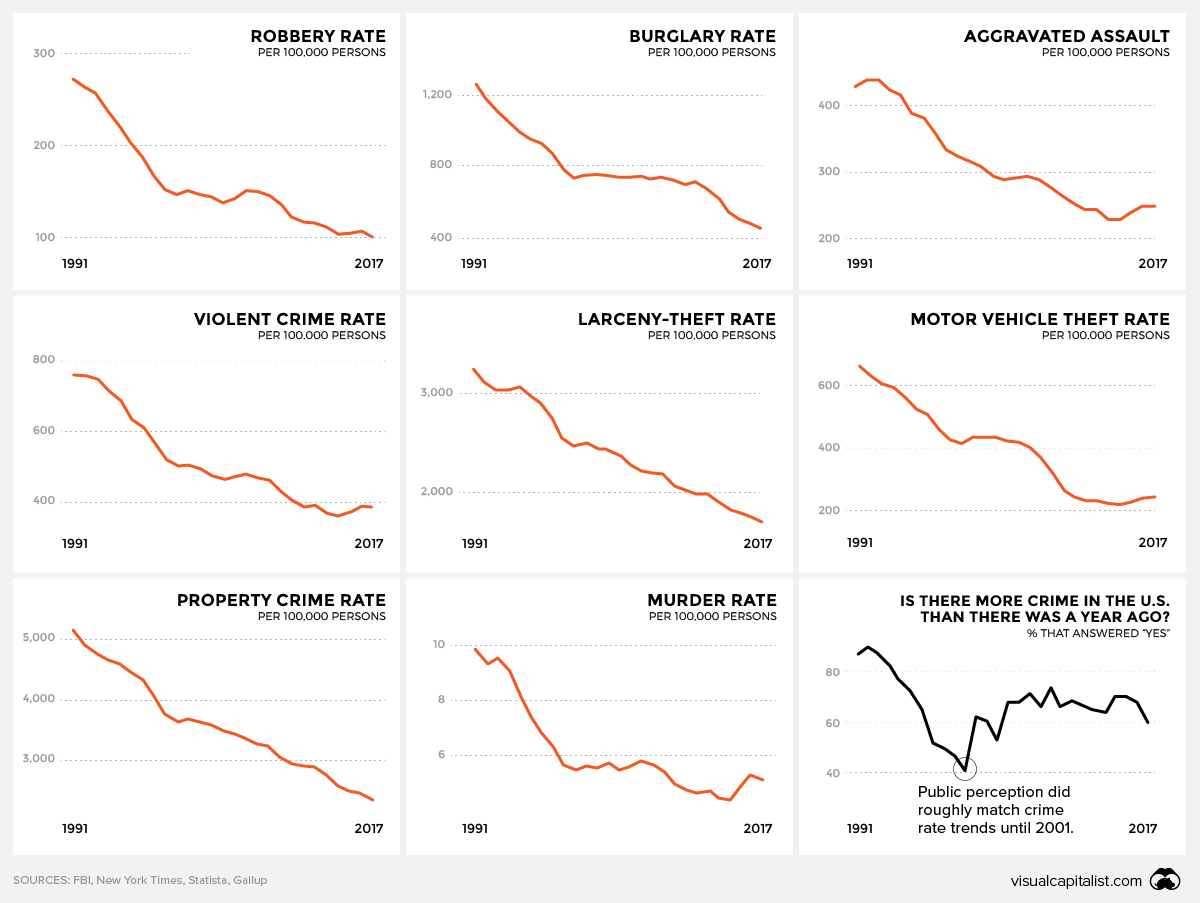
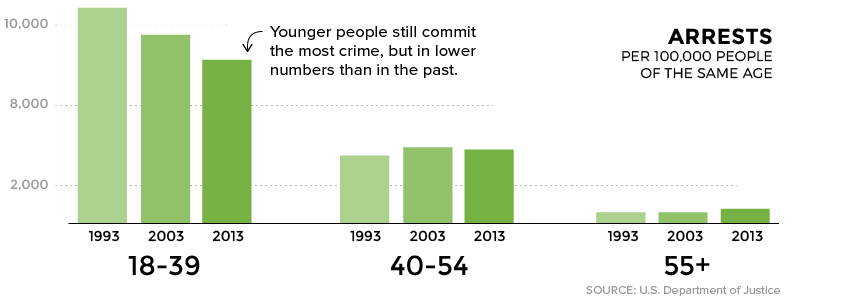
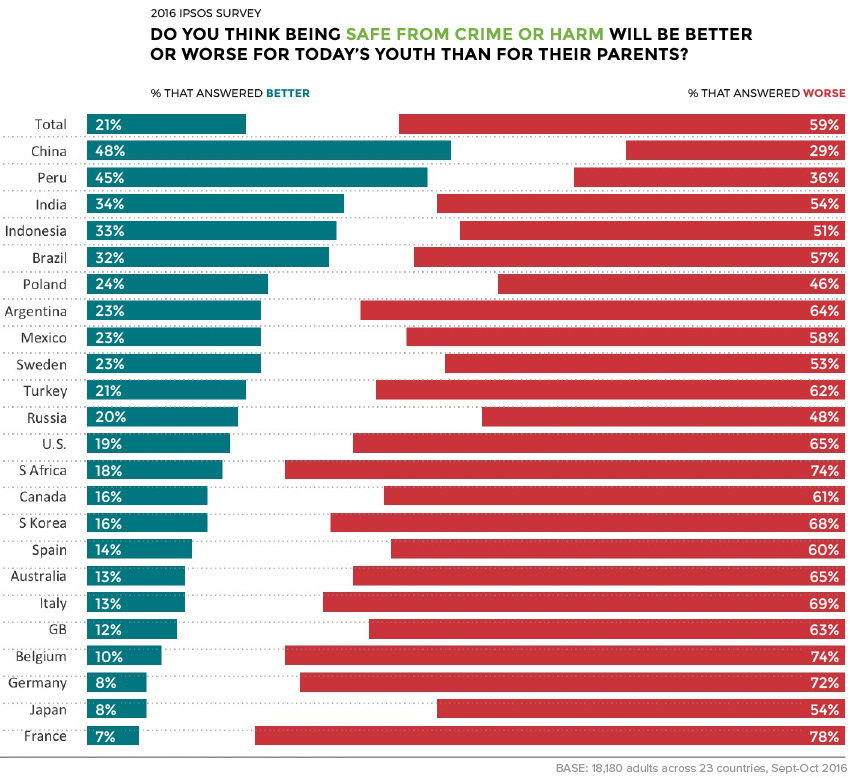
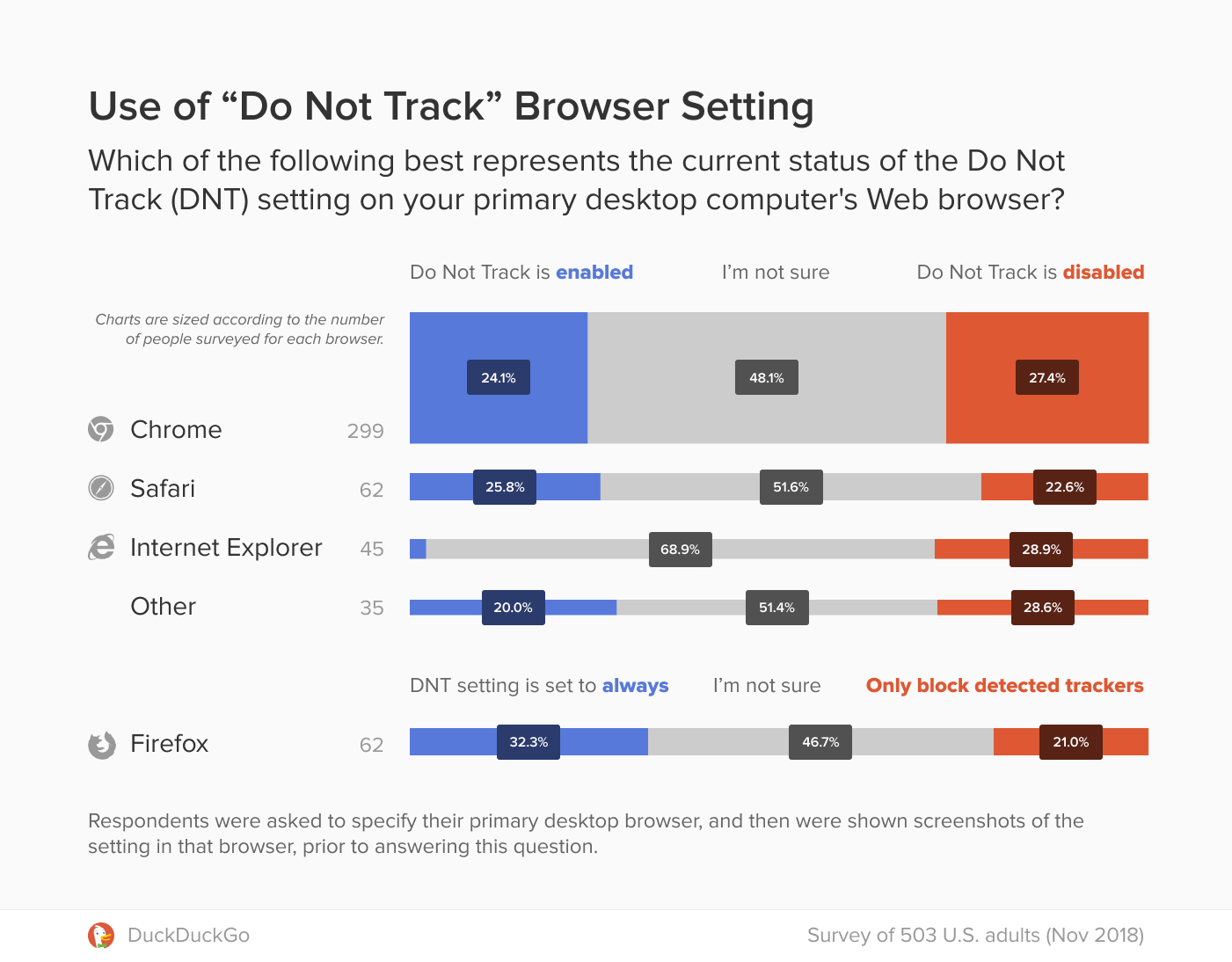
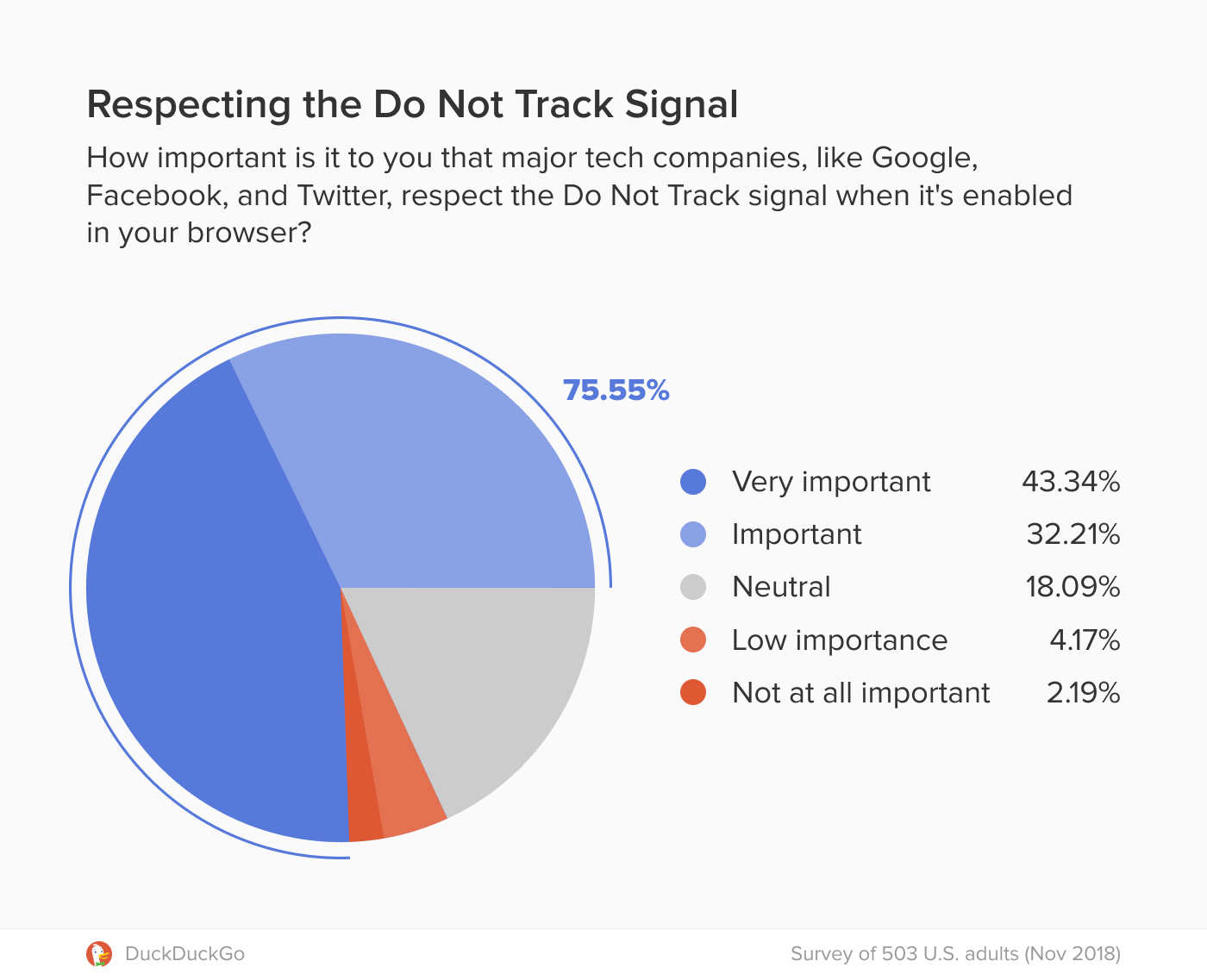
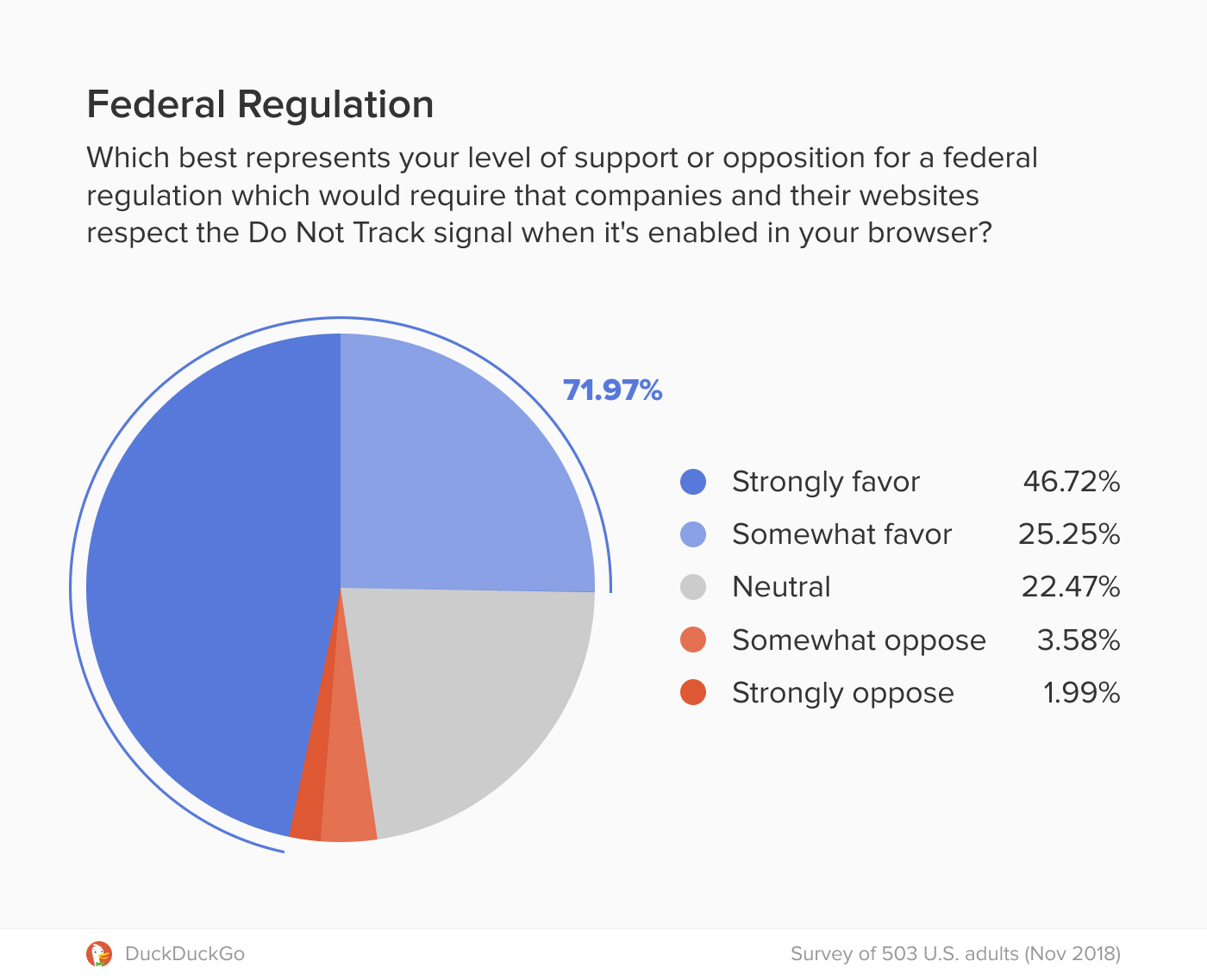
The last time the EU tweaked its copyright laws was in 2001, so the idea of updating regulations in the information age made a lot of sense. But critics became alarmed by two sections of the bill: Article 11 (aka the “link tax”) and Article 13 (aka the “upload filters”). In 2018, critics like Tim Berners-Lee, the inventor of the world wide web, began to warn that these portions of the legislation would have dire and unintended consequences.
Lawmakers hope to wrestle away some of the power that has been gobbled up by tech giants like Facebook and redirect money to struggling copyright holders and publications. Unfortunately, the law may create an environment that’s only navigable by the richest and most powerful organizations. As Wikipedia founder Jimmy Wales put it, “This is a complete disaster.”
[…]
If you’ve read our previous explanations of the problems with the copyright directive, congratulations, you’re mostly caught up. The biggest issues remain the same, though Electronic Frontier Foundation adviser Cory Doctorow called this new version “the worst one yet.”
The final text of Article 11 still seeks to impose a “link tax” on platforms whenever they use a hyperlink to a news publication and quote a short snippet of text. Even a small business or individual running a monetized blog could face penalties for linking to an article and reproducing “single words or very short extracts” from the text without first acquiring a license.
The idea is to get a company like Google to cough up money that would be redirected to news outlets. But Google has said it may just shut down Google News in the EU, just as it did in Spain when similar legislation was implemented in that country. Publishers would lose the traffic boost they get from users being directed to their sites from Google News. And perhaps most importantly, smaller platforms and individuals will be discouraged from sharing and quoting information. According to Julia Reda, a member of European Parliament from Germany, “we will have to wait and see how courts interpret what ‘very short’ means in practice – until then, hyperlinking (with snippets) will be mired in legal uncertainty.”
Article 13 still requires platforms to do everything possible to prevent users from uploading copyrighted materials. We’ve become used to systems like YouTube’s that comply with takedown notices after a user has submitted content that doesn’t belong to them. But the EU wants platforms to stop it before it happens. It will be virtually impossible for even the biggest companies to comply with this directive.
Under the legislation, any platform will have to use upload filters to catch offending material. YouTube spends millions of dollars trying to perfect its system, and it’s still absolutely awful. The little guys will presumably have to license some sort of system if building one in-house isn’t an option. And as critics have emphasized from the beginning, paranoid webmasters will simply clamp down hard on anything that could possibly get themselves in trouble. Who would want to go to court to defend the fair use of a user-submitted Stranger Things meme?
The finalized text of Article 13 also stipulates that platforms will be held liable for any copyright violations unless they demonstrate that they made “best efforts to obtain an authorisation.” If something slips by and the platform shows it did everything it could to prevent it, a platform can be given a pass as long as it acts “expeditiously” to remove the offending content and make “best efforts to prevent” any future occurrences. That leaves a good bit of room for interpretation, but MEP Reda interprets the rules to mean the only safe solution is to do everything in their power to “preemptively buy licences for anything that users may possibly upload – that is: all copyrighted content in the world.”
Source: The EU Just Finalized Copyright Legislation That Rewrites the Rules of the Web