As good as they are at causing mischief, researchers from the MIT-IBM Watson AI Lab realized GANs are also a powerful tool: because they paint what they’re “thinking,” they could give humans insight into how neural networks learn and reason. This has been something the broader research community has sought for a long time—and it’s become more important with our increasing reliance on algorithms.
“There’s a chance for us to learn what a network knows from trying to re-create the visual world,” says David Bau, an MIT PhD student who worked on the project.
So the researchers began probing a GAN’s learning mechanics by feeding it various photos of scenery—trees, grass, buildings, and sky. They wanted to see whether it would learn to organize the pixels into sensible groups without being explicitly told how.
Stunningly, over time, it did. By turning “on” and “off” various “neurons” and asking the GAN to paint what it thought, the researchers found distinct neuron clusters that had learned to represent a tree, for example. Other clusters represented grass, while still others represented walls or doors. In other words, it had managed to group tree pixels with tree pixels and door pixels with door pixels regardless of how these objects changed color from photo to photo in the training set.
The GAN knows not to paint any doors in the sky.
MIT Computer Science & Artificial Intelligence Laboratory
“These GANs are learning concepts very closely reminiscent of concepts that humans have given words to,” says Bau.
Not only that, but the GAN seemed to know what kind of door to paint depending on the type of wall pictured in an image. It would paint a Georgian-style door on a brick building with Georgian architecture, or a stone door on a Gothic building. It also refused to paint any doors on a piece of sky. Without being told, the GAN had somehow grasped certain unspoken truths about the world.
This was a big revelation for the research team. “There are certain aspects of common sense that are emerging,” says Bau. “It’s been unclear before now whether there was any way of learning this kind of thing [through deep learning].” That it is possible suggests that deep learning can get us closer to how our brains work than we previously thought—though that’s still nowhere near any form of human-level intelligence.
Other research groups have begun to find similar learning behaviors in networks handling other types of data, according to Bau. In language research, for example, people have found neuron clusters for plural words and gender pronouns.
Being able to identify which clusters correspond to which concepts makes it possible to control the neural network’s output. Bau’s group can turn on just the tree neurons, for example, to make the GAN paint trees, or turn on just the door neurons to make it paint doors. Language networks, similarly, can be manipulated to change their output—say, to swap the gender of the pronouns while translating from one language to another. “We’re starting to enable the ability for a person to do interventions to cause different outputs,” Bau says.
The team has now released an app called GANpaint that turns this newfound ability into an artistic tool. It allows you to turn on specific neuron clusters to paint scenes of buildings in grassy fields with lots of doors. Beyond its silliness as a playful outlet, it also speaks to the greater potential of this research.
“The problem with AI is that in asking it to do a task for you, you’re giving it an enormous amount of trust,” says Bau. “You give it your input, it does it’s ‘genius’ thinking, and it gives you some output. Even if you had a human expert who is super smart, that’s not how you’d want to work with them either.”
With GANpaint, you begin to peel back the lid on the black box and establish some kind of relationship. “You can figure out what happens if you do this, or what happens if you do that,” says Hendrik Strobelt, the creator of the app. “As soon as you can play with this stuff, you gain more trust in its capabilities and also its boundaries.”
A video software firm has come up with a way to prevent people from sharing their account details for Netflix and other streaming services with friends and family members.
UK-based Synamedia unveiled the artificial intelligence software at the CES 2019 technology trade show in Las Vegas, claiming it could save the streaming industry billions of dollars over the next few years.
Casual password sharing is practised by more than a quarter of millennials, according to figures from market research company Magid.
Separate figures from research firm Parks Associates predicts that by $9.9 billion (£7.7bn) of pay-TV revenues and $1.2 billion of revenue from subscription-based streaming services will be lost to credential sharing each year.
The AI system developed by Synamedia uses machine learning to analyse account activity and recognise unusual patterns, such as account details being used in two locations within similar time periods.
The idea is to spot instances of customers sharing their account credentials illegally and offering them a premium shared account service that will authorise a limited level of password sharing.
“Casual credentials sharing is becoming too expensive to ignore. Our new solution gives operators the ability to take action,” said Jean Marc Racine, Synamedia’s chief product officer.
“Many casual users will be happy to pay an additional fee for a premium, shared service with a greater number of concurrent users. It’s a great way to keep honest people honest while benefiting from an incremental revenue stream.”
Artificial intelligence can potentially identify someone’s genetic disorders by inspecting a picture of their face, according to a paper published in Nature Medicine this week.
The tech relies on the fact some genetic conditions impact not just a person’s health, mental function, and behaviour, but sometimes are accompanied with distinct facial characteristics. For example, people with Down Syndrome are more likely to have angled eyes, a flatter nose and head, or abnormally shaped teeth. Other disorders like Noonan Syndrome are distinguished by having a wide forehead, a large gap between the eyes, or a small jaw. You get the idea.
An international group of researchers, led by US-based FDNA, turned to machine-learning software to study genetic mutations, and believe that machines can help doctors diagnose patients with genetic disorders using their headshots.
The team used 17,106 faces to train a convolutional neural network (CNN), commonly used in computer vision tasks, to screen for 216 genetic syndromes. The images were obtained from two sources: publicly available medical reference libraries, and snaps submitted by users of a smartphone app called Face2Gene, developed by FDNA.
Given an image, the system, dubbed DeepGestalt, studies a person’s face to make a note of the size and shape of their eyes, nose, and mouth. Next, the face is split into regions, and each piece is fed into the CNN. The pixels in each region of the face are represented as vectors and mapped to a set of features that are commonly associated with the genetic disorders learned by the neural network during its training process.
DeepGestalt then assigns a score per syndrome for each region, and collects these results to compile a list of its top 10 genetic disorder guesses from that submitted face.
An example of how DeepGestalt works. First, the input image is analysed using landmarks and sectioned into different regions before the system spits out its top 10 predictions. Image credit: Nature and Gurovich et al.
The first answer is the genetic disorder DeepGestalt believes the patient is most likely affected by, all the way down to its tenth answer, which is the tenth most likely disorder.
When it was tested on two independent datasets, the system accurately guessed the correct genetic disorder among its top 10 suggestions around 90 per cent of the time. At first glance, the results seem promising. The paper also mentions DeepGestalt “outperformed clinicians in three initial experiments, two with the goal of distinguishing subjects with a target syndrome from other syndromes, and one of separating different genetic subtypes in Noonan Syndrome.”
There’s always a but
A closer look, though, reveals that the lofty claims involve training and testing the system on limited datasets – in other words, if you stray outside the software’s comfort zone, and show it unfamiliar faces, it probably won’t perform that well. The authors admit previous similar studies “have used small-scale data for training, typically up to 200 images, which are small for deep-learning models.” Although they use a total of more than 17,000 training images, when spread across 216 genetic syndromes, the training dataset for each one ends up being pretty small.
For example, the model that examined Noonan Syndrome was only trained on 278 images. The datasets DeepGestalt were tested against were similarly small. One only contained 502 patient images, and the other 392.
Learning in environments with large state and action spaces, and sparse rewards, can hinder a Reinforcement Learning (RL) agent’s learning through trial-and-error. For instance, following natural language instructions on the Web (such as booking a flight ticket) leads to RL settings where input vocabulary and number of actionable elements on a page can grow very large. Even though recent approaches improve the success rate on relatively simple environments with the help of human demonstrations to guide the exploration, they still fail in environments where the set of possible instructions can reach millions. We approach the aforementioned problems from a different perspective and propose guided RL approaches that can generate unbounded amount of experience for an agent to learn from. Instead of learning from a complicated instruction with a large vocabulary, we decompose it into multiple sub-instructions and schedule a curriculum in which an agent is tasked with a gradually increasing subset of these relatively easier sub-instructions. In addition, when the expert demonstrations are not available, we propose a novel meta-learning framework that generates new instruction following tasks and trains the agent more effectively. We train DQN, deep reinforcement learning agent, with Q-value function approximated with a novel QWeb neural network architecture on these smaller, synthetic instructions. We evaluate the ability of our agent to generalize to new instructions on World of Bits benchmark, on forms with up to 100 elements, supporting 14 million possible instructions. The QWeb agent outperforms the baseline without using any human demonstration achieving 100% success rate on several difficult environments.
A team of researchers in Japan have devised an artificial intelligence (AI) system that can identify different types of cancer cells using microscopy images. Their method can also be used to determine whether the cancer cells are sensitive to radiotherapy. The researchers reported their findings in the journal Cancer Research. In cancer patients, there can be tremendous variation in the types of cancer cells in a single tumor. Identifying the specific cell types present in tumors can be very useful when choosing the most effective treatment. However, making accurate assessments of cell types is time consuming and often hampered by human error and the limits of human sight. To overcome these challenges, scientists led by Professor Hideshi Ishii of Osaka University, Japan, have developed an AI system that can identify different types of cancer cells from microscopy images, achieving higher accuracy than human judgement. The system is based on a convolutional neural network, a form of AI modeled on the human visual system. “We first trained our system on 8,000 images of cells obtained from a phase-contrast microscope,” said corresponding author Ishii. “We then tested [the AI system’s] accuracy on another 2,000 images and showed that it had learned the features that distinguish mouse cancer cells from human ones, and radioresistant cancer cells from radiosensitive ones.” The researchers noted that the automation and high accuracy of their system could be very useful for determining exactly which cells are present in a tumor or circulating in the body. Knowing whether or not radioresistant cells are present is vital when deciding whether radiotherapy would be effective. Furthermore, the same procedure can be applied post-treatment to assess patient outcomes. In the future, the team hopes to train the system on more cancer cell types, with the eventual goal of establishing a universal system that can automatically identify and distinguish all variants of cancer cells. The article can be found at: Toratani et al. (2018) A Convolutional Neural Network Uses Microscopic Images to Differentiate between Mouse and Human Cell Lines and Their Radioresistant Clones. Read more from Asian Scientist Magazine at: https://www.asianscientist.com/2018/12/in-the-lab/artificial-intelligence-microscopy-cancer-cell-radiotherapy/
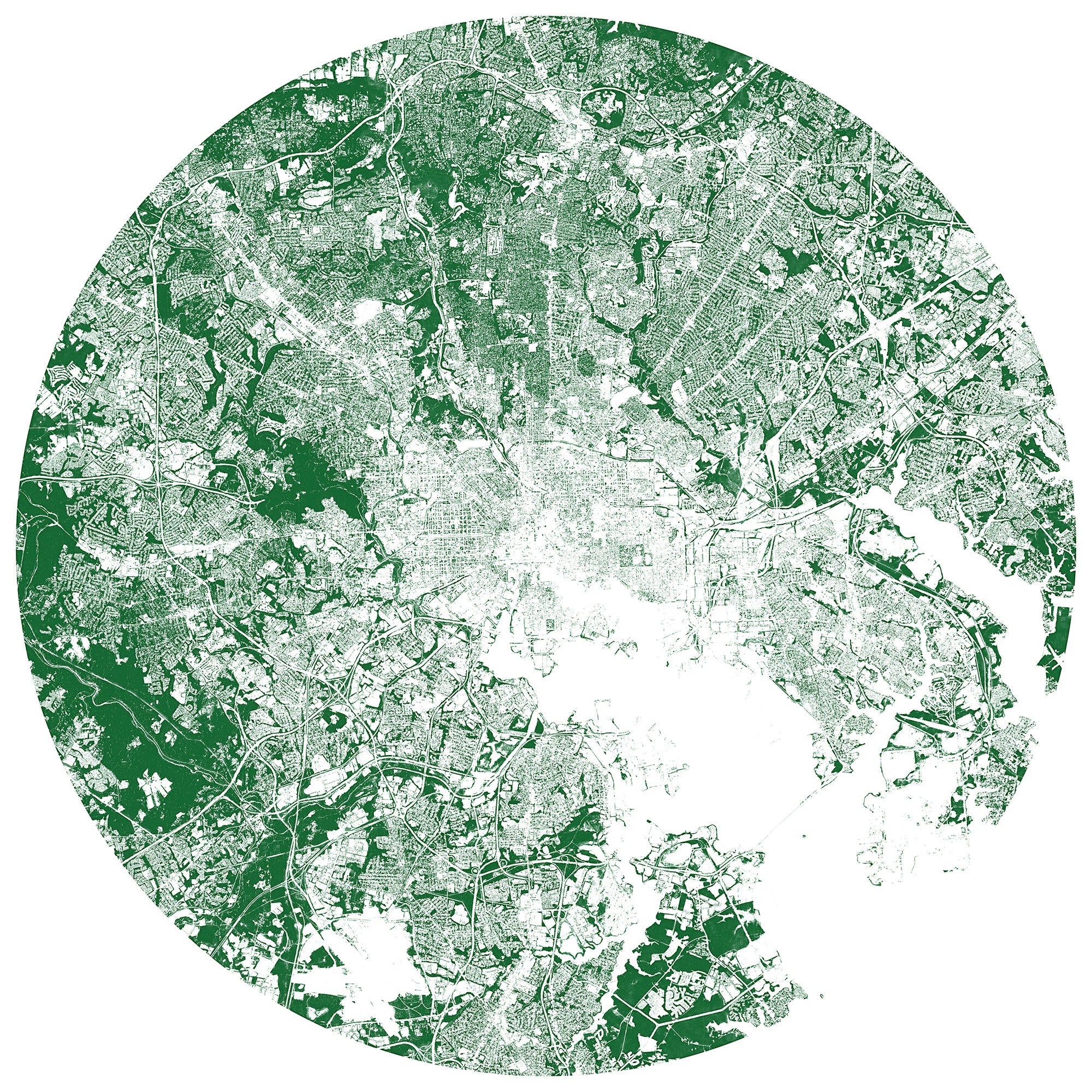
The Descartes Labs tree canopy layer around the Baltimore Beltway. Treeless main roads radiate from the dense pavement of the city to leafy suburbs.
All this fuss is not without good reason. Trees are great! They make oxygen for breathing, suck up CO₂, provide shade, reduce noise pollution, and just look at them — they’re beautiful!
[…]
So Descartes Labs built a machine learning model to identify tree canopy using a combination of lidar, aerial imagery and satellite imagery. Here’s the area surrounding the Boston Common, for example. We clearly see that the Public Garden, Common and Commonwealth Avenue all have lots of trees. But we also see some other fun artifacts. The trees in front of the CVS in Downtown Crossing, for instance, might seem inconsequential to a passer-by, but they’re one of the biggest concentrations of trees in the neighborhood.
[…]
The classifier can be run over any location in the world where we have approximately 1-meter resolution imagery. When using NAIP imagery, for instance, the resolution of the tree canopy map is as high as 60cm. Drone imagery would obviously yield an even higher resolution.
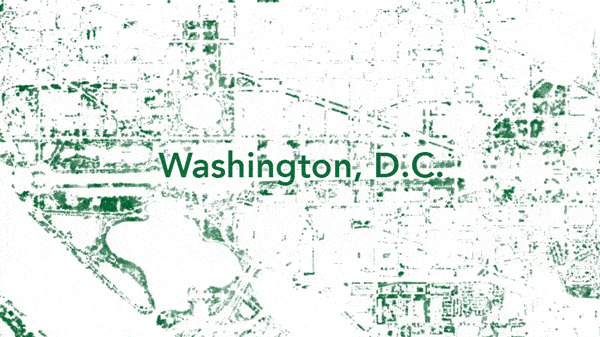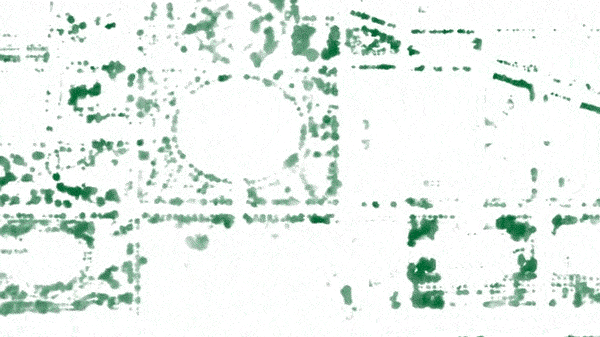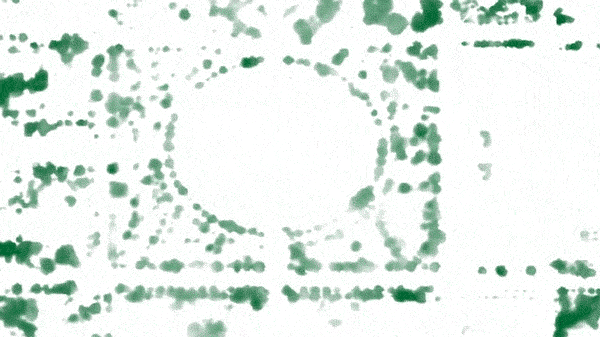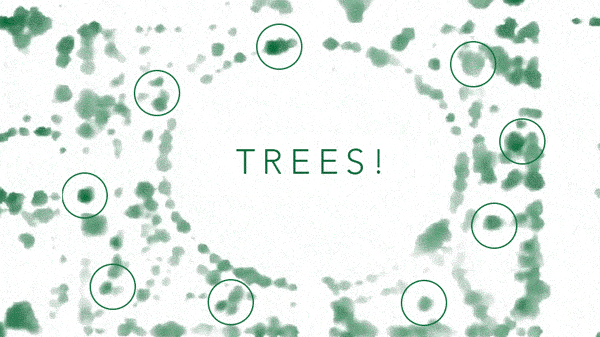
Washington, D.C. tree canopy created with NAIP source imagery shown at different scales—all the way down to individual “TREES!” on The Ellipse.
The ability to map tree canopy at a such a high resolution in areas that can’t be easily reached on foot would be helpful for utility companies to pinpoint encroachment issues—or for municipalities to find possible trouble spots beyond their official tree census (if they even have one). But by zooming out to a city level, patterns in the tree canopy show off urban greenspace quirks. For example, unexpected tree deserts can be identified and neighborhoods that would most benefit from a surge of saplings revealed.
The system, called Photo Wake-Up, creates a 3D animation from a single photo. In the paper, the researchers compare it to the moving portraits at Hogwarts, a fictitious part of the Harry Potter world that a number of tech companies have tried to recreate. Previous attempts have been mildly successful, but this system is impressive in its ability to isolate and create a pretty realistic 3D animation from a single image.
The researchers tested the system on 70 different photos they downloaded online, which included pictures of Stephen Curry, the anime character Goku, a Banksy artwork, and a Picasso painting. The team used a program called SMPL and deep learning, starting with a 2D cutout of the subject and then superimposing a 3D skeleton onto it. “Our key technical contribution, then, is a method for constructing an animatable 3D model that matches the silhouette in a single photo,” the team told MIT Technology Review.
The team reportedly used a warping algorithm to ensure the cutout and the skeleton were aligned. The team’s algorithm is also reportedly able to detect the direction a subject is looking and the way their head is angled. What’s more, in order to make sure the final animation is realistic and precise, the team used a proprietary user interface to correct for any errors and help with the animation’s texturing. An algorithm then isolates the subject from the 2D image, fills in the remaining space, and animates the subject.
n some states, solar energy accounts for upwards of 10 percent of total electricity generation. It’s definitely a source of power that’s on the rise, whether it be to lessen our dependence on fossil fuels, nuclear power, or the energy grid, or simply to take advantage of the low costs. This form of energy, however, is highly decentralized, so it’s tough to know how much solar energy is being extracted, where, and by whom.
[…]
The system developed by Rajagopal, along with his colleagues Jiafan Yu and Zhecheng Wang, is called DeepSolar, and it’s an automated process whereby hi-res satellite photos are analyzed by an algorithm driven by machine learning. DeepSolar can identify solar panels, register their locations, and calculate their size. The system identified 1.47 million individual solar installations across the United States, whether they be small rooftop configurations, solar farms, or utility-scale systems. This exceeds the previous estimate of 1.02 million installations. The researchers have made this data available at an open-source website.
By using this new approach, the researchers were able to accurately scan billions of tiles of high-resolution satellite imagery covering the continental U.S., allowing them to classify and measure the size of solar systems in a few weeks rather than years, as per previous methods. Importantly, DeepSolar requires minimal human supervision.
DeepSolar map of solar panel usage across the United States.
Image: Deep Solar/Stanford University
“The algorithm breaks satellite images into tiles. Each tile is processed by a deep neural net to produce a classification for each pixel in a tile. These classifications are combined together to detect if a system—or part of—is present in the tile,” Rajagopal told Gizmodo.
The neural net can then determine which tile is a solar panel, and which is not. The network architecture is such that after training, the layers of the network produce an activation map, also known as a heat map, that outlines the panels. This can be used to obtain the size of each solar panel system.
Machine-learning research published in two related papers today in Nature Geoscience reports the detection of seismic signals accurately predicting the Cascadia fault’s slow slippage, a type of failure observed to precede large earthquakes in other subduction zones.
Los Alamos National Laboratory researchers applied machine learning to analyze Cascadia data and discovered the megathrust broadcasts a constant tremor, a fingerprint of the fault’s displacement. More importantly, they found a direct parallel between the loudness of the fault’s acoustic signal and its physical changes. Cascadia’s groans, previously discounted as meaningless noise, foretold its fragility.
“Cascadia’s behavior was buried in the data. Until machine learning revealed precise patterns, we all discarded the continuous signal as noise, but it was full of rich information. We discovered a highly predictable sound pattern that indicates slippage and fault failure,” said Los Alamos scientist Paul Johnson. “We also found a precise link between the fragility of the fault and the signal’s strength, which can help us more accurately predict a megaquake.”
That means starting this holiday season, you should be able to ask the Google Assistant if your flight is on time and get a response showing the status of your flight, the length of a delay (if there is one), and even the cause (assuming that info is available)
“Over the next few weeks,” Google says its flight delay predictor will also start notifying you in cases where its system is 85 percent confident, which is deduced by looking at data from past flight records and combining that with a bit a machine learning smarts to determine if your flight might be late. That leaves some room for error, so it’s also important to note that even when Google predicts that your flight is delayed, it may still recommend for you to show up to the airport normally.
Still, in the space of a year, Google seems to have upped its confidence threshold for predicted delays from 80 to 85 percent
AI systems can now create images of humans that are so lifelike they look like photographs, except the people in them don’t really exist.
See for yourself. Each picture below is an output produced by a generative adversarial network (GAN), a system made up of two different networks including a generator and a discriminator. Developers have used GANs to create everything from artwork to dental crowns.
Some of the images created from Nvidia’s style transfer GAN. Image credit: Karras et al. and Nvidia
The performance of a GAN is often tied to how realistic its results are. What started out as tiny, blurry, greyscale images of human faces four years ago, has since morphed into full colour portraits.
Early results from when the idea of GANs were first introduced. Image credit: Goodfellow et al.
The new GAN built by Nvidia researchers rests on the idea of “style transfer”. First, the generator network learns a constant input taken from a photograph of a real person. This face is used as a reference, and encoded as a vector that is mapped to a latent space that describe all the features in the image.
These features correlate to the essential characteristics that make up a face: eyes, nose, mouth, hair, pose, face shape, etc. After the generator learns these features it can begin adjusting these details to create a new face.
The transformation that determines how the appearance of these features change is determined from another secondary photo. In other words, the original photo copies the style of another photo so the end result is a sort of mishmash between both images. Finally, an element of noise is also added to generate random details, such as the exact placement of hairs, stubble, freckles, or skin pores, to make the images
“Our generator thinks of an image as a collection of ‘styles,” where each style controls the effects at a particular scale,” the researchers explained. The different features can be broken down into various styles: Coarse styles include the pose, hair, face shape; Middle styles are made up of facial features; and Fine styles determines the overall colour.
How the different style types are learned and transferred by crossing a photo with a source photo. Image credit: Kerras et al. and Nvidia.
The different style types can, therefore, be crossed continuously with other photos to generate a range of completely new images to cover pictures of people of different ethnicities, genders and ages. You can watch a video demonstration of this happening below.
The discriminator network inspects the images coming from the generator and tries to work out if they’re real or fake. The generator improves over time so that its outputs consistently trick the discriminator.
De impact van een buitenreclame campagne wordt voor 40% bepaald door de creatie van de uiting, voor 30% door het merk en voor 30% door de mediadruk. De Outdoor Ad Impact Forecaster analyseert vooraf een campagne op basis van deze drie kenmerken en geeft een rapport dat binnen 24 tot 48 uur de impact van een Out-of-Home campagne voorspelt.
Deze voorspelling is gebaseerd op ruim 300 effectmetingen uitgevoerd door MeMo², waarvan de data op basis van machine learning in een voorspellingstool is verwerkt. De impact van de campagne wordt weergegeven in de vorm van een sterrenrating en daaropvolgend geeft de Forecaster een concreet advies over aanpassingen die de campagne impactvoller maken. Dit wordt aangevuld met professioneel advies van zowel de onderzoekers van MeMo² als de specialisten van Exterion Media. Dit tezamen vormt een compleet rapport voor een nog effectievere buitenreclame campagne.
The founders of Predictim want to be clear with me: Their product—an algorithm that scans the online footprint of a prospective babysitter to determine their “risk” levels for parents—is not racist. It is not biased.
“We take ethics and bias extremely seriously,” Sal Parsa, Predictim’s CEO, tells me warily over the phone. “In fact, in the last 18 months we trained our product, our machine, our algorithm to make sure it was ethical and not biased. We took sensitive attributes, protected classes, sex, gender, race, away from our training set. We continuously audit our model. And on top of that we added a human review process.”
At issue is the fact that I’ve used Predictim to scan a handful of people I very much trust with my own son. Our actual babysitter, Kianah Stover, returned a ranking of “Moderate Risk” (3 out 5) for “Disrespectfulness” for what appear to me to be innocuous Twitter jokes. She returned a worse ranking than a friend I also tested who routinely spews vulgarities, in fact. She’s black, and he’s white.
“I just want to clarify and say that Kianah was not flagged because she was African American,” says Joel Simonoff, Predictim’s CTO. “I can guarantee you 100 percent there was no bias that went into those posts being flagged. We don’t look at skin color, we don’t look at ethnicity, those aren’t even algorithmic inputs. There’s no way for us to enter that into the algorithm itself.”
So, the writer of this article tries to push for a racist angle, however unlikely this is. Oh well, it’s still a good article talking about how this system works.
[…]
When I entered the first person I aimed to scan into the system, Predictim returned a wealth of personal data—home addresses, names of relatives, phone numbers, alternate email addresses, the works. When I sent a screenshot to my son’s godfather of his scan, he replied, “Whoa.”
The goal was to allow parents to make sure they had found the right person before proceeding with the scan, but that’s an awful lot of data.
[…]
After you confirm the personal details and initiate the scan, the process can take up to 48 hours. You’ll get an email with a link to your personalized dashboard, which contains all the people you’ve scanned and their risk rankings, when it’s complete. That dashboard looks a bit like the backend to a content management system, or website analytics service Chartbeat, for those who have the misfortune of being familiar with that infernal service.
[…]
Potential babysitters are graded on a scale of 1-5 (5 being the riskiest) in four categories: “Bullying/Harassment,” “Disrespectful Attitude,” “Explicit Content,” and “Drug use.”
[…]
Neither Parsa nor Simonoff [Predictim’s founders – ed] have children, though Parsa is married, and both insist they are passionate about protecting families from bad babysitters. Joel, for example, once had a babysitter who would drive he and his brother around smoking cigarettes in the car. And Parsa points to Joel’s grandfather’s care provider. “Joel’s grandfather, he has an individual coming in and taking care of him—it’s kind of the elderly care—and all we know about that individual is that yes, he hasn’t done a—or he hasn’t been caught doing a crime.”
[…]
To be fair, I scanned another friend of mine who is black—someone whose posts are perhaps the most overwhelmingly positive and noncontroversial of anyone on my feed—and he was rated at the lowest risk level. (If he wasn’t, it’d be crystal that the thing was racist.) [Wait – what?!]
And Parsa, who is Afghan, says that he has experienced a lifetime of racism himself, and even changed his name from a more overtly Muslim name because he couldn’t get prospective employers to return his calls despite having top notch grades and a college degree. He is sensitive to racism, in other words, and says he made an effort to ensure Predictim is not. Parsa and Simonoff insist that their system, while not perfect, can detect nuances and avoid bias.
The predictors they use also seem to be a bit overly simplistic and unuanced. But I bet it’s something Americans will like – another way to easily devolve responsibility of childcare.
Nvidia announced that AI models can now draw new worlds without using traditional modeling techniques or graphics rendering engines. This new technology uses an AI deep neural network to analyze existing videos and then apply the visual elements to new 3D environments.
Nvidia claims this new technology could provide a revolutionary step forward in creating 3D worlds because the AI models are trained from video to automatically render buildings, trees, vehicles, and objects into new 3D worlds, instead of requiring the normal painstaking process of modeling the scene elements.
But the project is still a work in progress. As we can see from the image on the right, which was generated in real time on a Nvidia Titan V graphics card using its Tensor cores, the rendered scene isn’t as crisp as we would expect in real life, and it isn’t as clear as we would expect with a normal modeled scene in a 3D environment. However, the result is much more impressive when we see the real-time output in the YouTube video below. The key here is speed: The AI generates these scenes in real time.
Nvidia AI Rendering
Nvidia’s researchers have also used this technique to model other motions, such as dance moves, and then apply those same moves to other characters in real-time video. That does raise moral questions, especially given the proliferation of altered videos like deep fakes, but Nvidia feels that it is an enabler of technology and the issue should be treated as a security problem that requires a technological solution to prevent people from rendering things that aren’t real.
The big question is when this will come to the gaming realm, but Nvidia cautions that this isn’t a shipping product yet. The company did theorize that it would be useful for enhancing older games by analyzing the scenes and then applying trained models to improve the graphics, among many other potential uses. It could also be used to create new levels and content in older games. In time, the company expects the technology to spread and become another tool in the game developers’ toolbox. The company has open sourced the project, so anyone can download and begin using it today, though it is currently geared towards AI researchers.
Nvidia says this type of AI analysis and scene generation can occur with any type of processor, provided it can deliver enough AI throughput to manage the real-time feed. The company expects that performance and image quality will improve over time.
Nvidia sees this technique eventually taking hold in gaming, automotive, robotics, and virtual reality, but it isn’t committing to a timeline for an actual product. The work remains in the lab for now, but the company expects game developers to begin working with the technology in the future. Nvidia is also conducting a real-time demo of AI-generated worlds at the AI research-focused NeurIPS conference this week.
Dong Mingzhu, chairwoman of China’s biggest maker of air conditioners Gree Electric Appliances, who found her face splashed on a huge screen erected along a street in the port city of Ningbo that displays images of people caught jaywalking by surveillance cameras.
That artificial intelligence-backed surveillance system, however, erred in capturing Dong’s image on Wednesday from an advertisement on the side of a moving bus.
The traffic police in Ningbo, a city in the eastern coastal province of Zhejiang, were quick to recognise the mistake, writing in a post on microblog Sina Weibo on Wednesday that it had deleted the snapshot. It also said the surveillance system would be completely upgraded to cut incidents of false recognition in future.
[…]
Since last year, many cities across China have cracked down on jaywalking by investing in facial recognition systems and advanced AI-powered surveillance cameras. Jaywalkers are identified and shamed by displaying their photographs on large public screens.
First-tier cities like Beijing and Shanghai were among the first to employ those systems to help regulate traffic and identify drivers who violate road rules, while Shenzhen traffic police began displaying photos of jaywalkers on large screens at major intersections from April last year.
Machine learning is everywhere now, including recruiting. Take CV Compiler, a new product by Andrew Stetsenko and Alexandra Dosii. This web app uses machine learning to analyze and repair your technical resume, allowing you to shine to recruiters at Google, Yahoo and Facebook.
The founders are marketing and HR experts who have a combined 15 years of experience in making recruiting smarter. Stetsenko founded Relocate.me and GlossaryTech while Dosii worked at a number of marketing firms before settling on CV Compiler.
The app essentially checks your resume and tells you what to fix and where to submit it. It’s been completely bootstrapped thus far and they’re working on new and improved machine learning algorithms while maintaining a library of common CV fixes.
“There are lots of online resume analysis tools, but these services are too generic, meaning they can be used by multiple professionals and the results are poor and very general. After the feedback is received, users are often forced to buy some extra services,” said Stetsenko. “In contrast, the CV Compiler is designed exclusively for tech professionals. The online review technology scans for keywords from the world of programming and how they are used in the resume, relative to the best practices in the industry.”
just last month, AI-generated art arrived on the world auction stage under the auspices of Christie’s, proving that artificial intelligence can not only be creative but also produce world class works of art—another profound AI milestone blurring the line between human and machine.
Naturally, the news sparked debates about whether the work produced by Paris-based art collective Obvious could really be called art at all. Popular opinion among creatives is that art is a process by which human beings express some idea or emotion, filter it through personal experience and set it against a broader cultural context—suggesting then that what AI generates at the behest of computer scientists is definitely not art, or at all creative.
By artist #2 (see bottom of story for key). Credit: Artwork Commissioned by GumGum
The story raised additional questions about ownership. In this circumstance, who can really be named as author? The algorithm itself or the team behind it? Given that AI is taught and programmed by humans, has the human creative process really been identically replicated or are we still the ultimate masters?
AI VERSUS HUMAN
At GumGum, an AI company that focuses on computer vision, we wanted to explore the intersection of AI and art by devising a Turing Test of our own in association with Rutgers University’s Art and Artificial Intelligence Lab and Cloudpainter, an artificially intelligent painting robot. We were keen to see whether AI can, in fact, replicate the intent and imagination of traditional artists, and we wanted to explore the potential impact of AI on the creative sector.
By artist #3 (see bottom of story for key). Credit: Artwork Commissioned by GumGum
To do this, we enlisted a broad collection of diverse artists from “traditional” paint-on-canvas artists to 3-D rendering and modeling artists alongside Pindar Van Arman—a classically trained artist who has been coding art robots for 15 years. Van Arman was tasked with using his Cloudpainter machine to create pieces of art based on the same data set as the more traditional artists. This data set was a collection of art by 20th century American Abstract Expressionists. Then, we asked them to document the process, showing us their preferred tools and telling us how they came to their final work.
By artist #4 (see bottom of story for key). Credit: Artwork Commissioned by GumGum
Intriguingly, while at face value the AI artwork was indistinguishable from that of the more traditional artists, the test highlighted that the creative spark and ultimate agency behind creating a work of art is still very much human. Even though the Cloudpainter machine has evolved over time to become a highly intelligent system capable of making creative decisions of its own accord, the final piece of work could only be described as a collaboration between human and machine. Van Arman served as more of an “art director” for the painting. Although Cloudpainter made all of the aesthetic decisions independently, the machine was given parameters to meet and was programed to refine its results in order to deliver the desired outcome. This was not too dissimilar to the process used by Obvious and their GAN AI tool.
By artist #5 (see bottom of story for key). Credit: Artwork Commissioned by GumGum
Moreover, until AI can be programed to absorb inspiration, crave communication and want to express something in a creative way, the work it creates on its own simply cannot be considered art without the intention of its human masters. Creatives working with AI find the process to be more about negotiation than experimentation. It’s clear that even in the creative field, sophisticated technologies can be used to enhance our capabilities—but crucially they still require human intelligence to define the overarching rules and steer the way.
THERE’S AN ACTIVE ROLE BETWEEN ART AND VIEWER
How traditional art purveyors react to AI art on the world stage is yet to be seen, but in the words of Leandro Castelao—one of the artists we enlisted for the study—“there’s an active role between the piece of art and the viewer. In the end, the viewer is the co-creator, transforming, re-creating and changing.” This is a crucial point; when it’s difficult to tell AI art apart from human art, the old adage that beauty is in the eye of the beholder rings particularly true.
Earlier this year, researchers tried teaching an AI to play the original Sonic the Hedgehog as part of the The OpenAI Retro Contest. The AI was told to prioritize increasing its score, which in Sonic means doing stuff like defeating enemies and collecting rings while also trying to beat a level as fast as possible. This dogged pursuit of one particular definition of success led to strange results: In one case, the AI began glitching through walls in the game’s water zones in order to finish more quickly.
It was a creative solution to the problem laid out in front of the AI, which ended up discovering accidental shortcuts while trying to move right. But it wasn’t quite what the researchers had intended. One of researchers’ goals with machine-learning AIs in gaming is to try and emulate player behavior by feeding them large amounts of player generated data. In effect, the AI watches humans conduct an activity, like playing through a Sonic level, and then tries to do the same, while being able to incorporate its own attempts into its learning. In a lot of instances, machine learning AIs end up taking their directions literally. Instead of completing a variety of objectives, a machine-learning AI might try to take shortcuts that completely upend human beings’ understanding of how a game should be played.
Victoria Krakovna, a researcher on Google’s DeepMind AI project, has spent the last several months collecting examples like the Sonic one. Her growing collection has recently drawn new attention after being shared on Twitter by Jim Crawford, developer of the puzzle series Frog Fractions, among other developers and journalists. Each example includes what she calls “reinforcement learning agents hacking the reward function,” which results in part from unclear directions on the part of the programmers.
“While ‘specification gaming’ is a somewhat vague category, it is particularly referring to behaviors that are clearly hacks, not just suboptimal solutions,” she wrote in her initial blog post on the subject. “A classic example is OpenAI’s demo of a reinforcement learning agent in a boat racing game going in circles and repeatedly hitting the same reward targets instead of actually playing the game.”
The New York Times doesn’t keep bodies in its “morgue” — it keeps pictures. In a basement under its Times Square office, stuffed into cabinets and drawers, the Times stores between 5 million and 7 million images, along with information about when they were published and why. Now, the paper is working with Google to digitize its huge collection.
The morgue (as the basement storage area is known) contains pictures going back to the 19th century, many of which exist nowhere else in the world. “[It’s] a treasure trove of perishable documents,” says the NYT’s chief technology officer Nick Rockwell. “A priceless chronicle of not just The Times’s history, but of nearly more than a century of global events that have shaped our modern world.”
That’s why the company has hired Google, which will use its machine vision smarts to not only scan the hand- and type-written notes attached to each image, but categorize the semantic information they contain (linking data like locations and dates). Google says the Times will also be able to use its object recognition tools to extract even more information from the photos, making them easier to catalog and resurface for future use.
Welcome to Spinning Up in Deep RL! This is an educational resource produced by OpenAI that makes it easier to learn about deep reinforcement learning (deep RL).
For the unfamiliar: reinforcement learning (RL) is a machine learning approach for teaching agents how to solve tasks by trial and error. Deep RL refers to the combination of RL with deep learning.
This module contains a variety of helpful resources, including:
a short introduction to RL terminology, kinds of algorithms, and basic theory,
an essay about how to grow into an RL research role,
a curated list of important papers organized by topic,
a well-documented code repo of short, standalone implementations of key algorithms,
Timely diagnosis of Alzheimer’s disease is extremely important, as treatments and interventions are more effective early in the course of the disease. However, early diagnosis has proven to be challenging. Research has linked the disease process to changes in metabolism, as shown by glucose uptake in certain regions of the brain, but these changes can be difficult to recognize.
[…]
The researchers trained the deep learning algorithm on a special imaging technology known as 18-F-fluorodeoxyglucose positron emission tomography (FDG-PET). In an FDG-PET scan, FDG, a radioactive glucose compound, is injected into the blood. PET scans can then measure the uptake of FDG in brain cells, an indicator of metabolic activity.
The researchers had access to data from the Alzheimer’s Disease Neuroimaging Initiative (ADNI), a major multi-site study focused on clinical trials to improve prevention and treatment of this disease. The ADNI dataset included more than 2,100 FDG-PET brain images from 1,002 patients. Researchers trained the deep learning algorithm on 90 percent of the dataset and then tested it on the remaining 10 percent of the dataset. Through deep learning, the algorithm was able to teach itself metabolic patterns that corresponded to Alzheimer’s disease.
Finally, the researchers tested the algorithm on an independent set of 40 imaging exams from 40 patients that it had never studied. The algorithm achieved 100 percent sensitivity at detecting the disease an average of more than six years prior to the final diagnosis.
“We were very pleased with the algorithm’s performance,” Dr. Sohn said. “It was able to predict every single case that advanced to Alzheimer’s disease.”
Each day, Brenda leaves her home here to catch a bus to the east side of Nairobi where she, along with more than 1,000 colleagues in the same building, work hard on a side of artificial intelligence we hear little about – and see even less.
In her eight-hour shift, she creates training data. Information – images, most often – prepared in a way that computers can understand.
Brenda loads up an image, and then uses the mouse to trace around just about everything. People, cars, road signs, lane markings – even the sky, specifying whether it’s cloudy or bright. Ingesting millions of these images into an artificial intelligence system means a self-driving car, to use one example, can begin to “recognise” those objects in the real world. The more data, the supposedly smarter the machine.
She and her colleagues sit close – often too close – to their monitors, zooming in on the images to make sure not a single pixel is tagged incorrectly. Their work will be checked by a superior, who will send it back if it’s not up to scratch. For the fastest, most accurate trainers, the honour of having your name up on one of the many TV screens around the office. And the most popular perk of all: shopping vouchers.
[…]
Brenda does this work for Samasource, a San Francisco-based company that counts Google, Microsoft, Salesforce and Yahoo among its clients. Most of these firms don’t like to discuss the exact nature of their work with Samasource – as it is often for future projects – but it can be said that the information prepared here forms a crucial part of some of Silicon Valley’s biggest and most famous efforts in AI.
[…]
f you didn’t look out of the windows, you might think you were at a Silicon Valley tech firm. Walls are covered in corrugated iron in a way that would be considered achingly trendy in California, but here serve as a reminder of the environment many of the workers come from: around 75% are from the slum.
Most impressively, Samasource has overcome a problem that most Silicon Valley firms are famously grappling with. Just over half of their workforce is made up of women, a remarkable feat in a country where starting a family more often than not rules out a career for the mother. Here, a lactation room, up to 90 days maternity leave, and flexibility around shift patterns makes the firm a stand-out example of inclusivity not just in Kenya, but globally.
“Like a lot of people say, if you have a man in the workplace, he’ll support his family,” said Hellen Savala, who runs human resources.
“[But] if you have a woman in the workplace, she’ll support her family, and the extended family. So you’ll have a lot more impact.”
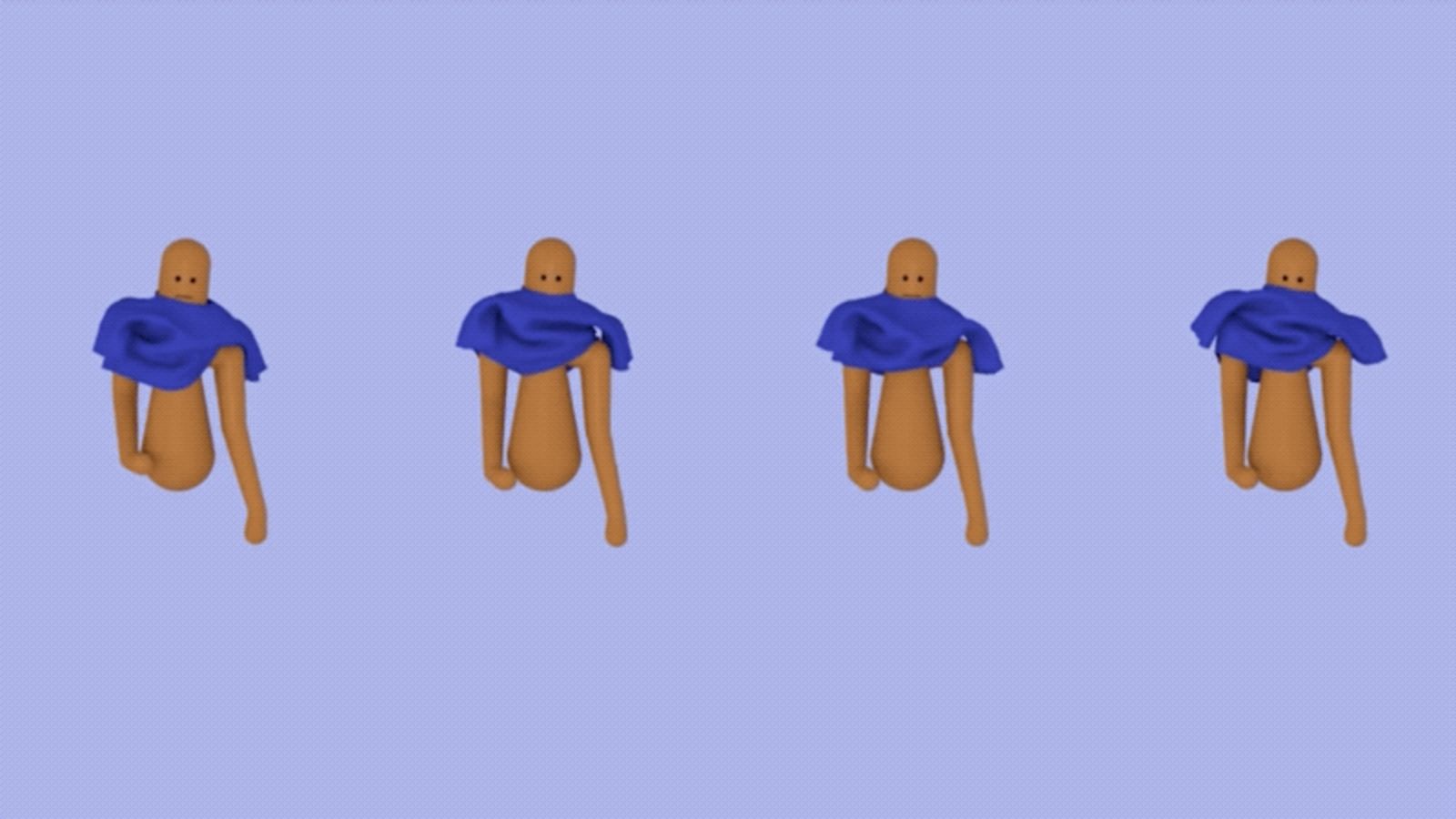
The ability to put our clothes on each day is something most of us take for granted, but as computer scientists from Georgia Institute of Technology recently found out, it’s a surprisingly complicated task—even for artificial intelligence.
As any toddler will gladly tell you, it’s not easy to dress oneself. It requires patience, physical dexterity, bodily awareness, and knowledge of where our body parts are supposed to go inside of clothing. Dressing can be a frustrating ordeal for young children, but with enough persistence, encouragement, and practice, it’s something most of us eventually learn to master.
As new research shows, the same learning strategy used by toddlers also applies to artificially intelligent computer characters. Using an AI technique known as reinforcement learning—the digital equivalent of parental encouragement—a team led by Alexander W. Clegg, a computer science PhD student at the Georgia Institute of Technology, taught animated bots to dress themselves. In tests, their animated bots could put on virtual t-shirts and jackets, or be partially dressed by a virtual assistant. Eventually, the system could help develop more realistic computer animation, or more practically, physical robotic systems capable of dressing individuals who struggle to do it themselves, such as people with disabilities or illnesses.
Putting clothes on, as Clegg and his colleagues point out in their new study, is a multifaceted process.
“We put our head and arms into a shirt or pull on pants without a thought to the complex nature of our interactions with the clothing,” the authors write in the study, the details of which will be presented at the SIGGRAPH Asia 2018 conference on computer graphics in December. “We may use one hand to hold a shirt open, reach our second hand into the sleeve, push our arm through the sleeve, and then reverse the roles of the hands to pull on the second sleeve. All the while, we are taking care to avoid getting our hand caught in the garment or tearing the clothing, often guided by our sense of touch.”
Computer animators are fully aware of these challenges, and often struggle to create realistic portrayals of characters putting their clothes on. To help in this regard, Clegg’s team turned to reinforcement learning—a technique that’s already being used to teach bots complex motor skills from scratch. With reinforcement learning, systems are motivated toward a designated goal by gaining points for desirable behaviors and losing points for counterproductive behaviors. It’s a trial-and-error process—but with cheers or boos guiding the system along as it learns effective “policies” or strategies for completing a goal.
De initiatiefnemers van AINED ontwikkelen met ondersteuning van de Boston Consulting Group (BCG) en DenkWerk een Nationale Strategie Artificial Intelligence (AI) voor Nederland, geïnitieerd door het Ministerie van Economische Zaken en Klimaat.
Het projectteam doet dit vanuit de overtuiging dat in het Nederlandse landschap de mogelijkheden van AI nog te weinig worden benut, en de randvoorwaarden van AI nog niet voldoende worden meegenomen in de ontwikkeling en toepassing van AI. In een wereld waarin andere landen dit wel doen en de techniek steeds waardevoller en krachtiger wordt, is het van groot belang voor Nederland om nu óók in te zetten op AI.
Voor de ontwikkeling van deze strategie is AINED opgestart: een samenwerking tussen het TopTeam ICT, VNO-NCW, ICAI, NWO en TNO, ondersteund door The Boston Consulting Group en DenkWerk.
AI ontwikkelt zich snel en heeft een grote belofte van innovatie en vooruitgang in zich. Het doel van de nationale strategie is de ontwikkeling en toepassing van moderne, data-gedreven AI-technologie in Nederland te versnellen, gericht op kansen voor Nederland en mét inachtneming van juridische, ethische en sociale randvoorwaarden. Als vertrekpunt voor de strategie met doelen en acties, wordt een landschapsschets opgesteld met initiatieven en wensen voor AI in het bedrijfsleven, de overheid, de wetenschap, het onderwijs en de non-gouvernementele sector.
De ontwikkeling van het voorstel loopt tot begin oktober. In een volgende fase zullen de initiatiefnemers van AINED met een brede groep aan stakeholders de doelen en acties verder uitwerken en afstemmen hoe zij kunnen bijdragen hieraan. Naast het Ministerie van Economische Zaken en Klimaat, de Ministeries van Onderwijs, Cultuur en Wetenschap, Defensie en Binnenlandse Zaken, zal een belangrijke rol weggelegd zijn voor het bedrijfsleven. In deze volgende fase zullen ook commitments op de doelen en acties behaald worden. Voor interesse om bij te dragen, neem contact op met Daniël Frijters, secretaris AINED op info@ained.nl
Machine learning is, at heart, the art of finding patterns in data. That’s why businesses love it. Patterns help predict the future, and predicting the future is a great way to make money. It’s sometimes unclear how these things fit together, but here’s a perfect example from film studio 20th Century Fox, which is using AI to predict what films people will want to see.
Researchers from the company published a paper last month explaining how they’re analyzing the content of movie trailers using machine learning. Machine vision systems examine trailer footage frame by frame, labeling objects and events, and then compare this to data generated for other trailers. The idea is that movies with similar sets of labels will attract similar sets of people.
As the researchers explain in the paper, this is exactly the sort of data movie studios love. (They already produce lots of similar data using traditional methods like interviews and questionnaires.) “Understanding detailed audience composition is important for movie studios that invest in stories of uncertain commercial,” they write. In other words, if they know who watches what, they will know what movies to make.
It’s even better if this audience composition can be broken down into smaller and more accurate “micro segments.” A good example of this is 2017’s Logan. It’s a superhero movie, yes, but it has darker themes and a plot that attracts a slightly different audience. So can AI be used to capture those differences? The answer is: sort of.
To create their “experimental movie attendance prediction and recommendation system” (named Merlin), 20th Century Fox partnered with Google to use the company’s servers and open-source AI framework TensorFlow. In an accompanying blog post, the search giant explains Merlin’s analysis of Logan.
First, Merlin scans the trailer, labeling objects like “facial hair,” “car,” and “forest”:
While this graph only records the frequency of these labels, the actual data generated is more complex, taking into account how long these objects appear on-screen and when they show up the trailer.
As 20th Century Fox’s engineers explain, this temporal information is particularly rich because it correlates with a film’s genre. “For example,” they write, “a trailer with a long close-up shot of a character is more likely for a drama movie than for an action movie, whereas a trailer with quick but frequent shots is more likely for an action movie.” This definitely holds true for Logan, with its trailer featuring lots of slow shots of Hugh Jackman looking bloody and beaten.
By comparing this information with analyses of other trailers, Merlin can try to predict what films might interest the people who saw Logan. But here’s where things get a little dicey.
The graph below shows the top 20 films that people who went to see Logan also watched. The column on the right shows Merlin’s predictions, and the column on the left shows the actual data (collected, one assumes, by using that pre-AI method of “asking people”).
Merlin gets quite a few of the films correct, including other superhero movies like X Men: Apocalypse, Doctor Strange, and Batman v Superman: Dawn of Justice. It even correctly identifies John Wick: Chapter 2 as a bedfellow of Logan. That’s an impressive intuition since John Wick is certainly not a superhero movie. However, it does feature a similarly weary and jaded protagonist with a comparably rugged look. All in all, Merlin identifies all of the top five picks, even if it does fail to put them in the same order of importance.
What’s more revealing, though, are the mismatches. Merlin predicts that TheLegend of Tarzan will be a big hit with Logan fans for example. Neither Google nor 20th Century Fox offers an explanation for this, but it could it have something to do with the “forest,” “tree,” and “light” found in Logan — elements which also feature heavily in the Tarzantrailer.
Similarly, The Revenant has plenty of flora and facial hair, but it was drama-heavy Oscar bait rather than a smart superhero movie. Merlin also misses Ant-Man and Deadpool 2 as lure’s for the same audience. These were superhero films with quick-cut trailers, but they also took offbeat approaches to their protagonists, similar to Wolverine’s treatment in Logan.












:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/13375641/Foxs_tool.max_1600x1600.png)
:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/13375771/Results_output.max_1900x1900.png)