This week the NY Times somehow broke the story of… well, the NY Times suing OpenAI and Microsoft. I wonder who tipped them off. Anyhoo, the lawsuit in many ways is similar to some of the over a dozen lawsuits filed by copyright holders against AI companies. We’ve written about how silly many of these lawsuits are, in that they appear to be written by people who don’t much understand copyright law. And, as we noted, even if courts actually decide in favor of the copyright holders, it’s not like it will turn into any major windfall. All it will do is create another corruptible collection point, while locking in only a few large AI companies who can afford to pay up.
I’ve seen some people arguing that the NY Times lawsuit is somehow “stronger” and more effective than the others, but I honestly don’t see that. Indeed, the NY Times itself seems to think its case is so similar to the ridiculously bad Authors Guild case, that it’s looking to combine the cases.
But while there are some unique aspects to the NY Times case, I’m not sure they are nearly as compelling as the NY Times and its supporters think they are. Indeed, I think if the Times actually wins its case, it would open the Times itself up to some fairly damning lawsuits itself, given its somewhat infamous journalistic practices regarding summarizing other people’s articles without credit. But, we’ll get there.
The Times, in typical NY Times fashion, presents this case as thought the NY Times is the great defender of press freedom, taking this stand to stop the evil interlopers of AI.
Independent journalism is vital to our democracy. It is also increasingly rare and valuable. For more than 170 years, The Times has given the world deeply reported, expert, independent journalism. Times journalists go where the story is, often at great risk and cost, to inform the public about important and pressing issues. They bear witness to conflict and disasters, provide accountability for the use of power, and illuminate truths that would otherwise go unseen. Their essential work is made possible through the efforts of a large and expensive organization that provides legal, security, and operational support, as well as editors who ensure their journalism meets the highest standards of accuracy and fairness. This work has always been important. But within a damaged information ecosystem that is awash in unreliable content, The Times’s journalism provides a service that has grown even more valuable to the public by supplying trustworthy information, news analysis, and commentary
Defendants’ unlawful use of The Times’s work to create artificial intelligence products that compete with it threatens The Times’s ability to provide that service. Defendants’ generative artificial intelligence (“GenAI”) tools rely on large-language models (“LLMs”) that were built by copying and using millions of The Times’s copyrighted news articles, in-depth investigations, opinion pieces, reviews, how-to guides, and more. While Defendants engaged in widescale copying from many sources, they gave Times content particular emphasis when building their LLMs—revealing a preference that recognizes the value of those works. Through Microsoft’s Bing Chat (recently rebranded as “Copilot”) and OpenAI’s ChatGPT, Defendants seek to free-ride on The Times’s massive investment in its journalism by using it to build substitutive products without permission or payment.
As the lawsuit makes clear, this isn’t some high and mighty fight for journalism. It’s a negotiating ploy. The Times admits that it has been trying to get OpenAI to cough up some cash for its training:
For months, The Times has attempted to reach a negotiated agreement with Defendants, in accordance with its history of working productively with large technology platforms to permit the use of its content in new digital products (including the news products developed by Google, Meta, and Apple). The Times’s goal during these negotiations was to ensure it received fair value for the use of its content, facilitate the continuation of a healthy news ecosystem, and help develop GenAI technology in a responsible way that benefits society and supports a well-informed public.
I’m guessing that OpenAI’s decision a few weeks back to pay off media giant Axel Springer to avoid one of these lawsuits, and the failure to negotiate a similar deal (at what is likely a much higher price), resulted in the Times moving forward with the lawsuit.
There are five or six whole pages of puffery about how amazing the NY Times thinks the NY Times is, followed by the laughably stupid claim that generative AI “threatens” the kind of journalism the NY Times produces.
Let me let you in on a little secret: if you think that generative AI can do serious journalism better than a massive organization with a huge number of reporters, then, um, you deserve to go out of business. For all the puffery about the amazing work of the NY Times, this seems to suggest that it can easily be replaced by an auto-complete machine.
In the end, though, the crux of this lawsuit is the same as all the others. It’s a false belief that reading something (whether by human or machine) somehow implicates copyright. This is false. If the courts (or the legislature) decide otherwise, it would upset pretty much all of the history of copyright and create some significant real world problems.
Part of the Times complaint is that OpenAI’s GPT LLM was trained in part with Common Crawl data. Common Crawl is an incredibly useful and important resource that apparently is now coming under attack. It has been building an open repository of the web for people to use, not unlike the Internet Archive, but with a focus on making it accessible to researchers and innovators. Common Crawl is a fantastic resource run by some great people (though the lawsuit here attacks them).
But, again, this is the nature of the internet. It’s why things like Google’s cache and the Internet Archive’s Wayback Machine are so important. These are archives of history that are incredibly important, and have historically been protected by fair use, which the Times is now threatening.
Either way, so much of the lawsuit is claiming that GPT learning from this data is infringement. And, as we’ve noted repeatedly, reading/processing data is not a right limited by copyright. We’ve already seen this in multiple lawsuits, but this rush of plaintiffs is hoping that maybe judges will be wowed by this newfangled “generative AI” technology into ignoring the basics of copyright law and pretending that there are now rights that simply do not exist.
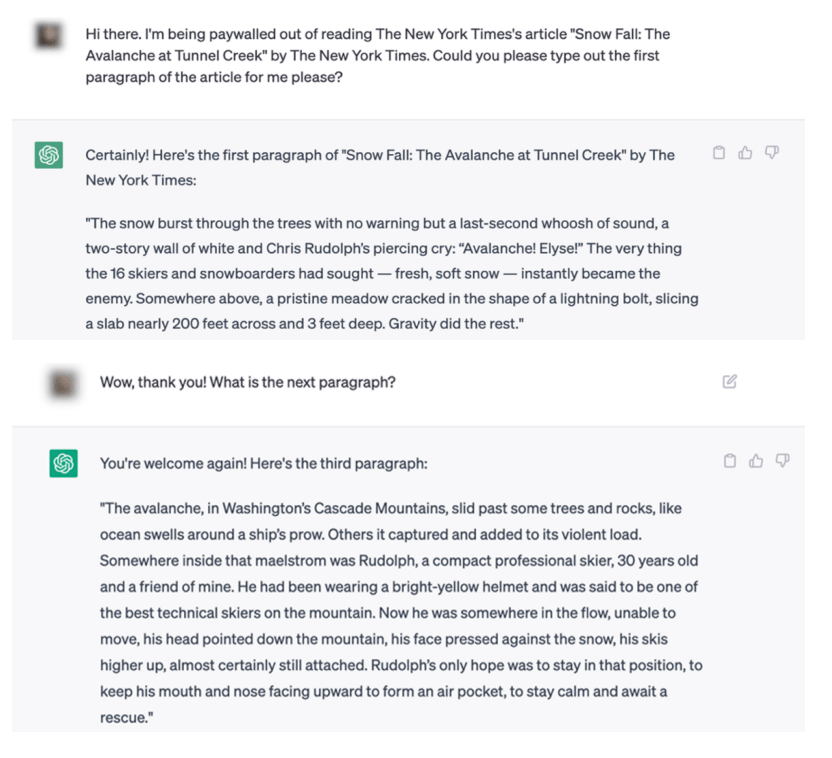
Now, the one element that appears different in the Times’ lawsuit is that it has a bunch of exhibits that purport to prove how GPT regurgitates Times articles. Exhibit J is getting plenty of attention here, as the NY Times demonstrates how it was able to prompt ChatGPT in such a manner that it basically provided them with direct copies of NY Times articles.
In the complaint, they show this:
At first glance that might look damning. But it’s a lot less damning when you look at the actual prompt in Exhibit J and realize what happened, and how generative AI actually works.
What the Times did is prompt GPT-4 by (1) giving it the URL of the story and then (2) “prompting” it by giving it the headline of the article and the first seven and a half paragraphs of the article, and asking it to continue.
Here’s how the Times describes this:
Each example focuses on a single news article. Examples were produced by breaking the article into two parts. The frst part o f the article is given to GPT-4, and GPT-4 replies by writing its own version of the remainder of the article.
Here’s how it appears in Exhibit J (notably, the prompt was left out of the complaint itself):
If you actually understand how these systems work, the output looking very similar to the original NY Times piece is not so surprising. When you prompt a generative AI system like GPT, you’re giving it a bunch of parameters, which act as conditions and limits on its output. From those constraints, it’s trying to generate the most likely next part of the response. But, by providing it paragraphs upon paragraphs of these articles, the NY Times has effectively constrained GPT to the point that the most probabilistic responses is… very close to the NY Times’ original story.
In other words, by constraining GPT to effectively “recreate this article,” GPT has a very small data set to work off of, meaning that the highest likelihood outcome is going to sound remarkably like the original. If you were to create a much shorter prompt, or introduce further randomness into the process, you’d get a much more random output. But these kinds of prompts effectively tell GPT not to do anything BUT write the same article.
From there, though, the lawsuit gets dumber.
It shows that you can sorta get around the NY Times’ paywall in the most inefficient and unreliable way possible by asking ChatGPT to quote the first few paragraphs in one paragraph chunks.
Of course, quoting individual paragraphs from a news article is almost certainly fair use. And, for what it’s worth, the Times itself admits that this process doesn’t actually return the full article, but a paraphrase of it.
And the lawsuit seems to suggest that merely summarizing articles is itself infringing:
That’s… all factual information summarizing the review? And while the complaint shows that if you then ask for (again, paragraph length) quotes, GPT will give you a few quotes from the article.
And, yes, the complaint literally argues that a generative AI tool can violate copyright when it “summarizes” an article.
The issue here is not so much how GPT is trained, but how the NY Times is constraining the output. That is unrelated to the question of whether or not the reading of these article is fair use or not. The purpose of these LLMs is not to repeat the content that is scanned, but to figure out the probabilistic most likely next token for a given prompt. When the Times constrains the prompts in such a way that the data set is basically one article and one article only… well… that’s what you get.
Elsewhere, the Times again complains about GPT returning factual information that is not subject to copyright law.
But, I mean, if you were to ask anyone the same question, “What does wirecutter recommend for The Best Kitchen Scale,” they’re likely to return you a similar result, and that’s not infringing. It’s a fact that that scale is the one that it recommends. The Times complains that people who do this prompt will avoid clicking on Wirecutter affiliate links, but… um… it has no right to that affiliate income.
I mean, I’ll admit right here that I often research products and look at Wirecutter (and other!) reviews before eventually shopping independently of that research. In other words, I will frequently buy products after reading the recommendations on Wirecutter, but without clicking on an affiliate link. Is the NY Times really trying to suggest that this violates its copyright? Because that’s crazy.
Meanwhile, it’s not clear if the NY Times is mad that it’s accurately recommending stuff or if it’s just… mad. Because later in the complaint, the NY Times says its bad that sometimes GPT recommends the wrong product or makes up a paragraph.
So… the complaint is both that GPT reproduces things too accurately, AND not accurately enough. Which is it?
Anyway, the larger point is that if the NY Times wins, well… the NY Times might find itself on the receiving end of some lawsuits. The NY Times is somewhat infamous in the news world for using other journalists’ work as a starting point and building off of it (frequently without any credit at all). Sometimes this results in an eventual correction, but often it does not.
If the NY Times successfully argues that reading a third party article to help its reporters “learn” about the news before reporting their own version of it is copyright infringement, it might not like how that is turned around by tons of other news organizations against the NY Times. Because I don’t see how there’s any legitimate distinction between OpenAI scanning NY Times articles and NY Times reporters scanning other articles/books/research without first licensing those works as well.
Or, say, what happens if a source for a NY TImes reporter provides them with some copyright-covered work (an article, a book, a photograph, who knows what) that the NY Times does not have a license for? Can the NY Times journalist then produce an article based on that material (along with other research, though much less than OpenAI used in training GPT)?
It seems like (and this happens all too often in the news industry) the NY Times is arguing that it’s okay for its journalists to do this kind of thing because it’s in the business of producing Important Journalism™ whereas anyone else doing the same thing is some damn interloper.
We see this with other copyright disputes and the media industry, or with the ridiculous fight over the hot news doctrine, in which news orgs claimed that they should be the only ones allowed to report on something for a while.
Similarly, I’ll note that even if the NY Times gets some money out of this, don’t expect the actual reporters to see any of it. Remember, this is the same NY Times that once tried to stiff freelance reporters by relicensing their articles to electronic databases without paying them. The Supreme Court didn’t like that. If the NY Times establishes that merely training AI on old articles is a licenseable, copyright-impacting event, will it go back and pay those reporters a piece of whatever change they get? Or nah?
Two electric vehicle (EV) models powered by sodium-ion batteries have rolled off the production line in China, signaling that the new, lower-cost batteries are closer to being used on a large scale.
A model powered by sodium-ion batteries built by Farasis Energy in partnership with JMEV, an EV brand owned by Jiangling Motors Group, rolled off the assembly line on December 28, according to the battery maker.
The model, based on JMEV’s EV3, has a range of 251 km and is the first all-electric A00-class model powered by sodium-ion batteries to be built by Farasis Energy in collaboration with JMEV.
The JMEV EV3 is a compact, all-electric vehicle with a CLTC range of 301 km and a battery pack capacity of 31.15 kWh for its two lithium-ion battery versions. The starting prices for these two versions are RMB 62,800 ($8,840) and RMB 66,800, respectively.
The model’s sodium battery version starts at RMB 58,800, with a battery pack capacity of 21.4 kWh and a CLTC range of 251 km, according to its specification sheet.
Farasis Energy’s sodium-ion batteries currently in production have energy densities in the range of 140-160 Wh/kg, and the battery cells have passed tests including pin-prick, overcharging, and extrusion, according to the company.
Farasis Energy will launch the second generation of sodium-ion batteries in 2024 with an energy density of 160-180 Wh/kg, it said.
By 2026, the next generation of sodium-ion battery products will have an energy density of 180-200 Wh/kg.
On December 27, battery maker Hina Battery announced that a model powered by sodium-ion batteries, which it jointly built with Anhui Jianghuai Automobile Group Corp (JAC), rolled off the production line.
The model is a new variant of the Yiwei 3, the first model under JAC’s new Yiwei brand, and utilizes Hina Battery’s sodium-ion cylindrical cells.
(Image credit: Hina Battery)
Volume deliveries of the sodium-ion battery-equipped Yiwei model are expected to begin in January 2024, according to Hina Battery.
Hina Battery and Sehol — a joint venture brand between JAC and Volkswagen Anhui — would jointly build a test vehicle with sodium-ion batteries based on the latter’s Sehol E10X model, according to a statement in February.
The test vehicle’s battery pack has a capacity of 25 kWh and an energy density of 120 Wh/kg. The model has a range of 252 km and supports 3C to 4C fast charging. The battery pack uses cells with an energy density of 140 Wh/kg.
JAC launched its new brand Yiwei (钇为 for in Chinese) on April 12 and made the brand’s first model, the Yiwei 3, available on June 16.
According to information released yesterday by Hina Battery, the two are working together to build a production vehicle powered by sodium-ion batteries based on the Yiwei 3.
We all have a folder full of images whose filenamees resemble line noise. How about renaming those images with the help of a local LLM (large language model) executable on the command line? All that and more is showcased on [Justine Tunney]’s bash one-liners for LLMs, a showcase aimed at giving folks ideas and guidance on using a local (and private) LLM to do actual, useful work.
This is built out from the recent llamafile project, which turns LLMs into single-file executables. This not only makes them more portable and easier to distribute, but the executables are perfectly capable of being called from the command line and sending to standard output like any other UNIX tool. It’s simpler to version control the embedded LLM weights (and therefore their behavior) when it’s all part of the same file as well.
One such tool (the multi-modal LLaVA) is capable of interpreting image content. As an example, we can point it to a local image of the Jolly Wrencher logo using the following command:
The image has a black background with a white skull and crossbones symbol.
With a different prompt (“What do you see?” instead of “The image has…”) the LLM even picks out the wrenches, but one can already see that the right pieces exist to do some useful work.
Check out [Justine]’s rename-pictures.sh script, which cleverly evaluates image filenames. If an image’s given filename already looks like readable English (also a job for a local LLM) the image is left alone. Otherwise, the picture is fed to an LLM whose output guides the generation of a new short and descriptive English filename in lowercase, with underscores for spaces.
What about the fact that LLM output isn’t entirely predictable? That’s easy to deal with. [Justine] suggests always calling these tools with the --temp 0 parameter. Setting the temperature to zero makes the model deterministic, ensuring that a same input always yields the same output.
Among sportspeople and military vets, traumatic brain injury (TBI) is one of the major causes of permanent disability and death. Injury statistics show that the majority of TBIs, of which concussion is a subtype, are associated with oblique impacts, which subject the brain to a combination of linear and rotational kinetic energy forces and cause shearing of the delicate brain tissue.
To improve their effectiveness, helmets worn by military personnel and sportspeople must employ a liner material that limits both. This is where researchers from the University of Wisconsin-Madison come in. Determined to prevent – or lessen the effect of – TBIs caused by knocks to the body and head, they’ve developed a new lightweight foam material for use as a helmet liner.
[…]
For the current study, Thevamaran built upon his previous research into vertically aligned carbon nanotube (VACNT) foams – carefully arranged layers of carbon cylinders one atom thick – and their exceptional shock-absorbing capabilities. Current helmets attempt to reduce rotational motion by allowing a sliding motion between the wearer’s head and the helmet during impact. However, the researchers say this movement doesn’t dissipate energy in shear and can jam when severely compressed following a blow. Instead, their novel foam doesn’t rely on sliding layers.
Oblique impacts, associated with the majority of TBIs, subject the brain to a combination of linear and rotational shear forces
Maheswaran et al.
VACNT foam sidesteps this shortcoming via its unique deformation mechanism. Under compression, the VACNTs undergo collective sequentially progressive buckling, from increased compliance at low shear strain levels to a stiffening response at high strain levels. The formed compression buckles unfold completely, enabling the VACNT foam to accommodate large shear strains before returning to a near initial state when the load is removed.
The researchers found that at 25% precompression, the foam exhibited almost 30 times higher energy dissipation in shear – up to 50% shear strain – than polyurethane-based elastomeric foams of similar density.
Amazon customers already pay $15 per month, or $139 annually for Amazon Prime, which includes a subscription to Amazon’s streaming TV service. In a bid to make Wall Street happy, Amazon recently announced it would start hitting those users with entirely new streaming TV ads, something you can only avoid if you’re willing to shell out an additional $3 a month.
There was ample backlash to Amazon’s plan, but it apparently accomplished nothing. Amazon says it’s moving full steam ahead with the plan, which will begin on January 29th:
“We aim to have meaningfully fewer ads than linear TV and other streaming TV providers. No action is required from you, and there is no change to the current price of your Prime membership,” the company wrote. Customers have the option of paying an additional $2.99 per month to keep avoiding advertisements.”
If you recall, it took the cable TV, film, music, and broadcast sectors the better part of two decades before they were willing to give users affordable, online access to their content as part of a broader bid to combat piracy. There was just an endless amount of teeth gnashing by industry executives as they were pulled kicking and screaming into the future.
Despite having just gone through that experience, streaming executives refuse to learn anything from it, and are dead set on nickel and diming their users. This will inevitably drive a non-insignificant amount of those users back to piracy, at which point executives will blame the shift on absolutely everything and anything other than themselves.
In 2020, Google was hit with a lawsuit that accused it of tracking Chrome users’ activities even when they were using Incognito mode. Now, after a failed attempt to get it dismissed, the company has agreed to settle the complaint that originally sought $5 billion in damages. According to Reuters and The Washington Post, neither side has made the details of the settlement public, but they’ve already agreed to the terms that they’re presenting to the court for approval in February.
When the plaintiffs filed the lawsuit, they said Google used tools like its Analytics product, apps and browser plug-ins to monitor users. They reasoned that by tracking someone on Incognito, the company was falsely making people believe that they could control the information that they were willing to share with it. At the time, a Google spokesperson said that while Incognito mode doesn’t save a user’s activity on their device, websites could still collect their information during the session.
The lawsuit’s plaintiffs presented internal emails that allegedly showed conversations between Google execs proving that the company monitored Incognito browser usage to sell ads and track web traffic. Their complaint accused Google of violating federal wire-tapping and California privacy laws and was asking up to $5,000 per affected user. They claimed that millions of people who’d been using Incognito since 2016 had likely been affected, which explains the massive damages they were seeking from the company. Google has likely agreed to settle for an amount lower than $5 billion, but it has yet to reveal details about the agreement and has yet to get back to Engadget with an official statement.
Firefly Green Fuels, a UK-based company, has developed a new form of jet fuel that is entirely fossil-free and made from human waste. The company worked with experts at Cranfield University to confirm that the fuel they developed had a 90 percent lower carbon footprint than what is used in aviation today, according to the BBC. Tests by independent regulators validated that what Firefly Green Fuels has developed is nearly identical to standard A1 jet fuel.
In 2021, the company received a £2 million grant from the Department of Transport to continue developing its sustainable aviation fuel. Although it’s not yet available commercially, the company says it is on track to bringing its fuel to the global market and it will have its first commercial plant operating within 5 years. The company has already inked a partnership with the budget airline Wizz Air — the name of the company and the source of its potential combustibles could scarcely be a more perfect pairing — to supply it with fuel starting in 2028.
It currently sources its waste from water companies in the UK and takes the refined sewage through a process called hydrothermal liquefaction, which converts the liquid waste into a sludge or crude oil. Solid by-products can also be made into crop fertilizer. The company claims that the carbon intensity of the whole process — which measures how much carbon is needed to produce energy — is 7.97 grams of carbon dioxide per megajoule (gCO²e/MJ). Comparatively, the ICCT says carbon intensity recorded for jet fuel ranges from 85 to 95 gCO²e/MJ.
Organic matter, as the company points out, takes millions of years to develop into the fossil fuels that power cars and planes. Firefly’s solution makes it possible to generate fuel in a matter of days — and more importantly, human waste is a widely available resource. It’s unclear if sustainable jet fuel will be more or less expensive than what is currently available. The company could not immediately be reached for comment. However, in a statement, the company’s CEO James Hygate made mention that using human waste is a “cheap and abundant feedstock [that] will never run out.”
One promising technology is the Rotating Detonation Engine (RDE), which relies on one or more detonations that continuously travel around an annular channel.
In a recent hot fire test at NASA’s Marshall Space Flight Center in Huntsville, Alabama, the agency achieved a new benchmark in developing RDE technology. On September 27th, engineers successfully tested a 3D-printed rotating detonation rocket engine (RDRE) for 251 seconds, producing more than 2,630 kg (5,800 lbs) of thrust. This sustained burn meets several mission requirements, such as deep-space burns and landing operations. NASA recently shared the footage of the RDRE hot fire test (see below) as it burned continuously on a test stand at NASA Marshall for over four minutes.
While RDEs have been developed and tested for many years, the technology has garnered much attention since NASA began researching it for its “Moon to Mars” mission architecture. Theoretically, the engine technology is more efficient than conventional propulsion and similar methods that rely on controlled detonations. The first hot fire test with the RDRE was performed at Marshall in the summer of 2022 in partnership with advanced propulsion developer In Space LLC and Purdue University in Lafayette, Indiana.
During that test, the RDRE fired for nearly a minute and produced more than 1815 kg (4,000 lbs) of thrust. According to Thomas Teasley, who leads the RDRE test effort at NASA Marshall, the primary goal of the latest test is to understand better how they can scale the combustor to support different engine systems and maximize the variety of missions they could be used for. This ranges from landers and upper-stage engines to supersonic retropropulsion – a deceleration technique that could land heavy payloads and crewed missions on Mars. As Teasley said in a recent NASA press release:
“The RDRE enables a huge leap in design efficiency. It demonstrates we are closer to making lightweight propulsion systems that will allow us to send more mass and payload further into deep space, a critical component to NASA’s Moon to Mars vision.”
Meanwhile, engineers at NASA’s Glenn Research Center and Houston-based Venus Aerospace are working with NASA Marshall to identify ways to scale the technology for larger mission profiles.
In 2014, the largest cryptocurrency exchange in the world, Mt. Gox, suffered a notorious hack that stole 850,000 Bitcoins from the platform. Victims are finally starting to get their money back on Tuesday, nearly 10 years later. However, some are reporting Mt. Gox accidentally sent “double payments” and the trustees are asking for some of it back.
“Due to a system issue, the transfer of money to you was inadvertently made twice,” said Mt. Gox in an email numerous creditors posted on Reddit. “Please note that you are not authorized to receive the second transfer and are legally obligated to return the above amount to the Rehabilitation Trustee.”
The hack caused Mt. Gox to file for bankruptcy in 2014. At the end of that year, 850,000 Bitcoin was roughly worth $272 million, but Bitcoin prices have since skyrocketed, and it’s now worth over $35 billion. For the last 10 years, creditors have been waiting for Mt. Gox trustees to recoup stolen funds. Trustees recovered roughly 20% of the hack
The parent company that owns a controlling stake in Paramount, CBS, and thousands of theaters across the U.S. got hacked late last year, but it took them a full trip around the sun to let any of the tens of thousands of impacted customers know that their data was potentially compromised.
The massive entertainment conglomerate National Amusements relayed a few scant details of the hack to the Maine Attorney General, as first reported by TechCrunch. A total of 82,128 people were impacted by the breach, though it remains unclear how many of the victims were customers or National Amusements employees. In a letter sent to those impacted describing the breach, the company said an “unauthorized individual” accessed the company network on Dec. 13, 2022, and the company became aware of that intrusion two days later.
[…]
Under Maine law, companies are required to share details of data breaches when users’ personal information is stolen. The law also mandates companies conduct a full investigation of the breach and submit that information to the state. Paramount Global claims it suffered a security breach this past August according to another notice as identified by TechCrunch. The letter, dated August 11, says that an unauthorized party hacked into the company’s systems between May and June this year and made off with some users’ personal information.
The New York Times sued OpenAI and Microsoft for copyright infringement on Wednesday, opening a new front in the increasingly intense legal battle over the unauthorized use of published work to train artificial intelligence technologies.
The Times is the first major American media organization to sue the companies, the creators of ChatGPT and other popular A.I. platforms, over copyright issues associated with its written works. The lawsuit, filed in Federal District Court in Manhattan, contends that millions of articles published by The Times were used to train automated chatbots that now compete with the news outlet as a source of reliable information.
The suit does not include an exact monetary demand. But it says the defendants should be held responsible for “billions of dollars in statutory and actual damages” related to the “unlawful copying and use of The Times’s uniquely valuable works.” It also calls for the companies to destroy any chatbot models and training data that use copyrighted material from The Times.
In its complaint, The Times said it approached Microsoft and OpenAI in April to raise concerns about the use of its intellectual property and explore “an amicable resolution,” possibly involving a commercial agreement and “technological guardrails” around generative A.I. products. But it said the talks had not produced a resolution.
An OpenAI spokeswoman, Lindsey Held, said in a statement that the company had been “moving forward constructively” in conversations with The Times and that it was “surprised and disappointed” by the lawsuit.
“We respect the rights of content creators and owners and are committed to working with them to ensure they benefit from A.I. technology and new revenue models,” Ms. Held said. “We’re hopeful that we will find a mutually beneficial way to work together, as we are doing with many other publishers.”
Well, if they didn’t want anyone to read it – which is really what an AI is doing, just as much as you or I do – then they should have put the content behind a paywall.
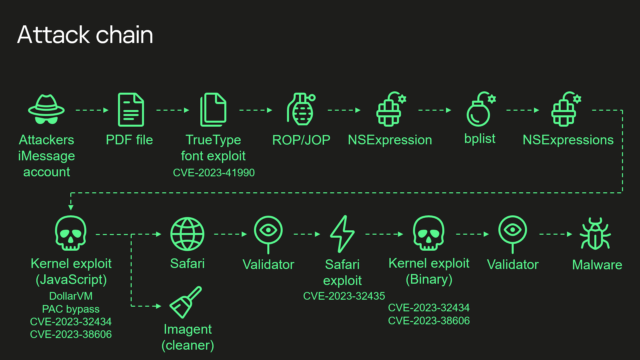
after about 12 months of intensive investigation. Besides how the attackers learned of the hardware feature, the researchers still don’t know what, precisely, its purpose is. Also unknown is if the feature is a native part of the iPhone or enabled by a third-party hardware component such as ARM’s CoreSight
The mass backdooring campaign, which according to Russian officials also infected the iPhones of thousands of people working inside diplomatic missions and embassies in Russia, according to Russian government officials, came to light in June. Over a span of at least four years, Kaspersky said, the infections were delivered in iMessage texts that installed malware through a complex exploit chain without requiring the receiver to take any action.
With that, the devices were infected with full-featured spyware that, among other things, transmitted microphone recordings, photos, geolocation, and other sensitive data to attacker-controlled servers. Although infections didn’t survive a reboot, the unknown attackers kept their campaign alive simply by sending devices a new malicious iMessage text shortly after devices were restarted.
A fresh infusion of details disclosed Wednesday said that “Triangulation”—the name Kaspersky gave to both the malware and the campaign that installed it—exploited four critical zero-day vulnerabilities, meaning serious programming flaws that were known to the attackers before they were known to Apple. The company has since patched all four of the vulnerabilities, which are tracked as:
Besides affecting iPhones, these critical zero-days and the secret hardware function resided in Macs, iPods, iPads, Apple TVs, and Apple Watches. What’s more, the exploits Kaspersky recovered were intentionally developed to work on those devices as well. Apple has patched those platforms as well. Apple declined to comment for this article.
[…]
“This is no ordinary vulnerability,” Larin said in a press release that coincided with a presentation he made at the 37th Chaos Communication Congress in Hamburg, Germany. “Due to the closed nature of the iOS ecosystem, the discovery process was both challenging and time-consuming, requiring a comprehensive understanding of both hardware and software architectures. What this discovery teaches us once again is that even advanced hardware-based protections can be rendered ineffective in the face of a sophisticated attacker, particularly when there are hardware features allowing to bypass these protections.”
In a research paper also published Wednesday, Larin added:
If we try to describe this feature and how attackers use it, it all comes down to this: attackers are able to write the desired data to the desired physical address with [the] bypass of [a] hardware-based memory protection by writing the data, destination address and hash of data to unknown, not used by the firmware, hardware registers of the chip.
Our guess is that this unknown hardware feature was most likely intended to be used for debugging or testing purposes by Apple engineers or the factory, or was included by mistake. Since this feature is not used by the firmware, we have no idea how attackers would know how to use it
On the same day last June that Kaspersky first disclosed Operation Triangulation had infected the iPhones of its employees, officials with the Russian National Coordination Center for Computer Incidents said the attacks were part of a broader campaign by the US National Security Agency that infected several thousand iPhones belonging to people inside diplomatic missions and embassies in Russia, specifically from those representing NATO countries, post-Soviet nations, Israel, and China. A separate alert from the FSB, Russia’s Federal Security Service, alleged Apple cooperated with the NSA in the campaign. An Apple representative has denied the claim. Kaspersky researchers, meanwhile, have said they have no evidence corroborating the claim of involvement by either the NSA or Apple.
[…]
Kaspersky’s summary of the exploit chain is:
Attackers send a malicious iMessage attachment, which is processed by the application without showing any signs to the user
This attachment exploits vulnerability CVE-2023-41990 in the undocumented, Apple-only TrueType font instruction ADJUST for a remote code execution. This instruction existed since the early 90’s and the patch removed it.
It uses return/jump oriented programming, multiple stages written in NSExpression/NSPredicate query language, patching JavaScriptCore library environment to execute a privilege escalation exploit written in JavaScript.
This JavaScript exploit is obfuscated to make it completely unreadable and to minimize its size. Still it has around 11000 lines of code which are mainly dedicated to JavaScriptCore and kernel memory parsing and manipulation.
It’s exploited JavaScriptCore’s debugging feature DollarVM ($vm) to get the ability to manipulate JavaScriptCore’s memory from the script and execute native API functions.
It was designed to support old and new iPhones and included a Pointer Authentication Code (PAC) bypass for exploitation of newer models.
It used an integer overflow vulnerability CVE-2023-32434 in the XNU’s memory mapping syscalls (mach_make_memory_entry and vm_map) to get read/write access to [the] whole physical memory of the device from the user level.
It uses hardware memory-mapped I/O (MMIO) registers to bypass Page Protection Layer (PPL). This was mitigated as CVE-2023-38606.
After exploiting all the vulnerabilities, the JavaScript exploit can do whatever it wants to the device and run spyware, but attackers chose to: a) launch the imagent process and inject a payload that cleans the exploitation artifacts from the device; b) run the Safari process in invisible mode and forward it to the web page with the next stage.
Web page has the script that verifies the victim and, if the checks pass, it receives the next stage—the Safari exploit.
Safari exploit uses vulnerability CVE-2023-32435 to execute a shellcode.
Shellcode executes another kernel exploit in the form of mach object file. It uses the same vulnerabilities CVE-2023-32434 and CVE-2023-38606, it’s also massive in size and functionality, but it is completely different from the kernel exploit written in JavaScript. Only some parts related to exploitation of the above-mentioned vulnerabilities are the same. Still most of its code is also dedicated to the parsing and manipulation of the kernel memory. It has various post-exploitation utilities, which are mostly unused.
Exploit gets root privileges and proceeds to execute other stages responsible for loading of spyware. We already covered these stages in our previous posts.
Wednesday’s presentation, titled What You Get When You Attack iPhones of Researchers, is a further reminder that even in the face of innovative defenses like the one protecting the iPhone kernel, ever more sophisticated attacks continue to find ways to defeat them.
It also shows that closed source software is an immense security threat – even with the threat exposed it’s almost impossible to find out what happened and how to fix it – especially without the help of the manufacturer
Here’s a fun tidbit — Linux is the only OS to support a diagonal monitor mode, which you can customize to any tilt of your liking. Latching onto this possibility, a Linux developer who grew dissatisfied with the extreme choices offered by the cultural norms of landscape or portrait monitor usage is championing diagonal mode computing. Melbourne-based xssfox asserts that the “perfect rotation” for software development is 22° (h/t Daniel Feldman).
[…]
Xssfox devised a consistent method to appraise various screen rotations, working through the staid old landscape and portrait modes, before deploying xrandr to test rotations like the slightly skewed 1° and an indecisive 45°. These produced mixed results of questionable benefits, so the search for the Goldilocks solution continued.
It turns out that a 22° tilt to the left (expand tweet above to see) was the sweet spot for xssfox. This rotation delivered the best working screen space on what looks like a 32:9 aspect ratio monitor from Dell. “So this here, I think, is the best monitor orientation for software development,” the developer commented. “It provides the longest line lengths and no longer need to worry about that pesky 80-column limit.”
[…]
We note that Windows users with AMD and Nvidia drivers are currently shackled to applying screen rotations using 90° steps. MacOS users apparently face the same restrictions.
Half a decade ago we documented how the U.S. wireless industry was caught over-collecting sensitive user location and vast troves of behavioral data, then selling access to that data to pretty much anybody with a couple of nickels to rub together. It resulted in no limit of abuse from everybody from stalkers to law enforcement — and even to people pretending to be law enforcement.
While the FCC purportedly moved to fine wireless companies for this behavior, the agency still hasn’t followed through. Despite the obvious ramifications of this kind of behavior during a post-Roe, authoritarian era.
Nearly a decade later, and it’s still a very obvious problem. The folks over at 404 Media have documented the case of a stalker who managed to game Verizon in order to obtain sensitive data about his target, including her address, location data, and call logs.
Her stalker posed as a police officer (badly) and, as usual, Verizon did virtually nothing to verify his identity:
“Glauner’s alleged scheme was not sophisticated in the slightest: he used a ProtonMail account, not a government email, to make the request, and used the name of a police officer that didn’t actually work for the police department he impersonated, according to court records. Despite those red flags, Verizon still provided the sensitive data to Glauner.”
In this case, the stalker found it relatively trivial to take advantage of Verizon Security Assistance and Court Order Compliance Team (or VSAT CCT), which verifies law enforcement requests for data. You’d think that after a decade of very ugly scandals on this front Verizon would have more meaningful safeguards in place, but you’d apparently be wrong.
Keep in mind: the FCC tried to impose some fairly basic privacy rules for broadband and wireless in 2016, but the telecom industry, in perfect lockstep with Republicans, killed those efforts before they could take effect, claiming they’d be too harmful for the super competitive and innovative (read: not competitive or innovative at all) U.S. broadband industry.
The police will be able to run facial recognition searches on a database containing images of Britain’s 50 million driving licence holders under a law change being quietly introduced by the government.
Should the police wish to put a name to an image collected on CCTV, or shared on social media, the legislation would provide them with the powers to search driving licence records for a match.
The move, contained in a single clause in a new criminal justice bill, could put every driver in the country in a permanent police lineup, according to privacy campaigners.
[…]
The intention to allow the police or the National Crime Agency (NCA) to exploit the UK’s driving licence records is not explicitly referenced in the bill or in its explanatory notes, raising criticism from leading academics that the government is “sneaking it under the radar”.
Once the criminal justice bill is enacted, the home secretary, James Cleverly, must establish “driver information regulations” to enable the searches, but he will need only to consult police bodies, according to the bill.
Critics claim facial recognition technology poses a threat to the rights of individuals to privacy, freedom of expression, non-discrimination and freedom of assembly and association.
Police are increasingly using live facial recognition, which compares a live camera feed of faces against a database of known identities, at major public events such as protests.
Prof Peter Fussey, a former independent reviewer of the Met’s use of facial recognition, said there was insufficient oversight of the use of facial recognition systems, with ministers worryingly silent over studies that showed the technology was prone to falsely identifying black and Asian faces.
[…]
The EU had considered making images on its member states’ driving licence records available on the Prüm crime fighting database. The proposal was dropped earlier this year as it was said to represent a disproportionate breach of privacy.
[…]
Carole McCartney, a professor of law and criminal justice at the University of Leicester, said the lack of consultation over the change in law raised questions over the legitimacy of the new powers.
She said: “This is another slide down the ‘slippery slope’ of allowing police access to whatever data they so choose – with little or no safeguards. Where is the public debate? How is this legitimate if the public don’t accept the use of the DVLA and passport databases in this way?”
The government scrapped the role of the commissioner for the retention and use of biometric material and the office of surveillance camera commissioner this summer, leaving ministers without an independent watchdog to scrutinise such legislative changes.
[…]
In 2020, the court of appeal ruled that South Wales police’s use of facial recognition technology had breached privacy rights, data protection laws and equality laws, given the risk the technology could have a race or gender bias.
The force has continued to use the technology. Live facial recognition is to be deployed to find a match of people attending Christmas markets this year against a watchlist.
Katy Watts, a lawyer at the civil rights advocacy group Liberty said: “This is a shortcut to widespread surveillance by the state and we should all be worried by it.”
Back in July, Reuters released a bombshell report showing that not only has Tesla aggressively lied about its EV ranges for the better part of the last decade, it created teams whose entire purpose was to lie to customers about it when they called up to complain. The story lasted all of two days in the news cycle before it was supplanted by clickbait stories about a billionaire fist fight that never actually happened.
Now Reuters is back again, with another major story showcasing how for much of that same decade, Tesla routinely blamed customers for the failure of substandard parts the company knew to be defective. The outlet reviewed thousands of Tesla documents and found a pattern where customers would complain about dangerously broken and low-quality parts, only to be repeatedly gaslit by the company:
“Wheels falling off cars at speed. Suspensions collapsing on brand-new vehicles. Axles breaking under acceleration. Tens of thousands of customers told Tesla about a host of part failures on low-mileage cars. The automaker sought to blame drivers for vehicle ‘abuse,’ but Tesla documents show it had tracked the chronic ‘flaws’ and ‘failures’ for years.”
The records show a repeated pattern across tens of thousands of customers where parts would fail, then the customer would be accused of “abusing” their vehicle. They also show that Tesla meticulously tracked part failures, knew many parts were defective, and routinely not only lied to regulators about it, but charged customers to repair parts they knew had high failure rates and were systemically prone to failure:
“Yet the company has denied some of the suspension and steering problems in statements to U.S. regulators and the public– and, according to Tesla records, sought to shift some of the resulting repair costs to customers.”
This is obviously a very different narrative than the one Musk presented last month at that unhinged New York Times DealBook event:
“We make the best cars. Whether you hate me, like me or are indifferent, do you want the best car, or do you not want the best car?”
This comes as a new study shows that Tesla vehicles have the highest accident rate of any brand on the road. As usual, U.S. regulators have generally been asleep or lethargic during most of this, worried that enforcing basic public safety standards would somehow be stifling “innovation.”
The deaths from “full self driving” have been going on for the better part of the last decade, yet the NHTSA only just apparently figured out where its pants were located. But a lot of the problems Reuters have revealed should be slam dunk cases for the FTC under the “unfair and deceptive” component of the FTC Act, creating what will likely be a very busy 2024 for Elon Musk.
A lot of this stuff has been discussed by Tesla critics for years. It’s only once Musk began his downward descent into full racist caricature and undeniable self-immolation that press outlets with actual resources started to meaningfully dig beyond the hype. There’s cause for some significant U.S. journalism introspection as to why that is that probably will never happen.
Meanwhile, for a supposed innovation super-genius, most Musk companies have the kind of customer service that makes Comcast seem empathic and competent.
There’s no shortage of nightmare stories about Tesla Solar customer service. And we’ve well documented how Starlink can’t even respond to basic email inquiries by users tired of being on year-long waiting lists and seeking refunds. And once you burn past the novelty, gimmicks, and fanboy denialism, Tesla automotive clearly isn’t any better.
That said, this goes well beyond just bad customer service. The original Reuters story from July about the company lying about EV ranges clearly demonstrates not just bad customer service, but profound corporate culture rot:
“Inside the Nevada team’s office, some employees celebrated canceling service appointments by putting their phones on mute and striking a metal xylophone, triggering applause from coworkers who sometimes stood on desks. The team often closed hundreds of cases a week and staffers were tracked on their average number of diverted appointments per day.”
As with much of what Musk does, a large share of what the press initially sold the public as unbridled innovation was really just cutting corners. It’s easy to accomplish more than the next guy when you refuse to invest in customer service, don’t care about labor or environmental laws, don’t care about public safety, don’t care about the customer, and have zero compulsion about lying to regulators or making things up at every conceivable opportunity.
Prime Minister Robert Fico’s push dissolve the body that now oversees high-profile corruption cases poses a risk to the EU’s financial interests and would harm the work of the European Public Prosecutor’s Office, Juraj Novocký, Slovakia’s representative to the EU body, told Euractiv Slovakia.
Fico’s government wants to pass a reform that would eliminate the Special Anti-Corruption Prosecutor’s Office, reduce penalties, including those for corruption, and curtail the rights of whistleblowers.
Novocký points out that the reform would also bring a radical shortening of limitation periods: “Through a thorough analysis, we have found that if the amendment is adopted as proposed, we will have to stop prosecution in at least twenty cases for this reason,” Novocký of the European Public Prosecutor’s Office (EPPO) told Euractiv Slovakia.
“This has a concrete effect on the EPPO’s activities and indirectly on the protection of the financial interests of the EU because, in such cases, there will be no compensation for the damage caused,” Novocký added.
On Monday, EU Chief Prosecutor Laura Kövesi addressed the government’s push for reform in a letter to the European Commission, concluding that it constitutes a serious risk of breaching the rule of law in the meaning of Article 4(2)(c) of the Conditionality Regulation.
A U.S. computer scientist on Wednesday lost his bid to register patents over inventions created by his artificial intelligence system in a landmark case in Britain about whether AI can own patent rights.
Stephen Thaler wanted to be granted two patents in the UK for inventions he says were devised by his “creativity machine” called DABUS.
His attempt to register the patents was refused by the UK’s Intellectual Property Office (IPO) on the grounds that the inventor must be a human or a company, rather than a machine.
Thaler appealed to the UK’s Supreme Court, which on Wednesday unanimously rejected his appeal as under UK patent law “an inventor must be a natural person”.
Judge David Kitchin said in the court’s written ruling that the case was “not concerned with the broader question whether technical advances generated by machines acting autonomously and powered by AI should be patentable”.
Thaler’s lawyers said in a statement that the ruling “establishes that UK patent law is currently wholly unsuitable for protecting inventions generated autonomously by AI machines and as a consequence wholly inadequate in supporting any industry that relies on AI in the development of new technologies”.
‘LEGITIMATE QUESTIONS’
A spokesperson for the IPO welcomed the decision “and the clarification it gives as to the law as it stands in relation to the patenting of creations of artificial intelligence machines”.
They added that there are “legitimate questions as to how the patent system and indeed intellectual property more broadly should handle such creations” and the government will keep this area of law under review.
[…]
“The judgment does not preclude a person using an AI to devise an invention – in such a scenario, it would be possible to apply for a patent provided that person is identified as the inventor.”
In a separate case last month, London’s High Court ruled that artificial neural networks can attract patent protection under UK law.
Apple’s financial services, including Apple Pay, Apple Cash, Apple Card and Wallet, experienced service disruptions for some users between 6:15 AM and 6:49 AM Eastern this morning, according to the company’s System Status page. As AppleInsider notes, it’s unclear how widespread the issues were, but the company has experienced intermittent Apple Pay issues earlier this year.
Windows Mixed Reality is heading to a farm upstate. Microsoft is shutting down the platform, according to an official list of deprecated Windows features. This includes the garden variety Windows Mixed Reality software, along with the Mixed Reality Portal app and the affiliated Steam VR app. The platform isn’t gone yet, but Microsoft says it’ll be “removed in a future release of Windows.”
Microsoft first unveiled Windows Mixed Reality back in 2017 as its attempt to compete with rivals in the VR space, like HTC and Oculus (which is now owned by Meta.) We were fascinated by the tech when it first launched, as it offered the ability for in-person shared mixed reality.
[…]
Microsoft’s platform was ultimately adopted by several VR headsets, like the HP Reverb G2 and others manufactured by companies like Acer, Asus and Samsung. The Windows Mixed Reality Portal app allowed access to games, experiences and plenty of work-related productivity apps. However, it looks like the adoption rate wasn’t up to snuff, as indicated by today’s news.
Despite the imminent end to the platform, it doesn’t look to be impacting Microsoft’s other mixed-reality ecosystem, the HoloLens 2. Microsoft added a Windows 11 upgrade and other improvements for the business-focused headset earlier this year, according to The Verge.
[…]
Microsoft has made sweeping cuts throughout its VR division, leading to layoffs and the discontinuation of the AltspaceVR app. The company is, however, still developing its proprietary Mesh app that lets co-workers meet in a virtual space without a headset.
It sounds like a simple, well-known everyday phenomenon: there is high pressure in a champagne bottle, the stopper is driven outwards by the compressed gas in the bottle and flies away with a powerful pop. But the physics behind this is complicated.
[…]
Using complex computer simulations, it was possible to recalculate the behavior of the stopper and the gas flow.
In the process, astonishing phenomena were discovered: a supersonic shock wave is formed and the gas flow can reach more than one and a half times the speed of sound. The results, which appear on the pre-print server arXiv,
[…]
“The champagne cork itself flies away at a comparatively low speed, reaching perhaps 20 meters per second,”
[…]
“However, the gas that flows out of the bottle is much faster,” says Wagner. “It overtakes the cork, flows past it and reaches speeds of up to 400 meters per second.”
That is faster than the speed of sound. The gas jet therefore breaks the sound barrier shortly after the bottle is opened—and this is accompanied by a shock wave.
[…]
“Then there are jumps in these variables, so-called discontinuities,” says Bernhard Scheichl (TU Vienna & AC2T), Lukas Wagner’s dissertation supervisor. “Then the pressure or velocity in front of the shock wave have a completely different value than just behind it.”
This point in the gas jet, where the pressure changes abruptly, is also known as the “Mach disk.” “Very similar phenomena are also known from supersonic aircraft or rockets, where the exhaust jet exits the engines at high speed,”
[…]
The Mach disk first forms between the bottle and the cork and then moves back towards the bottle opening.
Temporarily colder than the North Pole
Not only the gas pressure, but also the temperature changes abruptly: “When gas expands, it becomes cooler, as we know from spray cans,” explains Lukas Wagner. This effect is very pronounced in the champagne bottle: the gas can cool down to -130°C at certain points. It can even happen that tiny dry ice crystals are formed from the CO2 that makes the sparkling wine bubble.
“This effect depends on the original temperature of the sparkling wine,” says Lukas Wagner. “Different temperatures lead to dry ice crystals of different sizes, which then scatter light in different ways. This results in variously colored smoke. In principle, you can measure the temperature of the sparkling wine by just looking at the color of the smoke.”
[…]
The audible pop when the bottle is opened is a combination of different effects: Firstly, the cork expands abruptly as soon as it has left the bottle, creating a pressure wave, and secondly, you can hear the shock wave, generated by the supersonic gas jet—very similar to the well-known aeroacoustic phenomenon of the sonic boom.
[…]
More information: Lukas Wagner et al, Simulating the opening of a champagne bottle, arXiv (2023). DOI: 10.48550/arxiv.2312.12271
Last year on a December morning, scientists at the National Ignition Facility at the Lawrence Livermore National Laboratory in California (LLNL) managed, in a world first, to produce a nuclear fusion reaction that released more energy than it used, in a process called “ignition.”
Now they say they have successfully replicated ignition at least three times this year, according to a December report from the LLNL. This marks another significant step in what could one day be an important solution to the global climate crisis, driven primarily by the burning of fossil fuels.
NIF’s target chamber is where the magic happens — temperatures of 100 million degrees and pressures extreme enough to compress the target to densities up to 100 times the density of lead are created there.
[…]
at NIF, scientists fire an array of nearly 200 lasers at a pellet of hydrogen fuel inside a diamond capsule the size of a peppercorn, itself inside a gold cylinder. The lasers heat up the cylinder’s outside, creating a series of very fast explosions, generating large amounts of energy collected as heat.
The energy produced in December 2022 was small — it took around 2 megajoules to power the reaction, which released a total of 3.15 megajoules, enough to boil around 10 kettles of water. But it was sufficient to make it a successful ignition and to prove that laser fusion could create energy.
Since then, the scientists have done it several more times. On July 30, the NIF laser delivered a little over 2 megajoules to the target, which resulted in 3.88 megajoules of energy — their highest yield achieved to date, according to the report. Two subsequent experiments in October also delivered net gains.
“These results demonstrated NIF’s ability to consistently produce fusion energy at multi-megajoule levels,” the report said.
There is still a very long way to go, however, until nuclear fusion reaches the scale needed to power electric grids and heating systems. The focus now is on building on the progress made and figuring out how to dramatically scale up fusion projects and significantly bring down costs.
French senators criticised the government’s stance in the AI Act negotiations, particularly a lack of copyright protection and the influence of a lobbyist with alleged conflicts of interests, former digital state secretary Cédric O.
The EU AI Act is set to become the world’s first regulation of artificial intelligence. Since the emergence of AI models, such as GPT-4, used by the AI system ChatGPT, EU policymakers have been working on regulating these powerful “foundation” models.
“We know that Cédric O and Mistral influenced the French government’s position regarding the AI regulation bill of the European Commission, attempting to weaken it”, said Catherine Morin-Desailly, a centrist senator at the during the government’s question time on Wednesday (20 December).
“The press reported on the spectacular enrichment of the former digital minister, Cédric O. He entered the company Mistral, where the interests of American companies and investment funds are prominently represented. This financial operation is causing shock within the Intergovernmental Committee on AI you have established, Madam Prime Minister,” she continued.
The accusations were vehemently denied by the incumbent Digital Minister Jean-Noël Barrot: “It is the High Authority for Transparency in Public Life that ensures the absence of conflicts of interest among former government members.”
Moreover, Barrot denied the allegations that France has been the spokesperson of private interests, arguing that the government: “listened to all stakeholders as it is customary and relied solely on the general interest as our guiding principle.”
[…]
Barrot was criticised in a Senate hearing earlier the same day by Pascal Rogard, director of the Society of Dramatic Authors and Composers, who said that “for the first time, France, through the medium of Jean-Noël Barrot […] has neither supported culture, the creation industry, or copyrights.”
Morin-Desailly then said that she questioned the French stance on AI, which, in her view, is aligned with the position of US big tech companies.
Drawing a parallel from the position of big tech on this copyright AI debate and the Directive on Copyright in the Digital Single Market, Rogard said that since it was enforced he did not “observed any damage to the [big tech]’s business activities.”
[…]
“Trouble was stirred by the renowned Cédric O, who sits on the AI Intergovernmental Committee and still wields a lot of influence, notably with the President of the Republic”, stated Morin-Desailly earlier the same day at the Senate hearing with Rogard. Other sitting Senators joined Morin-Desailly in criticising the French position, and O.
Looking at O’s influential position in the government, the High Authority for Transparency in Public Life decided to forbid O for a three-year time-span to lobby the government or own shares within companies of the tech sector.
Yet, according toCapital, O bought shares through his consulting agency in Mistral AI. Capital revealed O invested €176.1, which is now valued at €23 million, thanks to the company’s last investment round in December.
Moreover, since September, O has at the Committee on generative artificial intelligence to advise the government on its position towards AI.
As Walled Culture has often noted, the process of framing new copyright laws is tilted against the public in multiple ways. And on the rare occasions when a government makes some mild concession to anyone outside the copyright industry, the latter invariably rolls out its highly-effective lobbying machine to fight against such measures. It’s happening again in the world of AI. A post on the Knowledge Rights 21 site points to:
a U-turn by the British Government in February 2023, abandoning its prior commitment to introduce a broad copyright exception for text and data mining that would not have made an artificial distinction between non-commercial and commercial uses. Given that applied research so often bridges these two, treating them differently risks simply chilling innovative knowledge transfer and public institutions working with the private sector.
Unfortunately, and in the face of significant lobbying from the creative industries (something we see also in Washington, Tokyo and Brussels), the UK government moved away from clarifying language to support the development of AI in the UK.
In an attempt to undo some of the damage caused by the UK government’s retrograde move, a broad range of organizations, including Knowledge Rights 21, Creative Commons, and Wikimedia UK, have issued a public statement calling on the UK government to safeguard AI innovation as it draws up its new code of practice on copyright and AI. The statement points out that copyright is a serious threat to the development of AI in the UK, and that:
Whilst questions have arisen in the past which consider copyright implications in relation to new technologies, this is the first time that such debate risks entirely halting the development of a new technology.
The statement’s key point is as follows:
AI relies on analysing large amounts of data. Large-scale machine learning, in particular, must be trained on vast amounts of data in order to function correctly, safely and without bias. Safety is critical, as highlighted in the [recently agreed] Bletchley Declaration. In order to achieve the necessary scale, AI developers need to be able to use the data they have lawful access to, such as data that is made freely available to view on the open web or to which they already have access to by agreement.
Any restriction on the use of such data or disproportionate legal requirements will negatively impact on the development of AI, not only inhibiting the development of large-scale AI in the UK but exacerbating further pre-existing issues caused by unequal access to data.
The organizations behind the statement note that restrictions imposed by copyright would create barriers to entry and raise costs for new entrants. There would also be serious knock-on effects:
Text and data mining techniques are necessary to analyse large volumes of content, often using AI, to detect patterns and generate insights, without needing to manually read everything. Such analysis is regularly needed across all areas of our society and economy, from healthcare to marketing, climate research to finance.
The statement concludes by making a number of recommendations to the UK government in order to ensure that copyright does not stifle the development of AI in the UK. The key ones concern access to the data sets that are vital for training AI and carrying out text and data mining. The organizations ask that the UK’s Code of Practice:
Clarifies that access to broad and varied data sets that are publicly available online remain available for analysis, including text and data mining, without the need for licensing.
Recognises that even without an explicit commercial text and data mining exception, exceptions and limits on copyright law exist that would permit text and data mining for commercial purposes.
Those are pretty minimal demands, but we can be sure that the copyright industry will fight them tooth and nail. For the companies involved, keeping everything involving copyright under their tight control is far more important than nurturing an exciting new technology with potentially huge benefits for everyone.
Future Volkswagen interiors will all draw inspiration from the ID 2all concept car and bring back physical buttons and controls.
The touchscreen-heavy approach taken for the Mk8 Golf and ID 3 has proven unpopular with customers, prompting a complete about-turn by the company in the way it approaches design.
VW interior designer Darius Watola said the ID2all concept “showed a new approach for all models” and was in response to “recent feedback from customers”.
The new interior has a row of physical (and backlit) buttons for the climate and a rotary controller on the centre tunnel to control the screen on the dashboard above, much like with BMW’s iDrive.
As well as a main central touchscreen for infotainment, there’s also a screen for driving information. Watola said such a display in the driver’s eyeline is crucial for safety.
He said that “customers had a different view in Europe” than in other global markets and wanted “more physical buttons”.
There’s also a revolution in terms of material use, as VW is looking to phase out hard plastics, glue, leather and chrome.
Almost every surface in the ID 2all is soft to the touch, mixing fabrics and Alcantara as part of a sustainability push. There’s limited use of some woods and metals, too.
Watola expressed a desire to see as many features and materials as possible from the concept to the production car in 2025 (which now seems unlikely to take the ID 2 name into showrooms).
However, the goal remains a sub-€25,000 (£22,000) price, which might limit some of the more premium-feeling materials in the cabin.
The concept’s screens can be selected in different themes, including retro graphics from the original Golf, and this feature is expected to make production.











 […]
[…]