De populaire betaal-app Tikkie biedt de mogelijkheid om geld over te boeken naar andere Tikkie-gebruikers op basis van hun 06-nummer. Daardoor was het mogelijk om de IBAN-nummers van vele nietsvermoedende Tikkie-gebruikers te achterhalen, met het gevaar voor identiteitsfraude en phishing.
Dat blijkt uit onderzoek van RTL Nieuws. ABN Amro bevestigt de kwetsbaarheid en heeft de nieuwe functie, Tikkie Pay, tijdelijk offline gehaald. “Bedankt voor de oplettendheid”, aldus de woordvoerder.
IBAN-nummers
Tikkie, dat 4 miljoen gebruikers heeft, toonde met zijn nieuwe functie alle gebruikers uit jouw contactenlijst die hun 06-nummer aan Tikkie hebben gekoppeld. Je kon op een naam drukken, vervolgens een bedrag overmaken en net voor de overboeking de Tikkie annuleren. In de omschrijving van de overboeking zag je dan het IBAN-nummer van de ontvanger, zonder dat diegene daar weet van heeft.
Why replace your things just because they’re not state-of-the-art? Smartians are cloud-connected motors that breathe new life into the things around you.
The Debian Project has patched a security flaw in its software manager Apt that can be exploited by network snoops to execute commands as root on victims’ boxes as they update or install packages.
The Linux distro’s curators have pushed out an fix to address CVE-2019-3462, a vulnerability uncovered and reported by researcher Max Justicz.
The flaw is related to the way Apt and apt-get handle HTTP redirects when downloading packages. Apt fetches packages over plain-old HTTP, rather than a more secure HTTPS connection, and uses cryptographic signatures to check whether the downloaded contents are legit and haven’t been tampered with.
This unfortunately means a man-in-the-middle (MITM) miscreant who was able to intercept and tamper with a victim’s network connection could potentially inject a redirect into the HTTP headers to change the URL used to fetch the package.
And the hacker would be able to control the hashes used by Apt to check the downloaded package, passing the package manager legit values to masquerade the fetched malware as sanctioned software.
All in all, users can be fed malware that’s run as root during installation, allowing it to commandeer the machine.
[…]
As an added wrinkle, Apt is updated by Apt itself. And seeing as the update mechanism is insecure, folks need to take extra steps to install the security fix securely. Admins will want to first disable redirects (see below) and then go through the usual apt update and upgrade steps.
Google engineers have proposed changes to the open-source Chromium browser that will break content-blocking extensions, including various ad blockers.
Adblock Plus will most likely not be affected, though similar third-party plugins will, for reasons we will explain. The drafted changes will also limit the capabilities available to extension developers, ostensibly for the sake of speed and safety. Chromium forms the central core of Google Chrome, and, soon, Microsoft Edge.
In a note posted Tuesday to the Chromium bug tracker, Raymond Hill, the developer behind uBlock Origin and uMatrix, said the changes contemplated by the Manifest v3 proposal will ruin his ad and content blocking extensions, and take control of content away from users.
Content blockers may be used to hide or black-hole ads, but they have broader applications. They’re predicated on the notion that users, rather than anyone else, should be able to control how their browser presents and interacts with remote resources.
Manifest v3 refers to the specification for browser extension manifest files, which enumerate the resources and capabilities available to browser extensions. Google’s stated rationale for making the proposed changes, cutting off blocking plugins, is to improve security, privacy and performance, and supposedly to enhance user control.
Supermarkets create cheap “magic boxes” with end of life food in them. You can see where to pick them up on the app. Jumbo NL has started a pilot in 13 shops.
Het van oorsprong Deense initiatief Too Good To Go heeft na één jaar in Nederland meer dan 200.000 maaltijden gered van de vuilnisbak. De gelijknamige app heeft ondertussen al meer dan 250.000 geregistreerde gebruikers en meer dan 1000 partners met dekking in alle provincies in Nederland.
Op de kaart of in de lijst in de app kunnen consumenten bekijken welke locaties iets lekkers voor ze klaar hebben liggen tegen sluitingstijd. Vervolgens bestellen en betalen zij direct in de app.
Sinds gisteren is bij Jumbo een pilot met Too Goo To Go in 13 winkels gestart. De pilot duurt een maand en is de eerste stap op weg naar een mogelijke landelijke uitrol.
Gebruikers zien in de Too Good To Go app welke Jumbo winkels een Magic Box aanbieden. Ze rekenen deze vervolgens af via de app en kunnen de verrassingsbox binnen een afgesproken tijdsslot ophalen in de winkel. De prijs is altijd een derde van de daadwerkelijke waarde: een box met een waarde van 15 euro kost dus slechts 5 euro.
Deelnemers aan de pilot zijn elf winkels in Amsterdam – waaronder de City winkels – en Foodmarkt Amsterdam en een City in Groningen.
Winkels bepalen zelf hoe ze de box samenstellen, waarbij beschikbaarheid en variatie belangrijke criteria zijn.
Vanaf vandaag is de stad Wageningen ook als locatie toegevoegd aan de app. Om de impact van de app van Too Good To Go op het consumentengedrag te meten en om te bepalen wat de volgende stukjes van de puzzel moeten worden, start Too Good To Go in samenwerking met Wageningen University & Research een onderzoek naar de verandering in bewustwording en het gedrag rond voedselverspilling.
Too Good To Go is al actief in negen Europese landen.
Last December, a whopping 3 terabytes of unprotected data from the Oklahoma Securities Commission was uncovered by Greg Pollock, a researcher with cybersecurity firm UpGuard. It amounted to millions of files, many on sensitive FBI investigations, all of which were left wide open on a server with no password, accessible to anyone with an internet connection, Forbes can reveal.
“It represents a compromise of the entire integrity of the Oklahoma department of securities’ network,” said Chris Vickery, head of research at UpGuard, which is revealing its technical findings on Wednesday. “It affects an entire state level agency. … It’s massively noteworthy.”
A breach back to the ’80s
The Oklahoma department regulates all financial securities business happening in the state. It may be little surprise there was leaked information on FBI cases. But the amount and variety of data astonished Vickery and Pollock.
Vickery said the FBI files contained “all sorts of archive enforcement actions” dating back seven years (the earliest file creation date was 2012). The documents included spreadsheets with agent-filled timelines of interviews related to investigations, emails from parties involved in myriad cases and bank transaction histories. There were also copies of letters from subjects, witnesses and other parties involved in FBI investigations.
[…]
Just as concerning, the leak also included email archives stretching back 17 years, thousands of social security numbers and data from the 1980s onwards.
[…]
After Vickery and Pollock disclosed the breach, they informed the commission it had mistakenly left open what’s known as an rsync server. Such servers are typically used to back up large batches of data and, if that information is supposed to be secure, should be protected by a username and password.
There were other signs of poor security within the leaked data. For instance, passwords for computers on the Oklahoma government’s network were also revealed. They were “not complicated,” quipped Chris Vickery, head of research on the UpGuard team. In one of the more absurd choices made by the department, it had stored an encrypted version of one document in the same file folder as a decrypted version. Passwords for remote access to agency computers were also leaked.
This is the latest in a series of incidents involving rsync servers. In December, UpGuard revealed that Level One Robotics, a car manufacturing supply chain company, was exposing information in the same way as the Oklahoma government division. Companies with data exposed in that event included Volkswagen, Chrysler, Ford, Toyota, General Motors and Tesla.
For whatever reason, governments and corporate giants alike still aren’t aware how easy it is for hackers to constantly scan the Web for such leaks. Starting with basics like passwords would help them keep their secrets secure.
Let’s Encrypt allows subscribers to validate
domain control using any one of a few different validation methods. For
much of the time Let’s Encrypt has been operating, the options were
“DNS-01”, “HTTP-01”, and “TLS-SNI-01”. We recently introduced the
“TLS-ALPN-01” method. Today we are announcing that we will end all
support for the TLS-SNI-01 validation method on February 13, 2019.
In January of 2018 we disabled the TLS-SNI-01 domain validation method for most subscribers due to a vulnerability enabled by some shared hosting infrastructure 1.1k.
We provided temporary exceptions for renewals and for a small handful
of hosting providers in order to smooth the transition to DNS-01 and
HTTP-01 validation methods. Most subscribers are now using DNS-01 or
HTTP-01.
If you’re still using TLS-SNI-01, please switch to one of the other
validation methods as soon as possible. We will also attempt to contact
subscribers who are still using TLS-SNI-01, if they provided contact
information.
We apologize for any inconvenience but we believe this is the right thing to do for the integrity of the Web PKI.
A team of researchers based at the Universities of Oxford and Edinburgh have recreated for the first time the famous Draupner freak wave measured in the North Sea in 1995.
The Draupner wave was one of the first confirmed observations of a freak wave in the ocean; it was observed on the 1st of January 1995 in the North Sea by measurements made on the Draupner Oil Platform. Freak waves are unexpectedly large in comparison to surrounding waves. They are difficult to predict, often appearing suddenly without warning, and are commonly attributed as probable causes for maritime catastrophes such as the sinking of large ships.
The team of researchers set out to reproduce the Draupner wave under laboratory conditions to understand how this freak wave was formed in the ocean. They successfully achieved this reconstruction by creating the wave using two smaller wave groups and varying the crossing angle – the angle at which the two groups travel.
Dr. Mark McAllister at the University of Oxford’s Department of Engineering Science said: “The measurement of the Draupner wave in 1995 was a seminal observation initiating many years of research into the physics of freak waves and shifting their standing from mere folklore to a credible real-world phenomenon. By recreating the Draupner wave in the lab we have moved one step closer to understanding the potential mechanisms of this phenomenon.”
It was the crossing angle between the two smaller groups that proved critical to the successful reconstruction. The researchers found it was only possible to reproduce the freak wave when the crossing angle between the two groups was approximately 120 degrees.
When waves are not crossing, wave breaking limits the height that a wave can achieve. However, when waves cross at large angles, wave breaking behaviour changes and no longer limits the height a wave can achieve in the same manner.
Prof Ton van den Bremer at the University of Oxford said: “Not only does this laboratory observation shed light on how the famous Draupner wave may have occurred, it also highlights the nature and significance of wave breaking in crossing sea conditions. The latter of these two findings has broad implications, illustrating previously unobserved wave breaking behaviour, which differs significantly from current state-of-the-art understanding of ocean wave breaking.”
To the researchers’ amazement, the wave they created bore an uncanny resemblance to “The Great Wave off Kanagawa’ – also known as “The Great Wave’ – a woodblock print published in the early 1800s by the Japanese artist Katsushika Hokusai. Hokusai’s image depicts an enormous wave threatening three fishing boats and towers over Mount Fuji which appears in the background. Hokusai’s wave is believed to depict a freak, or ‘rogue,” wave.
The laboratory-created freak wave also bears strong resemblances with photographs of freak waves in the ocean.
The researchers hope that this study will lay the groundwork for being able to predict these potentially catastrophic and hugely damaging waves that occur suddenly in the ocean without warning.
TAUS, the language data network, is an independent and neutral industry organization. We develop communities through a program of events and online user groups and by sharing knowledge, metrics and data that help all stakeholders in the translation industry develop a better service. We provide data services to buyers and providers of language and translation services.
The shared knowledge and data help TAUS members decide on effective localization strategies. The metrics support more efficient processes and the normalization of quality evaluation. The data lead to improved translation automation.
TAUS develops APIs that give members access to services like DQF, the DQF Dashboard and the TAUS Data Market through their own translation platforms and tools. TAUS metrics and data are already built in to most of the major translation technologies.
An online casino group has leaked information on over 108 million bets, including details about customers’ personal information, deposits, and withdrawals, ZDNet has learned.
The data leaked from an ElasticSearch server that was left exposed online without a password, Justin Paine, the security researcher who discovered the server, told ZDNet.
ElasticSearch is a portable, high-grade search engine that companies install to improve their web apps’ data indexing and search capabilities. Such servers are usually installed on internal networks and are not meant to be left exposed online, as they usually handle a company’s most sensitive information.
Last week, Paine came across one such ElasticSearch instance that had been left unsecured online with no authentication to protect its sensitive content. From a first look, it was clear to Paine that the server contained data from an online betting portal.
Despite being one server, the ElasticSearch instance handled a huge swathe of information that was aggregated from multiple web domains, most likely from some sort of affiliate scheme, or a larger company operating multiple betting portals.
After an analysis of the URLs spotted in the server’s data, Paine and ZDNet concluded that all domains were running online casinos where users could place bets on classic cards and slot games, but also other non-standard betting games.
Some of the domains that Paine spotted in the leaky server included kahunacasino.com, azur-casino.com, easybet.com, and viproomcasino.net, just to name a few.
After some digging around, some of the domains were owned by the same company, but others were owned by companies located in the same building at an address in Limassol, Cyprus, or were operating under the same eGaming license number issued by the government of Curacao –a small island in the Carribean– suggesting that they were most likely operated by the same entity.
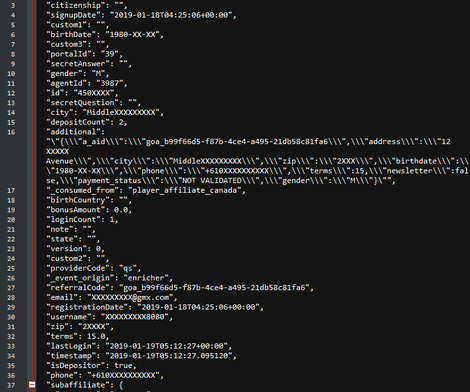
The user data that leaked from this common ElasticSearch server included a lot of sensitive information, such as real names, home addresses, phone numbers, email addresses, birth dates, site usernames, account balances, IP addresses, browser and OS details, last login information, and a list of played games.
A very small portion of the redacted user data leaked by the server
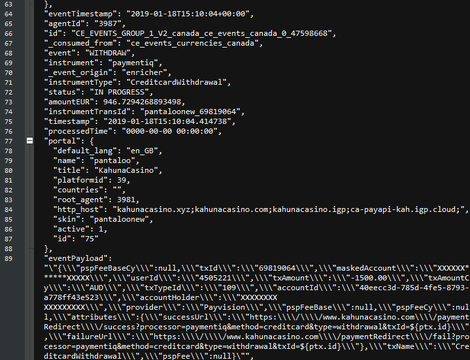
Furthermore, Paine also found roughly 108 million records containing information on current bets, wins, deposits, and withdrawals. Data on deposits and withdrawals also included payment card details.
A very small portion of the redacted transaction data leaked by the server
The good news is that the payment card details indexed in the ElasticSearch server were partially redacted, and they were not exposing the user’s full financial details.
The bad news is that anyone who found the database would have known the names, home addresses, and phone numbers of players who recently won large sums of money and could have used this information to target users as part of scams or extortion schemes.
ZDNet reached out with emails to all the online portals whose data Paine identified in the leaky server. At the time of writing, we have not received any response from any of the support teams we contacted last week, but today, the leaky server went offline and is not accessible anymore.
Google has been hit by a €50 million ($57 million) fine by French data privacy body CNIL (National Data Protection Commission) for failure to comply with the EU’s General Data Protection Regulation (GDPR) regulations.
The CNIL said that it was fining Google for “lack of transparency, inadequate information and lack of valid consent regarding the ads personalization,” according to a press release issued by the organization. The news was first reported by the AFP.
[…]
The crux of the complaints leveled at Google is that it acted illegally by forcing users to accept intrusive terms or lose access to the service. This “forced consent,” it’s argued, runs contrary to the principles set out by the GDPR that users should be allowed to choose whether to allow companies to use their data. In other words, technology companies shouldn’t be allowed to adopt a “take it or leave it” approach to getting users to agree to privacy-intruding terms and conditions.
[…]
The watchdog found two core privacy violations. First, it observed that the visibility of information relating to how Google processes data, for how long it stores it, and the kinds of information it uses to personalize advertisements, is not easy to access. It found that this information was “excessively disseminated across several documents, with buttons and links on which it is required to click to access complementary information.”
So in effect, the CNIL said there was too much friction for users to find the information they need, requiring up to six separate actions to get to the information. And even when they find the information, it was “not always clear nor comprehensive.” The CNIL stated:
Users are not able to fully understand the extent of the processing operations carried out by Google. But the processing operations are particularly massive and intrusive because of the number of services offered (about twenty), the amount and the nature of the data processed and combined. The restricted committee observes in particular that the purposes of processing are described in a too generic and vague manner, and so are the categories of data processed for these various purposes.
Secondly, the CNIL said that it found that Google does not “validly” gain user consent for processing their data to use in ads personalization. Part of the problem, it said, is that the consent it collects is not done so through specific or unambiguous means — the options involve users having to click additional buttons to configure their consent, while too many boxes are pre-selected and require the user to opt out rather than opt in. Moreover, Google, the CNIL said, doesn’t provide enough granular controls for each data-processing operation.
As provided by the GDPR, consent is ‘unambiguous’ only with a clear affirmative action from the user (by ticking a non-pre-ticked box for instance).
The BitTorrent protocol has a decentralized nature but the ecosystem surrounding it has some weak spots. Torrent sites, for example, use centralized search engines which are prone to outages and takedowns. Torrent-Paradise tackles this problem with IPFS, a searchable torrent indexer that’s shared by the people.
IPFS, short for InterPlanetary File System, has been around for a few years now.
While the name sounds alien to most people, it has a growing userbase among the tech-savvy.
In short, IPFS is a decentralized network where users make files available among each other. If a website uses IPFS, it is served by a “swarm” of people, much like BitTorrent users do when a file is shared.
The advantage of this system is that websites can become completely decentralized. If a website or other resource is hosted with IPFS, it remains accessible as long as the computer of one user who “pinned” it remains online.
The advantages of IPFS are clear. It allows archivists, content creators, researchers, and many others to distribute large volumes of data over the Internet. It’s censorship resistant and not vulnerable to regular hosting outages.
One day, hospital patients might be able to ingest tiny robots that deliver drugs directly to diseased tissue, thanks to research being carried out at EPFL and ETH Zurich.
A group of scientists led by Selman Sakar at EPFL and Bradley Nelson at ETH Zurich drew inspiration from bacteria to design smart, highly flexible biocompatible micro-robots. Because these devices are able to swim through fluids and modify their shape when needed, they can pass through narrow blood vessels and intricate systems without compromising on speed or maneuverability. They are made of hydrogel nanocomposites that contain magnetic nanoparticles, allowing them to be controlled via an electromagnetic field.
In an article appearing in Science Advances, the scientists describe a method for programming the robot’s shape so that it can easily travel through fluids that are dense, viscous or moving at rapid speeds.
Embodied intelligence
Fabricating miniaturized robots presents a host of challenges, which the scientists addressed using an origami-based folding method. Their novel locomotion strategy employs embodied intelligence, which is an alternative to the classical computation paradigm that is performed by embedded electronic systems. “Our robots have a special composition and structure that allows them to adapt to the characteristics of the fluid they are moving through. For instance, if they encounter a change in viscosity or osmotic concentration, they modify their shape to maintain their speed and maneuverability without losing control of the direction of motion,” says Sakar.
WPML (or WP MultiLingual), the most popular WordPress plugin for translating and serving WordPress sites in multiple languages.
According to its website, WPML has over 600,000 paying customers and is one of the very few WordPress plugins that is so reputable that it doesn’t need to advertise itself with a free version on the official WordPress.org plugins repository.
But on Saturday, ET timezone, the plugin faced its first major security incident since its launch in 2007.
The attacker, which the WPML team claims is a former employee, sent out a mass email to all the plugin’s customers. In the email, the attacker claimed he was a security researcher who reported several vulnerabilities to the WPML team, which were ignored. The email[1, 2, 3, 4, 5] urged customers to check their sites for possible compromises.
But the WPML team vehemently disputed these claims. Both on Twitter[1, 2] and in a follow-up mass email, the WPML team said the hacker is a former employee who left a backdoor on its official website and used it to gain access to its server and its customer database.
WPML claims the hacker used the email addresses and customer names he took from the website’s database to send the mass email, but he also used the backdoor to deface its website, leaving the email’s text as a blog post on its site [archived version here].
Developers said the former employee didn’t get access to financial information, as they don’t store this kind of details, but they didn’t rule that he could now log into customers’ WPML.org accounts as a result of compromising the site’s database.
The company says it’s now rebuilding its server from scratch to remove the backdoor and resetting all customer account passwords as a precaution.
The WPML team also said the hacker didn’t gain access to the source code of its official plugin and did not push a malicious version to customers’ sites.
The company and its management weren’t available for additional questions regarding the incident. It is unclear if they reported the employee to authorities at the time of writing. If the company’s claim is true, there is little chance of the former employee escaping jail time.
One of the successful projects will see albatrosses and petrels benefit from further research using ‘bird-borne’ radar devices. Developed by scientists at the British Antarctic Survey (BAS), the attached radars will measure how often tracked wandering albatrosses interact with legal and illegal fishing vessels in the south Atlantic to map the areas and times when birds of different age and sex are most susceptible to bycatch – becoming caught up in fishing nets.
The project’s results will be shared with stakeholders to better target bycatch observer programmes, monitor compliance with bycatch mitigation and highlight the impact of bycatch on seabirds.
The UK is a signatory to the Agreement on the Conservation of Albatrosses and Petrels (ACAP), part of the Convention on Migratory Species of Wild Animals (CMS). This agreement has been extremely successful in substantially reducing levels of seabird bycatch in a number of important fisheries where rates have been reduced to virtually zero from levels that were historically concerning.
Professor Richard Phillips, leader of the Higher Predators and Conservation group at the British Antarctic Survey (BAS) said:
The British Antarctic Survey is delighted to be awarded this funding from Darwin Plus, which is for a collaboration between BAS and BirdLife International. The project will use a range of technologies – GPS, loggers that record 3-D acceleration and novel radar-detecting tags – to quantify interactions of tracked wandering albatrosses with legal and illegal fishing vessels. The technology will provide much-needed information on the areas and periods of highest bycatch.
Copyright activists just scored a major victory in the ongoing fight over the European Union’s new copyright rules. An upcoming summit to advance the EU’s copyright directive has been canceled, as member states objected to the incoming rules as too restrictive to online creators.
The EU’s forthcoming copyright rules had drawn attention from activists for two measures, designated as Article 11 and Article 13, that would give publishers rights over snippets of news content shared online (the so-called “link tax”) and increase platform liability for user content. Concerns about those two articles led to the intial proposal being voted down by the European parliament in July, but a version with new safeguards was approved the following September. Until recently, experts expected the resulting proposal to be approved by plenary vote in the coming months.
After today, the directive’s future is much less certain. Member states were gathered to approve a new version of the directive drafted by Romania — but eleven countries reportedly opposed the text, many of them citing familiar concerns over the two controversial articles. Crucially, Italy’s new populist government takes a far more skeptical view of the strict copyright proposals. Member states have until the end of February to approve a new version of the text, although it’s unclear what compromise might be reached.
Whatever rules the European Union adopts will have a profound impact on companies doing business online. In particular, Article 13 could greatly expand the legal risks of hosting user content, putting services like Facebook and YouTube in a difficult position. As Cory Doctorow described it to The Verge, “this is just ContentID on steroids, for everything.”
More broadly, Article 13 would expand platform’s liability for user-uploaded content. “If you’re a platform, then you are liable for the material which appears on your platform,” said professor Martin Kretschmer, who teaches intellectual property law at the University of Glasgow. “That’s the council position as of May, and that has huge problems.”
“Changing the copyright regime without really understanding where the problem is is foolish,” he continued.
Still, today’s vote suggests the ongoing activism against the proposals is having an effect. “Public attention to the copyright reform is having an effect,” wrote Pirate Party representative Julia Reda in a blog post. “Keeping up the pressure in the coming weeks will be more important than ever to make sure that the most dangerous elements of the new copyright proposal will be rejected.”
[…] today most of us have indoor jobs, and when we do go outside, we’ve been taught to protect ourselves from dangerous UV rays, which can cause skin cancer. Sunscreen also blocks our skin from making vitamin D, but that’s OK, says the American Academy of Dermatology, which takes a zero-tolerance stance on sun exposure: “You need to protect your skin from the sun every day, even when it’s cloudy,” it advises on its website. Better to slather on sunblock, we’ve all been told, and compensate with vitamin D pills.
Yet vitamin D supplementation has failed spectacularly in clinical trials. Five years ago, researchers were already warning that it showed zero benefit, and the evidence has only grown stronger. In November, one of the largest and most rigorous trials of the vitamin ever conducted—in which 25,871 participants received high doses for five years—found no impact on cancer, heart disease, or stroke.
How did we get it so wrong? How could people with low vitamin D levels clearly suffer higher rates of so many diseases and yet not be helped by supplementation?
As it turns out, a rogue band of researchers has had an explanation all along. And if they’re right, it means that once again we have been epically misled.
These rebels argue that what made the people with high vitamin D levels so healthy was not the vitamin itself. That was just a marker. Their vitamin D levels were high because they were getting plenty of exposure to the thing that was really responsible for their good health—that big orange ball shining down from above.
Last spring, Marketplace host Charlsie Agro and her twin sister, Carly, bought home kits from AncestryDNA, MyHeritage, 23andMe, FamilyTreeDNA and Living DNA, and mailed samples of their DNA to each company for analysis.
Despite having virtually identical DNA, the twins did not receive matching results from any of the companies.
In most cases, the results from the same company traced each sister’s ancestry to the same parts of the world — albeit by varying percentages.
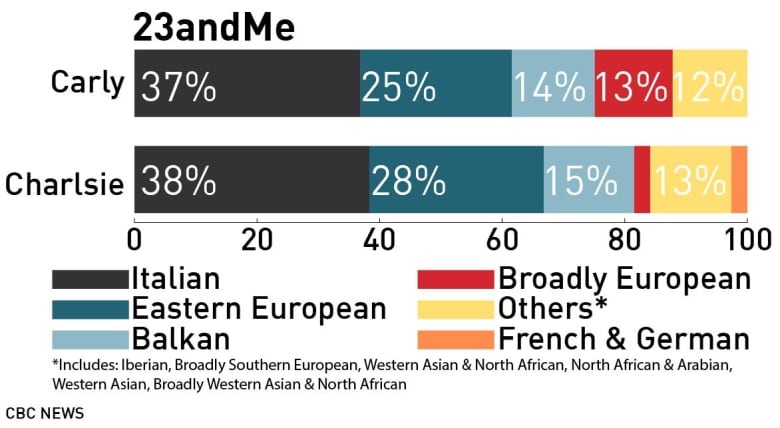
But the results from California-based 23andMe seemed to suggest each twin had unique twists in their ancestry composition.
According to 23andMe’s findings, Charlsie has nearly 10 per cent less “broadly European” ancestry than Carly. She also has French and German ancestry (2.6 per cent) that her sister doesn’t share.
The identical twins also apparently have different degrees of Eastern European heritage — 28 per cent for Charlsie compared to 24.7 per cent for Carly. And while Carly’s Eastern European ancestry was linked to Poland, the country was listed as “not detected” in Charlsie’s results.
“The fact that they present different results for you and your sister, I find very mystifying,” said Dr. Mark Gerstein, a computational biologist at Yale University.
[…]
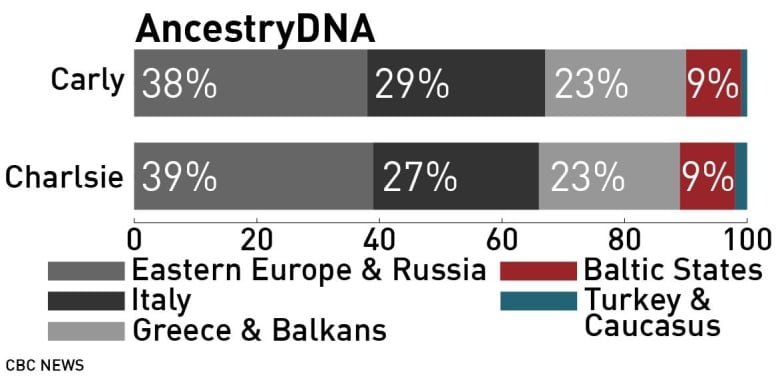
AncestryDNA found the twins have predominantly Eastern European ancestry (38 per cent for Carly and 39 per cent for Charlsie).
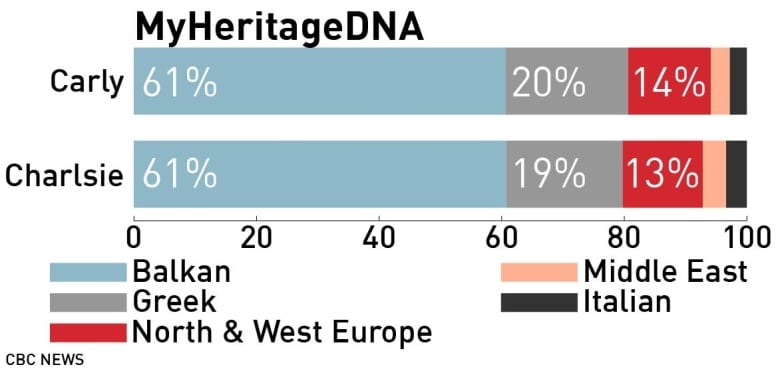
But the results from MyHeritage trace the majority of their ancestry to the Balkans (60.6 per cent for Carly and 60.7 per cent for Charlsie).
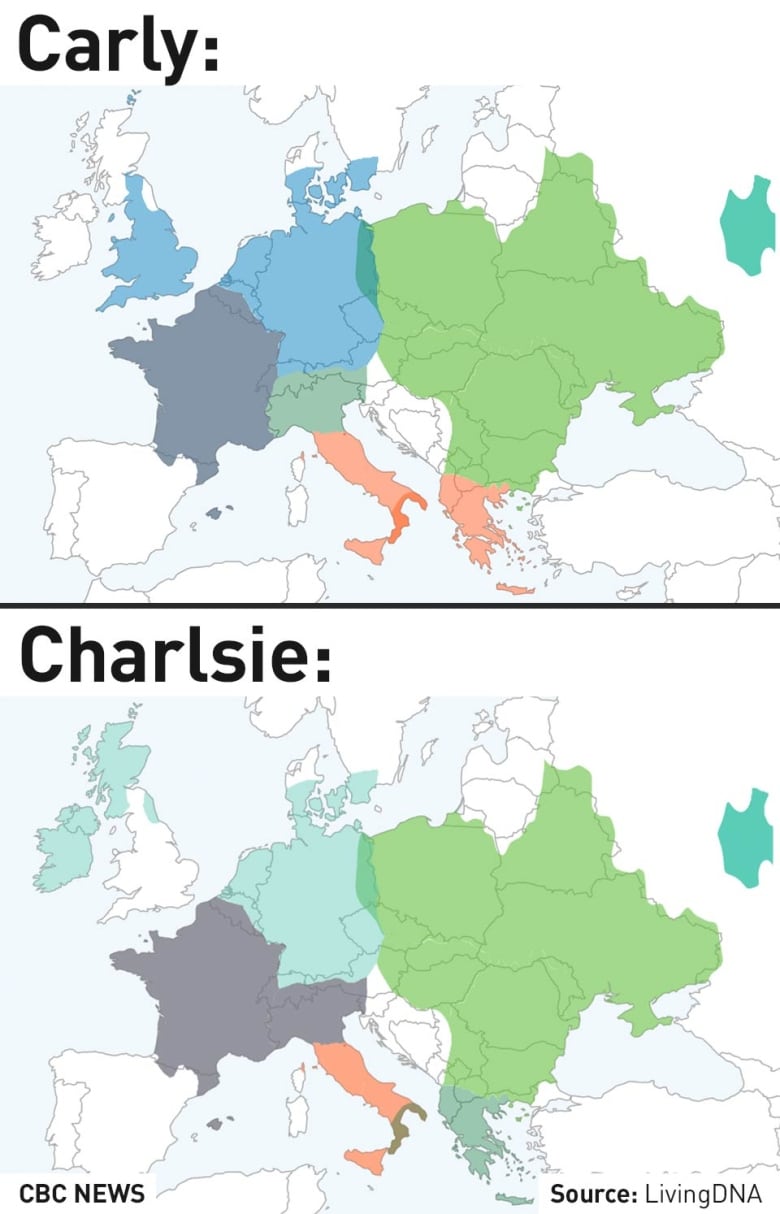
One of the more surprising findings was in Living DNA’s results, which pointed to a small percentage of ancestry from England for Carly, but Scotland and Ireland for Charlsie.
Another twist came courtesy of FamilyTreeDNA, which assigned 13-14 per cent of the twins’ ancestry to the Middle East — significantly more than the other four companies, two of which found no trace at all.
Paul Maier, chief geneticist at FamilyTreeDNA, acknowledges that identifying genetic distinctions in people from different places is a challenge.
“Finding the boundaries is itself kind of a frontiering science, so I would say that makes it kind of a science and an art,” Maier said in a phone interview.
The current DNS is unnecessarily slow and suffers from inability to deploy new features. To remediate these problems, vendors of DNS software and also big public DNS providers are going to remove certain workarounds on February 1st, 2019.
This change affects only sites which operate software which is not following published standards.
[…]
On or around Feb 1st, 2019, major open source resolver vendors will release updates that implement stricter EDNS handling. Specifically, the following versions introduce this change:
BIND 9.13.3 (development) and 9.14.0 (production)
Knot Resolver already implemented stricter EDNS handling in all current versions
Minimal working setup which will allow your domain to survive 2019 DNS flag day must not have timeout result in any of plain DNS and EDNS version 0 tests implemented in ednscomp tool. Please note that this minimal setup is still not standards compliant and will cause other issues sooner or later. For this reason we strongly recommend you to get full EDNS compliance (all tests ok) instead of doing just minimal cleanup otherwise you will have to face new issues later on.
[…]
Firewalls must not drop DNS packets with EDNS extensions, including unknown extensions. Modern DNS software may deploy new extensions (e.g. DNS cookies to protect from DoS attacks). Firewalls which drop DNS packets with such extensions are making the situation worse for everyone, including worsening DoS attacks and inducing higher latency for DNS traffic.
DNS software developers
The main change is that DNS software from vendors named above will interpret timeouts as sign of a network or server problem. Starting February 1st, 2019 there will be no attempt to disable EDNS as reaction to a DNS query timeout.
This effectively means that all DNS servers which do not respond at all to EDNS queries are going to be treated as dead.
Collection #1 is a set of email addresses and passwords totalling 2,692,818,238 rows.
It’s made up of many different individual data breaches from literally
thousands of different sources. (And yes, fellow techies, that’s a sizeable amount more than a 32-bit integer can hold.)
In total, there are 1,160,253,228 unique combinations of email addresses and passwords. This is when treating the password as case sensitive but the email address as not case
sensitive. This also includes some junk because hackers being hackers,
they don’t always neatly format their data dumps into an easily
consumable fashion. (I found a combination of different delimiter types
including colons, semicolons, spaces and indeed a combination of
different file types such as delimited text files, files containing SQL
statements and other compressed archives.)
The unique email addresses totalled 772,904,991. This is the headline you’re seeing as this is the volume of data that has now been loaded into Have I Been Pwned
(HIBP). It’s after as much clean-up as I could reasonably do and per
the previous paragraph, the source data was presented in a variety of
different formats and levels of “cleanliness”. This number makes it the
single largest breach ever to be loaded into HIBP.
There are 21,222,975 unique passwords.
As with the email addresses, this was after implementing a bunch of
rules to do as much clean-up as I could including stripping out
passwords that were still in hashed form, ignoring strings that
contained control characters and those that were obviously fragments of
SQL statements. Regardless of best efforts, the end result is not
perfect nor does it need to be. It’ll be 99.x% perfect though and that
x% has very little bearing on the practical use of this data. And yes,
they’re all now in Pwned Passwords, more on that soon.
That’s the numbers, let’s move onto where the data has actually come from.
Data Origins
Last
week, multiple people reached out and directed me to a large collection
of files on the popular cloud service, MEGA (the data has since been
removed from the service). The collection totalled over 12,000 separate
files and more than 87GB of data. One of my contacts pointed me to a
popular hacking forum where the data was being socialised, complete with
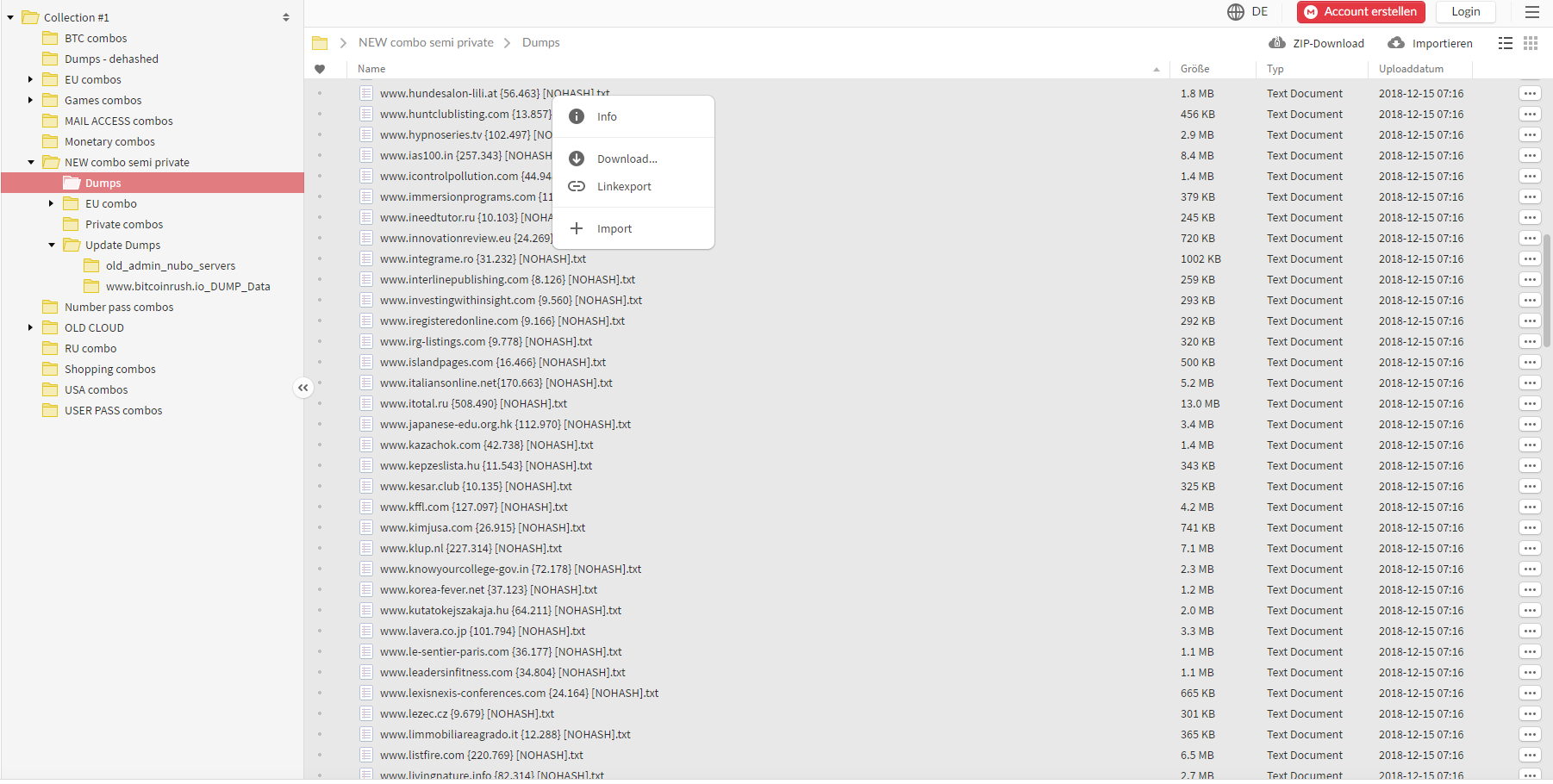
the following image:
As you can see at the top left of the image, the root folder is
called “Collection #1” hence the name I’ve given this breach. The
expanded folders and file listing give you a bit of a sense of the
nature of the data (I’ll come back to the word “combo” later), and as
you can see, it’s (allegedly) from many different sources. The post on
the forum referenced “a collection of 2000+ dehashed databases and
Combos stored by topic” and provided a directory listing of 2,890 of the
files which I’ve reproduced here. This gives you a sense of the origins of the data but again, I need to stress “allegedly”. I’ve written before about what’s involved in verifying data breaches
and it’s often a non-trivial exercise. Whilst there are many legitimate
breaches that I recognise in that list, that’s the extent of my
verification efforts and it’s entirely possible that some of them refer
to services that haven’t actually been involved in a data breach at all.
However,
what I can say is that my own personal data is in there and it’s
accurate; right email address and a password I used many years ago. Like
many of you reading this, I’ve been in multiple data breaches before
which have resulted in my email addresses and yes, my passwords,
circulating in public. Fortunately, only passwords that are no longer in
use, but I still feel the same sense of dismay that many people reading
this will when I see them pop up again. They’re also ones that were
stored as cryptographic hashes
in the source data breaches (at least the ones that I’ve personally
seen and verified), but per the quoted sentence above, the data contains
“dehashed” passwords which have been cracked and converted back to
plain text. (There’s an entirely different technical discussion about what makes a good hashing algorithm and why the likes of salted SHA1 is as good as useless.) In short, if you’re in this breach, one or more passwords you’ve previously used are floating around for others to see.
So that’s where the data has come from, let me talk about how to assess your own personal exposure.
A rocket carrying a satellite on a mission to deliver the world’s first artificial meteor shower blasted into space on Friday, Japanese scientists said.
A start-up based in Tokyo developed the micro-satellite for the celestial show over Hiroshima early next year as the initial experiment for what it calls a “shooting stars on demand” service.
The satellite is to release tiny balls that glow brightly as they hurtle through the atmosphere, simulating a meteor shower.
It hitched a ride on the small-size Epsilon-4 rocket that was launched from the Uchinoura space centre by the Japan Aerospace Exploration Agency (JAXA) on Friday morning.
[…]
The company ALE Co. Ltd plans to deliver its first out-of-this-world show over Hiroshima in the spring of 2020.
Lena Okajima, CEO of a space technology venture ALE is hoping to deliver shooting stars on demand and choreograph the cosmos
The satellite launched Friday carries 400 tiny balls whose chemical formula is a closely-guarded secret.
That should be enough for 20-30 events, as one shower will involve up to 20 stars, according to the company.
ALE’s satellite, released 500 kilometres (310 miles) above the Earth, will gradually descend to 400 kilometres over the coming year as it orbits the Earth.
Worldwide meteor shower shows
The company plans to launch a second satellite on a private-sector rocket in mid-2019.
ALE says it is targeting “the whole world” with its products and plans to build a stockpile of shooting stars in space that can be delivered across the world.
The annual Perseid meteor shower—seen here over eastern France—is a highlight for sky-watchers
When its two satellites are in orbit, they can be used separately or in tandem, and will be programmed to eject the balls at the right location, speed and direction to put on a show for viewers on the ground.
Tinkering with the ingredients in the balls should mean that it is possible to change the colours they glow, offering the possibility of a multi-coloured flotilla of shooting stars.
Robots normally need to be programmed in order to get them to perform a particular task, but they can be coaxed into writing the instructions themselves with the help of machine learning, according to research published in Science.
Engineers at Vicarious AI, a robotics startup based in California, USA, have built what they call a “visual cognitive computer” (VCC), a software platform connected to a camera system and a robot gripper. Given a set of visual clues, the VCC writes a short program of instructions to be followed by the robot so it knows how to move its gripper to do simple tasks.
“Humans are good at inferring the concepts conveyed in a pair of images and then applying them in a completely different setting,” the paper states.
“The human-inferred concepts are at a sufficiently high level to be effortlessly applied in situations that look very different, a capacity so natural that it is used by IKEA and LEGO to make language-independent assembly instructions.”
Don’t get your hopes up, however, these robots can’t put your flat-pack table or chair together for you quite yet. But it can do very basic jobs, like moving a block backwards and forwards.
It works like this. First, an input and output image are given to the system. The input image is a jumble of colored objects of various shapes and sizes, and the output image is an ordered arrangement of the objects. For example, the input image could be a number of red blocks and the output image is all the red blocks ordered to form a circle. Think of it a bit like a before and after image.
The VCC works out what commands need to be performed by the robot in order to organise the range of objects before it, based on the ‘before’ to the ‘after’ image. The system is trained to learn what action corresponds to what command using supervised learning.
Dileep George, cofounder of Vicarious, explained to The Register, “up to ten pairs [of images are used] for training, and ten pairs for testing. Most concepts are learned with only about five examples.”
Here’s a diagram of how it works:
A: A graph describing the robot’s components. B: The list of commands the VCC can use. Image credit: Vicarious AI
The left hand side is a schematic of all the different parts that control the robot. The visual hierarchy looks at the objects in front of the camera and categorizes them by object shape and colour. The attention controller decides what objects to focus on, whilst the fixation controller directs the robot’s gaze to the objects before the hand controller operates the robot’s arms to move the objects about.
The robot doesn’t need too many training examples to work because there are only 24 commands, listed on the right hand of the diagram, for the VCC controller.
An official warning by the Dutch Doctors guild to a serving doctor needs to be removed from Google’s search result, as the judge says that the privacy of the doctor is more important than the public good that arises from people being warned that this doctor has in some way misbehaved.
As a result of this landmark case, there’s a whole line of doctors requesting to be removed from Google.
Did you know that the manufacturing and construction industries use radio-frequency remote controllers to operate cranes, drilling rigs, and other heavy machinery? Doesn’t matter: they’re alarmingly vulnerable to being hacked, according to Trend Micro.
Available attack vectors for mischief-makers include the ability to inject commands, malicious re-pairing and even the ability to create one’s own custom havoc-wreaking commands to remotely controlled equipment.
“Our findings show that current industrial remote controllers are less secure than garage door openers,” said Trend Micro in its report – “A security analysis of radio remote controllers” – published today.
As a relatively obscure field, from the IT world’s point of view at any rate, remotely controlled industrial equipment appears to be surprisingly insecure by design, according to Trend: “One of the vendors that we contacted specifically mentioned multiple inquiries from its clients, which wanted to remove the need for physically pressing the buttons on the hand-held remote, replacing this with a computer, connected to the very same remote that will issue commands as part of a more complex automation process, with no humans in the loop.”
Even the pairing mechanisms between radio frequency (RF) controllers and their associated plant are only present “to prevent protocol-level interferences and allow multiple devices to operate simultaneously in a safe way,” Trend said.
Yes, by design some of these pieces of industrial gear allow one operator to issue simultaneous commands to multiple pieces of equipment.
In addition to basic replay attacks, where commands broadcast by a legitimate operator are recorded by an attacker and rebroadcast in order to take over a targeted plant, attack vectors also included command injection, “e-stop abuse” (where miscreants can induce a denial-of-service condition by continually broadcasting emergency stop commands) and even malicious reprogramming. During detailed testing of one controller/receiver pair, Trend Micro researchers found that forged e-stop commands drowned out legitimate operator commands to the target device.
One vendor’s equipment used identical checksum values in all of its RF packets, making it much easier for mischievous folk to sniff and successfully reverse-engineer those particular protocols. Another target device did not even implement a rolling code mechanism, meaning the receiving device did not authenticate received code in any way prior to executing it, like how a naughty child with an infrared signal recorder/transmitter could turn off the neighbour’s telly through the living room window.
Trend Micro also found that of the user-reprogrammable devices it tested, “none of them had implemented any protection mechanism to prevent unattended reprogramming (e.g. operator authentication)”.
A paper published Monday by United Nations University’s Institute for Water, Environment, and Health in the journal Science of the Total Environment found that desalination plants globally produce enough brine—a salty, chemical-laden byproduct—in a year to cover all of Florida in nearly a foot of it. That’s a lot of brine.
In fact, the study concluded that for every liter of freshwater a plant produces, 0.4 gallons (1.5 liters) of brine are produced on average. For all the 15,906 plants around the world, that means 37.5 billion gallons (142 billion liters) of this salty-ass junk every day. Brine production in just four Middle Eastern countries—Saudi Arabia, Kuwait, Qatar, and the United Arab Emirates—accounts for more than half of this.
The study authors, who hail from Canada, the Netherlands, and South Korea, aren’t saying desalination plants are evil. They’re raising the alarm that this level of waste requires a plan. This untreated salt water can’t just hang around in ponds—or, in worst-case scenarios, go into oceans or sewers. Disposal depends on geography, but typically the waste does go into oceans or sewers, if not injected into wells or kept in evaporation ponds. The high concentrations of salt, as well as chemicals like copper and chlorine, can make it toxic to marine life.
“Brine underflows deplete dissolved oxygen in the receiving waters,” said lead author Edward Jones, who worked at the institute and is now at Wageningen University in the Netherlands, in a press release. “High salinity and reduced dissolved oxygen levels can have profound impacts on benthic organisms, which can translate into ecological effects observable throughout the food chain.”
Instead of carelessly dumping this byproduct, the authors suggest recycling to generate new economic value. Some crop species tolerate saltwater, so why not use it to irrigate them? Or how about generating electricity with hydropower? Or why not recover the minerals (salt, chlorine, calcium) to reuse elsewhere? At the very least, we should be treating the brine so it’s safe to discharge into the ocean.
Countries that rely heavily on desalination have to be leaders in this space if they don’t want to erode their resources further. And this problem must be solved before our dependency on desalination grows.
The technology is becoming more affordable, as it should, so lower-income countries that need water may be able to hop on the wave soon. While this brine is a problem now, it doesn’t have to be by then.