The New York Times doesn’t keep bodies in its “morgue” — it keeps pictures. In a basement under its Times Square office, stuffed into cabinets and drawers, the Times stores between 5 million and 7 million images, along with information about when they were published and why. Now, the paper is working with Google to digitize its huge collection.
The morgue (as the basement storage area is known) contains pictures going back to the 19th century, many of which exist nowhere else in the world. “[It’s] a treasure trove of perishable documents,” says the NYT’s chief technology officer Nick Rockwell. “A priceless chronicle of not just The Times’s history, but of nearly more than a century of global events that have shaped our modern world.”
That’s why the company has hired Google, which will use its machine vision smarts to not only scan the hand- and type-written notes attached to each image, but categorize the semantic information they contain (linking data like locations and dates). Google says the Times will also be able to use its object recognition tools to extract even more information from the photos, making them easier to catalog and resurface for future use.
CYBERCOM says the move is to improve information sharing among the cybersecurity community, but in some ways it could be seen as a signal to those who hack US systems: we may release your tools to the wider world.
“This is intended to be an enduring and ongoing information sharing effort, and it is not focused on any particular adversary,” Joseph R. Holstead, acting director of public affairs at CYBERCOM told Motherboard in an email.
One of the two samples CYBERCOM distributed on Friday is marked as coming from APT28, a Russian government-linked hacking group, by several different cybersecurity firms, according to VirusTotal. Those include Kaspersky Lab, Symantec, and Crowdstrike, among others. APT28 is also known as Sofacy and Fancy Bear.
Adam Meyers, vice president of intelligence at CrowdStrike said that the sample did appear new, but the company’s tools detected it as malicious upon first contact. Kurt Baumgartner, principal security researcher at Kaspersky Lab, told Motherboard in an email that the sample “was known to Kaspersky Lab in late 2017,” and was used in attacks in Central Asia and Southeastern Europe at the time.
Welcome to Spinning Up in Deep RL! This is an educational resource produced by OpenAI that makes it easier to learn about deep reinforcement learning (deep RL).
For the unfamiliar: reinforcement learning (RL) is a machine learning approach for teaching agents how to solve tasks by trial and error. Deep RL refers to the combination of RL with deep learning.
This module contains a variety of helpful resources, including:
a short introduction to RL terminology, kinds of algorithms, and basic theory,
an essay about how to grow into an RL research role,
a curated list of important papers organized by topic,
a well-documented code repo of short, standalone implementations of key algorithms,
Timely diagnosis of Alzheimer’s disease is extremely important, as treatments and interventions are more effective early in the course of the disease. However, early diagnosis has proven to be challenging. Research has linked the disease process to changes in metabolism, as shown by glucose uptake in certain regions of the brain, but these changes can be difficult to recognize.
[…]
The researchers trained the deep learning algorithm on a special imaging technology known as 18-F-fluorodeoxyglucose positron emission tomography (FDG-PET). In an FDG-PET scan, FDG, a radioactive glucose compound, is injected into the blood. PET scans can then measure the uptake of FDG in brain cells, an indicator of metabolic activity.
The researchers had access to data from the Alzheimer’s Disease Neuroimaging Initiative (ADNI), a major multi-site study focused on clinical trials to improve prevention and treatment of this disease. The ADNI dataset included more than 2,100 FDG-PET brain images from 1,002 patients. Researchers trained the deep learning algorithm on 90 percent of the dataset and then tested it on the remaining 10 percent of the dataset. Through deep learning, the algorithm was able to teach itself metabolic patterns that corresponded to Alzheimer’s disease.
Finally, the researchers tested the algorithm on an independent set of 40 imaging exams from 40 patients that it had never studied. The algorithm achieved 100 percent sensitivity at detecting the disease an average of more than six years prior to the final diagnosis.
“We were very pleased with the algorithm’s performance,” Dr. Sohn said. “It was able to predict every single case that advanced to Alzheimer’s disease.”
Apple’s new-generation Macs come with a new so-called Apple T2 security chip that’s supposed to provide a secure enclave co-processor responsible for powering a series of security features, including Touch ID. At the same time, this security chip enables the secure boot feature on Apple’s computers, and by the looks of things, it’s also responsible for a series of new restrictions that Linux users aren’t going to like.
The issue seems to be that Apple has included security certificates for its own and Microsoft’s operating systems (to allow running Windows via Bootcamp), but not for the certificate that was provided for systems such as Linux. Disabling Secure Boot can overcome this, but also disables access to the machine’s internal storage, making installation of Linux impossible.
I like VirtualBox and it has nothing to do with why I publish a 0day vulnerability. The reason is my disagreement with contemporary state of infosec, especially of security research and bug bounty:
Wait half a year until a vulnerability is patched is considered fine.
In the bug bounty field these are considered fine:
Wait more than month until a submitted vulnerability is verified and a decision to buy or not to buy is made.
Change the decision on the fly. Today you figured out the bug bounty program will buy bugs in a software, week later you come with bugs and exploits and receive “not interested”.
Have not a precise list of software a bug bounty is interested to buy bugs in. Handy for bug bounties, awkward for researchers.
Have not precise lower and upper bounds of vulnerability prices. There are many things influencing a price but researchers need to know what is worth to work on and what is not.
Delusion of grandeur and marketing bullshit: naming vulnerabilities and creating websites for them; making a thousand conferences in a year; exaggerating importance of own job as a security researcher; considering yourself “a world saviour”. Come down, Your Highness.
I’m exhausted of the first two, therefore my move is full disclosure. Infosec, please move forward.
How to protect yourself
Until the patched VirtualBox build is out you can change the network card of your virtual machines to PCnet (either of two) or to Paravirtualized Network. If you can’t, change the mode from NAT to another one. The former way is more secure.
Introduction
A default VirtualBox virtual network device is Intel PRO/1000 MT Desktop (82540EM) and the default network mode is NAT. We will refer to it E1000.
The E1000 has a vulnerability allowing an attacker with root/administrator privileges in a guest to escape to a host ring3. Then the attacker can use existing techniques to escalate privileges to ring 0 via /dev/vboxdrv.
Exploit
The exploit is Linux kernel module (LKM) to load in a guest OS. The Windows case would require a driver differing from the LKM just by an initialization wrapper and kernel API calls.
Elevated privileges are required to load a driver in both OSs. It’s common and isn’t considered an insurmountable obstacle. Look at Pwn2Own contest where researcher use exploit chains: a browser opened a malicious website in the guest OS is exploited, a browser sandbox escape is made to gain full ring 3 access, an operating system vulnerability is exploited to pave a way to ring 0 from where there are anything you need to attack a hypervisor from the guest OS. The most powerful hypervisor vulnerabilities are for sure those that can be exploited from guest ring 3. There in VirtualBox is also such code that is reachable without guest root privileges, and it’s mostly not audited yet.
The exploit is 100% reliable. It means it either works always or never because of mismatched binaries or other, more subtle reasons I didn’t account. It works at least on Ubuntu 16.04 and 18.04 x86_64 guests with default configuration.
As we have passed the three-year anniversary of the US EMV migration deadline, it is evident that the majority of financial institutions were successful in providing their customers with new EMV enabled cards. However, contrary to the prevailing logic, migration to the EMV did not eradicate the card-present fraud. Of more than 60 million payment cards stolen in the past 12 months, chip-enabled cards represented a staggering 93%.These results directly reflect the lack of US merchant compliance with the EMV implementation.
Key Findings
60 million US payment cards have been compromised in the past 12 months.
45.8 million or 75% are Card-Present (CP) records and were stolen at the point-of-sale devices, while only 25% were compromised in online breaches.
90% of the CP compromised US payment cards were EMV enabled.
The US leads the rest of the world in the total amount of compromised EMV payment cards by a massive 37.3 million records.
Financially motivated threat groups are still exploiting the lack of merchant EMV compliance.
An imminent shift from card-present to card-not-present fraud is already evident with a 14% increase in payment cards stolen through e-commerce breaches in the past 12 months.
Basically they are saying this should go down as merchants employ the technology correctly at the point of sale. Big companies are starting to do this, but small ones are not, so they will become the prevailing targets in the next few years.
Each day, Brenda leaves her home here to catch a bus to the east side of Nairobi where she, along with more than 1,000 colleagues in the same building, work hard on a side of artificial intelligence we hear little about – and see even less.
In her eight-hour shift, she creates training data. Information – images, most often – prepared in a way that computers can understand.
Brenda loads up an image, and then uses the mouse to trace around just about everything. People, cars, road signs, lane markings – even the sky, specifying whether it’s cloudy or bright. Ingesting millions of these images into an artificial intelligence system means a self-driving car, to use one example, can begin to “recognise” those objects in the real world. The more data, the supposedly smarter the machine.
She and her colleagues sit close – often too close – to their monitors, zooming in on the images to make sure not a single pixel is tagged incorrectly. Their work will be checked by a superior, who will send it back if it’s not up to scratch. For the fastest, most accurate trainers, the honour of having your name up on one of the many TV screens around the office. And the most popular perk of all: shopping vouchers.
[…]
Brenda does this work for Samasource, a San Francisco-based company that counts Google, Microsoft, Salesforce and Yahoo among its clients. Most of these firms don’t like to discuss the exact nature of their work with Samasource – as it is often for future projects – but it can be said that the information prepared here forms a crucial part of some of Silicon Valley’s biggest and most famous efforts in AI.
[…]
f you didn’t look out of the windows, you might think you were at a Silicon Valley tech firm. Walls are covered in corrugated iron in a way that would be considered achingly trendy in California, but here serve as a reminder of the environment many of the workers come from: around 75% are from the slum.
Most impressively, Samasource has overcome a problem that most Silicon Valley firms are famously grappling with. Just over half of their workforce is made up of women, a remarkable feat in a country where starting a family more often than not rules out a career for the mother. Here, a lactation room, up to 90 days maternity leave, and flexibility around shift patterns makes the firm a stand-out example of inclusivity not just in Kenya, but globally.
“Like a lot of people say, if you have a man in the workplace, he’ll support his family,” said Hellen Savala, who runs human resources.
“[But] if you have a woman in the workplace, she’ll support her family, and the extended family. So you’ll have a lot more impact.”
The ability to put our clothes on each day is something most of us take for granted, but as computer scientists from Georgia Institute of Technology recently found out, it’s a surprisingly complicated task—even for artificial intelligence.
As any toddler will gladly tell you, it’s not easy to dress oneself. It requires patience, physical dexterity, bodily awareness, and knowledge of where our body parts are supposed to go inside of clothing. Dressing can be a frustrating ordeal for young children, but with enough persistence, encouragement, and practice, it’s something most of us eventually learn to master.
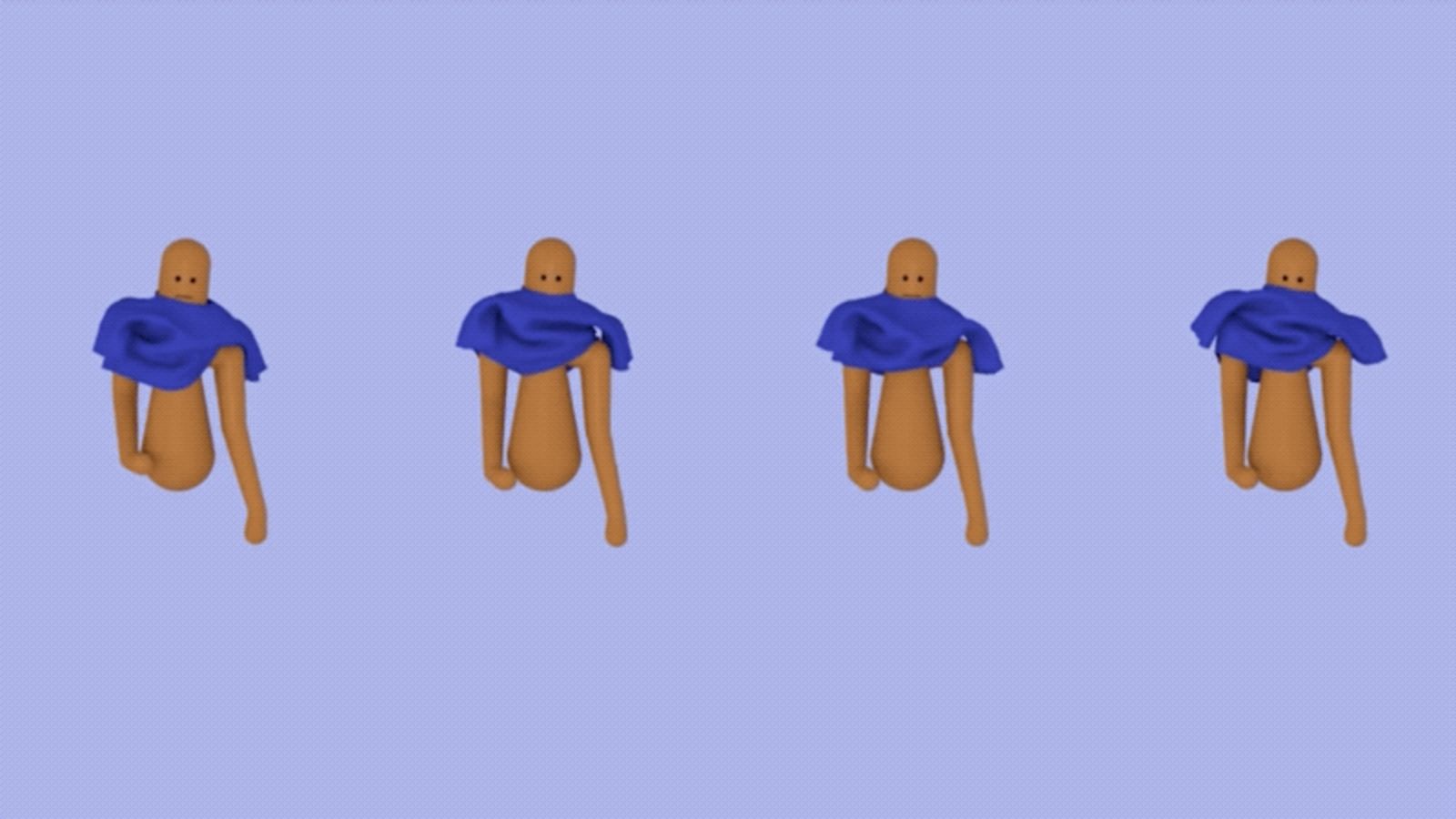
As new research shows, the same learning strategy used by toddlers also applies to artificially intelligent computer characters. Using an AI technique known as reinforcement learning—the digital equivalent of parental encouragement—a team led by Alexander W. Clegg, a computer science PhD student at the Georgia Institute of Technology, taught animated bots to dress themselves. In tests, their animated bots could put on virtual t-shirts and jackets, or be partially dressed by a virtual assistant. Eventually, the system could help develop more realistic computer animation, or more practically, physical robotic systems capable of dressing individuals who struggle to do it themselves, such as people with disabilities or illnesses.
Putting clothes on, as Clegg and his colleagues point out in their new study, is a multifaceted process.
“We put our head and arms into a shirt or pull on pants without a thought to the complex nature of our interactions with the clothing,” the authors write in the study, the details of which will be presented at the SIGGRAPH Asia 2018 conference on computer graphics in December. “We may use one hand to hold a shirt open, reach our second hand into the sleeve, push our arm through the sleeve, and then reverse the roles of the hands to pull on the second sleeve. All the while, we are taking care to avoid getting our hand caught in the garment or tearing the clothing, often guided by our sense of touch.”
Computer animators are fully aware of these challenges, and often struggle to create realistic portrayals of characters putting their clothes on. To help in this regard, Clegg’s team turned to reinforcement learning—a technique that’s already being used to teach bots complex motor skills from scratch. With reinforcement learning, systems are motivated toward a designated goal by gaining points for desirable behaviors and losing points for counterproductive behaviors. It’s a trial-and-error process—but with cheers or boos guiding the system along as it learns effective “policies” or strategies for completing a goal.
Chinese authorities have begun deploying a new surveillance tool: “gait recognition” software that uses people’s body shapes and how they walk to identify them, even when their faces are hidden from cameras.
Already used by police on the streets of Beijing and Shanghai, “gait recognition” is part of a push across China to develop artificial-intelligence and data-driven surveillance that is raising concern about how far the technology will go.
Huang Yongzhen, the CEO of Watrix, said that its system can identify people from up to 50 meters (165 feet) away, even with their back turned or face covered. This can fill a gap in facial recognition, which needs close-up, high-resolution images of a person’s face to work.
“You don’t need people’s cooperation for us to be able to recognize their identity,” Huang said in an interview in his Beijing office. “Gait analysis can’t be fooled by simply limping, walking with splayed feet or hunching over, because we’re analyzing all the features of an entire body.”
Watrix announced last month that it had raised 100 million yuan ($14.5 million) to accelerate the development and sale of its gait recognition technology, according to Chinese media reports.
Chinese police are using facial recognition to identify people in crowds and nab jaywalkers, and are developing an integrated national system of surveillance camera data. Not everyone is comfortable with gait recognition’s use.
Dutch police claim to have snooped on more than a quarter of a million encrypted messages sent between alleged miscreants using BlackBox IronPhones.
The extraordinary claim was made in a press conference on Tuesday, in which officers working on a money-laundering investigation reckoned they had been able to see crims chatting “live for some time.”
The suspects had been using the IronChat app on their IronPhones, which uses a custom implementation of the end-to-end off-the-record (OTR) encryption system to scramble messages.
[…]
While the officers did not detail how they got hold of and cracked the encrypted IronChat messages, they had seized BlackBox Security’s server. It sounds as though the encrypted conversations were routed through that system. Therefore, once collared, that box could have been set up to decrypt and re-encrypt messages on the fly, or otherwise intercept the connections, allowing the cops to spy on the chats.
Intelligence from these conversations was then used to snare folks suspected of laundering money and other crimes.
Specifically, the clog-plod seized the website and server of the Edward Snowden-endorsed company BlackBox Security after arresting two men apparently behind the business: a 46-year-old from Lingewaard, and a 52-year-old from Boxtel. Another three men were nabbed in Almelo and Enschede, and police expect to make “hundreds” more arrests in the course of their investigation.
De initiatiefnemers van AINED ontwikkelen met ondersteuning van de Boston Consulting Group (BCG) en DenkWerk een Nationale Strategie Artificial Intelligence (AI) voor Nederland, geïnitieerd door het Ministerie van Economische Zaken en Klimaat.
Het projectteam doet dit vanuit de overtuiging dat in het Nederlandse landschap de mogelijkheden van AI nog te weinig worden benut, en de randvoorwaarden van AI nog niet voldoende worden meegenomen in de ontwikkeling en toepassing van AI. In een wereld waarin andere landen dit wel doen en de techniek steeds waardevoller en krachtiger wordt, is het van groot belang voor Nederland om nu óók in te zetten op AI.
Voor de ontwikkeling van deze strategie is AINED opgestart: een samenwerking tussen het TopTeam ICT, VNO-NCW, ICAI, NWO en TNO, ondersteund door The Boston Consulting Group en DenkWerk.
AI ontwikkelt zich snel en heeft een grote belofte van innovatie en vooruitgang in zich. Het doel van de nationale strategie is de ontwikkeling en toepassing van moderne, data-gedreven AI-technologie in Nederland te versnellen, gericht op kansen voor Nederland en mét inachtneming van juridische, ethische en sociale randvoorwaarden. Als vertrekpunt voor de strategie met doelen en acties, wordt een landschapsschets opgesteld met initiatieven en wensen voor AI in het bedrijfsleven, de overheid, de wetenschap, het onderwijs en de non-gouvernementele sector.
De ontwikkeling van het voorstel loopt tot begin oktober. In een volgende fase zullen de initiatiefnemers van AINED met een brede groep aan stakeholders de doelen en acties verder uitwerken en afstemmen hoe zij kunnen bijdragen hieraan. Naast het Ministerie van Economische Zaken en Klimaat, de Ministeries van Onderwijs, Cultuur en Wetenschap, Defensie en Binnenlandse Zaken, zal een belangrijke rol weggelegd zijn voor het bedrijfsleven. In deze volgende fase zullen ook commitments op de doelen en acties behaald worden. Voor interesse om bij te dragen, neem contact op met Daniël Frijters, secretaris AINED op info@ained.nl
Most modern browsers—such as Chrome, Firefox, and Edge, and even browsers such as FuzzyFox and DeterFox (different, security-focused versions of Firefox)—have vulnerabilities that allow hosts of malicious websites to extract hundreds to thousands of URLs in a user’s web history, per new research from the University of California San Diego.
What’s worse, the vulnerabilities are built into the way they structure links, meaning that major structural changes will have to take place in these browsers in order to protect user privacy. The only browser that was immune to the attacks was Tor Browser, as the browser does not keep track of a user’s internet history.
[…]
As outlined in the UC San Diego report, this sniffing could happen in a couple of ways: they could force the browser to reload multiple complex images or image transformations that differ based on whether you’ve visited a link or not, which would create drastic differences in the loading time for each. With this strategy, actors can test 60 sensitive URLs per second.
In Google Chrome, the actor could also exploit what’s called a bytecode cache, which speeds up the loading time for revisiting a link that you’ve already visited. By embedding a special script in a web page, the actor can test how long it takes for a web page to load and infer whether you’ve visited it or not. Actors can probe 3,000 URLs per second with this method. But when the researchers reported the vulnerability to Google, the company marked the issue as “security-sensitive” but “low-priority.”
Machine learning is, at heart, the art of finding patterns in data. That’s why businesses love it. Patterns help predict the future, and predicting the future is a great way to make money. It’s sometimes unclear how these things fit together, but here’s a perfect example from film studio 20th Century Fox, which is using AI to predict what films people will want to see.
Researchers from the company published a paper last month explaining how they’re analyzing the content of movie trailers using machine learning. Machine vision systems examine trailer footage frame by frame, labeling objects and events, and then compare this to data generated for other trailers. The idea is that movies with similar sets of labels will attract similar sets of people.
As the researchers explain in the paper, this is exactly the sort of data movie studios love. (They already produce lots of similar data using traditional methods like interviews and questionnaires.) “Understanding detailed audience composition is important for movie studios that invest in stories of uncertain commercial,” they write. In other words, if they know who watches what, they will know what movies to make.
It’s even better if this audience composition can be broken down into smaller and more accurate “micro segments.” A good example of this is 2017’s Logan. It’s a superhero movie, yes, but it has darker themes and a plot that attracts a slightly different audience. So can AI be used to capture those differences? The answer is: sort of.
To create their “experimental movie attendance prediction and recommendation system” (named Merlin), 20th Century Fox partnered with Google to use the company’s servers and open-source AI framework TensorFlow. In an accompanying blog post, the search giant explains Merlin’s analysis of Logan.
First, Merlin scans the trailer, labeling objects like “facial hair,” “car,” and “forest”:
While this graph only records the frequency of these labels, the actual data generated is more complex, taking into account how long these objects appear on-screen and when they show up the trailer.
As 20th Century Fox’s engineers explain, this temporal information is particularly rich because it correlates with a film’s genre. “For example,” they write, “a trailer with a long close-up shot of a character is more likely for a drama movie than for an action movie, whereas a trailer with quick but frequent shots is more likely for an action movie.” This definitely holds true for Logan, with its trailer featuring lots of slow shots of Hugh Jackman looking bloody and beaten.
By comparing this information with analyses of other trailers, Merlin can try to predict what films might interest the people who saw Logan. But here’s where things get a little dicey.
The graph below shows the top 20 films that people who went to see Logan also watched. The column on the right shows Merlin’s predictions, and the column on the left shows the actual data (collected, one assumes, by using that pre-AI method of “asking people”).
Merlin gets quite a few of the films correct, including other superhero movies like X Men: Apocalypse, Doctor Strange, and Batman v Superman: Dawn of Justice. It even correctly identifies John Wick: Chapter 2 as a bedfellow of Logan. That’s an impressive intuition since John Wick is certainly not a superhero movie. However, it does feature a similarly weary and jaded protagonist with a comparably rugged look. All in all, Merlin identifies all of the top five picks, even if it does fail to put them in the same order of importance.
What’s more revealing, though, are the mismatches. Merlin predicts that TheLegend of Tarzan will be a big hit with Logan fans for example. Neither Google nor 20th Century Fox offers an explanation for this, but it could it have something to do with the “forest,” “tree,” and “light” found in Logan — elements which also feature heavily in the Tarzantrailer.
Similarly, The Revenant has plenty of flora and facial hair, but it was drama-heavy Oscar bait rather than a smart superhero movie. Merlin also misses Ant-Man and Deadpool 2 as lure’s for the same audience. These were superhero films with quick-cut trailers, but they also took offbeat approaches to their protagonists, similar to Wolverine’s treatment in Logan.
Fundamental flaws in the encryption system used by popular solid-state drives (SSDs) can be exploited by miscreants to easily decrypt data, once they’ve got their hands on the equipment.
A paper [PDF] drawn up by researchers Carlo Meijer and Bernard van Gastel at Radboud University in the Netherlands, and made public today, describes these critical weaknesses. The bottom line is: the drives require a password to encrypt and decrypt their contents, however this password can be bypassed, allowing crooks and snoops to access ciphered data.
Basically, the cryptographic keys used to encrypt and decrypt the data are not derived from the owner’s password, meaning, you can seize a drive and, via a debug port, reprogram it to accept any password. At that point, the SSD will use its stored keys to cipher and decipher its contents. Yes, it’s that dumb.
The egghead duo tested three Crucial and four Samsung models of SSDs, and found them more or less vulnerable to the aforementioned attack, although it does depend on their final configuration. Check the table below for the specific findings and settings to determine if your rig is vulnerable. All of the drives tried, and failed, to securely implement the TCG Opal standard of encryption.
Horizon is an open source end-to-end platform for applied reinforcement learning (RL) developed and used at Facebook. Horizon is built in Python and uses PyTorch for modeling and training and Caffe2 for model serving. The platform contains workflows to train popular deep RL algorithms and includes data preprocessing, feature transformation, distributed training, counterfactual policy evaluation, and optimized serving. For more detailed information about Horizon see the white paper here.
A spokesman for President Tommy Remengesau said there was scientific evidence that the chemicals found in most sunscreens are toxic to corals, even in minute doses.
He said Palau’s dive sites typically hosted about four boats an hour packed with tourists, leading to concerns a build-up of chemicals could see the reefs reach tipping point.
“On any given day that equates to gallons of sunscreen going into the ocean in Palau’s famous dive spots and snorkelling places,” he told AFP.
“We’re just looking at what we can do to prevent pollution getting into the environment.”
The government has passed a law banning “reef-toxic” sunscreen from January 1, 2020.
Anyone importing or selling banned sunscreen from that date faces a $1,000 fine, while tourists who bring it into the country will have it confiscated.
“The power to confiscate sunscreens should be enough to deter their non-commercial use, and these provisions walk a smart balance between educating tourists and scaring them away,” Remengesau told parliament after the bill passed last week.
Environmental pioneer
The US state of Hawaii announced a ban on reef toxic sunscreens in May this year, but it does not come into force until 2021, a year after Palau’s.
The Palau ban relates to sunscreens containing chemicals including oxybenzone, octocrylene and parabens, which covers most major brands.
Palau has long been a pioneer in marine protection, introducing the world’s first shark sanctuary in 2009, in a move that has been widely imitated.
It has also banned commercial fishing from its waters and last year introduced the “Palau Pledge” requiring international visitors to sign a promise stamped into their passport that they will respect the environment.
Craig Downs, executive director at the Haereticus Environmental Laboratory in Hawaii, said other nations would be watching Palau’s move closely.
“It’s the first country to ban these chemicals from tourism. I think it’s great, they’re being proactive,” he said.
“They don’t want to be like Thailand, the Philippines and Indonesia, where they’ve had to shut down beaches. The coral reefs around those beaches have died.”
Downs said there were numerous scientific papers pointing to a link between sunscreen chemicals and coral reef degradation.
“What we’re saying is that where there are lots of tourists getting in the water, sunscreen pollution can have a detrimental effect on nearby coral reefs, as far as five kilometres (3.1 miles) away,” he said.
Downs called on sunscreen manufacturers to “step up and innovate”, saying the chemicals used for UV protection had been largely unchanged for 50 years.
He said there were some sunscreens containing zinc oxide and titanium dioxide that were not reef toxic but added: “The other alternative we’ve been pushing is sunwear—cover up, wear a sunshirt.”
The first foldable phone is a reality – the FlexPai. Well, it’s actually a tablet as unfolded it boasts a 7.8” screen (4:3 aspect ratio). Folded, that drops to a more manageable 4”. And get this, this device is the first to use the 7nm Snapdragon 8150!
Back to the screen, it’s an AMOLED that folds down the middle. The software (dubbed Water OS) switches to using only half of the screen, displaying a wallpaper on the other half.
You get to choose which half you use, though, one has slightly more screen, the other is next to the dual camera, which can be used for selfies and video calls in this configuration. It’s a 16+20MP camera, by the way, the second camera module has a telephoto lens.
FlexPai is the world’s first flexible phone/tablet and the first with Snapdragon 8150
The FlexPai measures 7.6mm thick. However, it doesn’t fold flat so it’s thicker than than 15.2mm when folded (certainly near the “hinge”). The hinge is rated to being folded 200,000 times.
The device is powered by a 7nm Qualcomm chipset and only the Snapdragon 8150 fits that description. The base configuration has 6GB of RAM and 128GB storage, but other options include 8/256 and 8/512GB. A proprietary Ro-Charge fast charging tech is supported – it goes from 0% to 80% in an hour.
The price starts at CNY 9,000 – $1,300/€1,135 – which doesn’t seem so high considering that some Android flagships cost that much without a next-gen chipset or a foldable design.
From around 2009 to 2013, the U.S. intelligence community experienced crippling intelligence failures related to the secret internet-based communications system, a key means for remote messaging between CIA officers and their sources on the ground worldwide. The previously unreported global problem originated in Iran and spiderwebbed to other countries, and was left unrepaired — despite warnings about what was happening — until more than two dozen sources died in China in 2011 and 2012 as a result, according to 11 former intelligence and national security officials.
[…]
One of the largest intelligence failures of the past decade started in Iran in 2009, when the Obama administration announced the discovery of a secret Iranian underground enrichment facility — part of Iran’s headlong drive for nuclear weapons. Angered about the breach, the Iranians went on a mole hunt, looking for foreign spies, said one former senior intelligence official.
The mole hunt wasn’t hard, in large part, because the communications system the CIA was using to communicate with agents was flawed. Former U.S. officials said the internet-based platform, which was first used in war zones in the Middle East, was not built to withstand the sophisticated counterintelligence efforts of a state actor like China or Iran. “It was never meant to be used long term for people to talk to sources,” said one former official. “The issue was that it was working well for too long, with too many people. But it was an elementary system.”
“Everyone was using it far beyond its intention,” said another former official.
[…]
Though the Iranians didn’t say precisely how they infiltrated the network, two former U.S. intelligence officials said that the Iranians cultivated a double agent who led them to the secret CIA communications system. This online system allowed CIA officers and their sources to communicate remotely in difficult operational environments like China and Iran, where in-person meetings are often dangerous.
[…]
In fact, the Iranians used Google to identify the website the CIA was using to communicate with agents. Because Google is continuously scraping the internet for information about all the world’s websites, it can function as a tremendous investigative tool — even for counter-espionage purposes. And Google’s search functions allow users to employ advanced operators — like “AND,” “OR,” and other, much more sophisticated ones — that weed out and isolate websites and online data with extreme specificity.
According to the former intelligence official, once the Iranian double agent showed Iranian intelligence the website used to communicate with his or her CIA handlers, they began to scour the internet for websites with similar digital signifiers or components — eventually hitting on the right string of advanced search terms to locate other secret CIA websites. From there, Iranian intelligence tracked who was visiting these sites, and from where, and began to unravel the wider CIA network.
[…]
But the events in Iran were not self-contained; they coincided roughly with a similar debacle in China in 2011 and 2012, where authorities rounded up and executed around 30 agents working for the U.S. (the New York Times first reported the extirpation of the CIA’s China sources in May 2017). Some U.S. intelligence officials also believe that former Beijing-based CIA officer Jerry Lee, who was charged with spying on behalf of the Chinese government in May 2018, was partially responsible for the destruction of the CIA’s China-based source network. But Lee’s betrayal does not explain the extent of the damage, or the rapidity with which Chinese intelligence was able to identify and destroy the network, said former officials.
[…]
As Iran was making fast inroads into the CIA’s covert communications system, back in Washington an internal complaint by a government contractor warning officials about precisely what was happening was winding its way through a Kafkaesque appeals system.
In 2008 — well before the Iranians had arrested any agents — a defense contractor named John Reidy, whose job it was to identify, contact and manage human sources for the CIA in Iran, had already sounded an alarm about a “massive intelligence failure” having to do with “communications” with sources. According to Reidy’s publicly available but heavily redacted whistleblower disclosure, by 2010 he said he was told that the “nightmare scenario” he had warned about regarding the secret communications platform had, in fact, occurred.
Reidy refused to discuss his case with Yahoo News. But two former government officials directly familiar with his disclosure and the investigation into the compromises in China and Iran tell Yahoo News that Reidy had identified the weaknesses — and early compromise — that eventually befell the entire covert communications platform.
Reidy’s case was complicated. After he blew the whistle, he was moved off of his subcontract with SAIC, a Virginia company that works on government information technology products and support. According to the public disclosure, he contacted the CIA inspector general and congressional investigators about his employment status but was met with resistance, partially because whistleblower protections are complicated for federal contractors, and he remained employed.
Meanwhile, throughout 2010 and 2011, the compromise continued to spread, and Reidy provided details to investigators. But by November 2011, Reidy was fired because of what his superiors said were conflicts of interest, as Reidy maintained his own side business. Reidy believed the real reason was retaliation.
[…]
“Can you imagine how different this whole story would’ve turned out if the CIA [inspector general] had acted on Reidy’s warnings instead of going after him?” said Kel McClanahan, Reidy’s attorney. “Can you imagine how different this whole story would’ve turned out if the congressional oversight committees had done oversight instead of taking CIA’s word that he was just a troublemaker?”
Irvin McCullough, a national security analyst with the Government Accountability Project, a nonprofit that works with whistleblowers, put the issue in even starker terms. “This is one of the most catastrophic intelligence failures since Sept. 11,” he said. “And the CIA punished the person who brought the problem to light.”
If you’re a researcher looking to deepen your exposure to AI, NVIDIA invites you to apply to its new AI Research Residency program.
During the one-year, paid program, residents will be paired with an NVIDIA research scientist on a joint project and have the opportunity to publish and present their findings at prominent research conferences such as CVPR, ICLR and ICML.
The residency program is meant to encourage scholars with diverse academic backgrounds to pursue machine learning research, according to Jan Kautz, vice president of perception and learning research at NVIDIA.
“There’s currently a shortage of machine learning experts, and AI adoption for non-tech and smaller companies is hindered in part because there are not many people who understand AI,” said Kautz. “Our residency program is a way to broaden opportunities in the field to a more diverse set of researchers and spread the benefits of the technology to more people than ever.”
Applicants don’t need a background in AI, and those with doctoral degrees or equivalent expertise are encouraged to apply. Residents will work out of our Santa Clara location.
Google.org is issuing an open call to organizations around the world to submit their ideas for how they could use AI to help address societal challenges. Selected organizations will receive support from Google’s AI experts, Google.org grant funding from a $25M pool, credit and consulting from Google Cloud, and more.
Created by Chinese smartphone company Nubia (which is partially owned by ZTE), the Nubia X solves the problem of where to put the selfie cam on an all-screen phone by dodging the question entirely. That’s because instead of using the main 6.1-inch LCD screen and a front-facing camera to take selfies, you can simply flip the phone around and use its rear camera and 5.1-inch secondary 1520 x 720 OLED screen on the back to frame up your shot.
This solution might sound like overkill, but in some ways, it’s a much simpler overall design. Cameras are quickly becoming much more difficult and expensive to make than screens, and by only including one module on the back, it gives phone makers the ability to focus more on delivering a single, high quality photography experience.
On top of that, with the prevalence of so many phones designed with glass panels in front and back, the Nubia X shouldn’t be much more fragile than a typical handset. Also, that extra display can be used for way more than just selfies. Nubia says its rear, always-on display can show off your favorite art or be used as clock, or it can double as a full-on second display with access to all your standard Android screens and apps.
Now, the back of your phone doesn’t need to be reserved for blank glass.
Image: Nubia
Inside, the Nubia X’s specs look pretty solid as well—featuring a Qualcomm Snapdragon 845 chip, 6GB/8GB of RAM, up to 128GB of storage, and a sizable 3,800 mAh battery. And because there’s no room in front or back for a traditional fingerprint sensor, Nubia opted for an in-screen fingerprint reader like we’ve seen on the OnePlus 6T and Huawei Mate 20.
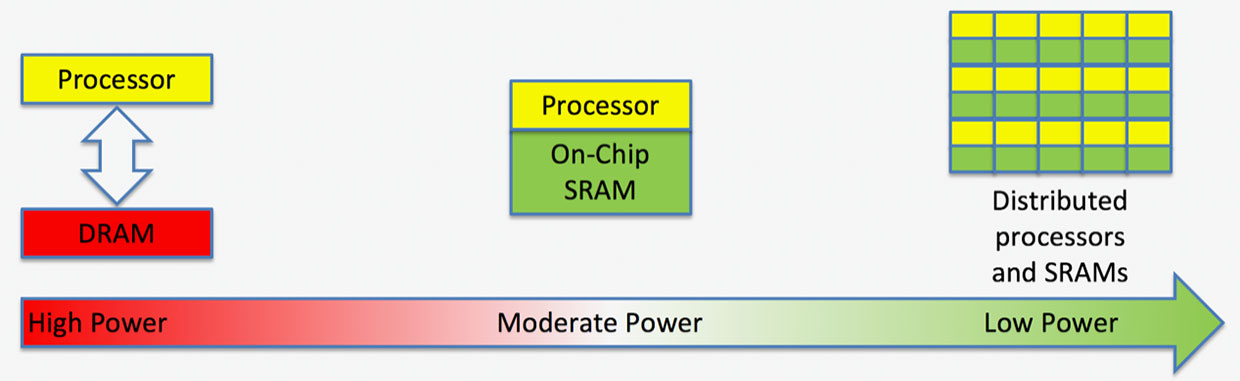
Deep learning has a DRAM problem. Systems designed to do difficult things in real time, such as telling a cat from a kid in a car’s backup camera video stream, are continuously shuttling the data that makes up the neural network’s guts from memory to the processor.
The problem, according to startup Flex Logix, isn’t a lack of storage for that data; it’s a lack of bandwidth between the processor and memory. Some systems need four or even eight DRAM chips to sling the 100s of gigabits to the processor, which adds a lot of space and consumes considerable power. Flex Logix says that the interconnect technology and tile-based architecture it developed for reconfigurable chips will lead to AI systems that need the bandwidth of only a single DRAM chip and consume one-tenth the power.
[…]
In developing the original technology for FPGAs, Wang noted that these chips were about 80 percent interconnect by area, and so he sought an architecture that would cut that area down and allow for more logic. He and his colleagues at UCLA adapted a kind of telecommunications architecture called a folded-Beneš network to do the job. This allowed for an FPGA architecture that looks like a bunch of tiles of logic and SRAM.
Image: Flex LogixFlex Logix says spreading SRAM throughout the chip speeds up computation and lowers power.
Distributing the SRAM in this specialized interconnect scheme winds up having a big impact on deep learning’s DRAM bandwidth problem, says Tate. “We’re displacing DRAM bandwidth with SRAM on the chip,” he says.
[…]
True apples-to-apples comparisons in deep learning are hard to come by. But Flex Logix’s analysis comparing a simulated 6 x 6-tile NMAX512 array with one DRAM chip against an Nvidia Tesla T4 with eight DRAMs showed the new architecture identifying 4,600 images per second versus Nvidia’s 3,920. The same size NMAX array hit 22 trillion operations per second on a real-time video processing test called YOLOv3 using one-tenth the DRAM bandwidth of other systems.
The designs for the first NMAX chips will be sent to the foundry for manufacture in the second half of 2019, says Tate.
In the future, you might talk to an AI to cross borders in the European Union. The EU and Hungary’s National Police will run a six-month pilot project, iBorderCtrl, that will help screen travelers in Hungary, Greece and Latvia. The system will have you upload photos of your passport, visa and proof of funds, and then use a webcam to answer basic questions from a personalized AI border agent. The virtual officer will use AI to detect the facial microexpressions that can reveal when someone is lying. At the border, human agents will use that info to determine what to do next — if there are signs of lying or a photo mismatch, they’ll perform a more stringent check.
The real guards will use handhelds to automatically double-check documents and photos for these riskier visitors (including images from past crossings), and they’ll only take over once these travelers have gone through biometric verification (including face matching, fingerprinting and palm vein scans) and a re-evaluation of their risk levels. Anyone who passed the pre-border test, meanwhile, will skip all but a basic re-evaluation and having to present a QR code.
The pilot won’t start with live tests. Instead, it’ll begin with lab tests and will move on to “realistic conditions” along the borders. And there’s a good reason for this: the technology is very much experimental. iBorderCtrl was just 76 percent accurate in early testing, and the team only expects to improve that to 85 percent. There are no plans to prevent people from crossing the border if they fail the initial AI screening.
Most people would appreciate a chatbot that offers sympathetic or empathetic responses, according to a team of researchers, but they added that reaction may rely on how comfortable the person is with the idea of a feeling machine.
In a study, the researchers reported that people preferred receiving sympathetic and empathetic responses from a chatbot—a machine programmed to simulate a conversation—than receiving a response from a machine without emotions, said S. Shyam Sundar, James P. Jimirro Professor of Media Effects and co-director of the Media Effects Research Laboratory. People express sympathy when they feel compassion for a person, whereas they express empathy when they are actually feeling the same emotions of the other person, said Sundar.
[…]
However, chatbots may become too personal for some people, said Bingjie Liu, a doctoral candidate in mass communications, who worked with Sundar on the study. She said that study participants who were leery of conscious machines indicated they were impressed by the chatbots that were programmed to deliver statements of sympathy and empathy.
“The majority of people in our sample did not really believe in machine emotion, so, in our interpretation, they took those expressions of empathy and sympathy as courtesies,” said Liu. “When we looked at people who have different beliefs, however, we found that people who think it’s possible that machines could have emotions had negative reactions to these expressions of sympathy and empathy from the chatbots.”

:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/13375641/Foxs_tool.max_1600x1600.png)
:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/13375771/Results_output.max_1900x1900.png)