Popular health websites are sharing private, personal medical data with big tech companies, according to an investigation by the Financial Times. The data, including medical diagnoses, symptoms, prescriptions, and menstrual and fertility information, are being sold to companies like Google, Amazon, Facebook, and Oracle and smaller data brokers and advertising technology firms, like Scorecard and OpenX.
The investigation: The FT analyzed 100 health websites, including WebMD, Healthline, health insurance group Bupa, and parenting site Babycentre, and found that 79% of them dropped cookies on visitors, allowing them to be tracked by third-party companies around the internet. This was done without consent, making the practice illegal under European Union regulations. By far the most common destination for the data was Google’s advertising arm DoubleClick, which showed up in 78% of the sites the FT tested.
Responses: The FT piece contains a list of all the comments from the many companies involved. Google, for example, said that it has “strict policies preventing advertisers from using such data to target ads.” Facebook said it was conducting an investigation and would “take action” against websites “in violation of our terms.” And Amazon said: “We do not use the information from publisher websites to inform advertising audience segments.”
A window into a broken industry: This sort of rampant rule -breaking has been a dirty secret in the advertising technology industry, which is worth $200 billion globally, ever since EU countries adopted the General Data Protection Regulation in May 2018. A recent inquiry by the UK’s data regulator found that the sector is rife with illegal practices, as in this case where privacy policies did not adequately outline which data would be shared with third parties or what it would be used for. The onus is now on EU and UK authorities to act to put an end to them.
The social media giant said the number of government demands for user data increased by 16% to 128,617 demands during the first half of this year compared to the second half of last year.
That’s the highest number of government demands it has received in any reporting period since it published its first transparency report in 2013.
The U.S. government led the way with the most number of requests — 50,741 demands for user data resulting in some account or user data given to authorities in 88% of cases. Facebook said two-thirds of all the U.S. government’s requests came with a gag order, preventing the company from telling the user about the request for their data.
But Facebook said it was able to release details of 11 so-called national security letters (NSLs) for the first time after their gag provisions were lifted during the period. National security letters can compel companies to turn over non-content data at the request of the FBI. These letters are not approved by a judge, and often come with a gag order preventing their disclosure. But since the Freedom Act passed in 2015, companies have been allowed to request the lifting of those gag orders.
The report also said the social media giant had detected 67 disruptions of its services in 15 countries, compared to 53 disruptions in nine countries during the second half of last year.
And, the report said Facebook also pulled 11.6 million pieces of content, up from 5.8 million in the same period a year earlier, which Facebook said violated its policies on child nudity and sexual exploitation of children.
The social media giant also included Instagram in its report for the first time, including removing 1.68 million pieces of content during the second and third quarter of the year.
The rise of the internet and the advent of social media have fundamentally changed the information ecosystem, giving the public direct access to more information than ever before. But it’s often nearly impossible to distinguish between accurate information and low-quality or false content. This means that disinformation — false or intentionally misleading information that aims to achieve an economic or political goal — can become rampant, spreading further and faster online than it ever could in another format.
As part of its Truth Decay initiative, RAND is responding to this urgent problem. Researchers identified and characterized the universe of online tools developed by nonprofits and civil society organizations to target online disinformation. The tools in this database are aimed at helping information consumers, researchers, and journalists navigate today’s challenging information environment. Researchers identified and characterized each tool on a number of dimensions, including the type of tool, the underlying technology, and the delivery format.
When you’re scrolling through Facebook’s app, the social network could be watching you back, concerned users have found. Multiple people have found and reported that their iPhone cameras were turned on in the background while they were looking at their feed.
The issue came to light through several posts on Twitter. Users noted that their cameras were activated behind Facebook’s app as they were watching videos or looking at photos on the social network.
After people clicked on the video to full screen, returning it back to normal would create a bug in which Facebook’s mobile layout was slightly shifted to the right. With the open space on the left, you could now see the phone’s camera activated in the background.
This was documented in multiple cases, with the earliest incident on Nov. 2.
It’s since been tweeted a couple other times, and CNET has also been able to replicate the issue.
John de Mol has successfully sued FB and forced them to remove fake ads in which it seems he endorses bitcoins and other cryptocurrencies (he doesn’t). They will not be allowed in the future either and FB must give him the details of the parties who placed the adverts on FB. FB is liable for fines up to EUR 1.1 million if they don’t comply.
Between Oktober 2018 and at least March 2019 a series of fake ads were placed on FB and Instagram that had him endorsing the crypto. He didn’t endorse them at all and not only that, they were a scam: the buyers never received any crypto after purchasing from the sites. The scammers received at least EUR 1.7 million.
The court did not accept FB’s argument that they are a neutral party just passing on information. The court argues that FB has a responsibility to guard against breaches of third party rights. After John de Mol had contacted FB and the ads decreased drastically in frequency shows the court that it is well within FB’s technical possibilities to guard against these breaches.
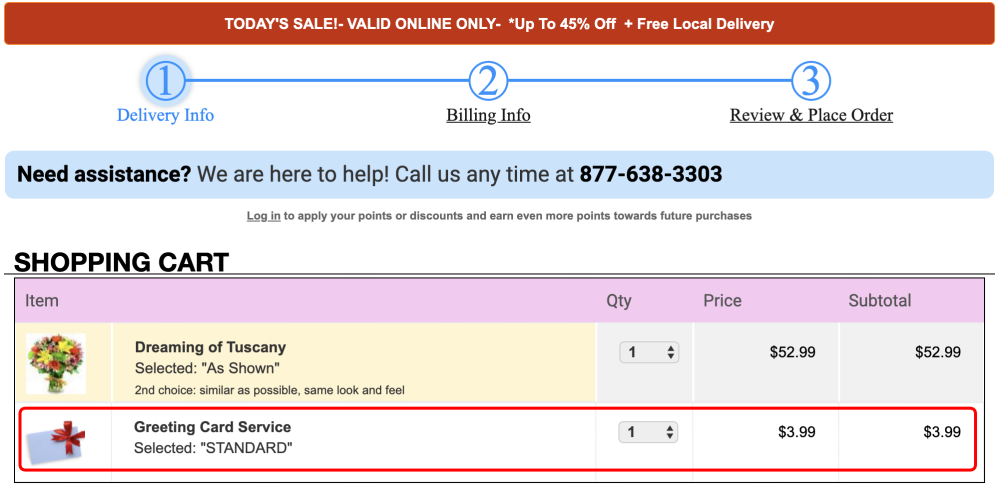
A large-scale academic study that analyzed more than 53,000 product pages on more than 11,000 online stores found widespread use of user interface “dark patterns”– practices meant to mislead customers into making purchases based on false or misleading information.
The study — presented last week at the ACM CSCW 2019 conference — found 1,818 instances of dark patterns present on 1,254 of the ∼11K shopping websites (∼11.1%) researchers scanned.
“Shopping websites that were more popular, according to Alexa rankings, were more likely to feature dark patterns,” researchers said.
But while the vast majority of UI dark patterns were meant to trick users into subscribing to newsletters or allowing broad data collection, some dark patterns were downright foul, trying to mislead users into making additional purchases, either by sneaking products into shopping carts or tricking users into believing products were about to sell out.
Of these, the research team found 234 instances, deployed across 183 websites.
Below are some of the examples of UI dark patterns that the research team found currently employed on today’s most popular online stores.
1. Sneak into basked
Adding additional products to users’ shopping carts without their consent.
Prevalence: 7 instances across 7 websites.
Image: Arunesh et al.
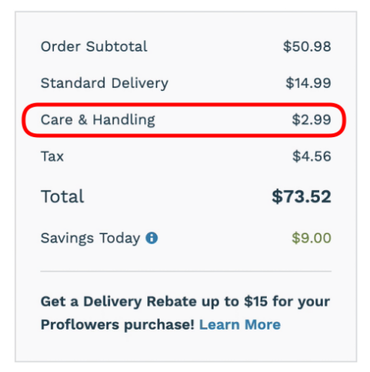
2. Hidden costs
Revealing previously undisclosed charges to users right before they make a purchase.
Prevalence: 5 instances across 5 websites.
Image: Arunesh et al.
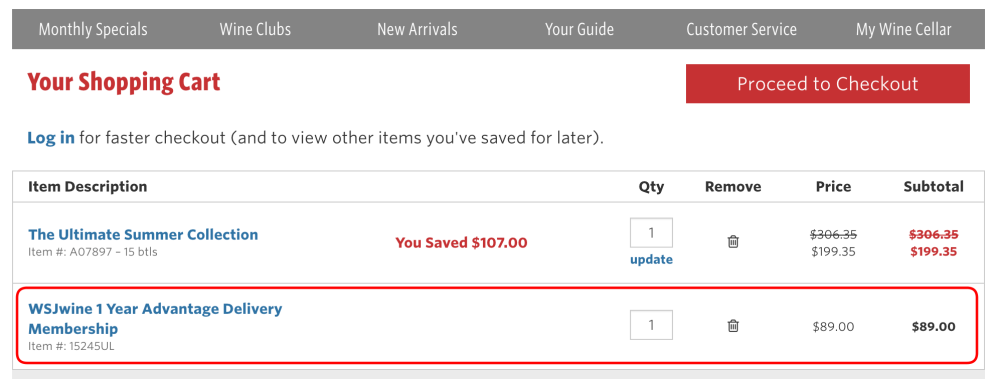
3. Hidden subscription
Charging users a recurring fee under the pretense of a one-time fee or a free trial.
Prevalence: 14 instances across 13 websites.
Image: Arunesh et al.
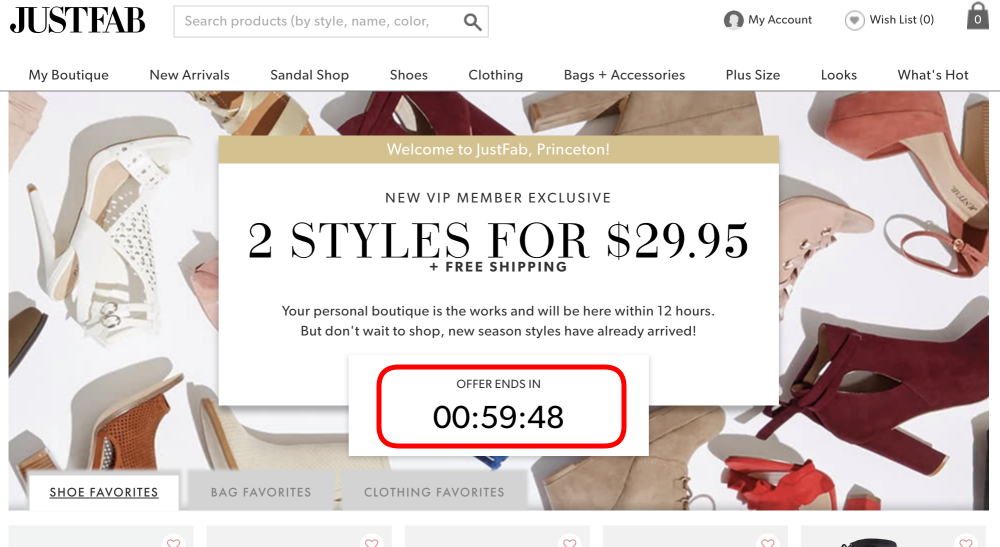
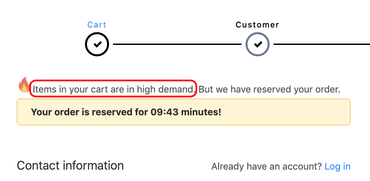
4. Countdown timer
Indicating to users that a deal or discount will expire using a counting-down timer.
Prevalence: 393 instances across 361 websites.
Image: Arunesh et al.
5. Limited-time message
Indicating to users that a deal or sale will expire will expire soon without specifying a deadline, thus creating uncertainty.
Prevalence: 88 instances across 84 websites.
Image: Arunesh et al.
6. Confirmshaming
Using language and emotion (shame) to steer users away from making a certain choice.
Prevalence: 169 instances across 164 websites.
Image: Arunesh et al.
7. Visual interference
Using style and visual presentation to steer users to or away from certain choices.
Prevalence: 25 instances across 24 websites.
Image: Arunesh et al.
8. Trick questions
Using confusing language to steer users into making certain choices.
Prevalence: 9 instances across 9 websites.
Image: Arunesh et al.
9. Pressured selling
Pre-selecting more expensive variations of a product, or pressuring the user to accept the more expensive variations of a product and related products.
Prevalence: 67 instances across 62 websites.
Image: Arunesh et al.
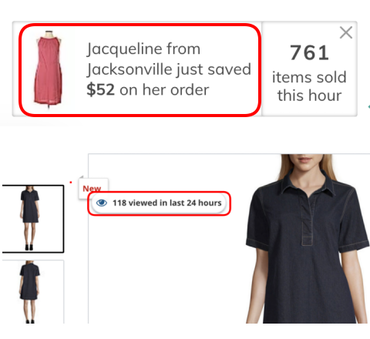
10. Activity messages
Informing the user about the activity on the website (e.g., purchases, views, visits).
Prevalence: 313 instances across 264 websites.
Image: Arunesh et al.
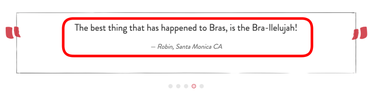
11. Testimonials of uncertain origin
Testimonials on a product page whose origin is unclear.
Prevalence: 12 instances across 12 websites
Image: Arunesh et al.
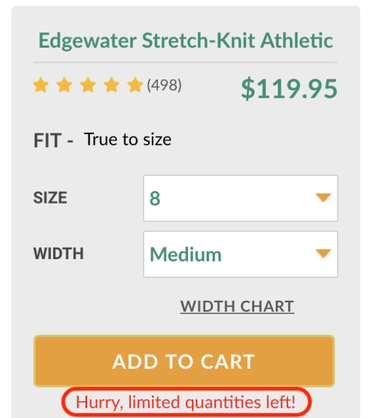
12. Low-stock message
Indicating to users that limited quantities of a product are available, increasing its desirability.
Prevalence: 632 instances across 581 websites.
Image: Arunesh et al.
13. High-demand message
Indicating to users that a product is in high-demand and likely to sell out soon, increasing its desirability
Prevalence: 47 instances across 43 websites.
Image: Arunesh et al.
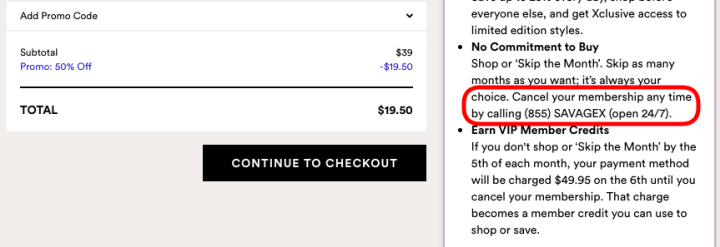
14. Hard to cancel
Making it easy for the user to sign up for a recurring subscription but cancellation requires emailing or calling customer care.
Prevalence: 31 instances across 31 websites.
Image: Arunesh et al.
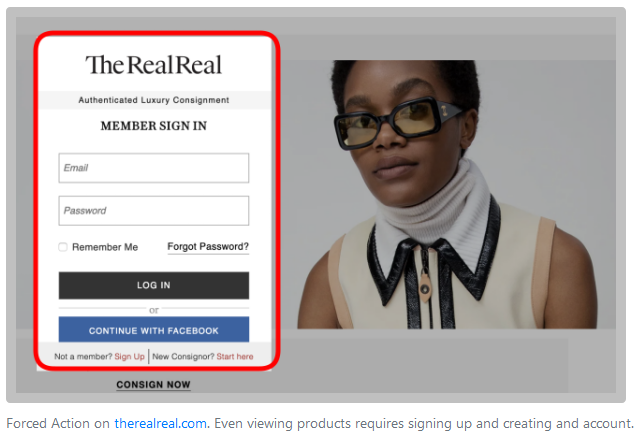
15. Forced enrollment
Coercing users to create accounts or share their information to complete their tasks.
Prevalence: 6 instances across 6 websites.
Image: Arunesh et al.
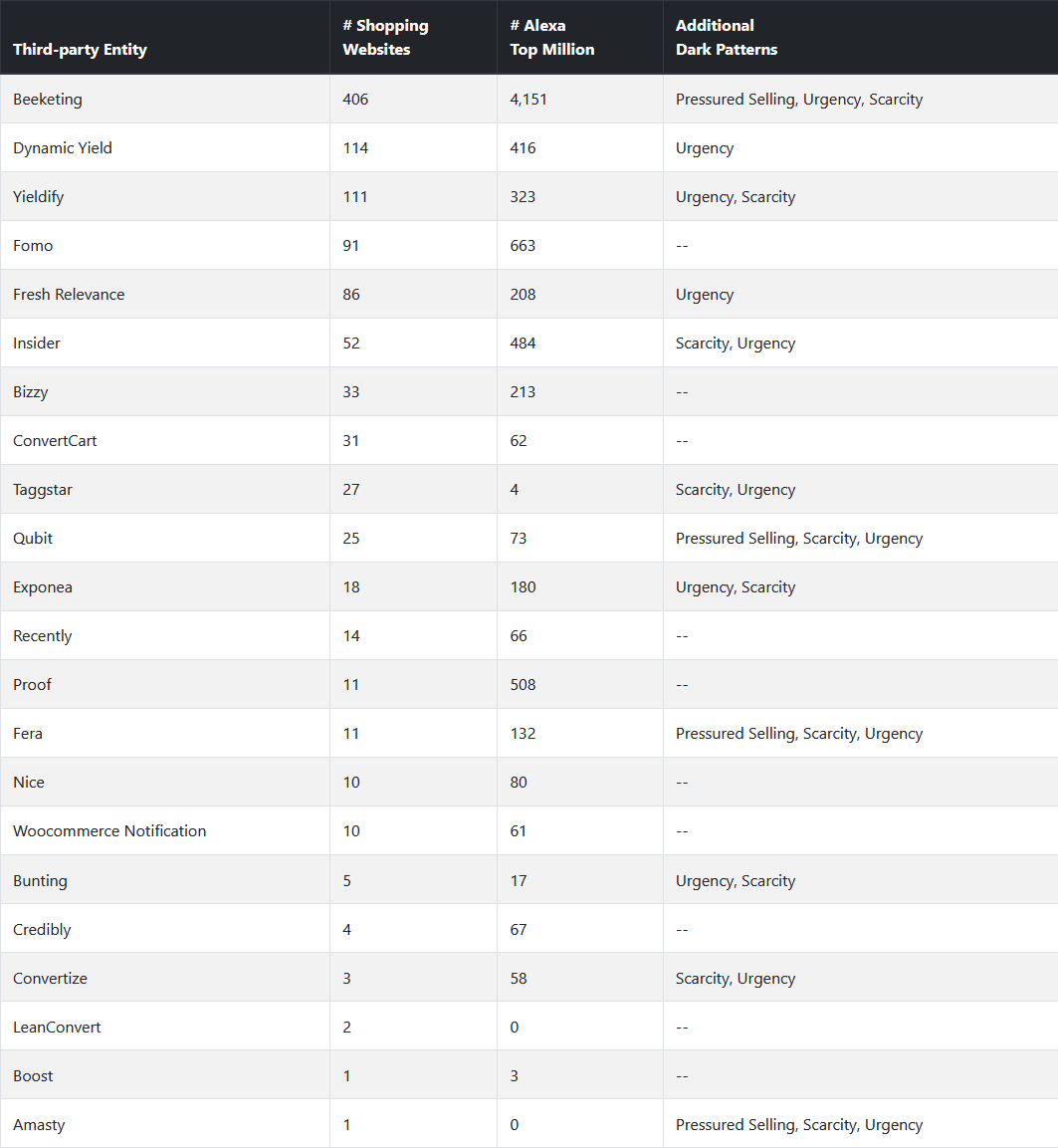
The research team behind this project, made up of academics from Princeton University and the University of Chicago, expect these UI dark patterns to become even more popular in the coming years.
One reason, they said, is that there are third-party companies that currently offer dark patterns as a turnkey solution, either in the form of store extensions and plugins or on-demand store customization services.
The table below contains the list of 22 third-parties that the research team identified following their study as providers of turnkey solutions for dark pattern-like behavior.
The Wall Street Journal reported Monday that the tech giant partnered with Ascension, a non-profit and Catholic health systems company, on the program code-named “Project Nightingale.” According to the Journal, Google began its initiative with Ascension last year, and it involves everything from diagnoses, lab results, birth dates, patient names, and other personal health data—all of it reportedly handed over to Google without first notifying patients or doctors. The Journal said this amounts to data on millions of Americans spanning 21 states.
“By working in partnership with leading healthcare systems like Ascension, we hope to transform the delivery of healthcare through the power of the cloud, data analytics, machine learning, and modern productivity tools—ultimately improving outcomes, reducing costs, and saving lives,” Tariq Shaukat, president of Google Cloud, said in a statement.
Beyond the alarming reality that a tech company can collect data about people without their knowledge for its own uses, the Journal noted it’s legal under the Health Insurance Portability and Accountability Act (HIPAA). When reached for comment, representatives for both companies pointed Gizmodo to a press release about the relationship—which the Journal stated was published after its report—that states: “All work related to Ascension’s engagement with Google is HIPAA compliant and underpinned by a robust data security and protection effort and adherence to Ascension’s strict requirements for data handling.”
Still, the Journal report raises concerns about whether the data handling is indeed as secure as both companies appear to think it is. Citing a source familiar with the matter as well as related documents, the paper said at least 150 employees at Google have access to a significant portion of the health data Ascension handed over on millions of people.
Google hasn’t exactly proven itself to be infallible when it comes to protecting user data. Remember when Google+ users had their data exposed and Google did nothing to alert in order to shield its own ass? Or when a Google contractor leaked more than a thousand Assistant recordings, and the company defended itself by claiming that most of its audio snippets aren’t reviewed by humans? Not exactly the kind of stuff you want to read about a company that may have your medical history on hand.
The agreement gives DeepMind access to a wide range of healthcare data on the 1.6 million patients who pass through three London hospitals run by the Royal Free NHS Trust – Barnet, Chase Farm and the Royal Free – each year. This will include information about people who are HIV-positive, for instance, as well as details of drug overdoses and abortions. The agreement also includes access to patient data from the last five years.
“The data-sharing agreement gives Google access to information on millions of NHS patients”
DeepMind announced in February that it was working with the NHS, saying it was building an app called Streams to help hospital staff monitor patients with kidney disease. But the agreement suggests that it has plans for a lot more.
This is the first we’ve heard of DeepMind getting access to historical medical records, says Sam Smith, who runs health data privacy group MedConfidential. “This is not just about kidney function. They’re getting the full data.”
The agreement clearly states that Google cannot use the data in any other part of its business. The data itself will be stored in the UK by a third party contracted by Google, not in DeepMind’s offices. DeepMind is also obliged to delete its copy of the data when the agreement expires at the end of September 2017.
All data needed
Google says that since there is no separate dataset for people with kidney conditions, it needs access to all of the data in order to run Streams effectively. In a statement, the Royal Free NHS Trust says that it “provides DeepMind with NHS patient data in accordance with strict information governance rules and for the purpose of direct clinical care only.”
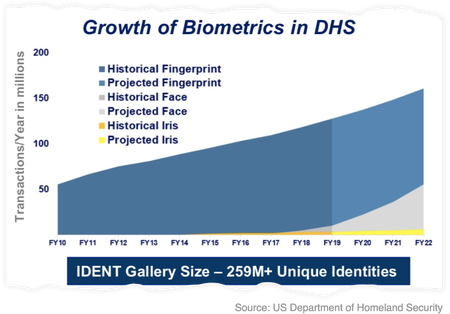
The US Department of Homeland Security (DHS) expects to have face, fingerprint, and iris scans of at least 259 million people in its biometrics database by 2022, according to a recent presentation from the agency’s Office of Procurement Operations reviewed by Quartz.
That’s about 40 million more than the agency’s 2017 projections, which estimated 220 million unique identities by 2022, according to previous figures cited by the Electronic Frontier Foundation (EFF), a San Francisco-based privacy rights nonprofit.
A slide deck, shared with attendees at an Oct. 30 DHS industry day, includes a breakdown of what its systems currently contain, as well as an estimate of what the next few years will bring. The agency is transitioning from a legacy system called IDENT to a cloud-based system (hosted by Amazon Web Services) known as Homeland Advanced Recognition Technology, or HART. The biometrics collection maintained by DHS is the world’s second-largest, behind only India’s countrywide biometric ID network in size. The traveler data kept by DHS is shared with other US agencies, state and local law enforcement, as well as foreign governments.
The first two stages of the HART system are being developed by US defense contractor Northrop Grumman, which won the $95 million contract in February 2018. DHS wasn’t immediately available to comment on its plans for its database.
[…]
Last month’s DHS presentation describes IDENT as an “operational biometric system for rapid identification and verification of subjects using fingerprints, iris, and face modalities.” The new HART database, it says, “builds upon the foundational functionality within IDENT,” to include voice data, DNA profiles, “scars, marks, and tattoos,” and the as-yet undefined “other biometric modalities as required.” EFF researchers caution some of the data will be “highly subjective,” such as information gleaned during “officer encounters” and analysis of people’s “relationship patterns.”
EFF worries that such tracking “will chill and deter people from exercising their First Amendment protected rights to speak, assemble, and associate,” since such specific data points could be used to identify “political affiliations, religious activities, and familial and friendly relationships.”
[…]
EFF researchers said in a 2018 blog post that facial-recognition software, like what the DHS is using, is “frequently…inaccurate and unreliable.” DHS’s own tests found the systems “falsely rejected as many as 1 in 25 travelers,” according to EFF, which calls out potential foreign partners in countries such as the UK, where false-positives can reportedly reach as high as 98%. Women and people of color are misidentified at rates significantly higher than whites and men, and darker skin tones increase one’s chances of being improperly flagged.
“DHS is also partnering with airlines and other third parties to collect face images from travelers entering and leaving the US,” the EFF said. “When combined with data from other government agencies, these troubling collection practices will allow DHS to build a database large enough to identify and track all people in public places, without their knowledge—not just in places the agency oversees, like airports, but anywhere there are cameras.”
Startup insurance provider Lemonade is trying to make the best of a sour situation after T-Mobile parent Deutsche Telekom claimed it owns the exclusive rights to the color magenta.
New York-based Lemonade is a 3-year-old company that lives completely online and mostly focuses on homeowners and renter’s insurance. The company uses a similar color to magenta — it says it’s “pink” — in its marketing materials and its website. But Lemonade was told by German courts that it must cease using its color after launching its services in that country, which is also home to T-Mobile owner Deutsche Telekom. Although the ruling only applies in Germany, Lemonade says it fears the decision will set a precedent and expand to other jurisdictions such as the U.S. or Europe.
“If some brainiac at Deutsche Telekom had invented the color, their possessiveness would make sense,” Daniel Schreiber, CEO and co-founder of Lemonade, said in a statement. “Absent that, the company’s actions just smack of corporate bully tactics, where legions of lawyers attempt to hog natural resources – in this case a primary color—that rightfully belong to everyone.”
A spokesman for Deutsche Telekom confirmed that it “asked the insurance company Lemonade to stop using the color magenta in the German market,” while adding that the “T” in “Deutsche Telekom” is registered to the brand. “Deutsche Telekom respects everyone’s trademark rights but expects others to do the same,” the spokesman said in an emailed statement to Ad Age.
Although Lemonade has complied with the ruling by removing its pink color from marketing materials in Germany, it’s also trying to turn the legal matter into an opportunity. The company today began throwing some shade in social media under the hashtag “#FreeThePink,” though a quick check on Twitter shows it’s gained little traction thus far: Schreiber, the company’s CEO, holds the top tweet under “#FreeThePink” with 13 retweets and 42 likes.
Lemonade also filed a motion today with the European Union Intellectual Property Office, or EUIPO, to invalidate Deutsche Telekom’s magenta trademark.
Facebook on Tuesday disclosed that as many as 100 software developers may have improperly accessed user data, including the names and profile pictures of people in specific groups on the social network.
The company recently discovered that some apps retained access to this type of user data despite making changes to its service in April 2018 to prevent this, Facebook said in a blog post. The company said it has removed this access and reached out to 100 developer partners who may have accessed the information. Facebook said that at least 11 developer partners accessed this type of data in the last 60 days.
“Although we’ve seen no evidence of abuse, we will ask them to delete any member data they may have retained and we will conduct audits to confirm that it has been deleted,” the company said in the blog post.
The company did not say how many users were affected.
Facebook has been restricting software developer access to its user data following reports in March 2018 that political consulting firm Cambridge Analytica had improperly accessed the data of 87 million Facebook users, potentially to influence the outcome of the 2016 U.S. presidential election.
Dutch Filmworks demanded the subscriber data linked to 377 IP adresses they determined illegally downloaded a movie. The judge said no, due to a complete lack of transparency by DFW on how their decision tree works and the amount of money they want to fine the suspects.
Click “Activity controls” from the left-hand sidebar.
Scroll down to the data type you wish to manage, then select “Manage Activity.”
On this next page, click on “Choose how long to keep” under the calendar icon.
Select the auto-deletion time you wish (three or 18 months), or you can choose to delete your data manually.
Click “Next” to save your changes.
Repeat these steps for each of the types of data you want to be auto-deleted. For your Location History in particular, you’ll need to click on “Today” in the upper-left corner first, and then click on the gear icon in the lower-right corner of your screen. Then, select “Automatically delete Location History,” and pick a time.
The vast majority of technology, media and telecom (TMT) companies want to monetise customer data, but are concerned about regulations such as Europe’s GDPR, according to research from law firm Simmons & Simmons.
The outfit surveyed 350 global business leaders in the TMT sector to understand their approach to data commercialisation. It found that 78 per cent of companies have some form of data commercialisation in place but only 20 per cent have an overarching plan for its use.
Alex Brown, global head of TMT Sector at Simmons & Simmons, observed that the firm’s clients are increasingly seeking advice on the legal ways they can monetise data. He said that can either be for internal use, how to use insights into customer behaviour to improve services, or ways to sell anonymised data to third parties.
One example of data monetisation within the sector is Telefónica’s Smart Steps business, which uses “fully anonymised and aggregated mobile network data to measure and compare the number of people visiting an area at any time”.
That information is then sold on to businesses to provide insight into their customer base.
Brown said: “All mobile network operators know your location because the phone is talking to the network, so through that they know a lot about people’s movement. That aggregated data could be used by town planners, transport networks, retailers work out best place to site new store.”
However, he added: “There is a bit of a data paralysis at the moment. GDPR and what we’ve seen recently in terms of enforcement – albeit related to breaches – and the Google fine in France… has definitely dampened some innovation.”
Earlier this year France’s data protection watchdog fined Google €50m for breaching European Union online privacy rules, the biggest penalty levied against a US tech giant. It said Google lacked transparency and clarity in the way it informs users about its handling of personal data and failed to properly obtain their consent for personalised ads.
But Brown pointed out that as long as privacy policies are properly laid out and the data is fully anonymised, companies wanting to make money off data should not fall foul of GDPR.
A confidential Sidewalk Labs document from 2016 lays out the founding vision of the Google-affiliated development company, which included having the power to levy its own property taxes, track and predict people’s movements and control some public services.
The document, which The Globe and Mail has seen, also describes how people living in a Sidewalk community would interact with and have access to the space around them – an experience based, in part, on how much data they’re willing to share, and which could ultimately be used to reward people for “good behaviour.”
Known internally as the “yellow book,” the document was designed as a pitch book for the company, and predates Sidewalk’s relationship and formal agreements with Toronto by more than a year. Peppered with references to Disney theme parks and noted futurist Buckminster Fuller, it says Sidewalk intended to “overcome cynicism about the future.”
But the 437-page book documents how much private control of city services and city life Google parent company Alphabet Inc.’s leadership envisioned when it created the company,
[…]
“The ideas contained in this 2016 internal paper represent the result of a wide-ranging brainstorming process very early in the company’s history,” Sidewalk spokesperson Keerthana Rang said. “Many, if not most, of the ideas it contains were never under consideration for Toronto or discussed with Waterfront Toronto and governments. The ideas that we are actually proposing – which we believe will achieve a new model of inclusive urban growth that makes housing more affordable for families, creates new jobs for residents, and sets a new standard for a healthier planet – can all be found at sidewalktoronto.ca.”
[…]
To carry out its vision and planned services, the book states Sidewalk wanted to control its area much like Disney World does in Florida, where in the 1960s it “persuaded the legislature of the need for extraordinary exceptions.” This could include granting Sidewalk taxation powers. “Sidewalk will require tax and financing authority to finance and provide services, including the ability to impose, capture and reinvest property taxes,” the book said. The company would also create and control its own public services, including charter schools, special transit systems and a private road infrastructure.
Sidewalk’s early data-driven vision also extended to public safety and criminal justice.
The book mentions both the data-collection opportunities for police forces (Sidewalk notes it would ask for local policing powers similar to those granted to universities) and the possibility of “an alternative approach to jail,” using data from so-called “root-cause assessment tools.” This would guide officials in determining a response when someone is arrested, such as sending someone to a substance abuse centre. The overall criminal justice system and policing of serious crimes and emergencies would be “likely to remain within the purview of the host government’s police department,” however.
Data collection plays a central role throughout the book. Early on, the company notes that a Sidewalk neighbourhood would collect real-time position data “for all entities” – including people. The company would also collect a “historical record of where things have been” and “about where they are going.” Furthermore, unique data identifiers would be generated for “every person, business or object registered in the district,” helping devices communicate with each other.
There would be a quid pro quo to sharing more data with Sidewalk, however. The document describes a tiered level of services, where people willing to share data can access certain perks and privileges not available to others. Sidewalk visitors and residents would be “encouraged to add data about themselves and connect their accounts, either to take advantage of premium services like unlimited wireless connectivity or to make interactions in the district easier,” it says.
Shoshana Zuboff, the Harvard University professor emerita whose book The Age of Surveillance Capitalism investigates the way Alphabet and other big-tech companies are reshaping the world, called the document’s revelations “damning.” The community Alphabet sought to build when it launched Sidewalk Labs, she said, was like a “for-profit China” that would “use digital infrastructure to modify and direct social and political behaviour.”
While Sidewalk has since moved away from many of the details in its book, Prof. Zuboff contends that Alphabet tends to “say what needs be said to achieve commercial objectives, while specifically camouflaging their actual corporate strategy.”
[…]
hose choosing to remain anonymous would not be able to access all of the area’s services: Automated taxi services would not be available to anonymous users, and some merchants might be unable to accept cash, the book warns.
The document also describes reputation tools that would lead to a “new currency for community co-operation,” effectively establishing a social credit system. Sidewalk could use these tools to “hold people or businesses accountable” while rewarding good behaviour, such as by rewarding a business’s good customer service with an easier or cheaper renewal process on its licence.
This “accountability system based on personal identity” could also be used to make financial decisions.
“A borrower’s stellar record of past consumer behaviour could make a lender, for instance, more likely to back a risky transaction, perhaps with the interest rates influenced by digital reputation ratings,” it says.
The company wrote that it would own many of the sensors it deployed in the community, foreshadowing a battle over data control that has loomed over the Toronto project.
Facebook has ended its appeal against the UK Information Commissioner’s Office and will pay the outstanding £500,000 fine for breaches of data protection law relating to the Cambridge Analytica scandal.
Prior to today’s announcement, the social network had been appealing against the fine, alleging bias and requesting access to ICO documents related to the regulator’s decision making. The ICO, in turn, was appealing a decision that it should hand over these documents.
The issue for the watchdog was the misuse of UK citizens’ Facebook profile information, specifically the harvesting and subsequent sale of data scraped from their profiles to Cambridge Analytica, the controversial British consulting firm used by US prez Donald Trump’s election campaign.
The app that collected the data was “thisisyourdigitallife”, created by Cambridge developer Aleksandr Kogan. It hoovered up Facebook users’ profiles, dates of birth, current city, photos in which those users were tagged, pages they had liked, posts on their timeline, friends’ lists, email addresses and the content of Facebook messages. The data was then processed in order to create a personality profile of the user.
“Given the way our platform worked at the time,” Zuck has said, “this meant Kogan was able to access tens of millions of their friends’ data”. Facebook has always claimed it learned of the data misuse from news reports, though this has been disputed.
Both sides will now end the legal fight and Facebook will pay the ICO a fine but make no admission of liability or guilt. The money is not kept by the data protection watchdog but goes to the Treasury consolidated fund and both sides will pay their own costs. The ICO spent an eye-watering £2.5m on the Facebook probe.
VP of product Scott Williamson announced on 10 October that “to make GitLab better faster, we need more data on how users are using GitLab”.
GitLab is a web application that runs on Linux, with options for self-hosting or using the company’s cloud service. It is open source, with both free and licensed editions.
Williamson said that while nothing was changing with the free self-hosted Community Edition, the hosted and licensed products would all now “include additional JavaScript snippets (both open source and proprietary) that will interact with both GitLab and possibly third-party SaaS telemetry services (we will be using Pendo)”. The only opt-out was to be support for the Do Not Track browser mechanism.
GitLab customers and even some staff were not pleased. For example, Yorick Peterse, a GitLab staff developer, said telemetry should be opt-in and that the requisite update to the terms of service would break some API usage (because bots do not know how to accept terms of service), adding: “We have plenty of customers who would not be able to use GitLab if it starts tracking data for on-premises installations.”
There is more background in the issue here, which concerns adding the identity of the user to the Snowplow analytics service used by GitLab.
“This effectively changes our Snowplow integration from being an anonymous aggregated thing to a thing that tracks user interaction,” engineering manager Lukas Eipert said back in July. “Ethically, I have problems with this and legally this could have a big impact privacy wise (GDPR). I hereby declare my highest degree of objection to this change that I can humanly express.”
On the other hand, GitLab CFO Paul Machle said: “This should not be an opt in or an opt out. It is a condition of using our product. There is an acceptance of terms and the use of this data should be included in that.”
On 23 October, an email was sent to GitLab customers announcing the changes.
Yesterday, however, CEO Sid Sijbrandij put the plans on hold, saying: “Based on considerable feedback from our customers, users, and the broader community, we reversed course the next day and removed those changes before they went into effect. Further, GitLab will commit to not implementing telemetry in our products that sends usage data to a third-party product analytics service.” Sijbrandij also promised a review of what went wrong. “We will put together a new proposal for improving the user experience and share it for feedback,” he said.
Despite this embarrassing backtrack, the incident has demonstrated that GitLab does indeed have an open process, with more internal discussion on view than would be the case with most companies. Nevertheless, the fact that GitLab came so close to using personally identifiable tracking without specific opt-in has tarnished its efforts to appear more community-driven than alternatives like Microsoft-owned GitHub. ®
Google’s Senior Vice President of Devices & Services, Rick Osterloh, broke the news on the official Google blog, saying:
Over the years, Google has made progress with partners in this space with Wear OS and Google Fit, but we see an opportunity to invest even more in Wear OS as well as introduce Made by Google wearable devices into the market. Fitbit has been a true pioneer in the industry and has created engaging products, experiences and a vibrant community of users. By working closely with Fitbit’s team of experts, and bringing together the best AI, software and hardware, we can help spur innovation in wearables and build products to benefit even more people around the world.
Earlier this week, on October 28, a report from Reuters surfaced to indicate that Google was in a bid to purchase Fitbit. It’s a big move, but it’s also one that makes good sense.
Google’s Wear OS wearable platform has been in something of a rut for the last few years. The company introduced the Android Wear to Wear OS rebrand in 2018 to revitalize its branding/image, but the hardware offerings have still been pretty ho-hum. Third-party watches like the Fossil Gen 5 have proven to be quite good, but without a proper “Made by Google” smartwatch and other major players, such as Samsung, ignoring the platform, it’s been left to just sort of exist.
Google employees are accusing the company’s leadership of developing an internal surveillance tool that they believe will be used to monitor workers’ attempts to organize protests and discuss labor rights.
Earlier this month, employees said they discovered that a team within the company was creating the new tool for the custom Google Chrome browser installed on all workers’ computers and used to search internal systems. The concerns were outlined in a memo written by a Google employee and reviewed by Bloomberg News and by three Google employees who requested anonymity because they aren’t authorized to talk to the press
The BBC has made its international news website available via the Tor network, in a bid to thwart censorship attempts.
The Tor browser is privacy-focused software used to access the dark web.
The browser can obscure who is using it and what data is being accessed, which can help people avoid government surveillance and censorship.
Countries including China, Iran and Vietnam are among those who have tried to block access to the BBC News website or programmes.
Instead of visiting bbc.co.uk/news or bbc.com/news, users of the Tor browser can visit the new bbcnewsv2vjtpsuy.onion web address. Clicking this web address will not work in a regular web browser.
The dark web copy of the BBC News website will be the international edition, as seen from outside the UK.
It will include foreign language services such as BBC Arabic, BBC Persian and BBC Russian.
But UK-only content and services such as BBC iPlayer will not be accessible, due to broadcast rights.
What is Tor?
Tor is a way to access the internet that requires software, known as the Tor browser, to use it.
The name is an acronym for The Onion Router. Just as there are many layers to the vegetable, there are many layers of encryption on the network.
It was originally designed by the US Naval Research Laboratory, and continues to receive funding from the US State Department.
It attempts to hide a person’s location and identity by sending data across the internet via a very circuitous route involving several “nodes” – which, in this context, means using volunteers’ PCs and computer servers as connection points.
Encryption applied at each hop along this route makes it very hard to connect a person to any particular activity.
The UK government could use facial recognition to verify the age of Brits online “so long as there is an appropriate concern for privacy,” junior minister for Digital, Culture, Media and Sport Matt Warman said.
The minister was responding to an urgent Parliamentary question directed to Culture Secretary Nicky Morgan about the future of Blighty’s online age-verification system, following her announcement this week that the controversial project had been dropped. He indicated the government is still keen to shield kids from adult material online, one way or another.
“In many ways, this is a technology problem that requires a technology solution,” Warman told the House of Commons on Thursday.
“People have talked about whether facial recognition could be used to verify age, so long as there is an appropriate concern for privacy. All of these are things I hope we will be able to wrap up in the new approach, because they will deliver better results for consumers – child or adult alike.”
The government also managed to spend £2.2m on the aforementioned-and-now-shelved proposal to introduce age-verification checks on netizens viewing online pornography, Warman admitted in his response.
For years I’ve gone back and forth over the practice of obscuring license plates on photos on the internet. License plates are already publicly-viewable things, so what’s the point in obscuring them, right? Well, now I think there actually is a good reason to obscure your license plates in photos because it appears that Google and Facebook are actually reading the plates in photos, and then making the actual license plate alphanumeric sequence searchable. I tested it. It works.
Starting with Google, the way this works is to search for the license plate number using Google Images. That’s it.
In my testing, I started with my own cars that I know have had images of their license plates in Jalopnik articles. For my Nissan Pao, a search of my license plate number brings up an image of my car, from one of my articles, as the first result:
It’s worth noting that the image search results aren’t even trying to differentiate the search term as a license plate; the number sequence has just been tagged to the photo automatically after whatever hidden Google OCR system reads the license plate. This can mean that someone searching a similar sequence of characters could likely end up with a result for your car if enough of those characters match your license plate.
[…]
I just checked a test I did on Facebook earlier today to see if they’re reading and tagging license plates, and, yep, it appears they are:
So, people can type your license plate into Facebook and, if it’s visible in any of your photos, it seems like it’ll show up! Great for you budding stalkers out there!
The takeaway here is that you should just assume your license plate is known and tagged to pictures of your car. Even if you obscure your plate in every image you yourself post, there’s no way to know what images your car and its license plate may be in the background of, meaning if it’s not searchable yet, it likely will be.
I suppose the positive side is that if you see a hit and run or someone’s blocking you in, it’s a lot easier to find out who’s being the jerk. On the negative side, it’s just a reminder that privacy in so many ways is eroding away, and there’s damn little we can do about it.
Today, when you use Wizards Unite or Pokémon Go or any of Niantic’s other apps, your every move is getting documented and stored—up to 13 times a minute, according to the results of a Kotaku investigation. Even players who know that the apps record their location data are usually astonished once they look at just how much they’ve told Niantic about their lives through their footsteps.
For years, users of these technologists’ products—from Google Street View to Pokémon Go—have been questioning how far they’re going with users’ information and whether those users are adequately educated on what they’re giving up and with whom it’s shared. In the process, those technologists have made mistakes, both major and minor, with regards to user privacy. As Niantic summits the world of augmented reality, it’s engineering that future of that big-money field, too. Should what Niantic does with its treasure trove of valuable data remain shrouded in the darkness particular to up-and-coming Silicon Valley darlings, that opacity might become so normalized that users lose any expectation of knowing how they’re being profited from.
Niantic publicly describes itself as a gaming company with an outsized passion for getting gamers outside. Its games, from Ingress to Pokémon Go to Wizards Unite, encourage players to navigate and interact with the real world around them, whether it be tree-lined suburbs, big cities, local landmarks, the Eiffel Tower, strip malls, or statues in the town square. Niantic’s ever-evolving gaming platform closely resembles Google Maps, in part because Niantic spawned from just that.
[…]
At 2019’s GDC, Hanke showed a video titled “Hyper-Reality,” by the media artist Keiichi Matsuda. It’s a dystopian look at a future in which the entire world is slathered with virtual overlays, an assault on the senses that everyone must view through an AR headset if they want to participate in modern society. In the video, the protagonist’s entire field of vision is a spread of neon notifications, apps, and advertisements, all viewed from a seat at the back of a city bus. Their hands swipe across a game they’re playing in augmented reality, while in the background an ad for Starbucks Coffee indicates they won a coupon for a free cup. Push notifications in their periphery indicate three new messages and directions for where to exit the bus. Walking through the aisle, where digital “get off now!” signs indicate it’s their stop, and onto the street, the physical world is annotated with virtual information. The more tasks they accomplish, the more points they receive. The whole world is now one big game. It showed a definitively dystopian vision of a world in which the barriers between IRL and URL have been fully collapsed.
Hanke said that the video made him feel “stressed and nervous.” Calling it a work of “critical design,” he noted that it was meant to question this dystopian future for AR, “a world where you’re tracked everywhere you go, where giant companies know everything about you, your identity is constantly at stake, and the world itself is noisy, and busy and plastered with distractions.”
But when a path appeared in front of the video’s protagonist showing them where to walk, Hanke’s response was: “That looks helpful.”
“Some people would say AR is a bad thing because we’ve seen this vision of how bad it can be,” Hanke said. “The point I want to make to you all is, it doesn’t have to be that way.” He showed an image of the Ferry Building, the 120-year-old piece of classical revival architecture in San Francisco where the company is currently headquartered. Just like in the video, it was overlaid with augmented reality windows showing the building’s history, a public transit schedule, and tabs for nearby restaurants. Hanke described a world where people can better navigate public transit and understand their surroundings because of digital mapping initiatives like Niantic. He talked about the possibility of hologram tour guides in San Francisco, and how they’d rely on a digital map to navigate their surroundings, and about designing shared experiences of Pokémon games in a Pokémon-augmented world.
[…]
Since its 2016 release, Pokémon Go has netted over $2.3 billion. In it, players collect items from PokeStops—also real-life locations and landmarks—so they can catch and collect Pokémon, which spawn around them. Almost immediately, Pokémon Go sparked its own privacy controversy, also blamed on a bug, which involved users giving Niantic a huge number of permissions: contacts, location, storage, camera and, for iPhone users, full Google account access, which was not integral to gameplay. Minnesota senator Al Franken penned a strongly-worded letter to Niantic about it, expressing concern “about the extent to which Niantic may be unnecessarily collecting, using, and sharing a wide range of users’ personal information without their appropriate consent.” Niantic said that the “account creation process on iOS erroneously requests full access permission,” adding that Pokémon Go only got user ID and email address info.
[…]
Players give Wizards Unite permission to track their movement using a combination of GPS, Wi-Fi, and mobile cell tower triangulation. To understand the extent of this location data, Kotaku asked for data from European players who had all filed personal information requests to Niantic under the GDPR, the European digital privacy legislation designed to give EU citizens more control over their personal data. Niantic sent these players all the data it had on them, which the players then shared with Kotaku.
The files we received contained detailed information about the lives of these players: the number of calories they likely burned during a given session, the distance they traveled, the promotions they engaged with. Crucially, each request also contained a large file of timestamped location data, as latitudes and longitudes.
In total, Kotaku analyzed more than 25,000 location records voluntarily shared with us by 10 players of Niantic games. On average, we found that Niantic kept about three location records per minute of gameplay of Wizards Unite, nearly twice as many as it did with Pokémon Go. For one player, Niantic had at least one location record taken during nearly every hour of the day, suggesting that the game was collecting data and sharing it with Niantic even when the player was not playing.
When Kotaku first asked Niantic why Wizards Unite was collecting location data even while the game was not actively being played, its first response was that we must be mistaken, since the game, it said, did not collect data while backgrounded. After we provided Niantic with more information about that player, it got back to us a few days later to let us know that its engineering team “did identify a bug in the Android version of the client code that led it to continue to ping our servers intermittently when the app was still open but had been backgrounded.” The bug, Niantic said, has now been fixed.
Because the location data collected by Wizards Unite and sent to Niantic is so granular, sometimes up to 13 location records a minute, it is possible to discern individual patterns of user behavior as well as intimate details about a player’s life.
[…]
Niantic is far from the only company collecting this sort of data. Last year, the New York Times published an expose on how over 75 companies receive pinpoint-accurate, anonymous location data from phone apps on over 200 million devices. Sometimes, these companies tracked users’ locations over 14,000 times a day. The result was always the same: Even though users had signed away their location data to these companies by agreeing to their user agreements, a lot of the time, they generally had no idea that companies were taking such exhaustive notes on what kind of person they are, where they’d been, where they were likely to go next, and whether they’d buy something there.
That Niantic is yet another company that can infer this type of mundane personal information may not be, in itself, surprising. Credit card companies, email providers, cellular services, and a variety of data brokers all have access to your personal information in increasingly opaque ways. Remember when Target figured out that a high school girl was pregnant before her family did?
It’s important to note that the personal data that players requested from Niantic and voluntarily shared with Kotaku is, according to Niantic, not something that a third party could buy from them, or otherwise be allowed to see. “Niantic does not share individual player data with third party sponsored location partners,” a representative said, adding that it uses “additional mechanisms to process the data so that it cannot be connected to an individual.”
Niantic’s Kawai told Kotaku that the anonymized data that Niantic shares with third parties is only in the form of “aggregated stats,” such as “how many people have had access or went to those in-game locations and how many actions people take in those in-game locations, how many PokeStop spins to get items happened on that day and… what unique number of people went to that location.”
“We don’t go any further than that,” he said.
The idea that data can successfully be anonymized has long been a contentious one. In July, researchers at Imperial College London were able to accurately reidentify 99.98 percent of Americans in an “anonymized” dataset. And in 2018, a New York Times investigation found that, when provided raw anonymized location data, companies could identify individuals with or without their consent. In fact, according to experts, it can take just four timestamped location records to specifically identify an individual from a collection of latitudes and longitudes that they have visited.
[…]
Niantic makes a staggering amount of money off in-game microtransactions, a reported $1.8 billion in Pokémon Go’s first two years. It also makes money from sponsorships. By late 2017, there were over 35,000 sponsored PokeStops, which players visited over 500 million times. Hanke described foot traffic as the “holy grail of retail businesses” in a 2017 talk to the Mobile World Congress. 13,000 of the sponsored stops were Starbucks locations.
[…]
“We have always been transparent about this product and feel it is a much better experience for our players than the kind of video and text ads frequently deployed in other mobile games,” Hanke told Kotaku. He then shared a link to an Ad Age article announcing Pokémon Go’s sponsored locations and detailing its “cost per visit” business model.
Big-money tech companies rarely make money in just one or two ways, and often inconspicuously employ money-making strategies that may be less palatable to privacy-minded consumers. Mobile app companies are notorious for this. One 2017 Oxford study, for example, analyzed 1 million smartphone apps and determined that the median Google Play Store app can share users’ behavioral data with 10 third parties, while one in five can share it with over 20. “Freemium” mobile apps can earn big revenue from sharing data with advertisers—and it’s all completely opaque to users, as a Buzzfeed News report explained in 2018.
A graph illustrating the number of location records captured for one Harry Potter: Wizards Unite user per minute, over the span of a few hours.
Image: Kotaku
Advertising market research company Emarketer projected that advertisers will spend $29 billion on location-targeted advertising, also referred to as “geoconquesting,” this year. Marketers target and tailor ads for app users in a specific location in real-time, segment a potential audience for an ad by location, learn about consumers based on where they were before they bought something, and connect online ads to offline purchases using location data—another manifestation of “ubiquitous computing.” One of the biggest location-targeted ad companies, GroundTruth, taps data from 120 million unique monthly users to drive people to businesses like Taco Bell, where it recently took credit for 170,000 visits after a location-targeted ad campaign.
[…]
Niantic said it is not in the business of selling user location data. But it will send its users to you. Wizards Unite recently partnered with Simon Malls, which owns over 200 shopping centers, to add “multiple sponsored Inns and Fortresses” at each location, “giving players more XP and more spell energy than at any other non-sponsored location in the U.S.”
[…]
If the goal is to unite the physical with the digital, insights gleaned from how long users loiter outside a Coach store and how long they might look at a Coach Instagram ad could be massively useful to these waning mall brands. Uniting these worlds for a field trip around Tokyo is one thing; uniting them to consolidate digital and physical ad profiles is another.
“This is a hot topic in mall operation—tracking the motion of people within a mall, what stores they’re going to, how long they’re going,” said Ron Merriman, a theme park business strategist based in Shanghai (who, he noted after we contacted him for this story, happened to go to business school with Hanke). Merriman says that tracking users in malls, aquariums, and theme parks to optimize merchandising, user experiences, and ad targeting is becoming the norm where he lives in Asia. Retailers polled by Emarketer in late 2018 planned on investing more in proximity and location-based marketing than other emerging, hot-topic technologies like AI.
Apple admits that it sends some user IP addresses to Tencent in the “About Safari & Privacy” section of its Safari settings which can be accessed on an iOS device by opening the Settings app and then selecting “Safari > About Privacy & Security.” Under the title “Fraudulent Website Warning,” Apple says:
“Before visiting a website, Safari may send information calculated from the website address to Google Safe Browsing and Tencent Safe Browsing to check if the website is fraudulent. These safe browsing providers may also log your IP address.”
The “Fraudulent Website Warning” setting is toggled on by default which means that unless iPhone or iPad users dive two levels deep into their settings and toggle it off, their IP addresses may be logged by Tencent or Google when they use the Safari browser. However, doing this makes browsing sessions less secure and leaves users vulnerable to accessing fraudulent websites.
[…]
Even if people install a third-party browser on their iOS device, viewing web pages inside apps still opens them in an integrated form of Safari called Safari View Controller instead of the third-party browser. Tapping links inside apps also opens them in Safari rather than a third-party browser. These behaviors that force people back into Safari make it difficult for people to avoid the Safari browser completely when using an iPhone or iPad.
Citing sources familiar with the program, Bloomberg reported Thursday that “dozens” of workers for the e-commerce giant who are based in Romania and India are tasked with reviewing footage collected by Cloud Cams—Amazon’s app-controlled, Alexa-compatible indoor security devices—to help improve AI functionality and better determine potential threats. Bloomberg reported that at one point, these human workers were responsible for reviewing and annotating roughly 150 security snippets of up to 30 seconds in length each day that they worked.
Two sources who spoke with Bloomberg told the outlet that some clips depicted private imagery, such as what Bloomberg described as “rare instances of people having sex.” An Amazon spokesperson told Gizmodo that reviewed clips are submitted either through employee trials or customer feedback submissions for improving the service.
[…]
So to be clear, customers are sharing clips for troubleshooting purposes, but they aren’t necessarily aware of what happens with that clip after doing so.
More troubling, however, is an accusation from one source who spoke with Bloomberg that some of these human workers tasked with annotating the clips may be sharing them with members outside of their restricted teams, despite the fact that reviews happen in a restricted area that prohibits phones. When asked about this, a spokesperson told Gizmodo by email that Amazon’s rules “strictly prohibit employee access to or use of video clips submitted for troubleshooting, and have a zero tolerance policy for about of our systems.”
[…]
To be clear, it’s not just Amazon who’s been accused of allowing human workers to listen in on whatever is going on in your home. Motherboard has reported that both Xbox recordings and Skype calls are reviewed by human contractors. Apple, too, was accused of capturing sensitive recordings that contractors had access to. The fact is these systems just aren’t ready for primetime and need human intervention to function and improve—a fact that tech companies have successfully downplayed in favor of appearing to be magical wizards of innovation.
Twitter says it was just an accident that caused the microblogging giant to let advertisers use private information to better target their marketing materials at users.
The social networking giant on Tuesday admitted to an “error” that let advertisers have access to the private information customers had given Twitter in order to place additional security protections on their accounts.
“We recently discovered that when you provided an email address or phone number for safety or security purposes (for example, two-factor authentication) this data may have inadvertently been used for advertising purposes, specifically in our Tailored Audiences and Partner Audiences advertising system,” Twitter said.
“When an advertiser uploaded their marketing list, we may have matched people on Twitter to their list based on the email or phone number the Twitter account holder provided for safety and security purposes. This was an error and we apologize.”
Twitter assures users that no “personal” information was shared, though we’re not sure what Twitter would consider “personal information” if your phone number and email address do not meet the bar.