The Alfa Romeo 33 Stradale is one of only a few cars out there that’ll be available with both a V6 engine and a fully electric drivetrain. While that lets it swing from both sides of the plate, it also highlights just how much heavier EVs are than their combustion counterparts these days. And try as Alfa Romeo might, there’s no way that doesn’t affect the supercar’s handling.
The limited-production, 33-unit-only Alfa supercar debuted earlier today, with one version using a 3.0-liter, twin-turbo V6, and the other a 102 kilowatt-hour battery feeding an 800-volt, tri-motor drivetrain. The difference in their weight is stark, with the V6 model said to weigh less than 3,307 pounds, and the EV a good 1,300 lbs more at (under) 4,630 lbs. Because of the EV’s power advantage though, the two are said to perform pretty much identically in a straight line, doing zero-to-60 in under three seconds, and stopping in a similar sub-108 feet. (That said, the EV runs out of steam at high speed, and has a slightly lower top speed.)
The new Alfa Romeo 33 Stradale. Alfa Romeo
Their handling differences may be minimized by torque vectoring, which seems to be offered only on the EV. But even then, it’s impossible to completely hide the effect that a 40-percent weight gain has on a car’s performance
In OpenAI’s motion to dismiss (filed in both lawsuits), the company asked a US district court in California to toss all but one claim alleging direct copyright infringement, which OpenAI hopes to defeat at “a later stage of the case.”
The authors’ other claims—alleging vicarious copyright infringement, violation of the Digital Millennium Copyright Act (DMCA), unfair competition, negligence, and unjust enrichment—need to be “trimmed” from the lawsuits “so that these cases do not proceed to discovery and beyond with legally infirm theories of liability,” OpenAI argued.
OpenAI claimed that the authors “misconceive the scope of copyright, failing to take into account the limitations and exceptions (including fair use) that properly leave room for innovations like the large language models now at the forefront of artificial intelligence.”
According to OpenAI, even if the authors’ books were a “tiny part” of ChatGPT’s massive data set, “the use of copyrighted materials by innovators in transformative ways does not violate copyright.”
[…]
The purpose of copyright law, OpenAI argued, is “to promote the Progress of Science and useful Arts” by protecting the way authors express ideas, but “not the underlying idea itself, facts embodied within the author’s articulated message, or other building blocks of creative,” which are arguably the elements of authors’ works that would be useful to ChatGPT’s training model. Citing a notable copyright case involving Google Books, OpenAI reminded the court that “while an author may register a copyright in her book, the ‘statistical information’ pertaining to ‘word frequencies, syntactic patterns, and thematic markers’ in that book are beyond the scope of copyright protection.”
So the authors are saying that if you read their book and then are inspired by it, you can’t use that memory – any of it – to write another book. Which also means that you presumably wouldn’t be able to use any words at all, as they are all copyrighted entities which have inspired you in the past as well.
The Act (DSA) sets rules that the EU designed to make very large online platforms (VLOPs) “tackle the spread of illegal content, online disinformation and other societal risks” presented by online service providers.”
The DSA and the Digital Market Act (DMA) are a double act. Both were introduced in 2022 and will be implemented in phases through early 2024. While the DMA applies to companies who act as gatekeepers of online services and are designed to ensure equal access for some third-party software, the DSA is all about ensuring that activities which are illegal in the real world are enforceably illegal online, too.
Under the DSA digital service providers – including hosting services, online platforms, VLOPs and even intermediary service providers like ISPs – have obligations to ensure that products sold are safe and not counterfeit, and to eliminate advertising that targets minors or is served using sensitive data. Another requirement is to get rid of dark patterns in advertising. Clarity on how orgs moderate content and a requirement to present their algorithms for scrutiny is also required.
VLOPs, which the DSA defines as platforms large enough to reach 10 percent of the EU’s population, or around 45 million people, have even more rules to comply with.
The EU believes that VLOPs present the most risk to the public due to their wide reach. In addition to rules that other digital service providers have to follow, VLOPs also have to share data with “vetted” researchers and governments, allow users to opt out of profiling recommendations, submit to regular audits, and have risk management and a crisis response plans in place.
The EU made its initial declaration to cover 17 VLOPs and two very large online search engines (Bing and Google) on April 25. The DSA will apply to any and all digital service providers come February 2024. VLOPs were told they had four months from the day they were designated to achieve compliance.
Non-compliant VLOPs could face fines of up to six percent of global turnover, rather than the relatively small fines they usually face. The EC said it also has the power to require immediate platform changes and, in the case of continued noncompliance, has the right to suspend offenders from the trading bloc entirely.
In the wake of the onslaught of the covid-19, employees across the world grew chummy with a perfectly appropriate remote work schedule that allows them to work from home. However, one of the companies that carried pandemic digital infrastructure on its back, Zoom, isn’t too keen on keeping remote workers away from the office since the video calling platform is making them too friendly, according to leaked audio of CEO Eric Yuan at an all-hands meeting at the company.
Insider first reported on the recording in which Yuan told employees within 50 miles of an office that they must report to the office a minimum of two days a week. The announcement came at a companywide meeting on August 3, during which Yuan said that it’s difficult for Zoomies—the pet name the company gives to employees—to build trust with each other on a computer screen. Yuan also reportedly added that it’s difficult to have innovative conversations and debates on the company’s own platform because it makes people too friendly.
“Over the past several years, we’ve hired so many new ‘Zoomies’ that it’s really hard to build trust,” Yuan said in the audio. “We cannot have a great conversation. We cannot debate each other well because everyone tends to be very friendly when you join a Zoom call.”
Zoom did not immediately return Gizmodo’s request for comment on the audio or when employees are expected to return to the office.
Yuan’s proposed hybrid schedule is not a huge ask as a lot of competently run companies are finding a happy medium between remote work and wholly in-office routine through hybrid arrangements. Yuan’s comments, however, point more toward the company’s beliefs in the ability of its platform—it makes you too friendly and is unable to help you build trust with the guests on your call or help you innovate.
The same federal agency that once helped bring down the biggest crypto-based dark web drug marketplace Silk Road got swindled by one of the oldest tricks in the crypto scammer playbook. The U.S. Drug Enforcement Administration reportedly handed a fraudster a little more than $55,000 in confiscated crypto funds after it was duped by a classic airdrop phishing scam.
Forbes first reported on a warrant put out by the FBI investigating the scam. Those funds were stored in a Trezor crypto wallet, a more secure kind of crypto storage than an exchange-based wallet. The funds were further secured inside a “secure facility.” However, since all transactions are public on the blockchain, a scammer noticed when the DEA sent a test amount of $45.36 in Tether to a wallet owned by the U.S. Marshals.
The alleged scammer then performed what’s known as an airdrop scam. Essentially, the fraudster created a new address with the first five and last four digits of the Marshals’ account. Each crypto wallet has a unique address that’s about 30 characters long. Then, the fraudster sent, or “airdropped” some Tether into the DEA’s account, which shows up as looking like it came from the marshal’s address.
This works because the two accounts seem similar, so any layperson who only looks at the first few and last few characters to confirm will simply copy and paste the whole address rather than type it out. Trezor actively warns its users against airdrop scams, though in most cases, fraudsters want to access the wallet’s entire balance through a website link. These scams usually work against users investing in a new coin drop, but eagle-eyed fraudsters looking at crypto addresses might get lucky with a quick phishing attack, as they did here.
Amid the confusion, the DEA ended up sending funds to the fake marshal’s address, and by the time the two separate Department of Justice agencies realized what had happened, the funds had already been moved out of the scammer’s account.
What the article doesn’t explain is why the Feds were sending around these wallets at all, considering they were supposed to be impounded and evidence?
Is Achmea or Bol.com customer service putting you on hold? Then everything you say can still be heard by some of their employees. This is evident from research by Radar.
When you call customer service, you often hear: “Please note: this conversation may be recorded for training purposes.” Nothing special. But if you call the insurer Zilveren Kruis, you will also hear: “Note: Even if you are on hold, our quality employees can hear what you are saying.”
Striking, because the Dutch Data Protection Authority states that recording customers ‘on hold’ is not allowed. Companies are allowed to record the conversation, for example to conclude a contract or to improve the service.
Both mortgage provider Woonfonds and insurers Zilveren Kruis, De Friesland and Interpolis confirm that the recording tape continues to run if you are on hold with them, while this violates privacy rules.
Bol.com also continues to eavesdrop on you while you are on hold, the webshop confirms. She also gives the same reason for this: “It is technically not possible to temporarily stop the recording and start it again when the conversation starts again.”KLM, Ziggo, Eneco, Vattenfall, T-Mobile, Nationale Nederlanden, ASR, ING and Rabobank say they don’t answer their customers while they are on hold.
A buzzy startup offering financial infrastructure to crypto companies has found itself bankrupt primarily because it can’t gain access to a physical crypto wallet with $38.9 million in it. The company also did not write down recovery phrases, locking itself out of the wallet forever in something it has called “The Wallet Event” to a bankruptcy judge.
Prime Trust pitches itself as a crypto fintech company designed to help other startups offer crypto retirement plans, know-your-customer interfaces, ensure liquidity, and a host of other services. It says it can help companies build crypto exchanges, payment platforms, and create stablecoins for its clients. The company has not had a good few months. In June, the state of Nevada filed to seize control of the company because it was near insolvency. It was then ordered to cease all operations by a federal judge because it allegedly used customers’ money to cover withdrawal requests from other companies.
The company filed for bankruptcy, and, according to a filing by its interim CEO, which you really should read in full, the company offers an “all-in-one solution for customers that remains unmatched in the marketplace.” A large problem, among more run-of-the-mill crypto economy problems such as “lack of operational and spending oversight” and “regulatory issues,” is the fact that it lost access to a physical wallet it was keeping a tens of millions of dollars in, and cannot get back into it.
[…]
It called one of these wallets the “98f Wallet,” because its address ended in “98f.”
[…]
If a user loses both the hardware device and the seed phrases, it is virtually impossible for that user to regain access to the digital wallet.”
[…]
Prime Trust opted to laser etch them into a piece of steel called “Cryptosteel Hardware,” which are called “Wallet Access Devices” in the court filings, and which look like this:
Image: Court records
According to the filing, it lost these devices, which is why it can’t get back into the wallet.
[…]
For several years, the company then took customer deposits into this address, to the tune of tens of millions of dollars. In December, 2021, “when a customer requested a significant withdrawal of ETH that the company could not fulfill [from other wallets,]” it went to withdraw it from this hardware wallet. “It was around this time that they discovered that the Company did not have the Wallet Access Devices and thus, could not access the cryptocurrency stored in the 98f Wallet.”
Fashion and social media are both ever evolving. So why not put the two together? New research in Manufacturing & Service Operations Management says utilizing social media to predict sales of apparel and footwear items based on social media posts and interactions about color is possible and successful.
“We partner with three multinational retailers—two apparel and one footwear—and combine their data sets with publicly available data on Twitter and the Google Search Volume Index. We implement a variety of models to develop forecasts that can be used in setting the initial shipment quantity for an item, arguably the most important decision for fashion retailers,” says Youran Fu of Amazon, one of the study authors.
Despite challenges like short product lifetimes, long manufacturing lead times and constant innovation of fashion products, social media information can enable efficiency and increased revenue.
“Our findings show that fine-grained social media information has significant predictive power in forecasting color and fit demands months in advance of the sales season, and therefore greatly helps in making the initial shipment quantity decision,” says Marshall Fisher of the University of Pennsylvania.
“The predictive power of including social media features, measured by the improvement of the out-of-sample mean absolute deviation over current practice, ranges from 24% to 57%,” Fisher continues.
The paper, “The Value of Social Media Data in Fashion Forecasting,” proves consistent results across all three retailers. The researchers demonstrate the robustness of the findings over market and geographic heterogeneity, and different forecast horizons.
The researchers note, “Changes in fashion demand are driven more by ‘bottom-up’ changes in consumer preferences than by ‘top-down’ influence from the fashion industry.”
More information: Youran Fu et al, The Value of Social Media Data in Fashion Forecasting, Manufacturing & Service Operations Management (2023). DOI: 10.1287/msom.2023.1193
A severely paralysed woman has been able to speak through an avatar using technology that translated her brain signals into speech and facial expressions.
[…]
The latest technology uses tiny electrodes implanted on the surface of the brain to detect electrical activity in the part of the brain that controls speech and face movements. These signals are translated directly into a digital avatar’s speech and facial expressions including smiling, frowning or surprise.
[…]
The patient, a 47-year-old woman, Ann, has been severely paralysed since suffering a brainstem stroke more than 18 years ago. She cannot speak or type and normally communicates using movement-tracking technology that allows her to slowly select letters at up to 14 words a minute. She hopes the avatar technology could enable her to work as a counsellor in future.
The team implanted a paper-thin rectangle of 253 electrodes on to the surface of Ann’s brain over a region critical for speech. The electrodes intercepted the brain signals that, if not for the stroke, would have controlled muscles in her tongue, jaw, larynx and face.
After implantation, Ann worked with the team to train the system’s AI algorithm to detect her unique brain signals for various speech sounds by repeating different phrases repeatedly.
The computer learned 39 distinctive sounds and a Chat GPT-style language model was used to translate the signals into intelligible sentences. This was then used to control an avatar with a voice personalised to sound like Ann’s voice before the injury, based on a recording of her speaking at her wedding.
The technology was not perfect, decoding words incorrectly 28% of the time in a test run involving more than 500 phrases, and it generated brain-to-text at a rate of 78 words a minute, compared with the 110-150 words typically spoken in natural conversation.
[…]
Prof Nick Ramsey, a neuroscientist at the University of Utrecht in the Netherlands, who was not involved in the research, said: “This is quite a jump from previous results. We’re at a tipping point.”
A crucial next step is to create a wireless version of the BCI that could be implanted beneath the skull.
Two founders of Tornado Cash were formally accused by US prosecutors today of laundering more than $1 billion in criminal proceeds through their cryptocurrency mixer.
As well as unsealing an indictment against the pair on Wednesday, the Feds also arrested one of them, 34-year-old Roman Storm, in his home state of Washington, and hauled him into court. Fellow founder and co-defendant Roman Semenov, a 35-year-old Russian citizen, is still at large.
As a cryptocurrency mixer, Tornado Cash is appealing to cybercriminals as it offers to provide them a degree of anonymity.
[…]
Tornado Cash was sanctioned by Uncle Sam a little over a year ago for helping North Korea’s Lazarus Group scrub funds stolen in the Axie Infinity hack. Additionally, the US Treasury Department said Tornado Cash was used to launder funds stolen in the Nomad bridge and Harmony bridge heists, both of which were also linked to Lazarus.
Storm and Semenov were both charged with conspiracy to commit money laundering and conspiracy to commit sanctions violations, each carrying a maximum penalty of 20 years in prison. A third charge, conspiracy to operate an unlicensed money transmitting business, could net the pair up to an additional five years upon conviction.
In the unsealed indictment [PDF], prosecutors said Tornado Cash boasted about its anonymizing features and that it could make money untraceable, and that Storm and Semenov refused to implement changes that would dial back Tornado’s thief-friendly money-laundering capabilities and bring it in line with financial regulations.
“Tornado Cash failed to establish an effective [anti money laundering] program or engage in any [know your customer] efforts,” Dept of Justice lawyers argued. Changes made publicly to make it appear as if Tornado Cash was legally compliant, the DoJ said, were laughed off as ineffective in private messages by the charged pair.
“While publicly claiming to offer a technically sophisticated privacy service, Storm and Semenov in fact knew that they were helping hackers and fraudsters conceal the fruits of their crimes,” said US Attorney Damian Williams. “Today’s indictment is a reminder that money laundering through cryptocurrency transactions violates the law, and those who engage in such laundering will face prosecution.”
What of the mysterious third founder?
While Storm and Semenov were the ones named on the rap sheet, they aren’t the only people involved with, or arrested over, their involvement in Tornado Cash. A third unnamed and uncharged person mentioned in the DoJ indictment referred to as “CC-1” is described as one of the three main people behind the sanctioned service.
Despite that, the Dept of Justice didn’t announce any charges against CC-1.
Clues point to CC-1 potentially being Alexey Persev, a Russian software developer linked to Tornado Cash who was arrested in The Netherlands shortly after the US sanctioned the crypto-mixing site. Persev was charged in that Euro nation with facilitating money laundering and concealing criminal financial flows, and is now out of jail on monitored home release awaiting trial.
Persev denies any wrongdoing, and claimed he wasn’t told why he was being detained. His defenders argued he shouldn’t be held accountable for writing Tornado Cash code since he didn’t do any of the alleged money laundering himself.
It’s not immediately clear if Pertsev is CC-1, nor is it clear why CC-1 wasn’t charged. We put those questions to the DoJ, and haven’t heard back.
A two-year human trial conducted by James Cook University (JCU) has concluded, demonstrating positive results using low-dose human hookworm therapy to treat chronic conditions, particularly in relation to type 2 diabetes. New Atlas reports: [O]f the 24 participants who received worms, when offered a dewormer at the end of the second year of the trial, with the option to stay in the study for another 12 months, only one person chose to kill off their gut buddies — and it was only because they had an impending planned medical procedure. “All trial participants had risk factors for developing cardiovascular disease and type 2 diabetes,” said Dr Doris Pierce, from JCU’s Australian Institute of Tropical Health and Medicine (AITHM). “The trial delivered some considerable metabolic benefits to the hookworm-treated recipients, particularly those infected with 20 larvae.”
In this double-blinded trial, 40 participants aged 27 to 50, with early signs of metabolic diseases, took part. They received either 20 or 40 microscopic larvae of the human hookworm species Necator americanus; another group took a placebo. As an intestinal parasite, the best survival skill is to keep the host healthy, which will provide a long-term stable home with nutrients ‘on tap.’ In return, these hookworms pay the rent in the form of creating an environment that suppresses inflammation and other adverse conditions that can upset that stable home. While the small, round worms can live for a decade, they don’t multiply unless outside the body, and good hygiene means transmission risk is very low.
As for the results, those with 20 hookworms saw a Homeostatic Model Assessment of Insulin Resistance (HOMA-IR) level drop from 3.0 units to 1.8 units within the first year, which restored their insulin resistance to a healthy range. The cohort with 40 hookworms still experienced a drop, from 2.4 to 2.0. Those who received the placebo saw their HOMA-IR levels increase from 2.2 to 2.9 during the same time frame. “These lowered HOMA-IR values indicated that people were experiencing considerable improvements in insulin sensitivity — results that were both clinically and statistically significant,” said Dr Pierce. Those with worms also had higher levels of cytokines, which play a vital role in triggering immune responses. The study was published in the journal Nature Communications.
Once tooth decay has set in, all a dentist can do is fill the gap with an artificial plug — a filling. But in a paper published in Cell, Hannele Ruohola-Baker, a stem-cell biologist at the University of Washington, and her colleagues offer a possible alternative. Economist: Stem cells are those that have the capacity to turn themselves into any other type of cell in the body. It may soon be possible, the researchers argue, to use those protean cells to regrow a tooth’s enamel naturally. The first step was to work out exactly how enamel is produced. That is tricky, because enamel-making cells, known as ameloblasts, disappear soon after a person’s adult teeth have finished growing. To get round that problem, the researchers turned to samples of tissue from human foetuses that had been aborted, either medically or naturally. Such tissues contain plenty of functioning ameloblasts. The researchers then checked to see which genes were especially active in the enamel-producing cells. Tooth enamel is made mostly of calcium phosphate, and genes that code for proteins designed to bind to calcium were particularly busy. They also assessed another type of cell called odontoblasts. These express genes that produce dentine, another type of hard tissue that lies beneath the outer enamel. Armed with that information, Dr Ruohola-Baker and her colleagues next checked to see whether the stem cells could be persuaded to transform into ameloblasts.
The team devised a cocktail of drugs designed to activate the genes that they knew were expressed in functioning ameloblasts. That did the trick, with the engineered ameloblasts turning out the same proteins as the natural sort. A different cocktail pushed the stem cells to become odontoblasts instead. Culturing the cells together produced what researchers call an organoid — a glob of tissue in a petri dish which mimics a biological organ. The organoids happily churned out the chemical components of enamel. Having both cell types seemed to be crucial: when odontoblasts were present alongside ameloblasts, genes coding for enamel proteins were more strongly expressed than with ameloblasts alone. For now, the work is more a proof of concept than a prototype of an imminent medical treatment. The next step, says Dr Ruohola-Baker, is to try to boost enamel production even further, with a view to eventually beginning clinical trials. The hope is that, one day, medical versions of the team’s organoids could be used as biological implants, to regenerate a patient’s decayed teeth.
A pair of astrophysicists at the Rochester Institute of Technology has found via simulations that some black holes might be traveling through space at nearly one-tenth the speed of light. In their study, reported in Physical Review Letters, James Healy and Carlos Lousto used supercomputer simulations to determine how fast black holes might be moving after formation due to a collision between two smaller black holes.
Prior research has shown that it is possible for two black holes to smash into each other. And when they do, they tend to merge. Mergers generate gravitational waves, and an ensuing recoil can occur in the opposite direction, similar to the recoil of a gun. The energy of that recoil can send the resulting black hole hurtling through space at incredible speeds.
Prior research has suggested such black holes may reach top speeds of approximately 5,000 km/sec. In this new effort, the researchers took a closer look at black hole speeds to determine just how fast they might travel after merging.
To that end, the researchers created a mathematical simulation. One of the main data points involved the angle at which the two black holes approached one another prior to merging. Prior research has shown that for all but a direct head-on collision, there is likely to be a period of time when the two black holes circle each other before merging.
The researchers ran their simulation on a supercomputer to calculate the results of merging by black holes that approach each other from 1,300 different angles, including direct collisions and close flybys.
They found that under the best-case scenario, grazing collisions, it should be possible for a recoil to send the merged black hole zipping through space at approximately 28,500 kilometers per second—a rate that would send it the distance between the Earth and the moon in just 13 seconds.
If you’ve never watched it, Kirby Ferguson’s “Everything is a Remix” series (which was recently updated from the original version that came out years ago) is an excellent look at how stupid our copyright laws are, and how they have really warped our view of creativity. As the series makes clear, creativity is all about remixing: taking inspiration and bits and pieces from other parts of culture and remixing them into something entirely new. All creativity involves this in some manner or another. There is no truly unique creativity.
And yet, copyright law assumes the opposite is true. It assumes that most creativity is entirely unique, and when remix and inspiration get too close, the powerful hand of the law has to slap people down.
[…]
It would have been nice if society had taken this issue seriously back then, recognized that “everything is a remix,” and that encouraging remixing and reusing the works of others to create something new and transformative was not just a good thing, but one that should be supported. If so, we might not be in the utter shitshow that is the debate over generative art from AI these days, in which many creators are rushing to AI to save them, even though that’s not what copyright was designed to do, nor is it a particularly useful tool in that context.
[…]
The moral panic is largely an epistemological crisis: We don’t have a socially acceptable status for the legibility of the remix as art-in-it’s-own-right. Instead of properly appreciating the remix and the art of the DJ, the remix, or the meme cultures, we have shoehorned all the cultural properties associated onto an 1800’s sheet music publishing -based model of artistic credibility. The fit was never really good, but no-one really cared because the scenes were small, underground and their breaking the rules was largely out-of-sight.
[…]
AI art tools are simply resurfacing an old problem we left behind unresolved during the 1980’s to early 2000’s. Now it’s time for us to blow the dust off these old books and apply what was learned to the situation we have at our hands now.
We should not forget the modern electronic dance music industry has already developed models that promote new artists via remixes of their work from more established artists. These real-world examples combined with the theoretical frameworks above should help us to explore a refreshed model of artistic credibility, where value is assigned to both the original artists and the authors of remixers
[…]
Art, especially popular forms of it, has always been a lot about transformation: Taking what exists and creating something that works in this particular context. In forms of art emphasizing the distinctiveness of the original less, transformation becomes the focus of the artform instead.
[…]
There are a lot of questions about how that would actually work in practice, but I do think this is a useful framework for thinking about some of these questions, challenging some existing assumptions, and trying to rethink the system into one that is actually helping creators and helping to enable more art to be created, rather than trying to leverage a system originally developed to provide monopolies to gatekeepers into one that is actually beneficial to the public who want to experience art, and creators who wish to make art.
Over the years we’ve covered a lot of attempts by relatively clueless governments and politicians to enact think-of-the-children internet censorship or surveillance legislation, but there’s a law from France in the works which we think has the potential to be one of the most sinister we’ve seen yet.
It’s likely that if they push this law through it will cause significant consternation over the rest of the European continent. We’d expect those European countries with less liberty-focused governments to enthusiastically jump on the bandwagon, and we’d also expect the European hacker community to respond with a plethora of ways for their French cousins to evade the snooping eyes of Paris. We have little confidence in the wisdom of the EU parliament in Brussels when it comes to ill-thought-out laws though, so we hope this doesn’t portend a future dark day for all Europeans. We find it very sad to see in any case, because France on the whole isn’t that kind of place.
Copyright issues have dogged AI since chatbot tech gained mass appeal, whether it’s accusations of entire novels being scraped to train ChatGPT or allegations that Microsoft and GitHub’s Copilot is pilfering code.
But one thing is for sure after a ruling [PDF] by the United States District Court for the District of Columbia – AI-created works cannot be copyrighted.
You’d think this was a simple case, but it has been rumbling on for years at the hands of one Stephen Thaler, founder of Missouri neural network biz Imagination Engines, who tried to copyright artwork generated by what he calls the Creativity Machine, a computer system he owns. The piece, A Recent Entrance to Paradise, pictured below, was reproduced on page 4 of the complaint [PDF]:
The US Copyright Office refused the application because copyright laws are designed to protect human works. “The office will not register works ‘produced by a machine or mere mechanical process’ that operates ‘without any creative input or intervention from a human author’ because, under the statute, ‘a work must be created by a human being’,” the review board told Thaler’s lawyer after his second attempt was rejected last year.
This was not a satisfactory response for Thaler, who then sued the US Copyright Office and its director, Shira Perlmutter. “The agency actions here were arbitrary, capricious, an abuse of discretion and not in accordance with the law, unsupported by substantial evidence, and in excess of Defendants’ statutory authority,” the lawsuit claimed.
But handing down her ruling on Friday, Judge Beryl Howell wouldn’t budge, pointing out that “human authorship is a bedrock requirement of copyright” and “United States copyright law protects only works of human creation.”
“Non-human actors need no incentivization with the promise of exclusive rights under United States law, and copyright was therefore not designed to reach them,” she wrote.
Though she acknowledged the need for copyright to “adapt with the times,” she shut down Thaler’s pleas by arguing that copyright protection can only be sought for something that has “an originator with the capacity for intellectual, creative, or artistic labor. Must that originator be a human being to claim copyright protection? The answer is yes.”
Unsurprisingly Thaler’s legal people took an opposing view. “We strongly disagree with the district court’s decision,” University of Surrey Professor Ryan Abbott told The Register.
“In our view, the law is clear that the American public is the primary beneficiary of copyright law, and the public benefits when the generation and dissemination of new works are promoted, regardless of how those works are made. We do plan to appeal.”
This is just one legal case Thaler is involved in. Earlier this year, the US Supreme Court also refused to hear arguments that AI algorithms should be recognized by law as inventors on patent filings, once again brought by Thaler.
He sued the US Patent and Trademark Office (USPTO) in 2020 because patent applications he had filed on behalf of another of his AI systems, DABUS, were rejected. The USPTO refused to accept them as it could only consider inventions from “natural persons.”
That lawsuit was quashed then was taken to the US Court of Appeals, where it lost again. Thaler’s team finally turned to the Supreme Court, which wouldn’t give it the time of day.
When The Register asked Thaler to comment on the US Copyright Office defeat, he told us: “What can I say? There’s a storm coming.”
Obtaining useful work from random fluctuations in a system at thermal equilibrium has long been considered impossible. In fact, in the 1960s eminent American physicist Richard Feynman effectively shut down further inquiry after he argued in a series of lectures that Brownian motion, or the thermal motion of atoms, cannot perform useful work.
Now, a new study published in Physical Review E titled “Charging capacitors from thermal fluctuations using diodes” has proven that Feynman missed something important.
Three of the paper’s five authors are from the University of Arkansas Department of Physics. According to first author Paul Thibado, their study rigorously proves that thermal fluctuations of freestanding graphene, when connected to a circuit with diodes having nonlinear resistance and storage capacitors, does produce useful work by charging the storage capacitors.
The authors found that when the storage capacitors have an initial charge of zero, the circuit draws power from the thermal environment to charge them.
The team then showed that the system satisfies both the first and second laws of thermodynamics throughout the charging process. They also found that larger storage capacitors yield more stored charge and that a smaller graphene capacitance provides both a higher initial rate of charging and a longer time to discharge. These characteristics are important because they allow time to disconnect the storage capacitors from the energy harvesting circuit before the net charge is lost.
This latest publication builds on two of the group’s previous studies. The first was published in a 2016 Physical Review Letters. In that study, Thibado and his co-authors identified the unique vibrational properties of graphene and its potential for energy harvesting.
The second was published in a 2020 Physical Review E article in which they discuss a circuit using graphene that can supply clean, limitless power for small devices or sensors.
This latest study progresses even further by establishing mathematically the design of a circuit capable of gathering energy from the heat of the earth and storing it in capacitors for later use.
“Theoretically, this was what we set out to prove,” Thibado explained. “There are well-known sources of energy, such as kinetic, solar, ambient radiation, acoustic, and thermal gradients. Now there is also nonlinear thermal power. Usually, people imagine that thermal power requires a temperature gradient. That is, of course, an important source of practical power, but what we found is a new source of power that has never existed before. And this new power does not require two different temperatures because it exists at a single temperature.”
In addition to Thibado, co-authors include Pradeep Kumar, John Neu, Surendra Singh, and Luis Bonilla. Kumar and Singh are also physics professors with the University of Arkansas, Neu with the University of California, Berkeley, and Bonilla with Universidad Carlos III de Madrid.
Representation of Nonlinear Thermal Current. Credit: Ben Goodwin
A decade of inquiry
The study represents the solution to a problem Thibado has been studying for well over a decade, when he and Kumar first tracked the dynamic movement of ripples in freestanding graphene at the atomic level. Discovered in 2004, graphene is a one-atom-thick sheet of graphite. The duo observed that freestanding graphene has a rippled structure, with each ripple flipping up and down in response to the ambient temperature.
“The thinner something is, the more flexible it is,” Thibado said. “And at only one atom thick, there is nothing more flexible. It’s like a trampoline, constantly moving up and down. If you want to stop it from moving, you have to cool it down to 20 Kelvin.”
His current efforts in the development of this technology are focused on building a device he calls a Graphene Energy Harvester (or GEH). GEH uses a negatively charged sheet of graphene suspended between two metal electrodes.
When the graphene flips up, it induces a positive charge in the top electrode. When it flips down, it positively charges the bottom electrode, creating an alternating current. With diodes wired in opposition, allowing the current to flow both ways, separate paths are provided through the circuit, producing a pulsing DC current that performs work on a load resistor.
Commercial applications
NTS Innovations, a company specializing in nanotechnology, owns the exclusive license to develop GEH into commercial products. Because GEH circuits are so small, mere nanometers in size, they are ideal for mass duplication on silicon chips. When multiple GEH circuits are embedded on a chip in arrays, more power can be produced. They can also operate in many environments, making them particularly attractive for wireless sensors in locations where changing batteries is inconvenient or expensive, such as an underground pipe system or interior aircraft cable ducts.
[…]
“I think people were afraid of the topic a bit because of Feynman. So, everybody just said, ‘I’m not touching that.’ But the question just kept demanding our attention. Honestly, its solution was only found through the perseverance and diverse approaches of our unique team.”
More information: P. M. Thibado et al, Charging capacitors from thermal fluctuations using diodes, Physical Review E (2023). DOI: 10.1103/PhysRevE.108.024130
[…] Knowing the wave function of such a quantum system is a challenging task—this is also known as quantum state tomography or quantum tomography in short. With the standard approaches (based on the so-called projective operations), a full tomography requires large number of measurements that rapidly increases with the system’s complexity (dimensionality).
Previous experiments conducted with this approach by the research group showed that characterizing or measuring the high-dimensional quantum state of two entangled photons can take hours or even days. Moreover, the result’s quality is highly sensitive to noise and depends on the complexity of the experimental setup.
The projective measurement approach to quantum tomography can be thought of as looking at the shadows of a high-dimensional object projected on different walls from independent directions. All a researcher can see is the shadows, and from them, they can infer the shape (state) of the full object. For instance, in CT scan (computed tomography scan), the information of a 3D object can thus be reconstructed from a set of 2D images.
In classical optics, however, there is another way to reconstruct a 3D object. This is called digital holography, and is based on recording a single image, called interferogram, obtained by interfering the light scattered by the object with a reference light.
The team, led byEbrahim Karimi, Canada Research Chair in Structured Quantum Waves, co-director of uOttawa Nexus for Quantum Technologies (NexQT) research institute and associate professor in the Faculty of Science, extended this concept to the case of two photons.
Reconstructing a biphoton state requires superimposing it with a presumably well-known quantum state, and then analyzing the spatial distribution of the positions where two photons arrive simultaneously. Imaging the simultaneous arrival of two photons is known as a coincidence image. These photons may come from the reference source or the unknown source. Quantum mechanics states that the source of the photons cannot be identified.
This results in an interference pattern that can be used to reconstruct the unknown wave function. This experiment was made possible by an advanced camera that records events with nanosecond resolution on each pixel.
Dr. Alessio D’Errico, a postdoctoral fellow at the University of Ottawa and one of the co-authors of the paper, highlighted the immense advantages of this innovative approach, “This method is exponentially faster than previous techniques, requiring only minutes or seconds instead of days. Importantly, the detection time is not influenced by the system’s complexity—a solution to the long-standing scalability challenge in projective tomography.”
The impact of this research goes beyond just the academic community. It has the potential to accelerate quantum technology advancements, such as improving quantum state characterization, quantum communication, and developing new quantum imaging techniques.
The study “Interferometric imaging of amplitude and phase of spatial biphoton states” was published in Nature Photonics.
More information: Danilo Zia et al, Interferometric imaging of amplitude and phase of spatial biphoton states, Nature Photonics (2023). DOI: 10.1038/s41566-023-01272-3
Last week we wrote about a lawsuit against Western Digital that alleged that the firm’s solid state drive didn’t live up to its marketing promises. More lawsuits have been filed against the company since. ArsTechnica: On Thursday, two more lawsuits were filed against Western Digital over its SanDisk Extreme series and My Passport portable SSDs. That brings the number of class-action complaints filed against Western Digital to three in two days. In May, Ars Technica reported about customer complaints that claimed SanDisk Extreme SSDs were abruptly wiping data and becoming unmountable. Ars senior editor Lee Hutchinson also experienced this problem with two Extreme SSDs. Western Digital, which owns SanDisk, released a firmware update in late May, saying that currently shipping products weren’t impacted. But the company didn’t mention customer complaints of lost data, only that drives could “unexpectedly disconnect from a computer.”
Further, last week The Verge claimed a replacement drive it received after the firmware update still wiped its data and became unreadable, and there are some complaints on Reddit pointing to recent problems with Extreme drives. All three cases filed against Western Digital this week seek class-action certification (Ars was told it can take years for a judge to officially state certification and that cases may proceed with class-wide resolutions possibly occurring before official certification). Ian Sloss, one of the lawyers representing Matthew Perrin and Brian Bayerl in a complaint filed yesterday, told Ars he doesn’t believe class-action certification will be a major barrier in a case “where there is a common defect in the firmware that is consistent in all devices.” He added that defect cases are “ripe for class treatment.”
More and more, as the video game industry matures, we find ourselves talking about game preservation and the disappearing culture of some older games as the original publishers abandon them. Often times leaving the public with no actual legit method for purchasing these old games, copyright law conspires with the situation to also prevent the public itself from clawing back its half of the copyright bargain. The end results are studios and publishers that have enjoyed the fruits of copyright law for a period of time, only for that cultural output to be withheld from the public later on. By any plain reading of American copyright law, that outcome shouldn’t be acceptable.
When it comes to one classic PlayStation 1 title, it seems that one enterprising individual has very much refused to accept this outcome. A fan of the first-party Sony title WipeOut, an exclusive to the PS1, has ported the game such that it can be played in a web browser. And, just to drive the point home, they have essentially dared Sony to do something about it.
“Either let it be, or shut this thing down and get a real remaster going,” he told Sony in a recent blog post (via VGC). Despite the release of the PlayStation Classic, 2017’s Wipeout Omega Collection, and PS Plus adding old PS1 games to PS5 like Twisted Metal, there’s no way to play the original WipeOut on modern consoles and experience the futuristic racer’s incredible soundtrack and neo-Tokyo aesthetic in all their glory. So fans have taken it upon themselves to make the Psygnosis-developed hit accessible on PC.
As Dominic Szablewski details in his post and in a series of videos detailing this labor of love, getting this all to work took a great deal of unraveling in the source code. The whole thing was a mess primarily because every iteration of the game simply had new code layered on top of the last iteration, meaning that there was a lot of onion-peeling to be done to make this all work.
But work it does!
After a lot of detective work and elbow grease, Szablewski managed to resurrect a modified playable version of the game with an uncapped framerate that looks crisp and sounds great. He still recommends two other existing PC ports over his own, WipeOut Phantom Edition and an unnamed project by a user named XProger. However, those don’t come with the original source code, the legality of which he admits is “questionable at best.”
But again, what is the public supposed to do here? The original game simply can’t be bought legitimately and hasn’t been available for some time. Violating copyright law certainly isn’t the right answer, but neither is allowing a publisher to let cultural output go to rot simply because it doesn’t want to do anything about it.
“Sony has demonstrated a lack of interest in the original WipeOut in the past, so my money is on their continuing absence,” Szablewski wrote. “If anyone at Sony is reading this, please consider that you have (in my opinion) two equally good options: either let it be, or shut this thing down and get a real remaster going. I’d love to help!”
Sadly, I’m fairly certain I know how this story will end.
The Mozilla Foundation has started a petition to stop the French government from forcing browsers like Mozilla’s Firefox to censor websites. “It would set a dangerous precedent, providing a playbook for other governments to also turn browsers like Firefox into censorship tools,” says the organization. “The government introduced the bill to parliament shortly before the summer break and is hoping to pass this as quickly and smoothly as possible; the bill has even been put on an accelerated procedure, with a vote to take place this fall.” You can add your name to their petition here.
The bill in question is France’s SREN Bill, which sets a precarious standard for digital freedoms by empowering the government to compile a list of websites to be blocked at the browser level. The Mozilla Foundation warns that this approach “is uncharted territory” and could give oppressive regimes an operational model that could undermine the effectiveness of censorship circumvention tools.
“Rather than mandate browser based blocking, we think the legislation should focus on improving the existing mechanisms already utilized by browsers — services such as Safe Browsing and Smart Screen,” says Mozilla. “The law should instead focus on establishing clear yet reasonable timelines under which major phishing protection systems should handle legitimate website inclusion requests from authorized government agencies. All such requests for inclusion should be based on a robust set of public criteria limited to phishing/scam websites, subject to independent review from experts, and contain judicial appellate mechanisms in case an inclusion request is rejected by a provider.”
On Friday, the Internet Archive put up a blog post noting that its digital book lending program was likely to change as it continues to fight the book publishers’ efforts to kill the Internet Archive. As you’ll recall, all the big book publishers teamed up to sue the Internet Archive over its Open Library project, which was created based on a detailed approach, backed by librarians and copyright lawyers, to recreate an online digital library that matches a physical library. Unfortunately, back in March, the judge decided (just days after oral arguments) that everything about the Open Library infringes on copyrights. There were many, many problems with this ruling, and the Archive is appealing.
However, in the meantime, the judge in the district court needed to sort out the details of the injunction in terms of what activities the Archive would change during the appeal. The Internet Archive and the publishers negotiated over the terms of such an injunction and asked the court to weigh in on whether or not it also covers books for which there are no ebooks available at all. The Archive said it should only cover books where the publishers make an ebook available, while the publishers said it should cover all books, because of course they did. Given Judge Koeltl’s original ruling, I expected him to side with the publishers, and effectively shut down the Open Library. However, this morning he surprised me and sided with the Internet Archive, saying only books that are already available in electronic form need to be removed. That’s still a lot, but at least it means people can still access those other works electronically. The judge rightly noted that the injunction should be narrowly targeted towards the issues at play in the case, and thus it made sense to only block works available as ebooks.
But, also on Friday, the RIAA decided to step in and to try to kick the Internet Archive while it’s down. For years now, the Archive has offered up its Great 78 Project, in which the Archive, in coordination with some other library/archival projects (including the Archive of Contemporary Music and George Blood LP), has been digitizing whatever 78rpm records they could find.
78rpm records were some of the earliest musical recordings, and were produced from 1898 through the 1950s when they were replaced by 33 1/3rpm and 45rpm vinyl records. I remember that when I was growing up my grandparents had a record player that could still play 78s, and there were a few of those old 78s in a cabinet. Most of the 78s were not on vinyl, but shellac, and were fairly brittle, meaning that many old 78s are gone forever. As such there is tremendous value in preserving and protecting old 78s, which is also why many libraries have collections of them. It’s also why those various archival libraries decided to digitize and preserve them. Without such an effort, many of those 78s would disappear.
If you’ve ever gone through the Great78 project, you know quite well that it is, in no way, a substitute for music streaming services like Spotify or Apple Music. You get a static page in which you (1) see a photograph of the original 78 label, (2) get some information on that recording, and (3) are able to listen to and download just that song. Here’s a random example I pulled:
Also, when you listen to it, you can clearly hear that this was digitized straight off of the 78 itself, including all the crackle and hissing of the record. It is nothing like the carefully remastered versions you hear on music streaming services.
Indeed, I’ve used the Great78 Project to discover old songs I’d never heard before, leading me to search out those artists on Spotify to add to my playlists, meaning that for me, personally, the Great78 Project has almost certainly resulted in the big record labels making more money, as it added more artists for me to listen to through licensed systems.
It’s no secret that the recording industry had it out for the Great78 Project. Three years ago, we wrote about how Senator Thom Tillis (who has spent his tenure in the Senate pushing for whatever the legacy copyright industries want) seemed absolutely apoplectic when the Internet Archive bought a famous old record store in order to get access to the 78s to digitize, and Tillis thought that this attempt to preserve culture was shameful.
The lawsuit, joined by all of the big RIAA record labels, was filed by one of the RIAA’s favorite lawyers for destroying anything good that expands access to music: Matt Oppenheim. Matt was at the RIAA and helped destroy both Napster and Grokster. He was also the lawyer who helped create some terrible precedents holding ISPs liable for subscribers who download music, enabling even greater copyright trolling. Basically, if you’ve seen anything cool and innovative in the world of music over the last two decades, Oppenheim has been there to kill it.
And now he’s trying to kill the world’s greatest library.
Much of the actual lawsuit revolves around the Music Modernization Act, which was passed in 2018 and had some good parts in it, in particular in moving some pre-1972 sound recordings into the public domain. As you might also recall, prior to February of 1972, sound recordings did not get federal copyright protection (though they might get some form of state copyright). Indeed, in most of the first half of the 20th century, many copyright experts believed that federal copyright could not apply to sound recordings and that it could only apply to the composition. After February of 1972, sound recordings were granted federal copyright, but that left pre-1972 works in a weird state, in which they were often protected by an amalgamation of obsolete state laws, meaning that some works might not reach the public domain for well over a century. This was leading to real concerns that some of our earliest recordings would disappear forever.
The Music Modernization Act sought to deal with some of that, creating a process by which pre-1972 sound recordings would be shifted under federal copyright, and a clear process began to move some of the oldest ones into the public domain. It also created a process for dealing with old orphaned works, where the copyright holder could not be found. The Internet Archive celebrated all of this, and noted that it would be useful for some of its archival efforts.
The lawsuit accuses the Archive (and Brewster Kahle directly) of then ignoring the limitations and procedures in the Music Modernization Act to just continue digitizing and releasing all of the 78s it could find, including those by some well known artists whose works are available on streaming platforms and elsewhere. It also whines that the Archive often posts links to newly digitized Great78 records on ex-Twitter.
When the Music Modernization Act’s enactment made clear that unauthorized copying, streaming, and distributing pre-1972 sound recordings is infringing, Internet Archive made no changes to its activities. Internet Archive did not obtain authorization to use the recordings on the Great 78 Project website. It did not remove any recordings from public access. It did not slow the pace at which it made new recordings publicly available. It did not change its policies regarding which recordings it would make publicly available.
Internet Archive has not filed any notices of non-commercial use with the Copyright Office. Accordingly, the safe harbor set forth in the Music Modernization Act is not applicable to Internet Archive’s activities.
Internet Archive knew full well that the Music Modernization Act had made its activities illegal under Federal law. When the Music Modernization Act went into effect, Internet Archive posted about it on its blog. Jeff Kaplan, The Music Modernization Act is now law which means some pre-1972 music goes public, INTERNET ARCHIVE (Oct. 15, 2018), https://blog.archive.org/2018/10/15/the-music-modernization-act-is-now-law-which-means-some-music-goes-public/. The blog post stated that “the MMA means that libraries can make some of these older recordings freely available to the public as long as we do a reasonable search to determine that they are not commercially available.” Id. (emphasis added). The blog post further noted that the MMA “expands an obscure provision of the library exception to US Copyright Law, Section 108(h), to apply to all pre-72 recordings. Unfortunately 108(h) is notoriously hard to implement.” Id. (emphasis added). Brewster Kahle tweeted a link to the blog post. Brewster Kahle (@brewster_kahle), TWITTER (Oct. 15, 2018 11:26 AM), https://twitter.com/brewster_kahle/status/1051856787312271361.
Kahle delivered a presentation at the Association for Recorded Sound Collection’s 2019 annual conference titled, “Music Modernization Act 2018. How it did not go wrong, and even went pretty right.” In the presentation, Kahle stated that, “We Get pre-1972 out-of-print to be ‘Library Public Domain’!”. The presentation shows that Kahle, and, by extension, Internet Archive and the Foundation, understood how the Music Modernization Act had changed federal law and was aware the Music Modernization Act had made it unlawful under federal law to reproduce, distribute, and publicly perform pre-1972 sound recordings.
Despite knowing that the Music Modernization Act made its conduct infringing under federal law, Internet Archive ignored the new law and plowed forward as if the Music Modernization Act had never been enacted.
There’s a lot in the complaint that you can read. It attacks Brewster Kahle personally, falsely claiming that Kahle “advocated against the copyright laws for years,” rather than the more accurate statement that Kahle has advocated against problematic copyright laws that lock down, hide, and destroy culture. The lawsuit even uses Kahle’s important, though unfortunately failed, Kahle v. Gonzalez lawsuit, which argued (compellingly, though unfortunately not to the 9th Circuit) that when Congress changed copyright law from opt-in copyright (in which you had to register anything to get a copyright) to “everything is automatically covered by copyright,” it changed the very nature of copyright law, and took it beyond the limits required under the Constitution. That was not an “anti-copyright” lawsuit. It was an “anti-massive expansion of copyright in a manner that harms culture” lawsuit.
It is entirely possible (perhaps even likely) that the RIAA will win this lawsuit. As Oppenheim knows well, the courts are often quite smitten with the idea that the giant record labels and publishers and movie studios “own” culture and can limit how the public experiences it.
But all this really does is demonstrate exactly how broken modern copyright law is. There is no sensible or rationale world in which an effort to preserve culture and make it available to people should be deemed a violation of the law. Especially when that culture is mostly works that the record labels themselves ignored for decades, allowing them to decay and disappear in many instances. To come back now, decades later, and try to kill off library preservation and archival efforts is just an insult to the way culture works.
It’s doubly stupid given that the RIAA, and Oppenheim in particular, spent years trying to block music from ever being available on the internet. It’s only now that the very internet they fought developed systems that have re-invigorated the bank accounts of the labels through streaming that the RIAA gets to pretend that of course it cares about music from the first half of the 20th century — music that it was happy to let decay and die off until just recently.
Whether or not the case is legally sound is one thing. Chances are the labels may win. But, on a moral level, everything about this is despicable. The Great78 project isn’t taking a dime away from artists or the labels. No one is listening to the those recordings as a replacement for licensed efforts. Again, if anything, it’s helping to rejuvenate interest in those old recordings for free.
And if this lawsuit succeeds, it could very well put the nail in the coffin of the Internet Archive, which is already in trouble due to the publishers’ lawsuit.
Over the last few years, the RIAA had sort of taken a step back from being the internet’s villain, but its instincts to kill off and spit on culture never went away.
These copyright goons really hate the idea of preserving culture. Can you imagine doing something once and then getting paid for it every time someone sees your work?! Crazy!
A Wednesday statement from the Commission brought news that in late July it wrote to Google to inform it of the ₩42.1 billion ($31.5 million) fine announced, and reported by The Register, in April 2023.
The Commission has also commenced monitoring activities to ensure that Google complies with requirements to allow competition with its Play store.
South Korea probed the operation of Play after a rival local Android app-mart named OneStore debuted in 2016.
OneStore had decent prospects of success because it merged app stores operated by South Korea’s top three telcos. Naver, an online portal similar in many ways to Google, also rolled its app store into OneStore.
Soon afterwards, Google told developers they were free to sell their wares in OneStore – but doing so would see them removed from the Play store.
Google also offered South Korean developers export assistance if they signed exclusivity deals in their home country.
Faced with the choice of being cut off from the larger markets Google owned, developer enthusiasm for dabbling in OneStore dwindled. Some popular games never made it into OneStore, so even though its founders had tens of millions of customers between them, the venture struggled.
Which is why Korea’s Fair Trade Commission intervened with an investigation, the fines mentioned above, and a requirement that Google revisit agreements with local developers.
Google has also been required to establish an internal monitoring system to ensure it complies with the Commission’s orders.
Commission chair Ki-Jeong Han used strong language in today’s announcement, describing his agency’s actions as “putting the brakes” on Google’s efforts to achieve global app store dominance.
“Monopolization of the app market may adversely affect the entire mobile ecosystem,” the Commissioner’s statement reads, adding “The recovery of competition in this market is very important.”
It’s also likely beneficial to South Korean companies. OneStore has tried to expand overseas, and Samsung – the world’s top smartphone vendor by unit volume – also stands to gain. It operates its own Galaxy Store that, despite its presence on hundreds of millions of handsets, enjoys trivial market share.
HP has failed to shunt aside class-action legal claims that it disables the scanners on its multifunction printers when their ink runs low. Though not for lack of trying.
On Aug. 10, a federal judge ruled that HP Inc. must face a class-action lawsuit claiming that the company designs its “all-in-one” inkjet printers to disable scanning and faxing functions whenever a single printer ink cartridge runs low. The company had sought — for the second time — to dismiss the lawsuit on technical legal grounds.
“It is well-documented that ink is not required in order to scan or to fax a document, and it is certainly possible to manufacture an all-in-one printer that scans or faxes when the device is out of ink,” the plaintiffs wrote in their complaint. “Indeed, HP designs its all-in-one printer products so they will not work without ink. Yet HP does not disclose this fact to consumers.”
The lawsuit charges that HP deliberately withholds this information from consumers to boost profits from the sale of expensive ink cartridges.
Color printers require four ink cartridges — one black and a set of three cartridges in cyan, magenta and yellow for producing colors. Some will also refuse to print if one of the color cartridges is low, even in black-and-white mode.
[…]
Worse, a significant amount of ink is never actually used to print documents because it’s consumed by printer maintenance cycles. In 2018, Consumer Reports tested hundreds of all-in-one inkjet printers and found that, when used intermittently, many models delivered less than half of their ink to printed documents. A few managed no more than 20% to 30%.
A few months ago, an engineer in a data center in Norway encountered some perplexing errors that caused a Windows server to suddenly reset its system clock to 55 days in the future. The engineer relied on the server to maintain a routing table that tracked cell phone numbers in real time as they moved from one carrier to the other. A jump of eight weeks had dire consequences because it caused numbers that had yet to be transferred to be listed as having already been moved and numbers that had already been transferred to be reported as pending.
[…]
The culprit was a little-known feature in Windows known as Secure Time Seeding. Microsoft introduced the time-keeping feature in 2016 as a way to ensure that system clocks were accurate. Windows systems with clocks set to the wrong time can cause disastrous errors when they can’t properly parse timestamps in digital certificates or they execute jobs too early, too late, or out of the prescribed order. Secure Time Seeding, Microsoft said, was a hedge against failures in the battery-powered onboard devices designed to keep accurate time even when the machine is powered down.
[…]
ometime last year, a separate engineer named Ken began seeing similar time drifts. They were limited to two or three servers and occurred every few months. Sometimes, the clock times jumped by a matter of weeks. Other times, the times changed to as late as the year 2159.
“It has exponentially grown to be more and more servers that are affected by this,” Ken wrote in an email. “In total, we have around 20 servers (VMs) that have experienced this, out of 5,000. So it’s not a huge amount, but it is considerable, especially considering the damage this does. It usually happens to database servers. When a database server jumps in time, it wreaks havoc, and the backup won’t run, either, as long as the server has such a huge offset in time. For our customers, this is crucial.”
Simen and Ken, who both asked to be identified only by their first names because they weren’t authorized by their employers to speak on the record, soon found that engineers and administrators had been reporting the same time resets since 2016.
[…]
“At this point, we are not completely sure why secure time seeding is doing this,” Ken wrote in an email. “Being so seemingly random, it’s difficult to [understand]. Microsoft hasn’t really been helpful in trying to track this, either. I’ve sent over logs and information, but they haven’t really followed this up. They seem more interested in closing the case.”
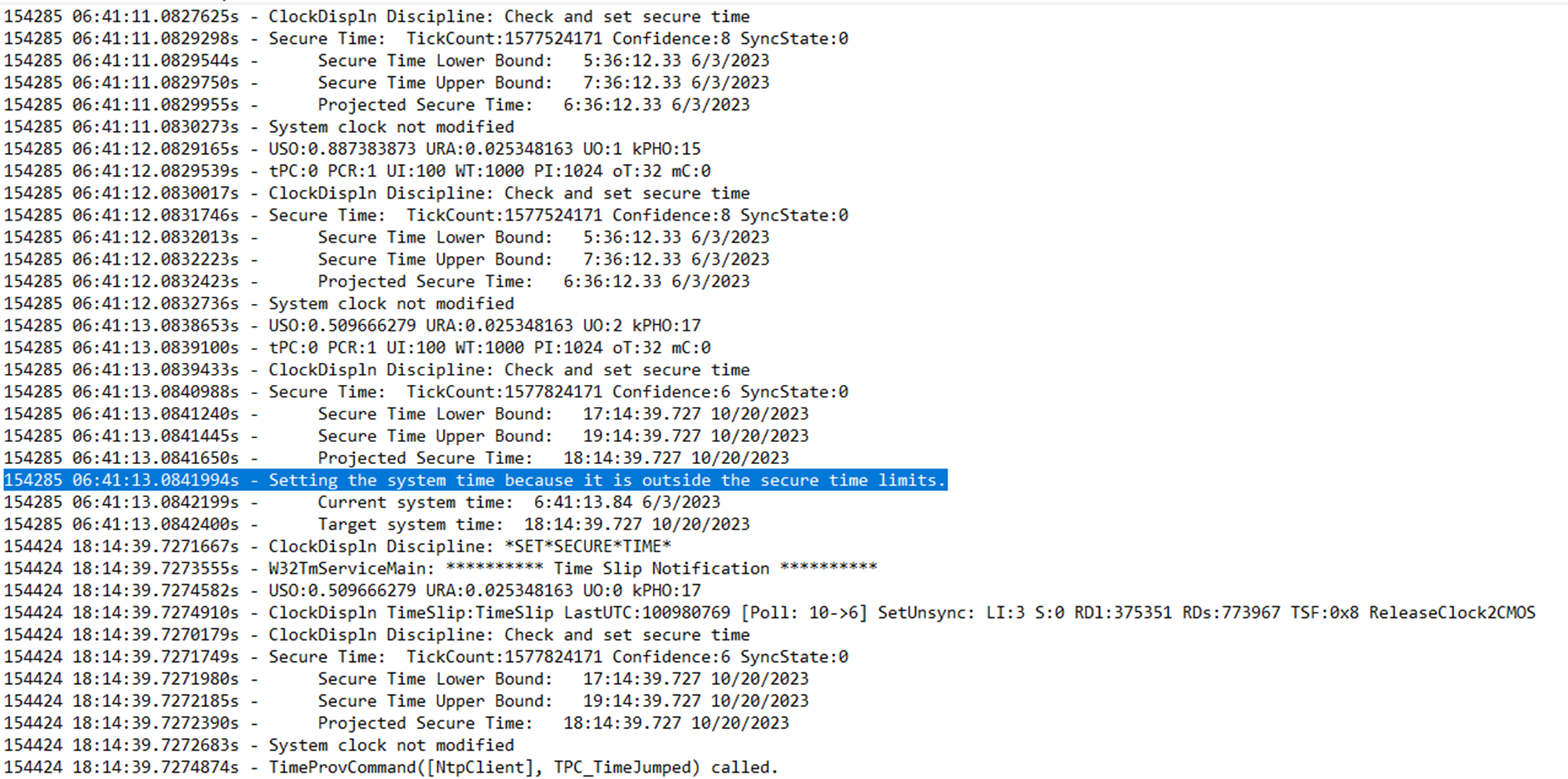
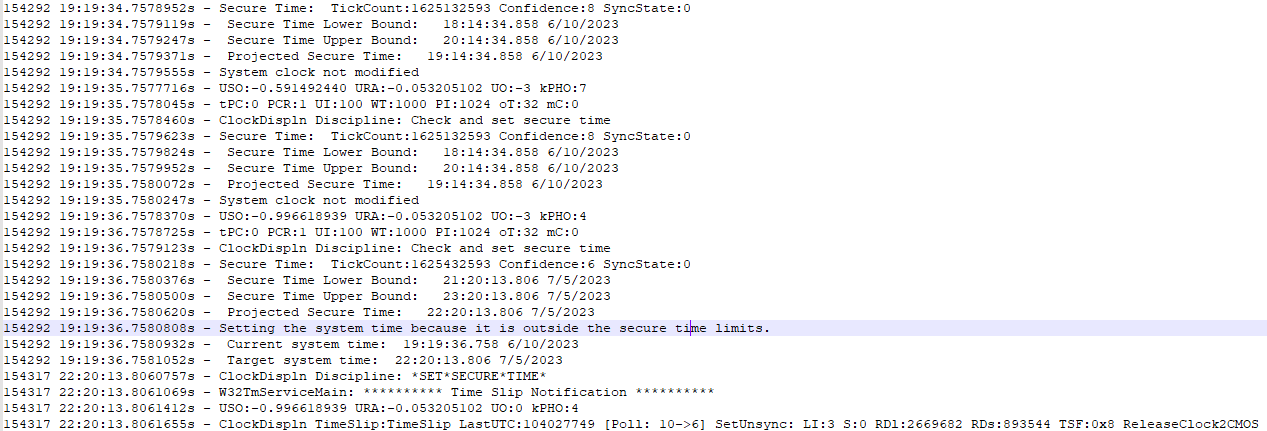
The logs Ken sent looked like the ones shown in the two screenshots below. They captured the system events that occurred immediately before and after the STS changed the times. The selected line in the first image shows the bounds of what STS calculates as the correct time based on data from SSL handshakes and the heuristics used to corroborate it.
Screenshot of a system event log as STS causes a system clock to jump to a date four months later than the current time.
Ken
Screenshot of a system event log when STS resets the system date to a few weeks later than the current date.
Ken
The “Projected Secure Time” entry immediately above the selected line shows that Windows estimates the current date to be October 20, 2023, more than four months later than the time shown in the system clock. STS then changes the system clock to match the incorrectly projected secure time, as shown in the “Target system time.”
The second image shows a similar scenario in which STS changes the date from June 10, 2023, to July 5, 2023.
[…]
As the creator and lead developer of the Metasploit exploit framework, a penetration tester, and a chief security officer, Moore has a deep background in security. He speculated that it might be possible for malicious actors to exploit STS to breach Windows systems that don’t have STS turned off. One possible exploit would work with an attack technique known as Server Side Request Forgery.
Microsoft’s repeated refusal to engage with customers experiencing these problems means that for the foreseeable future, Windows will by default continue to automatically reset system clocks based on values that remote third parties include in SSL handshakes. Further, it means that it will be incumbent on individual admins to manually turn off STS when it causes problems.
That, in turn, is likely to keep fueling criticism that the feature as it has existed for the past seven years does more harm than good.
STS “is more like malware than an actual feature,” Simen wrote. “I’m amazed that the developers didn’t see it, that QA didn’t see it, and that they even wrote about it publicly without anyone raising a red flag. And that nobody at Microsoft has acted when being made aware of it.”


")