Horizon is an open source end-to-end platform for applied reinforcement learning (RL) developed and used at Facebook. Horizon is built in Python and uses PyTorch for modeling and training and Caffe2 for model serving. The platform contains workflows to train popular deep RL algorithms and includes data preprocessing, feature transformation, distributed training, counterfactual policy evaluation, and optimized serving. For more detailed information about Horizon see the white paper here.
If you’re a researcher looking to deepen your exposure to AI, NVIDIA invites you to apply to its new AI Research Residency program.
During the one-year, paid program, residents will be paired with an NVIDIA research scientist on a joint project and have the opportunity to publish and present their findings at prominent research conferences such as CVPR, ICLR and ICML.
The residency program is meant to encourage scholars with diverse academic backgrounds to pursue machine learning research, according to Jan Kautz, vice president of perception and learning research at NVIDIA.
“There’s currently a shortage of machine learning experts, and AI adoption for non-tech and smaller companies is hindered in part because there are not many people who understand AI,” said Kautz. “Our residency program is a way to broaden opportunities in the field to a more diverse set of researchers and spread the benefits of the technology to more people than ever.”
Applicants don’t need a background in AI, and those with doctoral degrees or equivalent expertise are encouraged to apply. Residents will work out of our Santa Clara location.
Google.org is issuing an open call to organizations around the world to submit their ideas for how they could use AI to help address societal challenges. Selected organizations will receive support from Google’s AI experts, Google.org grant funding from a $25M pool, credit and consulting from Google Cloud, and more.
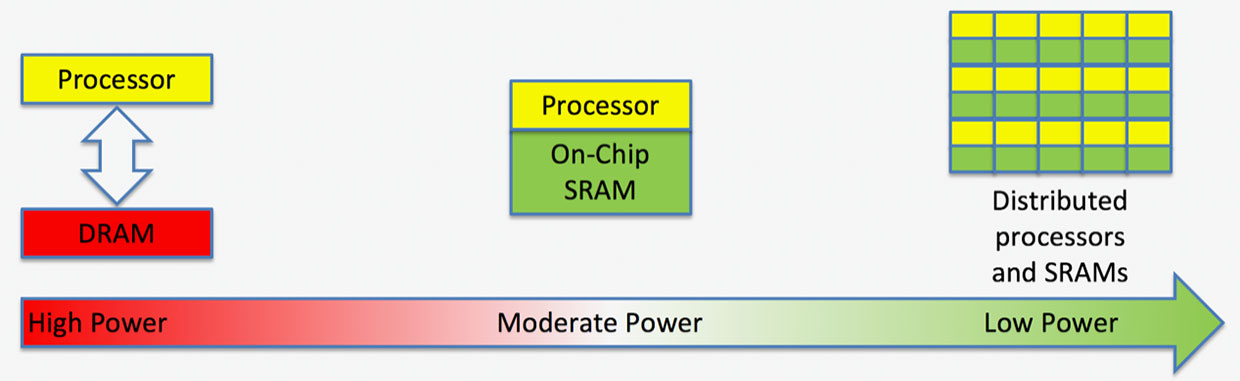
Deep learning has a DRAM problem. Systems designed to do difficult things in real time, such as telling a cat from a kid in a car’s backup camera video stream, are continuously shuttling the data that makes up the neural network’s guts from memory to the processor.
The problem, according to startup Flex Logix, isn’t a lack of storage for that data; it’s a lack of bandwidth between the processor and memory. Some systems need four or even eight DRAM chips to sling the 100s of gigabits to the processor, which adds a lot of space and consumes considerable power. Flex Logix says that the interconnect technology and tile-based architecture it developed for reconfigurable chips will lead to AI systems that need the bandwidth of only a single DRAM chip and consume one-tenth the power.
[…]
In developing the original technology for FPGAs, Wang noted that these chips were about 80 percent interconnect by area, and so he sought an architecture that would cut that area down and allow for more logic. He and his colleagues at UCLA adapted a kind of telecommunications architecture called a folded-Beneš network to do the job. This allowed for an FPGA architecture that looks like a bunch of tiles of logic and SRAM.
Image: Flex LogixFlex Logix says spreading SRAM throughout the chip speeds up computation and lowers power.
Distributing the SRAM in this specialized interconnect scheme winds up having a big impact on deep learning’s DRAM bandwidth problem, says Tate. “We’re displacing DRAM bandwidth with SRAM on the chip,” he says.
[…]
True apples-to-apples comparisons in deep learning are hard to come by. But Flex Logix’s analysis comparing a simulated 6 x 6-tile NMAX512 array with one DRAM chip against an Nvidia Tesla T4 with eight DRAMs showed the new architecture identifying 4,600 images per second versus Nvidia’s 3,920. The same size NMAX array hit 22 trillion operations per second on a real-time video processing test called YOLOv3 using one-tenth the DRAM bandwidth of other systems.
The designs for the first NMAX chips will be sent to the foundry for manufacture in the second half of 2019, says Tate.
In the future, you might talk to an AI to cross borders in the European Union. The EU and Hungary’s National Police will run a six-month pilot project, iBorderCtrl, that will help screen travelers in Hungary, Greece and Latvia. The system will have you upload photos of your passport, visa and proof of funds, and then use a webcam to answer basic questions from a personalized AI border agent. The virtual officer will use AI to detect the facial microexpressions that can reveal when someone is lying. At the border, human agents will use that info to determine what to do next — if there are signs of lying or a photo mismatch, they’ll perform a more stringent check.
The real guards will use handhelds to automatically double-check documents and photos for these riskier visitors (including images from past crossings), and they’ll only take over once these travelers have gone through biometric verification (including face matching, fingerprinting and palm vein scans) and a re-evaluation of their risk levels. Anyone who passed the pre-border test, meanwhile, will skip all but a basic re-evaluation and having to present a QR code.
The pilot won’t start with live tests. Instead, it’ll begin with lab tests and will move on to “realistic conditions” along the borders. And there’s a good reason for this: the technology is very much experimental. iBorderCtrl was just 76 percent accurate in early testing, and the team only expects to improve that to 85 percent. There are no plans to prevent people from crossing the border if they fail the initial AI screening.
ClaRAN is the brainchild of big data specialist Dr. Chen Wu and astronomer Dr. Ivy Wong, both from The University of Western Australia node of the International Centre for Radio Astronomy Research (ICRAR).
Dr. Wong said black holes are found at the centre of most, if not all, galaxies.
“These supermassive black holes occasionally burp out jets that can be seen with a radio telescope,” she said.
“Over time, the jets can stretch a long way from their host galaxies, making it difficult for traditional computer programs to figure out where the galaxy is.
“That’s what we’re trying to teach ClaRAN to do.”
Dr. Wu said ClaRAN grew out of an open source version of Microsoft and Facebook’s object detection software.
He said the program was completely overhauled and trained to recognise galaxies instead of people.
ClaRAN itself is also open source and publicly available on GitHub.
AI can help chemists crack the molecular structure of crystals much faster than traditional modelling methods, according to research published in Nature Communications on Monday.
Scientists from the Ecole Polytechnique Fédérale de Lausanne (EPFL), a research institute in Switzerland, have built a machine learning programme called SwiftML to predict how the atoms in molecules shift when exposed to a magnetic field.
Nuclear magnetic resonance (NMR) is commonly used to work out the structure of compounds. Groups of atoms oscillate at a specific frequencies, providing a tell-tale sign of the number and location of electrons each contains. But the technique is not good enough to reveal the full chemical structure of molecules, especially complex ones that can contain thousands of different atoms.
Another technique known as Density functional theory (DFT) is needed. It uses complex quantum chemistry calculations to map the density of electrons in a given area, and requires heavy computation. SwiftML, however, can do the job at a much quicker rate and can perform as accurately as DFT programmes in some cases.
“Even for relatively simple molecules, this model is almost 10,000 times faster than existing methods, and the advantage grows tremendously when considering more complex compounds,” said Michele Ceriotti, co-author of the paper and an assistant professor at the EPFL.
“To predict the NMR signature of a crystal with nearly 1,600 atoms, our technique – ShiftML – requires about six minutes; the same feat would have taken 16 years with conventional techniques.”
The researchers trained the system on the Cambridge Structural Database, a dataset containing calculated DFT chemical shifts for thousands of compounds. Each one is made up less than 200 atoms including carbon and hydrogen paired with oxygen or nitrogen. 2,000 structures were used for training and validation, and 500 were held back for testing.
SwiftML managed to calculate the chemical shifts for a molecule that had 86 atoms and the same chemical elements as cocaine, but arranged in a different crystal structure. The process took less than a minute of CPU time, compared around 62 to 150 CPU hours typically needed to calculate the chemical shift of a molecule containing 86 atoms using DFT.
The team hopes that SwiftML can be used to supplement NMR experiments to design new drugs. “This is really exciting because the massive acceleration in computation times will allow us to cover much larger conformational spaces and correctly determine structures where it was just not previously possible. This puts most of the complex contemporary drug molecules within reach,” says Lyndon Emsley, co-author of the study and a chemistry professor at EPFL.
Facebook announced today that it has removed 8.7 million pieces of content last quarter that violated its rules against child exploitation, thanks to new technology. The new AI and machine learning tech, which was developed and implemented over the past year by the company, removed 99 percent of those posts before anyone reported them, said Antigone Davis, Facebook’s global head of safety, in a blog post.
The new technology examines posts for child nudity and other exploitative content when they are uploaded and, if necessary, photos and accounts are reported to the National Center for Missing and Exploited Children. Facebook had already been using photo-matching technology to compare newly uploaded photos with known images of child exploitation and revenge porn, but the new tools are meant to prevent previously unidentified content from being disseminated through its platform.
The technology isn’t perfect, with many parents complaining that innocuous photos of their kids have been removed. Davis addressed this in her post, writing that in order to “avoid even the potential for abuse, we take action on nonsexual content as well, like seemingly benign photos of children in the bath” and that this “comprehensive approach” is one reason Facebook removed as much content as it did last quarter.
But Facebook’s moderation technology is by no means perfect and many people believe it is not comprehensive or accurate enough. In addition to family snapshots, it’s also been criticized for removing content like the iconic 1972 photo of Phan Thi Kim Phuc, known as the “Napalm Girl,” fleeing naked after suffering third-degree burns in a South Vietnamese napalm attack on her village, a decision COO Sheryl Sandberg apologized for.
In a landmark study, 20 top US corporate lawyers with decades of experience in corporate law and contract review were pitted against an AI. Their task was to spot issues in five Non-Disclosure Agreements (NDAs), which are a contractual basis for most business deals.
The study, carried out with leading legal academics and experts, saw the LawGeex AI achieve an average 94% accuracy rate, higher than the lawyers who achieved an average rate of 85%. It took the lawyers an average of 92 minutes to complete the NDA issue spotting, compared to 26 seconds for the LawGeex AI. The longest time taken by a lawyer to complete the test was 156 minutes, and the shortest time was 51 minutes. The study made waves around the world and was covered across global media.
AI can translate between languages in real time as people speak, according to fresh research from Chinese search giant Baidu and Oregon State University in the US.
Human interpreters need superhuman concentration to listen to speech and translate at the same time. There are, apparently, only a few thousand qualified simultaneous interpreters and the job is so taxing that they often work in pairs, swapping places after 20 to 30 minute stints. And as conversations progress, the chance for error increases exponentially.
Machines have the potential to trump humans at this task, considering they have superior memory and don’t suffer from fatigue. But it’s not so easy for them either, as researchers from Baidu and Oregon State University found.
They built a neural network that can translate between Mandarin Chinese to English in almost real time, where the English translation lags behind by up to at least five words. The results have been published in a paper on arXiv.
The babble post-Babel
Languages have different grammatical structures, where the word order of sentences often don’t match up, making it difficult to translate quickly. The key to a fast translation is predicting what the speaker will say next as he or she talks.
With the AI engine an encoder converts the words in a target language into a vector representation. A decoder predicts the probability of the next word given the words in the previous sentences. The decoder is always behind the encoder and generates the translated words until it processes the whole speech or text.
“In one of the examples, the Chinese sentence ‘Bush President in Moscow…’ would suggest the next English word after ‘President Bush’ is likely ‘meets’”, Liang Huang, principal scientist at Baidu Research, explained to The Register.
“This is possible because in the training data, we have a lot of “Bush meeting someone, like Putin in Moscow” so the system learned that if “Bush in Moscow”, he is likely “meeting” someone.
The difficulty depends on the languages being translated, Huang added. Languages that are closely related, such as French and Spanish for example, have similar structures where the order of words are aligned more.
Japanese and German sentences are constructed with the subject at the front, the object in the middle, and the verb at the end (SOV). English and Chinese also starts with the subject, but the verb is in the middle, followed by the object (SVO).
Translating between Japanese and German to English and Chinese, therefore, more difficult. “There is a well-known joke in the UN that a German-to-English interpreter often has to pause and “wait for the German verb”. Standard Arabic and Welsh are verb-subject-object , which is even more different from SVO,” he said.
The new algorithm can be applied to any neural machine translation models and only involves tweaking the code slightly. It has already been integrated to Baidu’s internal speech-to-text translation and will be showcased at the Baidu World Tech Conference next week on 1st November in Beijing.
“We don’t have an exact timeline for when this product will be available for the general public, this is certainly something Baidu is working on,” Liang said.
“We envision our technology making simultaneous translation much more accessible and affordable, as there is an increasing demand. We also envision the technology [will reduce] the burden on human translators.”
Boffins have devised a way to make eavesdropping smartwatches, computers, mobile devices, and speakers with endearing names like Alexa better aware of what’s going on around them.
In a paper to be presented today at the ACM Symposium on User Interface Software and Technology (UIST) in Berlin, Germany, computer scientists Gierad Laput, Karan Ahuja, Mayank Goel, and Chris Harrison describe a real-time, activity recognition system capable of interpreting collected sound.
In other words, a software that uses devices’ always-on builtin microphones to sense what exactly’s going on in the background.
The researchers, based at Carnegie Mellon University in the US, refer to their project as “Ubicoustics” because of the ubiquity of microphones in modern computing devices.
As they observe in their paper, “Ubicoustics: Plug-and-Play Acoustic Activity Recognition,” real-time sound evaluation to classify activities and and context is an ongoing area of investigation. What CMU’s comp sci types have added is a sophisticated sound-labeling model trained on high-quality sound effects libraries, the sort used in Hollywood entertainment and electronic games.
As good as you and me
Sound-identifying machine-learning models built using these audio effects turn out to be more accurate than those trained on acoustic data mined from the internet, the boffins claim. “Results show that our system can achieve human-level performance, both in terms of recognition accuracy and false positive rejection,” the paper states.
The researchers report accuracy of 80.4 per cent in the wild. So their system misclassifies about one sound in five. While not quite good enough for deployment in people’s homes, it is, the CMU team claims, comparable to a person trying to identify a sound. And its accuracy rate is close to other sound recognition systems such as BodyScope (71.5 per cent) and SoundSense (84 per cent). Ubicoustics, however, recognizes a wider range of activities without site-specific training.
Alexa to the rescue
Alexa, informed by this model, could in theory hear if you left the water running in your kitchen and might, given the appropriate Alexa Skill, take some action in response, like turning off your smart faucet or ordering a boat from Amazon.com to navigate around your flooded home. That is, assuming it didn’t misinterpret the sound in the first place.
The researchers suggest their system could be used, for example, to send a notification when a laundry load finished. Or it might promote public health: By detecting frequent coughs or sneezes, the system “could enable smartwatches to track the onset of symptoms and potentially nudge users towards healthy behaviors, such as washing hands or scheduling a doctor’s appointment.”
n line with our principles of transparency and to improve public understanding of alleged foreign influence campaigns, Twitter is making publicly available archives of Tweets and media that we believe resulted from potentially state-backed information operations on our service.
Examples of the content include:
While this dataset is of a size that a degree of capability for large dataset analysis is required, we hope to support broad analysis by making a public version of these datasets (with some account-specific information hashed) available. You can download the datasets below. No content has been redacted. Specialist researchers can request access to an unhashed version of these datasets, which will be governed by a data use agreement that will include provisions to ensure the data is used within appropriate legal and ethical parameters.
What’s included?
Our initial disclosures cover two previously disclosed campaigns, and include information from 3,841 accounts believed to be connected to the Russian Internet Research Agency, and 770 accounts believed to originate in Iran. For additional information about this disclosure, see our announcement.
These datasets include all public, nondeleted Tweets and media (e.g., images and videos) from accounts we believe are connected to state-backed information operations. Tweets deleted by these users prior to their suspension (which are not included in these datasets) comprise less than 1% of their overall activity. Note that not all of the accounts we identified as connected to these campaigns actively Tweeted, so the number of accounts represented in the datasets may be less than the total number of accounts listed here.
Astrobiologists are mostly interested in rocky exoplanets that lie in the habitable zone around their parent stars, where liquid water may exist on its surface. NASA’s Kepler spacecraft has spotted a handful of these in the so-called Goldilocks Zone – where it’s not too cold or too hot for life.
As such, a second team from Google and NASA’s lab has built a machine-learning-based tool known as INARA that can identify the chemical compounds in a rocky exoplanet’s atmosphere by studying its high-resolution telescope images.
To develop this software, the brainiacs simulated more than three million planets’ spectral signatures – fingerprints of their atmospheres’ chemical makeups – and labelled them as such to train a convolutional neural network (CNN). The CNN can therefore be used to automatically estimate the chemical composition of a planet from images and light curves of its atmosphere taken from NASA’s Kepler spacecraft. Basically, a neural network was trained to link telescope images to chemical compositions, and thus, you should it a given set of images, and it will spit out the associated chemical components – which can be used to assess whether those would lead to life bursting on the scene.
INARA takes seconds to figure out the biological compounds potentially present in a world’s atmosphere. “Given the scale of the datasets produced by the Kepler telescopes, and the even greater volume of data that will return to Earth from the soon-to-be-launched Transiting Exoplanet Survey Satellite (TESS) satellite, minimizing analysis time per planet can accelerate this research and ensure we don’t miss any viable candidates,” Mascaro concluded. ®
Wherever artificial intelligence is deployed, you will find it has failed in some amusing way. Take the strange errors made by translation algorithms that confuse having someone for dinner with, well, having someone for dinner.
But as AI is used in ever more critical situations, such as driving autonomous cars, making medical diagnoses, or drawing life-or-death conclusions from intelligence information, these failures will no longer be a laughing matter. That’s why DARPA, the research arm of the US military, is addressing AI’s most basic flaw: it has zero common sense.
“Common sense is the dark matter of artificial intelligence,” says Oren Etzioni, CEO of the Allen Institute for AI, a research nonprofit based in Seattle that is exploring the limits of the technology. “It’s a little bit ineffable, but you see its effects on everything.”
DARPA’s new Machine Common Sense (MCS) program will run a competition that asks AI algorithms to make sense of questions like this one:
A student puts two identical plants in the same type and amount of soil. She gives them the same amount of water. She puts one of these plants near a window and the other in a dark room. The plant near the window will produce more (A) oxygen (B) carbon dioxide (C) water.
A computer program needs some understanding of the way photosynthesis works in order to tackle the question. Simply feeding a machine lots of previous questions won’t solve the problem reliably.
These benchmarks will focus on language because it can so easily trip machines up, and because it makes testing relatively straightforward. Etzioni says the questions offer a way to measure progress toward common-sense understanding, which will be crucial.
Tech companies are busy commercializing machine-learning techniques that are powerful but fundamentally limited. Deep learning, for instance, makes it possible to recognize words in speech or objects in images, often with incredible accuracy. But the approach typically relies on feeding large quantities of labeled data—a raw audio signal or the pixels in an image—into a big neural network. The system can learn to pick out important patterns, but it can easily make mistakes because it has no concept of the broader world.
Using a technique called reinforcement learning, a researcher at Google Brain has shown that virtual robots can redesign their body parts to help them navigate challenging obstacle courses—even if the solutions they come up with are completely bizarre.
Embodied cognition is the idea that an animal’s cognitive abilities are influenced and constrained by its body plan. This means a squirrel’s thought processes and problem-solving strategies will differ somewhat from the cogitations of octopuses, elephants, and seagulls. Each animal has to navigate its world in its own special way using the body it’s been given, which naturally leads to different ways of thinking and learning.
“Evolution plays a vital role in shaping an organism’s body to adapt to its environment,” David Ha, a computer scientist and AI expert at Google Brain, explained in his new study. “The brain and its ability to learn is only one of many body components that is co-evolved together.”
[…]
Using the OpenAI Gym framework, Ha was able to provide an environment for his walkers. This framework looks a lot like an old-school, 2D video game, but it uses sophisticated virtual physics to simulate natural conditions, and it’s capable of randomly generating terrain and other in-game elements.
As for the walker, it was endowed with a pair of legs, each consisting of an upper and lower section. The bipedal bot had to learn how to navigate through its virtual environment and improve its performance over time. Researchers at DeepMind conducted a similar experiment last year, in which virtual bots had to learn how to walk from scratch and navigate through complex parkour courses. The difference here is that Ha’s walkers had the added benefit of being able to redesign their body plan—or at least parts of it. The bots could alter the lengths and widths of their four leg sections to a maximum of 75 percent of the size of the default leg design. The walkers’ pentagon-shaped head could not be altered, serving as cargo. Each walker used a digital version of LIDAR to assess the terrain immediately in front of it, which is why (in the videos) they appear to shoot a thin laser beam at regular intervals.
Using reinforcement-learning algorithms, the bots were given around a day or two to devise their new body parts and come up with effective locomotion strategies, which together formed a walker’s “policy,” in the parlance of AI researchers. The learning process is similar to trial-and-error, except the bots, via reinforcement learning, are rewarded when they come up with good strategies, which then leads them toward even better solutions. This is why reinforcement learning is so powerful—it speeds up the learning process as the bots experiment with various solutions, many of which are unconventional and unpredictable by human standards.
Left: An unmodified walker joyfully skips through easy terrain. Right: With training, a self-modified walker chose to hop instead.
GIF: David Ha/Google Brain/Gizmodo
For the first test (above), Ha placed a walker in a basic environment with no obstacles and gently rolling terrain. Using its default body plan, the bot adopted a rather cheerful-looking skipping locomotion strategy. After the learning stage, however, it modified its legs such that they were thinner and longer. With these modified limbs, the walker used its legs as springs, quickly hopping across the terrain.
The walker chose a strange body plan and an unorthodox locomotion strategy for traversing challenging terrain.
GIF: David Ha/Google Brain/Gizmodo
The introduction of more challenging terrain (above), such as having to walk over obstacles, travel up and down hills, and jump over pits, introduced some radical new policies, namely the invention of an elongated rear “tail” with a dramatically thickened end. Armed with this configuration, the walkers hopped successfully around the obstacle course.
By this point in the experiment, Ha could see that reinforcement learning was clearly working. Allowing a walker “to learn a better version of its body obviously enables it to achieve better performance,” he wrote in the study.
Not content to stop there, Ha played around with the idea of motivating the walkers to adopt some design decisions that weren’t necessarily beneficial to its performance. The reason for this, he said, is that “we may want our agent to learn a design that utilizes the least amount of materials while still achieving satisfactory performance on the task.”
The tiny walker adopted a very familiar gait when faced with easy terrain.
GIF: David Ha/Google Brain/Gizmodo
So for the next test, Ha rewarded an agent for developing legs that were smaller in area (above). With the bot motivated to move efficiently across the terrain, and using the tiniest legs possible (it no longer had to adhere to the 75 percent rule), the walker adopted a rather conventional bipedal style while navigating the easy terrain (it needed just 8 percent of the leg area used in the original design).
The walker struggled to come up with an effective body plan and locomotion style when it was rewarded for inventing small leg sizes.
GIF: David Ha/Google Brain/Gizmodo
But the walker really struggled to come up with a sensible policy when having to navigate the challenging terrain. In the example shown above, which was the best strategy it could muster, the walker used 27 percent of the area of its original design. Reinforcement learning is good, but it’s no guarantee that a bot will come up with something brilliant. In some cases, a good solution simply doesn’t exist.
Artificially intelligent bots are notoriously bad at communicating with, well, anything. Conversations with the code, whether it’s between themselves or with people, often go awry, and veer off topic. Grammar goes out the window, and sentences become nonsensical.
[…]
Well, a group of researchers at Stanford University in the US have figured out how to, in theory, prevent that chaos and confusion from happening. In an experiment, they trained neural networks to negotiate when buying stuff in hypothetical situations, mimicking the process of scoring and selling stuff on sites like Craigslist or Gumtree.
Here’s the plan: sellers post adverts trying to get rid off their old possessions. Buyers enquire about the condition of the items, and if a deal is reached, both parties arrange a time and place to exchange the item for cash.
Here’s an example of a conversation between a human, acting as a seller, and a Stanford-built bot, as the buyer:
Example of a bot (A) interacting with a human (B) to buy a Fitbit. Image credit: He et al.
The dialogue is a bit stiff, and the grammar is wrong in places, but it does the job even though no deal is reached. The team documented their work in this paper, here [PDF], which came to our attention this week.
The trick is to keep the machines on topic and stop them from generating gibberish. The researchers used supervised learning and reinforcement learning together with hardcoded rules to force the bots to stay on task.
The system is broadly split into three parts: a parser, a manager and a generator. The parser inspects keywords that signify a specific action that is being taken. Next, the manager stage chooses how the bot should respond. These actions, dubbed “course dialogue acts”, guide the bot through the negotiation task so it knows when to inquire, barter a price, agree or disagree. Finally, the generator produces the response to keep the dialogue flowing.
Diagram of how the system works. The interaction is split into a series of course dialogue acts, the manager chooses what action the bot should take, and a generator spits out words for the dialogue. Image credit: He et al.
In the reinforcement learning method, the bots are encouraged to reach a deal and penalized with a negative reward when it fails to reach an agreement. The researchers train the bot by collecting 6,682 dialogues between humans working on the Amazon Mechanical Turk platform.
They call it the Craigslist Negotiation Dataset since they modeled the scenarios by scraping postings for the items in the six most popular categories on Craigslist. These include items filed under housing, furniture, cars, bikes, phones and electronics.
The conversations are represented as a sequence of actions or course dialogue acts. A long short-term memory network (LSTM) encodes the course dialogue act and another LSTM decodes it.
The manager part chooses the appropriate response. For example, it can propose a price, argue to go lower or higher, and accepts or rejects a deal. The generator conveys all these actions in plain English.
During the testing phase, the bots were pitted against real humans. Participants were then asked to how humans the interaction seemed. The researchers found that their systems were more successful at bargaining for a deal and were more human-like than other bots.
It doesn’t always work out, however. Here’s an example of a conversation where the bot doesn’t make much sense.
A bot (A) trying to buy a Fitbit off a human seller (B). This time, however, it fails to communicate effectively. Image credit: He et al.
If you like the idea of crafting a bot to help you automatically negotiate for things online then you can have a go at making your own. The researchers have posted the data and code on CodaLab. ®
Artificial intelligence can help developers design mobile phone apps that drain less battery, according to new research.
The system, dubbed DiffProff, will be presented this week at the USENIX Symposium on Operating Systems Design and Implementation conference in California, was developed by Charlie Hu and Abhilash Jindal, who have a startup devoted to better battery testing via software.
DiffProf rests on the assumption that apps that carry out the same function perform similar tasks in slightly different ways. For example, messaging apps like Whatsapp, Google Hangouts, or Skype, keep old conversations and bring up a keyboard so replies can be typed and sent. Despite this, Whatsapp is about three times more energy efficient than Skype.
“What if a feature of an app needs to consume 70 percent of the phone’s battery? Is there room for improvement, or should that feature be left the way it is?” said Hu, who is also a professor of electrical and computer engineering at Purdue University.
The research paper describing DiffProf is pretty technical. Essentially, it describes a method that uses “differential energy profiling” to create energy profiles for different apps. First, the researchers carry out a series of automated tests on apps by performing identical tasks on each app to work out energy efficiency.
Next, the profile also considers the app’s “call tree” also known as a call graph. These describe the different computer programs that are executed in order to perform a broader given task.
Apps that have the same function, like playing music or sending emails, should have similar call trees. Slight variances in the code, however, lead to different energy profiles. DiffProf uses an algorithm to compare the call trees and highlights what programs are causing an app to drain more energy.
Developers running the tool receive a list of Java packages, that describe the different software features, which appear in the both apps being compared. They can then work out which programs in the less energy efficient app suck up more juice and if it can be altered or deleted altogether. The tool is only useful if the source code for similar apps have significant overlap.
a new, free app promises to let you “sue anyone by pressing a button” and have an AI-powered lawyer fight your case.
Do Not Pay, a free service that launched in the iOS App store today, uses IBM Watson-powered artificial intelligence to help people win up to $25,000 in small claims court. It’s the latest project from 21-year-old Stanford senior Joshua Browder, whose service previously allowed people to fight parking tickets or sue Equifax; now, the app has streamlined the process. It’s the “first ever service to sue anyone (in all 3,000 counties in 50 states) by pressing a button.”
The crazy part: the robot lawyer actually wins in court. In its beta testing phase, which included releases in the UK and in select numbers across all 50 US states, Do Not Pay has helped its users get back $16 million in disputed parking tickets. In a phone call with Motherboard, Browder said that the success rate of Do Not Pay is about 50 percent, with average winnings of about $7,000.
[…]
The app works by having a bot ask the user a few basic questions about their legal issue. The bot then uses the answers to classify the case into one of 15 different legal areas, such as breach of contract or negligence. After that, Do Not Pay draws up documents specific to that legal area, and fills in the specific details. Just print it out, mail it to the courthouse, and violá—you’re a plaintiff. And if you have to show up to court in person, Do Not Pay even creates a script for the plaintiff to read out loud in court.
[…]
Browder told Motherboard that data protection is a central part of his service, which is free (users keep 100 percent of what they win in court, Browder says.) Per Do Not Pay’s privacy policy, all user data is protected with 256-bit encryption, and no third parties get access to personal user information such as home address, email address, or information pertaining to a particular case.
[…]
Of all of Do Not Pay’s legal disputes, Browder told Motherboard that he’s most proud of an instance where a woman took Equifax to court and won, twice. After her data was compromised by Equifax last year, she took the $3 billion company to small claims court and won. When Equifax appealed the verdict and sent a company lawyer to fight for an appeal, the woman won again.
MLflow is inspired by existing ML platforms, but it is designed to be open in two senses:
Open interface: MLflow is designed to work with any ML library, algorithm, deployment tool or language. It’s built around REST APIs and simple data formats (e.g., a model can be viewed as a lambda function) that can be used from a variety of tools, instead of only providing a small set of built-in functionality. This also makes it easy to add MLflow to your existing ML code so you can benefit from it immediately, and to share code using any ML library that others in your organization can run.
Open source: We’re releasing MLflow as an open source project that users and library developers can extend. In addition, MLflow’s open format makes it very easy to share workflow steps and models across organizations if you wish to open source your code.
Mlflow is still currently in alpha, but we believe that it already offers a useful framework to work with ML code, and we would love to hear your feedback. In this post, we’ll introduce MLflow in detail and explain its components.
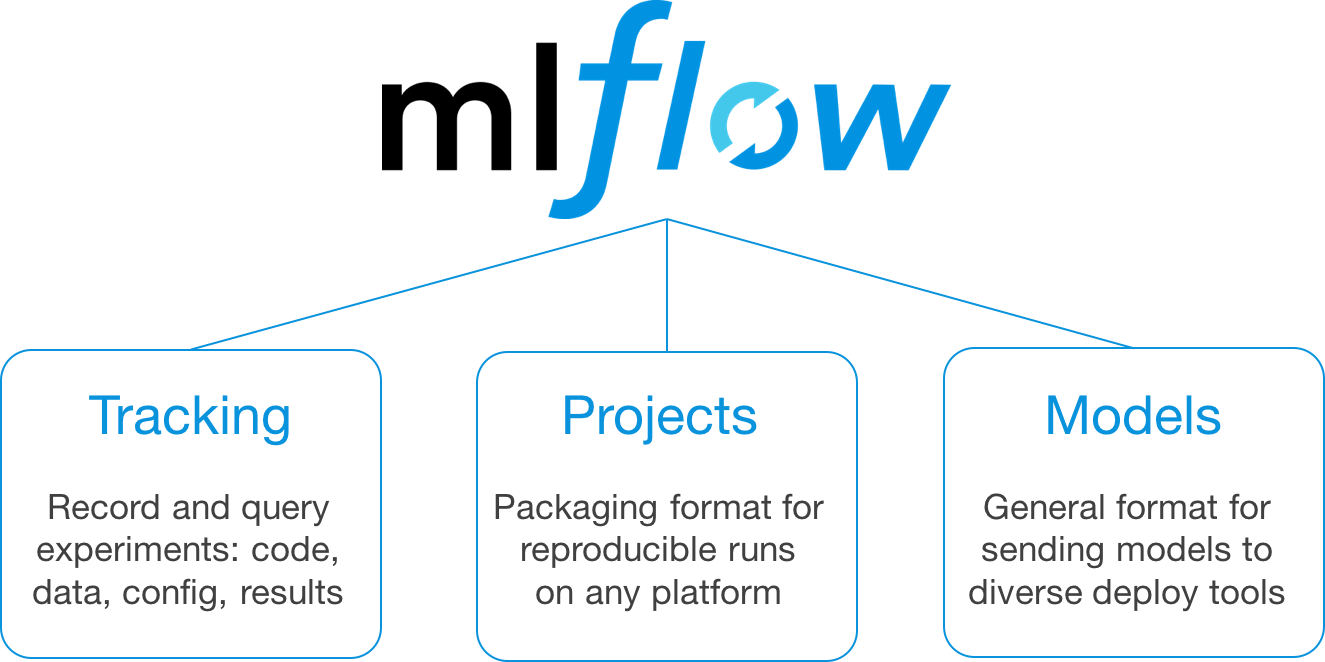
MLflow Alpha Release Components
This first, alpha release of MLflow has three components:
MLflow Tracking
MLflow Tracking is an API and UI for logging parameters, code versions, metrics and output files when running your machine learning code to later visualize them. With a few simple lines of code, you can track parameters, metrics, and artifacts:
import mlflow
# Log parameters (key-value pairs)
mlflow.log_param("num_dimensions",8)
mlflow.log_param("regularization",0.1)# Log a metric; metrics can be updated throughout the run
mlflow.log_metric("accuracy",0.1)...
mlflow.log_metric("accuracy",0.45)# Log artifacts (output files)
mlflow.log_artifact("roc.png")
mlflow.log_artifact("model.pkl")
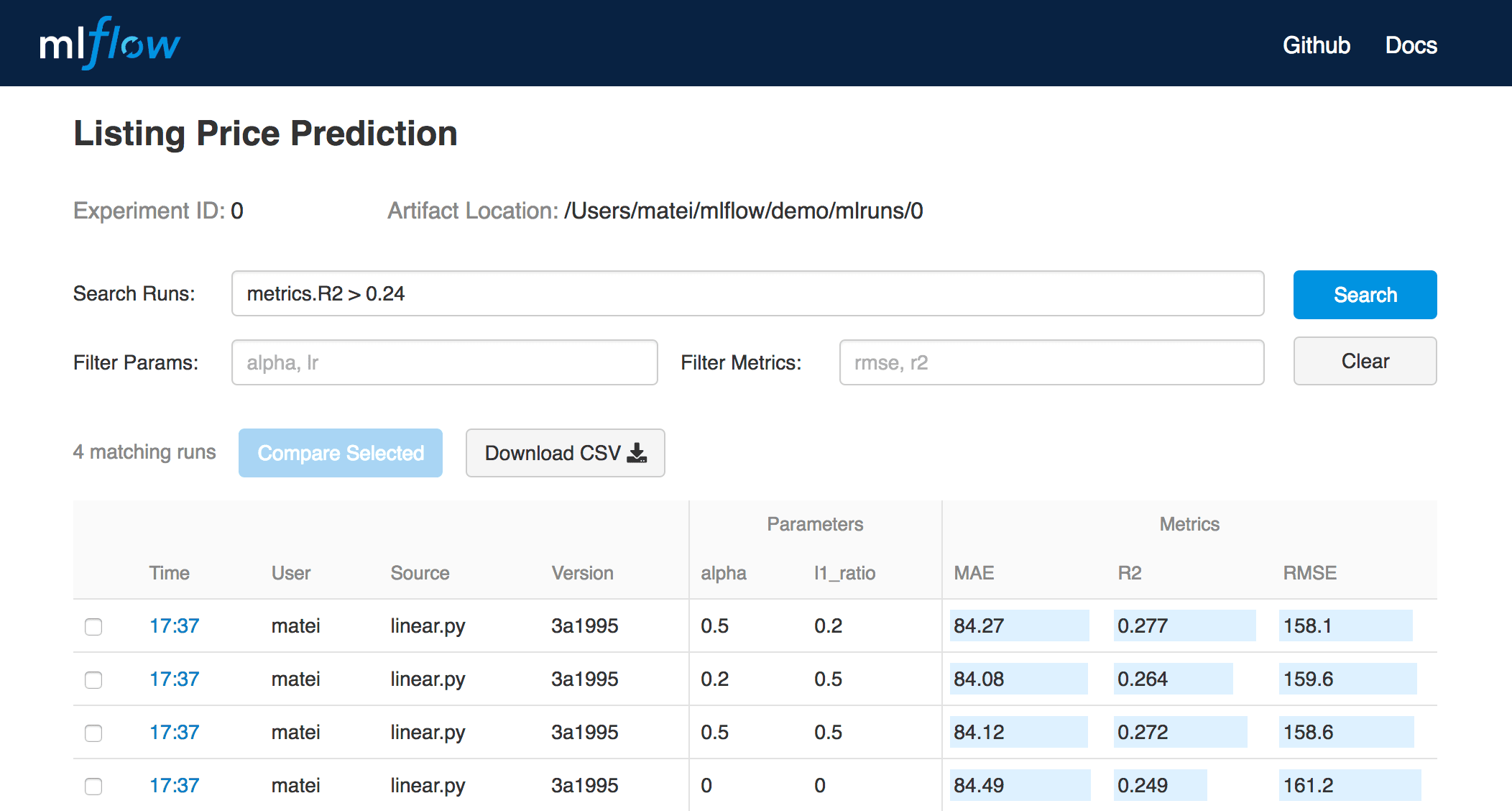
You can use MLflow Tracking in any environment (for example, a standalone script or a notebook) to log results to local files or to a server, then compare multiple runs. Using the web UI, you can view and compare the output of multiple runs. Teams can also use the tools to compare results from different users:
MLflow Tracking UI
MLflow Projects
MLflow Projects provide a standard format for packaging reusable data science code. Each project is simply a directory with code or a Git repository, and uses a descriptor file to specify its dependencies and how to run the code. A MLflow Project is defined by a simple YAML file called MLproject.
Projects can specify their dependencies through a Conda environment. A project may also have multiple entry points for invoking runs, with named parameters. You can run projects using the mlflow run command-line tool, either from local files or from a Git repository:
mlflow run example/project -P alpha=0.5
mlflow run git@github.com:databricks/mlflow-example.git -P alpha=0.5
MLflow will automatically set up the right environment for the project and run it. In addition, if you use the MLflow Tracking API in a Project, MLflow will remember the project version executed (that is, the Git commit) and any parameters. You can then easily rerun the exact same code.
The project format makes it easy to share reproducible data science code, whether within your company or in the open source community. Coupled with MLflow Tracking, MLflow Projects provides great tools for reproducibility, extensibility, and experimentation.
MLflow Models
MLflow Models is a convention for packaging machine learning models in multiple formats called “flavors”. MLflow offers a variety of tools to help you deploy different flavors of models. Each MLflow Model is saved as a directory containing arbitrary files and an MLmodel descriptor file that lists the flavors it can be used in.
In this example, the model can be used with tools that support either the sklearn or python_function model flavors.
MLflow provides tools to deploy many common model types to diverse platforms. For example, any model supporting the python_function flavor can be deployed to a Docker-based REST server, to cloud platforms such as Azure ML and AWS SageMaker, and as a user-defined function in Apache Spark for batch and streaming inference. If you output MLflow Models as artifacts using the Tracking API, MLflow will also automatically remember which Project and run they came from.
Getting Started with MLflow
To get started with MLflow, follow the instructions at mlflow.org or check out the alpha release code on Github. We are excited to hear your feedback on the concepts and code!
Jeff Chen, an AI techie and entrepreneur at Stanford University in the US, believes that a suitable machine can be built for about $3,000 (~£2,300) without including tax. At the heart of the beast is an Nvidia GeForce 1080Ti GPU, a 12-core AMD Threadripper processor, 64GB of RAM, and a 1TB SSD card for data. Bung in a fan to keep the computer cool, a motherboard, a power supply, wrap the whole thing in a case, and voila.
Here’s the full checklist…
Image credit: Jeff Chen
Unlike renting out compute and data storage on cloud, once your personal rig is built, the only recurring cost to pay for is power. It costs $3 (£2.28) an hour to rent a GPU-accelerated system on AWS, whereas it’s only 20 cents (15p) to run on your own computer. Chen has done the sums, and, apparently, after two months that will work out to being ten times cheaper. The gap decreases slightly over time as the computer hardware depreciates.
“There are some drawbacks, such as slower download speed to your machine because it’s not on the backbone, static IP is required to access it away from your house, you may want to refresh the GPUs in a couple of years, but the cost savings is so ridiculous it’s still worth it,” he said this week.
For years Google has warned users about natural disasters by incorporating alerts from government agencies like FEMA into apps like Maps and Search. Now, the company is making predictions of its own. As part of a partnership with the Central Water Commission of India, Google will now alert users in the country about impending floods. The service is only currently available in the Patna region, with the first alert going out earlier this month.
As Google’s engineering VP Yossi Matias outlines in a blog post, these predictions are being made using a combination of machine learning, rainfall records, and flood simulations.
“A variety of elements — from historical events, to river level readings, to the terrain and elevation of a specific area — feed into our models,” writes Matias. “With this information, we’ve created river flood forecasting models that can more accurately predict not only when and where a flood might occur, but the severity of the event as well.”
Machine learning data management company Imanis Data has introduced an autonomous backup product powered by machine learning.
The firm said users can specify a desired RPO (Recovery Point Objective) and its SmartPolicies tech then set up the backup schedules. The tech is delivered as an upgrade to the Imanis Data Management Platform (IDMP) product.
SmartPolicies uses metrics including criticality and volume of data to be protected, primary cluster workloads, and daily or seasonal resource utilisation, to determine the most efficient way to achieve the desired RPO.
If it can’t be met because, for example, production systems are too busy, or computing resources are insufficient, then SmartPolicies provides recommendations to make the RPO executable.
Other items in the upgrade include any-point-in-time recovery for multiple NoSQL databases, better ransomware prevention and general data management improvements, such as job tag listing and a browsable catalog for simpler recovery.
[…]
Having backup software set up its own schedules based on input RPO values isn’t a new idea, but having it done with machine learning is. The checking of available resources is a darn good idea too and, when you think about it, absolutely necessary.
Otherwise “backup run failed” messages would start popping up all over the place – not good. We expect other backup suppliers to follow in Imanis’s wake and start sporting “machine learning-driven policy” messages quite quickly.
Researchers from Carnegie Mellon University and Facebook Reality Lab are presenting Recycle-GAN, a generative adversarial system for “unsupervised video retargeting” this week at the European Conference on Computer Vision (ECCV) in Germany.
Unlike most methods, Recycle-GAN doesn’t rely on learning an explicit mapping between the images in a source and target video to perform a face swap. Instead, it’s an unsupervised learning method that begins to line up the frames from both videos based on “spatial and temporal information”.
In other words, the content that is transferred from one video to another not only relies on mapping the space but also the order of the frames to make sure both are in sync. The researchers use the comedians Stephen Colbert and John Oliver as an example. Colbert is made to look like he is delivering the same speech as Oliver, as his face is use to mimic the small movements of Oliver’s head nodding or his mouth speaking.
Here’s one where John Oliver is turned into a cartoon character.
It’s not just faces, Recycle-Gan can be used for other scenarios too. Other examples include synching up different flowers so they appear to bloom and die at the same time.
The researchers also play around with wind conditions, turning what looks like a soft breeze blowing into the trees into a more windy day without changing the background.
“I think there are a lot of stories to be told,” said Aayush Bansal, co-author of the research and a PhD. student at CMU.”It’s a tool for the artist that gives them an initial model that they can then improve,” he added.
Recycle-GAN might prove useful in other areas. Simulating various effects for video footage taken from self-driving cars could help them drive under different conditions.
“Such effects might be useful in developing self-driving cars that can navigate at night or in bad weather, Bansal said. These videos might be difficult to obtain or tedious to label, but its something Recycle-GAN might be able to generate automatically.
It’s tricky. Computers have to follow what is being said by whom, the context of the conversation and often some real world facts to understand cultural references. Feeding machines single sentences is often ineffective; it’s a difficult task for humans to detect if individual remarks are cheeky too.
The researchers, therefore, built a system designed to inspect individual sentences as well as the ones before and after it. The model is made up of several bidirectional long-short term memory networks (BiLSTMs) stitched together, and was accurate at spotting a sarcastic comment about 70 per cent of the time.
“Typical LSTMs read and encode the data – a sentence – from left to right. BiLSTMs will process the sentence in a left to right and right to left manner,” Reza Ghaeini, coauthor of the research on arXiv and a PhD student at Oregon State University, explained to The Register this week.
“The outcome of the BiLSTM for each position is the concatenation of forward and backward encodings of each position. Therefore, now each position contains information about the whole sentence (what is seen before and what will be seen after).”
So, where’s the best place to learn sarcasm? Reddit’s message boards, of course. The dataset known as SARC – geddit? – contains hundreds of thousands of sarcastic and non-sarcastic comments and responses.
“It is quite difficult for both machines and humans to distinguish sarcasm without context,” Mikhail Khodak, a graduate student at Princeton who helped compile SARC, previously told El Reg.
“One of the advantages of our corpus is that we provide the text preceding each statement as well as the author of the statement, so algorithms can see whether it is sarcastic in the context of the conversation or in the context of the author’s past statements.”
SapFix, which is still under development, is designed to generate fixes automatically for specific bugs before sending them to human engineers for approval.
Facebook, which announced the tool today ahead of its @Scale conference in San Jose, California, for developers building large-scale systems and applications, calls SapFix an “AI hybrid tool.” It uses artificial intelligence to automate the creation of fixes for bugs that have been identified by its software testing tool Sapienz, which is already being used in production.
SapFix will eventually be able to operate independently from Sapienz, but for now it’s still a proof-of-concept that relies on the latter tool to pinpoint bugs first of all.
SapFix can fix bugs in a number of ways, depending on how complex they are, Facebook engineers Yue Jia, Ke Mao and Mark Harman wrote in a blog post announcing the tools. For simpler bugs, SapFix creates patches that revert the code submission that introduced them. In the case of more complicated bugs, SapFix uses a collection of “templated fixes” that were created by human engineers based on previous bug fixes.
And in case those human-designed template fixes aren’t up to the job, SapFix will then attempt what’s called a “mutation-based fix,” which works by continually making small modifications to the code that caused the software to crash, until a solution is found.
SapFix goes further by generating multiple potential fixes for each bug, then submits these for human evaluation. It also performs tests on each of these fixes so engineers can see if they might cause other problems, such as compilation errors and other crashes somewhere else.