The latest dispute between the New York Times and OpenAI reinforces the distinction in understanding artificial intelligence (AI) between autonomy and automatons, which we have previouslyexamined.
The Gray Lady turned heads late this past year when it filed suit against OpenAI, alleging that the artificial intelligence giant’s ChatGPT software infringed its copyrights. Broadly speaking, the Timesalleged that the famous chatbot gobbled up enormous portions of the newspaper’s text and regurgitated it
Earlier this month, OpenAI struck back, arguing that the Times’ suit lacked merit and that the Gray Lady wasn’t “telling the full story.” So who’s right?
Via Adobe
To help understand the dispute, the autonomy-automaton dichotomy goes a long way. Recall that many AI enthusiasts contend that the new technology has achieved, or is approaching, independent activity, whether it can be described as what I previously labeled “a genuinely autonomous entity capable (now or soon) of cognition.” Into this school of thought fall many if not most OpenAI programmers and executives, techno-optimists like Marc Andreesen, and inventors and advocates for true AI autonomy like Stephen Thaler.
Arrayed against these AI exponents are the automaton-ers, a doughty bunch of computer scientists, intellectuals, and corporate types who consider artificial intelligence a mere reflection of its creators, or what I’ve called “a representation or avatar of its programmers.”
As we’ve seen, this distinction permeates the legal and policy debates over whether robots can be considered inventors for the purposes of awarding patents, whether they possess enough independence to warrant copyright protection as creators, and what rights and responsibilities should be attributed to them.
The same dichotomy applies to the Times–OpenAI battle. In its complaint, the newspaper alleged that ChatGPT and other generative AI products “were built by copying and using millions of The Times’s copyrighted news articles, in-depth investigations, opinion pieces, reviews, how-to guides, and more.” The complaint also claimed that OpenAI’s software “can generate output that recites Times content verbatim, closely summarizes it, and mimics its expressive style.” In short, the Times contended that ChatGPT and its ilk, far from creating works independently, copies, mimics, and generates content verbatim—like an automaton.
Finally, the Gray Lady argued in its complaint that OpenAI cannot shelter behind the fair use doctrine—which protects alleged copyright infringers who copy small portions of text, do not profit by them, or transform them into something new—because “there is nothing ‘transformative’ about” its use of the Times’s content. Denying that AI can genuinely create something new is a hallmark of the automaton mindset.
In contrast, in strenuously denying the NYT’s allegations, OpenAI expressly embraced autonomous themes. “Just as humans obtain a broad education to learn how to solve new problems,” the company said in its statement, “we want our AI models to observe the range of the world’s information, including from every language, culture, and industry.” Robots, like people, perceive and analyze data in order to resolve novel challenges independently.
In addition, OpenAI contended that “training AI models using publicly available internet materials is fair use, as supported by long-standing and widely accepted precedents.” From this perspective, exposing ChatGPT to a wide variety of publicly available content, far from enabling the chatbot to slavishly copy it, represents a step in training AI so that it can generate something new.
Finally, the AI giant downplayed the role of mimicry and verbatim copying trumpeted by the Times, asserting that “‘regurgitation’ is a rare bug that we are working to drive to zero” and characterizing “memorization [as] a rare failure of the learning process that we are continually making progress on.” In other words, even when acknowledging that, in certain limited circumstances, the Times may be correct, OpenAI reinforced the notion that AIs, like humans, learn and fail along the way. And to wrap it all in a bow, the company emphasized the “transformative potential of AI.”
Resolution of the battle between the automaton perspective exhibited by the Times and the autonomy paradigm exemplified by Open AI will go a long way to determining who will prevail in the parties’ legal fight.
A really balanced an informative piece showing the two different points of view. It’s nice to see something explain the situation without taking sides and pointing fingers in this issue.
Our planet sits in the Habitable Zone of our Sun, the special place where water can be liquid on the surface of a world. But that’s not the only thing special about us: we also sit in the Galactic Habitable Zone, the region within the Milky Way where the rate of star formation is just right.
The Earth was born with all the ingredients necessary for life – something that most other planets lack. Water as a solvent. Carbon, with its ability to form long chains and bind to many other atoms, a scaffold. Oxygen, easily radicalized and transformable from element to element, to provide the chain reactions necessary to store and harvest energy. And more: hydrogen, phosphorous, nitrogen. Some elements fused in the hearts of stars, other only created in more violent processes like the deaths of the most massive stars or the collisions of exotic white dwarfs.
And with that, a steady, long-lived Sun, free of the overwhelming solar flares that could drown the system in deadly radiation, providing over 10 billion years of life-giving warmth. Larger stars burn too bright and too fast, their enormous gravitational weight accelerating the fusion reactions in their cores to a frenetic pace, forcing the stars to burn themselves out in only a few million years. And on the other end of the spectrum sit the smaller red dwarf stars, some capable of living for 10 trillion years or more. But that longevity does not come without a cost. With their smaller sizes, their fusion cores are not very far from their surfaces, and any changes or fluctuations in energy result in massive flares that consume half their faces – and irradiate their systems.
And on top of it all, our neighborhood in the galaxy, on a small branch of a great spiral arm situated about 25,000 light-years from the center, seems tuned for life: a Galactic Habitable Zone.
Too close to the center and any emerging life must contend with an onslaught of deadly radiation from countless stellar deaths and explosions, a byproduct of the cramped conditions of the core. Yes, stars come and go, quickly building up a lot of the heavy elements needed for life, but stars can be hundreds of times closer together in the core. The Earth has already suffered some extinction events likely triggered by nearby supernovae, and in that environment we simply wouldn’t stand a chance. Explosions would rip away our protective ozone layer, exposing surface life to deadly solar UV radiation, or just rip away our atmosphere altogether.
And beyond our position, at greater galactic radii, we find a deserted wasteland. Yes, stars appear and live their lives in those outskirts, but they are too far and too lonely to effectively spread their elemental ash to create a life-supporting mixture. There simply isn’t enough density of stars to support sufficient levels of mixing and recycling of elements, meaning that it’s difficult to even build a planet out there in the first place.
And so it seems that life would almost inevitably arise here, on this world, around this Sun, in this region of the Milky Way galaxy. There’s little else that we could conceivably call home.
In response to new EU regulations, Apple on Thursday outlined plans to allow iOS developers to distribute apps outside the App Store starting in March, though developers must still submit apps for Apple’s review and pay commissions. Now critics say the changes don’t go far enough and Apple retains too much control.
Epic Games CEO Tim Sweeney: They are forcing developers to choose between App Store exclusivity and the store terms, which will be illegal under DMA (Digital Markets Act), or accept a new also-illegal anticompetitive scheme rife with new Junk Fees on downloads and new Apple taxes on payments they don’t process. 37signals’s David Heinemeier Hansson, who is also the creator of Ruby on Rails: Let’s start with the extortion regime that’ll befell any large developer who might be tempted to try hosting their app in one of these new alternative app stores that the EU forced Apple to allow. And let’s take Meta as a good example. Their Instagram app alone is used by over 300 million people in Europe. Let’s just say for easy math there’s 250 million of those in the EU. In order to distribute Instagram on, say, a new Microsoft iOS App Store, Meta would have to pay Apple $11,277,174 PER MONTH(!!!) as a “Core Technology Fee.” That’s $135 MILLION DOLLARS per year. Just for the privilege of putting Instagram into a competing store. No fee if they stay in Apple’s App Store exclusively.
Holy shakedown, batman! That might be the most blatant extortion attempt ever committed to public policy by any technology company ever. And Meta has many successful apps! WhatsApp is even more popular in Europe than Instagram, so that’s another $135M+/year. Then they gotta pay for the Facebook app too. There’s the Messenger app. You add a hundred million here and a hundred million there, and suddenly you’re talking about real money! Even for a big corporation like Meta, it would be an insane expense to offer all their apps in these new alternative app stores.
Which, of course, is the entire point. Apple doesn’t want Meta, or anyone, to actually use these alternative app stores. They want everything to stay exactly as it is, so they can continue with the rake undisturbed. This poison pill is therefore explicitly designed to ensure that no second-party app store ever takes off. Without any of the big apps, there will be no draw, and there’ll be no stores. All of the EU’s efforts to create competition in the digital markets will be for nothing. And Apple gets to send a clear signal: If you interrupt our tool-booth operation, we’ll make you regret it, and we’ll make you pay. Don’t resist, just let it be. Let’s hope the EU doesn’t just let it be. Coalition of App Fairness, an industry body that represents over 70 firms including Tinder, Spotify, Proton, Tile, and News Media Europe: “Apple clearly has no intention to comply with the DMA. Apple is introducing new fees on direct downloads and payments they do nothing to process, which violates the law. This plan does not achieve the DMA’s goal to increase competition and fairness in the digital market — it is not fair, reasonable, nor non-discriminatory,” said Rick VanMeter, Executive Director of the Coalition for App Fairness.
“Apple’s proposal forces developers to choose between two anticompetitive and illegal options. Either stick with the terrible status quo or opt into a new convoluted set of terms that are bad for developers and consumers alike. This is yet another attempt to circumvent regulation, the likes of which we’ve seen in the United States, the Netherlands and South Korea. Apple’s ‘plan’ is a shameless insult to the European Commission and the millions of European consumers they represent — it must not stand and should be rejected by the Commission.”
Apple’s new rules in the European Union mean browsers like Firefox can finally use their own engines on iOS. Although this may seem like a welcome change, Mozilla spokesperson Damiano DeMonte tells The Verge it’s “extremely disappointed” with the way things turned out.
“We are still reviewing the technical details but are extremely disappointed with Apple’s proposed plan to restrict the newly-announced BrowserEngineKit to EU-specific apps,” DeMonte says. “The effect of this would be to force an independent browser like Firefox to build and maintain two separate browser implementations — a burden Apple themselves will not have to bear.”
[…]
“Apple’s proposals fail to give consumers viable choices by making it as painful as possible for others to provide competitive alternatives to Safari,” DeMonte adds. “This is another example of Apple creating barriers to prevent true browser competition on iOS.”
Mozilla isn’t the only developer critical of Apple’s new rules, which also extend to game streaming apps, alternative app stores, and sideloading. Epic CEO Tim Sweeney called the new terms a “horror show,” while Spotify said the changes are a “farce.” Apple’s guidelines are still pending approval by the EU Commission.
[…] For the first time, new EU rules have forced the company to entertain the idea that you can shop for apps outside of Apple’s own App Store, as well as allow browsers other than Apple’s own Safari to run on iOS with their full suite of features.
Yet critics say those changes, although drastic, do not go far enough to comply with new EU rules, and a new fee system for developers reveals how Apple is not yet ready to release its grip on the App Store.
“The new fees and restrictions simply reinforce Apple’s hold over its ecosystem,” Andy Yen, founder and CEO of Swiss encrypted email and VPN provider, Proton, said in response to the changes.
[…]
The European Union’s solution was a law called the Digital Markets Act (DMA). The idea wasn’t to break up Big Tech, former French digital minister Cédric O explained in a press conference in 2022. Instead the law was designed to break these platforms open.
On January 25, the EU seemed like it was finally starting to succeed in that mission, when Apple shared the first details of how the residents of the EU’s 27 member states will soon be able to download apps from alternative app stores onto their iPhones and iPads. Developers will also be able to use third-party payment providers inside apps offered by the Apple App Store for free, and will pay a reduced commission of up to 17 percent for in-app goods and services, the company said.
[…]
Apple made it clear the company will maintain an element of control over the apps and new app stores operating on its devices—arguing this was necessary to reduce “privacy and security risks.” Apple said it will use a new system to track alternative app stores and payment systems, while charging developers a €0.50 ($0.54) “core technology fee” for every download—made through Apple’s App Store or an alternative—once an app is downloaded more than one million times.
“Especially for the big app developers with loads of downloads, who are the ones that really Apple make all their money from, that will rack up to a very high cost very quickly,” says Max von Thun, Europe director at Open Markets, a group dedicated to campaigning against monopolies.
[…]
The caveats sparked outrage from developers that had been hoping to benefit from DMA-inspired changes. “Allowing alternative payments and marketplaces seems positive on the surface, but the strings attached to Apple’s new policies mean that in practice it will be impossible for developers to benefit from them,” Proton’s Yen said in a statement. “Apple will continue stifling competition and innovation, and taking a cut even when developers opt out of its walled garden.”
Tim Sweeney, founder and CEO of Epic Games, went further, accusing Apple on X of “twisting this process to undermine competition and continue imposing Apple taxes on transactions they’re not involved in.”
[…]
With just a matter of weeks until the EU’s March deadline, Apple and developers alike will soon find out whether the EU thinks those changes have gone far enough.
When it comes to copyright suits or conflicts that never should have existed, one of the most common misunderstandings that births them is not understanding the idea/expression dichotomy in copyright law. Even to most laypeople, once you explain it, it’s quite simple. You can copyright a specific expression of something, such as literature, recorded music, etc., but you cannot copyright a general idea. So, while Superman may be subject to copyright protections as a character and in depictions of that character, you cannot copyright a superhero that flies, wears a cape, shoots beams from his eyes, and has super strength. For evidence of that, see: Homelander from The Boys.
But while Homelander is a good case study in the protections offered by the idea/expression dichotomy, a more perfect one might be the recently released PC game Palworld, which has often been described as “Pokémon, but with guns.” This thing is a megahit already, hitting Early Access mid-January and also already hitting 1 million concurrent players. And if you’re wondering just how “Pokémon, but with guns” this game is, well…
The art styles are similar, it’s essentially a monster-collecting game involving battles, etc. and so on. You get it. And this has led to a whole lot of speculation out there that all of this somehow constitutes copyright infringement, or plagiarism, on the part of publisher PocketPair. There is likewise speculation that it’s only a matter of time before Nintendo, Game Freak, or The Pokémon Co. sues the hell out of PocketPair over all of this.
And that may still happen — the Pokemon company says it’s investigating Palworld. All of those companies have shown themselves to be voracious IP enforcers, after all. But the fact is that there is nothing in this game that is a direct copy of any expression owned by any of those entities. To that end, when asked about any concerns over lawsuits, PocketPair is taking a very confident posture.
On the other hand, we had a chance to talk to PocketPair’s CEO Takuro Mizobe before Palworld’s release, and addressing this topic, Mizobe mentioned that Palworld has cleared legal reviews, and that there has been no action taken against it by other companies. Mizobe shared PocketPair’s stance on the issue, stating, “We make our games very seriously, and we have absolutely no intention of infringing upon the intellectual property of other companies.”
Mizobe has also commented that, in his personal opinion, Palworld is not at all that similar to Pokémon, even citing other IPs that Palworld more closely resembles. (Related article) He encouraged users to see past the rumors and give Palworld a chance.
And he’s right. The game mechanics themselves go far beyond anything Pokémon has on offer. And while we can certainly say that even some of the Pals themselves look as though they were inspired by some well-known Pokémon, there are more than enough differences in sum-total to make any claim that this is some kind of direct ripoff simply untrue. Some of the ideas are very, very similar. The expression, however, is different.
In addition to the legal review that Mizobe mentioned, it’s not like the game as a concept has been kept a secret, either.
Though it released just a few days ago, Palworld’s concept and content has been open to the public for quite a while, and were even presented at the Tokyo Game Show in both 2022 and 2023. Many users are of the opinion that, if there were basis for plagiarism-related legal action, the relevant parties would have already acted by now.
I would normally agree, but in this case, well, it’s Pokémon and Nintendo, so who knows. Maybe legal action is coming, maybe not. If it does come, however, it should fail. And fail miserably. All because of the idea/expression dichotomy.
It’s quite fortunate that Palworld has sold millions of copies quickly, because that means they should have the funds to withstand a legal onslaught from Nintendo. In justice it’s not often if you are right, but if you are rich.
Apple is making major changes to the App Store and other core parts of iOS in Europe in response to new European Union laws. Beginning in March, Apple will allow users within the EU to download apps and make purchases from outside of its App Store. The company is already testing many of these changes in its iOS 17.4 beta, which is available now to developers.
Apple has long resisted many of these changes, arguing that it would leave users susceptible to scams, malware and other privacy and security issues. But under the EU’s Digital Markets Act, which goes into effect March 7, major tech companies like Apple are required to make significant changes to their businesses.
[…]
The most significant changes will be for developers, who will be able to take payments and distribute apps from outside of the App Store for the first time. Under the new rules, Apple will still enforce a review process for apps that don’t come through its store. Called “Notarization,” the review will use automation and human reviewers and will be “focused on platform integrity and protecting users” from things like malware. But the company notes it has “less ability to address other risks — including apps that contain scams, fraud, and abuse, or that expose users to illicit, objectionable, or harmful content.”
Apple is also changing its often-criticized commission structure so that developers will pay 17 percent on subscriptions and in-app purchases with the fee reducing to 10 percent for “most developers” after the first year.
At the same time, Apple is tacking on a new 3 percent “payment processing” fee for transactions that go through its store. And a new “core technology fee” will charge a flat €0.50 fee for all app downloads, regardless of whether they come from the App Store or a third-party website, after the first 1 million installations.
[…]
pple will offer new APIs that will allow app makers to access the iPhone’s NFC chip for wireless payments, enabling tap-to-pay transactions that don’t rely on Apple Pay.
It’s also making a tweak to its Safari web browser so that iOS users in Europe will be immediately prompted about whether they want to change their default browser the first time they launch the app after the iOS 17.4 update. Additionally, browser developer will be able to use an engine besides Apple’s own WebKit, which could lead to browsers like Chrome and Firefox releasing new versions using their own technology for rendering sites.
So… I wonder how many apps will easily find their way through the “Notarization” process? And how do they justify charging for downloads from stores they do not own? It can not possibly be in the spirit of the EU laws to allow this.
Astronomers have discovered stars that appear to be blowing out plumes of smoke. The “old smokers”, as they have been nicknamed, challenge our ideas of what happens at the end of giant stars’ lives.
Generally, when red giant stars grow old, they begin to pulsate. They become brighter, dimmer, brighter again and so on, while simultaneously throwing off their outer layers. These pulsating stars are called Mira variables, and it is thought that the pulses are caused by waves of plasma travelling within the stars that help them shed material into space.
Read more
Is the universe conscious? It seems impossible until you do the maths
When Philip Lucas at the University of Hertfordshire in the UK and his colleagues peered towards the centre of our galaxy using the Visible and Infrared Survey Telescope for Astronomy in Chile, they saw many Mira variables – but they also spotted something else. “These old red giants not doing any pulsating – they’rejust sitting there as normal and then suddenly dimming for six months to several years,” says Lucas. “This is almost completely unheard of.”
Further observations revealed that the stars seem to be emitting huge plumes of dusty smoke that prevents their starlight reaching us. The smoke takes months to years to dissipate, offering an explanation for the prolonged dimming. This may be a new way for giant stars to end their lives, but it is unclear how or why it is happening.
The enormity of these stars gives them a powerful gravitational field that makes it difficult for them to blow any of their material away. The fact that they are not pulsating makes it even harder to explain the plumes of smoke. Lucas suggests that it may be connected to the high concentration of relatively heavy elements near the galactic centre, where most of these old smokers are located. That could make it easier for grains of dust to form and then float away as smoke. “It’s quite possible that it’s not that, but it’s the only thing that’s really weird about that region that could be connected,” he says.
The researchers are now looking for more of these strange stars – they have found about 90 so far, Lucas says. Their prevalence suggests that they could be important to the environment in the centre of the Milky Way, and maybe even more so in other galaxies with more heavy elements.
EV buyers are often motivated by a desire to save money on gas and/or drive something more environmentally friendly. But, a recent story out of Florida in The Miami Herald details how EV owners there have been blindsided by how fast they’re having to change the tires on their EVs.
The Herald spoke with the owner of a shop that specializes in EV repair who told them just how often he’s seeing owners in for tire wear and replacement.
At EV Garage Miami, a Sweetwater repair shop that services 90 percent electric vehicles, lead technician Jonathan Sanchez said tires are the most frequent thing customers come in about, no matter what model or make of EV they’re driving. Tire mileage can vary widely of course, but he frequently changes EV tires at just 8,000 to 10,000 miles — a fourth or even fifth of typical tire wear on a gas-burning car.
Neil Semel, the owner of a Mercedes EQS, told The Heraldthat if he had known how often he would be buying tires, he would’ve never bought the car. “If somebody looked at me and said, Mr. Semel, you are going to love this car but in about 7,000 miles you will have to pay 1,400 or 1,500 dollars to replace the tires, I wouldn’t have bought the car,” he said.
So why the fast wear? It’s a combination of lots of power that can be put down instantly and wild curb weights. But it also comes down to individual driving style, as Sanchez pointed out. “If you drive like grandma, the type of car shouldn’t make a difference,” Sanchez said.
What do tire companies have to say about all of this? They’re aware of the problem and are working on EV-specific solutions. Like Michelin who spoke to The Herald:
Michelin suggests getting the Primacy tire for electric vehicles, which they say offers an up to 7% increase in range. Michelin also launched “Self seal” which would self-repair punctures and cut back on some weight by not needing to keep a spare wheel in the back.
The Akira ransomware gang is claiming responsiblity for the “cybersecurity incident” at British bath bomb merchant.
Akira says it has stolen 110 GB of data from the UK-headquartered global cosmetics giant, which has more than 900 stores worldwide, allegedly including “a lot of personal documents” such as passport scans.
Passport scans are routinely collected to verify identities during the course of the hiring process, which suggests Akira’s affiliate likely had access to a system containing staff-related data.
Company documents relating to accounting, finances, tax, projects, and clients are also said to be included in the archives grabbed by the cybercriminals, who are threatening to make the data public soon. There is still no evidence to suggest customer data was exposed.
Akira’s retro-vibe website separates victims into different sections: One for companies who didn’t pay the ransom and thus had their data published, and another for those whose data is to be published on an undisclosed date.
A likely conclusion to draw, if the incident does indeed involve ransomware as the criminals claim, is that there may have been negotiations which have stalled, with Akira using the threat of data publication as a means to hurry along the talks.
The Register approached Lush for comment. Its representatives acknowledged the request but did not provide a statement in time for publication.
Lush last communicated about the situation on January 11, saying it was responding to an “incident” and working with outside forensic experts to investigate the issue – often phrasing used in a ransomware attack.
“The investigation is at an early stage but we have taken immediate steps to secure and screen all systems in order to contain the incident and limit the impact on our operations,” it said. “We take cybersecurity exceptionally seriously and have informed relevant authorities.”
The statement came a day after a post was made to the unofficial Lush Reddit community. Written by a user who seemingly had inside knowledge of the incident, the post claimed members of staff were instructed to send their laptops to head office for “cleaning” – an assertion that El Reg understands to be true.
A password-less database containing an estimated 1.3 million sets of Dutch COVID-19 testing records was left exposed to the open internet, and it’s not clear if anyone is taking responsibility.
Among the information revealed in the publicly accessible and seemingly insecurely configured database were 118,441 coronavirus test certificates, 506,663 appointment records, 660,173 testing samples and “a small number” of internal files. A bevy of personally identifiable information was included in the records – including patient names, dates of birth, passport numbers, email addresses, and other information.
The leaky database was discovered by perennial breach sniffer Jeremiah Fowler, who reckoned it belongs to one of the Netherlands’ largest commercial COVID-19 test providers, CoronaLab – a subsidiary of Amsterdam-based Microbe & Lab. The US Embassy in the Netherlands lists CoronaLab as one of its recommended commercial COVID-19 test providers in the country.
If someone with malicious intent managed to find the database they could do some serious damage, Fowler warned.
“Criminal[s] could potentially reference test dates, locations, or other insider information that only the patient and the laboratory would know,” he wrote. “Any potential exposure involving COVID test data combined with PII could potentially compromise the personal and medical privacy of the individuals listed in the documents.”
Will the responsible party please stand up?
The CoronaLab data exposure report reads in many ways like any other accidental data exposure news: It was found, and now the offending database is offline. But this one isn’t that simple.
According to Fowler, no-one at CoronaLab or Microbe & Lab ever responded to his repeated attempts to reach out and inform them of the exposure.
“I sent multiple responsible disclosure notices and did not receive any reply, and several phone calls also yielded no results,” Fowler claimed. “The database remained open for nearly three weeks before I contacted the cloud hosting provider and it was finally secured from public access.”
The Register has asked Microbe & Lab to get more information about the incident – and we haven’t heard back either.
Without more information from Microbe & Lab or CoronaLab itself, it’s impossible to know how long the database was actually exposed online. The CoronaLab website is down as of this writing – it’s not clear if the outage is related to the database exposure, or if the service will be brought back online.
Because no-one at the organization whose records were exposed can be reached, it’s also not clear if customers or patients are aware that their data was exposed online. Nor, importantly, do we know if European data protection authorities have been informed.
Per article 33 of the EU General Data Protection Regulation (GDPR), data breaches must be reported to local officials within 72 hours of detection, and notifications also have to be made to affected individuals. We reached out to the Dutch Data Protection Authority to learn if it had been notified of the CoronaLab data exposure, and didn’t immediately hear back.
Astronomers using the NASA/ESA Hubble Space Telescope observed the smallest exoplanet where water vapor has been detected in its atmosphere. At only approximately twice Earth’s diameter, the planet GJ 9827d could be an example of potential planets with water-rich atmospheres elsewhere in our galaxy.
GJ 9827d was discovered by NASA’s Kepler Space Telescope in 2017. It completes an orbit around a red dwarf star every 6.2 days. The star, GJ 9827, lies 97 light-years from Earth in the constellation Pisces.
“This would be the first time that we can directly show through an atmospheric detection that these planets with water-rich atmospheres can actually exist around other stars,” said team member Björn Benneke of the Université de Montréal. “This is an important step toward determining the prevalence and diversity of atmospheres on rocky planets.”
The study is published in The Astrophysical Journal Letters.
However, it remains too early to tell whether Hubble spectroscopically measured a small amount of water vapor in a puffy hydrogen-rich atmosphere, or if the planet’s atmosphere is mostly made of water, left behind after a primeval hydrogen/helium atmosphere evaporated under stellar radiation.
[…]
At present the team is left with two possibilities. The planet is still clinging to a hydrogen-rich envelope laced with water, making it a mini-Neptune. Alternatively, it could be a warmer version of Jupiter’s moon Europa, which has twice as much water as Earth beneath its crust. “The planet GJ 9827d could be half water, half rock. And there would be a lot of water vapor on top of some smaller rocky body,” said Benneke.
[…]
More information: Pierre-Alexis Roy et al, Water Absorption in the Transmission Spectrum of the Water World Candidate GJ 9827 d, The Astrophysical Journal Letters (2023). DOI: 10.3847/2041-8213/acebf0
[…] The Council of Europe (CoE), an international human rights body with 46 member countries, is approaching the finalisation of the Convention on Artificial Intelligence, Human Rights, Democracy, and the Rule of Law.
Since the beginning, the United States, the homeland of the world’s leading AI companies, has been pushing to exclude the private sector from the treaty, which, if ratified, would be binding for the signature country.
The United States is not a CoE member but participates in the process with an observer status. In other words, Washington does not have voting rights, but it can influence the discussion by saying it will not sign the convention.
[…]
By contrast, the European Commission, representing the EU in the negotiations, has opposed this carve out for the private sector. Two weeks ago, Euractiv revealed an internal note stating that “the Union should not agree with the alternative proposal(s) that limit the scope of the convention.”
However, in a consequent meeting of the Working Party on Telecommunications and Information Society, the technical body of the EU Council of Ministers in charge of digital policy, several member states asked the Commission to show more flexibility regarding the convention’s scope.
In particular, for countries like Germany, France, Spain, Czechia, Estonia, Ireland, Hungary and Romania, the intent of the treaty was to reach a global agreement, hence securing more signatories should be a priority as opposed to a broad convention with more limited international support.
Being composed of 27 countries out of the 46 that are part of the Council of Europe, the position of the bloc can in itself swing the balance inside the human rights body, where the decisions are taken by consensus.
The European Commission is preparing to push back on a US-led attempt to exempt the private sector from the world’s first international treaty on Artificial Intelligence while pushing for as much alignment as possible with the EU’s AI Act.
Limiting the convention’s scope would be a significant blow to the Commission’s global ambitions, which sees the treaty as a vehicle to set the EU’s AI Act, the world’s first comprehensive law on Artificial Intelligence, as the global benchmark in this area.
Indeed, the Commission’s mandate to negotiate on behalf of the Union is based on the AI Act, and the EU executive has shown little appetite to go beyond the AI regulation even in areas where there is no direct conflict, despite the fact the two initiatives differ significantly in nature.
As part of the alignment with the AI Act, the Commission is pushing for broad exemptions for AI uses in national security, defence and law enforcement. Thus, if the treaty was limited to only public bodies, with these carve-outs, there would be very little left.
In addition, Euractiv understands that such a major watering down of the AI treaty after several years of engagement from the countries involved might also discourage future initiatives in this area.
[…]
a paragraph has been added stressing that “to preserve the international character of the convention, the EU could nevertheless be open to consider the possibility for a Party to make a reservation and release itself from the obligation to apply the convention to private actors that are not acting on behalf of or procuring AI systems for public authorities, under certain conditions and limitations”.
The Commission’s proposal seems designed to address Washington’s argument that they cannot commit to anything beyond their national legal framework.
In October, US President Joe Biden signed an executive order setting out a framework for federal agencies to purchase and use AI tools safely and responsibly, hence the reference to companies not working with the public sector.
More precisely, the Commission is proposing an ‘opt-out’ option with temporal limitations, that can be revised at any time and with some guarantees that it is not abused. This approach would be the opposite of what the US administration proposed, namely exempting the private sector by default with an ‘opt-in’ possibility for signatories.
Still, the original ‘opt-in’ option was designed to avoid the embarrassment of the US administration having to exempt private companies from a human rights treaty. Euractiv understands Israel and Japan would not sign if the ‘opt-out’ approach made it into the final text, whereas the UK and Canada would follow the US decision.
So the US basically wants to make a useful treaty useless because they are run by self serving, profit seeking companies that want to trample on human rights. Who would have thought? Hopefully the EU can show some backbone and do what is right instead of what is being financially lobbied for (here’s looking at you, France!). It’s this kind of business based decision making that has led to climate change, cancer deaths, and many many more huge problems that could have been nipped in the bud.
iPhone apps including Facebook, LinkedIn, TikTok, and X/Twitter are skirting Apple’s privacy rules to collect user data through notifications, according to tests by security researchers at Mysk Inc., an app development company. Users sometimes close apps to stop them from collecting data in the background, but this technique gets around that protection. The data is unnecessary for processing notifications, the researchers said, and seems related to analytics, advertising, and tracking users across different apps and devices.
It’s par for the course that apps would find opportunities to sneak in more data collection, but “we were surprised to learn that this practice is widely used,” said Tommy Mysk, who conducted the tests along with Talal Haj Bakry. “Who would have known that an innocuous action as simple as dismissing a notification would trigger sending a lot of unique device information to remote servers? It is worrying when you think about the fact that developers can do that on-demand.”
These particular apps aren’t unusual bad actors. According to the researchers, it’s a widespread problem plaguing the iPhone ecosystem.
This isn’t the first time Mysk’s tests have uncovered data problems at Apple, which has spent untold millions convincing the world that “what happens on your iPhone, stays on your iPhone.” In October 2023, Mysk found that a lauded iPhone feature meant to protect details about your WiFi address isn’t as private as the company promises. In 2022, Apple was hit with over a dozen class action lawsuits after Gizmodo reported on Mysk’s finding that Apple collects data about its users even after they flip the switch on an iPhone privacy setting that promises to “disable the sharing of device analytics altogether.”
The data looks like information that’s used for “fingerprinting,” a technique companies use to identify you based on several seemingly innocuous details about your device. Fingerprinting circumvents privacy protections to track people and send them targeted ads
[…]
For example, the tests showed that when you interact with a notification from Facebook, the app collects IP addresses, the number of milliseconds since your phone was restarted, the amount of free memory space on your phone, and a host of other details. Combining data like these is enough to identify a person with a high level of accuracy. The other apps in the test collected similar information. LinkedIn, for example, uses notifications to gather which timezone you’re in, your display brightness, and what mobile carrier you’re using, as well as a host of other information that seems specifically related to advertising campaigns, Mysk said.
[…]
Apps can collect this kind of data about you when they’re open, but swiping an app closed is supposed to cut off the flow of data and stop an app from running whatsoever. However, it seems notifications provide a backdoor.
Apple provides special software to help your apps send notifications. For some notifications, the app might need to play a sound or download text, images, or other information. If the app is closed, the iPhone operating system lets the app wake up temporarily to contact company servers, send you the notification, and perform any other necessary business. The data harvesting Mysk spotted happened during this brief window.
France’s data privacy watchdog organization, the CNIL, has fined a logistics subsidiary of Amazon €32 million, or $35 million in US dollars, over the company’s use of an “overly intrusive” employee surveillance system. The CNIL says that the system employed by Amazon France Logistique “measured work interruptions with such accuracy, potentially requiring employees to justify every break or interruption.”
Of course, this system was forced on the company’s warehouse workers, as they seem to always get the short end of the Amazon stick. The CNIL says the surveillance software tracked the inactivity of employees via a mandatory barcode scanner that’s used to process orders. The system tracks idle time as interruptions in barcode scans, calling out employees for periods of downtime as low as one minute. The French organization ruled that the accuracy of this system was illegal, using Europe’s General Data Protection Regulation (GDPR) as a legal basis for the ruling.
To that end, this isn’t being classified as a labor case, but rather a data processing case regarding excessive monitoring. “As implemented, the processing is considered to be excessively intrusive,” the CNIL wrote, noting that Amazon uses this data to assess employee performance on a weekly basis. The organization also noted that Amazon held onto this data for all employees and temporary workers.
Samsung just announced that its self-repair program will now include certain home entertainment devices. The company has developed a range of step-by-step repair guides for various products in the category, in addition to providing genuine replacement parts and repair tools.
This program covers Samsung 2023 TVs, along with their remotes, and monitors released throughout the past year or so. Additionally, the self-repair program now includes the second-generation Freestyle projector and select soundbars. You can pick up replacement parts directly from the company.
Of course, the program doesn’t cover every repair issue. For TVs and monitors, the program only handles issues related to the picture, power, WiFi connection, sound and remote control. For soundbars, the program covers problems related to HDMI and optical connections, power, sound and wireless communication. According to Samsung, most of these issues can be fixed with common tools like a Phillips-head screwdriver.
The company’s been on something of a self-repair spree in recent months. Back in December, Samsung opened up the program to foldable devices, like the Galaxy Z Flip 5 and Z Fold 5. In the first part of 2023, the company added S22 and Galaxy Book devices to the program, joining pre-existing Galaxy products.
To that end, Samsung just announced a broader assortment of self-repair parts for devices already included in the program. This includes speakers, SIM trays, side keys, volume keys, display assemblies, back glass and charging ports for phones and tablets. Galaxy Book owners can also now conduct DIY repairs to fix the speakers and fan. Meanwhile, rival Apple doesn’t exactly have the best track record in the self-repair movement.
It’s good to see a return to being able to repair stuff. Not only does this make repairs cheaper, faster and easier but also it allows you to keep your device running for far longer. Considering the amount of damage being done to the environment by electronic device junk, is absolutely a good thing.
The rainbow looks different to a human than it does to a honeybee or a zebra finch. That’s because these animals can see colors that we humans simply can’t. Now scientists have developed a new video recording and analysis technique to better understand how the world looks through the eyes of other species. The accurate and relatively inexpensive method, described in a study published on January 23 in PLOS Biology, is already offering biologists surprising discoveries about the lives of different species.
Humans have three types of cone cells in their eyes. This trio of photoreceptors typically detects red, green and blue wavelengths of light, which combine into millions of distinct colors in the spectrum from 380 to 700 nanometers in wavelength—what we call “visible light.” Some animals, though, can see light with even higher frequencies, called ultraviolet, or UV, light. Most birds have this ability, along with honeybees, reptiles and certain bony fish.
[…]
To capture animal vision on video, Vasas and her colleagues developed a portable 3-D-printed enclosure containing a beam splitter that separates light into UV and the human-visible spectrum. The two streams are captured by two different cameras. One is a standard camera that detects visible-wavelength light, and the other is a modified camera that is sensitive to UV. On its own, the UV-sensitive camera wouldn’t be able to record detailed information on the rest of the light spectrum in a single shot. But paired together, the two cameras can simultaneously record high-quality video that encompasses a wide range of the light spectrum. Then a set of algorithms aligns the two videos and produces versions of the footage that are representative of different animals’ color views, such as those of birds or bees.
[…]
Capturing video in this way “fills a really important gap in our ability to model animal vision,” says Jolyon Troscianko, a visual ecologist at the University of Exeter in England, who wasn’t involved in the new research. He notes that in nature, “a lot of interesting things move,” such as animals that are engaging in mating dances or rapid defense displays. Until now, researchers studying these dynamic behaviors have been stuck with the human perspective.
[…]
The technique is already revealing unseen phenomena of the natural world, she adds: for example, by recording an iridescent peacock feather rotating under a light, the researchers found shifts in color that are even more vibrant to fellow peafowl than they are to humans. Vasas and her colleagues also captured the brief startle display of a black swallowtail caterpillar and saw for the first time that its hornlike defense appendages are UV-reflective.
“None of these things were hypotheses that we had in advance,” Vasas says. Moving forward, “I think it will reveal a lot of things that I can’t yet imagine.”
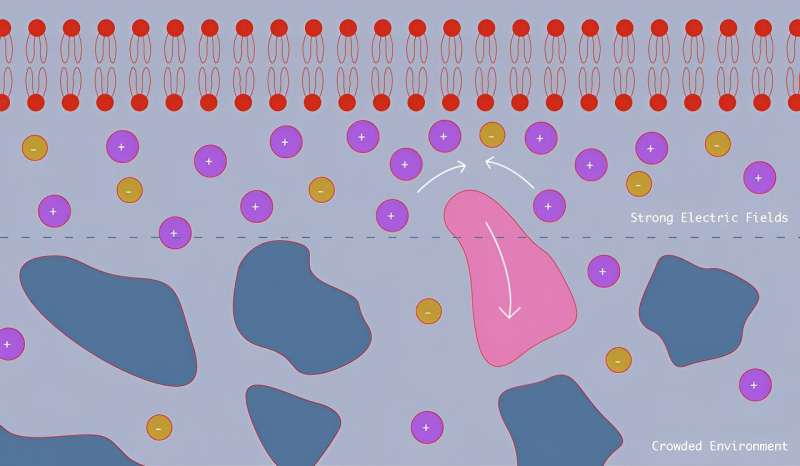
The humble membranes that enclose our cells have a surprising superpower: They can push away nano-sized molecules that happen to approach them. A team including scientists at the National Institute of Standards and Technology (NIST) has figured out why, by using artificial membranes that mimic the behavior of natural ones. Their discovery could make a difference in how we design the many drug treatments that target our cells.
The team’s findings, which appear in the Journal of the American Chemical Society, confirm that the powerful electrical fields that cell membranes generate are largely responsible for repelling nanoscale particles from the surface of the cell.
This repulsion notably affects neutral, uncharged nanoparticles, in part because the smaller, charged molecules the electric field attracts crowd the membrane and push away the larger particles. Since many drug treatments are built around proteins and other nanoscale particles that target the membrane, the repulsion could play a role in the treatments’ effectiveness.
The findings provide the first direct evidence that the electric fields are responsible for the repulsion.
[…]
Membranes form boundaries in nearly all kinds of cells. Not only does a cell have an outer membrane that contains and protects the interior, but often there are other membranes inside, forming parts of organelles such as mitochondria and the Golgi apparatus. Understanding membranes is important to medical science, not least because proteins lodged in the cell membrane are frequent drug targets. Some membrane proteins are like gates that regulate what gets into and out of the cell.
The region near these membranes can be a busy place. Thousands of types of different molecules crowd each other and the cell membrane—and as anyone who has tried to push through a crowd knows, it can be tough going. Smaller molecules such as salts move with relative ease because they can fit into tighter spots, but larger molecules, such as proteins, are limited in their movements.
[…]
“How does crowding affect the cell and its behavior?” he said. “How, for example, do molecules in this soup get sorted inside the cell, making some of them available for biological functions, but not others? The effect of the membrane could make a difference.”
[…]
scientists have paid scant attention to this effect at the nanoscale because it takes extremely powerful fields to move nanoparticles. But powerful fields are just what an electrically charged membrane generates.
“The electric field right near a membrane in a salty solution like our bodies produce can be astoundingly strong,” Hoogerheide said. “Its strength falls off rapidly with distance, creating large field gradients that we figured might repel nearby particles. So we used neutron beams to look into it.”
Neutrons can distinguish between different isotopes of hydrogen, and the team designed experiments that explored a membrane’s effect on nearby molecules of PEG, a polymer that forms chargeless nano-sized particles. Hydrogen is a major constituent of PEG, and by immersing the membrane and PEG into a solution of heavy water—which is made with deuterium in place of ordinary water’s hydrogen atoms—the team could measure how closely the PEG particles approached the membrane. They used a technique known as neutron reflectometry at the NCNR as well as instruments at Oak Ridge National Laboratory.
Together with molecular dynamics simulations, the experiments revealed the first-ever evidence that the membranes’ powerful field gradients were the culprit behind the repulsion: The PEG molecules were more strongly repelled from charged surfaces than from neutral surfaces.
[…]
More information: Marcel Aguilella-Arzo et al, Charged Biological Membranes Repel Large Neutral Molecules by Surface Dielectrophoresis and Counterion Pressure, Journal of the American Chemical Society (2024). DOI: 10.1021/jacs.3c12348. pubs.acs.org/doi/full/10.1021/jacs.3c12348
The AI Office will play a pivotal role in the enforcement architecture of the AI Act, the EU’s landmark law to regulate Artificial Intelligence, set to be formally adopted in the coming weeks based on a political agreement nailed down in December.
The idea of an AI Office to centralise the enforcement of the AI rulebook came from the European Parliament. Still, during the negotiations, it was downsized from being a little short of an agency to being integrated into the Commission, albeit with a separate budget line.
However, the question of how much autonomy the Office will be guaranteed remains sensitive inside the Commission, especially since it is unclear whether it will become an entity with its own political objectives or an extension of the unit responsible for the AI Act.
Euractiv understands that the obtained draft decision was amended following an internal consultation to include wording specifying that the Office should not interfere with the competencies of Commission departments.
According to the document, the decision should enter into force as a matter of urgency on 21 February, before the formal adoption of the EU’s AI law. Euractiv understands the decision is due to be adopted on Wednesday (24 January).
Policing powerful AI
The AI Office will have primarily a supporting role for what concerns the enforcement of the rules on AI systems, as the bulk of the competencies will be on national authorities. However, the Office has been assigned to policing General-Purpose AI (GPAI) models and systems, the most potent types of AI so far.
Recent advances in computing power, data harvesting, and algorithm techniques have led to the development of powerful GPAI models like OpenAI’s GPT-4, which powers the GPAI system ChatGPT, the world’s most famous chatbot.
The agreement on the AI Act includes a tiered approach to GPAI models to distinguish those that might entail a systemic risk for society from the rest. The AI Office is to develop the methodologies and benchmarks for evaluating the capabilities of GPAI models.
The Office should be able to set itself apart in monitoring the application of the rules on GPAI models and systems, notably when developed by the same provider, and the emergence of unforeseen risks from these models based on alerts from a scientific panel of independent experts.
The new EU entity is also set to have significant leeway to investigate possible infringements of rules related to GPAI by collecting complaints and alerts, issuing document requests, conducting evaluations and requesting mitigation or other enforcement measures.
The Office will also coordinate the enforcement of the AI Act on AI systems already covered under other EU legislation, like social media’s recommender systems under the Digital Services Act and search engines’ ranking algorithms under the Digital Markets Act.
Support & coordination
The AI Office is to have a supporting role in the preparation of secondary legislation implementing the AI Act, the uniform application of the regulation, the issuance of guidance and supporting tools like standardised protocols, the preparation of standardisation requests, the establishment of regulatory sandboxes, the developments of codes of practice and conduct at the EU level.
The entity will also provide the secretariat for the AI Board and administrative support for the stakeholder-run advisory forum and expert-made scientific panel. The draft decision explicitly references the requirement to consult regularly with scientific and civil society stakeholders.
In particular, the AI Office must “establish a forum for cooperation with the open-source community with a view to identifying and developing best practices for the safe development and use of open-source AI models and systems.”
In addition, the new entity is tasked with promoting innovation ecosystems and working with public and private actors and the start-up community. As revealed by Euractiv, the AI Office will be responsible for monitoring the progress of GenAI4EU, an initiative to promote the uptake of generative AI in strategic sectors.
The Office is also mandated to cooperate with the relevant EU bodies, like the European Data Protection Supervisor. Collaboration is also required with other Commission departments, notably the European Centre for Algorithmic Transparency, to test GPAI models and systems and facilitate the adoption of AI tools in relevant EU policies.
At the international level, the Office will promote the EU approach to AI, contribute to AI governance initiatives, and support the implementation of international agreements.
Financing
The financing aspect of the AI Office has been a sore point since the beginning. The lack of flexibility in the EU budget allocations and lack of appetite from member states to put more resources on the table means new tasks always face strict budgetary constraints.
The Commission’s digital policy department, DG CNECT, will assign human resources. The hiring of temporary staff and operational expenditure will be financed with the redeployment of the budget from the Digital Europe Programme.
[…] the public too often doesn’t understand how it happens that products stop working the way they did after updates are performed remotely, or why movies purchased through an online store suddenly disappear with no refund, or why other media types purchased online likewise go poof. There is a severe misalignment, in other words, between what consumers think their money is being spent on and what is actually being purchased.
With the pre-release of Prince of Persia: The Lost Crown started, Ubisoft has chosen this week to rebrand its Ubisoft+ subscription services, and introduce a PC version of the “Classics” tier at a lower price. And a big part of this, says the publisher’s director of subscriptions, Philippe Tremblay, is getting players “comfortable” with not owning their games.
He claims the company’s subscription service had its biggest ever month October 2023, and that the service has had “millions” of subscribers, and “over half a billion hours” played. Of course, a lot of this could be a result of Ubisoft’s various moments of refusing to release games to Steam, forcing PC players to use its services, and likely opting for a month’s subscription rather than the full price of the game they were looking to buy. But still, clearly people are opting to use it.
On the one hand, there are realms where it makes sense for a subscription based gaming service where you pay a monthly fee for access and essentially never buy a game. Xbox’s Game Pass, for instance, makes all the sense in the world for some people. If you’re a more casual gamer who doesn’t want to own a library of games, but rather merely wants to be able to play a broad swath of titles at a moment’s notice, a service like that is perfect.
But Game Pass is $10 a month and includes titles from all kinds of publishers. Ubisoft’s service is nearly double that rate and only includes Ubisoft titles. That’s a much tougher sell.
[…]
Given that most people, while being a part of the problem (hello), also think of this as a problem, it’s so weird to see it phrased as if some faulty thinking in the company’s audience.
“One of the things we saw is that gamers are used to, a little bit like DVD, having and owning their games. That’s the consumer shift that needs to happen. They got comfortable not owning their CD collection or DVD collection. That’s a transformation that’s been a bit slower to happen [in games]. As gamers grow comfortable in that aspect… you don’t lose your progress. If you resume your game at another time, your progress file is still there. That’s not been deleted. You don’t lose what you’ve built in the game or your engagement with the game. So it’s about feeling comfortable with not owning your game.“
That last sentence’s thoughts are so misaligned as to be nearly in the realm of nonsense. If it’s my game, then I do own it. The point Ubisoft is trying to make is that the public should get over ownership entirely and accept that it’s not my game at all. It’s my subscription service.
And while I appreciate Ubisoft saying the quiet part out loud for once, I don’t believe for a moment that this will go over well with the general gaming public.
The US Supreme Court has declined to hear the appeals filed by both Apple and Epic Games following a judge’s ruling that Apple must allow developers to offer alternative methods to pay for apps and services other than through the App Store. It did not provide an explanation as to why it refused to review either appeal, but it means the permanent injunction giving developers a way to avoid the 30 percent cut Apple takes will remain in place.
Apple made the appeal to the high court back in September of last year, requesting it review the circuit court’s decision it deemed “unconstitutional.” The case brought forward by Epic Games is the first to challenge the business model of the App store, which helps Apple rake in billions. In May 2023, Apple said that developers generated about $1 trillion in total billings through the App Store in 2022. Gaming apps sold on the App Store generate an estimated $100 billion in revenue each year.
While the Ninth Circuit ruled in favor of Epic’s appeal that Apple has indeed broken California’s Unfair Competition law, it rejected Epic’s claimthat the App store is a monopoly. In addition to declining to hear Apple’s appeal, SCOTUS also will not review Epic’s appeal that the district court had made “legal errors.”
Epic claimed that Apple violates federal antitrust laws through its business model, however, this is not an issue the high court will consider.
The European Parliament is calling for new regulations to ensure streaming services pay artists fairly. The proposal also calls for more transparency around how algorithms generate suggestions for which artists to stream and what tracks get the most promotion.
The proposed changes will be designed to ensure smaller artists are compensated fairly. Currently, royalty rates are set in a way that makes artists accept lower pay for the distribution of their content in exchange for visibility on streaming platforms like Spotify and Apple Music. The members of the European Parliament (MEPs) are primarily concerned with introducing new legal frameworks to help support artists.
MEPs believe that the current way royalties are distributed is unfair. Current algorithms favor major labels and artists when providing suggestions, making it more difficult for less popular and diverse genres to get exposure. “Cultural diversity and ensuring that authors are credited and fairly paid has always been our priority; this is why we ask for rules that ensure algorithms and recommendation tools used by music streaming services are transparent as well as in their use of AI tools, placing European authors at the centre,” rapporteur Ibán García del Blanco of Spain said.
As part of this call for change, the MEPs want there to be more regulation regarding the use of artificial intelligence. The actual implementation of a legal framework by EU regulators might take some time to come to fruition. Similarly, UK regulators also raised the issue of pay fairness on streaming apps and even started investigating the effects of algorithms on listening habits. It’s no secret that streaming platforms account for more than half of the music industry’s revenue. Streaming represents about 67 percent of the music industry’s revenue on a global scale.
OpenAI may finally have to answer for ChatGPT’s “hallucinations” in court after a Georgia judge recently ruled against the tech company’s motion to dismiss a radio host’s defamation suit.
OpenAI had argued that ChatGPT’s output cannot be considered libel, partly because the chatbot output cannot be considered a “publication,” which is a key element of a defamation claim. In its motion to dismiss, OpenAI also argued that Georgia radio host Mark Walters could not prove that the company acted with actual malice or that anyone believed the allegedly libelous statements were true or that he was harmed by the alleged publication.
It’s too early to say whether Judge Tracie Cason found OpenAI’s arguments persuasive. In her order denying OpenAI’s motion to dismiss, which MediaPost shared here, Cason did not specify how she arrived at her decision, saying only that she had “carefully” considered arguments and applicable laws.
There may be some clues as to how Cason reached her decision in a court filing from John Monroe, attorney for Walters, when opposing the motion to dismiss last year.
Monroe had argued that OpenAI improperly moved to dismiss the lawsuit by arguing facts that have yet to be proven in court. If OpenAI intended the court to rule on those arguments, Monroe suggested that a motion for summary judgment would have been the proper step at this stage in the proceedings, not a motion to dismiss.
Had OpenAI gone that route, though, Walters would have had an opportunity to present additional evidence. To survive a motion to dismiss, all Walters had to do was show that his complaint was reasonably supported by facts, Monroe argued.
Failing to convince the court that Walters had no case, OpenAI’s legal theories regarding its liability for ChatGPT’s “hallucinations” will now likely face their first test in court.
“We are pleased the court denied the motion to dismiss so that the parties will have an opportunity to explore, and obtain a decision on, the merits of the case,” Monroe told Ars.
What’s the libel case against OpenAI?
Walters sued OpenAI after a journalist, Fred Riehl, warned him that in response to a query, ChatGPT had fabricated an entire lawsuit. Generating an entire complaint with an erroneous case number, ChatGPT falsely claimed that Walters had been accused of defrauding and embezzling funds from the Second Amendment Foundation.
Walters is the host of Armed America Radio and has a reputation as the “Loudest Voice in America Fighting For Gun Rights.” He claimed that OpenAI “recklessly” disregarded whether ChatGPT’s outputs were false, alleging that OpenAI knew that “ChatGPT’s hallucinations were pervasive and severe” and did not work to prevent allegedly libelous outputs. As Walters saw it, the false statements were serious enough to be potentially career-damaging, “tending to injure Walter’s reputation and exposing him to public hatred, contempt, or ridicule.”
[…]
OpenAI introduced “a large amount of material” in its motion to dismiss that fell outside the scope of the complaint, Monroe argued. That included pointing to a disclaimer in ChatGPT’s terms of use that warns users that ChatGPT’s responses may not be accurate and should be verified before publishing. According to OpenAI, this disclaimer makes Riehl the “owner” of any libelous ChatGPT responses to his queries.
“A disclaimer does not make an otherwise libelous statement non-libelous,” Monroe argued. And even if the disclaimer made Riehl liable for publishing the ChatGPT output—an argument that may give some ChatGPT users pause before querying—”that responsibility does not have the effect of negating the responsibility of the original publisher of the material,” Monroe argued.
Samsung announced many interesting products and features at its latest Galaxy Unpacked event (including the Galaxy S24 series) but one of the more impressive developments isn’t actually unique to the Galaxy brand itself. The feature, Circle to Search, was developed in partnership with Google, which means it’ll live on Google phones, too.
What is Circle to Search?
In a nutshell, Circle to Search is a new way to search for anything without switching apps. To activate the feature, long press on the home button or navigation bar (if you have gesture navigation enabled). Then, when you see something on your screen that you want to look up, draw a circle around it with your finger, and your phone will return search results. For example, you could use Circle to Search to find an article of clothing you might have seen in a YouTube video, or get more info about a dish in a recipe you’re browsing online.
You don’t have to just circle the item you’re looking to search, either: You can also highlight it, scribble over it, or tap on it. As part of Google’s AI upgrades to search, you can search with text and pictures you’ve circled at the same time using multi-search. Google says that the Circle to Search gesture works on images, text, and videos. Basically, you’re able to find anything and everything using this feature.
These results appear inside the app you’re currently using, so you don’t need to interrupt what you’re doing to search. When you’re done, you can simply swipe the results away to get back to your previous task.
When does Circle to Search launch?
Circle to Search is set to launch globally on Jan. 31 for select premium Android smartphones like the Pixel 8 and Pixel 8 Pro and the newly announced Galaxy S24 series. The feature will be coming to more Android devices at a later date.
Have I Been Pwned has added almost 71 million email addresses associated with stolen accounts in the Naz.API dataset to its data breach notification service.
The Naz.API dataset is a massive collection of 1 billion credentials compiled using credential stuffing lists and data stolen by information-stealing malware.
Credential stuffing lists are collections of login name and password pairs stolen from previous data breaches that are used to breach accounts on other sites.
[…]
This dataset has been floating around the data breach community for quite a while but rose to notoriety after it was used to fuel an open-source intelligence (OSINT) platform called illicit.services.
This service allows visitors to search a database of stolen information, including names, phone numbers, email addresses, and other personal data.
The service shut down in July 2023 out of concerns it was being used for Doxxing and SIM-swapping attacks. However, the operator enabled the service again in September.
Illicit.services use data from various sources, but one of its largest sources of data came from the Naz.API dataset, which was shared privately among a small number of people.
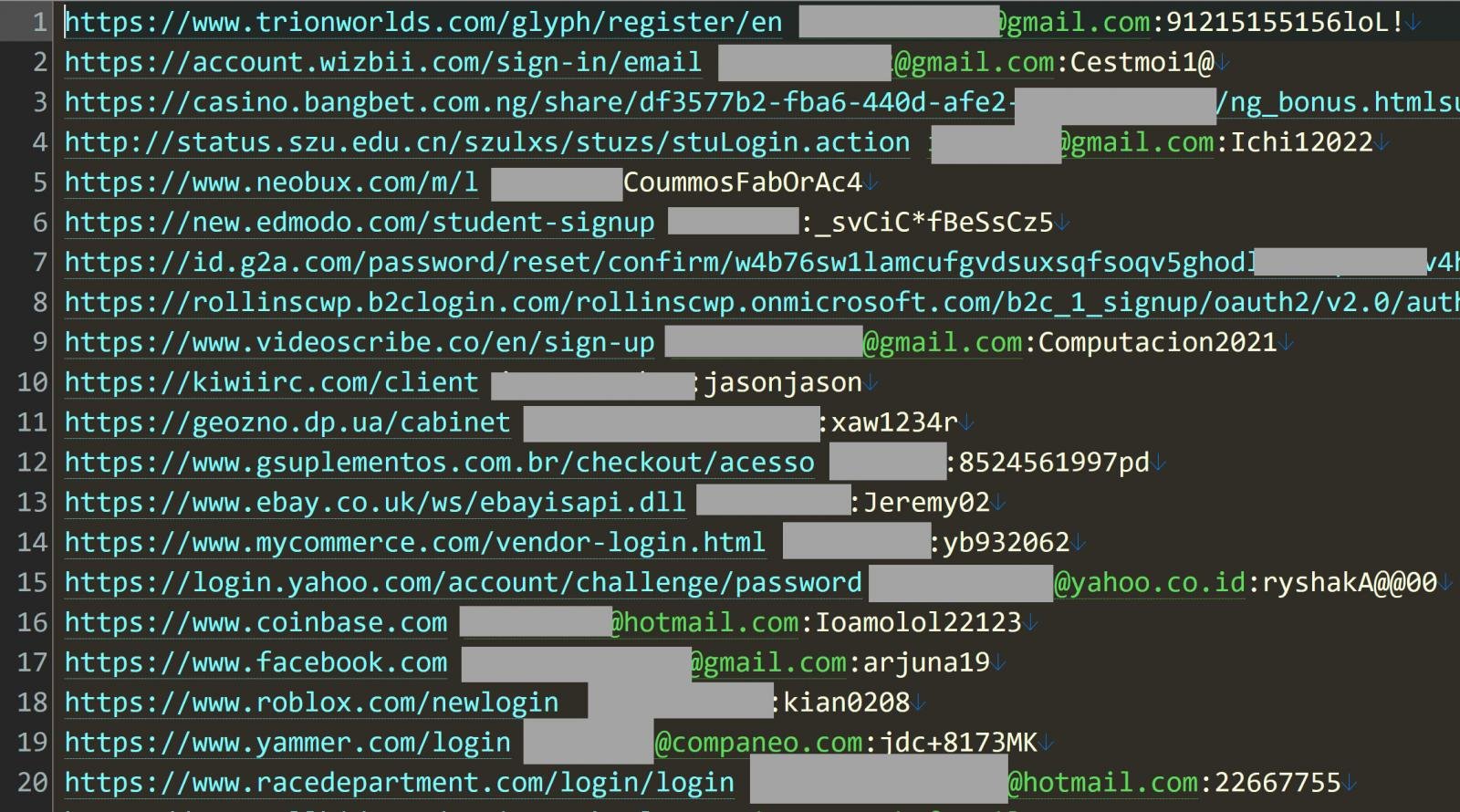
Each line in the Naz.API data consists of a login URL, its login name, and an associated password stolen from a person’s device
[…]
“Here’s the back story: this week I was contacted by a well-known tech company that had received a bug bounty submission based on a credential stuffing list posted to a popular hacking forum,” explained a blog post by Hunt.
“Whilst this post dates back almost 4 months, it hadn’t come across my radar until now and inevitably, also hadn’t been sent to the aforementioned tech company.”
“They took it seriously enough to take appropriate action against their (very sizeable) user base which gave me enough cause to investigate it further than your average cred stuffing list.”
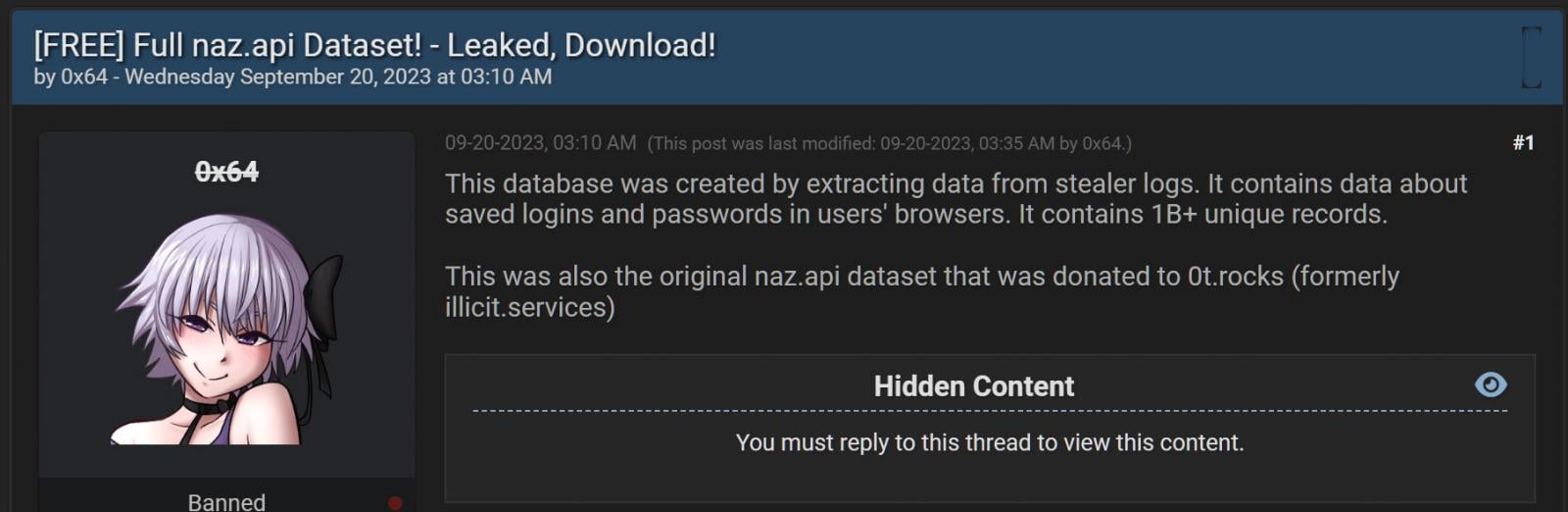
Threat actors sharing the Naz.API dataset on hacking forums Source: BleepingComputer
According to Hunt, the Naz.API dataset consists of 319 files totaling 104GB and containing 70,840,771 unique email addresses.
However, while there are close to 71 million unique emails, for each email address, there are likely many other records for the different sites’ credentials were stolen from.
Hunt says the Naz.API data is likely old, as it contained one of his and other HIBP subscribers’ passwords that were used in the past. Hunt says his password was used in 2011, meaning that some of the data is over 13 years old.
To check if your credentials are in the Naz.API dataset, you can perform a search at Have I Been Pwned. If your email is found to be associated with Naz.API, the site will warn you, indicating that your computer was infected with information-stealing malware at one point.