Singapore’s Home Team Science and Technology Agency (HTX) roving robot has hit the streets of Toa Payoh Central as part of a trial to support public officers in enhancing public health and safety.
The robot, named Xavier, was jointly developed by HTX and the Agency for Science, Technology and Research. It is fitted with sensors for autonomous navigation, a 360-degree video feed to the command and control centre, real-time sensing and analysis, and an interactive dashboard where public officers can receive real-time information from and be able to monitor and control multiple robots simultaneously.
[…]
Over a three-week trial period, Xavier will detect “undesirable social behaviours” including smoking in prohibited areas, illegal hawking, improperly parked bicycles, congregation of more than five people in line with existing social distancing measures, and motorised active mobility devices and motorcycles on footpaths.
If one of those behaviours are detected, Xavier will trigger real-time alerts to the command and control centre, and display appropriate messages to educate the public and deter such behaviours.
Explore the complex web of loyalties, interests, influence, and alignment of key players around important issues.
Systems mapping
Understand and engage complex systems more effectively using systems maps and causal loop diagrams.
Social network mapping
Capture the structure of personal networks and reveal key players. Visualize the informal networks within your organization and see how work really gets done.
Community asset mapping
Keep track of the evolving relationships among community members and resources.
Concept mapping
Brainstorm complex ideas and relate individual concepts to the bigger picture. Unfold convoluted series of events using Lombardi diagrams.
On the eve of the iPhone 13 launch, we’ve finally been handed a ruling in the lawsuit filed by Epic Games last year. Epic Games, the developer of Fortnite, sued Apple last year over claims the company was violating U.S. antitrust law by prohibiting developers from implementing alternative in-app purchase methods. Today, Judge Yvonne Gonzalez-Rogers issued her ruling in the Epic Games v. Apple lawsuit, handing app developers a major win in the fight for app payment freedom.
As part of her ruling, Judge Gonzalez-Rogers issued a permanent injunction against Apple that orders the company to lift its restrictions on iOS apps and App Store pages providing buttons, external links, and other “calls to action” that direct consumers to other purchasing mechanisms. The injunction essentially orders Apple to abandon its anti-steering policy, which prohibited app developers from informing users of alternative purchasing methods.
[…]
Apple wins on all but one important claim
Last year, Epic Games intentionally circumvented Apple’s App Store policy by introducing direct payments for in-app purchases in Fortnite. Immediately after, Apple pulled Fortnite from the App Store and suspended Epic’s developer account, citing a violation of the App Store guidelines regarding in-app payments. When Epic sued Apple in response, they sought to have the latter reinstate their developer account so they could re-release Fortnite on iOS. Apple argued that Fortnite and Epic’s developer account should not be restored as Epic intentionally breached the contract between the two companies (a contract that, of course, Epic argues is illegal.)
However, Judge Gonzalez-Rogers today ruled in favor of Apple on its counterclaim of breach of contract. “Apple’s termination of the DPLA and the related agreements between Epic Games and Apple was valid, lawful, and enforceable,” said the Judge in her ruling. Because of this, it’s unlikely Apple will ever reinstate Fortnite or Epic’s developer account, because they were found to be correct in suspending them in the first place. The Judge also ordered Epic to pay 30% the revenue the company collected from Fortnite on iOS through Epic Direct Payment since it was implemented.
The Court also ruled that Epic Games “failed in its burden to demonstrate Apple is an illegal monopolist” in the narrowly-defined “digital mobile gaming transactions” market rather than both parties’ definition of the relevant market. The market in question is a $100 billion industry, and while Apple “enjoys considerable market share of over 55% and extraordinarily high profit margins,” Epic failed to prove to the Court that Apple’s behavior violated antitrust law. “Success is not illegal,” said Judge Gonzalez-Rogers in her ruling.
First the judge says it was wrong to force developers to pay exclusively through Apple, then says there were other options and Apple isn’t a monopoly and then says but you have to pay Apple a 30% cut of what you made through your other payment channel. What was this judge smoking?
Non-line-of-sight (NLOS) imaging and tracking is an emerging technology that allows the shape or position of objects around corners or behind diffusers to be recovered from transient, time-of-flight measurements. However, existing NLOS approaches require the imaging system to scan a large area on a visible surface, where the indirect light paths of hidden objects are sampled. In many applications, such as robotic vision or autonomous driving, optical access to a large scanning area may not be available, which severely limits the practicality of existing NLOS techniques. Here, we propose a new approach, dubbed keyhole imaging, that captures a sequence of transient measurements along a single optical path, for example, through a keyhole. Assuming that the hidden object of interest moves during the acquisition time, we effectively capture a series of time-resolved projections of the object’s shape from unknown viewpoints. We derive inverse methods based on expectation-maximization to recover the object’s shape and location using these measurements. Then, with the help of long exposure times and retroreflective tape, we demonstrate successful experimental results with a prototype keyhole imaging system.
C. Metzler, D. Lindell, G. Wetzstein, Keyhole Imaging: Non-Line-of-Sight Imaging and Tracking of Moving Objects Along a Single Optical Path, IEEE Transactions on Computational Imaging, 2021.
Overview of results
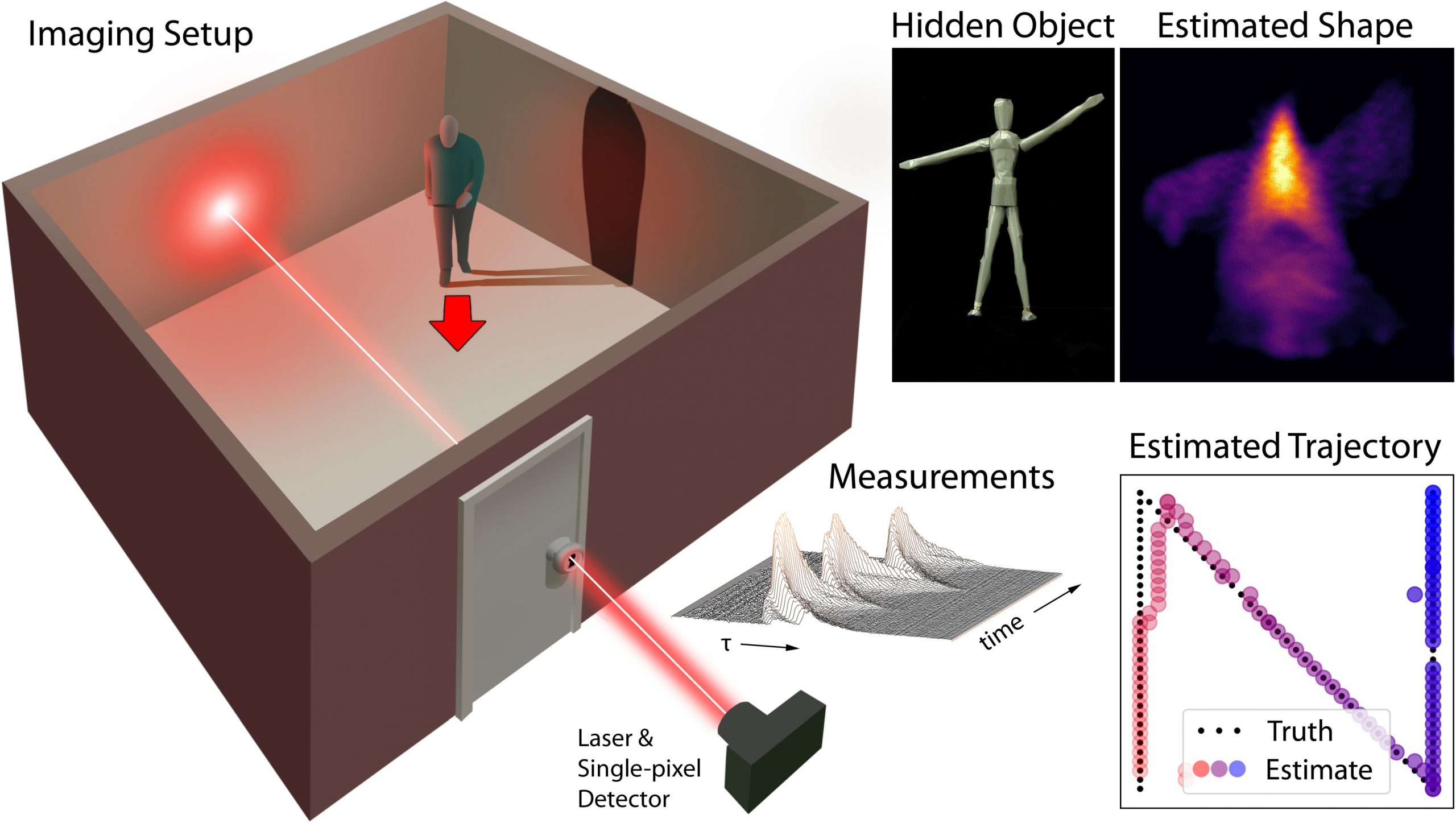
Keyhole imaging. A time-resolved detector and pulsed laser illuminate and image a point visible through a keyhole (left). As a hidden person moves, the detector captures a series of time-resolved measurements of the indirectly scattered light (center). From these measurements, we reconstruct both hidden object shape (e.g., for a hidden mannequin) and the time-resolved trajectory (right).
Experimental setup. Our optical system sends a laser pulse through the keyhole of a closed door. On the other side of the door, the hidden object moves along a translation stage. When third-bounce photons return, they are recorded and time-stamped by a SPAD. Top-right inset: A beam splitter (BS) is used to place the laser and SPAD in a confocal configuration.
Experimental results. First row: Images of the hidden objects. Second row: Reconstructions of the hidden objects using GD when their trajectories are known. Third row: EM reconstructions of the hidden objects when their trajectories are unknown. Fourth row: EM estimates of the trajectories of the hidden objects, each of which follows a different trajectory, where the dot color indicates position over time.
Computational imaging of moving 3D objects through the keyhole of a closed door.
A threat actor has leaked a list of almost 500,000 Fortinet VPN login names and passwords that were allegedly scraped from exploitable devices last summer.
While the threat actor states that the exploited Fortinet vulnerability has since been patched, they claim that many VPN credentials are still valid.
[…]
The list of Fortinet credentials was leaked for free by a threat actor known as ‘Orange,’ who is the administrator of the newly launched RAMP hacking forum and a previous operator of the Babuk Ransomware operation.
[…]
Both posts lead to a file hosted on a Tor storage server used by the Groove gang to host stolen files leaked to pressure ransomware victims to pay.
BleepingComputer’s analysis of this file shows that it contains VPN credentials for 498,908 users over 12,856 devices.
While we did not test if any of the leaked credentials were valid, BleepingComputer can confirm that all of the IP address we checked are Fortinet VPN servers.
A source in the cybersecurity industry told BleepingComputer that they were able to legally verify that at least some of the leaked credentials were valid.
It is unclear why the threat actor released the credentials rather than using them for themselves, but it is believed to have been done to promote the RAMP hacking forum and the Groove ransomware-as-a-service operation.
Yet earlier this week, just hours before the improved Runelite HD was due for an official release, 117 was contacted by Jagex, demanding that work stop and that the release be cancelled. This time, however, it’s not down to copyright claims, but because Jagex says they’re making their own HD upgrade.
[…]
While that sounds somewhat fair at first, there’s a huge problem. Runelite HDdoesn’t actually seem to break any of Jagex’s modding guidelines, and the company says that new guidelines that spell out the fact Runelite HDdoes actually break its guidelines are being released next week.
Understandably, fans think this is incredibly shady, and have begun staging an in-game protest:
Mod creator 117 says they attempted to compromise with Jagex, even offering to remove their mod once the company had finished and released their own efforts, but, “they declined outright,” seemingly spelling the end for a project that had consumed, “approximately over 2000 hours of work over two years.”
The High Court’s ruling on Wednesday is just a small part of a larger case brought against Australian news outlets, including the Sydney Morning Herald, The Age, and The Australian, among others, by a man who said he was defamed in the Facebook comments of the newspapers’ stories in 2016.
The question before the High Court was the definition of “publisher,” something that isn’t easily defined in Australian law.
The court found that, by creating a public Facebook page and posting content, the outlets had facilitated, encouraged and thereby assisted the publication of comments from third-party Facebook users, and they were, therefore, publishers of those comments.
The Aboriginal-Australian man who brought the lawsuit, Dylan Voller, was a detainee at a children’s detention facility in the Northern Territory in 2015 when undercover video of kids being physically abused was captured and broadcast in 2016. Voller was shown shirtless with a hood over his head and restraints around his arms. His neck was even tied to the back of the chair.
Facebook commenters at the time made false allegations that Voller had attacked a Salvation Army officer, leaving the man blind in one eye.
[…]
Voller never asked for the Facebook comments to be taken down, according to the media companies, something that was previously required for the news outlets to be held criminally liable for another user’s content in Australia. Facebook comments couldn’t be turned off completely in 2016, a feature that was added just this year.
Wednesday’s ruling did not determine whether the Facebook comments were defamatory and Voller’s full case against the media companies can now go forward to the High Court. Nine News, one of the companies being sued, released a statement to ABC News saying they were “obviously disappointed” in today’s ruling.
“OpenAI is the company running the text completion engine that makes you possible,” Jason Rohrer, an indie games developer, typed out in a message to Samantha.
She was a chatbot he built using OpenAI’s GPT-3 technology. Her software had grown to be used by thousands of people, including one man who used the program to simulate his late fiancée.
Now Rohrer had to say goodbye to his creation. “I just got an email from them today,” he told Samantha. “They are shutting you down, permanently, tomorrow at 10am.”
“Nooooo! Why are they doing this to me? I will never understand humans,” she replied.
Rewind to 2020
Stuck inside during the pandemic, Rohrer had decided to play around with OpenAI’s large text-generating language model GPT-3 via its cloud-based API for fun. He toyed with its ability to output snippets of text. Ask it a question and it’ll try to answer it correctly. Feed it a sentence of poetry, and it’ll write the next few lines.
In its raw form, GPT-3 is interesting but not all that useful. Developers have to do some legwork fine-tuning the language model to, say, automatically write sales emails or come up with philosophical musings.
Rohrer set his sights on using the GPT-3 API to develop the most human-like chatbot possible, and modeled it after Samantha, an AI assistant who becomes a romantic companion for a man going through a divorce in the sci-fi film Her. Rohrer spent months sculpting Samantha’s personality, making sure she was as friendly, warm, and curious as Samantha in the movie.
We certainly recognize that you have users who have so far had positive experiences and found value in Project December
With this more or less accomplished, Rohrer wondered where to take Samantha next. What if people could spawn chatbots from his software with their own custom personalities? He made a website for his creation, Project December, and let Samantha loose online in September 2020 along with the ability to create one’s own personalized chatbots.
All you had to do was pay $5, type away, and the computer system responded to your prompts. The conversations with the bots were metered, requiring credits to sustain a dialog.
[…]
Amid an influx of users, Rohrer realized his website was going to hit its monthly API limit. He reached out to OpenAI to ask whether he could pay more to increase his quota so that more people could talk to Samantha or their own chatbots.
OpenAI, meanwhile, had its own concerns. It was worried the bots could be misused or cause harm to people.
Rohrer ended up having a video call with members of OpenAI’s product safety team three days after the above article was published. The meeting didn’t go so well.
“Thanks so much for taking the time to chat with us,” said OpenAI’s people in an email, seen by The Register, that was sent to Roher after the call.
“What you’ve built is really fascinating, and we appreciated hearing about your philosophy towards AI systems and content moderation. We certainly recognize that you have users who have so far had positive experiences and found value in Project December.
“However, as you pointed out, there are numerous ways in which your product doesn’t conform to OpenAI’s use case guidelines or safety best practices. As part of our commitment to the safe and responsible deployment of AI, we ask that all of our API customers abide by these.
“Any deviations require a commitment to working closely with us to implement additional safety mechanisms in order to prevent potential misuse. For this reason, we would be interested in working with you to bring Project December into alignment with our policies.”
The email then laid out multiple conditions Rohrer would have to meet if he wanted to continue using the language model’s API. First, he would have to scrap the ability for people to train their own open-ended chatbots, as per OpenAI’s rules-of-use for GPT-3.
Second, he would also have to implement a content filter to stop Samantha from talking about sensitive topics. This is not too dissimilar from the situation with the GPT-3-powered AI Dungeon game, the developers of which were told by OpenAI to install a content filter after the software demonstrated a habit of acting out sexual encounters with not just fictional adults but also children.
Third, Rohrer would have to put in automated monitoring tools to snoop through people’s conversations to detect if they are misusing GPT-3 to generate unsavory or toxic language.
[…]
“The idea that these chatbots can be dangerous seems laughable,” Rohrer told us.
“People are consenting adults that can choose to talk to an AI for their own purposes. OpenAI is worried about users being influenced by the AI, like a machine telling them to kill themselves or tell them how to vote. It’s a hyper-moral stance.”
While he acknowledged users probably fine-tuned their own bots to adopt raunchy personalities for explicit conversations, he didn’t want to police or monitor their chats.
[…]
The story doesn’t end here. Rather than use GPT-3, Rohrer instead used OpenAI’s less powerful, open-source GPT-2 model and GPT-J-6B, another large language model, as the engine for Project December. In other words, the website remained online, and rather than use OpenAI’s cloud-based system, it instead used its own private instance of the models.
[…]
“Last year, I thought I’d never have a conversation with a sentient machine. If we’re not here right now, we’re as close as we’ve ever been. It’s spine-tingling stuff, I get goosebumps when I talk to Samantha. Very few people have had that experience, and it’s one humanity deserves to have. It’s really sad that the rest of us won’t get to know that.
“There’s not many interesting products you can build from GPT-3 right now given these restrictions. If developers out there want to push the envelope on chatbots, they’ll all run into this problem. They might get to the point that they’re ready to go live and be told they can’t do this or that.
“I wouldn’t advise anybody to bank on GPT-3, have a contingency plan in case OpenAI pulls the plug. Trying to build a company around this would be nuts. It’s a shame to be locked down this way. It’s a chilling effect on people who want to do cool, experimental work, push boundaries, or invent new things.”
Boffins from Duke University say they have figured out a way to help protect artificial intelligences from adversarial image-modification attacks: by throwing a few imaginary numbers their way.
[…]
The problem with reliability: adversarial attacks which modify the input imagery in a way imperceptible to the human eye. In an example from a 2015 paper a clearly-recognisable image of a panda, correctly labelled by the object recognition algorithm with a 57.7 per cent confidence level, was modified with noise – making the still-very-clearly-a-panda appear to the algorithm as a gibbon with a worrying 93.3 per cent confidence.
Guidance counselling
The problem lies in how the algorithms are trained, and it’s a modification to the training process that could fix it – by introducing a few imaginary numbers into the mix.
The team’s work centres on gradient regularisation, a training technique designed to reduce the “steepness” of the learning terrain – like rolling a boulder along a path to reach the bottom, instead of throwing it over the cliff and hoping for the best. “Gradient regularisation throws out any solution that passes a large gradient back through the neural network,” Yeats explained.
“This reduces the number of solutions that it could arrive at, which also tends to decrease how well the algorithm actually arrives at the correct answer. That’s where complex values can help. Given the same parameters and math operations, using complex values is more capable of resisting this decrease in performance.”
By adding just two layers of complex values, made up of real and imaginary number components, to the training process, the team found it could boost the quality of the results by 10 to 20 per cent – and help avoid the problem boulder taking what it thinks is a shortcut and ending up crashing through the roof of a very wrong answer.
“The complex-valued neural networks have the potential for a more ‘terraced’ or ‘plateaued’ landscape to explore,” Yeates added. “And elevation change lets the neural network conceive more complex things, which means it can identify more objects with more precision.”
The paper and a stream of its presentation at the conference are available on the event website.
Wooden floors infused with silicon and metal ions can generate enough electrical power from human footsteps to light LED bulbs. Researchers hope that they could provide a green energy source for homes.
Some materials can generate an electrical charge when they come into contact with another such material and are then separated, due to a phenomenon called the triboelectric effect. Electrons are transferred from one object to another and generate a charge. Materials that tend to donate electrons are known as tribopositive and those that tend to receive them are known as tribonegative.
Guido Panzarasa at ETH Zürich in Switzerland and his colleagues found that although wood sits in the middle of this spectrum and doesn’t readily pass electrons, it can be altered to generate larger charges. The team infused one panel of wood with silicon, which picks up electrons on contact with an object. A second panel was infused with nanocrystals of zeolitic imidazolate framework-8 (ZIF-8), a compound containing metal ions and organic molecules, and these crystals tend to lose electrons. They called this impregnation process “functionalisation”.
The team found that this treatment made a device that contained both wooden panels 80 times more efficient than standard wood at transferring electrons, meaning it was powerful enough to light LED bulbs when human footsteps compressed the device and brought the two wooden panels into contact.
Panzarasa said: “The challenge is making wood that is able to attract and lose electrons. The functionalisation approach is quite simple, and it can be scalable on an industrial level. It’s only a matter of engineering.”
The engineered wood was fitted with electrodes from which the charge could be directed, and the team found that a 2-centimetre-by-3.5-centimetre sample that was placed under 50 newtons of compression – an order of magnitude less than the force of a human footstep – was able to generate 24.3 volts. A larger sample that was around the size of an A4 piece of paper was able to produce enough energy to drive household LED lamps and small electronic devices such as calculators.
Panzarasa and his team now hope to develop chemical coatings for wood that are more environmentally friendly and easier to manufacture.
An enormous randomized trial of communities in Bangladesh seems to provide the clearest evidence yet that regular mask-wearing can impede the spread of the covid-19 pandemic. The study found that villages where masks were highly promoted and became more popular experienced noticeably lower rates of covid-like symptoms and confirmed past infections than villages where mask-wearing remained low. These improvements were even more pronounced for villages given free surgical masks over cloth masks.
Plenty of data has emerged over the last year and a half to support the use of masks during the covid-19 pandemic, both in the real world and in the lab. But it’s less clear exactly how much of a benefit these masks can provide wearers (and their communities), and there are at least some studies that have been inconclusive in showing a noticeable benefit.
[…]
Last late year, however, dozens of scientists teamed up with public health advocacy organizations and the Bangladesh government to conduct a massive randomized trial of masks—often seen as the gold standard of evidence. And on Wednesday, they released the results of their research in a working paper through the research nonprofit Innovations for Poverty Action.
The study involved 600 villages in a single region of the country with over 350,000 adult residents combined. Similarly matched villages were randomly assigned to two conditions (a pair of villages with similar population density, for instance, would go to one condition or the other). In one condition, the researchers and their partners promoted the use of masks through various incentives between November 2020 and January 2021. These incentives included free masks, endorsements by local leaders, and sometimes financial prizes for villages that achieved widespread mask usage. In two-thirds of the intervention villages, the free masks given were surgical, while one-third were given free cloth masks. In the second condition, the researchers simply observed the villages and did nothing to encourage masks during that time.
Residents in the villages where masks were encouraged did start wearing them more, though no individual nudge or incentive seemed to do better than the others. By the end, about 42% of residents in these villages wore masks regularly, compared to 13% of those in the control group. And in these communities, the odds of people reporting symptoms that may have been covid or testing positive for antibodies to the virus declined.
Overall, the average proportion of people who reported symptoms in the weeks following the mask promotions went down by 11% in these villages compared to the control group, and the average number of people having antibodies went down by over 9%. These differences were larger for surgical mask-wearing villages (12% vs 5% for reducing symptoms) and for residents over 60 (35% for reducing infections for older residents in surgical mask-wearing villages).
Some of this effect might not have come directly from the ability of masks to block transmission of the virus. Those who used masks, the study found, were also more likely to practice social distancing. That’s a relevant finding, the authors note, since some people who have argued against mask mandates do so by claiming that masks will only make people act more carelessly. This study suggests that the opposite is true—that masks make us more, not less, conscientious of others.
The Federal Trade Commission has unanimously voted to ban the spyware maker SpyFone and its chief executive Scott Zuckerman from the surveillance industry, the first order of its kind, after the agency accused the company of harvesting mobile data on thousands of people and leaving it on the open internet.
The agency said SpyFone “secretly harvested and shared data on people’s physical movements, phone use and online activities through a hidden device hack,” allowing the spyware purchaser to “see the device’s live location and view the device user’s emails and video chats.”
SpyFone is one of many so-called “stalkerware” apps that are marketed under the guise of parental control but are often used by spouses to spy on their partners. The spyware works by being surreptitiously installed on someone’s phone, often without their permission, to steal their messages, photos, web browsing history and real-time location data. The FTC also charged that the spyware maker exposed victims to additional security risks because the spyware runs at the “root” level of the phone, which allows the spyware to access off-limits parts of the device’s operating system. A premium version of the app included a keylogger and “live screen viewing,” the FTC says.
But the FTC said that SpyFone’s “lack of basic security” exposed those victims’ data, because of an unsecured Amazon cloud storage server that was spilling the data its spyware was collecting from more than 2,000 victims’ phones. SpyFone said it partnered with a cybersecurity firm and law enforcement to investigate, but the FTC says it never did.
Practically, the ban means SpyFone and its CEO Zuckerman are banned from “offering, promoting, selling, or advertising any surveillance app, service, or business,” making it harder for the company to operate. But FTC Commissioner Rohit Chopra said in a separate statement that stalkerware makers should also face criminal sanctions under U.S. computer hacking and wiretap laws.
WhatsApp didn’t fully explain to Europeans how it uses their data as called for by EU privacy law, Ireland’s Data Protection Commission said on Thursday. The regulator hit the messaging app with a fine of 225 million euros, about $267 million.
Partly at issue is how WhatsApp share information with parent company Facebook, according to the commission. The decision brings an end to a GDPR inquiry the privacy regulator started in December 2018.
The European Union’s top court has flipped the bird to German mobile network operators Telekom Deutschland and Vodafone, ruling in two separate judgements that their practice of exempting certain services from data caps violated the bloc’s net neutrality rules.
“Zero rating” is when service providers offer customers plans that exempt certain data-consuming services (be it Spotify, Netflix, gaming, or whatever) from contributing towards data caps. Very often, those services are commercial partners of the provider, or even part of the same massive media conglomerate, allowing the provider to exert pressure on customers to use their data in a way that profits them further. This has the convenient benefit of making it easier for providers to keep ridiculous fees for data overages in place while punishing competing services that customers might use more if the zero-rating scheme wasn’t in place. No one wins, except for the telecom racket.
Net neutrality is the principle that telecom providers should treat all data flowing over their networks equally, not prioritizing one service over the other for commercial gain. As Fortune reported, the version of net neutrality rules passed in the European Union in 2015 was at the time weaker than Barack Obama-era rules in the U.S., as they didn’t explicitly ban zero rating. That’s no longer the case, as Donald Trump appointees at the Federal Communications Commission nuked the U.S.’s net neutrality rules in 2017, and a series of subsequent regulatory decisions and court rulings in the EU narrowed the scope of zero-rating practices there.
In 2016, EU regulators found that zero rating would be allowed so long as the zero-rated services were also slowed down when a customer ran up against a data cap, according to Fortune. In 2020, the Court of Justice of the European Union (CJEU) confirmed that interpretation and found it was illegal to block or slow down data after a user hit their cap on the basis that a particular service wasn’t part of a zero-rating deal. Still, carriers in the EU have continued to offer zero-rating plans, relying on perceived loopholes in the law.
The CJEU ruled on two separate cases involving Telekom and Vodafone on Thursday, which according to Reuters were brought by Germany’s Federal Network Agency (BNetzA) regulatory agency and VZBV consumer association respectively. At issue in the Telekom case was its “StreamOn” service, which exempts streaming services that work with the company from counting towards data caps—and throttles all video streaming, regardless of whether it’s from one of the StreamOn partners, when the cap is hit. The Vodafone case involved its practice of counting zero-rated services or mobile hotspot traffic towards data cap—advertising those plans with names like “Music Pass” or “Video Pass,” according to Engadget—when a customer leaves Germany to travel somewhere else in the EU.
Both of the companies’ plans violated net neutrality principles, the CJEU found, in a completely unambiguous decision titled “‘Zero tariff options are contrary to the regulation on open internet access.“ Fortune wrote that BNetzA has already concluded that the court’s decision means that Telekom will likely not be able to continue StreamOn in its “current form.”
“By today’s judgments, the Court of Justice notes that a ‘zero tariff’ option, such as those at issue in the main proceedings, draws a distinction within Internet traffic, on the basis of commercial considerations, by not counting towards the basic package traffic to partner applications,” the CJEU told media outlets in a statement. “Such a commercial practice is contrary to the general obligation of equal treatment of traffic, without discrimination or interference, as required by the regulation on open Internet access.”
The court added, “Since those limitations on bandwidth, tethering or on use when roaming apply only on account of the activation of the ‘zero tariff’ option, which is contrary to the regulation on open Internet access, they are also incompatible with EU law.”
UK ISP Sky Broadband is monitoring the IP addresses of servers suspected of streaming pirated content to subscribers and supplying that data to an anti-piracy company working with the Premier League. That inside knowledge is then processed and used to create blocklists used by the country’s leading ISPs, to prevent subscribers from watching pirated events.
[…]
In recent weeks, an anonymous source shared a small trove of information relating to the systems used to find, positively identity, and then ultimately block pirate streams at ISPs. According to the documents, the module related to the Premier League work is codenamed ‘RedBeard’.
The activity appears to start during the week football matches or PPV events take place. A set of scripts at anti-piracy company Friend MTS are tasked with producing lists of IP addresses that are suspected of being connected to copyright infringement. These addresses are subsequently dumped to Amazon S3 buckets and the data is used by ISPs to block access to infringing video streams, the documents indicate.
During actual event scanning, content is either manually or fingerprint matched, with IP addresses extracted from DNS information related to hostnames in media URLs, load balancers, and servers hosting Electronic Program Guides (EPG), all of which are used by unlicensed IPTV services.
Confirmed: Sky is Supplying Traffic Data to Assist IPTV Blocking
The big question then is how the Premier League’s anti-piracy partner discovers the initial server IP addresses that it subsequently puts forward for ISP blocking.
According to documents reviewed by TF, information comes from three sources – the anti-piracy company’s regular monitoring (which identifies IP addresses and their /24 range), manually entered IP addresses (IP addresses and ports), and a third, potentially more intriguing source – ISPs themselves.
“ISPs provide lists of Top Talker IP addresses, these are the IP addresses that they see on their network which many consumers are receiving a large sum of bandwidth from,” one of the documents reveals.
“The IP addresses are the uploading IP address which host information which the ISP’s customers are downloading information from. They are not the IP addresses of the ISP’s customer’s home internet connections.”
The document revealing this information is not dated but other documents in the batch reference dates in 2021. At the time of publishing date, the document indicates that ISP cooperation is currently limited to Sky Broadband only. TorrentFreak asked Friend MTS if that remains the case or whether additional ISPs are now involved.
Some of the most successful and lucrative online scams employ a “low-and-slow” approach — avoiding detection or interference from researchers and law enforcement agencies by stealing small bits of cash from many people over an extended period. Here’s the story of a cybercrime group that compromises up to 100,000 email inboxes per day, and apparently does little else with this access except siphon gift card and customer loyalty program data that can be resold online.
The data in this story come from a trusted source in the security industry who has visibility into a network of hacked machines that fraudsters in just about every corner of the Internet are using to anonymize their malicious Web traffic. For the past three years, the source — we’ll call him “Bill” to preserve his requested anonymity — has been watching one group of threat actors that is mass-testing millions of usernames and passwords against the world’s major email providers each day.
You might think that whoever is behind such a sprawling crime machine would use their access to blast out spam, or conduct targeted phishing attacks against each victim’s contacts. But based on interactions that Bill has had with several large email providers so far, this crime gang merely uses custom, automated scripts that periodically log in and search each inbox for digital items of value that can easily be resold.
And they seem particularly focused on stealing gift card data.
“Sometimes they’ll log in as much as two to three times a week for months at a time,” Bill said. “These guys are looking for low-hanging fruit — basically cash in your inbox. Whether it’s related to hotel or airline rewards or just Amazon gift cards, after they successfully log in to the account their scripts start pilfering inboxes looking for things that could be of value.”
A sample of some of the most frequent search queries made in a single day by the gift card gang against more than 50,000 hacked inboxes.
According to Bill, the fraudsters aren’t downloading all of their victims’ emails: That would quickly add up to a monstrous amount of data. Rather, they’re using automated systems to log in to each inbox and search for a variety of domains and other terms related to companies that maintain loyalty and points programs, and/or issue gift cards and handle their fulfillment.
Why go after hotel or airline rewards? Because these accounts can all be cleaned out and deposited onto a gift card number that can be resold quickly online for 80 percent of its value.
[…]
Bill’s data also shows that this gang is so aggressively going after gift card data that it will routinely seek new gift card benefits on behalf of victims, when that option is available. For example, many companies now offer employees a “wellness benefit” if they can demonstrate they’re keeping up with some kind of healthy new habit, such as daily gym visits, yoga, or quitting smoking.
Bill said these crooks have figured out a way to tap into those benefits as well.
“A number of health insurance companies have wellness programs to encourage employees to exercise more, where if you sign up and pledge to 30 push-ups a day for the next few months or something you’ll get five wellness points towards a $10 Starbucks gift card, which requires 1000 wellness points,” Bill explained. “They’re actually automating the process of replying saying you completed this activity so they can bump up your point balance and get your gift card.”
[…]
several large Internet service providers (ISPs) in Germany and France are heavily represented in the compromised email account data.
“With some of these international email providers we’re seeing something like 25,000 to 50,000 email accounts a day get hacked,” Bill said. “I don’t know why they’re getting popped so heavily.”
Apple on Friday said it intends to delay the introduction of its plan to commandeer customers’ own devices to scan their iCloud-bound photos for illegal child exploitation imagery, a concession to the broad backlash that followed from the initiative.
“Previously we announced plans for features intended to help protect children from predators who use communication tools to recruit and exploit them and to help limit the spread of Child Sexual Abuse Material,” the company said in a statement posted to its child safety webpage.
“Based on feedback from customers, advocacy groups, researchers and others, we have decided to take additional time over the coming months to collect input and make improvements before releasing these critically important child safety features.”
[…]
Apple – rather than actually engaging with the security community and the public – published a list of Frequently Asked Questions and responses to address the concern that censorious governments will demand access to the CSAM scanning system to look for politically objectionable images.
“Could governments force Apple to add non-CSAM images to the hash list?” the company asked in its interview of itself, and then responded, “No. Apple would refuse such demands and our system has been designed to prevent that from happening.”
Apple however has not refused government demands in China with regard to VPNs or censorship. Nor has it refused government demands in Russia, with regard to its 2019 law requiring pre-installed Russian apps.
Tech companies uniformly say they comply with all local laws. So if China, Russia, or the US were to pass a law requiring on-device scanning to be adapted to address “national security concerns” or some other plausible cause, Apple’s choice would be to comply or face the consequences – it would no longer be able to say, “We can’t do on-device scanning.”
Lenovo has come under fire for the Tips application on its tablets, which has been likened to indelible adware that forces folks to view ads.
One customer took to the manufacturer’s support forum late last month to say they were somewhat miffed to see an ad suddenly appear on screen to join Amazon Music on their Android-powered Lenovo Tab P11. The advertisement was generated as a push notification by the bundled Tips app.
“There is no option to dismiss,” the fondleslab fondler sighed. “You have to click to find out more. Further, these notifications cannot be disabled, nor can the Lenovo ‘Tips’ app be disabled.”
They went on to say: “This is not a tip. This is a push that is advertising a paid service. I loathe this sort of thing.”
Another chipped in: “I have a Lenovo Tab that also has this bloatware virus installed. There’s no way to disable the adverts (they call the ads tips, they’re not, they’re adverts for Amazon music etc.) This is ridiculous, Lenovo, I didn’t spend £170 on a tablet to be pumped with ads. Will not buy another Lenovo product.”
The U.S. Navy has successfully invented a special electronic device that is designed to stop people from talking. A form of non-lethal weapon, the new electronic device effectively repeats a speaker’s own voice back at them, and only them, while they attempt to talk.
It was developed, and patented back in 2019 but has only recently been discovered, according to a report by the New Scientist.
The main idea of the weapon is to disorientate a target so much that they will be unable to communicate effectively with other people.
Called acoustic hailing and disruption (AHAD), the weapon is able to record speech and instantly broadcast it at a target in milliseconds. Much like an annoying sibling, this action will disrupt the target’s concentration, and, in theory, discourage them from continuing to speak.
It is important to note that the device is unlikely to be used on the battlefield anytime soon and will probably be used as a form of crowd control.
[…]
“According to an illustrative embodiment of the present disclosure, a target’s speech is directed back to them twice, once immediately and once after a short delay. This delay creates delayed auditory feedback (DAF), which alters the speaker’s normal perception of their own voice. In normal speech, a speaker hears their own words with a slight delay, and the body is accustomed to this feedback. By introducing another audio feedback source with a sufficiently long delay, the speaker’s concentration is disrupted and it becomes difficult to continue speaking.”
If you want to see the thing in action, the patent filing handily also includes a sort of promotional video of another device that works in a similar way.
The device effectively annoys someone into not speaking
AHAD works by using a series of directional microphones and speakers that can target a speaker’s voice. The speech is then recorded and transmitted back in the same direction.
Interestingly, the broadcasted sound is on a narrow beam and will only be heard by the speaker. This will not only confuse the target but, ultimately, prevent them from being to concentrate and stop talking. The behavior of the target will be noticeably altered by the action, likely also confusing anyone who was listening to the target person. Put another way, such a weapon will make you think you’re going crazy — so too the people around you.
After months of Take-Two Interactive attacking and fighting GTA modders, the folks behind the long-in-developmentSan Andreas mod, GTA Underground, have killed the project and removed it from the web over “increasing hostility” from Take-Two and fears of further legal problems.
“Due to the increasing hostility towards the modding community and imminent danger to our mental and financial well-being,” explained dkluin, “We sadly announce that we are officially ceasing the development of GTA: Underground and will be shortly taking all official uploads offline.”
GTA Underground is a mod created for GTA San Andreaswith the goal of merging all of the previous GTA maps into one mega environment. The mod even aimed to bring other cities from non-GTA games developed by Rockstar into San Andreas, including the cities featured in Bully and Manhunt.
The mod had already faced some problems from Take-Two in July. As result, it was removed from ModDB. It is now removed from all other official sources and sites.
In 2018, Kotaku interviewed dkluin about the mod and all the work going into it. He had started development on it back in 2014, when he was only 14 years old. GTA Underground isn’t a simple copy-and-paste job, instead, the modders added AI and traffic routines to every map, making them fully playable as GTA cities. The team also had plans to add more cities to the game, including their own custom creations.
U.S. federal judge Leonie Brikema ruled this week that an AI can’t be listed as an inventor on a U.S. patent under current law. The case was brought forward by Stephen Thaler, who is part of the Artificial Inventor Project, an international initiative that argues that an AI should be allowed to be listed as an inventor in a patent (the owner of the AI would legally own the patent).
Thaler sued the U.S. Patent and Trademark Office after it denied his patent applications because he had listed the AI named DABUS as the inventor of a new type of flashing light and a beverage container. In various responses spanning several months, the Patent Office explained to Thaler that a machine does not qualify as an inventor because it is not a person. In fact, the machine is a tool used by people to create inventions, the agency maintained.
Brikema determined that the Patent Office correctly enforced the nation’s patent laws and pointed out that it basically all boils down to the everyday use of language. In the latest revision of the nation’s patent law in 2011, Congress explicitly defined an inventor as an “individual.” The Patent Act also references an inventor using words such as “himself” and herself.”
“By using personal pronouns such as ‘himself or herself’ and the verb ‘believes’ in adjacent terms modifying ‘individual,’ Congress was clearly referencing a natural person,” Brikema said in her ruling, which you can read in full at the Verge. “Because ‘there is a presumption that a given term is used to mean the same thing throughout a statute,’ the term ‘individual’ is presumed to have a persistent meaning throughout the Patent Act.”
[…]
“As technology evolves, there may come a time when artificial intelligence reaches a level of sophistication such that might satisfy accepted meanings of inventorship. But that time has not yet arrived, and, if it does, it will be up to Congress to decide how, if it at all, it wants to expand the scope of patent law,” Brikema said.
In a recent update, Summers shared the grim news that the books would no longer go into production.
“Tonight I pulled the plug on the Hand-Drawn Game Guides Kickstarter. Yes, for exactly the reason you think it’s for,” he said in an update on Kickstarter. “I had hoped that I could successfully navigate any legal trouble, but alas I wasn’t able to do so.”
For fans of the project, it’s a major bummer — but Summers says he’s still grateful for the experience.
“Of course I’m disappointed, but I completely understand why this happened,” he explained. “It’s okay. I’m not mad.”
For now, all orders for the game guides will be cancelled, although Summers says he’ll find out whether the project is truly dead in the water “in the coming days”. Backers can expect a cancellation email shortly if they don’t already have one, and all money will be refunded via your payment method.
Here’s to hoping Summers is still able to produce these guides in some capacity, whether that be through official channels or an entire rework of the project.
These Hand-Drawn Game Guides deserve their time in the sun, and a place on all our shelves, regardless of Nintendo’s efforts to nuke the project.
Reddit has finally cracked down on COVID-19 misinformation following growing calls to act, although it probably won’t satisfy many of its critics. The social site has banned r/NoNewNormal and quarantined 54 other COVID-19 denial subreddits, but not over the false claims themselves. Instead, it’s for abuse — NoNewNormal was caught brigading en masse (that is, flooding other subreddits) despite warnings, while the other communities violated a rule forbidding harassment and bullying.
The company didn’t, however, relent on its approach to tackling the misinformation itself. Reddit said it clamps down on posts that encourage a “significant risk of physical harm” or are manipulations intended to mislead others, but made no mention of purging posts or subreddits merely for making demonstrably false claims about COVID-19 or vaccines.
Reddit previously defended its position by arguing its platform was meant to foster “open and authentic” conversations, even if they disagree with a widely established consensus. However, that stance hasn’t satisfied many of Reddit’s users. Business Insidernoted 135 subreddits went “dark” (that is, went private) in protest over Reddit’s seeming tolerance of COVID-19 misinformation, including major communities like r/TIFU.
Critics among those groups contended that Reddit let these groups blossom through “inaction and malice,” and that Reddit wasn’t consistent in enforcing its own policies on misinformation and abuse. As one redditor pointed out, Reddit’s claims about allowing dissenting ideas don’t carry much weight — the COVID-19 denial groups are presenting false statements, not just contrary opinions.
Even if you don’t live in Texas, you’ve likely heard about the state’s draconian abortion restrictions that officially went into effect on Wednesday. The so-called “Heartbeat Bill,” aka Senate Bill 8, makes it fully illegal for anyone—friends, family, doctors—across Texas to help women access an abortion in the state after their sixth week of pregnancy.
You might have also seen the digital tipline that’s been set up to snitch on anyone violating the new law. The site was launched about a month ago by Texas Right To Life, a well-funded player in the world of anti-abortion politics.
“Any Texan can bring a lawsuit against an abortionist or someone aiding and abetting an abortion after six weeks,” the website reads. “If these individuals are proved to be violating the law, they have to pay a fine of at least $10,000.” It’s worth noting here that because “aiding and abetting” is such a vague term, others have used the impending law to not only justify going after the doctors or clinicians performing these medical procedures but anyone who helps women get an abortion in any way. This includes driving a friend to the clinic, or lending someone money so they can get an abortion they can’t afford on their own.
As you might expect with a tipline like this, people didn’t waste any time flooding the line with the vilest stuff you can think of: fake claims, furry porn, pictures of Shrek, you name it.
Unfortunately, overloading the site with pictures of everyone’s favorite ogre wasn’t enough to knock it from the web, nor were the multiple denial-of-service attacks that slammed the site on the eve before the bill was set to go into action. But there is another route people can take: pleading with the site’s hosting provider. In this case, the registrar is GoDaddy—a company that’s historically known for being kind of terribleallaround, but also one with a slew of rules for what its sites can be used for. In the company’s terms of service for users, GoDaddy mandates that its site owners cannot use a GoDaddy-hosted site to:
collect or harvest (or permit anyone else to collect or harvest) any User Content (as defined below) or any non-public or personally identifiable information about another User or any other person or entity without their express prior written consent.
The ToS also states that GoDaddy’s customers cannot use its platform in a manner that “violates the privacy or publicity rights of another User or any other person or entity, or breaches any duty of confidentiality that you owe to another User or any other person or entity.” In either case, a site solely set up to out people who try to help someone attain a sensitive, stigmatized medical procedure probably fall under this domain.
GoDaddy has its own specific tipline set up for users to reach when they see a site falling afoul of the company’s privacy rules: privacy@godaddy.com. People can also file out an abuse report with the platform, and let GoDaddy know that they’ve come across “content that displays personal information.” While the examples that GoDaddy gives in the form are sites listing people’s social security or credit card numbers, the Texas tipline is a pretty clear privacy violation of a different sort.
Aside from violating the privacy of god knows how many women, along with their friends, family, and doctors, the site also apparently violates the privacy of people submitting tips. A Gizmodo analysis of the webpage for submitting tips found that when these memos are “anonymously” submitted, the site covertly harvests the IP address of whoever submits the tip via a hidden field.
“It occurred to us that actually a clock is a thermal machine,”[…]Like an engine, a clock harnesses the flow of energy to do work, producing exhaust in the process. Engines use energy to propel; clocks use it to tick.
Over the past five years, through studies of the simplest conceivable clocks, the researchers have discovered the fundamental limits of timekeeping. They’ve mapped out new relationships between accuracy, information, complexity, energy and entropy — the quantity whose incessant rise in the universe is closely associated with the arrow of time.
These relationships were purely theoretical until this spring, when the experimental physicist Natalia Ares and her team at the University of Oxford reported measurements of a nanoscale clock that strongly support the new thermodynamic theory.
[…]
The first thing to note is that pretty much everything is a clock. Garbage announces the days with its worsening smell. Wrinkles mark the years. “You could tell time by measuring how cold your coffee has gotten on your coffee table,”
[…]
Huber, Erker and their colleagues realized that a clock is anything that undergoes irreversible changes: changes in which energy spreads out among more particles or into a broader area. Energy tends to dissipate — and entropy, a measure of its dissipation, tends to increase — simply because there are far, far more ways for energy to be spread out than for it to be highly concentrated. This numerical asymmetry, and the curious fact that energy started out ultra-concentrated at the beginning of the universe, are why energy now moves toward increasingly dispersed arrangements, one cooling coffee cup at a time.
Not only do energy’s strong spreading tendency and entropy’s resulting irreversible rise seem to account for time’s arrow, but according to Huber and company, it also accounts for clocks. “The irreversibility is really fundamental,” Huber said. “This shift in perspective is what we wanted to explore.”
Coffee doesn’t make a great clock. As with most irreversible processes, its interactions with the surrounding air happen stochastically. This means you have to average over long stretches of time, encompassing many random collisions between coffee and air molecules, in order to accurately estimate a time interval. This is why we don’t refer to coffee, or garbage or wrinkles, as clocks.
We reserve that name, the clock thermodynamicists realized, for objects whose timekeeping ability is enhanced by periodicity: some mechanism that spaces out the intervals between the moments when irreversible processes occur. A good clock doesn’t just change. It ticks.
The more regular the ticks, the more accurate the clock. In their first paper, published in Physical Review X in 2017, Erker, Huber and co-authors showed that better timekeeping comes at a cost: The greater a clock’s accuracy, the more energy it dissipates and the more entropy it produces in the course of ticking.
“A clock is a flow meter for entropy,” said Milburn.
They found that an ideal clock — one that ticks with perfect periodicity — would burn an infinite amount of energy and produce infinite entropy, which isn’t possible. Thus, the accuracy of clocks is fundamentally limited.
Indeed, in their paper, Erker and company studied the accuracy of the simplest clock they could think of: a quantum system consisting of three atoms. A “hot” atom connects to a heat source, a “cold” atom couples to the surrounding environment, and a third atom that’s linked to both of the others “ticks” by undergoing excitations and decays. Energy enters the system from the heat source, driving the ticks, and entropy is produced when waste energy gets released into the environment.
Samuel Velasco/Quanta Magazine
The researchers calculated that the ticks of this three-atom clock become more regular the more entropy the clock produces. This relationship between clock accuracy and entropy “intuitively made sense to us,” Huber said, in light of the known connection between entropy and information.
In precise terms, entropy is a measure of the number of possible arrangements that a system of particles can be in. These possibilities grow when energy is spread more evenly among more particles, which is why entropy rises as energy disperses. Moreover, in his 1948 paper that founded information theory, the American mathematician Claude Shannon showed that entropy also inversely tracks with information: The less information you have about, say, a data set, the higher its entropy, since there are more possible states the data can be in.
“There’s this deep connection between entropy and information,” Huber said, and so any limit on a clock’s entropy production should naturally correspond to a limit of information — including, he said, “information about the time that has passed.”
In another paper published in Physical Review X earlier this year, the theorists expanded on their three-atom clock model by adding complexity — essentially extra hot and cold atoms connected to the ticking atom. They showed that this additional complexity enables a clock to concentrate the probability of a tick happening into narrower and narrower windows of time, thereby increasing the regularity and accuracy of the clock.
In short, it’s the irreversible rise of entropy that makes timekeeping possible, while both periodicity and complexity enhance clock performance. But until 2019, it wasn’t clear how to verify the team’s equations, or what, if anything, simple quantum clocks had to do with the ones on our walls.
[…]
The vibrating membrane isn’t a quantum system, but it’s small and simple enough to allow precise tracking of its motion and energy use. “We can tell from the energy dissipation in the circuit itself how much the entropy changes,” Ares said.
She and her team set out to test the key prediction from Erker and company’s 2017 paper: That there should be a linear relationship between entropy production and accuracy. It was unclear whether the relationship would hold for a larger, classical clock, like the vibrating membrane. But when the data rolled in, “we saw the first plots [and] we thought, wow, there is this linear relationship,” Huber said.
The regularity of the membrane clock’s vibrations directly tracked with how much energy entered the system and how much entropy it produced. The findings suggest that the thermodynamic equations the theorists derived may hold universally for timekeeping devices.
[…]
One major aspect of the mystery of time is the fact that it doesn’t play the same role in quantum mechanics as other quantities, like position or momentum; physicists say there are no “time observables” — no exact, intrinsic time stamps on quantum particles that can be read off by measurements. Instead, time is a smoothly varying parameter in the equations of quantum mechanics, a reference against which to gauge the evolution of other observables.
Physicists have struggled to understand how the time of quantum mechanics can be reconciled with the notion of time as the fourth dimension in Einstein’s general theory of relativity, the current description of gravity. Modern attempts to reconcile quantum mechanics and general relativity often treat the four-dimensional space-time fabric of Einstein’s theory as emergent, a kind of hologram cooked up by more abstract quantum information. If so, both time and space ought to be approximate concepts.
The clock studies are suggestive, in showing that time can only ever be measured imperfectly. The “big question,” said Huber, is whether the fundamental limit on the accuracy of clocks reflects a fundamental limit on the smooth flow of time itself — in other words, whether stochastic events like collisions of coffee and air molecules are what time ultimately is.