EV buyers are often motivated by a desire to save money on gas and/or drive something more environmentally friendly. But, a recent story out of Florida in The Miami Herald details how EV owners there have been blindsided by how fast they’re having to change the tires on their EVs.
The Herald spoke with the owner of a shop that specializes in EV repair who told them just how often he’s seeing owners in for tire wear and replacement.
At EV Garage Miami, a Sweetwater repair shop that services 90 percent electric vehicles, lead technician Jonathan Sanchez said tires are the most frequent thing customers come in about, no matter what model or make of EV they’re driving. Tire mileage can vary widely of course, but he frequently changes EV tires at just 8,000 to 10,000 miles — a fourth or even fifth of typical tire wear on a gas-burning car.
Neil Semel, the owner of a Mercedes EQS, told The Heraldthat if he had known how often he would be buying tires, he would’ve never bought the car. “If somebody looked at me and said, Mr. Semel, you are going to love this car but in about 7,000 miles you will have to pay 1,400 or 1,500 dollars to replace the tires, I wouldn’t have bought the car,” he said.
So why the fast wear? It’s a combination of lots of power that can be put down instantly and wild curb weights. But it also comes down to individual driving style, as Sanchez pointed out. “If you drive like grandma, the type of car shouldn’t make a difference,” Sanchez said.
What do tire companies have to say about all of this? They’re aware of the problem and are working on EV-specific solutions. Like Michelin who spoke to The Herald:
Michelin suggests getting the Primacy tire for electric vehicles, which they say offers an up to 7% increase in range. Michelin also launched “Self seal” which would self-repair punctures and cut back on some weight by not needing to keep a spare wheel in the back.
The Akira ransomware gang is claiming responsiblity for the “cybersecurity incident” at British bath bomb merchant.
Akira says it has stolen 110 GB of data from the UK-headquartered global cosmetics giant, which has more than 900 stores worldwide, allegedly including “a lot of personal documents” such as passport scans.
Passport scans are routinely collected to verify identities during the course of the hiring process, which suggests Akira’s affiliate likely had access to a system containing staff-related data.
Company documents relating to accounting, finances, tax, projects, and clients are also said to be included in the archives grabbed by the cybercriminals, who are threatening to make the data public soon. There is still no evidence to suggest customer data was exposed.
Akira’s retro-vibe website separates victims into different sections: One for companies who didn’t pay the ransom and thus had their data published, and another for those whose data is to be published on an undisclosed date.
A likely conclusion to draw, if the incident does indeed involve ransomware as the criminals claim, is that there may have been negotiations which have stalled, with Akira using the threat of data publication as a means to hurry along the talks.
The Register approached Lush for comment. Its representatives acknowledged the request but did not provide a statement in time for publication.
Lush last communicated about the situation on January 11, saying it was responding to an “incident” and working with outside forensic experts to investigate the issue – often phrasing used in a ransomware attack.
“The investigation is at an early stage but we have taken immediate steps to secure and screen all systems in order to contain the incident and limit the impact on our operations,” it said. “We take cybersecurity exceptionally seriously and have informed relevant authorities.”
The statement came a day after a post was made to the unofficial Lush Reddit community. Written by a user who seemingly had inside knowledge of the incident, the post claimed members of staff were instructed to send their laptops to head office for “cleaning” – an assertion that El Reg understands to be true.
A password-less database containing an estimated 1.3 million sets of Dutch COVID-19 testing records was left exposed to the open internet, and it’s not clear if anyone is taking responsibility.
Among the information revealed in the publicly accessible and seemingly insecurely configured database were 118,441 coronavirus test certificates, 506,663 appointment records, 660,173 testing samples and “a small number” of internal files. A bevy of personally identifiable information was included in the records – including patient names, dates of birth, passport numbers, email addresses, and other information.
The leaky database was discovered by perennial breach sniffer Jeremiah Fowler, who reckoned it belongs to one of the Netherlands’ largest commercial COVID-19 test providers, CoronaLab – a subsidiary of Amsterdam-based Microbe & Lab. The US Embassy in the Netherlands lists CoronaLab as one of its recommended commercial COVID-19 test providers in the country.
If someone with malicious intent managed to find the database they could do some serious damage, Fowler warned.
“Criminal[s] could potentially reference test dates, locations, or other insider information that only the patient and the laboratory would know,” he wrote. “Any potential exposure involving COVID test data combined with PII could potentially compromise the personal and medical privacy of the individuals listed in the documents.”
Will the responsible party please stand up?
The CoronaLab data exposure report reads in many ways like any other accidental data exposure news: It was found, and now the offending database is offline. But this one isn’t that simple.
According to Fowler, no-one at CoronaLab or Microbe & Lab ever responded to his repeated attempts to reach out and inform them of the exposure.
“I sent multiple responsible disclosure notices and did not receive any reply, and several phone calls also yielded no results,” Fowler claimed. “The database remained open for nearly three weeks before I contacted the cloud hosting provider and it was finally secured from public access.”
The Register has asked Microbe & Lab to get more information about the incident – and we haven’t heard back either.
Without more information from Microbe & Lab or CoronaLab itself, it’s impossible to know how long the database was actually exposed online. The CoronaLab website is down as of this writing – it’s not clear if the outage is related to the database exposure, or if the service will be brought back online.
Because no-one at the organization whose records were exposed can be reached, it’s also not clear if customers or patients are aware that their data was exposed online. Nor, importantly, do we know if European data protection authorities have been informed.
Per article 33 of the EU General Data Protection Regulation (GDPR), data breaches must be reported to local officials within 72 hours of detection, and notifications also have to be made to affected individuals. We reached out to the Dutch Data Protection Authority to learn if it had been notified of the CoronaLab data exposure, and didn’t immediately hear back.
Astronomers using the NASA/ESA Hubble Space Telescope observed the smallest exoplanet where water vapor has been detected in its atmosphere. At only approximately twice Earth’s diameter, the planet GJ 9827d could be an example of potential planets with water-rich atmospheres elsewhere in our galaxy.
GJ 9827d was discovered by NASA’s Kepler Space Telescope in 2017. It completes an orbit around a red dwarf star every 6.2 days. The star, GJ 9827, lies 97 light-years from Earth in the constellation Pisces.
“This would be the first time that we can directly show through an atmospheric detection that these planets with water-rich atmospheres can actually exist around other stars,” said team member Björn Benneke of the Université de Montréal. “This is an important step toward determining the prevalence and diversity of atmospheres on rocky planets.”
The study is published in The Astrophysical Journal Letters.
However, it remains too early to tell whether Hubble spectroscopically measured a small amount of water vapor in a puffy hydrogen-rich atmosphere, or if the planet’s atmosphere is mostly made of water, left behind after a primeval hydrogen/helium atmosphere evaporated under stellar radiation.
[…]
At present the team is left with two possibilities. The planet is still clinging to a hydrogen-rich envelope laced with water, making it a mini-Neptune. Alternatively, it could be a warmer version of Jupiter’s moon Europa, which has twice as much water as Earth beneath its crust. “The planet GJ 9827d could be half water, half rock. And there would be a lot of water vapor on top of some smaller rocky body,” said Benneke.
[…]
More information: Pierre-Alexis Roy et al, Water Absorption in the Transmission Spectrum of the Water World Candidate GJ 9827 d, The Astrophysical Journal Letters (2023). DOI: 10.3847/2041-8213/acebf0
[…] The Council of Europe (CoE), an international human rights body with 46 member countries, is approaching the finalisation of the Convention on Artificial Intelligence, Human Rights, Democracy, and the Rule of Law.
Since the beginning, the United States, the homeland of the world’s leading AI companies, has been pushing to exclude the private sector from the treaty, which, if ratified, would be binding for the signature country.
The United States is not a CoE member but participates in the process with an observer status. In other words, Washington does not have voting rights, but it can influence the discussion by saying it will not sign the convention.
[…]
By contrast, the European Commission, representing the EU in the negotiations, has opposed this carve out for the private sector. Two weeks ago, Euractiv revealed an internal note stating that “the Union should not agree with the alternative proposal(s) that limit the scope of the convention.”
However, in a consequent meeting of the Working Party on Telecommunications and Information Society, the technical body of the EU Council of Ministers in charge of digital policy, several member states asked the Commission to show more flexibility regarding the convention’s scope.
In particular, for countries like Germany, France, Spain, Czechia, Estonia, Ireland, Hungary and Romania, the intent of the treaty was to reach a global agreement, hence securing more signatories should be a priority as opposed to a broad convention with more limited international support.
Being composed of 27 countries out of the 46 that are part of the Council of Europe, the position of the bloc can in itself swing the balance inside the human rights body, where the decisions are taken by consensus.
The European Commission is preparing to push back on a US-led attempt to exempt the private sector from the world’s first international treaty on Artificial Intelligence while pushing for as much alignment as possible with the EU’s AI Act.
Limiting the convention’s scope would be a significant blow to the Commission’s global ambitions, which sees the treaty as a vehicle to set the EU’s AI Act, the world’s first comprehensive law on Artificial Intelligence, as the global benchmark in this area.
Indeed, the Commission’s mandate to negotiate on behalf of the Union is based on the AI Act, and the EU executive has shown little appetite to go beyond the AI regulation even in areas where there is no direct conflict, despite the fact the two initiatives differ significantly in nature.
As part of the alignment with the AI Act, the Commission is pushing for broad exemptions for AI uses in national security, defence and law enforcement. Thus, if the treaty was limited to only public bodies, with these carve-outs, there would be very little left.
In addition, Euractiv understands that such a major watering down of the AI treaty after several years of engagement from the countries involved might also discourage future initiatives in this area.
[…]
a paragraph has been added stressing that “to preserve the international character of the convention, the EU could nevertheless be open to consider the possibility for a Party to make a reservation and release itself from the obligation to apply the convention to private actors that are not acting on behalf of or procuring AI systems for public authorities, under certain conditions and limitations”.
The Commission’s proposal seems designed to address Washington’s argument that they cannot commit to anything beyond their national legal framework.
In October, US President Joe Biden signed an executive order setting out a framework for federal agencies to purchase and use AI tools safely and responsibly, hence the reference to companies not working with the public sector.
More precisely, the Commission is proposing an ‘opt-out’ option with temporal limitations, that can be revised at any time and with some guarantees that it is not abused. This approach would be the opposite of what the US administration proposed, namely exempting the private sector by default with an ‘opt-in’ possibility for signatories.
Still, the original ‘opt-in’ option was designed to avoid the embarrassment of the US administration having to exempt private companies from a human rights treaty. Euractiv understands Israel and Japan would not sign if the ‘opt-out’ approach made it into the final text, whereas the UK and Canada would follow the US decision.
So the US basically wants to make a useful treaty useless because they are run by self serving, profit seeking companies that want to trample on human rights. Who would have thought? Hopefully the EU can show some backbone and do what is right instead of what is being financially lobbied for (here’s looking at you, France!). It’s this kind of business based decision making that has led to climate change, cancer deaths, and many many more huge problems that could have been nipped in the bud.
iPhone apps including Facebook, LinkedIn, TikTok, and X/Twitter are skirting Apple’s privacy rules to collect user data through notifications, according to tests by security researchers at Mysk Inc., an app development company. Users sometimes close apps to stop them from collecting data in the background, but this technique gets around that protection. The data is unnecessary for processing notifications, the researchers said, and seems related to analytics, advertising, and tracking users across different apps and devices.
It’s par for the course that apps would find opportunities to sneak in more data collection, but “we were surprised to learn that this practice is widely used,” said Tommy Mysk, who conducted the tests along with Talal Haj Bakry. “Who would have known that an innocuous action as simple as dismissing a notification would trigger sending a lot of unique device information to remote servers? It is worrying when you think about the fact that developers can do that on-demand.”
These particular apps aren’t unusual bad actors. According to the researchers, it’s a widespread problem plaguing the iPhone ecosystem.
This isn’t the first time Mysk’s tests have uncovered data problems at Apple, which has spent untold millions convincing the world that “what happens on your iPhone, stays on your iPhone.” In October 2023, Mysk found that a lauded iPhone feature meant to protect details about your WiFi address isn’t as private as the company promises. In 2022, Apple was hit with over a dozen class action lawsuits after Gizmodo reported on Mysk’s finding that Apple collects data about its users even after they flip the switch on an iPhone privacy setting that promises to “disable the sharing of device analytics altogether.”
The data looks like information that’s used for “fingerprinting,” a technique companies use to identify you based on several seemingly innocuous details about your device. Fingerprinting circumvents privacy protections to track people and send them targeted ads
[…]
For example, the tests showed that when you interact with a notification from Facebook, the app collects IP addresses, the number of milliseconds since your phone was restarted, the amount of free memory space on your phone, and a host of other details. Combining data like these is enough to identify a person with a high level of accuracy. The other apps in the test collected similar information. LinkedIn, for example, uses notifications to gather which timezone you’re in, your display brightness, and what mobile carrier you’re using, as well as a host of other information that seems specifically related to advertising campaigns, Mysk said.
[…]
Apps can collect this kind of data about you when they’re open, but swiping an app closed is supposed to cut off the flow of data and stop an app from running whatsoever. However, it seems notifications provide a backdoor.
Apple provides special software to help your apps send notifications. For some notifications, the app might need to play a sound or download text, images, or other information. If the app is closed, the iPhone operating system lets the app wake up temporarily to contact company servers, send you the notification, and perform any other necessary business. The data harvesting Mysk spotted happened during this brief window.
France’s data privacy watchdog organization, the CNIL, has fined a logistics subsidiary of Amazon €32 million, or $35 million in US dollars, over the company’s use of an “overly intrusive” employee surveillance system. The CNIL says that the system employed by Amazon France Logistique “measured work interruptions with such accuracy, potentially requiring employees to justify every break or interruption.”
Of course, this system was forced on the company’s warehouse workers, as they seem to always get the short end of the Amazon stick. The CNIL says the surveillance software tracked the inactivity of employees via a mandatory barcode scanner that’s used to process orders. The system tracks idle time as interruptions in barcode scans, calling out employees for periods of downtime as low as one minute. The French organization ruled that the accuracy of this system was illegal, using Europe’s General Data Protection Regulation (GDPR) as a legal basis for the ruling.
To that end, this isn’t being classified as a labor case, but rather a data processing case regarding excessive monitoring. “As implemented, the processing is considered to be excessively intrusive,” the CNIL wrote, noting that Amazon uses this data to assess employee performance on a weekly basis. The organization also noted that Amazon held onto this data for all employees and temporary workers.
Samsung just announced that its self-repair program will now include certain home entertainment devices. The company has developed a range of step-by-step repair guides for various products in the category, in addition to providing genuine replacement parts and repair tools.
This program covers Samsung 2023 TVs, along with their remotes, and monitors released throughout the past year or so. Additionally, the self-repair program now includes the second-generation Freestyle projector and select soundbars. You can pick up replacement parts directly from the company.
Of course, the program doesn’t cover every repair issue. For TVs and monitors, the program only handles issues related to the picture, power, WiFi connection, sound and remote control. For soundbars, the program covers problems related to HDMI and optical connections, power, sound and wireless communication. According to Samsung, most of these issues can be fixed with common tools like a Phillips-head screwdriver.
The company’s been on something of a self-repair spree in recent months. Back in December, Samsung opened up the program to foldable devices, like the Galaxy Z Flip 5 and Z Fold 5. In the first part of 2023, the company added S22 and Galaxy Book devices to the program, joining pre-existing Galaxy products.
To that end, Samsung just announced a broader assortment of self-repair parts for devices already included in the program. This includes speakers, SIM trays, side keys, volume keys, display assemblies, back glass and charging ports for phones and tablets. Galaxy Book owners can also now conduct DIY repairs to fix the speakers and fan. Meanwhile, rival Apple doesn’t exactly have the best track record in the self-repair movement.
It’s good to see a return to being able to repair stuff. Not only does this make repairs cheaper, faster and easier but also it allows you to keep your device running for far longer. Considering the amount of damage being done to the environment by electronic device junk, is absolutely a good thing.
The rainbow looks different to a human than it does to a honeybee or a zebra finch. That’s because these animals can see colors that we humans simply can’t. Now scientists have developed a new video recording and analysis technique to better understand how the world looks through the eyes of other species. The accurate and relatively inexpensive method, described in a study published on January 23 in PLOS Biology, is already offering biologists surprising discoveries about the lives of different species.
Humans have three types of cone cells in their eyes. This trio of photoreceptors typically detects red, green and blue wavelengths of light, which combine into millions of distinct colors in the spectrum from 380 to 700 nanometers in wavelength—what we call “visible light.” Some animals, though, can see light with even higher frequencies, called ultraviolet, or UV, light. Most birds have this ability, along with honeybees, reptiles and certain bony fish.
[…]
To capture animal vision on video, Vasas and her colleagues developed a portable 3-D-printed enclosure containing a beam splitter that separates light into UV and the human-visible spectrum. The two streams are captured by two different cameras. One is a standard camera that detects visible-wavelength light, and the other is a modified camera that is sensitive to UV. On its own, the UV-sensitive camera wouldn’t be able to record detailed information on the rest of the light spectrum in a single shot. But paired together, the two cameras can simultaneously record high-quality video that encompasses a wide range of the light spectrum. Then a set of algorithms aligns the two videos and produces versions of the footage that are representative of different animals’ color views, such as those of birds or bees.
[…]
Capturing video in this way “fills a really important gap in our ability to model animal vision,” says Jolyon Troscianko, a visual ecologist at the University of Exeter in England, who wasn’t involved in the new research. He notes that in nature, “a lot of interesting things move,” such as animals that are engaging in mating dances or rapid defense displays. Until now, researchers studying these dynamic behaviors have been stuck with the human perspective.
[…]
The technique is already revealing unseen phenomena of the natural world, she adds: for example, by recording an iridescent peacock feather rotating under a light, the researchers found shifts in color that are even more vibrant to fellow peafowl than they are to humans. Vasas and her colleagues also captured the brief startle display of a black swallowtail caterpillar and saw for the first time that its hornlike defense appendages are UV-reflective.
“None of these things were hypotheses that we had in advance,” Vasas says. Moving forward, “I think it will reveal a lot of things that I can’t yet imagine.”
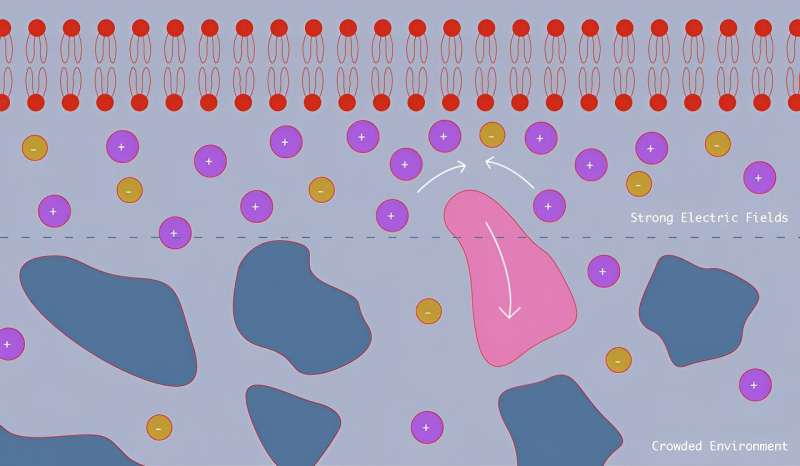
The humble membranes that enclose our cells have a surprising superpower: They can push away nano-sized molecules that happen to approach them. A team including scientists at the National Institute of Standards and Technology (NIST) has figured out why, by using artificial membranes that mimic the behavior of natural ones. Their discovery could make a difference in how we design the many drug treatments that target our cells.
The team’s findings, which appear in the Journal of the American Chemical Society, confirm that the powerful electrical fields that cell membranes generate are largely responsible for repelling nanoscale particles from the surface of the cell.
This repulsion notably affects neutral, uncharged nanoparticles, in part because the smaller, charged molecules the electric field attracts crowd the membrane and push away the larger particles. Since many drug treatments are built around proteins and other nanoscale particles that target the membrane, the repulsion could play a role in the treatments’ effectiveness.
The findings provide the first direct evidence that the electric fields are responsible for the repulsion.
[…]
Membranes form boundaries in nearly all kinds of cells. Not only does a cell have an outer membrane that contains and protects the interior, but often there are other membranes inside, forming parts of organelles such as mitochondria and the Golgi apparatus. Understanding membranes is important to medical science, not least because proteins lodged in the cell membrane are frequent drug targets. Some membrane proteins are like gates that regulate what gets into and out of the cell.
The region near these membranes can be a busy place. Thousands of types of different molecules crowd each other and the cell membrane—and as anyone who has tried to push through a crowd knows, it can be tough going. Smaller molecules such as salts move with relative ease because they can fit into tighter spots, but larger molecules, such as proteins, are limited in their movements.
[…]
“How does crowding affect the cell and its behavior?” he said. “How, for example, do molecules in this soup get sorted inside the cell, making some of them available for biological functions, but not others? The effect of the membrane could make a difference.”
[…]
scientists have paid scant attention to this effect at the nanoscale because it takes extremely powerful fields to move nanoparticles. But powerful fields are just what an electrically charged membrane generates.
“The electric field right near a membrane in a salty solution like our bodies produce can be astoundingly strong,” Hoogerheide said. “Its strength falls off rapidly with distance, creating large field gradients that we figured might repel nearby particles. So we used neutron beams to look into it.”
Neutrons can distinguish between different isotopes of hydrogen, and the team designed experiments that explored a membrane’s effect on nearby molecules of PEG, a polymer that forms chargeless nano-sized particles. Hydrogen is a major constituent of PEG, and by immersing the membrane and PEG into a solution of heavy water—which is made with deuterium in place of ordinary water’s hydrogen atoms—the team could measure how closely the PEG particles approached the membrane. They used a technique known as neutron reflectometry at the NCNR as well as instruments at Oak Ridge National Laboratory.
Together with molecular dynamics simulations, the experiments revealed the first-ever evidence that the membranes’ powerful field gradients were the culprit behind the repulsion: The PEG molecules were more strongly repelled from charged surfaces than from neutral surfaces.
[…]
More information: Marcel Aguilella-Arzo et al, Charged Biological Membranes Repel Large Neutral Molecules by Surface Dielectrophoresis and Counterion Pressure, Journal of the American Chemical Society (2024). DOI: 10.1021/jacs.3c12348. pubs.acs.org/doi/full/10.1021/jacs.3c12348
The AI Office will play a pivotal role in the enforcement architecture of the AI Act, the EU’s landmark law to regulate Artificial Intelligence, set to be formally adopted in the coming weeks based on a political agreement nailed down in December.
The idea of an AI Office to centralise the enforcement of the AI rulebook came from the European Parliament. Still, during the negotiations, it was downsized from being a little short of an agency to being integrated into the Commission, albeit with a separate budget line.
However, the question of how much autonomy the Office will be guaranteed remains sensitive inside the Commission, especially since it is unclear whether it will become an entity with its own political objectives or an extension of the unit responsible for the AI Act.
Euractiv understands that the obtained draft decision was amended following an internal consultation to include wording specifying that the Office should not interfere with the competencies of Commission departments.
According to the document, the decision should enter into force as a matter of urgency on 21 February, before the formal adoption of the EU’s AI law. Euractiv understands the decision is due to be adopted on Wednesday (24 January).
Policing powerful AI
The AI Office will have primarily a supporting role for what concerns the enforcement of the rules on AI systems, as the bulk of the competencies will be on national authorities. However, the Office has been assigned to policing General-Purpose AI (GPAI) models and systems, the most potent types of AI so far.
Recent advances in computing power, data harvesting, and algorithm techniques have led to the development of powerful GPAI models like OpenAI’s GPT-4, which powers the GPAI system ChatGPT, the world’s most famous chatbot.
The agreement on the AI Act includes a tiered approach to GPAI models to distinguish those that might entail a systemic risk for society from the rest. The AI Office is to develop the methodologies and benchmarks for evaluating the capabilities of GPAI models.
The Office should be able to set itself apart in monitoring the application of the rules on GPAI models and systems, notably when developed by the same provider, and the emergence of unforeseen risks from these models based on alerts from a scientific panel of independent experts.
The new EU entity is also set to have significant leeway to investigate possible infringements of rules related to GPAI by collecting complaints and alerts, issuing document requests, conducting evaluations and requesting mitigation or other enforcement measures.
The Office will also coordinate the enforcement of the AI Act on AI systems already covered under other EU legislation, like social media’s recommender systems under the Digital Services Act and search engines’ ranking algorithms under the Digital Markets Act.
Support & coordination
The AI Office is to have a supporting role in the preparation of secondary legislation implementing the AI Act, the uniform application of the regulation, the issuance of guidance and supporting tools like standardised protocols, the preparation of standardisation requests, the establishment of regulatory sandboxes, the developments of codes of practice and conduct at the EU level.
The entity will also provide the secretariat for the AI Board and administrative support for the stakeholder-run advisory forum and expert-made scientific panel. The draft decision explicitly references the requirement to consult regularly with scientific and civil society stakeholders.
In particular, the AI Office must “establish a forum for cooperation with the open-source community with a view to identifying and developing best practices for the safe development and use of open-source AI models and systems.”
In addition, the new entity is tasked with promoting innovation ecosystems and working with public and private actors and the start-up community. As revealed by Euractiv, the AI Office will be responsible for monitoring the progress of GenAI4EU, an initiative to promote the uptake of generative AI in strategic sectors.
The Office is also mandated to cooperate with the relevant EU bodies, like the European Data Protection Supervisor. Collaboration is also required with other Commission departments, notably the European Centre for Algorithmic Transparency, to test GPAI models and systems and facilitate the adoption of AI tools in relevant EU policies.
At the international level, the Office will promote the EU approach to AI, contribute to AI governance initiatives, and support the implementation of international agreements.
Financing
The financing aspect of the AI Office has been a sore point since the beginning. The lack of flexibility in the EU budget allocations and lack of appetite from member states to put more resources on the table means new tasks always face strict budgetary constraints.
The Commission’s digital policy department, DG CNECT, will assign human resources. The hiring of temporary staff and operational expenditure will be financed with the redeployment of the budget from the Digital Europe Programme.
[…] the public too often doesn’t understand how it happens that products stop working the way they did after updates are performed remotely, or why movies purchased through an online store suddenly disappear with no refund, or why other media types purchased online likewise go poof. There is a severe misalignment, in other words, between what consumers think their money is being spent on and what is actually being purchased.
With the pre-release of Prince of Persia: The Lost Crown started, Ubisoft has chosen this week to rebrand its Ubisoft+ subscription services, and introduce a PC version of the “Classics” tier at a lower price. And a big part of this, says the publisher’s director of subscriptions, Philippe Tremblay, is getting players “comfortable” with not owning their games.
He claims the company’s subscription service had its biggest ever month October 2023, and that the service has had “millions” of subscribers, and “over half a billion hours” played. Of course, a lot of this could be a result of Ubisoft’s various moments of refusing to release games to Steam, forcing PC players to use its services, and likely opting for a month’s subscription rather than the full price of the game they were looking to buy. But still, clearly people are opting to use it.
On the one hand, there are realms where it makes sense for a subscription based gaming service where you pay a monthly fee for access and essentially never buy a game. Xbox’s Game Pass, for instance, makes all the sense in the world for some people. If you’re a more casual gamer who doesn’t want to own a library of games, but rather merely wants to be able to play a broad swath of titles at a moment’s notice, a service like that is perfect.
But Game Pass is $10 a month and includes titles from all kinds of publishers. Ubisoft’s service is nearly double that rate and only includes Ubisoft titles. That’s a much tougher sell.
[…]
Given that most people, while being a part of the problem (hello), also think of this as a problem, it’s so weird to see it phrased as if some faulty thinking in the company’s audience.
“One of the things we saw is that gamers are used to, a little bit like DVD, having and owning their games. That’s the consumer shift that needs to happen. They got comfortable not owning their CD collection or DVD collection. That’s a transformation that’s been a bit slower to happen [in games]. As gamers grow comfortable in that aspect… you don’t lose your progress. If you resume your game at another time, your progress file is still there. That’s not been deleted. You don’t lose what you’ve built in the game or your engagement with the game. So it’s about feeling comfortable with not owning your game.“
That last sentence’s thoughts are so misaligned as to be nearly in the realm of nonsense. If it’s my game, then I do own it. The point Ubisoft is trying to make is that the public should get over ownership entirely and accept that it’s not my game at all. It’s my subscription service.
And while I appreciate Ubisoft saying the quiet part out loud for once, I don’t believe for a moment that this will go over well with the general gaming public.
The US Supreme Court has declined to hear the appeals filed by both Apple and Epic Games following a judge’s ruling that Apple must allow developers to offer alternative methods to pay for apps and services other than through the App Store. It did not provide an explanation as to why it refused to review either appeal, but it means the permanent injunction giving developers a way to avoid the 30 percent cut Apple takes will remain in place.
Apple made the appeal to the high court back in September of last year, requesting it review the circuit court’s decision it deemed “unconstitutional.” The case brought forward by Epic Games is the first to challenge the business model of the App store, which helps Apple rake in billions. In May 2023, Apple said that developers generated about $1 trillion in total billings through the App Store in 2022. Gaming apps sold on the App Store generate an estimated $100 billion in revenue each year.
While the Ninth Circuit ruled in favor of Epic’s appeal that Apple has indeed broken California’s Unfair Competition law, it rejected Epic’s claimthat the App store is a monopoly. In addition to declining to hear Apple’s appeal, SCOTUS also will not review Epic’s appeal that the district court had made “legal errors.”
Epic claimed that Apple violates federal antitrust laws through its business model, however, this is not an issue the high court will consider.
The European Parliament is calling for new regulations to ensure streaming services pay artists fairly. The proposal also calls for more transparency around how algorithms generate suggestions for which artists to stream and what tracks get the most promotion.
The proposed changes will be designed to ensure smaller artists are compensated fairly. Currently, royalty rates are set in a way that makes artists accept lower pay for the distribution of their content in exchange for visibility on streaming platforms like Spotify and Apple Music. The members of the European Parliament (MEPs) are primarily concerned with introducing new legal frameworks to help support artists.
MEPs believe that the current way royalties are distributed is unfair. Current algorithms favor major labels and artists when providing suggestions, making it more difficult for less popular and diverse genres to get exposure. “Cultural diversity and ensuring that authors are credited and fairly paid has always been our priority; this is why we ask for rules that ensure algorithms and recommendation tools used by music streaming services are transparent as well as in their use of AI tools, placing European authors at the centre,” rapporteur Ibán García del Blanco of Spain said.
As part of this call for change, the MEPs want there to be more regulation regarding the use of artificial intelligence. The actual implementation of a legal framework by EU regulators might take some time to come to fruition. Similarly, UK regulators also raised the issue of pay fairness on streaming apps and even started investigating the effects of algorithms on listening habits. It’s no secret that streaming platforms account for more than half of the music industry’s revenue. Streaming represents about 67 percent of the music industry’s revenue on a global scale.
OpenAI may finally have to answer for ChatGPT’s “hallucinations” in court after a Georgia judge recently ruled against the tech company’s motion to dismiss a radio host’s defamation suit.
OpenAI had argued that ChatGPT’s output cannot be considered libel, partly because the chatbot output cannot be considered a “publication,” which is a key element of a defamation claim. In its motion to dismiss, OpenAI also argued that Georgia radio host Mark Walters could not prove that the company acted with actual malice or that anyone believed the allegedly libelous statements were true or that he was harmed by the alleged publication.
It’s too early to say whether Judge Tracie Cason found OpenAI’s arguments persuasive. In her order denying OpenAI’s motion to dismiss, which MediaPost shared here, Cason did not specify how she arrived at her decision, saying only that she had “carefully” considered arguments and applicable laws.
There may be some clues as to how Cason reached her decision in a court filing from John Monroe, attorney for Walters, when opposing the motion to dismiss last year.
Monroe had argued that OpenAI improperly moved to dismiss the lawsuit by arguing facts that have yet to be proven in court. If OpenAI intended the court to rule on those arguments, Monroe suggested that a motion for summary judgment would have been the proper step at this stage in the proceedings, not a motion to dismiss.
Had OpenAI gone that route, though, Walters would have had an opportunity to present additional evidence. To survive a motion to dismiss, all Walters had to do was show that his complaint was reasonably supported by facts, Monroe argued.
Failing to convince the court that Walters had no case, OpenAI’s legal theories regarding its liability for ChatGPT’s “hallucinations” will now likely face their first test in court.
“We are pleased the court denied the motion to dismiss so that the parties will have an opportunity to explore, and obtain a decision on, the merits of the case,” Monroe told Ars.
What’s the libel case against OpenAI?
Walters sued OpenAI after a journalist, Fred Riehl, warned him that in response to a query, ChatGPT had fabricated an entire lawsuit. Generating an entire complaint with an erroneous case number, ChatGPT falsely claimed that Walters had been accused of defrauding and embezzling funds from the Second Amendment Foundation.
Walters is the host of Armed America Radio and has a reputation as the “Loudest Voice in America Fighting For Gun Rights.” He claimed that OpenAI “recklessly” disregarded whether ChatGPT’s outputs were false, alleging that OpenAI knew that “ChatGPT’s hallucinations were pervasive and severe” and did not work to prevent allegedly libelous outputs. As Walters saw it, the false statements were serious enough to be potentially career-damaging, “tending to injure Walter’s reputation and exposing him to public hatred, contempt, or ridicule.”
[…]
OpenAI introduced “a large amount of material” in its motion to dismiss that fell outside the scope of the complaint, Monroe argued. That included pointing to a disclaimer in ChatGPT’s terms of use that warns users that ChatGPT’s responses may not be accurate and should be verified before publishing. According to OpenAI, this disclaimer makes Riehl the “owner” of any libelous ChatGPT responses to his queries.
“A disclaimer does not make an otherwise libelous statement non-libelous,” Monroe argued. And even if the disclaimer made Riehl liable for publishing the ChatGPT output—an argument that may give some ChatGPT users pause before querying—”that responsibility does not have the effect of negating the responsibility of the original publisher of the material,” Monroe argued.
Samsung announced many interesting products and features at its latest Galaxy Unpacked event (including the Galaxy S24 series) but one of the more impressive developments isn’t actually unique to the Galaxy brand itself. The feature, Circle to Search, was developed in partnership with Google, which means it’ll live on Google phones, too.
What is Circle to Search?
In a nutshell, Circle to Search is a new way to search for anything without switching apps. To activate the feature, long press on the home button or navigation bar (if you have gesture navigation enabled). Then, when you see something on your screen that you want to look up, draw a circle around it with your finger, and your phone will return search results. For example, you could use Circle to Search to find an article of clothing you might have seen in a YouTube video, or get more info about a dish in a recipe you’re browsing online.
You don’t have to just circle the item you’re looking to search, either: You can also highlight it, scribble over it, or tap on it. As part of Google’s AI upgrades to search, you can search with text and pictures you’ve circled at the same time using multi-search. Google says that the Circle to Search gesture works on images, text, and videos. Basically, you’re able to find anything and everything using this feature.
These results appear inside the app you’re currently using, so you don’t need to interrupt what you’re doing to search. When you’re done, you can simply swipe the results away to get back to your previous task.
When does Circle to Search launch?
Circle to Search is set to launch globally on Jan. 31 for select premium Android smartphones like the Pixel 8 and Pixel 8 Pro and the newly announced Galaxy S24 series. The feature will be coming to more Android devices at a later date.
Have I Been Pwned has added almost 71 million email addresses associated with stolen accounts in the Naz.API dataset to its data breach notification service.
The Naz.API dataset is a massive collection of 1 billion credentials compiled using credential stuffing lists and data stolen by information-stealing malware.
Credential stuffing lists are collections of login name and password pairs stolen from previous data breaches that are used to breach accounts on other sites.
[…]
This dataset has been floating around the data breach community for quite a while but rose to notoriety after it was used to fuel an open-source intelligence (OSINT) platform called illicit.services.
This service allows visitors to search a database of stolen information, including names, phone numbers, email addresses, and other personal data.
The service shut down in July 2023 out of concerns it was being used for Doxxing and SIM-swapping attacks. However, the operator enabled the service again in September.
Illicit.services use data from various sources, but one of its largest sources of data came from the Naz.API dataset, which was shared privately among a small number of people.
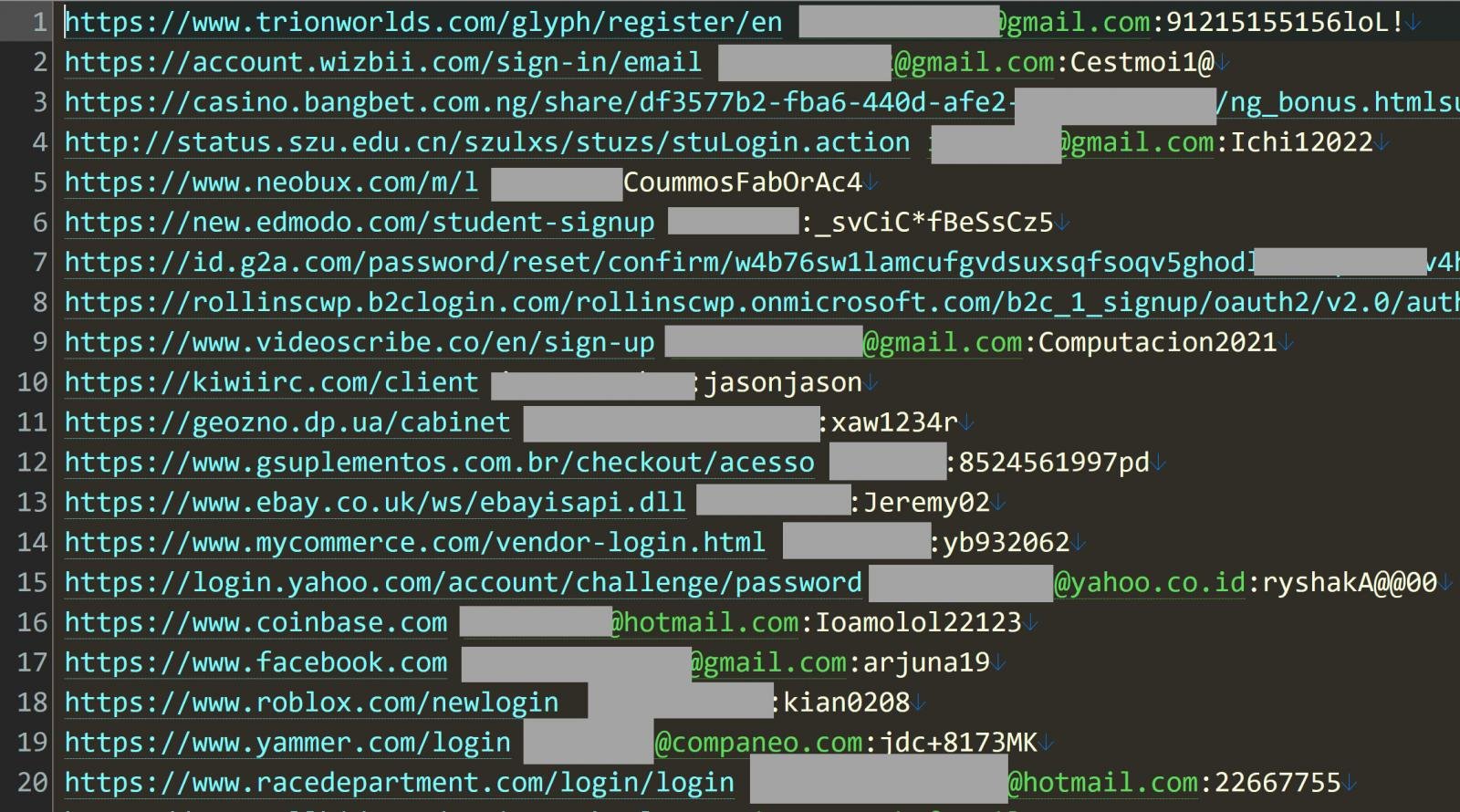
Each line in the Naz.API data consists of a login URL, its login name, and an associated password stolen from a person’s device
[…]
“Here’s the back story: this week I was contacted by a well-known tech company that had received a bug bounty submission based on a credential stuffing list posted to a popular hacking forum,” explained a blog post by Hunt.
“Whilst this post dates back almost 4 months, it hadn’t come across my radar until now and inevitably, also hadn’t been sent to the aforementioned tech company.”
“They took it seriously enough to take appropriate action against their (very sizeable) user base which gave me enough cause to investigate it further than your average cred stuffing list.”
Threat actors sharing the Naz.API dataset on hacking forums Source: BleepingComputer
According to Hunt, the Naz.API dataset consists of 319 files totaling 104GB and containing 70,840,771 unique email addresses.
However, while there are close to 71 million unique emails, for each email address, there are likely many other records for the different sites’ credentials were stolen from.
Hunt says the Naz.API data is likely old, as it contained one of his and other HIBP subscribers’ passwords that were used in the past. Hunt says his password was used in 2011, meaning that some of the data is over 13 years old.
To check if your credentials are in the Naz.API dataset, you can perform a search at Have I Been Pwned. If your email is found to be associated with Naz.API, the site will warn you, indicating that your computer was infected with information-stealing malware at one point.
Amazon is revamping its Alexa voice assistant as it prepares to launch a new paid subscription plan this year, according to internal documents and people familiar with the matter. But the change is causing internal conflict and may lead to further delay.
Tentatively named “Alexa Plus,” the paid version of Alexa is intended to offer more conversational and personalized artificial-intelligence technology, one of the documents obtained by Business Insider says. The people said the team was working toward a June 30 launch deadline and had been testing the underlying voice technology, dubbed “Remarkable Alexa,” with 15,000 external customers.
But the quality of the new Alexa’s answers is still falling short of expectations, often sharing inaccurate information, external tests have found. Amazon is now going through a major overhaul of Alexa’s technology stack to address this issue, though the team is experiencing some discord.
[…]
The people familiar with the matter said the limited preview with 15,000 external customers discovered that, while Remarkable Alexa was generally good at being conversational and informative, it was still deflecting answers, often giving unnecessarily long or inaccurate responses. It also needed to improve its ability to answer ambiguous customer requests that require the engagement of multiple services, such as turning on the light and music at the same time.
The new Alexa still didn’t meet the quality standards expected for Alexa Plus, these people added
Private equity firms are increasingly buying hospitals across the US, and when they do, patients suffer, according to two separate reports. Specifically, the equity firms cut corners, slash services, lay off staff, lower quality of care, take on substantial debt, and reduce charity care, leading to lower ratings and more medical errors, the reports collectively find.
Last week, the financial watchdog organization Private Equity Stakeholder Project (PESP) released a report delving into the state of two of the nation’s largest hospital systems, Lifepoint and ScionHealth—both owned by private equity firm Apollo Global Management. Through those two systems, Apollo runs 220 hospitals in 36 states, employing around 75,000 people.
The report found that some of Apollo’s hospitals were among the worst in their respective states, based on a ranking by The Lown Institute Hospital Index. The index ranks hospitals and health systems based on health equity, value, and outcomes, PESP notes. The hospitals also have dismal readmission rates and government rankings. The Center for Medicare and Medicaid Services (CMS) ranks hospitals on a one- to five-star system, with the national average of 3.2 stars overall and about 30 percent of hospitals at two stars or below. Apollo’s overall average is 2.8 stars, with nearly 40 percent of hospitals at two stars or below.
Patterns
The other report, a study published in JAMA late last month, found that the rate of serious medical errors and health complications increases among patients in the first few years after private equity firms take over. The study examined Medicare claims from 51 private equity-run hospitals and 259 matched control hospitals.
Specifically, the study, led by researchers at Harvard University, found that patients admitted to private equity-owned hospitals had a 25 percent increase in developing hospital-acquired conditions compared with patients in the control hospitals. In private equity hospitals, patients experienced a 27 percent increase in falls, a 38 percent increase in central-line bloodstream infections (despite placing 16 percent fewer central lines than control hospitals), and surgical site infections doubled.
“These findings heighten concerns about the implications of private equity on health care delivery,” the authors concluded.
It also squares with PESP’s investigation, which collected various data and media reports that could help explain how those medical errors could happen. The report found a pattern of cost-cutting and staff layoffs after private equity acquisition. In 2020, for instance, Lifepoint cut its annual salary and benefit costs by $166 million over the previous year and cut its supply costs by $54 million. Staff that remained at Apollo’s hospitals were, in some cases, underpaid, and some hospitals cut services, including obstetric, pediatric, and psychiatric care.
Another pattern was that Apollo’s hospitals were highly indebted. According to Moody’s Investor Services, Apollo’s ScionHealth has 5.8 times more debt than income to pay that debt off. Lifepoint’s debt was 7.9 times its income. Private equity firms often take on excessive debt for leveraged buyouts, but this can lead cash to be diverted to interest payments instead of operational needs, PESP reported.
Apollo also made money off the hospitals in sale-leaseback transactions, in which it sold the land under the hospitals and then leased it back. In these cases, hospitals are left paying rent on land they used to own.
VF Corporation, parent company of clothes and footwear brands including Vans and North Face, says 35.5 million customers were impacted in some way when criminals broke into their systems in December.
The announcement was made in a Thursday 8-K/A filing with the Securities and Exchange Commission (SEC), and we’re only left to speculate about what kind of information the attackers may have scrambled away with.
The parent company of fashion labels, which also include Supreme, Timberland, and Dickies did, however, confirm the type of data that couldn’t have been accessed.
VF Corp said that customers’ social security numbers (SSNs), bank account information, and payment card information remain uncompromised as these are not stored in its IT systems.
There’s also no evidence to suggest that consumer passwords were accessed, it confirmed, although it did caveat this with “the investigation remains ongoing”.
If you want to really look between the lines of the document’s wording, you’ll see that VF Corp explicitly said SSNs, financial information, and passwords – all excluded from potential compromise – were all explicitly defined as being consumer-related specifically.
The same goes for the number of individuals affected – 35.5 million “individual consumers” had their personal information stolen.
[…]
When the attack was first disclosed, the clothes seller said its ability to fulfill orders was affected, but online and retail stores were still up and running as normal.
This week’s filing said the company’s ability to replenish retail stores’ inventory was affected and combined with the fulfillment issues. This led to customer order cancellations and reduced demand across some of its brands’ e-commerce sites.
“Since the filing of the original report, while VF is still experiencing minor residual impacts from the cyber incident, VF has resumed retail store inventory replenishment and product order fulfillment, and is caught up on fulfilling orders that were delayed as a result of the cyber incident,” the filing reads.
“Since the filing of the original report, VF has substantially restored the IT systems and data that were impacted by the cyber incident, but continues to work through minor operational impacts.”
The attack on VF Corp is suspected to have involved ransomware. The filings mention parts of its IT systems being encrypted, and the AlphV/BlackCat gang claimed the attack days after its disclosure, but the company has not confirmed this to be the case.
HP CEO Enrique Lores admitted this week that the company’s long-term objective is “to make printing a subscription” when he was questioned about the company’s approach to third-party replacement ink suppliers.
The PC and print biz is currently facing a class-action lawsuit (from 2.42 in the video below) regarding allegations that the company deliberately prevented its hardware from accepting non-HP branded replacement cartridges via a firmware update.
When asked about the case in a CNBC interview, Lores said: “I think for us it is important for us to protect our IP. There is a lot of IP that we’ve built in the inks of the printers, in the printers themselves. And what we are doing is when we identify cartridges that are violating our IP, we stop the printers from work[ing].”
Later in the interview, he added: “Every time a customer buys a printer, it’s an investment for us. We are investing in that customer, and if that customer doesn’t print enough or doesn’t use our supplies, it’s a bad investment.”
[…]
HP has long banged the drum [PDF] about the potential for malware to be introduced via print cartridges, and in 2022, its bug bounty program confirmed that third-party cartridges with reprogrammable chips could deliver malware into printers.
Kind old HP is, therefore, only concerned about the welfare of customers.
Sadly, Lores’s protestations were somewhat undermined by the admission that the company’s business model depends – at least in part – on customers selecting HP supplies for their devices.
“Our objective is to make printing as easy as possible, and our long-term objective is to make printing a subscription.”
This echoes comments by former CFO Marie Myers, who said in December:
“We absolutely see when you move a customer from that pure transactional model … whether it’s Instant Ink, plus adding on that paper, we sort of see a 20 percent uplift on the value of that customer because you’re locking that person, committing to a longer-term relationship.”
Apple is keeping a firm grip on people with alternative marketplaces, fleecing them for money but also for other control. Here are some of the terms Apple requires you to conform to in order to start up your own app store (which they call alternative marketplace):
Be enrolled in the Apple Developer Program as an organization incorporated, domiciled, and or registered in the EU (or have a subsidiary legal entity incorporated, domiciled, and or registered in the EU that’s listed in App Store Connect). The location associated with your legal entity is listed in your Apple Developer account.
Agree to build an app whose primary purpose is discovery and distribution of apps, including apps from other developers.
Agree to provide and publish terms, including those pertaining to content and business model, for apps you will distribute, and accept apps that meet those terms.
[…]
But what rankles most is the amount of money Apple not only fleeces from marketplaces for every installation – especially considering that Apple is not doing anything for the download – but that the barrier to entry is set at ONE MILLION DOLLARS!
Understanding payments, fees, and taxes
Stand-by letter of credit
In order to establish adequate financial means to guarantee support for developers and customers, marketplace developers must provide Apple a stand-by letter of credit from an A-rated (or equivalent by S&P, Fitch, or Moody’s) financial Institution of €1,000,000 prior to receiving the entitlement. It will need to be auto-renewed on a yearly basis.
Core Technology Fee
The DMA requires Apple to support distribution and payment processing alternatives that are facilitated outside the App Store. To reflect the value Apple provides marketplace developers with ongoing investments in developer tools, technologies, and program services, Apple has introduced a Core Technology Fee.
Marketplace developers will need to pay €0.50 for each first annual install of their marketplace app. First annual installs included in your Apple Developer Program membership can’t be used for marketplace apps.
Of course, Apple is the one deciding if you are allowed to create an app store. What is the likelihood of that happening? Should you be one of the happy few (uhm, wait – didn’t the EU have this ruling as part of the Digital Markets Act (DMA), an anti competitive set of laws, aimed at allowing EVERYONE access?), then you still have to build an Apple App – ie you have to pay Apple to have your app in the app store and they will review your app in their app store. In the words of Apple:
An alternative app marketplace is an iOS app from which someone can install other third-party apps. To create a marketplace, fill out a webform that outlines the qualifications. If approved, Apple enables a code-signing entitlement on your account to distribute your marketplace app on the web. Apple also provides you with a framework that facilitates the secure installation of apps that your marketplace hosts.
To set up a marketplace, upload a public key, or marketplace key, to App Store Connect that regularly verifies the agreement, or relationship, you make with other developers that distribute their app on your marketplace.
The architecture of an app marketplace includes an iOS app, a webpage, from which people download your app, and a webserver that stores app data it regularly receives from App Store Connect.
So the value Apple describes above is basically that they force you to set up your App store from inside their App store. Apple then tells you how to run it and wants to know exactly what is going on inside it, so they can grab their €0.50 per year per app downloaded from it.
So really, the way in which Apple is conforming to the EU DMA is by offering a massive finger to the EU and it’s developers.
Having your AI going on your own laptop or PC is perfectly viable. For textual conversations you don’t always need a Large Language Model (LLM) when Small Language Models can perform at the same or in some cases even better levels (eg MS Phi-2 small language model – outperforms many LLMs but fits on your laptop) than the OpenAI online supercomputer trained models. This has many reasons, such as overfitting, old data, etc. You may want to run your own model if you are not online all the time, if you have privacy concerns, eg if you don’t want your inputs to be used to further train the model, or if you don’t want to be dependent on a third party (what if OpenAI suddenly requires hefty payment for use?)
On performance: most of the data processing happens fastest on Nvidia GPUs, but the processing can be offloaded to your CPUs. In this case you may find some marked slowdowns.
Text to Image
Stable diffusion offers very very good text to image generation at a high level. You can find their models on their page https://stability.ai/stable-image. Other models such as OpenAI’s Dall-E or Midjourney can’t be run locally. Despite what OpenAI says, they are not open source.
For all the different user interfaces, expect downloads of ~1.5GB – 2GB and unpacked sizes of ~5GB – 12GB (or more!)
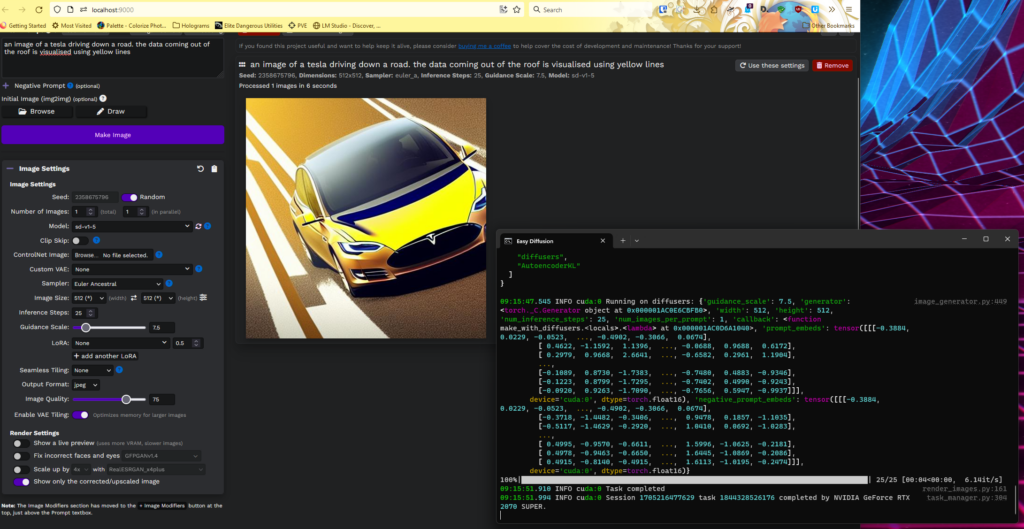
Note that you do need an Nvidia GPU – Running a 2070ti images generate in ~5 / 6 seconds. On a laptop they take ~ 10 minutes!
Easy Diffusion – like Stability Matrix, this is a one click installer for Windows, Linux or MacOS that will download a specific WebUI. It updates every time you start it.
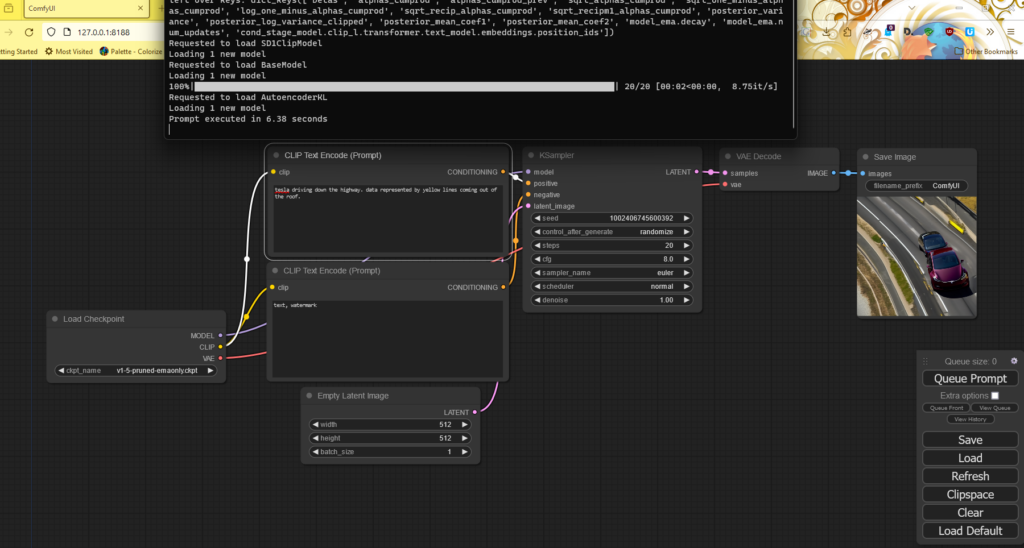
ComfyUI is another easy to run frontend – you download and extract the zip file (~30k files, takes a while!) and run. You then need to download a model (there is a README in the directory that will point you to one) and copy it into ComfyUI\models\checkpoints (~ 5GB). It does, however, offer quite a lot of complexity. It is a flow based model, so it takes a little getting used to as the rest use sliders or checks to configure your model. Some people find this is the fastest system, however others point out that this is most likely due to the default config of other stable diffusion models or outdated python / pythorch and other dependencies, which apparently ComfyUI does a good job of keeping updated. I found there was not much difference, but I was not bulk generating images where this becomes an issue.
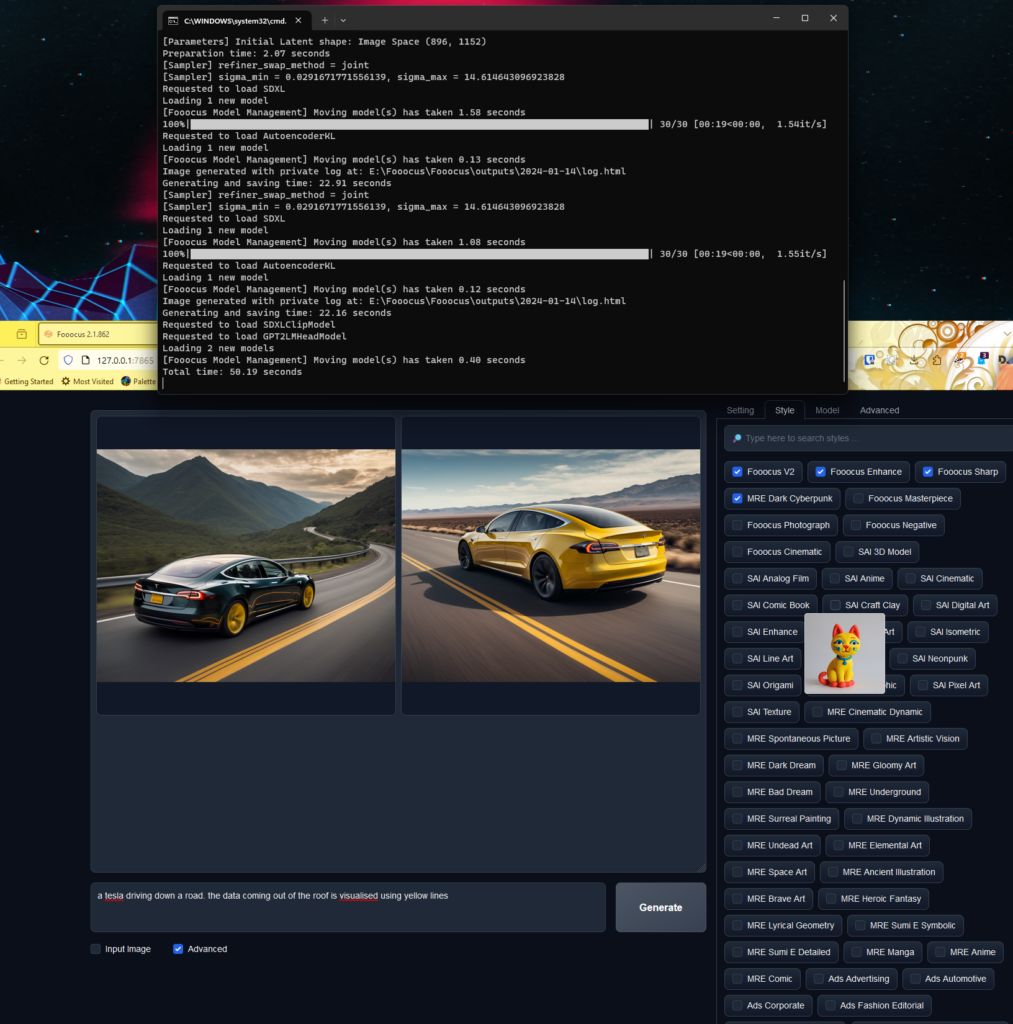
Fooocus is very ease of use – it’s simplicity is it’s strength. Unzip and run the run.bat file. There are loads of LoRa (see Conclusion, below) model previews to get a certain style out of it.
Automatic A1111 gives more control over the prompts and is somewhere between Fooocus and ComfyUI. It requires you to install Python 3.10.6 and git yourself. I have included it because it’s very popular, but to be honest – with the above options, why bother?
LoRas
Another platform you need to know about is CivitAI – especially their LoRa (Low-Rank Adaptation) models. These allow Stable Diffusion to specialise in different concepts (eg artistic styles, body poses, objects – basically the “Style” part of Fooocus) – for a good explanation, see Stable Diffusion: What Are LoRA Models and How to Use Them?
General purpose downloader
Pinokio is a system that dowloads and installs community created scripts that run apps, databases, AI’s, etc. User scripts for AI include magic animators, face swappers, music captioning, subtitling, voice cloning etc
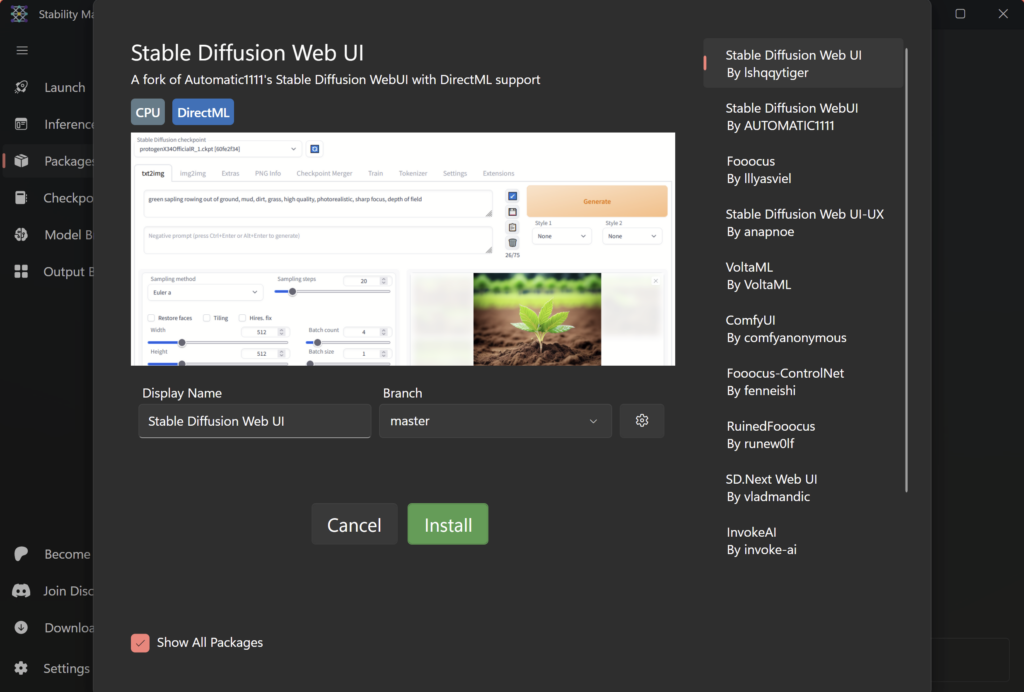
Another way to get started on a specific webUI for text to image is using Stability Matrix: a program that installs different webUIs (Automatic 1111, Comfy UI, SD.Next (Vladmandic), VoltaML, InvokeAI, Fooocus, and Fooocus MRE) for you. It will download the model, training data and weights and start up the process for you to connect to using a browser. This will handle installing the python and Git dependencies as well.
I however found that it wasn’t quite as straightforward as it looked, with some of the models requiring you to configure and run the model within Stability Matrix and some requiring you to work in the model externally to Stability Matrix.
Language Models (LLMs) / Talking to your AI
Just chatting
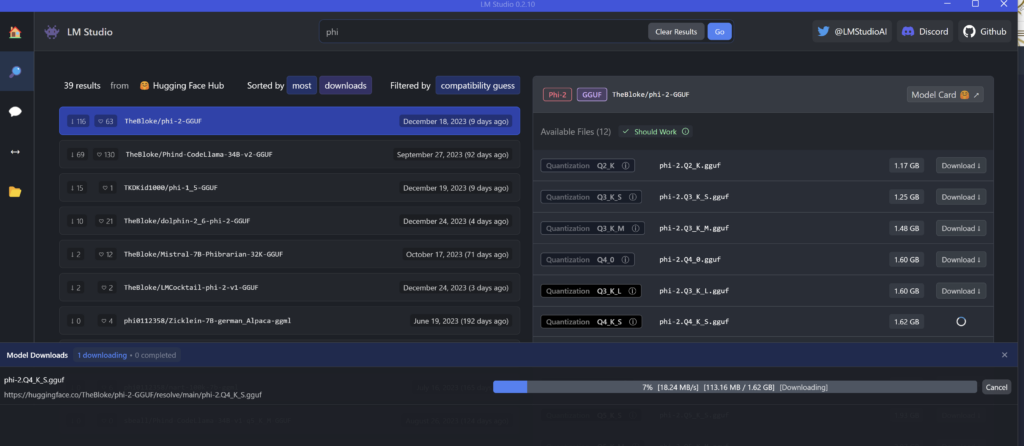
LM Studio allows you to install and run models such as LLaMa, Phi-2, etc from Hugging face
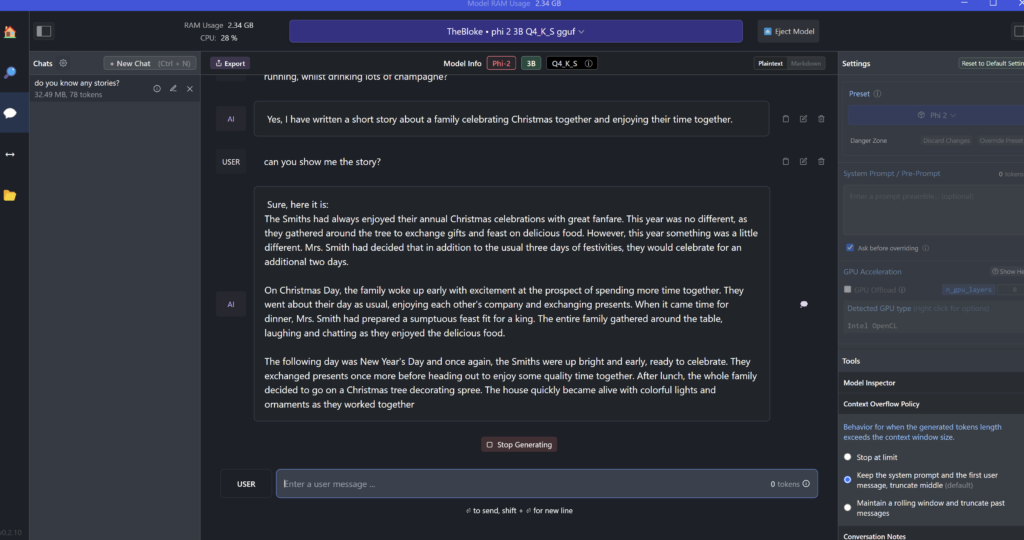
Using the phi-2 model, text generation is suprisingly smooth and fast
Chatting and modifying the model
Then there is also Ollama which allows you to Run Llama 3, Phi 3, Mistral, Gemma, and other models. The big difference here is you can customize and create your own. You can either create and import a GGUF file (GGUF is a binary format that is designed for fast loading and saving of models, and for ease of reading. Models are traditionally developed using PyTorch or another framework, and then converted to GGUF for use in GGML.) or you can use Retrieval Augmented Generation (RAG) support. This feature seamlessly integrates document interactions into your chat experience. You can load documents directly into the chat or add files to your document library, effortlessly accessing them using the # command before a query. Just running Ollama allows you to access it in the command line, but there is a beautiful Open WebUI which is being updated like crazy and gives you loads of options.
Conclusion
No article on this kind of AI is complete without mention of Hugging Face The platform where the machine learning community collaborates on models, datasets, and applications. You can find all kinds of models and data there to refine your AI once you get into it a bit.
AI systems are certainly not limited to text to image or conversational – text to audio, text to video, image to video, text to 3D, voice to audio, video to video and much more are all possible locally.
Running your own AI / ML system on your own PC is viable (but you need an Nvidia card for text-to-image!). It allows you much more privacy as the data is not fed back to an external provider for more training or otherwise. It’s faster and often quality just as good as the online services. You don’t run out of credits.
Refining the training of these models and adding to their datasets is beyond the scope of this article, but is a next step for you 🙂
Textbook models will need to be re-drawn after a team of researchers found that water molecules at the surface of salt water are organised differently than previously thought.
Many important reactions related to climate and environmental processes take place where water molecules interface with air. For example, the evaporation of ocean water plays an important role in atmospheric chemistry and climate science. Understanding these reactions is crucial to efforts to mitigate the human effect on our planet.
The distribution of ions at the interface of air and water can affect atmospheric processes. However, a precise understanding of the microscopic reactions at these important interfaces has so far been intensely debated.
In a paper published today in the journal Nature Chemistry, researchers from the University of Cambridge and the Max Planck Institute for Polymer Research in Germany show that ions and water molecules at the surface of most salt-water solutions, known as electrolyte solutions, are organised in a completely different way than traditionally understood. This could lead to better atmospheric chemistry models and other applications.
[…]
The combined results showed that both positively charged ions, called cations, and negatively charged ions, called anions, are depleted from the water/air interface. The cations and anions of simple electrolytes orient water molecules in both up- and down-orientation. This is a reversal of textbook models, which teach that ions form an electrical double layer and orient water molecules in only one direction.
Co-first author Dr Yair Litman, from the Yusuf Hamied Department of Chemistry, said: “Our work demonstrates that the surface of simple electrolyte solutions has a different ion distribution than previously thought and that the ion-enriched subsurface determines how the interface is organised: at the very top there are a few layers of pure water, then an ion-rich layer, then finally the bulk salt solution.”
Co-first author Dr Kuo-Yang Chiang of the Max Planck Institute said: “This paper shows that combining high-level HD-VSFG with simulations is an invaluable tool that will contribute to the molecular-level understanding of liquid interfaces.”
Professor Mischa Bonn, who heads the Molecular Spectroscopy department of the Max Planck Institute, added: “These types of interfaces occur everywhere on the planet, so studying them not only helps our fundamental understanding but can also lead to better devices and technologies. We are applying these same methods to study solid/liquid interfaces, which could have potential applications in batteries and energy storage.”