enter.
After that, the script will ask you which version of Windows you want to make a disc for. Answer with the version you have a product key for.
After that, the script will do its thing, which might take a while. When the process is done, you will see a message letting you know.
There will be a brand-new ISO file in the script’s directory. This ISO is perfect for setting up Windows in a virtual machine, which is how I’m hosting it, but it also works for installing to a device. You can burn this ISO file to a DVD, if you have an optical drive, or you can use a USB disk. Microsoft offers official instructions for this, which are pretty easy to follow.
However you install Windows from this ISO, know that it will be completely clean. You will not be prompted to create a Microsoft account, or even to sign in using one, and there will be no Microsoft services other than what you need in order to use the operating system.
This App Stops Windows 11 From Opening Search Results in Edge
Install MSEdgeRedirect to force Windows 11 to use your favorite browser
MSEdgeRedirect is the best way to stop Microsoft Edge from firing up every time you use Windows search. The app will also stop Edge from launching randomly, plus it’ll let you use third-party services instead of Microsoft’s own options for news, weather, and other live updates.
[…]
For most people, Active Mode is recommended. On the next page, you’ll see a number of Active Mode preferences. First, select Edge Stable unless you’re running a beta build of the browser. After that, go through the preferences to stop other Microsoft redirects such as Bing Discover, Bing Images, Bing Search, MSN News, MSN Weather, etc. For each of these, MSEdgeRedirect offers a few alternatives, so take your pick.
Take control of your browser and search engine
Once the app is installed, Windows 11’s search bar will be a lot more useful. Now, internet links will open in your default browser and use your preferred search engine.
How to Fix Search Results in the Windows 11 Start Menu
The fastest way to open something on Windows is to open the start menu and start typing the name of the app or file. The exact thing you’re looking for will show up, at which point you can hit “enter.” Or, at least, that’s how it used to work.
For years now, Microsoft has insisted on slowing down the start menu search by offering “helpful” information from the internet.
[…]
open the Registry Editor, which you can find in the start menu by searching (the irony is noted). The Registry Editor can be a bit confusing, and you can really mess things up by poking around, but don’t worry—this won’t be hard. The left panel has a series of folders, which are confusingly called “Keys.” You need to browse to: HKEY_CURRENT_USER\Software\Policies\Microsoft\Windows.
There may be a folder inside called Explorer. Don’t worry if there isn’t: Make one by right-clicking the “Windows” key in the left panel and clicking New > Key; name it “Explorer.” Open that folder and right-click in the right-panel, then click New > DWORD (32-bit) Value.
Name the new value DisableSearchBoxSuggestions, leave the Base as Hexadecimal, and change the Value data to 1.
Click OK and close the registry editor. Restart your computer and try to search something in the start menu.
How to Turn Off Those Pesky Start Menu Ads in Windows 11
Go to Settings > Personalization > Start, or use the Start menu search bar to open the settings panel. Then, select the option to toggle off Show recommendations for tips, shortcuts, new apps, and more. This will turn off any extra content and curated app suggestions. You might also consider selecting the layout option for More Pins so there are more slots for quickly pinning the apps you want to access.
As with everything in life, there are trade-offs to turning off the recommendations. The Start menu will function more like an app shelf—the equivalent to a bookshelf if you will—than an application drawer. You’ll need to curate apps you want to be pinned there, or it will render the overlay window useless beyond the search bar.
The app suggestions are enabled by default, but you can restore your previously pristine Windows experience if you’ve installed the update, fortunately. To do so, go into Settings and select Personalization > Start and switch the “Show recommendations for tips, app promotions and more” toggle to “off.”