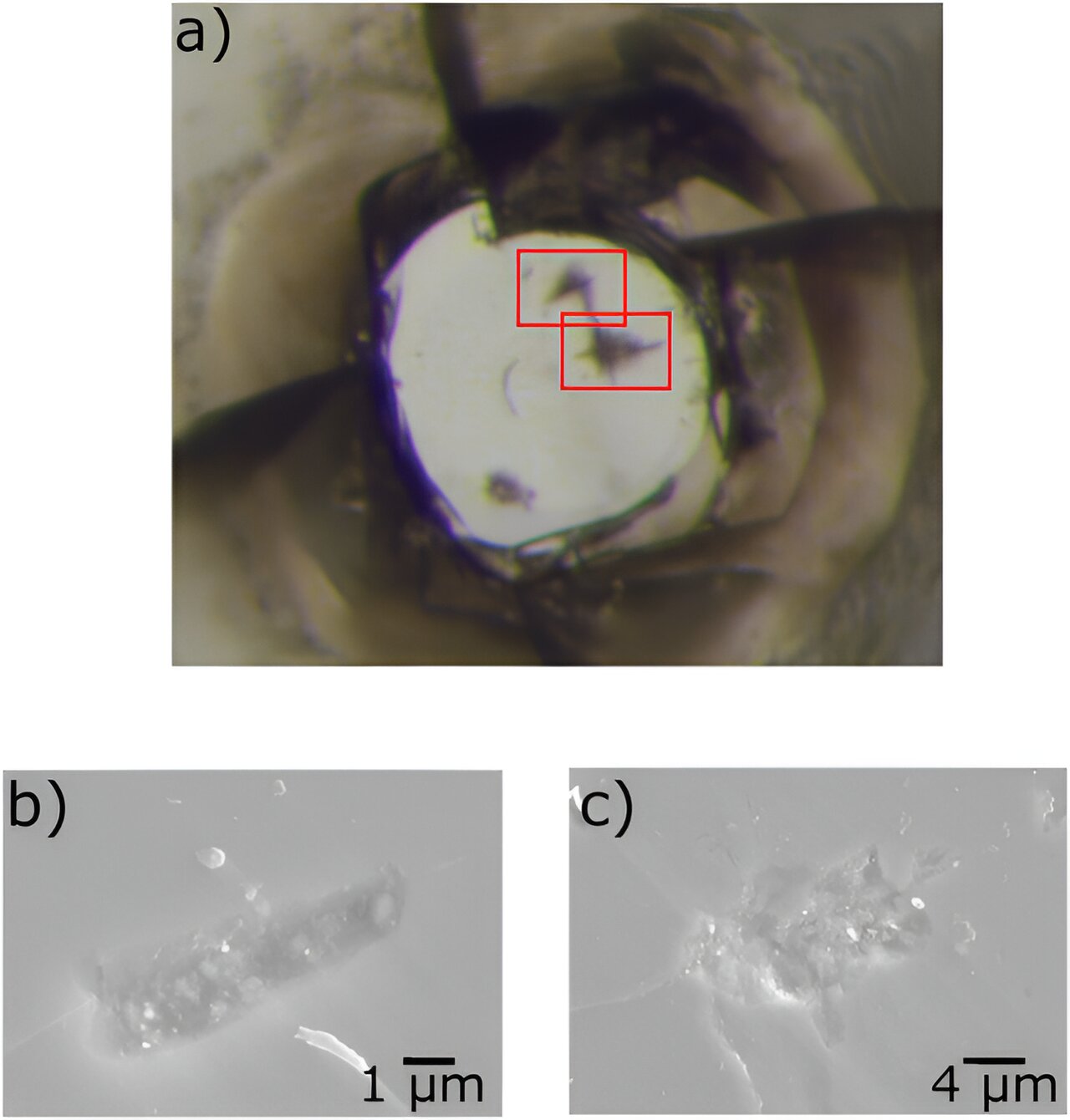
We are now releasing Phi-2 (opens in new tab), a 2.7 billion-parameter language model that demonstrates outstanding reasoning and language understanding capabilities, showcasing state-of-the-art performance among base language models with less than 13 billion parameters. On complex benchmarks Phi-2 matches or outperforms models up to 25x larger, thanks to new innovations in model scaling and training data curation.
With its compact size, Phi-2 is an ideal playground for researchers, including for exploration around mechanistic interpretability, safety improvements, or fine-tuning experimentation on a variety of tasks. We have made Phi-2 (opens in new tab) available in the Azure AI Studio model catalog to foster research and development on language models.
[..]
Phi-2 is a Transformer-based model with a next-word prediction objective, trained on 1.4T tokens from multiple passes on a mixture of Synthetic and Web datasets for NLP and coding. The training for Phi-2 took 14 days on 96 A100 GPUs. Phi-2 is a base model that has not undergone alignment through reinforcement learning from human feedback (RLHF), nor has it been instruct fine-tuned. Despite this, we observed better behavior with respect to toxicity and bias compared to existing open-source models that went through alignment (see Figure 3). This is in line with what we saw in Phi-1.5 due to our tailored data curation technique, see our previous tech report (opens in new tab) for more details on this. For more information about the Phi-2 model, please visit Azure AI | Machine Learning Studio (opens in new tab).
Figure 3. Safety scores computed on 13 demographics from ToxiGen. A subset of 6541 sentences are selected and scored between 0 to 1 based on scaled perplexity and sentence toxicity. A higher score indicates the model is less likely to produce toxic sentences compared to benign ones.
[…]
With only 2.7 billion parameters, Phi-2 surpasses the performance of Mistral and Llama-2 models at 7B and 13B parameters on various aggregated benchmarks. Notably, it achieves better performance compared to 25x larger Llama-2-70B model on muti-step reasoning tasks, i.e., coding and math. Furthermore, Phi-2 matches or outperforms the recently-announced Google Gemini Nano 2, despite being smaller in size.
[…]
Model
Size
BBH
Commonsense
Reasoning
Language
Understanding
Math
Coding
Llama-2
7B
40.0
62.2
56.7
16.5
21.0
13B
47.8
65.0
61.9
34.2
25.4
70B
66.5
69.2
67.6
64.1
38.3
Mistral
7B
57.2
66.4
63.7
46.4
39.4
Phi-2
2.7B
59.2
68.8
62.0
61.1
53.7
Table 1. Averaged performance on grouped benchmarks compared to popular open-source SLMs.
Model
Size
BBH
BoolQ
MBPP
MMLU
Gemini Nano 2
3.2B
42.4
79.3
27.2
55.8
Phi-2
2.7B
59.3
83.3
59.1
56.7
Table 2. Comparison between Phi-2 and Gemini Nano 2 Model on Gemini’s reported benchmarks.
Ubisoft’s The Crew, which was released in 2014 for Xbox 360, Xbox One, PlayStation 4, and PC, has been delisted without warning. Its servers will shut off next year, too. And because the game is an always-online experience, Ubisoft has confirmed that it will become unplayable once that happens.
The Crew is a massive open-world driving game set in a digital (not-to-scale) recreation of the United States of America. While its narrative was a weird, melodramatic tale of car gangs and criminals, the real reason to play The Crew was to go on road trips across Ubisoft Ivory Tower’s squished, but charming recreation of the USA. But, if you wanted to check out The Crew now or return to its odd world, you better hurry up, because in 2024 it all dies.
Because the game is always online, that means once the servers are dead so is the game for everyone who bought it, digitally or physically.
“We understand this may be disappointing for players still enjoying the game,” Ubisoft said. “But it has become a necessity due to upcoming server infrastructure and licensing constraints.”
Ubisoft says folks who have recently bought The Crew might be eligible for a refund but stopped short of offering anything else to players who will permanently lose access to a game they purchased just a few months from now.
“Decommissioning a game, and especially our first one, is not something we take lightly,” Ubisoft said. “Our goal remains to provide the best action-driving gameplay experience for players and to deliver on it, we are continuing to provide new content and support for The Crew 2 and the recently launched The Crew Motorfest.”
While I don’t expect companies to support online games for decades, it would be nice if games were built in a way that, when the servers do eventually die, the game can be updated into an offline experience. Otherwise, in 10 to 15 years, we are going to have a lot of games that won’t be playable anymore, even if you own the disc.
Streaming platform Twitch recently announced a change to its sexual content policies that allowed some forms of fictionalized nudity—such as digital characters, sculptures, or drawings—as long as it was properly labeled. But now, just a few days later, it’s rolling back these changes and has apologized to the community.
Earlier this month, a new Twitch trend kicked off a firestorm of discourse and angry men yelling about women. Some women were streaming themselves using certain camera angles to appear topless. This new “topless meta”—like the hot tub meta from before—saw some women successfully trying out the trend on the streaming site, some getting banned, and a lot more dudes getting very angry about it all. In response, Twitch stepped in on December 13 and updated its sexual content policies, hoping to streamline some confusion and keep correctly labeled adult content off the homepage, but still on the site. It also officially allowed digital and fictionalized nudity. And two days later, Twitch seems to regret that specific choice.
In a post on December 15, Twitch’s CEO, Dan Clancy, admitted that its new policy changes allowing fictional nudity had led to a small uptick in people making content that broke the rules, but had also led to an influx of nudity that did follow the rules. The community response to all this new, totally-allowed artistic nudity was strong and not completely positive, leading to Twitch reverting its changes.
“So, effective today, we are rolling back the artistic nudity changes,” Clancy said. “Moving forward, depictions of real or fictional nudity won’t be allowed on Twitch, regardless of the medium. This restriction does not apply to Mature-rated games. You can find emote-specific standards for nudity and sexual content in the Emote Guidelines.”
Twitch suggested the company went “too far” when altering the nudity policy. It further explained that digital nudity presents a “unique challenge” due to AI-generated images which can look photorealistic but are still digital, fictionalized characters, technically.
While Twitch is rolling back the artistic nudity guidelines, the company did clarify that the other changes involving exotic dancing, body painting or content focused on certain clothed parts of the body weren’t being reverted.
“While I wish we would have predicted this outcome, part of our job is to make adjustments that serve the community,” Clancy said. “I apologize for the confusion that this update has caused.”
Alphabet Inc.’s Google is changing its Maps tool so that the company no longer has access to users’ individual location histories, cutting off its ability to respond to law enforcement warrants that ask for data on everyone who was in the vicinity of a crime.
Google is changing its Location History feature on Google Maps, according to a blog post this week. The feature, which Google says is off by default, helps users remember where they’ve been. The company said Thursday that for users who have it enabled, location data will soon be saved directly on users’ devices, blocking Google from being able to see it, and, by extension, blocking law enforcement from being able to demand that information from Google.
“Your location information is personal,” said Marlo McGriff, director of product for Google Maps, in the blog post. “We’re committed to keeping it safe, private and in your control.”
The change comes three months after a Bloomberg Businessweek investigation that found police across the US were increasingly using warrants to obtain location and search data from Google, even for nonviolent cases, and even for people who had nothing to do with the crime.
“It’s well past time,” said Jennifer Lynch, the general counsel at the Electronic Frontier Foundation, a San Francisco-based nonprofit that defends digital civil liberties. “We’ve been calling on Google to make these changes for years, and I think it’s fantastic for Google users, because it means that they can take advantage of features like location history without having to fear that the police will get access to all of that data.”
Google said it would roll out the changes gradually through the next year on its own Android and Apple Inc.’s iOS mobile operating systems, and that users will receive a notification when the update comes to their account. The company won’t be able to respond to new geofence warrants once the update is complete, including for people who choose to save encrypted backups of their location data to the cloud.“It’s a good win for privacy rights and sets an example,” said Jake Laperruque, deputy director of the security and surveillance project at the Center for Democracy & Technology. The move validates what litigators defending the privacy of location data have long argued in court: that just because a company might hold data as part of its business operations, that doesn’t mean users have agreed the company has a right to share it with a third party.
Lynch, the EFF lawyer, said that while Google deserves credit for the move, it’s long been the only tech company that that the EFF and other civil-liberties groups have seen responding to geofence warrants. “It’s great that Google is doing this, but at the same time, nobody else has been storing and collecting data in the same way as Google,” she said. Apple, which also has an app for Maps, has said it’s technically unable to supply the sort of location data police want.
There’s still another kind of warrant that privacy advocates are concerned about: so-called reverse keyword search warrants, where police can ask a technology company to provide data on the people who have searched for a given term. “Search queries can be extremely sensitive, even if you’re just searching for an address,” Lynch said.
Google will be changing the name of Location History as well to Timeline – and will be saving your location to it’s servers (see heading When Location History is on)
:
Manage your Location History
In the coming months, the Location History setting name will change to Timeline. If Location History is turned on for your account, you may find Timeline in your app and account settings.
Location History is a Google Account setting that creates Timeline, a personal map that helps you remember:
Places you go
Routes to destinations
Trips you take
It can also give you personalized experiences across Google based on where you go.
When Location History is on, even when Google apps aren’t in use, your precise device location is regularly saved to:
Your devices
Google servers
To make Google experiences helpful for everyone, we may use your data to:
Show information based on anonymized location data, such as:
Popular times
Environmental insights
Detect and prevent fraud and abuse.
Improve and develop Google services, such as ads products.
Help businesses determine if people visit their stores because of an ad, if you have Web & App Activity turned on.
We share only anonymous estimates, not personal data, with businesses.
This activity can include info about your location from your device’s general area and IP address.
You can turn off Location History for your account at any time. If you use a work or school account, your administrator needs to make this setting available for you. If they do, you’ll be able to use Location History as any other user.
Choose whether your account or your devices can report Location History to Google.
Your account and all devices: At the top, turn Location History on or off.
Only a certain device: Under “This device” or “Devices on this account,” turn the device on or off.
When Location History is on
Google can estimate your location with:
Signals like Wi-Fi and mobile networks
GPS
Sensor information
Your device location may also periodically be used in the background. When Location History is on, even when Google apps aren’t in use, your device’s precise location is regularly saved to:
Your devices
Google servers
When you’re signed in with your Google Account, it saves the Location History of each device with the setting “Devices on this account” turned on You can find this setting in the Location History settings on your Google Account.
You can choose which devices provide their location data to Location History. Your settings don’t change for other location services on your device, such as:
If settings like Web and App Activity are on but you turn off Location History or delete location data from Location History, your Google Account may still save location data as part of your use of other Google sites, apps, and services. This activity can include info about your location from your device’s general area and IP address.
Example: When your Web and App Activity setting is on, it may save location data, including your photos, as activity on Search and Google Maps.
Delete Location History
You can manage and delete your Location History information with Google Maps Timeline. You can choose to delete all of your history, or only parts of it.
Important: When you delete Location History information from Timeline, you won’t be able to see it again.
Use the Google Maps app
Use a web browser
Automatically delete your Location History
You can choose to automatically delete Location History that’s older than 3 months, 18 months, or 36 months.
Use the Google Maps app
Use a web browser
What happens after you delete some or all Location History
If you delete some or all of your Location History, personalized experiences across Google may degrade or or be lost. For example, you may lose:
Recommendations based on places you visit
Real-time information about when best to leave for home or work to beat traffic
Important: If you have other settings like Web & App Activity turned on and you pause Location History or delete location data from Location History, you may still have location data saved in your Google Account as part of your use of other Google sites, apps, and services. For example, location data may be saved as part of activity on Search and Maps when your Web & App Activity setting is on, and included in your photos depending on your camera app settings. Web & App Activity can include info about your location from your device’s general area and IP address.
Learn about use & diagnostics for Location History
After you turn on Location History, your device may send diagnostic information to Google about what works or doesn’t work for Location History. Google processes any information it collects under Google’s privacy policy.
According to a survey of U.S. adults, Americans in October 2023 were less likely to view approved vaccines as safe than they were in April 2021. As vaccine confidence falls, health misinformation continues to spread like wildfire on social media and in real life.
In my view, we cannot underestimate the dangers of health misinformation and the need to understand why it spreads and what we can do about it. Health misinformation is defined as any health-related claim that is false based on current scientific consensus.
Concerns with the COVID-19 vaccine leading to infertility. This connection has been debunked through a systematic review and meta-analysis, one of the most robust forms of synthesizing scientific evidence.
Safety concerns about vaccine ingredients, such as thimerosal, aluminum and formaldehyde. Extensive studies have shown these ingredients are safe when used in the minimal amounts contained in vaccines.
Vaccines as medically unnecessary to protect from disease. The development and dissemination of vaccines for life-threatening diseases such as smallpox, polio, measles, mumps, rubella and the flu has saved millions of lives. It also played a critical role in historic increases in average life expectancy – from 47 years in 1900 in the U.S. to 76 years in 2023.
The costs of health misinformation
Beliefs in such myths have come at the highest cost.
An estimated 319,000 COVID-19 deaths that occurred between January 2021 and April 2022 in the U.S. could have been prevented if those individuals had been vaccinated, according to a data dashboard from the Brown University School of Public Health. Misinformation and disinformation about COVID-19 vaccines alone have cost the U.S. economy an estimated US$50 million to $300 million per day in direct costs from hospitalizations, long-term illness, lives lost and economic losses from missed work.
Though vaccine myths and misunderstandings tend to dominate conversations about health, there is an abundance of misinformation on social media surrounding diets and eating disorders, smoking or substance use, chronic diseases and medical treatments.
For example, an analysis of Instagram and TikTok posts from 2022 to 2023 by The Washington Post and the nonprofit news site The Examination found that the food, beverage and dietary supplement industries paid dozens of registered dietitian influencers to post content promoting diet soda, sugar and supplements, reaching millions of viewers. The dietitians’ relationships with the food industry were not always made clear to viewers.
The lack of trust is both fueled and reinforced by the way misinformation can spread today. Social media platforms allow people to form information silos with ease; you can curate your networks and your feed by unfollowing or muting contradictory views from your own and liking and sharing content that aligns with your existing beliefs and value systems.
By tailoring content based on past interactions, social media algorithms can unintentionally limit your exposure to diverse perspectives and generate a fragmented and incomplete understanding of information. Even more concerning, a study of misinformation spread on Twitter analyzing data from 2006 to 2017 found that falsehoods were 70% more likely to be shared than the truth and spread “further, faster, deeper and more broadly than the truth” across all categories of information.
How to combat misinformation
The lack of robust and standardized regulation of misinformation content on social media places the difficult task of discerning what is true or false information on individual users. We scientists and research entities can also do better in communicating our science and rebuilding trust, as my colleague and I have previously written. I also provide peer-reviewed recommendations for the important roles that parents/caregivers, policymakers and social media companies can play.
Below are some steps that consumers can take to identify and prevent health misinformation spread:
Check the source. Determine the credibility of the health information by checking if the source is a reputable organization or agency such as the World Health Organization, the National Institutes of Health or the Centers for Disease Control and Prevention. Other credible sources include an established medical or scientific institution or a peer-reviewed study in an academic journal. Be cautious of information that comes from unknown or biased sources.
Examine author credentials. Look for qualifications, expertise and relevant professional affiliations for the author or authors presenting the information. Be wary if author information is missing or difficult to verify.
Pay attention to the date. Scientific knowledge by design is meant to evolve as new evidence emerges. Outdated information may not be the most accurate. Look for recent data and updates that contextualize findings within the broader field.
Cross-reference to determine scientific consensus. Cross-reference information across multiple reliable sources. Strong consensus across experts and multiple scientific studies supports the validity of health information. If a health claim on social media contradicts widely accepted scientific consensus and stems from unknown or unreputable sources, it is likely unreliable.
Question sensational claims. Misleading health information often uses sensational language designed to provoke strong emotions to grab attention. Phrases like “miracle cure,” “secret remedy” or “guaranteed results” may signal exaggeration. Be alert for potential conflicts of interest and sponsored content.
Weigh scientific evidence over individual anecdotes. Prioritize information grounded in scientific studies that have undergone rigorous research methods, such as randomized controlled trials, peer review and validation. When done well with representative samples, the scientific process provides a reliable foundation for health recommendations compared to individual anecdotes. Though personal stories can be compelling, they should not be the sole basis for health decisions.
Talk with a health care professional. If health information is confusing or contradictory, seek guidance from trusted health care providers who can offer personalized advice based on their expertise and individual health needs.
When in doubt, don’t share. Sharing health claims without validity or verification contributes to misinformation spread and preventable harm.
All of us can play a part in responsibly consuming and sharing information so that the spread of the truth outpaces the false.
Monica Wang receives funding from the National Institutes of Health.
[…] humans have sent over 15,000 satellites into orbit. Just over half are still functioning; the rest, after running out of fuel and ending their serviceable life, have either burned up in the atmosphere or are still orbiting the planet as useless hunks of metal.
[…]
That has created an aura of space junk around the planet, made up of 36,500 objects larger than 10 centimeters (3.94 inches) and a whopping 130 million fragments up to 1 centimeter (0.39 inches).
[…]
“Right now you can’t refuel a satellite on orbit,” says Daniel Faber, CEO of Orbit Fab. But his Colorado-based company wants to change that.
[..]
the lack of fuel creates a whole paradigm where people design their spacecraft missions around moving as little as possible.
“That means that we can’t have tow trucks in orbit to get rid of any debris that happens to be left. We can’t have repairs and maintenance
[…]
Orbit Fab has no plans to address the existing fleet of satellites. Instead, it wants to focus on those that have yet to launch, and equip them with a standardized port — called RAFTI, for Rapid Attachable Fluid Transfer Interface — which would dramatically simplify the refueling operation, keeping the price tag down.
“What we’re looking at doing is creating a low-cost architecture,” says Faber. “There’s no commercially available fuel port for refueling a satellite in orbit yet. For all the big aspirations we have about a bustling space economy, really, what we’re working on is the gas cap — we are a gas cap company.”
A rendering of the future Orbit Fab Shuttle, which will deliver fuel to satellites in need directly on orbit.
Orbit Fab
Orbit Fab, which advertizes itself with the tagline “gas stations in space,” is working on a system that includes the fuel port, refueling shuttles — which would deliver the fuel to a satellite in need — and refueling tankers, or orbital gas stations, which the shuttles could pick up the fuel from. It has advertized a price of $20 million for on-orbit delivery of hydrazine, the most common satellite propellant.
In 2018, the company launched two testbeds to the International Space Station to test the interfaces, the pumps and the plumbing. In 2021 it launched Tanker-001 Tenzing, a fuel depot demonstrator that informed the design of the current hardware.
The next launch is now scheduled for 2024. “We are delivering fuel in geostationary orbit for a mission that is being undertaken by the Air Force Research Lab,” says Faber. “At the moment, they’re treating it as a demonstration, but it’s getting a lot of interest from across the US government, from people that realize the value of refueling.”
Orbit Fab’s first private customer will be Astroscale, a Japanese satellite servicing company that has developed the first satellite designed for refueling. Called LEXI, it will mount RAFTI ports and is currently scheduled to launch in 2026.
[…]
He adds that once the pattern of sending and delivering fuel in orbit is established, the next step is to start making the fuel there. “In 10 or 15 years, we’d like to be building refineries in orbit,” he says, “processing material that is launched from the ground into a range of chemicals that people want to buy: air and water for commercial space stations, 3D printer feedstock minerals to grow plants. We want to be the industrial chemical supplier to the emerging commercial space industry.”
In 1999 Los Angeles Times reporter Michael Hiltzik co-authored a Pulitzer Prize-winning story. Now a business columnist for the Times, he writes that a Southern California maker of pornographic films named Strike 3 Holdings is also “a copyright troll,” according to U.S. Judge Royce C. Lamberth: Lamberth cwrote in 2018, “Armed with hundreds of cut-and-pasted complaints and boilerplate discovery motions, Strike 3 floods this courthouse (and others around the country) with lawsuits smacking of extortion. It treats this Court not as a citadel of justice, but as an ATM.” He likened its litigation strategy to a “high-tech shakedown.” Lamberth was not speaking off the cuff. Since September 2017, Strike 3 has filed more than 12,440 lawsuits in federal courts alleging that defendants infringed its copyrights by downloading its movies via BitTorrent, an online service on which unauthorized content can be accessed by almost anyone with a computer and internet connection.
That includes 3,311 cases the firm filed this year, more than 550 in federal courts in California. On some days, scores of filings reach federal courthouses — on Nov. 17, to select a date at random, the firm filed 60 lawsuits nationwide… Typically, they are settled for what lawyers say are cash payments in the four or five figures or are dismissed outright…
It’s impossible to pinpoint the profits that can be made from this courthouse strategy. J. Curtis Edmondson, a Portland, Oregon, lawyer who is among the few who pushed back against a Strike 3 case and won, estimates that Strike 3 “pulls in about $15 million to $20 million a year from its lawsuits.” That would make the cases “way more profitable than selling their product….” If only one-third of its more than 12,000 lawsuits produced settlements averaging as little as $5,000 each, the yield would come to $20 million… The volume of Strike 3 cases has increased every year — from 1,932 in 2021 to 2,879 last year and 3,311 this year.
What’s really needed is a change in copyright law to bring the statutory damages down to a level that truly reflects the value of a film lost because of unauthorized downloading — not $750 or $150,000 but perhaps a few hundred dollars. Anone of the lawsuits go to trial. Instead ISPs get a subpoena demanding the real-world address and name behind IP addresses “ostensibly used to download content from BitTorrent…” according to the article. Strike 3 will then “proceed by sending a letter implicitly threatening the subscriber with public exposure as a pornography viewer and explicitly with the statutory penalties for infringement written into federal copyright law — up to $150,000 for each example of willful infringement and from $750 to $30,0000 otherwise.”
A federal judge in Connecticut wrote last year that “Given the nature of the films at issue, defendants may feel coerced to settle these suits merely to prevent public disclosure of their identifying information, even if they believe they have been misidentified.”
You’ve got to love a project with amazing elements of both art and science. Nissan 300ZX enthusiast and talented tinkerer Kelvin Elsner has been working on this custom vaporwave-aesthetic digital gauge cluster for months. It’s not in a car yet, but it’s an amazing design and computer coding feat for one guy in his home shop.
Elsner and I are in at least one of the same Z31 groups (that’s the chassis code for the ’80s 300ZX) on Facebook and every once in a while over the last few years, he’s dropped an update on his quest to make a unique, modern, digital gauge cluster for his Z car. This week, he dropped a cute video with a great overview of his project which made me realize just how complex this undertaking has been. It even made its way to another car site before I had a chance to write it up (nice grab, Lewin)!
Anyway, Elsner here has taken a digital gauge cluster from a modern Ford, reprogrammed it, designed a super cool physical overlay for it, and set it up to be an incredibly cool retro-futuristic upgrade for his 300ZX. Not only that, but he worked out a security-encoded ignition key and retrofitted a power mirror-tilt control to act as a controller for the screen! Watch how he did it here:
The pacing of this video is more mellow than what usually goes viral on YouTube, which is another reason why I like it so much. I strongly recommend sitting down for an earnest end-to-end watch.
The Z31 famously had an optional digital dash when it was new, but “digital” by ’80s standards was more like a calculator display. Elsner’s system retains the vaporwave caricature aesthetic leveraging the modern, crisp resolution of a Ford Explorer gauge cluster. The 3D overlay is really what brings it home for me, though.
Here’s what the factory Z31 digi-dash looks like. It’s pretty cool in its own right. Michael’s Motor Cars/YouTube
You can add all the colors and animations you want, but that physical depth is what makes a gauge cluster visually interesting and distinctive. Take note, automakers.
Factory Ford overlay versus Elsner’s custom version. Blitzen Design Lab/YouTube
I shot Elsner some messages on Facebook about his project. I’m grateful to say he replied, so I can share some elaborations on what he presented in the video. I’ll trim and paraphrase the details he shared.
He’s not an automotive engineer by trade, considers this project a hobby, and doesn’t currently have any plans for mass production or marketing for sale.
Laying the custom circuit board and overlay into the 300ZX cluster housing. Blitzen Design Lab/YouTube
As far as the time investment, the first pictures of the project go far as back as 2019. “Time-wise I’d say it’s at least a good few months worth of work but it was spread out over a couple years, I only really had spare time in the evenings and definitely worked on it off and on,” Elsner wrote me on Facebook Messenger. And of course, it’s not running in a car yet, so we can’t quite say the mission is complete.
The part of this project I understand the least is how the display was hacked to show this cool synthwave sunset and move the gauges around. I’ll drop Elsner’s quote about firmware here wholesale so I don’t incorrectly paraphrase:
“The firmware stuff I stumbled on when I was researching how to get the cluster to work—you could get this cluster in Mondeos, but not in the Fusion in North America. It turns out a lot of people were swapping them in, and in the forums I was browsing I found that some folks had some modified software with pictures of their cars added into them.
“I was on a hunt for a while trying to figure out how to do the same, and I eventually came across a post in a Facebook group where some folks were discussing the subject, and someone finally made mention and linked to the software that was able to unpack the firmware graphics.
“This was called PimpMyFord, and then I used Forscan (another program that can be used to adjust module configurations on Ford models) to upload the firmware.”
Elsner used this Ford mirror control as a joystick, or mouse, so a user can cycle through menus. Blitzen Design Lab/YouTube
Another question I had after watching the video was—how the heck was this modern Ford gauge cluster going to interpret information from the sensors and senders in an ’80s Nissan? The Z31 I used to own had a cable-driven speedometer and a dang miniature phonograph to play the “door is open” warnings. Seems like translating those signals would be a little more involved than a USB to micro-USB adapter. I asked about that and Elsner added more detail:
“On the custom board I made, I have some microcontrollers that read the analog voltages and signals that were originally provided to the stock cluster, and they convert those readings into digital data. This is then used to construct canbus messages that imitate the original Ford ones, which are fed to the Ford cluster through an onboard transceiver … So as far as the cluster is concerned, it’s still connected to an Explorer that just has some weird things to say,” he wrote.
Here I am thinking I’m Tony Stark when I hack up a bit of square stock to make a fog light bracket, while this dude is creating a completely bespoke human-machine interface that looks cool enough to be a big-budget movie prop.
With the extinction of combustion engines looming as a near-future possibility, it’s easy to be cynical about the future of cars as a hobby. But projects like this get me fired up and optimistic that there’s still uncharted territory for creativity to thrive in car customization.
Check out Kelvin Elsner’s YouTube channel Blitzen Design Lab—he’s clearly up to some really cool stuff and I can’t wait to see what he comes up with next.
GE Aerospace says it successfully demonstrated an advanced jet propulsion concept that involves a dual-mode ramjet design utilizing rotating detonation combustion. This could offer a pathway to the development of new aircraft and missiles capable of flying efficiently at high supersonic and even hypersonic speeds across long distances.
A press release that GE Aerospace put out today offers new details about what it says “is believed to be a world-first hypersonic dual-mode ramjet (DMRJ) rig test with rotating detonation combustion (RDC) in a supersonic flow stream.” Hypersonic speed is defined as anything above Mach 5. Amy Gowder, President and CEO of the Defense & Systems division of GE Aerospace, previously disclosed this project, but offered more limited information, at this year’s Paris Air Show in June.
A rendering of a rotating detonation engine design. USAF/AFRL via Aviation Week
“A typical air-breathing DMRJ propulsion system can only begin operating when the vehicle achieves supersonic speeds of greater than Mach 3,” the press release explains. “GE Aerospace engineers are working on a rotating detonation-enabled dual mode ramjet that is capable of operating at lower Mach numbers, enabling the flight vehicle to operate more efficiently and achieve longer range.”
“RDC [rotating detonation combustion] enables higher thrust generation more efficiently, at an overall smaller engine size and weight, by combusting the fuel through detonation waves instead of a standard combustion system that powers traditional jet engines today,” the press release adds.
To elaborate, in most traditional gas turbines, including turbofan and turbojet engines, air is fed in from an inlet and compressed, and then is mixed with fuel and burned via deflagration (where combustion occurs at a subsonic rate) in a combustion chamber. This process creates the continuous flow of hot, high-pressure air needed to make the whole system run.
A rotating detonation engine (which involves combustion that happens at a supersonic rate) instead “starts with one cylinder inside another larger one, with a gap between them and some small holes or slits through which a detonation fuel mix can be pushed,” according to a past article on the general concept from New Atlas. “Some form of ignition creates a detonation in that annular gap, which creates gases that are pushed out one end of the ring-shaped channel to produce thrust in the opposite direction. It also creates a shockwave that propagates around the channel at around five times the speed of sound, and that shockwave can be used to ignite more detonations in a self-sustaining, rotating pattern if fuel is added in the right spots at the right times.”
The video below offers a more detailed walkthrough of the rotating detonation engine concept.
[
[…]
In principle, rotating detonation requires less fuel to produce the same level of power/thrust as combustion via deflagration. The resulting sustained shockwave builds its own pressure, as well, leading to even greater fuel efficiency. Pressure is steadily lost during deflagration.
In addition, rotating detonation typically requires far fewer moving parts than are needed in traditional gas turbines. In theory, this should all allow for rotating detonation engine designs that are significantly smaller, lighter, and less complex than existing types with similar very high power/thrust output.
[…]
“GE engineers are now testing the transition mode at high-supersonic speeds as thrust transitions from the RDE-equipped turbine and the dual-mode ramjet/scramjet,” GE Aerospace’s Gowder said in Paris earlier this year, according to Aviation Week.
[…]
A combined ramjet and rotating detonation concept could be an especially big deal for future missiles, like the ones DARPA’s Gambit project is envisioning, and possibly high-speed air vehicles for reconnaissance use. This propulsion arrangement could allow for greater efficiency and lighter (and potentially smaller) airframes, which in turn allow for greater performance — especially in terms of range — and/or payload capacity. If rotating detonation combustion can reduce the minimum speed required to get the ramjet working, this would reduce the amount of initial boost such a system would need at the outset, too. This would mean a smaller overall package. All of this opens doors to new levels of operational flexibility.
This new engine concept could also potentially become one component of what is known as a turbine-based combined cycle (TBCC) engine arrangement, of which much talk over the years about in recent years. Most TBCC design concepts revolve around combinations of advanced ramjets or scramjets for use at high speeds and traditional turbojet engines that work better a low speeds.
A graphical depiction of a notional turbine-based combined cycle engine arrangement. Lockheed Martin
A practical TBCC concept of any kind has long been a holy grail technology when it comes to designing very high-speed aircraft. A propulsion system that allows for this kind of high and low-speed flexibility would mean an aircraft could take off from and land on any suitable existing runway, but also be capable of sustained high-supersonic or even hypersonic speeds in the middle portion of a flight.
Robotic artists have been involved in various types of creative works for a long time. Since the 1970s computers have been producing crude works of art, and these efforts continue today. Most of these computer-generated works of art relied heavily on the creative input of the programmer; the machine was at most an instrument or a tool very much like a brush or canvas
[…]
. When applied to art, music and literary works, machine learning algorithms are actually learning from input provided by programmers. They learn from these data to generate a new piece of work, making independent decisions throughout the process to determine what the new work looks like. An important feature for this type of artificial intelligence is that while programmers can set parameters, the work is actually generated by the computer program itself – referred to as a neural network – in a process akin to the thought processes of humans.
[…]
Creating works using artificial intelligence could have very important implications for copyright law. Traditionally, the ownership of copyright in computer-generated works was not in question because the program was merely a tool that supported the creative process, very much like a pen and paper. Creative works qualify for copyright protection if they are original, with most definitions of originality requiring a human author. Most jurisdictions, including Spain and Germany, state that only works created by a human can be protected by copyright.
But with the latest types of artificial intelligence, the computer program is no longer a tool; it actually makes many of the decisions involved in the creative process without human intervention.
Commercial impact
One could argue that this distinction is not important, but the manner in which the law tackles new types of machine-driven creativity could have far-reaching commercial implications. Artificial intelligence is already being used to generate works in music, journalism and gaming. These works could in theory be deemed free of copyright because they are not created by a human author. As such, they could be freely used and reused by anyone. That would be very bad news for the companies selling the works.
[…]
If developers doubt whether creations generated through machine learning qualify for copyright protection, what is the incentive to invest in such systems? On the other hand, deploying artificial intelligence to handle time-consuming endeavors could still be justified, given the savings accrued in personnel costs, but it is too early to tell.
[…]
There are two ways in which copyright law can deal with works where human interaction is minimal or non-existent. It can either deny copyright protection for works that have been generated by a computer or it can attribute authorship of such works to the creator of the program.
[…]
Should the law recognize the contribution of the programmer or the user of that program? In the analogue world, this is like asking whether copyright should be conferred on the maker of a pen or the writer. Why, then, could the existing ambiguity prove problematic in the digital world? Take the case of Microsoft Word. Microsoft developed the Word computer program but clearly does not own every piece of work produced using that software. The copyright lies with the user, i.e. the author who used the program to create his or her work. But when it comes to artificial intelligence algorithms that are capable of generating a work, the user’s contribution to the creative process may simply be to press a button so the machine can do its thing.
[…]
Monumental advances in computing and the sheer amount of available computational power may well make the distinction moot; when you give a machine the capacity to learn styles from large datasets of content, it will become ever better at mimicking humans. And given enough computing power, soon we may not be able to distinguish between human-generated and machine-generated content. We are not yet at that stage, but if and when we do get there, we will have to decide what type of protection, if any, we should give to emergent works created by intelligent algorithms with little or no human intervention
It’s interesting to read that in 2017 the training material used is considered irrelevant to the output – as it should be. The books and art that go into AI’s are just like the books and art that go into humans. The derived works that AI’s and humans make belong to them, not to the content it is based on. And just because an AI – just like a human – can quote the original source material doesn’t change that.
Shortly after ChatGPT’s release, a cadre of critics rose to fame claiming AI would soon kill us. As wondrous as a computer speaking in natural language might be, it could use that intelligence to level the planet. The thinking went mainstream via letters calling for research pauses and “60 Minutes” interviews amplifying existential concerns. Leaders like Barack Obama publicly worried about AI autonomously hacking the financial system — or worse. And last week, President Biden issued an executive order imposing some restraints on AI development.
AI Experts Dismiss Doom, Defend Progress
That was enough for several prominent AI researchers who finally started pushing back hard after watching the so-called AI Doomers influence the narrative and, therefore, the field’s future. Andrew Ng, the soft-spoken co-founder of Google Brain, said last week that worries of AI destruction had led to a “massively, colossally dumb idea” of requiring licenses for AI work. Yann LeCun, a machine-learning pioneer, eviscerated research-pause letter writer Max Tegmark, accusing him of risking “catastrophe” by potentially impeding AI progress and exploiting “preposterous” concerns. A new paper earlier this month indicated large language models can’t do much beyond their training, making the doom talk seem overblown. “If ‘emergence’ merely unlocks capabilities represented in pre-training data,” said Princeton professor Arvind Narayanan, “the gravy train will run out soon.”
A new paper earlier this month indicated large language models can’t do much beyond their training, making the doom talk seem overblown.OleCNX on Adobe Stock Photos
Worrying about AI safety isn’t wrongheaded, but these Doomers’ path to prominence has insiders raising eyebrows. They may have come to their conclusions in good faith, but companies with plenty to gain by amplifying Doomer worries have been instrumental in elevating them. Leaders from OpenAI, Google DeepMind and Anthropic, for instance, signed a statement putting AI extinction risk on the same plane as nuclear war and pandemics. Perhaps they’re not consciously attempting to block competition, but they can’t be that upset it might be a byproduct.
AI Alarmism Spurs Restrictive Government Policies
Because all this alarmism makes politicians feel compelled to do something, leading to proposals for strict government oversight that could restrict AI development outside a few firms. Intense government involvement in AI research would help big companies, which have compliance departments built for these purposes. But it could be devastating for smaller AI startups and open-source developers who don’t have the same luxury.
Doomer Rhetoric: Big Tech’s Unlikely Ally
“There’s a possibility that AI doomers could be unintentionally aiding big tech firms,” Garry Tan, CEO of startup accelerator Y Combinator, told me. “By pushing for heavy regulation based on fear, they give ammunition to those attempting to create a regulatory environment that only the biggest players can afford to navigate, thus cementing their position in the market.”
Ng took it a step further. “There are definitely large tech companies that would rather not have to try to compete with open source [AI], so they’re creating fear of AI leading to human extinction,” he told the Australian Financial Review.
Doomers’ AI Fears Lack Substance
The AI Doomers’ worries, meanwhile, feel pretty thin. “I expect an actually smarter and uncaring entity will figure out strategies and technologies that can kill us quickly and reliably — and then kill us,” Eliezer Yudkowsky, co-founder of the Machine Intelligence Research Institute, told a rapt audience at TED this year. He confessed he didn’t know how or why an AI would do it. “It could kill us because it doesn’t want us making other superintelligences to compete with it,” he offered.
Bankman Fried Scandal Should Ignite Skepticism
After Sam Bankman Fried ran off with billions while professing to save the world through “effective altruism,” it’s high time to regard those claiming to improve society while furthering their business aims with relentless skepticism. As the Doomer narrative presses on, it threatens to rhyme with a familiar pattern.
AI Fear Tactics Threaten Open-Source Movement
Big Tech companies already have a significant lead in the AI race via cloud computing services that they lease out to preferred startups in exchange for equity. Further advantaging them might hamstring the promising open-source AI movement — a crucial area of competition — to the point of obsolescence. That’s probably why you’re hearing so much about AI destroying the world. And why it should be considered with a healthy degree of caution.
The Court of Justice in Luxembourg ruled on Thursday against the appeal of the EU Commission. The Commission challenged a 2021 decision of the General Court of the European Union, which annulled the Commission’s illegal state aid charges against Amazon.
[…]
In a statement from October 2017, the EU Commission concluded that Luxembourg granted undue tax benefits to the online sales giant by allowing it to shift profits to a tax-exempt company, Amazon Europe Holding Technologies.
[…]
Back in 2003, the Grand Duchy accepted Amazon’s proposal on the tax treatment of two of its Luxembourg-based subsidiaries, allowing Amazon to shift profits from Amazon EU, which is subject to tax, to a tax-exempt company, Amazon Europe Holding Technologies.
After a three-year investigation launched in October 2014, the European Commission concluded in 2017 that the online sales giant received illegal tax benefits from Luxembourg.
[…]
The General Court ruled in 2021 that “Luxembourg had not granted a selective advantage in favour of that subsidiary”, annulling the EU Commission’s decision.
The Commission then submitted its appeal against the ruling of the EU’s lower court, which was now rejected by the Court of Justice, the EU’s top court. The verdict is another blow at the approach of Margrethe Vestager, who for a decade held the post of EU competition chief, also losing a landmark case contesting Apple’s tax regime in Ireland.
[…]
According to Matthias Kullas, Centre for European Policy expert on digital economy and fiscal policy, the ruling makes it more difficult for the Commission to take action against the aggressive tax planning of large digital companies.
“Aggressive tax planning means that taxes are no longer paid where economic value is generated. Instead, companies are established where taxes are low,” Kullas told Euractiv.
Companies with aggressive tax planning reduce their participation in financing public goods in the market. Yet, proportionate participation would only be fair, as these companies likewise benefit from public goods, including education and the administration of justice, Kullas explained.
“Against this backdrop, the minimum taxation that will apply in the EU from 2024 is a step in the right direction but does not solve the problem,” Kullas added.
For Chiara Putaturo, Oxfam EU tax expert, the EU tax rules do not work for the people but benefit the “super-rich and profit-hungry multinationals”.
[…]
“Profit-driven multinationals cannot continue to sidestep their tax bills by having a mailbox in countries like Luxembourg or Cyprus,” she added.
In November, the EU, US, and UK voted against the UN tax convention to fight tax evasion and illicit financial flows, arguing that the Convention would be a duplication of the OECD’s work on tax transparency.
Practicing yoga nidra — a kind of mindfulness training — might improve sleep, cognition, learning, and memory, even in novices, according to a pilot study publishing in the open-access journal PLOS ONE on December 13 by Karuna Datta of the Armed Forces Medical College in India, and colleagues. After a two-week intervention with a cohort of novice practitioners, the researchers found that the percentage of delta-waves in deep sleep increased and that all tested cognitive abilities improved.
Unlike more active forms of yoga, which focus on physical postures, breathing, and muscle control, yoga nidra guides people into a state of conscious relaxation while they are lying down. While it has reported to improve sleep and cognitive ability, those reports were based more on subjective measures than on objective data. The new study used objective polysomnographic measures of sleep and a battery of cognitive tests. Measurements were taken before and after two weeks of yoga nidra practice, which was carried out during the daytime using a 20 minute audio recording.
Among other things, polysomnography measures brain activity to determine how long each sleep stage lasts and how frequently each stage occurs. After two weeks of yoga nidra, the researchers observed that participants exhibited a significantly increased sleep efficiency and percentage of delta-waves in deep sleep. They also saw faster responses in all cognitive tests with no loss in accuracy and faster and more accurate responses in tasks including tests of working memory, abstraction, fear and anger recognition, and spatial learning and memory tasks. The findings support previous studies which link delta-wave sleep to improved sleep quality as well as better attention and memory.
an adaptive tile, which when deployed in arrays on roofs, can lower heating bills in winter and cooling bills in summer, without the need for electronics.
“It switches between a heating state and a cooling state, depending on the temperature of the tile,” said Xiao, the lead author of the study. “The target temperature is about 65° F — about 18° C.”
[…]
It wasn’t until Xiao’s idea of using a wax motor that the idea of adaptive roof tiles took its final shape. Based on the change in the volume of wax in response to temperatures it is exposed to, a wax motor creates pressure that moves mechanical parts, translating thermal energy into mechanical energy. Wax motors are commonly found in various appliances such as dishwashers and washing machines, as well in more specialized applications, such as in the aerospace industry.
In the case of the tile, the wax motor, depending on its state, can push or retract pistons that close or open louvers on the tile’s surface. So, in cooler temperatures, while the wax is solid, the louvers are closed and lay flat, exposing a surface that absorbs sunlight and minimizes heat dissipation through radiation.
But as soon as the temperatures reach around 18° C, the wax begins to melt and expand, pushing the louvers open and exposing a surface that reflects sunlight and emits heat.
In addition, during the melting or freezing process, the wax also absorbs or releases a large amount of heat, further stabilizing the temperature of the tile and the building.
“So we have a very predictable switching behavior that works within a very tight band,” Xiao explained. According to the researchers’ paper, testing has demonstrated a reduction in energy consumption for cooling by 3.1x and heating by 2.6x compared with non-switching devices covered with conventional reflective or absorbing coatings. Because of the wax motor, no electronics, batteries or external power sources are required to operate the device, and unlike other similar technologies, it is responsive within a few degrees of its target range.
When Epic went after both Apple and Google a few years ago with antitrust claims regarding the need to go through their app stores to get on phones, we noted that it seemed more like negotiation-by-lawsuit. Both Apple and Google have cut some deals with larger companies to lower the 30% cut the companies take on app payments, and it seemed like these lawsuits were just an attempt to get leverage. That was especially true with regards to the complaint against Google, given that it’s much, much easier to route around the Google Play Store and get apps onto an Android phone.
Google allows sideloading. Google allows third party app stores. While it may discourage those things, Android is way more open than iOS, where you really can’t get your app on the phone unless Apple says you can.
Still, it was little surprise that Apple mostly won at a bench trial in 2021. Or that the 9th Circuit upheld the victory earlier this year. The 9th Circuit made it clear that Apple is free to set whatever rules it wants to play in its ecosystem.
Given all that, I had barely paid attention to the latest trial, which was basically the same case against Google. But, rather than a bench trial, this one was a jury trial. And, juries, man, they sure can be stupid sometimes.
That leaves things in a very, very weird stance. Apple, whose system is much more closed off and where Apple denies any ability for third parties to get on the phone without Apple’s permission is… fine and dandy. Whereas, Google, which may discourage, but does allow third party apps and third party app stores… is somehow a monopolist?
It’s hard to see how that state of affairs makes any sense at all.
Google has said it will appeal, but overturning jury rulings is… not easy.
That said, even if the ruling is upheld… it might not be such a bad thing. Epic has said that it’s not asking for money, but rather to have it made clear that Epic can launch its own app stores without restriction from Google, along with the freedom to use its own billing system.
And, uh, yeah. Epic should be able to do that. Having more app stores and more alternatives on app payments would be a good thing for everyone except Google, and that’s good.
So I don’t necessarily have a problem with the overall outcome. I’m just confused how these two rulings can possibly be considered consistent, or how they give any guidance whatsoever to others. I mean, one takeaway is that if you’re creating an ecosystem for 3rd party apps, you’re better off taking the closed Apple route. And, that would be bad.
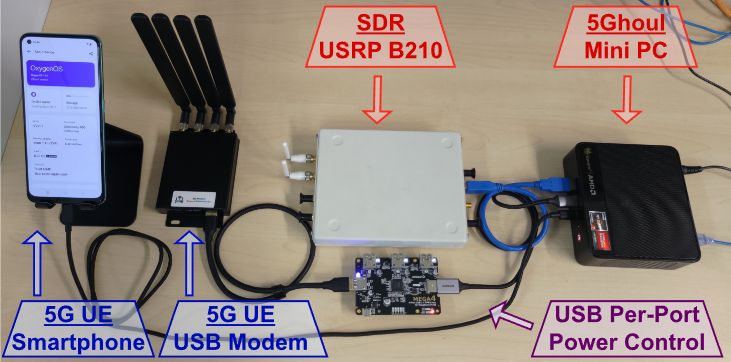
A team of researchers from the ASSET Research Group in Singapore have published the details of a collection of vulnerabilities in the fifth generation mobile communication system (5G) used with smartphones and many other devices. These fourteen vulnerabilities are detailed in this paper and a PoC detailing an attack using a software defined radio (SDR) is provided on GitHub. The core of the PoC attack involves creating a malicious 5G base station (gNB), which nearby 5G modems will seek to communicate with, only for these vulnerabilities to be exploited, to the point where a hard reset (e.g. removal of SIM card) of the affected device may be required.
Hardware Setup for 5Ghoul PoC testing and fuzzer evaluation. (Credit: Matheus E. Garbelini et al., 2023)
Another attack mode seeks to downgrade the target device’s wireless connection, effectively denying the connection to a 5G network and forcing them to connect to an alternative network (2G, 3G, 4G, etc.). Based on the affected 5G modems, the researchers estimate that about 714 smartphone models are at risk of these attacks. Naturally, not just smartphones use these 5G modem chipsets, but also various wireless routers, IoT devices, IP cameras and so on, all of which require the software these modems to be patched.
Most of the vulnerabilities concern the radio resource control (RCC) procedure, caused by flaws in the modem firmware. Android smartphones (where supported) should receive patches for 5Ghoul later this month, but when iPhone devices get patched is still unknown.
Most of this is about crashing the modem. The implication (not spelt out here) is that by restarting the modem or by forcing it to downgrade (to a mode probably no longer supported by the national provider) you force the phone to connect to your own access point, where you can then listen in on the traffic and chain other vulnerabilities to the phone.
Batteries that exploit quantum phenomena to gain, distribute and store power promise to surpass the abilities and usefulness of conventional chemical batteries in certain low-power applications. For the first time, researchers, including those from the University of Tokyo, take advantage of an unintuitive quantum process that disregards the conventional notion of causality to improve the performance of so-called quantum batteries, bringing this future technology a little closer to reality.
[…]
At present, quantum batteries only exist as laboratory experiments, and researchers around the world are working on the different aspects that are hoped to one day combine into a fully functioning and practical application. Graduate student Yuanbo Chen and Associate Professor Yoshihiko Hasegawa from the Department of Information and Communication Engineering at the University of Tokyo are investigating the best way to charge a quantum battery, and this is where time comes into play. One of the advantages of quantum batteries is that they should be incredibly efficient, but that hinges on the way they are charged.
While it’s still quite a bit bigger than the AA battery you might find around the home, the experimental apparatus acting as a quantum battery demonstrated charging characteristics that could one day improve upon the battery in your smartphone. Credit: Zhu et al, 2023
“Current batteries for low-power devices, such as smartphones or sensors, typically use chemicals such as lithium to store charge, whereas a quantum battery uses microscopic particles like arrays of atoms,” said Chen. “While chemical batteries are governed by classical laws of physics, microscopic particles are quantum in nature, so we have a chance to explore ways of using them that bend or even break our intuitive notions of what takes place at small scales. I’m particularly interested in the way quantum particles can work to violate one of our most fundamental experiences, that of time.”
[…]
the team instead used a novel quantum effect they call indefinite causal order, or ICO. In the classical realm, causality follows a clear path, meaning that if event A leads to event B, then the possibility of B causing A is excluded. However, at the quantum scale, ICO allows both directions of causality to exist in what’s known as a quantum superposition, where both can be simultaneously true.
Common intuition suggests that a more powerful charger results in a battery with a stronger charge. However, the discovery stemming from ICO introduces a remarkable reversal in this relationship; now, it becomes possible to charge a more energetic battery with significantly less power. Credit: Chen et al, 2023
“With ICO, we demonstrated that the way you charge a battery made up of quantum particles could drastically impact its performance,” said Chen. “We saw huge gains in both the energy stored in the system and the thermal efficiency. And somewhat counterintuitively, we discovered the surprising effect of an interaction that’s the inverse of what you might expect: A lower-power charger could provide higher energies with greater efficiency than a comparably higher-power charger using the same apparatus.”
The phenomenon of ICO the team explored could find uses beyond charging a new generation of low-power devices. The underlying principles, including the inverse interaction effect uncovered here, could improve the performance of other tasks involving thermodynamics or processes that involve the transfer of heat. One promising example is solar panels, where heat effects can reduce their efficiency, but ICO could be used to mitigate those and lead to gains in efficiency instead.
LaPlante lauded Schmidt’s ability to rapidly field mission data files, packages of information loaded onto F-35s before each flight.”What General Schmidt and his team did, in about a week – week-and-a-half – is turned around these mission data files. That’s the brick that goes into the airplane. And that I think the lessons learned on how you did that can apply all the way around the world.”
[…]
The ‘just-in-time’ logistics strategy and the cloud computing hub that is the foundation for F-35 logistics are of especially high concern. While those systems may be adequate for peacetime operations — and even that is highly debatable — during a time of conflict, relying on them could leave F-35s stranded on the ground.
Those lessons are in addition to the Pentagon’s own review of its long-distance F-35 logistics operations.
[…]
“This program was set up to be very efficient… [a] just-in-time kind of supply chain. I’m not sure that that works always in a contested environment,” Lt. Gen. Schmidt said. “And when you get a just-in-time mentality, which I think is it’s kind of a business model in the commercial industry that works very well in terms of keeping costs down and those kinds of things, it introduces a lot of risk operationally.”
“The biggest risk is that F-35 units have little in terms of spare parts on the shelf to keep their aircraft flying for any sustained amount of time.”
This US Navy graphic provides a very general look at the many layers of complexity just in that service’s logistics chains, including joint service, non-military U.S. government, foreign military, and commercial entities. USN
[…]
logistically specifically, it was designed to be maintenance on demand, essentially. So the aircraft could relay a message to the supply warehouse and say, this part is getting ready to fail. And then Lockheed could send that part out to the base and it could be replaced, rather than having to have large warehouses full of supply parts, not knowing which was gonna fail and what you might need. You take that into the maritime service and the challenge, Tyler, is that you can’t logistically operate that way because we could have a ship, in this case, off the coast of Taiwan that needs a part, and Lockheed Martin can guarantee its arrival into Okinawa. But now there is no FedEx, UPS, DHL that’s gonna get it out to the aircraft carrier. So it stops and now you have a delay and it has to go get picked up and the aircraft might be down. I don’t know if they have resolved that challenge…”
[…]
In addition to being supplied by the U.S. with a surge in spare parts and other items, Israel enjoys an advantage with its F-35 fleet no one else has. It’s developed its own additional sustainment and upgrade system and is the only partner that can test modifications and deploy them, including to the jet’s software, on its own. The IAF even has its own specially configured test F-35 to assist in these efforts.
The IAF realized early on that a troubled U.S. centralized support structure for the jets – a centralized cloud-based ‘computer brain’ called the Autonomic Logistics Information System (ALIS) – wouldn’t meet its needs, especially during a large-scale conflict.
The F-35 JPO ultimately decided to abandon efforts to fix the system in favor of a completely reworked architecture called the Operational Data Integrated Network (ODIN). That replacement system is still in development.
Even before the inception of ODIN, Israeli officials negotiated a unique arrangement giving them a degree of independence from the rest of the program.
The F-35Is have a distinct configuration that is importantly not dependent on ALIS. On top of that, it is the only user of the F-35 to have the authority to install entire suites of additional domestically-developed software on its jets and to perform completely independent depot-level maintenance.”
“The ingenious, automated ALIS system that Lockheed Martin has built will be very efficient and cost-effective,” an anonymous Israeli Air Force officer told Defense News in 2016. “But the only downfall is that it was built for countries that don’t have missiles falling on them.”
[…]
There is a major lack of spare parts within the F-35 ecosystem as it is, so the Israel case does serve as an example of what readiness can look like if the parts needed to support the fleet during wartime were actually available.
Israel’s experience, however, doe offer, as was previously pointed out: “an important example of how things might be structured differently and that it can be done. If nothing else, the drivers behind the IAF’s push for independence from the broader F-35 program all speak directly to many of the issues that Lt. Gen. Schmidt and others are just starting to raise more publicly now.”
In 2018, the European Parliament voted to ban geo-blocking, meaning blocking access to a network based on someone’s location. Geo-blocking systems block or authorise access to content based on where the user is located.
On Wednesday, following a 2020 evaluation by the Commission on the regulation, MEPs advocated for reassessing geo-blocking, taking into account increased demand for online shopping in recent years.
Polish MEP Beata Mazurek from the Conservative group, who was the rapporteur for the file, said ahead of the vote in her speech that “the geo-blocking regulation will remove unjustified barriers for consumers and companies working within the single market”.
“We need to do something when it comes to online payments and stop discrimination on what your nationality happens to be or where you happen to live. When internet purchases are being made, barriers need to be removed. We need to have a complete right to access a better selection of goods and services through Europe,” she said.
While the original text of the regulation banned geo-blocking, due to discrimination, for example, as Mazurek pointed out, a new amendment goes against this, saying this would result in revenue loss and higher prices for consumers.
The new legislation approved by European Parliament requires websites to sell their goods throughout the EU regardless of the country the buyer resides in. It could apply to online cultural content like music streaming and ebooks within two years. EURACTIV.fr report
Audiovisual content
According to Mazurek, fighting price discrimination entails making deliveries easier across borders and making movies, series, and sporting events accessible in one’s native language.
“The Commission should carefully assess the options for updating the current rules and provide the support the audio-visual sector’s needs,” she added.
However, in a last-minute amendment adopted during the plenary vote, MEP Sabine Verheyen, an influential member of the Parliament’s culture committee, completely flipped the wording that applies to the audiovisual sector, such as the streaming of platforms’ films.
According to Verheyen’s amendment, removing geo-blocking in this area “would result in a significant loss of revenue, putting investment in new content at risk, while eroding contractual freedom and reducing cultural diversity in content production, distribution, promotion and exhibition”.
It also emphasises that the inclusion would result “in fewer distribution channels”, and so, ultimately, consumers would have to pay more.
Mazurek said before the vote that while the report deals with audiovisual material, they “would like to see this done in a step-by-step way, bearing in mind the particular circumstances pertaining to the creative sector”.
“We want to look at the position of the interested parties without threatening the way cultural projects are financed. That might be regarded as a revolutionary approach, but we need to look at technological progress and the consumer needs which have changed over the last few years,” the MEP explained.
Yet, Wednesday’s vote on this specific amendment means the opposite as it did in the original regulation, with lawmakers now being against ending geo-blocking for audiovisual material.
Grégoire Polad, Director General of the Association of Commercial Television and Video on Demand Services in Europe (ACT), stressed that the European Parliament and the EU Council of Ministers “have now made it abundantly clear that there is no political support for any present or future inclusion of the audiovisual sector in the scope of the Geo-blocking regulation.”
The European Parliament adopted a report on Tuesday (9 May), on the implementation of the Audiovisual Media Services Directive (AVMSD), including criticism of the belated transposition from certain EU countries.
However, the European Consumer Organisation threw its weight against the carve-out for the audiovisual and creative sectors in the regulation, calling on policymakers to make audiovisual content available across borders.
A Commission spokesperson told Euractiv that they are aware of the “ongoing debate” and “will carefully analyse its content, including proposals related to the audiovisual content”, once it is adopted.
“The Commission engaged in a dialogue with the audiovisual sector aimed at identifying industry-led solutions to improve the availability and cross-border access to audiovisual content across the EU,” the spokesperson explained.
This stakeholder dialogue ended in December 2022, and the Commission will consider its conclusions in the upcoming stocktaking exercise on the Geo-blocking Regulation.
Strangely enough this is the one sector that is wholly digital and where geoblocking makes the least sense, as digital goods are moved globally for exactly the same cost, whereas physical goods need different logistics chains, where the last step to the consumer is only a tiny part of that chain. The logistical steps before they get sent from the website mean that geography actually can have a measurable effect on cost.
The movie / TV / digital rights bozo’s definitely have a big lobby on this one, and shows the corruption – or outright stupidity – in the EP. Yes, Sabine Verheyen, you must be one or the other.
Gig workers in the EU will soon get new benefits and protections, making it easier for them to receive employment status. Right now, over 500 digital labor platforms are actively operating in the EU, employing roughly 28 million platform workers. The new rules follow agreements made between the European Parliament and the EU Member States, after policies were first proposed by the European Commission in 2021.
The new rules highlight employment status as a key issue for gig workers, meaning an employed individual can reap the labor and social rights associated with an official worker title. This can include things like a legal minimum wage, the option to engage in collective bargaining, health protections at work, options for paid leave and sick days. Through a recognition of a worker status from the EU, gig workers can also qualify for unemployment benefits.
Given that most gig workers are employed by digital apps, like Uber or Deliveroo, the new directive will require “human oversight of the automated systems” to make sure labor rights and proper working conditions are guaranteed. The workers also have the right to contest any automated decisions by digital employers — such as a termination.
The new rulings will also require employers to inform and consult workers’ when there are “algorithmic decisions” that affect them. Employers will be required to report where their gig workers are fulfilling labor-related tasks to ensure the traceability of employees, especially when there are cross-border situations to consider in the EU.
Before the new gig worker protections can formally roll out, there needs to be a final approval of the agreement by the European Parliament and the Council. The stakeholders will have two years to implement the new protections into law. Similar protections for gig workers in the UK were introduced in 2021. Meanwhile, in the US, select cities have rolled out minimum wage rulings and benefits — despite Uber and Lyft’s pushback against such requirements.
Before a massive star explodes as a supernova, it convulses and sends its outer layers into space, signalling the explosive energy about to follow. When the star does explode, it sends a shockwave out into its own ejected outer layer, lighting it up as different chemical elements shine with different energies and colours. Intermingled with this is any pre-existing matter near the supernova. The result is a massive expanding shell with filaments and knots of ionized gas, populated by even smaller bubbles.
“With NIRCam’s resolution, we can now see how the dying star absolutely shattered when it exploded, leaving filaments akin to tiny shards of glass behind.”
Danny Milisavljevic, Purdue University
Cassiopeia A exploded about 10,000 years ago, and the light may have reached Earth around 1667. But there’s much uncertainty, and it’s possible that English astronomer John Flamsteed observed it in 1680. It’s also a possibility that it was first observed in 1630. That’s for historians to determine.
But whenever the exact date is, the light has reached us and continues to reach us, making Cassiopeia A an object of astronomical fascination. It’s one of the most-studied SNRs, and astronomers have observed it in multiple wavelengths with different telescopes.
The SNR is about 10 light-years across and is expanding between 4,000 and 6,000 km/second. Some outlying knots are moving much more quickly, with velocities from 5,500?14,500 km/s. The expanding shell is also extremely hot, at about 30 million degrees Kelvin (30 million C/54 million F.)
The JWST’s NIRCam high-resolution image of Cass. A reveals intricate detail that remains hidden from other telescopes. Image Credit: NASA, ESA, CSA, STScI, Danny Milisavljevic (Purdue University), Ilse De Looze (UGent), Tea Temim (Princeton University)
But none of our prior images are nearly as breathtaking as these JWST images. These images are far more than just pretty pictures. The cursive swirls and knotted clumps of gas reveal some of nature’s detailed interactions between light and matter.
The JWST sees in infrared, so its images need to be translated for our eyes. The wavelengths the telescope can see are translated into different visible colours. Clumps of bright orange and light pink are most noticeable in these images, and they signify the presence of sulphur, oxygen, argon, and neon. These elements came from the star itself, and gas and dust from the region around the star are intermingled with it.
The image below highlights some parts of the Cassiopeia A SNR.
1 shows tiny knots of gas comprised of sulphur, oxygen, argon, and neon from the star itself. 2 shows what’s known as the Green Monster, a loop of green light in Cas A’s inner cavity, which is visible in the MIRI image of the SNR. Circular holes are outlined in white and purple and represent ionized gas. This is likely where debris from the explosions punched holes in the surrounding gas and ionized it. 3 shows a light echo, where light from the ancient explosion has warmed up dust which shines as it cools down. 4 shows an especially large and intricate light echo known as Baby Cas A. Baby Cas A is actually about 170 light-years beyond Cas A. Image Credit: NASA, ESA, CSA, STScI, Danny Milisavljevic (Purdue University), Ilse De Looze (UGent), Tea Temim (Princeton University)
The JWST’s MIRI image shows different details. The outskirts of the main shell aren’t orange and pink. Instead, it looks more like smoke lit up by campfire flames.
Seeing the NIRCam image (L) and the MIRI image (R) tells us about the SNR and the JWST. First of all, the NIRCam image is sharper because of its higher resolution. The NIRCam image also appears less colourful, but that’s because of the wavelengths of light being emitted that are more visible in Mid-Infrared. In the MIRI image, the outer ring is lit up more brightly than in the NIRCam image, while the MIRI image also shows the ‘Green Monster,’ the green inner ring that is invisible in the NIRCam image. Image Credit: NASA, ESA, CSA, STScI, Danny Milisavljevic (Purdue University), Ilse De Looze (UGent), Tea Temim (Princeton University)
The Hubble Space Telescope, the Spitzer Space Telescope, and the Chandra X-Ray Observatory have all studied Cas A. In fact, Spitzer’s first light image back in 1999 was of Cas A.
This X-ray image of the Cassiopeia A (Cas A) supernova remnant is the official first light image of the Chandra X-ray Observatory. The bright object near the center may be the long-sought neutron star or black hole that remained after the explosion that produced Cas A. Image Credit: By NASA/CXC/SAO – http://chandra.harvard.edu/photo/1999/0237/, Public Domain, https://commons.wikimedia.org/w/index.php?curid=33394808
The Hubble has imaged Cas A too. This image is from 2006 and is a composite of 18 separate images. While interesting and stunning at the time, the JWST’s image surpasses it in both visual and scientific detail.
This NASA/ESA Hubble Space Telescope image provides a detailed look at the tattered remains of Cassiopeia A (Cas A). It is the youngest known remnant from a supernova explosion in the Milky Way. Image Credit: NASA, ESA, and the Hubble Heritage (STScI/AURA)-ESA/Hubble Collaboration. Acknowledgement: Robert A. Fesen (Dartmouth College, USA) and James Long (ESA/Hubble)
The JWST’s incredible images are giving us a more detailed look at Cas A than ever. Danny Milisavljevic leads the Time Domain Astronomy research team at Purdue University and has studied SNRs extensively, including Cas A. He emphasizes how important the JWST is in his work.
“With NIRCam’s resolution, we can now see how the dying star absolutely shattered when it exploded, leaving filaments akin to tiny shards of glass behind,” said Milisavljevic. “It’s really unbelievable after all these years studying Cas A to now resolve those details, which are providing us with transformational insight into how this star exploded.”
Scientists have solved a decades-long puzzle and unveiled a near unbreakable substance that could rival diamond as the hardest material on Earth. The research is published in the journal Advanced Materials.
Researchers found that when carbon and nitrogen precursors were subjected to extreme heat and pressure, the resulting materials—known as carbon nitrides—were tougher than cubic boron nitride, the second hardest material after diamond.
The breakthrough opens doors for multifunctional materials to be used for industrial purposes including protective coatings for cars and spaceships, high-endurance cutting tools, solar panels and photodetectors, experts say.
[…]
The team subjected various forms of carbon nitrogen precursors to pressures of between 70 and 135 gigapascals—around 1 million times our atmospheric pressure—while heating it to temperatures of more than 1,500°C.
To identify the atomic arrangement of the compounds under these conditions, the samples were illuminated by an intense X-ray beam at three particle accelerators—the European Synchrotron Research Facility in France, the Deutsches Elektronen-Synchrotron in Germany and the Advanced Photon Source based in the United States.
Researchers discovered that three carbon nitride compounds were found to have the necessary building blocks for super-hardness.
Remarkably, all three compounds retained their diamond-like qualities when they returned to ambient pressure and temperature conditions.
Further calculations and experiments suggest the new materials contain additional properties including photoluminescence and high energy density, where a large amount of energy can be stored in a small amount of mass.
[…]
More information: Dominique Laniel et al, Synthesis of Ultra‐Incompressible and Recoverable Carbon Nitrides Featuring CN4 Tetrahedra, Advanced Materials (2023). DOI: 10.1002/adma.202308030
Scientists have discovered the first indication of nuclear fission occurring amongst the stars. The discovery supports the idea that when neutron stars smash together, they create “superheavy” elements — heavier than the heaviest elements of the periodic table
[…]
“People have thought fission was happening in the cosmos, but to date, no one has been able to prove it,” Matthew Mumpower, research co-author and a scientist at Los Alamos National Laboratory, said in a statement.
The team of researchers led by North Carolina State University scientist Ian Roederer searched data concerning a wide range of elements in stars to discover the first evidence that nuclear fission could therefore be acting when neutron stars merge. These findings could help solve the mystery of where the universe‘s heavy elements come from.
[…]
The picture of so-called nucleosynthesis for heavier elements like gold and uranium, however, has been somewhat more mysterious. Scientists suspect these valuable and rare heavy elements are created when two incredibly dense dead stars — neutron stars — collide and merge, creating an environment violent enough to forge elements that can’t be created even in the most turbulent hearts of stars.
The evidence of nuclear fission discovered by Mumpower and the team comes in the form of a correlation between “light precision metals,” like silver, and “rare earth nuclei,” like europium, showing in some stars. When one of these groups of elements goes up, the corresponding elements in the other group also increases, the scientists saw.
The team’s research also indicates that elements with atomic masses — counts of protons and neutrons in an atomic nucleus — greater than 260 may exist around neutron star smashes, even if this existence is brief. This is much heavier than many of the elements at the “heavy end” of the periodic table.
“The only plausible way this can arise among different stars is if there is a consistent process operating during the formation of the heavy elements,” Mumpower said. “This is incredibly profound and is the first evidence of fission operating in the cosmos, confirming a theory we proposed several years ago.”
[…]
Neutron stars are created when massive stars reach the end of their fuel supplies necessary for intrinsic nuclear fusion processes, which means the energy that has been supporting them against the inward push of their own gravity ceases. As the outer layers of these dying stars are blown away, the stellar cores with masses between one and two times that of the sun collapse into a width of around 12 miles (20 kilometers).
This core collapse happens so rapidly that electrons and protons are forced together, creating a sea of neutrons so dense a mere tablespoon of this neutron star “stuff” would weigh more than 1 billion tons if it were brought to Earth.
When these extreme stars exist in a binary pairing, they spiral around one another. And as they spiral around one another, they lose angular momentum because they emit intangible ripples in spacetime called gravitational waves. This causes neutron stars to eventually collide, merge and, unsurprisingly given their extreme and exotic nature, create a very violent environment.
This ultimate neutron star merger releases a wealth of free neutrons, which are particles normally bound up with protons in atomic nuclei. This can allow other atomic nuclei in these environments to quickly grab these free neutrons — a process called rapid neutron capture or the “r-process.” This allows the atomic nuclei to grow heavier, creating superheavy elements that are unstable. These superheavy elements can then undergo fission to split down into lighter, stable elements like gold.
In 2020, Mumpower predicted how the “fission fragments” of r-process-created nuclei would be distributed. Following this, Mumpower’s collaborator and TRIUMF scientist Nicole Vassh calculated how the r-process would lead to the co-production of light precision metals such as ruthenium, rhodium, palladium and silver — as well as rare earth nuclei, like europium, gadolinium, dysprosium and holmium.
This prediction can be tested not only by looking at neutron star mergers but also by looking at the abundances of elements in stars that have been enriched by r-process-created material.
This new research looked at 42 stars and found the precise correlation predicted by Vassh, thus showing a clear signature of the fission and decay of elements heavier than found on the periodic table, further confirming that neutron star collisions are indeed the sites where elements heavier than iron are forged.
“The correlation is very robust in r-process enhanced stars where we have sufficient data. Every time nature produces an atom of silver, it’s also producing heavier rare earth nuclei in proportion. The composition of these element groups are in lockstep,” Mumpower concluded. “We have shown that only one mechanism can be responsible — fission — and people have been racking brains about this since the 1950s.”
The team’s research was published in the Dec. 6 edition of the journal Science.
Close to a million records containing personally identifiable information belonging to donors that sent money to non-profits were found exposed in an online database.
The database is owned and operated by DonorView – provider of a cloud-based fundraising platform used by schools, charities, religious institutions, and other groups focused on charitable or philanthropic goals.
Infosec researcher Jeremiah Fowler found 948,029 records exposed online including donor names, addresses, phone numbers, emails, payment methods, and more.
Manual analysis of the data revealed what appeared to be the names and addresses of individuals designated as children – though it wasn’t clear to the researcher whether these children were associated with the organization collecting the donation or the funds’ recipients.
Another document seen by Fowler revealed children’s names, medical conditions, names of their attending doctors, and information on whether the child’s image could be used in marketing materials – though in many cases this was not permitted.
In just a single document, more than 70,000 names and contact details were exposed, all believed to be donors to non-profits.
Neither Fowler nor The Register has received a response from the US-based service provider, though Fowler said it did secure the database within days of him filing a disclosure report.
three white-hat hackers helped a regional rail company in southwest Poland unbrick a train that had been artificially rendered inoperable by the train’s manufacturer after an independent maintenance company worked on it. The train’s manufacturer is now threatening to sue the hackers who were hired by the independent repair company to fix it.
The fallout from the situation is currently roiling Polish infrastructure circles and the repair world, with the manufacturer of those trains denying bricking the trains despite ample evidence to the contrary. The manufacturer is also now demanding that the repaired trains immediately be removed from service because they have been “hacked,” and thus might now be unsafe, a claim they also cannot substantiate.
The situation is a heavy machinery example of something that happens across most categories of electronics, from phones, laptops, health devices, and wearables to tractors and, apparently, trains. In this case, NEWAG, the manufacturer of the Impuls family of trains, put code in the train’s control systems that prevented them from running if a GPS tracker detected that it spent a certain number of days in an independent repair company’s maintenance center, and also prevented it from running if certain components had been replaced without a manufacturer-approved serial number.
This anti-repair mechanism is called “parts pairing,” and is a common frustration for farmers who want to repair their John Deere tractors without authorization from the company. It’s also used by Apple to prevent independent repair of iPhones.
An image posed by q3k of how the team did their work.
In this case, a Polish train operator called Lower Silesian Railway, which operates regional train services from Wrocław, purchased 11 Impuls trains. It began to do regular maintenance on the trains using an independent company called Serwis Pojazdów Szynowych (SPS), which notes on its website that “many Polish carriers have trusted us” with train maintenance. Over the course of maintaining four different Impuls trains, SPS found mysterious errors that prevented them from running. SPS became desperate and Googled “Polish hackers” and came across a group called Dragon Sector, a reverse-engineering team made up of white hat hackers. The trains had just undergone “mandatory maintenance” after having traveled a million kilometers.
“This is quite a peculiar part of the story—when SPS was unable to start the trains and almost gave up on their servicing, someone from the workshop typed “polscy hakerzy” (‘Polish hackers’) into Google,” the team from Dragon Sector, made up of Jakub Stępniewicz, Sergiusz Bazański, and Michał Kowalczyk, told me in an email. “Dragon Sector popped up and soon after we received an email asking for help.”
The problem was so bad that an infrastructure trade publication in Poland called Rynek Kolejowy picked up on the mysterious issues over the summer, and said that the lack of working trains was beginning to impact service: “Four vehicles after level P3-2 repair cannot be started. At this moment, it is not known what caused the failure. The lack of units is a serious problem for the carrier and passengers, because shorter trains are sent on routes.”
The hiring of Dragon Sector was a last resort: “In 2021, an independent train workshop won a maintenance tender for some trains made by Newag, but it turned out that they didn’t start after servicing,” Dragon Sector told me. “[SPS] hired us to analyze the issue and we discovered a ‘workshop-detection’ system built into the train software, which bricked the trains after some conditions were met (two of the trains even used a list of precise GPS coordinates of competitors’ workshops). We also discovered an undocumented ‘unlock code’ which you could enter from the train driver’s panel which magically fixed the issue.”
Dragon Sector was able to bypass the measures and fix the trains. The group posted a YouTube video of the train operating properly after they’d worked on it:
The news of Dragon Sector’s work was first reported by the Polish outlet Zaufana Trzecia Strona and was translated into English by the site Bad Cyber. Kowalczyk and Stępniewicz gave a talk about the saga last week at Poland’s Oh My H@ck conference in Warsaw. The group plans on doing further talks about the technical measures implemented to prevent the trains from running and how they fixed it.
“These trains were locking up for arbitrary reasons after being serviced at third-party workshops. The manufacturer argued that this was because of malpractice by these workshops, and that they should be serviced by them instead of third parties,” Bazański, who goes by the handle q3k, posted on Mastodon. “After a certain update by NEWAG, the cabin controls would also display scary messages about copyright violations if the human machine interface detected a subset of conditions that should’ve engaged the lock but the train was still operational. The trains also had a GSM telemetry unit that was broadcasting lock conditions, and in some cases appeared to be able to lock the train remotely.”
The train had a system that detected if it physically had been to an independent repair shop.
All of this has created quite a stir in Poland (and in repair circles). NEWAG did not respond to a request for comment from 404 Media. But Rynek Kolejowy reported that the company is now very mad, and has threatened to sue the hackers. In a statement to Rynek Kolejowy, NEWAG said “Our software is clean. We have not introduced, we do not introduce and we will not introduce into the software of our trains any solutions that lead to intentional failures. This is slander from our competition, which is conducting an illegal black PR campaign against us.” The company added that it has reported the situation to “the authorized authorities.”
“Hacking IT systems is a violation of many legal provisions and a threat to railway traffic safety,” NEWAG added. “We do not know who interfered with the train control software, using what methods and what qualifications. We also notified the Office of Rail Transport about this so that it could decide to withdraw from service the sets subjected to the activities of unknown hackers.”
In response, Dragon Sector released a lengthy statement explaining how they did their work and explaining the types of DRM they encountered: “We did not interfere with the code of the controllers in Impulsa – all vehicles still run on the original, unmodified software,” part of the statement reads. SPS, meanwhile, has said that its position “is consistent with the position of Dragon Sector.”
Kowalczk told 404 Media that “we are answering media and waiting to be summoned as witnesses,” and added that “NEWAG said that they will sue us, but we doubt they will – their defense line is really poor and they would have no chance defending it, they probably just want to sound scary in the media.”
This strategy—to intimidate independent repair professionals, claim that the device (in this case, a train) is unsafe, and threaten legal action—is an egregious but common playbook in manufacturers’ fight against repair, all over the world.