When Epic went after both Apple and Google a few years ago with antitrust claims regarding the need to go through their app stores to get on phones, we noted that it seemed more like negotiation-by-lawsuit. Both Apple and Google have cut some deals with larger companies to lower the 30% cut the companies take on app payments, and it seemed like these lawsuits were just an attempt to get leverage. That was especially true with regards to the complaint against Google, given that it’s much, much easier to route around the Google Play Store and get apps onto an Android phone.
Google allows sideloading. Google allows third party app stores. While it may discourage those things, Android is way more open than iOS, where you really can’t get your app on the phone unless Apple says you can.
Still, it was little surprise that Apple mostly won at a bench trial in 2021. Or that the 9th Circuit upheld the victory earlier this year. The 9th Circuit made it clear that Apple is free to set whatever rules it wants to play in its ecosystem.
Given all that, I had barely paid attention to the latest trial, which was basically the same case against Google. But, rather than a bench trial, this one was a jury trial. And, juries, man, they sure can be stupid sometimes.
That leaves things in a very, very weird stance. Apple, whose system is much more closed off and where Apple denies any ability for third parties to get on the phone without Apple’s permission is… fine and dandy. Whereas, Google, which may discourage, but does allow third party apps and third party app stores… is somehow a monopolist?
It’s hard to see how that state of affairs makes any sense at all.
Google has said it will appeal, but overturning jury rulings is… not easy.
That said, even if the ruling is upheld… it might not be such a bad thing. Epic has said that it’s not asking for money, but rather to have it made clear that Epic can launch its own app stores without restriction from Google, along with the freedom to use its own billing system.
And, uh, yeah. Epic should be able to do that. Having more app stores and more alternatives on app payments would be a good thing for everyone except Google, and that’s good.
So I don’t necessarily have a problem with the overall outcome. I’m just confused how these two rulings can possibly be considered consistent, or how they give any guidance whatsoever to others. I mean, one takeaway is that if you’re creating an ecosystem for 3rd party apps, you’re better off taking the closed Apple route. And, that would be bad.
There’s been this weird idea lately, even among people who used to recognize that copyright only empowers the largest gatekeepers, that in the AI world we have to magically flip the script on copyright and use it as a tool to get AI companies to pay for the material they train on. But, as we’ve explained repeatedly, this would be a huge mistake. Even if people are concerned about how AI works, copyright is not the right tool to use here, and the risk of it being used to destroy all sorts of important and useful tools is quite high (ignoring Elon Musk’s prediction that “Digital God” will obsolete all of this).
However, because so many people think that they’re supporting creators and “sticking it” to Big Tech in supporting these copyright lawsuits over AI, I thought it might be useful to play out how this would work in practice. And, spoiler alert, the end result would be a disaster for creators, and a huge benefit to big tech. It’s exactly what we should be fighting against.
And, we know this because we have decades of copyright law and the internet to observe. Copyright law, by its very nature as a monopoly right, has always served the interests of gatekeepers over artists. This is why the most aggressive enforcers of copyright are the very middlemen with long histories of screwing over the actual creatives: the record labels, the TV and movie studios, the book publishers, etc.
This is because the nature of copyright law is such that it is most powerful when a few large entities act as central repositories for the copyrights and can lord around their power and try to force other entities to pay up. This is how the music industry has worked for years, and you can see what’s happened. After years of fighting internet music, it finally devolved into a situation where there are a tiny number of online music services (Spotify, Apple, YouTube, etc.) who cut massive deals with the giant gatekeepers on the other side (the record labels, the performance rights orgs, the collection societies) while the actual creators get pennies.
This is why we’ve said that AI training will never fit neatly into a licensing regime. The almost certain outcome (because it’s what happens every other time a similar situation arises) is that there will be one (possibly two) giant entities who will be designated as the “collection society” with whom AI companies will have to negotiate or to just purchase a “training license” and that entity will then collect a ton of money, much of which will go towards “administration,” and actual artists will… get a tiny bit.
And, because of the nature of training data, which only needs to be collected once, it’s not likely that this will be a recurring payment, but a minuscule one-off for the right to train on the data.
But, given the enormity of the amount of content, and the structure of this kind of thing, the cost will be extremely high for the AI companies (a few pennies for every creator online can add up in aggregate), meaning that only the biggest of big tech will be able to afford it.
In other words, the end result of a win in this kind of litigation (or, if Congress decides to act to achieve something similar) would be the further locking-in of the biggest companies. Google, Meta, and OpenAI (with Microsoft’s money) can afford the license, and will toss off a tiny one-time payment to creators (while whatever collection society there is takes a big cut for administration).
And then all of the actually interesting smaller companies and open source models are screwed.
End result? More lock-in of the biggest of big tech in exchange for… a few pennies for creators?
That’s not a beneficial outcome. It’s a horrible outcome. It will not just limit innovation, but it will massively limit competition and provide an even bigger benefit to the biggest incumbents.
Google Play has reversed its latest ban on a web browser that keeps getting targeted by vague Digital Millennium Copyright Act (DMCA) notices. Downloader, an Android TV app that combines a browser with a file manager, was restored to Google Play last night.
Downloader, made by app developer Elias Saba, was suspended on Sunday after a DMCA notice submitted by copyright-enforcement firm MarkScan on behalf of Warner Bros. Discovery. It was the second time in six months that Downloader was suspended based on a complaint that the app’s web browser is capable of loading websites.
The first suspension in May lasted three weeks, but Google reversed the latest one much more quickly. As we wrote on Monday, the MarkScan DMCA notice didn’t even list any copyrighted works that Downloader supposedly infringed upon.
Instead of identifying specific copyrighted works, the MarkScan notice said only that Downloader infringed on “Properties of Warner Bros. Discovery Inc.” In the field where a DMCA complainant is supposed to provide an example of where someone can view an authorized example of the work, MarkScan simply entered the main Warner Bros. URL: https://www.warnerbros.com/.
DMCA notice was incomplete
Google has defended its DMCA-takedown process by saying that, under the law, it is obligated to remove any content when a takedown request contains the elements required by the copyright law. But in this case, Google Play removed Downloader even though the DMCA takedown request didn’t identify a copyrighted work—one of the elements required by the DMCA.
[…]
Downloader’s first suspension in May came after several Israeli TV companies complained that the app could be used to load a pirate website. In that case, an appeal that Saba filed with Google Play was quickly rejected. He also submitted a DMCA counter-notice, which gave the complainant 10 business days to file a legal action.
[…]
Saba still needed to republish the app to make it visible to users again. “I re-submitted the app last night in the Google Play Console, as instructed in the email, and it was approved and live a few hours later,” Saba told Ars today.
In a new blog post, Saba wrote that he expected the second suspension to last a few weeks, just like the first did. He speculated that it was reversed more quickly this time because the latest DMCA notice “provided no details as to how my app was infringing on copyrighted content, which, I believe, allowed Google to invalidate the takedown request.”
“Of course, I wish Google bothered to toss out the meritless DMCA takedown request when it was first submitted, as opposed to after taking ‘another look,’ but I understand that Google is probably flooded with invalid takedown requests because the DMCA is flawed,” Saba wrote. “I’m just glad Google stepped in when it did and I didn’t have to go through the entire DMCA counter notice process. The real blame for all of this goes to Warner Bros. Discovery and other corporations for funding companies like MarkScan which has issued DMCA takedowns in the tens of millions.”
Given that the overwhelming majority of DMCA takedown notices are generated by copyright bots that are only moderately good at their job, at best, perhaps it’s not terribly surprising that these bots keep finding new and interesting ways to cause collateral damage unintentionally.
[…]
a Tumblr site, called “Mapping La Sirena.” If you’re a fan of Star Trek: Picard, you will know that’s the name of the main starship in that series. But if you’re a copyright enforcer for a certain industry, the bots you’ve set up for yourself apparently aren’t programmed with Star Trek fandom.
Transparency.automattic reports Tumblr has received numerous DMCA takedown notices from DMCA Piracy Prevention Inc, a third-party copyright monitoring service used frequently by content creators to prevent infringement of their original work. And these complaints occurred all because of the name La Sirena which also happens to be the name of an adult content creator, La Sirena 69 who is one of Piracy Prevention’s customers.
In one copyright claim over 90 Tumblr posts were targeted by the monitoring service because of the keyword match to “la sirena.” But instead of Automattic being alerted to La Sirena 69’s potentially infringed content, the company reported many of mappinglasirena.tumblr.com’s original posts.
Pure collateral damage. While not intentional per se, this is obviously still a problem. One of two things has to be the case: either we stop allowing copyright enforcement to be farmed out to a bunch of dumb bots that suck at their jobs or we insist that the bots stop sucking, which ain’t going to happen anytime soon. What cannot be allowed to happen is to shrug this sort of thing off as an innocent accident and oh well, too bad, so sad for the impact on the speech rights of the innocent.
There was nothing that remotely infringed La Sirena 69’s content. Everything about the complaints and takedown notices was wrong.
Two men who allegedly used 65 Google accounts to bombard Google with fraudulent DMCA takedown notices targeting up to 620,000 URLs, have been named in a Google lawsuit filed in California on Monday. Google says the men weaponized copyright law’s notice-and-takedown system to sabotage competitors’ trade, while damaging the search engine’s business and those of its customers.
While all non-compliant DMCA takedown notices are invalid by default, there’s a huge difference between those sent in error and others crafted for purely malicious purposes.
Bogus DMCA takedown notices are nothing new, but the rise of organized groups using malicious DMCA notices as a business tool has been apparent in recent years.
Since the vast majority of culprits facing zero consequences, that may have acted as motivation to send more. Through a lawsuit filed at a California court on Monday, Google appears to be sending the message that enough is enough.
Defendants Weaponized DMCA Takedowns
Google’s complaint targets Nguyen Van Duc and Pham Van Thien, both said to be residents of Vietnam and the leaders of up to 20 Doe defendants. Google says the defendants systematically abused accounts “to submit a barrage” of fraudulent copyright takedown requests aimed at removing their competitors’ website URLs from Google Search results.
[…]
The misrepresentations in notices sent to Google were potentially damaging to other parties too. Under fake names, the defendants falsely claimed to represent large companies such as Amazon, Twitter, and NBC News, plus sports teams including the Philadelphia Eagles, Los Angeles Lakers, San Diego Padres.
In similarly false notices, they claimed to represent famous individuals including Elon Musk, Taylor Swift, LeVar Burton, and Kanye West.
The complaint notes that some notices were submitted under company names that do not exist in the United States, at addresses where innocent families and businesses can be found. Google says that despite these claims, the defendants can be found in Vietnam from where they proudly advertise their ‘SEO’ scheme to others, including via YouTube.
Who would have thought that such a super poorly designed piece of copyright law would be used for this? Probably almost everyone who has been hit by a DMCA with no recourse is all. This is but a tiny tiny fraction of the iceberg, with the actual copyright holders at the top. The only way to stop this is by taking down the whole DMCA system.
Many courts have already dealt with these lawsuits-come-lately filed by opportunistic people who failed to capitalize on their own pop culture cache but thought it was worth throwing a few hundred dollars in filing fees towards a federal court in hopes that the eventual payoff would be millions.
Most of these efforts have failed. Dance moves are tough to copyright, considering they’re often not a cohesive form of expression. On top of that, there’s a whole lot of independent invention because the human body is only capable of so many dance moves that portray talent, rather than just an inability to control your limbs.
Hence the federal court’s general hesitance to proclaim controlled flailing protectable. And hence the failure of most these Fortnite-is-worth-millions lawsuits written by people with dollar signs for eyes and Web 2.0 ambulance chasers for lawyers.
But one of these lawsuits has been revived by the Ninth Circuit, which has decided a certain number of sequential dance steps is actual intellectual property worth suing over. Here’s Wes Davis with more details for The Verge:
This week, a panel of US appeals court judges has renewed the legal battle over Fortnite dance moves by reversing the dismissal of a lawsuit filed last year by professional choreographer Kyle Hanagami against Epic Games.
[…]
The lower court said choreographic works are made up of poses that aren’t protectable alone.It found that the steps and poses of dance choreography used by characters in Fortnite were not “substantially similar, other than the four identical counts of poses” because they don’t “share any creative elements” with Hanagami’s work.
The 9th Circuit panel agreed with the lower court that “choreography is composed of various elements that are unprotectable when viewed in isolation.” However, Judge Richard Paez wrote this week that referring to portions of choreography as “poses” was like calling music “just ‘notes.’” They also found that choreography can involve other elements like timing, use of space, and even the energy of the performance.
This is a strange conclusion to reach given prior case law on the subject. But a lot of prior Fortnite case law is based on the fact that complainants never made any attempt to copyright their moves, but rather decided they were owed a living by Fortnite’s producer (Epic Games) simply because Fortnite (and Epic Games) were extremely successful.
That’s not the case here, as the Ninth Circuit [PDF] notes:
Plaintiff Kyle Hanagami (“Hanagami”) is a celebrity choreographer who owns a validly registered copyright in a five-minute choreographic work.
That’s a point in Hanagami’s favor. Whether or not this particular expression is protected under copyright law is no longer an open question. It has been registered with the US Copyright office, thus making it possible for Hanagami to seek a payout that far exceeds actual damages that can be proven in court.
As was noted above, the lower court compared Hanagami’s registered work with the allegedly infringing “emote” and found that, at best, only small parts had been copied.
The Ninth Circuit disagrees.
The district court erred by ruling that, as a matter of law, the Steps are unprotectable because they are relatively brief. Hanagami has more than plausibly alleged that the four-count portion has substantial qualitative significance to the overall Registered Choreography. The four counts in question are repeated eight times throughout the Registered Choreography, corresponding to the chorus and titular lyrics of the accompanying song. Hanagami alleges that the segment is the most recognizable and distinctive portion of his work, similar to the chorus of a song. Whether or not a jury would ultimately find the copied portion to be qualitatively significant is a question for another day. We conclude only that the district court erred in dismissing Hanagami’s copyright claim on the basis that Epic allegedly infringed only a relatively small amount of the Registered Choreography.
This allows the lawsuit to move forward. The Ninth Circuit does not establish a bright line ruling that would encourage/deter similar lawsuits. Nor does it establish a baseline to guide future rulings. Instead, it simply says some choreography is distinctive enough plaintiffs can sue over alleged infringement, but most likely, it will be a jury deciding these facts, rather than a judge handling motions to dismiss.
So… maybe that’s ok? I can understand the point that distinctive progressive dance steps are as significant as distinctive chord progressions when it comes to expression that can be copyrighted. But, on the other hand, the lack of guidance from the appellate level encourages speculative litigation because it refuses to make a call one way or the other but simply decides the lower court is (1) wrong and (2) should handle all the tough questions itself.
Where this ends up is tough to say. But, for now, it guarantees someone who rues every “emote” purchase made for my persistent offspring will only become more “get off my lawn” as this litigation progresses.
It truly is amazing that the video game industry is so heavily divided on the topic of user-made game mods. I truly don’t understand it. My take has always been very simple: mods are good for gamers and even better for game makers. Why? Simple, mods serve to extend the useful life of video games by adding new ways to play them and therefore making them more valuable, they can serve to fix or make better the original game thereby doing some of the game makers work for them for free, and can simply keep a classic game relevant decades later thanks to a dedicated group of fans of a franchise that continues to be a cash cow to this day.
On the other hand are all the studios and publishers that somehow see mods as some kind of threat, even outside of the online gaming space. Take Two, Nintendo, EA: the list goes on and on and on. In most of those cases, it simply appears that control is preferred by the publisher over building an active community and gaining all the benefits that come along with that modding community.
And then there’s Capcom, which recently made some statements essentially claiming that for all practical purposes mods are just a different form of cheating and that mods hurt the gaming experience for the public.
“For the purposes of anti-cheat and anti-piracy, all mods are defined as cheats,” Capcom explained. The only exception to this are mods which are “officially” supported by the developer and, as Capcom sees it, all user-created mods are “internally” no different than cheating.
Capcom goes on to say that some mods with offensive content can be “detrimental” to a game or franchise’s reputation. The publisher also explained that mods can create new bugs and lead to more players needing support, stretching resources, and leading to increased game development costs or even delays. (I can’t help but feel my eyes starting to roll…)
I’m sorry, but just… no. No to pretty much all of this. Mods do not need to be defined as cheats, particularly in offline single player games. Mods are mods, cheats are cheats. There are a zillion different aesthetic and/or quality of life mods that exist for hundreds of games that fall into this category. Skipping intro videos for games, which I do in Civilization, cannot possibly be equated to cheating within the game, but that’s a mod.
As to the claim that mods increase development time because support teams have to handle requests from people using mods that are causing problems within the games… come on, now. Support and dev teams are very distinct and I refuse to believe this is a big enough problem to even warrant a comment.
As to offensive mods, here I have some sympathy. But I also have a hard time believing that the general public is really looking with narrow eyes at publishers of games because of what third-party mods do to their product. Mods like that exist for all kinds of games and those publishers and developers appear to be getting on just fine.
Whatever the reason behind Capcom’s discomfort with mods, it should think long and hard about its stance and decide whether it’s valid. We have seen time and time again examples of modding communities being a complete boon to publishers and I see no reason why Capcom should be any different.
So they allow people to play the game in new and unexpected ways. The same does go for cheats. Sometimes you just don’t have the patience to do that boss fight for the 100th time. Sometimes you just want to get through the game. Sometimes you want to play that super 1/1000 drop chance rare item. If you’re not online, then mod and cheat the hell out of the game. It yours! You paid for it, installed the code on your hard drive. It’s out of the hands of the publisher.
These requirements would oblige AI developers to disclose a summary of all copyrighted material used to train their AI systems. Burdensome and impractical are the right words to describe the proposed rules.
In some cases it would basically come down to providing a summary of half the internet.
Leaving aside the impossibly large volume of material that might need to be summarized, another issue is that it is by no means clear when something is under copyright, making compliance even more infeasible. In any case, as the DisCo post rightly points out, the EU Copyright Directive already provides a legal framework that addresses the issue of training AI systems:
The existing European copyright rules are very simple: developers can copy and analyse vast quantities of data from the internet, as long as the data is publicly available and rights holders do not object to this kind of use. So, rights holders already have the power to decide whether AI developers can use their content or not.
This is a classic case of the copyright industry always wanting more, no matter how much it gets. When the EU Copyright Directive was under discussion, many argued that an EU-wide copyright exception for text and data mining (TDM) and AI in the form of machine learning would be hugely beneficial for the economy and society. But as usual, the copyright world insisted on its right to double dip, and to be paid again if copyright materials were used for mining or machine learning, even if a license had already been obtained to access the material.
As I wrote in a column five years ago, that’s ridiculous, because the right to read is the right to mine. Updated for our AI world, that can be rephrased as “the right to read is the right to train”. By failing to recognize that, the European Parliament has sabotaged its own AI Act. Its amendment to the text will make it far harder for AI companies to thrive in the EU, which will inevitably encourage them to set up shop elsewhere.
If the final text of the AI Act still has this requirement to provide a summary of all copyright material that is used for training, I predict that the EU will become a backwater for AI. That would be a huge loss for the region, because generative AI is widely expected to be one of the most dynamic and important new tech sectors. If that happens, backward-looking copyright dogma will once again have throttled a promising digital future, just as it has done so often in the recent past.
I am so frequently confused by companies that sue other companies for making their own sites and services more useful. It happens quite often. And quite often, the lawsuits are questionable CFAA claims against websites that scrape data to provide a better consumer experience, but one that still ultimately benefits the originating site.
Over the last few years various airlines have really been leading the way on this, with Southwest being particularly aggressive in suing companies that help people find Southwest flights to purchase. Unfortunately, many of these lawsuits are succeeding, to the point that a court has literally said that a travel company can’t tell others how much Southwest flights cost.
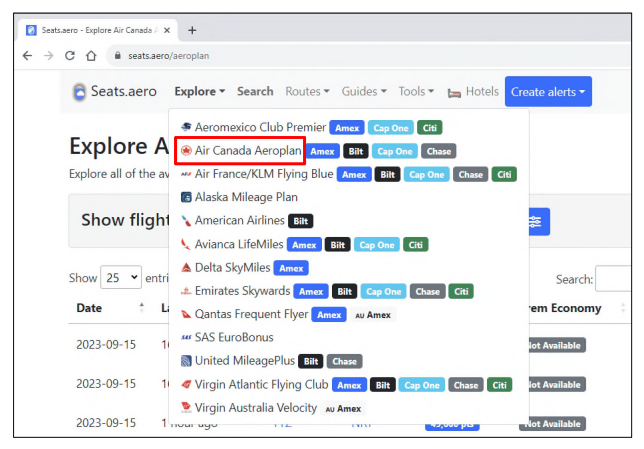
But the latest lawsuit of this nature doesn’t involve Southwest, and is quite possibly the dumbest one. Air Canada has sued the site Seats.aero that helps users figure out the best flights for their frequent flyer miles. Seats.aero is a small operation run by the company with the best name ever: Localhost, meaning that the lawsuit is technically “Air Canada v. Localhost” which sounds almost as dumb as this lawsuit is.
The Air Canada Group brings this action because Mr. Ian Carroll—through Defendant Localhost LLC—created a for-profit website and computer application (or “app”)— both called Seats.aero—that use substantial amounts of data unlawfully scraped from the Air Canada Group’s website and computer systems. In direct violation of the Air Canada Group’s web terms and conditions, Carroll uses automated digital robots (or “bots”) to continuously search for and harvest data from the Air Canada Group’s website and database. His intrusions are frequent and rapacious, causing multiple levels of harm, e.g., placing an immense strain on the Air Canada Group’s computer infrastructure, impairing the integrity and availability of the Air Canada Group’s data, soiling the customer experience with the Air Canada Group, interfering with the Air Canada Group’s business relations with its partners and customers, and diverting the Air Canada Group’s resources to repair the damage. Making matters worse, Carroll uses the Air Canada Group’s federally registered trademarks and logo to mislead people into believing that his site, app, and activities are connected with and/or approved by the real Air Canada Group and lending an air of legitimacy to his site and app. The Air Canada Group has tried to stop Carroll’s activities via a number of technological blocking measures. But each time, he employs subterfuge to fraudulently access and take the data—all the while boasting about his exploits and circumvention online.
Almost nothing in this makes any sense. Having third parties scrape sites for data about prices is… how the internet works. Whining about it is stupid beyond belief. And here, it’s doubly stupid, because anyone who finds a flight via seats.aero is then sent to Air Canada’s own website to book that flight. Air Canada is making money because Carroll’s company is helping people find Air Canada flights they can take.
Why are they mad?
Air Canada’s lawyers also seem technically incompetent. I mean, what the fuck is this?
Through screen scraping, Carroll extracts all of the data displayed on the website, including the text and images.
Carroll also employs the more intrusive API scraping to further feed Defendant’s website.
If the “API scraping” is “more intrusive” than screen scraping, you’re doing your APIs wrong. Is Air Canada saying that its tech team is so incompetent that its API puts more load on the site than scraping? Because, if so, Air Canada should fire its tech team. The whole point of an API is to make it easier for those accessing data from your website without needing to do the more cumbersome process of scraping.
And, yes, this lawsuit really calls into question Air Canada’s tech team and their ability to run a modern website. If your website can’t handle having its flights and prices scraped a few times every day, then you shouldn’t have a website. Get some modern technology, Air Canada:
Defendant’s avaricious data scraping generates frequent and myriad requests to the Air Canada Group’s database—far in excess of what the Air Canada Group’s infrastructure was designed to handle. Its scraping collects a large volume of data, including flight data within a wide date range and across extensive flight origins and destinations—multiple times per day.
Maybe… invest in better infrastructure like basically every other website that can handle some basic scraping? Or, set up your API so it doesn’t fall over when used for normal API things? Because this is embarrassing:
At times, Defendant’s voluminous requests have placed such immense burdens on the Air Canada Group’s infrastructure that it has caused “brownouts.” During a brownout, a website is unresponsive for a period of time because the capacity of requests exceeds the capacity the website was designed to accommodate. During brownouts caused by Defendant’s data scraping, legitimate customers are unable to use or the Air Canada + Aeroplan mobile app, including to search for available rewards, redeem Aeroplan points for the rewards, search for and view reward travel availability, book reward flights, contact Aeroplan customer support, and/or obtain service through the Aeroplan contact center due to the high volume of calls during brownouts.
Air Canada’s lawyers also seem wholly unfamiliar with the concept of nominative fair use for trademarks. If you’re displaying someone’s trademarks for the sake of accurately talking about them, there’s no likelihood of confusion and no concern about the source of the information. Air Canada claiming that this is trademark infringement is ridiculous:
I guarantee that no one using Seats.aero thinks that they’re on Air Canada’s website.
The whole thing is so stupid that it makes me never want to fly Air Canada again. I don’t trust an airline that can’t set up its website/API to handle someone making its flights more attractive to buyers.
But, of course, in these crazy times with the way the CFAA has been interpreted, there’s a decent chance Air Canada could win.
For its part, Carroll says that he and his lawyers have reached out to Air Canada “repeatedly” to try to work with them on how they “retrieve availability information,” and that “Air Canada has ignored these offers.” He also notes that tons of other websites are scraping the very same information, and he has no idea why he’s been singled out. He further notes that he’s always been open to adjusting the frequency of searches and working with the airlines to make sure that his activities don’t burden the website.
But, really, the whole thing is stupid. The only thing that Carroll’s website does is help people buy more flights. It points people to the Air Canada site to buy tickets. It makes people want to fly more on Air Canada.
Why would Air Canada want to stop that other than that it can’t admit that it’s website operations should all be replaced by a more competent team?
This blog has written a number of times about the reaction of creators to generative AI. Legal academic and copyright expert Andres Guadamuz has spotted what may be the first attempt to draw up a new law to regulate generative AI. It comes from French politicians, who have developed something of a habit of bringing in new laws attempting to control digital technology that they rarely understand but definitely dislike.
There are only four articles in the text of the proposal, which are intended to be added as amendments to existing French laws. Despite being short, the proposal contains some impressively bad ideas. The first of these is found in Article 2, which, as Guadamuz summarises, “assigns ownership of the [AI-generated] work (now protected by copyright) to the authors or assignees of the works that enabled the creation of the said artificial work.” Here’s the huge problem with that idea:
How can one determine the author of the works that facilitated the conception of the AI-generated piece? While it might seem straightforward if AI works are viewed as collages or summaries of existing copyrighted works, this is far from the reality. As of now, I’m unaware of any method to extract specific text from ChatGPT or an image from Midjourney and enumerate all the works that contributed to its creation. That’s not how these models operate.
Since there is no way to find out exactly who the creators are whose work helped generate a new piece of AI material using aggregated statistics, Guadamuz suggests that the French lawmakers might want creators to be paid according to their contribution to the training material that went into creating the generative AI system itself. Using his own writings as an example, he calculates what fraction of any given payout he would receive with this approach. For ChatGPT’s output, Guadamuz estimates he might receive 0.00001% of any payout that was made. To give an example, even if the licensing fee for a some hugely popular work generated using AI were €1,000,000, Guadamuz would only receive 10 cents. Most real-life payouts to creators would be vanishingly small.
Article 3 of the French proposal builds on this ridiculous approach by requiring the names of all the creators who contributed to some AI-generated output to be included in that work. But as Guadamuz has already noted, there’s no way to find out exactly whose works have contributed to an output, leaving the only option to include the names of every single creator whose work is present in the training set – potentially millions of names.
Interestingly, Article 4 seems to recognize the payment problem raised above, and offers a way to deal with it. Guadamuz explains:
As it will be not possible to find the author of an AI work (which remember, has copyright and therefore isn’t in the public domain), the law will place a tax on the company that operates the service. So it’s sort of in the public domain, but it’s taxed, and the tax will be paid by OpenAI, Google, Midjourney, StabilityAI, etc. But also by any open source operator and other AI providers (Huggingface, etc). And the tax will be used to fund the collective societies in France… so unless people are willing to join these societies from abroad, they will get nothing, and these bodies will reap the rewards.
In other words, the net effect of the French proposal seems to be to tax the emerging AI giants (mostly US companies) and pay the money to French collecting societies. Guadumuz goes so far as to say: “in my view, this is the real intention of the legislation”. Anyone who thinks this is a good solution might want to read Chapter 7 of Walled Culture the book (free digital versions available), which quotes from a report revealing “a long history of corruption, mismanagement, confiscation of funds, and lack of transparency [by collecting societies] that has deprived artists of the revenues they earned”. Trying to fit generative AI into the straitjacket of an outdated copyright system designed for books is clearly unwise; using it as a pretext for funneling yet more money away from creators and towards collecting societies is just ridiculous.
Universal Music has filed a copyright infringement lawsuit against artificial intelligence start-up Anthropic, as the world’s largest music group battles against chatbots that churn out its artists’ lyrics.
Universal and two other music companies allege that Anthropic scrapes their songs without permission and uses them to generate “identical or nearly identical copies of those lyrics” via Claude, its rival to ChatGPT.
When Claude is asked for lyrics to the song “I Will Survive” by Gloria Gaynor, for example, it responds with “a nearly word-for-word copy of those lyrics,” Universal, Concord, and ABKCO said in a filing with a US court in Nashville, Tennessee.
“This copyrighted material is not free for the taking simply because it can be found on the Internet,” the music companies said, while claiming that Anthropic had “never even attempted” to license their copyrighted work.
[…]
Universal earlier this year asked Spotify and other streaming services to cut off access to its music catalogue for developers using it to train AI technology.
So don’t think about memorising or even listening to copyrighted material from them because apparently they will come after you with the mighty and crazy arm of the law!
the informal nature of their collections means that they are exposed to serious threats from copyright, as the recent experience of The Museum of Classic Chicago Television makes clear. The Museum explains why it exists:
The Museum of Classic Chicago Television (FuzzyMemoriesTV) is constantly searching out vintage material on old videotapes saved in basements or attics, or sold at flea markets, garage sales, estate sales and everywhere in between. Some of it would be completely lost to history if it were not for our efforts. The local TV stations have, for the most part, regrettably done a poor job at preserving their history. Tapes were very expensive 25-30 years ago and there also was a lack of vision on the importance of preserving this material back then. If the material does not exist on a studio master tape, what is to be done? Do we simply disregard the thousands of off-air recordings that still exist holding precious “lost” material? We believe this would be a tragic mistake.
Dozens of TV professionals and private individuals have donated to the museum their personal copies of old TV programmes made in the 1970s and 1980s, many of which include rare and otherwise unavailable TV advertisements that were shown as part of the broadcasts. In addition to the main Museum of Classic Chicago Television site, there is also a YouTube channel with videos. However, as TorrentFreak recounts, the entire channel was under threat because of copyright takedown requests:
In a series of emails starting Friday and continuing over the weekend, [the museum’s president and lead curator] Klein began by explaining his team’s predicament, one that TorrentFreak has heard time and again over the past few years. Acting on behalf of a copyright owner, in this case Sony, India-based anti-piracy company Markscan hit the MCCTv channel with a flurry of copyright claims. If these cannot be resolved, the entire project may disappear.
One issue is that Klein was unable to contact Markscan to resolve the problem directly. He is quoted by TorrentFreak as saying: “I just need to reach a live human being to try to resolve this without copyright strikes. I am willing to remove the material manually to get the strikes reversed.”
Once the copyright enforcement machine is engaged, it can be hard to stop. As Walled Culture the book (free digital versions available) recounts, there are effectively no penalties for unreasonable or even outright false claims. The playing field is tipped entirely in the favour of the copyright world, and anyone that is targeted using one of the takedown mechanisms is unlikely to be able to do much to contest them, unless they have good lawyers and deep pockets. Fortunately, in this case, an Ars Technica article on the issue reported that:
Sony’s copyright office emailed Klein after this article was published, saying it would “inform MarkScan to request retractions for the notices issued in response to the 27 full-length episode postings of Bewitched” in exchange for “assurances from you that you or the Fuzzy Memories TV Channel will not post or re-post any infringing versions from Bewitched or other content owned or distributed by SPE [Sony Pictures Entertainment] companies.”
That “concession” by Sony highlights the main problem here: the fact that a group of public-spirited individuals trying to preserve unique digital artefacts must live with the constant threat of copyright companies taking action against them. Moreover, there is also the likelihood that some of their holdings will have to be deleted as a result of those legal threats, despite the material’s possible cultural value or the fact that it is the only surviving copy. No one wins in this situation, but the purity of copyright must be preserved at all costs, it seems.
Rick Klein and his team have been preserving TV adverts, forgotten tapes, and decades-old TV programming for years. Now operating as a 501(c)(3) non-profit, the Museum of Classic Chicago Television has called YouTube home since 2007. However, copyright notices sent on behalf of Sony, protecting TV shows between 40 and 60 years old, could shut down the project in 48 hours.
[…]
After being reborn on YouTube as The Museum of Classic Chicago Television (MCCTv), the last sixteen years have been quite a ride. Over 80 million views later, MCCTv is a much-loved 501(c)(3) non-profit Illinois corporation but in just 48 hours, may simply cease to exist.
In a series of emails starting Friday and continuing over the weekend, Klein began by explaining his team’s predicament, one that TorrentFreak has heard time and again over the past few years. Acting on behalf of a copyright owner, in this case Sony, India-based anti-piracy company Markscan hit the MCCTv channel with a flurry of copyright claims. If these cannot be resolved, the entire project may disappear.
[…]
No matter whether takedowns are justified, unjustified (Markscan hit Sony’s own website with a DMCA takedown recently), or simply disputed, getting Markscan’s attention is a lottery at best, impossible at worst. In MCCTv’s short experience, nothing has changed.
“Our YouTube channel with 150k subscribers is in danger of being terminated by September 6th if I don’t find a way to resolve these copyright claims that Markscan made,” Klein told TorrentFreak on Friday.
“At this point, I don’t even care if they were issued under authorization by Sony or not – I just need to reach a live human being to try to resolve this without copyright strikes. I am willing to remove the material manually to get the strikes reversed.”
[…]
Complaints Targeted TV Shows 40 to 60 years old
[…]
Two episodes of the TV series Bewitched dated 1964 aired on ABC Network and almost sixty years later, archive copies of those transmissions were removed from YouTube for violating Sony copyrights, with MCCTv receiving a strike.
[…]
Given that copyright law locks content down for decades, Klein understands that can sometimes cause issues, although 16 years on YouTube suggests that the overwhelming majority of rightsholders don’t consider his channel a threat. If they did, the option to monetize the recordings can be an option.
No Competition For Commercial Offers
Why most rightsholders have left MCCTv alone is hard to say; perhaps some see the historical value of the channel, maybe others don’t know it exists. At least in part, Klein believes the low quality of the videos could be significant.
“These were relatively low picture quality broadcast examples from various channels from various years at least 30-40 years ago, with the original commercial breaks intact. Also mixed in with these were examples of ’16mm network prints’ which are surviving original film prints that were sent out to TV stations back in the day from when the show originally aired. In many cases they include original sponsorship notices, original network commercials, ‘In Color’ notices, etc.,” he explains.
[…]
Klein says the team is happy to comply with Sony’s wishes and they hope that given a little leeway, the project won’t be consigned to history. Perhaps Sony will recall the importance of time-shifting while understanding that time itself is running out for The Museum of Classic Chicago Television.
In OpenAI’s motion to dismiss (filed in both lawsuits), the company asked a US district court in California to toss all but one claim alleging direct copyright infringement, which OpenAI hopes to defeat at “a later stage of the case.”
The authors’ other claims—alleging vicarious copyright infringement, violation of the Digital Millennium Copyright Act (DMCA), unfair competition, negligence, and unjust enrichment—need to be “trimmed” from the lawsuits “so that these cases do not proceed to discovery and beyond with legally infirm theories of liability,” OpenAI argued.
OpenAI claimed that the authors “misconceive the scope of copyright, failing to take into account the limitations and exceptions (including fair use) that properly leave room for innovations like the large language models now at the forefront of artificial intelligence.”
According to OpenAI, even if the authors’ books were a “tiny part” of ChatGPT’s massive data set, “the use of copyrighted materials by innovators in transformative ways does not violate copyright.”
[…]
The purpose of copyright law, OpenAI argued, is “to promote the Progress of Science and useful Arts” by protecting the way authors express ideas, but “not the underlying idea itself, facts embodied within the author’s articulated message, or other building blocks of creative,” which are arguably the elements of authors’ works that would be useful to ChatGPT’s training model. Citing a notable copyright case involving Google Books, OpenAI reminded the court that “while an author may register a copyright in her book, the ‘statistical information’ pertaining to ‘word frequencies, syntactic patterns, and thematic markers’ in that book are beyond the scope of copyright protection.”
So the authors are saying that if you read their book and then are inspired by it, you can’t use that memory – any of it – to write another book. Which also means that you presumably wouldn’t be able to use any words at all, as they are all copyrighted entities which have inspired you in the past as well.
If you’ve never watched it, Kirby Ferguson’s “Everything is a Remix” series (which was recently updated from the original version that came out years ago) is an excellent look at how stupid our copyright laws are, and how they have really warped our view of creativity. As the series makes clear, creativity is all about remixing: taking inspiration and bits and pieces from other parts of culture and remixing them into something entirely new. All creativity involves this in some manner or another. There is no truly unique creativity.
And yet, copyright law assumes the opposite is true. It assumes that most creativity is entirely unique, and when remix and inspiration get too close, the powerful hand of the law has to slap people down.
[…]
It would have been nice if society had taken this issue seriously back then, recognized that “everything is a remix,” and that encouraging remixing and reusing the works of others to create something new and transformative was not just a good thing, but one that should be supported. If so, we might not be in the utter shitshow that is the debate over generative art from AI these days, in which many creators are rushing to AI to save them, even though that’s not what copyright was designed to do, nor is it a particularly useful tool in that context.
[…]
The moral panic is largely an epistemological crisis: We don’t have a socially acceptable status for the legibility of the remix as art-in-it’s-own-right. Instead of properly appreciating the remix and the art of the DJ, the remix, or the meme cultures, we have shoehorned all the cultural properties associated onto an 1800’s sheet music publishing -based model of artistic credibility. The fit was never really good, but no-one really cared because the scenes were small, underground and their breaking the rules was largely out-of-sight.
[…]
AI art tools are simply resurfacing an old problem we left behind unresolved during the 1980’s to early 2000’s. Now it’s time for us to blow the dust off these old books and apply what was learned to the situation we have at our hands now.
We should not forget the modern electronic dance music industry has already developed models that promote new artists via remixes of their work from more established artists. These real-world examples combined with the theoretical frameworks above should help us to explore a refreshed model of artistic credibility, where value is assigned to both the original artists and the authors of remixers
[…]
Art, especially popular forms of it, has always been a lot about transformation: Taking what exists and creating something that works in this particular context. In forms of art emphasizing the distinctiveness of the original less, transformation becomes the focus of the artform instead.
[…]
There are a lot of questions about how that would actually work in practice, but I do think this is a useful framework for thinking about some of these questions, challenging some existing assumptions, and trying to rethink the system into one that is actually helping creators and helping to enable more art to be created, rather than trying to leverage a system originally developed to provide monopolies to gatekeepers into one that is actually beneficial to the public who want to experience art, and creators who wish to make art.
Copyright issues have dogged AI since chatbot tech gained mass appeal, whether it’s accusations of entire novels being scraped to train ChatGPT or allegations that Microsoft and GitHub’s Copilot is pilfering code.
But one thing is for sure after a ruling [PDF] by the United States District Court for the District of Columbia – AI-created works cannot be copyrighted.
You’d think this was a simple case, but it has been rumbling on for years at the hands of one Stephen Thaler, founder of Missouri neural network biz Imagination Engines, who tried to copyright artwork generated by what he calls the Creativity Machine, a computer system he owns. The piece, A Recent Entrance to Paradise, pictured below, was reproduced on page 4 of the complaint [PDF]:
The US Copyright Office refused the application because copyright laws are designed to protect human works. “The office will not register works ‘produced by a machine or mere mechanical process’ that operates ‘without any creative input or intervention from a human author’ because, under the statute, ‘a work must be created by a human being’,” the review board told Thaler’s lawyer after his second attempt was rejected last year.
This was not a satisfactory response for Thaler, who then sued the US Copyright Office and its director, Shira Perlmutter. “The agency actions here were arbitrary, capricious, an abuse of discretion and not in accordance with the law, unsupported by substantial evidence, and in excess of Defendants’ statutory authority,” the lawsuit claimed.
But handing down her ruling on Friday, Judge Beryl Howell wouldn’t budge, pointing out that “human authorship is a bedrock requirement of copyright” and “United States copyright law protects only works of human creation.”
“Non-human actors need no incentivization with the promise of exclusive rights under United States law, and copyright was therefore not designed to reach them,” she wrote.
Though she acknowledged the need for copyright to “adapt with the times,” she shut down Thaler’s pleas by arguing that copyright protection can only be sought for something that has “an originator with the capacity for intellectual, creative, or artistic labor. Must that originator be a human being to claim copyright protection? The answer is yes.”
Unsurprisingly Thaler’s legal people took an opposing view. “We strongly disagree with the district court’s decision,” University of Surrey Professor Ryan Abbott told The Register.
“In our view, the law is clear that the American public is the primary beneficiary of copyright law, and the public benefits when the generation and dissemination of new works are promoted, regardless of how those works are made. We do plan to appeal.”
This is just one legal case Thaler is involved in. Earlier this year, the US Supreme Court also refused to hear arguments that AI algorithms should be recognized by law as inventors on patent filings, once again brought by Thaler.
He sued the US Patent and Trademark Office (USPTO) in 2020 because patent applications he had filed on behalf of another of his AI systems, DABUS, were rejected. The USPTO refused to accept them as it could only consider inventions from “natural persons.”
That lawsuit was quashed then was taken to the US Court of Appeals, where it lost again. Thaler’s team finally turned to the Supreme Court, which wouldn’t give it the time of day.
When The Register asked Thaler to comment on the US Copyright Office defeat, he told us: “What can I say? There’s a storm coming.”
More and more, as the video game industry matures, we find ourselves talking about game preservation and the disappearing culture of some older games as the original publishers abandon them. Often times leaving the public with no actual legit method for purchasing these old games, copyright law conspires with the situation to also prevent the public itself from clawing back its half of the copyright bargain. The end results are studios and publishers that have enjoyed the fruits of copyright law for a period of time, only for that cultural output to be withheld from the public later on. By any plain reading of American copyright law, that outcome shouldn’t be acceptable.
When it comes to one classic PlayStation 1 title, it seems that one enterprising individual has very much refused to accept this outcome. A fan of the first-party Sony title WipeOut, an exclusive to the PS1, has ported the game such that it can be played in a web browser. And, just to drive the point home, they have essentially dared Sony to do something about it.
“Either let it be, or shut this thing down and get a real remaster going,” he told Sony in a recent blog post (via VGC). Despite the release of the PlayStation Classic, 2017’s Wipeout Omega Collection, and PS Plus adding old PS1 games to PS5 like Twisted Metal, there’s no way to play the original WipeOut on modern consoles and experience the futuristic racer’s incredible soundtrack and neo-Tokyo aesthetic in all their glory. So fans have taken it upon themselves to make the Psygnosis-developed hit accessible on PC.
As Dominic Szablewski details in his post and in a series of videos detailing this labor of love, getting this all to work took a great deal of unraveling in the source code. The whole thing was a mess primarily because every iteration of the game simply had new code layered on top of the last iteration, meaning that there was a lot of onion-peeling to be done to make this all work.
But work it does!
After a lot of detective work and elbow grease, Szablewski managed to resurrect a modified playable version of the game with an uncapped framerate that looks crisp and sounds great. He still recommends two other existing PC ports over his own, WipeOut Phantom Edition and an unnamed project by a user named XProger. However, those don’t come with the original source code, the legality of which he admits is “questionable at best.”
But again, what is the public supposed to do here? The original game simply can’t be bought legitimately and hasn’t been available for some time. Violating copyright law certainly isn’t the right answer, but neither is allowing a publisher to let cultural output go to rot simply because it doesn’t want to do anything about it.
“Sony has demonstrated a lack of interest in the original WipeOut in the past, so my money is on their continuing absence,” Szablewski wrote. “If anyone at Sony is reading this, please consider that you have (in my opinion) two equally good options: either let it be, or shut this thing down and get a real remaster going. I’d love to help!”
Sadly, I’m fairly certain I know how this story will end.
On Friday, the Internet Archive put up a blog post noting that its digital book lending program was likely to change as it continues to fight the book publishers’ efforts to kill the Internet Archive. As you’ll recall, all the big book publishers teamed up to sue the Internet Archive over its Open Library project, which was created based on a detailed approach, backed by librarians and copyright lawyers, to recreate an online digital library that matches a physical library. Unfortunately, back in March, the judge decided (just days after oral arguments) that everything about the Open Library infringes on copyrights. There were many, many problems with this ruling, and the Archive is appealing.
However, in the meantime, the judge in the district court needed to sort out the details of the injunction in terms of what activities the Archive would change during the appeal. The Internet Archive and the publishers negotiated over the terms of such an injunction and asked the court to weigh in on whether or not it also covers books for which there are no ebooks available at all. The Archive said it should only cover books where the publishers make an ebook available, while the publishers said it should cover all books, because of course they did. Given Judge Koeltl’s original ruling, I expected him to side with the publishers, and effectively shut down the Open Library. However, this morning he surprised me and sided with the Internet Archive, saying only books that are already available in electronic form need to be removed. That’s still a lot, but at least it means people can still access those other works electronically. The judge rightly noted that the injunction should be narrowly targeted towards the issues at play in the case, and thus it made sense to only block works available as ebooks.
But, also on Friday, the RIAA decided to step in and to try to kick the Internet Archive while it’s down. For years now, the Archive has offered up its Great 78 Project, in which the Archive, in coordination with some other library/archival projects (including the Archive of Contemporary Music and George Blood LP), has been digitizing whatever 78rpm records they could find.
78rpm records were some of the earliest musical recordings, and were produced from 1898 through the 1950s when they were replaced by 33 1/3rpm and 45rpm vinyl records. I remember that when I was growing up my grandparents had a record player that could still play 78s, and there were a few of those old 78s in a cabinet. Most of the 78s were not on vinyl, but shellac, and were fairly brittle, meaning that many old 78s are gone forever. As such there is tremendous value in preserving and protecting old 78s, which is also why many libraries have collections of them. It’s also why those various archival libraries decided to digitize and preserve them. Without such an effort, many of those 78s would disappear.
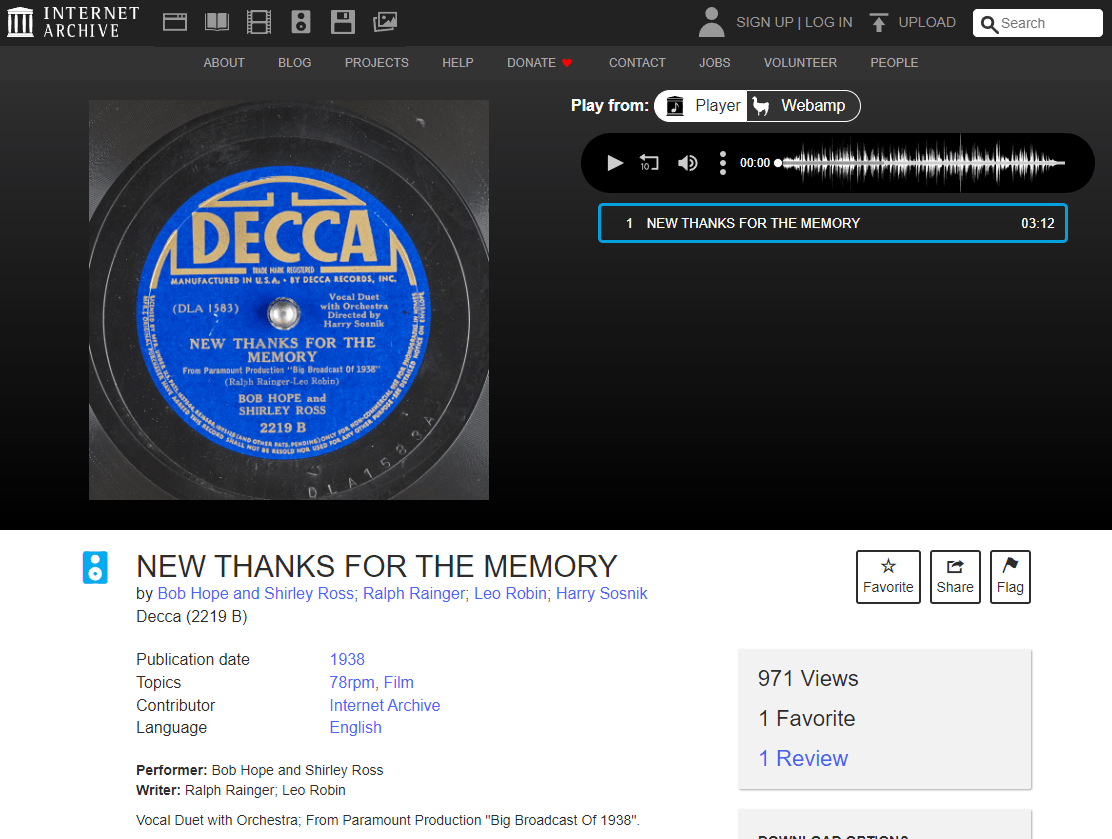
If you’ve ever gone through the Great78 project, you know quite well that it is, in no way, a substitute for music streaming services like Spotify or Apple Music. You get a static page in which you (1) see a photograph of the original 78 label, (2) get some information on that recording, and (3) are able to listen to and download just that song. Here’s a random example I pulled:
Also, when you listen to it, you can clearly hear that this was digitized straight off of the 78 itself, including all the crackle and hissing of the record. It is nothing like the carefully remastered versions you hear on music streaming services.
Indeed, I’ve used the Great78 Project to discover old songs I’d never heard before, leading me to search out those artists on Spotify to add to my playlists, meaning that for me, personally, the Great78 Project has almost certainly resulted in the big record labels making more money, as it added more artists for me to listen to through licensed systems.
It’s no secret that the recording industry had it out for the Great78 Project. Three years ago, we wrote about how Senator Thom Tillis (who has spent his tenure in the Senate pushing for whatever the legacy copyright industries want) seemed absolutely apoplectic when the Internet Archive bought a famous old record store in order to get access to the 78s to digitize, and Tillis thought that this attempt to preserve culture was shameful.
The lawsuit, joined by all of the big RIAA record labels, was filed by one of the RIAA’s favorite lawyers for destroying anything good that expands access to music: Matt Oppenheim. Matt was at the RIAA and helped destroy both Napster and Grokster. He was also the lawyer who helped create some terrible precedents holding ISPs liable for subscribers who download music, enabling even greater copyright trolling. Basically, if you’ve seen anything cool and innovative in the world of music over the last two decades, Oppenheim has been there to kill it.
And now he’s trying to kill the world’s greatest library.
Much of the actual lawsuit revolves around the Music Modernization Act, which was passed in 2018 and had some good parts in it, in particular in moving some pre-1972 sound recordings into the public domain. As you might also recall, prior to February of 1972, sound recordings did not get federal copyright protection (though they might get some form of state copyright). Indeed, in most of the first half of the 20th century, many copyright experts believed that federal copyright could not apply to sound recordings and that it could only apply to the composition. After February of 1972, sound recordings were granted federal copyright, but that left pre-1972 works in a weird state, in which they were often protected by an amalgamation of obsolete state laws, meaning that some works might not reach the public domain for well over a century. This was leading to real concerns that some of our earliest recordings would disappear forever.
The Music Modernization Act sought to deal with some of that, creating a process by which pre-1972 sound recordings would be shifted under federal copyright, and a clear process began to move some of the oldest ones into the public domain. It also created a process for dealing with old orphaned works, where the copyright holder could not be found. The Internet Archive celebrated all of this, and noted that it would be useful for some of its archival efforts.
The lawsuit accuses the Archive (and Brewster Kahle directly) of then ignoring the limitations and procedures in the Music Modernization Act to just continue digitizing and releasing all of the 78s it could find, including those by some well known artists whose works are available on streaming platforms and elsewhere. It also whines that the Archive often posts links to newly digitized Great78 records on ex-Twitter.
When the Music Modernization Act’s enactment made clear that unauthorized copying, streaming, and distributing pre-1972 sound recordings is infringing, Internet Archive made no changes to its activities. Internet Archive did not obtain authorization to use the recordings on the Great 78 Project website. It did not remove any recordings from public access. It did not slow the pace at which it made new recordings publicly available. It did not change its policies regarding which recordings it would make publicly available.
Internet Archive has not filed any notices of non-commercial use with the Copyright Office. Accordingly, the safe harbor set forth in the Music Modernization Act is not applicable to Internet Archive’s activities.
Internet Archive knew full well that the Music Modernization Act had made its activities illegal under Federal law. When the Music Modernization Act went into effect, Internet Archive posted about it on its blog. Jeff Kaplan, The Music Modernization Act is now law which means some pre-1972 music goes public, INTERNET ARCHIVE (Oct. 15, 2018), https://blog.archive.org/2018/10/15/the-music-modernization-act-is-now-law-which-means-some-music-goes-public/. The blog post stated that “the MMA means that libraries can make some of these older recordings freely available to the public as long as we do a reasonable search to determine that they are not commercially available.” Id. (emphasis added). The blog post further noted that the MMA “expands an obscure provision of the library exception to US Copyright Law, Section 108(h), to apply to all pre-72 recordings. Unfortunately 108(h) is notoriously hard to implement.” Id. (emphasis added). Brewster Kahle tweeted a link to the blog post. Brewster Kahle (@brewster_kahle), TWITTER (Oct. 15, 2018 11:26 AM), https://twitter.com/brewster_kahle/status/1051856787312271361.
Kahle delivered a presentation at the Association for Recorded Sound Collection’s 2019 annual conference titled, “Music Modernization Act 2018. How it did not go wrong, and even went pretty right.” In the presentation, Kahle stated that, “We Get pre-1972 out-of-print to be ‘Library Public Domain’!”. The presentation shows that Kahle, and, by extension, Internet Archive and the Foundation, understood how the Music Modernization Act had changed federal law and was aware the Music Modernization Act had made it unlawful under federal law to reproduce, distribute, and publicly perform pre-1972 sound recordings.
Despite knowing that the Music Modernization Act made its conduct infringing under federal law, Internet Archive ignored the new law and plowed forward as if the Music Modernization Act had never been enacted.
There’s a lot in the complaint that you can read. It attacks Brewster Kahle personally, falsely claiming that Kahle “advocated against the copyright laws for years,” rather than the more accurate statement that Kahle has advocated against problematic copyright laws that lock down, hide, and destroy culture. The lawsuit even uses Kahle’s important, though unfortunately failed, Kahle v. Gonzalez lawsuit, which argued (compellingly, though unfortunately not to the 9th Circuit) that when Congress changed copyright law from opt-in copyright (in which you had to register anything to get a copyright) to “everything is automatically covered by copyright,” it changed the very nature of copyright law, and took it beyond the limits required under the Constitution. That was not an “anti-copyright” lawsuit. It was an “anti-massive expansion of copyright in a manner that harms culture” lawsuit.
It is entirely possible (perhaps even likely) that the RIAA will win this lawsuit. As Oppenheim knows well, the courts are often quite smitten with the idea that the giant record labels and publishers and movie studios “own” culture and can limit how the public experiences it.
But all this really does is demonstrate exactly how broken modern copyright law is. There is no sensible or rationale world in which an effort to preserve culture and make it available to people should be deemed a violation of the law. Especially when that culture is mostly works that the record labels themselves ignored for decades, allowing them to decay and disappear in many instances. To come back now, decades later, and try to kill off library preservation and archival efforts is just an insult to the way culture works.
It’s doubly stupid given that the RIAA, and Oppenheim in particular, spent years trying to block music from ever being available on the internet. It’s only now that the very internet they fought developed systems that have re-invigorated the bank accounts of the labels through streaming that the RIAA gets to pretend that of course it cares about music from the first half of the 20th century — music that it was happy to let decay and die off until just recently.
Whether or not the case is legally sound is one thing. Chances are the labels may win. But, on a moral level, everything about this is despicable. The Great78 project isn’t taking a dime away from artists or the labels. No one is listening to the those recordings as a replacement for licensed efforts. Again, if anything, it’s helping to rejuvenate interest in those old recordings for free.
And if this lawsuit succeeds, it could very well put the nail in the coffin of the Internet Archive, which is already in trouble due to the publishers’ lawsuit.
Over the last few years, the RIAA had sort of taken a step back from being the internet’s villain, but its instincts to kill off and spit on culture never went away.
These copyright goons really hate the idea of preserving culture. Can you imagine doing something once and then getting paid for it every time someone sees your work?! Crazy!
And here we go again. we’ve been talking about how copyright has gotten in the way of cultural preservation generally for a while, and more specifically lately when it comes to the video game industry. The way this problem manifests itself is quite simple: video game publishers support the games they release for some period of time and then they stop. When they stop, depending on the type of game, it can make that game unavailable for legitimate purchase or use, either because the game is disappeared from retail and online stores, or because the servers needed to make them operational are taken offline. Meanwhile, copyright law prevents individuals and, in some cases, institutions from preserving and making those games available to the public, a la a library or museum would.
When you make these preservation arguments, one of the common retorts you get from the gaming industry and its apologists is that publishers already preserve these games for eventual re-release down the road, which is why they need to maintain their copyright protection on that content. We’ve pointed out failures to do so by the industry in the past, but the story about Hasbro wanting to re-release several older Transformers video games, but can’t, is about as perfect an example as I can find.
Released in June 2010, Transformers: War for Cybertron was a well-received third-person shooter that got an equally great sequel in 2012, Fall of Cybertron. (And then in 2014 we got Rise of Dark Spark, which wasn’t very good and was tied into the live-action films.) What made the first two games so memorable and beloved was that they told their own stories about the origins of popular characters like Megatron and Optimus Prime while featuring kick-ass combat that included the ability to transform into different vehicles. Sadly, in 2018, all of these Activision-published Transformers games (and several it commissioned from other developers) were yanked from digital stores, making them hard to acquire and play in 2023. It seems that Hasbro now wants that to change, suggesting the games could make a perfect fit for Xbox Game Pass, once Activision, uh…finds them.
You read that right: finds them. What does that mean? Well, when Hasbro came calling to Activision looking to see if this was a possibility, it devolved into Activision doing a theatrical production parody called Dude, Where’s My Hard Drive? It seems that these games may or may not exist on some piece of hardware, but Activision literally cannot find it. Or maybe not, as you’ll read below. There seems to be some confusion about what Activision can and cannot find.
And, yes, the mantra in the comments that pirate sites are essentially solving for this problem certainly applies here as well. So much so, in fact, that it sure sounds like Hasbro went that route to get what it needed for the toy design portion of this.
Interestingly, Activision’s lack of organization seems to have caused some headaches for Hasbro’s toy designers who are working on the Gamer Edition figures. The toy company explained that it had to load up the games on their original platforms and play through them to find specific details they wanted to recreate for the toys.
“For World of Cybertron we had to rip it ourselves, because [Activision] could not find it—they kept sending concept art instead, which we didn’t want,” explained Hasbro. “So we booted up an old computer and ripped them all out from there. Which was a learning experience and a long weekend, because we just wanted to get it right, so that’s why we did it like that.
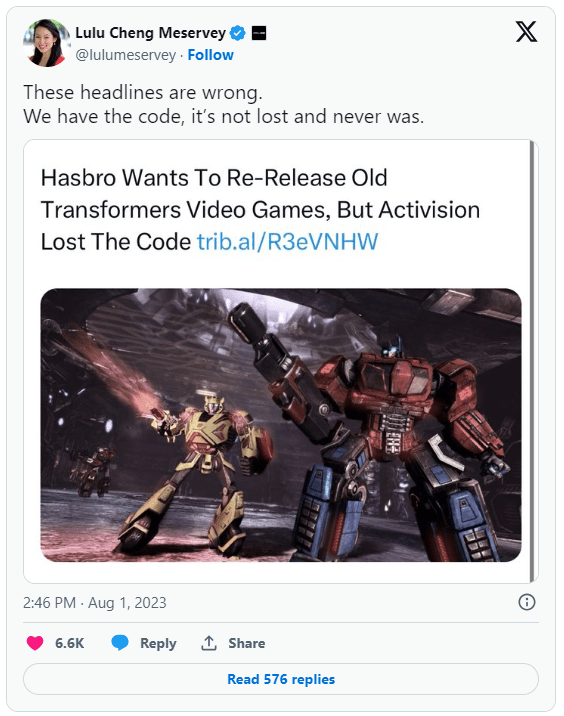
What’s strange is that despite the above, Activision responded to initial reports of all this indicating that the headlines were false and it does have… code. Or something.
Hasbro itself then followed up apologizing for the confusion, also saying that it made an error in stating the games were “lost”. But what’s strange about all that, in addition to the work that Hasbro did circumventing having access to the actual games themselves, is the time delta it took for Activision to respond to all of this.
Activision has yet to confirm if it actually knows where the source code for the games is specifically located. I also would love to know why Activision waited so long to comment (the initial interview was posted on July 28) and why Hasbro claimed to not have access to key assets when developing its toys based on the games.
It’s also strange that Hasbro, which says it wants to put these games on Game Pass, hasn’t done so for years now. If the games aren’t lost, give ‘em to Hasbro, then?
Indeed. If this was all a misunderstanding, so be it. But if this was all pure misunderstanding, the rest of the circumstances surrounding this story don’t make a great deal of sense. At the very least, it sounds like some of the concern that these games could have simply been lost to the world is concerning and yet another data point for an industry that simply needs to do better when it comes to preservation efforts.
In a well-intentioned yet dangerous move to fight online fraud, France is on the verge of forcing browsers to create a dystopian technical capability. Article 6 (para II and III) of the SREN Bill would force browser providers to create the means to mandatorily block websites present on a government provided list.
The post explains why this is an extremely dangerous approach:
A world in which browsers can be forced to incorporate a list of banned websites at the software-level that simply do not open, either in a region or globally, is a worrying prospect that raises serious concerns around freedom of expression. If it successfully passes into law, the precedent this would set would make it much harder for browsers to reject such requests from other governments.
If a capability to block any site on a government blacklist were required by law to be built in to all browsers, then repressive governments would be given an enormously powerful tool. There would be no way around that censorship, short of hacking the browser code. That might be an option for open source coders, but it certainly won’t be for the vast majority of ordinary users. As the Mozilla post points out:
Such a move will overturn decades of established content moderation norms and provide a playbook for authoritarian governments that will easily negate the existence of censorship circumvention tools.
It is even worse than that. If such a capability to block any site were built in to browsers, it’s not just authoritarian governments that would be rubbing their hands with glee: the copyright industry would doubtless push for allegedly infringing sites to be included on the block list too. We know this, because it has already done it in the past, as discussed in Walled Culture the book (free digital versions).
Not many people now remember, but in 2004, BT (British Telecom) caused something of a storm when it created CleanFeed:
British Telecom has taken the unprecedented step of blocking all illegal child pornography websites in a crackdown on abuse online. The decision by Britain’s largest high-speed internet provider will lead to the first mass censorship of the web attempted in a Western democracy.
Here’s how it worked:
Subscribers to British Telecom’s internet services such as BTYahoo and BTInternet who attempt to access illegal sites will receive an error message as if the page was unavailable. BT will register the number of attempts but will not be able to record details of those accessing the sites.
The key justification for what the Guardian called “the first mass censorship of the web attempted in a Western democracy” was that it only blocked illegal child sexual abuse material Web sites. It was therefore an extreme situation requiring an exceptional solution. But seven years later, the copyright industry were able to convince a High Court judge to ignore that justification, and to take advantage of CleanFeed to block a site, Newzbin 2, that had nothing to do with child sexual abuse material, and therefore did not require exceptional solutions:
Justice Arnold ruled that BT must use its blocking technology CleanFeed – which is currently used to prevent access to websites featuring child sexual abuse – to block Newzbin 2.
Exactly the logic used by copyright companies to subvert CleanFeed could be used to co-opt the censorship capabilities of browsers with built-in Web blocking lists. As with CleanFeed, the copyright industry would doubtless argue that since the technology already exists, why not to apply it to tackling copyright infringement too?
That very real threat is another reason to fight this pernicious, misguided French proposal. Because if it is implemented, it will be very hard to stop it becoming yet another technology that the copyright world demands should be bent to its own selfish purposes.
Jieun Kiaer, an Oxford professor of Korean linguistics, recently published an academic book called Emoji Speak: Communications and Behaviours on Social Media. As you can tell from the name, it’s a book about emoji, and about how people communicate with them:
Exploring why and how emojis are born, and the different ways in which people use them, this book highlights the diversity of emoji speak. Presenting the results of empirical investigations with participants of British, Belgian, Chinese, French, Japanese, Jordanian, Korean, Singaporean, and Spanish backgrounds, it raises important questions around the complexity of emoji use.
Though emojis have become ubiquitous, their interpretation can be more challenging. What is humorous in one region, for example, might be considered inappropriate or insulting in another. Whilst emoji use can speed up our communication, we might also question whether they convey our emotions sufficiently. Moreover, far from belonging to the youth, people of all ages now use emoji speak, prompting Kiaer to consider the future of our communication in an increasingly digital world.
Sounds interesting enough, but as Goldman highlights with an image from the book, Kiaer was apparently unable to actually show examples of many of the emoji she was discussing due to copyright fears. While companies like Twitter and Google have offered up their own emoji sets under open licenses, not all of them have, and some of the specifics about the variations in how different companies represent different emoji apparently were key to the book.
So, for those, Kiaer actually hired an artist, Loli Kim, to draw similar emoji!
The page reads as follows (with paragraph breaks added for readability):
Notes on Images of Emojis
Social media spaces are almost entirely copyright free. They do not follow the same rules as the offline world. For example, on Twitter you can retweet any tweet and add your own opinion. On Instagram, you can share any post and add stickers or text. On TikTok, you can even ‘duet’ a video to add your own video next to a pre-existing one. As much as each platform has its own rules and regulations, people are able to use and change existing material as they wish. Thinking about copyright brings to light barriers that exist between the online and offline worlds. You can use any emoji in your texts, tweets, posts and videos, but if you want to use them in the offline world, you may encounter a plethora of copyright issues.
In writing this book, I have learnt that online and offline exist upon two very different foundations. I originally planned to have plenty of images of emojis, stickers, and other multi-modal resources featured throughout this book, but I have been unable to for copyright reasons. In this moment, I realized how difficult it is to move emojis from the online world into the offline world.
Even though I am writing this book about emojis and their significance in our lives, I cannot use images of them in even an academic book. Were I writing a tweet or Instagram post, however, I would likely have no problem. Throughout this book, I stress that emoji speak in online spaces is a grassroots movement in which there are no linguistic authorities and corporations have little power to influence which emojis we use. Comparatively, in offline spaces, big corporations take ownership of our emoji speak, much like linguistic authorities dictate how we should write and speak properly.
This sounds like something out of a science fiction story, but it is an important fact of which to be aware. While the boundaries between our online and offline words may be blurring, barriers do still exist between them. For this reason, I have had to use an artist’s interpretation of the images that I originally had in mind for this book. Links to the original images have been provided as endnotes, in case readers would like to see them.
Just… incredible. Now, my first reaction to this is that using the emoji and stickers and whatnot in the book seems like a very clear fair use situation. But… that requires a publisher willing to take up the fight (and an insurance company behind the publisher willing to finance that fight). And, that often doesn’t happen. Publishers are notoriously averse to supporting fair use, because they don’t want to get sued.
But, really, this just ends up highlighting (once again) the absolute ridiculousness of copyright in the modern world. No one in their right mind would think that a book about emoji is somehow harming the market for whatever emoji or stickers the professor wished to include. Yet, due to the nature of copyright, here we are. With an academic book about emoji that can’t even include the emoji being spoken about.
Over the last few months there have been a flurry of lawsuits against AI companies, with most of them being focused on copyright claims. The site ChatGPTIsEatingTheWorld has been tracking all the lawsuits, which currently lists 11 lawsuits, seven of which are copyright claims. Five of those are from the same lawyers: Joseph Saveri and Matthew Butterick, who seem to want to corner the market on “suing AI companies for copyright.”
We already covered just how bad their two separate (though they’re currently trying to combine them, and no one can explain to me why it made sense to file them separately in the first place) lawsuits on behalf of authors are, as they show little understanding of how copyright actually works. But their original lawsuit against Stability AI, MidJourney, and DeviantArt was even worse, as we noted back in April. As we said at the time, they don’t allege a single act of infringement, but rather make vague statements about how what these AI tools are doing must be infringing.
(Also, the lawyers seemed to totally misunderstand what DeviantArt was doing, in that it was using open source tools to better enable DeviantArt artists to prevent their works from being used as inspiration in AI systems, and claimed that was infringing… but that’s a different issue).
It appears that the judge overseeing that lawsuit has noticed just how weak the claims are. Though we don’t have a written opinion yet, Reuters reports that Judge William Orrick was pretty clear at least week’s hearing that the case, as currently argued, has no chance.
U.S. District Judge William Orrick said during a hearing in San Francisco on Wednesday that he was inclined to dismiss most of a lawsuit brought by a group of artists against generative artificial intelligence companies, though he would allow them to file a new complaint.
Orrick said that the artists should more clearly state and differentiate their claims against Stability AI, Midjourney and DeviantArt, and that they should be able to “provide more facts” about the alleged copyright infringement because they have access to Stability’s relevant source code.
“Otherwise, it seems implausible that their works are involved,” Orrick said, noting that the systems have been trained on “five billion compressed images.”
Again, the theory of the lawsuit seemed to be that AI companies cut up little pieces of the content they train on and create a “collage” in response. Except, that’s not at all how it works. And since the complaint can’t show any specific work that has been infringed on by the output, the case seems like a loser. And it’s good the judge sees that.
He also recognizes that merely being inspired by someone else’s art doesn’t make the new art infringing:
“I don’t think the claim regarding output images is plausible at the moment, because there’s no substantial similarity” between images created by the artists and the AI systems, Orrick said.
It seems likely that Saveri and crew will file an amended complaint to try to more competently make this argument, but since the underlying technology doesn’t fundamentally do what the lawsuit pretends it does, it’s difficult to see how it can succeed.
But, of course, this is copyright, and copyright caselaw doesn’t always follow logic or what the law itself says. So it’s no surprise that Saveri and Butterick are trying multiple lawsuits with these theories. They might just find a judge confused enough to buy it.
There’s an interesting post on TorrentFreak that concerns so-called “pirate” subtitles for films. It’s absurd that anyone could consider subtitles to be piracy in any way. They are a good example of how ordinary people can add value by generously helping others enjoy films and TV programs in languages they don’t understand. In no sense do “pirate” subtitles “steal” from those films and programs, they manifestly enhance them. And yet the ownership-obsessed copyright world actively pursues people who dare to spread joy in this way. In discussing these subtitles, TorrentFreak mentions a site that I’ve not heard of before, Karagarga:
an illustrious BitTorrent tracker that’s been around for more than 18 years. Becoming a member of the private community isn’t easy but those inside gain access to a wealth of film obscurities.
The site focuses on archiving rare classic and cult movies, as well as other film-related content. Blockbusters and other popular Hollywood releases can’t be found on the site as uploading them is strictly forbidden.
TorrentFreak links to an article about Karagarga published some years ago by the Canadian newspaper National Post. Here’s a key point it makes:
It’s difficult to overstate the significance of such a resource. Movies of unflagging historical merit are otherwise lost to changes in technology and time every year: film prints are damaged or lost, musty VHS tapes aren’t upgraded, DVDs fall out of print without reissue, back catalogues never make the transition to digital. But should even a single copy of the film exist, however tenuously, it can survive on Karagarga: one person uploads a rarity and dozens more continue to share.
Although that mentions things like film prints being lost, or back catalogues that aren’t converted to digital formats, the underlying cause of films being lost is copyright. It is copyright that prevents people from making backups of films, whether analogue or digital. Even though people are painfully aware of the vulnerability of films that exist in a few copies or even just one copy, it is generally illegal for them to do anything about it, because of copyright. Instead, they must often sit by as cinematic masterpieces are lost forever.
Unless, of course, sites like Karagarga make unauthorized digital copies. It’s a great demonstration of the fact that copyright, far from preserving culture, often leads to its permanent loss. And that supposedly “evil” sites like Karagarga are the ones that save it for posterity.
Taco Bell succeeded in its petition to remove the “Taco Tuesday” trademark held by Taco John’s, claiming it held an unfair monopoly over the phrase. Taco John’s CEO Jim Creel backed down from the fight on Tuesday, saying it isn’t worth the legal fees to retain the regional chain’s trademark.
“We’ve always prided ourselves on being the home of Taco Tuesday, but paying millions of dollars to lawyers to defend our mark just doesn’t feel like the right thing to do,” Taco John’s CEO Jim Creel said in a statement to CNN.
Taco John’s adopted the “Taco Tuesday” slogan back in the early 1980s as a two-for-one deal, labeling the promotion as “Taco Twosday” in an effort to ramp up sales. The company trademarked the term in 1989 and owned the right to the phrase in all states with the exception of New Jersey where Gregory’s Restaurant & Tavern beat out Taco John’s by trademarking the term in 1982.
Three decades later, Taco John’s finally received pushback when Taco Bell filed a petition with the U.S. Patent and Trademark Office in May to cancel the trademark, saying any restaurant should be able to use “Taco Tuesday.”
If you think about it, the ability to copyright 2 common words following each other doesn’t make sense at all really. In any 2 word combination, there must have been prior common use.
You may have seen some headlines recently about some authors filing lawsuits against OpenAI. The lawsuits (plural, though I’m confused why it’s separate attempts at filing a class action lawsuit, rather than a single one) began last week, when authors Paul Tremblay and Mona Awad sued OpenAI and various subsidiaries, claiming copyright infringement in how OpenAI trained its models. They got a lot more attention over the weekend when another class action lawsuit was filed against OpenAI with comedian Sarah Silverman as the lead plaintiff, along with Christopher Golden and Richard Kadrey. The same day the same three plaintiffs (though with Kadrey now listed as the top plaintiff) also sued Meta, though the complaint is basically the same.
All three cases were filed by Joseph Saveri, a plaintiffs class action lawyer who specializes in antitrust litigation. As with all too many class action lawyers, the goal is generally enriching the class action lawyers, rather than actually stopping any actual wrong. Saveri is not a copyright expert, and the lawsuits… show that. There are a ton of assumptions about how Saveri seems to think copyright law works, which is entirely inconsistent with how it actually works.
The complaints are basically all the same, and what it comes down to is the argument that AI systems were trained on copyright-covered material (duh) and that somehow violates their copyrights.
Much of the material in OpenAI’s training datasets, however, comes from copyrighted works—including books written by Plaintiffs—that were copied by OpenAI without consent, without credit, and without compensation
But… this is both wrong and not quite how copyright law works. Training an LLM does not require “copying” the work in question, but rather reading it. To some extent, this lawsuit is basically arguing that merely reading a copyright-covered work is, itself, copyright infringement.
Under this definition, all search engines would be copyright infringing, because effectively they’re doing the same thing: scanning web pages and learning from what they find to build an index. But we’ve already had courts say that’s not even remotely true. If the courts have decided that search engines scanning content on the web to build an index is clearly transformative fair use, so to would be scanning internet content for training an LLM. Arguably the latter case is way more transformative.
And this is the way it should be, because otherwise, it would basically be saying that anyone reading a work by someone else, and then being inspired to create something new would be infringing on the works they were inspired by. I recognize that the Blurred Lines case sorta went in the opposite direction when it came to music, but more recent decisions have really chipped away at Blurred Lines, and even the recording industry (the recording industry!) is arguing that the Blurred Lines case extended copyright too far.
But, if you look at the details of these lawsuits, they’re not arguing any actual copying (which, you know, is kind of important for their to be copyright infringement), but just that the LLMs have learned from the works of the authors who are suing. The evidence there is, well… extraordinarily weak.
For example, in the Tremblay case, they asked ChatGPT to “summarize” his book “The Cabin at the End of the World,” and ChatGPT does so. They do the same in the Silverman case, with her book “The Bedwetter.” If those are infringing, so is every book report by every schoolchild ever. That’s just not how copyright law works.
The lawsuit tries one other tactic here to argue infringement, beyond just “the LLMs read our books.” It also claims that the corpus of data used to train the LLMs was itself infringing.
For instance, in its June 2018 paper introducing GPT-1 (called “Improving Language Understanding by Generative Pre-Training”), OpenAI revealed that it trained GPT-1 on BookCorpus, a collection of “over 7,000 unique unpublished books from a variety of genres including Adventure, Fantasy, and Romance.” OpenAI confirmed why a dataset of books was so valuable: “Crucially, it contains long stretches of contiguous text, which allows the generative model to learn to condition on long-range information.” Hundreds of large language models have been trained on BookCorpus, including those made by OpenAI, Google, Amazon, and others.
BookCorpus, however, is a controversial dataset. It was assembled in 2015 by a team of AI researchers for the purpose of training language models. They copied the books from a website called Smashwords that hosts self-published novels, that are available to readers at no cost. Those novels, however, are largely under copyright. They were copied into the BookCorpus dataset without consent, credit, or compensation to the authors.
If that’s the case, then they could make the argument that BookCorpus itself is infringing on copyright (though, again, I’d argue there’s a very strong fair use claim under the Perfect 10 cases), but that’s separate from the question of whether or not training on that data is infringing.
And that’s also true of the other claims of secret pirated copies of books that the complaint insists OpenAI must have relied on:
As noted in Paragraph 32, supra, the OpenAI Books2 dataset can be estimated to contain about 294,000 titles. The only “internet-based books corpora” that have ever offered that much material are notorious “shadow library” websites like Library Genesis (aka LibGen), Z-Library (aka Bok), Sci-Hub, and Bibliotik. The books aggregated by these websites have also been available in bulk via torrent systems. These flagrantly illegal shadow libraries have long been of interest to the AI-training community: for instance, an AI training dataset published in December 2020 by EleutherAI called “Books3” includes a recreation of the Bibliotik collection and contains nearly 200,000 books. On information and belief, the OpenAI Books2 dataset includes books copied from these “shadow libraries,” because those are the most sources of trainable books most similar in nature and size to OpenAI’s description of Books2.
Again, think of the implications if this is copyright infringement. If a musician were inspired to create music in a certain genre after hearing pirated songs in that genre, would that make the songs they created infringing? No one thinks that makes sense except the most extreme copyright maximalists. But that’s not how the law actually works.
This entire line of cases is just based on a total and complete misunderstanding of copyright law. I completely understand that many creative folks are worried and scared about AI, and in particular that it was trained on their works, and can often (if imperfectly) create works inspired by them. But… that’s also how human creativity works.
Humans read, listen, watch, learn from, and are inspired by those who came before them. And then they synthesize that with other things, and create new works, often seeking to emulate the styles of those they learned from. AI systems and LLMs are doing the same thing. It’s not infringing to learn from and be inspired by the works of others. It’s not infringing to write a book report style summary of the works of others.
I understand the emotional appeal of these kinds of lawsuits, but the legal reality is that these cases seem doomed to fail, and possibly in a way that will leave the plaintiffs having to pay legal fees (since in copyright legal fee awards are much more common).
That said, if we’ve learned anything at all in the past two plus decades of lawsuits about copyright and the internet, courts will sometimes bend over backwards to rewrite copyright law to pretend it says what they want it to say, rather than what it does say. If that happens here, however, it would be a huge loss to human creativity.