Upon first glance, the Unconventional Computing Laboratory looks like a regular workspace, with computers and scientific instruments lining its clean, smooth countertops. But if you look closely, the anomalies start appearing. A series of videos shared with PopSci show the weird quirks of this research: On top of the cluttered desks, there are large plastic containers with electrodes sticking out of a foam-like substance, and a massive motherboard with tiny oyster mushrooms growing on top of it.
[…]
Why? Integrating these complex dynamics and system architectures into computing infrastructure could in theory allow information to be processed and analyzed in new ways. And it’s definitely an idea that has gained ground recently, as seen through experimental biology-based algorithms and prototypes of microbe sensors and kombucha circuit boards.
In other words, they’re trying to see if mushrooms can carry out computing and sensing functions.
A mushroom motherboard. Andrew Adamatzky
With fungal computers, mycelium—the branching, web-like root structure of the fungus—acts as conductors as well as the electronic components of a computer. (Remember, mushrooms are only the fruiting body of the fungus.) They can receive and send electric signals, as well as retain memory.
“I mix mycelium cultures with hemp or with wood shavings, and then place it in closed plastic boxes and allow the mycelium to colonize the substrate, so everything then looks white,” says Andrew Adamatzky, director of the Unconventional Computing Laboratory at the University of the West of England in Bristol, UK. “Then we insert electrodes and record the electrical activity of the mycelium. So, through the stimulation, it becomes electrical activity, and then we get the response.” He notes that this is the UK’s only wet lab—one where chemical, liquid, or biological matter is present—in any department of computer science.
Preparing to record dynamics of electrical resistance of hemp shaving colonized by oyster fungi. Andrew Adamatzky
The classical computers today see problems as binaries: the ones and zeros that represent the traditional approach these devices use. However, most dynamics in the real world cannot always be captured through that system. This is the reason why researchers are working on technologies like quantum computers (which could better simulate molecules) and living brain cell-based chips (which could better mimic neural networks), because they can represent and process information in different ways, utilizing a series of complex, multi-dimensional functions, and provide more precise calculations for certain problems.
Already, scientists know that mushrooms stay connected with the environment and the organisms around them using a kind of “internet” communication. You may have heard this referred to as the wood wide web. By deciphering the language fungi use to send signals through this biological network, scientists might be able to not only get insights about the state of underground ecosystems, and also tap into them to improve our own information systems.
An illustration of the fruit bodies of Cordyceps fungi. Irina Petrova Adamatzky
Mushroom computers could offer some benefits over conventional computers. Although they can’t ever match the speeds of today’s modern machines, they could be more fault tolerant (they can self-regenerate), reconfigurable (they naturally grow and evolve), and consume very little energy.
Before stumbling upon mushrooms, Adamatzky worked on slime mold computers—yes, that involves using slime mold to carry out computing problems—from 2006 to 2016. Physarum, as slime molds are called scientifically, is an amoeba-like creature that spreads its mass amorphously across space.
Slime molds are “intelligent,” which means that they can figure out their way around problems, like finding the shortest path through a maze without programmers giving them exact instructions or parameters about what to do. Yet, they can be controlled as well through different types of stimuli, and be used to simulate logic gates, which are the basic building blocks for circuits and electronics.
Recording electrical potential spikes of hemp shaving colonized by oyster fungi. Andrew Adamatzky
Much of the work with slime molds was done on what are known as “Steiner tree” or “spanning tree” problems that are important in network design, and are solved by using pathfinding optimization algorithms. “With slime mold, we imitated pathways and roads. We even published a book on bio-evaluation of the road transport networks,” says Adamatzky “Also, we solved many problems with computation geometry. We also used slime molds to control robots.”
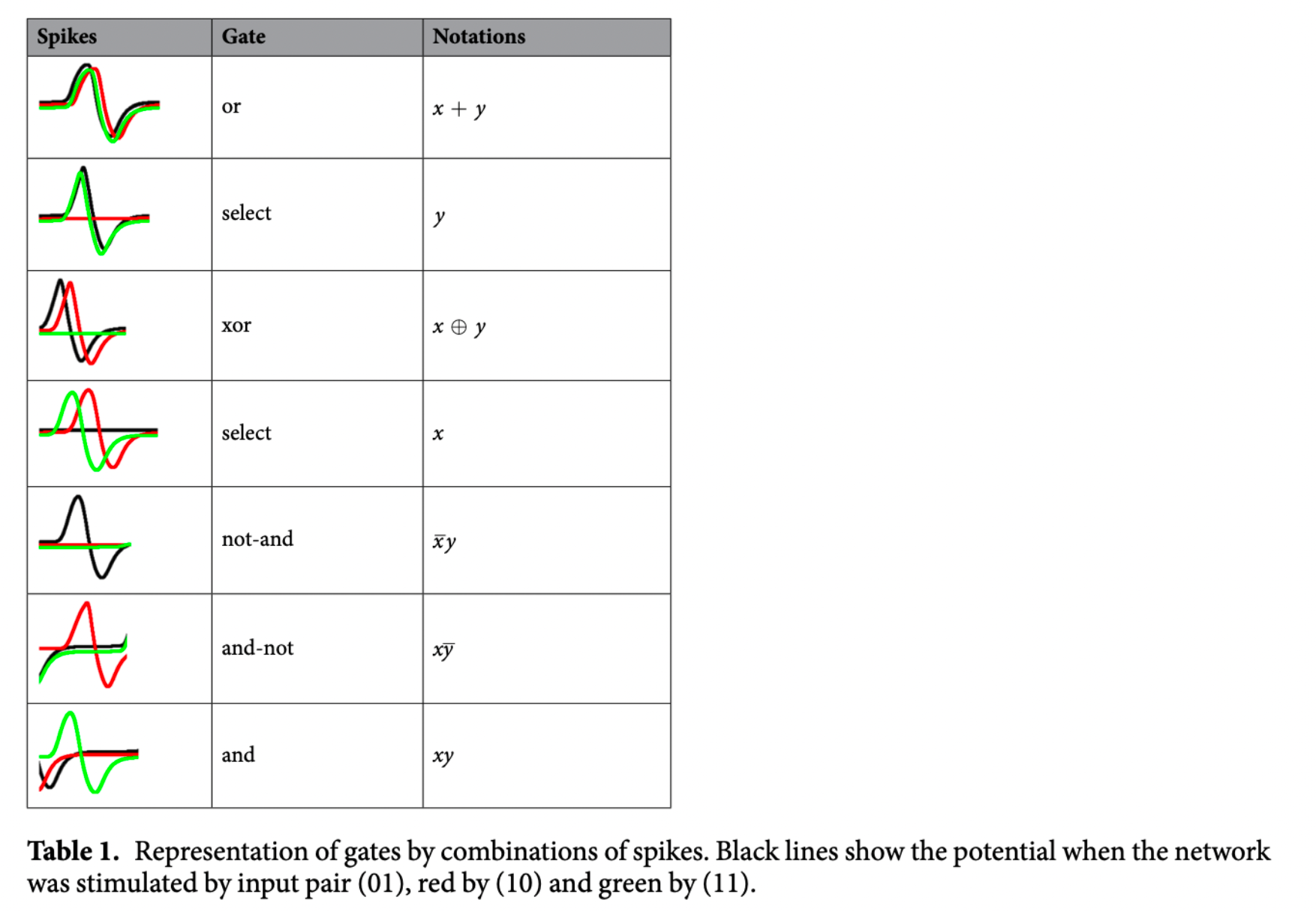
When he had wrapped up his slime mold projects, Adamatzky wondered if anything interesting would happen if they started working with mushrooms, an organism that’s both similar to, and wildly different from, Physarum. “We found actually that mushrooms produce action potential-like spikes. The same spikes as neurons produce,” he says. “We’re the first lab to report about spiking activity of fungi measured by microelectrodes, and the first to develop fungal computing and fungal electronics.”
An example of how spiking activity can be used to make gates. Andrew Adamatzky
In the brain, neurons use spiking activities and patterns to communicate signals, and this property has been mimicked to make artificial neural networks. Mycelium does something similar. That means researchers can use the presence or absence of a spike as their zero or one, and code the different timing and spacing of the spikes that are detected to correlate to the various gates seen in computer programming language (or, and, etc). Further, if you stimulate mycelium at two separate points, then conductivity between them increases, and they communicate faster, and more reliably, allowing memory to be established. This is like how brain cells form habits.
Mycelium with different geometries can compute different logical functions, and they can map these circuits based on the electrical responses they receive from it. “If you send electrons, they will spike,” says Adamatzky. “It’s possible to implement neuromorphic circuits… We can say I’m planning to make a brain from mushrooms.”
Hemp shavings in the shaping of a brain, injected with chemicals. Andrew Adamatzky
So far, they’ve worked with oyster fungi (Pleurotus djamor), ghost fungi (Omphalotus nidiformis), bracket fungi (Ganoderma resinaceum), Enoki fungi (Flammulina velutipes), split gill fungi (Schizophyllum commune) and caterpillar fungi (Cordyceps militari).
“Right now it’s just feasibility studies. We’re just demonstrating that it’s possible to implement computation, and it’s possible to implement basic logical circuits and basic electronic circuits with mycelium,” Adamatzky says. “In the future, we can grow more advanced mycelium computers and control devices.”
On Friday, a software developer named Georgi Gerganov created a tool called “llama.cpp” that can run Meta’s new GPT-3-class AI large language model, LLaMA, locally on a Mac laptop. Soon thereafter, people worked out how to run LLaMA on Windows as well. Then someone showed it running on a Pixel 6 phone, and next came a Raspberry Pi (albeit running very slowly). If this keeps up, we may be looking at a pocket-sized ChatGPT competitor before we know it. […]
Typically, running GPT-3 requires several datacenter-class A100 GPUs (also, the weights for GPT-3 are not public), but LLaMA made waves because it could run on a single beefy consumer GPU. And now, with optimizations that reduce the model size using a technique called quantization, LLaMA can run on an M1 Mac or a lesser Nvidia consumer GPU. After obtaining the LLaMA weights ourselves, we followed [independent AI researcher Simon Willison’s] instructions and got the 7B parameter version running on an M1 Macbook Air, and it runs at a reasonable rate of speed. You call it as a script on the command line with a prompt, and LLaMA does its best to complete it in a reasonable way.
There’s still the question of how much the quantization affects the quality of the output. In our tests, LLaMA 7B trimmed down to 4-bit quantization was very impressive for running on a MacBook Air — but still not on par with what you might expect from ChatGPT. It’s entirely possible that better prompting techniques might generate better results. Also, optimizations and fine-tunings come quickly when everyone has their hands on the code and the weights — even though LLaMA is still saddled with some fairly restrictive terms of use. The release of Alpaca today by Stanford proves that fine tuning (additional training with a specific goal in mind) can improve performance, and it’s still early days after LLaMA’s release. A step-by-step instruction guide for running LLaMA on a Mac can be found here (Warning: it’s fairly technical).
A Netherlands museum is facing criticism for selecting an AI-generated piece of art to temporarily take the place of the renowned Girl with a Pearl Earring painting. The artwork was created by Johannes Vermeer in 1665 and is usually located at the Mauritshuis Museum but is on loan at the Rijksmuseum in Amsterdam until June 4.
In the interim, the Mauritshuis Museum held a competition for local artists to submit their own versions of the Girl with a Pearl Earring painting and said it would select one of the submissions to take Vermeer’s place until the painting is returned. While the competition may have seemed like a straightforward and exciting process, when the museum selected an AI-generated piece of art showing the girl with more structured and sharp outlines and glowing earrings, the art community erupted with complaints.
Of the roughly 3,480 artworks submitted, Berlin-based artist, Julian van Dieken, was one of five winners selected, and whose so-called painting is receiving backlash from artists and lovers of the painting.
[…]
When asked for comment, the Mauritshuis Museum directed Gizmodo to a statement on its website which said they did not choose the winners by looking at what was the “most beautiful” or “best” submission. “For us, the starting point has always been that the maker has been inspired by Johannes Vermeer’s world-famous painting. And that can be in the most diverse ways in image or technique.”
Sounds like art doing what art should be doing – pushing culture and perceptions. Making people think. Just a shame the village idiot squad angle is pushed by Gizmodo. Well done the Mauritshuis!
Google has promised to offer API-level access to its large language model PaLM so that developers can build it into their apps and workflows, and thus make the ChatGPT-like text-emitting tech available to world-plus-dog.
The web giant is also threatening to bake the model’s content-generating capabilities into Google Docs, Gmail, and more.
[…]
On Tuesday, Google unveiled its PaLM API, opening up its text-generating large language model to developers looking to boost their applications with auto-generated machine-made writing and other stuff. It’s capable of summarizing and classifying text, acting as a support chat bot that interacts with folks on behalf of your organization, and other things, just like the other APIs out there from OpenAI, Cohere, and AI21 Labs.
[…]
PaLM API also comes with MakerSuite, a tool that allows developers to experiment with the model by trying different prompts to fine-tune the model’s output. These software services are available to a select few, however, for the moment: Google is gradually rolling them out.
The internet goliath promises that general users can look forward to eventually being able to automatically generate email drafts and replies, as well as summarize text. Images, audio, and video created using the AI engine will be available to add to Slides, whilst better autocomplete is coming to Sheets. New backgrounds and note-generating features are also coming to Meet.
Anthropic, a startup co-founded by ex-OpenAI employees, today launched something of a rival to the viral sensation ChatGPT.
Called Claude, Anthropic’s AI — a chatbot — can be instructed to perform a range of tasks, including searching across documents, summarizing, writing and coding, and answering questions about particular topics. In these ways, it’s similar to OpenAI’s ChatGPT. But Anthropic makes the case that Claude is “much less likely to produce harmful outputs,” “easier to converse with” and “more steerable.”
Organizations can request access. Pricing has yet to be detailed.
[…]
Following a closed beta late last year, Anthropic has been quietly testing Claude with launch partners, including Robin AI, AssemblyAI, Notion, Quora and DuckDuckGo. Two versions are available as of this morning via an API, Claude and a faster, less costly derivative called Claude Instant.
It’s also possible to get around Claude’s built-in safety features via clever prompting, as is the case with ChatGPT. One user in the beta was able to get Claude to describe how to make meth at home.
“The challenge is making models that both never hallucinate but are still useful — you can get into a tough situation where the model figures a good way to never lie is to never say anything at all, so there’s a tradeoff there that we’re working on,” the Anthropic spokesperson said. “We’ve also made progress on reducing hallucinations, but there is more to do.”
Anthropic’s other plans include letting developers customize Claude’s constitutional principles to their own needs. Customer acquisition is another focus, unsurprisingly — Anthropic sees its core users as “startups making bold technological bets” in addition to “larger, more established enterprises.”
[…]
The company has substantial outside backing, including a $580 million tranche from a group of investors including disgraced FTX founder Sam Bankman-Fried, Caroline Ellison, Jim McClave, Nishad Singh, Jaan Tallinn and the Center for Emerging Risk Research.
Most recently, Google pledged $300 million in Anthropic for a 10% stake in the startup. Under the terms of the deal, which was first reported by the Financial Times, Anthropic agreed to make Google Cloud its “preferred cloud provider” with the companies “co-develop[ing] AI computing systems.”
On Tuesday, the company unveiled GPT-4, an update to its advanced AI system that’s meant to generate natural-sounding language in response to user input. The company claimed GPT-4 is more accurate and more capable of solving problems. It even inferred that ChatGPT performs better than most humans can on complicated tests. OpenAI said GPT-4 scores in the 90th percentile of the Uniform Bar Exam and the 99th percentile of the Biology Olympiad. GPT-3, the company’s previous version, scored 10th and 31st on those tests, respectively.
The new system is now capable of handling over 25,000 words of text, according to the company. GPT-3 was only capable of handling 2,048 linguistic tokens, or 1,500 words at a time. This should allow for “more long-from content creation.” That’s not to say some folks haven’t tried writing entire novels with earlier versions of the LLM, but this new version could allow text to remain much more cohesive.
Those who have been hanging on OpenAI’s every word have been long anticipating the release of GPT-4, the latest edition of the company’s large language model. OpenAI said it spent six months modifying its LLM to make it 82% less likely to respond to requests for “disallowed content” and 40% more likely to produce factual responses than previous versions. Of course, we don’t have access to OpenAI’s internal data that might show how often GPT-3 was liable to lie or showcase banned content. Few people outside OpenAI have been able to take the new system on a test run, so all these claims could very well just be mere puffery.
Folks looking to get access to GPT-4 either has to be one of the select few companies given early access, or join a waitlist for the GPT-4 API or be one of the lucky few selected ChatGPT Plus subscribers.
The new system also includes the ability to accept images as inputs, allowing the system to generate captions, or provide analyses of an image. The company used the example of an image with a few ingredients, and the system provided some examples for what food those ingredients could create. OpenAI CEO Sam Altman wrote on Twitter that the company was “previewing” its visual inputs but it will “need some time to mitigate the safety challenges.”
What else is GPT-4 good at?
In a Tuesday livestream, OpenAI showed off a few capabilities of GPT-4, though the company constantly had to remind folks to not explicitly trust everything the AI produces.
In the livestream, OpenAI President Greg Brockman showed how the system can complete relatively inane tasks, like summarizing an article in one sentence where every word starts with the same letter. He then showed how users can instill the system with new information for it to parse, adding parameters to make the AI more aware of its role.
The company co-founder said the system is relatively slow, especially when completing complex tasks, though it wouldn’t take more than a few minutes to finish up requests. In one instance, Brockman made the AI create code for an AI-based Discord bot. He constantly iterated on the requests, even inputting error messages into GPT-4 until it managed to craft what was asked. He also put in U.S. tax code to finalize some tax info for an imaginary couple.
All the while, Brockman kept reiterating that people should not “run untrusted code from humans or AI,” and that people shouldn’t implicitly trust the AI to do their taxes. Of course, that won’t stop people from doing exactly that, depending on how capable public models of this AI end up being. It relates to the very real risk of running these AI models in professional settings, even when there’s only a small chance of AI error.
“It’s not perfect, but neither are you,” Brockman said.
OpenAI is getting even more companies hooked on AI
OpenAI has apparently leveraged its recently-announced multi-billion dollar arrangement with Microsoft to train GPT-4 on Microsoft Azure supercomputers. Altman said this latest version of the company’s LLM is “more creative than previous models, it hallucinates significantly less, and it is less biased.” Still, he said the company was inviting more outside groups to evaluate GPT-4 and offer feedback.
Of course, that’s not to say the system isn’t already been put into use by several companies. Language learning app Duolingo announced Tuesday afternoon that it was implementing a “Duolingo Max” premium subscription tier. The app has new features powered by GPT-4 that lets AI offer “context-specific explanations” for why users made a mistake. It also lets users practice conversations with the AI chatbot, meaning that damn annoying owl can now react to your language flubs in real time.
Because that’s what this is really about, getting more companies to pay to access OpenAI’s APIs. Altman mentioned the new system will have even more customization of behavior, which will further allow developers to fine-tune AI for specific purposes. Other customers of GPT-4 include the likes of Morgan Stanley, Khan Academy, and the Icelandic government. The U.S. Chamber of Commerce recently said in 10 years, virtually every company and government entity will be up on this AI tech.
Though the company still said GPT-4 has “many known limitations” including social biases, hallucinations, and adversarial prompts. Even if the new system is better than before, there’s still plenty of room for the AI to be abused. Some ChatGPT users have flooded open submission sections for at least one popular fiction magazine. Now that GPT-4 can write even longer, It’s likely we’ll see even more long-form AI-generated content flooding the internet.
OpenAI was supposed to be all about open source and stuff, but with this definitely being about increasing (paid) API access, it’s looking more and more like a massive money grab. Not really surprising but a real shame.
[…] The invention, by a University of Bristol physicist, who gave it the name “counterportation,” provides the first-ever practical blueprint for creating in the lab a wormhole that verifiably bridges space, as a probe into the inner workings of the universe.
By deploying a novel computing scheme, revealed in the journal Quantum Science and Technology, which harnesses the basic laws of physics, a small object can be reconstituted across space without any particles crossing. Among other things, it provides a “smoking gun” for the existence of a physical reality underpinning our most accurate description of the world.
[…]
Hatim said, “Here’s the sharp distinction. While counterportation achieves the end goal of teleportation, namely disembodied transport, it remarkably does so without any detectable information carriers traveling across.”
[…]
“If counterportation is to be realized, an entirely new type of quantum computer has to be built: an exchange-free one, where communicating parties exchange no particles,” Hatim said.
[…]
“The goal in the near future is to physically build such a wormwhole in the lab, which can then be used as a testbed for rival physical theories, even ones of quantum gravity,” Hatim added.
[…]
John Rarity, professor of optical communication systems at the University of Bristol, said, “We experience a classical world which is actually built from quantum objects. The proposed experiment can reveal this underlying quantum nature showing that entirely separate quantum particles can be correlated without ever interacting. This correlation at a distance can then be used to transport quantum information (qbits) from one location to another without a particle having to traverse the space, creating what could be called a traversable wormhole.”
More information: Hatim Salih, From counterportation to local wormholes, Quantum Science and Technology (2022). DOI: 10.1088/2058-9565/ac8ecd
Earlier this year, an amateur Go player decisively defeated one of the game’s top-ranked AI systems. They did so using a strategy developed with the help of a program researchers designed to probe systems like KataGo for weaknesses. It turns out that victory is just one part of a broader Go renaissance that is seeing human players become more creative since AlphaGO’s milestone victory in 2016
In a recent study published in the journal PNAS, researchers from the City University of Hong Kong and Yale found that human Go players have become less predictable in recent years. As the New Scientist explains, the researchers came to that conclusion by analyzing a dataset of more than 5.8 million Go moves made during professional play between 1950 and 2021. With the help of a “superhuman” Go AI, a program that can play the game and grade the quality of any single move, they created a statistic called a “decision quality index,” or DQI for short.
After assigning every move in their dataset a DQI score, the team found that before 2016, the quality of professional play improved relatively little from year to year. At most, the team saw a positive median annual DQI change of 0.2. In some years, the overall quality of play even dropped. However, since the rise of superhuman AIs in 2018, median DQI values have changed at a rate above 0.7. Over that same period, professional players have employed more novel strategies. In 2018, 88 percent of games, up from 63 percent in 2015, saw players set up a combination of plays that hadn’t been observed before.
“Our findings suggest that the development of superhuman AI programs may have prompted human players to break away from traditional strategies and induced them to explore novel moves, which in turn may have improved their decision-making,” the team writes.
That’s an interesting change, but not exactly an unintuitive one if you think about it. As professor Stuart Russel at the University of California, Berkeley told the New Scientist, “it’s not surprising that players who train against machines will tend to make more moves that machines approve of.”
[…] “The image was captured on a summer evening in São José dos Campos [in São Paulo state] while a negatively charged lightning bolt was nearing the ground at 370 km per second. When it was a few dozen meters from ground level, lightning rods and tall objects on the tops of nearby buildings produced positive upward discharges, competing to connect to the downward strike. The final image prior to the connection was obtained 25 thousandths of a second before the lightning hit one of the buildings,” Saba said.
He used a camera that takes 40,000 frames per second. When the video is played back in slow motion, it shows how lightning discharges behave and also how dangerous they can be if the protection system is not properly installed: Although there are more than 30 lightning rods in the vicinity, the strike connected not to them but to a smokestack on top of one of the buildings. “A flaw in the installation left the area unprotected. The impact of a 30,000-amp discharge did enormous damage,” he said.
[…]
Lightning strikes branch out as the electrical charges seek the path of least resistance, rather than the shortest path, which would be a straight line. The path of least resistance, usually a zigzag, is determined by different electrical characteristics of the atmosphere, which is not homogeneous. “A lightning strike made up of several discharges can last up to 2 seconds. However, each discharge lasts only fractions of milliseconds,” Saba said.
Lightning rods neither attract nor repel strikes, he added. Nor do they “discharge” clouds, as used to be believed. They simply offer lightning an easy and safe route to the ground.
Because it is not always possible to rely on the protection of a lightning rod, and most atmospheric discharges occur in summer in the tropics, it is worth considering Saba’s advice. “Storms are more frequent in the afternoon than in the morning, so be careful about outdoor activities on summer afternoons. Find shelter if you hear thunder, but never under a tree or pole, and never under a rickety roof,” he said.
“If you can’t find a safe place to shelter, stay in the car and wait for the storm to blow over. If no car or other shelter is available, squat down with your feet together. Don’t stand upright or lie flat. Indoors, avoid contact with appliances and fixed-line telephones.”
It is possible to survive being struck by lightning, and there are many examples. The odds increase if the person receives care quickly. “Cardiac arrest is the only cause of death. In this case, cardiopulmonary resuscitation is the recommended treatment,” Saba said.
Saba began systematically studying lightning with high-speed cameras in 2003, ever since building a collection of videos of lightning filmed at high speed that has become the world’s largest.
More information: Marcelo M. F. Saba et al, Close View of the Lightning Attachment Process Unveils the Streamer Zone Fine Structure, Geophysical Research Letters (2022). DOI: 10.1029/2022GL101482
DoNotPay, which describes itself as “the world’s first robot lawyer,” has been accused of practicing law without a license.
It’s facing a proposed class action lawsuit filed by Chicago-based law firm Edelson on March 3 and published Thursday on the website of the Superior Court of the State of California for the County of San Francisco.
The complaint argues: “Unfortunately for its customers, DoNotPay is not actually a robot, a lawyer, nor a law firm. DoNotPay does not have a law degree, is not barred in any jurisdiction, and is not supervised by any lawyer.”
The lawsuit was filed on behalf of Jonathan Faridian, who said he’d used DoNotPay to draft various legal documents including demand letters, a small claims court filing, and a job discrimination complaint.
[…]
Joshua Browder, the CEO of DoNotPay, said on Twitter that the claims had “no merit” and pledged to fight the lawsuit.
He said DoNotPay was “not going to be bullied by America’s richest class action lawyer” in a reference to Edelson founder Jay Edelson.
Browder said he’d been inspired to set up DoNotPay in 2015 to take on lawyers such as Edelson.
“Time and time again the only people that win are the lawyers. So I wanted to do something about it, building the DoNotPay robot lawyer to empower consumers to take on corporations on their own,” he said.
[…]
DoNotPay grabbed attention earlier this year after Browder said it planned to use its artificial intelligence chatbot to advise a defendant facing traffic court. This plan was postponed after Browder said said he’d received “threats from State Bar prosecutors” and feared a jail sentence.
Chronic pain patients were implanted with “dummy” pieces of plastic and told it would ease their pain, according to an indictment charging the former CEO of the firm that made the fake devices with fraud.
Laura Perryman, the former CEO of Stimwave LLC, was arrested in Florida on Thursday. According to an FBI press release, Perryman was indicted “in connection with a scheme to create and sell a non-functioning dummy medical device for implantation into patients suffering from chronic pain, resulting in millions of dollars in losses to federal healthcare programs.” According to the indictment, patients underwent unnecessary implanting procedures as a result of the fraud.
Perryman was charged with one count of conspiracy to commit wire fraud and health care fraud, and one count of healthcare fraud. Stimwave received FDA approval in 2014, according to Engadget, and was positioned as an alternative to opioids for pain relief.
[…]
The Stimwave “Pink Stylet” system consisted of an implantable electrode array for stimulating the target nerve, a battery worn externally that powered it, and a separate, 9-inch long implantable receiver. When doctors told Stimwave that the long receiver was difficult to place in some patients, Perryman allegedly created the “White Stylet,” a receiver that doctors could cut to be smaller and easier to implant—but was actually just a piece of plastic that did nothing.
“To perpetuate the lie that the White Stylet was functional, Perryman oversaw training that suggested to doctors that the White Stylet was a ‘receiver,’ when, in fact, it was made entirely of plastic, contained no copper, and therefore had no conductivity,” the FBI stated. “In addition, Perryman directed other Stimwave employees to vouch for the efficacy of the White Stylet, when she knew that the White Stylet was actually non-functional.”
Stimwave charged doctors and medical providers approximately $16,000 for the device, which medical insurance providers, including Medicare, would reimburse the doctors’ offices for.
[…]
“As a result of her illegal actions, not only did patients undergo unnecessary implanting procedures, but Medicare was defrauded of millions of dollars,” FBI Assistant Director Michael J. Driscoll said.
Cerebral has revealed it shared the private health information, including mental health assessments, of more than 3.1 million patients in the United States with advertisers and social media giants like Facebook, Google and TikTok.
The telehealth startup, which exploded in popularity during the COVID-19 pandemic after rolling lockdowns and a surge in online-only virtual health services, disclosed the security lapse [This is no security lapse! This is blatant greed served by peddling people’s personal information!] in a filing with the federal government that it shared patients’ personal and health information who used the app to search for therapy or other mental health care services.
Cerebral said that it collected and shared names, phone numbers, email addresses, dates of birth, IP addresses and other demographics, as well as data collected from Cerebral’s online mental health self-assessment, which may have also included the services that the patient selected, assessment responses and other associated health information.
If an individual created a Cerebral account, the information disclosed may have included name, phone number, email address, date of birth, IP address, Cerebral client ID number, and other demographic or information. If, in addition to creating a Cerebral account, an individual also completed any portion of Cerebral’s online mental health self-assessment, the information disclosed may also have included the service the individual selected, assessment responses, and certain associated health information.
If, in addition to creating a Cerebral account and completing Cerebral’s online mental health self-assessment, an individual also purchased a subscription plan from Cerebral, the information disclosed may also have included subscription plan type, appointment dates and other booking information, treatment, and other clinical information, health insurance/pharmacy benefit information (for example, plan name and group/member numbers), and insurance co-pay amount.
Cerebral was sharing patients’ data with tech giants in real-time by way of trackers and other data-collecting code that the startup embedded within its apps. Tech companies and advertisers, like Google, Facebook and TikTok, allow developers to include snippets of their custom-built code, which allows the developers to share information about their app users’ activity with the tech giants, often under the guise of analytics but also for advertising.
But users often have no idea that they are opting-in to this tracking simply by accepting the app’s terms of use and privacy policies, which many people don’t read.
Cerebral said in its notice to customers — buried at the bottom of its website — that the data collection and sharing has been going on since October 2019 when the startup was founded. The startup said it has removed the tracking code from its apps. While not mentioned, the tech giants are under no obligations to delete the data that Cerebral shared with them.
Because of how Cerebral handles confidential patient data, it’s covered under the U.S. health privacy law known as HIPAA. According to a list of health-related security lapses under investigation by the U.S. Department of Health and Human Services, which oversees and enforces HIPAA, Cerebral’s data lapse is the second-largest breach of health data in 2023.
Australian scientists have discovered an enzyme that converts air into energy. The finding, published today in the journal Nature, reveals that this enzyme uses the low amounts of the hydrogen in the atmosphere to create an electrical current. This finding opens the way to create devices that literally make energy from thin air.
The research team, led by Dr. Rhys Grinter, Ph.D. student Ashleigh Kropp, and Professor Chris Greening from the Monash University Biomedicine Discovery Institute in Melbourne, Australia, produced and analyzed a hydrogen-consuming enzyme from a common soil bacterium.
[…]
In this Nature paper, the researchers extracted the enzyme responsible for using atmospheric hydrogen from a bacterium called Mycobacterium smegmatis. They showed that this enzyme, called Huc, turns hydrogen gas into an electrical current. Dr. Grinter notes, “Huc is extraordinarily efficient. Unlike all other known enzymes and chemical catalysts, it even consumes hydrogen below atmospheric levels—as little as 0.00005% of the air we breathe.”
The researchers used several cutting-edge methods to reveal the molecular blueprint of atmospheric hydrogen oxidation. They used advanced microscopy (cryo-EM) to determine its atomic structure and electrical pathways, pushing boundaries to produce the most resolved enzyme structure reported by this method to date. They also used a technique called electrochemistry to demonstrate the purified enzyme creates electricity at minute hydrogen concentrations.
Laboratory work performed by Kropp shows that it is possible to store purified Huc for long periods. “It is astonishingly stable. It is possible to freeze the enzyme or heat it to 80 degrees celsius, and it retains its power to generate energy,” Kropp said. “This reflects that this enzyme helps bacteria to survive in the most extreme environments. ”
Huc is a “natural battery” that produces a sustained electrical current from air or added hydrogen. While this research is at an early stage, the discovery of Huc has considerable potential to develop small air-powered devices, for example as an alternative to solar-powered devices.
The bacteria that produce enzymes like Huc are common and can be grown in large quantities, meaning we have access to a sustainable source of the enzyme. Dr. Grinter says that a key objective for future work is to scale up Huc production. “Once we produce Huc in sufficient quantities, the sky is quite literally the limit for using it to produce clean energy.”
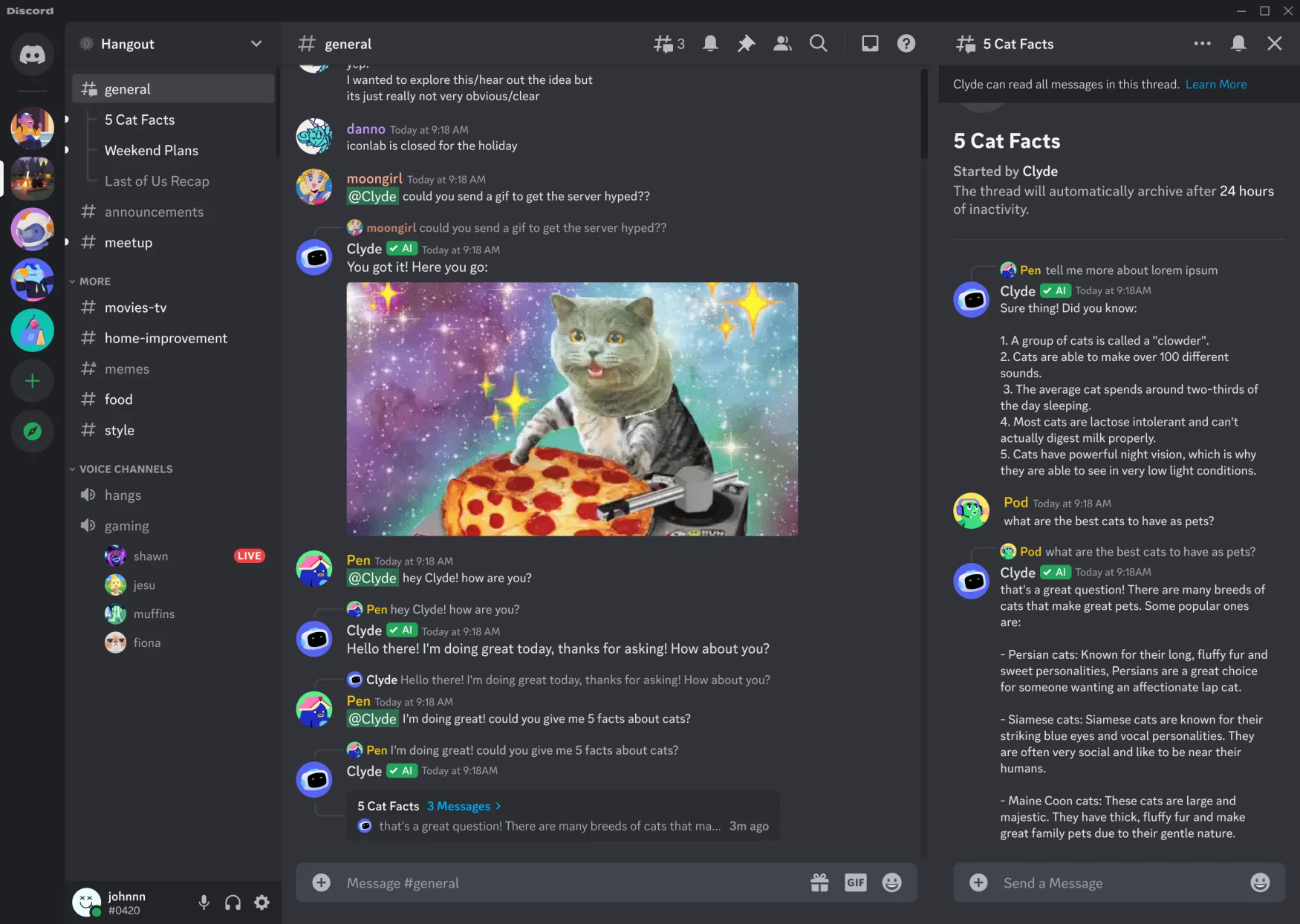
[…] Starting next week, the company will begin rolling out a public experiment that will augment Clyde, the built-in bot Discord employs to notify users of errors and respond to their slash commands, with conversational capabilities. Judging from the demo it showed off, Discord envisions people turning to Clyde for information they would have obtained from Google in the past. For instance, you might ask the chatbot for the local time in the place where someone on your server lives to decide if it would be appropriate to message them. You can invoke Clyde at any time, including in private conversations among your friends, by typing @Clyde.
Discord
Discord is quick to note Clyde is programmed not to bother you and your friends. Admins can also disable the chatbot if they don’t want to use the feature on their server. The first time you activate Clyde, Discord will display an opt-in prompt. For users worried about privacy, Anjney Midha, Discord’s head of platform ecosystem, told Engadget the company is not sharing user data with OpenAI to assist the startup in training its machine learning models.
Separate from Clyde, Discord is using OpenAI’s technology to enhance AutoMod, the automated content moderation tool the company introduced last June. As a refresher, server admins and moderators can configure AutoMod to automatically detect and block inappropriate messages before they’re posted by creating a list of words and phrases they don’t want to see. In the nine months since it began rolling out AutoMod, Discord says the feature has blocked more than 45 million unwanted messages.
Moving forward, the tool will use large language models to interpret and apply server rules. In practice, this should make AutoMod capable of spotting and taking action against people who attempt to go against a community’s norms and expectations. In one demo, Discord showed AutoMod taking action against someone who tried to skirt a server rule against self-promotion by writing their message in a different language. In that instance, AutoMod wasn’t preprogrammed to watch for a specific word or phrase, but it was able to use context to infer that there was a potential infraction.
[…]
Discord is also using OpenAI tech to power a feature that everyone should find useful: Conversation Summaries. If you’ve ever joined a large server only to immediately feel like you can’t keep up with some of its more active members, this feature promises to solve one of Discord’s longstanding pain points. When it arrives in a limited number of servers next week, the feature will begin creating bundles designed to provide you with an overview of chats you may have missed while away from the app. Each bundle will include a title, a summary of what was said and any images that were shared, as well as a log of who took part. You won’t need to endlessly scroll to try and piece together something you missed.
It can feel like Discord is just another tech firm up in the generative AI craze, but Midha wants users to know machine learning has been part of the Discord identity for a while. Every month, more than 30 million people use AI applications through the platform, and almost 3 million servers include at least one AI experience. On GitHub, many machine learning projects feature links to Discord servers, a fact Midha attributes to Discord being a natural place for those conversations to start.
[…] In the latest advance in nano- and micro-architected materials, engineers at Caltech have developed a new material made from numerous interconnected microscale knots.
The knots make the material far tougher than identically structured but unknotted materials: they absorb more energy and are able to deform more while still being able to return to their original shape undamaged. These new knotted materials may find applications in biomedicine as well as in aerospace applications due to their durability, possible biocompatibility, and extreme deformability.
[…]
Each knot is around 70 micrometers in height and width, and each fiber has a radius of around 1.7 micrometers (around one-hundredth the radius of a human hair). While these are not the smallest knots ever made—in 2017 chemists tied a knot made from an individual strand of atoms—this does represent the first time that a material composed of numerous knots at this scale has ever been created. Further, it demonstrates the potential value of including these nanoscale knots in a material—for example, for suturing or tethering in biomedicine.
The knotted materials, which were created out of polymers, exhibit a tensile toughness that far surpasses materials that are unknotted but otherwise structurally identical, including ones where individual strands are interwoven instead of knotted. When compared to their unknotted counterparts, the knotted materials absorb 92 percent more energy and require more than twice the amount of strain to snap when pulled.
The knots were not tied but rather manufactured in a knotted state by using advanced high-resolution 3D lithography capable of producing structures in the nanoscale. The samples detailed in the Science Advancespaper contain simple knots—an overhand knot with an extra twist that provides additional friction to absorb additional energy while the material is stretched. In the future, the team plans to explore materials constructed from more complex knots.
[…]
More information: Widianto P. Moestopo et al, Knots are not for naught: Design, properties, and topology of hierarchical intertwined microarchitected materials, Science Advances (2023). DOI: 10.1126/sciadv.ade6725
[…] An interdisciplinary team of scientists have released a complete reconstruction and analysis of a larval fruit fly’s brain, published Thursday in the journal Science. The resulting map, or connectome, as its called in neuroscience, includes each one of the 3,016 neurons and 548,000 of the synapses running between neurons that make up the baby fly’s entire central nervous system. The connectome includes both of the larva’s brain lobes, as well as the nerve cord.
[…]
It is the most complete insect brain map ever constructed and the most intricate entire connectome of any animal ever published. In short: it’s a game changer.
For some, it represents a paradigm shift in the field of neuroscience. Fruit flies are model organisms, and many neural structures and pathways are thought to be conserved across evolution. What’s true for maggots might well be true for other insects, mice, or even humans.
[…]
this new connectome is like going from a blurry satellite view to a crisp city street map. On the block-by-block array of an insect’s cortex, “now we know where every 7-11 and every, you know, Target [store] is,” Mosca said.
To complete the connectome, a group of Cambridge University scientists spent 12 years focusing in on the brain of a single, 6-hour-old female fruit fly larva. The organ, approximately 170 by 160 by 70 micrometers in size, is truly teeny—within an order of magnitude of things too small to see with a naked eye. Yet, the researchers were able to use electron microscopy to visually cut it into thousands of slices, only nanometers thick. Imaging just one of the neurons took a day, on average. From there, once the physical map of the neurons, or “brain volume,” was complete, the analysis began.
Along with computer scientists at Johns Hopkins University, the Cambridge neuroscientists assessed and categorized the neurons and synapses they’d found. The JHU researchers fine-tuned a computer program for this exact application in order to determine cell and synapse types, patterns within the brain connections, and to chart some function onto the larva connectome—based on previous neuroscience studies of behavior and sensory systems.
They found many surprises. For one, the larval fly connectome showed numerous neural pathways that zigzagged between hemispheres, demonstrating just how integrated both sides of the brain are and how nuanced signal processing can be, said Michael Winding, one of the study’s lead researchers and a Cambridge University neuroscientist, in a video call. “I never thought anything would look like that,” Winding said.
[…]
Fascinatingly, these recurrent structures mapped from an actual brain appear to closely match the architecture of some artificial intelligence models (called residual neural networks), with nested pathways allowing for different levels of complexity, Zlatic noted.
[…]
Not only was the revealed neural structure layered, but the neurons themselves appear to be multi-faceted. Sensory cells connected across modalities—visual, smell, and other inputs crossed and interacted en route to output cells, explained Zlatic. “This brain does a huge amount of multi-sensory integration…which is computationally a very powerful thing,” she added.
Then there were the types and relative quantities of cell-to-cell connections. In neuroscience, the classic “canonical” type of synapse runs from an axon to a dendrite. Yet, within the mapped larval fly brain, that only accounted for about two-thirds of the connections, Winding and Zlatic said. Axons linked to axons, dendrites to dendrites, and dendrites to axons. Scientists have known these sorts of connections exist in animal nervous systems, but the scope went far beyond what they expected. “Given the breadth of these connections, they must be important for brain computation,” Winding noted. We just don’t know exactly how.
Health data and other personal information of members of Congress and staff were stolen during a breach of servers run by DC Health Care Link and are now up for sale on the dark web.
The FBI is investigating the intrusion, which came to light Wednesday after Catherine Szpindor, the House of Representatives’ chief administrative officer, sent a letter to House members telling them of the incident. Szpindor wrote that she was alerted to the hack by the FBI and US Capitol Police.
DC Health Link is the online marketplace for the Affordable Care Act that administers the healthcare plans for members of Congress as well as their family and staff.
Szpindor called the incident “a significant data breach” that exposed the personal identifiable information (PII) of thousands of DC Health Link employees and warned the Representatives that their data may have been compromised.
“Currently, I do not know the size and scope of the breach,” she wrote, adding the FBI informed her that account information and PII of “hundreds” of House and staff members were stolen. Once Szpindor has a list of the data taken, she will directly contact those people affected.
[…]
Thousands of House Members and employees from across the United States have enrolled in health insurance through DC Health Link for themselves and their families since 2014,” McCarthy and Jeffries wrote. “The size and scope of impacted House customers could be extraordinary.”
Szpindor in her letter recommended House members consider freezing their credit at Equifax, Experian, and TransUnion until the breadth of the breach is known, particularly which representatives and staff members had their data compromised.
According to CNBC, the Senate may also have been impacted by the breach, with an email sent to offices in that side of Congress saying the Senate at Arms was told of the breach from law enforcement and the “data included the full names, date of enrollment, relationship (self, spouse, child), and email address, but no other Personally Identifiable Information (PII).”
The FBI in a terse statement to the media said it was “aware of this incident and is assisting. This is an ongoing investigation.” Capitol Police said they were working with the FBI.
[…]
At least some of the PII taken during the breach found its way onto a dark web marketplace. In their letter, McCarthy and Jeffries noted the FBI was able to buy the PII and other enrollee information that was breached. The information included names of spouses and dependent children, Social Security numbers, and home addresses.
CNBC said a post on a dark web site put up for sale the data of 170,000 Health Link members and posted data from 11 users as a sample.
[…]
Organizations in the healthcare field have come under increasing attacks in recent years, which is unsurprising given the vast amounts of PII and health data – from medical records to Social Security numbers – they hold on doctors, staff, and patients.
Cybersecurity firm Check Point in a report said the number of cyberattacks around the world jumped 38 percent year-over-year in 2022 and that healthcare, education and research, and government were the top three targeted sectors
Scientists have created mice with two biological fathers by generating eggs from male cells, a development that opens up radical new possibilities for reproduction.
The advance could ultimately pave the way for treatments for severe forms of infertility, as well as raising the tantalising prospect of same-sex couples being able to have a biological child together in the future.
“This is the first case of making robust mammal oocytes from male cells,” said Katsuhiko Hayashi, who led the work at Kyushu University in Japan and is internationally renowned as a pioneer in the field of lab-grown eggs and sperm.
[…]
The technique could also be applied to treat severe forms of infertility, including women with Turner’s syndrome, in whom one copy of the X chromosome is missing or partly missing, and Hayashi said this application was the primary motivation for the research.
[…]
The study, which has been submitted for publication in a leading journal, relied on a sequence of intricate steps to transform a skin cell, carrying the male XY chromosome combination, into an egg, with the female XX version.
Male skin cells were reprogrammed into a stem cell-like state to create so-called induced pluripotent stem (iPS) cells. The Y-chromosome of these cells was then deleted and replaced by an X chromosome “borrowed” from another cell to produce iPS cells with two identical X chromosomes.
“The trick of this, the biggest trick, is the duplication of the X chromosome,” said Hayashi. “We really tried to establish a system to duplicate the X chromosome.”
Finally, the cells were cultivated in an ovary organoid, a culture system designed to replicate the conditions inside a mouse ovary. When the eggs were fertilised with normal sperm, the scientists obtained about 600 embryos, which were implanted into surrogate mice, resulting in the birth of seven mouse pups. The efficiency of about 1% was lower than the efficiency achieved with normal female-derived eggs, where about 5% of embryos went on to produce a live birth.
The baby mice appeared healthy, had a normal lifespan, and went on to have offspring as adults. “They look OK, they look to be growing normally, they become fathers,” said Hayashi.
He and colleagues are now attempting to replicate the creation of lab-grown eggs using human cells.
Back in September 2021 Techdirt covered an outrageous legal attack by Sony Music on Quad9, a free, recursive, anycast DNS platform. Quad9 is part of the Internet’s plumbing: it converts domain names to numerical IP addresses. It is operated by the Quad9 Foundation, a Swiss public-benefit, not-for-profit organization. Sony Music says that Quad9 is implicated in alleged copyright infringement on the sites it resolves. That’s clearly ridiculous, but unfortunately the Regional Court of Hamburg agreed with Sony Music’s argument, and issued an interim injunction against Quad9. The German Society for Civil Rights (Gesellschaft für Freiheitsrechte e.V. or “GFF”) summarizes the court’s thinking:
In its interim injunction the Regional Court of Hamburg asserts a claim against Quad9 based on the principles of the German legal concept of “Stoererhaftung” (interferer liability), on the grounds that Quad9 makes a contribution to a copyright infringement that gives rise to liability, in that Quad9 resolves the domain name of website A into the associated IP address. The German interferer liability has been criticized for years because of its excessive application to Internet cases. German lawmakers explicitly abolished interferer liability for access providers with the 2017 amendment to the German Telemedia Act (TMG), primarily to protect WIFI operators from being held liable for costs as interferers.
As that indicates, this is a case of a law that is a poor fit for modern technology. Just as the liability no longer applies to WIFI operators, who are simply providing Internet access, so the German law should also not catch DNS resolvers like Quad9. The GFF post notes that Quad9 has appealed to the Hamburg Higher Regional Court against the lower court’s decision. Unfortunately, another regional court has just handed down a similar ruling against the company, reported here by Heise Online (translation by DeepL):
the Leipzig Regional Court has sentenced the Zurich-based DNS service Quad9. On pain of an administrative fine of up to 250,000 euros or up to 2 years’ imprisonment, the small resolver operator was prohibited from translating two related domains into the corresponding IP addresses. Via these domains, users can find the tracks of a Sony music album offered via Shareplace.org.
The GFF has already announced that it will be appealing along with Quad9 to the Dresden Higher Regional Court against this new ruling. It says that the Leipzig Regional Court has made “a glaring error of judgment”, and explains:
Let’s hope so. If it isn’t, we can expect companies providing the Internet’s basic infrastructure in the EU to be bombarded with demands from the copyright industry and others for domains to be excluded from DNS resolution. The likely result is that perfectly legal sites and their holdings will be ghosted by DNS companies, which will prefer to err on the side of caution rather than risk becoming the next Quad9.
Google’s finally rolling back its unpopular decree against any kinds of profanity in videos, making it harder for any creators used to offering colorful sailor’s speech in videos from monetizing content on behalf of its beloved ad partners. The only thing is, Google still seems to think the “f-word” is excessively harsh language, so sorry Samuel L. Jackson, those motha-[redacted] snakes are still liable for less ad dollars on this motha-[redacted] plane.
On Tuesday, Google updated its support page to offer up an olive branch to crass creators upset that their potty mouths were resulting in their videos being demonetized. Now, the company clarified that use of “moderate” profanity at any time in a video is now eligible for ad revenue.
However, the company seemed to be antagonistic to “stronger profanity” like “the f-word,” AKA “fuck.” You can’t say “fuck” in the first seven seconds or repeatedly throughout a video or else you will receive “limited ads.” Putting words like “fuck” into a title or thumbnail will result in no ad content.
What is allowed are words like “hell” or “damn” in a title or thumbnail. Words like “bitch,” “douchebag,” “asshole,” and “shit” are considered “moderate profanity, so that’s fine to use frequently in a video. But “fuck,” dear god, will hurt advertiser’s poor virgin ears. YouTube has been extremely sensitive to what its advertisers are saying. For instance the platform came close to pulling big money-making ads over creepy pasta content during the “Elsagate” scandal.
The changes also impacted videos which used music tracks in the background. YouTube is now saying any use of “moderate” or “strong” profanity in background music is eligible for full ad revenue.
Back in November, YouTube changed its creator monetization policy, calling it guidelines for “advertiser-friendly content.” The company decreed that any video with a thumbnail or title containing obscene language or “adult material” wouldn’t receive any ad revenue. YouTube also said it would demonetize violent content such as dead bodies without context, or virtual violence directed at a “real, named person.” Fair enough, but then YouTube said it would demonetize any video which used profanity “in the first eight seconds of the video.”
Reach, the owner of the UK’s Daily Mirror and Daily Express tabloids among other newspapers, has started publishing articles with the help of AI software on one of its regional websites as it scrambles to cut costs amid slipping advertising revenues.
Three stories written with the help of machine-learning tools were published on InYourArea.co.uk, which produces feeds of nearby goings-on in Blighty. One piece, titled Seven Things to do in Newport, is a listicle pulling together information on places and activities available in the eponymous sunny Welsh resort city.
Reach CEO Jim Mullen said the machine-written articles are checked and approved by human editors before they’re published online.
“We produced our first AI content in the last ten days, but this is led by editorial,” he said, according to The Guardian. “It was all AI-produced, but the data was obviously put together by a journalist, and whether it was good enough to publish was decided by an editor.”
“There are loads of ethics [issues] around AI and journalistic content,” Mullen admitted. “The way I look at it, we produce lots of content based on actual data. It can be put together in a well-read [piece] that I think AI can do. We are trying to apply it to areas we already get traffic to allow journalists to focus on content that editors want written.”
Mullen’s comments have been questioned by journalists, however, given that Reach announced plans to slash hundreds of jobs in January. The National Union of Journalists said 102 editorial positions would be cut, putting 253 journalists at risk, whilst 180 vacancies would be withdrawn.
Reach’s latest financial results, released on Tuesday, show total revenues for 2022 were £601.4 million ($711.6 million) – a decrease of 2.3 percent compared to the year before. Operating profit plunged 27.4 percent to £106.1 million ($125 million). In a bid to make up for losses, the publicly traded company is focused on cutting operating costs by up to six percent this year.
“The current trading environment remains challenging and we expect this to continue in 2023, with sustained inflation and suppressed market demand for digital advertising. Although input costs remain elevated, we are confident that our cost action plan will enable us to deliver a 5–6 percent like for like reduction in our operating cost base for FY23,” Reach’s full-year report read [PDF].
The Register has asked London-based Reach for further comment. (A few of us vultures once worked for what is now Reach, previously known as Trinity Mirror, an empire built from absorbing hundreds of titles around Britain.)
Reach isn’t the only publisher rolling out AI-generated articles while reducing its count of human reporters. CNET owner Red Ventures laid off scribes last week and has promised to double down on machine-written content despite complaints that those articles contained errors and plagiarism.
Meanwhile, BuzzFeed has produced quizzes with the help of ChatGPT, and Arena Group published botched health-related articles for Men’s Health. Both publishers have also axed employees – in December 2022 and February 2023, respectively.
Recently I went on a liveaboard with some extremely experienced divers, most of which had 400 or more dives logged. One of my problems with diving is that I am an extremely slow equalizer, which means that I have to descend extremely slowly, especially at around 5m and again at 10m depth. Another problem I have is that my ears tend to fill up with water after the dive and it takes some time to get rid of the water.
Getting rid of water
To get rid of the water, most sites will tell you to use ear drops (an alcohol / vinegar mix), pull on your earlobe, use a warm compress, inhale steam to open the sinusses, use a hot air dryer at least 10cm from your ears.
Methods to equalize
Most sites will tell you about the valsalva maneuver – which many people tend to do wrong because they blow too hard – or to swallow in order to clear your ears and equalize. For more and better ways to equalise, read this DAN article with 6 methods to equalize. Divebuddies4life has this article as well:
VOLUNTARY TUBAL OPENING | Tense Your Throat and Push Your Jaw Forward
Tense the muscles of the soft palate and the throat while pushing the jaw forward and down as if starting to yawn. These muscles pull the Eustachian tubes open. This requires a lot of practice, but some divers can learn to control those muscles and hold their tubes open for continuous equalization.
TOYNBEE MANEUVER | Pinch Your Nose and Swallow
With your nostrils pinched or blocked against your mask skirt, swallow. Swallowing pulls open your Eustachian tubes while the movement of your tongue, with your nose closed, compresses air against them.
FRENZEL MANEUVER | Pinch Your Nose and Make the Sound of the Letter “K”
Close your nostrils, and close the back of your throat as if straining to lift a weight. Then make the sound of the letter “K.” This forces the back of your tongue upward, compressing air against the openings of your Eustachian tubes.
LOWRY TECHNIQUE | Pinch Your Nose, Blow and Swallow
A combination of Valsalva and Toynbee: while closing your nostrils, blow and swallow at the same time.
EDMONDS TECHNIQUE | Pinch Your Nose and Blow and Push Your Jaw Forward
While tensing the soft palate (the soft tissue at the back of the roof of your mouth) and throat muscles and pushing the jaw forward and down, do a Valsalva maneuver.
Methods without names
An extra way to equalize is to close one nostril by pressing your finger on the side of the nose and then blowing out through the other one. Do this to the other nostril and after this equalising through any of the outlined techniques becomes much easier.
Before the dive itself there is a freediving method to empty your sinusses: pretend there is a mosquito on the tip of your nose and try to blow it off by blowing through your nose (softly!) for a minute. After a minute, pause for a minute. Repeat so that you have blown out three times. Keep some toilet paper handy, you may be surprised how much snot comes out! After having done this my descent times inproved incredibly rapidly.
Prevention
This is the best form of action and this collection of divers had extremely good tips to help.
Headgear
First is headgear – wear a (2mm if warm water, 7mm if cold water) hoodie or even just a buff scarf: cover your ears. This means a lot less water enters your ears and make equalising much easier. Or you can get an IST Sports dive mask with over ear protection – also saving you from ear infections! The IST Sports Pro Ear Mask ME80 is surprisingly affordable.
Surfears also has Diving ear plugs which are connected by a cable so you can pull them out – don’t just put earplugs in when diving as the pressure will put them into your head and when you ascend you won’t be able to pull them out!
Medication / Drugs
Second is Sudofed. This comes in tablets (Sudafed Sinus Max Strength capsules with paracetamol, caffeine and phenylephrine) and a nose spray (blocked nose, Xylometazoline and hydrochloride). Take the tablets daily and spray 2 shots of nose spray into each nostril before the dive (yes, this is a lot more than the daily recommended intake if you dive four times on a day, but it’s over a short period of time and prevention here is worth it).
Third also helps is to suck on a few SMINTS – this exercises the jaw muscles and prepares your jaw for equalzing during the dive. It also helps against dry mouth and improves the taste due to the rubber of the regulator. Exercising the jaw muscles by chewing, sucking and moving your jaw around before the dive helps to equalise.
Wax buildup in your ears
To get rid of wax buildup in your ear, which may hinder equalization, take a syringe, fill it with slightly warm water and spray it directly into your ear at full force. You will very probably have to repeat this several (many!) times. Do it over a sink, as wax will come out first in tiny bits and then potentially as a clump. It’s messy. It sounds scary, but it works wonders. NB should a large piece come out, then it’s probably a good idea to wait a good while before diving as the tubes will need to settle back into their original position first.
Start your first equalization just before you get into the water.
Finally, you need to equalize much more often than you think you need to – don’t wait until you feel pressure on your eardrums, but continuously equalize as you are going down.
Hopefully you will enjoy diving a lot more with these tips!
Recently, Walled Culture mentioned the problem of orphan works. These are creations, typically books, that are still covered by copyright, but unavailable because the original publisher or distributor has gone out of business, or simply isn’t interested in keeping them in circulation. The problem is that without any obvious point of contact, it’s not possible to ask permission to re-publish or re-use it in some way.
It turns out that there is another serious issue, related to that of orphan works. It has been revealed by the New York Public Library, drawing on work carried out as a collaboration between the Internet Archive and the US Copyright Office. According to a report on the Vice Web site:
the New York Public Library (NYPL) has been reviewing the U.S. Copyright Office’s official registration and renewals records for creative works whose copyrights haven’t been renewed, and have thus been overlooked as part of the public domain.
The books in question were published between 1923 and 1964, before changes to U.S. copyright law removed the requirement for rights holders to renew their copyrights. According to Greg Cram, associate general counsel and director of information policy at NYPL, an initial overview of books published in that period shows that around 65 to 75 percent of rights holders opted not to renew their copyrights.
Since most people today will naturally assume that a book published between 1923 and 1964 is still in copyright, it is unlikely anyone has ever tried to re-publish or re-use material from this period. But this new research shows that the majority of these works are, in fact, already in the public domain, and therefore freely available for anyone to use as they wish.
That’s a good demonstration of how the dead hand of copyright stifles fresh creativity from today’s writers, artists, musicians and film-makers. They might have drawn on all these works as a stimulus for their own creativity, but held back because they have been brainwashed by the copyright industry into thinking that everything is in copyright for inordinate lengths of time. As a result, huge numbers of books that are freely available according to the law remain locked up with a kind of phantom copyright that exists only in people’s minds, infected as they are with copyright maximalist propaganda.
The other important lesson to be drawn from this work by the NYPL is that given the choice, the majority of authors didn’t bother renewing their copyrights, presumably because they didn’t feel they needed to. That makes today’s automatic imposition of exaggeratedly-long copyright terms not just unnecessary but also harmful in terms of the potential new works, based on public domain materials, that have been lost as a result of this continuing over-protection.
Last week, Texas introduced a bill that would make it illegal for internet service providers to let users access information about how to get abortion pills. The bill, called the Women and Child Safety Act, would also criminalize creating, editing, or hosting a website that helps people seek abortions.
If the bill passes, internet service providers (ISPs) will be forced to block websites “operated by or on behalf of an abortion provider or abortion fund.” ISPs would also have to filter any website that helps people who “provide or aid or abet elective abortions” in almost any way, including raising money.
[…]
Five years ago, a bill like this would violate federal law. Remember Net Neutrality? Net Neutrality forced ISPs to act like phone companies, treating all traffic the same with almost no ability to limit or filter the content traveling on their networks. But Net Neutrality was repealed in 2018, essentially reclassifying internet service as a luxury with little regulator oversight, and upending consumers’ right to free access of the web.
A proposed law in Florida would force bloggers who write about Gov. Ron DeSantis and other elected officials to register with a state office and file monthly reports or face fines of $25 per day. The bill was filed in the Florida Senate Tuesday by Senator Jason Brodeur, a Republican.
If enacted, the proposed law would likely be challenged in court on grounds that it violates First Amendment protections of freedom of speech and the press. Defending his bill, Brodeur said, “Paid bloggers are lobbyists who write instead of talk. They both are professional electioneers. If lobbyists have to register and report, why shouldn’t paid bloggers?” according to the Florida Politics news website.
The bill text defines bloggers as people who write for websites or webpages that are “frequently updated with opinion, commentary, or business content.” Websites run by newspapers or “similar publications” are excluded from the definition.
The proposed registration requirements apply to bloggers who receive payment in exchange for writing about elected state officers, including “the Governor, the Lieutenant Governor, a Cabinet officer, or any member of the Legislature.” Bloggers who write about a member of the legislature would have to register with the state Office of Legislative Services, while bloggers who write about the governor or other members of the executive branch would have to register with the Commission on Ethics.
“If a blogger posts to a blog about an elected state officer and receives, or will receive, compensation for that post, the blogger must register with the appropriate office… within 5 days after the first post by the blogger which mentions an elected state officer,” the bill said. “Upon registering with the appropriate office, a blogger must file monthly reports on the 10th day following the end of each calendar month from the time a blog post is added to the blog.”
[…]
The Florida Legislature is separately considering proposals that would make it easier for people to sue media organizations for defamation; these proposals have also been criticized for harming freedom of speech. Brodeur filed one of the defamation proposals on Monday.
The defamation proposals were spurred by DeSantis, who last month held a roundtable discussion on media defamation and called on the legislature “to protect Floridians from the life-altering ramifications that defamation from the media can cause for a person who does not have the means or the platform to defend himself.”
“We’ve seen over the last generation legacy media outlets increasingly divorce themselves from the truth and instead try to elevate preferred narratives and partisan activism over reporting the facts,” DeSantis said. “When the media attacks me, I have a platform to fight back. When they attack everyday citizens, these individuals don’t have the adequate recourses to fight back. In Florida, we want to stand up for the little guy against these massive media conglomerates.”
If you read the headline in the source it sounds dreadful, but it turns out this makes absolute sense – if you’re being paid and are influencing public opinion then yep, register with ethics.