NASA’s Parker Solar Probe has racked up an impressive list of superlatives in its first five years of operations: It’s the closest spacecraft to the sun, the fastest human-made object and the first mission to ever “touch the sun.”
Now, Parker has one more feather to add to its sun-kissed cap: It’s the first spacecraft ever to fly through a powerful solar explosion near the sun.
As detailed in a new study published Sept. 5 in The Astrophysical Journal—exactly one year after the event occurred—Parker Solar Probe passed through a coronal mass ejection (CME).
These fierce eruptions can expel magnetic fields and sometimes billions of tons of plasma at speeds ranging from 60 to 1,900 miles (100 to 3,000 kilometers) per second. When directed toward Earth, these ejections can bend and mold our planet’s magnetic field, generating spectacular auroral shows and, if strong enough, potentially devastate satellite electronics and electrical grids on the ground.
Cruising on the far side of the sun just 5.7 million miles (9.2 million kilometers) from the solar surface—22.9 million miles (36.8 million kilometers) closer than Mercury ever gets to the sun—Parker Solar Probe first detected the CME remotely before skirting along its flank. The spacecraft later passed into the structure, crossing the wake of its leading edge (or shock wave), and then finally exited through the other side.
A composite of images collected by Parker Solar Probe’s Wide-field Imager for Solar Probe (WISPR) instrument captures the moment the spacecraft passed through a coronal mass ejection (CME) on Sept. 5, 2022. The event becomes visible at 0:14 seconds. The sun, depicted on the left, comes closest on Sept. 6, when Parker reached its 13th perihelion. The sound in the background is magnetic field data converted into audio. Credit: NASA/Johns Hopkins APL/Naval Research Laboratory/Brendan Gallagher/Guillermo Stenborg/Emmanuel Masongsong/Lizet Casillas/Robert Alexander/David Malaspina
In all, the sun-grazing spacecraft spent nearly two days observing the CME, providing physicists an unparalleled view into these stellar events and an opportunity to study them early in their evolution.
“This is the closest to the sun we’ve ever observed a CME,” said Nour Raouafi, the Parker Solar Probe project scientist at the Johns Hopkins Applied Physics Laboratory (APL) in Laurel, Maryland, which built the spacecraft within NASA’s timeline and budget, and currently manages and operates the mission. “We’ve never seen an event of this magnitude at this distance.”
The CME on Sept. 5, 2022, was an extreme one. As Parker passed behind the shock wave, its Solar Wind Electrons, Alphas and Protons (SWEAP) instrument suite clocked particles accelerating up to 840 miles (1,350 kilometers) per second. Had it been directed toward Earth, Raouafi suspects it would have been close in magnitude to the Carrington Event—a solar storm in 1859 that is held as the most powerful on record to hit Earth.
[…]
More information: O. M. Romeo et al, Near-Sun In Situ and Remote-sensing Observations of a Coronal Mass Ejection and its Effect on the Heliospheric Current Sheet, The Astrophysical Journal (2023). DOI: 10.3847/1538-4357/ace62e
A recent study submitted to Acta Astronautica explores the potential for using aerographite solar sails for traveling to Mars and interstellar space, which could dramatically reduce both the time and fuel required for such missions. This study comes while ongoing research into the use of solar sails is being conducted by a plethora of organizations along with the successful LightSail2 mission by The Planetary Society, and holds the potential to develop faster and more efficient propulsion systems for long-term space missions.
“Solar sail propulsion has the potential for rapid delivery of small payloads (sub-kilogram) throughout the solar system,” Dr. René Heller, who is an astrophysicist at the Max Planck Institute for Solar System Research and a co-author on the study, tells Universe Today. “Compared to conventional chemical propulsion, which can bring hundreds of tons of payload to low-Earth orbit and deliver a large fraction of that to the Moon, Mars, and beyond, this sounds ridiculously small. But the key value of solar sail technology is speed.”
Unlike conventional rockets, which rely on fuel in the form of a combustion of chemicals to exert an external force out the back of the spacecraft, solar sails don’t require fuel. Instead, they use sunlight for their propulsion mechanism, as the giant sails catch solar photons much like wind sails catching the wind when traveling across water. The longer the solar sails are deployed, the more solar photons are captured, which gradually increases the speed of the spacecraft.
For the study, the researchers conducted simulations on how fast a solar sail made of aerographite with a mass up to 1 kilogram (2.2 pounds), including 720 grams of aerographite with a cross-sectional area of 104 square meters, could reach Mars and the interstellar medium, also called the heliopause, using two trajectories from Earth known as direct outward transfer and inward transfer methods, respectively.
The direct outward transfer method for both the trip to Mars and the heliopause involved the solar sail both deploying and departing directly from a polar orbit around the Earth. The researchers determined that Mars being in opposition (directly opposite Earth from the Sun) at the time of solar sail deployment and departure from Earth would yield the best results for both velocity and travel time. This same polar orbit deployment and departure was also used for the heliopause trajectory, as well. For the inward transfer method, the solar sail would be delivered to approximately 0.6 astronomical units (AU) from the Sun via traditional chemical rockets, where the solar sail would deploy and begin its journey to either Mars or the heliopause. But how does an aerographite solar sail make this journey more feasible?
Image taken by The Planetary Society’s LightSail 2 on 25 November 2019 during its mission orbiting the Earth. The curved appearance of the sails is from the spacecraft’s 185-degree fisheye camera lens, and the image was processed with color-correction along with removal of parts of the distortion. (Credit: The Planetary Society)
“With its low density of 0.18 kilograms per cubic meter, aerographite undercuts all conventional solar sail materials,” Julius Karlapp, who is a Research Assistant at the Dresden University of Technology and lead author of the study, tells Universe Today. “Compared to Mylar (a metallized polyester foil), for example, the density is four orders of magnitude smaller. Assuming that the thrust developed by a solar sail is directly dependent on the mass of the sail, the resulting thrust force is much higher. In addition to the acceleration advantage, the mechanical properties of aerographite are amazing.”
Through these simulations, the researchers found the direct outward transfer method and inward transfer method resulted in the solar sail reaching Mars in 26 days and 126 days, respectively, with the first 103 days being the travel time from Earth to the deployment point at 0.6 AU. For the journey to the heliopause, both methods resulted in 5.3 years and 4.2 years, respectively, with the first 103 days of the inward transfer method also being devoted to the travel time from the Earth to the deployment point at 0.6 AU, as well. The reason the heliopause is reached in a faster time with the inward transfer method is due to the solar sail achieving maximum speed at 300 days, as opposed to achieving maximum speed with the outward transfer method at approximately 2 years.
Current travel times to Mars range between 7-9 months, which only happens during specified launch windows every two years while relying on the positions of both planets to be aligned at both launch and arrival of any spacecraft going to, or coming from, Mars. Estimating current travel times to the heliopause can be done using NASA’s Voyager 1 and Voyager 2 probes, which reached the heliopause at approximately 35 years and 41 years, respectively.
The researchers note that one major question of using solar sails is deceleration, or slowing down, upon arriving at the destination, specifically Mars, and while they mention aerocapture as one solution, they admit this still requires further study.
“Aerocapture maneuvers for hyperbolic trajectories (like flying from Earth to Mars) use the atmosphere to gradually reduce velocity due to drag,” Dr. Martin Tajmar, who is a physicist and Professor of Space System at the Dresden University of Technology and a co-author on the study, tells Universe Today. “Therefore, less fuel is required to enter the Martian orbit. We use this braking maneuver to eliminate the need for additional braking thrusters, which in turn reduces the mass of the spacecraft. We’re currently researching what alternative strategies might work for us. Yet the braking method is only one of many different challenges we are currently facing.”
While solar sail technology has been proposed by NASA as far back as the 1970s, a recent example of solar sail technology is the NASA Solar Cruiser, which is currently scheduled to launch in February 2025.
What new discoveries will researchers make about solar sail technology in the coming years and decades? Only time will tell, and this is why we science!
OSIRIS-REx weighs 4,650 pounds (or 2,110 kg). On September 8th of 2016, NASA first launched the spacecraft on its 3.8-billion mile mission to land on an asteroid and retrieve a sample.
That sample has just returned.
Throughout Sunday morning, NASA tweeted historic updates from the sample’s landing site in Utah. “We’ve spotted the #OSIRISREx capsule on the ground,” they announced about 80 minutes ago (including a 23-second video clip). “The parachute has separated, and the helicopters are arriving at the site. We’re ready to recover that sample!”
UPI notes that the capsule “reached temperatures up to 5,000 degrees Fahrenheit during reentry, so protective masks and gloves are required to handle it,” describing its payload as “a 250-gram dust sample.”
15 minutes later NASA shared footage of “the first persons to come into contact with this hardware since it was on the other side of the solar system.” A recovery team approached the capsule to perform an environmental safety sweep confirming there were no hazardous gas.
“The impossible became possible,” NASA administrator Bill Nelson said in a statement. The Guardian reports he confirmed the capsule “brought something extraordinary — the largest asteroid sample ever received on Earth.
“It’s going to help scientists investigate planet formation, it’s going to improve our understanding of the asteroids that could possibly impact the earth and it will deepen our understanding of the origin of our solar system and its formation.”
“This mission proves that NASA does big things, things that have inspired us, things that unite us…
“The mission continues with incredible science and analysis to come. But I want to thank you all, for everybody that made this Osiris-Rex mission possible.”
Professor Neil Bowles of the University of Oxford, one of the scientists who will study the sample, told the Guardian that he was excited to see the sample heading to the clean room at Johnson Space Center. “So much new science to come!”
And that 4,650-pound spacecraft is still hurtling through space. 20 minutes after delivering its sample, the craft ” fired its engines to divert past Earth toward its new mission to asteroid Apophis,” NASA reports. The name of its new mission? OSIRIS-APEX. Roughly 1,000 feet wide, Apophis will come within 20,000 miles of Earth — less than one-tenth the distance between Earth and the Moon — in 2029. OSIRIS-APEX is scheduled to enter orbit of Apophis soon after the asteroid’s close approach of Earth to see how the encounter affected the asteroid’s orbit, spin rate, and surface.
Amazon has always handled its streaming video slate a little differently than the competition. Other companies have slyly introduced a cheaper ad-free option while slowly raising prices on non-ad-based subscription tiers, Prime Video is taking a different tack. The streaming service plans to hold ad-free watching hostage, and it’s demanding a $3 ransom starting early next year.
In a Friday release, Amazon said it would start adding “limited advertisements” to Prime Video starting out in 2024. The company promised fewer ads than other streaming TV providers or old-school linear TV. This change will impact all users in the U.S., UK, Germany, and Canada. Other regions won’t have long to savor the lack of ads, as eventually more places like France, Italy, Spain, Mexico, and Australia will all have ads shoved in front of their unwilling eyeballs.
But don’t worry, all you have to do to help ignore all the ads is slip Amazon an extra $3 a month for a new ad-free option, at least for U.S. Prime members. That bumps the monthly cost of Prime to $18 from $15 a month. Users should get a message in their emails about how they can sign up for Amazon’s latest penny-pinching plan several weeks before ads start flooding Prime Video.
The Dutch Data Protection Foundation (SDBN) wants to enforce a mass claim for 11 million people through the courts against social media company X, the former Twitter. Between 2013 and 2021, that company owned the advertising platform MoPub, which, according to the privacy foundation, illegally traded in data from users of more than 30,000 free apps such as Wordfeud, Buienradar and Duolingo.
SDBN has been trying to reach an agreement with X since November last year, but according to the foundation, without success. That is why SDBN is now starting a lawsuit at the Rotterdam court. Central to this is MoPub’s handling of personal data such as religious beliefs, sexual orientation and health. In addition to compensation, SDBN wants this data to be destroyed.
The foundation also believes that users are entitled to profit contributions. A lot of money can be made by sharing personal data with thousands of companies, says SDBN chairman Anouk Ruhaak. Although she says it is difficult to find out exactly which companies had access to the data. “By holding X. Corp liable, we hope not only to obtain compensation for all victims, but also to put a stop to this type of practice,” said Ruhaak. “Unfortunately, these types of companies often only listen when it hurts financially.”
Alphabet’s Google pays more than $10 billion a year to maintain its position as the default search engine on web browsers and mobile devices, stifling competition, the US Justice Department said Tuesday at the start of a high-stakes antitrust trial in Washington. From a report: “This case is about the future of the internet and whether Google’s search engine will ever face meaningful competition,” Kenneth Dintzer, a government lawyer, said in his opening statement. “The evidence will show they demanded default exclusivity to block rivals.” Dintzer said Google became a monopoly by at least 2010 and today controls more than 89% of the online search market.
“The company pays billions for defaults because they are uniquely powerful,” he said. “For the last 12 years, Google has abused its monopoly in general search.” The monopolization trial is the first pitting the federal government against a US technology company in more than two decades. The Justice Department and 52 attorneys general from states and US territories allege Google illegally maintained its monopoly by paying billions to tech rivals, smartphone makers and wireless providers in exchange for being set as the preselected option or default on mobile phones and web browsers.
An anonymous reader quotes a report from Engadget: The ALPHV/BlackCat ransomware group claimed responsibility for the MGM Resorts cyber outage on Tuesday, according to a post by malware archive vx-underground. The group claims to have used common social engineering tactics, or gaining trust from employees to get inside information, to try and get a ransom out of MGM Resorts, but the company reportedly refuses to pay. The conversation that granted initial access took just 10 minutes, according to the group.
“All ALPHV ransomware group did to compromise MGM Resorts was hop on LinkedIn, find an employee, then call the Help Desk,” the organization wrote in a post on X. Those details came from ALPHV, but have not been independently confirmed by security researchers. The international resort chain started experiencing outages earlier this week, as customers noticed slot machines at casinos owned by MGM Resorts shut down on the Las Vegas strip. As of Wednesday morning, MGM Resorts still shows signs that it’s experiencing downtime, like continued website disruptions. In a statement on Tuesday, MGM Resorts said: “Our resorts, including dining, entertainment and gaming are currently operational.” However, the company said Wednesday that the cyber incident has significantly disrupted properties across the United States and represents a material risk to the company.
“[T]he major credit rating agency Moody’s warned that the cyberattack could negatively affect MGM’s credit rating, saying the attack highlighted ‘key risks’ within the company,” reports CNBC. “The company’s corporate email, restaurant reservation and hotel booking systems remain offline as a result of the attack, as do digital room keys. MGM on Wednesday filed a 8-K report with the Securities and Exchange Commission noting that on Tuesday the company issued a press release ‘regarding a cybersecurity issue involving the Company.'” MGM’s share price has declined more than 6% since Monday.
These Mymanu CLIK S are a pair of bluetooth earbuds that pair with an app on your phone to offer live translations of over 37 languages, including Spanish, German, French, Japanese, Arabic, Chinese, Finnish, Thai, Korean, and Japanese. The earbuds cost $157, and the app is included.
Obviously, these earbuds can be ideal for international travelers. They use an exclusive translation app called MyJuno, which is also where you can see the full list of translatable languages.
The CLIK S can translate for individual or group speakers, but only individual speakers get their translations played live in your earbud. You just select the relevant languages in the app, then hold the button on your earbud when you want to talk. A translation will be visible on your phone and will play audibly. When your conversation partner wants to talk, they just speak into your phone. For groups of speakers, the CLIK S will keep a written log of the conversation.
Fully charged, these earbuds can last for up to 10 hours, and the charging case can extend that to 30 hours. You can get the Mymanu CLIK S Translation Earbuds for $157, though prices can change at any time.
On the morning of his arrest, Grigor Sargsyan was still fixing matches. Four cellphones buzzed on his nightstand with calls and messages from around the world.
Sargsyan was sprawled on a bed in his parents’ apartment, making deals between snatches of sleep. It was 3 a.m. in Brussels, which meant it was 8 a.m. in Thailand. The W25 Hua Hin tournament was about to start.
Sargsyan was negotiating with professional tennis players preparing for their matches, athletes he had assiduously recruited over years. He needed them to throw a game or a set — or even just a point — so he and a global network of associates could place bets on the outcomes.
That’s how Sargsyan had become rich. As gambling on tennis exploded into a $50 billion industry, he had infiltrated the sport, paying pros more to lose matches, or parts of matches, than they could make by winning tournaments.
Sargsyan had crisscrossed the globe building his roster, which had grown to include more than 180 professional players across five continents. It was one of the biggest match-fixing rings in modern sports, large enough to earn Sargsyan a nickname whispered throughout the tennis world: the Maestro.
This Washington Post investigation of Sargsyan’s criminal enterprise, and how the changing nature of gambling has corrupted tennis, is based on dozens of interviews with players, coaches, investigators, tennis officials and match fixers.
Specifically, the web giant’s Privacy Sandbox APIs, a set of ad delivery and analysis technologies, now function in the latest version of the Chrome browser. Website developers can thus write code that calls those APIs to deliver and measure ads to visitors with compatible browsers.
That is to say, sites can ask Chrome directly what kinds of topics you’re interested in – topics automatically selected by Chrome from your browsing history – so that ads personalized to your activities can be served. This is supposed to be better than being tracked via third-party cookies, support for which is being phased out. There are other aspects to the sandbox that we’ll get to.
While Chrome is the main vehicle for Privacy Sandbox code, Microsoft Edge, based on the open source Chromium project, has also shown signs of supporting the technology. Apple and Mozilla have rejected at least the Topics API for interest-based ads on privacy grounds.
[…]
“The Privacy Sandbox technologies will offer sites and apps alternative ways to show you personalized ads while keeping your personal information more private and minimizing how much data is collected about you.”
These APIs include:
Topics: Locally track browsing history to generate ads based on demonstrated user interests without third-party cookies or identifiers that can track across websites.
Protected Audience (FLEDGE): Serve ads for remarketing (e.g. you visited a shoe website so we’ll show you a shoe ad elsewhere) while mitigating third-party tracking across websites.
Attribution Reporting: Data to link ad clicks or ad views to conversion events (e.g. sales).
Private Aggregation: Generate aggregate data reports using data from Protected Audience and cross-site data from Shared Storage.
Shared Storage: Allow unlimited, cross-site storage write access with privacy-preserving read access. In other words, you graciously provide local storage via Chrome for ad-related data or anti-abuse code.
Fenced Frames: Securely embed content onto a page without sharing cross-site data. Or iframes without the security and privacy risks.
These technologies, Google and industry allies believe, will allow the super-corporation to drop support for third-party cookies in Chrome next year without seeing a drop in targeted advertising revenue.
[…]
“Privacy Sandbox removes the ability of website owners, agencies and marketers to target and measure their campaigns using their own combination of technologies in favor of a Google-provided solution,” James Rosewell, co-founder of MOW, told The Register at the time.
[…]
Controversially, in the US, where lack of coherent privacy rules suit ad companies just fine, the popup merely informs the user that these APIs are now present and active in the browser but requires visiting Chrome’s Settings page to actually manage them – you have to opt-out, if you haven’t already. In the EU, as required by law, the notification is an invitation to opt-in to interest-based ads via Topics.
Using Solar Orbiter’s Extreme Ultraviolet Imager (EUI), the team of scientists behind the mission was able to record part of the Sun’s atmosphere at extreme ultraviolet wavelengths. The last-minute modification to the instrument involved adding a small, protruding “thumb” to block the bright light coming from the Sun such that the fainter light of its atmosphere could be made visible.
“It was really a hack,” Frédéric Auchère, an astrophysicist at the Institute of Astrophysics of the Université Paris-Sud in France, and a member of the EUI team, said in a statement. “I had the idea to just do it and see if it would work. It is actually a very simple modification to the instrument.”
EUI produces high-resolution images of the structures in the Sun’s atmosphere. The team behind the instrument added a thumb to a safety door on EUI, which slides out of the way to let light into the camera so it can capture images of the Sun. If the door stops halfway, however, the thumb ends up shielding the bright light coming from the Sun’s disc in the center so that the fainter ultraviolet light coming from the corona (the outermost part of the atmosphere) can be visible.
A new way to view the Sun
The result is an ultraviolet image of the Sun’s corona. An ultraviolet image of the Sun’s disc has been superimposed in the middle, in the area left blank by the thumb hack, according to ESA.
The corona is usually hidden by the bright light of the Sun’s surface, and can mostly be seen during a total solar eclipse. The camera hack sort of mimics that same effect of the eclipse by blocking out the Sun’s light. The Sun’s corona has long baffled scientists as it is much hotter than the surface of the Sun with temperatures reaching 1.8 million degrees Fahrenheit (1 million degrees Celsius), one of the greatest mysteries surrounding our host star.
“We’ve shown that this works so well that you can now consider a new type of instrument that can do both imaging of the Sun and the corona around it,” Daniel Müller, ESA’s Project Scientist for Solar Orbiter, said in a statement.
An anonymous reader shared this report from Bloomberg: China-linked hackers breached the corporate account of a Microsoft engineer and are suspected of using that access to steal a valuable key that enabled the hack of senior U.S. officials’ email accounts, the company said in a blog post. The hackers used the key to forge authentication tokens to access email accounts on Microsoft’s cloud servers, including those belonging to Commerce Secretary Gina Raimondo, Representative Don Bacon and State Department officials earlier this year.
The U.S. Cybersecurity and Infrastructure Security Agency and Microsoft disclosed the breach in June, but it was still unclear at the time exactly how hackers were able to steal the key that allowed them to access the email accounts. Microsoft said the key had been improperly stored within a “crash dump,” which is data stored after a computer or application unexpectedly crashes…
The incident has brought fresh scrutiny to Microsoft’s cybersecurity practices.
Microsoft’s blog post says they corrected two conditions which allowed this to occur. First, “a race condition allowed the key to be present in the crash dump,” and second, “the key material’s presence in the crash dump was not detected by our systems.” We found that this crash dump, believed at the time not to contain key material, was subsequently moved from the isolated production network into our debugging environment on the internet connected corporate network. This is consistent with our standard debugging processes. Our credential scanning methods did not detect its presence (this issue has been corrected).
After April 2021, when the key was leaked to the corporate environment in the crash dump, the Storm-0558 actor was able to successfully compromise a Microsoft engineer’s corporate account. This account had access to the debugging environment containing the crash dump which incorrectly contained the key. Due to log retention policies, we don’t have logs with specific evidence of this exfiltration by this actor, but this was the most probable mechanism by which the actor acquired the key.
On Monday, local news outlets in Las Vegas caught wind of various complaints from patrons of MGM businesses; some said ATMs at associated hotels and casinos didn’t appear to be working; others said their hotel room keys had stopped functioning; still others noted that bars and restaurants located within MGM complexes had suddenly been shuttered. If you head to MGM’s website, meanwhile, you’ll note it’s definitely not working the way that it’s supposed to.
MGM put out a short statement Monday saying that it had been the victim of an undisclosed “cybersecurity issue.” The Associated Press notes that computer outages connected to said issue appear to be impacting MGM venues across the U.S.—in Vegas but also in places as far flung as Mississippi, Ohio, Michigan, and large parts of the northeast.
The Foundation for the Protection of Privacy Interests and the Consumers’ Association are taking the next step in their fight against Google. The tech company is being taken to court today for ‘large-scale privacy violations’.
The proceedings demand, among other things, that Google stop its constant surveillance and sharing of personal data through online advertising auctions and also pay damages to consumers. Since the announcement of this action on May 23, 2023, more than 82,000 Dutch people have already joined the mass claim.
According to the organizations, Google is acting in violation of Dutch and European privacy legislation. The tech giant collects users’ online behavior and location data on an immense scale through its services and products. Without providing enough information or having obtained permission. Google then shares that data, including highly sensitive personal data about health, ethnicity and political preference, for example, with hundreds of parties via its online advertising platform.
Google is constantly monitoring everyone. Even when using third-party cookies – which are invisible – Google continues to collect data through other people’s websites and apps, even when someone is not using its products or services. This enables Google to monitor almost the entire internet behavior of its users.
All these matters have been discussed with Google, to no avail.
The Foundation for the Protection of Privacy Interests represents the interests of users of Google’s products and services living in the Netherlands who have been harmed by privacy violations. The foundation is working together with the Consumers’ Association in the case against Google. Consumers’ Association Claimservice, a partnership between the Consumers’ Association and ConsumersClaim, processes the registrations of affiliated victims.
More than 82,000 consumers have already registered for the Google claim. They demand compensation of 750 euros per participant.
A lawsuit by the American government against Google starts today in the US . Ten weeks have been set aside for this. This mainly revolves around the power of Google’s search engine.
Essentially, Google is accused of entering into exclusive agreements to guarantee the use of its search engine. These are agreements that prevent alternative search engines from being pre-installed, or from Google’s search app being removed.
Last year, BMW underwent media and customer hellfire over its decision to offer a monthly subscription for heated seats. While seat heating wasn’t the only option available for subscription, it was the one that seemed to infuriate everyone the most, since it concerned hardware already present in the car from the factory. After months of customers continuously expressing their displeasure with the plan, BMW has finally decided to abandon recurring charges for hardware-based functions.
“What we don’t do any more—and that is a very well-known example—is offer seat heating by [monthly subscriptions]” BMW marketing boss Pieter Nota said to Autocar. “It’s either in or out. We offer it by the factory and you either have it or you don’t have it.”
BMW’s move wasn’t solely about charging customers monthly for heated seats. Rather, the luxury automaker wanted to streamline production and reduce costs there by physically installing heated seats in every single car, since 90% of all BMWs are bought with seat heaters anyway. Then, owners who didn’t spec heated seats from the factory could digitally unlock them later with either a monthly subscription or a one-time perma-buy option. Nota still believes it was a good idea.
[…]
BMW was absolutely double dipping with heated seat subscriptions. The company started down that route to reduce production costs, making each car cheaper to build by streamlining the process. Fair enough. However, those reduced costs weren’t then passed down to buyers via lower MSRPs. Customers were technically paying for those heated seats anyway, no matter whether they wanted them. Then, BMW was not only charging extra to use a feature already installed in the car, but also subjecting it to subscription billing, even though seat heating is static hardware not designed to change or improve over time.
Customers weren’t happy, and rightfully made their grievance known. While it’s good that BMW ultimately buckled to the public’s wishes here, it doesn’t seem like the automaker’s board members truly understand why the outrage happened in the first place.
Philips and sleep specialists Kokoon have partnered to create an unparalleled sleep headphone.
The Philips Sleep Headphones, powered by Kokoon, blends sleep science and ergonomic know-how with Philips’ century-long reputation for crafting top-notch products.
[…]
Experience a comfort revolution. After numerous nights of testing, our team has crafted an earbud that flawlessly conforms to the shape of your ear for maximum comfort during side sleeping.
[…]
Sleep soundly with advanced biosensors that detect when you drift off and adjust sound levels accordingly, ensuring a peaceful and uninterrupted night.
[…]
Our biosensors introduce white noise during the night to assist with blocking out disruptive sounds such as snoring or external noise. Discover a more peaceful sleeping environment.
[…]
Get a better night’s sleep with sounds backed by science. Select from a variety of options including meditations, soundscapes, binaural beats, and more to ease into slumber.
The person behind an AI-generated song that went viral earlier this year has submitted the track for Grammy Awards consideration. The Recording Academy has stated that such works aren’t eligible for certain gongs. However, Ghostwriter, the pseudonymous person behind “Heart on My Sleeve,” has submitted the track in the best rap song and song of the year categories, according to Variety. Both of those are songwriting honors. The Academy has suggested it’s open to rewarding tracks that are mostly written by a human, even if the actual recording is largely AI-generated.
Ghostwriter composed the song’s lyrics rather than leaving them up to, say, ChatGPT. But rather than sing or rap those words, they employed a generative AI model to mimic the vocals of Drake and The Weeknd, which helped the song to pick up buzz. The artists’ label Universal Music Group wasn’t happy about that and it filed copyright claims to remove “Heart on My Sleeve” from streaming services. Before that, though, the track racked up hundreds of thousands of listens on Spotify and more than 15 million on TikTok.
[…]
It seems there’s one major roadblock as things stand, though. For a song to be eligible for a Grammy, it needs to have “general distribution” across the US through the likes of brick-and-mortar stores, online retailers and streaming services. Ghostwriter is reportedly aware of this restriction, but it’s unclear how they plan to address that.
In any case, this may well be a canary in the coal mine for rewarding the use of generative AI in art.
Senator Tuberville’s blanket hold on general officer nominations reaches its six-month anniversary this week. This all seems to have started with a reckless idea dreamed up by a staffer with no experience in the Senate who then left the Senator’s employment after taking credit for it in a Washington Post exposé. From its shaky foundations, the hold strategy has now morphed into a take-no-prisoners stand against federal funding of abortion and “wokeness” in the military. Tuberville appears to have no concept of an end game except total victory. Barring capitulation by the Senator, which doesn’t seem to be in the cards, the rest of the Senate needs to come up with a Plan B.
There are now 301 general and flag officer positions, including five spots on the Joint Chiefs of Staff, which are impacted by these holds. By year’s end, that number may rise to 650. Tuberville argues that there is no readiness impact for having acting officers in place. He may eventually be right in the sense that the military is a mission-driven organization and will adjust whether or not the Senate acts. Since military rotations are on a two-year cycle, fairly soon every general and admiral in the military will be in an acting position. This may be the likeliest future outcome.
[…]
Regular order and unscripted debates on amendments died long ago and as a result, the Senate can’t pass annual authorization bills except for the defense policy bill. The civilian nominations process is broken with over 180 confirmed positions still unfilled two and a half years into the current administration, and now the military nominations process has come unglued.
Trying to convince Senator Tuberville to withdraw his holds has been an exercise in futility. There is equally no appetite to modify the rules for holds and bundle these confirmations as that might set undesirable precedents. That leaves the option of doing nothing or altering what positions the Senate is required to confirm. The latter should be considered.
Until the Tuberville holds, the Senate routinely considered 50,000 military nominees a year primarily by unanimous consent. The biggest question one must ask is why? All military officers above the O-4 level (a major or lieutenant commander) must go through Senate confirmation for each promotion. This is referred to as a constitutional responsibility and yet an O-4 is the equivalent to a GS-13 in the civil service, while general officers are the equivalent of the Senior Executive Service (SES). The Senate does not confirm the nearly 490,000 federal employees at the GS-13 level or above nor the over 8,000 members of the SES even though they are all technically officers of the federal government as defined by the Constitution.
[…]
What would parity look like? Currently, 61 civilians at the Department of Defense (DoD) require Senate confirmation. That is a good starting point to consider for military generals, but just focusing on the 41 four-star generals in service according to the latest DoD data is probably enough. Confirming just these officers could take over four months of floor time if holds were placed on them. Still, the Senate now needs to structure its rules and plan its calendar around standing holds on all nominations—civilian or military. That means limiting the number of individuals that require confirmation.
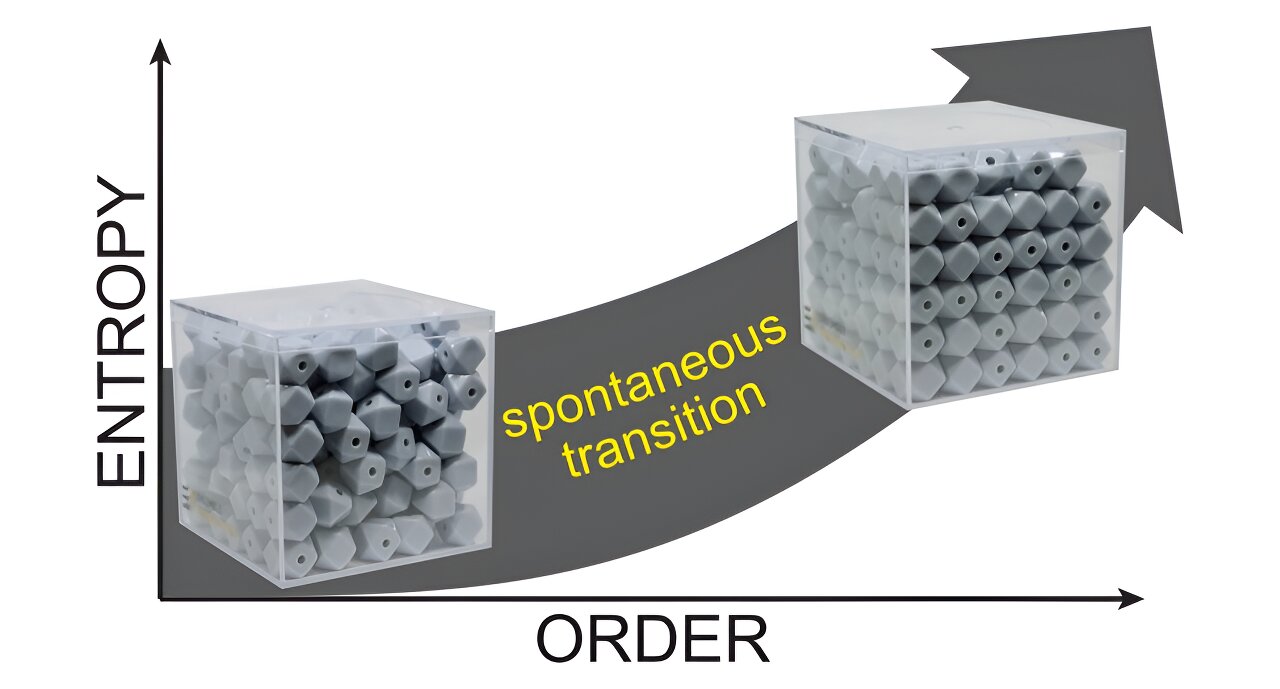
Though a cornerstone of thermodynamics, entropy remains one of the most vexing concepts to teach budding physicists in the classroom. As a result, many people oversimplify the concept as the amount of disorder in the universe, neglecting its underlying quantitative nature.
In The Physics Teacher, researcher T. Ryan Rogers designed a hand-held model to demonstrate the concept of entropy for students. Using everyday materials, Rogers’ approach allows students to confront the topic with new intuition—one that takes specific aim at the confusion between entropy and disorder.
“It’s a huge conceptual roadblock,” Rogers said. “The good news is that we’ve found that it’s something you can correct relatively easily early on. The bad news is that this misunderstanding gets taught so early on.”
While many classes opt for the imperfect, qualitative shorthand of calling entropy “disorder,” it’s defined mathematically as the number of ways energy can be distributed in a system. Such a definition merely requires students to understand how particles store energy, formally known as “degrees of freedom.”
To tackle the problem, Rogers developed a model in which small objects such as dice and buttons are poured into a box, replicating a simple thermodynamic system. Some particles in the densely filled box are packed in place, meaning they have fewer degrees of freedom, leading to an overall low-entropy system.
As students shake the box, they introduce energy into the system, which loosens up locked-in particles. This increases the overall number of ways energy can be distributed within the box.
“You essentially zoom in on entropy so students can say, ‘Aha! There is where I saw the entropy increase,'” Rogers said.
As students shake further, the particles settle into a configuration that more evenly portions out the energy among them. The catch: at this point of high entropy, the particles fall into an orderly alignment.
“Even though it looks more orientationally ordered, there’s actually higher entropy,” Rogers said.
All the students who participated in the lesson were able to reason to the correct definition of entropy after the experiment.
Next, Rogers plans to extend the reach of the model by starting a conversation about entropy with other educators and creating a broader activity guide for ways to use the kits for kindergarten through college. He hopes his work inspires others to clarify the distinction in their classrooms, even if by DIY means.
“Grapes and Cheez-It crackers are very effective, as well,” Rogers said.
The article, “Hands-on Model for Investigating Entropy and Disorder in the Classroom,” is authored by T. Ryan Rogers and is published in The Physics Teacher.
More information: T. Ryan Rogers, Hands-on Model for Investigating Entropy and Disorder in the Classroom, The Physics Teacher (2023). DOI: 10.1119/5.0089761
Microsoft will finally stop forcing Windows 11 users in Europe into Edge if they click a link from the Windows Widgets panel or from search results. The software giant has started testing the changes to Windows 11 in recent test builds of the operating system, but the changes are restricted to countries within the European Economic Area (EEA).
“In the European Economic Area (EEA), Windows system components use the default browser to open links,” reads a change note from a Windows 11 test build released to Dev Channel testers last month. I asked Microsoft to comment on the changes and, in particular, why they’re only being applied to EU countries. Microsoft refused to comment.
Microsoft has been ignoring default browser choices in its search experience in Windows 10 and the taskbar widget that forces users into Edge if they click a link instead of their default browser. Windows 11 continued this trend, with search still forcing users into Edge and a new dedicated widgets area that also ignores the default browser setting.
The independent study of the DSA’s risk management framework published by the EU’s executive arm, the European Commission, concluded that commitments by social media platforms to mitigate the reach and influence of global online disinformation campaigns have been generally unsuccessful.
The reach of Kremlin-sponsored disinformation has only increased since the major platforms all signed a voluntary Code of Practice on Disinformation in mid-2022.
“In theory, the requirements of this voluntary Code were applied during the second half of 2022 – during our period of study,” the researchers said. We’re sure you’re just as shocked as we are that social media companies failed to uphold a voluntary commitment.
Between January and May of 2023, “average engagement [of pro-Kremlin accounts rose] by 22 percent across all online platforms,” the study said. By absolute numbers, the report found, Meta led the pack on engagement with Russian misinformation. However, the increase was “largely driven by Twitter, where engagement grew by 36 percent after CEO Elon Musk decided to lift mitigation measures on Kremlin-backed accounts,” researchers concluded. Twitter, now known as X, pulled out of the disinformation Code in May.
Across the platforms studied – Facebook, Instagram, Telegram, TikTok, Twitter and YouTube – Kremlin-backed accounts have amassed some 165 million followers and have had their content viewed at least 16 billion times “in less than a year.” None of the platforms we contacted responded to questions.
[…]
The EU’s Digital Services Act and its requirements that VLOPs (defined by the Act as companies large enough to reach 10 percent of the EU, or roughly 45 million people) police illegal content and disinformation became enforceable late last month.
Under the DSA, VLOPs are also required “to tackle the spread of illegal content, online disinformation and other societal risks,” such as, say, the massive disinformation campaign being waged by the Kremlin since Putin decided to invade Ukraine last year.
[…]
Now that VLOPs are bound by the DSA, will anything change? We asked the European Commission if it can take any enforcement actions, or whether it’ll make changes to the DSA to make disinformation rules tougher, but have yet to hear back.
Two VLOPs are fighting their designation: Amazon and German fashion retailer Zalando. The two orgs claim that as retailers, they shouldn’t be considered in the same category as Facebook, Pinterest, and Wikipedia.
Rick Klein and his team have been preserving TV adverts, forgotten tapes, and decades-old TV programming for years. Now operating as a 501(c)(3) non-profit, the Museum of Classic Chicago Television has called YouTube home since 2007. However, copyright notices sent on behalf of Sony, protecting TV shows between 40 and 60 years old, could shut down the project in 48 hours.
[…]
After being reborn on YouTube as The Museum of Classic Chicago Television (MCCTv), the last sixteen years have been quite a ride. Over 80 million views later, MCCTv is a much-loved 501(c)(3) non-profit Illinois corporation but in just 48 hours, may simply cease to exist.
In a series of emails starting Friday and continuing over the weekend, Klein began by explaining his team’s predicament, one that TorrentFreak has heard time and again over the past few years. Acting on behalf of a copyright owner, in this case Sony, India-based anti-piracy company Markscan hit the MCCTv channel with a flurry of copyright claims. If these cannot be resolved, the entire project may disappear.
[…]
No matter whether takedowns are justified, unjustified (Markscan hit Sony’s own website with a DMCA takedown recently), or simply disputed, getting Markscan’s attention is a lottery at best, impossible at worst. In MCCTv’s short experience, nothing has changed.
“Our YouTube channel with 150k subscribers is in danger of being terminated by September 6th if I don’t find a way to resolve these copyright claims that Markscan made,” Klein told TorrentFreak on Friday.
“At this point, I don’t even care if they were issued under authorization by Sony or not – I just need to reach a live human being to try to resolve this without copyright strikes. I am willing to remove the material manually to get the strikes reversed.”
[…]
Complaints Targeted TV Shows 40 to 60 years old
[…]
Two episodes of the TV series Bewitched dated 1964 aired on ABC Network and almost sixty years later, archive copies of those transmissions were removed from YouTube for violating Sony copyrights, with MCCTv receiving a strike.
[…]
Given that copyright law locks content down for decades, Klein understands that can sometimes cause issues, although 16 years on YouTube suggests that the overwhelming majority of rightsholders don’t consider his channel a threat. If they did, the option to monetize the recordings can be an option.
No Competition For Commercial Offers
Why most rightsholders have left MCCTv alone is hard to say; perhaps some see the historical value of the channel, maybe others don’t know it exists. At least in part, Klein believes the low quality of the videos could be significant.
“These were relatively low picture quality broadcast examples from various channels from various years at least 30-40 years ago, with the original commercial breaks intact. Also mixed in with these were examples of ’16mm network prints’ which are surviving original film prints that were sent out to TV stations back in the day from when the show originally aired. In many cases they include original sponsorship notices, original network commercials, ‘In Color’ notices, etc.,” he explains.
[…]
Klein says the team is happy to comply with Sony’s wishes and they hope that given a little leeway, the project won’t be consigned to history. Perhaps Sony will recall the importance of time-shifting while understanding that time itself is running out for The Museum of Classic Chicago Television.
The foundation, the Firefox browser maker’s netizen-rights org, assessed the privacy policies and practices of 25 automakers and found all failed its consumer privacy tests and thereby earned its Privacy Not Included (PNI) warning label.
If you care even a little about privacy, stay as far away from Nissan’s cars as you possibly can
In research published Tuesday, the org warned that manufacturers may collect and commercially exploit much more than location history, driving habits, in-car browser histories, and music preferences from today’s internet-connected vehicles. Instead, some makers may handle deeply personal data, such as – depending on the privacy policy – sexual activity, immigration status, race, facial expressions, weight, health, and even genetic information, the Mozilla team found.
Cars may collect at least some of that info about drivers and passengers using sensors, microphones, cameras, phones, and other devices people connect to their network-connected cars, according to Mozilla. And they collect even more info from car apps – such as Sirius XM or Google Maps – plus dealerships, and vehicle telematics.
Some car brands may then share or sell this information to third parties. Mozilla found 21 of the 25 automakers it considered say they may share customer info with service providers, data brokers, and the like, and 19 of the 25 say they can sell personal data.
More than half (56 percent) also say they share customer information with the government or law enforcement in response to a “request.” This isn’t necessarily a court-ordered warrant, and can also be a more informal request.
And some – like Nissan – may also use this private data to develop customer profiles that describe drivers’ “preferences, characteristics, psychological trends, predispositions, behavior, attitudes, intelligence, abilities, and aptitudes.”
Yes, you read that correctly. According to Mozilla’s privacy researchers, Nissan says it can infer how smart you are, then sell that assessment to third parties.
[…]
Nissan isn’t the only brand to collect information that seems completely irrelevant to the vehicle itself or the driver’s transportation habits.
“Kia mentions sex life,” Caltrider said. “General Motors and Ford both mentioned race and sexual orientation. Hyundai said that they could share data with government and law enforcement based on formal or informal requests. Car companies can collect even more information than reproductive health apps in a lot of ways.”
[…]
the Privacy Not Included team contacted Nissan and all of the other brands listed in the research: that’s Lincoln, Mercedes-Benz, Acura, Buick, GMC, Cadillac, Fiat, Jeep, Chrysler, BMW, Subaru, Dacia, Hyundai, Dodge, Lexus, Chevrolet, Tesla, Ford, Honda, Kia, Audi, Volkswagen, Toyota and Renault.
Only three – Mercedes-Benz, Honda, and Ford – responded, we’re told.
“Mercedes-Benz did answer a few of our questions, which we appreciate,” Caltrider said. “Honda pointed us continually to their public privacy documentation to answer your questions, but they didn’t clarify anything. And Ford said they discussed our request internally and made the decision not to participate.”
This makes Mercedes’ response to The Register a little puzzling. “We are committed to using data responsibly,” a spokesperson told us. “We have not received or reviewed the study you are referring to yet and therefore decline to comment to this specifically.”
A spokesperson for the four Fiat-Chrysler-owned brands (Fiat, Chrysler, Jeep, and Dodge) told us: “We are reviewing accordingly. Data privacy is a key consideration as we continually seek to serve our customers better.”
[…]
The Mozilla Foundation also called out consent as an issue some automakers have placed in a blind spot.
“I call this out in the Subaru review, but it’s not limited to Subaru: it’s the idea that anybody that is a user of the services of a connected car, anybody that’s in a car that uses services is considered a user, and any user is considered to have consented to the privacy policy,” Caltrider said.
Opting out of data collection is another concern.
Tesla, for example, appears to give users the choice between protecting their data or protecting their car. Its privacy policy does allow users to opt out of data collection but, as Mozilla points out, Tesla warns customers: “If you choose to opt out of vehicle data collection (with the exception of in-car Data Sharing preferences), we will not be able to know or notify you of issues applicable to your vehicle in real time. This may result in your vehicle suffering from reduced functionality, serious damage, or inoperability.”
While technically this does give users a choice, it also essentially says if you opt out, “your car might become inoperable and not work,” Caltrider said. “Well, that’s not much of a choice.”
In November 2022, the password manager service LastPass disclosed a breach in which hackers stole password vaults containing both encrypted and plaintext data for more than 25 million users. Since then, a steady trickle of six-figure cryptocurrency heists targeting security-conscious people throughout the tech industry has led some security experts to conclude that crooks likely have succeeded at cracking open some of the stolen LastPass vaults.
[…]
Since late December 2022, Monahan and other researchers have identified a highly reliable set of clues that they say connect recent thefts targeting more than 150 people, Collectively, these individuals have been robbed of more than $35 million worth of crypto.
Monahan said virtually all of the victims she has assisted were longtime cryptocurrency investors, and security-minded individuals. Importantly, none appeared to have suffered the sorts of attacks that typically preface a high-dollar crypto heist, such as the compromise of one’s email and/or mobile phone accounts.
[…]
Monahan has been documenting the crypto thefts via Twitter/X since March 2023, frequently expressing frustration in the search for a common cause among the victims. Then on Aug. 28, Monahan said she’d concluded that the common thread among nearly every victim was that they’d previously used LastPass to store their “seed phrase,” the private key needed to unlock access to their cryptocurrency investments.
[…]
Bax, Monahan and others interviewed for this story say they’ve identified a unique signature that links the theft of more than $35 million in crypto from more than 150 confirmed victims, with roughly two to five high-dollar heists happening each month since December 2022.
[…]
But the researchers have published findings about the dramatic similarities in the ways that victim funds were stolen and laundered through specific cryptocurrency exchanges. They also learned the attackers frequently grouped together victims by sending their cryptocurrencies to the same destination crypto wallet.
A graphic published by @tayvano_ on Twitter depicting the movement of stolen cryptocurrencies from victims who used LastPass to store their crypto seed phrases.
By identifying points of overlap in these destination addresses, the researchers were then able to track down and interview new victims. For example, the researchers said their methodology identified a recent multi-million dollar crypto heist victim as an employee at Chainalysis, a blockchain analysis firm that works closely with law enforcement agencies to help track down cybercriminals and money launderers.
Chainalysis confirmed that the employee had suffered a high-dollar cryptocurrency heist late last month, but otherwise declined to comment for this story.
[…]
I’ve been urging my friends and family who use LastPass to change all of their passwords and migrate any crypto that may have been exposed, despite knowing full well how tedious that is.”
A study published last month in the journal Environmental Pollution outlines how paper cups can leach toxic materials into the surrounding environment. This is because paper cups are often coated in a layer of polylactic acid, otherwise known as PLA. It’s a bioplastic and is touted as a biodegradable alternative to traditional plastic. However, researchers found that it caused adverse health effects in aquatic midge larvae.
Researchers at the University of Gothenburg tested the effects of both plastic cups and paper cups on the midge larvae. Both types of cups were put in water or sediments for up to four weeks. The larvae were then put into aquariums that contained the sediment and water that once held the plastic and paper cups. The contaminated sediment and water were tested separately.
“We observed a significant growth inhibition with all the materials tested when the larvae were exposed in contaminated sediment,” the researchers wrote in the study. “Developmental delays were also observed for all materials, both in contaminated water and sediment.”
They found that growth challenges and developmental delays were observed in environments where the cups leached into them for only one week. The negative effects of the exposure increased in the water and sediment that held the paper and plastic cups for longer periods of time. This challenges the belief that bioplastics are safer. PLA does break down faster than traditional fossil fuel-based plastic material, but the study results show that they aren’t much safer.
“Bioplastics does not break down effectively when they end up in the environment, in water,” Bethanie Carney Almroth, a professor at the University of Gothenburg and study author, said in a press release. “There may be a risk that the plastic remains in nature and resulting microplastics can be ingested by animals and humans, just as other plastics do. Bioplastics contain at least as many chemicals as conventional plastic.”
Other previous studies have found that the plastic coating in paper cups can also create microplastics that enter the liquid in the cup. In 2019, a research group based out of India filled paper cups with hot water and found that there were an alarming amount of microplastic particles in a paper cup after filling the cups with hot liquids, Wired reported. The researchers found that there were about 25,000 particles per 100 ml cup after 15 minutes.