The Foundation for the Protection of Privacy Interests and the Consumers’ Association are taking the next step in their fight against Google. The tech company is being taken to court today for ‘large-scale privacy violations’.
The proceedings demand, among other things, that Google stop its constant surveillance and sharing of personal data through online advertising auctions and also pay damages to consumers. Since the announcement of this action on May 23, 2023, more than 82,000 Dutch people have already joined the mass claim.
According to the organizations, Google is acting in violation of Dutch and European privacy legislation. The tech giant collects users’ online behavior and location data on an immense scale through its services and products. Without providing enough information or having obtained permission. Google then shares that data, including highly sensitive personal data about health, ethnicity and political preference, for example, with hundreds of parties via its online advertising platform.
Google is constantly monitoring everyone. Even when using third-party cookies – which are invisible – Google continues to collect data through other people’s websites and apps, even when someone is not using its products or services. This enables Google to monitor almost the entire internet behavior of its users.
All these matters have been discussed with Google, to no avail.
The Foundation for the Protection of Privacy Interests represents the interests of users of Google’s products and services living in the Netherlands who have been harmed by privacy violations. The foundation is working together with the Consumers’ Association in the case against Google. Consumers’ Association Claimservice, a partnership between the Consumers’ Association and ConsumersClaim, processes the registrations of affiliated victims.
More than 82,000 consumers have already registered for the Google claim. They demand compensation of 750 euros per participant.
A lawsuit by the American government against Google starts today in the US . Ten weeks have been set aside for this. This mainly revolves around the power of Google’s search engine.
Essentially, Google is accused of entering into exclusive agreements to guarantee the use of its search engine. These are agreements that prevent alternative search engines from being pre-installed, or from Google’s search app being removed.
Microsoft will finally stop forcing Windows 11 users in Europe into Edge if they click a link from the Windows Widgets panel or from search results. The software giant has started testing the changes to Windows 11 in recent test builds of the operating system, but the changes are restricted to countries within the European Economic Area (EEA).
“In the European Economic Area (EEA), Windows system components use the default browser to open links,” reads a change note from a Windows 11 test build released to Dev Channel testers last month. I asked Microsoft to comment on the changes and, in particular, why they’re only being applied to EU countries. Microsoft refused to comment.
Microsoft has been ignoring default browser choices in its search experience in Windows 10 and the taskbar widget that forces users into Edge if they click a link instead of their default browser. Windows 11 continued this trend, with search still forcing users into Edge and a new dedicated widgets area that also ignores the default browser setting.
The independent study of the DSA’s risk management framework published by the EU’s executive arm, the European Commission, concluded that commitments by social media platforms to mitigate the reach and influence of global online disinformation campaigns have been generally unsuccessful.
The reach of Kremlin-sponsored disinformation has only increased since the major platforms all signed a voluntary Code of Practice on Disinformation in mid-2022.
“In theory, the requirements of this voluntary Code were applied during the second half of 2022 – during our period of study,” the researchers said. We’re sure you’re just as shocked as we are that social media companies failed to uphold a voluntary commitment.
Between January and May of 2023, “average engagement [of pro-Kremlin accounts rose] by 22 percent across all online platforms,” the study said. By absolute numbers, the report found, Meta led the pack on engagement with Russian misinformation. However, the increase was “largely driven by Twitter, where engagement grew by 36 percent after CEO Elon Musk decided to lift mitigation measures on Kremlin-backed accounts,” researchers concluded. Twitter, now known as X, pulled out of the disinformation Code in May.
Across the platforms studied – Facebook, Instagram, Telegram, TikTok, Twitter and YouTube – Kremlin-backed accounts have amassed some 165 million followers and have had their content viewed at least 16 billion times “in less than a year.” None of the platforms we contacted responded to questions.
[…]
The EU’s Digital Services Act and its requirements that VLOPs (defined by the Act as companies large enough to reach 10 percent of the EU, or roughly 45 million people) police illegal content and disinformation became enforceable late last month.
Under the DSA, VLOPs are also required “to tackle the spread of illegal content, online disinformation and other societal risks,” such as, say, the massive disinformation campaign being waged by the Kremlin since Putin decided to invade Ukraine last year.
[…]
Now that VLOPs are bound by the DSA, will anything change? We asked the European Commission if it can take any enforcement actions, or whether it’ll make changes to the DSA to make disinformation rules tougher, but have yet to hear back.
Two VLOPs are fighting their designation: Amazon and German fashion retailer Zalando. The two orgs claim that as retailers, they shouldn’t be considered in the same category as Facebook, Pinterest, and Wikipedia.
Rick Klein and his team have been preserving TV adverts, forgotten tapes, and decades-old TV programming for years. Now operating as a 501(c)(3) non-profit, the Museum of Classic Chicago Television has called YouTube home since 2007. However, copyright notices sent on behalf of Sony, protecting TV shows between 40 and 60 years old, could shut down the project in 48 hours.
[…]
After being reborn on YouTube as The Museum of Classic Chicago Television (MCCTv), the last sixteen years have been quite a ride. Over 80 million views later, MCCTv is a much-loved 501(c)(3) non-profit Illinois corporation but in just 48 hours, may simply cease to exist.
In a series of emails starting Friday and continuing over the weekend, Klein began by explaining his team’s predicament, one that TorrentFreak has heard time and again over the past few years. Acting on behalf of a copyright owner, in this case Sony, India-based anti-piracy company Markscan hit the MCCTv channel with a flurry of copyright claims. If these cannot be resolved, the entire project may disappear.
[…]
No matter whether takedowns are justified, unjustified (Markscan hit Sony’s own website with a DMCA takedown recently), or simply disputed, getting Markscan’s attention is a lottery at best, impossible at worst. In MCCTv’s short experience, nothing has changed.
“Our YouTube channel with 150k subscribers is in danger of being terminated by September 6th if I don’t find a way to resolve these copyright claims that Markscan made,” Klein told TorrentFreak on Friday.
“At this point, I don’t even care if they were issued under authorization by Sony or not – I just need to reach a live human being to try to resolve this without copyright strikes. I am willing to remove the material manually to get the strikes reversed.”
[…]
Complaints Targeted TV Shows 40 to 60 years old
[…]
Two episodes of the TV series Bewitched dated 1964 aired on ABC Network and almost sixty years later, archive copies of those transmissions were removed from YouTube for violating Sony copyrights, with MCCTv receiving a strike.
[…]
Given that copyright law locks content down for decades, Klein understands that can sometimes cause issues, although 16 years on YouTube suggests that the overwhelming majority of rightsholders don’t consider his channel a threat. If they did, the option to monetize the recordings can be an option.
No Competition For Commercial Offers
Why most rightsholders have left MCCTv alone is hard to say; perhaps some see the historical value of the channel, maybe others don’t know it exists. At least in part, Klein believes the low quality of the videos could be significant.
“These were relatively low picture quality broadcast examples from various channels from various years at least 30-40 years ago, with the original commercial breaks intact. Also mixed in with these were examples of ’16mm network prints’ which are surviving original film prints that were sent out to TV stations back in the day from when the show originally aired. In many cases they include original sponsorship notices, original network commercials, ‘In Color’ notices, etc.,” he explains.
[…]
Klein says the team is happy to comply with Sony’s wishes and they hope that given a little leeway, the project won’t be consigned to history. Perhaps Sony will recall the importance of time-shifting while understanding that time itself is running out for The Museum of Classic Chicago Television.
The foundation, the Firefox browser maker’s netizen-rights org, assessed the privacy policies and practices of 25 automakers and found all failed its consumer privacy tests and thereby earned its Privacy Not Included (PNI) warning label.
If you care even a little about privacy, stay as far away from Nissan’s cars as you possibly can
In research published Tuesday, the org warned that manufacturers may collect and commercially exploit much more than location history, driving habits, in-car browser histories, and music preferences from today’s internet-connected vehicles. Instead, some makers may handle deeply personal data, such as – depending on the privacy policy – sexual activity, immigration status, race, facial expressions, weight, health, and even genetic information, the Mozilla team found.
Cars may collect at least some of that info about drivers and passengers using sensors, microphones, cameras, phones, and other devices people connect to their network-connected cars, according to Mozilla. And they collect even more info from car apps – such as Sirius XM or Google Maps – plus dealerships, and vehicle telematics.
Some car brands may then share or sell this information to third parties. Mozilla found 21 of the 25 automakers it considered say they may share customer info with service providers, data brokers, and the like, and 19 of the 25 say they can sell personal data.
More than half (56 percent) also say they share customer information with the government or law enforcement in response to a “request.” This isn’t necessarily a court-ordered warrant, and can also be a more informal request.
And some – like Nissan – may also use this private data to develop customer profiles that describe drivers’ “preferences, characteristics, psychological trends, predispositions, behavior, attitudes, intelligence, abilities, and aptitudes.”
Yes, you read that correctly. According to Mozilla’s privacy researchers, Nissan says it can infer how smart you are, then sell that assessment to third parties.
[…]
Nissan isn’t the only brand to collect information that seems completely irrelevant to the vehicle itself or the driver’s transportation habits.
“Kia mentions sex life,” Caltrider said. “General Motors and Ford both mentioned race and sexual orientation. Hyundai said that they could share data with government and law enforcement based on formal or informal requests. Car companies can collect even more information than reproductive health apps in a lot of ways.”
[…]
the Privacy Not Included team contacted Nissan and all of the other brands listed in the research: that’s Lincoln, Mercedes-Benz, Acura, Buick, GMC, Cadillac, Fiat, Jeep, Chrysler, BMW, Subaru, Dacia, Hyundai, Dodge, Lexus, Chevrolet, Tesla, Ford, Honda, Kia, Audi, Volkswagen, Toyota and Renault.
Only three – Mercedes-Benz, Honda, and Ford – responded, we’re told.
“Mercedes-Benz did answer a few of our questions, which we appreciate,” Caltrider said. “Honda pointed us continually to their public privacy documentation to answer your questions, but they didn’t clarify anything. And Ford said they discussed our request internally and made the decision not to participate.”
This makes Mercedes’ response to The Register a little puzzling. “We are committed to using data responsibly,” a spokesperson told us. “We have not received or reviewed the study you are referring to yet and therefore decline to comment to this specifically.”
A spokesperson for the four Fiat-Chrysler-owned brands (Fiat, Chrysler, Jeep, and Dodge) told us: “We are reviewing accordingly. Data privacy is a key consideration as we continually seek to serve our customers better.”
[…]
The Mozilla Foundation also called out consent as an issue some automakers have placed in a blind spot.
“I call this out in the Subaru review, but it’s not limited to Subaru: it’s the idea that anybody that is a user of the services of a connected car, anybody that’s in a car that uses services is considered a user, and any user is considered to have consented to the privacy policy,” Caltrider said.
Opting out of data collection is another concern.
Tesla, for example, appears to give users the choice between protecting their data or protecting their car. Its privacy policy does allow users to opt out of data collection but, as Mozilla points out, Tesla warns customers: “If you choose to opt out of vehicle data collection (with the exception of in-car Data Sharing preferences), we will not be able to know or notify you of issues applicable to your vehicle in real time. This may result in your vehicle suffering from reduced functionality, serious damage, or inoperability.”
While technically this does give users a choice, it also essentially says if you opt out, “your car might become inoperable and not work,” Caltrider said. “Well, that’s not much of a choice.”
In the past I’ve sometimes described Australia as the land where internet policy is completely upside down. Rather than having a system that protects intermediaries from liability for third party content, Australia went the opposite direction. Rather than recognizing that a search engine merely links to content and isn’t responsible for the content at those links, Australia has said that search engines can be held liable for what they link to. Rather than protect the free expression of people on the internet who criticize the rich and powerful, Australia has extremely problematic defamation laws that result in regular SLAPP suits and suppression of speech. Rather than embrace encryption that protects everyone’s privacy and security, Australia requires companies to break encryption, insisting only criminals use it.
It’s basically been “bad internet policy central,” or the place where good internet policy goes to die.
Of course, in France, the Data Protection authority released a paper similarly noting that age verification was a privacy and security nightmare… and the French government just went right on mandating the use of the technology. In Australia, the eSafety Commission pointed to the French concerns as a reason not to rush into the tech, meaning that Australia took the lessons from French data protection experts more seriously than the French government did.
In OpenAI’s motion to dismiss (filed in both lawsuits), the company asked a US district court in California to toss all but one claim alleging direct copyright infringement, which OpenAI hopes to defeat at “a later stage of the case.”
The authors’ other claims—alleging vicarious copyright infringement, violation of the Digital Millennium Copyright Act (DMCA), unfair competition, negligence, and unjust enrichment—need to be “trimmed” from the lawsuits “so that these cases do not proceed to discovery and beyond with legally infirm theories of liability,” OpenAI argued.
OpenAI claimed that the authors “misconceive the scope of copyright, failing to take into account the limitations and exceptions (including fair use) that properly leave room for innovations like the large language models now at the forefront of artificial intelligence.”
According to OpenAI, even if the authors’ books were a “tiny part” of ChatGPT’s massive data set, “the use of copyrighted materials by innovators in transformative ways does not violate copyright.”
[…]
The purpose of copyright law, OpenAI argued, is “to promote the Progress of Science and useful Arts” by protecting the way authors express ideas, but “not the underlying idea itself, facts embodied within the author’s articulated message, or other building blocks of creative,” which are arguably the elements of authors’ works that would be useful to ChatGPT’s training model. Citing a notable copyright case involving Google Books, OpenAI reminded the court that “while an author may register a copyright in her book, the ‘statistical information’ pertaining to ‘word frequencies, syntactic patterns, and thematic markers’ in that book are beyond the scope of copyright protection.”
So the authors are saying that if you read their book and then are inspired by it, you can’t use that memory – any of it – to write another book. Which also means that you presumably wouldn’t be able to use any words at all, as they are all copyrighted entities which have inspired you in the past as well.
Is Achmea or Bol.com customer service putting you on hold? Then everything you say can still be heard by some of their employees. This is evident from research by Radar.
When you call customer service, you often hear: “Please note: this conversation may be recorded for training purposes.” Nothing special. But if you call the insurer Zilveren Kruis, you will also hear: “Note: Even if you are on hold, our quality employees can hear what you are saying.”
Striking, because the Dutch Data Protection Authority states that recording customers ‘on hold’ is not allowed. Companies are allowed to record the conversation, for example to conclude a contract or to improve the service.
Both mortgage provider Woonfonds and insurers Zilveren Kruis, De Friesland and Interpolis confirm that the recording tape continues to run if you are on hold with them, while this violates privacy rules.
Bol.com also continues to eavesdrop on you while you are on hold, the webshop confirms. She also gives the same reason for this: “It is technically not possible to temporarily stop the recording and start it again when the conversation starts again.”KLM, Ziggo, Eneco, Vattenfall, T-Mobile, Nationale Nederlanden, ASR, ING and Rabobank say they don’t answer their customers while they are on hold.
Two founders of Tornado Cash were formally accused by US prosecutors today of laundering more than $1 billion in criminal proceeds through their cryptocurrency mixer.
As well as unsealing an indictment against the pair on Wednesday, the Feds also arrested one of them, 34-year-old Roman Storm, in his home state of Washington, and hauled him into court. Fellow founder and co-defendant Roman Semenov, a 35-year-old Russian citizen, is still at large.
As a cryptocurrency mixer, Tornado Cash is appealing to cybercriminals as it offers to provide them a degree of anonymity.
[…]
Tornado Cash was sanctioned by Uncle Sam a little over a year ago for helping North Korea’s Lazarus Group scrub funds stolen in the Axie Infinity hack. Additionally, the US Treasury Department said Tornado Cash was used to launder funds stolen in the Nomad bridge and Harmony bridge heists, both of which were also linked to Lazarus.
Storm and Semenov were both charged with conspiracy to commit money laundering and conspiracy to commit sanctions violations, each carrying a maximum penalty of 20 years in prison. A third charge, conspiracy to operate an unlicensed money transmitting business, could net the pair up to an additional five years upon conviction.
In the unsealed indictment [PDF], prosecutors said Tornado Cash boasted about its anonymizing features and that it could make money untraceable, and that Storm and Semenov refused to implement changes that would dial back Tornado’s thief-friendly money-laundering capabilities and bring it in line with financial regulations.
“Tornado Cash failed to establish an effective [anti money laundering] program or engage in any [know your customer] efforts,” Dept of Justice lawyers argued. Changes made publicly to make it appear as if Tornado Cash was legally compliant, the DoJ said, were laughed off as ineffective in private messages by the charged pair.
“While publicly claiming to offer a technically sophisticated privacy service, Storm and Semenov in fact knew that they were helping hackers and fraudsters conceal the fruits of their crimes,” said US Attorney Damian Williams. “Today’s indictment is a reminder that money laundering through cryptocurrency transactions violates the law, and those who engage in such laundering will face prosecution.”
What of the mysterious third founder?
While Storm and Semenov were the ones named on the rap sheet, they aren’t the only people involved with, or arrested over, their involvement in Tornado Cash. A third unnamed and uncharged person mentioned in the DoJ indictment referred to as “CC-1” is described as one of the three main people behind the sanctioned service.
Despite that, the Dept of Justice didn’t announce any charges against CC-1.
Clues point to CC-1 potentially being Alexey Persev, a Russian software developer linked to Tornado Cash who was arrested in The Netherlands shortly after the US sanctioned the crypto-mixing site. Persev was charged in that Euro nation with facilitating money laundering and concealing criminal financial flows, and is now out of jail on monitored home release awaiting trial.
Persev denies any wrongdoing, and claimed he wasn’t told why he was being detained. His defenders argued he shouldn’t be held accountable for writing Tornado Cash code since he didn’t do any of the alleged money laundering himself.
It’s not immediately clear if Pertsev is CC-1, nor is it clear why CC-1 wasn’t charged. We put those questions to the DoJ, and haven’t heard back.
If you’ve never watched it, Kirby Ferguson’s “Everything is a Remix” series (which was recently updated from the original version that came out years ago) is an excellent look at how stupid our copyright laws are, and how they have really warped our view of creativity. As the series makes clear, creativity is all about remixing: taking inspiration and bits and pieces from other parts of culture and remixing them into something entirely new. All creativity involves this in some manner or another. There is no truly unique creativity.
And yet, copyright law assumes the opposite is true. It assumes that most creativity is entirely unique, and when remix and inspiration get too close, the powerful hand of the law has to slap people down.
[…]
It would have been nice if society had taken this issue seriously back then, recognized that “everything is a remix,” and that encouraging remixing and reusing the works of others to create something new and transformative was not just a good thing, but one that should be supported. If so, we might not be in the utter shitshow that is the debate over generative art from AI these days, in which many creators are rushing to AI to save them, even though that’s not what copyright was designed to do, nor is it a particularly useful tool in that context.
[…]
The moral panic is largely an epistemological crisis: We don’t have a socially acceptable status for the legibility of the remix as art-in-it’s-own-right. Instead of properly appreciating the remix and the art of the DJ, the remix, or the meme cultures, we have shoehorned all the cultural properties associated onto an 1800’s sheet music publishing -based model of artistic credibility. The fit was never really good, but no-one really cared because the scenes were small, underground and their breaking the rules was largely out-of-sight.
[…]
AI art tools are simply resurfacing an old problem we left behind unresolved during the 1980’s to early 2000’s. Now it’s time for us to blow the dust off these old books and apply what was learned to the situation we have at our hands now.
We should not forget the modern electronic dance music industry has already developed models that promote new artists via remixes of their work from more established artists. These real-world examples combined with the theoretical frameworks above should help us to explore a refreshed model of artistic credibility, where value is assigned to both the original artists and the authors of remixers
[…]
Art, especially popular forms of it, has always been a lot about transformation: Taking what exists and creating something that works in this particular context. In forms of art emphasizing the distinctiveness of the original less, transformation becomes the focus of the artform instead.
[…]
There are a lot of questions about how that would actually work in practice, but I do think this is a useful framework for thinking about some of these questions, challenging some existing assumptions, and trying to rethink the system into one that is actually helping creators and helping to enable more art to be created, rather than trying to leverage a system originally developed to provide monopolies to gatekeepers into one that is actually beneficial to the public who want to experience art, and creators who wish to make art.
Copyright issues have dogged AI since chatbot tech gained mass appeal, whether it’s accusations of entire novels being scraped to train ChatGPT or allegations that Microsoft and GitHub’s Copilot is pilfering code.
But one thing is for sure after a ruling [PDF] by the United States District Court for the District of Columbia – AI-created works cannot be copyrighted.
You’d think this was a simple case, but it has been rumbling on for years at the hands of one Stephen Thaler, founder of Missouri neural network biz Imagination Engines, who tried to copyright artwork generated by what he calls the Creativity Machine, a computer system he owns. The piece, A Recent Entrance to Paradise, pictured below, was reproduced on page 4 of the complaint [PDF]:
The US Copyright Office refused the application because copyright laws are designed to protect human works. “The office will not register works ‘produced by a machine or mere mechanical process’ that operates ‘without any creative input or intervention from a human author’ because, under the statute, ‘a work must be created by a human being’,” the review board told Thaler’s lawyer after his second attempt was rejected last year.
This was not a satisfactory response for Thaler, who then sued the US Copyright Office and its director, Shira Perlmutter. “The agency actions here were arbitrary, capricious, an abuse of discretion and not in accordance with the law, unsupported by substantial evidence, and in excess of Defendants’ statutory authority,” the lawsuit claimed.
But handing down her ruling on Friday, Judge Beryl Howell wouldn’t budge, pointing out that “human authorship is a bedrock requirement of copyright” and “United States copyright law protects only works of human creation.”
“Non-human actors need no incentivization with the promise of exclusive rights under United States law, and copyright was therefore not designed to reach them,” she wrote.
Though she acknowledged the need for copyright to “adapt with the times,” she shut down Thaler’s pleas by arguing that copyright protection can only be sought for something that has “an originator with the capacity for intellectual, creative, or artistic labor. Must that originator be a human being to claim copyright protection? The answer is yes.”
Unsurprisingly Thaler’s legal people took an opposing view. “We strongly disagree with the district court’s decision,” University of Surrey Professor Ryan Abbott told The Register.
“In our view, the law is clear that the American public is the primary beneficiary of copyright law, and the public benefits when the generation and dissemination of new works are promoted, regardless of how those works are made. We do plan to appeal.”
This is just one legal case Thaler is involved in. Earlier this year, the US Supreme Court also refused to hear arguments that AI algorithms should be recognized by law as inventors on patent filings, once again brought by Thaler.
He sued the US Patent and Trademark Office (USPTO) in 2020 because patent applications he had filed on behalf of another of his AI systems, DABUS, were rejected. The USPTO refused to accept them as it could only consider inventions from “natural persons.”
That lawsuit was quashed then was taken to the US Court of Appeals, where it lost again. Thaler’s team finally turned to the Supreme Court, which wouldn’t give it the time of day.
When The Register asked Thaler to comment on the US Copyright Office defeat, he told us: “What can I say? There’s a storm coming.”
More and more, as the video game industry matures, we find ourselves talking about game preservation and the disappearing culture of some older games as the original publishers abandon them. Often times leaving the public with no actual legit method for purchasing these old games, copyright law conspires with the situation to also prevent the public itself from clawing back its half of the copyright bargain. The end results are studios and publishers that have enjoyed the fruits of copyright law for a period of time, only for that cultural output to be withheld from the public later on. By any plain reading of American copyright law, that outcome shouldn’t be acceptable.
When it comes to one classic PlayStation 1 title, it seems that one enterprising individual has very much refused to accept this outcome. A fan of the first-party Sony title WipeOut, an exclusive to the PS1, has ported the game such that it can be played in a web browser. And, just to drive the point home, they have essentially dared Sony to do something about it.
“Either let it be, or shut this thing down and get a real remaster going,” he told Sony in a recent blog post (via VGC). Despite the release of the PlayStation Classic, 2017’s Wipeout Omega Collection, and PS Plus adding old PS1 games to PS5 like Twisted Metal, there’s no way to play the original WipeOut on modern consoles and experience the futuristic racer’s incredible soundtrack and neo-Tokyo aesthetic in all their glory. So fans have taken it upon themselves to make the Psygnosis-developed hit accessible on PC.
As Dominic Szablewski details in his post and in a series of videos detailing this labor of love, getting this all to work took a great deal of unraveling in the source code. The whole thing was a mess primarily because every iteration of the game simply had new code layered on top of the last iteration, meaning that there was a lot of onion-peeling to be done to make this all work.
But work it does!
After a lot of detective work and elbow grease, Szablewski managed to resurrect a modified playable version of the game with an uncapped framerate that looks crisp and sounds great. He still recommends two other existing PC ports over his own, WipeOut Phantom Edition and an unnamed project by a user named XProger. However, those don’t come with the original source code, the legality of which he admits is “questionable at best.”
But again, what is the public supposed to do here? The original game simply can’t be bought legitimately and hasn’t been available for some time. Violating copyright law certainly isn’t the right answer, but neither is allowing a publisher to let cultural output go to rot simply because it doesn’t want to do anything about it.
“Sony has demonstrated a lack of interest in the original WipeOut in the past, so my money is on their continuing absence,” Szablewski wrote. “If anyone at Sony is reading this, please consider that you have (in my opinion) two equally good options: either let it be, or shut this thing down and get a real remaster going. I’d love to help!”
Sadly, I’m fairly certain I know how this story will end.
The Mozilla Foundation has started a petition to stop the French government from forcing browsers like Mozilla’s Firefox to censor websites. “It would set a dangerous precedent, providing a playbook for other governments to also turn browsers like Firefox into censorship tools,” says the organization. “The government introduced the bill to parliament shortly before the summer break and is hoping to pass this as quickly and smoothly as possible; the bill has even been put on an accelerated procedure, with a vote to take place this fall.” You can add your name to their petition here.
The bill in question is France’s SREN Bill, which sets a precarious standard for digital freedoms by empowering the government to compile a list of websites to be blocked at the browser level. The Mozilla Foundation warns that this approach “is uncharted territory” and could give oppressive regimes an operational model that could undermine the effectiveness of censorship circumvention tools.
“Rather than mandate browser based blocking, we think the legislation should focus on improving the existing mechanisms already utilized by browsers — services such as Safe Browsing and Smart Screen,” says Mozilla. “The law should instead focus on establishing clear yet reasonable timelines under which major phishing protection systems should handle legitimate website inclusion requests from authorized government agencies. All such requests for inclusion should be based on a robust set of public criteria limited to phishing/scam websites, subject to independent review from experts, and contain judicial appellate mechanisms in case an inclusion request is rejected by a provider.”
On Friday, the Internet Archive put up a blog post noting that its digital book lending program was likely to change as it continues to fight the book publishers’ efforts to kill the Internet Archive. As you’ll recall, all the big book publishers teamed up to sue the Internet Archive over its Open Library project, which was created based on a detailed approach, backed by librarians and copyright lawyers, to recreate an online digital library that matches a physical library. Unfortunately, back in March, the judge decided (just days after oral arguments) that everything about the Open Library infringes on copyrights. There were many, many problems with this ruling, and the Archive is appealing.
However, in the meantime, the judge in the district court needed to sort out the details of the injunction in terms of what activities the Archive would change during the appeal. The Internet Archive and the publishers negotiated over the terms of such an injunction and asked the court to weigh in on whether or not it also covers books for which there are no ebooks available at all. The Archive said it should only cover books where the publishers make an ebook available, while the publishers said it should cover all books, because of course they did. Given Judge Koeltl’s original ruling, I expected him to side with the publishers, and effectively shut down the Open Library. However, this morning he surprised me and sided with the Internet Archive, saying only books that are already available in electronic form need to be removed. That’s still a lot, but at least it means people can still access those other works electronically. The judge rightly noted that the injunction should be narrowly targeted towards the issues at play in the case, and thus it made sense to only block works available as ebooks.
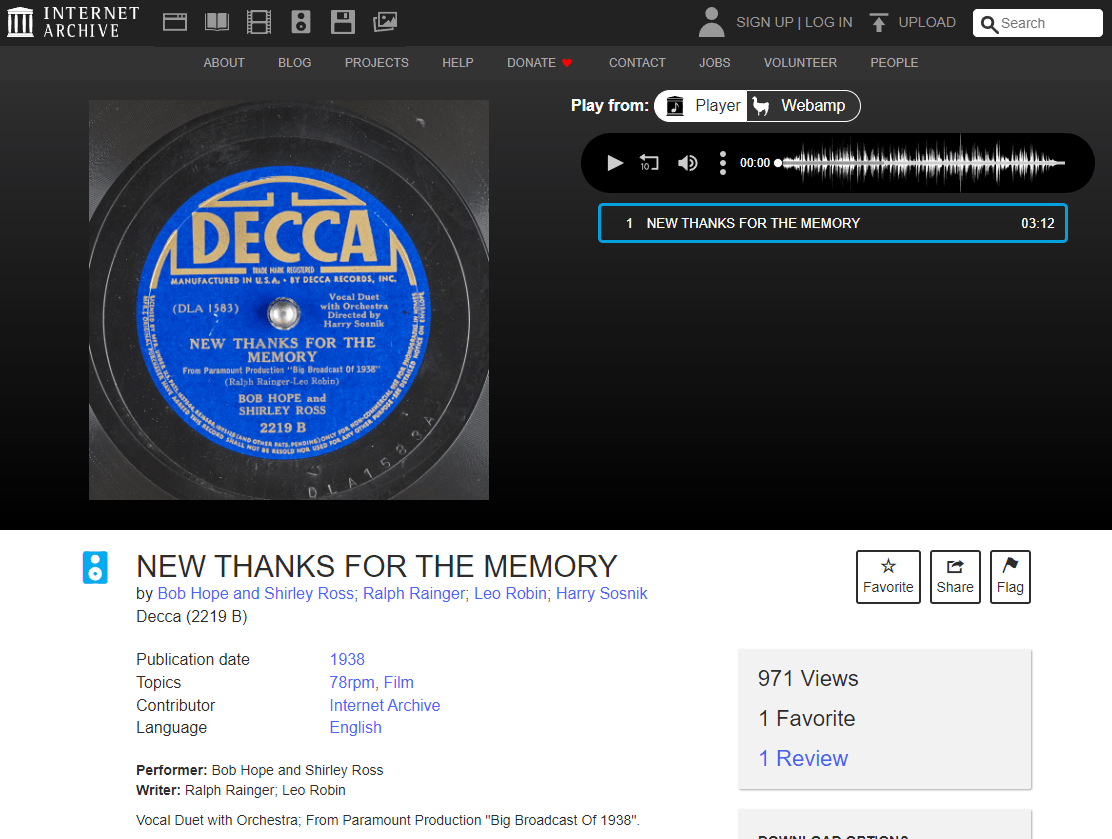
But, also on Friday, the RIAA decided to step in and to try to kick the Internet Archive while it’s down. For years now, the Archive has offered up its Great 78 Project, in which the Archive, in coordination with some other library/archival projects (including the Archive of Contemporary Music and George Blood LP), has been digitizing whatever 78rpm records they could find.
78rpm records were some of the earliest musical recordings, and were produced from 1898 through the 1950s when they were replaced by 33 1/3rpm and 45rpm vinyl records. I remember that when I was growing up my grandparents had a record player that could still play 78s, and there were a few of those old 78s in a cabinet. Most of the 78s were not on vinyl, but shellac, and were fairly brittle, meaning that many old 78s are gone forever. As such there is tremendous value in preserving and protecting old 78s, which is also why many libraries have collections of them. It’s also why those various archival libraries decided to digitize and preserve them. Without such an effort, many of those 78s would disappear.
If you’ve ever gone through the Great78 project, you know quite well that it is, in no way, a substitute for music streaming services like Spotify or Apple Music. You get a static page in which you (1) see a photograph of the original 78 label, (2) get some information on that recording, and (3) are able to listen to and download just that song. Here’s a random example I pulled:
Also, when you listen to it, you can clearly hear that this was digitized straight off of the 78 itself, including all the crackle and hissing of the record. It is nothing like the carefully remastered versions you hear on music streaming services.
Indeed, I’ve used the Great78 Project to discover old songs I’d never heard before, leading me to search out those artists on Spotify to add to my playlists, meaning that for me, personally, the Great78 Project has almost certainly resulted in the big record labels making more money, as it added more artists for me to listen to through licensed systems.
It’s no secret that the recording industry had it out for the Great78 Project. Three years ago, we wrote about how Senator Thom Tillis (who has spent his tenure in the Senate pushing for whatever the legacy copyright industries want) seemed absolutely apoplectic when the Internet Archive bought a famous old record store in order to get access to the 78s to digitize, and Tillis thought that this attempt to preserve culture was shameful.
The lawsuit, joined by all of the big RIAA record labels, was filed by one of the RIAA’s favorite lawyers for destroying anything good that expands access to music: Matt Oppenheim. Matt was at the RIAA and helped destroy both Napster and Grokster. He was also the lawyer who helped create some terrible precedents holding ISPs liable for subscribers who download music, enabling even greater copyright trolling. Basically, if you’ve seen anything cool and innovative in the world of music over the last two decades, Oppenheim has been there to kill it.
And now he’s trying to kill the world’s greatest library.
Much of the actual lawsuit revolves around the Music Modernization Act, which was passed in 2018 and had some good parts in it, in particular in moving some pre-1972 sound recordings into the public domain. As you might also recall, prior to February of 1972, sound recordings did not get federal copyright protection (though they might get some form of state copyright). Indeed, in most of the first half of the 20th century, many copyright experts believed that federal copyright could not apply to sound recordings and that it could only apply to the composition. After February of 1972, sound recordings were granted federal copyright, but that left pre-1972 works in a weird state, in which they were often protected by an amalgamation of obsolete state laws, meaning that some works might not reach the public domain for well over a century. This was leading to real concerns that some of our earliest recordings would disappear forever.
The Music Modernization Act sought to deal with some of that, creating a process by which pre-1972 sound recordings would be shifted under federal copyright, and a clear process began to move some of the oldest ones into the public domain. It also created a process for dealing with old orphaned works, where the copyright holder could not be found. The Internet Archive celebrated all of this, and noted that it would be useful for some of its archival efforts.
The lawsuit accuses the Archive (and Brewster Kahle directly) of then ignoring the limitations and procedures in the Music Modernization Act to just continue digitizing and releasing all of the 78s it could find, including those by some well known artists whose works are available on streaming platforms and elsewhere. It also whines that the Archive often posts links to newly digitized Great78 records on ex-Twitter.
When the Music Modernization Act’s enactment made clear that unauthorized copying, streaming, and distributing pre-1972 sound recordings is infringing, Internet Archive made no changes to its activities. Internet Archive did not obtain authorization to use the recordings on the Great 78 Project website. It did not remove any recordings from public access. It did not slow the pace at which it made new recordings publicly available. It did not change its policies regarding which recordings it would make publicly available.
Internet Archive has not filed any notices of non-commercial use with the Copyright Office. Accordingly, the safe harbor set forth in the Music Modernization Act is not applicable to Internet Archive’s activities.
Internet Archive knew full well that the Music Modernization Act had made its activities illegal under Federal law. When the Music Modernization Act went into effect, Internet Archive posted about it on its blog. Jeff Kaplan, The Music Modernization Act is now law which means some pre-1972 music goes public, INTERNET ARCHIVE (Oct. 15, 2018), https://blog.archive.org/2018/10/15/the-music-modernization-act-is-now-law-which-means-some-music-goes-public/. The blog post stated that “the MMA means that libraries can make some of these older recordings freely available to the public as long as we do a reasonable search to determine that they are not commercially available.” Id. (emphasis added). The blog post further noted that the MMA “expands an obscure provision of the library exception to US Copyright Law, Section 108(h), to apply to all pre-72 recordings. Unfortunately 108(h) is notoriously hard to implement.” Id. (emphasis added). Brewster Kahle tweeted a link to the blog post. Brewster Kahle (@brewster_kahle), TWITTER (Oct. 15, 2018 11:26 AM), https://twitter.com/brewster_kahle/status/1051856787312271361.
Kahle delivered a presentation at the Association for Recorded Sound Collection’s 2019 annual conference titled, “Music Modernization Act 2018. How it did not go wrong, and even went pretty right.” In the presentation, Kahle stated that, “We Get pre-1972 out-of-print to be ‘Library Public Domain’!”. The presentation shows that Kahle, and, by extension, Internet Archive and the Foundation, understood how the Music Modernization Act had changed federal law and was aware the Music Modernization Act had made it unlawful under federal law to reproduce, distribute, and publicly perform pre-1972 sound recordings.
Despite knowing that the Music Modernization Act made its conduct infringing under federal law, Internet Archive ignored the new law and plowed forward as if the Music Modernization Act had never been enacted.
There’s a lot in the complaint that you can read. It attacks Brewster Kahle personally, falsely claiming that Kahle “advocated against the copyright laws for years,” rather than the more accurate statement that Kahle has advocated against problematic copyright laws that lock down, hide, and destroy culture. The lawsuit even uses Kahle’s important, though unfortunately failed, Kahle v. Gonzalez lawsuit, which argued (compellingly, though unfortunately not to the 9th Circuit) that when Congress changed copyright law from opt-in copyright (in which you had to register anything to get a copyright) to “everything is automatically covered by copyright,” it changed the very nature of copyright law, and took it beyond the limits required under the Constitution. That was not an “anti-copyright” lawsuit. It was an “anti-massive expansion of copyright in a manner that harms culture” lawsuit.
It is entirely possible (perhaps even likely) that the RIAA will win this lawsuit. As Oppenheim knows well, the courts are often quite smitten with the idea that the giant record labels and publishers and movie studios “own” culture and can limit how the public experiences it.
But all this really does is demonstrate exactly how broken modern copyright law is. There is no sensible or rationale world in which an effort to preserve culture and make it available to people should be deemed a violation of the law. Especially when that culture is mostly works that the record labels themselves ignored for decades, allowing them to decay and disappear in many instances. To come back now, decades later, and try to kill off library preservation and archival efforts is just an insult to the way culture works.
It’s doubly stupid given that the RIAA, and Oppenheim in particular, spent years trying to block music from ever being available on the internet. It’s only now that the very internet they fought developed systems that have re-invigorated the bank accounts of the labels through streaming that the RIAA gets to pretend that of course it cares about music from the first half of the 20th century — music that it was happy to let decay and die off until just recently.
Whether or not the case is legally sound is one thing. Chances are the labels may win. But, on a moral level, everything about this is despicable. The Great78 project isn’t taking a dime away from artists or the labels. No one is listening to the those recordings as a replacement for licensed efforts. Again, if anything, it’s helping to rejuvenate interest in those old recordings for free.
And if this lawsuit succeeds, it could very well put the nail in the coffin of the Internet Archive, which is already in trouble due to the publishers’ lawsuit.
Over the last few years, the RIAA had sort of taken a step back from being the internet’s villain, but its instincts to kill off and spit on culture never went away.
These copyright goons really hate the idea of preserving culture. Can you imagine doing something once and then getting paid for it every time someone sees your work?! Crazy!
A Wednesday statement from the Commission brought news that in late July it wrote to Google to inform it of the ₩42.1 billion ($31.5 million) fine announced, and reported by The Register, in April 2023.
The Commission has also commenced monitoring activities to ensure that Google complies with requirements to allow competition with its Play store.
South Korea probed the operation of Play after a rival local Android app-mart named OneStore debuted in 2016.
OneStore had decent prospects of success because it merged app stores operated by South Korea’s top three telcos. Naver, an online portal similar in many ways to Google, also rolled its app store into OneStore.
Soon afterwards, Google told developers they were free to sell their wares in OneStore – but doing so would see them removed from the Play store.
Google also offered South Korean developers export assistance if they signed exclusivity deals in their home country.
Faced with the choice of being cut off from the larger markets Google owned, developer enthusiasm for dabbling in OneStore dwindled. Some popular games never made it into OneStore, so even though its founders had tens of millions of customers between them, the venture struggled.
Which is why Korea’s Fair Trade Commission intervened with an investigation, the fines mentioned above, and a requirement that Google revisit agreements with local developers.
Google has also been required to establish an internal monitoring system to ensure it complies with the Commission’s orders.
Commission chair Ki-Jeong Han used strong language in today’s announcement, describing his agency’s actions as “putting the brakes” on Google’s efforts to achieve global app store dominance.
“Monopolization of the app market may adversely affect the entire mobile ecosystem,” the Commissioner’s statement reads, adding “The recovery of competition in this market is very important.”
It’s also likely beneficial to South Korean companies. OneStore has tried to expand overseas, and Samsung – the world’s top smartphone vendor by unit volume – also stands to gain. It operates its own Galaxy Store that, despite its presence on hundreds of millions of handsets, enjoys trivial market share.
Apple’s “Batterygate” legal saga is finally swinging shut – in the US, at least – with a final appeal being voluntarily dismissed, clearing the way for payouts to class members.
The US lawsuit, which combined 66 separate class actions into one big legal proceeding in California, was decided in 2020, with the outcome requiring Apple to pay out between $310 million and $500 million to claimants.
Some US claimants were unhappy with the outcome of the case, and appealed to the Ninth Circuit Court of Appeals. That appeal was finally dropped last week, allowing for payments to those who filed a claim before October 6, 2020, to begin. With around 3 million claims received, claimants will be due around $65 each.
“The settlement is the result of years of investigation and hotly contested litigation. We are extremely proud that this deal has been approved, and following the Ninth Circuit’s order, we can finally provide immediate cash payments to impacted Apple customers,” said Mark Molumphy, an attorney for plaintiffs in the case.
Apple didn’t respond to our questions.
A settlement nearly a decade in the making
For those who’ve chosen to forget about the whole Batterygate fiasco, it all started in 2016 when evidence began pointing to Apple throttling CPUs in older iPhones to prevent accelerated battery drain caused by newer software and loss of battery capacity in aging devices.
Devices affected by Apple’s CPU throttling include iPhone 6 and 7 series handsets as well as the first-generation iPhone SE.
Apple admitted as much in late 2017, and just a day later lawsuits began pouring in around the US from angry iDevice owners looking for recompense. Complaints continued into 2020 from users of older iPhones updated to iOS 14.2, who said their devices started overheating and the battery would drain in mere minutes.
The US case, as mentioned above, was decided in favor of the plaintiffs in 2020, though late last year the settlement was overturned by the Ninth Circuit, which said the lower court judge had applied the wrong legal standard in making his decision. The settlement was reinstated after a second examination earlier this year.
The reason for the objection and its withdrawal isn’t immediately clear. Lawyers for Sarah Feldman and Hondo Jan, who filed both objections to the settlement, didn’t immediately respond to questions from The Register.
Apple also won’t be completely off the hook for its iPhone throttling – it’s also facing a similar complaint in the UK, where a case was filed last year that Apple asked to have tossed in May. That attempt failed, and hearings in the case are scheduled for late August and early September.
The UK case, brought by consumer advocate Justin Gutmann, is seeking to recover £1.6 billion ($2 billion) from Apple if, like the US case, the courts end up deciding against Cook and co.
Were you hoping Canon might be held accountable for its all-in-one printers that mysteriously can’t scan when they’re low on ink, forcing you to buy more? Tough: the lawsuit we told you about last year quietly ended in a private settlement rather than becoming a big class-action.
I just checked, and a judge already dismissed David Leacraft’s lawsuit in November, without Canon ever being forced to show what happens when you try to scan without a full ink cartridge. (Numerous Canon customer support reps wrote that it simply doesn’t work.)
Here’s the good news: HP, an even larger and more shameless manufacturer of printers, is still possibly facing down a class-action suit for the same practice.
As Reuters reports, a judge has refused to dismiss a lawsuit by Gary Freund and Wayne McMath that alleges many HP printers won’t scan or fax documents when their ink cartridges report that they’ve run low.
[…]
Interestingly, neither Canon nor HP spent any time trying to argue their printers do scan when they’re low on ink in the lawsuit responses I’ve read. Perhaps they can’t deny it? Epson, meanwhile, has an entire FAQ dedicated to reassuring customers that it hasn’t pulled that trick since 2008. (Don’t worry, Epson has other forms of printer enshittification.)
And here we go again. we’ve been talking about how copyright has gotten in the way of cultural preservation generally for a while, and more specifically lately when it comes to the video game industry. The way this problem manifests itself is quite simple: video game publishers support the games they release for some period of time and then they stop. When they stop, depending on the type of game, it can make that game unavailable for legitimate purchase or use, either because the game is disappeared from retail and online stores, or because the servers needed to make them operational are taken offline. Meanwhile, copyright law prevents individuals and, in some cases, institutions from preserving and making those games available to the public, a la a library or museum would.
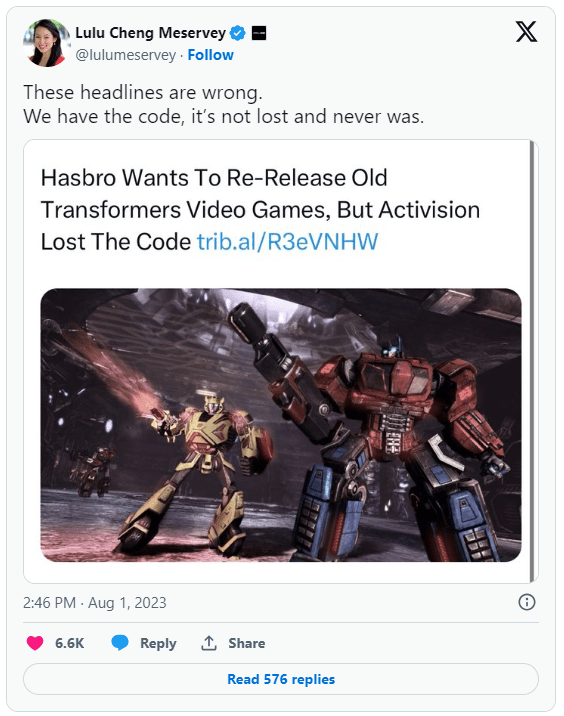
When you make these preservation arguments, one of the common retorts you get from the gaming industry and its apologists is that publishers already preserve these games for eventual re-release down the road, which is why they need to maintain their copyright protection on that content. We’ve pointed out failures to do so by the industry in the past, but the story about Hasbro wanting to re-release several older Transformers video games, but can’t, is about as perfect an example as I can find.
Released in June 2010, Transformers: War for Cybertron was a well-received third-person shooter that got an equally great sequel in 2012, Fall of Cybertron. (And then in 2014 we got Rise of Dark Spark, which wasn’t very good and was tied into the live-action films.) What made the first two games so memorable and beloved was that they told their own stories about the origins of popular characters like Megatron and Optimus Prime while featuring kick-ass combat that included the ability to transform into different vehicles. Sadly, in 2018, all of these Activision-published Transformers games (and several it commissioned from other developers) were yanked from digital stores, making them hard to acquire and play in 2023. It seems that Hasbro now wants that to change, suggesting the games could make a perfect fit for Xbox Game Pass, once Activision, uh…finds them.
You read that right: finds them. What does that mean? Well, when Hasbro came calling to Activision looking to see if this was a possibility, it devolved into Activision doing a theatrical production parody called Dude, Where’s My Hard Drive? It seems that these games may or may not exist on some piece of hardware, but Activision literally cannot find it. Or maybe not, as you’ll read below. There seems to be some confusion about what Activision can and cannot find.
And, yes, the mantra in the comments that pirate sites are essentially solving for this problem certainly applies here as well. So much so, in fact, that it sure sounds like Hasbro went that route to get what it needed for the toy design portion of this.
Interestingly, Activision’s lack of organization seems to have caused some headaches for Hasbro’s toy designers who are working on the Gamer Edition figures. The toy company explained that it had to load up the games on their original platforms and play through them to find specific details they wanted to recreate for the toys.
“For World of Cybertron we had to rip it ourselves, because [Activision] could not find it—they kept sending concept art instead, which we didn’t want,” explained Hasbro. “So we booted up an old computer and ripped them all out from there. Which was a learning experience and a long weekend, because we just wanted to get it right, so that’s why we did it like that.
What’s strange is that despite the above, Activision responded to initial reports of all this indicating that the headlines were false and it does have… code. Or something.
Hasbro itself then followed up apologizing for the confusion, also saying that it made an error in stating the games were “lost”. But what’s strange about all that, in addition to the work that Hasbro did circumventing having access to the actual games themselves, is the time delta it took for Activision to respond to all of this.
Activision has yet to confirm if it actually knows where the source code for the games is specifically located. I also would love to know why Activision waited so long to comment (the initial interview was posted on July 28) and why Hasbro claimed to not have access to key assets when developing its toys based on the games.
It’s also strange that Hasbro, which says it wants to put these games on Game Pass, hasn’t done so for years now. If the games aren’t lost, give ‘em to Hasbro, then?
Indeed. If this was all a misunderstanding, so be it. But if this was all pure misunderstanding, the rest of the circumstances surrounding this story don’t make a great deal of sense. At the very least, it sounds like some of the concern that these games could have simply been lost to the world is concerning and yet another data point for an industry that simply needs to do better when it comes to preservation efforts.
China has released draft regulations to govern the country’s facial recognition technology that include prohibitions on its use to analyze race or ethnicity.
According to the the Cyberspace Administration of China(CAC), the purpose is to “regulate the application of face recognition technology, protect the rights and interests of personal information and other personal and property rights, and maintain social order and public safety” as outlined by a smattering of data security, personal information, and network laws.
The draft rules, which are open for comments until September 7, include some vague directives not to use face recognition technology to disrupt social order, endanger national security, or infringe on the rights of individuals and organizations.
The rules also state that facial recognition tech must be used only when there is a specific purpose and sufficient necessity, strict protection measures are taken, and only when non-biometric measures won’t do.
It makes requirements to obtain consent before processing face information, except for cases where it’s not required, which The Reg assumes means for individuals such as prisoners and in instances of national security. Parental or guardian consent is needed for those under the age of 14.
Building managers can’t require its use to enter and exit property – they must provide alternative measures of verifying a personal identity for those who want it.
It also can’t be leaned into for “major personal interests” such as social assistance and real estate disposal. For that, manual verification of personal identity must be used with facial recognition used only as an auxiliary means of verifying personal identity.
And collecting images for internal management should only be done in a reasonably sized area.
In businesses like hotels, banks, airports, art galleries, and more, the tech should not be used to verify personal identity. If the individual chooses to link their identity to the image, they should be informed either verbally or in writing and provide consent.
Collecting images is also not allowed in private spaces like hotel rooms, public bathrooms, and changing rooms.
Furthermore, those using facial surveillance techniques must display reminder signs, and personal images along with identification information must also be kept confidential, and only anonymized data may be saved.
Under the draft regs, those that store face information of more than 10,000 people must register with a local branch of the CAC within 30 working days.
Most interesting, however, is Article 11, which, when translated from Chinese via automated tools, reads:
No organization or individual shall use face recognition technology to analyze personal race, ethnicity, religion, sensitive personal information such as beliefs, health status, social class, etc.
The CAC does not say if the Chinese Communist Party counts as an “organization.”
Human rights groups have credibly asserted that Uyghurs are routinely surveilled using facial recognition technology, in addition to being incarcerated, required to perform forced labor, re-educated to abandon their beliefs and cultural practices, and may even be subjected to sterilization campaigns.
Just last month, physical security monitoring org IPVM reported it came into possession of a contract between China-based Hikvision and Hainan Province’s Chengmai County for $6 million worth of cameras that could detect whether a person was ethnically Uyghur using minority recognition technology.
Hikvision denied the report and said it last provided such functionality in 2018.
Beyond facilitating identification of Uyghurs, it’s clear the cat is out of the bag when it comes to facial recognition technology in China by both government and businesses alike. Local police use it to track down criminals and its use feeds into China’s social credit system.
“‘Sky Net,’ a facial recognition system that can scan China’s population of about 1.4 billion people in a second, is being used in 16 Chinese cities and provinces to help police crackdown on criminals and improve security,” said state-sponsored media in 2018.
Regardless, the CAC said those violating the new draft rules once passed would be held to criminal and civil liability.
In a well-intentioned yet dangerous move to fight online fraud, France is on the verge of forcing browsers to create a dystopian technical capability. Article 6 (para II and III) of the SREN Bill would force browser providers to create the means to mandatorily block websites present on a government provided list.
The post explains why this is an extremely dangerous approach:
A world in which browsers can be forced to incorporate a list of banned websites at the software-level that simply do not open, either in a region or globally, is a worrying prospect that raises serious concerns around freedom of expression. If it successfully passes into law, the precedent this would set would make it much harder for browsers to reject such requests from other governments.
If a capability to block any site on a government blacklist were required by law to be built in to all browsers, then repressive governments would be given an enormously powerful tool. There would be no way around that censorship, short of hacking the browser code. That might be an option for open source coders, but it certainly won’t be for the vast majority of ordinary users. As the Mozilla post points out:
Such a move will overturn decades of established content moderation norms and provide a playbook for authoritarian governments that will easily negate the existence of censorship circumvention tools.
It is even worse than that. If such a capability to block any site were built in to browsers, it’s not just authoritarian governments that would be rubbing their hands with glee: the copyright industry would doubtless push for allegedly infringing sites to be included on the block list too. We know this, because it has already done it in the past, as discussed in Walled Culture the book (free digital versions).
Not many people now remember, but in 2004, BT (British Telecom) caused something of a storm when it created CleanFeed:
British Telecom has taken the unprecedented step of blocking all illegal child pornography websites in a crackdown on abuse online. The decision by Britain’s largest high-speed internet provider will lead to the first mass censorship of the web attempted in a Western democracy.
Here’s how it worked:
Subscribers to British Telecom’s internet services such as BTYahoo and BTInternet who attempt to access illegal sites will receive an error message as if the page was unavailable. BT will register the number of attempts but will not be able to record details of those accessing the sites.
The key justification for what the Guardian called “the first mass censorship of the web attempted in a Western democracy” was that it only blocked illegal child sexual abuse material Web sites. It was therefore an extreme situation requiring an exceptional solution. But seven years later, the copyright industry were able to convince a High Court judge to ignore that justification, and to take advantage of CleanFeed to block a site, Newzbin 2, that had nothing to do with child sexual abuse material, and therefore did not require exceptional solutions:
Justice Arnold ruled that BT must use its blocking technology CleanFeed – which is currently used to prevent access to websites featuring child sexual abuse – to block Newzbin 2.
Exactly the logic used by copyright companies to subvert CleanFeed could be used to co-opt the censorship capabilities of browsers with built-in Web blocking lists. As with CleanFeed, the copyright industry would doubtless argue that since the technology already exists, why not to apply it to tackling copyright infringement too?
That very real threat is another reason to fight this pernicious, misguided French proposal. Because if it is implemented, it will be very hard to stop it becoming yet another technology that the copyright world demands should be bent to its own selfish purposes.
Jieun Kiaer, an Oxford professor of Korean linguistics, recently published an academic book called Emoji Speak: Communications and Behaviours on Social Media. As you can tell from the name, it’s a book about emoji, and about how people communicate with them:
Exploring why and how emojis are born, and the different ways in which people use them, this book highlights the diversity of emoji speak. Presenting the results of empirical investigations with participants of British, Belgian, Chinese, French, Japanese, Jordanian, Korean, Singaporean, and Spanish backgrounds, it raises important questions around the complexity of emoji use.
Though emojis have become ubiquitous, their interpretation can be more challenging. What is humorous in one region, for example, might be considered inappropriate or insulting in another. Whilst emoji use can speed up our communication, we might also question whether they convey our emotions sufficiently. Moreover, far from belonging to the youth, people of all ages now use emoji speak, prompting Kiaer to consider the future of our communication in an increasingly digital world.
Sounds interesting enough, but as Goldman highlights with an image from the book, Kiaer was apparently unable to actually show examples of many of the emoji she was discussing due to copyright fears. While companies like Twitter and Google have offered up their own emoji sets under open licenses, not all of them have, and some of the specifics about the variations in how different companies represent different emoji apparently were key to the book.
So, for those, Kiaer actually hired an artist, Loli Kim, to draw similar emoji!
The page reads as follows (with paragraph breaks added for readability):
Notes on Images of Emojis
Social media spaces are almost entirely copyright free. They do not follow the same rules as the offline world. For example, on Twitter you can retweet any tweet and add your own opinion. On Instagram, you can share any post and add stickers or text. On TikTok, you can even ‘duet’ a video to add your own video next to a pre-existing one. As much as each platform has its own rules and regulations, people are able to use and change existing material as they wish. Thinking about copyright brings to light barriers that exist between the online and offline worlds. You can use any emoji in your texts, tweets, posts and videos, but if you want to use them in the offline world, you may encounter a plethora of copyright issues.
In writing this book, I have learnt that online and offline exist upon two very different foundations. I originally planned to have plenty of images of emojis, stickers, and other multi-modal resources featured throughout this book, but I have been unable to for copyright reasons. In this moment, I realized how difficult it is to move emojis from the online world into the offline world.
Even though I am writing this book about emojis and their significance in our lives, I cannot use images of them in even an academic book. Were I writing a tweet or Instagram post, however, I would likely have no problem. Throughout this book, I stress that emoji speak in online spaces is a grassroots movement in which there are no linguistic authorities and corporations have little power to influence which emojis we use. Comparatively, in offline spaces, big corporations take ownership of our emoji speak, much like linguistic authorities dictate how we should write and speak properly.
This sounds like something out of a science fiction story, but it is an important fact of which to be aware. While the boundaries between our online and offline words may be blurring, barriers do still exist between them. For this reason, I have had to use an artist’s interpretation of the images that I originally had in mind for this book. Links to the original images have been provided as endnotes, in case readers would like to see them.
Just… incredible. Now, my first reaction to this is that using the emoji and stickers and whatnot in the book seems like a very clear fair use situation. But… that requires a publisher willing to take up the fight (and an insurance company behind the publisher willing to finance that fight). And, that often doesn’t happen. Publishers are notoriously averse to supporting fair use, because they don’t want to get sued.
But, really, this just ends up highlighting (once again) the absolute ridiculousness of copyright in the modern world. No one in their right mind would think that a book about emoji is somehow harming the market for whatever emoji or stickers the professor wished to include. Yet, due to the nature of copyright, here we are. With an academic book about emoji that can’t even include the emoji being spoken about.
This weekend, a federal court tossed a subpoena in a case against the internet service provider Grande that would require Reddit to reveal the identities of anonymous users that torrent movies.
The case was originally filed in 2021 by 20 movie producers against Grande Communications in the Western District of Texas federal court. The lawsuit claims that Grande is committing copyright infringement against the producers for allegedly ignoring the torrenting of 45 of their movies that occurred on its networks. As part of the case, the plaintiffs attempted to subpoena Reddit for IP addresses and user data for accounts that openly discussed torrenting on the platform. This weekend, Magistrate Judge Laurel Beeler denied the subpoena—meaning Reddit is off the hook.
“The plaintiffs thus move to compel Reddit to produce the identities of its users who are the subject of the plaintiffs’ subpoena,” Magistrate Judge Beeler wrote in her decision. “The issue is whether that discovery is permissible despite the users’ right to speak anonymously under the First Amendment. The court denies the motion because the plaintiffs have not demonstrated a compelling need for the discovery that outweighs the users’ First Amendment right to anonymous speech.”
Reddit was previously cleared of a similar subpoena in a similar lawsuit by the same judge back in May as reported by ArsTechnica. Reddit was asked to unmask eight users who were active in piracy threads on the platform, but the social media website pulled the same First Amendment defense.
Over the last few months there have been a flurry of lawsuits against AI companies, with most of them being focused on copyright claims. The site ChatGPTIsEatingTheWorld has been tracking all the lawsuits, which currently lists 11 lawsuits, seven of which are copyright claims. Five of those are from the same lawyers: Joseph Saveri and Matthew Butterick, who seem to want to corner the market on “suing AI companies for copyright.”
We already covered just how bad their two separate (though they’re currently trying to combine them, and no one can explain to me why it made sense to file them separately in the first place) lawsuits on behalf of authors are, as they show little understanding of how copyright actually works. But their original lawsuit against Stability AI, MidJourney, and DeviantArt was even worse, as we noted back in April. As we said at the time, they don’t allege a single act of infringement, but rather make vague statements about how what these AI tools are doing must be infringing.
(Also, the lawyers seemed to totally misunderstand what DeviantArt was doing, in that it was using open source tools to better enable DeviantArt artists to prevent their works from being used as inspiration in AI systems, and claimed that was infringing… but that’s a different issue).
It appears that the judge overseeing that lawsuit has noticed just how weak the claims are. Though we don’t have a written opinion yet, Reuters reports that Judge William Orrick was pretty clear at least week’s hearing that the case, as currently argued, has no chance.
U.S. District Judge William Orrick said during a hearing in San Francisco on Wednesday that he was inclined to dismiss most of a lawsuit brought by a group of artists against generative artificial intelligence companies, though he would allow them to file a new complaint.
Orrick said that the artists should more clearly state and differentiate their claims against Stability AI, Midjourney and DeviantArt, and that they should be able to “provide more facts” about the alleged copyright infringement because they have access to Stability’s relevant source code.
“Otherwise, it seems implausible that their works are involved,” Orrick said, noting that the systems have been trained on “five billion compressed images.”
Again, the theory of the lawsuit seemed to be that AI companies cut up little pieces of the content they train on and create a “collage” in response. Except, that’s not at all how it works. And since the complaint can’t show any specific work that has been infringed on by the output, the case seems like a loser. And it’s good the judge sees that.
He also recognizes that merely being inspired by someone else’s art doesn’t make the new art infringing:
“I don’t think the claim regarding output images is plausible at the moment, because there’s no substantial similarity” between images created by the artists and the AI systems, Orrick said.
It seems likely that Saveri and crew will file an amended complaint to try to more competently make this argument, but since the underlying technology doesn’t fundamentally do what the lawsuit pretends it does, it’s difficult to see how it can succeed.
But, of course, this is copyright, and copyright caselaw doesn’t always follow logic or what the law itself says. So it’s no surprise that Saveri and Butterick are trying multiple lawsuits with these theories. They might just find a judge confused enough to buy it.
Italy’s brand new anti-piracy law has just received full approval from telecoms regulator AGCOM. In a statement issued Thursday, AGCOM noted its position “at the forefront of the European scene in combating online piracy.” The new law comes into force on August 8 and authorizes nationwide ISP blocking of live events and enables the state to issue fines of up to 5,000 euros to users of pirate streams .
Unanimously approved by the Chamber of Deputies back in March and then unanimously approved by the Senate earlier this month, Italy’s new anti-piracy law has just been unanimously approved by telecoms regulator AGCOM.
In a statement published Thursday, AGCOM welcomed the amendments to Online Copyright Enforcement regulation 680/13/CONS, which concern measures to counter the illegal distribution of live sports streams, as laid out in Resolution 189/23/CONS.
The new provisions grant AGCOM the power to issue “dynamic injunctions” against online service providers of all kinds, a privilege usually reserved for judges in Europe’s highest courts. The aim is to streamline blocking measures against unlicensed IPTV services, with the goal of rendering them inaccessible across all of Italy.
“With such measures, it will be possible to disable access to pirated content in the first 30 minutes of the event broadcast by blocking DNS resolution of domain names and blocking the routing of network traffic to IP addresses uniquely intended for illicit activities,” AGCOM says.
[…]
Penalties For Challenging AGCOM’s New Powers
When AGCOM issues blocking instructions to service providers, their details will be passed to the Public Prosecutor’s Office at the Court of Rome.
After carrying out AGCOM’s instructions, those providers will be required to send a report “without delay” to the Public Prosecutor’s Office. It must detail “all activities carried out in fulfillment of the aforementioned measures” along with “any existing data or information in their possession that may allow for the identification of the providers of the content disseminated abusively.”
In other words, ISPs will be expected to block pirates and gather intelligence on the way. Failure to comply with the instructions of AGCOM will result in a sanction as laid out in LEGGE 31 luglio 1997, n. 249 (Law 249 of July 31, 1997); an administrative fine of 20 million lira to 500 million lira, or in today’s currency – €10,620 to €265,000.
Those involved in the supply/distribution of infringing streams will now face up to three years in prison and a fine of up to €15,000. That’s just €5,000 higher than the minimum punishment intermediaries risk should they fail to follow blocking instructions. Notably, it’s still €250,000 less than the maximum fine a service provider could face if they fail to block piracy carried out by actual pirates.
Watch Pirate Streams? There’s a Fine For That
Unlike the United States where simply consuming pirated streams probably isn’t illegal, in 2017 the Court of Justice of the European Union confirmed that consuming illicit streams in the EU runs contrary to law.
With new deterrents in place against operators of pirate services and otherwise innocent online service providers, Italy has a new deterrent for people who consume pirated streams. From August 8, 2023, they risk a fine of up to €5,000. At least on paper, that has the potential to become quite interesting.
IPSOS research carried out in Italy over the past few years found that roughly 25% of the adult population consume pirate IPTV streams to some extent during a year.
Italy has a population of around 59 million so even with some aggressive rounding that’s still a few million potential pirates. How evidence of this offense can be obtained and then attributed to an individual is unclear.
There’s an interesting post on TorrentFreak that concerns so-called “pirate” subtitles for films. It’s absurd that anyone could consider subtitles to be piracy in any way. They are a good example of how ordinary people can add value by generously helping others enjoy films and TV programs in languages they don’t understand. In no sense do “pirate” subtitles “steal” from those films and programs, they manifestly enhance them. And yet the ownership-obsessed copyright world actively pursues people who dare to spread joy in this way. In discussing these subtitles, TorrentFreak mentions a site that I’ve not heard of before, Karagarga:
an illustrious BitTorrent tracker that’s been around for more than 18 years. Becoming a member of the private community isn’t easy but those inside gain access to a wealth of film obscurities.
The site focuses on archiving rare classic and cult movies, as well as other film-related content. Blockbusters and other popular Hollywood releases can’t be found on the site as uploading them is strictly forbidden.
TorrentFreak links to an article about Karagarga published some years ago by the Canadian newspaper National Post. Here’s a key point it makes:
It’s difficult to overstate the significance of such a resource. Movies of unflagging historical merit are otherwise lost to changes in technology and time every year: film prints are damaged or lost, musty VHS tapes aren’t upgraded, DVDs fall out of print without reissue, back catalogues never make the transition to digital. But should even a single copy of the film exist, however tenuously, it can survive on Karagarga: one person uploads a rarity and dozens more continue to share.
Although that mentions things like film prints being lost, or back catalogues that aren’t converted to digital formats, the underlying cause of films being lost is copyright. It is copyright that prevents people from making backups of films, whether analogue or digital. Even though people are painfully aware of the vulnerability of films that exist in a few copies or even just one copy, it is generally illegal for them to do anything about it, because of copyright. Instead, they must often sit by as cinematic masterpieces are lost forever.
Unless, of course, sites like Karagarga make unauthorized digital copies. It’s a great demonstration of the fact that copyright, far from preserving culture, often leads to its permanent loss. And that supposedly “evil” sites like Karagarga are the ones that save it for posterity.