Heat pumps are more than twice as efficient as fossil fuel heating systems in cold temperatures, research shows.
Even at temperatures approaching -30C, heat pumps outperform oil and gas heating systems, according to the research from Oxford University and the Regulatory Assistance Project thinktank.
[…]
The research, published in the specialist energy research journal Joule, used data from seven field studies in North America, Asia and Europe. It found that at temperatures below zero, heat pumps were between two and three times more efficient than oil and gas heating systems.
The authors said the findings showed that heat pumps were suitable for almost all homes in Europe, including the UK, and should provide policymakers with the impetus to bring in new measures to roll them out as rapidly as possible.
Dr Jan Rosenow, the director of European programmes at the Regulatory Assistance Project and co-author of the report, said: “There has been a campaign spreading false information about heat pumps [including casting doubt on whether they work in cold weather]. People [in the UK] don’t know much about heat pumps, so it’s very easy to scare them by giving them wrong information.”
The Guardian and the investigative journalism organisation DeSmog recently revealed that lobbyists associated with the gas boiler sector had attempted to delay a key government measure to increase the uptake of heat pumps.
On August 15, 2023, the threat actor “Ransomed,” operating under the alias “RansomForums,” posted on Telegram advertising their new forum and Telegram chat channel. On the same day, the domain ransomed[.]vc was registered.
But before activity on Ransomed had even really begun, the forum was the victim of a distributed denial-of-service (DDoS) attack. In response, the operators of the site quickly pivoted to rebrand it as a ransomware blog that, similar to other ransomware collectives, would adopt the approach of publicly listing victim names while issuing threats of data exposure unless ransoms are paid.
[…]
Ransomed is leveraging an extortion tactic that has not been observed before—according to communications from the group, they use data protection laws like the EU’s GDPR to threaten victims with fines if they do not pay the ransom. This tactic marks a departure from typical extortionist operations by twisting protective laws against victims to justify their illegal attacks.
[…]
The group has disclosed ransom demands for its victims, which span from €50,000 EUR to €200,000 EUR. For comparison, GDPR fines can climb into the millions and beyond—the highest ever was over €1 billion EUR. It is likely that Ransomed’s strategy is to set ransom amounts lower than the price of a fine for a data security violation, which may allow them to exploit this discrepancy in order to increase the chance of payment.
As of August 28, Ransomed operators have listed two Bitcoin addresses for payment on their site. Typically, threat actors do not make their wallet addresses public, instead sharing them directly with victims via a ransom note or negotiations portal.
These unconventional choices have set Ransomed apart from other ransomware operations, although it is still unproven if their tactics will be successful.
[…]
It is likely that Ransomed is a financially motivated project, and one of several other short-lived projects from its creators.
The owner of the Ransomed Telegram chat claims to have the source code of Raid Forums and said they intend to use it in the future, indicating that while the owner is running a ransomware blog for now, there are plans to turn it back into a forum later—although the timeline for this reversion is not clear.
The forum has gained significant attention in the information security community and in threat communities for its bold statements of targeting large organizations. However, there is limited evidence that the attacks published on the Ransomed blog actually took place, beyond the threat actors’ claims.
[…]
As the security community continues to monitor this enigmatic group’s activities, one thing remains clear: the landscape of ransomware attacks continues to evolve, challenging defenders to adapt and innovate in response.
How massive is the Milky Way? It’s an easy question to ask, but a difficult one to answer. Imagine a single cell in your body trying to determine your total mass, and you get an idea of how difficult it can be. Despite the challenges, a new study has calculated an accurate mass of our galaxy, and it’s smaller than we thought.
One way to determine a galaxy’s mass is by looking at what’s known as its rotation curve. Measure the speed of stars in a galaxy versus their distance from the galactic center. The speed at which a star orbits is proportional to the amount of mass within its orbit, so from a galaxy’s rotation curve you can map the function of mass per radius and get a good idea of its total mass. We’ve measured the rotation curves for several nearby galaxies such as Andromeda, so we know the masses of many galaxies quite accurately.
But since we are in the Milky Way itself, we don’t have a great view of stars throughout the galaxy. Toward the center of the galaxy, there is so much gas and dust we can’t even see stars on the far side. So instead we measure the rotation curve using neutral hydrogen, which emits faint light with a wavelength of about 21 centimeters. This isn’t as accurate as stellar measurements, but it has given us a rough idea of our galaxy’s mass. We’ve also looked at the motions of the globular clusters that orbit in the halo of the Milky Way. From these observations, our best estimate of the mass of the Milky Way is about a trillion solar masses, give or take.
The distribution of stars seen by the Gaia surveys. Credit: Data: ESA/Gaia/DPAC, A. Khalatyan(AIP) & StarHorse team; Galaxy map: NASA/JPL-Caltech/R. Hurt
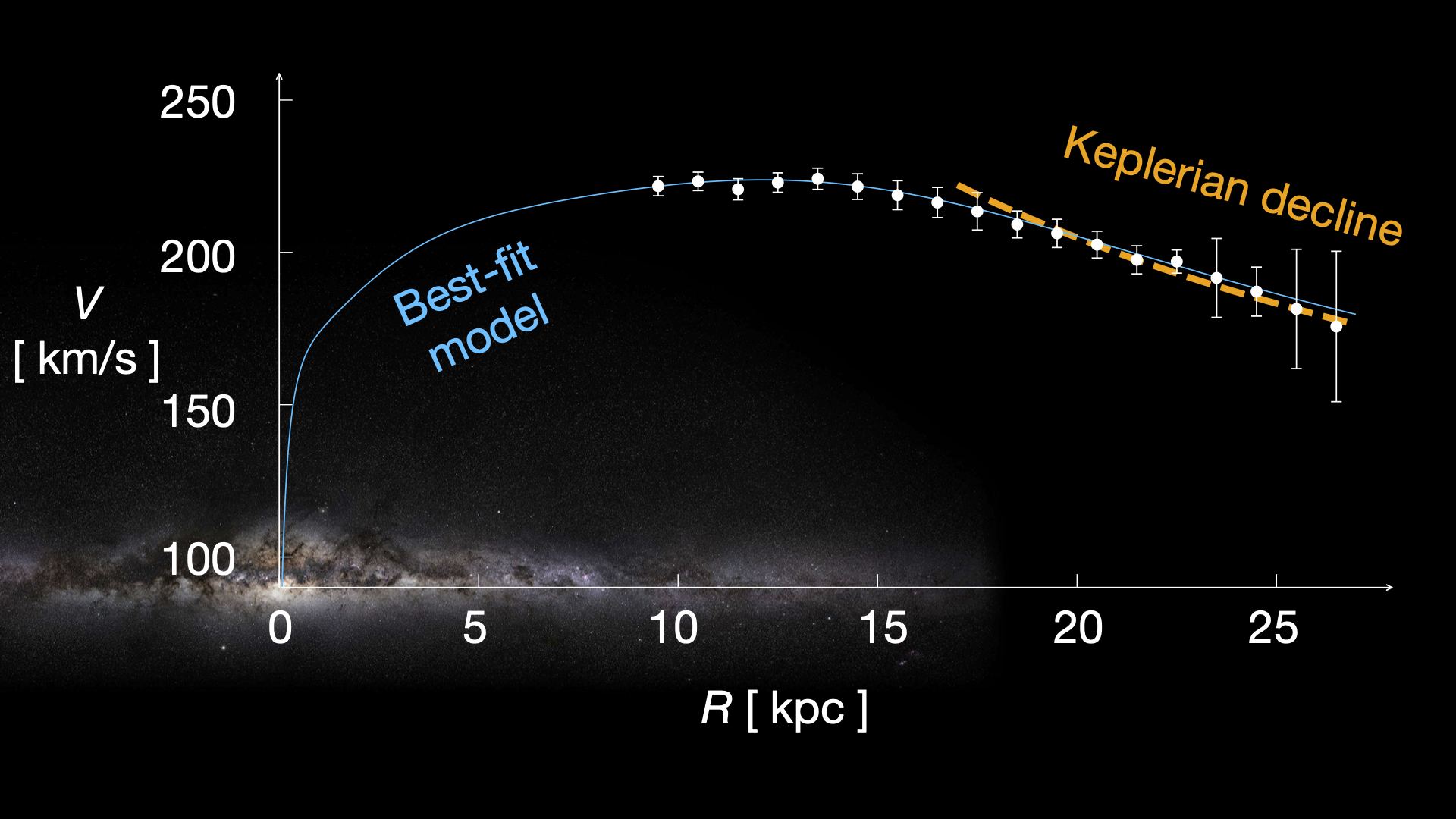
This new study is based on the third data release of the Gaia spacecraft. It contains the positions of more than 1.8 billion stars and the motions of more than 1.5 billion stars. While this is only a fraction of the estimated 100-400 billion stars in our galaxy, it is a large enough number to calculate an accurate rotation curve. Which is exactly what the team did. Their resulting rotation curve is so precise, that the team could identify what’s known as the Keplerian decline. This is the outer region of the Milky Way where stellar speeds start to drop off roughly in accordance with Kepler’s laws since almost all of the galaxy’s mass is closer to the galactic center.
The Keplerian decline allows the team to place a clear upper limit on the mass of the Milky Way. What they found was surprising. The best fit to their data placed the mass at about 200 billion solar masses, which is a fifth of previous estimates. The absolute upper mass limit for the Milky Way is 540 billion, meaning that the Milky Way is at least half as massive as we thought. Given the amount of known regular matter in the galaxy, this means the Milky Way has significantly less dark matter than we thought.
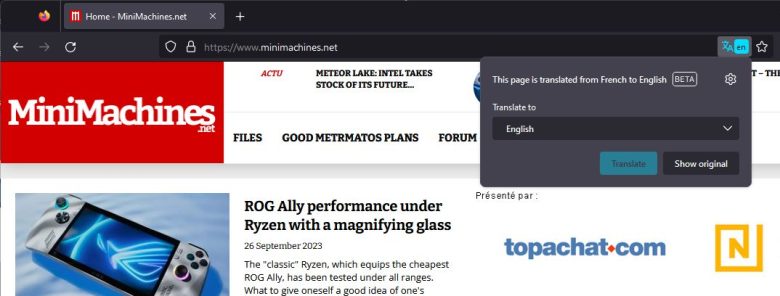
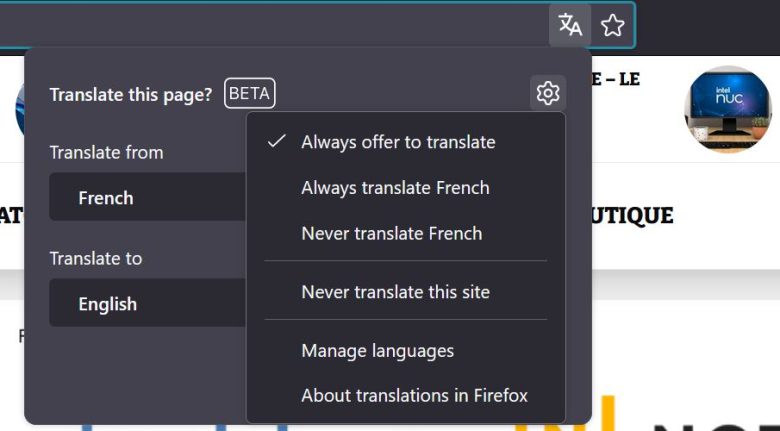
Web browsers have had tools that let you translate websites for years. But they typically rely on cloud-based translation services like Google Translate or Microsoft’s Bing Translator.
The latest version of Mozilla’s Firefox web browser does things differently. Firefox 118 brings support for Fullpage Translation, which can translate websites entirely in your browser. In other words, everything happens locally on your computer without any data sent to Microsoft, Google, or other companies.
Here’s how it works. Firefox will notice when you visit a website in a supported language that’s different from your default language, and a translate icon will show up in the address bar.
Tap that icon and you’ll see a pop-up window that asks what languages you’d like to translate from and to. If the browser doesn’t automatically detect the language of the website you’re visiting, you can set these manually.
Then click the “Translate” button, and a moment later the text on the page should be visible in your target language. If you’d prefer to go back to the original language, just tap the translate icon again and choose the option that says “show original.”
You can also tap the settings icon in the translation menu and choose to “always translate” or “never translate” a specific language so that you won’t have to manually invoke the translation every time you visit sites in that language.
Now for the bad news: Firefox Fullpage Translation only supports 9 languages so far:
Back in July, Reuters released a bombshell report documenting how Tesla not only spent a decade falsely inflating the range of their EVs, but created teams dedicated to bullshitting Tesla customers who called in to complain about it. If you recall, Reuters noted how these teams would have a little, adorable party every time they got a pissed off user to cancel a scheduled service call. Usually by lying to them:
“Inside the Nevada team’s office, some employees celebrated canceling service appointments by putting their phones on mute and striking a metal xylophone, triggering applause from coworkers who sometimes stood on desks. The team often closed hundreds of cases a week and staffers were tracked on their average number of diverted appointments per day.”
The story managed to stay in the headlines for all of a day or two, quickly supplanted by gossip surrounding a non-existent Elon Musk Mark Zuckerberg fist fight.
But here in reality, Tesla’s routine misrepresentation of their product (and almost joyous gaslighting of their paying customers) has caught the eye of federal regulators, who are now investigating the company for fraudulent behavior:
“federal prosecutors have opened a probe into Tesla’s alleged range-exaggerating scheme, which involved rigging its cars’ software to show an inflated range projection that would then abruptly switch to an accurate projection once the battery dipped below 50% charged. Tesla also reportedly created an entire secret “diversion team” to dissuade customers who had noticed the problem from scheduling service center appointments.”
This pretty clearly meets the threshold definition of “unfair and deceptive” under the FTC Act, so this shouldn’t be that hard of a case. Of course, whether it results in any sort of meaningful penalties or fines is another matter entirely. It’s very clear Musk historically hasn’t been very worried about what’s left of the U.S. regulatory and consumer protection apparatus holding him accountable for… anything.
Still, it’s yet another problem for a company that’s facing a flood of new competitors with an aging product line. And it’s another case thrown in Tesla’s lap on top of the glacially-moving inquiry into the growing pile of corpses caused by obvious misrepresentation of under-cooked “self driving” technology, and an investigation into Musk covertly using Tesla funds to build himself a glass mansion.
When contemplating the emissions from road vehicles, our first thought is often about the various gases coming out of the tailpipe. However, new research shows that we should be more concerned with the harmful particles that are shed from tires and brakes.
Scientists have a good understanding of engine emissions, which typically consist of unburnt fuel, oxides of carbon and nitrogen, and particulate matter related to combustion. However, new research shared by Yale Environment 360 indicates that there may be a whole host of toxic chemicals being shed from tires and brakes that have been largely ignored until now. Even worse, these emissions may be so significant that they actually exceed those from a typical car’s exhaust output.
A research paper published in 2020 highlighted the impact of tire pollution by examining the plight of coho salmon in West Coast streams. Scientists eventually identified a chemical called 6PPD, typically used in tire manufacturing to slow cracking and degradation. When exposed to ozone in the atmosphere, the chemical transforms into multiple other species, including 6PPD-quinone—which was found to be highly toxic to multiple fish, including coho salmon. The same chemical has since been detected in human urine, though any potential health impacts remain unknown.
The discovery of 6PPD-q and its impact has brought new scrutiny to the pollution generated by particles shedding from tires and brakes. In particular, tire rubber is made up of over 400 different chemical compounds, many of which are known to have negative effects on human health.
Particulate emissions from tires—and, to a lesser extent, brakes—are becoming a new focus for researchers looking into automobile pollution.
New research efforts are only just beginning to reveal the impact of near-invisible tire and brake dust. A report from the Pew Charitable Trust found that 78 percent of ocean microplastics are from synthetic tire rubber. These toxic particles often end up ingested by marine animals, where they can cause neurological effects, behavioral changes, and abnormal growth.
Meanwhile, British firm Emissions Analytics spent three years studying tires. The group found that a single car’s four tires collectively release 1 trillion “ultrafine” particles for every single kilometer (0.6 miles) driven. These particles, under 100 nanometers in size, are so tiny that they can pass directly through the lungs and into the blood. They can even cross the body’s blood-brain barrier. The Imperial College London has also studied the issue, noting that “There is emerging evidence that tire wear particles and other particulate matter may contribute to a range of negative health impacts including heart, lung, developmental, reproductive, and cancer outcomes.”
It’s an emissions problem that won’t go away with the transition to EVs, either. According to data from Emissions Analytics, EVs tend to shed around 20 percent more from their tires due to their higher weight and high torque compared to traditional internal combustion engine-powered vehicles.
Indeed, the scale of these emissions is significant. Particulate emissions from tires and brakes, particularly in the PM2.5 and PM10 size ranges, are believed to exceed the mass of tailpipe emissions from modern vehicle fleets, as per a study published in Science of the Total Environmentthis year.
This issue has largely flown under the radar until recently. Tailpipe emissions are easy to study, simply requiring the capture or sensing of gases directly at the engine’s exhaust. Capturing the fine particulates emitted from tires and brakes is altogether more difficult. Doing so in a way that accurately reflects the quantity of those emissions is yet harder. Such pollution is perhaps unlikely to have a direct impact on issues like climate change, but the potential toxicity for humans, animals, and the broader environment is a prime concern.
Regulators are already scrambling to tackle this issue, heretofore largely ignored by governments around the world. In the EU, the Euro 7 standards will regulate tire and brake emissions from 2025. In the U.S., the California EPA will require tire manufacturers to find an alternative chemical to 6PPD by 2024, to help reduce 6PPD-q entering the environment going forward. In turn, manufacturers are exploring everything from alternate tire compositions to special electrostatic methods to capture particulate output.
Expect this issue to gain greater prominence in coming years as regulators have more accurate data to act upon. There is great scope to slash this form of pollution if we properly understand the impacts of our cars in full.
Today, we’re delighted to announce the launch of Raspberry Pi 5, coming at the end of October. Priced at $60 for the 4GB variant, and $80 for its 8GB sibling (plus your local taxes), virtually every aspect of the platform has been upgraded, delivering a no-compromises user experience. Raspberry Pi 5 comes with new features, it’s over twice as fast as its predecessor, and it’s the first Raspberry Pi computer to feature silicon designed in‑house here in Cambridge, UK.
Key features include:
2.4GHz quad-core 64-bit Arm Cortex-A76 CPU
VideoCore VII GPU, supporting OpenGL ES 3.1, Vulkan 1.2
Dual 4Kp60 HDMI® display output
4Kp60 HEVC decoder
Dual-band 802.11ac Wi-Fi®
Bluetooth 5.0 / Bluetooth Low Energy (BLE)
High-speed microSD card interface with SDR104 mode support
2 × USB 3.0 ports, supporting simultaneous 5Gbps operation
2 × USB 2.0 ports
Gigabit Ethernet, with PoE+ support (requires separate PoE+ HAT, coming soon)
2 × 4-lane MIPI camera/display transceivers
PCIe 2.0 x1 interface for fast peripherals
Raspberry Pi standard 40-pin GPIO header
Real-time clock
Power button
In a break from recent tradition, we are announcing Raspberry Pi 5 before the product arrives on shelves. Units are available to pre-order today from many of our Approved Reseller partners, and we expect the first units to ship by the end of October.
Researchers at the University of California San Diego have figured out a way to turn everyday earbuds into high-tech gadgets that can record electrical activity inside the brain. The 3D screen-printed, flexible sensors are not only able to detect electrophysiological activity coming from the brain but they can also harvest sweat. Yes, sweat.
More specifically, sweat lactate, which is an organic acid that the body produces during exercise and normal metabolic activity. Because the ear contains sweat glands and is anatomically adjacent to the brain, earbuds are an ideal tool to gather this kind of data.
You may be wondering why scientists are interested in collecting biometric info about brain activity at the intersection of human sweat. Together, EEG and sweat lactate data can be used to diagnose different types of seizures. There are more than 30 different types of recorded seizures, which are categorized differently according to the areas of the brain that are impacted during an event.
But even beyond diagnostics, these variables can be helpful if you want to get a better picture of personal performance during exercise. Additionally, these biometric data points can be used to monitor stress and focus levels.
Erik Jepsen, UC San Diego
And while in-ear sensing of biometric data is not a new innovation, the sensor technology is unique in that it can measure both brain activity and lactate. However, what’s more important is that the researchers believe, with more refinement and development, we will eventually see more wearables that use neuroimaging sensors like the one being made to collect health data on everyday devices. In a statement, UC San Diego bioengineering professor Gert Cauwenberghs said that, “Being able to measure the dynamics of both brain cognitive activity and body metabolic state in one in-ear integrated device,” can open up tremendous opportunities for everyday health monitoring.
[…]
Despite their capabilities and rosy future as a potential diagnostic aid, the 3D printed sensors really need a considerable amount of sweat in order to be useful for data analysis. But the researchers said down the line the sensors will be more precise, so hard workouts may not be necessary for meaningful sweat analysis.
Hackers backed by the Chinese government are planting malware into routers that provides long-lasting and undetectable backdoor access to the networks of multinational companies in the US and Japan, governments in both countries said Wednesday. The hacking group, tracked under names including BlackTech, Palmerworm, Temp.Overboard, Circuit Panda, and Radio Panda, has been operating since at least 2010, a joint advisory published by government entities in the US and Japan reported. The group has a history of targeting public organizations and private companies in the US and East Asia. The threat actor is somehow gaining administrator credentials to network devices used by subsidiaries and using that control to install malicious firmware that can be triggered with “magic packets” to perform specific tasks.
The hackers then use control of those devices to infiltrate networks of companies that have trusted relationships with the breached subsidiaries. “Specifically, upon gaining an initial foothold into a target network and gaining administrator access to network edge devices, BlackTech cyber actors often modify the firmware to hide their activity across the edge devices to further maintain persistence in the network,” officials wrote in Wednesday’s advisory. “To extend their foothold across an organization, BlackTech actors target branch routers — typically smaller appliances used at remote branch offices to connect to a corporate headquarters — and then abuse the trusted relationship of the branch routers within the corporate network being targeted. BlackTech actors then use the compromised public-facing branch routers as part of their infrastructure for proxying traffic, blending in with corporate network traffic, and pivoting to other victims on the same corporate network.”
Most of Wednesday’s advisory referred to routers sold by Cisco. In an advisory of its own, Cisco said the threat actors are compromising the devices after acquiring administrative credentials and that there’s no indication they are exploiting vulnerabilities. Cisco also said that the hacker’s ability to install malicious firmware exists only for older company products. Newer ones are equipped with secure boot capabilities that prevent them from running unauthorized firmware, the company said. “It would be trivial for the BlackTech actors to modify values in their backdoors that would render specific signatures of this router backdoor obsolete,” the advisory stated. “For more robust detection, network defenders should monitor network devices for unauthorized downloads of bootloaders and firmware images and reboots. Network defenders should also monitor for unusual traffic destined to the router, including SSH.”
To detect and mitigate this threat, the advisory recommends administrators disable outbound connections on virtual teletype (VTY) lines, monitor inbound and outbound connections, block unauthorized outbound connections, restrict administration service access, upgrade to secure boot-capable devices, change compromised passwords, review network device logs, and monitor firmware changes for unauthorized alterations.
Ars Technica notes: “The advisory didn’t provide any indicators of compromise that admins can use to determine if they have been targeted or infected.”
In the world of business, “audit readiness” is not just another buzzword—it’s a critical aspect of maintaining financial integrity and ensuring smooth operations. Whether you’re a seasoned entrepreneur or a small business owner, understanding what audit readiness entails can make the difference between success and financial turmoil. In this article, we’ll delve into the ins and outs of audit readiness, sharing practical tips and real-life experiences to help you navigate this essential aspect of business management.
What is Audit Readiness?
Before we dive into the tips, let’s establish a clear understanding of what audit readiness means. Simply put, audit readiness refers to the state of preparedness an organization maintains to undergo financial audits with ease and confidence. These audits, conducted by internal or external auditors, scrutinize a company’s financial records, transactions, and compliance with relevant laws and regulations.
The Importance of Audit Readiness
Why is audit readiness so crucial? Well, imagine your business as a ship sailing through treacherous waters. Without proper preparation, you might find yourself navigating blindly through financial storms. Audit readiness is your compass, ensuring you stay on course and avoid potential disasters. Here’s why it matters:
1. Regulatory Compliance
Adhering to legal and financial regulations is non-negotiable. When you’re audit-ready, you demonstrate your commitment to following the rules. Failure to comply can result in hefty fines, legal complications, and damage to your reputation.
2. Financial Accuracy
An audit uncovers inaccuracies, discrepancies, or fraud within your financial records. Being audit-ready means you’re consistently maintaining accurate financial data, which is essential for informed decision-making and financial stability.
3. Investor and Stakeholder Confidence
Investors and stakeholders want assurance that their investments are in safe hands. Audit readiness fosters trust, attracting potential investors and ensuring your current stakeholders remain confident in your business’s financial health.
4. Operational Efficiency
A well-organized audit-ready system streamlines your financial processes. This not only makes audits smoother but also enhances overall operational efficiency, reducing the risk of financial mismanagement.
Now that you understand why audit readiness is vital, let’s explore some essential tips to help you achieve and maintain it.
Tips for Achieving Audit Readiness
1. Maintain Impeccable Record Keeping
One of the cornerstones of audit readiness is maintaining impeccable records. Your financial documents should be accurate, complete, and organized. This includes invoices, receipts, bank statements, payroll records, and tax filings. Regularly reconcile accounts to catch and correct errors promptly.
2. Implement Robust Internal Controls
Establishing internal controls is like setting up a safeguard around your finances. These controls include segregation of duties, authorization processes, and thorough documentation. They not only deter fraudulent activities but also ensure financial accuracy.
Real-Life Experience:
I once worked for a small manufacturing company that neglected internal controls. It led to a significant embezzlement case, causing financial turmoil and damaging the company’s reputation. Implementing robust internal controls was the turning point that helped us regain trust and financial stability.
3. Educate Your Team
Your team plays a crucial role in audit readiness. Educate your employees about the importance of proper record-keeping and adherence to financial procedures. Provide training and clear guidelines to ensure everyone understands their responsibilities.
4. Regularly Review Financial Statements
Don’t wait for an audit to identify financial discrepancies. Regularly review your financial statements and conduct internal audits. This proactive approach helps you spot and rectify issues before they escalate.
5. Engage Professional Auditors
External auditors bring an unbiased perspective to the table. Consider hiring reputable audit firms to conduct periodic audits. Their expertise can uncover hidden issues and provide valuable insights into improving your financial processes.
6. Embrace Technology
Modern accounting software and financial management tools can be your best allies in achieving audit readiness. They streamline record-keeping, reduce human error, and provide real-time insights into your financial health.
Real-Life Experience:
At my previous company, transitioning to cloud-based accounting software revolutionized our audit readiness. It not only saved us time and resources but also improved our financial accuracy.
7. Conduct Mock Audits
Think of mock audits as dress rehearsals for the real thing. Periodically simulate the audit process internally to identify weaknesses and areas that need improvement. This practice helps you fine-tune your audit readiness strategies.
8. Stay Informed About Regulatory Changes
Financial regulations are subject to change. Stay informed about updates and adapt your processes accordingly. Failure to do so can result in non-compliance during an audit.
Audit Readiness in Action
Let’s take a look at a real-life scenario that highlights the importance of audit readiness.
Real-Life Experience:
Sarah, a diligent business owner, operated a successful e-commerce store. Her business was thriving, but she neglected her financial records. When the time came for a surprise tax audit, she was ill-prepared. The auditor uncovered numerous discrepancies, leading to hefty fines and a tarnished reputation.
Determined not to repeat the same mistake, Sarah implemented a robust record-keeping system, hired a professional accountant, and embraced accounting software. Over time, her business became audit-ready. When the next audit rolled around, Sarah confidently presented her meticulous records, and the process went smoothly.
Conclusion
Achieving and maintaining audit readiness is not an option; it’s a necessity for any business. It’s your shield against financial storms and your key to maintaining regulatory compliance. By following the tips outlined in this article, you can set your business on the path to audit readiness, ensuring a secure and prosperous future.
But remember, audit readiness is not a one-time effort; it’s an ongoing commitment. Regularly assess and improve your financial processes, stay informed about regulatory changes, and never underestimate the importance of meticulous record-keeping. By doing so, you’ll not only navigate financial audits with ease but also ensure the long-term success and stability of your business.
So, as you sail through the turbulent waters of the business world, make audit readiness your guiding star, and rest assured that your financial ship will stay on course, no matter what challenges may arise.
Bio
Kyle Geers is a seasoned professional with over nine years of public accounting experience, including seven years within a large international CPA firm. Kyle has been involved with financial statement and integrated audits of both public and private businesses, ranging from emerging start-ups to multinational corporations with complex operations.
The Philips Hue ecosystem of home automation devices is “collapsing into stupidity,” writes Rachel Kroll, veteran sysadmin and former production engineer at Facebook. “Unfortunately, the idiot C-suite phenomenon has happened here too, and they have been slowly walking down the road to full-on enshittification.” From her blog post: I figured something was up a few years ago when their iOS app would block entry until you pushed an upgrade to the hub box. That kind of behavior would never fly with any product team that gives a damn about their users — want to control something, so you start up the app? Forget it, we are making you placate us first! How is that user-focused, you ask? It isn’t.
Their latest round of stupidity pops up a new EULA and forces you to take it or, again, you can’t access your stuff. But that’s just more unenforceable garbage, so who cares, right? Well, it’s getting worse.
It seems they are planning on dropping an update which will force you to log in. Yep, no longer will your stuff Just Work across the local network. Now it will have yet another garbage “cloud” “integration” involved, and they certainly will find a way to make things suck even worse for you. If you have just the lights and smart outlets, Kroll recommends deleting the units from the Hue Hub and adding them to an IKEA Dirigera hub. “It’ll run them just fine, and will also export them to HomeKit so that much will keep working as well.” That said, it’s not a perfect solution. You will lose motion sensor data, the light level, the temperature of that room, and the ability to set custom behaviors with those buttons.
“Also, there’s no guarantee that IKEA won’t hop on the train to sketchville and start screwing over their users as well,” adds Kroll.
The ability to regrow your own teeth could be just around the corner.
A team of scientists, led by a Japanese pharmaceutical startup, are getting set to start human trials on a new drug that has successfully grown new teeth in animal test subjects.
Toregem Biopharma is slated to begin clinical trials in July of next year after it succeeded growing new teeth in mice five years ago, the Japan Times reports.
Dr. Katsu Takahashi, a lead researcher on the project and head of the dentistry and oral surgery department at the Medical Research Institute Kitano Hospital, says “the idea of growing new teeth is every dentist’s dream.”
In his research, which he’s been conducting at Kyoto University since 2005, Takahashi learned of a particular gene in mice that affects the growth of their teeth.
The antibody for this gene, USAG-1, can help stimulate tooth growth if it is suppressed – and scientists have since worked to develop a “neutralizing antibody medicine” that is able to block USAG-1.
Now, his team has been testing the theory that “blocking” this protein could grow more teeth.
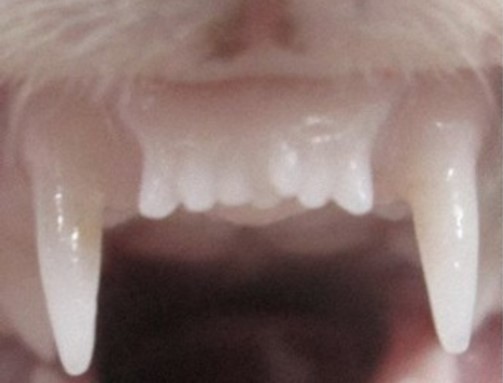
After their successful tests on mice, the team went on to perform similarly positive trials on ferrets – animals who have a similar dental pattern to humans.
The front teeth of a ferret treated with tooth regrowth medicine. The medicine induced the growth of an additional seventh tooth (centre). Courtesy / Dr. Katsu Takahash
Now, testing will turn to healthy adult humans and, if all goes well, the team plans to hold a clinical trial for the drug from 2025 for children between two and six years old with anodontia – a rare genetic disorder that results in the absence of six or more baby and/or adult teeth.
According to the Japan Times, the children involved in the clinical trial will be injected with one dose of the drug to see if it induces teeth growth.
If successful, the medicine could be available for regulatory approval by 2030.
Takahashi hopes the new medicine could be just another option for those who don’t have a full set of teeth.
“In any case, we’re hoping to see a time when tooth-regrowth medicine is a third choice alongside dentures and implants,” Takahashi told Mainichi.
Well now why would I want a single-button keyboard, you might be asking yourself. We say it all depends on how you build the thing, and how you program it. Would you believe that the MagiClick by [Modular] is capable of showing live weather information or the date and time, acting as animated dice, or being a stopwatch and Pomodoro timer? Now you’re beginning to understand.
Before we get much further, yes, this bad boy has two additional buttons on the sides. But the spirit of the thing is in the single large switch in the middle. It’s hiding beneath the 0.85″ 128×128 display, which is protected from pressure and fingerprints by that Pop-o-Matic bubble over the top. While the big button is the main operator used to access the function options, the side buttons are used as auxiliaries to exit and return to the home screen.
MagiClick is based on the ESP32-S3 and is designed to run on CircuitPython. In addition to everything else packed into this thing, there are blinkenlights and a small speaker inside, plus a GPIO expansion header around back. Everything is available on GitHub if you want to build your own.
A chip startup and several of its employees are being sued by Apple for theft of trade secrets and breach of contract and filed a countersuit.
Rivos was sued [PDF] by Apple early last year over claims it lured away a gaggle of Apple employees working on the system-on-chip (SoC) designs like those in its Mac and iPhone devices. Rivos and several of its employees who previously worked at Apple were named in the suit, and six of them participated with Rivos in the countersuit [PDF] filed in the District Court for the Northern District of California on Friday.
In the original lawsuit, Apple accused Rivos, which was founded in 2021 to develop RISC-V SoCs for servers, of a “coordinated campaign to target Apple employees with access to Apple proprietary and trade secret information about Apple’s SoC designs.” When informed of confidentiality and intellectual property agreements (IPAs), Apple claimed Rivos never responded.
Instead, “after accepting their offers from Rivos, some of these employees took gigabytes of sensitive SoC specifications and design files during their last days of employment with Apple,” lawyers for Cupertino alleged.
A judge in the lawsuit dismissed [PDF] claims of trade secret theft against Rivos and two of its employees in August with leave to amend, but let other Defend Trade Secrets Act claims against individual employees, as well as the breach of contract claims, stand.
Apple has tried this before and failed, reasons Rivos
In its countersuit, Rivos and six of its employees argue that, rather than competing, “Apple has resorted to trying to thwart emerging startups through anticompetitive measures, including illegally restricting employee mobility.”
Methods Apple has used to stymie employee mobility include the aforementioned IPAs, which Rivos lawyers argue violate California’s Business and Professions Code rules voiding contracts that restrict an individual’s ability to engage in a lawful business, profession or trade.
Under California law, Rivos lawyers claim, such a violation means Apple is engaging in unfair and unlawful business practices that have caused injury to Rivos through the need to fight such a lengthy and, if the contracts are unenforceable, unnecessary court battle.
“Apple’s actions not only violate the laws and public policy of the State of California, but also undermine the free and open competition that has made the state the birthplace of countless innovative businesses,” Rivos’s lawyers argue in the lawsuit.
Rivos also claims that Apple’s method of applying its IPA is piecemeal and often abused to allow Apple future legal opportunities.
“Even when Apple knows its employees are leaving to work somewhere that Apple (rightly or wrongly) perceives as a competitive threat, it does not consistently conduct exit interviews or give employees any meaningful instruction about what they should do with supposedly ‘confidential’ Apple material upon leaving,” the countersuit claims.
“Apple lets these employees walk out the door with material they may have inadvertently ‘retained’ simply by using the Apple systems (such as iCloud or iMessage) that Apple effectively mandates they use as part of their work.”
Rivos argues in its filing that Apple tried this exact same scheme before and it failed then too.
That incident involved Arm-compatible chipmaker Nuvia, which was founded by former Apple chip chief Gerard Williams in 2019. Apple sued Williams that same year over claims he violated his contract with Apple and tried to poach employees for his startup.
Williams unsurprisingly made the same claims as Rivos – that the Apple contracts were unenforceable under California law – and after a couple years of stalling, Apple finally abandoned its suit against Williams with little justification.
The iGiant didn’t respond to our questions about the countersuit.
The FTC – and 17 state attorneys general – have come out swinging at Amazon with a lawsuit accusing the ecommerce giant of being a monopolist.
Amazon, the FTC alleges, engages in anticompetitive conduct in two markets: online ecommerce and also the market for marketplace services used by sellers. The tactics used by Amazon to thwart competition include anti-discounting measures that punish sellers for offering prices lower than Amazons, and requiring vendors to use – and pay for – Amazon’s fulfillment services to make their products eligible for free Prime shipments, the FTC claims.
“Our complaint lays out how Amazon has used a set of punitive and coercive tactics to unlawfully maintain its monopolies,” said FTC Chair and perennial Amazon opponent Lina Khan.
Khan describes Amazon’s as exploiting monopolistic power to enrich itself by raising product prices and degrading services for its customers and businesses. “Today’s lawsuit seeks to hold Amazon to account for these monopolistic practices and restore the lost promise of free and fair competition,” Khan added.
Amazon’s “monopoly rents” are extracted from “everyone within its reach,” the FTC alleges. This hurts customers by replacing relevant organic search results with ads and boosting Amazon’s own products in search results. In addition, excessive fees are allegedly leveled at Amazon sellers, which the FTC said can amount to close to half of a store’s revenue going directly to the online souk, and which it asserts are passed on to consumers.
[…]
“We can and should break up Amazon,” said Athena Coalition, a self-described anti-Amazon grassroots group, in a statement. “Amazon has a long history of combining and utilizing its many businesses together as an integrated whole to leverage its power against workers, businesses, and ultimately all of us.”
The group said that an FTC victory would free Amazon sellers to work with whomever they chose, rather than being forced to go to Amazon. Rather than harming consumers, Athena said that an Amazon reigned in by the FTC would also mean more choice and lower costs for Amazon customers, too.
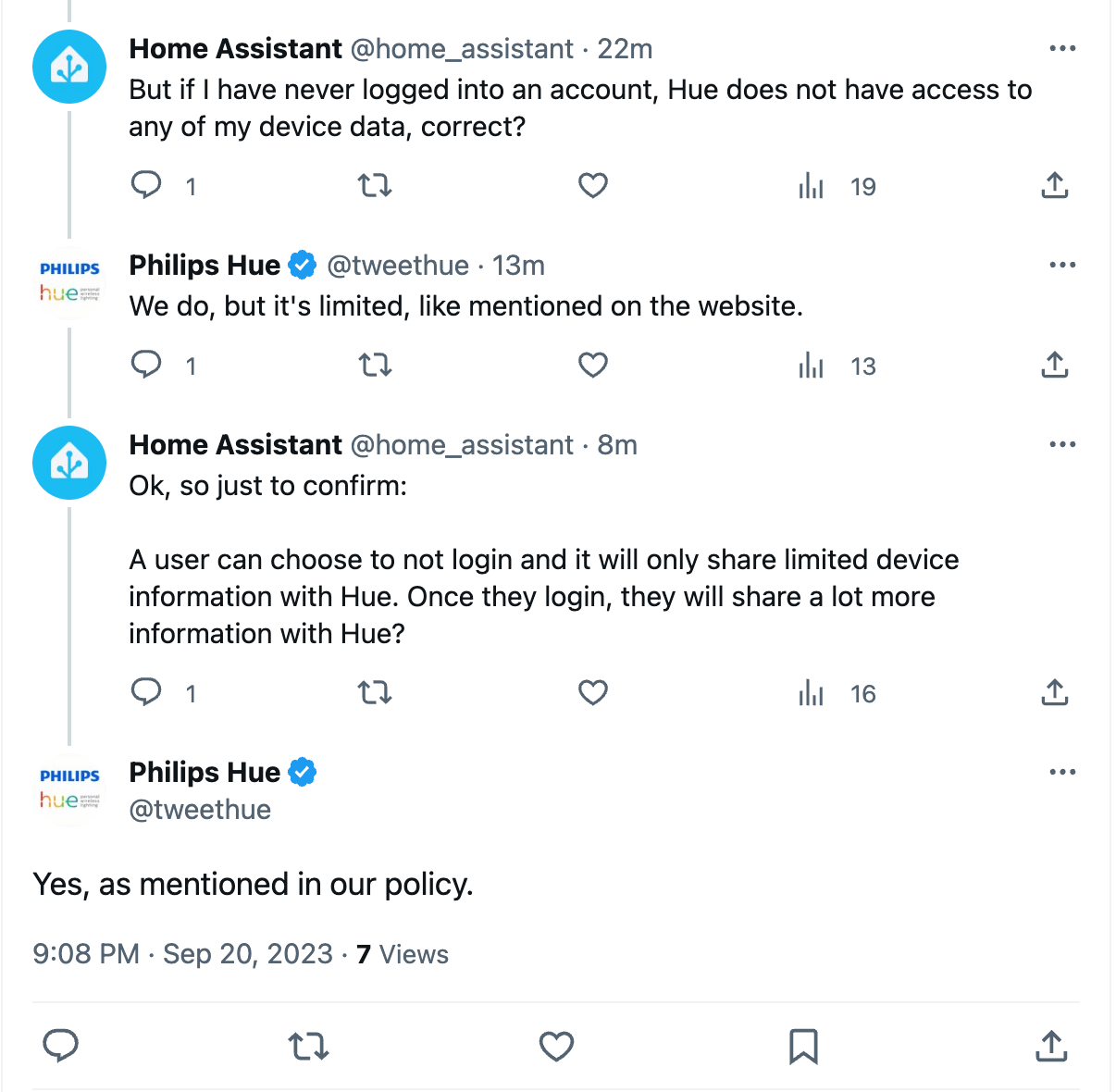
Today’s story is about Philips Hue by Signify. They will soon start forcing accounts on all users and upload user data to their cloud. For now, Signify says you’ll still be able to control your Hue lights locally as you’re currently used to, but we don’t know if this may change in the future. The privacy policy allows them to store the data and share it with partners.
[…]
When you open the Philips Hue app you will now be prompted with a new message: Starting soon, you’ll need to be signed in.
[…]
So today, you can choose to not share your information with Signify by not creating an account. But this choice will soon be taken away and all users need to share their data with Philips Hue.
Confirming the news
I didn’t want to cry wolf, so I decided to verify the above statement with Signify. They sadly confirmed:
Twitter conversation with Philips Hue (source: Twitter)
When asked what drove this change, the answer is the usual: security. Well Signify, you know what keeps user data even more secure? Not uploading it all to your cloud.
[…]
As a user, we encourage you to reach out to Signify support and voice your concern.
NOTE: Their support form doesn’t work. You can visit their Facebook page though
Dear Signify, please reconsider your decision and do not move forward with it. You’ve reversed bad decisions before. People care about privacy and forcing accounts will hurt the brand in the long term. The pain caused by this is not worth the gain.
No, Philips / Signify – I have used these devices for years without having to have an account or be connected to the internet. It’s one of the reasons I bought into Hue. Making us give up data to use something we bought after we bought it is a dangerous decision considering the private and exploitable nature of the data, as well as greedy and rude.
American Airlines, Southwest Airlines, and United Airlines are among a growing list of air carriers that have grounded aircraft in the wake of a fake jet engine parts scandal that has rocked the aviation industry. Multiple have already replaced the uncertified parts and returned their planes to service, but close to 100 planes may still be affected worldwide.
Earlier this month, news broke that British aerospace parts supplier AOG Technics had forged certification documents for dozens of parts used in the CFM56 turbofan. This is the world’s most widely used jet engine, powering workhorses like the Airbus A320 and Boeing 737. The origin of the fake parts isn’t yet known, but some of their destinations are: The engines of at least four airlines around the globe.
Citing Bloomberg, Simple Flying reports Southwest Airlines was the first to find AOG parts in its aircraft. It traced its supply chain to the installation of two AOG-supplied low-pressure turbine blades in a 737, which it replaced on September 8 with certified parts before returning the Boeing to service. Virgin Australia reportedly later found and replaced the same part, along with a seal on an inner high-pressure turbine nozzle.
American Airlines also tracked down AOG parts on what a spokesperson reportedly described as “a small number of aircraft” during “internal audits,” leading to the planes being “immediately taken out of service.” United Airlines also reportedly found AOG-sourced compressor stator vanes on two of its planes, though whether those two planes have returned to service was not indicated.
AOG’s uncertified parts are currently believed to have made their way into as many as 96 planes worldwide. The Federal Aviation Administration has advised airlines and the rest of the aerospace industry to inspect their planes and audit inventories for uncertified, AOG-supplied parts.
Ken Loach’s 1977 film ‘Star Wars Episode IV – No Hope’.
George Lucas was unhappy with Loach’s depressing subject matter combined with there being no actual space scenes (with all the action taking place on a UK council estate).
He immediately halted filming, recast many parts (Carrie Fisher replacing Kathy Burke for example), did extensive reshoots, and released his more family-friendly cut under new name ‘A New Hope’ (whatever that means!!)
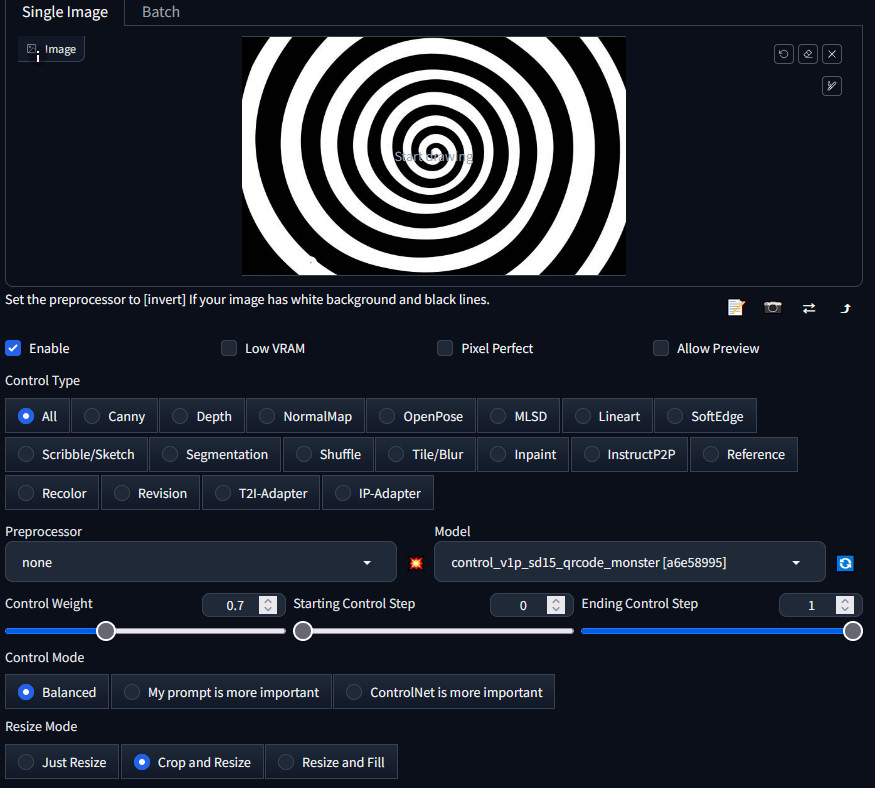
[…]a Reddit user named “Ugleh” posted an AI-generated image of a spiral-shaped medieval village that rapidly gained attention on social media for its remarkable geometric qualities. Follow-up posts garnered even more praise, including a tweet with over 145,000 likes. Ugleh created the images using Stable Diffusion and a guidance technique called ControlNet.
[….]
In June, we covered a technique that used the AI image synthesis model Stable Diffusion and ControlNet to create QR codes that look like rich artworks, including anime-inspired art. Ugleh took the same neural network optimized for creating those QR codes (which themselves are geometric shapes) and fed simple images of spirals and checkerboard patterns into it instead.
When guided by the prompt, “Medieval village scene with busy streets and castle in the distance (masterpiece:1.4), (best quality), (detailed),” ControlNet rendered scenes where artistic elements of the images match the perceptual shapes of spirals and checkerboards. In one image, the clouds arc overhead and people stand in a gentle curve to match the spiral guidance. In another, squares of clouds, hedges, building faces, and a wagon cart make up a checkerboard-shaped scene.
The magic of ControlNet
So how does it work? We’ve covered Stable Diffusion frequently before. It’s a neural network model trained on millions of images scraped from the Internet. But the key here is ControlNet, which first appeared in a research paper titled “Adding Conditional Control to Text-to-Image Diffusion Models” by Lvmin Zhang, Anyi Rao, and Maneesh Agrawala in February 2023, and quickly became popular in the Stable Diffusion community.
Typically, a Stable Diffusion image is created using a text prompt (called text2image) or an image prompt (img2img). ControlNet introduces additional guidance that can take the form of extracted information from a source image, including pose detection, depth mapping, normal mapping, edge detection, and much more. Using ControlNet, someone generating AI artwork can much more closely replicate the shape or pose of a subject in an image.
Using ControlNet and similar prompts, it’s easy to replicate Ugleh’s work, and others have done so to amusing effect, including checkerboard anime characters, an animation, medieval village “goatse” (surprisingly safe for work), and a medieval village version of “Girl with a Pearl Earring.”
[…]
If you want to experiment with ControlNet, this site has a good tutorial. Also, Ugleh posted a step-by-step workflow, including the spiral and checkerboard template files, on Imgur.
While the artwork is remarkable, current US copyright policy suggests that the images do not meet the standards to receive copyright protection, so they may be in the public domain. While AI-generated artwork is still a contentious subject for many on ethical and legal grounds, creative enthusiasts continue to push the boundaries of what is possible for an unskilled or untrained practitioner using these new tools.
[…] Have I Been Pwned started life as a hobby project. In fact, Troy wasn’t working in the cybersecurity industry until a chance encounter tweaked his curiosity.
[…]
Hackers had stolen the email addresses and passwords of 152 million of Adobe’s customers in November 2013 — including, as it turned out, Troy’s.
Only, he wasn’t an Adobe customer. He did some digging and found that Adobe had acquired another company that he did have an account with, and his data along with it.
But that wasn’t where it ended. Another question weighed on Troy’s mind — one he would soon become synonymous with. Where else had his data been leaked?
So, two months after the Adobe breach, he launched Have I Been Pwned — a website that would answer this exact question for anyone in the world.
Even though it’s grown into an industry behemoth, the day-to-day reality of running the site hasn’t changed all that much since 2013.
[…]
He only collects (and encrypts) the mobile numbers, emails and passwords that he finds in the breaches, discarding the victims’ names, physical addresses, bank details and other sensitive information.
The idea is to let users find out where their data has been leaked from, but without exposing them to further risk.
Once he identifies where a data breach has occurred, Troy also contacts the organisation responsible to allow it to inform its users before he does. This, he says, is often the hardest step of the process because he has to convince them it’s legitimate and not some kind of scam itself.
He’s not required to give organisations this opportunity, much less persist when they ignore his messages or accuse him of trying to shake them down for money.
[…]
These days, major tech companies like Mozilla and 1Password use Have I Been Pwned, and Troy likes to point out that dozens of national governments and law enforcement agencies also partner with his service.
[…]
the reality is Troy doesn’t answer to an electorate, or even a board.
“He’s not a company that’s audited. He’s just a dude on the web,” says Jane Andrew, an expert on data breaches at the University of Sydney.
“I think it’s so shocking that this is where we find out information about ourselves.
“It’s just one guy facilitating this. It’s a critical global risk.”
She says governments and law enforcement have, in general, left it to individuals to deal with the fallout from data breaches.
[…]
Without an effective global regulator, Professor Andrew says, a crucial part of the world’s cybersecurity infrastructure is left to rely on the goodwill of this one man on the Gold Coast.
T-Mobile US has had another bad week on the infosec front – this time stemming from a system glitch that exposed customer account data, followed by allegations of another breach the carrier denied.
According to customers who complained of the issue on Reddit and X, the T-Mobile app was displaying other customers’ data instead of their own – including the strangers’ purchase history, credit card information, and address.
This being T-Mobile’s infamously leaky US operation, people immediately began leaping to the obvious conclusion: another cyber attack or breach.
“There was no cyber attack or breach at T-Mobile,” the telco assured us in an emailed statement. “This was a temporary system glitch related to a planned overnight technology update involving limited account information for fewer than 100 customers, which was quickly resolved.”
Note, as Reddit poster Jman100_JCMP did, T-Mobile means fewer than 100 customers had their data exposed – but far more appear to have been able to view those 100 customers’ data.
As for the breach, the appearance of exposed T-Mobile data was alleged by malware repository vx-underground’s X (Twitter) account. The Register understands T-Mobile examined the data and determined that independently owned T-Mobile dealer, Connectivity Source, was the source – resulting from a breach it suffered in April. We understand T-Mobile believes vx-underground misinterpreted a data dump.
Connectivity Source was indeed the subject of a breach in April, in which an unknown attacker made off with employee data including names and social security numbers – around 17,835 of them from across the US, where Connectivity appears to do business exclusively as a white-labelled T-Mobile US retailer.
Looks like the carier really dodged the bullet on this one – there’s no way Connectivity Source employees could be mistaken for its own staff.
T-Mobile US has already experienced two prior breaches this year, but that hasn’t imperilled the biz much – its profits have soared recently and some accompanying sizable layoffs will probably keep things in the black for the foreseeable future.
Since 1999, Slashdot hasbeencoveringtheannualIgNobelprize ceremonies — which honor real scientific research into strange or surprising subjects. “Each winner (or winning team) has done something that makes people LAUGH, then THINK,” explains the ceremony web page, promising that “a gaggle of genuine, genuinely bemused Nobel laureates handed the Ig Nobel Prizes to the new Ig Nobel winners.” As co-founder Marc Abrahams says on his LinkedIn profile, “All these things celebrate the unusual, honor the imaginative — and spur people’s interest in science, medicine, and technology.”
COMMUNICATION PRIZE [ARGENTINA, SPAIN, COLOMBIA, CHILE, CHINA, USA] — María José Torres-Prioris, Diana López-Barroso, Estela Càmara, Sol Fittipaldi, Lucas Sedeño, Agustín Ibáñez, Marcelo Berthier, and Adolfo García, for studying the mental activities of people who are expert at speaking backward.
EDUCATION PRIZE [HONG KONG, CHINA, CANADA, UK, THE NETHERLANDS, IRELAND, USA, JAPAN] — Katy Tam, Cyanea Poon, Victoria Hui, Wijnand van Tilburg, Christy Wong, Vivian Kwong, Gigi Yuen, and Christian Chan, for methodically studying the boredom of teachers and students.
PHYSICS PRIZE [SPAIN, GALICIA, SWITZERLAND, FRANCE, UK] — Bieito Fernández Castro, Marian Peña, Enrique Nogueira, Miguel Gilcoto, Esperanza Broullón, Antonio Comesaña, Damien Bouffard, Alberto C. Naveira Garabato, and Beatriz Mouriño-Carballido, for measuring the extent to which ocean-water mixing is affected by the sexual activity of anchovies.
It’s hard to read the headlines today without feeling like the world couldn’t possibly get much worse. And then tomorrow rolls around, and a fresh set of headlines puts the lie to that thought. On a macro level, there’s not much that you can do about that, but on a personal level, illustrating your news feed with mostly wrong, AI-generated images might take the edge off things a little.
Let us explain. [Roy van der Veen] liked the idea of an e-paper display newsfeed, but the crushing weight of the headlines was a little too much to bear. To lighten things up, he decided to employ Stable Diffusion to illustrate his feed, displaying both the headline and a generated image on a 7.3″ Inky 7-color e-paper display. Every five hours, a script running on a Raspberry Pi Zero 2W fetches a headline from a random source — we’re pleased the list includes Hackaday — and composes a prompt for Stable Diffusion based on the headline, adding on a randomly selected prefix and suffix to spice things up. For example, a prompt might look like, “Gothic painting of (Driving a Motor with an Audio Amp Chip). Gloomy, dramatic, stunning, dreamy.” You can imagine the results.
We have to say, from the examples [Roy] shows, the idea pretty much works — sometimes the images are so far off the mark that just figuring out how Stable Diffusion came up with them is enough to soften the blow. We’d have preferred if the news of the floods in Libya had been buffered by a slightly less dismal scene, but finding out that what was thought to be a “ritual mass murder” was really only a yoga class was certainly heartening.
At this point, you gotta figure that you’re at least being listened to almost everywhere you go, whether it be a home assistant or your very own phone. So why not roll with the punches and turn lemons into something like a still life of lemons that’s a bit wonky? What we mean is, why not take our conversations and use AI to turn them into art? That’s the idea behind this next-generation digital photo frame created by [TheMorehavoc].
Essentially, it uses a Raspberry Pi and a Respeaker four-mic array to listen to conversations in the room. It listens and records 15-20 seconds of audio, and sends that to the OpenWhisper API to generate a transcript.
This repeats until five minutes of audio is collected, then the entire transcript is sent through GPT-4 to extract an image prompt from a single topic in the conversation. Then, that prompt is shipped off to Stable Diffusion to get an image to be displayed on the screen. As you can imagine, the images generated run the gamut from really weird to really awesome.
The natural lulls in conversation presented a bit of a problem in that the transcription was still generating during silences, presumably because of ambient noise. The answer was in voice activity detection software that gives a probability that a voice is present.
Naturally, people were curious about the prompts for the images, so [TheMorehavoc] made a little gallery sign with a MagTag that uses Adafruit.io as the MQTT broker. Build video is up after the break, and you can check out the images here (warning, some are NSFW).
The European Commission has imposed a €376.36 million ($400 million) fine on Intel for blocking the sales of devices powered by its competitors’ x86 CPUs. This brings one part of the company’s long-running antitrust court battle with the European authority to a close. If you’ll recall, the Commission slapped the chipmaker with a record-breaking €1.06 billion ($1.13 billion) fine in 2009 after it had determined that Intel abused its dominant position in the market. ye
It found back then that the company gave hidden rebates and incentives to manufacturers like HP, Dell and Lenovo for buying all or almost all their processors from Intel. The Commission also found that Intel paid manufacturers to delay or to completely cease the launch of products powered by its rivals’ CPUs “naked restrictions.” Other times, Intel apparently paid companies to limit those products’ sales channels. The Commission calls these actions “naked restrictions.”
[…]
In its announcement, the European Commission gave a few examples of how Intel hindered the sales of competing products. It apparently paid HP between November 2002 and May 2005 to sell AMD-powered business desktops only to small- and medium-sized enterprises and via direct distribution channels. It also paid Acer to delay the launch of an AMD-based notebook from September 2003 to January 2004. Intel paid Lenovo to push back the launch of AMD-based notebooks for half a year, as well.
The Commission has since appealed the General Court’s decision to dismiss the part of the case related to the rebates Intel offered its clients. Intel, however, did not lodge an appeal for the court’s ruling on naked restrictions, setting it in stone. “With today’s decision, the Commission has re-imposed a fine on Intel only for its naked restrictions practice,” the European authority wrote. “The fine does not relate to Intel’s conditional rebates practice. The fine amount, which is based on the same parameters as the 2009 Commission’s decision, reflects the narrower scope of the infringement compared to that decision.” Seeing as the rebates part of the case is under appeal, Intel could still pay the rest of the fine in the future.






 Twitter conversation with Philips Hue (source:
Twitter conversation with Philips Hue (source: